This is the multi-page printable view of this section. Click here to print.
June
Getting Started with OpenTelemetry on a Gardener Shoot Cluster
In this blog post, we will explore how to set up an OpenTelemetry based observability stack on a Gardener shoot cluster. OpenTelemetry is an open-source observability framework that provides a set of APIs, SDKs, agents, and instrumentation to collect telemetry data from applications and systems. It provides a unified approach for collecting, processing, and exporting telemetry data such as traces, metrics, and logs. In addition, it gives flexibility in designing observability stacks, helping avoid vendor lock-in and allowing users to choose the most suitable tools for their use cases.
Here we will focus on setting up OpenTelemetry for a Gardener shoot cluster, collecting both logs and metrics and exporting them to various backends. We will use the OpenTelemetry Operator to simplify the deployment and management of OpenTelemetry collectors on Kubernetes and demonstrate some best practices for configuration including security and performance considerations.
Prerequisites
To follow along with this guide, you will need:
- A Gardener Shoot Cluster.
kubectlconfigured to access the cluster.shoot-cert-serviceenabled on the shoot cluster, to manage TLS certificates for the OpenTelemetry Collectors and backends.
Component Overview of the Sample OpenTelemetry Stack
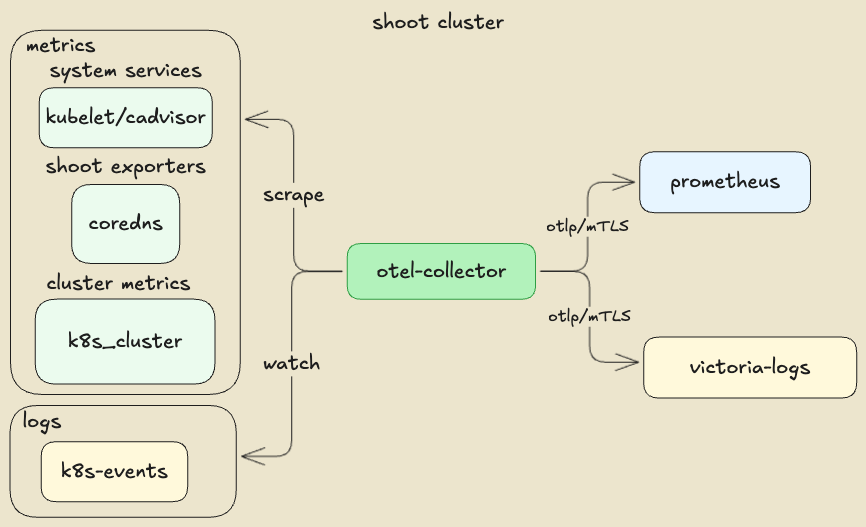
Setting Up a Gardener Shoot for mTLS Certificate Management
Here we use a self managed mTLS architecture with an illustration purpose. In a production environment, you would typically use a managed certificate authority (CA) or a service mesh to handle mTLS certificates and encryption. However, there might be cases where you want to have flexibility in authentication and authorization mechanisms, for example, by leveraging Kubernetes RBAC to determine whether a service is authorized to connect to a backend or not. In our illustration, we will use a kube-rbac-proxy as a sidecar to the backends, to enforce the mTLS authentication and authorization. The kube-rbac-proxy is a reverse proxy that uses Kubernetes RBAC to control access to services, allowing us to define fine-grained access control policies.
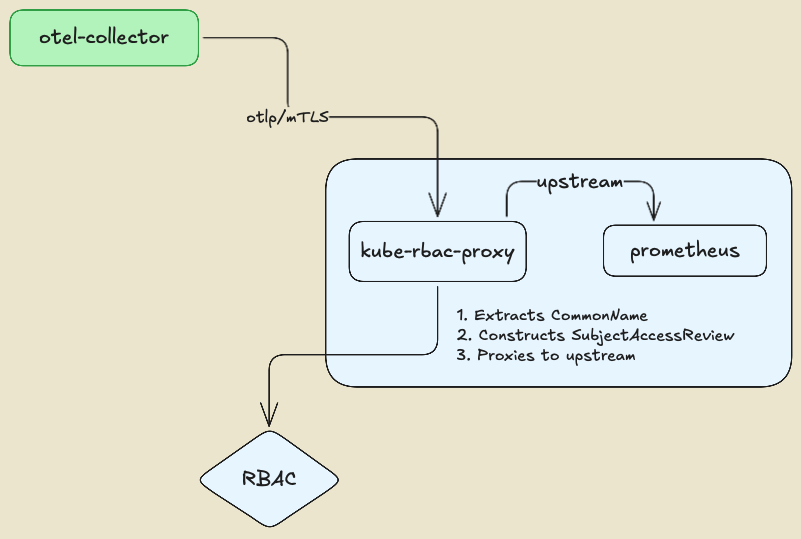
The kube-rbac-proxy extracts the identity of the client (OpenTelemetry collector) from the CommonName (CN) field of the TLS certificate and uses it to perform authorization checks against the Kubernetes API server. This enables fine-grained access control policies based on client identity, ensuring that only authorized clients can connect to the backends.
First, set up the Issuer certificate in the Gardener shoot cluster, allowing you to later issue and manage TLS certificates for the OpenTelemetry collectors and the backends. To allow a custom issuer, the shoot cluster shall be configured with the shoot-cert-service extension.
kind: Shoot
apiVersion: core.gardener.cloud/v1beta1
metadata:
name: my-shoot
namespace: my-project
...
spec:
extensions:
- type: shoot-cert-service
providerConfig:
apiVersion: service.cert.extensions.gardener.cloud/v1alpha1
kind: CertConfig
shootIssuers:
enabled: true
...
Once the shoot is reconciled, the Issuer.cert.gardener.cloud resources will be available.
We can use openssl to create a self-signed CA certificate that will be used to sign the TLS certificates for the OpenTelemetry Collector and backends.
openssl genrsa -out ./ca.key 4096
openssl req -x509 -new -nodes -key ./ca.key -sha256 -days 365 -out ./ca.crt -subj "/CN=ca"
# Create namespace and apply the CA secret and issuer
kubectl create namespace certs \
--dry-run=client -o yaml | kubectl apply -f -
# Create the CA secret in the certs namespace
kubectl create secret tls ca --namespace certs \
--key=./ca.key --cert=./ca.crt \
--dry-run=client -o yaml | kubectl apply -f -
Next, we will create the cluster Issuer resource, referencing the CA secret we just created.
apiVersion: cert.gardener.cloud/v1alpha1
kind: Issuer
metadata:
name: issuer-selfsigned
namespace: certs
spec:
ca:
privateKeySecretRef:
name: ca
namespace: certs
Later, we can create Certificate resources to securely connect the OpenTelemetry collectors to the backends.
Setting Up the OpenTelemetry Operator
To deploy the OpenTelemetry Operator on your Gardener Shoot Cluster, we can use the project helm chart with a minimum configuration. The important part is to set the collector image to the latest contrib distribution image which determines the set of receivers, processors, and exporters plugins that will be available in the OpenTelemetry collector instance. There are several pre-built distributions available such as: otelcol, otelcol-contrib, otelcol-k8s, otelcol-otlp, and otelcol-ebpf-profiler. For the purpose of this guide, we will use the otelcol-contrib distribution, which includes a wide range of plugins for various backends and data sources.
manager:
collectorImage:
repository: "otel/opentelemetry-collector-contrib"
Setting Up the Backends (prometheus, victoria-logs)
Setting up the backends is a straightforward process. We will use plain resource manifests for illustration purposes, outlining the important parts allowing OpenTelemetry collectors to connect securely to the backends using mTLS. An important part is enabling the respective OTLP ingestion endpoints on the backends, which will be used by the OpenTelemetry collectors to send telemetry data. In a production environment, the lifecycle of the backends will be probably managed by the respective component’s operators
Setting Up Prometheus (Metrics Backend)
Here is the complete list of manifests for deploying a single prometheus instance with the OTLP ingestion endpoint and a kube-rbac-proxy sidecar for mTLS authentication and authorization:
Prometheus Certificate That is the serving certificate of the
kube-rbac-proxysidecar. The OpenTelemetry collector needs to trust the signing CA, hence we use the sameIssuerwe created earlier.Prometheus The prometheus needs to be configured to allow
OTLPingestion endpoint:--web.enable-OTLP-receiver. That allows the OpenTelemetry collector to push metrics to the Prometheus instance (via thekube-rbac-proxysidecar).Prometheus Configuration In Prometheus’ case, the
OpenTelemetryresource attributes usually set by the collectors can be used to determine labels for the metrics. This is illustrated in the collector’sprometheusreceiver configuration. A common and unified set of labels across all metrics collected by the OpenTelemetry collector is a fundamental requirement for sharing and understanding the data across different teams and systems. This common set is defined by the OpenTelemetry Semantic Conventions specification. For example ,k8s.pod.name,k8s.namespace.name,k8s.node.name, etc. are some of the common labels that can be used to identify the source of the observability signals. Those are also common across the different types of telemetry data (traces, metrics, logs), serving correlation and analysis use cases.mTLS Proxy rbac This example defines a
Roleallowing requests to the prometheus backend to pass the kube-rbac-proxy.rules: - apiGroups: ["authorization.kubernetes.io"] resources: - observabilityapps/prometheus verbs: ["get", "create"] # GET, POSTIn this example, we allow
GETandPOSTrequests to reach the prometheus upstream service, if the request is authenticated with a valid mTLS certificate and the identified user is allowed to access the Prometheus service by the correspondingRoleBinding.PATCHandDELETErequests are not allowed. The mapping between the http request methods and the Kubernetes RBAC verbs is seen at kube-rbac-proxy/proxy.go.subjects: - apiGroup: rbac.authorization.k8s.io kind: User name: clientmTLS Proxy resource-attributes
kube-rbac-proxycreates KubernetesSubjectAccessReviewto determine if the request is allowed to pass. TheSubjectAccessReviewis created with theresourceAttributesset to the upstream service, in this case the Prometheus service.
Setting Up victoria-logs (Logs Backend)
In our example, we will use victoria-logs as the logs backend. victoria-logs is a high-performance, cost-effective, and scalable log management solution. It is designed to work seamlessly with Kubernetes and provides powerful querying capabilities. It is important to note that any OTLP compatible backend can be used as a logs backend, allowing flexibility in choosing the best tool for the concrete needs.
Here is the complete manifests for deploying a single victoria-logs instance with the OTLP ingestion endpoint enabled and kube-rbac-proxy sidecar for mTLS authentication and authorization, using the upstream helm chart:
- Victoria-Logs Certificate
That is the serving certificate of the
kube-rbac-proxysidecar. The OpenTelemetry collector needs to trust the signing CA hence we use the sameIssuerwe created earlier. - Victoria-Logs chart values
The certificate secret shall be mounted in the VictoriaLogs pod as a volume, as it is referenced by the
kube-rbac-proxysidecar. - Victoria-Logs mTLS Proxy rbac
There is no fundamental difference compared to how we configured the Prometheus mTLS proxy. The
Roleallows requests to the VictoriaLogs backend to pass the kube-rbac-proxy. - Victoria-Logs mTLS Proxy resource-attributes
By now we shall have a working Prometheus and victoria-logs backends, both secured with mTLS and ready to accept telemetry data from the OpenTelemetry collector.
Setting Up the OpenTelemetry Collectors
We are going to deploy two OpenTelemetry collectors: k8s-events and shoot-metrics. Both collectors will emit their own telemetry data in addition to the data collected from the respective receivers.
k8s-events collector
In this example, we use 2 receivers:
- k8s_events receiver to collect Kubernetes events from the cluster.
- k8s_cluster receiver to collect Kubernetes cluster metrics.
Here is an example of Kubernetes events persited in the victoria-logs backend. It filters logs which represents events from kube-system namesapce related to a rollout restart of the target statefulset. Then it formats the UI to show the event reason and object name.
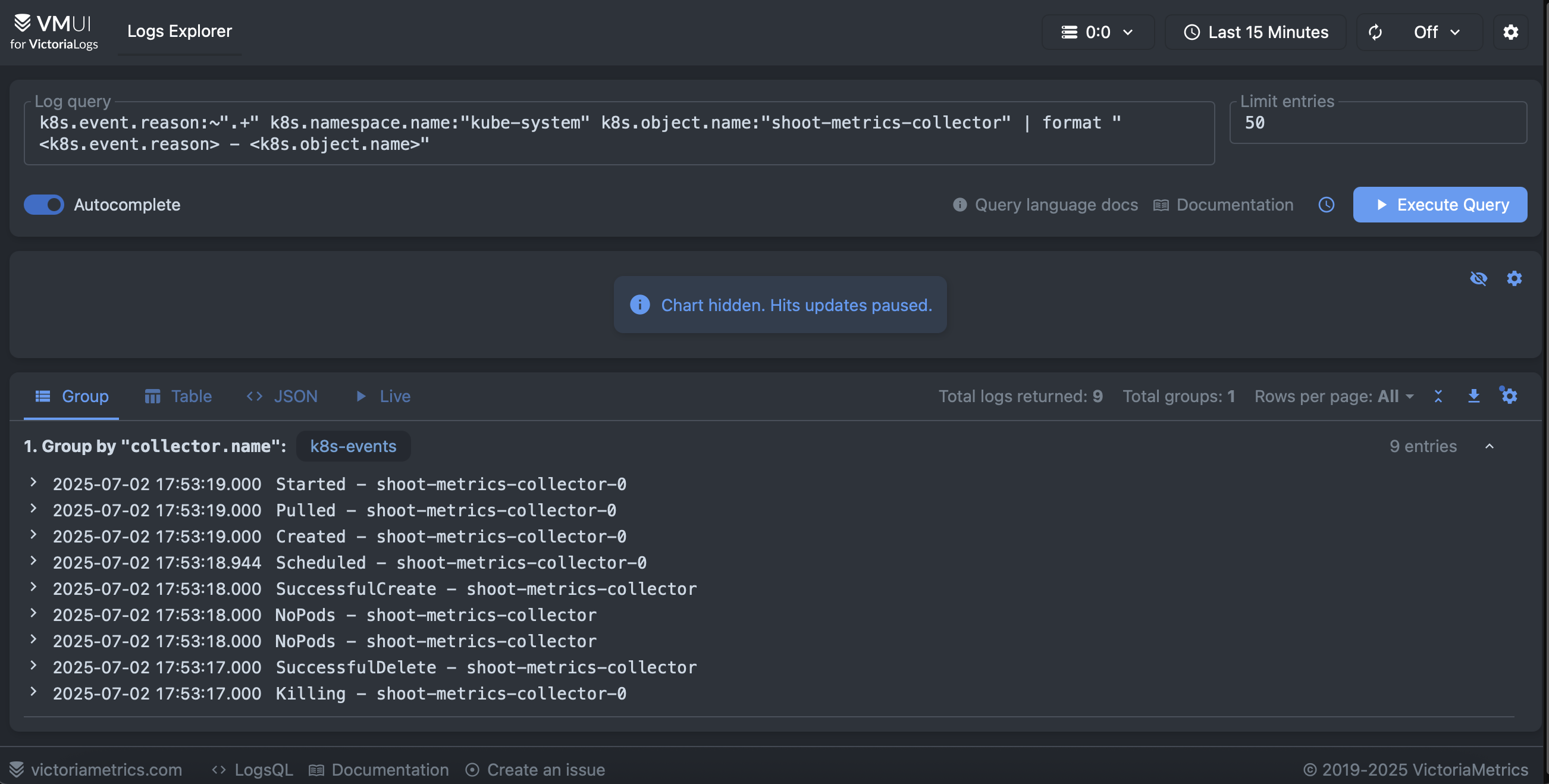
The collector features few important configurations related to reliability and performance. The collected metrics points are are sent in batches to the Prometheus backend using the corresponding OTLP exporter and the memory consumption of the collector is also limited. In general, it is always a good practice to set a memory limiter and batch processing in the collector pipeline.
processors:
memory_limiter:
check_interval: 1s
limit_percentage: 80
spike_limit_percentage: 2
batch:
timeout: 5s
send_batch_size: 1000
Allowing the collector to emit its own telemetry data is configured in the service section of the collector configuration.
service:
# Configure the collector own telemetry
telemetry:
# Emit collector logs to stdout, you can also push them to a backend.
logs:
level: info
encoding: console
output_paths: [stdout]
error_output_paths: [stderr]
# Push collector internal metrics to Prometheus
metrics:
level: detailed
readers:
- # push metrics to Prometheus backend
periodic:
interval: 30000
timeout: 10000
exporter:
OTLP:
protocol: http/protobuf
endpoint: "${env:PROMETHEUS_URL}/api/v1/OTLP/v1/metrics"
insecure: false # Ensure server certificate is validated against the CA
certificate: /etc/cert/ca.crt
client_certificate: /etc/cert/tls.crt
client_key: /etc/cert/tls.key
The majority of the samples use an prometheus receiver to scrape the collector metrics endpoint, however that is not a clean solution because it puts the metrics via the pipeline, thus consuming resources and potentially causing performance issues. Instead, we use the periodic reader to push the metrics directly to the Prometheus backend.
Since the k8s-events collector obtains telemetry data from the kube-apiserver, it requires a corresponding set of permissions defined at k8s-events rbac manifests.
shoot-metrics collector
In this example, we have a single receiver:
- prometheus receiver scraping metrics from Gardener managed exporters present in the shoot cluster, including the
kubeletsystem service metrics. This receiver accepts standard Prometheus scrape configurations usingkubernetes_sd_configsto discover the targets dynamically. Thekubernetes_sd_configsallows the receiver to discover Kubernetes resources such as pods, nodes, and services, and scrape their metrics endpoints.
Here, the example illustrates the prometheus receiver scraping metrics from the kubelet service, adding node kubernetes labels as labels to the scraped metrics and filtering the metrics to keep only the relevant ones. Since the kubelet metrics endpoint is secured, it needs the corresponding bearer token to be provided in the scrape configuration. The bearer token is automatically mounted in the pod by Kubernetes, allowing the OpenTelemetry collector to authenticate with the kubelet service.
- job_name: shoot-kube-kubelet
honor_labels: false
scheme: https
tls_config:
insecure_skip_verify: true
metrics_path: /metrics
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
kubernetes_sd_configs:
- role: node
relabel_configs:
- source_labels:
- job
target_label: __tmp_prometheus_job_name
- target_label: job
replacement: kube-kubelet
action: replace
- target_label: type
replacement: shoot
action: replace
- source_labels:
- __meta_kubernetes_node_address_InternalIP
target_label: instance
action: replace
- regex: __meta_kubernetes_node_label_(.+)
action: labelmap
replacement: "k8s_node_label_$${1}"
metric_relabel_configs:
- source_labels:
- __name__
regex: ^(kubelet_running_pods|process_max_fds|process_open_fds|kubelet_volume_stats_available_bytes|kubelet_volume_stats_capacity_bytes|kubelet_volume_stats_used_bytes|kubelet_image_pull_duration_seconds_bucket|kubelet_image_pull_duration_seconds_sum|kubelet_image_pull_duration_seconds_count)$
action: keep
- source_labels:
- namespace
regex: (^$|^kube-system$)
action: keep
The collector also illustrates collecting metrics from cadvisor endpoints and Gardener specific exporters such as
shoot-apiserver-proxy, shoot-coredns, etc. The exporters usually reside in the kube-system namespace and are configured to expose metrics on a specific port.
Since we aimed at unified set of resources attribues accross all telemetry data, we can translate exporters metrics which do not conform the conventions in OpenTelemetry.
Here is an example of translating the metrics, produced by the kubelet, to the OpenTelemetry conventions using the transform/metrics processor:
# Convert Prometheus metrics names to OpenTelemetry metrics names
transform/metrics:
error_mode: ignore
metric_statements:
- context: datapoint
statements:
- set(attributes["k8s.container.name"], attributes["container"]) where attributes["container"] != nil
- delete_key(attributes, "container") where attributes["container"] != nil
- set(attributes["k8s.pod.name"], attributes["pod"]) where attributes["pod"] != nil
- delete_key(attributes, "pod") where attributes["pod"] != nil
- set(attributes["k8s.namespace.name"], attributes["namespace"]) where attributes["namespace"] != nil
- delete_key(attributes, "namespace") where attributes["namespace"] != nil
Here is a visualization of container_network_transmit_bytes_total metric collected from the cadvisor endpoint of the kubelet service, showing the network traffic in bytes transmitted by the vpn-shoot containers.
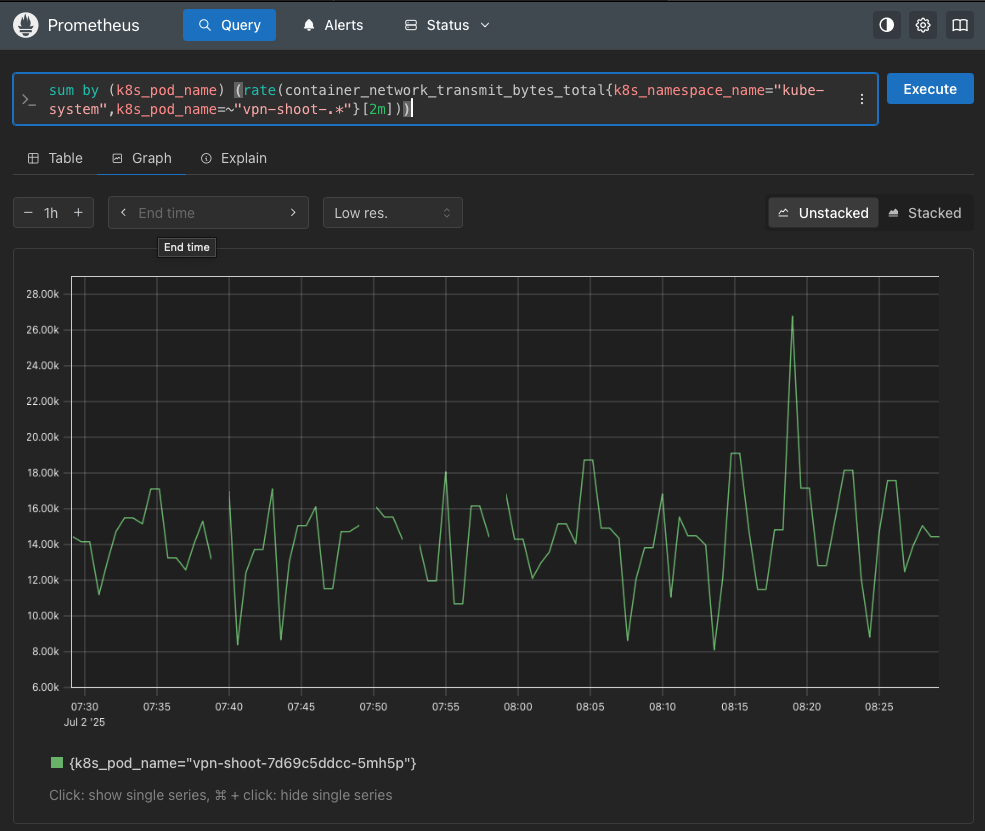
Similarly to the k8s-events collector, the shoot-metrics collector also emits its own telemetry data, including metrics and logs. The collector is configured to push its own metrics to the Prometheus backend using the periodic reader, avoiding the need for a separate Prometheus scrape configuration. It requires a corresponding set of permissions defined at shoot-metrics rbac manifest.
Summary
In this blog post, we have explored how to set up an OpenTelemetry based observability stack on a Gardener Shoot Cluster. We have demonstrated how to deploy the OpenTelemetry Operator, configure the backends prometheus and victoria-logs), and deploy OpenTelemetry collectors to obtain telemetry data from the cluster. We have also discussed best practices for configuration, including security and performance considerations. In this blog we have shown the unified set of resource attributes that can be used to identify the source of the telemetry data, allowing correlation and analysis across different teams and systems. We have demonstrated how to transform metrics labels which do not conform to the OpenTelemetry conventions, achieving a unified set of labels across all telemetry data. Finally, we have illustrated how to securely connect the OpenTelemetry collectors to the backends using mTLS and kube-rbac-proxy for authentication and authorization.
We hope this guide will inspire you to get started with OpenTelemetry on a Gardener managed shoot cluster and equip you with ideas and best practices for building a powerful observability stack that meets your needs. For more information, please refer to the OpenTelemetry documentation and the Gardener documentation.
Manifests List
Enabling Seamless IPv4 to Dual-Stack Migration for Kubernetes Clusters on GCP
Gardener continues to enhance its networking capabilities, now offering a streamlined migration path for existing IPv4-only shoot clusters on Google Cloud Platform (GCP) to dual-stack (IPv4 and IPv6). This allows clusters to leverage the benefits of IPv6 networking while maintaining IPv4 compatibility.
The Shift to Dual-Stack: What Changes?
Transitioning a Gardener-managed Kubernetes cluster on GCP from a single-stack IPv4 to a dual-stack setup involves several key modifications to the underlying infrastructure and networking configuration.
Triggering the Migration
The migration process is initiated by updating the shoot specification. Users simply need to add IPv6 to the spec.networking.ipFamilies field, changing it from [IPv4] to [IPv4, IPv6].
Infrastructure Adaptations
Once triggered, Gardener orchestrates the necessary infrastructure changes on GCP:
- IPv6-Enabled Subnets: The existing subnets (node subnet and internal subnet) within the Virtual Private Cloud (VPC) get external IPv6 ranges assigned.
- New IPv6 Service Subnet: A new subnet is provisioned specifically for services, also equipped with an external IPv6 range.
- Secondary IPv4 Range for Node Subnet: The node subnet is allocated an additional (secondary) IPv4 range. This is crucial as dual-stack load balancing on GCP, is managed via
ingress-gce, which utilizes alias IP ranges.
Enhanced Pod Routing on GCP
A significant change occurs in how pod traffic is routed. In the IPv4-only setup with native routing, the Cloud Controller Manager (CCM) creates individual routes in the VPC route table for each node’s pod CIDR. During the migration to dual-stack:
- These existing pod-specific cloud routes are systematically deleted from the VPC routing table.
- To maintain connectivity, the corresponding alias IP ranges are directly added to the Network Interface Card (NICs) of the Kubernetes worker nodes (VM instances).
The Migration Journey
The migration is a multi-phase process, tracked by a DualStackNodesMigrationReady constraint in the shoot’s status, which gets removed after a successfull migration.
Phase 1: Infrastructure Preparation Immediately after the
ipFamiliesfield is updated, an infrastructure reconciliation begins. This phase includes the subnet modifications mentioned above. A critical step here is the transition from VPC routes to alias IP ranges for existing nodes. The system carefully manages the deletion of old routes and the creation of new alias IP ranges on the virtual machines to ensure a smooth transition. Information about the routes to be migrated is temporarily persisted during this step in the infrastructure state.Phase 2: Node Upgrades For nodes to become dual-stack aware (i.e., receive IPv6 addresses for themselves and their pods), they need to be rolled out. This can happen during the next scheduled Kubernetes version or gardenlinux update or can be expedited by manually deleting the nodes, allowing Gardener to recreate the nodes with a new dual-stack configuration. Once all nodes have been updated and posses IPv4 and IPv6 pod CIDRs, the
DualStackNodesMigrationReadyconstraint will change toTrue.Phase 3: Finalizing Dual-Stack Activation With the infrastructure and nodes prepared, the final step involves configuring the remaining control plane components like kube-apiserver and the Container Network Interface (CNI) plugin like Calico or Cilium for dual-stack operation. After these components are fully dual-stack enabled, the migration constraint is removed, and the cluster operates in a full dual-stack mode. Existing IPv4 pods keep their IPv4 address, new ones receive both (IPv4 and IPv6) addresses.
Important Considerations for GCP Users
Before initiating the migration, please note the following:
- Native Routing Prerequisite: The IPv4-only cluster must be operating in native routing mode this. This means the pod overlay network needs to be disabled.
- GCP Route Quotas: When using native routing, especially for larger clusters, be mindful of GCP’s default quota for static routes per VPC (often 200, referred to as
STATIC_ROUTES_PER_NETWORK). It might be necessary to request a quota increase via the GCP cloud console before enabling native routing or migrating to dual-stack to avoid hitting limits.
This enhancement provides a clear path for Gardener users on GCP to adopt IPv6, paving the way for future-ready network architectures.
For further details, you can refer to the official pull request and the relevant segment of the developer talk. Additional documentation can also be found within the Gardener documentation.
Enhancing Meltdown Protection with Dependency-Watchdog Annotations
Gardener’s dependency-watchdog is a crucial component for ensuring cluster stability. During infrastructure-level outages where worker nodes cannot communicate with the control plane, it activates a “meltdown protection” mechanism. This involves scaling down key control plane components like the machine-controller-manager (MCM), cluster-autoscaler (CA), and kube-controller-manager (KCM) to prevent them from taking incorrect actions based on stale information, such as deleting healthy nodes that are only temporarily unreachable.
The Challenge: Premature Scale-Up During Reconciliation
Previously, a potential race condition could undermine this protection. While dependency-watchdog scaled down the necessary components, a concurrent Shoot reconciliation, whether triggered manually by an operator or by other events, could misinterpret the situation. The reconciliation logic, unaware that the scale-down was a deliberate protective measure, would attempt to restore the “desired” state by scaling the machine-controller-manager and cluster-autoscaler back up.
This premature scale-up could have serious consequences. An active machine-controller-manager, for instance, might see nodes in an Unknown state due to the ongoing outage and incorrectly decide to delete them, defeating the entire purpose of the meltdown protection.
The Solution: A New Annotation for Clearer Signaling
To address this, Gardener now uses a more explicit signaling mechanism between dependency-watchdog and gardenlet. When dependency-watchdog scales down a deployment as part of its meltdown protection, it now adds the following annotation to the resource:
dependency-watchdog.gardener.cloud/meltdown-protection-active
This annotation serves as a clear, persistent signal that the component has been intentionally scaled down for safety.
How It Works
The gardenlet component has been updated to recognize and respect this new annotation. During a Shoot reconciliation, before scaling any deployment, gardenlet now checks for the presence of the dependency-watchdog.gardener.cloud/meltdown-protection-active annotation.
If the annotation is found, gardenlet will not scale up the deployment. Instead, it preserves the current replica count set by dependency-watchdog, ensuring that the meltdown protection remains effective until the underlying infrastructure issue is resolved and dependency-watchdog itself restores the components. This change makes the meltdown protection mechanism more robust and prevents unintended node deletions during any degradation of connectivity between the nodes and control plane.
Additionally on a deployment which has dependency-watchdog.gardener.cloud/meltdown-protection-active annotation set, if the operator decides to ignores such a deployment from meltdown consideration by annotating it with dependency-watchdog.gardener.cloud/ignore-scaling, then for such deployments dependency-watchdog shall remove the dependency-watchdog.gardener.cloud/meltdown-protection-active annotation and the deployment shall be considered for scale-up as part of next shoot reconciliation. The operator can also explicitly scale up such a deployment and not wait for the next shoot reconciliation.
For More Information
To dive deeper into the implementation details, you can review the changes in the corresponding pull request.
Improving Credential Management for Seed Backups
Gardener has introduced a new feature gate, DoNotCopyBackupCredentials, to enhance the security and clarity of how backup credentials for managed seeds are handled. This change moves away from an implicit credential-copying mechanism to a more explicit and secure configuration practice.
The Old Behavior and Its Drawbacks
Previously, when setting up a managed seed, the controller would automatically copy the shoot’s infrastructure credentials to serve as the seed’s backup credentials if a backup secret was not explicitly provided. While this offered some convenience, it had several disadvantages:
- Promoted Poor Security Practices: It encouraged the use of the same credentials for both shoot infrastructure and seed backups, violating the principle of least privilege and credential segregation.
- Caused Confusion: The implicit copying of secrets could be confusing for operators, as the source of the backup credential was not immediately obvious from the configuration.
- Inconsistent with Modern Credentials: The mechanism worked for
Secret-based credentials but was not compatible withWorkloadIdentity, which cannot be simply copied.
The New Approach: Explicit Credential Management
The new DoNotCopyBackupCredentials feature gate, when enabled in gardenlet, disables this automatic copying behavior. With the gate active, operators are now required to explicitly create and reference a secret for the seed backup.
If seed.spec.backup.credentialsRef points to a secret that does not exist, the reconciliation process will fail with an error, ensuring that operators consciously provide a dedicated credential for backups. This change promotes the best practice of using separate, segregated credentials for infrastructure and backups, significantly improving the security posture of the landscape.
For Operators: What You Need to Do
When you enable the DoNotCopyBackupCredentials feature gate, you must ensure that any Seed you configure has a pre-existing secret for its backup.
For setups where credentials were previously copied, Gardener helps with the transition. The controller will stop managing the lifecycle of these copied secrets. To help operators identify them for cleanup, these secrets will be labeled with secret.backup.gardener.cloud/status=previously-managed. You can then review these secrets and manage them accordingly.
This enhancement is a step towards more robust, secure, and transparent operations in Gardener, giving operators clearer control over credential management.
Further Reading
Enhanced Extension Management: Introducing `autoEnable` and `clusterCompatibility`
Gardener’s extension mechanism has been enhanced with two new fields in the ControllerRegistration and operatorv1alpha1.Extension APIs, offering operators more granular control and improved safety when managing extensions. These changes, detailed in PR #11982, introduce autoEnable and clusterCompatibility for resources of kind: Extension.
Fine-Grained Automatic Enablement with autoEnable
Previously, operators could use the globallyEnabled field to automatically enable an extension resource for all shoot clusters. This field is now deprecated and will be removed in Gardener v1.123.
The new autoEnable field replaces globallyEnabled and provides more flexibility. Operators can now specify an array of cluster types for which an extension should be automatically enabled. The supported cluster types are:
shootseedgarden
This allows, for example, an extension to be automatically enabled for all seed clusters or a combination of cluster types, which was not possible with the boolean globallyEnabled field.
If autoEnable includes shoot, it behaves like the old globallyEnabled: true for shoot clusters. If an extension is not set to autoEnable for a specific cluster type, it must be explicitly enabled in the respective cluster’s manifest (e.g., Shoot manifest for a shoot cluster).
# Example in ControllerRegistration or operatorv1alpha1.Extension spec.resources
- kind: Extension
type: my-custom-extension
autoEnable:
- shoot
- seed
# globallyEnabled: true # This field is deprecated
Ensuring Correct Deployments with clusterCompatibility
To enhance safety and prevent misconfigurations, the clusterCompatibility field has been introduced. This field allows extension developers and operators to explicitly define which cluster types a generic Gardener extension is compatible with. The supported cluster types are:
shootseedgarden
Gardener will validate that an extension is only enabled or automatically enabled for cluster types listed in its clusterCompatibility definition. If clusterCompatibility is not specified for an Extension kind, it defaults to ['shoot']. This provides an important safeguard, ensuring that extensions are not inadvertently deployed to environments they are not designed for.
# Example in ControllerRegistration or operatorv1alpha1.Extension spec.resources
- kind: Extension
type: my-custom-extension
autoEnable:
- shoot
clusterCompatibility: # Defines where this extension can be used
- shoot
- seed
Important Considerations for Operators
- Deprecation of
globallyEnabled: Operators should migrate fromgloballyEnabledto the newautoEnablefield forkind: Extensionresources.globallyEnabledis deprecated and scheduled for removal in Gardenerv1.123. - Breaking Change for Garden Extensions: The introduction of
clusterCompatibilityis a breaking change for operators managing garden extensions viagardener-operator. If yourGardencustom resource specifiesspec.extensions, you must update the correspondingoperatorv1alpha1.Extensionresources to includegardenin theclusterCompatibilityarray for those extensions intended to run in the garden cluster.
These new fields provide more precise control over extension lifecycle management across different cluster types within the Gardener ecosystem, improving both operational flexibility and system stability.
For further details, you can review the original pull request (#11982) and watch the demonstration in the Gardener Review Meeting (starting at 41:23).
Enhanced Internal Traffic Management: L7 Load Balancing for kube-apiservers in Gardener
Gardener continuously evolves to optimize performance and reliability. A recent improvement focuses on how internal control plane components communicate with kube-apiserver instances, introducing cluster-internal Layer 7 (L7) load balancing to ensure better resource distribution and system stability.
The Challenge: Unbalanced Internal Load on kube-apiservers
Previously, while external access to Gardener-managed kube-apiservers (for Shoots and the Virtual Garden) benefited from L7 load balancing via Istio, internal traffic took a more direct route. Components running within the seed cluster, such as gardener-resource-manager and gardener-controller-manager, would access the kube-apiserver’s internal Kubernetes service directly. This direct access bypassed the L7 load balancing capabilities of the Istio ingress gateway.
This could lead to situations where certain kube-apiserver instances might become overloaded, especially if a particular internal client generated a high volume of requests, potentially impacting the stability and performance of the control plane.
The Solution: Extending L7 Load Balancing Internally
To address this, Gardener now implements cluster-internal L7 load balancing for traffic destined for kube-apiservers from within the control plane. This enhancement ensures that requests from internal components are distributed efficiently across available kube-apiserver replicas, mirroring the sophisticated load balancing already in place for external traffic, but crucially, without routing this internal traffic externally.
Key aspects of this solution include:
- Leveraging Existing Istio Ingress Gateway: The system utilizes the existing Istio ingress gateway, which already handles L7 load balancing for external traffic.
- Dedicated Internal Service: A new, dedicated internal
ClusterIPservice is created for the Istio ingress gateway pods. This service provides an internal entry point for the load balancing. - Smart Kubeconfig Adjustments: The
kubeconfigfiles used by internal components (specifically, the generic token kubeconfigs) are configured to point to thekube-apiserver’s public, resolvable DNS address. - Automated Configuration Injection: A new admission webhook, integrated into
gardener-resource-managerand namedpod-kube-apiserver-load-balancing, plays a crucial role. When control plane pods are created, this webhook automatically injects:- Host Aliases: It adds a host alias to the pod’s
/etc/hostsfile. This alias maps thekube-apiserver’s public DNS name to the IP address of the new internalClusterIPservice for the Istio ingress gateway. - Network Policy Labels: Necessary labels are added to ensure network policies permit this traffic flow.
- Host Aliases: It adds a host alias to the pod’s
With this setup, when an internal component attempts to connect to the kube-apiserver using its public DNS name, the host alias redirects the traffic to the internal Istio ingress gateway service. The ingress gateway then performs L7 load balancing, distributing the requests across the available kube-apiserver instances.
Benefits
This approach offers several advantages:
- Improved Resource Distribution: Load from internal components is now evenly spread across
kube-apiserverinstances, preventing hotspots. - Enhanced Reliability: By avoiding overloading individual
kube-apiserverpods, the overall stability and reliability of the control plane are improved. - Internalized Traffic: Despite using the
kube-apiserver’s public DNS name in configurations, traffic remains within the cluster, avoiding potential costs or latency associated with external traffic routing.
This enhancement represents a significant step in refining Gardener’s internal traffic management, contributing to more robust and efficiently managed Kubernetes clusters.
Further Information
To dive deeper into the technical details, you can explore the following resources:
- Issue: gardener/gardener#8810
- Pull Request: gardener/gardener#12260
- Project Summary: Cluster-Internal L7 Load-Balancing Endpoints For kube-apiservers
- Recording Segment: Watch the introduction of this feature
Gardener Enhances Observability with OpenTelemetry Integration for Logging
Gardener is advancing its observability capabilities by integrating OpenTelemetry, starting with log collection and processing. This strategic move, outlined in GEP-34: OpenTelemetry Operator And Collectors, lays the groundwork for a more standardized, flexible, and powerful observability framework in line with Gardener’s Observability 2.0 vision.
The Drive Towards Standardization
Gardener’s previous observability stack, though effective, utilized vendor-specific formats and protocols. This presented challenges in extending components and integrating with diverse external systems. The adoption of OpenTelemetry addresses these limitations by aligning Gardener with open standards, enhancing interoperability, and paving the way for future innovations like unified visualization, comprehensive tracing support and even LLM integrations via MCP (Model Context Propagation) enabled services.
Core Components: Operator and Collectors
The initial phase of this integration introduces two key OpenTelemetry components into Gardener-managed clusters:
- OpenTelemetry Operator: Deployed on seed clusters (specifically in the
gardennamespace usingManagedResources), the OpenTelemetry Operator for Kubernetes will manage the lifecycle of OpenTelemetry Collector instances across shoot control planes. Its deployment follows a similar pattern to the existing Prometheus and Fluent Bit operators and occurs during theSeedreconciliation flow. - OpenTelemetry Collectors: A dedicated OpenTelemetry Collector instance will be provisioned for each shoot control plane namespace (e.g.,
shoot--project--name). These collectors, managed asDeployments by the OpenTelemetry Operator via anOpenTelemetryCollectorCustom Resource created duringShootreconciliation, are responsible for receiving, processing, and exporting observability data, with an initial focus on logs.
Key Changes and Benefits for Logging
- Standardized Log Transport: Logs from various sources will now be channeled through the OpenTelemetry Collector.
- Shoot Node Log Collection: The existing
valitailsystemd service on shoot nodes is being replaced by an OpenTelemetry Collector. This new collector will gather systemd logs (e.g., fromkernel,kubelet.service,containerd.service) with parity tovalitail’s previous functionality and forward them to the OpenTelemetry Collector instance residing in the shoot control plane. - Fluent Bit Integration: Existing Fluent Bit instances, which act as log shippers on seed clusters, will be configured to forward logs to the OpenTelemetry Collector’s receivers. This ensures continued compatibility with the Vali-based setup previously established by GEP-19.
- Shoot Node Log Collection: The existing
- Backend Agility: While initially the OpenTelemetry Collector will be configured to use its Loki exporter to send logs to the existing Vali backend, this architecture introduces significant flexibility. It allows Gardener to switch to any OpenTelemetry-compatible backend in the future, with plans to eventually migrate to Victoria-Logs.
- Phased Rollout: The transition to OpenTelemetry is designed as a phased approach. Existing observability tools like Vali, Fluent Bit, and Prometheus will be gradually integrated and some backends such as Vali will be replaced.
- Foundation for Future Observability: Although this GEP primarily targets logging, it critically establishes the foundation for incorporating other observability signals, such as metrics and traces, into the OpenTelemetry framework. Future enhancements may include:
- Utilizing the OpenTelemetry Collector on shoot nodes to also scrape and process metrics.
- Replacing the current event logger component with the OpenTelemetry Collector’s
k8s-eventreceiver within the shoot’s OpenTelemetry Collector instance.
Explore Further
This integration marks a significant step in Gardener’s observability journey, promising a more robust and adaptable system.
- Dive deeper into the technical details by reading the full proposal: GEP-34: OpenTelemetry Operator And Collectors.
- Watch the segment from the Gardener Review Meeting discussing this feature: Recording (starts at 14:09).
- Learn more about the overall strategy in the Observability 2.0 vision for Gardener.
Taking Gardener to the Next Level: Highlights from the 7th Gardener Community Hackathon in Schelklingen
Taking Gardener to the Next Level: Highlights from the 7th Gardener Community Hackathon in Schelklingen
The latest “Hack The Garden” event, held in June 2025 at Schlosshof in Schelklingen, brought together members of the Gardener community for an intensive week of collaboration, coding, and problem-solving. The hackathon focused on a wide array of topics aimed at enhancing Gardener’s capabilities, modernizing its stack, and improving user experience. You can find a full summary of all topics on GitHub and watch the wrap-up presentations on YouTube.

Here’s a look at some of the key achievements and ongoing efforts:
🚀 Modernizing Core Infrastructure and Networking
A significant focus was on upgrading and refining Gardener’s foundational components.
One major undertaking was the replacement of OpenVPN with Wireguard (watch presentation). The goal is to modernize the VPN stack for communication between control and data planes, leveraging Wireguard’s reputed performance and simplicity. OpenVPN, while established, presents challenges like TCP-in-TCP. The team developed a Proof of Concept (POC) for a Wireguard-based VPN connection for a single shoot in a local setup, utilizing a reverse proxy like mwgp to manage connections without needing a load balancer per control plane. A document describing the approach is available. Next steps involve thorough testing of resilience and throughput, aggregating secrets for MWGP configuration, and exploring ways to update MWGP configuration without restarts. Code contributions can be found in forks of gardener, vpn2, and mwgp.
Another critical area is overcoming the 450 Node limit on Azure (watch presentation).
Current Azure networking for Gardener relies on route tables, which have size limitations.
The team analyzed the hurdles and discussed a potential solution involving a combination of route tables and virtual networks.
Progress here depends on an upcoming Azure preview feature.
The hackathon also saw progress on cluster-internal L7 Load-Balancing for kube-apiservers.
Building on previous work for external endpoints, this initiative aims to provide L7 load-balancing for internal traffic from components like gardener-resource-manager.
Achievements include an implementation leveraging generic token kubeconfig and a dedicated ClusterIP service for Istio ingress gateway pods.
The PR #12260 is awaiting review to merge this improvement, addressing issue #8810.
🔭 Enhancing Observability and Operations
Improving how users monitor and manage Gardener clusters was another key theme.
A significant step towards Gardener’s Observability 2.0 initiative was made with the OpenTelemetry Transport for Shoot Metrics (watch presentation).
The current method of collecting shoot metrics via the Kubernetes API server /proxy endpoint lacks fine-tuning capabilities.
The hackathon proved the viability of collecting and filtering shoot metrics via OpenTelemetry collector instances on shoots, transporting them to Prometheus OTLP ingestion endpoints on seeds. This allows for more flexible and modern metrics collection.
For deeper network insights, the Cluster Network Observability project (watch presentation) enhanced the Retina tool by Microsoft. The team successfully added labeling for source and destination availability zones to Retina’s traffic metrics (see issue #1654 and PR #1657). This will help identify cross-AZ traffic, potentially reducing costs and latency.
To support lightweight deployments, efforts were made to make gardener-operator Single-Node Ready (watch presentation).
This involved making several components, including Prometheus deployments, configurable to reduce resource overhead in single-node or bare-metal scenarios.
Relevant PRs include those for gardener-extension-provider-gcp #1052, gardener-extension-provider-openstack #1042, fluent-operator #1616, and gardener #12248, along with fixes in forked Cortex and Vali repositories.
Streamlining node management was the focus of the Worker Group Node Roll-out project (watch presentation).
A PoC was created (see rrhubenov/gardener branch) allowing users to trigger a node roll-out for specific worker groups via a shoot annotation (gardener.cloud/operation=rollout-workers=<pool-names>), which is particularly useful for scenarios like dual-stack migration.
Proactive workload management is the aim of the Instance Scheduled Events Watcher (watch presentation). This initiative seeks to create an agent that monitors cloud provider VM events (like reboots or retirements) and exposes them as node events or dashboard warnings. A PR #9170 for cloud-provider-azure was raised to enable this for Azure, allowing users to take timely action.
🛡️ Bolstering Security and Resource Management
Security and efficient resource handling remain paramount.
The Signing of ManagedResource Secrets project (watch presentation) addressed a potential privilege escalation vector.
A PoC demonstrated that signing ManagedResource secrets with a key known only to the Gardener Resource Manager (GRM) is feasible, allowing GRM to verify secret integrity.
This work is captured in gardener PR #12247.
Simplifying operations was the goal of Migrating Control Plane Reconciliation of Provider Extensions to ManagedResources (watch presentation). Instead of using the chart applier, this change wraps control-plane components in ManagedResources, improving scalability and automation (e.g., scaling components imperatively).
Gardener PR #12251 was created for this, with a stretch goal related to issue #12250 explored in a compare branch.
A quick win, marked as a 🏎️ fast-track item, was to Expose EgressCIDRs in the shoot-info ConfigMap (watch presentation).
This makes egress CIDRs available to workloads within the shoot cluster, useful for controllers like Crossplane.
This was implemented and merged during the hackathon via gardener PR #12252.
✨ Improving User and Developer Experience
Enhancing the usability of Gardener tools is always a priority.
The Dashboard Usability Improvements project (watch presentation) tackled several areas based on dashboard issue #2469. Achievements include:
- Allowing custom display names for projects via annotations (dashboard PR #2470).
- Configurable default values for Shoot creation, like AutoScaler min/max replicas (dashboard PR #2476).
- The ability to hide certain UI elements, such as Control Plane HA options (dashboard PR #2478).
The Documentation Revamp (watch presentation) aimed to improve the structure and discoverability of Gardener’s documentation. Metadata for pages was enhanced (documentation PR #652), the glossary was expanded (documentation PR #653), and a PoC for using VitePress as a more modern documentation generator was created.
🔄 Advancing Versioning and Deployment Strategies
Flexibility in managing Gardener versions and deployments was also explored.
The topic of Multiple Parallel Versions in a Gardener Landscape (formerly Canary Deployments) (watch presentation) investigated ways to overcome tight versioning constraints.
It was discovered that the current implementation already allows rolling out different extension versions across different seeds using controller registration seat selectors.
Further discussion is needed on some caveats, particularly around the primary field in ControllerRegistration resources.
Progress was also made on GEP-32 – Version Classification Lifecycles (🏎️ fast-track). This initiative, started in a previous hackathon, aims to automate version lifecycle management. The previous PR (metal-stack/gardener #9) was rebased and broken into smaller, more reviewable PRs.
🌱 Conclusion
The Hack The Garden event in Schelklingen was a testament to the community’s dedication and collaborative spirit. Numerous projects saw significant progress, from PoCs for major architectural changes to practical improvements in daily operations and user experience. Many of these efforts are now moving into further development, testing, and review, promising exciting enhancements for the Gardener ecosystem.
Stay tuned for more updates as these projects mature and become integrated into Gardener!
The next hackathon takes place in early December 2025. If you’d like to join, head over to the Gardener Slack. Happy to meet you there! ✌️