This is the multi-page printable view of this section. Click here to print.
2018
Gardener Cookies
Green Tea Matcha Cookies
For a team event during the Christmas season we decided to completely reinterpret the topic cookies. :-)

Matcha cookies have the delicate flavor and color of green tea. These soft, pillowy and chewy green tea cookies are perfect with tea. And of course they fit perfectly to our logo.
Ingredients
- 1 stick butter, softened
- ⅞ cup of granulated sugar
- 1 cup + 2 tablespoons all-purpose flour
- 2 eggs
- 1¼ tablespoons culinary grade matcha powder
- 1 teaspoon baking powder
- pinch of salt
Instructions
- Cream together the butter and sugar in a large mixing bowl - it should be creamy colored and airy. A hand blender or stand mixer works well for this. This helps the cookie become fluffy and chewy.
- Gently incorporate the eggs to the butter mixture one at a time.
- In a separate bowl, sift together all the dry ingredients.
- Add the dry ingredients to the wet by adding a little at a time and folding or gently mixing the batter together. Keep going until you’ve incorporated all the remaining flour mixture. The dough should be a beautiful green color.
- Chill the dough for at least an hour - up to overnight. The longer the better!
- Preheat your oven to 325 F.
- Roll the dough into balls the size of ping pong balls and place them on a non-stick cookie sheet.
- Bake them for 12-15 minutes until the bottoms just start to become golden brown and the cookie no longer looks wet in the middle. Note: you can always bake them at 350 F for a less moist, fluffy cookie. It will bake faster by about 2-4 minutes 350 F so watch them closely.
- Remove and let cool on a rack and enjoy!
Note
Make sure you get culinary grade matcha powder. You should be able to find this in Asian or natural grocers.




Cookies Are Dangerous...
…they mess up the figure.

For a team event during the Christmas season we decided to completely reinterpret the topic cookies… since the vegetables have gone on a well-deserved vacation. :-)
Get the recipe at Gardener Cookies.
Hibernate a Cluster to Save Money
You want to experiment with Kubernetes or set up a customer scenario, but don’t want to run the cluster 24 / 7 due to cost reasons?

Gardener gives you the possibility to scale your cluster down to zero nodes.
Learn more on Hibernate a Cluster.
Anti Patterns

Running as Root User
Whenever possible, do not run containers as root users. One could be tempted to say that in Kubernetes, the node and pods are well separated, however, the host and the container share the same kernel. If the container is compromised, a root user can damage the underlying node.
Instead of running a root user, use RUN groupadd -r anygroup && useradd -r -g anygroup myuser to create a group and a user in it. Use the USER command to switch to this user.
Storing Data or Logs in Containers
Containers are ideal for stateless applications and should be transient. This means that no data or logs should be stored in the container, as they are lost when the container is closed. If absolutely necessary, you can use persistence volumes instead to persist them outside the containers.
However, an ELK stack is preferred for storing and processing log files.
Learn more on Common Kubernetes Antipattern.
Auditing Kubernetes for Secure Setup
In summer 2018, the Gardener project team asked Kinvolk to execute several penetration tests in its role as a third-party contractor. The goal of this ongoing work is to increase the security of all Gardener stakeholders in the open source community. Following the Gardener architecture, the control plane of a Gardener managed shoot cluster resides in the corresponding seed cluster. This is a Control-Plane-as-a-Service with a network air gap.

Along the way we found various kinds of security issues, for example, due to misconfiguration or missing isolation, as well as two special problems with upstream Kubernetes and its Control-Plane-as-a-Service architecture.
Learn more on Auditing Kubernetes for Secure Setup.
Big Things Come in Small Packages
Microservices tend to use smaller runtimes but you can use what you have today - and this can be a problem in Kubernetes.
Switching your architecture from a monolith to microservices has many advantages, both in the way you write software and the way it is used throughout its lifecycle. In this post, my attempt is to cover one problem which does not get as much attention and discussion - size of the technology stack.
General Purpose Technology Stack
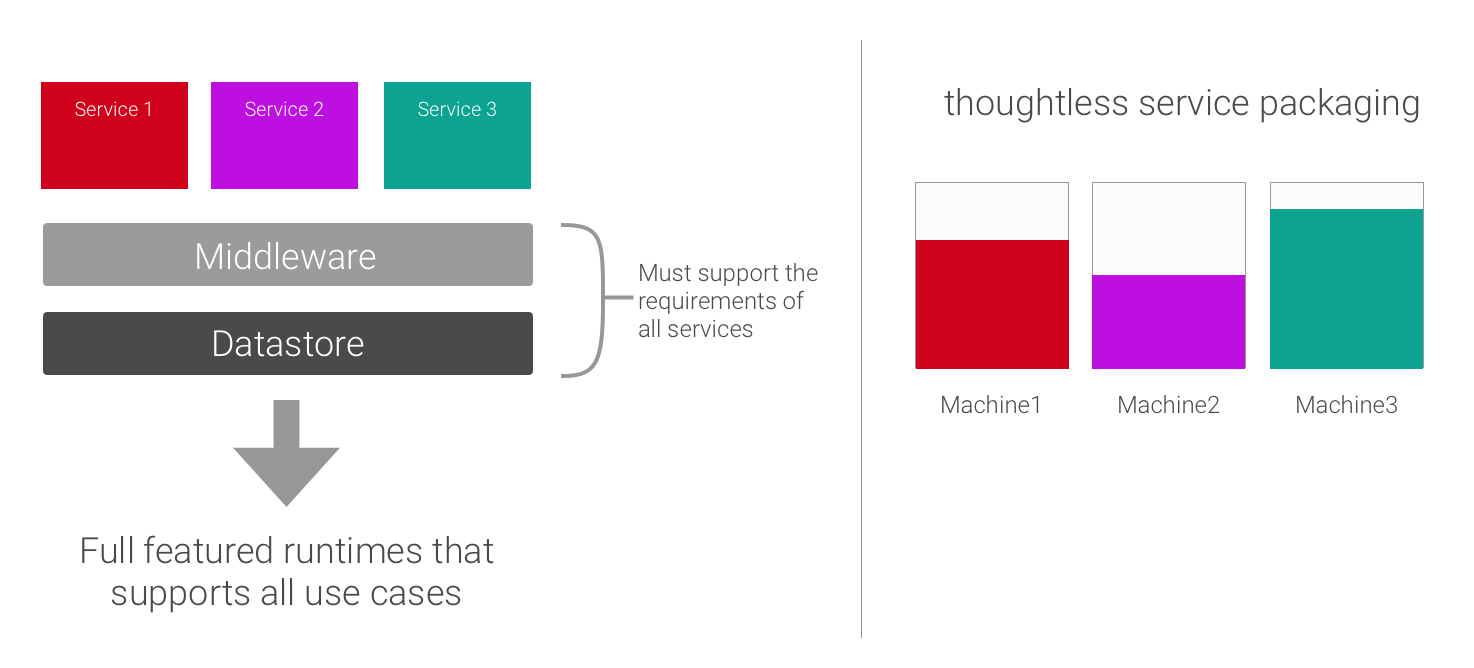
There is a tendency to be more generalized in development and to apply this pattern to all services. One feels that a homogeneous image of the technology stack is good if it is the same for all services.
One forgets, however, that a large percentage of the integrated infrastructure is not used by all services in the same way, and is therefore only a burden. Thus, resources are wasted and the entire application becomes expensive in operation and scales very badly.
Light Technology Stack
Due to the lightweight nature of your service, you can run more containers on a physical server and virtual machines. The result is higher resource utilization.
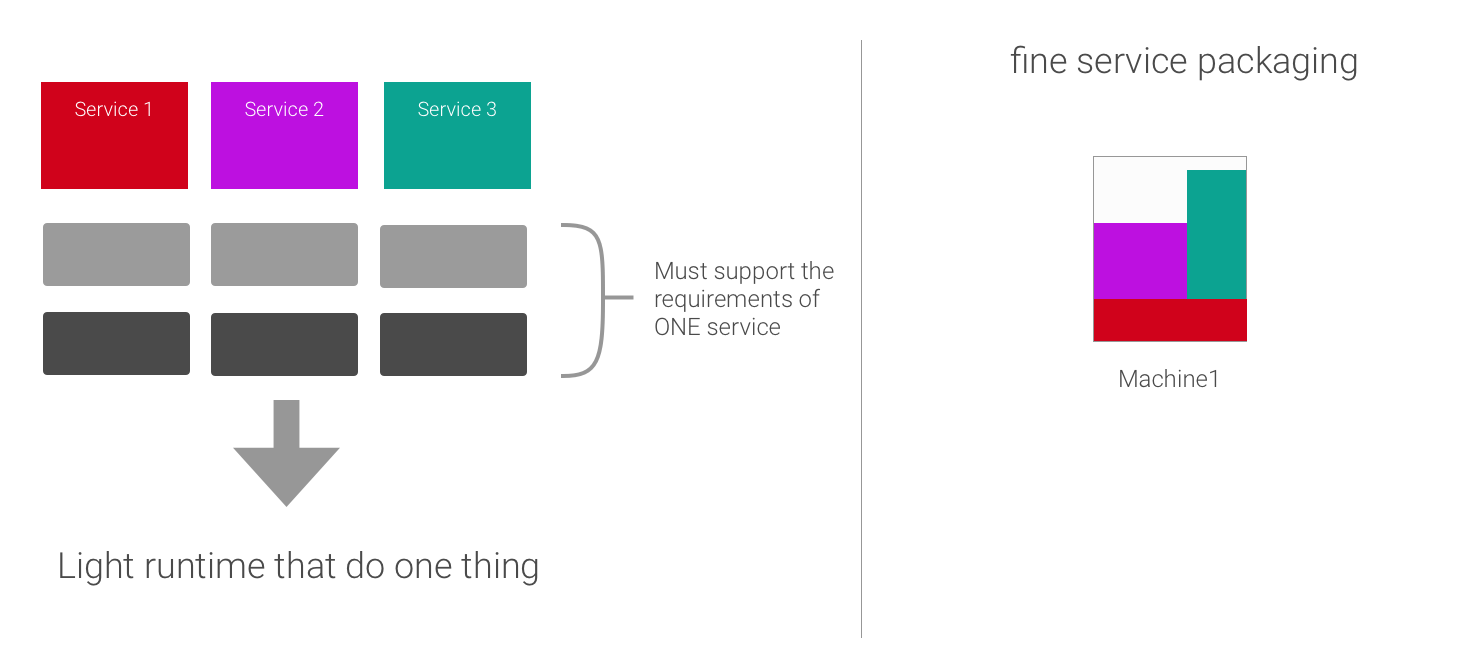
Additionally, microservices are developed and deployed as containers independently of each another. This means that a development team can develop, optimize, and deploy a microservice without impacting other subsystems.
Hardening the Gardener Community Setup
The Gardener project team has analyzed the impact of the Gardener CVE-2018-2475 and the Kubernetes CVE-2018-1002105 on the Gardener Community Setup. Following some recommendations it is possible to mitigate both vulnerabilities.
Kubernetes is Available in Docker for Mac 17.12 CE
 | Kubernetes is only available in Docker for Mac 17.12 CE and higher on the Edge channel. Kubernetes
support is not included in Docker for Mac Stable releases. To find out more about Stable and Edge channels
and how to switch between them, see
general configuration. |
The Kubernetes client command, kubectl, is included and configured to connect to the local Kubernetes server. If you have kubectl already installed and pointing to some other environment, such as minikube or a GKE cluster, be sure to change the context so that kubectl is pointing to docker-for-desktop. Read more on Docker.com.
I recommend to setup your shell to see which KUBECONFIG is active.
Namespace Isolation
…or DENY all traffic from other namespaces
You can configure a NetworkPolicy to deny all traffic from other namespaces while allowing all traffic coming from the same namespace the pod is deployed to. There are many reasons why you may choose to configure Kubernetes network policies:
- Isolate multi-tenant deployments
- Regulatory compliance
- Ensure containers assigned to different environments (e.g. dev/staging/prod) cannot interfere with each another
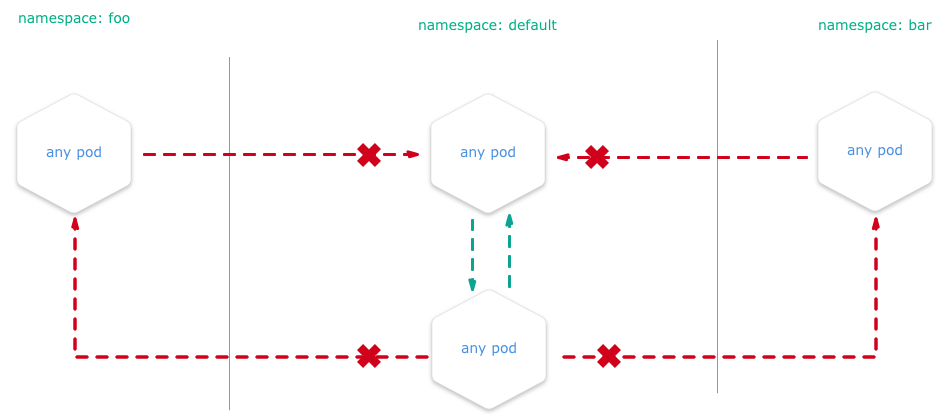
Learn more on Namespace Isolation.
Namespace Scope
Should I use:
- ❌ one namespace per user/developer?
- ❌ one namespace per team?
- ❌ one per service type?
- ❌ one namespace per application type?
- 😄 one namespace per running instance of your application?
Apply the Principle of Least Privilege
All user accounts should run as few privileges as possible at all times, and also launch applications with as few privileges as possible. If you share a cluster for a different user separated by a namespace, the user has access to all namespaces and services per default. It can happen that a user accidentally uses and destroys the namespace of a productive application or the namespace of another developer.
Keep in mind - By default namespaces don’t provide:
- Network Isolation
- Access Control
- Audit Logging on user level
ReadWriteMany - Dynamically Provisioned Persistent Volumes Using Amazon EFS
The efs-provisioner allows you to mount EFS storage as PersistentVolumes in Kubernetes. It consists of a container that has access to an AWS EFS resource. The container reads a configmap containing the EFS filesystem ID, the AWS region and the name identifying the efs-provisioner. This name will be used later when you create a storage class.
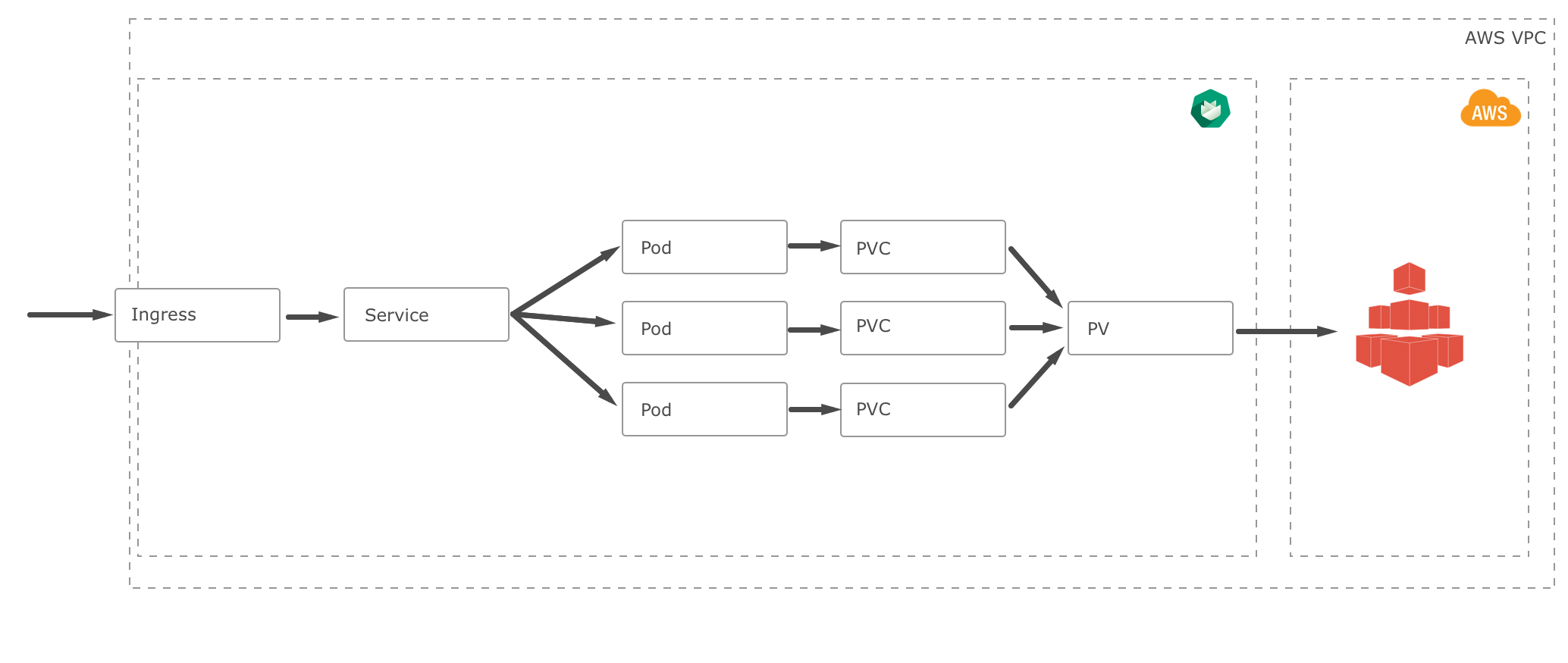
Why EFS
- When you have an application running on multiple nodes which require shared access to a file system.
- When you have an application that requires multiple virtual machines to access the same file system at the same time, AWS EFS is a tool that you can use.
- EFS supports encryption.
- EFS is SSD based storage and its storage capacity and pricing will scale in or out as needed, so there is no need for the system administrator to do additional operations. It can grow to a petabyte scale.
- EFS now supports NFSv4 lock upgrading and downgrading, so yes, you can use sqlite with EFS… even if it was possible before.
- EFS is easy to setup.
Why Not EFS
- Sometimes when you think about using a service like EFS, you may also think about vendor lock-in and its negative sides.
- Making an EFS backup may decrease your production FS performance; the throughput used by backups counts towards your total file system throughput.
- EFS is expensive when compared to EBS (roughly twice the price of EBS storage).
- EFS is not the magical solution for all your distributed FS problems, it can be slow in many cases. Test, benchmark, and measure to ensure that EFS is a good solution for your use case.
- EFS distributed architecture results in a latency overhead for each file read/write operation.
- If you have the possibility to use a CDN, don’t use EFS, use it for the files which can’t be stored in a CDN.
- Don’t use EFS as a caching system, sometimes you could be doing this unintentionally.
- Last but not least, even if EFS is a fully managed NFS, you will face performance problems in many cases, resolving them takes time and needs effort.
Shared Storage with S3 Backend
The storage is definitely the most complex and important part of an application setup. Once this part is completed, one of the most problematic parts could be solved.
Mounting an S3 bucket into a pod using FUSE allows you to access data stored in S3 via the filesystem. The mount is a pointer to an S3 location, so the data is never synced locally. Once mounted, any pod can read or even write from that directory without the need for explicit keys.
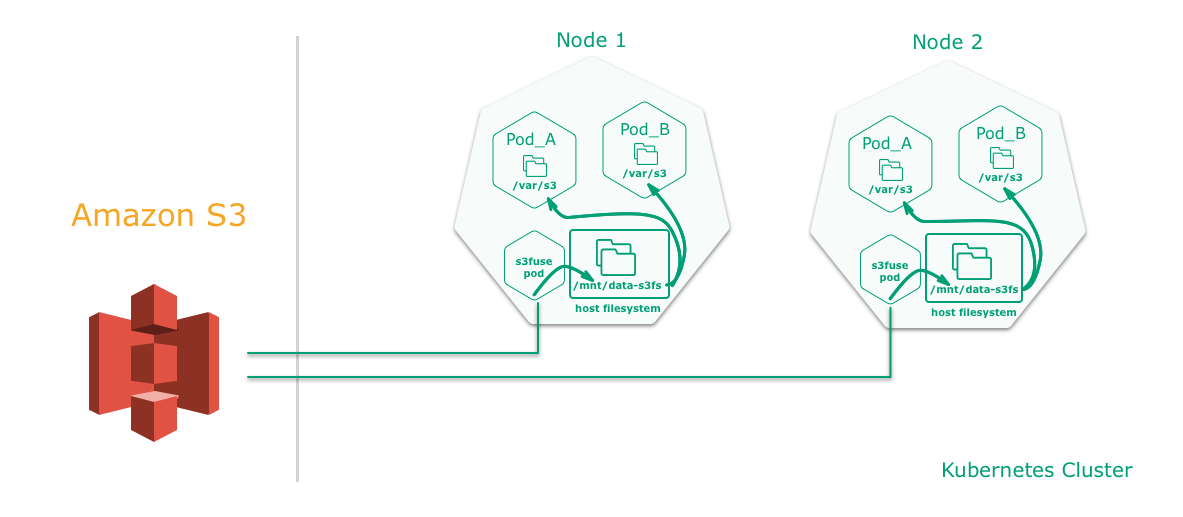
However, it can be used to import and parse large amounts of data into a database.
Learn more on Shared S3 Storage.
Watching Logs of Several Pods
One thing that always bothered me was that I couldn’t get the logs of several pods at once with kubectl. A simple tail -f <path-to-logfile> isn’t possible. Certainly, you can use kubectl logs -f <pod-id>, but it doesn’t help if you want to monitor more than one pod at a time.
This is something you really need a lot, at least if you run several instances of a pod behind a deploymentand you don’t have a log viewer service like Kibana set up.
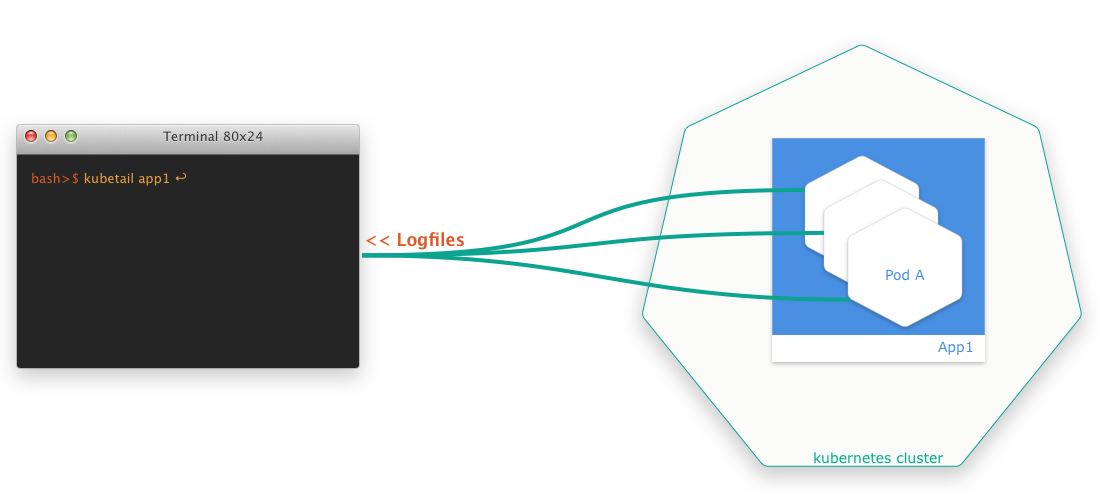
In that case, kubetail comes to the rescue. It is a small bash script that allows you to aggregate the log files of several pods at the same time in a simple way. The script is called kubetail and is available at GitHub.