This is the multi-page printable view of this section. Click here to print.
Infrastructure Extensions
1 - Provider Alicloud
Gardener Extension for Alicloud provider
Project Gardener implements the automated management and operation of Kubernetes clusters as a service. Its main principle is to leverage Kubernetes concepts for all of its tasks.
Recently, most of the vendor specific logic has been developed in-tree. However, the project has grown to a size where it is very hard to extend, maintain, and test. With GEP-1 we have proposed how the architecture can be changed in a way to support external controllers that contain their very own vendor specifics. This way, we can keep Gardener core clean and independent.
This controller implements Gardener’s extension contract for the Alicloud provider.
An example for a ControllerRegistration resource that can be used to register this controller to Gardener can be found here.
Please find more information regarding the extensibility concepts and a detailed proposal here.
Supported Kubernetes versions
This extension controller supports the following Kubernetes versions:
| Version | Support | Conformance test results |
|---|---|---|
| Kubernetes 1.33 | 1.33.0+ | N/A |
| Kubernetes 1.32 | 1.32.0+ | |
| Kubernetes 1.31 | 1.31.0+ | |
| Kubernetes 1.30 | 1.30.0+ | |
| Kubernetes 1.29 | 1.29.0+ | |
| Kubernetes 1.28 | 1.28.0+ | |
| Kubernetes 1.27 | 1.27.0+ |
Please take a look here to see which versions are supported by Gardener in general.
How to start using or developing this extension controller locally
You can run the controller locally on your machine by executing make start.
Static code checks and tests can be executed by running make verify. We are using Go modules for Golang package dependency management and Ginkgo/Gomega for testing.
Feedback and Support
Feedback and contributions are always welcome!
Please report bugs or suggestions as GitHub issues or reach out on Slack (join the workspace here).
Learn more!
Please find further resources about out project here:
- Our landing page gardener.cloud
- “Gardener, the Kubernetes Botanist” blog on kubernetes.io
- “Gardener Project Update” blog on kubernetes.io
- GEP-1 (Gardener Enhancement Proposal) on extensibility
- GEP-4 (New
core.gardener.cloud/v1beta1API) - Extensibility API documentation
- Gardener Extensions Golang library
- Gardener API Reference
1.1 - Tutorials
1.1.1 - Create a Kubernetes Cluster on Alibaba Cloud with Gardener
Overview
Gardener allows you to create a Kubernetes cluster on different infrastructure providers. This tutorial will guide you through the process of creating a cluster on Alibaba Cloud.
Prerequisites
- You have created an Alibaba Cloud account.
- You have access to the Gardener dashboard and have permissions to create projects.
Steps
Go to the Gardener dashboard and create a project.
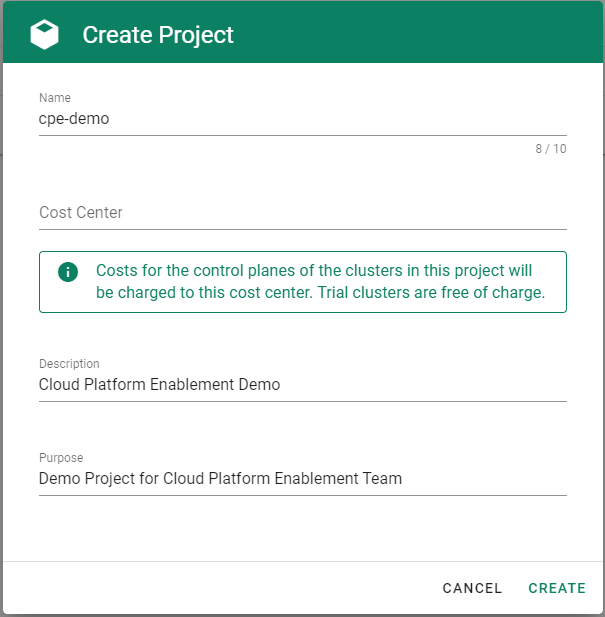
To be able to add shoot clusters to this project, you must first create a technical user on Alibaba Cloud with sufficient permissions.
Choose Secrets, then the plus icon
 and select AliCloud.
and select AliCloud.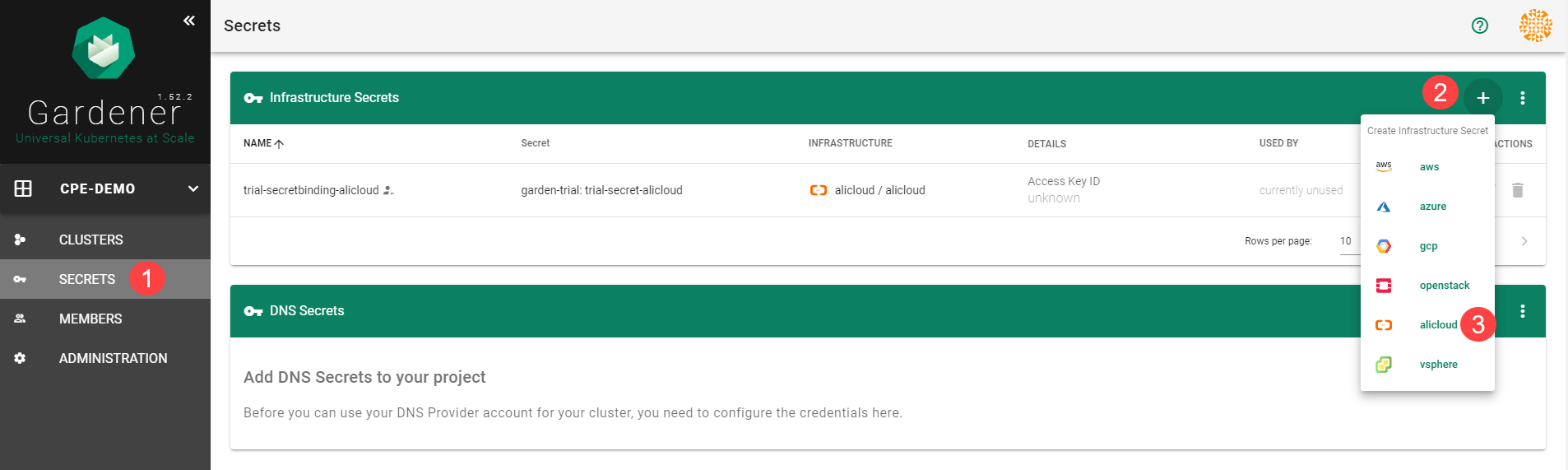
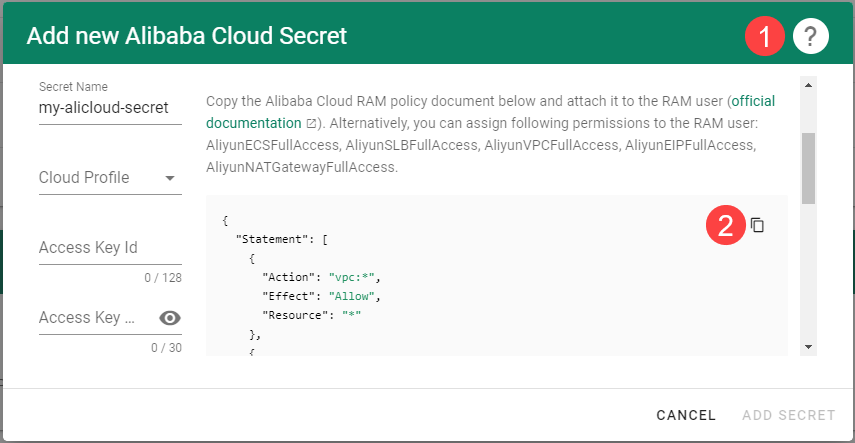
To copy the policy for Alibaba Cloud from the Gardener dashboard, click on the help icon
 for Alibaba Cloud secrets, and choose copy
for Alibaba Cloud secrets, and choose copy  .
.
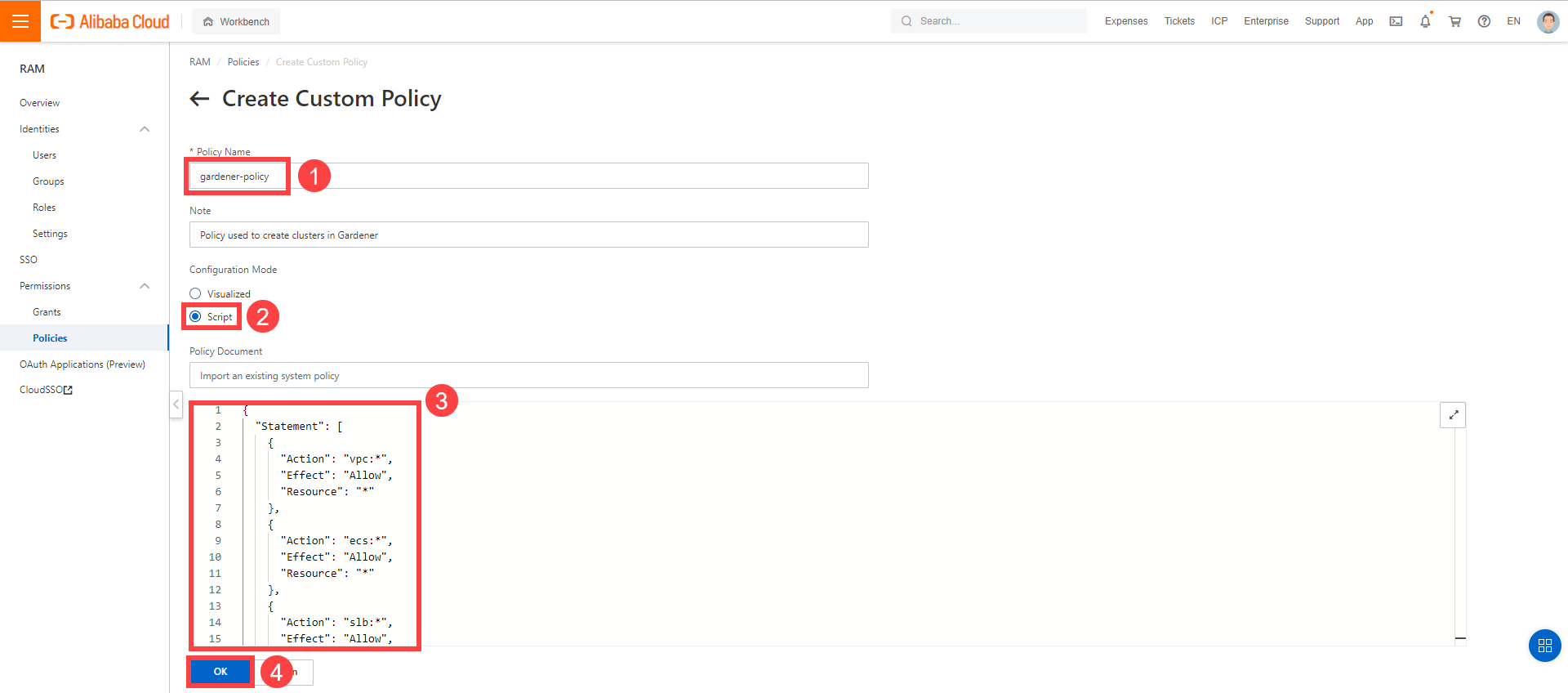
Create a custom policy in Alibaba Cloud:
Log on to your Alibaba account and choose RAM > Permissions > Policies.
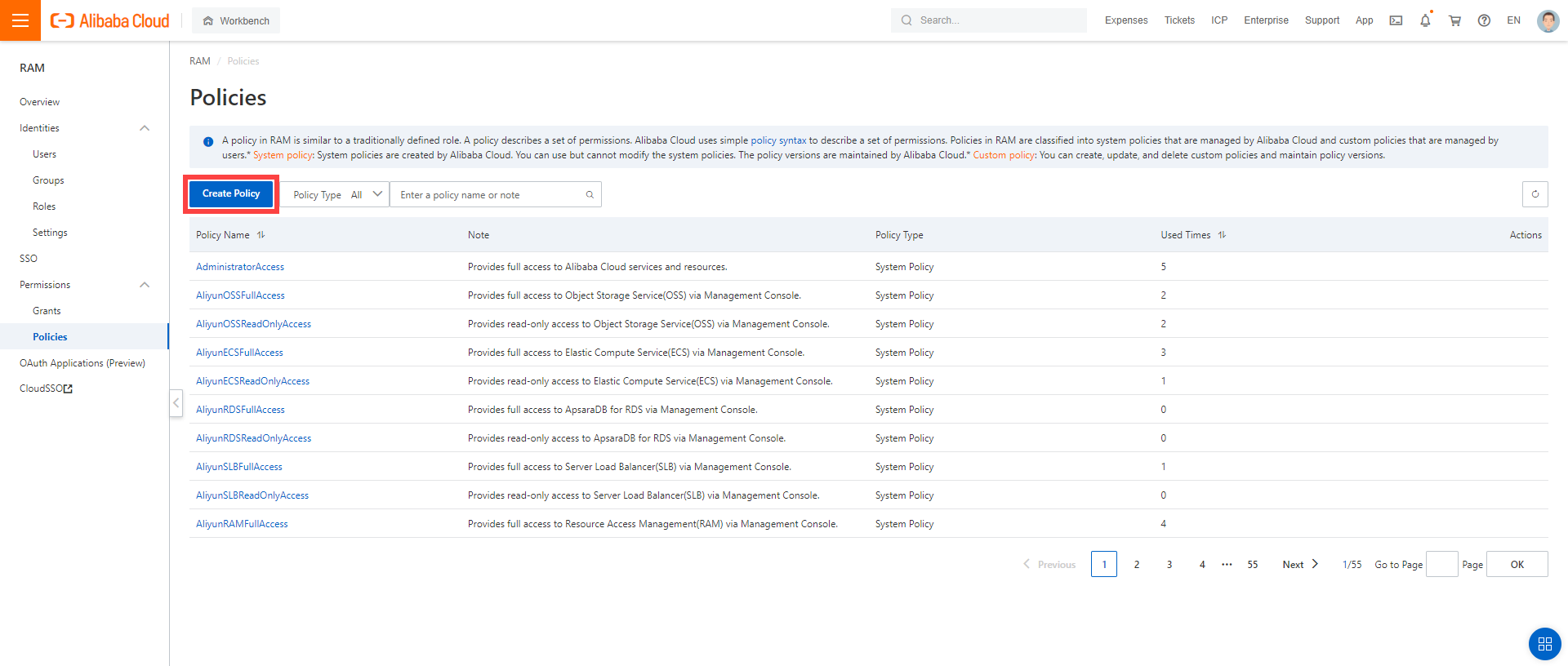
Enter the name of your policy.
Select
Script.Paste the policy that you copied from the Gardener dashboard to this custom policy.
Choose OK.
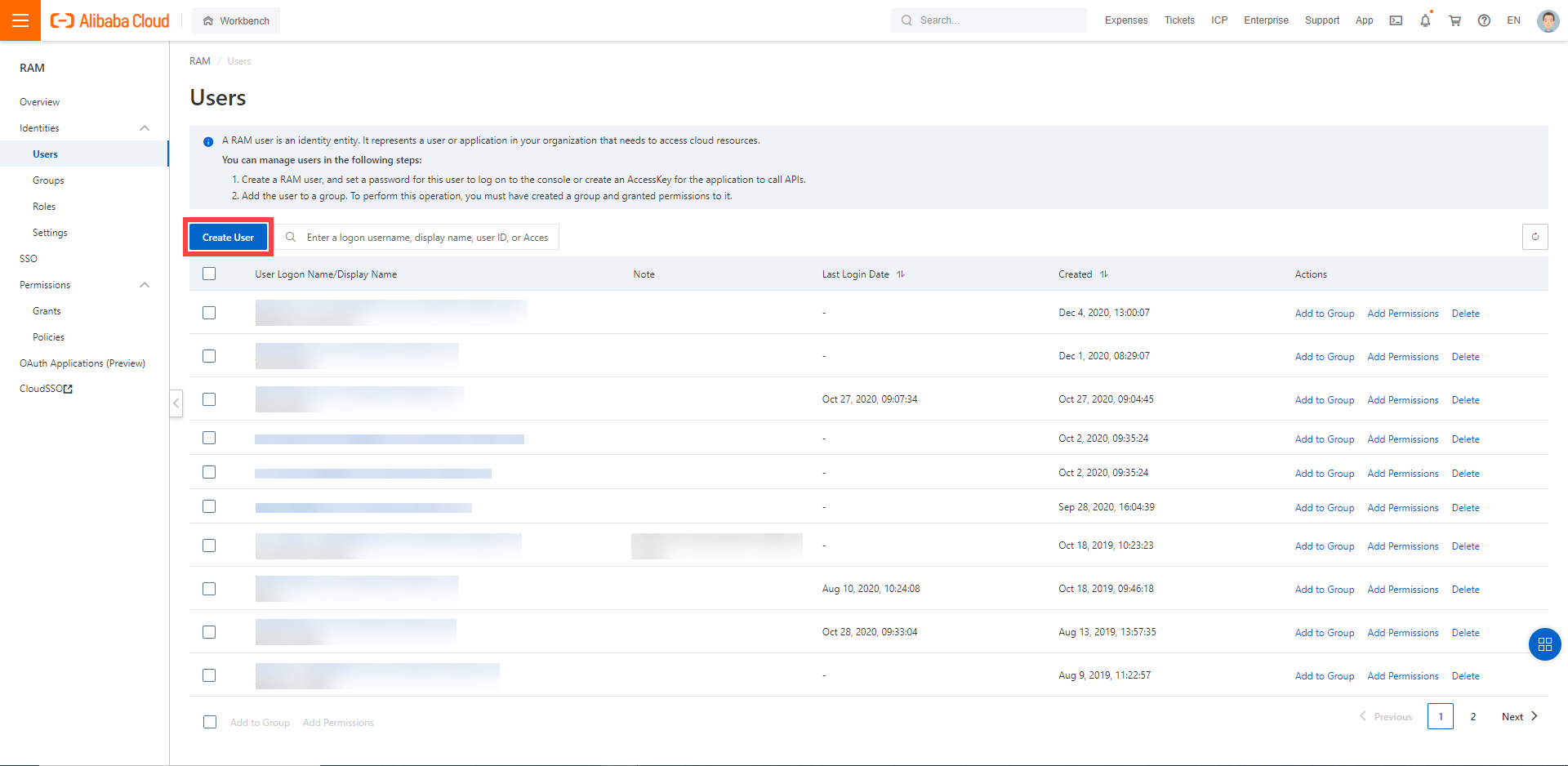
In the Alibaba Cloud console, create a new technical user:
Choose RAM > Users.
Choose Create User.
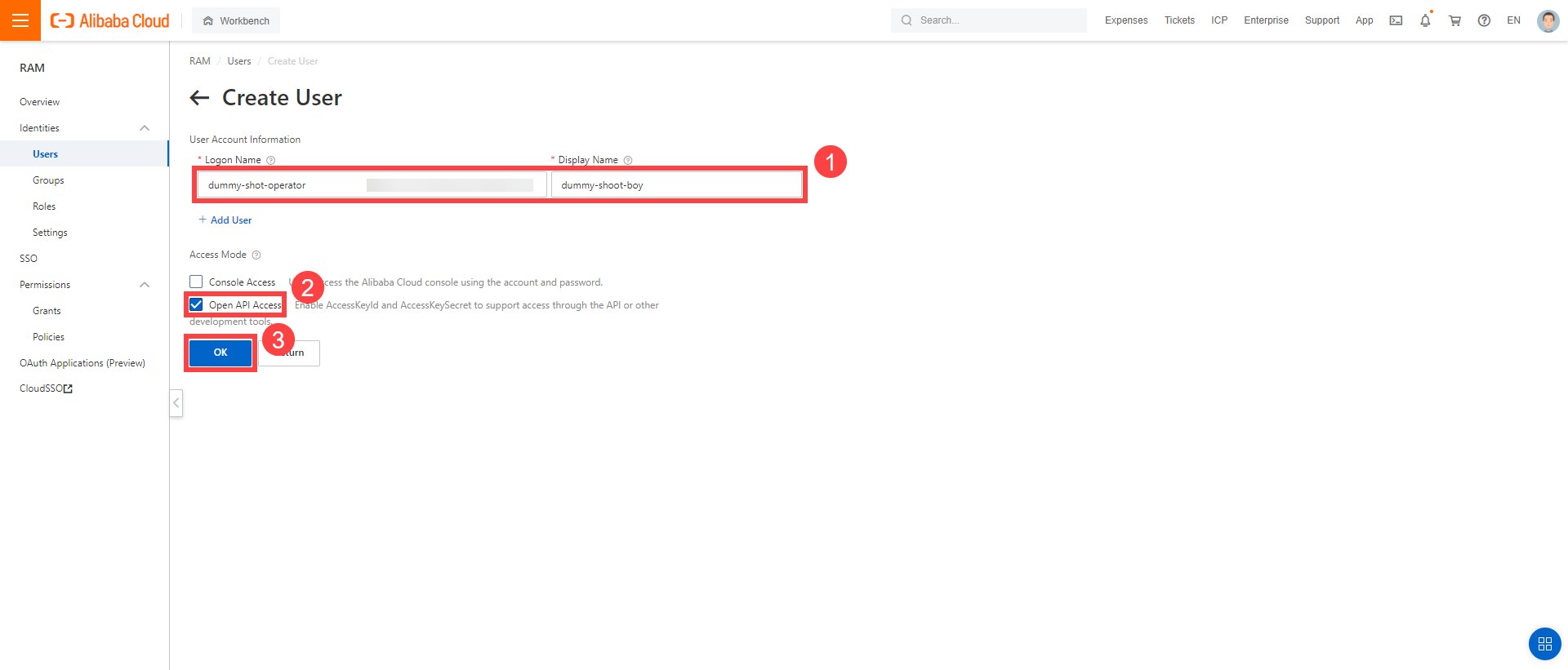
Enter a logon and display name for your user.
Select Open API Access.
Choose OK.
After the user is created,
AccessKeyIdandAccessKeySecretare generated and displayed. Remember to save them. TheAccessKeyis used later to create secrets for Gardener.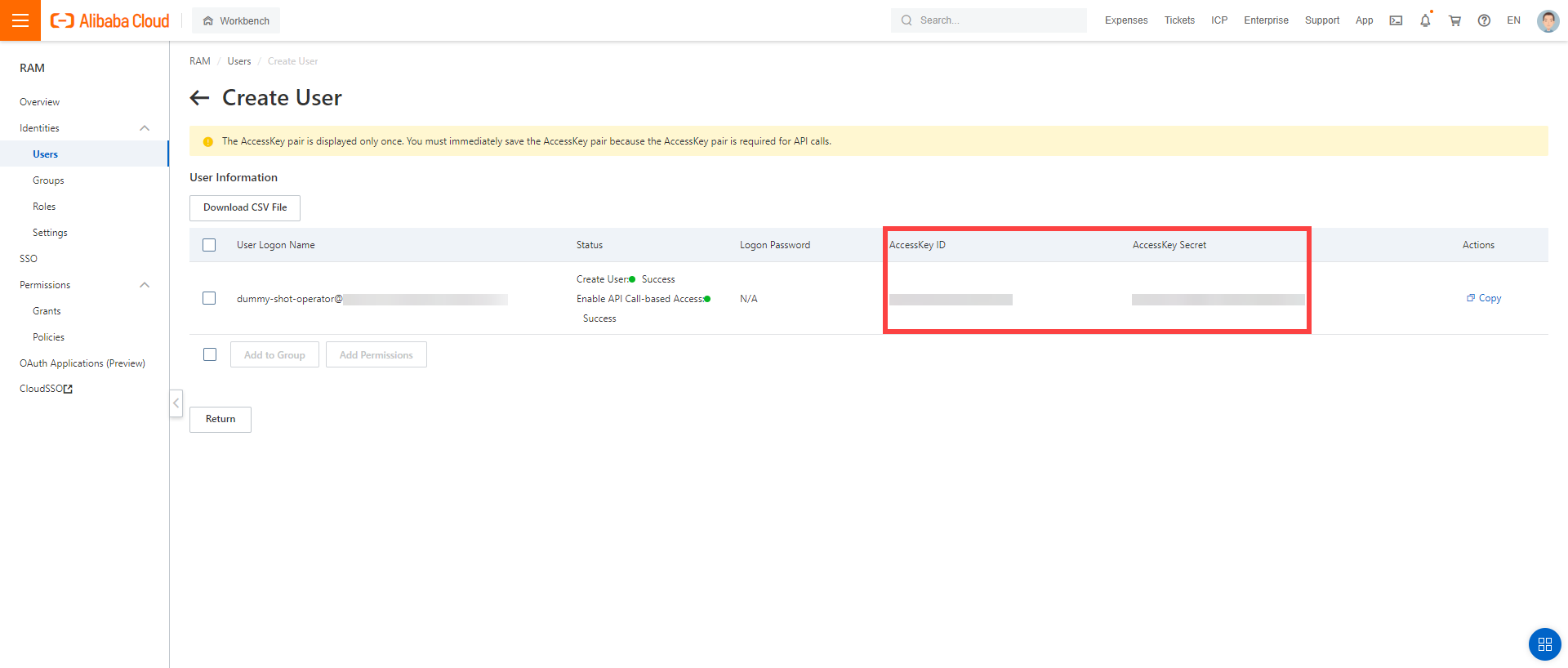
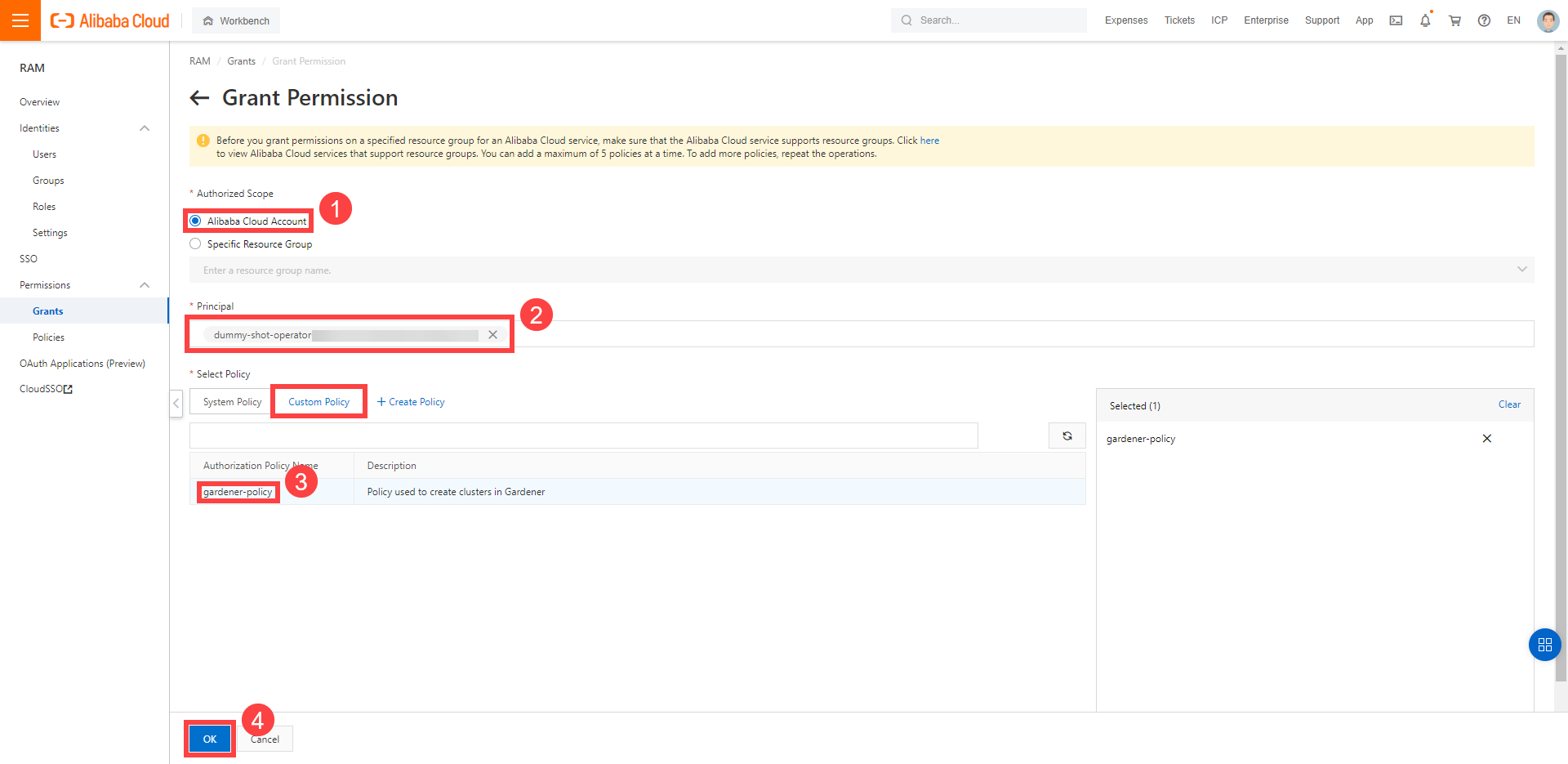
Assign the policy you created to the technical user:
Choose RAM > Permissions > Grants.
Choose Grant Permission.

Select Alibaba Cloud Account.
Assign the policy you’ve created before to the technical user.
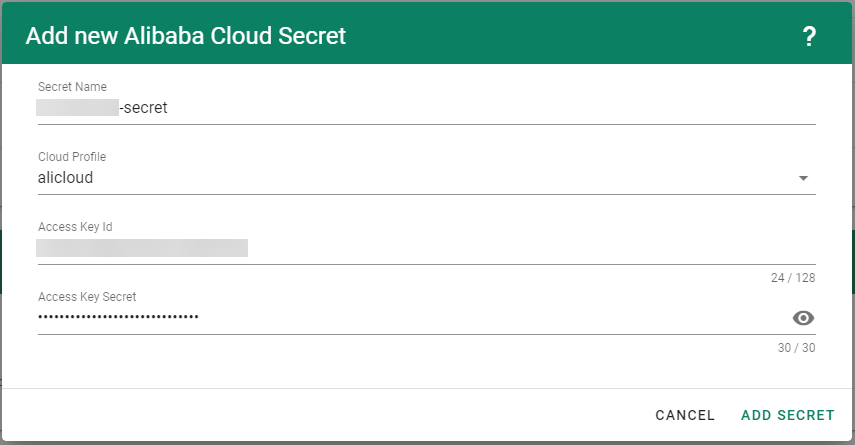
Create your secret.
- Type the name of your secret.
- Copy and paste the
Access Key IDandSecret Access Keyyou saved when you created the technical user on Alibaba Cloud. - Choose Add secret.
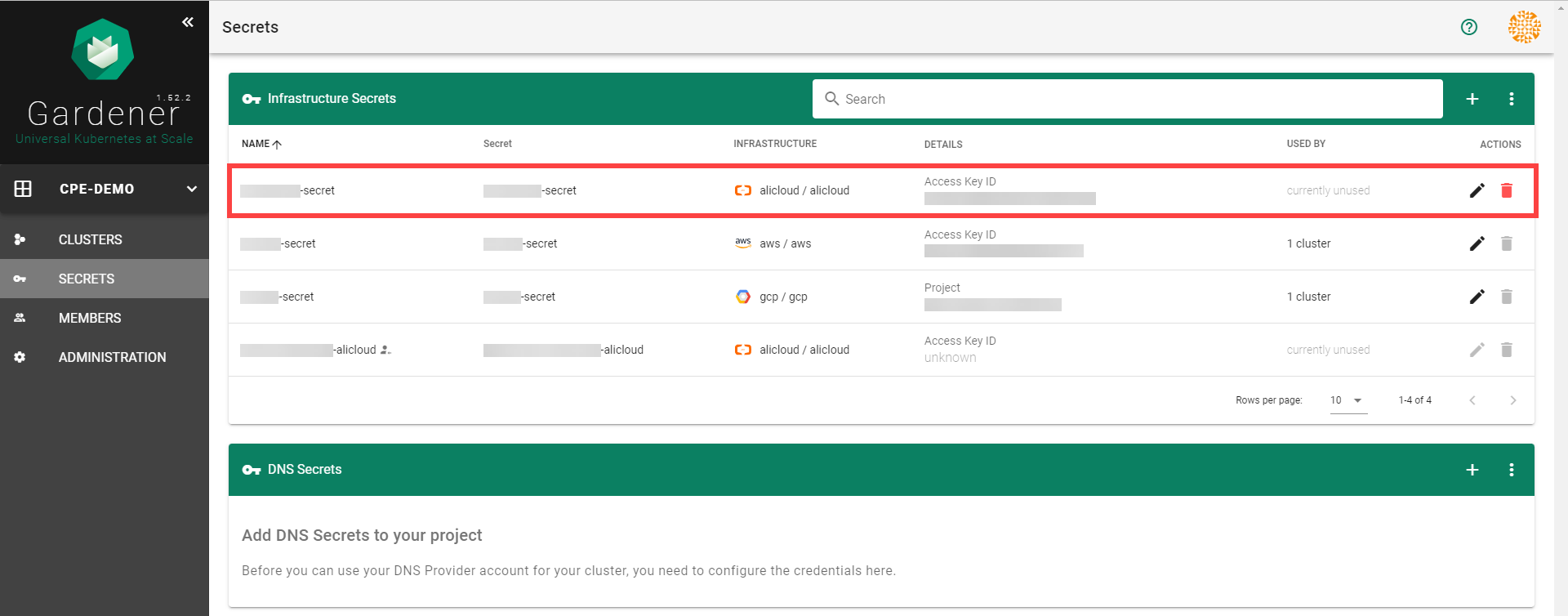
After completing these steps, you should see your newly created secret in the Infrastructure Secrets section.
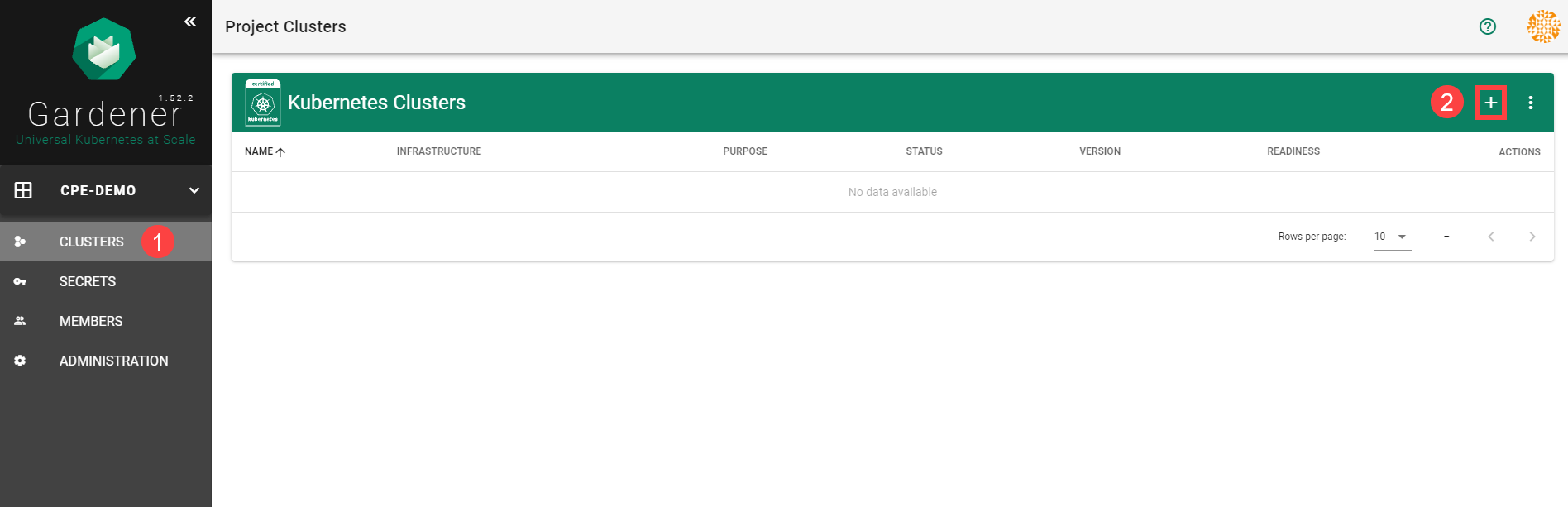
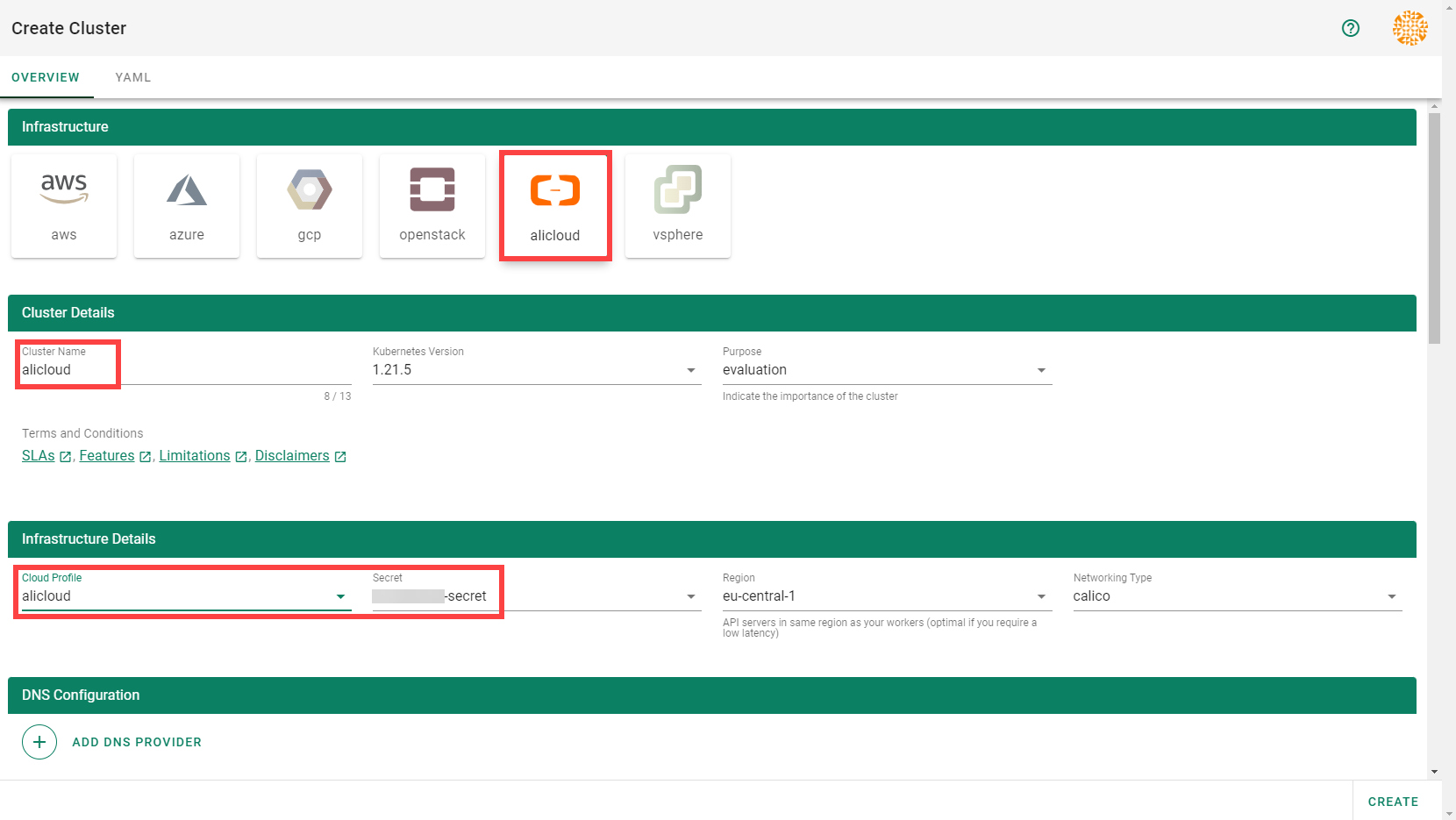
To create a new cluster, choose Clusters and then the plus sign in the upper right corner.
In the Create Cluster section:
Select AliCloud in the Infrastructure tab.
Type the name of your cluster in the Cluster Details tab.
Choose the secret you created before in the Infrastructure Details tab.
Choose Create.
Wait for your cluster to get created.
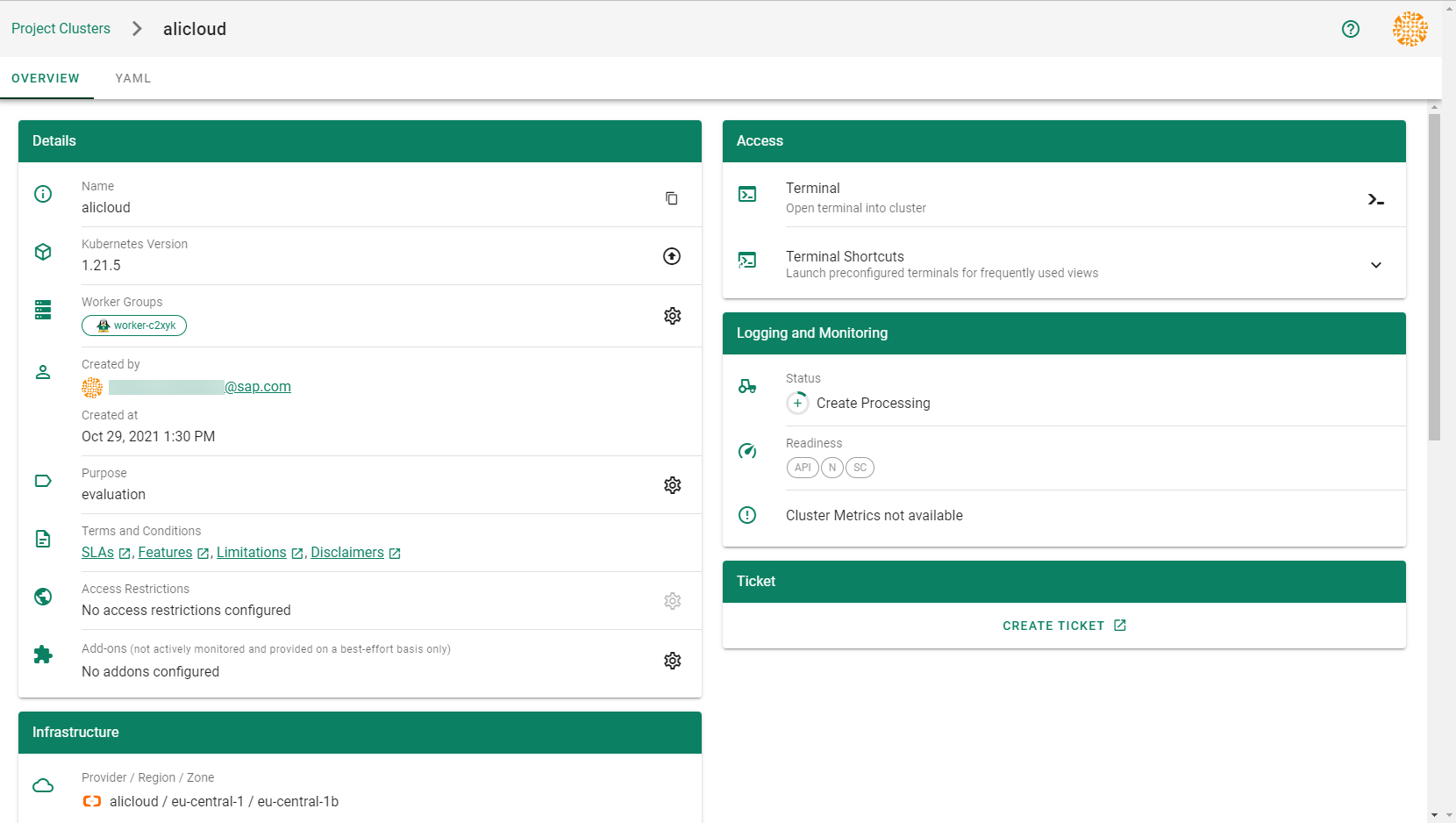
Result
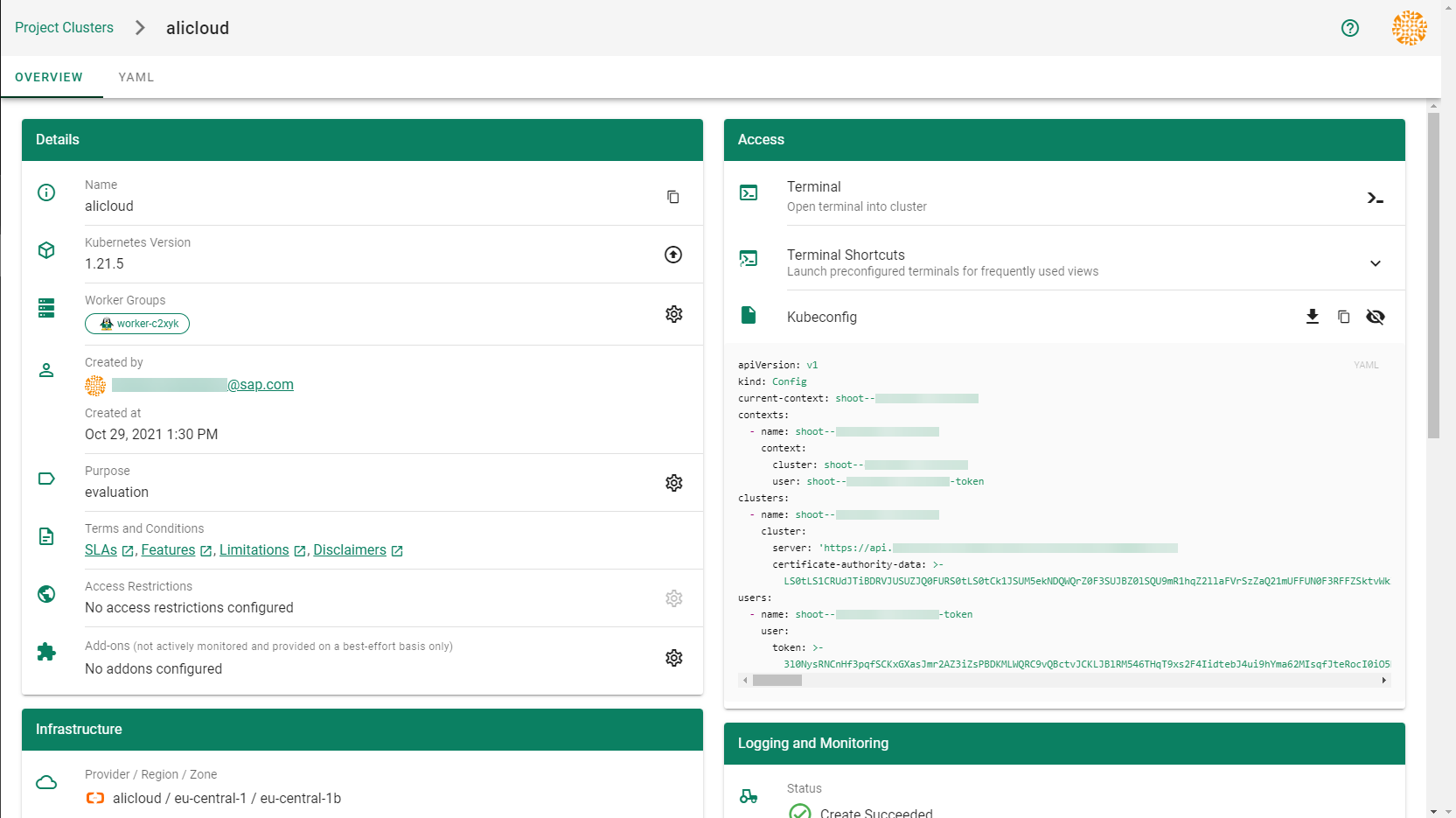
After completing the steps in this tutorial, you will be able to see and download the kubeconfig of your cluster. With it you can create shoot clusters on Alibaba Cloud.
The size of persistent volumes in your shoot cluster must at least be 20 GiB large. If you choose smaller sizes in your Kubernetes PV definition, the allocation of cloud disk space on Alibaba Cloud fails.
1.2 - Deployment
Deployment of the AliCloud provider extension
Disclaimer: This document is NOT a step by step installation guide for the AliCloud provider extension and only contains some configuration specifics regarding the installation of different components via the helm charts residing in the AliCloud provider extension repository.
gardener-extension-admission-alicloud
Authentication against the Garden cluster
There are several authentication possibilities depending on whether or not the concept of Virtual Garden is used.
Virtual Garden is not used, i.e., the runtime Garden cluster is also the target Garden cluster.
Automounted Service Account Token
The easiest way to deploy the gardener-extension-admission-alicloud component will be to not provide kubeconfig at all. This way in-cluster configuration and an automounted service account token will be used. The drawback of this approach is that the automounted token will not be automatically rotated.
This will allow for automatic rotation of the service account token by the kubelet. The configuration can be achieved by setting both .Values.global.serviceAccountTokenVolumeProjection.enabled: true and .Values.global.kubeconfig in the respective chart’s values.yaml file.
Virtual Garden is used, i.e., the runtime Garden cluster is different from the target Garden cluster.
Service Account
The easiest way to setup the authentication will be to create a service account and the respective roles will be bound to this service account in the target cluster. Then use the generated service account token and craft a kubeconfig which will be used by the workload in the runtime cluster. This approach does not provide a solution for the rotation of the service account token. However, this setup can be achieved by setting .Values.global.virtualGarden.enabled: true and following these steps:
- Deploy the
applicationpart of the charts in thetargetcluster. - Get the service account token and craft the
kubeconfig. - Set the crafted
kubeconfigand deploy theruntimepart of the charts in theruntimecluster.
Client Certificate
Another solution will be to bind the roles in the target cluster to a User subject instead of a service account and use a client certificate for authentication. This approach does not provide a solution for the client certificate rotation. However, this setup can be achieved by setting both .Values.global.virtualGarden.enabled: true and .Values.global.virtualGarden.user.name, then following these steps:
- Generate a client certificate for the
targetcluster for the respective user. - Deploy the
applicationpart of the charts in thetargetcluster. - Craft a
kubeconfigusing the already generated client certificate. - Set the crafted
kubeconfigand deploy theruntimepart of the charts in theruntimecluster.
1.3 - Local Setup
admission-alicloud
admission-alicloud is an admission webhook server which is responsible for the validation of the cloud provider (Alicloud in this case) specific fields and resources. The Gardener API server is cloud provider agnostic and it wouldn’t be able to perform similar validation.
Follow the steps below to run the admission webhook server locally.
Start the Gardener API server.
For details, check the Gardener local setup.
Start the webhook server
Make sure that the
KUBECONFIGenvironment variable is pointing to the local garden cluster.make start-admissionSetup the
ValidatingWebhookConfiguration.hack/dev-setup-admission-alicloud.shwill configure the webhook Service which will allow the kube-apiserver of your local cluster to reach the webhook server. It will also apply theValidatingWebhookConfigurationmanifest../hack/dev-setup-admission-alicloud.sh
You are now ready to experiment with the admission-alicloud webhook server locally.
1.4 - Operations
Using the Alicloud provider extension with Gardener as operator
The core.gardener.cloud/v1beta1.CloudProfile resource declares a providerConfig field that is meant to contain provider-specific configuration.
The core.gardener.cloud/v1beta1.Seed resource is structured similarly.
Additionally, it allows configuring settings for the backups of the main etcds’ data of shoot clusters control planes running in this seed cluster.
This document explains the necessary configuration for this provider extension. In addition, this document also describes how to enable the use of customized machine images for Alicloud.
CloudProfile resource
This section describes, how the configuration for CloudProfile looks like for Alicloud by providing an example CloudProfile manifest with minimal configuration that can be used to allow the creation of Alicloud shoot clusters.
CloudProfileConfig
The cloud profile configuration contains information about the real machine image IDs in the Alicloud environment (AMIs).
You have to map every version that you specify in .spec.machineImages[].versions here such that the Alicloud extension knows the AMI for every version you want to offer.
An example CloudProfileConfig for the Alicloud extension looks as follows:
apiVersion: alicloud.provider.extensions.gardener.cloud/v1alpha1
kind: CloudProfileConfig
machineImages:
- name: coreos
versions:
- version: 2023.4.0
regions:
- name: eu-central-1
id: coreos_2023_4_0_64_30G_alibase_20190319.vhd
Example CloudProfile manifest
Please find below an example CloudProfile manifest:
apiVersion: core.gardener.cloud/v1beta1
kind: CloudProfile
metadata:
name: alicloud
spec:
type: alicloud
kubernetes:
versions:
- version: 1.32.0
- version: 1.31.1
expirationDate: "2026-03-31T23:59:59Z"
machineImages:
- name: coreos
versions:
- version: 2023.4.0
machineTypes:
- name: ecs.sn2ne.large
cpu: "2"
gpu: "0"
memory: 8Gi
volumeTypes:
- name: cloud_efficiency
class: standard
- name: cloud_essd
class: premium
regions:
- name: eu-central-1
zones:
- name: eu-central-1a
- name: eu-central-1b
providerConfig:
apiVersion: alicloud.provider.extensions.gardener.cloud/v1alpha1
kind: CloudProfileConfig
machineImages:
- name: coreos
versions:
- version: 2023.4.0
regions:
- name: eu-central-1
id: coreos_2023_4_0_64_30G_alibase_20190319.vhd
Enable customized machine images for the Alicloud extension
Customized machine images can be created for an Alicloud account and shared with other Alicloud accounts.
The same customized machine image has different image ID in different regions on Alicloud.
If you need to enable encrypted system disk, you must provide customized machine images.
Administrators/Operators need to explicitly declare them per imageID per region as below:
machineImages:
- name: customized_coreos
regions:
- imageID: <image_id_in_eu_central_1>
region: eu-central-1
- imageID: <image_id_in_cn_shanghai>
region: cn-shanghai
...
version: 2191.4.1
...
End-users have to have the permission to use the customized image from its creator Alicloud account. To enable end-users to use customized images, the images are shared from Alicloud account of Seed operator with end-users’ Alicloud accounts. Administrators/Operators need to explicitly provide Seed operator’s Alicloud account access credentials (base64 encoded) as below:
machineImageOwnerSecret:
name: machine-image-owner
accessKeyID: <base64_encoded_access_key_id>
accessKeySecret: <base64_encoded_access_key_secret>
As a result, a Secret named machine-image-owner by default will be created in namespace of Alicloud provider extension.
Operators should also maintain custom image IDs which are to be shared with end-users as below:
toBeSharedImageIDs:
- <image_id_1>
- <image_id_2>
- <image_id_3>
Example ControllerDeployment manifest for enabling customized machine images
apiVersion: core.gardener.cloud/v1beta1
kind: ControllerDeployment
metadata:
name: extension-provider-alicloud
spec:
type: helm
providerConfig:
chart: |
H4sIFAAAAAAA/yk...
values:
config:
machineImageOwnerSecret:
accessKeyID: <base64_encoded_access_key_id>
accessKeySecret: <base64_encoded_access_key_secret>
toBeSharedImageIDs:
- <image_id_1>
- <image_id_2>
...
machineImages:
- name: customized_coreos
regions:
- imageID: <image_id_in_eu_central_1>
region: eu-central-1
- imageID: <image_id_in_cn_shanghai>
region: cn-shanghai
...
version: 2191.4.1
...
csi:
enableADController: true
resources:
limits:
cpu: 500m
memory: 1Gi
requests:
memory: 128Mi
Seed resource
This provider extension does not support any provider configuration for the Seed’s .spec.provider.providerConfig field.
However, it supports to managing of backup infrastructure, i.e., you can specify a configuration for the .spec.backup field.
Backup configuration
A Seed of type alicloud can be configured to perform backups for the main etcds’ of the shoot clusters control planes using Alicloud Object Storage Service.
The location/region where the backups will be stored defaults to the region of the Seed (spec.provider.region).
Please find below an example Seed manifest (partly) that configures backups using Alicloud Object Storage Service.
---
apiVersion: core.gardener.cloud/v1beta1
kind: Seed
metadata:
name: my-seed
spec:
provider:
type: alicloud
region: cn-shanghai
backup:
provider: alicloud
credentialsRef:
apiVersion: v1
kind: Secret
name: backup-credentials
namespace: garden
...
An example of the referenced secret containing the credentials for the Alicloud Object Storage Service can be found in the example folder.
Permissions for Alicloud Object Storage Service
Please make sure the RAM user associated with the provided AccessKey pair has the following permission.
- AliyunOSSFullAccess
1.5 - Usage
Using the Alicloud provider extension with Gardener as end-user
The core.gardener.cloud/v1beta1.Shoot resource declares a few fields that are meant to contain provider-specific configuration.
This document describes the configurable options for Alicloud and provides an example Shoot manifest with minimal configuration that can be used to create an Alicloud cluster (modulo the landscape-specific information like cloud profile names, secret binding names, etc.).
Alicloud Provider Credentials
In order for Gardener to create a Kubernetes cluster using Alicloud infrastructure components, a Shoot has to provide credentials with sufficient permissions to the desired Alicloud project.
Every shoot cluster references a SecretBinding or a CredentialsBinding which itself references a Secret, and this Secret contains the provider credentials of the Alicloud project.
This Secret must look as follows:
apiVersion: v1
kind: Secret
metadata:
name: core-alicloud
namespace: garden-dev
type: Opaque
data:
accessKeyID: base64(access-key-id)
accessKeySecret: base64(access-key-secret)
The SecretBinding/CredentialsBinding is configurable in the Shoot cluster with the field secretBindingName/credentialsBindingName.
The required credentials for the Alicloud project are an AccessKey Pair associated with a Resource Access Management (RAM) User. A RAM user is a special account that can be used by services and applications to interact with Alicloud Cloud Platform APIs. Applications can use AccessKey pair to authorize themselves to a set of APIs and perform actions within the permissions granted to the RAM user.
Make sure to create a Resource Access Management User, and create an AccessKey Pair that shall be used for the Shoot cluster.
Permissions
Please make sure the provided credentials have the correct privileges. You can use the following Alicloud RAM policy document and attach it to the RAM user backed by the credentials you provided.
Click to expand the Alicloud RAM policy document!
{
"Statement": [
{
"Action": [
"vpc:*"
],
"Effect": "Allow",
"Resource": [
"*"
]
},
{
"Action": [
"ecs:*"
],
"Effect": "Allow",
"Resource": [
"*"
]
},
{
"Action": [
"slb:*"
],
"Effect": "Allow",
"Resource": [
"*"
]
},
{
"Action": [
"ram:GetRole",
"ram:CreateRole",
"ram:CreateServiceLinkedRole"
],
"Effect": "Allow",
"Resource": [
"*"
]
},
{
"Action": [
"ros:*"
],
"Effect": "Allow",
"Resource": [
"*"
]
}
],
"Version": "1"
}
InfrastructureConfig
The infrastructure configuration mainly describes how the network layout looks like in order to create the shoot worker nodes in a later step, thus, prepares everything relevant to create VMs, load balancers, volumes, etc.
An example InfrastructureConfig for the Alicloud extension looks as follows:
apiVersion: alicloud.provider.extensions.gardener.cloud/v1alpha1
kind: InfrastructureConfig
networks:
vpc: # specify either 'id' or 'cidr'
# id: my-vpc
cidr: 10.250.0.0/16
# gardenerManagedNATGateway: true
zones:
- name: eu-central-1a
workers: 10.250.1.0/24
# natGateway:
# eipAllocationID: eip-ufxsdg122elmszcg
The networks.vpc section describes whether you want to create the shoot cluster in an already existing VPC or whether to create a new one:
- If
networks.vpc.idis given then you have to specify the VPC ID of the existing VPC that was created by other means (manually, other tooling, …). - If
networks.vpc.cidris given then you have to specify the VPC CIDR of a new VPC that will be created during shoot creation. You can freely choose a private CIDR range. - Either
networks.vpc.idornetworks.vpc.cidrmust be present, but not both at the same time. - When
networks.vpc.idis present, in addition, you can also choose to setnetworks.vpc.gardenerManagedNATGateway. It is by defaultfalse. When it is set totrue, Gardener will create an Enhanced NATGateway in the VPC and associate it with a VSwitch created in the first zone in thenetworks.zones. - Please note that when
networks.vpc.idis present, andnetworks.vpc.gardenerManagedNATGatewayisfalseor not set, you have to manually create an Enhance NATGateway and associate it with a VSwitch that you manually created. In this case, make sure the worker CIDRs innetworks.zonesdo not overlap with the one you created. If a NATGateway is created manually and a shoot is created in the same VPC withnetworks.vpc.gardenerManagedNATGatewaysettrue, you need to manually adjust the route rule accordingly. You may refer to here.
The networks.zones section describes which subnets you want to create in availability zones.
For every zone, the Alicloud extension creates one subnet:
- The
workerssubnet is used for all shoot worker nodes, i.e., VMs which later run your applications.
For every subnet, you have to specify a CIDR range contained in the VPC CIDR specified above, or the VPC CIDR of your already existing VPC. You can freely choose these CIDR and it is your responsibility to properly design the network layout to suit your needs.
If you want to use multiple availability zones then add a second, third, … entry to the networks.zones[] list and properly specify the AZ name in networks.zones[].name.
Apart from the VPC and the subnets the Alicloud extension will also create a NAT gateway (only if a new VPC is created), a key pair, elastic IPs, VSwitches, a SNAT table entry, and security groups.
By default, the Alicloud extension will create a corresponding Elastic IP that it attaches to this NAT gateway and which is used for egress traffic.
The networks.zones[].natGateway.eipAllocationID field allows you to specify the Elastic IP Allocation ID of an existing Elastic IP allocation in case you want to bring your own.
If provided, no new Elastic IP will be created and, instead, the Elastic IP specified by you will be used.
⚠️ If you change this field for an already existing infrastructure then it will disrupt egress traffic while Alicloud applies this change, because the NAT gateway must be recreated with the new Elastic IP association. Also, please note that the existing Elastic IP will be permanently deleted if it was earlier created by the Alicloud extension.
ControlPlaneConfig
The control plane configuration mainly contains values for the Alicloud-specific control plane components.
Today, the Alicloud extension deploys the cloud-controller-manager and the CSI controllers.
An example ControlPlaneConfig for the Alicloud extension looks as follows:
apiVersion: alicloud.provider.extensions.gardener.cloud/v1alpha1
kind: ControlPlaneConfig
csi:
enableADController: true
# cloudControllerManager:
# featureGates:
# SomeKubernetesFeature: true
The csi.enableADController is used as the value of environment DISK_AD_CONTROLLER, which is used for AliCloud csi-disk-plugin. This field is optional. When a new shoot is creatd, this field is automatically set true. For an existing shoot created in previous versions, it remains unchanged. If there are persistent volumes created before year 2021, please be cautious to set this field true because they may fail to mount to nodes.
The cloudControllerManager.featureGates contains a map of explicitly enabled or disabled feature gates.
For production usage it’s not recommend to use this field at all as you can enable alpha features or disable beta/stable features, potentially impacting the cluster stability.
If you don’t want to configure anything for the cloudControllerManager simply omit the key in the YAML specification.
WorkerConfig
The Alicloud extension does not support a specific WorkerConfig. However, it supports additional data volumes (plus encryption) per machine.
By default (if not stated otherwise), all the disks are unencrypted.
For each data volume, you have to specify a name.
It also supports encrypted system disk.
However, only Customized image is currently supported to be used as a basic image for encrypted system disk.
Please be noted that the change of system disk encryption flag will cause reconciliation of a shoot, and it will result in nodes rolling update within the worker group.
The following YAML is a snippet of a Shoot resource:
spec:
provider:
workers:
- name: cpu-worker
...
volume:
type: cloud_efficiency
size: 20Gi
encrypted: true
dataVolumes:
- name: kubelet-dir
type: cloud_efficiency
size: 25Gi
encrypted: true
Example Shoot manifest (one availability zone)
Please find below an example Shoot manifest for one availability zone:
apiVersion: core.gardener.cloud/v1beta1
kind: Shoot
metadata:
name: johndoe-alicloud
namespace: garden-dev
spec:
cloudProfile:
name: alicloud
region: eu-central-1
secretBindingName: core-alicloud
provider:
type: alicloud
infrastructureConfig:
apiVersion: alicloud.provider.extensions.gardener.cloud/v1alpha1
kind: InfrastructureConfig
networks:
vpc:
cidr: 10.250.0.0/16
zones:
- name: eu-central-1a
workers: 10.250.0.0/19
controlPlaneConfig:
apiVersion: alicloud.provider.extensions.gardener.cloud/v1alpha1
kind: ControlPlaneConfig
workers:
- name: worker-xoluy
machine:
type: ecs.sn2ne.large
minimum: 2
maximum: 2
volume:
size: 50Gi
type: cloud_efficiency
zones:
- eu-central-1a
networking:
nodes: 10.250.0.0/16
type: calico
kubernetes:
version: 1.28.2
maintenance:
autoUpdate:
kubernetesVersion: true
machineImageVersion: true
addons:
kubernetesDashboard:
enabled: true
nginxIngress:
enabled: true
Example Shoot manifest (two availability zones)
Please find below an example Shoot manifest for two availability zones:
apiVersion: core.gardener.cloud/v1beta1
kind: Shoot
metadata:
name: johndoe-alicloud
namespace: garden-dev
spec:
cloudProfile:
name: alicloud
region: eu-central-1
secretBindingName: core-alicloud
provider:
type: alicloud
infrastructureConfig:
apiVersion: alicloud.provider.extensions.gardener.cloud/v1alpha1
kind: InfrastructureConfig
networks:
vpc:
cidr: 10.250.0.0/16
zones:
- name: eu-central-1a
workers: 10.250.0.0/26
- name: eu-central-1b
workers: 10.250.0.64/26
controlPlaneConfig:
apiVersion: alicloud.provider.extensions.gardener.cloud/v1alpha1
kind: ControlPlaneConfig
workers:
- name: worker-xoluy
machine:
type: ecs.sn2ne.large
minimum: 2
maximum: 4
volume:
size: 50Gi
type: cloud_efficiency
# NOTE: Below comment is for the case when encrypted field of an existing shoot is updated from false to true.
# It will cause affected nodes to be rolling updated. Users must trigger a MAINTAIN operation of the shoot.
# Otherwise, the shoot will fail to reconcile.
# You could do it either via Dashboard or annotating the shoot with gardener.cloud/operation=maintain
encrypted: true
zones:
- eu-central-1a
- eu-central-1b
networking:
nodes: 10.250.0.0/16
type: calico
kubernetes:
version: 1.28.2
maintenance:
autoUpdate:
kubernetesVersion: true
machineImageVersion: true
addons:
kubernetesDashboard:
enabled: true
nginxIngress:
enabled: true
Kubernetes Versions per Worker Pool
This extension supports gardener/gardener’s WorkerPoolKubernetesVersion feature gate, i.e., having worker pools with overridden Kubernetes versions since gardener-extension-provider-alicloud@v1.33.
Shoot CA Certificate and ServiceAccount Signing Key Rotation
This extension supports gardener/gardener’s ShootCARotation feature gate since gardener-extension-provider-alicloud@v1.36 and ShootSARotation feature gate since gardener-extension-provider-alicloud@v1.37.
2 - Provider AWS
Gardener Extension for AWS provider
Project Gardener implements the automated management and operation of Kubernetes clusters as a service. Its main principle is to leverage Kubernetes concepts for all of its tasks.
Recently, most of the vendor specific logic has been developed in-tree. However, the project has grown to a size where it is very hard to extend, maintain, and test. With GEP-1 we have proposed how the architecture can be changed in a way to support external controllers that contain their very own vendor specifics. This way, we can keep Gardener core clean and independent.
This controller implements Gardener’s extension contract for the AWS provider.
An example for a ControllerRegistration resource that can be used to register this controller to Gardener can be found here.
Please find more information regarding the extensibility concepts and a detailed proposal here.
Supported Kubernetes versions
This extension controller supports the following Kubernetes versions:
| Version | Support | Conformance test results |
|---|---|---|
| Kubernetes 1.33 | 1.33.0+ | N/A |
| Kubernetes 1.32 | 1.32.0+ | |
| Kubernetes 1.31 | 1.31.0+ | |
| Kubernetes 1.30 | 1.30.0+ | |
| Kubernetes 1.29 | 1.29.0+ | |
| Kubernetes 1.28 | 1.28.0+ | |
| Kubernetes 1.27 | 1.27.0+ |
Please take a look here to see which versions are supported by Gardener in general.
Compatibility
The following lists known compatibility issues of this extension controller with other Gardener components.
| AWS Extension | Gardener | Action | Notes |
|---|---|---|---|
<= v1.15.0 | >v1.10.0 | Please update the provider version to > v1.15.0 or disable the feature gate MountHostCADirectories in the Gardenlet. | Applies if feature flag MountHostCADirectories in the Gardenlet is enabled. Shoots with CSI enabled (Kubernetes version >= 1.18) miss a mount to the directory /etc/ssl in the Shoot API Server. This can lead to not trusting external Root CAs when the API Server makes requests via webhooks or OIDC. |
How to start using or developing this extension controller locally
You can run the controller locally on your machine by executing make start.
Static code checks and tests can be executed by running make verify. We are using Go modules for Golang package dependency management and Ginkgo/Gomega for testing.
Feedback and Support
Feedback and contributions are always welcome!
Please report bugs or suggestions as GitHub issues or reach out on Slack (join the workspace here).
Learn more!
Please find further resources about out project here:
- Our landing page gardener.cloud
- “Gardener, the Kubernetes Botanist” blog on kubernetes.io
- “Gardener Project Update” blog on kubernetes.io
- GEP-1 (Gardener Enhancement Proposal) on extensibility
- GEP-4 (New
core.gardener.cloud/v1beta1API) - Extensibility API documentation
- Gardener Extensions Golang library
- Gardener API Reference
2.1 - Tutorials
Overview
Gardener allows you to create a Kubernetes cluster on different infrastructure providers. This tutorial will guide you through the process of creating a cluster on AWS.
Prerequisites
- You have created an AWS account.
- You have access to the Gardener dashboard and have permissions to create projects.
Steps
Go to the Gardener dashboard and create a Project.
Choose Secrets, then the plus icon
 and select AWS.
and select AWS.
To copy the policy for AWS from the Gardener dashboard, click on the help icon
 for AWS secrets, and choose copy
for AWS secrets, and choose copy  .
.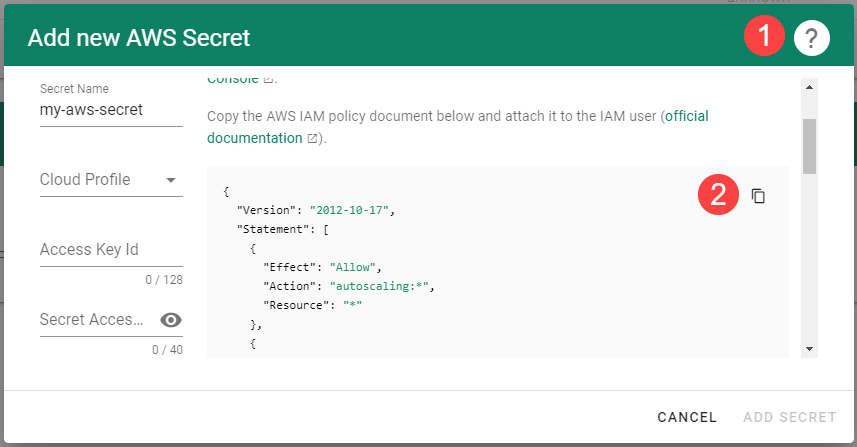
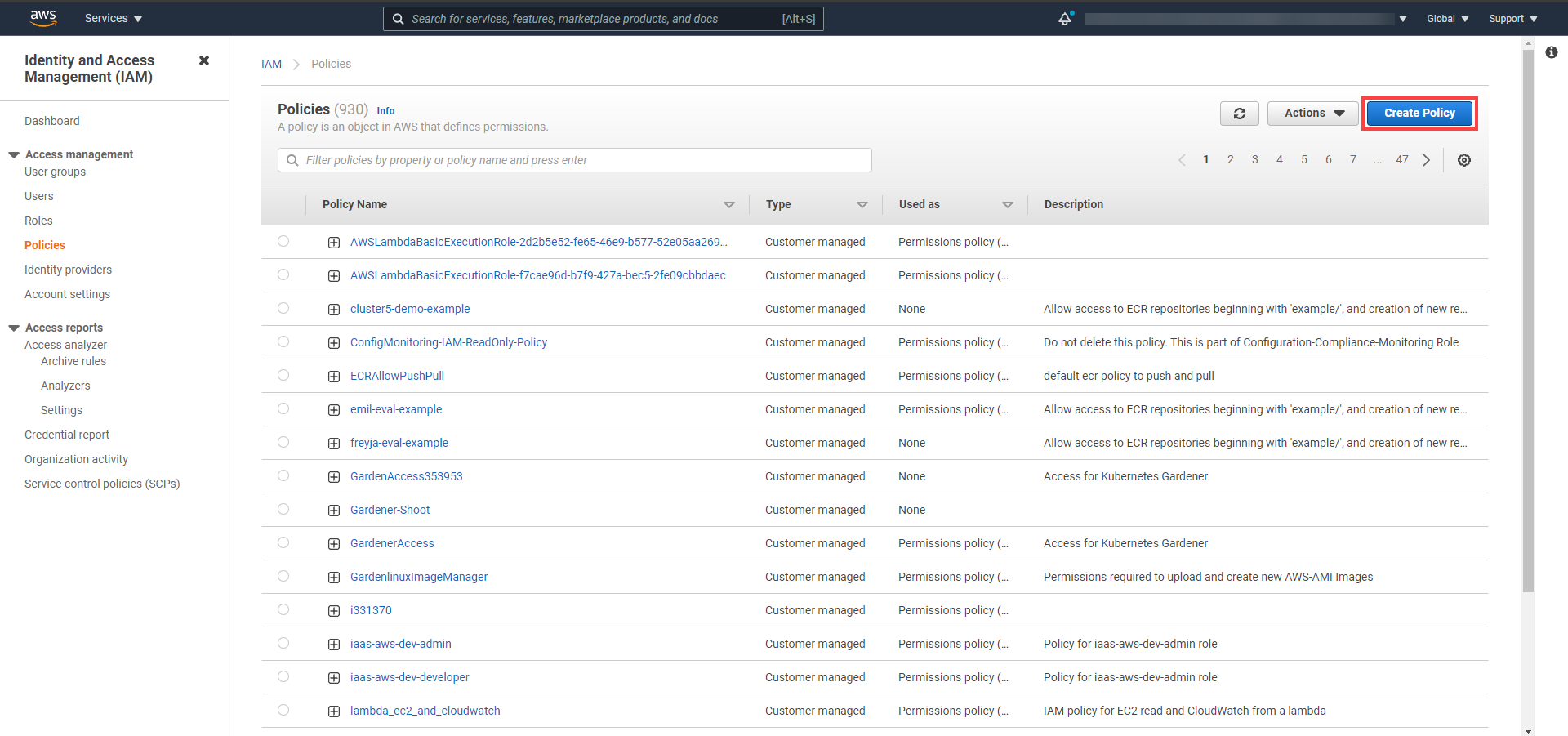
Create a new policy in AWS:
Choose Create policy.
Paste the policy that you copied from the Gardener dashboard to this custom policy.
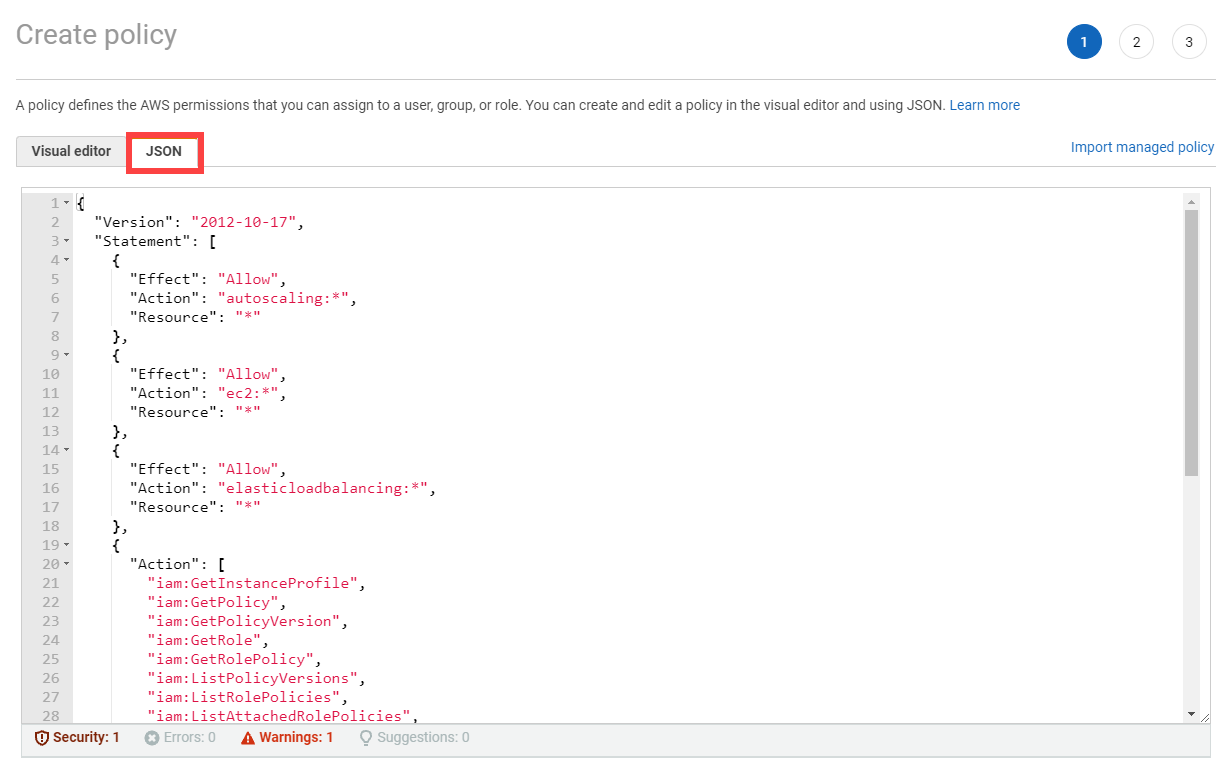
Choose Next until you reach the Review section.
Fill in the name and description, then choose Create policy.
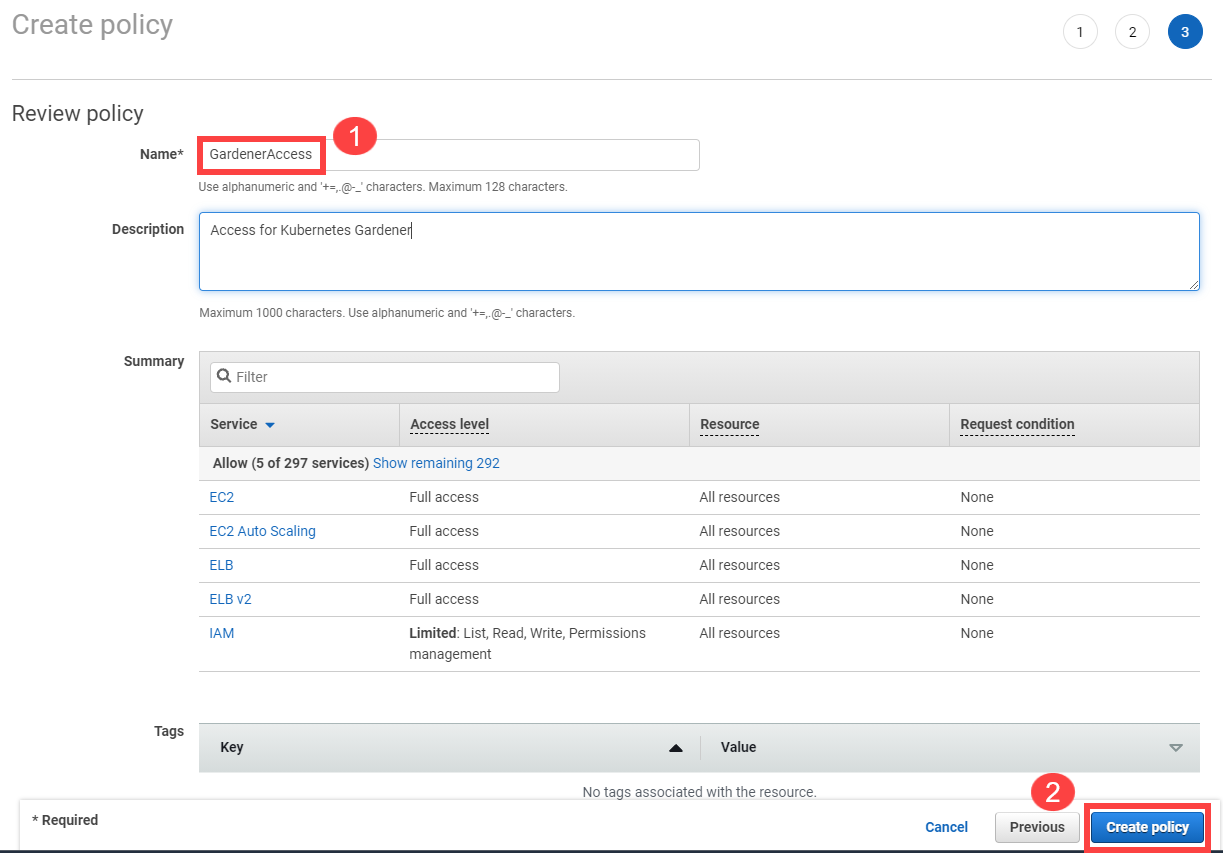
Create a new technical user in AWS:
Type in a username and select the access key credential type.
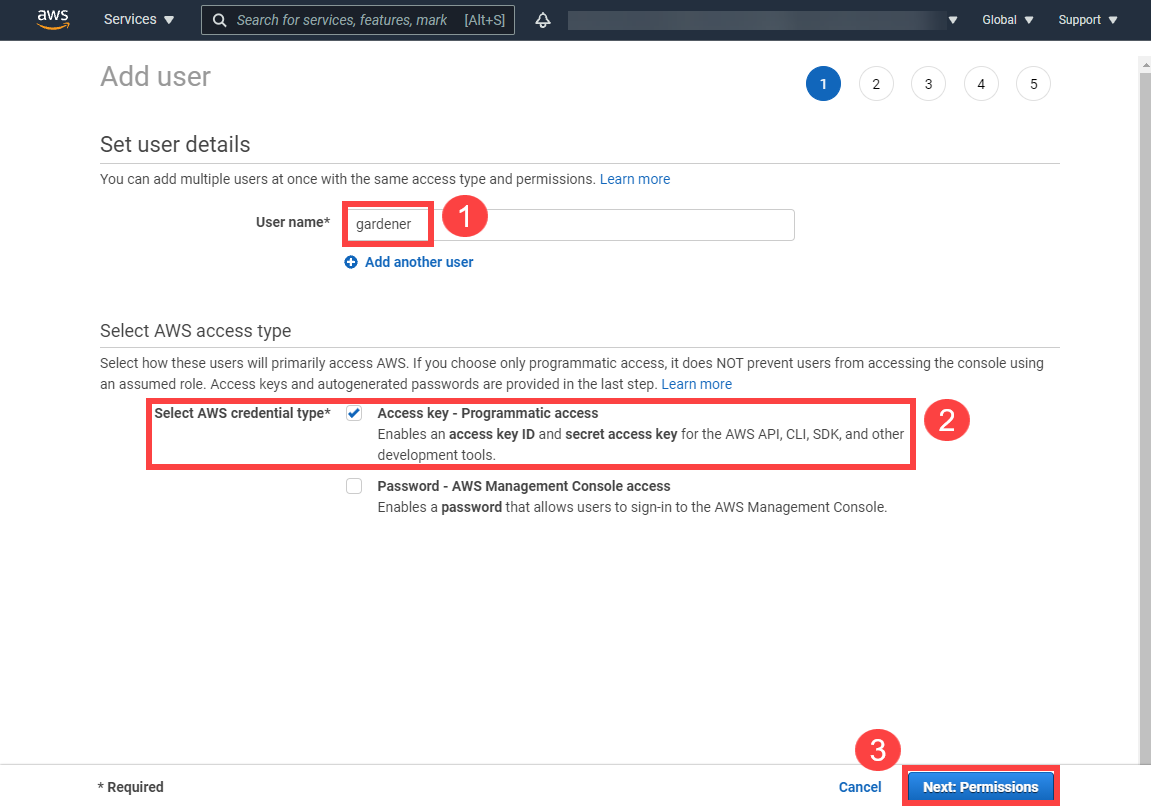
Choose Attach an existing policy.
Select GardenerAccess from the policy list.
Choose Next until you reach the Review section.
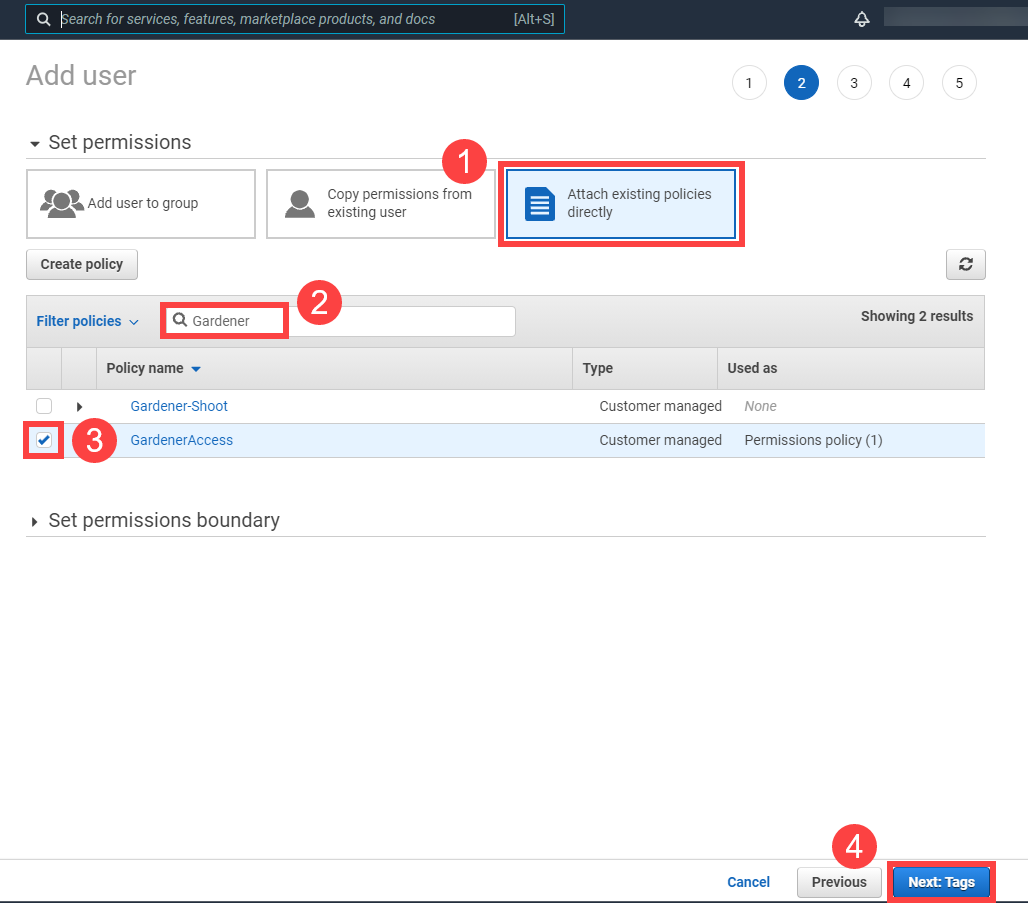
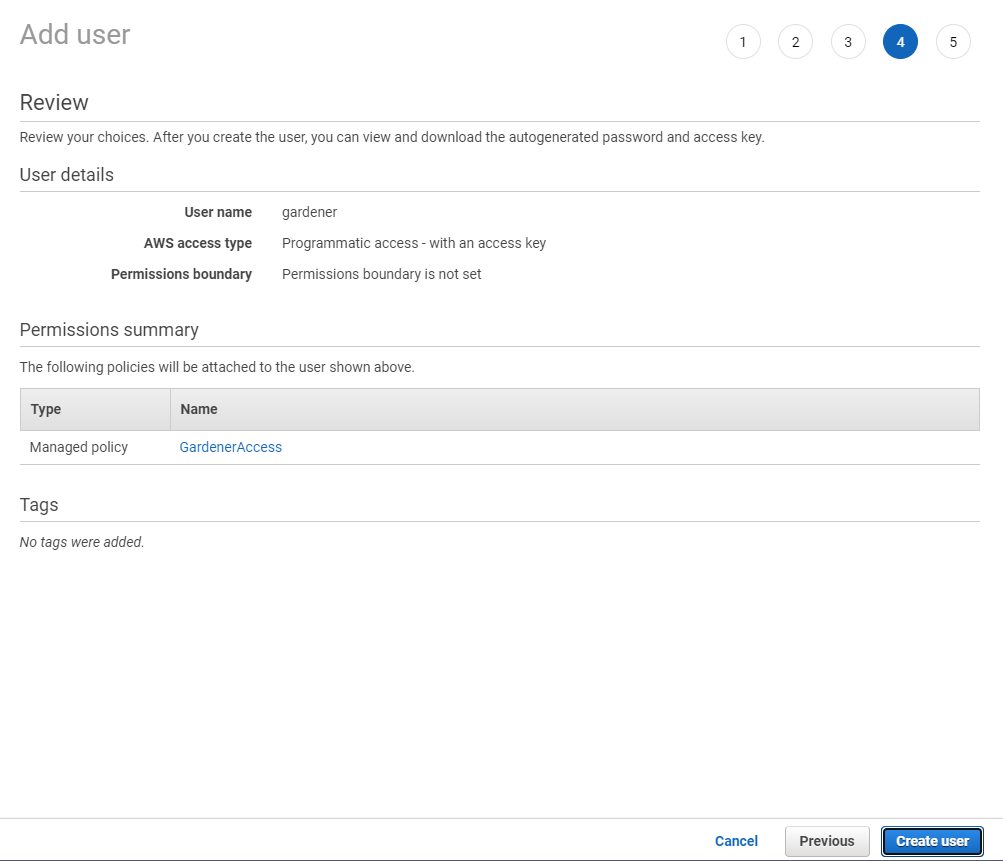
Note
After the user is created,
Access key IDandSecret access keyare generated and displayed. Remember to save them. TheAccess key IDis used later to create secrets for Gardener.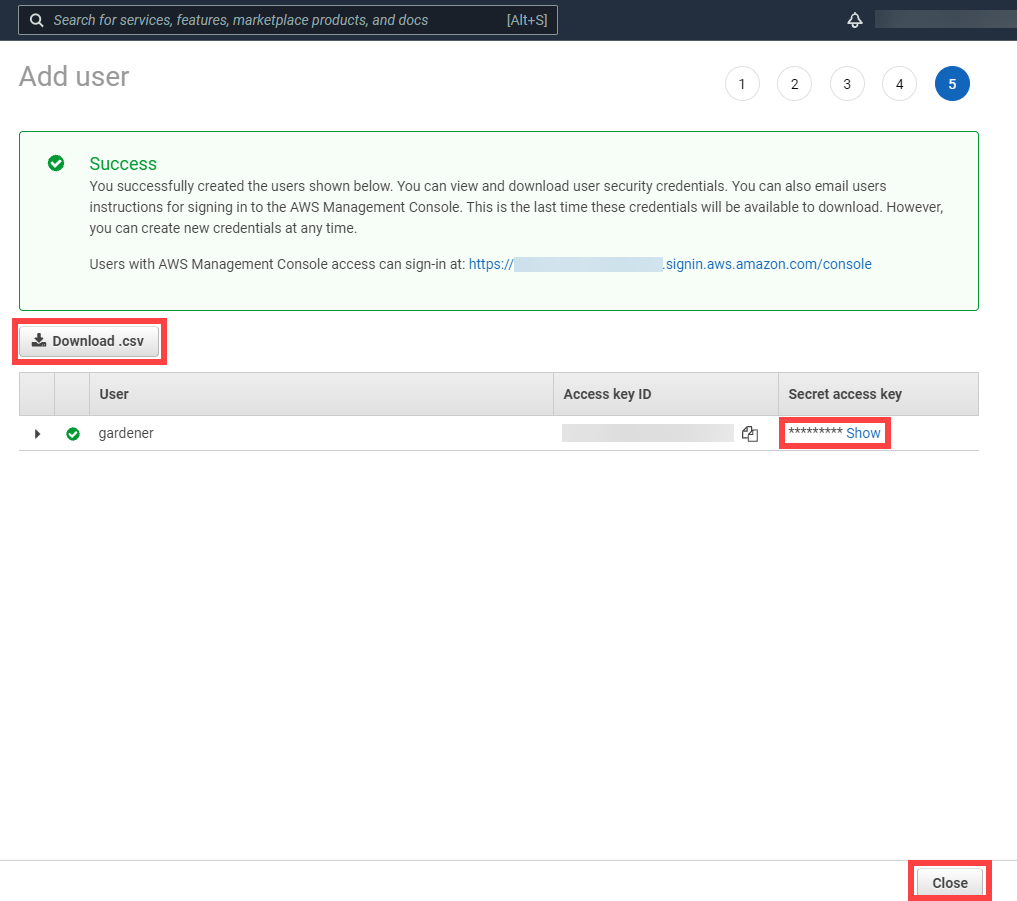
On the Gardener dashboard, choose Secrets and then the plus sign
. Select AWS from the drop down menu to add a new AWS secret.Create your secret.
- Type the name of your secret.
- Copy and paste the
Access Key IDandSecret Access Keyyou saved when you created the technical user on AWS. - Choose Add secret.

After completing these steps, you should see your newly created secret in the Infrastructure Secrets section.
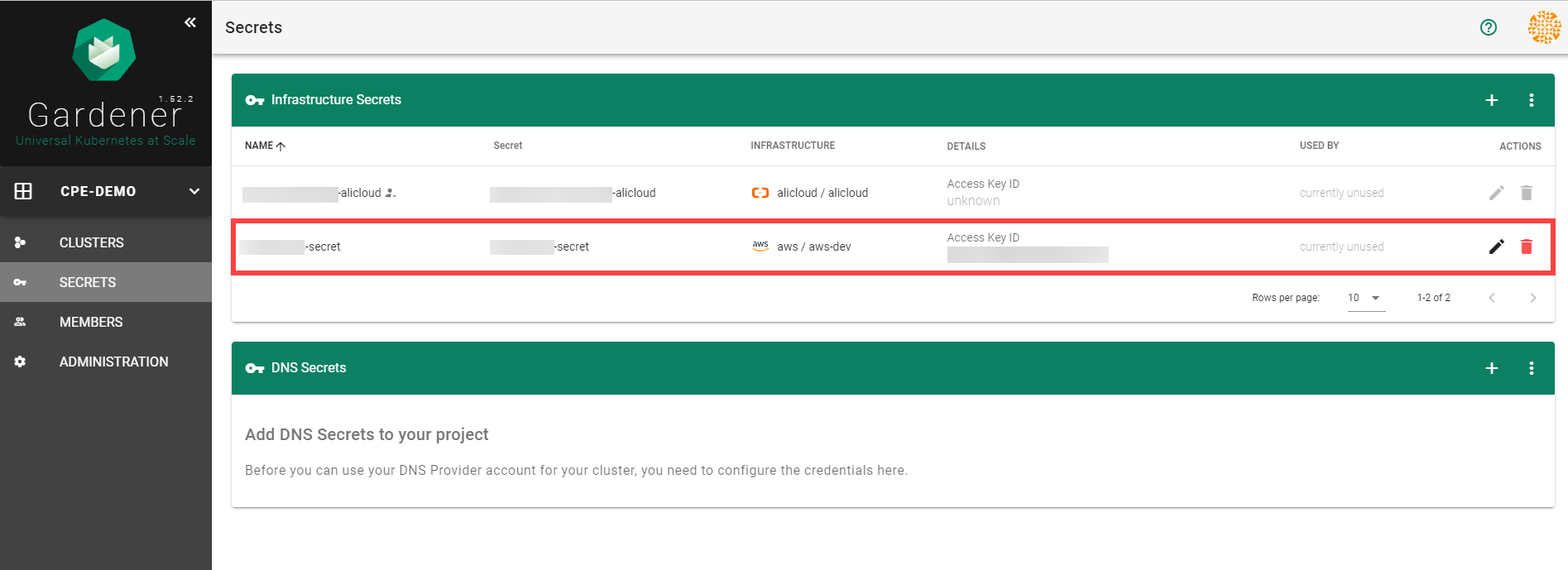
To create a new cluster, choose Clusters and then the plus sign in the upper right corner.
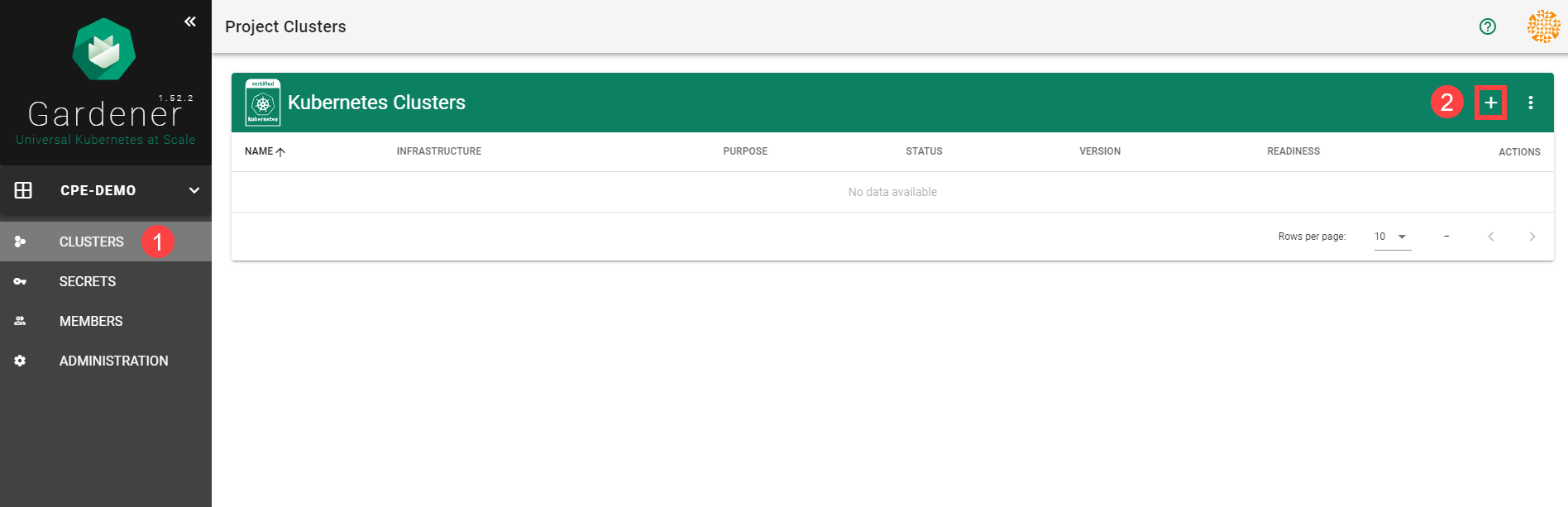
In the Create Cluster section:
- Select AWS in the Infrastructure tab.
- Type the name of your cluster in the Cluster Details tab.
- Choose the secret you created before in the Infrastructure Details tab.
- Choose Create.
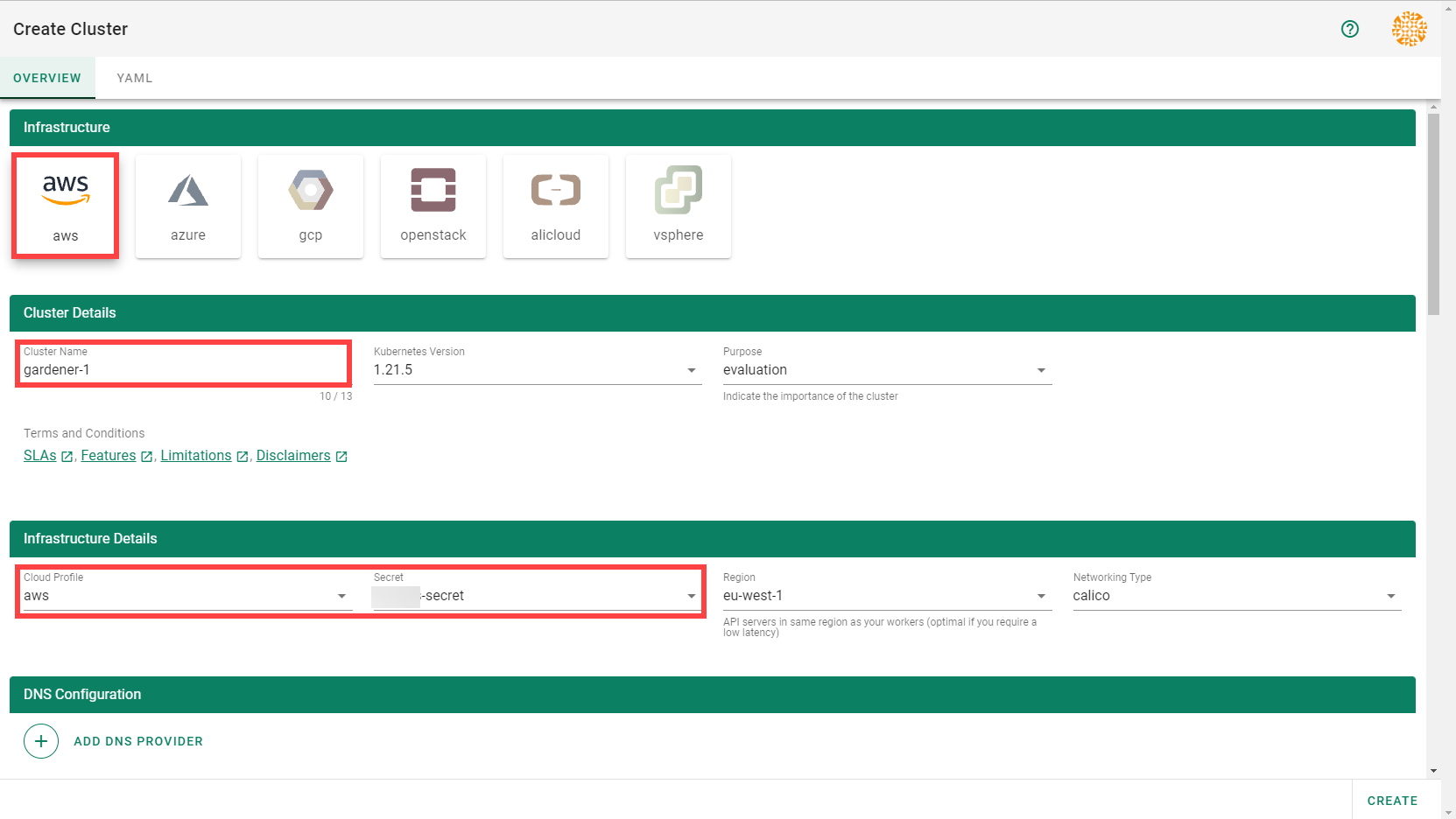
Wait for your cluster to get created.
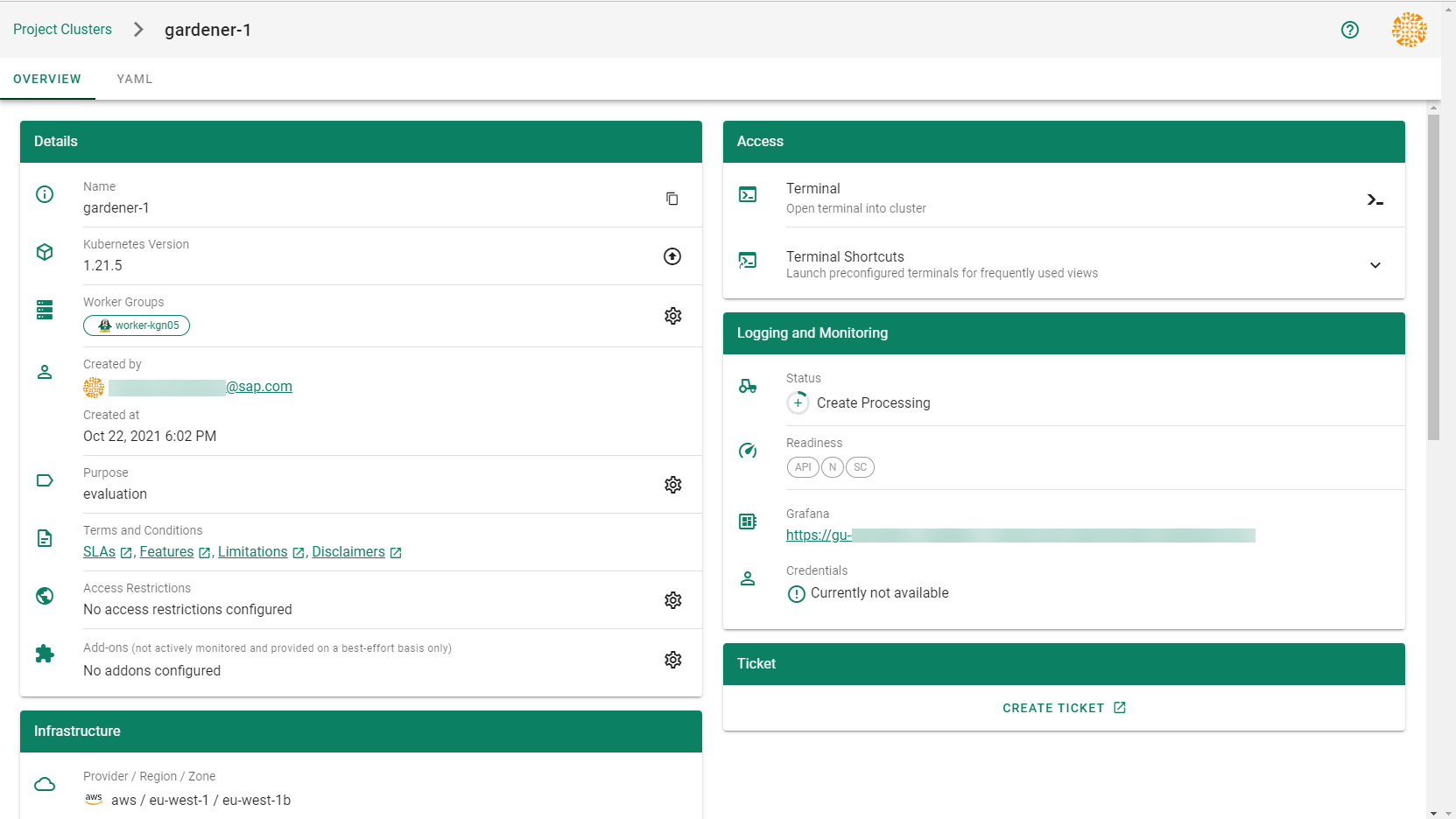
Result
After completing the steps in this tutorial, you will be able to see and download the kubeconfig of your cluster.
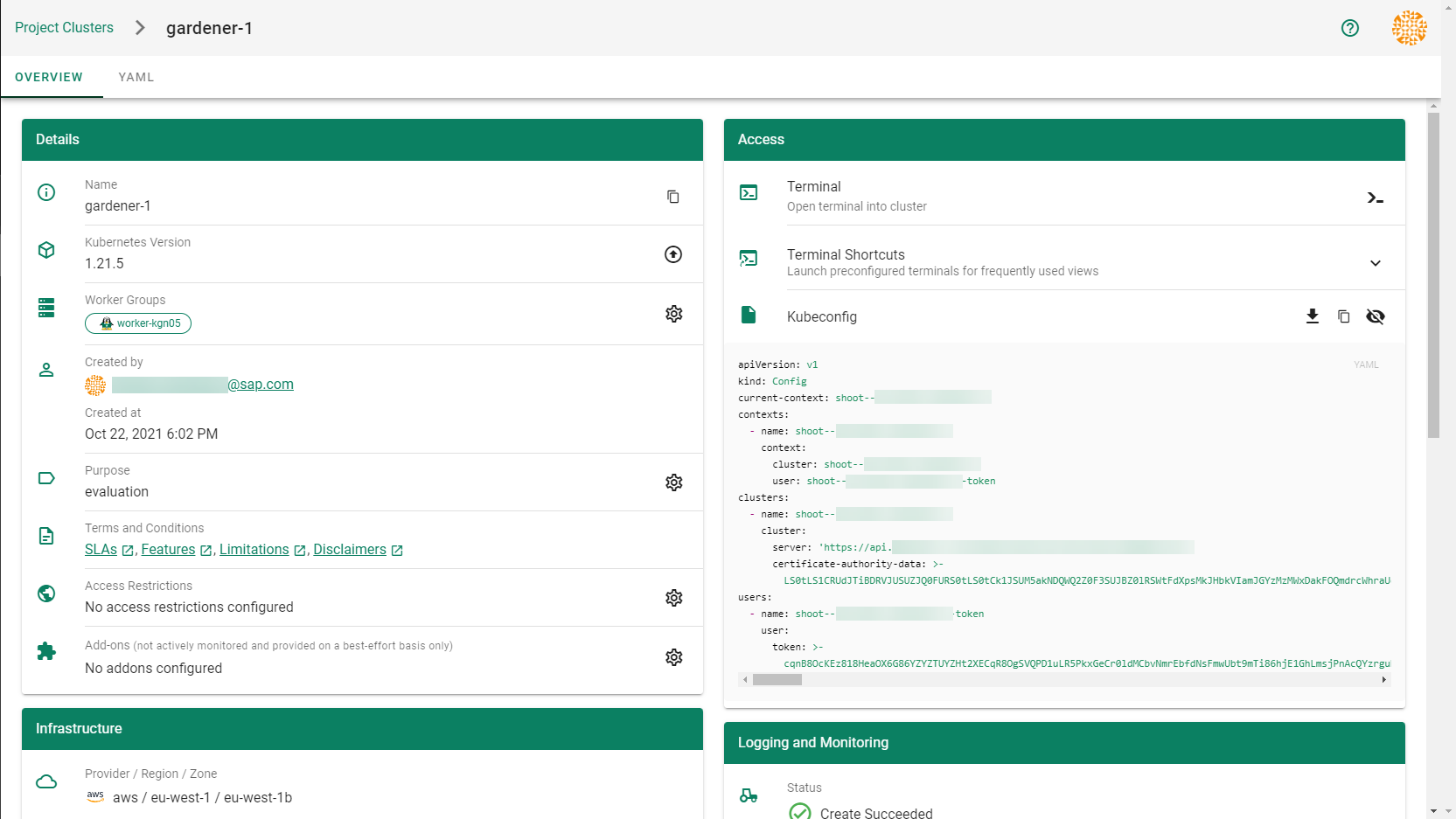
2.2 - Deployment
Deployment of the AWS provider extension
Disclaimer: This document is NOT a step by step installation guide for the AWS provider extension and only contains some configuration specifics regarding the installation of different components via the helm charts residing in the AWS provider extension repository.
gardener-extension-admission-aws
Authentication against the Garden cluster
There are several authentication possibilities depending on whether or not the concept of Virtual Garden is used.
Virtual Garden is not used, i.e., the runtime Garden cluster is also the target Garden cluster.
Automounted Service Account Token
The easiest way to deploy the gardener-extension-admission-aws component will be to not provide kubeconfig at all. This way in-cluster configuration and an automounted service account token will be used. The drawback of this approach is that the automounted token will not be automatically rotated.
Service Account Token Volume Projection
Another solution will be to use Service Account Token Volume Projection combined with a kubeconfig referencing a token file (see example below).
apiVersion: v1
kind: Config
clusters:
- cluster:
certificate-authority-data: <CA-DATA>
server: https://default.kubernetes.svc.cluster.local
name: garden
contexts:
- context:
cluster: garden
user: garden
name: garden
current-context: garden
users:
- name: garden
user:
tokenFile: /var/run/secrets/projected/serviceaccount/token
This will allow for automatic rotation of the service account token by the kubelet. The configuration can be achieved by setting both .Values.global.serviceAccountTokenVolumeProjection.enabled: true and .Values.global.kubeconfig in the respective chart’s values.yaml file.
Virtual Garden is used, i.e., the runtime Garden cluster is different from the target Garden cluster.
Service Account
The easiest way to setup the authentication will be to create a service account and the respective roles will be bound to this service account in the target cluster. Then use the generated service account token and craft a kubeconfig which will be used by the workload in the runtime cluster. This approach does not provide a solution for the rotation of the service account token. However, this setup can be achieved by setting .Values.global.virtualGarden.enabled: true and following these steps:
- Deploy the
applicationpart of the charts in thetargetcluster. - Get the service account token and craft the
kubeconfig. - Set the crafted
kubeconfigand deploy theruntimepart of the charts in theruntimecluster.
Client Certificate
Another solution will be to bind the roles in the target cluster to a User subject instead of a service account and use a client certificate for authentication. This approach does not provide a solution for the client certificate rotation. However, this setup can be achieved by setting both .Values.global.virtualGarden.enabled: true and .Values.global.virtualGarden.user.name, then following these steps:
- Generate a client certificate for the
targetcluster for the respective user. - Deploy the
applicationpart of the charts in thetargetcluster. - Craft a
kubeconfigusing the already generated client certificate. - Set the crafted
kubeconfigand deploy theruntimepart of the charts in theruntimecluster.
Projected Service Account Token
This approach requires an already deployed and configured oidc-webhook-authenticator for the target cluster. Also the runtime cluster should be registered as a trusted identity provider in the target cluster. Then projected service accounts tokens from the runtime cluster can be used to authenticate against the target cluster. The needed steps are as follows:
- Deploy OWA and establish the needed trust.
- Set
.Values.global.virtualGarden.enabled: trueand.Values.global.virtualGarden.user.name. Note: username value will depend on the trust configuration, e.g.,<prefix>:system:serviceaccount:<namespace>:<serviceaccount> - Set
.Values.global.serviceAccountTokenVolumeProjection.enabled: trueand.Values.global.serviceAccountTokenVolumeProjection.audience. Note: audience value will depend on the trust configuration, e.g.,<cliend-id-from-trust-config>. - Craft a kubeconfig (see example below).
- Deploy the
applicationpart of the charts in thetargetcluster. - Deploy the
runtimepart of the charts in theruntimecluster.
apiVersion: v1
kind: Config
clusters:
- cluster:
certificate-authority-data: <CA-DATA>
server: https://virtual-garden.api
name: virtual-garden
contexts:
- context:
cluster: virtual-garden
user: virtual-garden
name: virtual-garden
current-context: virtual-garden
users:
- name: virtual-garden
user:
tokenFile: /var/run/secrets/projected/serviceaccount/token
2.3 - Dual Stack Ingress
Using IPv4/IPv6 (dual-stack) Ingress in an IPv4 single-stack cluster
Motivation
IPv6 adoption is continuously growing, already overtaking IPv4 in certain regions, e.g. India, or scenarios, e.g. mobile. Even though most IPv6 installations deploy means to reach IPv4, it might still be beneficial to expose services natively via IPv4 and IPv6 instead of just relying on IPv4.
Disadvantages of full IPv4/IPv6 (dual-stack) Deployments
Enabling full IPv4/IPv6 (dual-stack) support in a kubernetes cluster is a major endeavor. It requires a lot of changes and restarts of all pods so that all pods get addresses for both IP families. A side-effect of dual-stack networking is that failures may be hidden as network traffic may take the other protocol to reach the target. For this reason and also due to reduced operational complexity, service teams might lean towards staying in a single-stack environment as much as possible. Luckily, this is possible with Gardener and IPv4/IPv6 (dual-stack) ingress on AWS.
Simplifying IPv4/IPv6 (dual-stack) Ingress with Protocol Translation on AWS
Fortunately, the network load balancer on AWS supports automatic protocol translation, i.e. it can expose both IPv4 and IPv6 endpoints while communicating with just one protocol to the backends. Under the hood, automatic protocol translation takes place. Client IP address preservation can be achieved by using proxy protocol.
This approach enables users to expose IPv4 workload to IPv6-only clients without having to change the workload/service. Without requiring invasive changes, it allows a fairly simple first step into the IPv6 world for services just requiring ingress (incoming) communication.
Necessary Shoot Cluster Configuration Changes for IPv4/IPv6 (dual-stack) Ingress
To be able to utilize IPv4/IPv6 (dual-stack) Ingress in an IPv4 shoot cluster, the cluster needs to meet two preconditions:
dualStack.enabledneeds to be set totrueto configure VPC/subnet for IPv6 and add a routing rule for IPv6. (This does not add IPv6 addresses to kubernetes nodes.)loadBalancerController.enabledneeds to be set totrueas well to use the load balancer controller, which supports dual-stack ingress.
apiVersion: core.gardener.cloud/v1beta1
kind: Shoot
...
spec:
provider:
type: aws
infrastructureConfig:
apiVersion: aws.provider.extensions.gardener.cloud/v1alpha1
kind: InfrastructureConfig
dualStack:
enabled: true
controlPlaneConfig:
apiVersion: aws.provider.extensions.gardener.cloud/v1alpha1
kind: ControlPlaneConfig
loadBalancerController:
enabled: true
...
When infrastructureConfig.networks.vpc.id is set to the ID of an existing VPC, please make sure that your VPC has an Amazon-provided IPv6 CIDR block added.
After adapting the shoot specification and reconciling the cluster, dual-stack load balancers can be created using kubernetes services objects.
Creating an IPv4/IPv6 (dual-stack) Ingress
With the preconditions set, creating an IPv4/IPv6 load balancer is as easy as annotating a service with the correct annotations:
apiVersion: v1
kind: Service
metadata:
annotations:
service.beta.kubernetes.io/aws-load-balancer-ip-address-type: dualstack
service.beta.kubernetes.io/aws-load-balancer-scheme: internet-facing
service.beta.kubernetes.io/aws-load-balancer-nlb-target-type: instance
service.beta.kubernetes.io/aws-load-balancer-type: external
name: ...
namespace: ...
spec:
...
type: LoadBalancer
In case the client IP address should be preserved, the following annotation can be used to enable proxy protocol. (The pod receiving the traffic needs to be configured for proxy protocol as well.)
service.beta.kubernetes.io/aws-load-balancer-proxy-protocol: "*"
Please note that changing an existing Service to dual-stack may cause the creation of a new load balancer without
deletion of the old AWS load balancer resource. While this helps in a seamless migration by not cutting existing
connections it may lead to wasted/forgotten resources. Therefore, the (manual) cleanup needs to be taken into account
when migrating an existing Service instance.
For more details see AWS Load Balancer Documentation - Network Load Balancer.
DNS Considerations to Prevent Downtime During a Dual-Stack Migration
In case the migration of an existing service is desired, please check if there are DNS entries directly linked to the corresponding load balancer. The migrated load balancer will have a new domain name immediately, which will not be ready in the beginning. Therefore, a direct migration of the domain name entries is not desired as it may cause a short downtime, i.e. domain name entries without backing IP addresses.
If there are DNS entries directly linked to the corresponding load balancer and they are managed by the
shoot-dns-service, you can identify this via
annotations with the prefix dns.gardener.cloud/. Those annotations can be linked to a Service, Ingress or
Gateway resources. Alternatively, they may also use DNSEntry or DNSAnnotation resources.
For a seamless migration without downtime use the following three step approach:
- Temporarily prevent direct DNS updates
- Migrate the load balancer and wait until it is operational
- Allow DNS updates again
To prevent direct updates of the DNS entries when the load balancer is migrated add the annotation
dns.gardener.cloud/ignore: 'true' to all affected resources next to the other dns.gardener.cloud/... annotations
before starting the migration. For example, in case of a Service ensure that the service looks like the following:
kind: Service
metadata:
annotations:
dns.gardener.cloud/ignore: 'true'
dns.gardener.cloud/class: garden
dns.gardener.cloud/dnsnames: '...'
...
Next, migrate the load balancer to be dual-stack enabled by adding/changing the corresponding annotations.
You have multiple options how to check that the load balancer has been provisioned successfully. It might be useful
to peek into status.loadBalancer.ingress of the corresponding Service to identify the load balancer:
- Check in the AWS console for the corresponding load balancer provisioning state
- Perform domain name lookups with
nslookup/digto check whether the name resolves to an IP address. - Call your workload via the new load balancer, e.g. using
curl --resolve <my-domain-name>:<port>:<IP-address> https://<my-domain-name>:<port>, which allows you to call your service with the “correct” domain name without using actual name resolution. - Wait a fixed period of time as load balancer creation is usually finished within 15 minutes
Once the load balancer has been provisioned, you can remove the annotation dns.gardener.cloud/ignore: 'true' again
from the affected resources. It may take some additional time until the domain name change finally propagates
(up to one hour).
2.4 - Ipv6
Support for IPv6
Overview
Gardener supports different levels of IPv6 support in shoot clusters. This document describes the differences between them and what to consider when using them.
In IPv6 Ingress for IPv4 Shoot Clusters, the focus is on how an existing IPv4-only shoot cluster can provide dual-stack services to clients. Section IPv6-only Shoot Clusters describes how to create a shoot cluster that only supports IPv6. Finally, Dual-Stack Shoot Clusters explains how to create a shoot cluster that supports both IPv4 and IPv6.
IPv6 Ingress for IPv4 Shoot Clusters
Per default, Gardener shoot clusters use only IPv4. Therefore, they also expose their services only via load balancers with IPv4 addresses. To allow external clients to also use IPv6 to access services in an IPv4 shoot cluster, the cluster needs to be configured to support dual-stack ingress.
It is possible to configure a shoot cluster to support dual-stack ingress, see Using IPv4/IPv6 (dual-stack) Ingress in an IPv4 single-stack cluster for more information.
The main benefit of this approach is that the existing cluster stays almost as is without major changes, keeping the operational simplicity. It works very well for services that only require incoming communication, e.g. pure web services.
The main drawback is that certain scenarios, especially related to IPv6 callbacks, are not possible. This means that services, which actively call to their clients via web hooks, will not be able to do so over IPv6. Hence, those services will not be able to allow full-usage via IPv6.
IPv6-only Shoot Clusters
Motivation
IPv6-only shoot clusters are the best option to verify that services are fully IPv6-compatible. While Dual-Stack Shoot Clusters may fall back on using IPv4 transparently, IPv6-only shoot clusters enforce the usage of IPv6 inside the cluster. Therefore, it is recommended to check with IPv6-only shoot clusters if a workload is fully IPv6-compatible.
In addition to being a good testbed for IPv6 compatibility, IPv6-only shoot clusters may also be a desirable eventual target in the IPv6 migration as they allow to support both IPv4 and IPv6 clients while having a single-stack with the cluster.
Creating an IPv6-only Shoot Cluster
To create an IPv6-only shoot cluster, the following needs to be specified in the Shoot resource (see also here):
kind: Shoot
apiVersion: core.gardener.cloud/v1beta1
metadata:
...
spec:
...
networking:
type: ...
ipFamilies:
- IPv6
...
provider:
type: aws
infrastructureConfig:
apiVersion: aws.provider.extensions.gardener.cloud/v1alpha1
kind: InfrastructureConfig
networks:
vpc:
cidr: 192.168.0.0/16
zones:
- name: ...
public: 192.168.32.0/20
internal: 192.168.48.0/20
Warning
Please note that
nodes,podsandservicesshould not be specified in.spec.networkingresource.
In contrast to that, it is still required to specify IPv4 ranges for the VPC and the public/internal subnets. This is mainly due to the fact that public/internal load balancers still require IPv4 addresses as there are no pure IPv6-only load balancers as of now. The ranges can be sized according to the expected amount of load balancers per zone/type.
The IPv6 address ranges are provided by AWS. It is ensured that the IPv6 ranges are globally unique und internet routable.
Load Balancer Configuration
The AWS Load Balancer Controller is automatically deployed when using an IPv6-only shoot cluster. When creating a load balancer, the corresponding annotations need to be configured, see AWS Load Balancer Documentation - Network Load Balancer for details.
The AWS Load Balancer Controller allows dual-stack ingress so that an IPv6-only shoot cluster can serve IPv4 and IPv6 clients. You can find an example here.
Warning
When accessing Network Load Balancers (NLB) from within the same IPv6-only cluster, it is crucial to add the annotation
service.beta.kubernetes.io/aws-load-balancer-target-group-attributes: preserve_client_ip.enabled=false. Without this annotation, if a request is routed by the NLB to the same target instance from which it originated, the client IP and destination IP will be identical. This situation, known as the hair-pinning effect, will prevent the request from being processed. (This also happens for internal load balancers in IPv4 clusters, but is mitigated by the NAT gateway for external IPv4 load balancers.)
Connectivity to IPv4-only Services
The IPv6-only shoot cluster can connect to IPv4-only services via DNS64/NAT64. The cluster is configured to use the DNS64/NAT64 service of the underlying cloud provider. This allows the cluster to resolve IPv4-only DNS names and to connect to IPv4-only services.
Please note that traffic going through NAT64 incurs the same cost as ordinary NAT traffic in an IPv4-only cluster. Therefore, it might be beneficial to prefer IPv6 for services, which provide IPv4 and IPv6.
Dual-Stack Shoot Clusters
Motivation
Dual-stack shoot clusters support IPv4 and IPv6 out-of-the-box. They can be the intermediate step on the way towards IPv6 for any existing (IPv4-only) clusters.
Creating a Dual-Stack Shoot Cluster
To create a dual-stack shoot cluster, the following needs to be specified in the Shoot resource:
kind: Shoot
apiVersion: core.gardener.cloud/v1beta1
metadata:
...
spec:
...
networking:
type: ...
pods: 192.168.128.0/17
nodes: 192.168.0.0/18
services: 192.168.64.0/18
ipFamilies:
- IPv4
- IPv6
...
provider:
type: aws
infrastructureConfig:
apiVersion: aws.provider.extensions.gardener.cloud/v1alpha1
kind: InfrastructureConfig
networks:
vpc:
cidr: 192.168.0.0/18
zones:
- name: ...
workers: 192.168.0.0/19
public: 192.168.32.0/20
internal: 192.168.48.0/20
Please note that the only change compared to an IPv4-only shoot cluster is the addition of IPv6 to the .spec.networking.ipFamilies field.
The order of the IP families defines the preference of the IP family.
In this case, IPv4 is preferred over IPv6, e.g. services specifying no IP family will get only an IPv4 address.
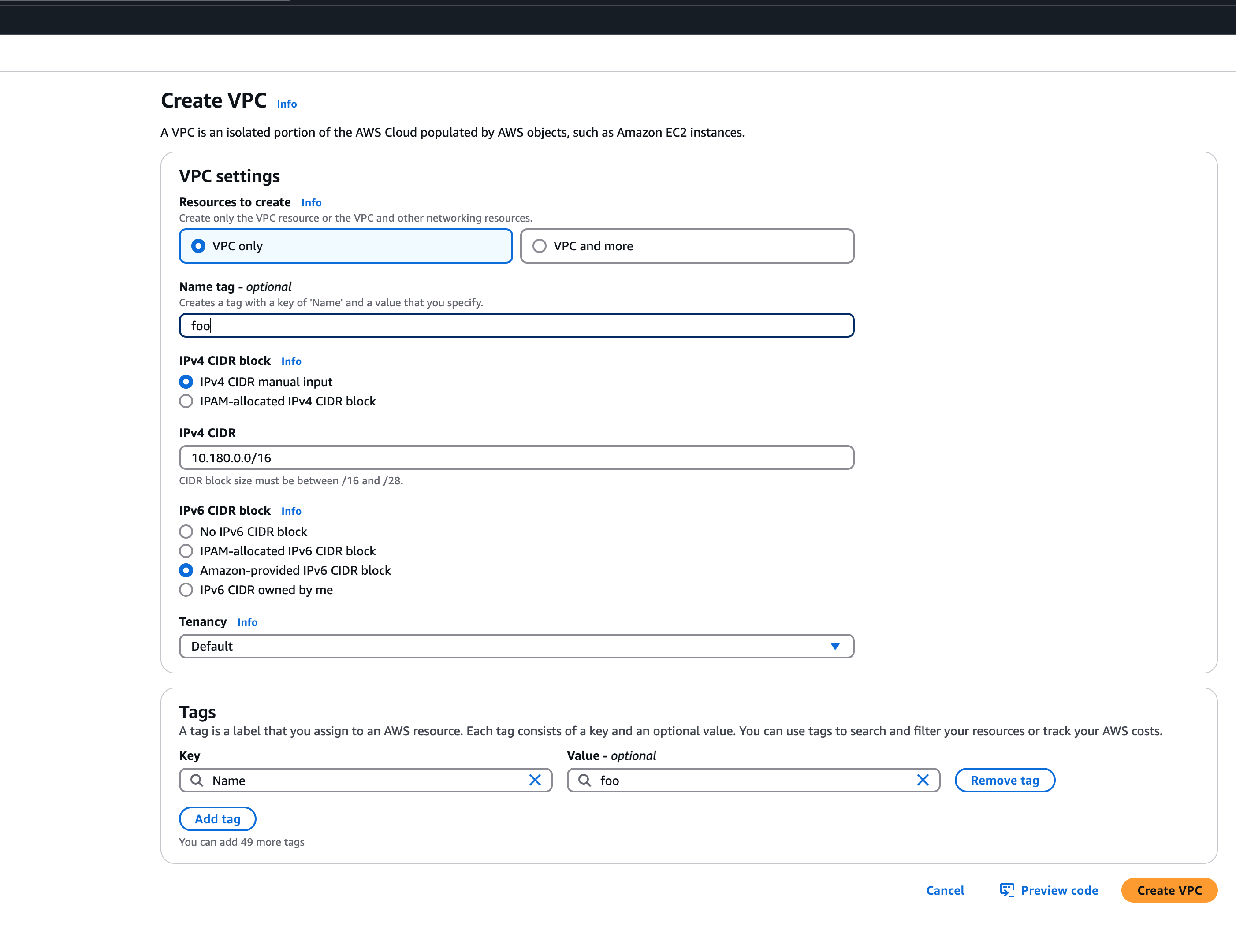
Bring your own VPC
To create an IPv6 shoot cluster or a dual-stack shoot within your own Virtual Private Cloud (VPC), it is necessary to have an Amazon-provided IPv6 CIDR block added to the VPC. This block can be assigned during the initial setup of the VPC, as illustrated in the accompanying screenshot.
 An egress-only internet gateway is required for outbound internet traffic (IPv6) from the instances within your VPC. Please create one egress-only internet gateway and attach it to the VPC. Please also make sure that the VPC has an attached internet gateway and the following attributes set:
An egress-only internet gateway is required for outbound internet traffic (IPv6) from the instances within your VPC. Please create one egress-only internet gateway and attach it to the VPC. Please also make sure that the VPC has an attached internet gateway and the following attributes set: enableDnsHostnames and enableDnsSupport as described under usage.
Migration of IPv4-only Shoot Clusters to Dual-Stack
To migrate an IPv4-only shoot cluster to Dual-Stack simply change the .spec.networking.ipFamilies field in the Shoot resource from IPv4 to IPv4, IPv6 as shown below.
kind: Shoot
apiVersion: core.gardener.cloud/v1beta1
metadata:
...
spec:
...
networking:
type: ...
ipFamilies:
- IPv4
- IPv6
...
You can find more information about the process and the steps required here.
Warning
Please note that the dual-stack migration requires the IPv4-only cluster to run in native routing mode, i.e. pod overlay network needs to be disabled. The default quota of routes per route table in AWS is 50. This restricts the cluster size to about 50 nodes. Therefore, please adapt (if necessary) the routes per route table limit in the Amazon Virtual Private Cloud quotas accordingly before switching to native routing. The maximum setting is currently 1000.
Load Balancer Configuration
The AWS Load Balancer Controller is automatically deployed when using a dual-stack shoot cluster. When creating a load balancer, the corresponding annotations need to be configured, see AWS Load Balancer Documentation - Network Load Balancer for details.
Warning
Please note that load balancer services without any special annotations will default to IPv4-only regardless how
.spec.ipFamiliesis set.
The AWS Load Balancer Controller allows dual-stack ingress so that a dual-stack shoot cluster can serve IPv4 and IPv6 clients. You can find an example here.
Warning
When accessing external Network Load Balancers (NLB) from within the same cluster via IPv6 or internal NLBs via IPv4, it is crucial to add the annotation
service.beta.kubernetes.io/aws-load-balancer-target-group-attributes: preserve_client_ip.enabled=false. Without this annotation, if a request is routed by the NLB to the same target instance from which it originated, the client IP and destination IP will be identical. This situation, known as the hair-pinning effect, will prevent the request from being processed.
2.5 - Local Setup
admission-aws
admission-aws is an admission webhook server which is responsible for the validation of the cloud provider (AWS in this case) specific fields and resources. The Gardener API server is cloud provider agnostic and it wouldn’t be able to perform similar validation.
Follow the steps below to run the admission webhook server locally.
Start the Gardener API server.
For details, check the Gardener local setup.
Start the webhook server
Make sure that the
KUBECONFIGenvironment variable is pointing to the local garden cluster.make start-admissionSetup the
ValidatingWebhookConfiguration.hack/dev-setup-admission-aws.shwill configure the webhook Service which will allow the kube-apiserver of your local cluster to reach the webhook server. It will also apply theValidatingWebhookConfigurationmanifest../hack/dev-setup-admission-aws.sh
You are now ready to experiment with the admission-aws webhook server locally.
2.6 - Operations
Using the AWS provider extension with Gardener as operator
The core.gardener.cloud/v1beta1.CloudProfile resource declares a providerConfig field that is meant to contain provider-specific configuration.
Similarly, the core.gardener.cloud/v1beta1.Seed resource is structured.
Additionally, it allows to configure settings for the backups of the main etcds’ data of shoot clusters control planes running in this seed cluster.
This document explains what is necessary to configure for this provider extension.
CloudProfile resource
In this section we are describing how the configuration for CloudProfiles looks like for AWS and provide an example CloudProfile manifest with minimal configuration that you can use to allow creating AWS shoot clusters.
CloudProfileConfig
The cloud profile configuration contains information about the real machine image IDs in the AWS environment (AMIs).
You have to map every version that you specify in .spec.machineImages[].versions here such that the AWS extension knows the AMI for every version you want to offer.
For each AMI an architecture field can be specified which specifies the CPU architecture of the machine on which given machine image can be used.
An example CloudProfileConfig for the AWS extension looks as follows:
apiVersion: aws.provider.extensions.gardener.cloud/v1alpha1
kind: CloudProfileConfig
machineImages:
- name: coreos
versions:
- version: 2135.6.0
regions:
- name: eu-central-1
ami: ami-034fd8c3f4026eb39
# architecture: amd64 # optional
Example CloudProfile manifest
Please find below an example CloudProfile manifest:
apiVersion: core.gardener.cloud/v1beta1
kind: CloudProfile
metadata:
name: aws
spec:
type: aws
kubernetes:
versions:
- version: 1.32.1
- version: 1.31.4
expirationDate: "2022-10-31T23:59:59Z"
machineImages:
- name: coreos
versions:
- version: 2135.6.0
machineTypes:
- name: m5.large
cpu: "2"
gpu: "0"
memory: 8Gi
usable: true
volumeTypes:
- name: gp2
class: standard
usable: true
- name: io1
class: premium
usable: true
regions:
- name: eu-central-1
zones:
- name: eu-central-1a
- name: eu-central-1b
- name: eu-central-1c
providerConfig:
apiVersion: aws.provider.extensions.gardener.cloud/v1alpha1
kind: CloudProfileConfig
machineImages:
- name: coreos
versions:
- version: 2135.6.0
regions:
- name: eu-central-1
ami: ami-034fd8c3f4026eb39
# architecture: amd64 # optional
Seed resource
This provider extension does not support any provider configuration for the Seed’s .spec.provider.providerConfig field.
However, it supports to manage backup infrastructure, i.e., you can specify configuration for the .spec.backup field.
Backup configuration
Please find below an example Seed manifest (partly) that configures backups.
As you can see, the location/region where the backups will be stored can be different to the region where the seed cluster is running.
apiVersion: v1
kind: Secret
metadata:
name: backup-credentials
namespace: garden
type: Opaque
data:
accessKeyID: base64(access-key-id)
secretAccessKey: base64(secret-access-key)
---
apiVersion: core.gardener.cloud/v1beta1
kind: Seed
metadata:
name: my-seed
spec:
provider:
type: aws
region: eu-west-1
backup:
provider: aws
region: eu-central-1
credentialsRef:
apiVersion: v1
kind: Secret
name: backup-credentials
namespace: garden
...
Please look up https://docs.aws.amazon.com/general/latest/gr/aws-sec-cred-types.html#access-keys-and-secret-access-keys as well.
Permissions for AWS IAM user
Please make sure that the provided credentials have the correct privileges. You can use the following AWS IAM policy document and attach it to the IAM user backed by the credentials you provided (please check the official AWS documentation as well):
Click to expand the AWS IAM policy document!
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "s3:*",
"Resource": "*"
}
]
}
Rolling Update Triggers
Changes to the Shoot worker-pools are applied in-place where possible.
In case this is not possible a rolling update of the workers will be performed to apply the new configuration, as outlined in the Gardener documentation.
The exact fields that trigger this behavior are defined in the Gardener doc, with a few additions:
.spec.provider.workers[].providerConfig.spec.provider.workers[].volume.encrypted.spec.provider.workers[].dataVolumes[].size(only the affected worker pool).spec.provider.workers[].dataVolumes[].type(only the affected worker pool).spec.provider.workers[].dataVolumes[].encrypted(only the affected worker pool)
For now, if the feature gate NewWorkerPoolHash is enabled, the same fields are used.
This behavior might change once MCM supports in-place volume updates.
If updateStrategy is set to inPlace and NewWorkerPoolHash is enabled,
all the fields mentioned above except of the providerConifg are used.
If in-place-updates are enabled for a worker-pool, then updates to the fields that trigger rolling updates will be disallowed.
2.7 - Usage
Using the AWS provider extension with Gardener as an end-user
The core.gardener.cloud/v1beta1.Shoot resource declares a few fields that are meant to contain provider-specific configuration.
In this document we are describing how this configuration looks like for AWS and provide an example Shoot manifest with minimal configuration that you can use to create an AWS cluster (modulo the landscape-specific information like cloud profile names, secret binding names, etc.).
Accessing AWS APIs
In order for Gardener to create a Kubernetes cluster using AWS infrastructure components, a Shoot has to provide an authentication mechanism giving sufficient permissions to the desired AWS account.
Every shoot cluster references a SecretBinding or a CredentialsBinding.
Important
While
SecretBindings can only referenceSecrets,CredentialsBindings can also referenceWorkloadIdentitys which provide an alternative authentication method.WorkloadIdentitys do not directly contain credentials but are rather a representation of the workload that is going to access the user’s account. If the user has configured OIDC Federation with Gardener’s Workload Identity Issuer then the AWS infrastructure components can access the user’s account without the need of preliminary exchange of credentials.
Important
The
SecretBinding/CredentialsBindingis configurable in the Shoot cluster with the fieldsecretBindingName/credentialsBindingName.SecretBindings are considered legacy and will be deprecated in the future. It is advised to useCredentialsBindings instead.
Provider Secret Data
Every shoot cluster references a SecretBinding or a CredentialsBinding which itself references a Secret, and this Secret contains the provider credentials of your AWS account.
This Secret must look as follows:
apiVersion: v1
kind: Secret
metadata:
name: core-aws
namespace: garden-dev
type: Opaque
data:
accessKeyID: base64(access-key-id)
secretAccessKey: base64(secret-access-key)
The AWS documentation explains the necessary steps to enable programmatic access, i.e. create access key ID and access key, for the user of your choice.
Warning
For security reasons, we recommend creating a dedicated user with programmatic access only. Please avoid re-using a IAM user which has access to the AWS console (human user).
Depending on your AWS API usage it can be problematic to reuse the same AWS Account for different Shoot clusters in the same region due to rate limits. Please consider spreading your Shoots over multiple AWS Accounts if you are hitting those limits.
AWS Workload Identity Federation
Users can choose to trust Gardener’s Workload Identity Issuer and eliminate the need for providing AWS Access Key credentials.
1. Configure OIDC Federation with Gardener’s Workload Identity Issuer.
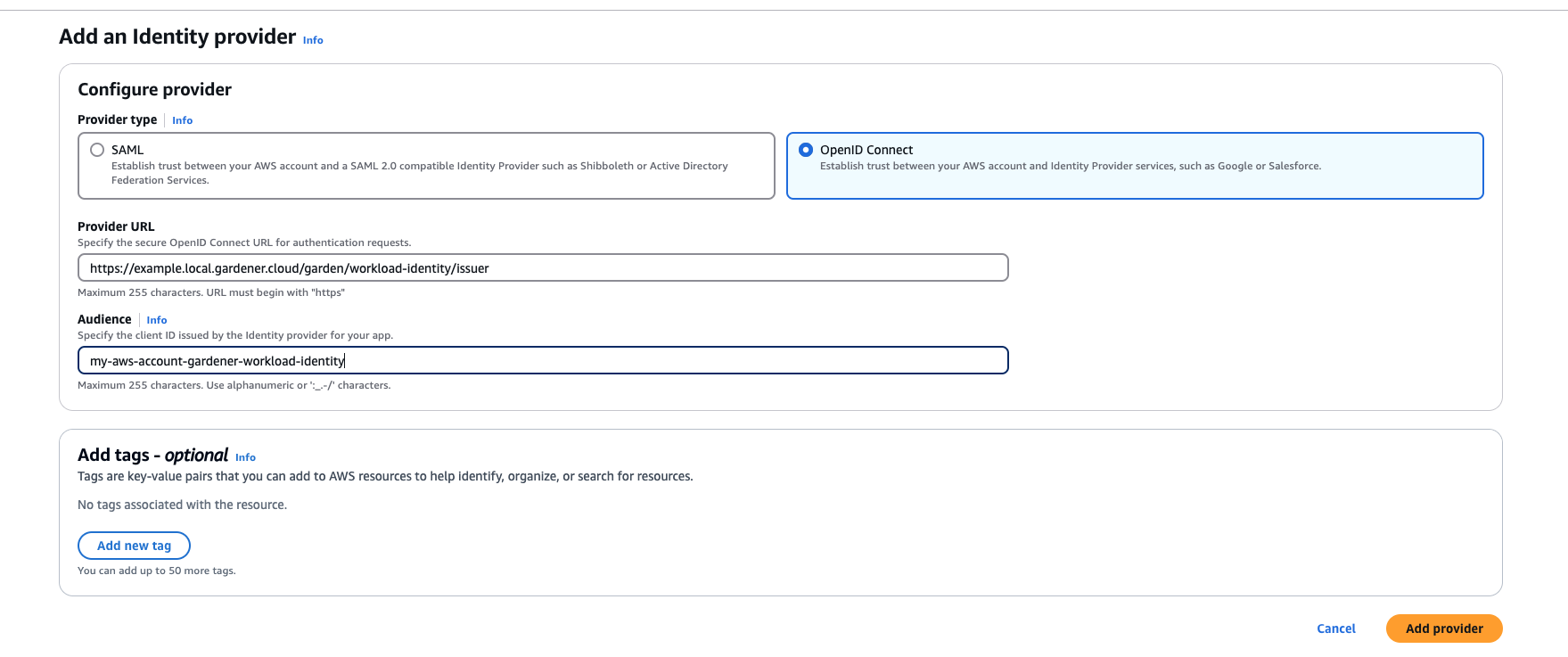
Tip
You can retrieve Gardener’s Workload Identity Issuer URL directly from the Garden cluster by reading the contents of the Gardener Info ConfigMap.
kubectl -n gardener-system-public get configmap gardener-info -o yaml
Important
Use an audience that will uniquely identify the trust relationship between your AWS account and Gardener.
2. Create a policy listing the required permissions.
3. Create a role that trusts the external web identity.
In the Identity Provider dropdown menu choose the Gardener’s Workload Identity Provider.
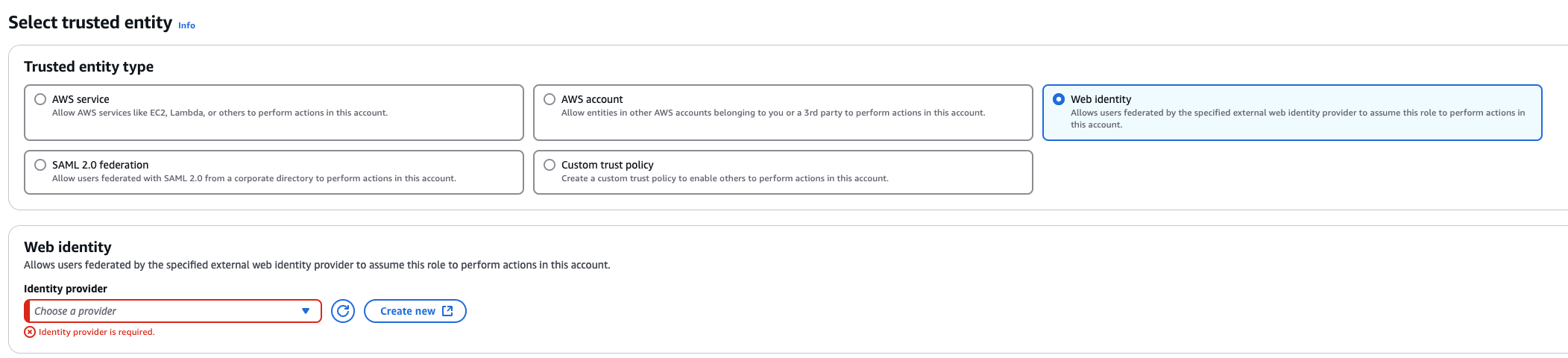
Add the newly created policy that will grant the required permissions.

4. Configure the trust relationship.
Caution
Remember to reduce the scope of the identities that can assume this role only to your own controlled identities! In the example shown below
WorkloadIdentitys that are created in thegarden-myprojnamespace and have the nameawswill be authenticated and granted permissions. Later on, the scope of the trust configuration can be reduced further by replacing the wildcard “*” with the actual id of theWorkloadIdentityand converting the “StringLike” condition to “StringEquals”. This is currently not possible since we do not have the id of theWorkloadIdentityyet.{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": "sts:AssumeRoleWithWebIdentity", "Principal": { "Federated": "arn:aws:iam::123456789012:oidc-provider/example.local.gardener.cloud/garden/workload-identity/issuer" }, "Condition": { "StringEquals": { "example.local.gardener.cloud/garden/workload-identity/issuer:aud": [ "my-aws-account-gardener-workload-identity" ] }, "StringLike": { "example.local.gardener.cloud/garden/workload-identity/issuer:sub": "gardener.cloud:workloadidentity:garden-myproj:aws:*" } } } ] }
5. Create the WorkloadIdentity in the Garden cluster.
This step will require the ARN of the role that was created in the previous step. The identity will be used by infrastructure components to authenticate against AWS APIs. A sample of such resource is shown below:
apiVersion: security.gardener.cloud/v1alpha1
kind: WorkloadIdentity
metadata:
name: aws
namespace: garden-myproj
spec:
audiences:
- my-aws-account-gardener-workload-identity
targetSystem:
type: aws
providerConfig:
apiVersion: aws.provider.extensions.gardener.cloud/v1alpha1
kind: WorkloadIdentityConfig
roleARN: arn:aws:iam::123456789012:role/gardener-workload-identity
Tip
Once created you can extract the whole subject of the workload identity and edit the created Role’s trust relationship configuration to also include the workload identity’s id. Obtain the complete
subby running the following:SUBJECT=$(kubectl -n garden-myproj get workloadidentity aws -o=jsonpath='{.status.sub}') echo "$SUBJECT"
6. Create a CredentialsBinding referencing the AWS WorkloadIdentity and use it in your Shoot definitions.
apiVersion: security.gardener.cloud/v1alpha1
kind: CredentialsBinding
metadata:
name: aws
namespace: garden-myproj
credentialsRef:
apiVersion: security.gardener.cloud/v1alpha1
kind: WorkloadIdentity
name: aws
namespace: garden-myproj
provider:
type: aws
apiVersion: core.gardener.cloud/v1beta1
kind: Shoot
metadata:
name: aws
namespace: garden-myproj
spec:
credentialsBindingName: aws
...
Permissions
Please make sure that the provided credentials have the correct privileges. You can use the following AWS IAM policy document and attach it to the IAM user backed by the credentials you provided (please check the official AWS documentation as well):
Click to expand the AWS IAM policy document!
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "autoscaling:*",
"Resource": "*"
},
{
"Effect": "Allow",
"Action": "ec2:*",
"Resource": "*"
},
{
"Effect": "Allow",
"Action": "elasticloadbalancing:*",
"Resource": "*"
},
{
"Action": [
"iam:GetInstanceProfile",
"iam:GetPolicy",
"iam:GetPolicyVersion",
"iam:GetRole",
"iam:GetRolePolicy",
"iam:ListPolicyVersions",
"iam:ListRolePolicies",
"iam:ListAttachedRolePolicies",
"iam:ListInstanceProfilesForRole",
"iam:CreateInstanceProfile",
"iam:CreatePolicy",
"iam:CreatePolicyVersion",
"iam:CreateRole",
"iam:CreateServiceLinkedRole",
"iam:AddRoleToInstanceProfile",
"iam:AttachRolePolicy",
"iam:DetachRolePolicy",
"iam:RemoveRoleFromInstanceProfile",
"iam:DeletePolicy",
"iam:DeletePolicyVersion",
"iam:DeleteRole",
"iam:DeleteRolePolicy",
"iam:DeleteInstanceProfile",
"iam:PutRolePolicy",
"iam:PassRole",
"iam:UpdateAssumeRolePolicy"
],
"Effect": "Allow",
"Resource": "*"
},
// The following permission set is only needed, if AWS Load Balancer controller is enabled (see ControlPlaneConfig)
{
"Effect": "Allow",
"Action": [
"cognito-idp:DescribeUserPoolClient",
"acm:ListCertificates",
"acm:DescribeCertificate",
"iam:ListServerCertificates",
"iam:GetServerCertificate",
"waf-regional:GetWebACL",
"waf-regional:GetWebACLForResource",
"waf-regional:AssociateWebACL",
"waf-regional:DisassociateWebACL",
"wafv2:GetWebACL",
"wafv2:GetWebACLForResource",
"wafv2:AssociateWebACL",
"wafv2:DisassociateWebACL",
"shield:GetSubscriptionState",
"shield:DescribeProtection",
"shield:CreateProtection",
"shield:DeleteProtection"
],
"Resource": "*"
}
]
}
InfrastructureConfig
The infrastructure configuration mainly describes how the network layout looks like in order to create the shoot worker nodes in a later step, thus, prepares everything relevant to create VMs, load balancers, volumes, etc.
An example InfrastructureConfig for the AWS extension looks as follows:
apiVersion: aws.provider.extensions.gardener.cloud/v1alpha1
kind: InfrastructureConfig
enableECRAccess: true
dualStack:
enabled: false
networks:
vpc: # specify either 'id' or 'cidr'
# id: vpc-123456
cidr: 10.250.0.0/16
# gatewayEndpoints:
# - s3
zones:
- name: eu-west-1a
internal: 10.250.112.0/22
public: 10.250.96.0/22
workers: 10.250.0.0/19
# elasticIPAllocationID: eipalloc-123456
ignoreTags:
keys: # individual ignored tag keys
- SomeCustomKey
- AnotherCustomKey
keyPrefixes: # ignored tag key prefixes
- user.specific/prefix/
The enableECRAccess flag specifies whether the AWS IAM role policy attached to all worker nodes of the cluster shall contain permissions to access the Elastic Container Registry of the respective AWS account.
If the flag is not provided it is defaulted to true.
Please note that if the iamInstanceProfile is set for a worker pool in the WorkerConfig (see below) then enableECRAccess does not have any effect.
It only applies for those worker pools whose iamInstanceProfile is not set.
Click to expand the default AWS IAM policy document used for the instance profiles!
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"ec2:DescribeInstances"
],
"Resource": [
"*"
]
},
// Only if `.enableECRAccess` is `true`.
{
"Effect": "Allow",
"Action": [
"ecr:GetAuthorizationToken",
"ecr:BatchCheckLayerAvailability",
"ecr:GetDownloadUrlForLayer",
"ecr:GetRepositoryPolicy",
"ecr:DescribeRepositories",
"ecr:ListImages",
"ecr:BatchGetImage"
],
"Resource": [
"*"
]
}
]
}
The dualStack.enabled flag specifies whether dual-stack or IPv4-only should be supported by the infrastructure.
When the flag is set to true an Amazon provided IPv6 CIDR block will be attached to the VPC.
All subnets will receive a /64 block from it and a route entry is added to the main route table to route all IPv6 traffic over the IGW.
The networks.vpc section describes whether you want to create the shoot cluster in an already existing VPC or whether to create a new one:
- If
networks.vpc.idis given then you have to specify the VPC ID of the existing VPC that was created by other means (manually, other tooling, …). Please make sure that the VPC has attached an internet gateway - the AWS controller won’t create one automatically for existing VPCs. To make sure the nodes are able to join and operate in your cluster properly, please make sure that your VPC has enabled DNS Support, explicitly the attributesenableDnsHostnamesandenableDnsSupportmust be set totrue. - If
networks.vpc.cidris given then you have to specify the VPC CIDR of a new VPC that will be created during shoot creation. You can freely choose a private CIDR range. - Either
networks.vpc.idornetworks.vpc.cidrmust be present, but not both at the same time. networks.vpc.gatewayEndpointsis optional. If specified then each item is used as service name in a corresponding Gateway VPC Endpoint.
The networks.zones section contains configuration for resources you want to create or use in availability zones.
For every zone, the AWS extension creates three subnets:
- The
internalsubnet is used for internal AWS load balancers. - The
publicsubnet is used for public AWS load balancers. - The
workerssubnet is used for all shoot worker nodes, i.e., VMs which later run your applications.
For every subnet, you have to specify a CIDR range contained in the VPC CIDR specified above, or the VPC CIDR of your already existing VPC. You can freely choose these CIDRs and it is your responsibility to properly design the network layout to suit your needs.
Also, the AWS extension creates a dedicated NAT gateway for each zone.
By default, it also creates a corresponding Elastic IP that it attaches to this NAT gateway and which is used for egress traffic.
The elasticIPAllocationID field allows you to specify the ID of an existing Elastic IP allocation in case you want to bring your own.
If provided, no new Elastic IP will be created and, instead, the Elastic IP specified by you will be used.
Warning
If you change this field for an already existing infrastructure then it will disrupt egress traffic while AWS applies this change. The reason is that the NAT gateway must be recreated with the new Elastic IP association. Also, please note that the existing Elastic IP will be permanently deleted if it was earlier created by the AWS extension.
You can configure Gateway VPC Endpoints by adding items in the optional list networks.vpc.gatewayEndpoints. Each item in the list is used as a service name and a corresponding endpoint is created for it. All created endpoints point to the service within the cluster’s region. For example, consider this (partial) shoot config:
spec:
region: eu-central-1
provider:
type: aws
infrastructureConfig:
apiVersion: aws.provider.extensions.gardener.cloud/v1alpha1
kind: InfrastructureConfig
networks:
vpc:
gatewayEndpoints:
- s3
The service name of the S3 Gateway VPC Endpoint in this example is com.amazonaws.eu-central-1.s3.
If you want to use multiple availability zones then add a second, third, … entry to the networks.zones[] list and properly specify the AZ name in networks.zones[].name.
Apart from the VPC and the subnets the AWS extension will also create DHCP options and an internet gateway (only if a new VPC is created), routing tables, security groups, elastic IPs, NAT gateways, EC2 key pairs, IAM roles, and IAM instance profiles.
The ignoreTags section allows to configure which resource tags on AWS resources managed by Gardener should be ignored during
infrastructure reconciliation. By default, all tags that are added outside of Gardener’s
reconciliation will be removed during the next reconciliation. This field allows users and automation to add
custom tags on AWS resources created and managed by Gardener without loosing them on the next reconciliation.
Tags can be ignored either by specifying exact key values (ignoreTags.keys) or key prefixes (ignoreTags.keyPrefixes).
In both cases it is forbidden to ignore the Name tag or any tag starting with kubernetes.io or gardener.cloud.
Please note though, that the tags are only ignored on resources created on behalf of the Infrastructure CR (i.e. VPC,
subnets, security groups, keypair, etc.), while tags on machines, volumes, etc. are not in the scope of this controller.
ControlPlaneConfig
The control plane configuration mainly contains values for the AWS-specific control plane components.
Today, the only component deployed by the AWS extension is the cloud-controller-manager.
An example ControlPlaneConfig for the AWS extension looks as follows:
apiVersion: aws.provider.extensions.gardener.cloud/v1alpha1
kind: ControlPlaneConfig
cloudControllerManager:
# featureGates:
# SomeKubernetesFeature: true
useCustomRouteController: true
# loadBalancerController:
# enabled: true
# ingressClassName: alb
# ipamController:
# enabled: true
storage:
managedDefaultClass: false
The cloudControllerManager.featureGates contains a map of explicitly enabled or disabled feature gates.
For production usage it’s not recommend to use this field at all as you can enable alpha features or disable beta/stable features, potentially impacting the cluster stability.
If you don’t want to configure anything for the cloudControllerManager simply omit the key in the YAML specification.
The cloudControllerManager.useCustomRouteController controls if the custom routes controller should be enabled.
If enabled, it will add routes to the pod CIDRs for all nodes in the route tables for all zones.
The storage.managedDefaultClass controls if the default storage / volume snapshot classes are marked as default by Gardener. Set it to false to mark another storage / volume snapshot class as default without Gardener overwriting this change. If unset, this field defaults to true.
If the AWS Load Balancer Controller should be deployed, set loadBalancerController.enabled to true.
In this case, it is assumed that an IngressClass named alb is created by the user.
You can overwrite the name by setting loadBalancerController.ingressClassName.
Please note, that currently only the “instance” mode is supported.
Examples for Ingress and Service managed by the AWS Load Balancer Controller:
- Prerequisites
Make sure you have created an IngressClass. For more details about parameters, please see AWS Load Balancer Controller - IngressClass
apiVersion: networking.k8s.io/v1
kind: IngressClass
metadata:
name: alb # default name if not specified by `loadBalancerController.ingressClassName`
spec:
controller: ingress.k8s.aws/alb
- Ingress
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
namespace: default
name: echoserver
annotations:
# complete set of annotations: https://kubernetes-sigs.github.io/aws-load-balancer-controller/latest/guide/ingress/annotations/
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: instance # target-type "ip" NOT supported in Gardener
spec:
ingressClassName: alb
rules:
- http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: echoserver
port:
number: 80
For more details see AWS Load Balancer Documentation - Ingress Specification
- Service of Type
LoadBalancer
This can be used to create a Network Load Balancer (NLB).
apiVersion: v1
kind: Service
metadata:
annotations:
# complete set of annotations: https://kubernetes-sigs.github.io/aws-load-balancer-controller/latest/guide/service/annotations/
service.beta.kubernetes.io/aws-load-balancer-nlb-target-type: instance # target-type "ip" NOT supported in Gardener
service.beta.kubernetes.io/aws-load-balancer-scheme: internet-facing
name: ingress-nginx-controller
namespace: ingress-nginx
...
spec:
...
type: LoadBalancer
loadBalancerClass: service.k8s.aws/nlb # mandatory to be managed by AWS Load Balancer Controller (otherwise the Cloud Controller Manager will act on it)
For more details see AWS Load Balancer Documentation - Network Load Balancer
Warning
When using Network Load Balancers (NLB) as internal load balancers, it is crucial to add the annotation
service.beta.kubernetes.io/aws-load-balancer-target-group-attributes: preserve_client_ip.enabled=false. Without this annotation, if a request is routed by the NLB to the same target instance from which it originated, the client IP and destination IP will be identical. This situation, known as the hairpinning effect, will prevent the request from being processed.
WorkerConfig
The AWS extension supports encryption for volumes plus support for additional data volumes per machine.
For each data volume, you have to specify a name.
By default, (if not stated otherwise), all the disks (root & data volumes) are encrypted.
Please make sure that your instance-type supports encryption.
If your instance-type doesn’t support encryption, you will have to disable encryption (which is enabled by default) by setting volume.encrpyted to false (refer below shown YAML snippet).
The following YAML is a snippet of a Shoot resource:
spec:
provider:
workers:
- name: cpu-worker
...
volume:
type: gp2
size: 20Gi
encrypted: false
dataVolumes:
- name: kubelet-dir
type: gp2
size: 25Gi
encrypted: true
Note
The AWS extension does not support EBS volume (root & data volumes) encryption with customer managed CMK. Support for customer managed CMK is out of scope for now. Only AWS managed CMK is supported.
Additionally, it is possible to provide further AWS-specific values for configuring the worker pools. The additional configuration must be specified in the providerConfig field of the respective worker.
spec:
provider:
workers:
- name: cpu-worker
...
providerConfig:
# AWS worker config
The configuration will be evaluated when the provider-aws will reconcile the worker pools for the respective shoot.
An example WorkerConfig for the AWS extension looks as follows:
spec:
provider:
workers:
- name: cpu-worker
...
providerConfig:
apiVersion: aws.provider.extensions.gardener.cloud/v1alpha1
kind: WorkerConfig
volume:
iops: 10000
throughput: 200
dataVolumes:
- name: kubelet-dir
iops: 12345
throughput: 150
snapshotID: snap-1234
iamInstanceProfile: # (specify either ARN or name)
name: my-profile
instanceMetadataOptions:
httpTokens: required
httpPutResponseHopLimit: 2
# arn: my-instance-profile-arn
nodeTemplate: # (to be specified only if the node capacity would be different from cloudprofile info during runtime)
capacity:
cpu: 2 # inherited from pool's machine type if un-specified
gpu: 0 # inherited from pool's machine type if un-specified
memory: 50Gi # inherited from pool's machine type if un-specified
ephemeral-storage: 10Gi # override to specify explicit ephemeral-storage for scale fro zero
resource.com/dongle: 4 # Example of a custom, extended resource.
The .volume.iops is the number of I/O operations per second (IOPS) that the volume supports.
For io1 and gp3 volume type, this represents the number of IOPS that are provisioned for the volume.
For gp2 volume type, this represents the baseline performance of the volume and the rate at which the volume accumulates I/O credits for bursting. For more information about General Purpose SSD baseline performance, I/O credits, IOPS range and bursting, see Amazon EBS Volume Types (http://docs.aws.amazon.com/AWSEC2/latest/UserGuide/EBSVolumeTypes.html) in the Amazon Elastic Compute Cloud User Guide.
Constraint: IOPS should be a positive value. Validation of IOPS (i.e. whether it is allowed and is in the specified range for a particular volume type) is done on aws side.
The volume.throughput is the throughput that the volume supports, in MiB/s. As of 16th Aug 2022, this parameter is valid only for gp3 volume types and will return an error from the provider side if specified for other volume types. Its current range of throughput is from 125MiB/s to 1000 MiB/s. To know more about throughput and its range, see the official AWS documentation here.
The .dataVolumes can optionally contain configurations for the data volumes stated in the Shoot specification in the .spec.provider.workers[].dataVolumes list.
The .name must match to the name of the data volume in the shoot.
It is also possible to provide a snapshot ID. It allows to restore the data volume from an existing snapshot.
The iamInstanceProfile section allows to specify the IAM instance profile name xor ARN that should be used for this worker pool.
If not specified, a dedicated IAM instance profile created by the infrastructure controller is used (see above).
The instanceMetadataOptions controls access to the instance metadata service (IMDS) for members of the worker. You can do the following operations:
- access IMDSv1 (default)
- access IMDSv2 -
httpPutResponseHopLimit >= 2 - access IMDSv2 only (restrict access to IMDSv1) -
httpPutResponseHopLimit >=2,httpTokens = "required" - disable access to IMDS -
httpTokens = "required"
Note
The accessibility of IMDS discussed in the previous point is referenced from the point of view of containers NOT running in the host network. By default on host network IMDSv2 is already enabled (but not accessible from inside the pods). It is currently not possible to create a VM with complete restriction to the IMDS service. It is however possible to restrict access from inside the pods by setting
httpTokenstorequiredand not settinghttpPutResponseHopLimit(or setting it to 1).
You can find more information regarding the options in the AWS documentation.
cpuOptions grants more finegrained control over the worker’s CPU configuration. It has two attributes:
coreCount: Specify a custom amount of cores the instance should be configured with.threadsPerCore: How many threads should there be on each core. Set to1to disable multi-threading.
Note that if you decide to configure cpuOptions both these values need to be provided. For a list of valid combinations of these values refer to the AWS documentation.
Example Shoot manifest (one availability zone)
Please find below an example Shoot manifest for one availability zone:
apiVersion: core.gardener.cloud/v1beta1
kind: Shoot
metadata:
name: johndoe-aws
namespace: garden-dev
spec:
cloudProfile:
name: aws
region: eu-central-1
credentialsBindingName: core-aws
provider:
type: aws
infrastructureConfig:
apiVersion: aws.provider.extensions.gardener.cloud/v1alpha1
kind: InfrastructureConfig
networks:
vpc:
cidr: 10.250.0.0/16
zones:
- name: eu-central-1a
internal: 10.250.112.0/22
public: 10.250.96.0/22
workers: 10.250.0.0/19
controlPlaneConfig:
apiVersion: aws.provider.extensions.gardener.cloud/v1alpha1
kind: ControlPlaneConfig
workers:
- name: worker-xoluy
machine:
type: m5.large
minimum: 2
maximum: 2
volume:
size: 50Gi
type: gp2
# The following provider config is valid if the volume type is `io1`.
# providerConfig:
# apiVersion: aws.provider.extensions.gardener.cloud/v1alpha1
# kind: WorkerConfig
# volume:
# iops: 10000
zones:
- eu-central-1a
networking:
nodes: 10.250.0.0/16
type: calico
kubernetes:
version: 1.28.2
maintenance:
autoUpdate:
kubernetesVersion: true
machineImageVersion: true
addons:
kubernetesDashboard:
enabled: true
nginxIngress:
enabled: true
---
apiVersion: security.gardener.cloud/v1alpha1
kind: CredentialsBinding
metadata:
name: core-aws
namespace: garden-dev
credentialsRef:
apiVersion: v1
kind: Secret
name: core-aws
namespace: garden-dev
provider:
type: aws
---
apiVersion: v1
kind: Secret
metadata:
name: core-aws
namespace: garden-dev
type: Opaque
data:
accessKeyID: base64(access-key-id)
secretAccessKey: base64(secret-access-key)
Example Shoot manifest (three availability zones)
Please find below an example Shoot manifest for three availability zones:
apiVersion: core.gardener.cloud/v1beta1
kind: Shoot
metadata:
name: johndoe-aws
namespace: garden-dev
spec:
cloudProfile:
name: aws
region: eu-central-1
credentialsBindingName: core-aws
provider:
type: aws
infrastructureConfig:
apiVersion: aws.provider.extensions.gardener.cloud/v1alpha1
kind: InfrastructureConfig
networks:
vpc:
cidr: 10.250.0.0/16
zones:
- name: eu-central-1a
workers: 10.250.0.0/26
public: 10.250.96.0/26
internal: 10.250.112.0/26
- name: eu-central-1b
workers: 10.250.0.64/26
public: 10.250.96.64/26
internal: 10.250.112.64/26
- name: eu-central-1c
workers: 10.250.0.128/26
public: 10.250.96.128/26
internal: 10.250.112.128/26
controlPlaneConfig:
apiVersion: aws.provider.extensions.gardener.cloud/v1alpha1
kind: ControlPlaneConfig
workers:
- name: worker-xoluy
machine:
type: m5.large
minimum: 3
maximum: 9
volume:
size: 50Gi
type: gp2
zones:
- eu-central-1a
- eu-central-1b
- eu-central-1c
networking:
nodes: 10.250.0.0/16
type: calico
kubernetes:
version: 1.28.2
maintenance:
autoUpdate:
kubernetesVersion: true
machineImageVersion: true
addons:
kubernetesDashboard:
enabled: true
nginxIngress:
enabled: true
Example Shoot manifest (IPv6)
Please find below an example Shoot manifest for an IPv6 shoot cluster:
apiVersion: core.gardener.cloud/v1beta1
kind: Shoot
metadata:
name: johndoe-aws-ipv6
namespace: garden-dev
spec:
cloudProfile:
name: aws
region: eu-central-1
credentialsBindingName: core-aws
provider:
type: aws
infrastructureConfig:
apiVersion: aws.provider.extensions.gardener.cloud/v1alpha1
kind: InfrastructureConfig
networks:
vpc:
cidr: 10.250.0.0/16
zones:
- name: eu-central-1a
public: 10.250.96.0/22
internal: 10.250.112.0/22
controlPlaneConfig:
apiVersion: aws.provider.extensions.gardener.cloud/v1alpha1
kind: ControlPlaneConfig
workers:
- ...
networking:
ipFamilies:
- IPv6
type: calico
kubernetes:
version: 1.28.2
...
addons:
kubernetesDashboard:
enabled: true
nginxIngress:
enabled: false
CSI volume provisioners
Every AWS shoot cluster will be deployed with the AWS EBS CSI driver.
It is compatible with the legacy in-tree volume provisioner that was deprecated by the Kubernetes community and will be removed in future versions of Kubernetes.
End-users might want to update their custom StorageClasses to the new ebs.csi.aws.com provisioner.
Node-specific Volume Limits
The Kubernetes scheduler allows configurable limit for the number of volumes that can be attached to a node. See https://k8s.io/docs/concepts/storage/storage-limits/#custom-limits.
CSI drivers usually have a different procedure for configuring this custom limit.
By default, the EBS CSI driver parses the machine type name and then decides the volume limit.
However, this is only a rough approximation and not good enough in most cases.
Specifying the volume attach limit via command line flag (--volume-attach-limit) is currently the alternative until a more sophisticated solution presents itself (dynamically discovering the maximum number of attachable volume per EC2 machine type, see also https://github.com/kubernetes-sigs/aws-ebs-csi-driver/issues/347).
The AWS extension allows the --volume-attach-limit flag of the EBS CSI driver to be configurable via aws.provider.extensions.gardener.cloud/volume-attach-limit annotation on the Shoot resource.
ℹ️ Please note: If the annotation is added to an existing Shoot, then reconciliation needs to be triggered manually (see Immediate reconciliation), as adding an annotation to a resource is not a change that leads to an increase of .metadata.generation in general.
Other CSI options
The newer versions of EBS CSI driver are not readily compatible with the use of XFS volumes on nodes using a kernel version <= 5.4.
A workaround was added that enables the use of a “legacy XFS” mode that introduces a backwards compatible volume formating for the older kernels.
You can enable this option for your shoot by annotating it with aws.provider.extensions.gardener.cloud/legacy-xfs=true.
ℹ️ Please note: If the annotation is added to an existing Shoot, then reconciliation needs to be triggered manually (see Immediate reconciliation), as adding an annotation to a resource is not a change that leads to an increase of .metadata.generation in general.
Support for VolumeAttributesClasses (Beta in k8s 1.31)
To have the CSI-driver configured to support the necessary features for VolumeAttributesClasses on AWS for shoots with a k8s-version of at least 1.31, use the aws.provider.extensions.gardener.cloud/enable-volume-attributes-class annotation on the shoot. Keep in mind to also enable the required feature flags and runtime-config on the common kubernetes controllers (as outlined in the link above) in the shoot-spec.
For more information and examples, see this markdown in the aws-ebs-csi-driver repository. Please take special note of the considerations mentioned.
Kubernetes Versions per Worker Pool
This extension supports gardener/gardener’s WorkerPoolKubernetesVersion feature gate, i.e., having worker pools with overridden Kubernetes versions since gardener-extension-provider-aws@v1.34.
Shoot CA Certificate and ServiceAccount Signing Key Rotation
This extension supports gardener/gardener’s ShootCARotation and ShootSARotation feature gates since gardener-extension-provider-aws@v1.36.
Flow Infrastructure Reconciler
The extension offers two different reconciler implementations for the infrastructure resource:
- terraform-based
- native Go SDK based (dubbed the “flow”-based implementation)
The default implementation currently is the terraform reconciler which uses the https://github.com/gardener/terraformer as the backend for managing the shoot’s infrastructure.
The “flow” implementation is a newer implementation that is trying to solve issues we faced with managing terraform infrastructure on Kubernetes. The goal is to have more control over the reconciliation process and be able to perform fine-grained tuning over it. The implementation is completely backwards-compatible and offers a migration route from the legacy terraformer implementation.
For most users there will be no noticeable difference. However for certain use-cases, users may notice a slight deviation from the previous behavior. For example, with flow-based infrastructure users may be able to perform certain modifications to infrastructure resources without having them reconciled back by terraform. Operations that would degrade the shoot infrastructure are still expected to be reverted back.
For the time-being, to take advantage of the flow reconciler users have to “opt-in” by annotating the shoot manifest with: aws.provider.extensions.gardener.cloud/use-flow="true". For existing shoots with this annotation, the migration will take place on the next infrastructure reconciliation (on maintenance window or if other infrastructure changes are requested). The migration is not revertible.
BackupBucket
Gardener manages etcd's backups for Shoot clusters using provider specific storage solutions. On AWS, this storage is implemented through AWS S3, which store the backups/snapshots of the etcd's cluster data.
The BackupBucket resource abstracts the backup infrastructure, enabling Gardener and its extension controllers to manage it seamlessly. This abstraction allows Gardener to create, delete, and maintain backup buckets across various cloud providers in a standardized manner.
The BackupBucket resource includes a spec field, which defines the configuration details for the backup bucket. These details include:
- A
regionis reference to a region where the bucket should be created. - A
secretRefis reference to the secret containing credentials for accessing the cloud provider. - A
typefield defines the storage provider type like aws, azure etc. - A
providerConfigfield defines provider specific configurations.
BackupBucketConfig
The BackupBucketConfig describes the configuration that needs to be passed over for creation of the backup bucket infrastructure. Configuration for immutability feature a.k.a object lock in S3 that can be set on the bucket are specified in BackupBucketConfig.
Immutability feature (WORM, i.e. write-once-read-many model) ensures that once backups is written to the bucket, it will prevent locked object versions from being permanently deleted, hence it cannot be modified or deleted for a specified period. This feature is crucial for protecting backups from accidental or malicious deletion, ensuring data safety and availability for restoration.
Note
With enabling S3 object lock, S3 versioning will also get enabled.
The Gardener extension provider for AWS supports creating bucket (and enabling already existing buckets if immutability configured) to use object lock feature provided by storage provider AWS S3.
Here is an example configuration for BackupBucketConfig:
apiVersion: aws.provider.extensions.gardener.cloud/v1alpha1
kind: BackupBucketConfig
immutability:
retentionType: bucket
retentionPeriod: 24h
mode: compliance
retentionType: Specifies the type of retention policy. Currently, S3 supports object lock onbucketlevel as well as onobjectlevel. The allowed value isbucket, which applies the retention policy and retention period to the entire bucket. For more details, refer to the documentation. Objects in the bucket will inherit the retention period which is set on the bucket. Please refer here to see working of backups/snapshots with immutable feature.retentionPeriod: Defines the duration for which object version in the bucket will remain immutable. AWS S3 only supports immutability durations in days or years, therefore this field must be set as multiple of 24h.mode: Defines the mode for object locked enabled S3 bucket, S3 provides two retention modes that apply different levels of protection to objects:- Governance mode: Users with special permissions can overwrite, delete or alter object versions during retention period.
- Compliance mode: No users(including root user) can overwrite, delete or alter object versions during retention period.
To configure a BackupBucket with immutability feature, include the BackupBucketConfig in the .spec.providerConfig of the BackupBucket resource.
Here is an example of configuring a BackupBucket S3 object lock with retentionPeriod set to 24h i.e 1 Day and with mode Compliance.
apiVersion: extensions.gardener.cloud/v1alpha1
kind: BackupBucket
metadata:
name: my-backup-bucket
spec:
type: aws
region: eu-west-1
secretRef:
name: my-aws-secret
namespace: my-namespace
providerConfig:
apiVersion: aws.provider.extensions.gardener.cloud/v1alpha1
kind: BackupBucketConfig
immutability:
retentionType: bucket
retentionPeriod: 24h
mode: compliance
Note
Once S3 Object Lock is enabled, it cannot be disabled, nor can S3 versioning. However, you can remove the default retention settings by removing the
BackupBucketConfigfrom.spec.providerConfig.
3 - Provider Azure
Gardener Extension for Azure provider
Project Gardener implements the automated management and operation of Kubernetes clusters as a service. Its main principle is to leverage Kubernetes concepts for all of its tasks.
Recently, most of the vendor specific logic has been developed in-tree. However, the project has grown to a size where it is very hard to extend, maintain, and test. With GEP-1 we have proposed how the architecture can be changed in a way to support external controllers that contain their very own vendor specifics. This way, we can keep Gardener core clean and independent.
This controller implements Gardener’s extension contract for the Azure provider.
An example for a ControllerRegistration resource that can be used to register this controller to Gardener can be found here.
Please find more information regarding the extensibility concepts and a detailed proposal here.
Supported Kubernetes versions
This extension controller supports the following Kubernetes versions:
| Version | Support | Conformance test results |
|---|---|---|
| Kubernetes 1.33 | 1.33.0+ | N/A |
| Kubernetes 1.32 | 1.32.0+ | |
| Kubernetes 1.31 | 1.31.0+ | |
| Kubernetes 1.30 | 1.30.0+ | |
| Kubernetes 1.29 | 1.29.0+ | |
| Kubernetes 1.28 | 1.28.0+ | |
| Kubernetes 1.27 | 1.27.0+ |
Please take a look here to see which versions are supported by Gardener in general.
How to start using or developing this extension controller locally
You can run the controller locally on your machine by executing make start.
Static code checks and tests can be executed by running make verify. We are using Go modules for Golang package dependency management and Ginkgo/Gomega for testing.
Feedback and Support
Feedback and contributions are always welcome!
Please report bugs or suggestions as GitHub issues or reach out on Slack (join the workspace here).
Learn more!
Please find further resources about out project here:
- Our landing page gardener.cloud
- “Gardener, the Kubernetes Botanist” blog on kubernetes.io
- “Gardener Project Update” blog on kubernetes.io
- GEP-1 (Gardener Enhancement Proposal) on extensibility
- GEP-4 (New
core.gardener.cloud/v1beta1API) - Extensibility API documentation
- Gardener Extensions Golang library
- Gardener API Reference
3.1 - Tutorials
3.1.1 - Create a Kubernetes Cluster on Azure with Gardener
Overview
Gardener allows you to create a Kubernetes cluster on different infrastructure providers. This tutorial will guide you through the process of creating a cluster on Azure.
Prerequisites
- You have created an Azure account.
- You have access to the Gardener dashboard and have permissions to create projects.
- You have an Azure Service Principal assigned to your subscription.
Steps
Go to the Gardener dashboard and create a Project.
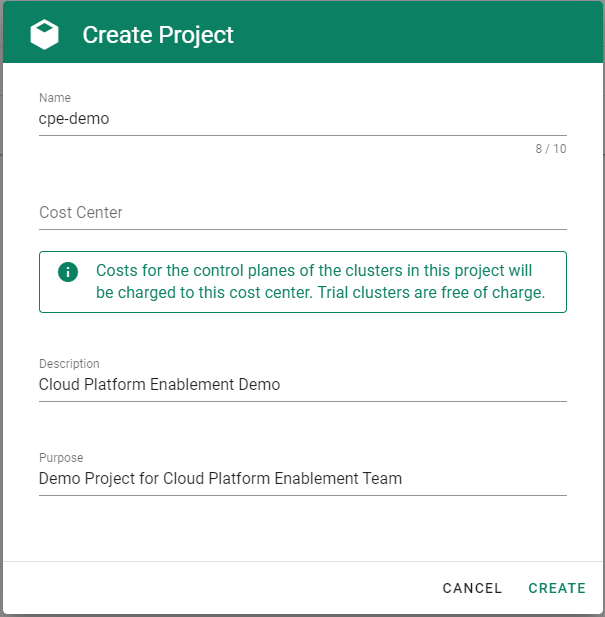
Get the properties of your Azure AD tenant, Subscription and Service Principal.
Before you can provision and access a Kubernetes cluster on Azure, you need to add the Azure service principal, AD tenant and subscription credentials in Gardener. Gardener needs the credentials to provision and operate the Azure infrastructure for your Kubernetes cluster.
Ensure that the Azure service principal has the actions defined within the Azure Permissions within your Subscription assigned. If no fine-grained permission/actions are required, then simply the built-in
Contributorrole can be assigned.Tenant ID
To find your
TenantID, follow this guide.SubscriptionID
To find your
SubscriptionID, search for and select Subscriptions.
After that, copy the
SubscriptionIDfrom your subscription of choice.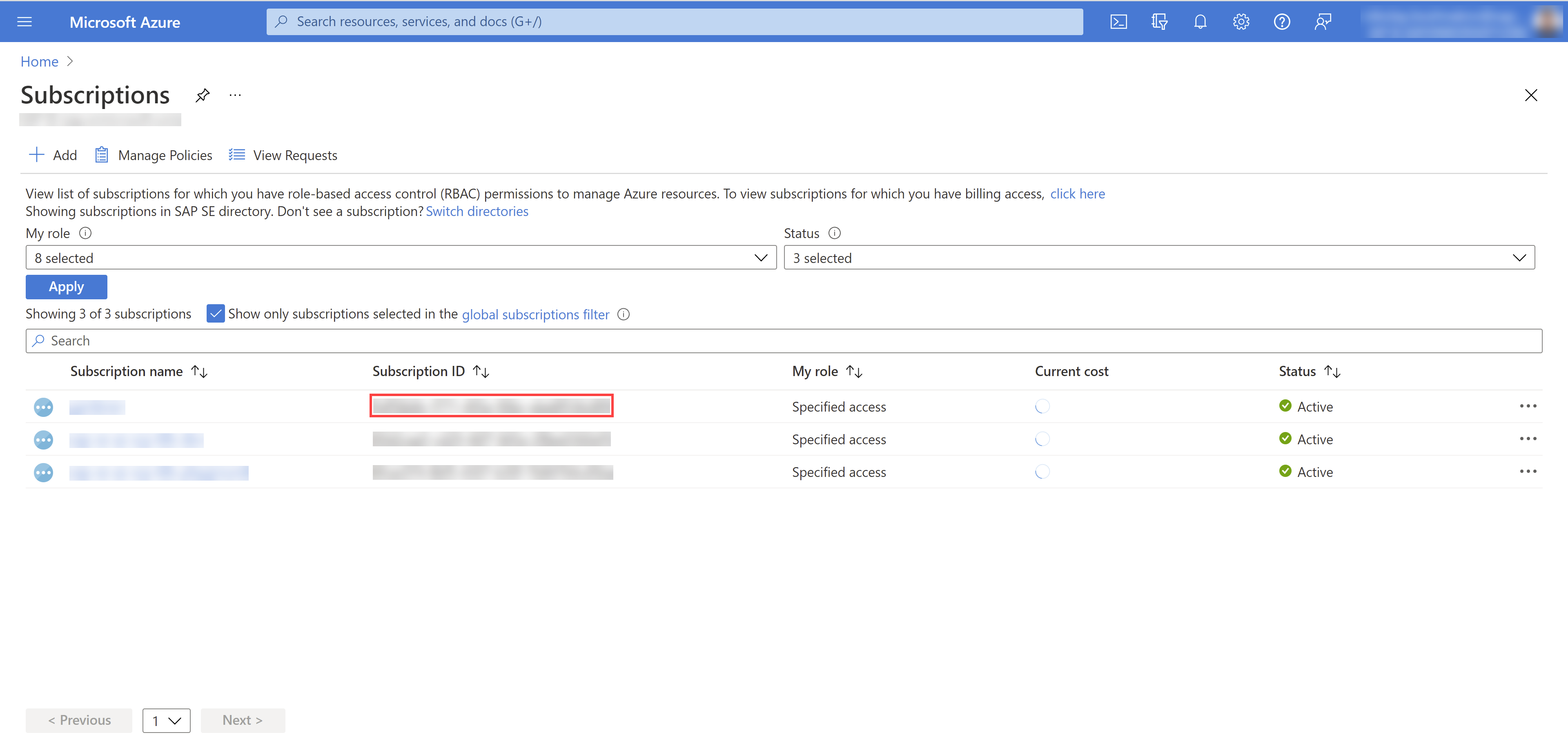
Service Principal (SPN)
A service principal consist of a
ClientID(also calledApplicationID) and a Client Secret. For more information, see Application and service principal objects in Azure Active Directory. You need to obtain the:Client ID
Access the Azure Portal and navigate to the Active Directory service. Within the service navigate to App registrations and select your service principal. Copy the
ClientIDyou see there.Client Secret
Secrets for the Azure Account/Service Principal can be generated/rotated via the Azure Portal. After copying your
ClientID, in the Detail view of your Service Principal navigate to Certificates & secrets. In the section, you can generate a new secret.
Choose Secrets, then the plus icon
 and select Azure.
and select Azure.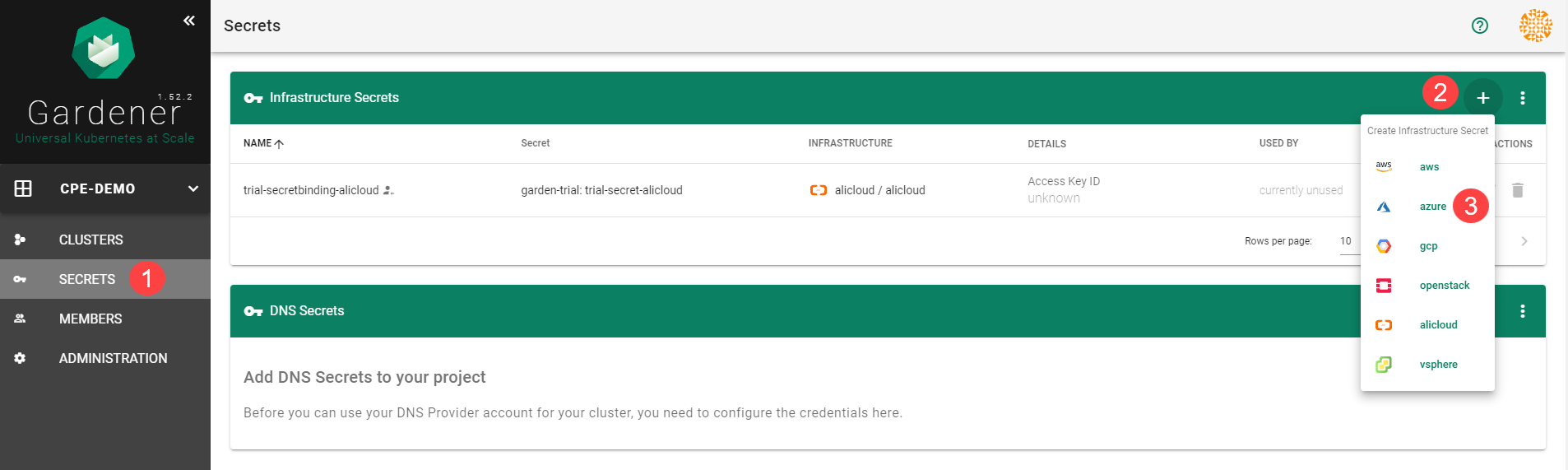
Create your secret.
- Type the name of your secret.
- Copy and paste the
TenantID,SubscriptionIDand the Service Principal credentials (ClientIDandClientSecret). - Choose Add secret.
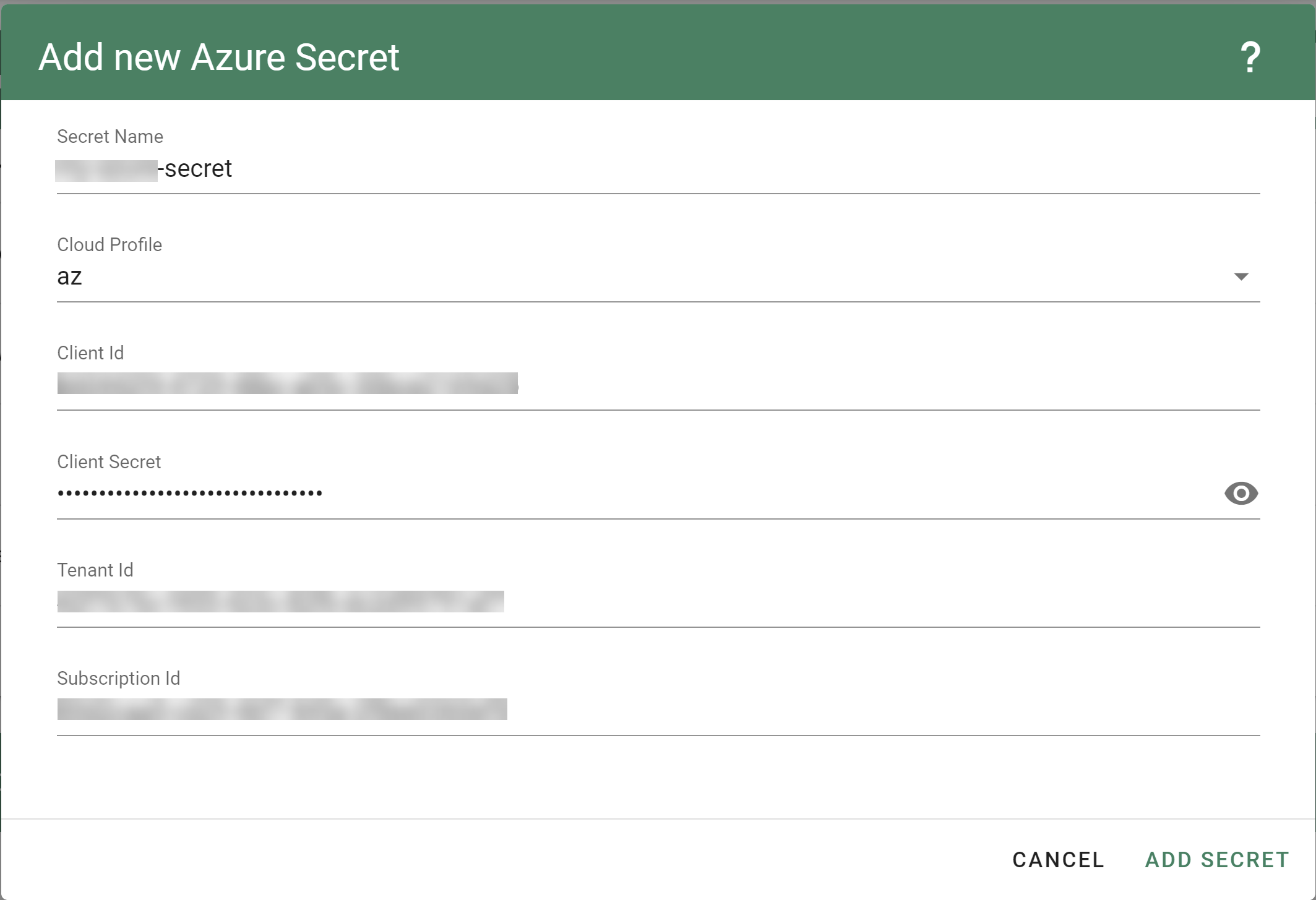
After completing these steps, you should see your newly created secret in the Infrastructure Secrets section.
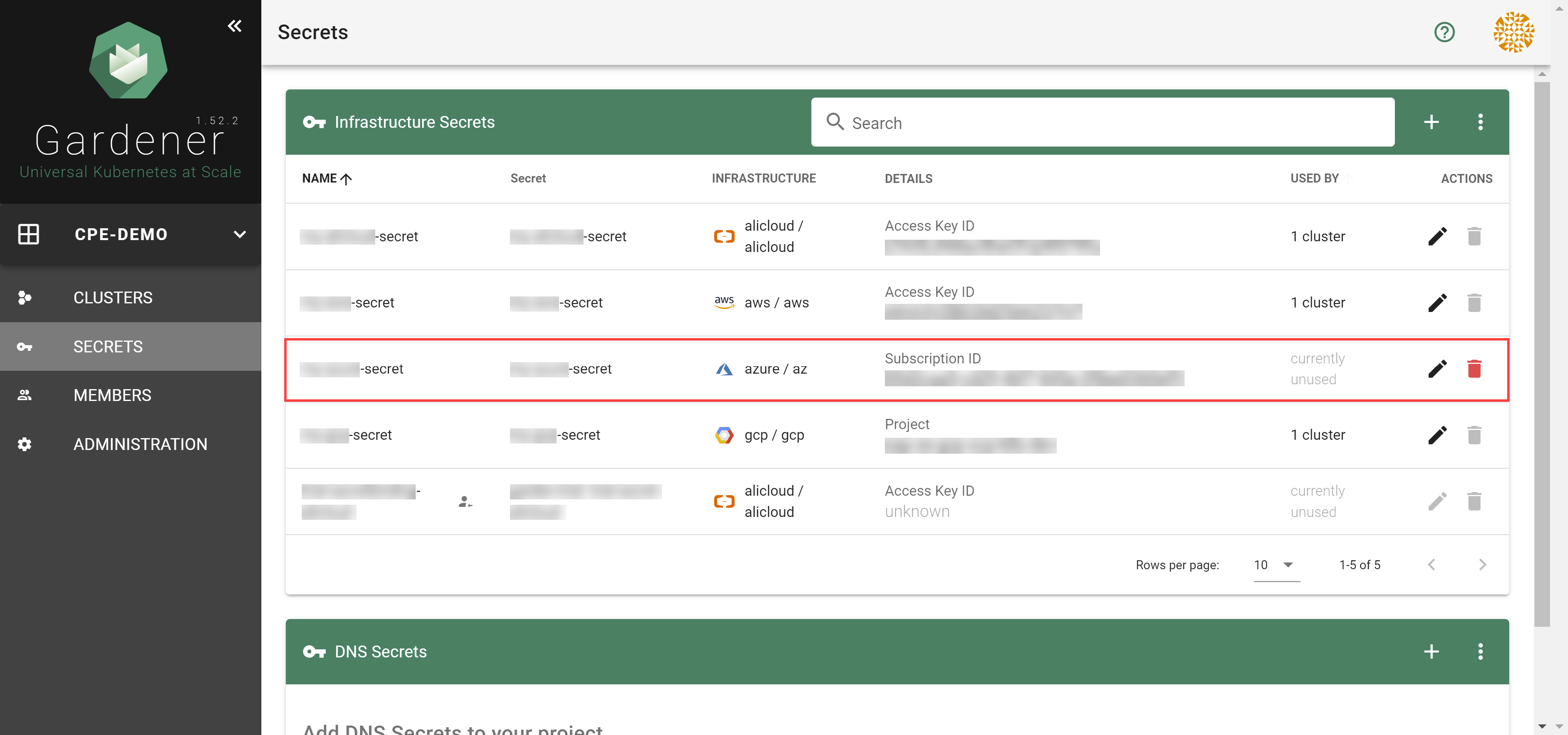
Register resource providers for your subscription.
- Go to your Azure dashboard
- Navigate to Subscriptions -> <your_subscription>
- Pick resource providers from the sidebar
- Register microsoft.Network
- Register microsoft.Compute
To create a new cluster, choose Clusters and then the plus sign in the upper right corner.
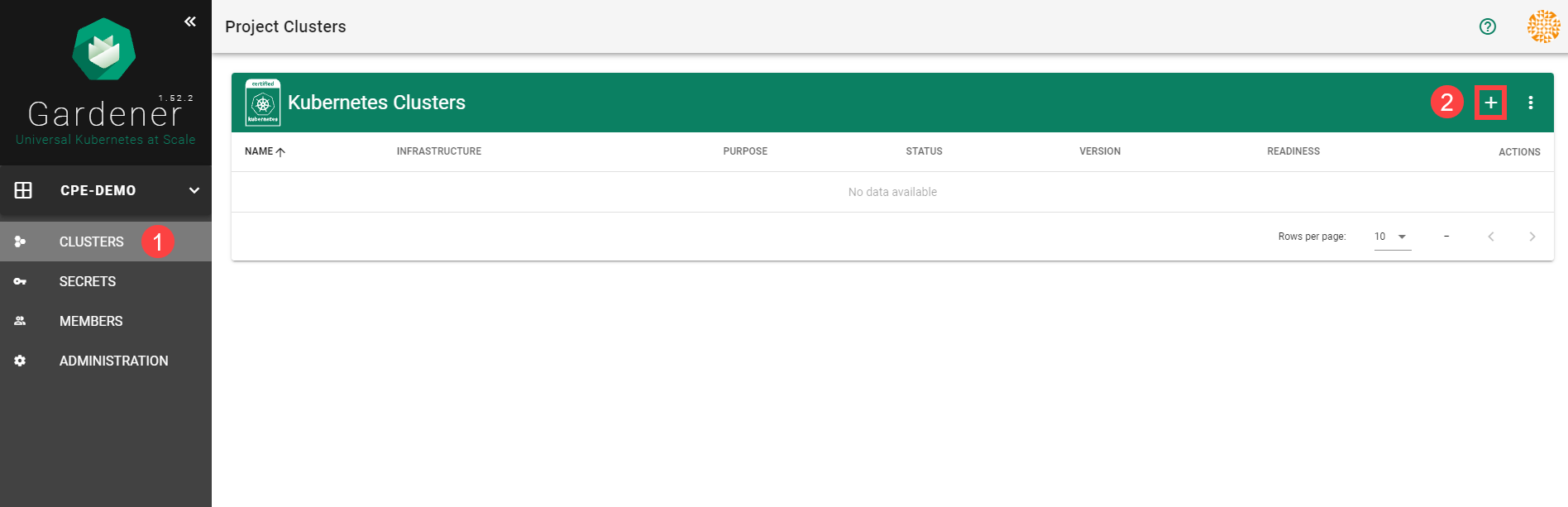
In the Create Cluster section:
- Select Azure in the Infrastructure tab.
- Type the name of your cluster in the Cluster Details tab.
- Choose the secret you created before in the Infrastructure Details tab.
- Choose Create.
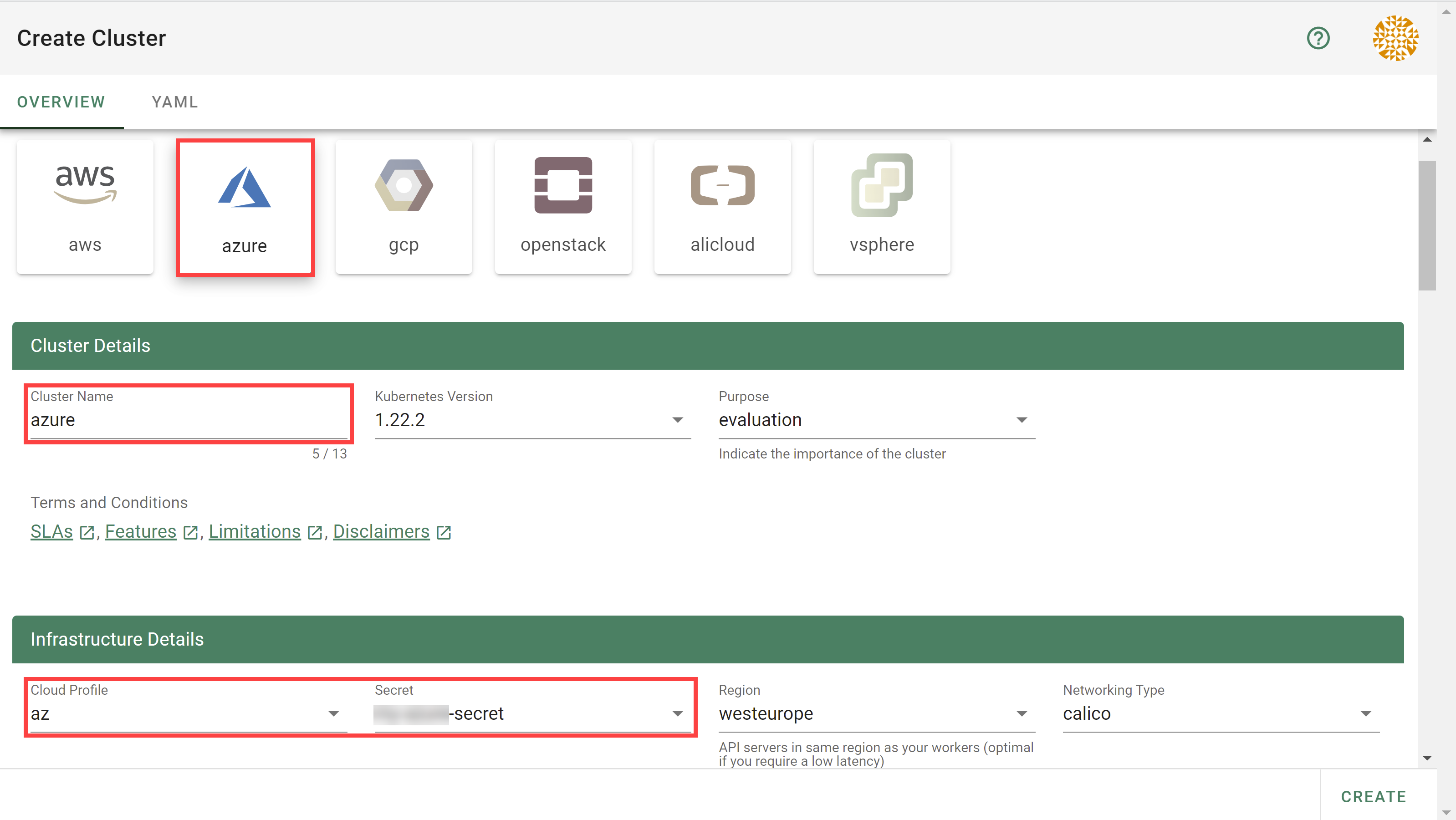
Wait for your cluster to get created.
Result
After completing the steps in this tutorial, you will be able to see and download the kubeconfig of your cluster.
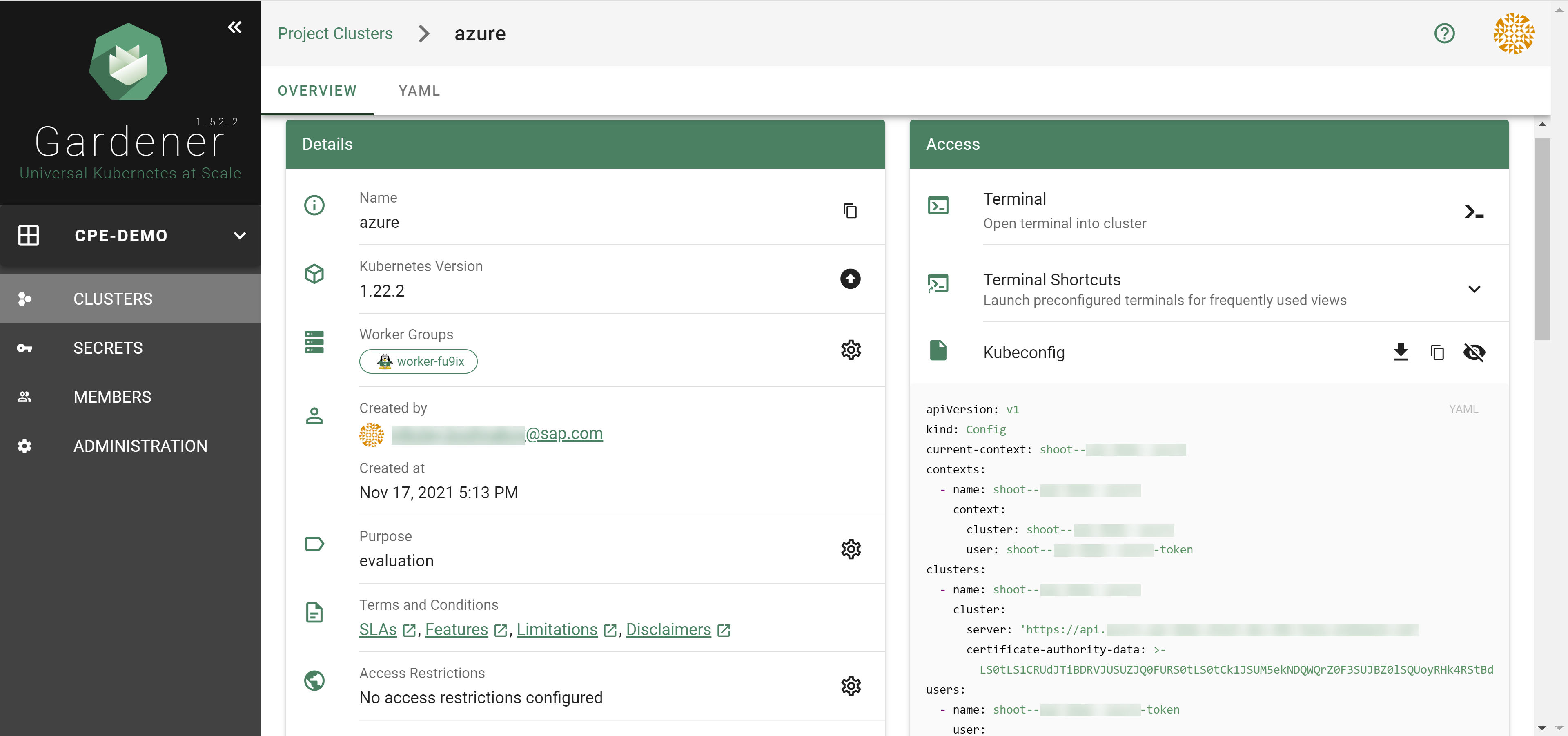
3.2 - Azure Permissions
Azure Permissions
The following document describes the required Azure actions manage a Shoot cluster on Azure split by the different Azure provider/services.
Be aware some actions are just required if particular deployment scenarios or features e.g. bring your own vNet, use Azure-file, let the Shoot act as Seed, immutable buckets, etc. should be used.
Microsoft.Compute
# Required if a non zonal cluster based on Availability Set should be used.
Microsoft.Compute/availabilitySets/delete
Microsoft.Compute/availabilitySets/read
Microsoft.Compute/availabilitySets/write
# Required to let Kubernetes manage Azure disks.
Microsoft.Compute/disks/delete
Microsoft.Compute/disks/read
Microsoft.Compute/disks/write
# Required for to fetch meta information about disk and virtual machines sizes.
Microsoft.Compute/locations/diskOperations/read
Microsoft.Compute/locations/operations/read
Microsoft.Compute/locations/vmSizes/read
# Required if csi snapshot capabilities should be used and/or the Shoot should act as a Seed.
Microsoft.Compute/snapshots/delete
Microsoft.Compute/snapshots/read
Microsoft.Compute/snapshots/write
# Required to let Gardener/Machine-Controller-Manager manage the cluster nodes/machines.
Microsoft.Compute/virtualMachines/delete
Microsoft.Compute/virtualMachines/read
Microsoft.Compute/virtualMachines/start/action
Microsoft.Compute/virtualMachines/write
# Required if a non zonal cluster based on VMSS Flex (VMO) should be used.
Microsoft.Compute/virtualMachineScaleSets/delete
Microsoft.Compute/virtualMachineScaleSets/read
Microsoft.Compute/virtualMachineScaleSets/write
Microsoft.ManagedIdentity
# Required if a user provided Azure managed identity should attached to the cluster nodes.
Microsoft.ManagedIdentity/userAssignedIdentities/assign/action
Microsoft.ManagedIdentity/userAssignedIdentities/read
Microsoft.MarketplaceOrdering
# Required if nodes/machines should be created with images hosted on the Azure Marketplace.
Microsoft.MarketplaceOrdering/offertypes/publishers/offers/plans/agreements/read
Microsoft.MarketplaceOrdering/offertypes/publishers/offers/plans/agreements/write
Microsoft.Network
# Required to let Kubernetes manage services of type 'LoadBalancer'.
Microsoft.Network/loadBalancers/backendAddressPools/join/action
Microsoft.Network/loadBalancers/delete
Microsoft.Network/loadBalancers/read
Microsoft.Network/loadBalancers/write
# Required in case the Shoot should use NatGateway(s).
Microsoft.Network/natGateways/delete
Microsoft.Network/natGateways/join/action
Microsoft.Network/natGateways/read
Microsoft.Network/natGateways/write
# Required to let Gardener/Machine-Controller-Manager manage the cluster nodes/machines.
Microsoft.Network/networkInterfaces/delete
Microsoft.Network/networkInterfaces/ipconfigurations/join/action
Microsoft.Network/networkInterfaces/ipconfigurations/read
Microsoft.Network/networkInterfaces/join/action
Microsoft.Network/networkInterfaces/read
Microsoft.Network/networkInterfaces/write
# Required to let Gardener maintain the basic infrastructure of the Shoot cluster and maintaing LoadBalancer services.
Microsoft.Network/networkSecurityGroups/delete
Microsoft.Network/networkSecurityGroups/join/action
Microsoft.Network/networkSecurityGroups/read
Microsoft.Network/networkSecurityGroups/write
# Required for managing LoadBalancers and NatGateways.
Microsoft.Network/publicIPAddresses/delete
Microsoft.Network/publicIPAddresses/join/action
Microsoft.Network/publicIPAddresses/read
Microsoft.Network/publicIPAddresses/write
# Required for managing the basic infrastructure of a cluster and maintaing LoadBalancer services.
Microsoft.Network/routeTables/delete
Microsoft.Network/routeTables/join/action
Microsoft.Network/routeTables/read
Microsoft.Network/routeTables/routes/delete
Microsoft.Network/routeTables/routes/read
Microsoft.Network/routeTables/routes/write
Microsoft.Network/routeTables/write
# Required to let Gardener maintain the basic infrastructure of the Shoot cluster.
# Only a subset is required for the bring your own vNet scenario.
Microsoft.Network/virtualNetworks/delete # not required for bring your own vnet
Microsoft.Network/virtualNetworks/read
Microsoft.Network/virtualNetworks/subnets/delete
Microsoft.Network/virtualNetworks/subnets/join/action
Microsoft.Network/virtualNetworks/subnets/read
Microsoft.Network/virtualNetworks/subnets/write
Microsoft.Network/virtualNetworks/write # not required for bring your own vnet
Microsoft.Resources
# Required to let Gardener maintain the basic infrastructure of the Shoot cluster.
Microsoft.Resources/subscriptions/resourceGroups/delete
Microsoft.Resources/subscriptions/resourceGroups/read
Microsoft.Resources/subscriptions/resourceGroups/write
Microsoft.Storage
# Required if Azure File should be used and/or if the Shoot should act as Seed.
Microsoft.Storage/operations/read
Microsoft.Storage/storageAccounts/blobServices/containers/delete
Microsoft.Storage/storageAccounts/blobServices/containers/read
Microsoft.Storage/storageAccounts/blobServices/containers/write
Microsoft.Storage/storageAccounts/blobServices/read
Microsoft.Storage/storageAccounts/delete
Microsoft.Storage/storageAccounts/listkeys/action
Microsoft.Storage/storageAccounts/read
Microsoft.Storage/storageAccounts/write
# Required if Shoot should act as Seed with immutable ABS containers.
Microsoft.Storage/storageAccounts/blobServices/containers/immutabilityPolicies/extend/action
Microsoft.Storage/storageAccounts/blobServices/containers/immutabilityPolicies/delete
Microsoft.Storage/storageAccounts/blobServices/containers/immutabilityPolicies/write
Microsoft.Storage/storageAccounts/blobServices/containers/immutabilityPolicies/lock/action
Microsoft.Storage/storageAccounts/blobServices/containers/immutabilityPolicies/read
Microsoft.Storage/storageAccounts/managementPolicies/delete
Microsoft.Storage/storageAccounts/managementPolicies/read
Microsoft.Storage/storageAccounts/managementPolicies/write
# Required to configure storage key rotation
Microsoft.Storage/storageAccounts/regeneratekey/action
3.3 - Deployment
Deployment of the Azure provider extension
Disclaimer: This document is NOT a step by step installation guide for the Azure provider extension and only contains some configuration specifics regarding the installation of different components via the helm charts residing in the Azure provider extension repository.
gardener-extension-admission-azure
Authentication against the Garden cluster
There are several authentication possibilities depending on whether or not the concept of Virtual Garden is used.
Virtual Garden is not used, i.e., the runtime Garden cluster is also the target Garden cluster.
Automounted Service Account Token
The easiest way to deploy the gardener-extension-admission-azure component will be to not provide kubeconfig at all. This way in-cluster configuration and an automounted service account token will be used. The drawback of this approach is that the automounted token will not be automatically rotated.
Virtual Garden is used, i.e., the runtime Garden cluster is different from the target Garden cluster.
Service Account
The easiest way to setup the authentication will be to create a service account and the respective roles will be bound to this service account in the target cluster. Then use the generated service account token and craft a kubeconfig which will be used by the workload in the runtime cluster. This approach does not provide a solution for the rotation of the service account token. However, this setup can be achieved by setting .Values.global.virtualGarden.enabled: true and following these steps:
- Deploy the
applicationpart of the charts in thetargetcluster. - Get the service account token and craft the
kubeconfig. - Set the crafted
kubeconfigand deploy theruntimepart of the charts in theruntimecluster.
Client Certificate
Another solution will be to bind the roles in the target cluster to a User subject instead of a service account and use a client certificate for authentication. This approach does not provide a solution for the client certificate rotation. However, this setup can be achieved by setting both .Values.global.virtualGarden.enabled: true and .Values.global.virtualGarden.user.name, then following these steps:
- Generate a client certificate for the
targetcluster for the respective user. - Deploy the
applicationpart of the charts in thetargetcluster. - Craft a
kubeconfigusing the already generated client certificate. - Set the crafted
kubeconfigand deploy theruntimepart of the charts in theruntimecluster.
3.4 - Local Setup
admission-azure
admission-azure is an admission webhook server which is responsible for the validation of the cloud provider (Azure in this case) specific fields and resources. The Gardener API server is cloud provider agnostic and it wouldn’t be able to perform similar validation.
Follow the steps below to run the admission webhook server locally.
Start the Gardener API server.
For details, check the Gardener local setup.
Start the webhook server
Make sure that the
KUBECONFIGenvironment variable is pointing to the local garden cluster.make start-admissionSetup the
ValidatingWebhookConfiguration.hack/dev-setup-admission-azure.shwill configure the webhook Service which will allow the kube-apiserver of your local cluster to reach the webhook server. It will also apply theValidatingWebhookConfigurationmanifest../hack/dev-setup-admission-azure.sh
You are now ready to experiment with the admission-azure webhook server locally.
3.5 - Operations
Using the Azure provider extension with Gardener as an operator
The core.gardener.cloud/v1beta1.CloudProfile resource declares a providerConfig field that is meant to contain provider-specific configuration.
The core.gardener.cloud/v1beta1.Seed resource is structured similarly.
Additionally, it allows configuring settings for the backups of the main etcds’ data of shoot clusters control planes running in this seed cluster.
This document explains the necessary configuration for the Azure provider extension.
CloudProfile resource
This section describes, how the configuration for CloudProfiles looks like for Azure by providing an example CloudProfile manifest with minimal configuration that can be used to allow the creation of Azure shoot clusters.
CloudProfileConfig
The cloud profile configuration contains information about the real machine image IDs in the Azure environment (image urn, id, communityGalleryImageID or sharedGalleryImageID).
You have to map every version that you specify in .spec.machineImages[].versions to an available VM image in your subscription.
The VM image can be either from the Azure Marketplace and will then get identified via a urn, it can be a custom VM image from a shared image gallery and is then identified sharedGalleryImageID, or it can be from a community image gallery and is then identified by its communityGalleryImageID. You can use id field also to specifiy the image location in the azure compute gallery (in which case it would have a different kind of path) but it is not recommended as it sometimes faces problems in cross subscription image sharing.
For each machine image version an architecture field can be specified which specifies the CPU architecture of the machine on which given machine image can be used.
An example CloudProfileConfig for the Azure extension looks as follows:
apiVersion: azure.provider.extensions.gardener.cloud/v1alpha1
kind: CloudProfileConfig
countUpdateDomains:
- region: westeurope
count: 5
countFaultDomains:
- region: westeurope
count: 3
machineTypes:
- name: Standard_D3_v2
acceleratedNetworking: true
- name: Standard_X
machineImages:
- name: coreos
versions:
- version: 2135.6.0
urn: "CoreOS:CoreOS:Stable:2135.6.0"
# architecture: amd64 # optional
acceleratedNetworking: true
- name: myimage
versions:
- version: 1.0.0
id: "/subscriptions/<subscription ID where the gallery is located>/resourceGroups/myGalleryRG/providers/Microsoft.Compute/galleries/myGallery/images/myImageDefinition/versions/1.0.0"
- name: GardenLinuxCommunityImage
versions:
- version: 1.0.0
communityGalleryImageID: "/CommunityGalleries/gardenlinux-567905d8-921f-4a85-b423-1fbf4e249d90/Images/gardenlinux/Versions/576.1.1"
- name: SharedGalleryImageName
versions:
- version: 1.0.0
sharedGalleryImageID: "/SharedGalleries/sharedGalleryName/Images/sharedGalleryImageName/Versions/sharedGalleryImageVersionName"
The cloud profile configuration contains information about the update via .countUpdateDomains[] and failure domain via .countFaultDomains[] counts in the Azure regions you want to offer.
The .machineTypes[] list contain provider specific information to the machine types e.g. if the machine type support Azure Accelerated Networking, see .machineTypes[].acceleratedNetworking.
Additionally, it contains the real machine image identifiers in the Azure environment. You can provide either URN for Azure Market Place images or id of Shared Image Gallery images.
When Shared Image Gallery is used, you have to ensure that the image is available in the desired regions and the end-user subscriptions have access to the image or to the whole gallery.
You have to map every version that you specify in .spec.machineImages[].versions here such that the Azure extension knows the machine image identifiers for every version you want to offer.
Furthermore, you can specify for each image version via .machineImages[].versions[].acceleratedNetworking if Azure Accelerated Networking is supported.
Example CloudProfile manifest
The possible values for .spec.volumeTypes[].name on Azure are Standard_LRS, StandardSSD_LRS and Premium_LRS. There is another volume type called UltraSSD_LRS but this type is not supported to use as os disk. If an end user select a volume type whose name is not equal to one of the valid values then the machine will be created with the default volume type which belong to the selected machine type. Therefore it is recommended to configure only the valid values for the .spec.volumeType[].name in the CloudProfile.
Please find below an example CloudProfile manifest:
apiVersion: core.gardener.cloud/v1beta1
kind: CloudProfile
metadata:
name: azure
spec:
type: azure
kubernetes:
versions:
- version: 1.28.2
- version: 1.23.8
expirationDate: "2022-10-31T23:59:59Z"
machineImages:
- name: coreos
versions:
- version: 2135.6.0
machineTypes:
- name: Standard_D3_v2
cpu: "4"
gpu: "0"
memory: 14Gi
- name: Standard_D4_v3
cpu: "4"
gpu: "0"
memory: 16Gi
volumeTypes:
- name: Standard_LRS
class: standard
usable: true
- name: StandardSSD_LRS
class: premium
usable: false
- name: Premium_LRS
class: premium
usable: false
regions:
- name: westeurope
providerConfig:
apiVersion: azure.provider.extensions.gardener.cloud/v1alpha1
kind: CloudProfileConfig
machineTypes:
- name: Standard_D3_v2
acceleratedNetworking: true
- name: Standard_D4_v3
countUpdateDomains:
- region: westeurope
count: 5
countFaultDomains:
- region: westeurope
count: 3
machineImages:
- name: coreos
versions:
- version: 2303.3.0
urn: CoreOS:CoreOS:Stable:2303.3.0
# architecture: amd64 # optional
acceleratedNetworking: true
- version: 2135.6.0
urn: "CoreOS:CoreOS:Stable:2135.6.0"
# architecture: amd64 # optional
Seed resource
This provider extension does not support any provider configuration for the Seed’s .spec.provider.providerConfig field.
However, it supports managing of backup infrastructure, i.e., you can specify a configuration for the .spec.backup field.
Backup configuration
A Seed of type azure can be configured to perform backups for the main etcds’ of the shoot clusters control planes using Azure Blob storage.
The location/region where the backups will be stored defaults to the region of the Seed (spec.provider.region), but can also be explicitly configured via the field spec.backup.region.
The region of the backup can be different from where the Seed cluster is running.
However, usually it makes sense to pick the same region for the backup bucket as used for the Seed cluster.
Please find below an example Seed manifest (partly) that configures backups using Azure Blob storage.
---
apiVersion: core.gardener.cloud/v1beta1
kind: Seed
metadata:
name: my-seed
spec:
provider:
type: azure
region: westeurope
backup:
provider: azure
region: westeurope # default region
credentialsRef:
apiVersion: v1
kind: Secret
name: backup-credentials
namespace: garden
...
The referenced secret has to contain the provider credentials of the Azure subscription. Please take a look here on how to create an Azure Application, Service Principle and how to obtain credentials. The example below demonstrates how the secret has to look like.
apiVersion: v1
kind: Secret
metadata:
name: core-azure
namespace: garden-dev
type: Opaque
data:
clientID: base64(client-id)
clientSecret: base64(client-secret)
subscriptionID: base64(subscription-id)
tenantID: base64(tenant-id)
Permissions for Azure Blob storage
Please make sure the Azure application has the following IAM roles.
Miscellaneous
Gardener managed Service Principals
The operators of the Gardener Azure extension can provide a list of managed service principals (technical users) that can be used for Azure Shoots. This eliminates the need for users to provide own service principals for their clusters.
The user would need to grant the managed service principal access to their subscription with proper permissions.
As service principals are managed in an Azure Active Directory for each supported Active Directory, an own service principal needs to be provided.
In case the user provides an own service principal in the Shoot secret, this one will be used instead of the managed one provided by the operator.
Each managed service principal will be maintained in a Secret like that:
apiVersion: v1
kind: Secret
metadata:
name: service-principal-my-tenant
namespace: extension-provider-azure
labels:
azure.provider.extensions.gardener.cloud/purpose: tenant-service-principal-secret
data:
tenantID: base64(my-tenant)
clientID: base64(my-service-princiapl-id)
clientSecret: base64(my-service-princiapl-secret)
type: Opaque
The user needs to provide in its Shoot secret a tenantID and subscriptionID.
The managed service principal will be assigned based on the tenantID.
In case there is a managed service principal secret with a matching tenantID, this one will be used for the Shoot.
If there is no matching managed service principal secret then the next Shoot operation will fail.
One of the benefits of having managed service principals is that the operator controls the lifecycle of the service principal and can rotate its secrets.
After the service principal secret has been rotated and the corresponding secret is updated, all Shoot clusters using it need to be reconciled or the last operation to be retried.
Rolling Update Triggers
Changes to the Shoot worker-pools are applied in-place where possible.
In case this is not possible a rolling update of the workers will be performed to apply the new configuration,
as outlined in the Gardener documentation.
The exact fields that trigger this behavior are defined in the Gardener doc,
with a few additions:
.spec.provider.workers[].providerConfig.spec.provider.infrastructureConfig.identity.spec.provider.infrastructureConfig.zoned.spec.provider.workers[].dataVolumes[].size(only the affected worker pool).spec.provider.workers[].dataVolumes[].type(only the affected worker pool)
Additionally, if the VMO name of a worker pool changes, the worker pool will be rolled.
This can occur if the countFaultDomains field in the cloud profile is modified.
For now, if the feature gate NewWorkerPoolHash is enabled, the exact same fields are used.
This behavior may change once MCM supports in-place updates, such as volume updates.
3.6 - Usage
Using the Azure provider extension with Gardener as end-user
The core.gardener.cloud/v1beta1.Shoot resource declares a few fields that are meant to contain provider-specific configuration.
This document describes the configurable options for Azure and provides an example Shoot manifest with minimal configuration that can be used to create an Azure cluster (modulo the landscape-specific information like cloud profile names, secret binding names, etc.).
Azure Provider Credentials
In order for Gardener to create a Kubernetes cluster using Azure infrastructure components, a Shoot has to provide credentials with sufficient permissions to the desired Azure subscription.
Every shoot cluster references a SecretBinding or a CredentialsBinding.
SecretBindings reference a Secret while CredentialsBindings can reference a Secret or a WorkloadIdentity.
A Secret would contain the provider credentials of the Azure subscription while a WorkloadIdentity would be used to represent an identity of Gardener managed workload.
Important
The
SecretBinding/CredentialsBindingis configurable in the Shoot cluster with the fieldsecretBindingName/credentialsBindingName.SecretBindings are considered legacy and will be deprecated in the future. It is advised to useCredentialsBindings instead.
Create an Azure Application and Service Principle and obtain its credentials.
Please ensure that the Azure application (spn) has the IAM actions defined here assigned. If no fine-grained permissions/actions required then simply assign the Contributor role.
The example below demonstrates how the secret containing the client credentials of the Azure Application has to look like:
apiVersion: v1
kind: Secret
metadata:
name: core-azure
namespace: garden-dev
type: Opaque
data:
clientID: base64(client-id)
clientSecret: base64(client-secret)
subscriptionID: base64(subscription-id)
tenantID: base64(tenant-id)
Warning
Depending on your API usage it can be problematic to reuse the same Service Principal for different Shoot clusters due to rate limits. Please consider spreading your Shoots over Service Principals from different Azure subscriptions if you are hitting those limits.
Managed Service Principals
The operators of the Gardener Azure extension can provide managed service principals. This eliminates the need for users to provide an own service principal for a Shoot.
To make use of a managed service principal, the Azure secret of a Shoot cluster must contain only a subscriptionID and a tenantID field, but no clientID and clientSecret.
Removing those fields from the secret of an existing Shoot will also let it adopt the managed service principal.
Based on the tenantID field, the Gardener extension will try to assign the managed service principal to the Shoot.
If no managed service principal can be assigned then the next operation on the Shoot will fail.
Warning
The managed service principal need to be assigned to the users Azure subscription with proper permissions before using it.
Azure Workload Identity Federation
Users can choose to trust Gardener’s Workload Identity Issuer and eliminate the need for providing Azure credentials.
As a first step a resource of type WorkloadIdentity should be created in the Garden cluster and configured with the required Azure information.
This identity will be used by infrastructure components to authenticate against Azure APIs.
A sample of such resource is shown below:
apiVersion: security.gardener.cloud/v1alpha1
kind: WorkloadIdentity
metadata:
name: azure
namespace: garden-myproj
spec:
audiences:
# This is the audience that you configure during the creation of a federated credential
- api://AzureADTokenExchange-my-application
targetSystem:
type: azure
providerConfig:
apiVersion: azure.provider.extensions.gardener.cloud/v1alpha1
kind: WorkloadIdentityConfig
clientID: 00000000-0000-0000-0000-000000000001 # This is the id of the application (client)
tenantID: 00000000-0000-0000-0000-000000000002 # This is the id of the directory (tenant)
subscriptionID: 00000000-0000-0000-0000-000000000003 # This is the id of the Azure subscription
Once created the WorkloadIdentity will get its own id which will be used to form the subject of the said WorkloadIdentity.
The subject can be obtained by running the following command:
kubectl -n garden-myproj get wi azure -o=jsonpath={.status.sub}
As a second step users should configure Workload Identity Federation so that their application trusts Gardener’s Workload Identity Issuer.
Tip
You can retrieve Gardener’s Workload Identity Issuer URL directly from the Garden cluster by reading the contents of the Gardener Info ConfigMap.
kubectl -n gardener-system-public get configmap -o yaml
In the shown example a WorkloadIdentity with name azure with id 00000000-0000-0000-0000-000000000000 from the garden-myproj namespace will be trusted by the Azure application.
Important
You should replace the subject indentifier in the example below with the subject that is populated in the status of the
WorkloadIdentity, obtained in a previous step.
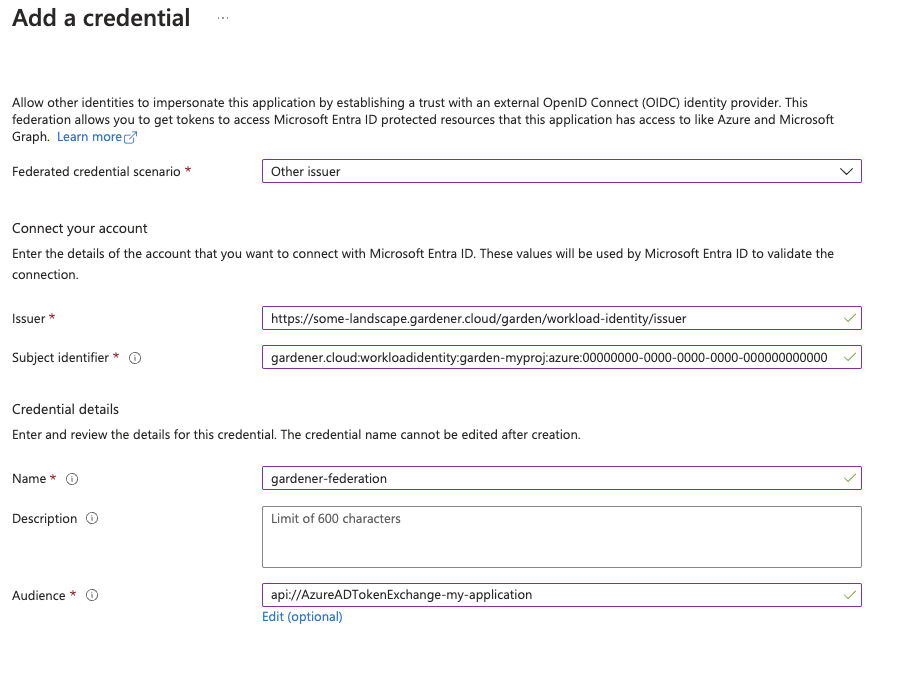
Please ensure that the Azure application (spn) has the proper IAM actions assigned. If no fine-grained permissions/actions required then simply assign the Contributor role.
Once you have everything set you can create a CredentialsBinding that reference the WorkloadIdentity and configure your shoot to use it.
Please see the following examples:
apiVersion: security.gardener.cloud/v1alpha1
kind: CredentialsBinding
metadata:
name: azure
namespace: garden-myproj
credentialsRef:
apiVersion: security.gardener.cloud/v1alpha1
kind: WorkloadIdentity
name: azure
namespace: garden-myproj
provider:
type: azure
apiVersion: core.gardener.cloud/v1beta1
kind: Shoot
metadata:
name: azure
namespace: garden-myproj
spec:
credentialsBindingName: azure
...
InfrastructureConfig
The infrastructure configuration mainly describes how the network layout looks like in order to create the shoot worker nodes in a later step, thus, prepares everything relevant to create VMs, load balancers, volumes, etc.
An example InfrastructureConfig for the Azure extension looks as follows:
apiVersion: azure.provider.extensions.gardener.cloud/v1alpha1
kind: InfrastructureConfig
networks:
vnet: # specify either 'name' and 'resourceGroup' or 'cidr'
# name: my-vnet
# resourceGroup: my-vnet-resource-group
cidr: 10.250.0.0/16
# ddosProtectionPlanID: /subscriptions/test/resourceGroups/test/providers/Microsoft.Network/ddosProtectionPlans/test-ddos-protection-plan
workers: 10.250.0.0/19
# natGateway:
# enabled: false
# idleConnectionTimeoutMinutes: 4
# zone: 1
# ipAddresses:
# - name: my-public-ip-name
# resourceGroup: my-public-ip-resource-group
# zone: 1
# serviceEndpoints:
# - Microsoft.Test
# zones:
# - name: 1
# cidr: "10.250.0.0/24
# - name: 2
# cidr: "10.250.0.0/24"
# natGateway:
# enabled: false
zoned: false
# resourceGroup:
# name: mygroup
#identity:
# name: my-identity-name
# resourceGroup: my-identity-resource-group
# acrAccess: true
Currently, it’s not yet possible to deploy into existing resource groups.
The .resourceGroup.name field will allow specifying the name of an already existing resource group that the shoot cluster and all infrastructure resources will be deployed to.
Via the .zoned boolean you can tell whether you want to use Azure availability zones or not.
If you didn’t use zones in the past then an availability set was created and only basic load balancers were used.
Now VMSS-FLex (VMO) has become the default also for non-zonal clusters and only standard load balancers are used.
The networks.vnet section describes whether you want to create the shoot cluster in an already existing VNet or whether to create a new one:
- If
networks.vnet.nameandnetworks.vnet.resourceGroupare given then you have to specify the VNet name and VNet resource group name of the existing VNet that was created by other means (manually, other tooling, …). - If
networks.vnet.cidris given then you have to specify the VNet CIDR of a new VNet that will be created during shoot creation. You can freely choose a private CIDR range. - Either
networks.vnet.nameandneworks.vnet.resourceGroupornetworks.vnet.cidrmust be present, but not both at the same time. - The
networks.vnet.ddosProtectionPlanIDfield can be used to specify the id of a ddos protection plan which should be assigned to the VNet. This will only work for a VNet managed by Gardener. For externally managed VNets the ddos protection plan must be assigned by other means. - If a vnet name is given and cilium shoot clusters are created without a network overlay within one vnet make sure that the pod CIDR specified in
shoot.spec.networking.podsis not overlapping with any other pod CIDR used in that vnet. Overlapping pod CIDRs will lead to disfunctional shoot clusters. - It’s possible to place multiple shoot cluster into the same vnet
The networks.workers section describes the CIDR for a subnet that is used for all shoot worker nodes, i.e., VMs which later run your applications.
The specified CIDR range must be contained in the VNet CIDR specified above, or the VNet CIDR of your already existing VNet.
You can freely choose this CIDR and it is your responsibility to properly design the network layout to suit your needs.
In the networks.serviceEndpoints[] list you can specify the list of Azure service endpoints which shall be associated with the worker subnet. All available service endpoints and their technical names can be found in the (Azure Service Endpoint documentation](https://docs.microsoft.com/en-us/azure/virtual-network/virtual-network-service-endpoints-overview).
The networks.natGateway section contains configuration for the Azure NatGateway which can be attached to the worker subnet of a Shoot cluster. Here are some key information about the usage of the NatGateway for a Shoot cluster:
- NatGateway usage is optional and can be enabled or disabled via
.networks.natGateway.enabled. - If the NatGateway is not used then the egress connections initiated within the Shoot cluster will be nated via the LoadBalancer of the clusters (default Azure behaviour, see here).
- NatGateway is only available for zonal clusters
.zoned=true. - The NatGateway is currently not zone redundantly deployed. That mean the NatGateway of a Shoot cluster will always be in just one zone. This zone can be optionally selected via
.networks.natGateway.zone. - Caution: Modifying the
.networks.natGateway.zonesetting requires a recreation of the NatGateway and the managed public ip (automatically used if no own public ip is specified, see below). That mean you will most likely get a different public ip for egress connections. - It is possible to bring own zonal public ip(s) via
networks.natGateway.ipAddresses. Those public ip(s) need to be in the same zone as the NatGateway (seenetworks.natGateway.zone) and be of SKUstandard. For each public ip thename, theresourceGroupand thezoneneed to be specified. - The field
networks.natGateway.idleConnectionTimeoutMinutesallows the configuration of NAT Gateway’s idle connection timeout property. The idle timeout value can be adjusted from 4 minutes, up to 120 minutes. Omitting this property will set the idle timeout to its default value according to NAT Gateway’s documentation.
In the identity section you can specify an Azure user-assigned managed identity which should be attached to all cluster worker machines. With identity.name you can specify the name of the identity and with identity.resourceGroup you can specify the resource group which contains the identity resource on Azure. The identity need to be created by the user upfront (manually, other tooling, …). Gardener/Azure Extension will only use the referenced one and won’t create an identity. Furthermore the identity have to be in the same subscription as the Shoot cluster. Via the identity.acrAccess you can configure the worker machines to use the passed identity for pulling from an Azure Container Registry (ACR).
Caution: Adding, exchanging or removing the identity will require a rolling update of all worker machines in the Shoot cluster.
Apart from the VNet and the worker subnet the Azure extension will also create a dedicated resource group, route tables, security groups, and an availability set (if not using zoned clusters).
InfrastructureConfig with dedicated subnets per zone
Another deployment option for zonal clusters only, is to create and configure a separate subnet per availability zone. This network layout is recommended to users that require fine-grained control over their network setup. One prevalent usecase is to create a zone-redundant NAT Gateway deployment by taking advantage of the ability to deploy separate NAT Gateways for each subnet.
To use this configuration the following requirements must be met:
- the
zonedfield must be set totrue. - the
networks.vnetsection must not be empty and must contain a valid configuration. For existing clusters that were not using thenetworks.vnetsection, it is enough ifnetworks.vnet.cidrfield is set to the currentnetworks.workervalue.
For each of the target zones a subnet CIDR range must be specified. The specified CIDR range must be contained in the VNet CIDR specified above, or the VNet CIDR of your already existing VNet. In addition, the CIDR ranges must not overlap with the ranges of the other subnets.
ServiceEndpoints and NatGateways can be configured per subnet. Respectively, when networks.zones is specified, the fields networks.workers, networks.serviceEndpoints and networks.natGateway cannot be set. All the configuration for the subnets must be done inside the respective zone’s configuration.
Example:
apiVersion: azure.provider.extensions.gardener.cloud/v1alpha1
kind: InfrastructureConfig
networks:
zoned: true
vnet: # specify either 'name' and 'resourceGroup' or 'cidr'
cidr: 10.250.0.0/16
zones:
- name: 1
cidr: "10.250.0.0/24"
- name: 2
cidr: "10.250.0.0/24"
natGateway:
enabled: false
Migrating to zonal shoots with dedicated subnets per zone
For existing zonal clusters it is possible to migrate to a network layout with dedicated subnets per zone. The migration works by creating additional network resources as specified in the configuration and progressively roll part of your existing nodes to use the new resources. To achieve the controlled rollout of your nodes, parts of the existing infrastructure must be preserved which is why the following constraint is imposed:
One of your specified zones must have the exact same CIDR range as the current network.workers field. Here is an example of such migration:
infrastructureConfig:
apiVersion: azure.provider.extensions.gardener.cloud/v1alpha1
kind: InfrastructureConfig
networks:
vnet:
cidr: 10.250.0.0/16
workers: 10.250.0.0/19
zoned: true
to
infrastructureConfig:
apiVersion: azure.provider.extensions.gardener.cloud/v1alpha1
kind: InfrastructureConfig
networks:
vnet:
cidr: 10.250.0.0/16
zones:
- name: 3
cidr: 10.250.0.0/19 # note the preservation of the 'workers' CIDR
# optionally add other zones
# - name: 2
# cidr: 10.250.32.0/19
# natGateway:
# enabled: true
zoned: true
Another more advanced example with user-provided public IP addresses for the NAT Gateway and how it can be migrated:
infrastructureConfig:
apiVersion: azure.provider.extensions.gardener.cloud/v1alpha1
kind: InfrastructureConfig
networks:
vnet:
cidr: 10.250.0.0/16
workers: 10.250.0.0/19
natGateway:
enabled: true
zone: 1
ipAddresses:
- name: pip1
resourceGroup: group
zone: 1
- name: pip2
resourceGroup: group
zone: 1
zoned: true
to
infrastructureConfig:
apiVersion: azure.provider.extensions.gardener.cloud/v1alpha1
kind: InfrastructureConfig
zoned: true
networks:
vnet:
cidr: 10.250.0.0/16
zones:
- name: 1
cidr: 10.250.0.0/19 # note the preservation of the 'workers' CIDR
natGateway:
enabled: true
ipAddresses:
- name: pip1
resourceGroup: group
zone: 1
- name: pip2
resourceGroup: group
zone: 1
# optionally add other zones
# - name: 2
# cidr: 10.250.32.0/19
# natGateway:
# enabled: true
# ipAddresses:
# - name: pip3
# resourceGroup: group
You can apply such change to your shoot by issuing a kubectl patch command to replace your current .spec.provider.infrastructureConfig section:
$ cat new-infra.json
[
{
"op": "replace",
"path": "/spec/provider/infrastructureConfig",
"value": {
"apiVersion": "azure.provider.extensions.gardener.cloud/v1alpha1",
"kind": "InfrastructureConfig",
"networks": {
"vnet": {
"cidr": "<your-vnet-cidr>"
},
"zones": [
{
"name": 1,
"cidr": "10.250.0.0/24",
"natGateway": {
"enabled": true
}
},
{
"name": 1,
"cidr": "10.250.1.0/24",
"natGateway": {
"enabled": true
}
},
]
},
"zoned": true
}
}
]
kubectl patch --type="json" --patch-file new-infra.json shoot <my-shoot>
Warning
The migration to shoots with dedicated subnets per zone is a one-way process. Reverting the shoot to the previous configuration is not supported. During the migration a subset of the nodes will be rolled to the new subnets.
ControlPlaneConfig
The control plane configuration mainly contains values for the Azure-specific control plane components.
Today, the only component deployed by the Azure extension is the cloud-controller-manager.
An example ControlPlaneConfig for the Azure extension looks as follows:
apiVersion: azure.provider.extensions.gardener.cloud/v1alpha1
kind: ControlPlaneConfig
cloudControllerManager:
# featureGates:
# SomeKubernetesFeature: true
The cloudControllerManager.featureGates contains a map of explicitly enabled or disabled feature gates.
For production usage it’s not recommend to use this field at all as you can enable alpha features or disable beta/stable features, potentially impacting the cluster stability.
If you don’t want to configure anything for the cloudControllerManager simply omit the key in the YAML specification.
storage contains options for storage-related control plane component.
storage.managedDefaultStorageClass is enabled by default and will deploy a storageClass and mark it as a default (via the storageclass.kubernetes.io/is-default-class annotation)
storage.managedDefaultVolumeSnapshotClass is enabled by default and will deploy a volumeSnapshotClass and mark it as a default (via the snapshot.storage.kubernetes.io/is-default-classs annotation)
In case you want to manage your own default storageClass or volumeSnapshotClass you need to disable the respective options above, otherwise reconciliation of the controlplane may fail.
WorkerConfig
The Azure extension supports encryption for volumes plus support for additional data volumes per machine.
Please note that you cannot specify the encrypted flag for Azure disks as they are encrypted by default/out-of-the-box.
For each data volume, you have to specify a name.
The following YAML is a snippet of a Shoot resource:
spec:
provider:
workers:
- name: cpu-worker
...
volume:
type: Standard_LRS
size: 20Gi
dataVolumes:
- name: kubelet-dir
type: Standard_LRS
size: 25Gi
Additionally, it supports for other Azure-specific values and could be configured under .spec.provider.workers[].providerConfig
An example WorkerConfig for the Azure extension looks like:
apiVersion: azure.provider.extensions.gardener.cloud/v1alpha1
kind: WorkerConfig
nodeTemplate: # (to be specified only if the node capacity would be different from cloudprofile info during runtime)
capacity:
cpu: 2
gpu: 1
memory: 50Gi
diagnosticsProfile:
enabled: true
# storageURI: https://<storage-account-name>.blob.core.windows.net/
dataVolumes:
- name: test-image
imageRef:
communityGalleryImageID: /CommunityGalleries/gardenlinux-13e998fe-534d-4b0a-8a27-f16a73aef620/Images/gardenlinux/Versions/1443.10.0
# sharedGalleryImageID: /SharedGalleries/82fc46df-cc38-4306-9880-504e872cee18-VSMP_MEMORYONE_GALLERY/Images/vSMP_MemoryONE/Versions/1062800168.0.0
# id: /Subscriptions/2ebd38b6-270b-48a2-8e0b-2077106dc615/Providers/Microsoft.Compute/Locations/westeurope/Publishers/sap/ArtifactTypes/VMImage/Offers/gardenlinux/Skus/greatest/Versions/1443.10.0
# urn: sap:gardenlinux:greatest:1443.10.0
The .nodeTemplate is used to specify resource information of the machine during runtime. This then helps in Scale-from-Zero.
Some points to note for this field:
- Currently only cpu, gpu and memory are configurable.
- a change in the value lead to a rolling update of the machine in the worker pool
- all the resources needs to be specified
The .diagnosticsProfile is used to enable machine boot diagnostics (disabled per default).
A storage account is used for storing vm’s boot console output and screenshots.
If .diagnosticsProfile.StorageURI is not specified azure managed storage will be used (recommended way).
The .dataVolumes field is used to add provider specific configurations for dataVolumes.
.dataVolumes[].name must match with one of the names in workers.dataVolumes[].name.
To specify an image source for the dataVolume either use communityGalleryImageID, sharedGalleryImageID, id or urn as imageRef.
However, users have to make sure that the image really exists, there’s yet no check in place.
If the image does not exist the machine will get stuck in creation.
Example Shoot manifest (non-zoned)
Please find below an example Shoot manifest for a non-zoned cluster:
apiVersion: core.gardener.cloud/v1beta1
kind: Shoot
metadata:
name: johndoe-azure
namespace: garden-dev
spec:
cloudProfile:
name: azure
region: westeurope
credentialsBindingName: core-azure
provider:
type: azure
infrastructureConfig:
apiVersion: azure.provider.extensions.gardener.cloud/v1alpha1
kind: InfrastructureConfig
networks:
vnet:
cidr: 10.250.0.0/16
workers: 10.250.0.0/19
zoned: false
controlPlaneConfig:
apiVersion: azure.provider.extensions.gardener.cloud/v1alpha1
kind: ControlPlaneConfig
workers:
- name: worker-xoluy
machine:
type: Standard_D4_v3
minimum: 2
maximum: 2
volume:
size: 50Gi
type: Standard_LRS
# providerConfig:
# apiVersion: azure.provider.extensions.gardener.cloud/v1alpha1
# kind: WorkerConfig
# nodeTemplate: # (to be specified only if the node capacity would be different from cloudprofile info during runtime)
# capacity:
# cpu: 2
# gpu: 1
# memory: 50Gi
networking:
type: calico
pods: 100.96.0.0/11
nodes: 10.250.0.0/16
services: 100.64.0.0/13
kubernetes:
version: 1.28.2
maintenance:
autoUpdate:
kubernetesVersion: true
machineImageVersion: true
addons:
kubernetesDashboard:
enabled: true
nginxIngress:
enabled: true
Example Shoot manifest (zoned)
Please find below an example Shoot manifest for a zoned cluster:
apiVersion: core.gardener.cloud/v1beta1
kind: Shoot
metadata:
name: johndoe-azure
namespace: garden-dev
spec:
cloudProfile:
name: azure
region: westeurope
credentialsBindingName: core-azure
provider:
type: azure
infrastructureConfig:
apiVersion: azure.provider.extensions.gardener.cloud/v1alpha1
kind: InfrastructureConfig
networks:
vnet:
cidr: 10.250.0.0/16
workers: 10.250.0.0/19
zoned: true
controlPlaneConfig:
apiVersion: azure.provider.extensions.gardener.cloud/v1alpha1
kind: ControlPlaneConfig
workers:
- name: worker-xoluy
machine:
type: Standard_D4_v3
minimum: 2
maximum: 2
volume:
size: 50Gi
type: Standard_LRS
zones:
- "1"
- "2"
networking:
type: calico
pods: 100.96.0.0/11
nodes: 10.250.0.0/16
services: 100.64.0.0/13
kubernetes:
version: 1.28.2
maintenance:
autoUpdate:
kubernetesVersion: true
machineImageVersion: true
addons:
kubernetesDashboard:
enabled: true
nginxIngress:
enabled: true
Example Shoot manifest (zoned with NAT Gateways per zone)
Please find below an example Shoot manifest for a zoned cluster using NAT Gateways per zone:
apiVersion: core.gardener.cloud/v1beta1
kind: Shoot
metadata:
name: johndoe-azure
namespace: garden-dev
spec:
cloudProfile:
name: azure
region: westeurope
credentialsBindingName: core-azure
provider:
type: azure
infrastructureConfig:
apiVersion: azure.provider.extensions.gardener.cloud/v1alpha1
kind: InfrastructureConfig
networks:
vnet:
cidr: 10.250.0.0/16
zones:
- name: 1
cidr: 10.250.0.0/24
serviceEndpoints:
- Microsoft.Storage
- Microsoft.Sql
natGateway:
enabled: true
idleConnectionTimeoutMinutes: 4
- name: 2
cidr: 10.250.1.0/24
serviceEndpoints:
- Microsoft.Storage
- Microsoft.Sql
natGateway:
enabled: true
zoned: true
controlPlaneConfig:
apiVersion: azure.provider.extensions.gardener.cloud/v1alpha1
kind: ControlPlaneConfig
workers:
- name: worker-xoluy
machine:
type: Standard_D4_v3
minimum: 2
maximum: 2
volume:
size: 50Gi
type: Standard_LRS
zones:
- "1"
- "2"
networking:
type: calico
pods: 100.96.0.0/11
nodes: 10.250.0.0/16
services: 100.64.0.0/13
kubernetes:
version: 1.28.2
maintenance:
autoUpdate:
kubernetesVersion: true
machineImageVersion: true
addons:
kubernetesDashboard:
enabled: true
nginxIngress:
enabled: true
CSI volume provisioners
Every Azure shoot cluster will be deployed with the Azure Disk CSI driver and the Azure File CSI driver.
Kubernetes Versions per Worker Pool
This extension supports gardener/gardener’s WorkerPoolKubernetesVersion feature gate, i.e., having worker pools with overridden Kubernetes versions since gardener-extension-provider-azure@v1.25.
Shoot CA Certificate and ServiceAccount Signing Key Rotation
This extension supports gardener/gardener’s ShootCARotation and ShootSARotation feature gates since gardener-extension-provider-azure@v1.28.
Miscellaneous
Azure Accelerated Networking
All worker machines of the cluster will be automatically configured to use Azure Accelerated Networking if the prerequisites are fulfilled.
The prerequisites are that the cluster must be zoned, and the used machine type and operating system image version are compatible for Accelerated Networking.
Availability Set based shoot clusters will not be enabled for accelerated networking even if the machine type and operating system support it, this is necessary because all machines from the availability set must be scheduled on special hardware, more details can be found here.
Supported machine types are listed in the CloudProfile in .spec.providerConfig.machineTypes[].acceleratedNetworking and the supported operating system image versions are defined in .spec.providerConfig.machineImages[].versions[].acceleratedNetworking.
Support for other Azure instances
The provider extension can be configured to connect to Azure instances other than the public one by providing additional configuration in the CloudProfile:
spec:
…
providerConfig:
apiVersion: azure.provider.extensions.gardener.cloud/v1alpha1
kind: CloudProfileConfig
cloudConfiguration:
name: AzurePublic # AzurePublic | AzureGovernment | AzureChina
machineTypes:
…
…
…
If no configuration is specified the extension will default to the public instance.
Azure instances other than AzurePublic, AzureGovernment, or AzureChina are not supported at this time.
Disabling the automatic deployment of allow-{tcp,udp} loadbalancer services
Using the azure-cloud-controller-manager when a user first creates a loadbalancer service in the cluster, a new Load Balancer is created in Azure and all nodes of the cluster are registered as backend.
When a NAT Gateway is not used, then this Load Balancer is used as a NAT device for outbound traffic by using one of the registered FrontendIPs assigned to the k8s LB service.
In cases where a NATGateway is not used, provider-azure will deploy by default a set of 2 Load Balancer services in the kube-system.
These are responsible for allowing outbound traffic in all cases for UDP and TCP.
There is a way for users to disable the deployment of these additional LBs by using the azure.provider.extensions.gardener.cloud/skip-allow-egress="true" annotation on their shoot.
[!WARNING]
Disabling the system Load Balancers may affect the outbound of your shoot.
Before disabling them, users are highly advised to have created at least one Load Balancer for TCP and UDP or forward outbound traffic via a different route.
Support for VolumeAttributesClasses (Beta in k8s 1.31)
To have the CSI-driver configured to support the necessary features for VolumeAttributesClasses on Azure for shoots with a k8s-version greater than 1.31, use the azure.provider.extensions.gardener.cloud/enable-volume-attributes-class annotation on the shoot. Keep in mind to also enable the required feature flags and runtime-config on the common kubernetes controllers (as outlined in the link above) in the shoot-spec.
For more information and examples on how to configure the volume attributes class, see example provided in the the azuredisk-csi-driver repository.
Shoot clusters with VMSS Flexible Orchestration (VMSS Flex/VMO)
The machines of an Azure cluster can be created while being attached to an Azure Virtual Machine ScaleSet with flexible orchestration.
Azure VMSS Flex is the replacement of Azure AvailabilitySet for non-zoned Azure Shoot clusters as VMSS Flex come with less disadvantages like no blocking machine operations or compatibility with Standard SKU loadbalancer etc.
Now, Azure Shoot clusters are using VMSS Flex by default for non-zoned clusters. In the past you used to need to do the following:
- The
InfrastructureConfigof the Shoot configuration need to contain.zoned=false
Some key facts about VMSS Flex based clusters:
- Unlike regular non-zonal Azure Shoot clusters, which have a primary AvailabilitySet which is shared between all machines in all worker pools of a Shoot cluster, a VMSS Flex based cluster has an own VMSS for each workerpool
- In case the configuration of the VMSS will change (e.g. amount of fault domains in a region change; configured in the CloudProfile) all machines of the worker pool need to be rolled
- It is not possible to migrate an existing primary AvailabilitySet based Shoot cluster to VMSS Flex based Shoot cluster and vice versa
- VMSS Flex based clusters are using
StandardSKU LoadBalancers instead ofBasicSKU LoadBalancers for AvailabilitySet based Shoot clusters
Migrating AvailabilitySet shoots to VMSS Flex
Azure plans to deprecate Basic SKU public IP addresses.
See the official announcement.
This will create issues with existing legacy non-zonal clusters since their existing LoadBalancers are using Basic SKU and they can’t directly migrate to Standard SKU.
Provider-azure is offering a migration path from availability sets to VMSS Flex.
You have to annotate your shoot with the following annotation: migration.azure.provider.extensions.gardener.cloud/vmo='true' and trigger the shoot Maintenance.
The process for the migration closely traces the process outlined by Azure
This will allow you to preserve your public IPs during the migration.
During this process there will be downtime that users need to plan.
For the transition the Loadbalancer will have to be deleted and recreated.
Also all nodes will have to roll out to the VMSS flex workers.
The rollout is controlled by the worker’s MCM settings, but it is suggested that you speed up this process so that traffic to your cluster is restored as quickly as possible (for example by using higher maxUnavailable values)
BackupBucketConfig
Immutable Buckets
The extension provides a gated feature currently in alpha called enableImmutableBuckets.
To make use of this feature, and enable the extension to react to the configuration below, you will need to set config.featureGates.enableImmutableBuckets: true in your helm charts’ values.yaml. See values.yaml for an example.
Before enabling this feature, you will need to add additional permissions to your Azure credential. Please check the linked section in docs/usage/azure-permissions.md.
BackupBucketConfig describes the configuration that needs to be passed over for creation of the backup bucket infrastructure. Configuration like immutability (WORM, i.e. write-once-read-many) that can be set on the bucket are specified here. Objects in the bucket will inherit the immutability duration which is set on the bucket, and they can not be modified or deleted for that duration.
This extension supports creating (and migrating already existing buckets if enabled) to use container-level WORM policies.
Example:
apiVersion: azure.provider.extensions.gardener.cloud/v1alpha1
kind: BackupBucketConfig
immutability:
retentionType: "bucket"
retentionPeriod: 24h
locked: false
Options:
retentionType: Specifies the type of retention policy. The allowed value isbucket, which applies the retention policy to the entire bucket. See the documentation.retentionPeriod: Defines the duration for which objects in the bucket will remain immutable. Azure Blob Storage only supports immutability durations in days, therefore this field must be set as multiples of 24h.locked: A boolean indicating whether the retention policy is locked. Once locked, the policy cannot be removed or shortened, ensuring immutability. Learn more about locking policies here.
To configure a BackupBucket with immutability, include the BackupBucketConfig in the ProviderConfig of the BackupBucket resource. If the locked field is set to true, the retention policy will be locked, preventing further changes. However, the retention interval can be lengthened for a locked policy up to five times, but it can’t be shortened.
Here is an example of configuring a BackupBucket with immutability:
apiVersion: extensions.gardener.cloud/v1alpha1
kind: BackupBucket
metadata:
name: my-backup-bucket
spec:
region: westeurope
secretRef:
name: my-azure-secret
namespace: my-namespace
providerConfig:
apiVersion: azure.provider.extensions.gardener.cloud/v1alpha1
kind: BackupBucketConfig
immutability:
retentionType: "bucket"
retentionPeriod: 24h
locked: true
Storage Account Key Rotation
Here is an example of configuring a BackupBucket configured with key rotation:
apiVersion: extensions.gardener.cloud/v1alpha1
kind: BackupBucket
metadata:
name: my-backup-bucket
spec:
region: westeurope
secretRef:
name: my-azure-secret
namespace: my-namespace
providerConfig:
apiVersion: azure.provider.extensions.gardener.cloud/v1alpha1
kind: BackupBucketConfig
rotationConfig:
rotationPeriodDays: 2
expirationPeriodDays: 10
Storage account key rotation is only enabled when the rotationConfig is configured.
A storage account in Azure is always created with 2 different keys.
Every triggered rotation by the BackupBucket controller will rotate the key that is not currently in use, and update the BackupBucket referenced secret to the new key.
In addition operators can annotate a BackupBucket with azure.provider.extensions.gardener.cloud/rotate=true to trigger a key rotation on the next reconciliation, regardless of the key’s age.
Options:
rotationPeriodDays: Defines the period after its creation that anstorage account keyshould be rotated.expirationPeriodDays: When specified it will install an expiration policy for keys in the Azure storage account.
Warning
A full rotation (a rotation of both storage account keys) is completed after 2*
rotationPeriod. It is suggested that therotationPeriodis configured at least twice the maintenance interval of the shoots. This will ensure that at least one active key is currently used by the etcd-backup pods.
4 - Provider Equinix Metal
!!Equinix Metal Sunset!!
Please be advised to Equinix Metal Sunset notice!
Equinix has stopped commercial sales of Equinix Metal and will sunset the service at the end of June 2026. Customers have to find alternative solutions for their infrastructure.
Gardener Extension for Equinix Metal provider
Project Gardener implements the automated management and operation of Kubernetes clusters as a service. Its main principle is to leverage Kubernetes concepts for all of its tasks.
Recently, most of the vendor specific logic has been developed in-tree. However, the project has grown to a size where it is very hard to extend, maintain, and test. With GEP-1 we have proposed how the architecture can be changed in a way to support external controllers that contain their very own vendor specifics. This way, we can keep Gardener core clean and independent.
This controller implements Gardener’s extension contract for the Equinix Metal provider.
An example for a ControllerRegistration resource that can be used to register this controller to Gardener can be found here.
Please find more information regarding the extensibility concepts and a detailed proposal here.
Supported Kubernetes versions
This extension controller supports the following Kubernetes versions:
| Version | Support | Conformance test results |
|---|---|---|
| Kubernetes 1.31 | untested | N/A |
| Kubernetes 1.30 | untested | N/A |
| Kubernetes 1.29 | untested | N/A |
| Kubernetes 1.28 | untested | N/A |
| Kubernetes 1.27 | untested | N/A |
Please take a look here to see which versions are supported by Gardener in general.
How to start using or developing this extension controller locally
You can run the controller locally on your machine by executing make start.
Static code checks and tests can be executed by running make verify. We are using Go modules for Golang package dependency management and Ginkgo/Gomega for testing.
Caveats
You can use all available disks on your Equinix instance, but only under certain conditions:
- You must use Flatcar
- You must have a homogenous worker pool (all workers use the same OS and container engine)
- You must set any value for
DataVolume
Feedback and Support
Feedback and contributions are always welcome!
Please report bugs or suggestions as GitHub issues or reach out on Slack (join the workspace here).
Learn more!
Please find further resources about out project here:
- Our landing page gardener.cloud
- “Gardener, the Kubernetes Botanist” blog on kubernetes.io
- “Gardener Project Update” blog on kubernetes.io
- GEP-1 (Gardener Enhancement Proposal) on extensibility
- GEP-4 (New
core.gardener.cloud/v1beta1API) - Extensibility API documentation
- Gardener Extensions Golang library
- Gardener API Reference
4.1 - Operations
Using the Equinix Metal provider extension with Gardener as operator
The core.gardener.cloud/v1beta1.CloudProfile resource declares a providerConfig field that is meant to contain provider-specific configuration.
In this document we are describing how this configuration looks like for Equinix Metal and provide an example CloudProfile manifest with minimal configuration that you can use to allow creating Equinix Metal shoot clusters.
Example CloudProfile manifest
Please find below an example CloudProfile manifest:
apiVersion: core.gardener.cloud/v1beta1
kind: CloudProfile
metadata:
name: equinix-metal
spec:
type: equinixmetal
kubernetes:
versions:
- version: 1.27.2
#expirationDate: "2023-03-15T23:59:59Z"
machineImages:
- name: flatcar
versions:
- version: 0.0.0-stable
machineTypes:
- name: t1.small
cpu: "4"
gpu: "0"
memory: 8Gi
usable: true
regions: # List of offered metros
- name: ny
zones: # List of offered facilities within the respective metro
- name: ewr1
- name: ny5
- name: ny7
providerConfig:
apiVersion: equinixmetal.provider.extensions.gardener.cloud/v1alpha1
kind: CloudProfileConfig
machineImages:
- name: flatcar
versions:
- version: 0.0.0-stable
id: flatcar_stable
- version: 3510.2.2
ipxeScriptUrl: https://stable.release.flatcar-linux.net/amd64-usr/3510.2.2/flatcar_production_packet.ipxe
CloudProfileConfig
The cloud profile configuration contains information about the real machine image IDs in the Equinix Metal environment (IDs).
You have to map every version that you specify in .spec.machineImages[].versions here such that the Equinix Metal extension knows the ID for every version you want to offer.
Equinix Metal supports two different options to specify the image:
- Supported Operating System: Images that are provided by Equinix Metal. They are referenced by their ID (
slug). See (Operating Systems Reference)[https://deploy.equinix.com/developers/docs/metal/operating-systems/supported/#operating-systems-reference] for all supported operating system and their ids. - Custom iPXE Boot: Equinix Metal supports passing custom iPXE scripts during provisioning, which allows you to install a custom operating system manually. This is useful if you want to have a custom image or want to pin to a specific version. See Custom iPXE Boot for details.
An example CloudProfileConfig for the Equinix Metal extension looks as follows:
apiVersion: equinixmetal.provider.extensions.gardener.cloud/v1alpha1
kind: CloudProfileConfig
machineImages:
- name: flatcar
versions:
- version: 0.0.0-stable
id: flatcar_stable
- version: 3510.2.2
ipxeScriptUrl: https://stable.release.flatcar-linux.net/amd64-usr/3510.2.2/flatcar_production_packet.ipxe
NOTE:
CloudProfileConfigis not a Custom Resource, so you cannot create it directly.
4.2 - Usage
Using the Equinix Metal provider extension with Gardener as end-user
The core.gardener.cloud/v1beta1.Shoot resource declares a few fields that are meant to contain provider-specific configuration.
In this document we are describing how this configuration looks like for Equinix Metal and provide an example Shoot manifest with minimal configuration that you can use to create an Equinix Metal cluster (modulo the landscape-specific information like cloud profile names, secret binding names, etc.).
Provider secret data
Every shoot cluster references a SecretBinding which itself references a Secret, and this Secret contains the provider credentials of your Equinix Metal project.
This Secret must look as follows:
apiVersion: v1
kind: Secret
metadata:
name: my-secret
namespace: garden-dev
type: Opaque
data:
apiToken: base64(api-token)
projectID: base64(project-id)
Please look up https://metal.equinix.com/developers/api/ as well.
With Secret created, create a SecretBinding resource referencing it. It may look like this:
apiVersion: core.gardener.cloud/v1beta1
kind: SecretBinding
metadata:
name: my-secret
namespace: garden-dev
secretRef:
name: my-secret
quotas: []
InfrastructureConfig
Currently, there is no infrastructure configuration possible for the Equinix Metal environment.
An example InfrastructureConfig for the Equinix Metal extension looks as follows:
apiVersion: equinixmetal.provider.extensions.gardener.cloud/v1alpha1
kind: InfrastructureConfig
The Equinix Metal extension will only create a key pair.
ControlPlaneConfig
The control plane configuration mainly contains values for the Equinix Metal-specific control plane components.
Today, the Equinix Metal extension deploys the cloud-controller-manager and the CSI controllers, however, it doesn’t offer any configuration options at the moment.
An example ControlPlaneConfig for the Equinix Metal extension looks as follows:
apiVersion: equinixmetal.provider.extensions.gardener.cloud/v1alpha1
kind: ControlPlaneConfig
WorkerConfig
The Equinix Metal extension supports specifying IDs for reserved devices that should be used for the machines of a specific worker pool.
An example WorkerConfig for the Equinix Metal extension looks as follows:
apiVersion: equinixmetal.provider.extensions.gardener.cloud/v1alpha1
kind: WorkerConfig
reservationIDs:
- my-reserved-device-1
- my-reserved-device-2
reservedDevicesOnly: false
The .reservationIDs[] list contains the list of IDs of the reserved devices.
The .reservedDevicesOnly field indicates whether only reserved devices from the provided list of reservation IDs should be used when new machines are created.
It always will attempt to create a device from one of the reservation IDs.
If none is available, the behaviour depends on the setting:
true: return an errorfalse: request a regular on-demand device
The default value is false.
Example Shoot manifest
Please find below an example Shoot manifest:
apiVersion: core.gardener.cloud/v1beta1
kind: Shoot
metadata:
name: my-shoot
namespace: garden-dev
spec:
cloudProfileName: equinix-metal
region: ny # Corresponds to a metro
secretBindingName: my-secret
provider:
type: equinixmetal
infrastructureConfig:
apiVersion: equinixmetal.provider.extensions.gardener.cloud/v1alpha1
kind: InfrastructureConfig
controlPlaneConfig:
apiVersion: equinixmetal.provider.extensions.gardener.cloud/v1alpha1
kind: ControlPlaneConfig
workers:
- name: worker-pool1
machine:
type: t1.small
minimum: 2
maximum: 2
volume:
size: 50Gi
type: storage_1
zones: # Optional list of facilities, all of which MUST be in the metro; if not provided, then random facilities within the metro will be chosen for each machine.
- ewr1
- ny5
- name: reserved-pool
machine:
type: t1.small
minimum: 1
maximum: 2
providerConfig:
apiVersion: equinixmetal.provider.extensions.gardener.cloud/v1alpha1
kind: WorkerConfig
reservationIDs:
- reserved-device1
- reserved-device2
reservedDevicesOnly: true
volume:
size: 50Gi
type: storage_1
networking:
type: calico
kubernetes:
version: 1.27.2
maintenance:
autoUpdate:
kubernetesVersion: true
machineImageVersion: true
addons:
kubernetesDashboard:
enabled: true
nginxIngress:
enabled: true
⚠️ Note that if you specify multiple facilities in the .spec.provider.workers[].zones[] list then new machines are randomly created in one of the provided facilities.
Particularly, it is not ensured that all facilities are used or that all machines are equally or unequally distributed.
Kubernetes Versions per Worker Pool
This extension supports gardener/gardener’s WorkerPoolKubernetesVersion feature gate, i.e., having worker pools with overridden Kubernetes versions since gardener-extension-provider-equinix-metal@v2.2.
Shoot CA Certificate and ServiceAccount Signing Key Rotation
This extension supports gardener/gardener’s ShootCARotation feature gate since gardener-extension-provider-equinix-metal@v2.3 and ShootSARotation feature gate since gardener-extension-provider-equinix-metal@v2.4.
5 - Provider GCP
Gardener Extension for GCP provider
Project Gardener implements the automated management and operation of Kubernetes clusters as a service. Its main principle is to leverage Kubernetes concepts for all of its tasks.
Recently, most of the vendor specific logic has been developed in-tree. However, the project has grown to a size where it is very hard to extend, maintain, and test. With GEP-1 we have proposed how the architecture can be changed in a way to support external controllers that contain their very own vendor specifics. This way, we can keep Gardener core clean and independent.
This controller implements Gardener’s extension contract for the GCP provider.
An example for a ControllerRegistration resource that can be used to register this controller to Gardener can be found here.
Please find more information regarding the extensibility concepts and a detailed proposal here.
Supported Kubernetes versions
This extension controller supports the following Kubernetes versions:
| Version | Support | Conformance test results |
|---|---|---|
| Kubernetes 1.33 | 1.33.0+ | N/A |
| Kubernetes 1.32 | 1.32.0+ | |
| Kubernetes 1.31 | 1.31.0+ | |
| Kubernetes 1.30 | 1.30.0+ | |
| Kubernetes 1.29 | 1.29.0+ | |
| Kubernetes 1.28 | 1.28.0+ | |
| Kubernetes 1.27 | 1.27.0+ |
Please take a look here to see which versions are supported by Gardener in general.
How to start using or developing this extension controller locally
You can run the controller locally on your machine by executing make start.
Static code checks and tests can be executed by running make verify. We are using Go modules for Golang package dependency management and Ginkgo/Gomega for testing.
Feedback and Support
Feedback and contributions are always welcome!
Please report bugs or suggestions as GitHub issues or reach out on Slack (join the workspace here).
Learn more!
Please find further resources about out project here:
- Our landing page gardener.cloud
- “Gardener, the Kubernetes Botanist” blog on kubernetes.io
- “Gardener Project Update” blog on kubernetes.io
- GEP-1 (Gardener Enhancement Proposal) on extensibility
- GEP-4 (New
core.gardener.cloud/v1beta1API) - Extensibility API documentation
- Gardener Extensions Golang library
- Gardener API Reference
5.1 - Tutorials
5.1.1 - Create a Кubernetes Cluster on GCP with Gardener
Overview
Gardener allows you to create a Kubernetes cluster on different infrastructure providers. This tutorial will guide you through the process of creating a cluster on GCP.
Prerequisites
- You have created a GCP account.
- You have access to the Gardener dashboard and have permissions to create projects.
Steps
Go to the Gardener dashboard and create a Project.
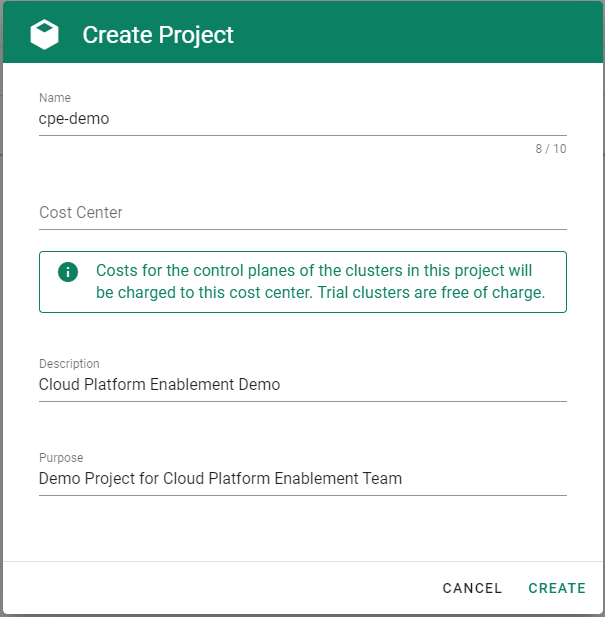
Check which roles are required by Gardener.
Choose Secrets, then the plus icon
 and select GCP.
and select GCP.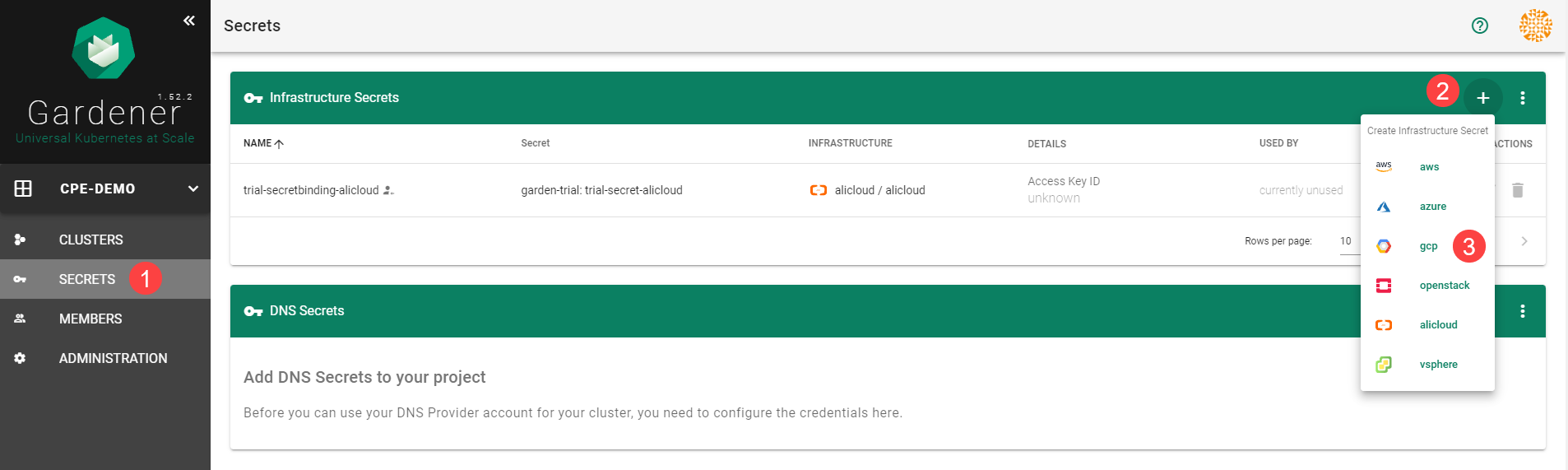
Click on the help button
 .
.
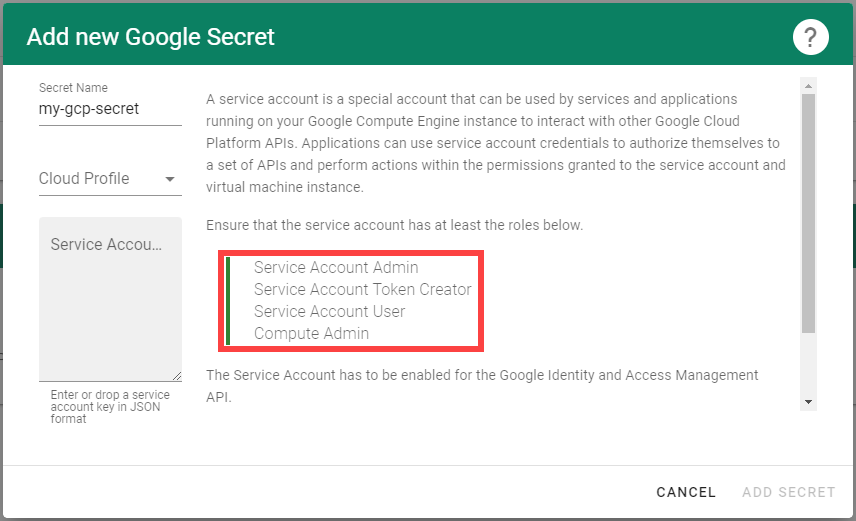
Create a service account with the correct roles in GCP:
Create a new service account in GCP.

Enter the name and description of your service account.
Assign the roles required by Gardener.
Choose Done.
Create a key for your service:
Locate your service account, then choose Actions and Manage keys.
Choose Add Key, then Create new key.
Save the private key of the service account in JSON format.
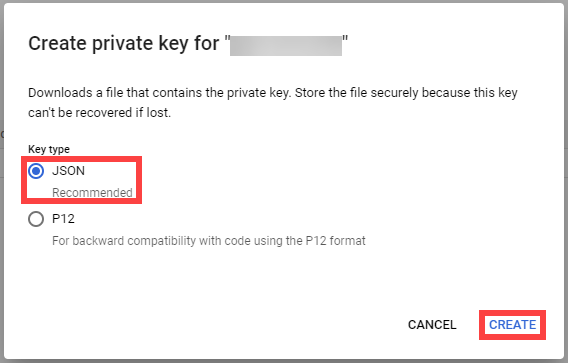
Tip
Save the key of the user, it’s used later to create secrets for Gardener.
Enable the Google Compute API by following these steps.
When you are finished, you should see the following page:
Enable the Google IAM API by following these steps.
When you are finished, you should see the following page:
On the Gardener dashboard, choose Secrets and then the plus sign
. Select GCP from the drop down menu to add a new GCP secret.Create your secret.
- Type the name of your secret.
- Select your Cloud Profile.
- Copy and paste the contents of the .JSON file you saved when you created the secret key on GCP.
- Choose Add secret.
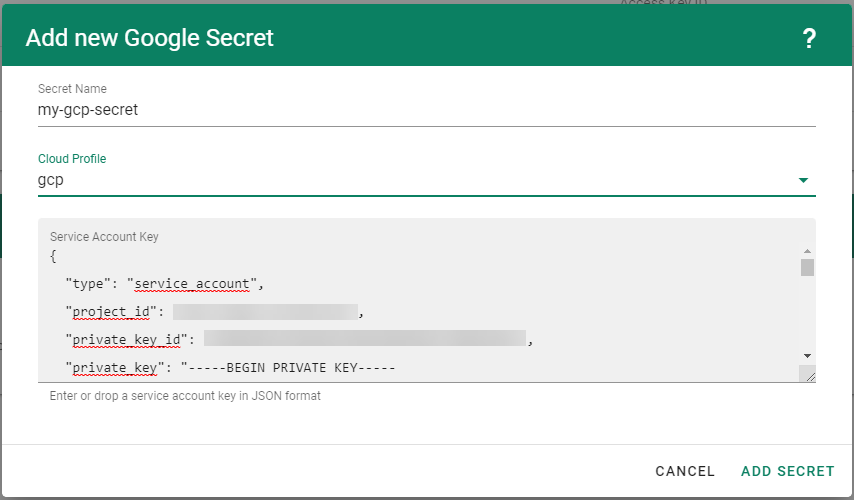
After completing these steps, you should see your newly created secret in the Infrastructure Secrets section.
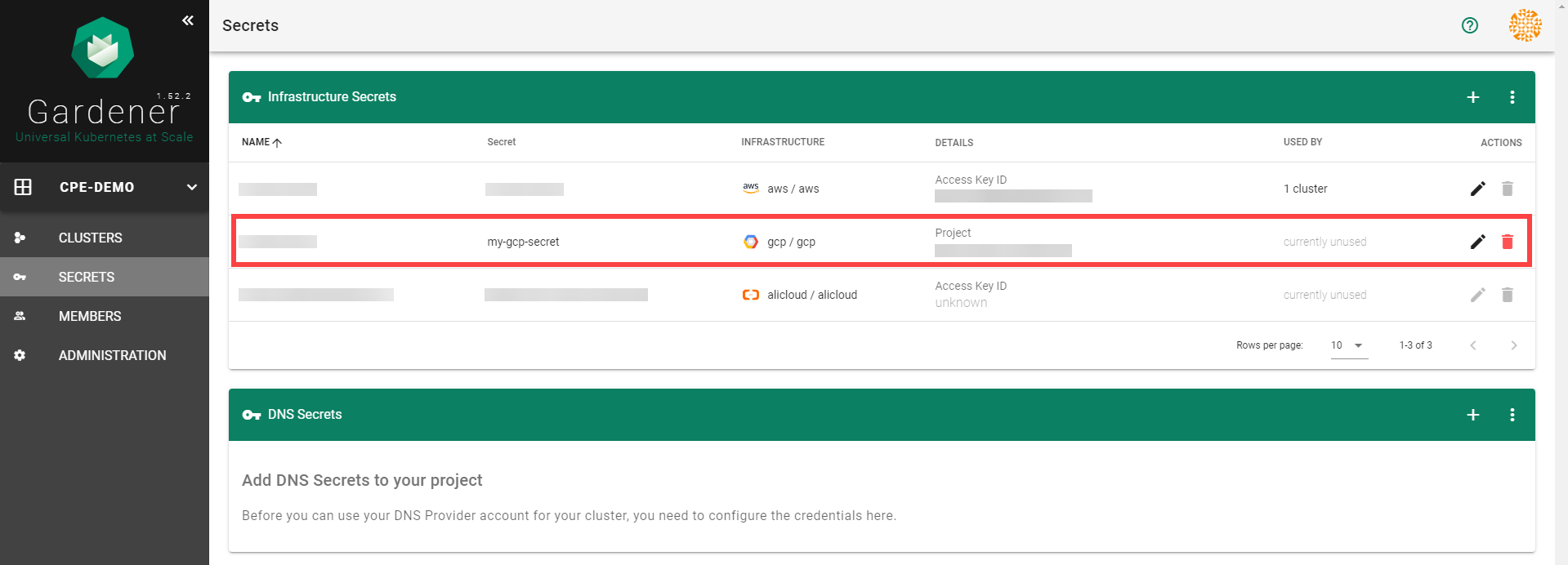
To create a new cluster, choose Clusters and then the plus sign in the upper right corner.
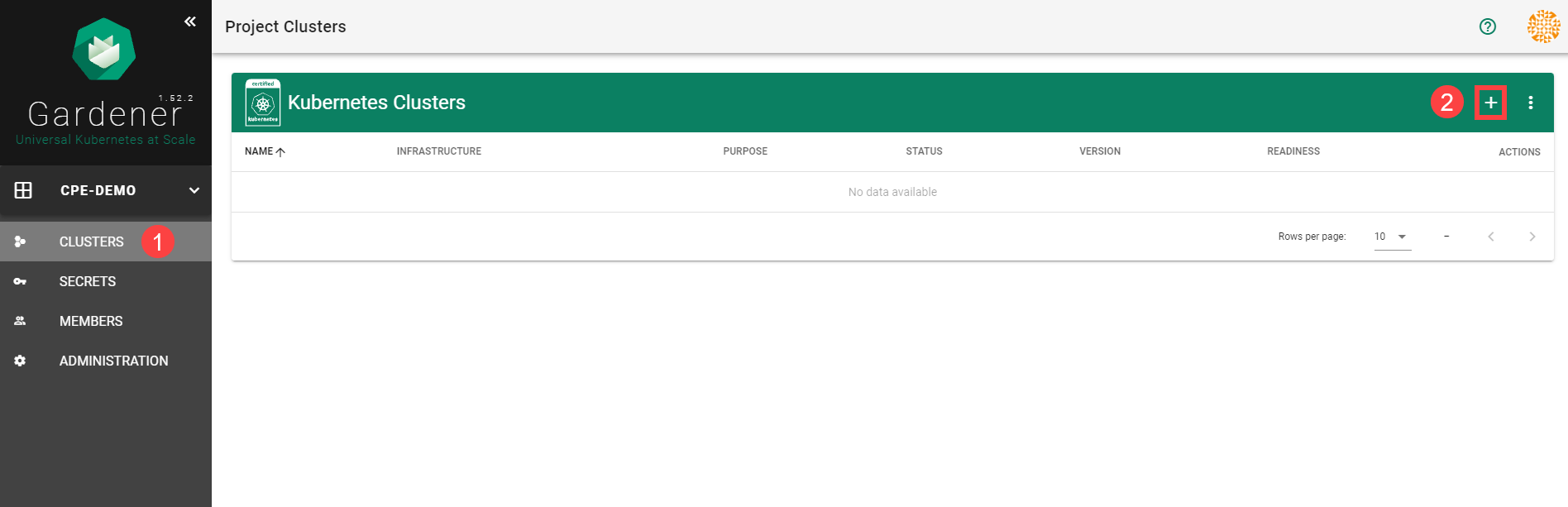
In the Create Cluster section:
- Select GCP in the Infrastructure tab.
- Type the name of your cluster in the Cluster Details tab.
- Choose the secret you created before in the Infrastructure Details tab.
- Choose Create.
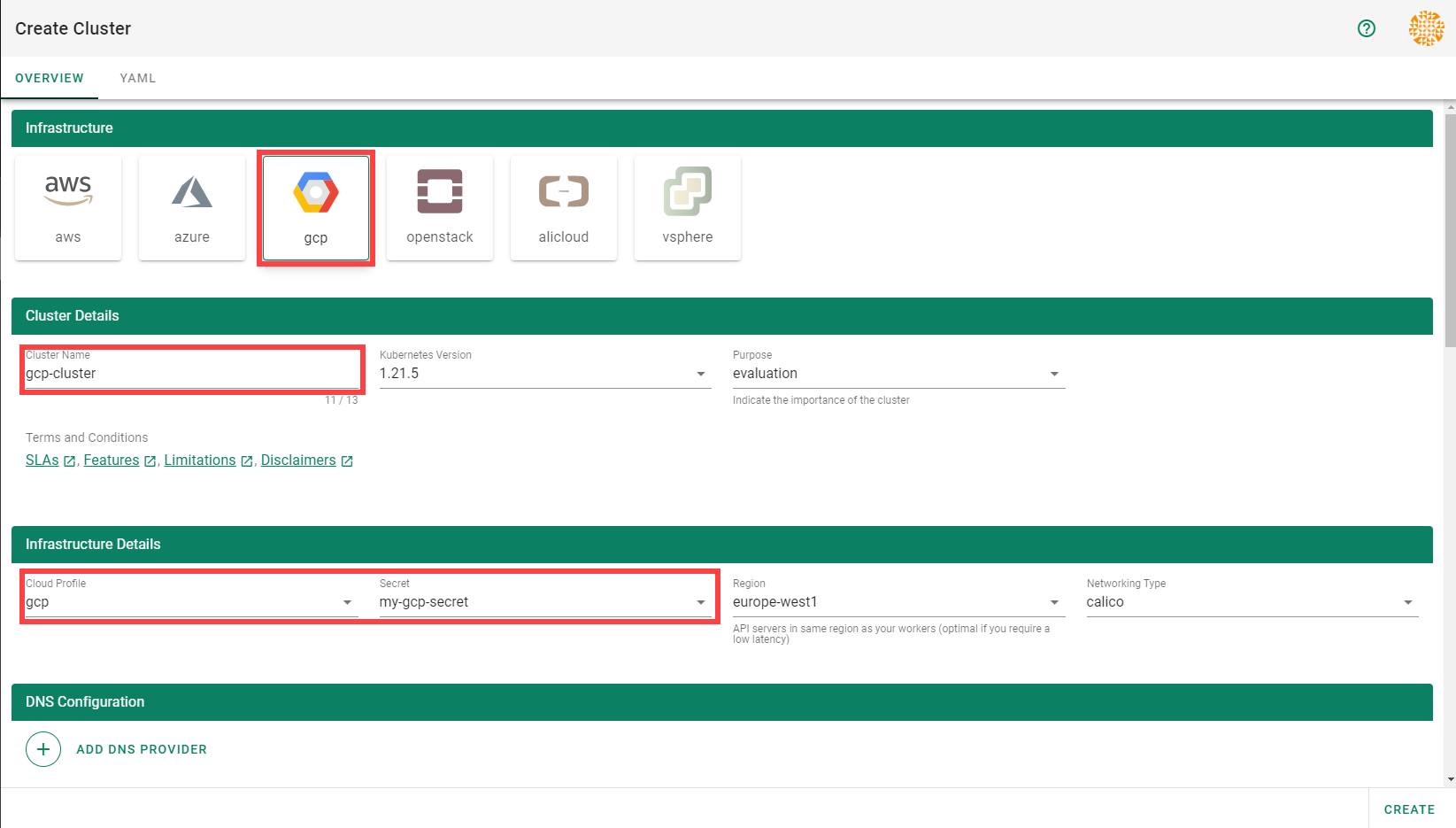
Wait for your cluster to get created.
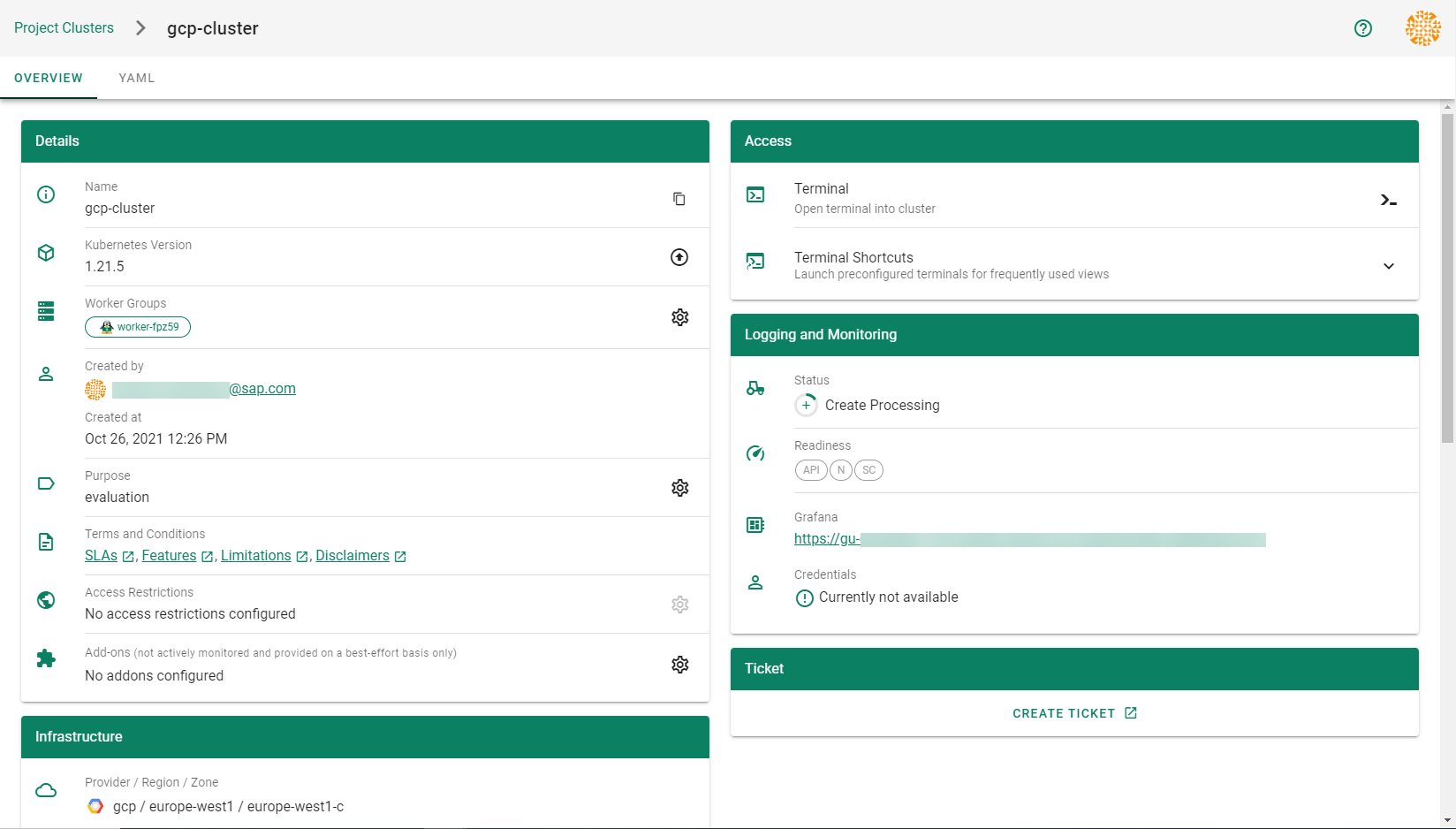
Result
After completing the steps in this tutorial, you will be able to see and download the kubeconfig of your cluster.
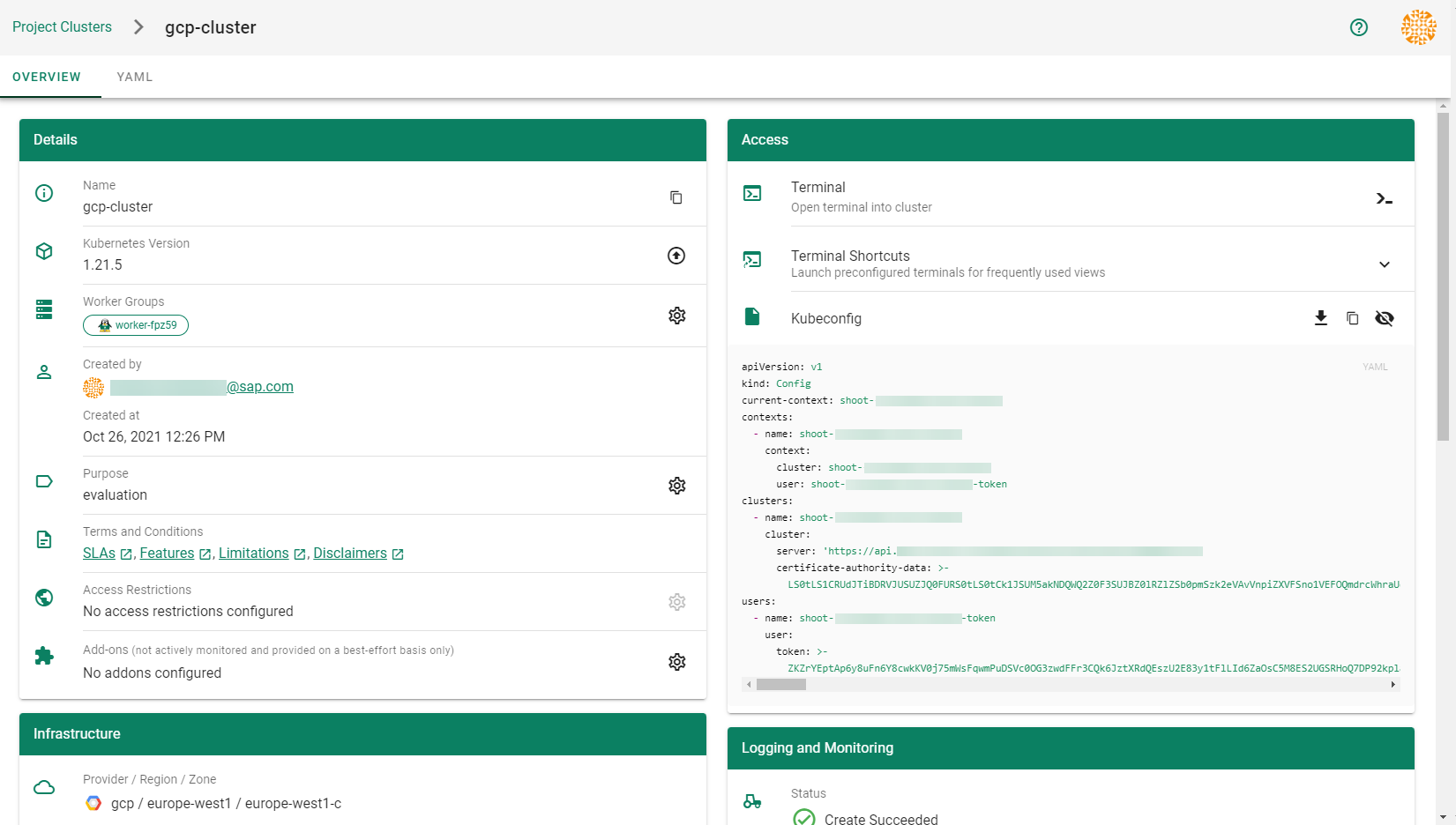
5.2 - Data Disk Restore From Image
Data Disk Restore From Image
Table of Contents
Summary
Currently, we have no support either in the shoot spec or in the MCM GCP Provider for restoring GCP Data Disks from images.
Motivation
The primary motivation is to support Integration of vSMP MemeoryOne in Azure. We implemented support for this in AWS via Support for data volume snapshot ID . In GCP we have the option to restore data disk from a custom image which is more convenient and flexible.
Goals
- Extend the GCP provider specific WorkerConfig section in the shoot YAML and support provider configuration for data-disks to support data-disk creation from an image name by supplying an image name.
Proposal
Shoot Specification
At this current time, there is no support for provider specific configuration of data disks in an GCP shoot spec. The below shows an example configuration at the time of this proposal:
providerConfig:
apiVersion: gcp.provider.extensions.gardener.cloud/v1alpha1
kind: WorkerConfig
volume:
interface: NVME
encryption: # optional, skipped detail here
serviceAccount:
email: foo@bar.com
scopes:
- https://www.googleapis.com/auth/cloud-platform
gpu:
acceleratorType: nvidia-tesla-t4
count: 1
We propose that the worker config section be enahnced to support data disk configuration
providerConfig:
apiVersion: gcp.provider.extensions.gardener.cloud/v1alpha1
kind: WorkerConfig
volume:
interface: NVME
encryption: # optional, skipped detail here
dataVolumes: # <-- NEW SUB_SECTION
- name: vsmp1
image: imgName
serviceAccount:
email: foo@bar.com
scopes:
- https://www.googleapis.com/auth/cloud-platform
gpu:
acceleratorType: nvidia-tesla-t4
count: 1
In the above imgName specified in providerConfig.dataVolumes.image represents the image name of a previously created image created by a tool or process.
See Google Cloud Create Image.
The MCM GCP Provider will ensure when a VM instance is instantiated, that the data
disk(s) for the VM are created with the source image set to the provided imgName.
The mechanics of this is left to MCM GCP provider. See image param to --create-disk flag in
Google Cloud Instance Creation
5.3 - Deployment
Deployment of the GCP provider extension
Disclaimer: This document is NOT a step-by-step installation guide for the GCP provider extension and only contains some configuration specifics regarding the installation of different components via the helm charts residing in the GCP provider extension repository.
gardener-extension-admission-gcp
Authentication against the Garden cluster
There are several authentication possibilities depending on whether or not the concept of Virtual Garden is used.
Virtual Garden is not used, i.e., the runtime Garden cluster is also the target Garden cluster.
Automounted Service Account Token
The easiest way to deploy the gardener-extension-admission-gcp component will be to not provide kubeconfig at all. This way in-cluster configuration and an automounted service account token will be used. The drawback of this approach is that the automounted token will not be automatically rotated.
Service Account Token Volume Projection
Another solution will be to use Service Account Token Volume Projection combined with a kubeconfig referencing a token file (see example below).
apiVersion: v1
kind: Config
clusters:
- cluster:
certificate-authority-data: <CA-DATA>
server: https://default.kubernetes.svc.cluster.local
name: garden
contexts:
- context:
cluster: garden
user: garden
name: garden
current-context: garden
users:
- name: garden
user:
tokenFile: /var/run/secrets/projected/serviceaccount/token
This will allow for automatic rotation of the service account token by the kubelet. The configuration can be achieved by setting both .Values.global.serviceAccountTokenVolumeProjection.enabled: true and .Values.global.kubeconfig in the respective chart’s values.yaml file.
Virtual Garden is used, i.e., the runtime Garden cluster is different from the target Garden cluster.
Service Account
The easiest way to setup the authentication will be to create a service account and the respective roles will be bound to this service account in the target cluster. Then use the generated service account token and craft a kubeconfig which will be used by the workload in the runtime cluster. This approach does not provide a solution for the rotation of the service account token. However, this setup can be achieved by setting .Values.global.virtualGarden.enabled: true and following these steps:
- Deploy the
applicationpart of the charts in thetargetcluster. - Get the service account token and craft the
kubeconfig. - Set the crafted
kubeconfigand deploy theruntimepart of the charts in theruntimecluster.
Client Certificate
Another solution will be to bind the roles in the target cluster to a User subject instead of a service account and use a client certificate for authentication. This approach does not provide a solution for the client certificate rotation. However, this setup can be achieved by setting both .Values.global.virtualGarden.enabled: true and .Values.global.virtualGarden.user.name, then following these steps:
- Generate a client certificate for the
targetcluster for the respective user. - Deploy the
applicationpart of the charts in thetargetcluster. - Craft a
kubeconfigusing the already generated client certificate. - Set the crafted
kubeconfigand deploy theruntimepart of the charts in theruntimecluster.
Projected Service Account Token
This approach requires an already deployed and configured oidc-webhook-authenticator for the target cluster. Also the runtime cluster should be registered as a trusted identity provider in the target cluster. Then projected service accounts tokens from the runtime cluster can be used to authenticate against the target cluster. The needed steps are as follows:
- Deploy OWA and establish the needed trust.
- Set
.Values.global.virtualGarden.enabled: trueand.Values.global.virtualGarden.user.name. Note: username value will depend on the trust configuration, e.g.,<prefix>:system:serviceaccount:<namespace>:<serviceaccount> - Set
.Values.global.serviceAccountTokenVolumeProjection.enabled: trueand.Values.global.serviceAccountTokenVolumeProjection.audience. Note: audience value will depend on the trust configuration, e.g.,<cliend-id-from-trust-config>. - Craft a kubeconfig (see example below).
- Deploy the
applicationpart of the charts in thetargetcluster. - Deploy the
runtimepart of the charts in theruntimecluster.
apiVersion: v1
kind: Config
clusters:
- cluster:
certificate-authority-data: <CA-DATA>
server: https://virtual-garden.api
name: virtual-garden
contexts:
- context:
cluster: virtual-garden
user: virtual-garden
name: virtual-garden
current-context: virtual-garden
users:
- name: virtual-garden
user:
tokenFile: /var/run/secrets/projected/serviceaccount/token
5.4 - Ipv6
Dual-Stack Support for Gardener GCP Extension
This document provides an overview of dual-stack support for the Gardener GCP extension. Furthermore it clarifies which components are utilized, how the infrastructure is setup and how a dual-stack cluster can be provisioned.
Overview
Gardener allows to create dual-stack clusters on GCP. In this mode, both IPv4 and IPv6 are supported within the cluster. This significantly expands the available address space, enables seamless communication across both IPv4 and IPv6 environments, and ensures compliance with modern networking standards.
Key Components for Dual-Stack Support
- Dual-Stack Subnets: Separate subnets are created for nodes and services, with explicit IPv4 and external IPv6 ranges.
- Ingress-GCE: Responsible for creating dual-stack (IPv4,IPv6) Load Balancers.
- Cloud Allocator: Manages the assignment of IPv4 and IPv6 ranges to nodes and pods.
Dual-Stack Subnets
When provisioning a dual-stack cluster, the GCP provider creates distinct subnets:
1. Node Subnet
- Primary IPv4 Range: Used for IPv4 nodes.
- Secondary IPv4 Range: Used for IPv4 pods.
- External IPv6 Range: Auto-assigned with a
/64prefix. Each VM gets an interface with a/96prefix. - Customization:
- IPv4 ranges (pods and nodes) can be defined in the shoot object.
- IPv6 ranges are automatically filled by the GCP provider.
2. Service Subnet
- This subnet is dedicated to IPv6 services. It is created due to GCP’s limitation of not supporting IPv6 range reservations.
3. Internal Subnet (optional)
- This subnet is dedicated for internal load balancer. Currently, only internal IPv4 loadbalancer are supported. They are provisioned by the Cloud Controller Manager (CCM).
Ingress-GCE
The ingress-gce is a mandatory component for dual-stack clusters. It is responsible for creating dual-stack (IPv4,IPv6) Load Balancers. This is necessary because the GCP Cloud Controller Manager does not support provisioning IPv6 Load Balancer.
Cloud Allocator
The Cloud Allocator is part of the GCP Cloud Controller Manager and plays a critical role in managing IPAM (IP Address Management) for dual-stack clusters.
Responsibilities
- Assigning PODCIDRs to Node Objects: Ensures that both IPv4 and IPv6 pod ranges are correctly assigned to the node objects.
- Leveraging Secondary IPv4 Range:
- Uses the secondary IPv4 range in the node subnet to allocate pod IP ranges.
- Assigns both IPv4 and IPv6 pod ranges in compliance with GCP’s networking model.
Operational Details
- The Cloud Allocator assigns a
/112pod cidr range/subrange from the/96cidr range assigned to each VM. - This ensures efficient utilization of IPv6 address space while maintaining compatibility with Kubernetes networking requirements.
Why Use a Secondary IPv4 Range for Pods?
The secondary IPv4 range is essential for:
- Enabling the Cloud Allocator to function correctly in assigning IP ranges.
- Supporting both IPv4 and IPv6 pods in dual-stack clusters.
- Aligning with GCP CCM’s requirement to separate pod IP ranges within the node subnet.
Creating a Dual-Stack Cluster
To create a dual-stack cluster, both IP families (IPv4,IPv6) need to be specified under spec.networking.ipFamilies. Below is an example of a dual-stack shoot cluster configuration:
apiVersion: core.gardener.cloud/v1beta1
kind: Shoot
metadata:
...
spec:
...
provider:
type: gcp
infrastructureConfig:
apiVersion: gcp.provider.extensions.gardener.cloud/v1alpha1
kind: InfrastructureConfig
networks:
workers: 10.250.0.0/16
...
networking:
type: ...
ipFamilies:
- IPv4
- IPv6
nodes: 10.250.0.0/16
...
Migration of IPv4-Only Shoot Clusters to Dual-Stack
To migrate an IPv4-only shoot cluster to Dual-Stack simply change the .spec.networking.ipFamilies field in the Shoot resource from IPv4 to IPv4, IPv6 as shown below.
kind: Shoot
apiVersion: core.gardener.cloud/v1beta1
metadata:
...
spec:
...
networking:
type: ...
ipFamilies:
- IPv4
- IPv6
...
You can find more information about the process and the steps required here.
Warning
Please note that the dual-stack migration requires the IPv4-only cluster to run in native routing mode, i.e. pod overlay network needs to be disabled. The default quota of static routes per VPC in GCP is 200. This restricts the cluster size. Therefore, please adapt (if necessary) the quota for the routes per VPC (
STATIC_ROUTES_PER_NETWORK) in the gcp cloud console accordingly before switching to native routing.
After triggering the migration a constraint of type DualStackNodesMigrationReady is added to the shoot status. It is in state False until all nodes have an IPv4 and IPv6 address assigned.
Changing the ipFamilies field triggers immediately an infrastructure reconciliation, where the infrastructure is reconfigured to additionally support IPv6. During this infrastructure migration process the subnets get an external IPv6 range and the node subnet gets a secondary IPv4 range. Pod specific cloud routes are deleted from the VPC route table and alias IP ranges for the pod routes are added to the NIC of Kubernetes nodes/instances.
With the next node roll-out which is a manual step and will not be triggered automatically, all nodes will get an IPv6 address and an IPv6 prefix for pods assigned. When all nodes have IPv4 and IPv6 pod ranges, the status of the DualStackNodesMigrationReady constraint will be changed to True.
Once all nodes are migrated, the remaining control plane components and the Container Network Interface (CNI) are configured for dual-stack networking and the migration constraint is removed at the end of this step.
Load Balancer Service Configuration
To create a dual-stack LoadBalancer the spec.ipFamilies and spec.ipFamilyPolicy field needs to be specified in the Kubernetes service.
An example configuration is shown below:
apiVersion: v1
kind: Service
metadata:
name: nginx
namespace: default
annotations:
cloud.google.com/l4-rbs: enabled
spec:
ipFamilies:
- IPv4
- IPv6
ipFamilyPolicy: PreferDualStack
ports:
- port: 12345
protocol: TCP
targetPort: 80
selector:
run: nginx
type: LoadBalancer
The required annotation cloud.google.com/l4-rbs: enabled for ingress-gce is added automatically via webhook for services of type: LoadBalancer.
Internal Load Balancer
- Internal IPv6 LoadBalancers are currently not supported.
- To create internal IPv4 LoadBalancers, you can set one of the the following annotations:
"networking.gke.io/load-balancer-type=Internal""cloud.google.com/load-balancer-type=internal"(deprecated). Internal load balancers are created by cloud-controller-manger and get an IPv4 address from the internal subnet.
5.5 - Local Setup
admission-gcp
admission-gcp is an admission webhook server which is responsible for the validation of the cloud provider (GCP in this case) specific fields and resources. The Gardener API server is cloud provider agnostic and it wouldn’t be able to perform similar validation.
Follow the steps below to run the admission webhook server locally.
Start the Gardener API server.
For details, check the Gardener local setup.
Start the webhook server
Make sure that the
KUBECONFIGenvironment variable is pointing to the local garden cluster.make start-admissionSetup the
ValidatingWebhookConfiguration.hack/dev-setup-admission-gcp.shwill configure the webhook Service which will allow the kube-apiserver of your local cluster to reach the webhook server. It will also apply theValidatingWebhookConfigurationmanifest../hack/dev-setup-admission-gcp.sh
You are now ready to experiment with the admission-gcp webhook server locally.
5.6 - Operations
Using the GCP provider extension with Gardener as operator
The core.gardener.cloud/v1beta1.CloudProfile resource declares a providerConfig field that is meant to contain provider-specific configuration.
The core.gardener.cloud/v1beta1.Seed resource is structured similarly.
Additionally, it allows configuring settings for the backups of the main etcds’ data of shoot clusters control planes running in this seed cluster.
This document explains the necessary configuration for this provider extension.
CloudProfile resource
This section describes, how the configuration for CloudProfiles looks like for GCP by providing an example CloudProfile manifest with minimal configuration that can be used to allow the creation of GCP shoot clusters.
CloudProfileConfig
The cloud profile configuration contains information about the real machine image IDs in the GCP environment (image URLs).
You have to map every version that you specify in .spec.machineImages[].versions here such that the GCP extension knows the image URL for every version you want to offer.
For each machine image version an architecture field can be specified which specifies the CPU architecture of the machine on which given machine image can be used.
An example CloudProfileConfig for the GCP extension looks as follows:
apiVersion: gcp.provider.extensions.gardener.cloud/v1alpha1
kind: CloudProfileConfig
machineImages:
- name: coreos
versions:
- version: 2135.6.0
image: projects/coreos-cloud/global/images/coreos-stable-2135-6-0-v20190801
# architecture: amd64 # optional
Example CloudProfile manifest
If you want to allow that shoots can create VMs with local SSDs volumes then you have to specify the type of the disk with SCRATCH in the .spec.volumeTypes[] list.
Please find below an example CloudProfile manifest:
apiVersion: core.gardener.cloud/v1beta1
kind: CloudProfile
metadata:
name: gcp
spec:
type: gcp
kubernetes:
versions:
- version: 1.32.0
- version: 1.31.2
expirationDate: "2026-03-31T23:59:59Z"
machineImages:
- name: coreos
versions:
- version: 2135.6.0
machineTypes:
- name: n1-standard-4
cpu: "4"
gpu: "0"
memory: 15Gi
volumeTypes:
- name: pd-standard
class: standard
- name: pd-ssd
class: premium
- name: SCRATCH
class: standard
regions:
- region: europe-west1
names:
- europe-west1-b
- europe-west1-c
- europe-west1-d
providerConfig:
apiVersion: gcp.provider.extensions.gardener.cloud/v1alpha1
kind: CloudProfileConfig
machineImages:
- name: coreos
versions:
- version: 2135.6.0
image: projects/coreos-cloud/global/images/coreos-stable-2135-6-0-v20190801
# architecture: amd64 # optional
Seed resource
This provider extension does not support any provider configuration for the Seed’s .spec.provider.providerConfig field.
However, it supports to managing of backup infrastructure, i.e., you can specify a configuration for the .spec.backup field.
Backup configuration
A Seed of type gcp can be configured to perform backups for the main etcds’ of the shoot clusters control planes using Google Cloud Storage buckets.
The location/region where the backups will be stored defaults to the region of the Seed (spec.provider.region), but can also be explicitly configured via the field spec.backup.region.
The region of the backup can be different from where the seed cluster is running.
However, usually it makes sense to pick the same region for the backup bucket as used for the Seed cluster.
Please find below an example Seed manifest (partly) that configures backups using Google Cloud Storage buckets.
---
apiVersion: core.gardener.cloud/v1beta1
kind: Seed
metadata:
name: my-seed
spec:
provider:
type: gcp
region: europe-west1
backup:
provider: gcp
region: europe-west1 # default region
credentialsRef:
apiVersion: v1
kind: Secret
name: backup-credentials
namespace: garden
...
An example of the referenced secret containing the credentials for the GCP Cloud storage can be found in the example folder.
Permissions for GCP Cloud Storage
Please make sure the service account associated with the provided credentials has the following IAM roles.
Rolling Update Triggers
Changes to the Shoot worker-pools are applied in-place where possible.
In case this is not possible a rolling update of the workers will be performed to apply the new configuration,
as outlined in the Gardener documentation.
The exact fields that trigger this behaviour depend on whether the feature gate NewWorkerPoolHash is enabled.
If it is not enabled, only the fields mentioned in the Gardener doc plus the providerConfig are used.
If the feature gate is enabled, it’s the same with a few additions:
.spec.provider.workers[].dataVolumes[].name.spec.provider.workers[].dataVolumes[].size.spec.provider.workers[].dataVolumes[].type
We exclude .spec.provider.workers[].dataVolumes[].encrypted from the hash calculation because GCP disks are encrypted by default,
and the field does not influence disk encryption behavior.
Everything related to disk encryption is handled by the providerConfig.
5.7 - Usage
Using the GCP provider extension with Gardener as end-user
The core.gardener.cloud/v1beta1.Shoot resource declares a few fields that are meant to contain provider-specific configuration.
This document describes the configurable options for GCP and provides an example Shoot manifest with minimal configuration that can be used to create a GCP cluster (modulo the landscape-specific information like cloud profile names, secret binding names, etc.).
Accessing GCP APIs
In order for Gardener to create a Kubernetes cluster using GCP infrastructure components, a Shoot has to provide an authentication mechanism giving sufficient permissions to the desired GCP project.
Every shoot cluster references a SecretBinding or a CredentialsBinding.
Important
While
SecretBindings can only referenceSecrets,CredentialsBindings can also referenceWorkloadIdentitys which provide an alternative authentication method.WorkloadIdentitys do not directly contain credentials but are rather a representation of the workload that is going to access the user’s account. If the user has configured Workload Identity Federation with Gardener’s Workload Identity Issuer then the GCP infrastructure components can access the user’s account without the need of preliminary exchange of credentials.
Important
The
SecretBinding/CredentialsBindingis configurable in the Shoot cluster with the fieldsecretBindingName/credentialsBindingName.SecretBindings are considered legacy and will be deprecated in the future. It is advised to useCredentialsBindings instead.
GCP Service Account Credentials
The required credentials for the GCP project are a Service Account Key to authenticate as a GCP Service Account. A service account is a special account that can be used by services and applications to interact with Google Cloud Platform APIs. Applications can use service account credentials to authorize themselves to a set of APIs and perform actions within the permissions granted to the service account.
Make sure to enable the Google Identity and Access Management (IAM) API. Create a Service Account that shall be used for the Shoot cluster. Grant at least the following IAM roles to the Service Account.
- Service Account Admin
- Service Account Token Creator
- Service Account User
- Compute Admin
Create a JSON Service Account key for the Service Account.
Provide it in the Secret (base64 encoded for field serviceaccount.json), that is being referenced by the SecretBinding in the Shoot cluster configuration.
This Secret must look as follows:
apiVersion: v1
kind: Secret
metadata:
name: core-gcp
namespace: garden-dev
type: Opaque
data:
serviceaccount.json: base64(serviceaccount-json)
Warning
Depending on your API usage it can be problematic to reuse the same Service Account Key for different Shoot clusters due to rate limits. Please consider spreading your Shoots over multiple Service Accounts on different GCP projects if you are hitting those limits, see https://cloud.google.com/compute/docs/api-rate-limits.
GCP Workload Identity Federation
Users can choose to trust Gardener’s Workload Identity Issuer and eliminate the need for providing GCP Service Account credentials.
As a first step users should configure Workload Identity Federation with Gardener’s Workload Identity Issuer.
Tip
You can retrieve Gardener’s Workload Identity Issuer URL directly from the Garden cluster by reading the contents of the Gardener Info ConfigMap.
kubectl -n gardener-system-public get configmap gardener-info -o yaml
In the example attribute mapping shown below all WorkloadIdentitys that are created in the garden-myproj namespace will be authenticated.
Now that the Workload Identity Federation is configured the user should download the credential configuration file.
Important
If required, users can use a stricter mapping to authenticate only certain
WorkloadIdentitys. Please, refer to the attribute mappings documentation for more information.
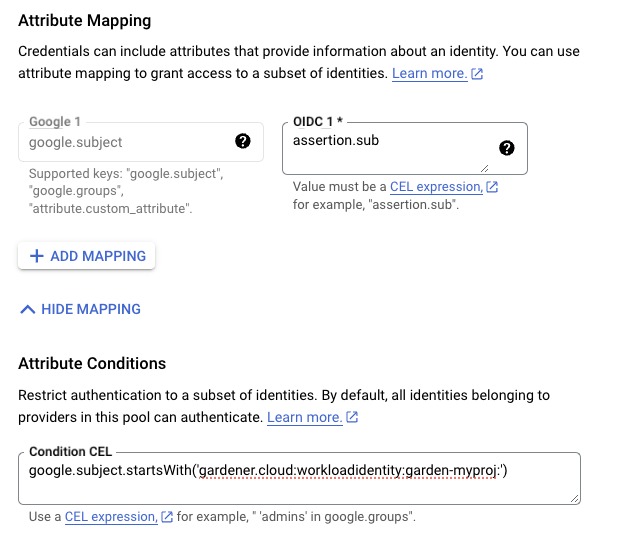
Users should now create a Service Account that is going to be impersonated by the federated identity. Make sure to enable the Google Identity and Access Management (IAM) API. Create a Service Account that shall be used for the Shoot cluster. Grant at least the following IAM roles to the Service Account.
- Service Account Token Creator
- Service Account User
- Compute Admin
As a next step a resource of type WorkloadIdentity should be created in the Garden cluster and configured with the information from the already downloaded credential configuration file.
This identity will be used to impersonate the Service Account in order to call GCP APIs.
Mind that the service_account_impersonation_url is probably not present in the downloaded credential configuration file.
You can use the example template or download a new credential configuration file once we grant the permission to the federated identity to impersonate the Service Account.
A sample of such resource is shown below:
apiVersion: security.gardener.cloud/v1alpha1
kind: WorkloadIdentity
metadata:
name: gcp
namespace: garden-myproj
spec:
audiences:
# This is the audience that you configure during workload identity pool creation
- https://iam.googleapis.com/projects/<project_number>/locations/global/workloadIdentityPools/<pool_name>/providers/<provider_name>
targetSystem:
type: gcp
providerConfig:
apiVersion: gcp.provider.extensions.gardener.cloud/v1alpha1
kind: WorkloadIdentityConfig
projectID: gcp-project-name # This is the name of the project which the workload identity will access
# Use the downloaded credential configuration file to set this field. The credential_source field is not important to Gardener and should be omitted.
credentialsConfig:
universe_domain: "googleapis.com"
type: "external_account"
audience: "//iam.googleapis.com/projects/<project_number>/locations/global/workloadIdentityPools/<pool_name>/providers/<provider_name>"
subject_token_type: "urn:ietf:params:oauth:token-type:jwt"
service_account_impersonation_url: "https://iamcredentials.googleapis.com/v1/projects/-/serviceAccounts/<service_account_email>:generateAccessToken"
token_url: "https://sts.googleapis.com/v1/token"
Now users should give permissions to the WorkloadIdentity to impersonate the Service Account.
In order to construct the principal that will be used for impersonation retrieve the subject of the created WorkloadIdentity.
SUBJECT=$(kubectl -n garden-myproj get workloadidentity gcp -o=jsonpath='{.status.sub}')
echo "principal://iam.googleapis.com/projects/<project_number>/locations/global/workloadIdentityPools/<pool_name>/subject/$SUBJECT"
The principal template is also shown in the Google Console Workload Identity Pool UI.
Users should give this principal the Role Workload Identity User so that it can impersonate the Service Account.
One can do this through the Service Account Permissions tab, through the Google Console Workload Identity Pool UI or by using the gcloud cli.
As a final step create a CredentialsBinding referencing the GCP WorkloadIdentity and use it in your Shoot definitions.
apiVersion: security.gardener.cloud/v1alpha1
kind: CredentialsBinding
metadata:
name: gcp
namespace: garden-myproj
credentialsRef:
apiVersion: security.gardener.cloud/v1alpha1
kind: WorkloadIdentity
name: gcp
namespace: garden-myproj
provider:
type: gcp
apiVersion: core.gardener.cloud/v1beta1
kind: Shoot
metadata:
name: gcp
namespace: garden-myproj
spec:
credentialsBindingName: gcp
...
Warning
One can omit the creation of Service Account and directly grant access to the federated identity’s principal, skipping the Service Account impersonation. This although recommended, will not always work because federated identities do not fall under the
allAuthenticatedUserscategory and cannot access machine images that are not made available toallUsers. This means that machine images should be made available toallUsersor permissions should be explicitly given to the federated identity in order for this to work.GCP imposes some restrictions on which images can be accessible to
allUsers. As of now, Gardenlinux images are not published in a way that they can be accessed byallUsers. See the following issue for more details https://github.com/gardenlinux/glci/issues/148.
InfrastructureConfig
The infrastructure configuration mainly describes how the network layout looks like in order to create the shoot worker nodes in a later step, thus, prepares everything relevant to create VMs, load balancers, volumes, etc.
An example InfrastructureConfig for the GCP extension looks as follows:
apiVersion: gcp.provider.extensions.gardener.cloud/v1alpha1
kind: InfrastructureConfig
networks:
# vpc:
# name: my-vpc
# cloudRouter:
# name: my-cloudrouter
workers: 10.250.0.0/16
# internal: 10.251.0.0/16
# cloudNAT:
# minPortsPerVM: 2048
# maxPortsPerVM: 65536
# endpointIndependentMapping:
# enabled: false
# enableDynamicPortAllocation: false
# natIPNames:
# - name: manualnat1
# - name: manualnat2
# udpIdleTimeoutSec: 30
# icmpIdleTimeoutSec: 30
# tcpEstablishedIdleTimeoutSec: 1200
# tcpTransitoryIdleTimeoutSec: 30
# tcpTimeWaitTimeoutSec: 120
# flowLogs:
# aggregationInterval: INTERVAL_5_SEC
# flowSampling: 0.2
# metadata: INCLUDE_ALL_METADATA
The networks.vpc section describes whether you want to create the shoot cluster in an already existing VPC or whether to create a new one:
If
networks.vpc.nameis given then you have to specify the VPC name of the existing VPC that was created by other means (manually, other tooling, …). If you want to get a fresh VPC for the shoot then just omit thenetworks.vpcfield.If a VPC name is not given then we will create the cloud router + NAT gateway to ensure that worker nodes don’t get external IPs.
If a VPC name is given then a cloud router name must also be given, failure to do so would result in validation errors and possibly clusters without egress connectivity.
If a VPC name is given and calico shoot clusters are created without a network overlay within one VPC make sure that the pod CIDR specified in
shoot.spec.networking.podsis not overlapping with any other pod CIDR used in that VPC. Overlapping pod CIDRs will lead to disfunctional shoot clusters.
The networks.workers section describes the CIDR for a subnet that is used for all shoot worker nodes, i.e., VMs which later run your applications.
The networks.internal section is optional and can describe a CIDR for a subnet that is used for internal load balancers,
The networks.cloudNAT.minPortsPerVM is optional and is used to define the minimum number of ports allocated to a VM for the CloudNAT
The networks.cloudNAT.natIPNames is optional and is used to specify the names of the manual ip addresses which should be used by the nat gateway
The networks.cloudNAT.endpointIndependentMapping is optional and is used to define the endpoint mapping behavior. You can enable it or disable it at any point by toggling networks.cloudNAT.endpointIndependentMapping.enabled. By default, it is disabled.
networks.cloudNAT.enableDynamicPortAllocation is optional (default: false) and allows one to enable dynamic port allocation (https://cloud.google.com/nat/docs/ports-and-addresses#dynamic-port). Note that enabling this puts additional restrictions on the permitted values for networks.cloudNAT.minPortsPerVM and networks.cloudNAT.minPortsPerVM, namely that they now both are required to be powers of two. Also, maxPortsPerVM may not be given if dynamic port allocation is disabled.
networks.cloudNAT.udpIdleTimeoutSec, networks.cloudNAT.icmpIdleTimeoutSec, networks.cloudNAT.tcpEstablishedIdleTimeoutSec, networks.cloudNAT.tcpTransitoryIdleTimeoutSec, and networks.cloudNAT.tcpTimeWaitTimeoutSec give more fine-granular control over various timeout-values. For more details see https://cloud.google.com/nat/docs/public-nat#specs-timeouts.
The specified CIDR ranges must be contained in the VPC CIDR specified above, or the VPC CIDR of your already existing VPC. You can freely choose these CIDRs and it is your responsibility to properly design the network layout to suit your needs.
The networks.flowLogs section describes the configuration for the VPC flow logs. In order to enable the VPC flow logs at least one of the following parameters needs to be specified in the flow log section:
networks.flowLogs.aggregationIntervalan optional parameter describing the aggregation interval for collecting flow logs. For more details, see aggregation_interval reference.networks.flowLogs.flowSamplingan optional parameter describing the sampling rate of VPC flow logs within the subnetwork where 1.0 means all collected logs are reported and 0.0 means no logs are reported. For more details, see flow_sampling reference.networks.flowLogs.metadataan optional parameter describing whether metadata fields should be added to the reported VPC flow logs. For more details, see metadata reference.
Apart from the VPC and the subnets the GCP extension will also create a dedicated service account for this shoot, and firewall rules.
ControlPlaneConfig
The control plane configuration mainly contains values for the GCP-specific control plane components.
Today, the only component deployed by the GCP extension is the cloud-controller-manager.
An example ControlPlaneConfig for the GCP extension looks as follows:
apiVersion: gcp.provider.extensions.gardener.cloud/v1alpha1
kind: ControlPlaneConfig
zone: europe-west1-b
cloudControllerManager:
# featureGates:
# SomeKubernetesFeature: true
storage:
managedDefaultStorageClass: true
managedDefaultVolumeSnapshotClass: true
# csiFilestore:
# enabled: true
The zone field tells the cloud-controller-manager in which zone it should mainly operate.
You can still create clusters in multiple availability zones, however, the cloud-controller-manager requires one “main” zone.
⚠️ You always have to specify this field!
The cloudControllerManager.featureGates contains a map of explicitly enabled or disabled feature gates.
For production usage it’s not recommend to use this field at all as you can enable alpha features or disable beta/stable features, potentially impacting the cluster stability.
If you don’t want to configure anything for the cloudControllerManager simply omit the key in the YAML specification.
The members of the storage allows to configure the provided storage classes further.
If storage.managedDefaultStorageClass is enabled (the default), the default StorageClass deployed will be marked as default (via storageclass.kubernetes.io/is-default-class annotation).
Similarly, if storage.managedDefaultVolumeSnapshotClass is enabled (the default), the default VolumeSnapshotClass deployed will be marked as default.
In case you want to set a different StorageClass or VolumeSnapshotClass as default you need to set the corresponding option to false as at most one class should be marked as default in each case and the ResourceManager will prevent any changes from the Gardener managed classes to take effect.
Furthermore, the storage.csiFilestore.enabled field can be set to true to
enable the GCP Filestore CSI driver.
Additionally, you have to make sure that your IAM user has the permission roles/file.editor and
that the filestore API is enabled in your GCP project.
WorkerConfig
The worker configuration contains:
Local SSD interface for the additional volumes attached to GCP worker machines.
If you attach the disk with
SCRATCHtype, either anNVMeinterface or aSCSIinterface must be specified. It is only meaningful to provide this volume interface if onlySCRATCHdata volumes are used.Volume Encryption config that specifies values for
kmsKeyNameandkmsKeyServiceAccountName.- The
kmsKeyNameis the key name of the cloud kms disk encryption key and must be specified if CMEK disk encryption is needed. - The
kmsKeyServiceAccountis the service account granted theroles/cloudkms.cryptoKeyEncrypterDecrypteron thekmsKeyNameIf empty, then the role should be given to the Compute Engine Service Agent Account. This CESA account usually has the name:service-PROJECT_NUMBER@compute-system.iam.gserviceaccount.com. See: https://cloud.google.com/iam/docs/service-agents#compute-engine-service-agent - Prior to use, the operator should add IAM policy binding using the gcloud CLI:
gcloud projects add-iam-policy-binding projectId --member serviceAccount:name@projectIdgserviceaccount.com --role roles/cloudkms.cryptoKeyEncrypterDecrypter - Setting
.spec.provider.workers[].(data)Volumes[].encryptedhas no impact because GCP disks are encrypted by default.
- The
Setting a volume image with
dataVolumes.sourceImage. However, this parameter should only be used with particular caution. For example Gardenlinux works with filesystem LABELs only and creating another disk form the very same image causes the LABELs to be duplicated. See: https://github.com/gardener/gardener-extension-provider-gcp/issues/323Some hyperdisks allow adjustment of their default values for
provisionedIopsandprovisionedThroughput. Keep in mind though that Hyperdisk Extreme and Hyperdisk Throughput volumes can’t be used as boot disks.Service Account with their specified scopes, authorized for this worker.
Service accounts created in advance that generate access tokens that can be accessed through the metadata server and used to authenticate applications on the instance.
Note: If you do not provide service accounts for your workers, the Compute Engine default service account will be used. For more details on the default account, see https://cloud.google.com/compute/docs/access/service-accounts#default_service_account. If the
DisableGardenerServiceAccountCreationfeature gate is disabled, Gardener will create a shared service accounts to use for all instances. This feature gate is currently in beta and it will no longer be possible to re-enable the service account creation via feature gate flag.GPU with its type and count per node. This will attach that GPU to all the machines in the worker grp
Note:
A rolling upgrade of the worker group would be triggered in case the
acceleratorTypeorcountis updated.Some machineTypes like a2 family come with already attached gpu of
a100type and pre-defined count. If your workerPool consists of such machineTypes, please specify exact GPU configuration for the machine type as specified in Google cloud documentation.acceleratorTypeto use for families with attached gpu are stated below:- a2 family ->
nvidia-tesla-a100 - g2 family ->
nvidia-l4
- a2 family ->
Sufficient quota of gpu is needed in the GCP project. This includes quota to support autoscaling if enabled.
GPU-attached machines can’t be live migrated during host maintenance events. Find out how to handle that in your application here
GPU count specified here is considered for forming node template during scale-from-zero in Cluster Autoscaler
The
.nodeTemplateis used to specify resource information of the machine during runtime. This then helps in Scale-from-Zero. Some points to note for this field:- Currently only cpu, gpu and memory are configurable.
- a change in the value lead to a rolling update of the machine in the workerpool
- all the resources needs to be specified
An example
WorkerConfigfor the GCP looks as follows:
apiVersion: gcp.provider.extensions.gardener.cloud/v1alpha1
kind: WorkerConfig
volume:
interface: NVME
encryption:
kmsKeyName: "projects/projectId/locations/<zoneName>/keyRings/<keyRingName>/cryptoKeys/alpha"
kmsKeyServiceAccount: "user@projectId.iam.gserviceaccount.com"
dataVolumes:
- name: test
sourceImage: projects/sap-se-gcp-gardenlinux/global/images/gardenlinux-gcp-gardener-prod-amd64-1443-3-c261f887
provisionedIops: 3000
provisionedThroughput: 140
serviceAccount:
email: foo@bar.com
scopes:
- https://www.googleapis.com/auth/cloud-platform
gpu:
acceleratorType: nvidia-tesla-t4
count: 1
nodeTemplate: # (to be specified only if the node capacity would be different from cloudprofile info during runtime)
capacity:
cpu: 2
gpu: 1
memory: 50Gi
Example Shoot manifest
Please find below an example Shoot manifest:
apiVersion: core.gardener.cloud/v1beta1
kind: Shoot
metadata:
name: johndoe-gcp
namespace: garden-dev
spec:
cloudProfile:
name: gcp
region: europe-west1
credentialsBindingName: core-gcp
provider:
type: gcp
infrastructureConfig:
apiVersion: gcp.provider.extensions.gardener.cloud/v1alpha1
kind: InfrastructureConfig
networks:
workers: 10.250.0.0/16
controlPlaneConfig:
apiVersion: gcp.provider.extensions.gardener.cloud/v1alpha1
kind: ControlPlaneConfig
zone: europe-west1-b
workers:
- name: worker-xoluy
machine:
type: n1-standard-4
minimum: 2
maximum: 2
volume:
size: 50Gi
type: pd-standard
zones:
- europe-west1-b
networking:
nodes: 10.250.0.0/16
type: calico
kubernetes:
version: 1.28.2
maintenance:
autoUpdate:
kubernetesVersion: true
machineImageVersion: true
addons:
kubernetesDashboard:
enabled: true
nginxIngress:
enabled: true
CSI volume provisioners
Every GCP shoot cluster will be deployed with the GCP PD CSI driver.
It is compatible with the legacy in-tree volume provisioner that was deprecated by the Kubernetes community and will be removed in future versions of Kubernetes.
End-users might want to update their custom StorageClasses to the new pd.csi.storage.gke.io provisioner.
Support for VolumeAttributesClasses (Beta in k8s 1.31)
To have the CSI-driver configured to support the necessary features for VolumeAttributesClasses on GCP for shoots with a k8s-version greater than 1.31, use the gcp.provider.extensions.gardener.cloud/enable-volume-attributes-class annotation on the shoot. Keep in mind to also enable the required feature flags and runtime-config on the common kubernetes controllers (as outlined in the link above) in the shoot-spec.
Kubernetes Versions per Worker Pool
This extension supports gardener/gardener’s WorkerPoolKubernetesVersion feature gate, i.e., having worker pools with overridden Kubernetes versions since gardener-extension-provider-gcp@v1.21.
Shoot CA Certificate and ServiceAccount Signing Key Rotation
This extension supports gardener/gardener’s ShootCARotation and ShootSARotation feature gates since gardener-extension-provider-gcp@v1.23.
BackupBucket
Gardener manages etcd backups for Shoot clusters using provider-specific backup storage solutions. On GCP, this storage is implemented through Google Cloud Storage (GCS) buckets, which store snapshots of the cluster’s etcd data.
The BackupBucket resource abstracts the backup infrastructure, enabling Gardener and its extension controllers to manage it seamlessly. This abstraction allows Gardener to create, delete, and maintain backup buckets across various cloud providers in a standardized manner.
The BackupBucket resource includes a spec field, which defines the configuration details for the backup bucket. These details include:
- The region where the bucket should be created.
- A reference to the secret containing credentials for accessing the cloud provider.
- A
ProviderConfigfield for provider-specific configurations.
BackupBucketConfig
The BackupBucketConfig represents the configuration for a backup bucket. It includes an optional immutability configuration that enforces retention policies on the backup bucket.
The Gardener extension provider for GCP supports creating and managing immutable backup buckets by leveraging the bucket lock feature. Immutability ensures that once data is written to the bucket, it cannot be modified or deleted for a specified period. This feature is crucial for protecting backups from accidental or malicious deletion, ensuring data safety and availability for restoration.
Here is an example configuration for BackupBucketConfig:
apiVersion: gcp.provider.extensions.gardener.cloud/v1alpha1
kind: BackupBucketConfig
immutability:
retentionType: bucket
retentionPeriod: "24h"
locked: false
retentionType: Specifies the type of retention policy. The allowed value isbucket, which applies the retention policy to the entire bucket. For more details, refer to the documentation.retentionPeriod: Defines the duration for which objects in the bucket will remain immutable. The value should follow GCP-supported formats, such as"24h"for 24 hours. Refer to retention period formats for more information. The minimum retention period is 24 hours.locked: A boolean indicating whether the retention policy is locked. Once locked, the policy cannot be removed or shortened, ensuring immutability. Learn more about locking policies here.
To configure a BackupBucket with immutability, include the BackupBucketConfig in the ProviderConfig of the BackupBucket resource. If the locked field is set to true, the retention policy will be locked, preventing the retention policy from being removed and the retention period from being reduced. However, it’s still possible to increase the retention period.
Here is an example of configuring a BackupBucket with immutability:
apiVersion: extensions.gardener.cloud/v1alpha1
kind: BackupBucket
metadata:
name: my-backup-bucket
spec:
provider:
region: europe-west1
secretRef:
name: my-gcp-secret
namespace: my-namespace
providerConfig:
apiVersion: gcp.provider.extensions.gardener.cloud/v1alpha1
kind: BackupBucketConfig
immutability:
retentionType: bucket
retentionPeriod: 24h
locked: true
6 - Provider Openstack
Gardener Extension for OpenStack provider
Project Gardener implements the automated management and operation of Kubernetes clusters as a service. Its main principle is to leverage Kubernetes concepts for all of its tasks.
Recently, most of the vendor specific logic has been developed in-tree. However, the project has grown to a size where it is very hard to extend, maintain, and test. With GEP-1 we have proposed how the architecture can be changed in a way to support external controllers that contain their very own vendor specifics. This way, we can keep Gardener core clean and independent.
This controller implements Gardener’s extension contract for the OpenStack provider.
An example for a ControllerRegistration resource that can be used to register this controller to Gardener can be found here.
Please find more information regarding the extensibility concepts and a detailed proposal here.
Supported Kubernetes versions
This extension controller supports the following Kubernetes versions:
| Version | Support | Conformance test results |
|---|---|---|
| Kubernetes 1.33 | 1.33.0+ | N/A |
| Kubernetes 1.32 | 1.32.0+ | |
| Kubernetes 1.31 | 1.31.0+ | |
| Kubernetes 1.30 | 1.30.0+ | |
| Kubernetes 1.29 | 1.29.0+ | |
| Kubernetes 1.28 | 1.28.0+ | |
| Kubernetes 1.27 | 1.27.0+ |
Please take a look here to see which versions are supported by Gardener in general.
Compatibility
The following lists known compatibility issues of this extension controller with other Gardener components.
| OpenStack Extension | Gardener | Action | Notes |
|---|---|---|---|
< v1.12.0 | > v1.10.0 | Please update the provider version to >= v1.12.0 or disable the feature gate MountHostCADirectories in the Gardenlet. | Applies if feature flag MountHostCADirectories in the Gardenlet is enabled. This is to prevent duplicate volume mounts to /usr/share/ca-certificates in the Shoot API Server. |
How to start using or developing this extension controller locally
You can run the controller locally on your machine by executing make start.
Static code checks and tests can be executed by running make verify. We are using Go modules for Golang package dependency management and Ginkgo/Gomega for testing.
Feedback and Support
Feedback and contributions are always welcome!
Please report bugs or suggestions as GitHub issues or reach out on Slack (join the workspace here).
Learn more!
Please find further resources about out project here:
- Our landing page gardener.cloud
- “Gardener, the Kubernetes Botanist” blog on kubernetes.io
- “Gardener Project Update” blog on kubernetes.io
- GEP-1 (Gardener Enhancement Proposal) on extensibility
- GEP-4 (New
core.gardener.cloud/v1beta1API) - Extensibility API documentation
- Gardener Extensions Golang library
- Gardener API Reference
6.1 - Deployment
Deployment of the OpenStack provider extension
Disclaimer: This document is NOT a step by step installation guide for the OpenStack provider extension and only contains some configuration specifics regarding the installation of different components via the helm charts residing in the OpenStack provider extension repository.
gardener-extension-admission-openstack
Authentication against the Garden cluster
There are several authentication possibilities depending on whether or not the concept of Virtual Garden is used.
Virtual Garden is not used, i.e., the runtime Garden cluster is also the target Garden cluster.
Automounted Service Account Token
The easiest way to deploy the gardener-extension-admission-openstack component will be to not provide kubeconfig at all. This way in-cluster configuration and an automounted service account token will be used. The drawback of this approach is that the automounted token will not be automatically rotated.
Service Account Token Volume Projection
Another solution will be to use Service Account Token Volume Projection combined with a kubeconfig referencing a token file (see example below).
apiVersion: v1
kind: Config
clusters:
- cluster:
certificate-authority-data: <CA-DATA>
server: https://default.kubernetes.svc.cluster.local
name: garden
contexts:
- context:
cluster: garden
user: garden
name: garden
current-context: garden
users:
- name: garden
user:
tokenFile: /var/run/secrets/projected/serviceaccount/token
This will allow for automatic rotation of the service account token by the kubelet. The configuration can be achieved by setting both .Values.global.serviceAccountTokenVolumeProjection.enabled: true and .Values.global.kubeconfig in the respective chart’s values.yaml file.
Virtual Garden is used, i.e., the runtime Garden cluster is different from the target Garden cluster.
Service Account
The easiest way to setup the authentication will be to create a service account and the respective roles will be bound to this service account in the target cluster. Then use the generated service account token and craft a kubeconfig which will be used by the workload in the runtime cluster. This approach does not provide a solution for the rotation of the service account token. However, this setup can be achieved by setting .Values.global.virtualGarden.enabled: true and following these steps:
- Deploy the
applicationpart of the charts in thetargetcluster. - Get the service account token and craft the
kubeconfig. - Set the crafted
kubeconfigand deploy theruntimepart of the charts in theruntimecluster.
Client Certificate
Another solution will be to bind the roles in the target cluster to a User subject instead of a service account and use a client certificate for authentication. This approach does not provide a solution for the client certificate rotation. However, this setup can be achieved by setting both .Values.global.virtualGarden.enabled: true and .Values.global.virtualGarden.user.name, then following these steps:
- Generate a client certificate for the
targetcluster for the respective user. - Deploy the
applicationpart of the charts in thetargetcluster. - Craft a
kubeconfigusing the already generated client certificate. - Set the crafted
kubeconfigand deploy theruntimepart of the charts in theruntimecluster.
Projected Service Account Token
This approach requires an already deployed and configured oidc-webhook-authenticator for the target cluster. Also the runtime cluster should be registered as a trusted identity provider in the target cluster. Then projected service accounts tokens from the runtime cluster can be used to authenticate against the target cluster. The needed steps are as follows:
- Deploy OWA and establish the needed trust.
- Set
.Values.global.virtualGarden.enabled: trueand.Values.global.virtualGarden.user.name. Note: username value will depend on the trust configuration, e.g.,<prefix>:system:serviceaccount:<namespace>:<serviceaccount> - Set
.Values.global.serviceAccountTokenVolumeProjection.enabled: trueand.Values.global.serviceAccountTokenVolumeProjection.audience. Note: audience value will depend on the trust configuration, e.g.,<cliend-id-from-trust-config>. - Craft a kubeconfig (see example below).
- Deploy the
applicationpart of the charts in thetargetcluster. - Deploy the
runtimepart of the charts in theruntimecluster.
apiVersion: v1
kind: Config
clusters:
- cluster:
certificate-authority-data: <CA-DATA>
server: https://virtual-garden.api
name: virtual-garden
contexts:
- context:
cluster: virtual-garden
user: virtual-garden
name: virtual-garden
current-context: virtual-garden
users:
- name: virtual-garden
user:
tokenFile: /var/run/secrets/projected/serviceaccount/token
6.2 - Local Setup
admission-openstack
admission-openstack is an admission webhook server which is responsible for the validation of the cloud provider (OpenStack in this case) specific fields and resources. The Gardener API server is cloud provider agnostic and it wouldn’t be able to perform similar validation.
Follow the steps below to run the admission webhook server locally.
Start the Gardener API server.
For details, check the Gardener local setup.
Start the webhook server
Make sure that the
KUBECONFIGenvironment variable is pointing to the local garden cluster.make start-admissionSetup the
ValidatingWebhookConfiguration.hack/dev-setup-admission-openstack.shwill configure the webhook Service which will allow the kube-apiserver of your local cluster to reach the webhook server. It will also apply theValidatingWebhookConfigurationmanifest../hack/dev-setup-admission-openstack.sh
You are now ready to experiment with the admission-openstack webhook server locally.
6.3 - Operations
Using the OpenStack provider extension with Gardener as operator
The core.gardener.cloud/v1beta1.CloudProfile resource declares a providerConfig field that is meant to contain provider-specific configuration.
In this document we are describing how this configuration looks like for OpenStack and provide an example CloudProfile manifest with minimal configuration that you can use to allow creating OpenStack shoot clusters.
CloudProfileConfig
The cloud profile configuration contains information about the real machine image IDs in the OpenStack environment (image names).
You have to map every version that you specify in .spec.machineImages[].versions here such that the OpenStack extension knows the image ID for every version you want to offer.
It also contains optional default values for DNS servers that shall be used for shoots.
In the dnsServers[] list you can specify IP addresses that are used as DNS configuration for created shoot subnets.
Also, you have to specify the keystone URL in the keystoneURL field to your environment.
Additionally, you can influence the HTTP request timeout when talking to the OpenStack API in the requestTimeout field.
This may help when you have for example a long list of load balancers in your environment.
In case your OpenStack system uses Octavia for network load balancing then you have to set the useOctavia field to true such that the cloud-controller-manager for OpenStack gets correctly configured (it defaults to false).
Some hypervisors (especially those which are VMware-based) don’t automatically send a new volume size to a Linux kernel when a volume is resized and in-use.
For those hypervisors you can enable the storage plugin interacting with Cinder to telling the SCSI block device to refresh its information to provide information about it’s updated size to the kernel. You might need to enable this behavior depending on the underlying hypervisor of your OpenStack installation. The rescanBlockStorageOnResize field controls this. Please note that it only applies for Kubernetes versions where CSI is used.
Some openstack configurations do not allow to attach more volumes than a specific amount to a single node.
To tell the k8s scheduler to not over schedule volumes on a node, you can set nodeVolumeAttachLimit which defaults to 256.
Some openstack configurations have different names for volume and compute availability zones, which might cause pods to go into pending state as there are no nodes available in the detected volume AZ. To ignore the volume AZ when scheduling pods, you can set ignoreVolumeAZ to true (it defaults to false).
See CSI Cinder driver.
The cloud profile config also contains constraints for floating pools and load balancer providers that can be used in shoots.
If your OpenStack system supports server groups, the serverGroupPolicies property will enable your end-users to create shoots with workers where the nodes are managed by Nova’s server groups.
Specifying serverGroupPolicies is optional and can be omitted. If enabled, the end-user can choose whether or not to use this feature for a shoot’s workers. Gardener will handle the creation of the server group and node assignment.
To enable this feature, an operator should:
- specify the allowed policy values (e.g.
affintity,anti-affinity) in this section. Only the policies in the allow-list will be available for end-users. - make sure that your OpenStack project has enough server group capacity. Otherwise, shoot creation will fail.
If your OpenStack system has multiple volume-types, the storageClasses property enables the creation of kubernetes storageClasses for shoots.
Set storageClasses[].parameters.type to map it with an openstack volume-type. Specifying storageClasses is optional and can be omitted.
An example CloudProfileConfig for the OpenStack extension looks as follows:
apiVersion: openstack.provider.extensions.gardener.cloud/v1alpha1
kind: CloudProfileConfig
machineImages:
- name: coreos
versions:
- version: 2135.6.0
# Fallback to image name if no region mapping is found
# Only works for amd64 and is strongly discouraged. Prefer image IDs!
image: coreos-2135.6.0
regions:
- name: europe
id: "1234-amd64"
architecture: amd64 # optional, defaults to amd64
- name: europe
id: "1234-arm64"
architecture: arm64
- name: asia
id: "5678-amd64"
architecture: amd64
# keystoneURL: https://url-to-keystone/v3/
# keystoneURLs:
# - region: europe
# url: https://europe.example.com/v3/
# - region: asia
# url: https://asia.example.com/v3/
# dnsServers:
# - 10.10.10.11
# - 10.10.10.12
# requestTimeout: 60s
# useOctavia: true
# useSNAT: true
# rescanBlockStorageOnResize: true
# ignoreVolumeAZ: true
# nodeVolumeAttachLimit: 30
# serverGroupPolicies:
# - soft-anti-affinity
# - anti-affinity
# resolvConfOptions:
# - rotate
# - timeout:1
# storageClasses:
# - name: example-sc
# default: false
# provisioner: cinder.csi.openstack.org
# volumeBindingMode: WaitForFirstConsumer
# parameters:
# type: storage_premium_perf0
constraints:
floatingPools:
- name: fp-pool-1
# region: europe
# loadBalancerClasses:
# - name: lb-class-1
# floatingSubnetID: "1234"
# floatingNetworkID: "4567"
# subnetID: "7890"
# - name: "fp-pool-*"
# region: europe
# loadBalancerClasses:
# - name: lb-class-1
# floatingSubnetID: "1234"
# floatingNetworkID: "4567"
# subnetID: "7890"
# - name: "fp-pool-eu-demo"
# region: europe
# domain: demo
# loadBalancerClasses:
# - name: lb-class-1
# floatingSubnetID: "1234"
# floatingNetworkID: "4567"
# subnetID: "7890"
# - name: "fp-pool-eu-dev"
# region: europe
# domain: dev
# nonConstraining: true
# loadBalancerClasses:
# - name: lb-class-1
# floatingSubnetID: "1234"
# floatingNetworkID: "4567"
# subnetID: "7890"
loadBalancerProviders:
- name: haproxy
# - name: f5
# region: asia
# - name: haproxy
# region: asia
Please note that it is possible to configure a region mapping for keystone URLs, floating pools, and load balancer providers.
Additionally, floating pools can be constrainted to a keystone domain by specifying the domain field.
Floating pool names may also contains simple wildcard expressions, like * or fp-pool-* or *-fp-pool. Please note that the * must be either single or at the beginning or at the end. Consequently, fp-*-pool is not possible/allowed.
The default behavior is that, if found, the regional (and/or domain restricted) entry is taken.
If no entry for the given region exists then the fallback value is the most matching entry (w.r.t. wildcard matching) in the list without a region field (or the keystoneURL value for the keystone URLs).
If an additional floating pool should be selectable for a region and/or domain, you can mark it as non constraining
with setting the optional field nonConstraining to true.
Multiple loadBalancerProviders can be specified in the CloudProfile. Each provider may specify a region constraint for where it can be used.
If at least one region specific entry exists in the CloudProfile, the shoot’s specified loadBalancerProvider must adhere to the list of the available providers of that region. Otherwise, one of the non-regional specific providers should be used.
Each entry in the loadBalancerProviders must be uniquely identified by its name and if applicable, its region.
The loadBalancerClasses field is an optional list of load balancer classes which can be when the corresponding floating pool network is choosen. The load balancer classes can be configured in the same way as in the ControlPlaneConfig in the Shoot resource, therefore see here for more details.
Some OpenStack environments don’t need these regional mappings, hence, the region and keystoneURLs fields are optional.
If your OpenStack environment only has regional values and it doesn’t make sense to provide a (non-regional) fallback then simply
omit keystoneURL and always specify region.
If Gardener creates and manages the router of a shoot cluster, it is additionally possible to specify that the enable_snat field is set to true via useSNAT: true in the CloudProfileConfig.
On some OpenStack enviroments, there may be the need to set options in the file /etc/resolv.conf on worker nodes.
If the field resolvConfOptions is set, a systemd service will be installed which copies /run/systemd/resolve/resolv.conf
on every change to /etc/resolv.conf and appends the given options.
Example CloudProfile manifest
Please find below an example CloudProfile manifest:
apiVersion: core.gardener.cloud/v1beta1
kind: CloudProfile
metadata:
name: openstack
spec:
type: openstack
kubernetes:
versions:
- version: 1.32.0
- version: 1.31.1
expirationDate: "2026-03-31T23:59:59Z"
machineImages:
- name: coreos
versions:
- version: 2135.6.0
architectures: # optional, defaults to [amd64]
- amd64
- arm64
machineTypes:
- name: medium_4_8
cpu: "4"
gpu: "0"
memory: 8Gi
architecture: amd64 # optional, defaults to amd64
storage:
class: standard
type: default
size: 40Gi
- name: medium_4_8_arm
cpu: "4"
gpu: "0"
memory: 8Gi
architecture: arm64
storage:
class: standard
type: default
size: 40Gi
regions:
- name: europe-1
zones:
- name: europe-1a
- name: europe-1b
- name: europe-1c
providerConfig:
apiVersion: openstack.provider.extensions.gardener.cloud/v1alpha1
kind: CloudProfileConfig
machineImages:
- name: coreos
versions:
- version: 2135.6.0
# Fallback to image name if no region mapping is found
# Only works for amd64 and is strongly discouraged. Prefer image IDs!
image: coreos-2135.6.0
regions:
- name: europe
id: "1234-amd64"
architecture: amd64 # optional, defaults to amd64
- name: europe
id: "1234-arm64"
architecture: arm64
- name: asia
id: "5678-amd64"
architecture: amd64
keystoneURL: https://url-to-keystone/v3/
constraints:
floatingPools:
- name: fp-pool-1
loadBalancerProviders:
- name: haproxy
Rolling Update Triggers
Changes to the Shoot worker-pools are applied in-place where possible.
In case this is not possible a rolling update of the workers will be performed to apply the new configuration,
as outlined in the Gardener documentation.
The exact fields that trigger this behavior are defined in the Gardener doc,
with a few additions:
.spec.provider.workers[].providerConfig.serverGroup(ID of the server group).spec.provider.workers[].providerConfig.MachineLabels[](ifMachineLabels.triggerRollingUpdateis set totrue)
The featuregate NewWorkerPoolHash has no impact on the hash calculation for now.
6.4 - Usage
Using the OpenStack provider extension with Gardener as end-user
The core.gardener.cloud/v1beta1.Shoot resource declares a few fields that are meant to contain provider-specific configuration.
In this document we are describing how this configuration looks like for OpenStack and provide an example Shoot manifest with minimal configuration that you can use to create an OpenStack cluster (modulo the landscape-specific information like cloud profile names, secret binding names, etc.).
Provider Secret Data
Every shoot cluster references a SecretBinding or a CredentialsBinding which itself references a Secret, and this Secret contains the provider credentials of your OpenStack tenant.
This Secret must look as follows:
apiVersion: v1
kind: Secret
metadata:
name: core-openstack
namespace: garden-dev
type: Opaque
data:
domainName: base64(domain-name)
tenantName: base64(tenant-name)
# either use username/password
username: base64(user-name)
password: base64(password)
# or application credentials
#applicationCredentialID: base64(app-credential-id)
#applicationCredentialName: base64(app-credential-name) # optional
#applicationCredentialSecret: base64(app-credential-secret)
Please look up https://docs.openstack.org/keystone/pike/admin/identity-concepts.html as well.
For authentication with username/password see Keystone username/password
Alternatively, for authentication with application credentials see Keystone Application Credentials.
⚠️ Depending on your API usage it can be problematic to reuse the same provider credentials for different Shoot clusters due to rate limits. Please consider spreading your Shoots over multiple credentials from different tenants if you are hitting those limits.
InfrastructureConfig
The infrastructure configuration mainly describes how the network layout looks like in order to create the shoot worker nodes in a later step, thus, prepares everything relevant to create VMs, load balancers, volumes, etc.
An example InfrastructureConfig for the OpenStack extension looks as follows:
apiVersion: openstack.provider.extensions.gardener.cloud/v1alpha1
kind: InfrastructureConfig
floatingPoolName: MY-FLOATING-POOL
# floatingPoolSubnetName: my-floating-pool-subnet-name
networks:
# id: 12345678-abcd-efef-08af-0123456789ab
# router:
# id: 1234
workers: 10.250.0.0/19
# shareNetwork:
# enabled: true
The floatingPoolName is the name of the floating pool you want to use for your shoot.
If you don’t know which floating pools are available look it up in the respective CloudProfile.
With floatingPoolSubnetName you can explicitly define to which subnet in the floating pool network (defined via floatingPoolName) the router should be attached to.
networks.id is an optional field. If it is given, you can specify the uuid of an existing private Neutron network (created manually, by other tooling, …) that should be reused. A new subnet for the Shoot will be created in it.
If a networks.id is given and calico shoot clusters are created without a network overlay within one network make sure that the pod CIDR specified in shoot.spec.networking.pods is not overlapping with any other pod CIDR used in that network.
Overlapping pod CIDRs will lead to disfunctional shoot clusters.
The networks.router section describes whether you want to create the shoot cluster in an already existing router or whether to create a new one:
If
networks.router.idis given then you have to specify the router id of the existing router that was created by other means (manually, other tooling, …). If you want to get a fresh router for the shoot then just omit thenetworks.routerfield.In any case, the shoot cluster will be created in a new subnet.
The networks.workers section describes the CIDR for a subnet that is used for all shoot worker nodes, i.e., VMs which later run your applications.
You can freely choose these CIDRs and it is your responsibility to properly design the network layout to suit your needs.
Apart from the router and the worker subnet the OpenStack extension will also create a network, router interfaces, security groups, and a key pair.
The optional networks.shareNetwork.enabled field controls the creation of a share network. This is only needed if shared
file system storage (like NFS) should be used. Note, that in this case, the ControlPlaneConfig needs additional configuration, too.
ControlPlaneConfig
The control plane configuration mainly contains values for the OpenStack-specific control plane components.
Today, the only component deployed by the OpenStack extension is the cloud-controller-manager.
An example ControlPlaneConfig for the OpenStack extension looks as follows:
apiVersion: openstack.provider.extensions.gardener.cloud/v1alpha1
kind: ControlPlaneConfig
loadBalancerProvider: haproxy
loadBalancerClasses:
- name: lbclass-1
purpose: default
floatingNetworkID: fips-1-id
floatingSubnetName: internet-*
- name: lbclass-2
floatingNetworkID: fips-1-id
floatingSubnetTags: internal,private
- name: lbclass-3
purpose: private
subnetID: internal-id
# cloudControllerManager:
# featureGates:
# SomeKubernetesFeature: true
# storage:
# csiManila:
# enabled: true
The loadBalancerProvider is the provider name you want to use for load balancers in your shoot.
If you don’t know which types are available look it up in the respective CloudProfile.
The loadBalancerClasses field contains an optional list of load balancer classes which will be available in the cluster. Each entry can have the following fields:
nameto select the load balancer class via the kubernetes service annotationsloadbalancer.openstack.org/class=namepurposewith valuesdefaultorprivate- The configuration of the
defaultload balancer class will be used as default for all other kubernetes loadbalancer services without a class annotation - The configuration of the
privateload balancer class will be also set to the global loadbalancer configuration of the cluster, but will be overridden by thedefaultpurpose
- The configuration of the
floatingNetworkIDcan be specified to receive an ip from an floating/external network, additionally the subnet in this network can be selected viafloatingSubnetNamecan be either a full subnet name or a regex/glob to match subnet namefloatingSubnetTagsa comma seperated list of subnet tagsfloatingSubnetIDthe id of a specific subnet
subnetIDcan be specified by to receive an ip from an internal subnet (will not have an effect in combination with floating/external network configuration)
The cloudControllerManager.featureGates contains a map of explicitly enabled or disabled feature gates.
For production usage it’s not recommended to use this field at all as you can enable alpha features or disable beta/stable features, potentially impacting the cluster stability.
If you don’t want to configure anything for the cloudControllerManager simply omit the key in the YAML specification.
The optional storage.csiManila.enabled field is used to enable the deployment of the CSI Manila driver to support NFS persistent volumes.
In this case, please ensure to set networks.shareNetwork.enabled=true in the InfrastructureConfig, too.
Additionally, if CSI Manila driver is enabled, for each availability zone a NFS StorageClass will be created on the shoot
named like csi-manila-nfs-<zone>.
WorkerConfig
Each worker group in a shoot may contain provider-specific configurations and options. These are contained in the providerConfig section of a worker group and can be configured using a WorkerConfig object.
An example of a WorkerConfig looks as follows:
apiVersion: openstack.provider.extensions.gardener.cloud/v1alpha1
kind: WorkerConfig
serverGroup:
policy: soft-anti-affinity
# nodeTemplate: # (to be specified only if the node capacity would be different from cloudprofile info during runtime)
# capacity:
# cpu: 2
# gpu: 0
# memory: 50Gi
# machineLabels:
# - name: my-label
# value: foo
# - name: my-rolling-label
# value: bar
# triggerRollingOnUpdate: true # means any change of the machine label value will trigger rolling of all machines of the worker pool
ServerGroups
When you specify the serverGroup section in your worker group configuration, a new server group will be created with the configured policy for each worker group that enabled this setting and all machines managed by this worker group will be assigned as members of the created server group.
For users to have access to the server group feature, it must be enabled on the CloudProfile by your operator.
Existing clusters can take advantage of this feature by updating the server group configuration of their respective worker groups. Worker groups that are already configured with server groups can update their setting to change the policy used, or remove it altogether at any time.
Users must be aware that any change to the server group settings will result in a rolling deployment of new nodes for the affected worker group.
Please note the following restrictions when deploying workers with server groups:
- The
serverGroupsection is optional, but if it is included in the worker configuration, it must contain a valid policy value. - The available
policyvalues that can be used, are defined in the provider specific section ofCloudProfileby your operator. - Certain policy values may induce further constraints. Using the
affinitypolicy is only allowed when the worker group utilizes a single zone.
MachineLabels
The machineLabels section in the worker group configuration allows to specify additional machine labels. These labels are added to the machine
instances only, but not to the node object. Additionally, they have an optional triggerRollingOnUpdate field. If it is set to true, changing the label value
will trigger a rolling of all machines of this worker pool.
Node Templates
Node templates allow users to override the capacity of the nodes as defined by the server flavor specified in the CloudProfile’s machineTypes. This is useful for certain dynamic scenarios as it allows users to customize cluster-autoscaler’s behavior for these workergroup with their provided values.
Example Shoot manifest (one availability zone)
Please find below an example Shoot manifest for one availability zone:
apiVersion: core.gardener.cloud/v1beta1
kind: Shoot
metadata:
name: johndoe-openstack
namespace: garden-dev
spec:
cloudProfile:
name: openstack
region: europe-1
secretBindingName: core-openstack
provider:
type: openstack
infrastructureConfig:
apiVersion: openstack.provider.extensions.gardener.cloud/v1alpha1
kind: InfrastructureConfig
floatingPoolName: MY-FLOATING-POOL
networks:
workers: 10.250.0.0/19
controlPlaneConfig:
apiVersion: openstack.provider.extensions.gardener.cloud/v1alpha1
kind: ControlPlaneConfig
loadBalancerProvider: haproxy
workers:
- name: worker-xoluy
machine:
type: medium_4_8
minimum: 2
maximum: 2
zones:
- europe-1a
networking:
nodes: 10.250.0.0/16
type: calico
kubernetes:
version: 1.28.2
maintenance:
autoUpdate:
kubernetesVersion: true
machineImageVersion: true
addons:
kubernetesDashboard:
enabled: true
nginxIngress:
enabled: true
CSI volume provisioners
Every OpenStack shoot cluster will be deployed with the OpenStack Cinder CSI driver.
It is compatible with the legacy in-tree volume provisioner that was deprecated by the Kubernetes community and will be removed in future versions of Kubernetes.
End-users might want to update their custom StorageClasses to the new cinder.csi.openstack.org provisioner.
Kubernetes Versions per Worker Pool
This extension supports gardener/gardener’s WorkerPoolKubernetesVersion feature gate, i.e., having worker pools with overridden Kubernetes versions since gardener-extension-provider-openstack@v1.23.
Shoot CA Certificate and ServiceAccount Signing Key Rotation
This extension supports gardener/gardener’s ShootCARotation and ShootSARotation feature gates since gardener-extension-provider-openstack@v1.26.