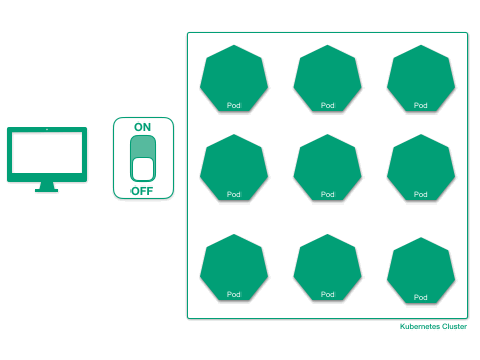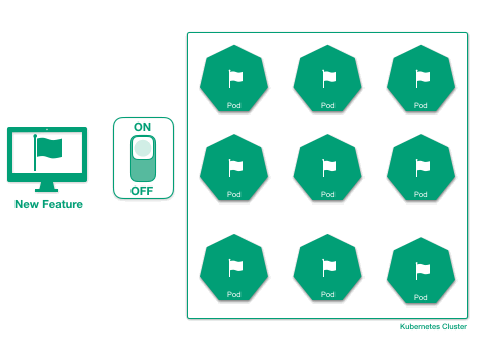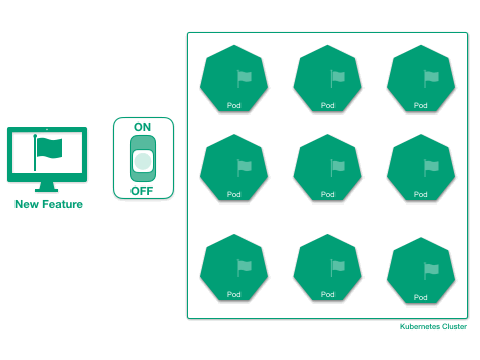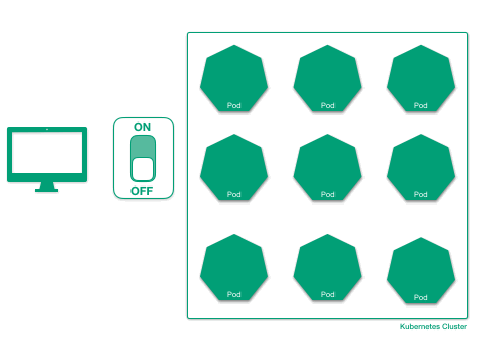
Enabling Seamless IPv4 to Dual-Stack Migration for Kubernetes Clusters on GCP
Gardener continues to enhance its networking capabilities, now offering a streamlined migration path for existing IPv4-only shoot clusters on Google Cloud Platform (GCP) to dual-stack (IPv4 and IPv6). This allows clusters to leverage the benefits of IPv6 networking while maintaining IPv4 compatibility.
The Shift to Dual-Stack: What Changes?
Transitioning a Gardener-managed Kubernetes cluster on GCP from a single-stack IPv4 to a dual-stack setup involves several key modifications to the underlying infrastructure and networking configuration.
Triggering the Migration
The migration process is initiated by updating the shoot specification. Users simply need to add IPv6 to the spec.networking.ipFamilies field, changing it from [IPv4] to [IPv4, IPv6].
Infrastructure Adaptations
Once triggered, Gardener orchestrates the necessary infrastructure changes on GCP:
IPv6-Enabled Subnets: The existing subnets (node subnet and internal subnet) within the Virtual Private Cloud (VPC) get external IPv6 ranges assigned.
New IPv6 Service Subnet: A new subnet is provisioned specifically for services, also equipped with an external IPv6 range.
Secondary IPv4 Range for Node Subnet: The node subnet is allocated an additional (secondary) IPv4 range. This is crucial as dual-stack load balancing on GCP, is managed via ingress-gce, which utilizes alias IP ranges.
Enhanced Pod Routing on GCP
A significant change occurs in how pod traffic is routed. In the IPv4-only setup with native routing, the Cloud Controller Manager (CCM) creates individual routes in the VPC route table for each node’s pod CIDR. During the migration to dual-stack:
These existing pod-specific cloud routes are systematically deleted from the VPC routing table.
To maintain connectivity, the corresponding alias IP ranges are directly added to the Network Interface Card (NICs) of the Kubernetes worker nodes (VM instances).
The Migration Journey
The migration is a multi-phase process, tracked by a DualStackNodesMigrationReady constraint in the shoot’s status, which gets removed after a successfull migration.
Phase 1: Infrastructure Preparation
Immediately after the ipFamilies field is updated, an infrastructure reconciliation begins. This phase includes the subnet modifications mentioned above. A critical step here is the transition from VPC routes to alias IP ranges for existing nodes. The system carefully manages the deletion of old routes and the creation of new alias IP ranges on the virtual machines to ensure a smooth transition. Information about the routes to be migrated is temporarily persisted during this step in the infrastructure state.
Phase 2: Node Upgrades
For nodes to become dual-stack aware (i.e., receive IPv6 addresses for themselves and their pods), they need to be rolled out. This can happen during the next scheduled Kubernetes version or gardenlinux update or can be expedited by manually deleting the nodes, allowing Gardener to recreate the nodes with a new dual-stack configuration. Once all nodes have been updated and posses IPv4 and IPv6 pod CIDRs, the DualStackNodesMigrationReady constraint will change to True.
Phase 3: Finalizing Dual-Stack Activation
With the infrastructure and nodes prepared, the final step involves configuring the remaining control plane components like kube-apiserver and the Container Network Interface (CNI) plugin like Calico or Cilium for dual-stack operation. After these components are fully dual-stack enabled, the migration constraint is removed, and the cluster operates in a full dual-stack mode. Existing IPv4 pods keep their IPv4 address, new ones receive both (IPv4 and IPv6) addresses.
Important Considerations for GCP Users
Before initiating the migration, please note the following:
Native Routing Prerequisite: The IPv4-only cluster must be operating in native routing mode this. This means the pod overlay network needs to be disabled.
GCP Route Quotas: When using native routing, especially for larger clusters, be mindful of GCP’s default quota for static routes per VPC (often 200, referred to as STATIC_ROUTES_PER_NETWORK). It might be necessary to request a quota increase via the GCP cloud console before enabling native routing or migrating to dual-stack to avoid hitting limits.
This enhancement provides a clear path for Gardener users on GCP to adopt IPv6, paving the way for future-ready network architectures.
Gardener has introduced a new feature gate, DoNotCopyBackupCredentials, to enhance the security and clarity of how backup credentials for managed seeds are handled. This change moves away from an implicit credential-copying mechanism to a more explicit and secure configuration practice.
The Old Behavior and Its Drawbacks
Previously, when setting up a managed seed, the controller would automatically copy the shoot’s infrastructure credentials to serve as the seed’s backup credentials if a backup secret was not explicitly provided. While this offered some convenience, it had several disadvantages:
Promoted Poor Security Practices: It encouraged the use of the same credentials for both shoot infrastructure and seed backups, violating the principle of least privilege and credential segregation.
Caused Confusion: The implicit copying of secrets could be confusing for operators, as the source of the backup credential was not immediately obvious from the configuration.
Inconsistent with Modern Credentials: The mechanism worked for Secret-based credentials but was not compatible with WorkloadIdentity, which cannot be simply copied.
The New Approach: Explicit Credential Management
The new DoNotCopyBackupCredentials feature gate, when enabled in gardenlet, disables this automatic copying behavior. With the gate active, operators are now required to explicitly create and reference a secret for the seed backup.
If seed.spec.backup.credentialsRef points to a secret that does not exist, the reconciliation process will fail with an error, ensuring that operators consciously provide a dedicated credential for backups. This change promotes the best practice of using separate, segregated credentials for infrastructure and backups, significantly improving the security posture of the landscape.
For Operators: What You Need to Do
When you enable the DoNotCopyBackupCredentials feature gate, you must ensure that any Seed you configure has a pre-existing secret for its backup.
For setups where credentials were previously copied, Gardener helps with the transition. The controller will stop managing the lifecycle of these copied secrets. To help operators identify them for cleanup, these secrets will be labeled with secret.backup.gardener.cloud/status=previously-managed. You can then review these secrets and manage them accordingly.
This enhancement is a step towards more robust, secure, and transparent operations in Gardener, giving operators clearer control over credential management.
Enhanced Extension Management: Introducing `autoEnable` and `clusterCompatibility`
Gardener’s extension mechanism has been enhanced with two new fields in the ControllerRegistration and operatorv1alpha1.Extension APIs, offering operators more granular control and improved safety when managing extensions. These changes, detailed in PR #11982, introduce autoEnable and clusterCompatibility for resources of kind: Extension.
Fine-Grained Automatic Enablement with autoEnable
Previously, operators could use the globallyEnabled field to automatically enable an extension resource for all shoot clusters. This field is now deprecated and will be removed in Gardener v1.123.
The new autoEnable field replaces globallyEnabled and provides more flexibility. Operators can now specify an array of cluster types for which an extension should be automatically enabled. The supported cluster types are:
shoot
seed
garden
This allows, for example, an extension to be automatically enabled for all seed clusters or a combination of cluster types, which was not possible with the boolean globallyEnabled field.
If autoEnable includes shoot, it behaves like the old globallyEnabled: true for shoot clusters. If an extension is not set to autoEnable for a specific cluster type, it must be explicitly enabled in the respective cluster’s manifest (e.g., Shoot manifest for a shoot cluster).
# Example in ControllerRegistration or operatorv1alpha1.Extension spec.resources- kind: Extension
type: my-custom-extension
autoEnable:
- shoot
- seed
# globallyEnabled: true # This field is deprecated
Ensuring Correct Deployments with clusterCompatibility
To enhance safety and prevent misconfigurations, the clusterCompatibility field has been introduced. This field allows extension developers and operators to explicitly define which cluster types a generic Gardener extension is compatible with. The supported cluster types are:
shoot
seed
garden
Gardener will validate that an extension is only enabled or automatically enabled for cluster types listed in its clusterCompatibility definition. If clusterCompatibility is not specified for an Extension kind, it defaults to ['shoot']. This provides an important safeguard, ensuring that extensions are not inadvertently deployed to environments they are not designed for.
# Example in ControllerRegistration or operatorv1alpha1.Extension spec.resources- kind: Extension
type: my-custom-extension
autoEnable:
- shoot
clusterCompatibility: # Defines where this extension can be used - shoot
- seed
Important Considerations for Operators
Deprecation of globallyEnabled: Operators should migrate from globallyEnabled to the new autoEnable field for kind: Extension resources. globallyEnabled is deprecated and scheduled for removal in Gardener v1.123.
Breaking Change for Garden Extensions: The introduction of clusterCompatibility is a breaking change for operators managing garden extensions via gardener-operator. If your Garden custom resource specifies spec.extensions, you must update the corresponding operatorv1alpha1.Extension resources to include garden in the clusterCompatibility array for those extensions intended to run in the garden cluster.
These new fields provide more precise control over extension lifecycle management across different cluster types within the Gardener ecosystem, improving both operational flexibility and system stability.
Enhanced Internal Traffic Management: L7 Load Balancing for kube-apiservers in Gardener
Gardener continuously evolves to optimize performance and reliability. A recent improvement focuses on how internal control plane components communicate with kube-apiserver instances, introducing cluster-internal Layer 7 (L7) load balancing to ensure better resource distribution and system stability.
The Challenge: Unbalanced Internal Load on kube-apiservers
Previously, while external access to Gardener-managed kube-apiservers (for Shoots and the Virtual Garden) benefited from L7 load balancing via Istio, internal traffic took a more direct route. Components running within the seed cluster, such as gardener-resource-manager and gardener-controller-manager, would access the kube-apiserver’s internal Kubernetes service directly. This direct access bypassed the L7 load balancing capabilities of the Istio ingress gateway.
This could lead to situations where certain kube-apiserver instances might become overloaded, especially if a particular internal client generated a high volume of requests, potentially impacting the stability and performance of the control plane.
The Solution: Extending L7 Load Balancing Internally
To address this, Gardener now implements cluster-internal L7 load balancing for traffic destined for kube-apiservers from within the control plane. This enhancement ensures that requests from internal components are distributed efficiently across available kube-apiserver replicas, mirroring the sophisticated load balancing already in place for external traffic, but crucially, without routing this internal traffic externally.
Key aspects of this solution include:
Leveraging Existing Istio Ingress Gateway: The system utilizes the existing Istio ingress gateway, which already handles L7 load balancing for external traffic.
Dedicated Internal Service: A new, dedicated internal ClusterIP service is created for the Istio ingress gateway pods. This service provides an internal entry point for the load balancing.
Smart Kubeconfig Adjustments: The kubeconfig files used by internal components (specifically, the generic token kubeconfigs) are configured to point to the kube-apiserver’s public, resolvable DNS address.
Automated Configuration Injection: A new admission webhook, integrated into gardener-resource-manager and named pod-kube-apiserver-load-balancing, plays a crucial role. When control plane pods are created, this webhook automatically injects:
Host Aliases: It adds a host alias to the pod’s /etc/hosts file. This alias maps the kube-apiserver’s public DNS name to the IP address of the new internal ClusterIP service for the Istio ingress gateway.
Network Policy Labels: Necessary labels are added to ensure network policies permit this traffic flow.
With this setup, when an internal component attempts to connect to the kube-apiserver using its public DNS name, the host alias redirects the traffic to the internal Istio ingress gateway service. The ingress gateway then performs L7 load balancing, distributing the requests across the available kube-apiserver instances.
Benefits
This approach offers several advantages:
Improved Resource Distribution: Load from internal components is now evenly spread across kube-apiserver instances, preventing hotspots.
Enhanced Reliability: By avoiding overloading individual kube-apiserver pods, the overall stability and reliability of the control plane are improved.
Internalized Traffic: Despite using the kube-apiserver’s public DNS name in configurations, traffic remains within the cluster, avoiding potential costs or latency associated with external traffic routing.
This enhancement represents a significant step in refining Gardener’s internal traffic management, contributing to more robust and efficiently managed Kubernetes clusters.
Further Information
To dive deeper into the technical details, you can explore the following resources:
Taking Gardener to the Next Level: Highlights from the 7th Gardener Community Hackathon in Schelklingen
Taking Gardener to the Next Level: Highlights from the 7th Gardener Community Hackathon in Schelklingen
The latest “Hack The Garden” event, held in June 2025 at Schlosshof in Schelklingen, brought together members of the Gardener community for an intensive week of collaboration, coding, and problem-solving.
The hackathon focused on a wide array of topics aimed at enhancing Gardener’s capabilities, modernizing its stack, and improving user experience.
You can find a full summary of all topics on GitHub and watch the wrap-up presentations on YouTube.
Here’s a look at some of the key achievements and ongoing efforts:
🚀 Modernizing Core Infrastructure and Networking
A significant focus was on upgrading and refining Gardener’s foundational components.
One major undertaking was the replacement of OpenVPN with Wireguard (watch presentation).
The goal is to modernize the VPN stack for communication between control and data planes, leveraging Wireguard’s reputed performance and simplicity.
OpenVPN, while established, presents challenges like TCP-in-TCP. The team developed a Proof of Concept (POC) for a Wireguard-based VPN connection for a single shoot in a local setup, utilizing a reverse proxy like mwgp to manage connections without needing a load balancer per control plane.
A document describing the approach is available.
Next steps involve thorough testing of resilience and throughput, aggregating secrets for MWGP configuration, and exploring ways to update MWGP configuration without restarts.
Code contributions can be found in forks of gardener, vpn2, and mwgp.
Another critical area is overcoming the 450 Node limit on Azure (watch presentation).
Current Azure networking for Gardener relies on route tables, which have size limitations.
The team analyzed the hurdles and discussed a potential solution involving a combination of route tables and virtual networks.
Progress here depends on an upcoming Azure preview feature.
The hackathon also saw progress on cluster-internal L7 Load-Balancing for kube-apiservers.
Building on previous work for external endpoints, this initiative aims to provide L7 load-balancing for internal traffic from components like gardener-resource-manager.
Achievements include an implementation leveraging generic token kubeconfig and a dedicated ClusterIP service for Istio ingress gateway pods.
The PR #12260 is awaiting review to merge this improvement, addressing issue #8810.
🔭 Enhancing Observability and Operations
Improving how users monitor and manage Gardener clusters was another key theme.
A significant step towards Gardener’s Observability 2.0 initiative was made with the OpenTelemetry Transport for Shoot Metrics (watch presentation).
The current method of collecting shoot metrics via the Kubernetes API server /proxy endpoint lacks fine-tuning capabilities.
The hackathon proved the viability of collecting and filtering shoot metrics via OpenTelemetry collector instances on shoots, transporting them to Prometheus OTLP ingestion endpoints on seeds. This allows for more flexible and modern metrics collection.
For deeper network insights, the Cluster Network Observability project (watch presentation) enhanced the Retina tool by Microsoft.
The team successfully added labeling for source and destination availability zones to Retina’s traffic metrics (see issue #1654 and PR #1657).
This will help identify cross-AZ traffic, potentially reducing costs and latency.
Streamlining node management was the focus of the Worker Group Node Roll-out project (watch presentation).
A PoC was created (see rrhubenov/gardener branch) allowing users to trigger a node roll-out for specific worker groups via a shoot annotation (gardener.cloud/operation=rollout-workers=<pool-names>), which is particularly useful for scenarios like dual-stack migration.
Proactive workload management is the aim of the Instance Scheduled Events Watcher (watch presentation).
This initiative seeks to create an agent that monitors cloud provider VM events (like reboots or retirements) and exposes them as node events or dashboard warnings.
A PR #9170 for cloud-provider-azure was raised to enable this for Azure, allowing users to take timely action.
🛡️ Bolstering Security and Resource Management
Security and efficient resource handling remain paramount.
The Signing of ManagedResource Secrets project (watch presentation) addressed a potential privilege escalation vector.
A PoC demonstrated that signing ManagedResource secrets with a key known only to the Gardener Resource Manager (GRM) is feasible, allowing GRM to verify secret integrity.
This work is captured in gardener PR #12247.
Simplifying operations was the goal of Migrating Control Plane Reconciliation of Provider Extensions to ManagedResources (watch presentation). Instead of using the chart applier, this change wraps control-plane components in ManagedResources, improving scalability and automation (e.g., scaling components imperatively).
Gardener PR #12251 was created for this, with a stretch goal related to issue #12250 explored in a compare branch.
A quick win, marked as a 🏎️ fast-track item, was to Expose EgressCIDRs in the shoot-info ConfigMap (watch presentation).
This makes egress CIDRs available to workloads within the shoot cluster, useful for controllers like Crossplane.
This was implemented and merged during the hackathon via gardener PR #12252.
✨ Improving User and Developer Experience
Enhancing the usability of Gardener tools is always a priority.
Allowing custom display names for projects via annotations (dashboard PR #2470).
Configurable default values for Shoot creation, like AutoScaler min/max replicas (dashboard PR #2476).
The ability to hide certain UI elements, such as Control Plane HA options (dashboard PR #2478).
The Documentation Revamp (watch presentation) aimed to improve the structure and discoverability of Gardener’s documentation.
Metadata for pages was enhanced (documentation PR #652), the glossary was expanded (documentation PR #653), and a PoC for using VitePress as a more modern documentation generator was created.
🔄 Advancing Versioning and Deployment Strategies
Flexibility in managing Gardener versions and deployments was also explored.
The topic of Multiple Parallel Versions in a Gardener Landscape (formerly Canary Deployments) (watch presentation) investigated ways to overcome tight versioning constraints.
It was discovered that the current implementation already allows rolling out different extension versions across different seeds using controller registration seat selectors.
Further discussion is needed on some caveats, particularly around the primary field in ControllerRegistration resources.
Progress was also made on GEP-32 – Version Classification Lifecycles (🏎️ fast-track).
This initiative, started in a previous hackathon, aims to automate version lifecycle management.
The previous PR (metal-stack/gardener #9) was rebased and broken into smaller, more reviewable PRs.
🌱 Conclusion
The Hack The Garden event in Schelklingen was a testament to the community’s dedication and collaborative spirit.
Numerous projects saw significant progress, from PoCs for major architectural changes to practical improvements in daily operations and user experience.
Many of these efforts are now moving into further development, testing, and review, promising exciting enhancements for the Gardener ecosystem.
Stay tuned for more updates as these projects mature and become integrated into Gardener!
The next hackathon takes place in early December 2025.
If you’d like to join, head over to the Gardener Slack.
Happy to meet you there! ✌️
May
Fine-Tuning kube-proxy Readiness: Ensuring Accurate Health Checks During Node Scale-Down
Gardener has recently refined how it determines the readiness of kube-proxy components within managed Kubernetes clusters. This adjustment leads to more accurate system health reporting, especially during node scale-down operations orchestrated by cluster-autoscaler.
The Challenge: kube-proxy Readiness During Node Scale-Down
Previously, Gardener utilized kube-proxy’s /healthz endpoint for its readiness probe. While generally effective, this endpoint’s behavior changed in Kubernetes 1.28 (as part of KEP-3836 and implemented in kubernetes/kubernetes#116470). The /healthz endpoint now reports kube-proxy as unhealthy if its node is marked for deletion by cluster-autoscaler (e.g., via a specific taint) or has a deletion timestamp.
This behavior is intended to help external load balancers (particularly those using externalTrafficPolicy: Cluster on infrastructures like GCP) avoid sending new traffic to nodes that are about to be terminated. However, for Gardener’s internal system component health checks, this meant that kube-proxy could appear unready for extended periods if node deletion was delayed due to PodDisruptionBudgets or long terminationGracePeriodSeconds. This could lead to misleading “unhealthy” states for the cluster’s system components.
The Solution: Aligning with Upstream kube-proxy Enhancements
To address this, Gardener now leverages the /livez endpoint for kube-proxy’s readiness probe in clusters running Kubernetes version 1.28 and newer. The /livez endpoint, also introduced as part of the aforementioned kube-proxy improvements, checks the actual liveness of the kube-proxy process itself, without considering the node’s termination status.
For clusters running Kubernetes versions 1.27.x and older (where /livez is not available), Gardener will continue to use the /healthz endpoint for the readiness probe.
This change, detailed in gardener/gardener#12015, ensures that Gardener’s readiness check for kube-proxy accurately reflects kube-proxy’s operational status rather than the node’s lifecycle state. It’s important to note that this adjustment does not interfere with the goals of KEP-3836; cloud controller managers can still utilize the /healthz endpoint for their load balancer health checks as intended.
Benefits for Gardener Operators
This enhancement brings a key benefit to Gardener operators:
More Accurate System Health: The system components health check will no longer report kube-proxy as unhealthy simply because its node is being gracefully terminated by cluster-autoscaler. This reduces false alarms and provides a clearer view of the cluster’s actual health.
Smoother Operations: Operations teams will experience fewer unnecessary alerts related to kube-proxy during routine scale-down events, allowing them to focus on genuine issues.
By adapting its kube-proxy readiness checks, Gardener continues to refine its operational robustness, providing a more stable and predictable management experience.
New in Gardener: Forceful Redeployment of gardenlets for Enhanced Operational Control
Gardener continues to enhance its operational capabilities, and a recent improvement introduces a much-requested feature for managing gardenlets: the ability to forcefully trigger their redeployment. This provides operators with greater control and a streamlined recovery path for specific scenarios.
The Standard gardenlet Lifecycle
gardenlets, crucial components in the Gardener architecture, are typically deployed into seed clusters. For setups utilizing the seedmanagement.gardener.cloud/v1alpha1.Gardenlet resource, particularly in unmanaged seeds (those not backed by a shoot cluster and ManagedSeed resource), the gardener-operator handles the initial deployment of the gardenlet.
Once this initial deployment is complete, the gardenlet takes over its own lifecycle, leveraging a self-upgrade strategy to keep itself up-to-date. Under normal circumstances, the gardener-operator does not intervene further after this initial phase.
When Things Go Awry: The Need for Intervention
While the self-upgrade mechanism is robust, certain situations can arise where a gardenlet might require a more direct intervention. For example:
The gardenlet’s client certificate to the virtual garden cluster might have expired or become invalid.
The gardenlet Deployment in the seed cluster might have been accidentally deleted or become corrupted.
In such cases, because the gardener-operator’s responsibility typically ends after the initial deployment, the gardenlet might not be able to recover on its own, potentially leading to operational issues.
Empowering Operators: The Force-Redeploy Annotation
To address these challenges, Gardener now allows operators to instruct the gardener-operator to forcefully redeploy a gardenlet. This is achieved by annotating the specific Gardenlet resource with:
gardener.cloud/operation=force-redeploy
When this annotation is applied, it signals the gardener-operator to re-initiate the deployment process for the targeted gardenlet, effectively overriding the usual hands-off approach after initial setup.
How It Works
The process for a forceful redeployment is straightforward:
An operator identifies a gardenlet that requires redeployment due to issues like an expired certificate or a missing deployment.
The operator applies the gardener.cloud/operation=force-redeploy annotation to the corresponding seedmanagement.gardener.cloud/v1alpha1.Gardenlet resource in the virtual garden cluster.
Important: If the gardenlet is for a remote cluster and its kubeconfig Secret was previously removed (a standard cleanup step after initial deployment), this Secret must be recreated, and its reference (.spec.kubeconfigSecretRef) must be re-added to the Gardenlet specification.
The gardener-operator detects the annotation and proceeds to redeploy the gardenlet, applying its configurations and charts anew.
Once the redeployment is successfully completed, the gardener-operator automatically removes the gardener.cloud/operation=force-redeploy annotation from the Gardenlet resource. Similar to the initial deployment, it will also clean up the referenced kubeconfig Secret and set .spec.kubeconfigSecretRef to nil if it was provided.
Benefits
This new feature offers significant advantages for Gardener operators:
Enhanced Recovery: Provides a clear and reliable mechanism to recover gardenlets from specific critical failure states.
Improved Operational Flexibility: Offers more direct control over the gardenlet lifecycle when exceptional circumstances demand it.
Reduced Manual Effort: Streamlines the process of restoring a misbehaving gardenlet, minimizing potential downtime or complex manual recovery procedures.
This enhancement underscores Gardener’s commitment to operational excellence and responsiveness to the needs of its user community.
Dive Deeper
To learn more about this feature, you can explore the following resources:
Streamlined Node Onboarding: Introducing `gardenadm token` and `gardenadm join`
Gardener continues to enhance its gardenadm tool, simplifying the management of autonomous Shoot clusters. Recently, new functionalities have been introduced to streamline the process of adding worker nodes to these clusters: the gardenadm token command suite and the corresponding gardenadm join command. These additions offer a more convenient and Kubernetes-native experience for cluster expansion.
Managing Bootstrap Tokens with gardenadm token
A key aspect of securely joining nodes to a Kubernetes cluster is the use of bootstrap tokens. The new gardenadm token command provides a set of subcommands to manage these tokens effectively within your autonomous Shoot cluster’s control plane node. This functionality is analogous to the familiar kubeadm token commands.
The available subcommands include:
gardenadm token list: Displays all current bootstrap tokens. You can also use the --with-token-secrets flag to include the token secrets in the output for easier inspection.
gardenadm token generate: Generates a cryptographically random bootstrap token. This command only prints the token; it does not create it on the server.
gardenadm token create [token]: Creates a new bootstrap token on the server. If you provide a token (in the format [a-z0-9]{6}.[a-z0-9]{16}), it will be used. If no token is supplied, gardenadm will automatically generate a random one and create it.
A particularly helpful option for this command is --print-join-command. When used, instead of just outputting the token, it prints the complete gardenadm join command, ready to be copied and executed on the worker node you intend to join. You can also specify flags like --description, --validity, and --worker-pool-name to customize the token and the generated join command.
gardenadm token delete <token-value...>: Deletes one or more bootstrap tokens from the server. You can specify tokens by their ID, the full token string, or the name of the Kubernetes Secret storing the token (e.g., bootstrap-token-<id>).
These commands provide comprehensive control over the lifecycle of bootstrap tokens, enhancing security and operational ease.
Joining Worker Nodes with gardenadm join
Once a bootstrap token is created (ideally using gardenadm token create --print-join-command on a control plane node), the new gardenadm join command facilitates the process of adding a new worker node to the autonomous Shoot cluster.
The command is executed on the prospective worker machine and typically looks like this:
--bootstrap-token: The token obtained from the gardenadm token create command.
--ca-certificate: The base64-encoded CA certificate bundle of the cluster’s API server.
--gardener-node-agent-secret-name: The name of the Secret in the kube-system namespace of the control plane that contains the OperatingSystemConfig (OSC) for the gardener-node-agent. This OSC dictates how the node should be configured.
<control_plane_api_server_address>: The address of the Kubernetes API server of the autonomous cluster.
Upon execution, gardenadm join performs several actions:
It discovers the Kubernetes version of the control plane using the provided bootstrap token and CA certificate.
It checks if the gardener-node-agent has already been initialized on the machine.
If not already joined, it prepares the gardener-node-init configuration. This involves setting up a systemd service (gardener-node-init.service) which, in turn, downloads and runs the gardener-node-agent.
The gardener-node-agent then uses the bootstrap token to securely download its specific OperatingSystemConfig from the control plane.
Finally, it applies this configuration, setting up the kubelet and other necessary components, thereby officially joining the node to the cluster.
After the node has successfully joined, the bootstrap token used for the process will be automatically deleted by the kube-controller-manager once it expires. However, it can also be manually deleted immediately using gardenadm token delete on the control plane node for enhanced security.
These new gardenadm commands significantly simplify the expansion of autonomous Shoot clusters, providing a robust and user-friendly mechanism for managing bootstrap tokens and joining worker nodes.
Recording of the demo: Watch the demo starting at 12m48s
Enhanced Network Flexibility: Gardener Now Supports CIDR Overlap for Non-HA Shoots
Gardener is continually evolving to offer greater flexibility and efficiency in managing Kubernetes clusters. A significant enhancement has been introduced that addresses a common networking challenge: the requirement for completely disjoint network CIDR blocks between a shoot cluster and its seed cluster. Now, Gardener allows for IPv4 network overlap in specific scenarios, providing users with more latitude in their network planning.
Addressing IP Address Constraints
Previously, all shoot cluster networks (pods, services, nodes) had to be distinct from the seed cluster’s networks. This could be challenging in environments with limited IP address space or complex network topologies. With this new feature, IPv4 or dual-stack shoot clusters can now define pod, service, and node networks that overlap with the IPv4 networks of their seed cluster.
How It Works: NAT for Seamless Connectivity
This capability is enabled through a double Network Address Translation (NAT) mechanism within the VPN connection established between the shoot and seed clusters. When IPv4 network overlap is configured, Gardener intelligently maps the overlapping shoot and seed networks to a dedicated set of newly reserved IPv4 ranges. These ranges are used exclusively within the VPN pods to ensure seamless communication, effectively resolving any conflicts that would arise from the overlapping IPs.
The reserved mapping ranges are:
241.0.0.0/8: Seed Pod Mapping Range
242.0.0.0/8: Shoot Node Mapping Range
243.0.0.0/8: Shoot Service Mapping Range
244.0.0.0/8: Shoot Pod Mapping Range
Conditions for Utilizing Overlapping Networks
To leverage this new network flexibility, the following conditions must be met:
Non-Highly-Available VPN: The shoot cluster must utilize a non-highly-available (non-HA) VPN. This is typically the configuration for shoots with a non-HA control plane.
IPv4 or Dual-Stack Shoots: The shoot cluster must be configured as either single-stack IPv4 or dual-stack (IPv4/IPv6). The overlap feature specifically pertains to IPv4 networks.
Non-Use of Reserved Ranges: The shoot cluster’s own defined networks (for pods, services, and nodes) must not utilize any of the Gardener-reserved IP ranges, including the newly introduced mapping ranges listed above, or the existing 240.0.0.0/8 range (Kube-ApiServer Mapping Range).
It’s important to note that Gardener will prevent the migration of a non-HA shoot to an HA setup if its network ranges currently overlap with the seed, as this feature is presently limited to non-HA VPN configurations. For single-stack IPv6 shoots, Gardener continues to enforce non-overlapping IPv6 networks to avoid any potential issues, although IPv6 address space exhaustion is less common.
Benefits for Gardener Users
This enhancement offers increased flexibility in IP address management, particularly beneficial for users operating numerous shoot clusters or those in environments with constrained IPv4 address availability. By relaxing the strict disjointedness requirement for non-HA shoots, Gardener simplifies network allocation and reduces the operational overhead associated with IP address planning.
Explore Further
To dive deeper into this feature, you can review the original pull request and the updated documentation:
Enhanced Node Management: Introducing In-Place Updates in Gardener
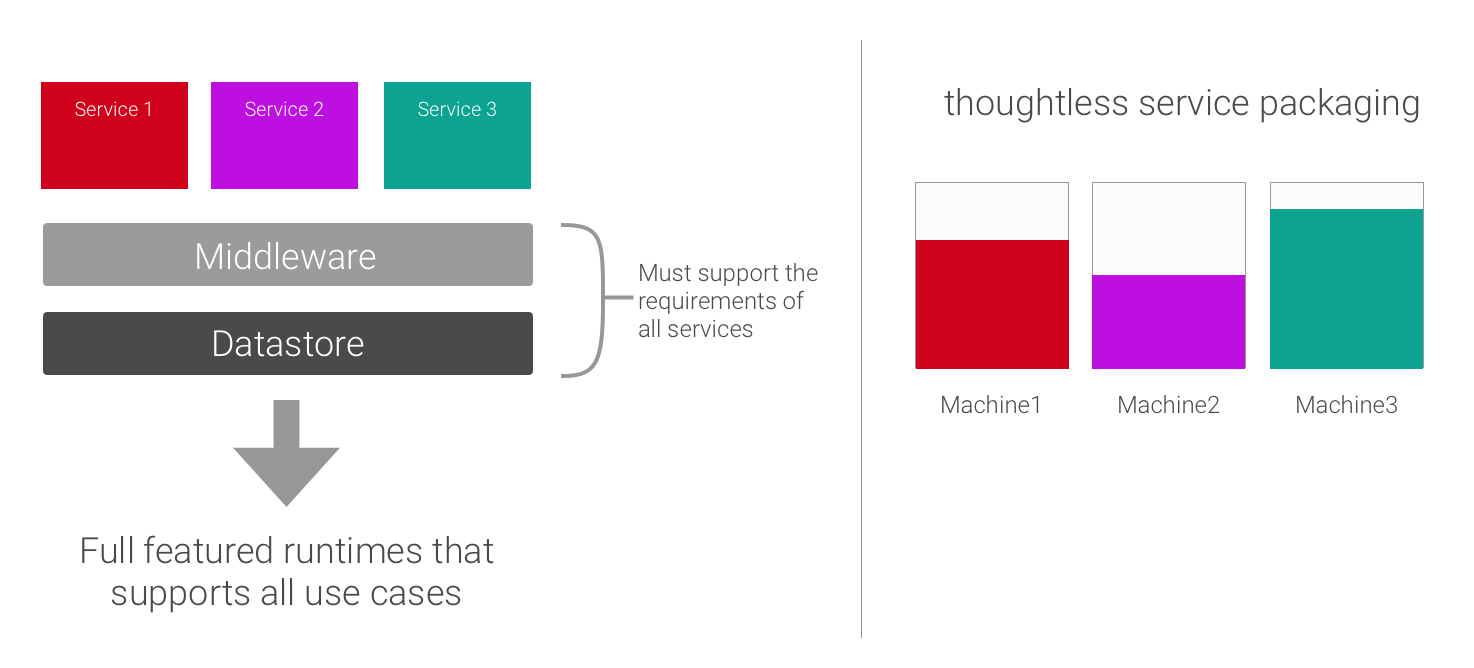
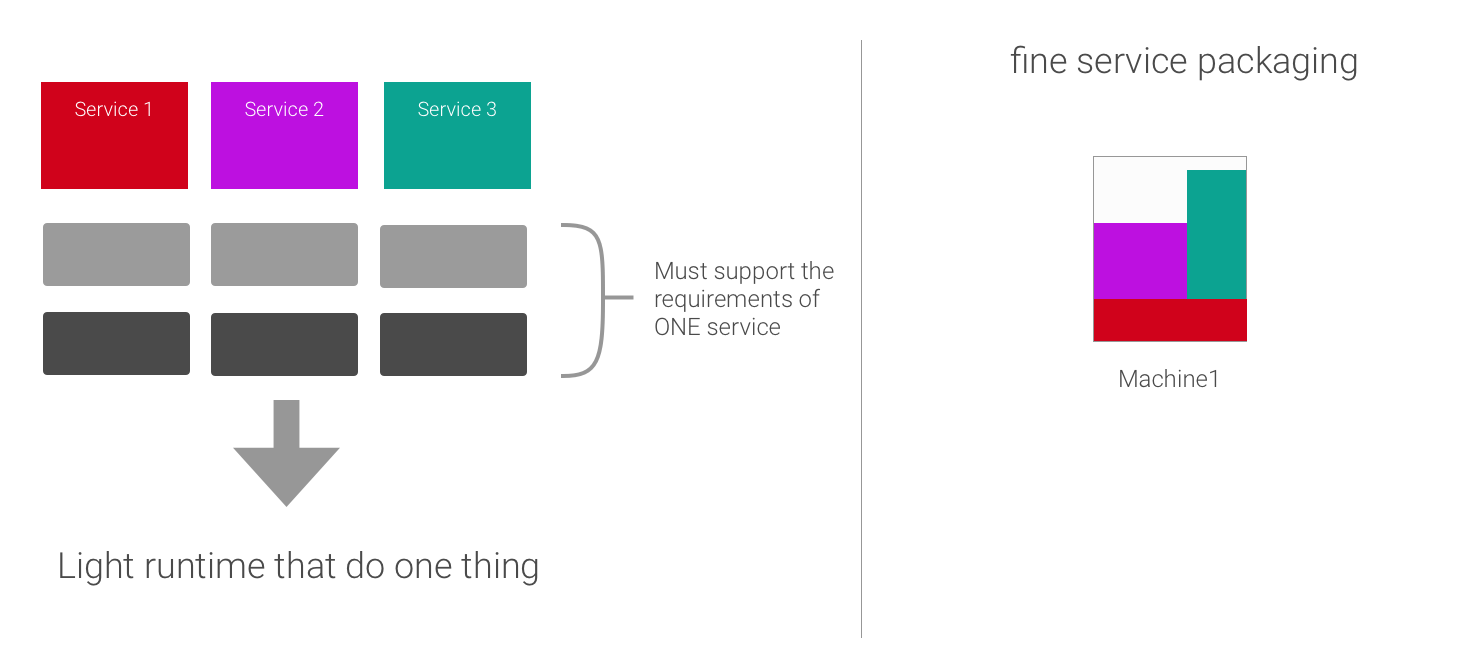
Gardener is committed to providing efficient and flexible Kubernetes cluster management. Traditionally, updates to worker pool configurations, such as machine image or Kubernetes minor version changes, trigger a rolling update. This process involves replacing existing nodes with new ones, which is a robust approach for many scenarios. However, for environments with physical or bare-metal nodes, or stateful workloads sensitive to node replacement, or if the virtual machine type is scarce, this can introduce challenges like extended update times and potential disruptions.
To address these needs, Gardener now introduces In-Place Node Updates. This new capability allows certain updates to be applied directly to existing worker nodes without requiring their replacement, significantly reducing disruption and speeding up update processes for compatible changes.
New Update Strategies for Worker Pools
Gardener now supports three distinct update strategies for your worker pools, configurable via the updateStrategy field in the Shoot specification’s worker pool definition:
AutoRollingUpdate: This is the classic and default strategy. When updates occur, nodes are cordoned, drained, terminated, and replaced with new nodes incorporating the changes.
AutoInPlaceUpdate: With this strategy, compatible updates are applied directly to the existing nodes. The MachineControllerManager (MCM) automatically selects nodes, cordons and drains them, and then signals the Gardener Node Agent (GNA) to perform the update. Once GNA confirms success, MCM uncordons the node.
ManualInPlaceUpdate: This strategy also applies updates directly to existing nodes but gives operators fine-grained control. After an update is specified, MCM marks all nodes in the pool as candidates. Operators must then manually label individual nodes to select them for the in-place update process, which then proceeds similarly to the AutoInPlaceUpdate strategy.
The AutoInPlaceUpdate and ManualInPlaceUpdate strategies are available when the InPlaceNodeUpdates feature gate is enabled in the gardener-apiserver.
What Can Be Updated In-Place?
In-place updates are designed to handle a variety of common operational tasks more efficiently:
Machine Image Updates: Newer versions of a machine image can be rolled out by executing an update command directly on the node, provided the image and cloud profile are configured to support this.
Kubernetes Minor Version Updates: Updates to the Kubernetes minor version of worker nodes can be applied in-place.
Kubelet Configuration Changes: Modifications to the Kubelet configuration can be applied directly.
Credentials Rotation: Critical for security, rotation of Certificate Authorities (CAs) and ServiceAccount signing keys can now be performed on existing nodes without replacement.
However, some changes still necessitate a rolling update (node replacement):
Changing the machine image name (e.g., switching from Ubuntu to Garden Linux).
Modifying the machine type.
Altering volume types or sizes.
Changing the Container Runtime Interface (CRI) name (e.g., from Docker to containerd).
Enabling or disabling node-local DNS.
Key API and Component Adaptations
Several Gardener components and APIs have been enhanced to support in-place updates:
CloudProfile: The CloudProfile API now allows specifying inPlaceUpdates configuration within machineImage.versions. This includes a boolean supported field to indicate if a version supports in-place updates and an optional minVersionForUpdate string to define the minimum OS version from which an in-place update to the current version is permissible.
Shoot Specification: As mentioned, the spec.provider.workers[].updateStrategy field allows selection of the desired update strategy. Additionally, spec.provider.workers[].machineControllerManagerSettings now includes machineInPlaceUpdateTimeout and disableHealthTimeout (which defaults to true for in-place strategies to prevent premature machine deletion during lengthy updates). For ManualInPlaceUpdate, maxSurge defaults to 0 and maxUnavailable to 1.
OperatingSystemConfig (OSC): The OSC resource, managed by OS extensions, now includes status.inPlaceUpdates.osUpdate where extensions can specify the command and args for the Gardener Node Agent to execute for machine image (Operating System) updates. The spec.inPlaceUpdates field in the OSC will carry information like the target Operating System version, Kubelet version, and credential rotation status to the node.
Gardener Node Agent (GNA): GNA is responsible for executing the in-place updates on the node. It watches for a specific node condition ( InPlaceUpdate with reason ReadyForUpdate) set by MCM, performs the OS update, Kubelet updates, or credentials rotation, restarts necessary pods (like DaemonSets), and then labels the node with the update outcome.
MachineControllerManager (MCM): MCM orchestrates the in-place update process. For in-place strategies, while new machine classes and machine sets are created to reflect the desired state, the actual machine objects are not deleted and recreated. Instead, their ownership is transferred to the new machine set. MCM handles cordoning, draining, and setting node conditions to coordinate with GNA.
Shoot Status & Constraints: To provide visibility, the status.inPlaceUpdates.pendingWorkerUpdates field in the Shoot now lists worker pools pending autoInPlaceUpdate or manualInPlaceUpdate. A new ShootManualInPlaceWorkersUpdated constraint is added if any manual in-place updates are pending, ensuring users are aware.
Worker Status: The Worker extension resource now includes status.inPlaceUpdates.workerPoolToHashMap to track the configuration hash of worker pools that have undergone in-place updates. This helps Gardener determine if a pool is up-to-date.
Forcing Updates: If an in-place update is stuck, the gardener.cloud/operation=force-in-place-update annotation can be added to the Shoot to allow subsequent changes or retries.
Benefits of In-Place Updates
Reduced Disruption: Minimizes workload interruptions by avoiding full node replacements for compatible updates.
Faster Updates: Applying changes directly can be quicker than provisioning new nodes, especially for OS patches or configuration changes.
Bare-Metal Efficiency: Particularly beneficial for bare-metal environments where node provisioning is more time-consuming and complex.
Stateful Workload Friendly: Lessens the impact on stateful applications that might be sensitive to node churn.
In-place node updates represent a significant step forward in Gardener’s operational flexibility, offering a more nuanced and efficient approach to managing node lifecycles, especially in demanding or specialized environments.
Dive Deeper
To explore the technical details and contributions that made this feature possible, refer to the following resources:
Parent Issue for “[GEP-31] Support for In-Place Node Updates”: Issue #10219
Gardener Dashboard version 1.80 introduces several significant enhancements aimed at improving user experience, credentials management, and overall operational efficiency. These updates bring more clarity to credential handling, a smoother experience for managing large numbers of clusters, and a move towards a more reactive interface.
Unified and Enhanced Credentials Management
The management of secrets and credentials has been significantly revamped for better clarity and functionality:
Introducing CredentialsBindings: The dashboard now fully supports CredentialsBinding resources alongside the existing SecretBinding resources. This allows for referencing both Secrets and, in the future, Workload Identities more explicitly. While CredentialsBindings referencing Workload Identity resources are visible for cluster creation, editing or deleting them via the dashboard is not yet supported.
“Credentials” Page: The former “Secrets” page has been renamed to “Credentials.” It features a new “Kind” column and distinct icons to clearly differentiate between SecretBinding and CredentialsBinding types, especially useful when resources share names. The column showing the referenced credential resource name has been removed as this information is part of the binding’s details.
Contextual Information and Safeguards: When editing a secret, all its associated data is now displayed, providing better context. If an underlying secret is referenced by multiple bindings, a hint is shown to prevent unintended impacts. Deletion of a binding is prevented if the underlying secret is still in use by another binding.
Simplified Creation and Editing: New secrets created via the dashboard will now automatically generate a CredentialsBinding. While existing SecretBindings remain updatable, the creation of new SecretBindings through the dashboard is no longer supported, encouraging the adoption of the more versatile CredentialsBinding. The edit dialog for secrets now pre-fills current data, allowing for easier modification of specific fields.
Handling Missing Secrets: The UI now provides clear information and guidance if a CredentialsBinding or SecretBinding references a secret that no longer exists.
Revamped Cluster List for Improved Scalability
Navigating and managing a large number of clusters is now more efficient:
Virtual Scrolling: The cluster list has adopted virtual scrolling. Rows are rendered dynamically as you scroll, replacing the previous pagination system. This significantly improves performance and provides a smoother browsing experience, especially for environments with hundreds or thousands of clusters.
Optimized Row Display: The height of individual rows in the cluster list has been reduced, allowing more clusters to be visible on the screen at once. Additionally, expandable content within a row (like worker details or ticket labels) now has a maximum height with internal scrolling, ensuring consistent row sizes and smooth virtual scrolling performance.
Real-Time Updates for Projects
The dashboard is becoming more dynamic with the introduction of real-time updates:
Instant Project Changes: Modifications to projects, such as creation or deletion, are now reflected instantly in the project list and interface without requiring a page reload. This is achieved through WebSocket communication.
Foundation for Future Reactivity: This enhancement for projects lays the groundwork for bringing real-time updates to other resources within the dashboard, such as Seeds and the Garden resource, in future releases.
Other Notable Enhancements
Kubeconfig Update: The kubeconfig generated for garden cluster access via the “Account” page now uses the --oidc-pkce-method flag, replacing the deprecated --oidc-use-pkce flag. Users encountering deprecation messages should redownload their kubeconfig.
Notification Behavior: Kubernetes warning notifications are now automatically dismissed after 5 seconds. However, all notifications will remain visible as long as the mouse cursor is hovering over them, giving users more time to read important messages.
API Server URL Path: Support has been added for kubeconfigs that include a path in the API server URL.
These updates in Gardener Dashboard 1.80 collectively enhance usability, provide better control over credentials, and improve performance for large-scale operations.
For a comprehensive list of all features, bug fixes, and contributor acknowledgments, please refer to the official release notes.
You can also view the segment of the community call discussing these dashboard updates here.
Gardener: Powering Enterprise Kubernetes at Scale and Europe's Sovereign Cloud Future
The Kubernetes ecosystem is dynamic, offering a wealth of tools to manage the complexities of modern cloud-native applications. For enterprises seeking to provision and manage Kubernetes clusters efficiently, securely, and at scale, a robust and comprehensive solution is paramount. Gardener, born from years of managing tens of thousands of clusters efficiently across diverse platforms and in demanding environments, stands out as a fully open-source choice for delivering fully managed Kubernetes Clusters as a Service. It already empowers organizations like SAP, STACKIT, T-Systems, and others (see adopters) and has become a core technology for NeoNephos, a project aimed at advancing digital autonomy in Europe (see KubeCon London 2025 Keynote and press announcement).
The Gardener Approach: An Architecture Forged by Experience
At the heart of Gardener’s architecture is the concept of “Kubeception” (see readme and architecture). This approach involves using Kubernetes to manage Kubernetes. Gardener runs on a Kubernetes cluster (called a runtime cluster), facilitates access through a self-managed node-less Kubernetes cluster (the garden cluster), manages Kubernetes control planes as pods within other self-managed Kubernetes clusters that provide high scalability (called seed clusters), and ultimately provisions end-user Kubernetes clusters (called shoot clusters).
This multi-layered architecture isn’t complexity for its own sake. Gardener’s design and extensive feature set are the product of over eight years of continuous development and refinement, directly shaped by the high-scale, security-sensitive, and enterprise-grade requirements of its users. Experience has shown that such a sophisticated structure is key to addressing significant challenges in scalability, security, and operational manageability. For instance:
Scalability: Gardener achieves considerable scalability through its use of seed clusters, which it also manages. This allows for the distribution of control planes, preventing bottlenecks. The design even envisions leveraging Gardener to host its own management components (as an autonomous cluster), showcasing its resilience without risking circular dependencies.
Security: A fundamental principle in Gardener is the strict isolation of control planes from data planes. This extends to Gardener itself, which runs in a dedicated management cluster but exposes its API to end-users through a workerless virtual cluster. This workerless cluster acts as an isolated access point, presenting no compute surface for potentially malicious pods, thereby significantly enhancing security.
API Power & User Experience: Gardener utilizes the full capabilities of the Kubernetes API server. This enables advanced functionalities and sophisticated API change management. Crucially, for the end-user, interaction remains 100% Kubernetes-native. Users employ standard custom resources to instruct Gardener, meaning any tool, library, or language binding that supports Kubernetes CRDs inherently supports Gardener.
Delivering Fully Managed Kubernetes Clusters as a Service
Gardener provides a comprehensive “fully managed Kubernetes Clusters as a Service” offering. This means it handles much more than just spinning up a cluster; it manages the entire lifecycle and operational aspects. Here’s a glimpse into its capabilities:
Full Cluster Lifecycle Management:
Infrastructure Provisioning: Gardener takes on the provisioning and management of underlying cloud infrastructure, including VPCs, subnets, NAT gateways, security groups, IAM roles, and virtual machines across a wide range of providers like AWS, Azure, GCP, OpenStack, and more.
Worker Node Management: It meticulously manages worker pools, covering OS images, machine types, autoscaling configurations (min/max/surge), update strategies, volume management, CRI configuration, and provider-specific settings.
Enterprise Platform Governance:
Cloud Profiles: Gardener is designed with the comprehensive needs of enterprise platform operators in mind. Managing a fleet of clusters for an organization requires more than just provisioning; it demands clear governance over available resources, versions, and their lifecycle. Gardener addresses this through its declarative API, allowing platform administrators to define and enforce policies such as which Kubernetes versions are “supported,” “preview,” or “deprecated,” along with their expiration dates. Similarly, it allows control over available machine images, their versions, and lifecycle status. This level of granular control and lifecycle management for the underlying components of a Kubernetes service is crucial for enterprise adoption and stable operations. This is a key consideration often left as an additional implementation burden for platform teams using other cluster provisioning tools, where such governance features must be built on top. Gardener, by contrast, integrates these concerns directly into its API and operational model, simplifying the task for platform operators.
Advanced Networking:
CNI Plugin Management: Gardener manages the deployment and configuration of CNI plugins such as Calico or Cilium.
Dual-Stack Networking: It offers comprehensive support for IPv4, IPv6, and dual-stack configurations for pods, services, and nodes.
NodeLocal DNS Cache: To enhance DNS performance and reliability, Gardener can deploy and manage NodeLocal DNS.
Comprehensive Autoscaling:
Cluster Autoscaler: Gardener manages the Cluster Autoscaler for worker nodes, enabling dynamic scaling based on pod scheduling demands.
Horizontal and Vertical Pod Autoscaler (VPA): It manages HPA/VPA for workloads and applies it to control plane components, optimizing resource utilization (see blog).
Operational Excellence & Maintenance:
Automated Kubernetes Upgrades: Gardener handles automated Kubernetes version upgrades for both control plane and worker nodes, with configurable maintenance windows.
Automated OS Image Updates: It manages automated machine image updates for worker nodes.
Cluster Hibernation: To optimize costs, Gardener supports hibernating clusters, scaling down components during inactivity.
Scheduled Maintenance: It allows defining specific maintenance windows for predictability.
Robust Credentials Rotation: Gardener features automated mechanisms for rotating all credentials. It provisions fine-grained, dedicated, and individual CAs, certificates, credentials, and secrets for each component — whether Kubernetes-related (such as service account keys or etcd encryption keys) or Gardener-specific (such as opt-in SSH keys or observability credentials). The Gardener installation, the seeds, and all shoots have their own distinct sets of credentials — amounting to more than 150 per shoot cluster control plane and hundreds of thousands for larger Gardener installations overall. All these credentials are rotated automatically and without downtime — most continuously, while some (like the API server CA) require user initiation to ensure operational awareness. For a deeper dive into Gardener’s credential rotation, see our Cloud Native Rejekts talk). This granular approach effectively prevents lateral movement, significantly strengthening the security posture.
Enhanced Security & Access Control:
OIDC Integration: Gardener supports OIDC configuration for the kube-apiserver for secure user authentication.
Customizable Audit Policies: It allows specifying custom audit policies for detailed logging.
Managed Service Account Issuers: Gardener can manage service account issuers, enhancing workload identity security.
SSH Access Control: It provides mechanisms to manage SSH access to worker nodes securely if opted in (Gardener itself doesn’t require SSH access to worker nodes).
Workload Identity: Gardener supports workload identity features, allowing pods to securely authenticate to cloud provider services.
Powerful Extensibility:
Extension Framework and Ecosystem: Gardener features a robust extension mechanism for deep integration of cloud providers, operating systems, container runtimes, or services like DNS management, certificate management, registry caches, network filtering, image signature verification, and more.
Catered to Platform Builders: This extensibility also allows platform builders to deploy custom extensions into the self-managed seed cluster infrastructure that hosts shoot cluster control planes. This offers robust isolation for these custom components from the user’s shoot cluster worker nodes, enhancing both security and operational stability.
Integrated DNS and Certificate Management:
External DNS Management: Gardener can manage DNS records for the cluster’s API server and services via its shoot-dns-service extension.
Automated Certificate Management: Through extensions like shoot-cert-service, it manages TLS certificates, including ACME integration. Gardener also provides its own robust DNS (dns-management) and certificate (cert-management) solutions designed for enterprise scale. These custom solutions were developed because, at the scale Gardener operates, many deep optimizations were necessary, e.g., to avoid being rate-limited by upstream providers.
A Kubernetes-Native Foundation for Sovereign Cloud
The modern IT landscape is rapidly evolving away from primitive virtual machines towards distributed systems. Kubernetes has emerged as the de facto standard for deploying and managing these modern, cloud-native applications and services at scale. Gardener is squarely positioned at the forefront of this shift, offering a Kubernetes-native approach to managing Kubernetes clusters themselves. It possesses a mature, declarative, Kubernetes-native API for full cluster lifecycle management. Unlike services that might expose proprietary APIs, Gardener’s approach is inherently Kubernetes-native and multi-cloud. This unified API is comprehensive, offering a consistent way to manage diverse cluster landscapes.
Its nature as a fully open-source project is particularly relevant for initiatives like NeoNephos, which aim to build sovereign cloud solutions. All core features, stable releases, and essential operational components are available to the community. This inherent cloud-native, Kubernetes-centric design, coupled with its open-source nature and ability to run on diverse infrastructures (including on-premise and local cloud providers), provides the transparency, control, and technological independence crucial for digital sovereignty. Gardener delivers full sovereign control today, enabling organizations to run all modern applications and services at scale with complete authority over their infrastructure and data. This is a significant reason why many cloud providers and enterprises that champion sovereignty are choosing Gardener as their foundation and actively contributing to its ecosystem.
Operational Depth Reflecting Real-World Scale
Gardener’s operational maturity is a direct reflection of its long evolution, shaped by the demands of enterprise users and real-world, large-scale deployments. This maturity translates into statistical evidence and track records of uptime for end-users and their critical services. For instance, Gardener includes fully automated, incremental etcd backups with a recovery point objective (RPO) of five minutes and supports autonomous, hands-off restoration workflows via etcd-druid. Features like Vertical Pod Autoscalers (VPAs), PodDisruptionBudgets (PDBs), NetworkPolicies, PriorityClasses, and sophisticated pod placement strategies are integral to Gardener’s offering, ensuring high availability and fault tolerance. Gardener’s automation deals with many of the usual exceptions and does not require human DevOps intervention for most operational tasks. Gardener’s commitment to robust security is evident in Gardener’s proactive security posture, which has proven effective in real-world scenarios. This depth of experience and automation ultimately translates into first-class Service Level Agreements (SLAs) that businesses can trust and rely on. As a testament to this, SAP entrusts Gardener with its Systems of Record. This level of operational excellence enables Gardener to meet the expectations of today’s most demanding Kubernetes use cases.
Conclusion: A Solid Foundation for Your Kubernetes Strategy
For enterprises and organizations seeking a comprehensive, truly open-source solution for managing the full lifecycle of Kubernetes clusters at scale, Gardener offers a compelling proposition. Its mature architecture, rich feature set, operational robustness, built-in enterprise governance capabilities, and commitment to the open-source community provide a solid foundation for running demanding Kubernetes workloads with confidence. This makes it a suitable technical underpinning for ambitious projects like NeoNephos, contributing to a future of greater digital autonomy.
We invite you to explore Gardener and discover how it can empower your enterprise-grade and -scale Kubernetes journey.
April
Leaner Clusters, Lower Bills: How Gardener Optimized Kubernetes Compute Costs
As organizations embrace Kubernetes for managing containerized applications at scale, the underlying infrastructure costs, particularly for compute resources, become a critical factor. Gardener, the open-source Kubernetes management platform, empowers organizations like SAP, STACKIT, T-Systems, and others (see adopters) to operate tens of thousands of Kubernetes clusters efficiently across diverse environments. Gardener’s role as a core technology in initiatives like NeoNephos, aimed at advancing digital autonomy in Europe (see KubeCon London 2025 Keynote and press announcement), further underscores the need for cost-effective and sustainable operations.
At the heart of Gardener’s architecture is the concept of “Kubeception” (see readme and architecture): Gardener runs on Kubernetes (called a runtime cluster), facilitates access through a self-managed node-less Kubernetes cluster (called the garden cluster), manages Kubernetes control planes as pods within self-managed Kubernetes clusters that provide high scalability to Gardener (called seed clusters), and provisions end-user Kubernetes clusters (called shoot clusters). Therefore, optimizing Gardener’s own Kubernetes-related resource consumption directly translates into cost savings across all these layers, benefiting both Gardener service providers and the end-users consuming the managed clusters.
While infrastructure costs span compute, storage, and networking, compute resources (the virtual machines running Kubernetes nodes) typically represent the largest share of the bill. Over the past years, the Gardener team has undertaken a significant effort to optimize these costs. This blog post details our journey, focusing heavily on the compute optimizations that go beyond standard autoscaling practices, ultimately delivering substantial savings that benefit the entire Gardener ecosystem.
We’ll build upon the foundations laid out in our Pod Autoscaling Best Practices Guide. You may want to check it out beforehand, as we’ll only touch upon a few key recommendations from it in this blog post, not delving into the full depth required for effective pod autoscaling – a prerequisite for the compute optimizations discussed here.
Visibility and Initial Measures
Know Your Spending: Leveraging Observability and IaaS Cost Tools
You can’t optimize what you can’t measure. Our first step was to gain deep visibility into our spending patterns. We leveraged:
IaaS Cost Reports & Alerts: Regularly analyzing detailed cost breakdowns from cloud providers (AWS Cost Explorer, Azure Cost Management, GCP Billing Reports) helped us identify major cost drivers across compute, storage, and network usage. Setting up alerts for cost anomalies makes us aware of regressions and unexpected budget overruns.
Cloud Provider Recommendation Tools: Tools like AWS Trusted Advisor, Azure Advisor’s Cost recommendations, and Google Cloud’s machine type rightsizing recommendations provided initial, manual pointers towards obvious inefficiencies like underutilized virtual machines or suboptimal instance types.
Internal Usage Reports: We generated custom reports detailing our own resource consumption. This helped identify and drive down the number and uptime of development and other non-production clusters. Automating the configuration of Gardener’s cluster hibernation feature or reporting on clusters with poor hibernation schedules further curbed unnecessary spending. These insights are now integrated into the Gardener Dashboard (our GUI).
The Reserved Instance / Savings Plan Imperative: Planning for Discounts
Cloud providers offer significant discounts for commitment: Reserved Instances (RIs) on AWS/Azure, Savings Plans (SPs) on AWS/Azure, and Committed Use Discounts (CUDs) on GCP. However, maximizing their benefit requires careful planning, which is not the primary subject of this blog post. Companies typically have tools that generate recommendations from cost reports, suggesting the purchase of new RIs, SPs, or CUDs if on-demand usage consistently increases. Two key learnings emerged in this context, though:
Coordination between Operations and Controlling: We discovered that technical optimizations and discount commitment purchases must go hand-in-hand. A significant 20% utilization improvement can be completely negated if the remaining workload runs on expensive on-demand instances because the RI/SP/CUD purchase didn’t account for the change. On-demand pricing can easily be twice or more expensive than committed pricing.
Commitments vs. Spot Pricing: While Spot Instances/Preemptible virtual machines offer deep discounts, their ephemeral nature makes them unsuitable for critical control plane components. For predictable baseline workloads, well-planned RIs/SPs/CUDs provide substantial, reliable savings and are often more beneficial overall. Spot Instance/Preemptible VM discounts are generally not higher than, and often less than, RI/SP/CUD discounts for comparable commitment levels.
Early Wins: Finding and Eliminating Resource Waste
We also actively looked for waste, specifically orphaned resources. Development and experimentation inevitably lead to forgotten resources (virtual machines, disks, load balancers, etc.). We implemented processes like requiring all resources to include a personal identifier in the name or as a label/tag to facilitate later cleanup. Initially, we generated simple reports, but it became clear that this task required a more professional approach. Unaccounted-for resources aren’t just costly; they can also pose security risks or indicate security incidents. Therefore, we developed the gardener/inventory tool. This tool understands Gardener installations and cross-references expected cloud provider resources (based on Gardener’s desired state and implementation) against actually existing resources. It acts as an additional safety net, alerting on discrepancies (e.g., unexpected load balancers for a seed, unmanaged virtual machines in a VPC) which could indicate either cost leakage or a potential security issue, complementing Gardener’s existing security measures like high-frequency credentials rotation, image signing and admission, network policies, Falco, etc.
Consolidation: Avoiding a Fragmented Seed Landscape
If possible, avoid operating too many small seeds unless required by regulations or driven by end-user demand. As Gardener supports control plane migration, you can consolidate your control planes into fewer, larger seeds where reasonable. Since starting Gardener in production in 2017, we’ve encountered technological advancements (e.g., Azure Availability Sets to Zones) and corrected initial misconfigurations (e.g., too-small CIDR ranges limiting pod/node counts) that necessitated recreating seeds. While hard conflicts (like seed/shoot cluster IP address overlaps) can sometimes block migration to differently configured seeds, you can often at least merge multiple seeds into one or fewer. The key takeaway is that a less fragmented seed landscape generally leads to better efficiency.
However, there is a critical caveat: Gardener allows control planes to reside in different regions (or even different cloud providers) than their worker nodes. This flexibility comes at the cost of inter-regional or internet network traffic. These additional network-related costs can easily negate efficiency gains from seed consolidation. Therefore, consolidate thoughtfully, being mindful that excessive consolidation across regions can significantly increase network costs (intra-region traffic is cheaper than inter-region traffic, and internet traffic is usually the most expensive).
Quick Wins in Networking and Storage
While compute was our main focus, we also addressed significant cost drivers in networking and storage early on.
Centralized Ingress & Caching
Centralized Ingress: In Gardener’s early days, each shoot control plane had its own Load Balancer (LB), plus another for the reverse tunnel connection to worker nodes (to reach webhooks, scrape metrics, stream logs, exec into pods, etc.). This proliferation of LBs was expensive. We transitioned to a model using a central Istio ingress-gateway per seed cluster with a single LB, leveraging SNI (Server Name Indication) routing to direct traffic to the correct control plane API servers. We also reversed the connection direction: shoots now connect to seed clusters, and seeds connect to the garden cluster. This reduced the need for LBs exposing seed components and enabled private shoots or even private seeds behind firewalls.
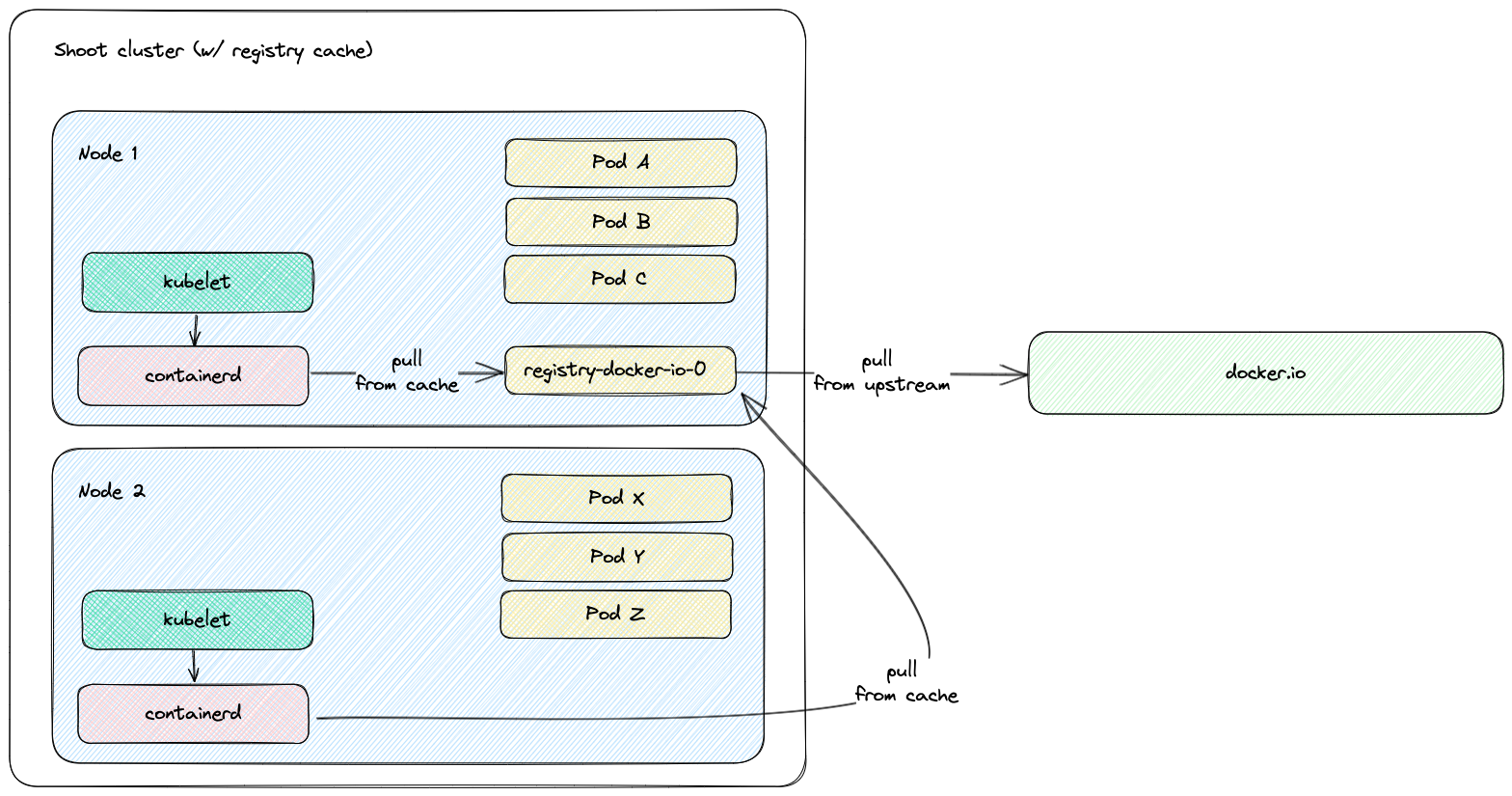
Registry Cache: Pulling container images for essential components (like CNI, CSI drivers, kube-proxy) on every new node startup generated significant network traffic and costs. We implemented a registry cache extension, drastically reducing external image pulls (see blog post).
Smarter Networking Habits
Efficient API Usage: Well-implemented controllers use watch requests rather than frequent list requests to minimize API server load and improve responsiveness. Leveraging server-side filtering via label selectors and field selectors reduces the amount of data transferred.
Reducing Cross-Zonal Traffic: Data transfer between availability zones, necessary for highly available control planes, is generally more expensive than within a single zone. We enabled Kubernetes’ Topology Aware Routing to help route API server traffic within the same zone where possible, reducing cross-zonal traffic and therefore costs (see Gardener Issue #6718).
Avoiding Large Resources: Storing large amounts of data directly in Kubernetes resources (ConfigMaps, Secrets) is inefficient and strains etcd and the network. We utilize blob stores for large payloads, such as control plane etcd or state backups used for automated restoration or control plane migration (with data compressed and encrypted in transit and at rest).
Regression Monitoring: Implementing regression monitoring for network traffic helped catch seemingly innocent code changes that could inadvertently cause massive spikes in data transfer costs.
Conscious Storage Consumption
Storage costs were addressed by being mindful of Persistent Volume Claim (PVC) size and performance tiers (e.g., standard HDD vs. premium SSD). Choosing the right storage class based on actual workload needs prevents overspending on unused capacity or unnecessary IOPS.
Deep Dive into Compute Cost Optimization
This is where the most significant savings were realized. Optimizing compute utilization in Kubernetes is a multi-faceted challenge involving the interplay of several components.
Understanding Utilization: The Interplay of Scheduler, Cluster Autoscaler, HPA, and VPA
We think of utilization optimization in two stages:
Packing Pods onto Nodes (Requests vs. Allocatable): How efficiently are the resource requests of your pods filling up the allocatable capacity of your nodes? This is primarily influenced by the Kube-Scheduler and the Cluster Autoscaler (CA).
Right-Sizing Pods (Usage vs. Requests): How closely does the actual resource usage of your pods match their requests? This is where Horizontal Pod Autoscaler (HPA) and Vertical Pod Autoscaler (VPA) come in.
You need to optimize both stages for maximum efficiency.
Optimizing Scheduling: Bin-Packing and Pod Priorities with Kube-Scheduler
Bin-Packing: By default, Kube-Scheduler tries to spread pods across nodes (using the LeastAllocated strategy). For cost optimization, packing pods tightly onto fewer nodes (using the MostAllocated strategy, often called bin-packing) is more effective. Gardener runs Kubernetes control planes as pods on seed clusters. Switching the Kube-Scheduler profile in our seed clusters to prioritize bin-packing yielded over 20% reduction in machine costs for these clusters simply by requiring fewer nodes. We also made this scheduling profile available for shoot clusters (see Gardener PR #6251).
Pod Priorities: Assigning proper Pod Priorities is important not just for stability but also for cost. High-priority pods (like control plane components) can preempt lower-priority pods if necessary, reducing the need to maintain excess capacity just in case a critical pod needs scheduling space. This avoids unnecessary over-provisioning.
Voluntary Disruptions: Pod Disruption Budgets
Pod Disruption Budgets: Defining proper Pod Disruption Budgets (PDBs) helps manage and steer voluntary disruptions safely. We define them consistently for all Gardener components. This provides the necessary control to rebalance, compact, or generally replace underlying machines as needed by us or our automation, contributing to cost efficiency by enabling node consolidation.
Enabling Higher Pod Density per Node
Node Configuration: To effectively utilize larger instance types and enable better bin-packing, nodes must be configured to handle more pods. We observed nodes becoming pod-bound (unable to schedule more pods despite available CPU/memory). To prevent this, ensure you provide:
A large enough --node-cidr-mask-size (e.g., /22 for ~1024 IPs, though assume ~80% effective due to IP reuse; see kube-controller-manager docs) to allocate sufficient IPs per node.
Sufficient --kube-reserved resources (see kubelet docs) to account for system overhead.
An increased --max-pods value (again, see kubelet docs) to inform the kubelet and scheduler of the node’s actual pod capacity.
Fine-Tuning the Cluster Autoscaler: Scaling Nodes Efficiently
The cluster autoscaler (CA) adds or removes nodes based on pending pods and node utilization. We tuned its behavior for better cost efficiency:
--scale-down-unneeded-time=15m: Time a node must be underutilized before CA considers it for removal, allowing removal of persistently unneeded capacity.
--scale-down-delay-after-add=30m: Prevents CA from removing a node too soon after adding one, reducing potential node thrashing during fluctuating load.
--scale-down-utilization-threshold=0.9: We significantly increased this threshold (default is 0.5). It instructs CA to attempt removing any node running below 90% utilization if it can safely reschedule the existing pods onto other available nodes; otherwise, it does nothing. We have run with this setting successfully for a long time, supported by properly tuned pod priorities, PDBs managing voluntary disruptions, highly available control planes, and Kubernetes’ level-triggered, asynchronous nature.
Mastering Pod Autoscaling: HPA, VPA, and Best Practices
Right-sizing pods dynamically is key. Kubernetes offers HPA and VPA:
Horizontal Pod Autoscaling (HPA): Scales the number of pod replicas based on metrics (CPU/memory utilization, custom metrics). Ideal for stateless applications handling variable request loads.
Vertical Pod Autoscaler (VPA): Adjusts the CPU/memory requests of existing pods. Ideal for stateless and also stateful applications or workloads with fluctuating resource needs over time, without changing replica count.
Our Best Practices & Learnings:
Combine HPA and VPA for API Servers Safely: You can use HPA and VPA together, even on the same metric (like CPU), but careful configuration is essential. The key is to configure HPA to scale based on the average value (target.type: AverageValue) rather than utilization percentage (target.type: Utilization). This prevents conflicts where VPA changes the requests, which would otherwise immediately invalidate HPA’s utilization calculation.
Example HPA targeting average CPU/Memory values:
spec:
minReplicas: 3
maxReplicas: 12
metrics:
- resource:
name: cpu
target:
averageValue: 6 # Target 6 cores average usage per pod (Note: String value often required)
type: AverageValue
type: Resource
- resource:
name: memory
target:
averageValue: 24Gi # Target 24Gi average usage per pod type: AverageValue
type: Resource
behavior: # Fine-tune scaling behavior scaleDown:
policies:
- periodSeconds: 300
type: Pods
value: 1
selectPolicy: Max
stabilizationWindowSeconds: 1800
scaleUp:
policies:
- periodSeconds: 60
type: Percent
value: 100
selectPolicy: Max
stabilizationWindowSeconds: 60
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: kube-apiserver
Tune VPA Configuration:
We adjusted VPA parameters like --target-cpu-percentile / --target-memory-percentile (determining the percentile of historical usage data to include in target recommendations, ignoring spikes above) and margin/bound parameters to make VPA less sensitive to tiny spikes and react faster and more accurately to sustained changes.
We also tuned parameters like --cpu-histogram-decay-half-life (from 24h to 15m) and --recommendation-lower-bound-cpu-percentile (from 0.5 to 0.7) to follow changes in CPU utilization more closely (work on memory is ongoing).
VPA minAllowed: We set minAllowed (per VPA resource) based on observed usage patterns and historical outage data related to VPA scaling down too aggressively.
VPA maxAllowed: We set maxAllowed (per VPA controller) to prevent request recommendations from exceeding node capacity. We found maxAllowed couldn’t be configured centrally in the VPA controller, so we contributed this feature upstream (see Kubernetes Autoscaler Issue #7147 and corresponding PR).
Set Pod Requests: We always set CPU and memory requests for our containers or let VPA manage those.
Tune Pod Requests: We systematically processed hundreds of components:
Some deployments were placed under VPA management. Others (very small, below VPA’s resolution of ~10m cores / 10Mi memory) were removed from VPA and given static requests.
“Initial” Requests: For pods managed by VPA, we set initial requests to the observed P5 (5th percentile) of historical usage. This provides a reasonable starting point for VPA.
“Static” Requests: For pods not managed by VPA, we set requests to the P95 (95th percentile). This ensures they generally have enough resources; only exceptional spikes might cause issues, where VPA wouldn’t typically help either.
Quality of Service (QoS): Prefer the Burstable QoS class (requests set, ideally no limits) for most workloads. Avoid BestEffort (no requests/limits), as these pods are the first to be evicted under pressure. Avoid Guaranteed (requests match limits), as limits often cause more harm than good. See our Pod Autoscaling Best Practices Guide. Pods in the Guaranteed QoS class, or generally those with limits, will be actively CPU-throttled and can be OOMKilled even if the node has ample spare capacity. Worse, if containers in the pod are under VPA, their CPU requests/limits often won’t scale up appropriately because CPU throttling goes unnoticed by VPA.
Avoid Limits: In Gardener’s context (and often also elsewhere), setting CPU limits offers few advantages and significant disadvantages, primarily unnecessary throttling. Setting memory limits can prevent runaway processes but may also prematurely kill pods. We generally avoid setting limits unless the theoretical maximum resource consumption of a component is well understood. When unsure, let VPA manage requests and rely on monitoring/alerting for excessive usage.
Data-Driven Machine Type Selection
Continuous Monitoring: Understanding How Well Our Machines are Utilized
Before optimizing machine type selection, we established comprehensive machine utilization monitoring. This was important during individual improvement steps to validate their effectiveness. We collect key metrics per Gardener installation, cloud provider, seed, and worker pool, and created dashboards to visualize and monitor our machine costs. These dashboards include:
Total CPU [in thousand cores], Total Memory [in TB], Total Number of Control Planes [count]
Used Capacity CPU [%], Used Capacity Memory [%], Unused vs. Capacity Cost [Currency]
Requested Allocatable CPU [%], Requested Allocatable Memory [%], Unrequested vs. Allocatable Cost [Currency]
Used Requested CPU [%], Used Requested Memory [%], Unused vs. Requested Cost [Currency]
Used Reserved CPU [%, can exceed 100%], Used Reserved Memory [%, can exceed 100%], Unused vs. Reserved Cost [Currency]
Nodes with >99% filling levels, broken down by CPU, memory, volumes, and pods (to identify the most critical resource blocking further usage)
Effective CPU:memory ratio of the workload (more on that later)
Why Machine Types Matter: Size, Ratios, Generations, and Hidden Constraints
Selecting the right machine type is critical for cost efficiency. Several factors come into play:
Size: Larger machines generally lead to less fragmentation (less wasted CPU/memory remainder per node) and better overhead efficiency (system components like kubelet/containerd consume a smaller percentage of total resources). However, smaller machines can be better for low-load scenarios while meeting high-availability constraints (e.g., needing to spread critical pods across 3 zones requires at least 3 nodes).
CPU:Memory Ratio: Cloud providers offer instance families with different CPU:memory ratios (e.g., high-cpu 1:2, standard 1:4, high-memory 1:8). Matching the instance ratio to your workload’s aggregate CPU:memory request ratio minimizes waste.
Generations: Newer instance generations usually offer better performance and, crucially, better price-performance. This can also shift the effective CPU:memory ratio required by the workload due to performance differences.
Hidden Constraints: Volume Limits: This proved to be a major factor, especially on AWS and Azure. Each instance type has a maximum number of network-attached volumes it can support. Gardener control planes, each with its own etcd cluster requiring persistent volumes for each replica, are heavily impacted. We often found ourselves limited by volume attachments long before hitting CPU or memory limits. Interestingly, ARM-based instance types on Azure support a slightly higher volume limit.
The Case for Dedicated Pools: Isolating Workloads
While mixing diverse workloads seems efficient at first glance, dedicated node pools for specific workload types proved beneficial for several reasons:
Handling safe-to-evict: false: Some pods (like single-replica stateful components for non-HA clusters) cannot be safely evicted by the Cluster Autoscaler. Mixing these with evictable pods on the same node can prevent the CA from scaling down that node, even if it’s underutilized, negating cost savings. Placing these non-evictable pods in a dedicated pool (where scale-down might be disabled or carefully managed) isolates this behavior.
Volume Concentration: Our “etcd” worker pools host primarily etcd pods (high volume count) and daemonsets, while “standard” pools host API servers, controllers, etc. (lower volume concentration). This difference influences the optimal machine type due to volume attachment limits.
Preventing Scheduling Traps: Ensure critical, long-running pods (like Istio gateways) have node affinities/selectors to land only on their preferred, optimized node pools. Avoid them landing on temporary, large nodes spun up for short-lived bulky pods; if such a pod prevents the large node from scaling down (e.g., because the pool is at its minimum node count), the CA won’t automatically replace the underutilized large node with a smaller one. That’s a concept called “workload consolidation”, today only supported by Karpenter, which isn’t supporting as many cloud providers as CA.
Analyzing Workload Profiles: Finding the Optimal Instance Size and Family
Early on, we used a guide for operators to estimate a reasonable machine size for a seed cluster based on the number of hosted control planes, e.g.:
Optimal Worker Pool (CPUxMem+Vols)
Very Low Seed Utilization 0 <= |control planes| < 15
Low Seed Utilization 5 <= |control planes| < 30
Medium Seed Utilization 10 <= |control planes| < 70
High Seed Utilization 30 <= |control planes| < 180
Very High Seed Utilization 120 <= |control planes| < ∞
AWS
m5.large(2x8+26)
r7i.large(2x16+32)
r7i.xlarge(4x32+32)
r7i.2xlarge(8x64+32)
r7i.2xlarge(8x64+32)
Azure
Standard_D2s_v5(2x8+4)
Standard_D4s_v5(4x16+8)
Standard_D8s_v5(8x32+16)
Standard_D16s_v5(16x64+32)
Standard_D16s_v5(16x64+32)
GCP
n1-standard-2(2x8+127)
n1-standard-4(4x15+127)
n1-standard-8(8x30+127)
n1-standard-16(16x60+127)
n1-standard-16(16x60+127)
This guide also recommended specific instance families. Choosing the right family requires calculating the workload’s aggregate CPU:memory ratio (total requested CPU : total requested memory across similar workloads). For example, 1000 cores and 6000 GB memory yields a 1:6 ratio.
Next, one must calculate the cost per core and per GB for different instance families and determine the break-even CPU:memory ratio – the point where the resource waste of two families is equal. The cluster autoscaler doesn’t perform this cost-aware analysis; it always weights CPU and memory equally (1:1).
To find the optimal family manually, we followed these steps when adding new generations/families:
Cost per Resource Unit: Determine the effective cost per core and per GB. Example:
Instance A (2 cores, 4 GB) costs €48/month.
Instance B (2 cores, 8 GB) costs €64/month.
Difference: 4 GB and €16 -> €4 per GB.
Cost of 2 cores = €48 - (4 GB * €4/GB) = €32 -> €16 per core.
Break-Even Analysis: Using the unit costs, calculate the break-even CPU:memory ratio where the cost of waste balances out between two families for your specific workload ratio.
For instance, if the break-even ratio between standard (1:4) and high-memory (1:8) families is 1:5.7, and your workload runs at 1:6, the high-memory family is likely more cost-effective.
Automating the Choice: A Machine Type Recommender
This manual process was tedious, error-prone, and infrequently performed, leading to suboptimal machine types running in many seeds. To address this, we developed an automated pool recommender based on the following principles:
Comprehensive Data Collection: The recommender gathers metrics across the entire Gardener installation for specific seed sets (groups of seeds with similar configurations like provider and region). For every relevant seed, it collects:
CSI Node Info: Maximum attachable volume counts per node.
Pod Specs: Resource requests (CPU, memory) for all pods, distinguishing daemonset pods.
Actual Node Usage: Detailed usage statistics obtained directly from the kubelet summary API (/api/v1/nodes/NODENAME/proxy/stats/summary). This provides actual cgroup-level data on CPU and memory consumption for kubelet, container runtime, system overhead, and individual pods. Especially for memory, this was the only reliable method we found to get accurate working set bytes overall (simply summing pod metrics is inaccurate due to page cache/sharing; see kernel docs for cgroup-v1 and cgroup-v2).
Analyzing the Data: Before recommending new types, the recommender calculates key metrics that act as predictors and provide context:
Measured Overhead Ratios:Measured Reserved Core : Pod Count, Measured Reserved GB : Pod Count.
Aggregation: Machines are grouped by pool within a seed set.
Performance Normalization: CPU metrics (usage) are normalized based on relative performance indicators of the analyzed machine type.
Simulating Workload on Candidate Machines: This is the core recommendation logic:
Candidate Iteration: The system iterates through all potential machine types available for the specific provider and region(s).
Resource Calculation per Candidate: For each candidate machine type:
Calculate kube-reserved: Estimates CPU/memory needed for kubelet/runtime using our measurement-based model, tailored to the candidate’s capacity (more on that later).
Account for DaemonSets: Subtracts the average CPU/memory requests of DaemonSet pods (derived from current aggregated pool data).
Performance Adjustment: Adjusts CPU calculations (reserved, daemonset, workload requests) based on the candidate’s performance factor relative to a baseline.
Calculate Allocatable Resources: Determines CPU/memory available for workload pods after subtracting reserved and DaemonSet resources.
Unschedulable Buffer: Reduces allocatable resources slightly (e.g., by the equivalent of an “average pod”) to account for resource fragmentation and imperfect bin-packing, slightly favoring larger nodes.
Constraint Checking & Usable Resources: Projects how much of the aggregated current workload (total requests) could fit onto the candidate. It considers multiple dimensions, converting them to a common unit (GB-equivalent) using the measured workload ratios:
Performance-adjusted Allocatable CPU (converted to GB-equivalent)
Allocatable Memory (GB)
Attachable Volumes (converted to GB-equivalent)
Schedulable Pods (converted to GB-equivalent)
The minimum of these values determines the actual usable resources for that candidate machine type under the given workload profile – identifying the true bottleneck, i.e. whether a candidate is CPU-, memory-, volume-, pod-, or load-bound and thus potentially suboptimal.
Cost & Waste Analysis:
Calculates the base machine_costs (Cores * Cost per Core + GBs * Cost per GB) for the candidate.
Estimates excess_costs (waste) per machine due to factors like:
Imperfect Packing: Assumes the “last” node in a zone is only half-utilized on average.
Scale-Down Disabled: Increases estimated waste if scale-down is disabled.
Volume Packing: Adds potential waste if the workload is heavily volume-constrained, assuming not all nodes can be packed efficiently with volumes.
Efficiency Score Calculation: Computes a relative efficiency score for each candidate:
Efficiency = (Cost_of_Usable_Resources) / (Base_Machine_Cost + Estimated_Excess_Cost)
This score reflects how cost-effectively the candidate machine type can serve the workload, factoring in estimated waste.
Ranking & Selection:
Sorting: Candidates are ranked primarily by Efficiency / Cost per Core. Dividing by cost per core helps prioritize newer/cheaper instance generations or those with better RI/SP coverage, while still heavily favoring the calculated efficiency.
Preferred Type & Hysteresis: The top-ranked type is marked as preferred and receives the highest CA expander priority. A threshold (e.g., >5% efficiency improvement) prevents switching the preferred type too frequently, avoiding churn (flapping).
Priority Assignment: Priorities are assigned for the cluster autoscaler expander, favoring the preferred type and then ranking others based on the sort order.
Handling Existing/Legacy Pools: Ensures that pools with currently running nodes, even if suboptimal or using non-standard names, are preserved to avoid disruption. Legacy pools are tainted with a NoSchedule taint to allow workload to slowely migrate away from them.
This data-driven, simulation-based approach allowed us to abandon guides like above and manual operations and consistently select machine types that offer the best balance of performance and cost for the specific workloads running on our Gardener seeds.
Reserving Capacity for Kubelet and Container Runtime: Tailoring kube-reserved Beyond Workload-Naive Formulas
As pod packing density increases, accurately accounting for resources needed by the system itself (kubelet, container runtime, OS) becomes critical. Standard cloud provider formulas for kube-reserved (see kubelet options) are often workload-naive, based only on total node CPU/memory capacity (see summary blog post). They can either over-reserve (wasting resources) or under-reserve (risking node stability). Our experience showed that formulas considering only node capacity and potentially maxPods were often significantly inaccurate, leading to either waste or instability.
Therefore, instead of relying on static formulas, we adopted a measurement-based approach combined with predictive modeling:
Measure Actual Overhead: We utilize the data already retrieved via the kubelet summary API. By querying this endpoint across thousands of nodes for all our seeds, we collect the actual CPU (usageNanoCores) and memory (workingSetBytes) consumed by the kubelet and runtime system containers under various conditions (different machine types, workload profiles like ETCD pools, varying pod densities).
Derive Workload-Aware Ratios: We then calculate key ratios that correlate overhead with workload characteristics, specifically pod density:
ratio_1_used_reserved_core_to_pods: Average number of pods running per actually used reserved core (performance-normalized across machine types).
ratio_1_used_reserved_gi_to_pods: Average number of pods running per actually used reserved GB of memory.
These ratios capture how much system overhead is typically generated per pod on average within a specific pool type for a given seed set. We explored other potential predictors (containers, probes) but found pod count to be the most useful predictor with acceptable standard deviation.
Predict Expected kube-reserved: We use these measured ratios to predict the necessary kube-reserved for any candidate machine type considered by the Pool Recommender. The model works as follows:
Base Load: We observed a consistent base memory overhead even on lightly loaded nodes (e.g., ~200MiB with Garden Linux, Gardener’s own Debian-based container-optimized OS) and negligible base CPU overhead.
Estimate Pod-Driven Overhead: Using the predicted pod density for a candidate machine type (based on its capacity and the workload profile), we multiply this density by the measured ratio_1_used_reserved_core_to_pods and ratio_1_used_reserved_gi_to_pods to estimate the required kube-reserved CPU and memory, respectively. This tailors the reservation to the candidate’s specific capacity and performance characteristics.
Apply Thresholds for Stability: To prevent minor fluctuations in calculated recommendations from causing constant configuration changes (increasing kube-reserved can trigger pod evictions), we apply thresholds (hysteresis).
This tailored, data-driven approach to kube-reserved provides better cost optimization and enhanced stability compared to generic, workload-naive formulas.
Note on system-reserved: You might wonder why we only discussed kube-reserved and not system-reserved. Similar to our reasoning against resource limits, configuring system-reserved can lead to unexpected CPU throttling or OOM kills for critical system processes outside Kubernetes’ direct management. Therefore, Gardener focuses on configuring kube-reserved and relies on the kubelet’s eviction mechanisms to manage overall node pressure. See also Reserve Compute Resources for System Daemons.
Looking Ahead: Continuous Improvement and Future Optimizations
Cost optimization is an ongoing process, not a one-time fix. We’re actively exploring further improvements:
Addressing Load Imbalances: VPA assigns the same request to all pods in a managed group (Deployment/StatefulSet/DaemonSet). This is inefficient for workloads with inherent imbalances (e.g., controller leaders vs. followers, etcd leader vs. followers, uneven load distribution across DaemonSet pods).
Request-Based Load Balancing: For components like the kube-apiserver, default connection-based load balancing can lead to uneven load distribution that VPA handles poorly (resulting in over-provisioning for some pods, under-provisioning for others). We have implemented request-based load balancing to distribute load more evenly, allowing VPA to set more accurate requests (see related work).
In-place pod resource updates (a Kubernetes enhancement) would be particularly beneficial in the future, allowing VPA to adjust resources without requiring pod restarts, further improving efficiency and stability.
Exploring Cilium / Replacing kube-proxy: Initial tests suggest switching the CNI from Calico to Cilium could yield 5-10% CPU savings on worker nodes, partly because Cilium can replace kube-proxy, reducing overhead. Memory usage appears similar and Gardener has supported Cilium for years. Alternatively, to eliminate kube-proxy without changing CNIs, we could evaluate Calico’s eBPF data plane, which can also replace kube-proxy.
ARM Architecture: We are evaluating ARM-based CPUs (AWS Graviton, Azure Cobalt, GCP Axion). They are generally cheaper per core. Even if slightly slower per core (but often with a better price-performance), they offer additional instance family options, potentially allowing a better match to the workload’s CPU:memory ratio (e.g., a 1:6 workload x86 ratio might turn into a performance-adjusted 1:5 ARM ratio and thereby result in less waste than x86 instance families of either a 1:4 or 1:8 ratio). Additionally, Azure’s ARM instances sometimes offer slightly higher volume attachment limits.
Conclusion: Sustainable Savings and Key Takeaways
Optimizing Kubernetes compute costs at scale is a complex but rewarding endeavor. Our journey with Gardener involved a multi-pronged approach:
Establish Visibility: Use cloud cost tools and internal monitoring to understand spending.
Strategic Purchasing: Tightly align RI/SP/CUD purchases with technical optimizations and workload forecasts.
Clean Up Waste: Eliminate orphaned resources and leverage features like cluster hibernation.
Tune Kubernetes Core Components: Utilize scheduler bin-packing, fine-tune cluster autoscaler parameters, and master HPA/VPA configurations, including safe combined usage.
Data-Driven Machine Selection: Analyze workload profiles, use dedicated pools strategically, consider all constraints (especially non-obvious ones like volume limits), and automate machine type recommendations based on real data and simulation.
Accurate Overheads: Measure and tailor kube-reserved based on actual system usage patterns rather than static formulas.
These efforts have yielded substantial cost reductions for operating Gardener itself and, by extension, for all Gardener adopters running managed Kubernetes clusters. We hope sharing our journey provides valuable insights for your own optimization efforts, whether you’re just starting or looking to refine your existing strategies.
March
Gardener at KubeCon + CloudNativeCon Europe, London 2025
Gardener at KubeCon + CloudNativeCon Europe, London 2025
The open-source project Gardener is set to showcase its cutting-edge Kubernetes-as-a-Service (KaaS) capabilities at KubeCon + CloudNativeCon Europe 2025 in London.
Gardener has been pioneering hosted control planes long before they became mainstream and is now the default choice within SAP and other organizations for provisioning Kubernetes clusters.
Organizations looking to transform their Infrastructure-as-a-Service (IaaS) into a Kubernetes-as-a-Service (KaaS) platform can experience Gardener’s powerful automation, security, and multi-cloud extensibility firsthand at the event or directly in the browser.
Revolutionizing Kubernetes Management with Gardener
Gardener provides a fully managed Kubernetes cluster solution that is:
Infinitely Extensible: Gardener offers limitless extensibility, supporting AWS, Azure, Alicloud, GCP, OpenStack, and other infrastructures. Run nodes with Garden Linux, SuSE, Ubuntu, or Flatcar OS while utilizing runc or gVisor for container runtime flexibility and Calico or Cilium for CNI. Explore the Gardener Extensions Library for even more customization options.
Automated Lifecycle Management: Simplified provisioning, scaling, and updates with built-in automation.
Security & Compliance: Enforced policies and strict isolation to meet regulatory and enterprise security requirements, with support for automated credential rotation.
Multi-Tenancy & Cost Efficiency: Designed for organizations running at scale, optimizing resources without sacrificing performance.
Also, explore our other open-source projects:
etcd-druid – Our in-house operator responsible for managing etcd instances in Gardener’s hosted control planes, ensuring the stability and performance of Kubernetes clusters.
openMCP – Our latest open-source offering that enables organizations to streamline application development using control plane methodology, making it easy to roll out, upgrade, and replicate cloud environments securely and seamlessly.
As Kubernetes adoption continues to accelerate, Gardener remains the go-to choice for managing Kubernetes at scale across multi-cloud and hybrid environments. Stop by our booth S561 at KubeCon + CloudNativeCon Europe 2025 to experience Gardener firsthand and meet the team to see how Gardener empowers organizations to run secure, scalable, and efficient Kubernetes clusters with ease.
2024
Unleashing Potential: Highlights from the 6th Gardener Community Hackathon
🌐 IPv6 Support on IronCore: The team successfully created dual-stack shoot clusters on IronCore, although LoadBalancer services for IPv6 traffic still need some work.
🔁 Version Classification Lifecycle in CloudProfile: A Gardener Enhancement Proposal (GEP) was developed to predefine the timestamps for Kubernetes or machine image version classifications in CloudProfiles.
⬆️ Deploy Prow Via Flux: Prow, Gardener’s CI and automation system, was deployed using Flux, a cloud-native solution for continuous delivery based on GitOps.
🫄 cluster-autoscaler’s ProvisioningRequest API: The ProvisioningRequest API in cluster-autoscaler was introduced, allowing users to provision new nodes or check if a pod would fit in the existing cluster without scaling up.
🐢 Cluster API Provider For Gardener: The cluster API in Gardener was supported, allowing for the deployment and deletion of shoot clusters via the cluster API.
👨🏼💻 Make cluster-autoscaler Work In Local Setup: The cluster-autoscaler was made to work in the local setup, setting the nodeTemplate in the MachineClass for the cluster-autoscaler to get the resource capacity of the nodes.
These outcomes reflect the ongoing progress and collaborative spirit of the Gardener community. We’re eager to see what the next Hackathon will bring. Keep an eye out for more updates on the Gardener project!
Introducing the New Gardener Demo Environment: Your Hands-On Playground for Kubernetes Management
We’re thrilled to announce the launch of our new Gardener demo environment!
This interactive playground is designed to provide you with a hands-on experience of Gardener, our open-source project that offers a Kubernetes-based solution for managing Kubernetes clusters across various cloud providers uniformly.
Why a Demo Environment?
We understand that the best way to learn is by doing.
That’s why we’ve created this demo environment.
It’s a space where you can experiment with Gardener, explore its features, and see firsthand how it can simplify your Kubernetes operations - all without having to install anything on your local machine.
Easy Access, Quick Learning
Getting started is as simple as logging in with your GitHub account.
Once you’re in, you’ll have access to a terminal session running a pre-configured Gardener system (based on the local setup which you can also install on your machine if preferred).
This means you can dive right in and start creating and managing Kubernetes clusters.
Whether you’re a seasoned Kubernetes user or just starting your Kubernetes journey, this demo environment is a great way to learn about Gardener. It’s designed to be intuitive and interactive, helping you learn at your own pace.
Discover the Power of Gardener
Gardener is all about making Kubernetes management easier and more efficient.
With its ability to manage Kubernetes clusters homogenously across different cloud providers, it’s a powerful tool that can optimize your resources, improve performance, and enhance the resilience of your Kubernetes workloads.
But don’t just take our word for it - try it out for yourself!
The Gardener demo environment is your playground to discover the power of Gardener.
Start Your Gardener Journey Today
We’re excited to see what you’ll create with Gardener.
Log in with your GitHub account and start your hands-on Gardener journey today.
Happy exploring!
Many innovative observability and application performance management (APM) products and services were released over the last few years. They often adopt or enhance concepts that Prometheus invented more than a decade ago. However, Prometheus, as an open-source project, has never lost its importance in this fast-moving industry and is the core of Gardener’s monitoring stack.
On September 11th and 12th, Prometheus developers and users met for PromCon EU 2024 in Berlin. The single-track conference provided a good mix of talks about the latest Prometheus development and governance by many core contributors, as well as users who shared their experiences with monitoring in a cloud-native environment. The overarching topic of the event was the upcoming Prometheus 3.0 release. Many of the presented innovations will also be interesting for the future of Gardener’s observability stack. We will take a closer look at the changes in the Prometheus and Perses projects in the remainder of this article.
Prometheus 3.0 - OpenTelemetry Everywhere
A first beta version of Prometheus 3.0 was released during the first day of the conference. The main focus of the new major release is compatibility with OpenTelemetry and full support for metric ingestion using the OpenTelemetry protocol (OTLP). While OpenTelemetry and Prometheus metrics have many things in common, a lot of incompatibilities still need to be sorted out.
One of the differences can be found in the naming conventions for metrics and label or attribute names. Instead of simply replacing dots with underscores, the Prometheus developers decided to introduce full UTF-8 support to achieve the best possible compatibility. This plan brought up interesting syntactical challenges for PromQL queries, as well as a demand for conversion when interacting with systems that still have the restrictions of previous Prometheus releases.
The development of native histograms in Prometheus has been ongoing for a while. The more efficient way to represent histograms also contributes to OpenTelemetry compatibility.
While Prometheus traditionally uses labels to enrich a time series with metadata, OpenTelemetry describes the concepts of metric attributes and resource attributes. While the new release contains a new Info PromQL function to ease the enrichment with resource attributes, the development of a new metadata store has been initiated to improve the experience even more in the long term.
A new UI makes the creation of ad-hoc queries easier and provides better feedback about the structure of a query and possible mistakes to the user.
The Prometheus project has reached a high level of maturity after more than 12 years of development by an active community of contributors. To ensure that the community can continue growing, a new governance model was proposed, including clearly defined roles and a new steering committee.
Perses - The New Kid in The Sandbox
Perses was of particular interest to us working on monitoring at Gardener. As you may know, Gardener is currently using Plutono, a fork of Grafana’s most recent Apache-licensed version. This was introduced in g/g#7318 over a year ago and intended as a stop-gap solution. Since then, we have been interested in finding a more sustainable solution, as we’re cut off from the enhancements to Grafana. If you’ve ever made a change to a dashboard in Gardener, you’ll know that there are some pain points in working with Plutono.
Therefore, we were looking forward especially to a talk on a project known as Perses. An open-source dashboard solution that recently joined the CNCF as a sandbox project. Driven by development from Amadeus, Chronosphere, and Red Hat Openshift, Perses already offers a variety of dashboard panels, supports dashboards-as-code workflows, and has data-source plugins for metrics and distributed traces. It also brings tooling to convert Grafana dashboards to Perses, which also works for Plutono!
Adjacent to the Perses project itself is a Perses operator which enables deployment of Perses on Kubernetes using Custom Resource Definitions (CRDs). This is not a new concept - we also use the Prometheus operator in Gardener and would like to use it for Perses as well. One of the areas in which Perses is still lacking is the ability to use it to visualize logs, a key feature of Plutono. With work on the plugin architecture continuing, we hope to be able to work on this feature in the not-too-distant future. We are excited to see how Perses will develop and are looking forward to contributing to the project.
Conclusion
PromCon EU 2024 brought together open-source developers, commercial vendors, and users of observability tools. The event provided excellent learning opportunities during many high-quality talks and the chance to network with peers from the community while enjoying a BBQ after the first conference day. The large and healthy Prometheus community shows that open-source observability tools can coexist with commercial solutions.
Gardener at KubeCon + CloudNativeCon North America 2024
KubeCon + CloudNativeCon NA is just around the corner, taking place this year amidst the stunning backdrop of the Rocky Mountains in Salt Lake City, Utah.
This year, we’re thrilled to announce that the Gardener open-source project will have its own booth at the event.
If you’re passionate about multi-cloud Kubernetes clusters, optimizing for low TCO, built with enterprise-grade features, then Gardener should be on your must-visit list at KubeCon.
Why You Should Visit the Gardener Booth
The Gardener team will be presenting several features and enhancements that demonstrate the project’s continuous progress. Here are some highlights you’ll be able to experience first-hand:
Extensible and Automated Kubernetes Cluster Management: Learn how Gardener simplifies and automates Kubernetes cluster management across various infrastructures, allowing for consistent and reliable deployments.
Hosted Control Planes with Enhanced Security: Get insights into Gardener’s security features for hosted control planes. Discover how Gardener ensures robust isolation, scalability, and performance while keeping security at the forefront.
Multi-Cloud Strategy: Gardener has been built with multi-cloud in mind. Whether you’re deploying clusters across AWS, Azure, Google Cloud, or on-prem, Gardener has the flexibility to manage them all seamlessly.
etcd Cluster Operator: Explore our advancements with our in-house operator etcd-druid, a key component responsible for managing etcd instances of Gardener’s hosted control planes, ensuring the stability and performance of Kubernetes clusters.
Latest Project Developments and Roadmap: Stay ahead of the curve by getting a sneak peek at the latest updates, ongoing enhancements, and future plans for Gardener.
Software Lifecycle Management with Open Component Model (OCM): Learn how OCM supports compliant and secure software lifecycle management, and how it can help streamline processes across various projects and environments.
Meet the Gardener Team
One of the best parts of KubeCon is the opportunity to meet the community behind the projects. At the Gardener booth, you’ll have the chance to connect directly with the maintainers who are driving innovation in Kubernetes cluster management. Whether you’re new to the project or already using Gardener in production, our team will be there to answer questions, provide demos, and discuss best practices.
See You in Salt Lake City!
Don’t miss the chance to explore how Gardener can streamline your Kubernetes management operations. Visit us at KubeCon + CloudNativeCon North America 2024. Our booth will be located at R39. We look forward to seeing you there!
Innovation Unleashed: A Deep Dive into the 5th Gardener Community Hackathon
The Gardener community recently concluded its 5th Hackathon, a week-long event that brought together multiple companies to collaborate on common topics of interest. The Hackathon, held at Schlosshof Freizeitheim in Schelklingen, Germany, was a testament to the power of collective effort and open-source, producing a tremendous number of results in a short time and moving the Gardener project forward with innovative solutions.
A Week of Collaboration and Innovation
The Hackathon addressed a wide range of topics, from improving the maturity of the Gardener API to harmonizing development setups and automating additional preparation tasks for Gardener installations. The event also saw the introduction of new resources and configurations, the rewriting of VPN components from Bash to Golang, and the exploration of a Tailscale-based VPN to secure shoot clusters.
Key Achievements
🗃️ OCI Helm Release Reference for ControllerDeployment: The Hackathon introduced the core.gardener.cloud/v1 API, which supports OCI repository-based Helm chart references. This innovation reduces operational complexity and enables reusability for other scenarios.
👨🏼💻 Local gardener-operator Development Setup with gardenlet: A new Skaffold configuration was created to harmonize the development setups for Gardener. This configuration deploys gardener-operator and its Garden CRD together with a deployment of gardenlet to register a seed cluster, allowing for a full-fledged Gardener setup.
👨🏻🌾 Extensions for Garden Cluster via gardener-operator: The Hackathon focused on automating additional preparation tasks for Gardener installations. The Garden controller was augmented to deploy extensions as part of its reconciliation flow, reducing operational complexity.
🪄 Gardenlet Self-Upgrades for Unmanaged Seeds: A new Gardenlet resource was introduced, allowing for the specification of deployment values and component configurations. A new controller within gardenlet watches these resources and updates the gardenlet’s Helm chart and configuration accordingly, effectively implementing self-upgrades.
🦺 Type-Safe Configurability in OperatingSystemConfig: The Hackathon improved the configurability of the OperatingSystemConfig for containerd, DNS, NTP, etc. The OperatingSystemConfig API was augmented to support containerd-config related use-cases.
⌨️ Rewrite gardener/vpn2 from Bash to Golang: The Hackathon improved the VPN components by rewriting them in Golang. All functionality was successfully rewritten, and the pull requests have been opened for gardener/vpn2 and the integration into gardener/gardener.
🕳️ Pure IPv6-Based VPN Tunnel: The Hackathon addressed the restriction of the VPN network CIDR by switching the VPN tunnel to a pure IPv6-based network (follow-up of gardener/gardener#9597). This allows for more flexibility in network design.
👐 Harmonize Local VPN Setup with Real-World Scenario: The Hackathon aimed to align the local VPN setup with real-world scenarios regarding the VPN connection. provider-local was augmented to dynamically create Calico’s IPPool resources to emulate the real-world’s networking situation.
🐝 Support Cilium v1.15+ for HA Shoots: The Hackathon addressed the issue of Cilium v1.15+ not considering StatefulSet labels in NetworkPolicys. A prototype was developed to make the Service resources for vpn-seed-serverheadless.
🍞 Compression for ManagedResourceSecrets: The Hackathon focused on reducing the size of Secret related to ManagedResources by leveraging the Brotli compression algorithm. This reduces network I/O and related costs, improving scalability and reducing load on the ETCD cluster.
📦 Consider Embedded Files for Local Image Builds: The Hackathon addressed the issue that changes to embedded files don’t lead to automatic rebuilds of the Gardener images by Skaffold for local development. The related hack script was augmented to detect embedded files and make them part of the list of dependencies.
Note that a significant portion of the above topics have been built on top of the achievements of previous Hackathons.This continuity and progression of these Hackathons, with each one building on the achievements of the last, is a testament to the power of sustained collaborative effort.
Looking Ahead
As we look towards the future, the Gardener community is already gearing up for the next Hackathon slated for the end of 2024. The anticipation is palpable, as these events have consistently proven to be a hotbed of creativity, innovation, and collaboration. The 5th Gardener Community Hackathon has once again demonstrated the remarkable outcomes that can be achieved when diverse minds unite to work on shared interests. The event has not only yielded an impressive array of results in a short span but has also sparked innovations that promise to propel the Gardener project to new heights. The community eagerly awaits the next Hackathon, ready to tackle new challenges and continue the journey of innovation and growth.
Gardener's Registry Cache Extension: Another Cost Saving Win and More
Use Cases
In Kubernetes, on every Node the container runtime daemon pulls the container images that are configured in the Pods’ specifications running on the corresponding Node. Although these container images are cached on the Node’s file system after the initial pull operation, there are imperfections with this setup.
New Nodes are often created due to events such as auto-scaling (scale up), rolling updates, or replacements of unhealthy Nodes. A new Node would need to pull the images running on it from the container registry because the Node’s cache is initially empty. Pulling an image from a registry incurs network traffic and registry costs.
To reduce network traffic and registry costs for your Shoot cluster, it is recommended to enable the Gardener’s Registry Cache extension to run a registry as pull-through cache in the Shoot cluster.
The use cases of using a pull-through cache are not only limited to cost savings. Using a pull-through cache makes the Kubernetes cluster resilient to failures with the upstream registry - outages, failures due to rate limiting.
Solution
Gardener’s Registry Cache extension deploys and manages a pull-through cache registry in the Shoot cluster.
A pull-through cache registry is a registry that caches container images in its storage. The first time when an image is requested from the pull-through cache, it pulls the image from the upstream registry, returns it to the client, and stores it in its local storage. On subsequent requests for the same image, the pull-through cache serves the image from its storage, avoiding network traffic to the upstream registry.
Imagine that you have a DaemonSet in your Kubernetes cluster. In a cluster without a pull-through cache, every Node must pull the same container image from the upstream registry. In a cluster with a pull-through cache, the image is pulled once from the upstream registry and served later for all Nodes.
A Shoot cluster setup with a registry cache for Docker Hub (docker.io).
Cost Considerations
An image pull represents ingress traffic for a virtual machine (data is entering to the system from outside) and egress traffic for the upstream registry (data is leaving the system).
Ingress traffic from the internet to a virtual machine is free of charge on AWS, GCP, and Azure. However, the cloud providers charge NAT gateway costs for inbound and outbound data processed by the NAT gateway based on the processed data volume (per GB). The container registry offerings on the cloud providers charge for egress traffic - again, based on the data volume (per GB).
Having all of this in mind, the Registry Cache extension reduces NAT gateway costs for the Shoot cluster and container registry costs.
Try It Out!
We would also like to encourage you to try it! As a Gardener user, you can also reduce your infrastructure costs and increase resilience by enabling the Registry Cache for your Shoot clusters. The Registry Cache extension is a great fit for long running Shoot clusters that have high image pull rate.
SpinKube on Gardener - Serverless WASM on Kubernetes
With the rising popularity of WebAssembly (WASM) and WebAssembly System Interface (WASI) comes a variety of integration possibilities. WASM is now not only suitable for the browser, but can be also utilized for running workloads on the server. In this post we will explore how you can get started writing serverless applications powered by SpinKube on a Gardener Shoot cluster. This post is inspired by a similar tutorial that goes through the steps of Deploying the Spin Operator on Azure Kubernetes Service. Keep in mind that this post does not aim to define a production environment. It is meant to show that Gardener Shoot clusters are able to run WebAssembly workloads, giving users the chance to experiment and explore this cutting-edge technology.
For this showcase I am using a Gardener Shoot cluster on AWS infrastructure with nodes powered by Garden Linux, although the steps should be applicable for other infrastructures as well, since Gardener aims to provide a homogenous Kubernetes experience.
As a prerequisite for next steps, verify that you have access to your Gardener Shoot cluster.
# Verify the access to the Gardener Shoot clusterkubectl get ns
NAME STATUS AGE
default Active 4m1s
kube-node-lease Active 4m1s
kube-public Active 4m1s
kube-system Active 4m1s
If you are having troubles accessing the Gardener Shoot cluster, please consult the Accessing Shoot Clusters documentation page.
Deploy the Spin Operator
As a first step, we will install the Spin Operator Custom Resource Definitions and the Runtime Class needed by wasmtime-spin-v2.
Next, we will install cert-manager, which is required for provisioning TLS certificates used by the admission webhook of the Spin Operator. If you face issues installing cert-manager, please consult the cert-manager installation documentation.
# Add and update the Jetstack repositoryhelm repo add jetstack https://charts.jetstack.io
helm repo update
# Install the cert-manager chart alongside with CRDs needed by cert-managerhelm install \
cert-manager jetstack/cert-manager \
--namespace cert-manager \
--create-namespace \
--version v1.14.4 \
--set installCRDs=true
In order to install the containerd-wasm-shim on the Kubernetes nodes we will use the kwasm-operator. There is also a successor of kwasm-operator - runtime-class-manager which aims to address some of the limitations of kwasm-operator and provide a production grade implementation for deploying containerd shims on Kubernetes nodes. Since kwasm-operator is easier to install, for the purpose of this post we will use it instead of the runtime-class-manager.
# Add the kwasm helm repositoryhelm repo add kwasm http://kwasm.sh/kwasm-operator/
helm repo update
# Install KWasm operatorhelm install \
kwasm-operator kwasm/kwasm-operator \
--namespace kwasm \
--create-namespace \
--set kwasmOperator.installerImage=ghcr.io/spinkube/containerd-shim-spin/node-installer:v0.13.1
# Annotate all nodes in the cluster so kwasm can select them and provision the required containerd shimkubectl annotate node --all kwasm.sh/kwasm-node=true
We can see that a pod has started and completed in the kwasm namespace.
kubectl -n kwasm get pod
NAME READY STATUS RESTARTS AGE
ip-10-180-7-60.eu-west-1.compute.internal-provision-kwasm-qhr8r 0/1 Completed 0 8s
kwasm-operator-6c76c5f94b-8zt4s 1/1 Running 0 15s
The logs of the kwasm-operator also indicate that the node was provisioned with the required shim.
kubectl -n kwasm logs kwasm-operator-6c76c5f94b-8zt4s
{"level":"info","node":"ip-10-180-7-60.eu-west-1.compute.internal","time":"2024-04-18T05:44:25Z","message":"Trying to Deploy on ip-10-180-7-60.eu-west-1.compute.internal"}
{"level":"info","time":"2024-04-18T05:44:31Z","message":"Job ip-10-180-7-60.eu-west-1.compute.internal-provision-kwasm is still Ongoing"}
{"level":"info","time":"2024-04-18T05:44:31Z","message":"Job ip-10-180-7-60.eu-west-1.compute.internal-provision-kwasm is Completed. Happy WASMing"}
Finally we can deploy the spin-operator alongside with a shim-executor.
We can see the available routes served by the application. Let’s port forward to the application service and test them out.
kubectl port-forward services/simple-spinapp 8000:80
Forwarding from 127.0.0.1:8000 -> 80
Forwarding from [::1]:8000 -> 80
In another terminal, we can verify that the application returns a response.
curl http://localhost:8000/hello
Hello world from Spin!%
This sets the ground for further experimentation and testing. What the SpinApp CRD provides as capabilities and API can be explored through the SpinApp CRD reference.
Cleanup
Let’s clean all deployed resources so far.
# Delete the spin app and its executorkubectl delete spinapp simple-spinapp
kubectl delete spinappexecutors.core.spinoperator.dev containerd-shim-spin
# Uninstall the spin-operator charthelm -n spin-operator uninstall spin-operator
# Remove the kwasm.sh/kwasm-node annotation from nodeskubectl annotate node --all kwasm.sh/kwasm-node-
# Uninstall the kwasm-operator charthelm -n kwasm uninstall kwasm-operator
# Uninstall the cert-manager charthelm -n cert-manager uninstall cert-manager
# Delete the runtime class and SpinApp CRDskubectl delete runtimeclass wasmtime-spin-v2
kubectl delete crd spinappexecutors.core.spinoperator.dev
kubectl delete crd spinapps.core.spinoperator.dev
Conclusion
In my opinion, WASM on the server is here to stay. Communities are expressing more and more interest in integrating Kubernetes with WASM workloads. As shown Gardener clusters are perfectly capable of supporting this use case. This setup is a great way to start exploring the capabilities that WASM can bring to the server. As stated in the introduction, bear in mind that this post does not define a production environment, but is rather meant to define a playground suitable for exploring and trying out ideas.
KubeCon / CloudNativeCon Europe 2024 Highlights
KubeCon + CloudNativeCon Europe 2024, recently held in Paris, was a testament to the robustness of the open-source community and its pivotal role in driving advancements in AI and cloud-native technologies. With a record attendance of over +12,000 participants, the conference underscored the ubiquity of cloud-native architectures and the business opportunities they provide.
AI Everywhere
LLMs and GenAI took center stage at the event, with discussions on challenges such as security, data management, and energy consumption. A popular quote stated, “If #inference is the new web application, #kubernetes is the new web server”. The conference emphasized the need for more open data models for AI to democratize the technology. Cloud-native platforms offer advantages for AI innovation, such as packaging models and dependencies as Docker packages and enhancing resource management for proper model execution. The community is exploring AI workload management, including using CPUs for inferencing and preprocessing data before handing it over to GPUs. CNCF took the initiative and put together an AI whitepaper outlining the apparent synergy between cloud-native technologies and AI.
Cluster Autopilot
The conference showcased popular projects in the cloud-native ecosystem, including Kubernetes, Istio, and OpenTelemetry. Kubernetes was highlighted as a platform for running massive AI workloads. The UXL Foundation aims to enable multi-vendor AI workloads on Kubernetes, allowing developers to move AI workloads without being locked into a specific infrastructure. Every vendor we interacted with has assembled an AI-powered chatbot, which performs various functions – from assessing cluster health through analyzing cost efficiency and proposing workload optimizations to troubleshooting issues and alerting for potential challenges with upcoming Kubernetes version upgrades. Sysdig went even further with a chatbot, which answers the popular question, “Do any of my products have critical CVEs in production?” and analyzes workloads’ structure and configuration. Some chatbots leveraged the k8sgpt project, which joined the CNCF sandbox earlier this year.
Sophisticated Fleet Management
The ecosystem showcased maturity in observability, platform engineering, security, and optimization, which will help operationalize AI workloads. Data demands and costs were also in focus, touching on data observability and cloud-cost management. Cloud-native technologies, also going beyond Kubernetes, are expected to play a crucial role in managing the increasing volume of data and scaling AI. Google showcased fleet management in their Google Hosted Cloud offering (ex-Anthos). It allows for defining teams and policies at the fleet level, later applied to all the Kubernetes clusters in the fleet, irrespective of the infrastructure they run on (GCP and beyond).
WASM Everywhere
The conference also highlighted the growing interest in WebAssembly (WASM) as a portable binary instruction format for executable programs and its integration with Kubernetes and other functions. The topic here started with a dedicated WASM pre-conference day, the sessions of which are available in the following playlist. WASM is positioned as the smoother approach to software distribution and modularity, providing more lightweight runtime execution options and an easier way for app developers to enter.
The event showcased the importance of Internal Developer Platforms (IDPs), both commercial and open-source, in facilitating the development process across all types of organizations – from Allianz to Mercedes. Backstage leads the pack by a large margin, with all relevant sessions being full or at capacity. Much effort goes into the modularization of Backstage, which was also a notable highlight at the conference.
Sustainability
Sustainability was a key theme, with discussions on the role of cloud-native technologies in promoting green practices. The KubeCost application folks put a lot of effort into emphasizing the large amount of wasted money, which hyperscalers benefit from. In parallel – the kube-green project emphasized optimizing your cluster footprint to minimize CO2 emissions. The conference also highlighted the importance of open source in creating a level playing field for multiple players to compete, fostering diverse participation, and solving global challenges.
Customer Stories
In contrast to the Chicago KubeCon in 2023, the one in Paris outlined multiple case studies, best practices, and reference scenarios. Many enterprises and their IT teams were well represented at KubeCon - regarding sessions, sponsorships, and participation. These companies strive to excel forward, reaping the efficiency and flexibility benefits cloud-native architectures provide.
We came across multiple companies using Gardener as their Kubernetes management underlay – including FUGA Cloud, STACKIT, and metal-stack Cloud. We eagerly anticipate more companies embracing Gardener at future events. The consistent feedback from these companies has been overwhelmingly positive—they absolutely love using Gardener and our shared excitement grows as the community thrives!
Notable Talks
Notable talks from leaders in the cloud-native world, including Solomon Hykes, Bob Wise, and representatives from KCP for Platforms and the United Nations, provided valuable insights into the future of AI and cloud-native technologies. All the talks are now uploaded to YouTube in the following playlist. Those do not include the various pre-conference days, available as separate playlists by CNCF.
In Conclusion…
In conclusion, KubeCon 2024 showcased the intersection of AI and cloud-native technologies, the open-source community’s growth, and the cloud-native ecosystem’s maturity. Many enterprises are actively engaged there, innovating, trying, and growing their internal expertise. They’re using KubeCon as a recruiting event, expanding their internal talent pool and taking more of their internal operations and processes into their own hands. The event served as a platform for global collaboration, cross-company alignments, innovation, and the exchange of ideas, setting the stage for the future of cloud-native computing.
2023
High Availability and Zone Outage Toleration
Developing highly available workload that can tolerate a zone outage is no trivial task. In this blog, we will explore various recommendations to get closer to that goal. While many recommendations are general enough, the examples are specific in how to achieve this in a Gardener-managed cluster and where/how to tweak the different control plane components. If you do not use Gardener, it may be still a worthwhile read as most settings can be influenced with most of the Kubernetes providers.
First however, what is a zone outage? It sounds like a clear-cut “thing”, but it isn’t. There are many things that can go haywire. Here are some examples:
Elevated cloud provider API error rates for individual or multiple services
Network bandwidth reduced or latency increased, usually also effecting storage sub systems as they are network attached
No networking at all, no DNS, machines shutting down or restarting, …
Functional issues, of either the entire service (e.g., all block device operations) or only parts of it (e.g., LB listener registration)
All services down, temporarily or permanently (the proverbial burning down data center 🔥)
This and everything in between make it hard to prepare for such events, but you can still do a lot. The most important recommendation is to not target specific issues exclusively - tomorrow another service will fail in an unanticipated way. Also, focus more on meaningful availability than on internal signals (useful, but not as relevant as the former). Always prefer automation over manual intervention (e.g., leader election is a pretty robust mechanism, auto-scaling may be required as well, etc.).
Also remember that HA is costly - you need to balance it against the cost of an outage as silly as this may sound, e.g., running all this excess capacity “just in case” vs. “going down” vs. a risk-based approach in between where you have means that will kick in, but they are not guaranteed to work (e.g., if the cloud provider is out of resource capacity). Maybe some of your components must run at the highest possible availability level, but others not - that’s a decision only you can make.
Control Plane
The Kubernetes cluster control plane is managed by Gardener (as pods in separate infrastructure clusters to which you have no direct access) and can be set up with no failure tolerance (control plane pods will be recreated best-effort when resources are available) or one of the failure tolerance types node or zone.
Strictly speaking, static workload does not depend on the (high) availability of the control plane, but static workload doesn’t rhyme with Cloud and Kubernetes and also means, that when you possibly need it the most, e.g., during a zone outage, critical self-healing or auto-scaling functionality won’t be available to you and your workload, if your control plane is down as well. That’s why it’s generally recommended to use the failure tolerance type zone for the control planes of productive clusters, at least in all regions that have 3+ zones. Regions that have only 1 or 2 zones don’t support the failure tolerance type zone and then your second best option is the failure tolerance type node, which means a zone outage can still take down your control plane, but individual node outages won’t.
In the shoot resource it’s merely only this what you need to add:
apiVersion: core.gardener.cloud/v1beta1
kind: Shoot
spec:
controlPlane:
highAvailability:
failureTolerance:
type: zone # valid values are `node` and `zone` (only available if your control plane resides in a region with 3+ zones)
This setting will scale out all control plane components for a Gardener cluster as necessary, so that no single zone outage can take down the control plane for longer than just a few seconds for the fail-over to take place (e.g., lease expiration and new leader election or readiness probe failure and endpoint removal). Components run highly available in either active-active (servers) or active-passive (controllers) mode at all times, the persistence (ETCD), which is consensus-based, will tolerate the loss of one zone and still maintain quorum and therefore remain operational. These are all patterns that we will revisit down below also for your own workload.
Worker Pools
Now that you have configured your Kubernetes cluster control plane in HA, i.e. spread it across multiple zones, you need to do the same for your own workload, but in order to do so, you need to spread your nodes across multiple zones first.
Prefer regions with at least 2, better 3+ zones and list the zones in the zones section for each of your worker pools. Whether you need 2 or 3 zones at a minimum depends on your fail-over concept:
Consensus-based software components (like ETCD) depend on maintaining a quorum of (n/2)+1, so you need at least 3 zones to tolerate the outage of 1 zone.
Primary/Secondary-based software components need just 2 zones to tolerate the outage of 1 zone.
Then there are software components that can scale out horizontally. They are probably fine with 2 zones, but you also need to think about the load-shift and that the remaining zone must then pick up the work of the unhealthy zone. With 2 zones, the remaining zone must cope with an increase of 100% load. With 3 zones, the remaining zones must only cope with an increase of 50% load (per zone).
In general, the question is also whether you have the fail-over capacity already up and running or not. If not, i.e. you depend on re-scheduling to a healthy zone or auto-scaling, be aware that during a zone outage, you will see a resource crunch in the healthy zones. If you have no automation, i.e. only human operators (a.k.a. “red button approach”), you probably will not get the machines you need and even with automation, it may be tricky. But holding the capacity available at all times is costly. In the end, that’s a decision only you can make. If you made that decision, please adapt the minimum and maximum settings for your worker pools accordingly.
If you want to be ready for a sudden spike or have some buffer in general, over-provision nodes by means of “placeholder” pods with low priority and appropriate resource requests. This way, they will demand nodes to be provisioned for them, but if any pod comes up with a regular/higher priority, the low priority pods will be evicted to make space for the more important ones. Strictly speaking, this is not related to HA, but it may be important to keep this in mind as you generally want critical components to be rescheduled as fast as possible and if there is no node available, it may take 3 minutes or longer to do so (depending on the cloud provider). Besides, not only zones can fail, but also individual nodes.
Replicas (Horizontal Scaling)
Now let’s talk about your workload. In most cases, this will mean to run multiple replicas. If you cannot do that (a.k.a. you have a singleton), that’s a bad situation to be in. Maybe you can run a spare (secondary) as backup? If you cannot, you depend on quick detection and rescheduling of your singleton (more on that below).
Obviously, things get messier with persistence. If you have persistence, you should ideally replicate your data, i.e. let your spare (secondary) “follow” your main (primary). If your software doesn’t support that, you have to deploy other means, e.g., volume snapshotting or side-backups (specific to the software you deploy; keep the backups regional, so that you can switch to another zone at all times). If you have to do those, your HA scenario becomes more a DR scenario and terms like RPO and RTO become relevant to you:
Recovery Point Objective (RPO): Potential data loss, i.e. how much data will you lose at most (time between backups)
Recovery Time Objective (RTO): Time until recovery, i.e. how long does it take you to be operational again (time to restore)
Also, keep in mind that your persistent volumes are usually zonal, i.e. once you have a volume in one zone, it’s bound to that zone and you cannot get up your pod in another zone w/o first recreating the volume yourself (Kubernetes won’t help you here directly).
Anyway, best avoid that, if you can (from technical and cost perspective). The best solution (and also the most costly one) is to run multiple replicas in multiple zones and keep your data replicated at all times, so that your RPO is always 0 (best). That’s what we do for Gardener-managed cluster HA control planes (ETCD) as any data loss may be disastrous and lead to orphaned resources (in addition, we deploy side cars that do side-backups for disaster recovery, with full and incremental snapshots with an RPO of 5m).
So, how to run with multiple replicas? That’s the easiest part in Kubernetes and the two most important resources, Deployments and StatefulSet, support that out of the box:
The problem comes with the number of replicas. It’s easy only if the number is static, e.g., 2 for active-active/passive or 3 for consensus-based software components, but what with software components that can scale out horizontally? Here you usually do not set the number of replicas statically, but make use of the horizontal pod autoscaler or HPA for short (built-in; part of the kube-controller-manager). There are also other options like the cluster proportional autoscaler, but while the former works based on metrics, the latter is more a guestimate approach that derives the number of replicas from the number of nodes/cores in a cluster. Sometimes useful, but often blind to the actual demand.
So, HPA it is then for most of the cases. However, what is the resource (e.g., CPU or memory) that drives the number of desired replicas? Again, this is up to you, but not always are CPU or memory the best choices. In some cases, custom metrics may be more appropriate, e.g., requests per second (it was also for us).
You will have to create specific HorizontalPodAutoscaler resources for your scale target and can tweak the general HPA knobs for Gardener-managed clusters like this:
While it is important to set a sufficient number of replicas, it is also important to give the pods sufficient resources (CPU and memory). This is especially true when you think about HA. When a zone goes down, you might need to get up replacement pods, if you don’t have them running already to take over the load from the impacted zone. Likewise, e.g., with active-active software components, you can expect the remaining pods to receive more load. If you cannot scale them out horizontally to serve the load, you will probably need to scale them out (or rather up) vertically. This is done by the vertical pod autoscaler or VPA for short (not built-in; part of the kubernetes/autoscaler repository).
A few caveats though:
You cannot use HPA and VPA on the same metrics as they would influence each other, which would lead to pod trashing (more replicas require fewer resources; fewer resources require more replicas)
Scaling horizontally doesn’t cause downtimes (at least not when out-scaling and only one replica is affected when in-scaling), but scaling vertically does (if the pod runs OOM anyway, but also when new recommendations are applied, resource requests for existing pods may be changed, which causes the pods to be rescheduled). Although the discussion is going on for a very long time now, that is still not supported in-place yet (see KEP 1287, implementation in Kubernetes, implementation in VPA).
VPA is a useful tool and Gardener-managed clusters deploy a VPA by default for you (HPA is supported anyway as it’s built into the kube-controller-manager). You will have to create specific VerticalPodAutoscaler resources for your scale target and can tweak the general VPA knobs for Gardener-managed clusters like this:
While horizontal pod autoscaling is relatively straight-forward, it takes a long time to master vertical pod autoscaling. We saw performance issues, hard-coded behavior (on OOM, memory is bumped by +20% and it may take a few iterations to reach a good level), unintended pod disruptions by applying new resource requests (after 12h all targeted pods will receive new requests even though individually they would be fine without, which also drives active-passive resource consumption up), difficulties to deal with spiky workload in general (due to the algorithmic approach it takes), recommended requests may exceed node capacity, limit scaling is proportional and therefore often questionable, and more. VPA is a double-edged sword: useful and necessary, but not easy to handle.
For the Gardener-managed components, we mostly removed limits. Why?
CPU limits have almost always only downsides. They cause needless CPU throttling, which is not even easily visible. CPU requests turn into cpu shares, so if the node has capacity, the pod may consume the freely available CPU, but not if you have set limits, which curtail the pod by means of cpu quota. There are only certain scenarios in which they may make sense, e.g., if you set requests=limits and thereby define a pod with guaranteedQoS, which influences your cgroup placement. However, that is difficult to do for the components you implement yourself and practically impossible for the components you just consume, because what’s the correct value for requests/limits and will it hold true also if the load increases and what happens if a zone goes down or with the next update/version of this component? If anything, CPU limits caused outages, not helped prevent them.
As for memory limits, they are slightly more useful, because CPU is compressible and memory is not, so if one pod runs berserk, it may take others down (with CPU, cpu shares make it as fair as possible), depending on which OOM killer strikes (a complicated topic by itself). You don’t want the operating system OOM killer to strike as the result is unpredictable. Better, it’s the cgroup OOM killer or even the kubelet’s eviction, if the consumption is slow enough as it takes priorities into consideration even. If your component is critical and a singleton (e.g., node daemon set pods), you are better off also without memory limits, because letting the pod go OOM because of artificial/wrong memory limits can mean that the node becomes unusable. Hence, such components also better run only with no or a very high memory limit, so that you can catch the occasional memory leak (bug) eventually, but under normal operation, if you cannot decide about a true upper limit, rather not have limits and cause endless outages through them or when you need the pods the most (during a zone outage) where all your assumptions went out of the window.
The downside of having poor or no limits and poor and no requests is that nodes may “die” more often. Contrary to the expectation, even for managed services, the managed service is not responsible or cannot guarantee the health of a node under all circumstances, since the end user defines what is run on the nodes (shared responsibility). If the workload exhausts any resource, it will be the end of the node, e.g., by compressing the CPU too much (so that the kubelet fails to do its work), exhausting the main memory too fast, disk space, file handles, or any other resource.
The kubelet allows for explicit reservation of resources for operating system daemons (system-reserved) and Kubernetes daemons (kube-reserved) that are subtracted from the actual node resources and become the allocatable node resources for your workload/pods. All managed services configure these settings “by rule of thumb” (a balancing act), but cannot guarantee that the values won’t waste resources or always will be sufficient. You will have to fine-tune them eventually and adapt them to your needs. In addition, you can configure soft and hard eviction thresholds to give the kubelet some headroom to evict “greedy” pods in a controlled way. These settings can be configured for Gardener-managed clusters like this:
apiVersion: core.gardener.cloud/v1beta1
kind: Shoot
spec:
kubernetes:
kubelet:
systemReserved: # explicit resource reservation for operating system daemons cpu: 100m
memory: 1Gi
ephemeralStorage: 1Gi
pid: 1000
kubeReserved: # explicit resource reservation for Kubernetes daemons cpu: 100m
memory: 1Gi
ephemeralStorage: 1Gi
pid: 1000
evictionSoft: # soft, i.e. graceful eviction (used if the node is about to run out of resources, avoiding hard evictions) memoryAvailable: 200Mi
imageFSAvailable: 10%
imageFSInodesFree: 10%
nodeFSAvailable: 10%
nodeFSInodesFree: 10%
evictionSoftGracePeriod: # caps pod's `terminationGracePeriodSeconds` value during soft evictions (specific grace periods) memoryAvailable: 1m30s
imageFSAvailable: 1m30s
imageFSInodesFree: 1m30s
nodeFSAvailable: 1m30s
nodeFSInodesFree: 1m30s
evictionHard: # hard, i.e. immediate eviction (used if the node is out of resources, avoiding the OS generally run out of resources fail processes indiscriminately) memoryAvailable: 100Mi
imageFSAvailable: 5%
imageFSInodesFree: 5%
nodeFSAvailable: 5%
nodeFSInodesFree: 5%
evictionMinimumReclaim: # additional resources to reclaim after hitting the hard eviction thresholds to not hit the same thresholds soon after again memoryAvailable: 0Mi
imageFSAvailable: 0Mi
imageFSInodesFree: 0Mi
nodeFSAvailable: 0Mi
nodeFSInodesFree: 0Mi
evictionMaxPodGracePeriod: 90 # caps pod's `terminationGracePeriodSeconds` value during soft evictions (general grace periods) evictionPressureTransitionPeriod: 5m0s # stabilization time window to avoid flapping of node eviction state
You can tweak these settings also individually per worker pool (spec.provider.workers.kubernetes.kubelet...), which makes sense especially with different machine types (and also workload that you may want to schedule there).
Physical memory is not compressible, but you can overcome this issue to some degree (alpha since Kubernetes v1.22 in combination with the feature gate NodeSwap on the kubelet) with swap memory. You can read more in this introductory blog and the docs. If you chose to use it (still only alpha at the time of this writing) you may want to consider also the risks associated with swap memory:
Reduced performance predictability
Reduced performance up to page trashing
Reduced security as secrets, normally held only in memory, could be swapped out to disk
That said, the various options mentioned above are only remotely related to HA and will not be further explored throughout this document, but just to remind you: if a zone goes down, load patterns will shift, existing pods will probably receive more load and will require more resources (especially because it is often practically impossible to set “proper” resource requests, which drive node allocation - limits are always ignored by the scheduler) or more pods will/must be placed on the existing and/or new nodes and then these settings, which are generally critical (especially if you switch on bin-packing for Gardener-managed clusters as a cost saving measure), will become even more critical during a zone outage.
Probes
Before we go down the rabbit hole even further and talk about how to spread your replicas, we need to talk about probes first, as they will become relevant later. Kubernetes supports three kinds of probes: startup, liveness, and readiness probes. If you are a visual thinker, also check out this slide deck by Tim Hockin (Kubernetes networking SIG chair).
Basically, the startupProbe and the livenessProbe help you restart the container, if it’s unhealthy for whatever reason, by letting the kubelet that orchestrates your containers on a node know, that it’s unhealthy. The former is a special case of the latter and only applied at the startup of your container, if you need to handle the startup phase differently (e.g., with very slow starting containers) from the rest of the lifetime of the container.
Now, the readinessProbe helps you manage the ready status of your container and thereby pod (any container that is not ready turns the pod not ready). This again has impact on endpoints and pod disruption budgets:
If the pod is not ready, the endpoint will be removed and the pod will not receive traffic anymore
If the pod is not ready, the pod counts into the pod disruption budget and if the budget is exceeded, no further voluntary pod disruptions will be permitted for the remaining ready pods (e.g., no eviction, no voluntary horizontal or vertical scaling, if the pod runs on a node that is about to be drained or in draining, draining will be paused until the max drain timeout passes)
As you can see, all of these probes are (also) related to HA (mostly the readinessProbe, but depending on your workload, you can also leverage livenessProbe and startupProbe into your HA strategy). If Kubernetes doesn’t know about the individual status of your container/pod, it won’t do anything for you (right away). That said, later/indirectly something might/will happen via the node status that can also be ready or not ready, which influences the pods and load balancer listener registration (a not ready node will not receive cluster traffic anymore), but this process is worker pool global and reacts delayed and also doesn’t discriminate between the containers/pods on a node.
In addition, Kubernetes also offers pod readiness gates to amend your pod readiness with additional custom conditions (normally, only the sum of the container readiness matters, but pod readiness gates additionally count into the overall pod readiness). This may be useful if you want to block (by means of pod disruption budgets that we will talk about next) the roll-out of your workload/nodes in case some (possibly external) condition fails.
Pod Disruption Budgets
One of the most important resources that help you on your way to HA are pod disruption budgets or PDB for short. They tell Kubernetes how to deal with voluntary pod disruptions, e.g., during the deployment of your workload, when the nodes are rolled, or just in general when a pod shall be evicted/terminated. Basically, if the budget is reached, they block all voluntary pod disruptions (at least for a while until possibly other timeouts act or things happen that leave Kubernetes no choice anymore, e.g., the node is forcefully terminated). You should always define them for your workload.
Very important to note is that they are based on the readinessProbe, i.e. even if all of your replicas are lively, but not enough of them are ready, this blocks voluntary pod disruptions, so they are very critical and useful. Here an example (you can specify either minAvailable or maxUnavailable in absolute numbers or as percentage):
And please do not specify a PDB of maxUnavailable being 0 or similar. That’s pointless, even detrimental, as it blocks then even useful operations, forces always the hard timeouts that are less graceful and it doesn’t make sense in the context of HA. You cannot “force” HA by preventing voluntary pod disruptions, you must work with the pod disruptions in a resilient way. Besides, PDBs are really only about voluntary pod disruptions - something bad can happen to a node/pod at any time and PDBs won’t make this reality go away for you.
PDBs will not always work as expected and can also get in your way, e.g., if the PDB is violated or would be violated, it may possibly block whatever you are trying to do to salvage the situation, e.g., drain a node or deploy a patch version (if the PDB is or would be violated, not even unhealthy pods would be evicted as they could theoretically become healthy again, which Kubernetes doesn’t know). In order to overcome this issue, it is now possible (alpha since Kubernetes v1.26 in combination with the feature gate PDBUnhealthyPodEvictionPolicy on the API server) to configure the so-called unhealthy pod eviction policy. The default is still IfHealthyBudget as a change in default would have changed the behavior (as described above), but you can now also set AlwaysAllow at the PDB (spec.unhealthyPodEvictionPolicy). For more information, please check out this discussion, the PR and this document and balance the pros and cons for yourself. In short,
the new AlwaysAllow option is probably the better choice in most of the cases while IfHealthyBudget is useful only if you have frequent temporary transitions or for special cases where you have already implemented controllers that depend on the old behavior.
Pod Topology Spread Constraints
Pod topology spread constraints or PTSC for short (no official abbreviation exists, but we will use this in the following) are enormously helpful to distribute your replicas across multiple zones, nodes, or any other user-defined topology domain. They complement and improve on pod (anti-)affinities that still exist and can be used in combination.
PTSCs are an improvement, because they allow for maxSkew and minDomains. You can steer the “level of tolerated imbalance” with maxSkew, e.g., you probably want that to be at least 1, so that you can perform a rolling update, but this all depends on your deployment (maxUnavailable and maxSurge), etc. Stateful sets are a bit different (maxUnavailable) as they are bound to volumes and depend on them, so there usually cannot be 2 pods requiring the same volume. minDomains is a hint to tell the scheduler how far to spread, e.g., if all nodes in one zone disappeared because of a zone outage, it may “appear” as if there are only 2 zones in a 3 zones cluster and the scheduling decisions may end up wrong, so a minDomains of 3 will tell the scheduler to spread to 3 zones before adding another replica in one zone. Be careful with this setting as it also means, if one zone is down the “spread” is already at least 1, if pods run in the other zones. This is useful where you have exactly as many replicas as you have zones and you do not want any imbalance. Imbalance is critical as if you end up with one, nobody is going to do the (active) re-balancing for you (unless you deploy and configure additional non-standard components such as the descheduler). So, for instance, if you have something like a DBMS that you want to spread across 2 zones (active-passive) or 3 zones (consensus-based), you better specify minDomains of 2 respectively 3 to force your replicas into at least that many zones before adding more replicas to another zone (if supported).
Anyway, PTSCs are critical to have, but not perfect, so we saw (unsurprisingly, because that’s how the scheduler works), that the scheduler may block the deployment of new pods because it takes the decision pod-by-pod (see for instance #109364).
Pod Affinities and Anti-Affinities
As said, you can combine PTSCs with pod affinities and/or anti-affinities. Especially inter-pod (anti-)affinities may be helpful to place pods apart, e.g., because they are fall-backs for each other or you do not want multiple potentially resource-hungry “best-effort” or “burstable” pods side-by-side (noisy neighbor problem), or together, e.g., because they form a unit and you want to reduce the failure domain, reduce the network latency, and reduce the costs.
Topology Aware Hints
While topology aware hints are not directly related to HA, they are very relevant in the HA context. Spreading your workload across multiple zones may increase network latency and cost significantly, if the traffic is not shaped. Topology aware hints (beta since Kubernetes v1.23, replacing the now deprecated topology aware traffic routing with topology keys) help to route the traffic within the originating zone, if possible. Basically, they tell kube-proxy how to setup your routing information, so that clients can talk to endpoints that are located within the same zone.
Be aware however, that there are some limitations. Those are called safeguards and if they strike, the hints are off and traffic is routed again randomly. Especially controversial is the balancing limitation as there is the assumption, that the load that hits an endpoint is determined by the allocatable CPUs in that topology zone, but that’s not always, if even often, the case (see for instance #113731 and #110714). So, this limitation hits far too often and your hints are off, but then again, it’s about network latency and cost optimization first, so it’s better than nothing.
Networking
We have talked about networking only to some small degree so far (readiness probes, pod disruption budgets, topology aware hints). The most important component is probably your ingress load balancer - everything else is managed by Kubernetes. AWS, Azure, GCP, and also OpenStack offer multi-zonal load balancers, so make use of them. In Azure and GCP, LBs are regional whereas in AWS and OpenStack, they need to be bound to a zone, which the cloud-controller-manager does by observing the zone labels at the nodes (please note that this behavior is not always working as expected, see #570 where the AWS cloud-controller-manager is not readjusting to newly observed zones).
Please be reminded that even if you use a service mesh like Istio, the off-the-shelf installation/configuration usually never comes with productive settings (to simplify first-time installation and improve first-time user experience) and you will have to fine-tune your installation/configuration, much like the rest of your workload.
Relevant Cluster Settings
Following now a summary/list of the more relevant settings you may like to tune for Gardener-managed clusters:
apiVersion: core.gardener.cloud/v1beta1
kind: Shoot
spec:
controlPlane:
highAvailability:
failureTolerance:
type: zone # valid values are `node` and `zone` (only available if your control plane resides in a region with 3+ zones) kubernetes:
kubeAPIServer:
defaultNotReadyTolerationSeconds: 300
defaultUnreachableTolerationSeconds: 300
kubelet:
...
kubeScheduler:
featureGates:
MinDomainsInPodTopologySpread: true kubeControllerManager:
nodeMonitorPeriod: 10s
nodeMonitorGracePeriod: 40s
horizontalPodAutoscaler:
syncPeriod: 15s
tolerance: 0.1
downscaleStabilization: 5m0s
initialReadinessDelay: 30s
cpuInitializationPeriod: 5m0s
verticalPodAutoscaler:
enabled: true evictAfterOOMThreshold: 10m0s
evictionRateBurst: 1
evictionRateLimit: -1
evictionTolerance: 0.5
recommendationMarginFraction: 0.15
updaterInterval: 1m0s
recommenderInterval: 1m0s
clusterAutoscaler:
expander: "least-waste" scanInterval: 10s
scaleDownDelayAfterAdd: 60m
scaleDownDelayAfterDelete: 0s
scaleDownDelayAfterFailure: 3m
scaleDownUnneededTime: 30m
scaleDownUtilizationThreshold: 0.5
provider:
workers:
- name: ...
minimum: 6
maximum: 60
maxSurge: 3
maxUnavailable: 0
zones:
- ... # list of zones you want your worker pool nodes to be spread across, see above kubernetes:
kubelet:
... # similar to `kubelet` above (cluster-wide settings), but here per worker pool (pool-specific settings), see above machineControllerManager: # optional, it allows to configure the machine-controller settings. machineCreationTimeout: 20m
machineHealthTimeout: 10m
machineDrainTimeout: 60h
systemComponents:
coreDNS:
autoscaling:
mode: horizontal # valid values are `horizontal` (driven by CPU load) and `cluster-proportional` (driven by number of nodes/cores)
On spec.controlPlane.highAvailability.failureTolerance.type
If set, determines the degree of failure tolerance for your control plane. zone is preferred, but only available if your control plane resides in a region with 3+ zones. See above and the docs.
On spec.kubernetes.kubeAPIServer.defaultUnreachableTolerationSeconds and defaultNotReadyTolerationSeconds
This is a very interesting API server setting that lets Kubernetes decide how fast to evict pods from nodes whose status condition of type Ready is either Unknown (node status unknown, a.k.a unreachable) or False (kubelet not ready) (see node status conditions; please note that kubectl shows both values as NotReady which is a somewhat “simplified” visualization).
You can also override the cluster-wide API server settings individually per pod:
This will evict pods on unreachable or not-ready nodes immediately, but be cautious: 0 is very aggressive and may lead to unnecessary disruptions. Again, you must decide for your own workload and balance out the pros and cons (e.g., long startup time).
Please note, these settings replace spec.kubernetes.kubeControllerManager.podEvictionTimeout that was deprecated with Kubernetes v1.26 (and acted as an upper bound).
On spec.kubernetes.kubeScheduler.featureGates.MinDomainsInPodTopologySpread
Required to be enabled for minDomains to work with PTSCs (beta since Kubernetes v1.25, but off by default). See above and the docs. This tells the scheduler, how many topology domains to expect (=zones in the context of this document).
On spec.kubernetes.kubeControllerManager.nodeMonitorPeriod and nodeMonitorGracePeriod
This is another very interesting kube-controller-manager setting that can help you speed up or slow down how fast a node shall be considered Unknown (node status unknown, a.k.a unreachable) when the kubelet is not updating its status anymore (see node status conditions), which effects eviction (see spec.kubernetes.kubeAPIServer.defaultUnreachableTolerationSeconds and defaultNotReadyTolerationSeconds above). The shorter the time window, the faster Kubernetes will act, but the higher the chance of flapping behavior and pod trashing, so you may want to balance that out according to your needs, otherwise stick to the default which is a reasonable compromise.
On spec.kubernetes.kubeControllerManager.horizontalPodAutoscaler...
This configures horizontal pod autoscaling in Gardener-managed clusters. See above and the docs for the detailed fields.
On spec.kubernetes.verticalPodAutoscaler...
This configures vertical pod autoscaling in Gardener-managed clusters. See above and the docs for the detailed fields.
On spec.kubernetes.clusterAutoscaler...
This configures node auto-scaling in Gardener-managed clusters. See above and the docs for the detailed fields, especially about expanders, which may become life-saving in case of a zone outage when a resource crunch is setting in and everybody rushes to get machines in the healthy zones.
In case of a zone outage, it may be interesting to understand how the cluster autoscaler will put a worker pool in one zone into “back-off”. Unfortunately, the official cluster autoscaler documentation does not explain these details, but you can find hints in the source code:
If a node fails to come up, the node group (worker pool in that zone) will go into “back-off”, at first 5m, then exponentially longer until the maximum of 30m is reached. The “back-off” is reset after 3 hours. This in turn means, that nodes must be first considered Unknown, which happens when spec.kubernetes.kubeControllerManager.nodeMonitorPeriod.nodeMonitorGracePeriod lapses. Then they must either remain in this state until spec.provider.workers.machineControllerManager.machineHealthTimeout lapses for them to be recreated, which will fail in the unhealthy zone, or spec.kubernetes.kubeAPIServer.defaultUnreachableTolerationSeconds lapses for the pods to be evicted (usually faster than node replacements, depending on your configuration), which will trigger the cluster autoscaler to create more capacity, but very likely in the same zone as it tries to balance its node groups at first, which will also fail in the unhealthy zone. It will be considered failed only when maxNodeProvisionTime lapses (usually close to spec.provider.workers.machineControllerManager.machineCreationTimeout) and only then put the node group into “back-off” and not retry for 5m at first and then exponentially longer. It’s critical to keep that in mind and accommodate for it. If you have already capacity up and running, the reaction time is usually much faster with leases (whatever you set) or endpoints (spec.kubernetes.kubeControllerManager.nodeMonitorPeriod.nodeMonitorGracePeriod), but if you depend on new/fresh capacity, the above should inform you how long you will have to wait for it.
On spec.provider.workers.minimum, maximum, maxSurge, maxUnavailable, zones, and machineControllerManager
Each worker pool in Gardener may be configured differently. Among many other settings like machine type, root disk, Kubernetes version, kubelet settings, and many more you can also specify the lower and upper bound for the number of machines (minimum and maximum), how many machines may be added additionally during a rolling update (maxSurge) and how many machines may be in termination/recreation during a rolling update (maxUnavailable), and of course across how many zones the nodes shall be spread (zones).
Interesting is also the configuration for Gardener’s machine-controller-manager or MCM for short that provisions, monitors, terminates, replaces, or updates machines that back your nodes:
The shorter machineCreationTimeout is, the faster MCM will retry to create a machine/node, if the process is stuck on cloud provider side. It is set to useful/practical timeouts for the different cloud providers and you probably don’t want to change those (in the context of HA at least). Please align with the cluster autoscaler’s maxNodeProvisionTime.
The shorter machineHealthTimeout is, the faster MCM will replace machines/nodes in case the kubelet isn’t reporting back, which translates to Unknown, or reports back with NotReady, or the node-problem-detector that Gardener deploys for you reports a non-recoverable issue/condition (e.g., read-only file system). If it is too short however, you risk node and pod trashing, so be careful.
The shorter machineDrainTimeout is, the faster you can get rid of machines/nodes that MCM decided to remove, but this puts a cap on the grace periods and PDBs. They are respected up until the drain timeout lapses - then the machine/node will be forcefully terminated, whether or not the pods are still in termination or not even terminated because of PDBs. Those PDBs will then be violated, so be careful here as well. Please align with the cluster autoscaler’s maxGracefulTerminationSeconds.
Especially the last two settings may help you recover faster from cloud provider issues.
On spec.systemComponents.coreDNS.autoscaling
DNS is critical, in general and also within a Kubernetes cluster. Gardener-managed clusters deploy CoreDNS, a graduated CNCF project. Gardener supports 2 auto-scaling modes for it, horizontal (using HPA based on CPU) and cluster-proportional (using cluster proportional autoscaler that scales the number of pods based on the number of nodes/cores, not to be confused with the cluster autoscaler that scales nodes based on their utilization). Check out the docs, especially the trade-offs why you would chose one over the other (cluster-proportional gives you more configuration options, if CPU-based horizontal scaling is insufficient to your needs). Consider also Gardener’s feature node-local DNS to decouple you further from the DNS pods and stabilize DNS. Again, that’s not strictly related to HA, but may become important during a zone outage, when load patterns shift and pods start to initialize/resolve DNS records more frequently in bulk.
More Caveats
Unfortunately, there are a few more things of note when it comes to HA in a Kubernetes cluster that may be “surprising” and hard to mitigate:
If the kubelet restarts, it will report all pods as NotReady on startup until it reruns its probes (#100277), which leads to temporary endpoint and load balancer target removal (#102367). This topic is somewhat controversial. Gardener uses rolling updates and a jitter to spread necessary kubelet restarts as good as possible.
If a kube-proxy pod on a node turns NotReady, all load balancer traffic to all pods (on this node) under services with externalTrafficPolicylocal will cease as the load balancer will then take this node out of serving. This topic is somewhat controversial as well. So, please remember that externalTrafficPolicylocal not only has the disadvantage of imbalanced traffic spreading, but also a dependency to the kube-proxy pod that may and will be unavailable during updates. Gardener uses rolling updates to spread necessary kube-proxy updates as good as possible.
These are just a few additional considerations. They may or may not affect you, but other intricacies may. It’s a reminder to be watchful as Kubernetes may have one or two relevant quirks that you need to consider (and will probably only find out over time and with extensive testing).
Meaningful Availability
Finally, let’s go back to where we started. We recommended to measure meaningful availability. For instance, in Gardener, we do not trust only internal signals, but track also whether Gardener or the control planes that it manages are externally available through the external DNS records and load balancers, SNI-routing Istio gateways, etc. (the same path all users must take). It’s a huge difference whether the API server’s internal readiness probe passes or the user can actually reach the API server and it does what it’s supposed to do. Most likely, you will be in a similar spot and can do the same.
What you do with these signals is another matter. Maybe there are some actionable metrics and you can trigger some active fail-over, maybe you can only use it to improve your HA setup altogether. In our case, we also use it to deploy mitigations, e.g., via our dependency-watchdog that watches, for instance, Gardener-managed API servers and shuts down components like the controller managers to avert cascading knock-off effects (e.g., melt-down if the kubelets cannot reach the API server, but the controller managers can and start taking down nodes and pods).
Either way, understanding how users perceive your service is key to the improvement process as a whole. Even if you are not struck by a zone outage, the measures above and tracking the meaningful availability will help you improve your service.
Thank you for your interest and we wish you no or a “successful” zone outage next time. 😊
All channels for getting in touch or learning about the project are listed on our landing page. We are cordially inviting interested parties to join our bi-weekly meetings.
2022
Community Call - Get more computing power in Gardener by overcoming Kubelet limitations with CRI-resource-manager
Alexander Kanevskiy begins the community call by giving an overview of CRI-resource-manager, describing it as a “hardware aware container runtime”, and also going over what it brings to the user in terms of features and policies.
Pawel Palucki continues by giving details on the policy that will later be used in the demo and the use case demonstrated in it. He then goes over the “must have” features of any extension - observability and the ability to deploy and configure objects with it.
The demo then begins, mixed with slides giving further information at certain points regarding the installation process, static and dynamic configuration flow, healthchecks and recovery mode, and access to logs, among others.
The presentation is concluded by Pawel showcasing the new features coming to CRI-resource-manager with its next releases and sharing some tips for other extension developers.
If you are left with any questions regarding the content, you might find the answers at the Q&A session and discussion held at the end, as well as the questions asked and answered throughout the meeting.
This meeting explores the uses of Cilium, an open source software used to secure the network connectivity between application services deployed using Kubernetes, and Hubble, the networking and security observability platform built on top of it.
Raymond de Jong begins the meeting by giving an introduction of Cillium and eBPF and how they are both used in Kubernetes networking and services. He then goes over the ways of running Cillium - either by using a supported cloud provider or by CNI chaining.
The next topic introduced is the Cluster Mesh and the different use cases for it, offering high availability, shared services, local and remote service affinity, and the ability to split services.
In regards to security, being an identity-based security solution utilizing API-aware authorization, Cillium implements Hubble in order to increase its observability. Hubble combines hubble UI, hubble API and hubble Metrics - Grafana and Prometheus, in order to provide service dependency maps, detailed flow visibility and built-in metrics for operations and applications stability.
The final topic covered is the Service Mesh, offering service maps and the ability to integrate Cluster Mesh features.
If you are left with any questions regarding the content, you might find the answers at the Q&A session and discussion held at the end, as well as the questions asked and answered throughout the meeting.
Recording
Community Call - Gardener Extension Development
Presenters
This community call was led by Jens Schneider and Lothar Gesslein.
Overview
Starting the development of a new Gardener extension can be challenging, when you are not an expert in the Gardener ecosystem yet. Therefore, the first half of this community call led by Jens Schneider aims to provide a “getting started tutorial” at a beginner level. 23Technologies have developed a minimal working example for Gardener extensions, gardener-extension-mwe, hosted in a Github repository. Jens is following the Getting started with Gardener extension development tutorial, which aims to provide exactly that.
In the second part of the community call, Lothar Gesslein introduces the gardener-extension-shoot-flux, which allows for the automated installation of arbitrary Kubernetes resources into shoot clusters. As this extension relies on Flux, an overview of Flux’s capabilities is also provided.
If you are left with any questions regarding the content, you might find the answers at the Q&A session and discussion held at the end.
You can find the tutorials in this community call at:
So far, deploying Gardener locally was not possible end-to-end. While you certainly could run the Gardener components in a minikube or kind cluster, creating shoot clusters always required to register seeds backed by cloud provider infrastructure like AWS, Azure, etc..
Consequently, developing Gardener locally was similarly complicated, and the entry barrier for new contributors was way too high.
In a previous community call (Hackathon “Hack The Metal”), we already presented a new approach for overcoming these hurdles and complexities.
Now we would like to present the Local Provider Extension for Gardener and show how it can be used to deploy Gardener locally, allowing you to quickly get your feet wet with the project.
In this session, Tim Ebert goes through the process of setting up a local Gardener cluster. After his demonstration, Rafael Franzke showcases a different approach to building your clusters locally, which, while more complicated, offers a much faster build time.
You can find the tutorials in this community call at:
Watch the recording of our February 2022 Community call to see how to get started with the gardenctl-v2 and watch a walkthrough for gardenctl-v2 features. You’ll learn about targeting, secure shoot cluster access, SSH, and how to use cloud provider CLIs natively.
The session is led by Lukas Gross, who begins by giving some information on the motivations behind creating a new version of gardenctl - providing secure access to shoot clustes, enabling direct usage of kubectl and cloud provider CLIs and managing cloud provider resources for SSH access.
Holger Kosser then takes over in order to delve deeper into the concepts behind the implementation of gardenctl-2, going over Targeting, Gardenlogin and Cloud Provider CLIs. After that, Peter Sutter does the first demo, where he presents the main features in gardenctl-2.
The next part details how to get started with gardenctl, followed by another demo. The landscape requirements are also discussed, as well as future plans and enhancement requests.
You can find the slides for this community call at Google Slides.
If you are left with any questions regarding the content, you might find the answers at the Q&A session and discussion held at the end, as well as the questions asked and answered throughout the meeting.
Recording
2021
Navigating Cloud-Native Security - Lessons from a Recent Container Service Vulnerability
The cloud-native landscape is constantly evolving, bringing immense benefits in agility and scale. However, with this evolution comes a complex and ever-changing threat landscape. Recently, a significant vulnerability was reported by Unit 42 concerning Azure Container Instances (ACI), a service designed to run containers in a multi-tenant environment. This incident offers valuable lessons for the entire community, and we at Gardener believe in sharing insights that can help strengthen collective security.
This particular vulnerability underscores the critical importance of vigilance, timely patching, and defense-in-depth, principles we have long championed within the Gardener project.
Understanding the ACI Vulnerability
As detailed in the Unit 42 report, the attack vector on ACI involved several stages, leveraging a combination of outdated software and architectural choices:
Outdated runc: The initial entry point exploited a version of runc from October 2016. This version was susceptible to CVE-2019-5736, a critical vulnerability allowing host takeover. This vulnerability was widely publicized in early 2019.
Lateral Movement via Kubelet Impersonation: After gaining node access, the next step involved attempting to impersonate the Kubelet to interact with the Kubernetes API server. The ACI clusters were reportedly running Kubernetes versions (v1.8.x - v1.10.x) from 2017/2018, which were, in principle, vulnerable to such an attack.
Exploiting a Custom Bridge Component: While the direct Kubelet impersonation didn’t work as initially expected, investigators found that a custom bridge component, designed to abstract the underlying Kubernetes, became the next target. This proprietary component inadvertently held a service account token with cluster-admin privileges. By capturing this token, attackers could gain full control over the Kubernetes cluster.
Control Plane Access: The report also noted that the API server appeared to be self-hosted, potentially allowing easier movement from the data plane to the control plane environment once cluster-admin privileges were obtained.
Alternative Attack Vector: A second distinct attack vector, also leveraging the custom bridge component, was identified, pointing to another area where security hardening could have prevented compromise.
Gardener’s Proactive Security Posture
The ACI incident highlights several threat vectors that the Gardener team has actively worked to mitigate over the years, often well in advance of them becoming widely exploited.
Timely Patching of Critical Vulnerabilities (e.g., runc CVE-2019-5736): When CVE-2019-5736 was pre-disclosed, the Gardener team treated it with utmost seriousness. We had announcements and patches prepared, rolling them out on the day of public disclosure. This rapid response is crucial for minimizing exposure to known high-severity vulnerabilities.
Hardening Against Exploits: The Kubelet impersonation vector mentioned in the ACI report is particularly relevant to Gardener. The underlying Kubernetes vulnerability (CVE-2020-8558, tracked as Kubernetes issue #85867) that could allow a compromised node/Kubelet to redirect API server traffic (like kubectl exec) was discovered and reported by Alban Crequy from Kinvolk. This discovery was made during a penetration test commissioned by the Gardener project, specifically asking to find loopholes in our seed clusters. We were able to implement mitigations in Gardener even before the upstream Kubernetes fix was available, further securing our seed cluster architecture. The second distinct attack vector was also discovered during such a penetration test and Gardener further hardened its network policies.
Principle of Least Privilege and Secure Component Design: The ACI bridge component’s cluster-admin token is a stark reminder of the dangers of overly privileged components, especially those interacting with user workloads. Within Gardener, we’ve invested heavily in mechanisms like the Gardener Seed Authorizer (as discussed in Gardener issue #1723). It goes beyond standard RBAC to strictly limit the capabilities of components and prevent lateral movement, ensuring that even if one part is compromised, the blast radius is contained. We also meticulously review and restrict permissions for all components.
Strict Separation of Concerns: A core architectural principle in Gardener is the strict separation between the control plane and the data plane - at all levels. Being an administrator in a shoot cluster does not grant any access to the underlying seed cluster’s control plane execution environment or the upper hierarchy of runtime and garden cluster, a critical defense against escalation.
Learning and Moving Forward
The ACI vulnerability is a powerful reminder that security is not a one-time task but a continuous process of vigilance, proactive hardening, and learning from every incident, whether our own or others’. No system is impenetrable, and the assumption that any single entity, regardless of size, has perfected security can lead to complacency.
At Gardener, we remain committed to:
Staying current: Diligently updating dependencies and core components.
Defense-in-depth: Implementing multiple layers of security controls.
Proactive discovery: Continuously testing and seeking out potential weaknesses.
Community collaboration: Sharing knowledge and contributing to upstream security efforts.
We believe that by fostering a culture of security awareness and investing in robust, layered defenses, we can build more resilient cloud-native systems for everyone. This recent industry event, while unfortunate for those affected, provides crucial learning points that reinforce our commitment to the security principles embedded in Gardener. We will continue to evolve Gardener’s security posture, always striving to stay ahead of emerging threats.
Happy Anniversary, Gardener! Three Years of Open Source Kubernetes Management
Happy New Year Gardeners!
As we greet 2021, we also celebrate Gardener’s third anniversary. Gardener was born with its first open source
commit
on 10.1.2018 (its inception within SAP was of course some 9 months earlier):
commit d9619d01845db8c7105d27596fdb7563158effe1
Author: Gardener Development Community <gardener.opensource@sap.com>
Date: Wed Jan 10 13:07:09 2018 +0100
Initial version of gardener
This is the initial contribution to the Open Source Gardener project.
...
Looking back, three years down the line, the project initiators were working towards a special goal: Publishing Gardener as an open source project on Github.com.
Join us as we look back at how it all began, the challenges Gardener aims to solve, and why open source and the community was and is the project’s key enabler.
Gardener Kick-Off: “We opted to BUILD ourselves”
Early 2017, SAP put together a small, jelled team of experts with a clear mission: work out how SAP could serve Kubernetes based
environments (as a service) for all teams within the company. Later that same year, SAP also joined the CNCF as a platinum member.
We first deliberated intensively on the BUY options (including acquisitions, due to the size and estimated volume needed at SAP). There were some early products from commercial vendors and startups available that did not bind exclusively to one of the hyperscalers, but these products did not cover many of our crucial and immediate requirements for a multi-cloud environment.
Ultimately, we opted to BUILD ourselves. This decision was not made lightly, because right from the start, we knew that we would have to cover thousands of clusters, across the globe, on all kinds of infrastructures. We would have to be able to create them at scale as well as manage them 24x7. And thus, we predicted the need to invest into automation of all aspects, to keep the service TCO at a minimum, and to offer an enterprise worthy SLA early on. This particular endeavor grew into launching the project Gardener, first internally, and ultimately fulfilling all checks, externally based on open source.
Its mission statement, in a nutshell, is “Universal Kubernetes at scale”.
Now, that’s quite bold. But we also had a nifty innovation that helped us tremendously along the way. And we can openly reveal the secret here: Gardener was built, not only for creating Kubernetes at scale, but it was built (recursively) in Kubernetes itself.
What Do You Get with Gardener?
Gardener offers managed and homogenous Kubernetes clusters on IaaS providers like AWS, Azure, GCP, AliCloud, Open Telekom Cloud, SCS, OVH and more, but also covers versatile infrastructures like OpenStack, VMware or bare metal. Day-1 and Day-2 operations are an integral part of a cluster’s feature set. This means that Gardener is not only capable of provisioning or de-provisioning thousands of clusters, but also of monitoring your cluster’s health state, upgrading components in a rolling fashion, or scaling the control plane as well as worker nodes up and down depending on the current resource demand.
Some features mentioned above might sound familiar to you, simply because they’re squarely derived from Kubernetes. Concretely, if you explore a Gardener managed end-user cluster, you’ll never see the so-called “control plane components” (Kube-Apiserver, Kube-Controller-Manager, Kube-Scheduler, etc.) The reason is that they run as Pods inside another, hosting/seeding Kubernetes cluster. Speaking in Gardener terms, the latter is called a Seed cluster, and the end-user cluster is called a Shoot cluster; and thus the botanical naming scheme for Gardener was born. Further assets like infrastructure components or worker machines are modelled as managed Kubernetes objects too. This allows Gardener to leverage all the great and production proven features of Kubernetes for managing Kubernetes clusters. Our blog post on Kubernetes.io reveals more details about the architectural refinements.
Figure 1: Gardener architecture overview
End-users directly benefit from Gardener’s recursive architecture. Many of the requirements that we identified for the Gardener service turned out to be highly convenient for shoot owners. For instance, Seed clusters are usually equipped with DNS and x509 services. At the same time, these service offerings can be extended to requests coming from the Shoot clusters i.e., end-users get domain names and certificates for their applications out of the box.
Recognizing the Power of Open Source
The Gardener team immediately profited from open source: from Kubernetes obviously, and all its ecosystem projects. That all facilitated our project’s very fast and robust development. But it does not answer:
“Why would SAP open source a tool that clearly solves a monetizable enterprise requirement?"_
Short spoiler alert: it initially involved a leap of faith. If we just look at our own decision path, it is undeniable that developers, and with them entire industries, gravitate towards open source. We chose Linux, Containers, and Kubernetes exactly because they are open, and we could bet on network effects, especially around skills. The same decision process is currently replicated in thousands of companies, with the same results. Why? Because all companies are digitally transforming. They are becoming software companies as well to a certain extent. Many of them are also our customers and in many discussions, we recognized that they have the same challenges that we are solving with Gardener. This, in essence, was a key eye opener. We were confident that if we developed Gardener as open source, we’d not only seize the opportunity to shape a Kubernetes management tool that finds broad interest and adoption outside of our use case at SAP, but we could solve common challenges faster with the help of a community, and that in consequence would sustain continuous feature development.
Coincidently, that was also when the SAP Open Source Program Office (OSPO) was launched. It supported us making a case to develop Gardener completely as open source.
Today, we can witness that this strategy has unfolded. It opened the gates not only for adoption, but for co-innovation, investment security, and user feedback directly in code. Below you can see an example of how the Gardener project benefits from this external community power as contributions are submitted right away.
Figure 2: Example immediate community contribution
Differentiating Gardener from Other Kubernetes Management Solutions
Imagine that you have created a modern solid cloud native app or service, fully scalable, in containers. And the business case requires you to run the service on multiple clouds, like AWS, AliCloud, Azure, … maybe even on-premises like OpenStack or VMware. Your development team has done everything to ensure that the workload is highly portable. But they would need to qualify each providers’ managed Kubernetes offering and their custom Bill-of-Material (BoM), their versions, their deprecation plan, roadmap etc. Your TCD would explode and this is exactly what teams at SAP experienced. Now, with Gardener you can, instead, roll out homogeneous clusters and stay in control of your versions and a single roadmap. Across all supported providers!
Also, teams that have serious, or say, more demanding workloads running on Kubernetes will come to the same conclusion: They require the full management control of the Kubernetes underlay. Not only that, they need access, visibility, and all the tuning options for the control plane to safeguard their service. This is a conclusion not only from teams at SAP, but also from our community members, like PingCap, who use Gardener to serve TiDB Cloud service. Whenever you need to get serious and need more than one or two clusters, Gardener is your friend.
Who Is Using Gardener?
Well, there is SAP itself of course, but also the number of Gardener adopters and companies interested in Gardener is growing (~1700 GitHub stars), as more are challenged by multi-cluster and multi-cloud requirements.
Flant, PingCap, STACKIT, T-Systems, Sky, or b’nerd are among these companies, to name a few. They use Gardener to either run products they sell on top or offer managed Kubernetes clusters directly to their clients, or even only components that are re-usable from Gardener.
An interesting journey in the open source space started with Finanz Informatik Technologie Service (FI-TS), an European Central Bank regulated and certified hoster for banks. They operate in very restricted environments, as you can imagine, and as such, they re-designed their datacenter for cloud native workloads from scratch, that is from cabling, racking and stacking to an API that serves bare metal servers.
For Kubernetes-as-a-Service, they evaluated and chose Gardener because it was open and a perfect candidate. With Gardener’s extension capabilities, it was possible to bring managed Kubernetes clusters to their very own bare metal stack, metal-stack.io.
Of course, this meant implementation effort. But by reusing the Gardener project, FI-TS was able to leverage our standard with minimal adjustments for their special use-case. Subsequently, with their contributions, SAP was able to make Gardener more open for the community.
Full Speed Ahead with the Community in 2021
Some of the current and most active topics are about the installer (Landscaper),
control plane migration,
automated seed management and
documentation. Even though once you are into Kubernetes and then Gardener, all complexity falls into place, you can make all the semantic connections yourself. But beginners that join the community without much prior knowledge should experience a ramp-up with slighter slope. And that is currently a pain point. Experts directly ask questions about documentation not being up-to-date or clear enough. We prioritized the functionality of what you get with Gardener at the outset and need to catch up.
But here is the good part: Now that we are starting the installation subject, later we will have a much broader picture of what we need to install and maintain Gardener, and how we will build it.
In a community call last summer, we gave an overview of what we are building:
The Landscaper. With this tool, we will be able to not only install a full Gardener landscape, but we will also streamline patches, updates and upgrades with the Landscaper. Gardener adopters can then attach to a release train from the project and deploy Gardener into a dev, canary and multiple production environments sequentially. Like we do at SAP.
Key Takeaways in Three Years of Gardener
#1 Open Source is Strategic
Open Source is not just about using freely available libraries, components, or tools to optimize your own software production anymore. It is strategic, unfolds for projects like Gardener, and that in the meantime has also reached the Board Room.
#2 Solving Concrete Challenges by Co-Innovation
Users of a particular product or service increasingly vote/decide for open source variants, such as project Gardener, because that allows them to freely innovate and solve concrete challenges by developing exactly what they require (see FI-TS example). This user-centric process has tremendous advantages. It clears out the middleman and other vested interests. You have access to the full code. And lastly, if others start using and contributing to your innovation, it allows enterprises to secure their investments for the long term. And that re-enforces point #1 for enterprises that have yet to create a strategic Open Source Program Office.
#3 Cloud Native Skills
Gardener solves problems by applying Kubernetes and Kubernetes principles itself. Developers and operators who obtain familiarity with Kubernetes will immediately notice and appreciate our concept and can contribute intuitively. The Gardener maintainers feel responsible to facilitate community members and contributors. Barriers will further be reduced by our ongoing landscaper and documentation efforts. This is why we are so confident on Gardener adoption.
The Gardener team is gladly welcoming new community members, especially regarding adoption and contribution. Feel invited to try out your very own Gardener installation, join our Slack workspace or community calls. We’re looking forward to seeing you there!
Machine Controller Manager
Kubernetes is a cloud-native enabler built around the principles for a resilient, manageable, observable, highly automated, loosely coupled system. We know that Kubernetes is infrastructure agnostic with the help of a provider specific Cloud Controller Manager. But Kubernetes has explicitly externalized the management of the nodes. Once they appear - correctly configured - in the cluster, Kubernetes can use them. If nodes fail, Kubernetes can’t do anything about it, external tooling is required. But every tool, every provider is different. So, why not elevate node management to a first class Kubernetes citizen? Why not create a Kubernetes native resource that manages machines just like pods? Such an approach is brought to you by the Machine Controller Manager (aka MCM), which, of course, is an open sourced project. MCM gives you the following benefits:
seamlessly manage machines/nodes with a declarative API (of course, across different cloud providers)
transport the immutability design principle to machine/nodes
implement e.g. rolling upgrades of machines/nodes
Machine Controller Manager aka MCM
Machine Controller Manager is a group of cooperative controllers that manage the lifecycle of the worker machines. It is inspired by the design of Kube Controller Manager in which various sub controllers manage their respective Kubernetes Clients.
Machine Controller Manager reconciles a set of Custom Resources namely MachineDeployment, MachineSet and Machines which are managed & monitored by their controllers MachineDeployment Controller, MachineSet Controller, Machine Controller respectively along with another cooperative controller called the Safety Controller.
Understanding the sub-controllers and Custom Resources of MCM
The Custom Resources MachineDeployment, MachineSet and Machines are very much analogous to the native K8s resources of Deployment, ReplicaSet and Pods respectively. So, in the context of MCM:
MachineDeployment provides a declarative update for MachineSet and Machines. MachineDeployment Controller reconciles the MachineDeployment objects and manages the lifecycle of MachineSet objects. MachineDeployment consumes a provider specific MachineClass in its spec.template.spec, which is the template of the VM spec that would be spawned on the cloud by MCM.
MachineSet ensures that the specified number of Machine replicas are running at a given point of time. MachineSet Controller reconciles the MachineSet objects and manages the lifecycle of Machine objects.
Machines are the actual VMs running on the cloud platform provided by one of the supported cloud providers. Machine Controller is the controller that actually communicates with the cloud provider to create/update/delete machines on the cloud.
There is a Safety Controller responsible for handling the unidentified or unknown behaviours from the cloud providers.
Along with the above Custom Controllers and Resources, MCM requires the MachineClass to use K8s Secret that stores cloudconfig (initialization scripts used to create VMs) and cloud specific credentials.
Workings of MCM
Figure 1: In-Tree Machine Controller Manager
In MCM, there are two K8s clusters in the scope — a Control Cluster and a Target Cluster. The Control Cluster is the K8s cluster where the MCM is installed to manage the machine lifecycle of the Target Cluster. In other words, the Control Cluster is the one where the machine-* objects are stored. The Target Cluster is where all the node objects are registered. These clusters can be two distinct clusters or the same cluster, whichever fits.
When a MachineDeployment object is created, the MachineDeployment Controller creates the corresponding MachineSet object. The MachineSet Controller in-turn creates the Machine objects. The Machine Controller then talks to the cloud provider API and actually creates the VMs on the cloud.
The cloud initialization script that is introduced into the VMs via the K8s Secret consumed by the MachineClasses talks to the KCM (K8s Controller Manager) and creates the node objects. After registering themselves to the Target Cluster, nodes start sending health signals to the machine objects. That is when MCM updates the status of the machine object from Pending to Running.
More on Safety Controller
Safety Controller contains the following functions:
Orphan VM Handling
It lists all the VMs in the cloud; matching the tag of given cluster name and maps the VMs with the Machine objects using the ProviderID field. VMs without any backing Machine objects are logged and deleted after confirmation.
This handler runs every 30 minutes and is configurable via --machine-safety-orphan-vms-period flag.
Freeze Mechanism
Safety Controller freezes the MachineDeployment and MachineSet controller if the number of Machine objects goes beyond a certain threshold on top of the Spec.Replicas. It can be configured by the flag --safety-up or --safety-down and also --machine-safety-overshooting-period.
Safety Controller freezes the functionality of the MCM if either of the target-apiserver or the control-apiserver is not reachable.
Safety Controller unfreezes the MCM automatically once situation is resolved to normal. A freeze label is applied on MachineDeployment/MachineSet to enforce the freeze condition.
Evolution of MCM from In-Tree to Out-of-Tree (OOT)
MCM supports declarative management of machines in a K8s Cluster on various cloud providers like AWS, Azure, GCP, AliCloud, OpenStack, Metal-stack, Packet, KubeVirt, VMWare, Yandex. It can, of course, be easily extended to support other cloud providers.
Going ahead, having the implementation of the Machine Controller Manager supporting too many cloud providers would be too much upkeep from both a development and a maintenance point of view. Which is why the Machine Controller component of MCM has been moved to Out-of-Tree design, where the Machine Controller for each respective cloud provider runs as an independent executable, even though typically packaged under the same deployment.
This OOT Machine Controller will implement a common interface to manage the VMs on the respective cloud provider. Now, while the Machine Controller deals with the Machine objects, the Machine Controller Manager (MCM) deals with higher level objects such as the MachineSet and MachineDeployment objects.
A lot of contributions are already being made towards an OOT Machine Controller Manager for various cloud providers. Below are the links to the repositories:
MCM is originally developed and employed by a K8s Control Plane as a Service called Gardener. However, the MCM’s design is elegant enough to be employed when managing the machines of any independent K8s clusters, without having to necessarily associate it with Gardener.
Metal-stack is a set of microservices that implements Metal as a Service (MaaS). It enables you to turn your hardware into elastic cloud infrastructure. Metal-stack employs the adopted Machine Controller Manager to their Metal API. Check out an introduction to it in metal-stack - kubernetes on bare metal.
Also, other interesting use cases with MCM are implemented by Kubernetes enthusiasts, who for example adjusted the Machine Controller Manager to provision machines in the cloud to extend a local Raspberry-Pi K3s cluster. This topic is covered in detail in the 2020-07-03 Gardener Community Meeting on our Gardener Project YouTube channel.
Conclusion
Machine Controller Manager is the leading automation tool for machine management for, and in, Kubernetes. And the best part is that it is open sourced. It is freely (and easily) usable and extensible, and the community more than welcomes contributions.
If you want to know more about Machine Controller Manager or find out about a similar scope for your solutions, feel free to visit the GitHub page machine-controller-manager. We are so excited to see what you achieve with Machine Controller Manager.
2020
STACKIT Kubernetes Engine with Gardener
STACKIT is a digital brand of Europe’s biggest retailer, the Schwarz Group, which consists of Lidl, Kaufland, as well as production and recycling companies. Following the industry trend, the Schwarz Group is in the process of a digital transformation. STACKIT enables this transformation by helping to modernize the internal IT of the company branches.
What is STACKIT and the STACKIT Kubernetes Engine (SKE)?
STACKIT started with colocation solutions for internal and external customers in Europe-based data centers, which was then expanded to a full cloud platform stack providing an IaaS layer with VMs, storage and network, as well as a PaaS layer including Cloud Foundry and a growing set of cloud services, like databases, messaging, etc.
With containers and Kubernetes becoming the lingua franca of the cloud, we are happy to announce the STACKIT Kubernetes Engine (SKE), which has been released as Beta in November this year. We decided to use Gardener as the cluster management engine underneath SKE - for good reasons as you will see – and we would like to share our experiences with Gardener when working on the SKE Beta release, and serve as a testimonial for this technology.
Figure 1: STACKIT Component Diagram
Why We Chose Gardener as a Cluster Management Tool
We started with the Kubernetes endeavor in the beginning of 2020 with a newly formed agile team that consisted of software engineers, highly experienced in IT operations and development. After some exploration and a short conceptual phase, we had a clear-cut opinion on how the cluster management for STACKIT should look like: we were looking for a highly customizable tool that could be adapted to the specific needs of STACKIT and the Schwarz Group, e.g. in terms of network setup or the infrastructure layer it should be running on. Moreover, the tool should be scalable to a high number of managed Kubernetes clusters and should therefore provide a fully automated operation experience. As an open source project, contributing and influencing the tool, as well as collaborating with a larger community were important aspects that motivated us. Furthermore, we aimed to offer cluster management as a self-service in combination with an excellent user experience. Our objective was to have the managed clusters come with enterprise-grade SLAs – i.e. with “batteries included”, as some say.
With this mission, we started our quest through the world of Kubernetes and soon found Gardener to be a hot candidate of cluster management tools that seemed to fulfill our demands. We quickly got in contact and received a warm welcome from the Gardener community. As an interested potential adopter, but in the early days of the COVID-19 lockdown, we managed to organize an online workshop during which we got an introduction and deep dive into Gardener and discussed the STACKIT use cases. We learned that Gardener is extensible in many dimensions, and that contributions are always welcome and encouraged. Once we understood the basic Gardener concepts of Garden, Shoot and Seed clusters, its inception design and how this extends Kubernetes concepts in a natural way, we were eager to evaluate this tool in more detail.
After this evaluation, we were convinced that this tool fulfilled all our requirements - a decision was made and off we went.
How Gardener was Adapted and Extended by SKE
After becoming familiar with Gardener, we started to look into its code base to adapt it to the specific needs of the STACKIT OpenStack environment. Changes and extensions were made in order to get it integrated into the STACKIT environment, and whenever reasonable, we contributed those changes back:
To run smoothly with the STACKIT OpenStack layer, the Gardener configuration was adapted in different places, e.g. to support CSI driver or to configure the domains of a shoot API server or ingress.
Gardener was extended to support shoots and shooted seeds in dual stack and dual home setup. This is used in SKE for the communication between shooted seeds and the Garden cluster.
SKE uses a private image registry for the Gardener installation in order to resolve dependencies to public image registries and to have more control over the used Gardener versions. To install and run Gardener with the private image registry, some new configurations need to be introduced into Gardener.
Gardener is a first-class API based service what allowed us to smoothly integrate it into the STACKIT User Interface. We were also able to jump-start and utilize the Gardener Dashboard for our Beta release by merely adjusting the look-&-feel, i.e. colors, labels and icons.
Figure 2: Gardener Dashboard adapted to STACKIT UI style
Experience with Gardener Operations
As no OpenStack installation is identical to one another, getting Gardener to run stable on the STACKIT IaaS layer revealed some operational challenges. For instance, it was challenging to find the right configuration for Cinder CSI.
To test for its resilience, we tried to break the managed clusters with a Chaos Monkey test, e.g. by deleting services or components needed by Kubernetes and Gardener to work properly. The reconciliation feature of Gardener fixed all those problems automatically, so that damaged Shoot clusters became operational again after a short period of time. Thus, we were not able to break Shoot clusters from an end user perspective permanently, despite our efforts. Which again speaks for Gardener’s first-class cloud native design.
We also participated in a fruitful community support: For several challenges we contacted the community channel and help was provided in a timely manner. A lesson learned was that raising an issue in the community early on, before getting stuck too long on your own with an unresolved problem, is essential and efficient.
Summary
Gardener is used by SKE to provide a managed Kubernetes offering for internal use cases of the Schwarz Group as well as for the public cloud offering of STACKIT. Thanks to Gardener, it was possible to get from zero to a Beta release in only about half a year’s time – this speaks for itself. Within this period, we were able to integrate Gardener into the STACKIT environment, i.e. in its OpenStack IaaS layer, its management tools and its identity provisioning solution.
Gardener has become a vital building block in STACKIT’s cloud native platform offering. For the future, the possibility to manage clusters also on other infrastructures and hyperscalers is seen as another great opportunity for extended use cases. The open co-innovation exchange with the Gardener community member companies has also opened the door to commercial co-operation.
Gardener v1.13 Released
Dear community, we’re happy to announce a new minor release of Gardener, in fact, the 16th in 2020!
v1.13 came out just today after a couple of weeks of code improvements and feature implementations.
As usual, this blog post provides brief summaries for the most notable changes that we introduce with this version.
Behind the scenes (and not explicitly highlighted below) we are progressing on internal code restructurings and refactorings to ease further extensions and to enhance development productivity.
Speaking of those: You might be interested in watching the recording of the last Gardener Community Meeting which includes a detailed session for v2 of Terraformer, a complete rewrite in Golang, and improved state handling.
Notable Changes in v1.13
The main themes of Gardener’s v1.13 release are increments for feature gate promotions, scalability and robustness, and cleanups and refactorings.
The community plans to continue on those and wants to deliver at least one more release in 2020.
Gardener already supports ResourceQuotas since the last release, however, it was still up to operators/administrators to create these objects in project namespaces.
Obviously, in large Gardener installations with thousands of projects, this is a quite challenging task.
With this release, we are shipping an improvement in the Project controller in the gardener-controller-manager that allows operators to automatically create ResourceQuotas based on configuration.
Operators can distinguish via project label selectors which default quotas shall be defined for various projects.
Please find more details at Gardener Controller Manager!
The larger the Gardener landscape, the more seed clusters you require.
Naturally, they have limits of how many shoots they can accommodate (based on constraints of the underlying infrastructure provider and/or seed cluster configuration).
Until this release, there were no means to prevent a seed cluster from becoming overloaded (and potentially die due to this load).
Now you define resource capacity and reservations in the gardenlet’s component configuration, similar to how the kubelet announces allocatable resources for Node objects.
We are defaulting this to 250 shoots, but you might want to adapt this value for your own environment.
With the same motivation, i.e., to improve catering with large landscapes, we allow operators to configure distributed rollouts of gardenlets for shooted seeds.
When a new Gardener version is being deployed in landscapes with a high number of shooted seeds, gardenlets of earlier versions were immediately re-deploying copies of themselves into the shooted seeds they manage.
This leads to a large number of new gardenlet pods that all roughly start at the same time.
Depending on the size of the landscape, this may trouble the gardener-apiservers as all of them are starting to fill their caches and create watches at the same time.
By default, this rollout is now randomized within a 5m time window, i.e., it may take up to 5m until all gardenlets in all seeds have been updated.
The alpha APIServerSNI feature will drastically reduce the costs for load balancers in the seed clusters, thus, it is effectively contributing to Gardener’s “minimal TCO” goal.
In this release we are introducing an important improvement that optimizes the connectivity when pods talk to their control plane by avoiding an extra network hop.
This is realized by a MutatingWebhookConfiguration whose server runs as a sidecar container in the kube-apiserver pod in the seed (only when the APIServerSNI feature gate is enabled).
The webhook injects a KUBERNETES_SERVICE_HOST environment variable into pods in the shoot which prevents the additional network hop to the apiserver-proxy on all worker nodes.
You can read more about it in APIServerSNI environment variable injection.
A main capability beloved by Gardener users is its openness when it comes to configurability and fine-tuning of the Kubernetes control plane components.
Most managed Kubernetes offerings are not exposing options of the master components, but Gardener’s Shoot API offers a selected set of settings.
With this release we are allowing to change the maximum number of (non-)mutating requests for the kube-apiserver of shoot clusters.
Similarly, the grace period before deleting pods on failed nodes can now be fine-grained for the kube-controller-manager.
Projects are an important resource in the Gardener ecosystem as they enable collaboration with team members.
A couple of improvements have landed into this release.
Firstly, duplicates in the member list were not validated so far.
With this release, the gardener-apiserver is automatically merging them, and in future releases requests with duplicates will be denied.
Secondly, specific Projects may now be excluded from the stale checks if desired.
Lastly, namespaces for Projects that were adopted (i.e., those that exist before the Project already) will now no longer be deleted when the Project is being deleted.
Please note that this only applies for newly created Projects.
The core.gardener.cloud API group succeeded the old garden.sapcloud.io API group in the beginning of 2020, however, a lot of labels and annotations with the old API group name were still supported.
We have continued with the process of removing those deprecated (but replaced with the new API group name) names.
Concretely, the project labels garden.sapcloud.io/role=project and project.garden.sapcloud.io/name=<project-name> are no longer supported now.
Similarly, the shoot.garden.sapcloud.io/use-as-seed and shoot.garden.sapcloud.io/ignore-alerts annotations got deleted.
We are not finished yet, but we do small increments and plan to progress on the topic until we finally get rid of all artifacts with the old API group name.
The alpha NodeLocalDNS feature was already introduced and explained with Gardener v1.8 with the motivation to overcome certain bottlenecks with the horizontally auto-scaled CoreDNS in all shoot clusters.
Unfortunately, due to a bug in the network policy rules, it was not working in all environments.
We have fixed this one now, so it should be ready for further tests and investigations.
Come give it a try!
Please bear in mind that this blog post only highlights the most noticeable changes and improvements, but there is a whole bunch more, including a ton of bug fixes in older versions! Come check out the full release notes and share your feedback in Slack!
Case Study: Migrating ETCD Volumes in Production
In this case study, our friends from metal-stack lead you through their journey of migrating Gardener ETCD volumes in their production environment.
metal-stack is a software that provides an API for provisioning and managing physical servers in the data center. To categorize this product, the terms “Metal-as-a-Service” (MaaS) or “bare metal cloud” are commonly used.
One reason that you stumbled upon this blog post could be that you saw errors like the following in your ETCD instances:
etcd-main-0 etcd 2020-09-03 06:00:07.556157 W | etcdserver: read-only range request "key:\"/registry/deployments/shoot--pwhhcd--devcluster2/kube-apiserver\" " with result "range_response_count:1 size:9566" took too long (13.95374909s) to execute
As it turns out, 14 seconds are way too slow for running Kubernetes API servers. It makes them go into a crash loop (leader election fails). Even worse, this whole thing is self-amplifying: The longer a response takes, the more requests queue up, leading to response times increasing further and further. The system is very unlikely to recover. 😞
On Github, you can easily find the reason for this problem. Most probably your disks are too slow (see etcd-io/etcd#10860). So, when you are (like in our case) on GKE and run your ETCD on their default persistent volumes, consider moving from standard disks to SSDs and the error messages should disappear. A guide on how to use SSD volumes on GKE can be found at Using SSD persistent disks.
Case closed? Well. For some people it might be. But when you are seeing this in your Gardener infrastructure, it’s likely that there is something going wrong. The entire ETCD management is fully managed by Gardener, which makes the problem a bit more interesting to look at. This blog post strives to cover topics such as:
Gardener operating principles
Gardener architecture and ETCD management
Pitfalls with multi-cloud environments
Migrating GCP volumes to a new storage class
We from metal-stack learned quite a lot about the capabilities of Gardener through this problem. We are happy to share this experience with a broader audience. Gardener adopters and operators read on.
How Gardener Manages ETCDs
In our infrastructure, we use Gardener to provision Kubernetes clusters on bare metal machines in our own data centers using metal-stack. Even if the entire stack could be running on-premise, our initial seed cluster and the metal control plane are hosted on GKE. This way, we do not need to manage a single Kubernetes cluster in our entire landscape manually. As soon as we have Gardener deployed on this initial cluster, we can spin up further Seeds in our own data centers through the concept of ManagedSeeds.
To make this easier to understand, let us give you a simplified picture of how our Gardener production setup looks like:
Figure 1: Simplified View on Our Production Setup
For every shoot cluster, Gardener deploys an individual, standalone ETCD as a stateful set into a shoot namespace. The deployment of the ETCD stateful set is managed by a controller called etcd-druid, which reconciles a special resource of the kind etcds.druid.gardener.cloud. This Etcd resource is getting deployed during the shoot provisioning flow in the gardenlet.
For failure-safety, the etcd-druid deploys the official ETCD container image along with a sidecar project called etcd-backup-restore. The sidecar automatically takes backups of the ETCD and stores them at a cloud provider, e.g. in S3 Buckets, Google Buckets, or similar. In case the ETCD comes up without or with corrupted data, the sidecar looks into the backup buckets and automatically restores the latest backup before ETCD starts up. This entire approach basically takes away the pain for operators to manually have to restore data in the event of data loss.
Note
We found the etcd-backup-restore project very intriguing. It was the inspiration for us to come up with a similar sidecar for the databases we use with metal-stack. This project is called backup-restore-sidecar. We can cope with postgres and rethinkdb database at the moment and more to come. Feel free to check it out when you are interested.
As it’s the nature for multi-cloud applications to act upon a variety of cloud providers, with a single installation of Gardener, it is easily possible to spin up new Kubernetes clusters not only on GCP, but on other supported cloud platforms, too.
When the Gardenlet deploys a resource like the Etcd resource into a shoot namespace, a provider-specific extension-controller has the chance to manipulate it through a mutating webhook. This way, a cloud provider can adjust the generic Gardener resource to fit the provider-specific needs. For every cloud that Gardener supports, there is such an extension-controller. For metal-stack, we also maintain one, called gardener-extension-provider-metal.
Note
A side note for cloud providers: Meanwhile, new cloud providers can be added fully out-of-tree, i.e. without touching any of Gardener’s sources. This works through API extensions and CRDs. Gardener handles generic resources and backpacks provider-specific configuration through raw extensions. When you are a cloud provider on your own, this is really encouraging because you can integrate with Gardener without any burdens. You can find documentation on how to integrate your cloud into Gardener at Adding Cloud Providers and Extensibility Overview.
The Mistake Is in the Deployment
Note
This section contains code examples from Gardener v1.8.
Now that we know how the ETCDs are managed by Gardener, we can come back to the original problem from the beginning of this article. It turned out that the real problem was a misconfiguration in our deployment. Gardener actually does use SSD-backed storage on GCP for ETCDs by default. During reconciliation, the gardener-extension-controller-gcp deploys a storage class called gardener.cloud-fast that enables accessing SSDs on GCP.
But for some reason, in our cluster we did not find such a storage class. And even more interesting, we did not use the gardener-extension-provider-gcp for any shoot reconciliation, only for ETCD backup purposes. And that was the big mistake we made: We reconciled the shoot control plane completely with gardener-extension-provider-metal even though our initial Seed actually runs on GKE and specific parts of the shoot control plane should be reconciled by the GCP extension-controller instead!
This is how the initial Seed resource looked like:
Surprisingly, this configuration was working pretty well for a long time. The initial seed properly produced the Kubernetes control planes of our managed seeds that looked like this:
$ kubectl get controlplanes.extensions.gardener.cloud
NAME TYPE PURPOSE STATUS AGE
fra-equ01 metal Succeeded 85d
fra-equ01-exposure metal exposure Succeeded 85d
And this is another interesting observation: There are two ControlPlane resources. One regular resource and one with an exposure purpose. Gardener distinguishes between two types for this exact reason: Environments where the shoot control plane runs on a different cloud provider than the Kubernetes worker nodes. The regular ControlPlane resource gets reconciled by the provider configured in the Shoot resource, and the exposure type ControlPlane by the provider configured in the Seed resource.
With the existing configuration the gardener-extension-provider-gcp does not kick in and hence, it neither deploys the gardener.cloud-fast storage class nor does it mutate the Etcd resource to point to it. And in the end, we are left with ETCD volumes using the default storage class (which is what we do for ETCD stateful sets in the metal-stack seeds, because our default storage class uses csi-lvm that writes into logical volumes on the SSD disks in our physical servers).
The correction we had to make was a one-liner: Setting the provider type of the initial Seed resource to gcp.
This change moved over the control plane exposure reconciliation to the gardener-extension-provider-gcp:
$ kubectl get -n <shoot-namespace> controlplanes.extensions.gardener.cloud
NAME TYPE PURPOSE STATUS AGE
fra-equ01 metal Succeeded 85d
fra-equ01-exposure gcp exposure Succeeded 85d
And boom, after some time of waiting for all sorts of magic reconciliations taking place in the background, the missing storage class suddenly appeared:
$ kubectl get sc
NAME PROVISIONER
gardener.cloud-fast kubernetes.io/gce-pd
standard (default) kubernetes.io/gce-pd
Also, the Etcd resource was now configured properly to point to the new storage class:
$ kubectl get -n <shoot-namespace> etcd etcd-main -o yaml
apiVersion: druid.gardener.cloud/v1alpha1
kind: Etcd
metadata:
...
name: etcd-main
spec:
...
storageClass: gardener.cloud-fast # <-- was pointing to default storage class before! volumeClaimTemplate: main-etcd
...
Note
Only the etcd-main storage class gets changed to gardener.cloud-fast. The etcd-events configuration will still point to standard disk storage because this ETCD is much less occupied as compared to the etcd-main stateful set.
The Migration
Now that the deployment was in place such that this mistake would not repeat in the future, we still had the ETCDs running on the default storage class. The reconciliation does not delete the existing persistent volumes (PVs) on its own.
To bring production back up quickly, we temporarily moved the ETCD pods to other nodes in the GKE cluster. These were nodes which were less occupied, such that the disk throughput was a little higher than before. But surely that was not a final solution.
For a proper solution we had to move the ETCD data out of the standard disk PV into a SSD-based PV.
Even though we had the etcd-backup-restore sidecar, we did not want to fully rely on the restore mechanism to do the migration. The backup should only be there for emergency situations when something goes wrong. Thus, we came up with another approach to introduce the SSD volume: GCP disk snapshots. This is how we did the migration:
Scale down etcd-druid to zero in order to prevent it from disturbing your migration
Scale down the kube-apiservers deployment to zero, then wait for the ETCD stateful to take another clean snapshot
Scale down the ETCD stateful set to zero as well
(in order to prevent Gardener from trying to bring up the downscaled resources, we used small shell constructs like while true; do kubectl scale deploy etcd-druid --replicas 0 -n garden; sleep 1; done)
Take a drive snapshot in GCP from the volume that is referenced by the ETCD PVC
Create a new disk in GCP from the snapshot on a SSD disk
Delete the existing PVC and PV of the ETCD (oops, data is now gone!)
Manually deploy a PV into your Kubernetes cluster that references this new SSD disk
Manually deploy a PVC with the name of the original PVC and let it reference the PV that you have just created
Scale up the ETCD stateful set and check that ETCD is running properly
(if something went terribly wrong, you still have the backup from the etcd-backup-restore sidecar, delete the PVC and PV again and let the sidecar bring up ETCD instead)
Scale up the kube-apiserver deployment again
Scale up etcd-druid again
(stop your shell hacks ;D)
This approach worked very well for us and we were able to fix our production deployment issue. And what happened: We have never seen any crashing kube-apiservers again. 🎉
Conclusion
As bad as problems in production are, they are the best way for learning from your mistakes. For new users of Gardener it can be pretty overwhelming to understand the rich configuration possibilities that Gardener brings. However, once you get a hang of how Gardener works, the application offers an exceptional versatility that makes it very much suitable for production use-cases like ours.
This example has shown how Gardener:
Can handle arbitrary layers of infrastructure hosted by different cloud providers.
Allows provider-specific tweaks to gain ideal performance for every cloud you want to support.
Leverages Kubernetes core principles across the entire project architecture, making it vastly extensible and resilient.
Brings useful disaster recovery mechanisms to your infrastructure (e.g. with etcd-backup-restore).
We hope that you could take away something new through this blog post. With this article we also want to thank the SAP Gardener team for helping us to integrate Gardener with metal-stack. It’s been a great experience so far. 😄 😍
Gardener v1.11 and v1.12 Released
Two months after our last Gardener release update, we are happy again to present release v1.11 and v1.12 in this blog post. Control plane migration, load balancer consolidation, and new security features are just a few topics we progressed with. As always, a detailed list of features, improvements, and bug fixes can be found in the release notes of each release. If you are going to update from a previous Gardener version, please take the time to go through the action items in the release notes.
Notable Changes in v1.12
Release v1.12, fresh from the oven, is shipped with plenty of improvements, features, and some API changes we want to pick up in the next sections.
This release drops the support for the so-called functionless DNS providers. Those are providers in a shoot’s specification (.spec.dns.providers) which don’t serve the shoot’s domain (.spec.dns.domain), but are created by Gardener in the seed cluster to serve DNS requests coming from the shoot cluster. If such providers don’t specify a type or secretName, the creation or update request for the corresponding shoot is denied.
In an earlier release, we reserved a dedicated section in seed.spec.settings as a replacement for disable-capacity-reservation, disable-dns, invisible taints. These already deprecated taints were still considered and synced, which gave operators enough time to switch their integration to the new settings field. As of version v1.12, support for them has been discontinued and they are automatically removed from seed objects. You may use the actual taint names in a future release of Gardener again.
As Gardener is capable of managing thousands of clusters, it is crucial to keep operation efforts at a minimum. This release demonstrates this endeavor by further improving error reporting to the end user. During a shoot’s reconciliation, Gardener creates Services of type LoadBalancer in the shoot cluster, e.g. for VPN or Nginx-Ingress addon, and waits for a successful creation. However, in the past we experienced that occurring issues caused by the party creating the load balancer (typically Cloud-Controller-Manager) are only exposed in the logs or as events. Gardener now fetches these event messages and propagates them to the shoot status in case of a failure. Users can then often fix the problem themselves, if for example the failure discloses an exhausted quota on the cloud provider.
Since release v1.6, Gardener has been capable of reversing the tunnel direction from the seed to the shoot via the KonnectivityTunnel feature gate. With this release we make it possible to control the feature per shoot. We recommend to selectively enable the KonnectivityTunnel, as it is still in alpha state.
Shoot clusters may refer to external objects, like Secrets for specified DNS providers or they have a reference to an audit policy ConfigMap. Deleting those objects while any shoot still references them causes server errors, often only recoverable by an immense amount of manual operations effort. To prevent such scenarios, Gardener now adds a new finalizer gardener.cloud/reference-protection to these objects and removes it as soon as the object itself becomes releasable. Due to compatibility reasons, we decided that the handling for the audit policy ConfigMaps is delivered as an opt-in feature first, so please familiarize yourself with the necessary settings in the Gardener Controller Manager component config if you already plan to enable it.
After the Kubernetes upstream change (kubernetes/kubernetes#93537) for externalizing the backing admission plugin has been accepted, we are happy to announce the support of ResourceQuotas for Gardener offered resource kinds. ResourceQuotas allow you to specify a maximum number of objects per namespace, especially for end-user objects like Shoots or SecretBindings in a project namespace. Even though the admission plugin is enabled by default in the Gardener API Server, make sure the Kube Controller Manager runs the resourcequota controller as well.
Although not related only to Gardener core, the preparation towards Terraformer v2 in the extensions library is still an important milestone to mention. With Terraformer v2, Gardener extensions using Terraform scripts will benefit from great consistency improvements. Please check out PR #3034, which demonstrates necessary steps to transition to Terraformer v2 as soon as it’s released.
Notable Changes in v1.11
The Gardener community worked eagerly to deliver plenty of improvements with version v1.11. Those help us to further progress with topics like control plane migration, which is actively being worked on, or to harden our load balancer consolidation (APIServerSNI) feature.
Besides improvements and fixes (full list available in release notes), this release contains major features as well, and we don’t want to miss a chance to walk you through them.
In this release, all admission related HTTP handlers moved from the Gardener Controller Manager (GCM) to the new component Gardener Admission Controller. The admission controller is rather a small component as opposed to GCM with regards to memory footprint and CPU consumption, and thus allows you to run multiple replicas of it much cheaper than it was before. We certainly recommend specifying the admission controller deployment with more than one replica, since it reduces the odds of a system-wide outage and increases the performance of your Gardener service.
Besides the already known Namespace and Kubeconfig Secret validation, a new admission handler Resource-Size-Validator was added to the admission controller. It allows operators to restrict the size for all kinds of Kubernetes objects, especially sent by end-users to the Kubernetes or Gardener API Server. We address a security concern with this feature to prevent denial of service attacks in which an attacker artificially increases the size of objects to exhaust your object store, API server caches, or to let Gardener and Kubernetes controllers run out-of-memory. The documentation reveals an approach of finding the right resource size for your setup and why you should create exceptions for technical users and operators.
Shoot progress reporting is the continuous update process of a shoot’s .status.lastOperation field while the shoot is being reconciled by Gardener. Many steps are involved during reconciliation and depending on the size of your setup, the updates might become an issue for the Gardener API Server, which will refrain from processing further requests for a certain period.
With .controllers.shoot.progressReportPeriod in Gardenlet’s component configuration, you can now delay these updates for the specified period.
A while ago, we added support for different policies in ControllerRegistrations which determine under which circumstances the deployments of registration controllers happen in affected seed clusters. If you specify the new policy AlwaysExceptNoShoots, the respective extension controller will be deployed to all seed cluster hosting at least one shoot cluster. After all shoot clusters from a seed are gone, the extension deployment will be deleted again.
A full list of supported policies can be found at Registering Extension Controllers.
Gardener Integrates with KubeVirt
The Gardener team is happy to announce that Gardener now offers support for an additional, often requested, infrastructure/virtualization technology, namely KubeVirt! Gardener can now provide Kubernetes-conformant clusters using KubeVirt managed Virtual Machines in the environment of your choice. This integration has been tested and works with any qualified Kubernetes (provider) cluster that is compatibly configured to host the required KubeVirt components, in particular for example Red Hat OpenShift Virtualization.
Gardener enables Kubernetes consumers to centralize and operate efficiently homogenous Kubernetes clusters across different IaaS providers and even private environments. This way the same cloud-based application version can be hosted and operated by its vendor or consumer on a variety of infrastructures. When a new customer or your development team demands for a new infrastructure provider, Gardener helps you to quickly and easily on-board your workload. Furthermore, on this new infrastructure, Gardener keeps the seamless Kubernetes management experience for your Kubernetes operators, while upholding the consistency of the CI/CD pipeline of your software development team.
Architecture and Workflow
Gardener is based on the idea of three types of clusters – Garden cluster, Seed cluster and Shoot cluster (see Figure 1). The Garden cluster is used to control the entire Kubernetes environment centrally in a highly scalable design. The highly available seed clusters are used to host the end users (shoot) clusters’ control planes. Finally, the shoot clusters consist only of worker nodes to host the cloud native applications.
Figure 1: Gardener Architecture
An integration of the Gardener open source project with a new cloud provider follows a standard Gardener extensibility approach. The integration requires two new components: a provider extension and a Machine Controller Manager (MCM) extension. Both components together enable Gardener to instruct the new cloud provider. They run in the Gardener seed clusters that host the control planes of the shoots based on that cloud provider. The role of the provider extension is to manage the provider-specific aspects of the shoot clusters’ lifecycle, including infrastructure, control plane, worker nodes, and others. It works in cooperation with the MCM extension, which in particular is responsible to handle machines that are provisioned as worker nodes for the shoot clusters. To get this job done, the MCM extension leverages the VM management/API capabilities available with the respective cloud provider.
Setting up a Kubernetes cluster always involves a flow of interdependent steps (see Figure 2), beginning with the generation of certificates and preparation of the infrastructure, continuing with the provisioning of the control plane and the worker nodes, and ending with the deployment of system components. Gardener can be configured to utilize the KubeVirt extensions in its generic workflow at the right extension points, and deliver the desired outcome of a KubeVirt backed cluster.
Figure 2: Generic cluster reconciliation flow with extension points
The KubeVirt Provider Extension consists of three separate controllers that handle respectively the infrastructure, the control plane, and the worker nodes of the shoot cluster.
The Infrastructure Controller configures the network communication between the shoot worker nodes. By default, shoot worker nodes only use the provider cluster’s pod network. To achieve higher level of network isolation and better performance, it is possible to add more networks and replace the default pod network with a different network using container network interface (CNI) plugins available in the provider cluster. This is currently based on Multus CNI and NetworkAttachmentDefinitions.
Example infrastructure configuration in a shoot definition:
The Control Plane Controller deploys a Cloud Controller Manager (CCM). This is a Kubernetes control plane component that embeds cloud-specific control logic. As any other CCM, it runs the Node controller that is responsible for initializing Node objects, annotating and labeling them with cloud-specific information, obtaining the node’s hostname and IP addresses, and verifying the node’s health. It also runs the Service controller that is responsible for setting up load balancers and other infrastructure components for Service resources that require them.
Finally, the Worker Controller is responsible for managing the worker nodes of the Gardener shoot clusters.
Example worker configuration in a shoot definition:
Enabling Your Gardener Setup to Leverage a KubeVirt Compatible Environment
The very first step required is to define the machine types (VM types) for VMs that will be available. This is achieved via the CloudProfile custom resource. The machine types configuration includes details such as CPU, GPU, memory, OS image, and more.
Once a machine type is defined, it can be referenced in shoot definitions. This information is used by the KubeVirt Provider Extension to generate MachineDeployment and MachineClass custom resources required by the KubeVirt MCM extension for managing the worker nodes of the shoot clusters during the reconciliation process.
The KubeVirt MCM Extension is responsible for managing the VMs that are used as worker nodes of the Gardener shoot clusters using the virtualization capabilities of KubeVirt. This extension handles all necessary lifecycle management activities, such as machines creation, fetching, updating, listing, and deletion.
The KubeVirt MCM Extension implements the Gardener’s common driver interface for managing VMs in different cloud providers. As already mentioned, the KubeVirt MCM Extension is using the MachineDeployments and MachineClasses – an abstraction layer that follows the Kubernetes native declarative approach - to get instructions from the KubeVirt Provider Extension about the required machines for the shoot worker nodes. Also, the cluster austoscaler integrates with the scale subresource of the MachineDeployment resource. This way, Gardener offers a homogeneous autoscaling experience across all supported providers.
When a new shoot cluster is created or when a new worker node is needed for an existing shoot cluster, a new Machine will be created, and at that time, the KubeVirt MCM extension will create a new KubeVirt VirtualMachine in the provider cluster. This VirtualMachine will be created based on a set of configurations in the MachineClass that follows the specification of the KubeVirt provider.
The KubeVirt MCM Extension has two main components. The MachinePlugin is responsible for handling the machine objects, and the PluginSPI is in charge of making calls to the cloud provider interface, to manage its resources.
Figure 4: KubeVirt MCM extension workflow and architecture
As shown in Figure 4, the MachinePlugin receives a machine request from the MCM and starts its processing by decoding the request, doing partial validation, extracting the relevant information, and sending it to the PluginSPI.
The PluginSPI then creates, gets, or deletes VirtualMachines depending on the method called by the MachinePlugin. It extracts the kubeconfig of the provider cluster and handles all other required KubeVirt resources such as the secret that holds the cloud-init configurations, and DataVolumes that are mounted as disks to the VMs.
Supported Environments
The Gardener KubeVirt support is currently qualified on:
There are also plans for further improvements and new features, for example integration with CSI drivers for storage management. Details about the implementation progress can be found in the Gardener project on GitHub.
You can find further resources about the open source project Gardener at https://gardener.cloud.
Shoot Reconciliation Details
Do you want to understand how Gardener creates and updates Kubernetes clusters (Shoots)?
Well, it’s complicated, but if you are not afraid of large diagrams and are a visual learner like me, this might be useful to you.
Introduction
In this blog post I will share a technical diagram which attempts to tie together the various components involved when Gardener creates a Kubernetes cluster.
I have created and curated the diagram, which visualizes the Shoot reconciliation flow since I started developing on Gardener.
Aside from serving as a memory aid for myself, I created it in hopes that it may potentially help contributors to understand a core piece of the complex Gardener machinery.
Please be advised that the diagram and components involved are large.
Although it can be easily divided into multiple diagrams, I want to show all the components and connections in a single diagram to create an overview of the reconciliation flow.
The goal is to visualize the interactions of the components involved in the Shoot creation.
It is not intended to serve as a documentation of every component involved.
In essence, Gardener is an extension API server
that comes along with a bundle of custom controllers.
It introduces new API objects in an existing Kubernetes cluster (which is called a garden cluster) in order to use them for the
management of end-user Kubernetes clusters (which are called shoot clusters).
These shoot clusters are described via declarative cluster specifications which are observed by the controllers.
They will bring up the clusters, reconcile their state, perform automated updates and make sure they are always up and running.
This means that Gardener, just like any Kubernetes controller, creates Kubernetes clusters (Shoots) using a reconciliation loop.
The Gardenlet contains the controller and reconciliation loop responsible for the creation, update, deletion, and migration of Shoot clusters (there are more, but we spare them in this article).
In addition, the Gardener Controller Manager also reconciles Shoot resources, but only for seed-independent functionality such as Shoot hibernation, Shoot maintenance or quota control.
This blog post is about the reconciliation loop in the Gardenlet responsible for creating and updating Shoot clusters.
The code can be found in the gardener/gardener repository.
The reconciliation loops of the extension controllers can be found in their individual repositories.
Shoot Reconciliation Flow Diagram
When Gardner creates a Shoot cluster, there are three conceptual layers involved: the Garden cluster, the Seed cluster and the Shoot cluster.
Each layer represents a top-level section in the diagram (similar to a lane in a BPMN diagram).
It might seem confusing that the Shoot cluster itself is a layer, because the whole flow in the first place is about creating the Shoot cluster.
I decided to introduce this separate layer to make a clear distinction between which resources exist in the Seed API server (managed by Gardener) and which in the Shoot API server (accessible by the Shoot owner).
Each section contains several components.
Components are mostly Kubernetes resources in a Gardener installation (e.g. the gardenlet deployment in the Seed cluster).
This is the list of components:
(Virtual) Garden Cluster
Gardener Extension API server
Validating Provider Webhooks
Project Namespace
Seed Cluster
Gardenlet
Seed API server
every Shoot Control Plane has a dedicated namespace in the Seed.
Cloud Provider (owned by Stakeholder)
Arguably part of the Shoot cluster but used by components in the Seed cluster to create the infrastructure for the Shoot.
Shoot API server (in the Shoot Namespace in the Seed cluster)
Shoot Cluster
Cloud Provider Compute API (owned by Stakeholder) - for VM/Node creation.
VM / Bare metal node hosted by Cloud Provider (in Stakeholder owned account).
How to Use the Diagram
The diagram:
should be read from top to bottom - starting in the top left corner with the creation of the Shoot resource via the Gardener Extension API server.
should not require an encompassing documentation / description.
More detailed documentation on the components itself can usually be found in the respective repository.
does not show which activities execute in parallel (many) and also does not describe the exact dependencies between the steps.
This can be found out by looking at the source code.
It however tries to put the activities in a logical order of execution during the reconciliation flow.
Occasionally, there is an info box with additional information next to parts in the diagram that in my point of view require further explanation.
Large example resource for the Gardener CRDs (e.g Worker CRD, Infrastructure CRD) are placed on the left side and are referenced by a dotted line (—–).
Be aware that Gardener is an evolving project, so the diagram will most likely be already outdated by the time you are reading this.
Nevertheless, it should give a solid starting point for further explorations into the details of Gardener.
Flow Diagram
The diagram can be found below and on GitHub.
There are multiple formats available (svg, vsdx, draw.io, html).
Please open an issue or open a PR in the repository if information is missing or is incorrect.
Thanks!
Gardener v1.9 and v1.10 Released
Summer holidays aren’t over yet, still, the Gardener community was able to release two new minor versions in the past weeks.
Despite being limited in capacity these days, we were able to reach some major milestones, like adding Kubernetes v1.19 support and the long-delayed automated gardenlet certificate rotation.
Whilst we continue to work on topics related to scalability, robustness, and better observability, we agreed to adjust our focus a little more into the areas of development productivity, code quality and unit/integration testing for the upcoming releases.
Notable Changes in v1.10
Gardener v1.10 was a comparatively small release (measured by the number of changes) but it comes with some major features!
The newest minor release of Kubernetes is now supported by Gardener (and all the maintained provider extensions)!
Predominantly, we have enabled CSI migration for OpenStack now that it got promoted to beta, i.e. 1.19 shoots will no longer use the in-tree Cinder volume provisioner.
The CSI migration enablement for Azure got postponed (to at least 1.20) due to some issues that the Kubernetes community is trying to fix in the 1.20 release cycle.
As usual, the 1.19 release notes should be considered before upgrading your shoot clusters.
Similar to the kubelet, the gardenlet supports TLS bootstrapping when deployed into a new seed cluster.
It will request a client certificate for the garden cluster using the CertificateSigningRequest API of Kubernetes and store the generated results in a Secret object in the garden namespace of its seed.
These certificates are usually valid for one year.
We have now added support for automatic renewals if the expiration dates are approaching.
We have worked on a larger refactoring to improve reliability and accuracy of our monitoring alerts for both shoot control planes in the seed, as well as shoot system components running on worker nodes.
The improvements are primarily for operators and should result in less false positive alerts.
Also, the alerts should fire less frequently and are better grouped in order to reduce to overall amount of alerts.
Our validation to improve robustness and countermeasures against accidental mistakes has been improved.
Earlier, it was possible to remove the use-as-seed annotation for shooted seeds or directly set the deletionTimestamp on Seed objects, despite of the fact that they might still run shoot control planes.
Seed deletion would not start in these cases, although, it would disrupt the system unnecessarily, and result in some unexpected behaviour.
The Gardener API server is now forbidding such requests if the seeds are not completely empty yet.
Logging Improvements for Loki (multiple PRs)
After we released our large logging stack refactoring (from EFK to Loki) with Gardener v1.8, we have continued to work on reliability, quality and user feedback in general.
We aren’t done yet, though, Gardener v1.10 includes a bunch of improvements which will help to graduate the Logging feature gate to beta and GA, eventually.
Notable Changes in v1.9
The v1.9 release contained tons of small improvements and adjustments in various areas of the code base and a little less new major features.
However, we don’t want to miss the opportunity to highlight a few of them.
A couple of releases back we have introduced support for containerd and the ContainerRuntime extension API.
The supported container runtimes are operating system specific, and until now it wasn’t possible for end-users to easily figure out whether they can enable containerd or other ContainerRuntime extensions for their shoots.
With this change, Gardener administrators/operators can now provide that information in the .spec.machineImages section in the CloudProfile resource.
This also allows for enhanced validation and prevents misconfigurations.
The shoot controllers in both the gardener-controller-manager and gardenlet fire several Events for some important operations (e.g., automated hibernation/wake-up due to hibernation schedule, automated Kubernetes/machine image version update during maintenance, etc.).
Earlier, the only way to prolong the lifetime of these events was to modify the --event-ttl command line parameter of the garden cluster’s kube-apiserver.
This came with the disadvantage that all events were kept for a longer time (not only those related to Shoots that an operator is usually interested in and ideally wants to store for a couple of days).
The new shoot event controller allows to achieve this by deleting non-shoot events.
This helps operators and end-users to better understand which changes were applied to their shoots by Gardener.
Since the first introduction of the Logging feature gate two years back, the logging stack was only deployed at the very end of the shoot creation.
This had the disadvantage that control plane pod logs were not kept in case the shoot creation flow is interrupted before the logging stack could be deployed.
In some situations, this was preventing fetching relevant information about why a certain control plane component crashed.
We now deploy the logging stack very early in the shoot creation flow to always have access to such information.
Gardener v1.8.0 Released
Even if we are in the midst of the summer holidays, a new Gardener release came out yesterday: v1.8.0! It’s main themes are the large change of our logging stack to Loki (which was already explained in detail on a blog post on grafana.com), more configuration options to optimize the utilization of a shoot, node-local DNS, new project roles, and significant improvements for the Kubernetes client that Gardener uses to interact with the many different clusters.
Since two years or so, Gardener could optionally provision a dedicated logging stack per seed and per shoot which was based on fluent-bit, fluentd, ElasticSearch and Kibana. This feature was still hidden behind an alpha-level feature gate and never got promoted to beta so far. Due to various limitations of this solution, we decided to replace the EFK stack with Loki. As we already have Prometheus and Grafana deployments for both users and operators by default for all clusters, the choice was just natural.
Please find out more on this topic at this dedicated blog post.
The shoot control plane migration topic is ongoing since a few months already, and we are very much progressing with it. A first alpha version will probably make it out soon. As part of these endeavors, we introduced cluster identities and the usage of DNSOwner objects in this release. Both are needed to gracefully migrate the DNSEntry extension objects from the old seed to the new seed as part of the control plane migration process.
Please find out more on this topic at this blog post.
New uam Role for Project Members to Limit User Access Management Privileges (gardener/gardener#2611)
In order to allow external user access management system to integrate with Gardener and to fulfil certain compliance aspects, we have introduced a new role called uam for Project members (next to admin and viewer). Only if a user has this role, then he/she is allowed to add/remove other human users to the respective Project. By default, all newly created Projects assign this role only to the owner while, for backwards-compatibility reasons, it will be assigned for all members for existing projects. Project owners can steadily revoke this access as desired.
Interestingly, the uam role is backed by a custom RBAC verb called manage-members, i.e., the Gardener API server is only admitting changes to the human Project members if the respective user is bound to this RBAC verb.
By default, we are using CoreDNS as DNS plugin in shoot clusters which we auto-scale horizontally using HPA. However, in some situations we are discovering certain bottlenecks with it, e.g., unreliable UDP connections, unnecessary node hopping, inefficient load balancing, etc.
To further optimize the DNS performance for shoot clusters, it is now possible to enable a new alpha-level feature gate in the gardenlet’s componentconfig: NodeLocalDNS. If enabled, all shoots will get a new DaemonSet to run a DNS server on each node.
One large benefit of Gardener is that it allows you to optimize the usage of your control plane as well as worker nodes by exposing relevant configuration parameters in the Shoot API.
In this version, we are adding support to configure kubelet’s values for systemReserved and kubeReserved resources as well as the kube-apiserver’s watch cache sizes.
This allows end-users to get to better node utilization and/or performance for their shoot clusters.
One very central component in Project Gardener is the machine-controller-manager for managing the worker nodes of shoot clusters. It has extensive qualities with respect to node lifecycle management and rolling updates. As such, it uses certain timeout values, e.g. when creating or draining nodes, or when checking their health.
Earlier, those were not customizable by end-users, but we are adding this possibility now. You can fine-grain these settings per worker pool in the Shoot API such that you can optimize the lifecycle management of your worker nodes even more!
In the last Gardener release v1.7 we have introduced a huge refactoring the clients that we use to interact with the many different Kubernetes clusters. This is to further optimize the network I/O performed by leveraging watches and caches as good as possible. It’s still an alpha-level feature that must be explicitly enabled in the Gardenlet’s component configuration, though, with this release we have improved certain things in order to pave the way for beta promotion. For example, we were initially also using a cached client when interacting with shoots. However, as the gardenlet runs in the seed as well (and thus can communicate cluster-internally with the kube-apiservers of the respective shoots) this cache is not necessary and just memory overhead. We have removed it again and saw the memory usage getting lower again. More to come!
The Shoot API already exposed the possibility to encrypt the root disks of worker nodes since quite a while, but it was disabled by default (for backwards-compatibility reasons). With this release we have change this default, so new shoot worker nodes will be provisioned with encrypted root disks out-of-the-box. However, the g4dn instance types of AWS don’t support this encryption, so when you use them you have to explicitly disable the encryption in the worker pool configuration.
A small, but very valuable improvement is the introduction of a liveness probe for our Gardener API server. As it’s built with the same library like the Kubernetes API server, it exposes two endpoints at /livez and /readyz which were created exactly for the purpose of live- and readiness probes.
With Gardener v1.8, the Helm chart contains a liveness probe configuration by default, and we are awaiting an upstream fix (kubernetes/kubernetes#93599) to also enable the readiness probe. This will help in a smoother rolling update of the Gardener API server pods, i.e., preventing clients from talking to a not yet initialized or already terminating API server instance.
In order to make it possible to run Gardener on OpenShift clusters as well, we had to make a change in the port configuration for the webhooks we are using in both Gardener and the extension controllers. Earlier, all the webhook servers directly exposed port 443, i.e., a system port which is a security concern and disallowed in OpenShift. We have changed this port now across all places and also adapted our network policies accordingly. This is most likely not the last necessary change to enable this scenario, however, it’s a great improvement to push the project forward.
PingCAP’s Experience in Implementing Their Managed TiDB Service with Gardener
Gardener is showing successful collaboration with its growing community of contributors and adopters. With this come some success stories, including PingCAP using Gardener to implement its managed service.
About PingCAP and Its TiDB Cloud
PingCAP started in 2015, when three seasoned infrastructure engineers working at leading Internet companies got sick and tired of the way databases were managed, scaled and maintained. Seeing no good solution on the market, they decided to build their own - the open-source way. With the help of a first-class team and hundreds of contributors from around the globe, PingCAP is building a distributed NewSQL, hybrid transactional and analytical processing (HTAP) database.
Its flagship project, TiDB, is a cloud-native distributed SQL database with MySQL compatibility, and one of the most popular open-source database projects - with 23.5K+ stars and 400+ contributors. Its sister project TiKV is a Cloud Native Interactive Landscape project.
PingCAP envisioned their managed TiDB service, known as TiDB Cloud, to be multi-tenant, secure, cost-efficient, and to be compatible with different cloud providers. As a result, the company turned to Gardener to build their managed TiDB cloud service offering.
TiDB Cloud Beta Preview
Limitations with Other Public Managed Kubernetes Services
Previously, PingCAP encountered issues while using other public managed K8s cluster services, to develop the first version of its TiDB Cloud. Their worst pain point was that they felt helpless when encountering certain malfunctions. PingCAP wasn’t able to do much to resolve these issues, except waiting for the providers’ help. More specifically, they experienced problems due to cloud-provider specific Kubernetes system upgrades, delays in the support response (which could be avoided in exchange of a costly support fee), and no control over when things got fixed.
There was also a lot of cloud-specific integration work needed to follow a multi-cloud strategy, which proved to be expensive both to produce and maintain. With one of these managed K8s services, you would have to integrate the instance API, as opposed to a solution like Gardener, which provides a unified API for all clouds. Such a unified API eliminates the need to worry about cloud specific-integration work altogether.
Why PingCAP Chose Gardener to Build TiDB Cloud
“Gardener has similar concepts to Kubernetes. Each Kubernetes cluster is just like a Kubernetes pod, so the similar concepts apply, and the controller pattern makes Gardener easy to manage. It was also easy to extend, as the team was already very familiar with Kubernetes, so it wasn’t hard for us to extend Gardener. We also saw that Gardener has a very active community, which is always a plus!”
- Aylei Wu, (Cloud Engineer) at PingCAP
At first glance, PingCAP had initial reservations about using Gardener - mainly due to its adoption level (still at the beginning) and an apparent complexity of use. However, these were soon eliminated as they learned more about the solution. As Aylei Wu mentioned during the last Gardener community meeting, “a good product speaks for itself”, and once the company got familiar with Gardener, they quickly noticed that the concepts were very similar to Kubernetes, which they were already familiar with.
They recognized that Gardener would be their best option, as it is highly extensible and provides a unified abstraction API layer. In essence, the machines can be managed via a machine controller manager for different cloud providers - without having to worry about the individual cloud APIs.
They agreed that Gardener’s solution, although complex, was definitely worth it. Even though it is a relatively new solution, meaning they didn’t have access to other user testimonials, they decided to go with the service since it checked all the boxes (and as SAP was running it productively with a huge fleet). PingCAP also came to the conclusion that building a managed Kubernetes service themselves would not be easy. Even if they were to build a managed K8s service, they would have to heavily invest in development and would still end up with an even more complex platform than Gardener’s. For all these reasons combined, PingCAP decided to go with Gardener to build its TiDB Cloud.
Here are certain features of Gardener that PingCAP found appealing:
Cloud agnostic: Gardener’s abstractions for cloud-specific integrations dramatically reduce the investment in supporting more than one cloud infrastructure. Once the integration with Amazon Web Services was done, moving on to Google Cloud Platform proved to be relatively easy. (At the moment, TiDB Cloud has subscription plans available for both GCP and AWS, and they are planning to support Alibaba Cloud in the future.)
Familiar concepts: Gardener is K8s native; its concepts are easily related to core Kubernetes concepts. As such, it was easy to onboard for a K8s experienced team like PingCAP’s SRE team.
Easy to manage and extend: Gardener’s API and extensibility are easy to implement, which has a positive impact on the implementation, maintenance costs and time-to-market.
Active community: Prompt and quality responses on Slack from the Gardener team tremendously helped to quickly onboard and produce an efficient solution.
How PingCAP Built TiDB Cloud with Gardener
On a technical level, PingCAP’s set-up overview includes the following:
A Base Cluster globally, which is the top-level control plane of TiDB Cloud
A Seed Cluster per cloud provider per region, which makes up the fundamental data plane of TiDB Cloud
A Shoot Cluster is dynamically provisioned per tenant per cloud provider per region when requested
A tenant may create one or more TiDB clusters in a Shoot Cluster
As a real world example, PingCAP sets up the Base Cluster and Seed Clusters in advance. When a tenant creates its first TiDB cluster under the us-west-2 region of AWS, a Shoot Cluster will be dynamically provisioned in this region, and will host all the TiDB clusters of this tenant under us-west-2. Nevertheless, if another tenant requests a TiDB cluster in the same region, a new Shoot Cluster will be provisioned. Since different Shoot Clusters are located in different VPCs and can even be hosted under different AWS accounts, TiDB Cloud is able to achieve hard isolation between tenants and meet the critical security requirements for our customers.
To automate these processes, PingCAP creates a service in the Base Cluster, known as the TiDB Cloud “Central” service. The Central is responsible for managing shoots and the TiDB clusters in the Shoot Clusters. As shown in the following diagram, user operations go to the Central, being authenticated, authorized, validated, stored and then applied asynchronously in a controller manner. The Central will talk to the Gardener API Server to create and scale Shoot clusters. The Central will also access the Shoot API Service to deploy and reconcile components in the Shoot cluster, including control components (TiDB Operator, API Proxy, Usage Reporter for billing, etc.) and the TiDB clusters.
TiDB Cloud on Gardener Architecture Overview
What’s Next for PingCAP and Gardener
With the initial success of using the project to build TiDB Cloud, PingCAP is now working heavily on the stability and day-to-day operations of TiDB Cloud on Gardener. This includes writing Infrastructure-as-Code scripts/controllers with it to achieve GitOps, building tools to help diagnose problems across regions and clusters, as well as running chaos tests to identify and eliminate potential risks. After benefiting greatly from the community, PingCAP will continue to contribute back to Gardener.
In the future, PingCAP also plans to support more cloud providers like AliCloud and Azure. Moreover, PingCAP may explore the opportunity of running TiDB Cloud in on-premise data centers with the constantly expanding support this project provides. Engineers at PingCAP enjoy the ease of learning from Gardener’s Kubernetes-like concepts and being able to apply them everywhere. Gone are the days of heavy integrations with different clouds and worrying about vendor stability. With this project, PingCAP now sees broader opportunities to land TiDB Cloud on various infrastructures to meet the needs of their global user group.
Stay tuned, more blog posts to come on how Gardener is collaborating with its contributors and adopters to bring fully-managed clusters at scale everywhere! If you want to join in on the fun, connect with our community.
A completely new landing page, emphasizing both on Gardener’s value proposition and the open community behind it.
The Community page was reconstructed for quick access to the various community channels and will soon merge the Adopters page. It will provide a better insight into success stories from the community.
Improved blogs layout. One-click sharing options are available starting with simple URL copy link and twitter button and others will closely follow up. While we are at it, give it a try. Spread the word.
Website builds also got to a new level with:
Containerization. The whole build environment is containerized now, eliminating differences between local and CI/CD setup and reducing content developers focus only to the /documentation repository. Running a local server for live preview of changes as you make them when developing content for the website, is now as easy as runing make serve in your local /documentation clone.
Numerous improvements to the buld scripts. More configuration options, authenticated requests, fault tolerance and performance.
Good news for Windows WSL users who will now enjoy a significantly support. See the updated README for details on that.
A number of improvements in layouts styles, site assets and hugo site-building techniques.
But hey, THAT’S NOT ALL!
Stay tuned for more improvements around the corner. The biggest ones are aligning the documentation with the new theme and restructuring it along, more emphasis on community success stories all around, more sharing options and more than a handful of shortcodes for content development and … let’s cut the spoilers here.
I hope you will like it. Let us know what you think about it. Feel free to leave comments and discuss on Twitter and Slack, or in case of issues - on GitHub.
Feature flags are used to change the behavior of a program at runtime without forcing a restart.
Although they are essential in a native cloud environment, they cannot be implemented without significant effort on some platforms. Kubernetes has made this trivial. Here we will implement them through labels and annotations, but you can also implement them by connecting directly to the Kubernetes API Server.
Possible Use Cases
Turn on/off a specific instance
Turn on/off the profiling of a specific instance
Change the logging level, to capture detailed logs during a specific event
Change caching strategy at runtime
Change timeouts in production
Toggle on/off some special verification
Organizing Access Using kubeconfig Files
The kubectl command-line tool uses kubeconfig files to find the information it needs in order to choose a cluster and communicate with its API server.
What happens if the kubeconfig file of your production cluster is leaked or published by accident?
Since there is no possibility to rotate or revoke the initial kubeconfig, there is only one way to protect your infrastructure or application if the kubeconfig has leaked - delete the cluster.
KubeCon Rewind: SIG Cluster API & Gardener – Managing Machines Automatically
The KubeCon + CloudNativeCon Europe buzz might be settling, but the energy from our deep dive session with the incredible folks at SIG Cluster API is still palpable! We, from the Gardener team, were absolutely thrilled to share the stage and explore the powerful, declarative world of Kubernetes cluster lifecycle management.
For those who don’t know, Gardener has been on a mission since 2017 to provide a fully managed Kubernetes experience, uniquely running customer control planes as pods within dedicated “seed” clusters, a.k.a. “Kubeception”. This approach demanded robust automation for the underlying infrastructure. To solve this, we pioneered the Machine Controller Manager, introducing the core abstractions you might recognize: Machine, MachineSet, and MachineDeployment. These concepts were born out of real-world needs to declaratively manage VMs and their lifecycles as if they were just another Kubernetes resource.
It’s exciting to see these foundational ideas embraced and extended by the wider community through Cluster API! Our joint talk was a fantastic opportunity to showcase how these abstractions, originally developed within Gardener, now form a cornerstone of Cluster API’s approach to creating, configuring, and managing Kubernetes clusters in a standardized way, across any provider. Incidentally, this also made Gardener the first adopter of the machine API.
We dove into:
The “why” behind Cluster API – the drive to stop reinventing the wheel for cluster provisioning.
The core API types (yes, including those familiar Machine, MachineSet, and MachineDeployment concepts!) that provide the declarative power.
How you can bootstrap Cluster API and get it managing your clusters.
The vibrant community and how everyone can get involved.
This collaboration isn’t just about shared code; it’s about a shared vision for a more consistent, automated, and less painful Kubernetes world. Seeing Gardener’s early innovations become part of a community-driven standard like Cluster API is a testament to the power of open source.
If you were there, thank you for the great questions and engagement! If you missed it, keep an eye out for the recording. The journey to simplify cluster management is a collective one, and we’re stoked to be building that future together with SIG Cluster API and all of you!
2018
Gardener Cookies
Green Tea Matcha Cookies
For a team event during the Christmas season we decided to completely reinterpret the topic cookies. :-)
Matcha cookies have the delicate flavor and color of green tea. These soft, pillowy and chewy green tea cookies
are perfect with tea. And of course they fit perfectly to our logo.
Ingredients
1 stick butter, softened
⅞ cup of granulated sugar
1 cup + 2 tablespoons all-purpose flour
2 eggs
1¼ tablespoons culinary grade matcha powder
1 teaspoon baking powder
pinch of salt
Instructions
Cream together the butter and sugar in a large mixing bowl - it should be creamy colored and airy. A hand blender or stand mixer works well for this. This helps the cookie become fluffy and chewy.
Gently incorporate the eggs to the butter mixture one at a time.
In a separate bowl, sift together all the dry ingredients.
Add the dry ingredients to the wet by adding a little at a time and folding or gently mixing the batter together. Keep going until you’ve incorporated all the remaining flour mixture. The dough should be a beautiful green color.
Chill the dough for at least an hour - up to overnight. The longer the better!
Preheat your oven to 325 F.
Roll the dough into balls the size of ping pong balls and place them on a non-stick cookie sheet.
Bake them for 12-15 minutes until the bottoms just start to become golden brown and the cookie no longer looks wet in the middle. Note: you can always bake them at 350 F for a less moist, fluffy cookie. It will bake faster by about 2-4 minutes 350 F so watch them closely.
Remove and let cool on a rack and enjoy!
Note
Make sure you get culinary grade matcha powder. You should be able to find this in Asian or natural grocers.
Cookies Are Dangerous...
…they mess up the figure.
For a team event during the Christmas season we decided to completely reinterpret the topic cookies… since the vegetables have gone on a well-deserved vacation. :-)
Whenever possible, do not run containers as root users. One could be tempted to say that in Kubernetes, the node and pods are well separated, however, the host and the container share the same kernel. If the container is compromised, a root user can damage the underlying node.
Instead of running a root user, use RUN groupadd -r anygroup && useradd -r -g anygroup myuser to create a group and a user in it. Use the USER command to switch to this user.
Storing Data or Logs in Containers
Containers are ideal for stateless applications and should be transient. This means that no data or logs should be stored in the container, as they are lost when the container is closed. If absolutely necessary, you can use persistence volumes instead to persist them outside the containers.
However, an ELK stack is preferred for storing and processing log files.
In summer 2018, the Gardener project team asked Kinvolk to execute several penetration tests in its role as a third-party contractor. The goal of this ongoing work is to increase the security of all Gardener stakeholders in the open source community. Following the Gardener architecture, the control plane of a Gardener managed shoot cluster resides in the corresponding seed cluster. This is a Control-Plane-as-a-Service with a network air gap.
Along the way we found various kinds of security issues, for example, due to misconfiguration or missing isolation, as well as two special problems with upstream Kubernetes and its Control-Plane-as-a-Service architecture.
Microservices tend to use smaller runtimes but you can use what you have today - and this can be a problem in Kubernetes.
Switching your architecture from a monolith to microservices has many advantages, both in the way you write software and the way it is used throughout its lifecycle. In this post, my attempt is to cover one problem which does not get as much attention and discussion - size of the technology stack.
General Purpose Technology Stack
There is a tendency to be more generalized in development and to apply this pattern to all services. One feels that a homogeneous image of the technology stack is good if it is the same for all services.
One forgets, however, that a large percentage of the integrated infrastructure is not used by all services in the same way, and is therefore only a burden. Thus, resources are wasted and the entire application becomes expensive in operation and scales very badly.
Light Technology Stack
Due to the lightweight nature of your service, you can run more containers on a physical server and virtual machines. The result is higher resource utilization.
Additionally, microservices are developed and deployed as containers independently of each another. This means that a development team can develop, optimize, and deploy a microservice without impacting other subsystems.
Kubernetes is Available in Docker for Mac 17.12 CE
Kubernetes is only available in Docker for Mac 17.12 CE and higher on the Edge channel. Kubernetes
support is not included in Docker for Mac Stable releases. To find out more about Stable and Edge channels
and how to switch between them, see
general configuration.
Docker for Mac 17.12 CE (and higher) Edge includes a standalone Kubernetes server that runs on Mac, so that you can test deploying your Docker workloads on Kubernetes.
The Kubernetes client command, kubectl, is included and configured to connect to the local Kubernetes server. If you have kubectl already installed and pointing to some other environment, such as minikube or a GKE cluster, be sure to change the context so that kubectl is pointing to docker-for-desktop. Read more on Docker.com.
I recommend to setup your shell to see which KUBECONFIG is active.
Namespace Isolation
…or DENY all traffic from other namespaces
You can configure a NetworkPolicy to deny all traffic from other namespaces while allowing all traffic coming from the same namespace the pod is deployed to. There are many reasons why you may choose to configure Kubernetes network policies:
Isolate multi-tenant deployments
Regulatory compliance
Ensure containers assigned to different environments (e.g. dev/staging/prod) cannot interfere with each another
All user accounts should run as few privileges as possible at all times, and also launch applications with as few privileges as possible. If you share a cluster for a different user separated by a namespace, the user has access to all namespaces and services per default. It can happen that a user accidentally uses and destroys the namespace of a productive application or the namespace of another developer.
Keep in mind - By default namespaces don’t provide:
Network Isolation
Access Control
Audit Logging on user level
ReadWriteMany - Dynamically Provisioned Persistent Volumes Using Amazon EFS
The efs-provisioner allows you to mount EFS storage as PersistentVolumes in Kubernetes. It consists of a container that has access to an AWS EFS resource. The container reads a configmap containing the EFS filesystem ID, the AWS region and the name identifying the efs-provisioner. This name will be used later when you create a storage class.
Why EFS
When you have an application running on multiple nodes which require shared access to a file system.
When you have an application that requires multiple virtual machines to access the same file system at the same time, AWS EFS is a tool that you can use.
EFS supports encryption.
EFS is SSD based storage and its storage capacity and pricing will scale in or out as needed, so there is no need for the system administrator to do additional operations. It can grow to a petabyte scale.
EFS now supports NFSv4 lock upgrading and downgrading, so yes, you can use sqlite with EFS… even if it was possible before.
EFS is easy to setup.
Why Not EFS
Sometimes when you think about using a service like EFS, you may also think about vendor lock-in and its negative sides.
Making an EFS backup may decrease your production FS performance; the throughput used by backups counts towards your total file system throughput.
EFS is expensive when compared to EBS (roughly twice the price of EBS storage).
EFS is not the magical solution for all your distributed FS problems, it can be slow in many cases. Test, benchmark, and measure to ensure that EFS is a good solution for your use case.
EFS distributed architecture results in a latency overhead for each file read/write operation.
If you have the possibility to use a CDN, don’t use EFS, use it for the files which can’t be stored in a CDN.
Don’t use EFS as a caching system, sometimes you could be doing this unintentionally.
Last but not least, even if EFS is a fully managed NFS, you will face performance problems in many cases, resolving them takes time and needs effort.
Shared Storage with S3 Backend
The storage is definitely the most complex and important part of an application setup. Once this part is completed, one of the most problematic parts could be solved.
Mounting an S3 bucket into a pod using FUSE allows you to access data stored in S3 via the filesystem. The mount is a pointer to an S3 location, so the data is never synced locally. Once mounted, any pod can read or even write from that directory without the need for explicit keys.
However, it can be used to import and parse large amounts of data into a database.
One thing that always bothered me was that I couldn’t get the logs of several pods at once with kubectl. A simple tail -f <path-to-logfile> isn’t possible. Certainly, you can use kubectl logs -f <pod-id>, but it doesn’t help if you want to monitor more than one pod at a time.
This is something you really need a lot, at least if you run several instances of a pod behind a deploymentand you don’t have a log viewer service like Kibana set up.
In that case, kubetail comes to the rescue. It is a small bash script that allows you to aggregate the log files of several pods at the same time in a simple way. The script is called kubetail and is available at GitHub.