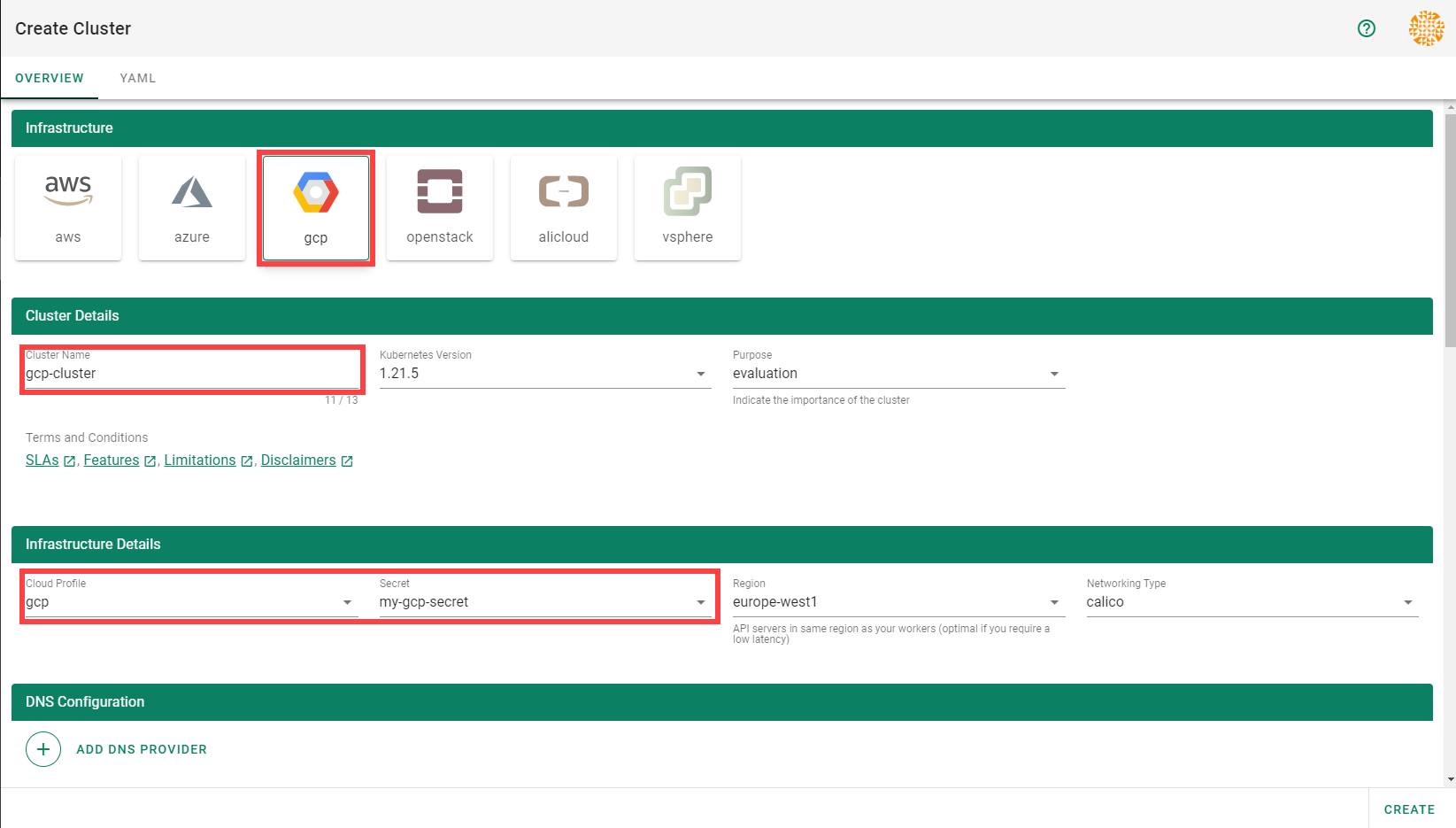
3 - Deployment
Deployment of the GCP provider extension
Disclaimer: This document is NOT a step-by-step installation guide for the GCP provider extension and only contains some configuration specifics regarding the installation of different components via the helm charts residing in the GCP provider extension repository.
gardener-extension-admission-gcp
Authentication against the Garden cluster
There are several authentication possibilities depending on whether or not the concept of Virtual Garden is used.
Virtual Garden is not used, i.e., the runtime Garden cluster is also the target Garden cluster.
Automounted Service Account Token
The easiest way to deploy the gardener-extension-admission-gcp component will be to not provide kubeconfig at all. This way in-cluster configuration and an automounted service account token will be used. The drawback of this approach is that the automounted token will not be automatically rotated.
Service Account Token Volume Projection
Another solution will be to use Service Account Token Volume Projection combined with a kubeconfig referencing a token file (see example below).
apiVersion: v1
kind: Config
clusters:
- cluster:
certificate-authority-data: <CA-DATA>
server: https://default.kubernetes.svc.cluster.local
name: garden
contexts:
- context:
cluster: garden
user: garden
name: garden
current-context: garden
users:
- name: garden
user:
tokenFile: /var/run/secrets/projected/serviceaccount/token
This will allow for automatic rotation of the service account token by the kubelet. The configuration can be achieved by setting both .Values.global.serviceAccountTokenVolumeProjection.enabled: true and .Values.global.kubeconfig in the respective chart’s values.yaml file.
Virtual Garden is used, i.e., the runtime Garden cluster is different from the target Garden cluster.
Service Account
The easiest way to setup the authentication will be to create a service account and the respective roles will be bound to this service account in the target cluster. Then use the generated service account token and craft a kubeconfig which will be used by the workload in the runtime cluster. This approach does not provide a solution for the rotation of the service account token. However, this setup can be achieved by setting .Values.global.virtualGarden.enabled: true and following these steps:
- Deploy the
application part of the charts in the target cluster. - Get the service account token and craft the
kubeconfig. - Set the crafted
kubeconfig and deploy the runtime part of the charts in the runtime cluster.
Client Certificate
Another solution will be to bind the roles in the target cluster to a User subject instead of a service account and use a client certificate for authentication. This approach does not provide a solution for the client certificate rotation. However, this setup can be achieved by setting both .Values.global.virtualGarden.enabled: true and .Values.global.virtualGarden.user.name, then following these steps:
- Generate a client certificate for the
target cluster for the respective user. - Deploy the
application part of the charts in the target cluster. - Craft a
kubeconfig using the already generated client certificate. - Set the crafted
kubeconfig and deploy the runtime part of the charts in the runtime cluster.
Projected Service Account Token
This approach requires an already deployed and configured oidc-webhook-authenticator for the target cluster. Also the runtime cluster should be registered as a trusted identity provider in the target cluster. Then projected service accounts tokens from the runtime cluster can be used to authenticate against the target cluster. The needed steps are as follows:
- Deploy OWA and establish the needed trust.
- Set
.Values.global.virtualGarden.enabled: true and .Values.global.virtualGarden.user.name. Note: username value will depend on the trust configuration, e.g., <prefix>:system:serviceaccount:<namespace>:<serviceaccount> - Set
.Values.global.serviceAccountTokenVolumeProjection.enabled: true and .Values.global.serviceAccountTokenVolumeProjection.audience. Note: audience value will depend on the trust configuration, e.g., <cliend-id-from-trust-config>. - Craft a kubeconfig (see example below).
- Deploy the
application part of the charts in the target cluster. - Deploy the
runtime part of the charts in the runtime cluster.
apiVersion: v1
kind: Config
clusters:
- cluster:
certificate-authority-data: <CA-DATA>
server: https://virtual-garden.api
name: virtual-garden
contexts:
- context:
cluster: virtual-garden
user: virtual-garden
name: virtual-garden
current-context: virtual-garden
users:
- name: virtual-garden
user:
tokenFile: /var/run/secrets/projected/serviceaccount/token
4 - Ipv6
Dual-Stack Support for Gardener GCP Extension
This document provides an overview of dual-stack support for the Gardener GCP extension.
Furthermore it clarifies which components are utilized, how the infrastructure is setup and how a dual-stack cluster can be provisioned.
Overview
Gardener allows to create dual-stack clusters on GCP. In this mode, both IPv4 and IPv6 are supported within the cluster.
This significantly expands the available address space, enables seamless communication across both IPv4 and IPv6 environments, and ensures compliance with modern networking standards.
Key Components for Dual-Stack Support
- Dual-Stack Subnets: Separate subnets are created for nodes and services, with explicit IPv4 and external IPv6 ranges.
- Ingress-GCE: Responsible for creating dual-stack (IPv4,IPv6) Load Balancers.
- Cloud Allocator: Manages the assignment of IPv4 and IPv6 ranges to nodes and pods.
Dual-Stack Subnets
When provisioning a dual-stack cluster, the GCP provider creates distinct subnets:
1. Node Subnet
- Primary IPv4 Range: Used for IPv4 nodes.
- Secondary IPv4 Range: Used for IPv4 pods.
- External IPv6 Range: Auto-assigned with a
/64 prefix. Each VM gets an interface with a /96 prefix. - Customization:
- IPv4 ranges (pods and nodes) can be defined in the shoot object.
- IPv6 ranges are automatically filled by the GCP provider.
2. Service Subnet
- This subnet is dedicated to IPv6 services. It is created due to GCP’s limitation of not supporting IPv6 range reservations.
3. Internal Subnet (optional)
- This subnet is dedicated for internal load balancer. Currently, only internal IPv4 loadbalancer are supported. They are provisioned by the Cloud Controller Manager (CCM).
Ingress-GCE
The ingress-gce is a mandatory component for dual-stack clusters. It is responsible for creating dual-stack (IPv4,IPv6) Load Balancers. This is necessary because the GCP Cloud Controller Manager does not support provisioning IPv6 Load Balancer.
Cloud Allocator
The Cloud Allocator is part of the GCP Cloud Controller Manager and plays a critical role in managing IPAM (IP Address Management) for dual-stack clusters.
Responsibilities
- Assigning PODCIDRs to Node Objects: Ensures that both IPv4 and IPv6 pod ranges are correctly assigned to the node objects.
- Leveraging Secondary IPv4 Range:
- Uses the secondary IPv4 range in the node subnet to allocate pod IP ranges.
- Assigns both IPv4 and IPv6 pod ranges in compliance with GCP’s networking model.
Operational Details
- The Cloud Allocator assigns a
/112 pod cidr range/subrange from the /96 cidr range assigned to each VM. - This ensures efficient utilization of IPv6 address space while maintaining compatibility with Kubernetes networking requirements.
Why Use a Secondary IPv4 Range for Pods?
The secondary IPv4 range is essential for:
- Enabling the Cloud Allocator to function correctly in assigning IP ranges.
- Supporting both IPv4 and IPv6 pods in dual-stack clusters.
- Aligning with GCP CCM’s requirement to separate pod IP ranges within the node subnet.
Creating a Dual-Stack Cluster
To create a dual-stack cluster, both IP families (IPv4,IPv6) need to be specified under spec.networking.ipFamilies. Below is an example of a dual-stack shoot cluster configuration:
apiVersion: core.gardener.cloud/v1beta1
kind: Shoot
metadata:
...
spec:
...
provider:
type: gcp
infrastructureConfig:
apiVersion: gcp.provider.extensions.gardener.cloud/v1alpha1
kind: InfrastructureConfig
networks:
workers: 10.250.0.0/16
...
networking:
type: ...
ipFamilies:
- IPv4
- IPv6
nodes: 10.250.0.0/16
...
Migration of IPv4-Only Shoot Clusters to Dual-Stack
To migrate an IPv4-only shoot cluster to Dual-Stack simply change the .spec.networking.ipFamilies field in the Shoot resource from IPv4 to IPv4, IPv6 as shown below.
kind: Shoot
apiVersion: core.gardener.cloud/v1beta1
metadata:
...
spec:
...
networking:
type: ...
ipFamilies:
- IPv4
- IPv6
...
You can find more information about the process and the steps required here.
Please note that the dual-stack migration requires the IPv4-only cluster to run in native routing mode, i.e. pod overlay network needs to be disabled.
The default quota of static routes per VPC in GCP is 200. This restricts the cluster size. Therefore, please adapt (if necessary) the quota for the routes per VPC (STATIC_ROUTES_PER_NETWORK) in the gcp cloud console accordingly before switching to native routing.
After triggering the migration a constraint of type DualStackNodesMigrationReady is added to the shoot status. It is in state False until all nodes have an IPv4 and IPv6 address assigned.
Changing the ipFamilies field triggers immediately an infrastructure reconciliation, where the infrastructure is reconfigured to additionally support IPv6. During this infrastructure migration process the subnets get an external IPv6 range and the node subnet gets a secondary IPv4 range. Pod specific cloud routes are deleted from the VPC route table and alias IP ranges for the pod routes are added to the NIC of Kubernetes nodes/instances.
With the next node roll-out which is a manual step and will not be triggered automatically, all nodes will get an IPv6 address and an IPv6 prefix for pods assigned. When all nodes have IPv4 and IPv6 pod ranges, the status of the DualStackNodesMigrationReady constraint will be changed to True.
Once all nodes are migrated, the remaining control plane components and the Container Network Interface (CNI) are configured for dual-stack networking and the migration constraint is removed at the end of this step.
Load Balancer Service Configuration
To create a dual-stack LoadBalancer the spec.ipFamilies and spec.ipFamilyPolicy field needs to be specified in the Kubernetes service.
An example configuration is shown below:
apiVersion: v1
kind: Service
metadata:
name: nginx
namespace: default
annotations:
cloud.google.com/l4-rbs: enabled
spec:
ipFamilies:
- IPv4
- IPv6
ipFamilyPolicy: PreferDualStack
ports:
- port: 12345
protocol: TCP
targetPort: 80
selector:
run: nginx
type: LoadBalancer
The required annotation cloud.google.com/l4-rbs: enabled for ingress-gce is added automatically via webhook for services of type: LoadBalancer.
Internal Load Balancer
- Internal IPv6 LoadBalancers are currently not supported.
- To create internal IPv4 LoadBalancers, you can set one of the the following annotations:
"networking.gke.io/load-balancer-type=Internal""cloud.google.com/load-balancer-type=internal" (deprecated).
Internal load balancers are created by cloud-controller-manger and get an IPv4 address from the internal subnet.
6 - Operations
Using the GCP provider extension with Gardener as operator
The core.gardener.cloud/v1beta1.CloudProfile resource declares a providerConfig field that is meant to contain provider-specific configuration.
The core.gardener.cloud/v1beta1.Seed resource is structured similarly.
Additionally, it allows configuring settings for the backups of the main etcds’ data of shoot clusters control planes running in this seed cluster.
This document explains the necessary configuration for this provider extension.
CloudProfile resource
This section describes, how the configuration for CloudProfiles looks like for GCP by providing an example CloudProfile manifest with minimal configuration that can be used to allow the creation of GCP shoot clusters.
CloudProfileConfig
The cloud profile configuration contains information about the real machine image IDs in the GCP environment (image URLs).
You have to map every version that you specify in .spec.machineImages[].versions here such that the GCP extension knows the image URL for every version you want to offer.
For each machine image version an architecture field can be specified which specifies the CPU architecture of the machine on which given machine image can be used.
An example CloudProfileConfig for the GCP extension looks as follows:
apiVersion: gcp.provider.extensions.gardener.cloud/v1alpha1
kind: CloudProfileConfig
machineImages:
- name: coreos
versions:
- version: 2135.6.0
image: projects/coreos-cloud/global/images/coreos-stable-2135-6-0-v20190801
# architecture: amd64 # optional
Example CloudProfile manifest
If you want to allow that shoots can create VMs with local SSDs volumes then you have to specify the type of the disk with SCRATCH in the .spec.volumeTypes[] list.
Please find below an example CloudProfile manifest:
apiVersion: core.gardener.cloud/v1beta1
kind: CloudProfile
metadata:
name: gcp
spec:
type: gcp
kubernetes:
versions:
- version: 1.32.0
- version: 1.31.2
expirationDate: "2026-03-31T23:59:59Z"
machineImages:
- name: coreos
versions:
- version: 2135.6.0
machineTypes:
- name: n1-standard-4
cpu: "4"
gpu: "0"
memory: 15Gi
volumeTypes:
- name: pd-standard
class: standard
- name: pd-ssd
class: premium
- name: SCRATCH
class: standard
regions:
- region: europe-west1
names:
- europe-west1-b
- europe-west1-c
- europe-west1-d
providerConfig:
apiVersion: gcp.provider.extensions.gardener.cloud/v1alpha1
kind: CloudProfileConfig
machineImages:
- name: coreos
versions:
- version: 2135.6.0
image: projects/coreos-cloud/global/images/coreos-stable-2135-6-0-v20190801
# architecture: amd64 # optional
Seed resource
This provider extension does not support any provider configuration for the Seed’s .spec.provider.providerConfig field.
However, it supports to managing of backup infrastructure, i.e., you can specify a configuration for the .spec.backup field.
Backup configuration
A Seed of type gcp can be configured to perform backups for the main etcds’ of the shoot clusters control planes using Google Cloud Storage buckets.
The location/region where the backups will be stored defaults to the region of the Seed (spec.provider.region), but can also be explicitly configured via the field spec.backup.region.
The region of the backup can be different from where the seed cluster is running.
However, usually it makes sense to pick the same region for the backup bucket as used for the Seed cluster.
Please find below an example Seed manifest (partly) that configures backups using Google Cloud Storage buckets.
---
apiVersion: core.gardener.cloud/v1beta1
kind: Seed
metadata:
name: my-seed
spec:
provider:
type: gcp
region: europe-west1
backup:
provider: gcp
region: europe-west1 # default region
credentialsRef:
apiVersion: v1
kind: Secret
name: backup-credentials
namespace: garden
...
An example of the referenced secret containing the credentials for the GCP Cloud storage can be found in the example folder.
Permissions for GCP Cloud Storage
Please make sure the service account associated with the provided credentials has the following IAM roles.
Rolling Update Triggers
Changes to the Shoot worker-pools are applied in-place where possible.
In case this is not possible a rolling update of the workers will be performed to apply the new configuration,
as outlined in the Gardener documentation.
The exact fields that trigger this behaviour depend on whether the feature gate NewWorkerPoolHash is enabled.
If it is not enabled, only the fields mentioned in the Gardener doc plus the providerConfig are used.
If the feature gate is enabled, it’s the same with a few additions:
.spec.provider.workers[].dataVolumes[].name.spec.provider.workers[].dataVolumes[].size.spec.provider.workers[].dataVolumes[].type
We exclude .spec.provider.workers[].dataVolumes[].encrypted from the hash calculation because GCP disks are encrypted by default,
and the field does not influence disk encryption behavior.
Everything related to disk encryption is handled by the providerConfig.
7 - Usage
Using the GCP provider extension with Gardener as end-user
The core.gardener.cloud/v1beta1.Shoot resource declares a few fields that are meant to contain provider-specific configuration.
This document describes the configurable options for GCP and provides an example Shoot manifest with minimal configuration that can be used to create a GCP cluster (modulo the landscape-specific information like cloud profile names, secret binding names, etc.).
Accessing GCP APIs
In order for Gardener to create a Kubernetes cluster using GCP infrastructure components, a Shoot has to provide an authentication mechanism giving sufficient permissions to the desired GCP project.
Every shoot cluster references a SecretBinding or a CredentialsBinding.
While SecretBindings can only reference Secrets, CredentialsBindings can also reference WorkloadIdentitys which provide an alternative authentication method.
WorkloadIdentitys do not directly contain credentials but are rather a representation of the workload that is going to access the user’s account.
If the user has configured Workload Identity Federation with Gardener’s Workload Identity Issuer then the GCP infrastructure components can access the user’s account without the need of preliminary exchange of credentials.
The SecretBinding/CredentialsBinding is configurable in the Shoot cluster with the field secretBindingName/credentialsBindingName.
SecretBindings are considered legacy and will be deprecated in the future.
It is advised to use CredentialsBindings instead.
GCP Service Account Credentials
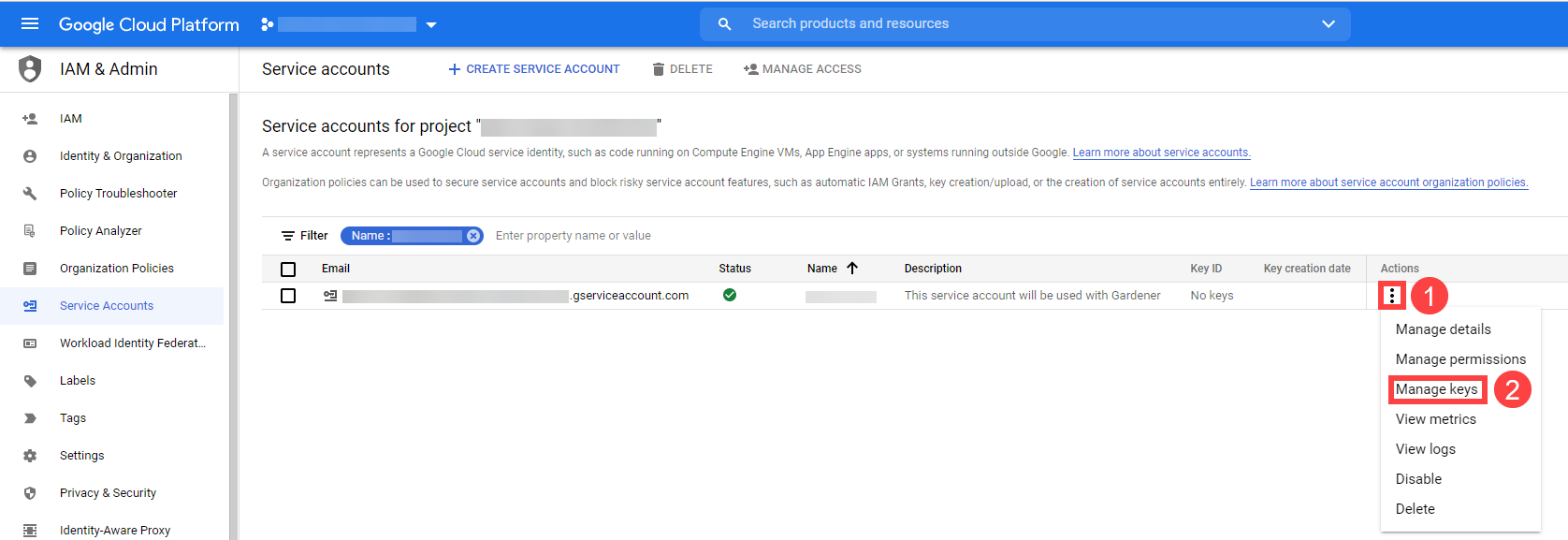
The required credentials for the GCP project are a Service Account Key to authenticate as a GCP Service Account.
A service account is a special account that can be used by services and applications to interact with Google Cloud Platform APIs.
Applications can use service account credentials to authorize themselves to a set of APIs and perform actions within the permissions granted to the service account.
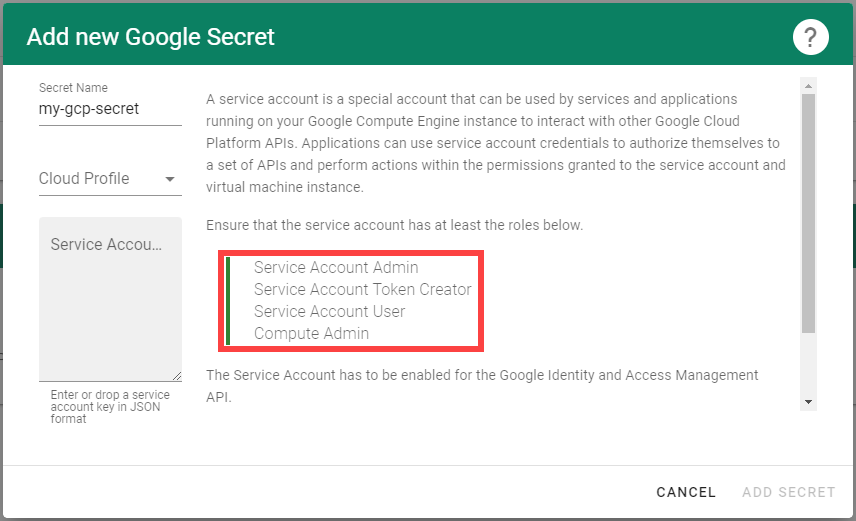
Make sure to enable the Google Identity and Access Management (IAM) API.
Create a Service Account that shall be used for the Shoot cluster.
Grant at least the following IAM roles to the Service Account.
- Service Account Admin
- Service Account Token Creator
- Service Account User
- Compute Admin
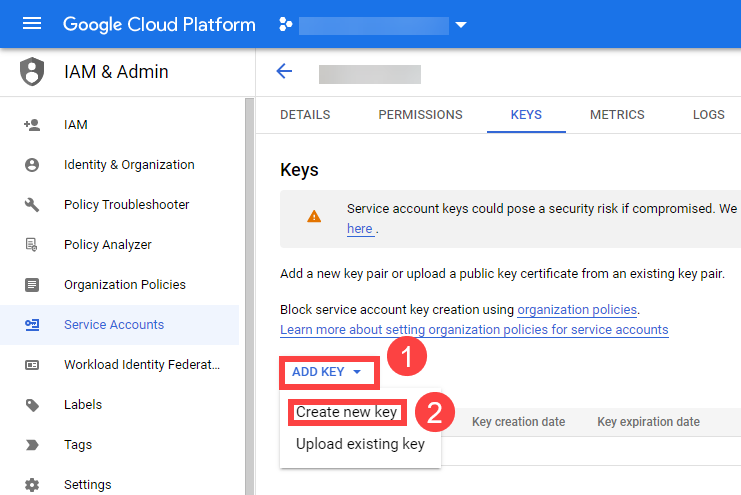
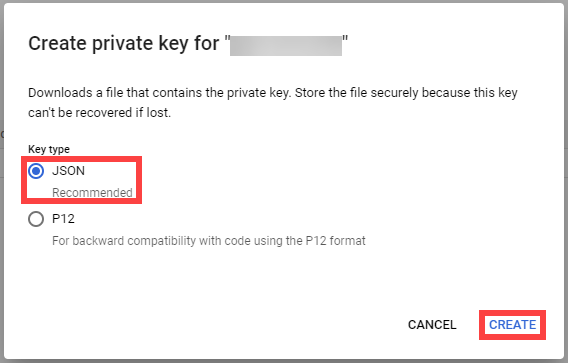
Create a JSON Service Account key for the Service Account.
Provide it in the Secret (base64 encoded for field serviceaccount.json), that is being referenced by the SecretBinding in the Shoot cluster configuration.
This Secret must look as follows:
apiVersion: v1
kind: Secret
metadata:
name: core-gcp
namespace: garden-dev
type: Opaque
data:
serviceaccount.json: base64(serviceaccount-json)
Depending on your API usage it can be problematic to reuse the same Service Account Key for different Shoot clusters due to rate limits.
Please consider spreading your Shoots over multiple Service Accounts on different GCP projects if you are hitting those limits, see https://cloud.google.com/compute/docs/api-rate-limits.
GCP Workload Identity Federation
Users can choose to trust Gardener’s Workload Identity Issuer and eliminate the need for providing GCP Service Account credentials.
As a first step users should configure Workload Identity Federation with Gardener’s Workload Identity Issuer.
You can retrieve Gardener’s Workload Identity Issuer URL directly from the Garden cluster by reading the contents of the Gardener Info ConfigMap.
kubectl -n gardener-system-public get configmap gardener-info -o yaml
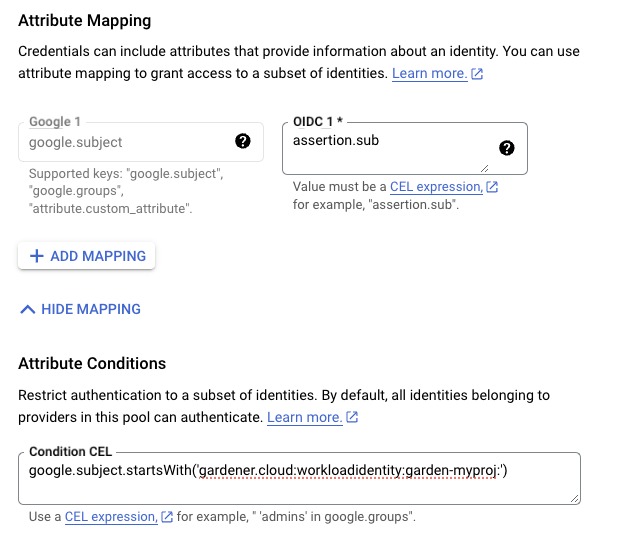
In the example attribute mapping shown below all WorkloadIdentitys that are created in the garden-myproj namespace will be authenticated.
Now that the Workload Identity Federation is configured the user should download the credential configuration file.
If required, users can use a stricter mapping to authenticate only certain WorkloadIdentitys.
Please, refer to the attribute mappings documentation for more information.
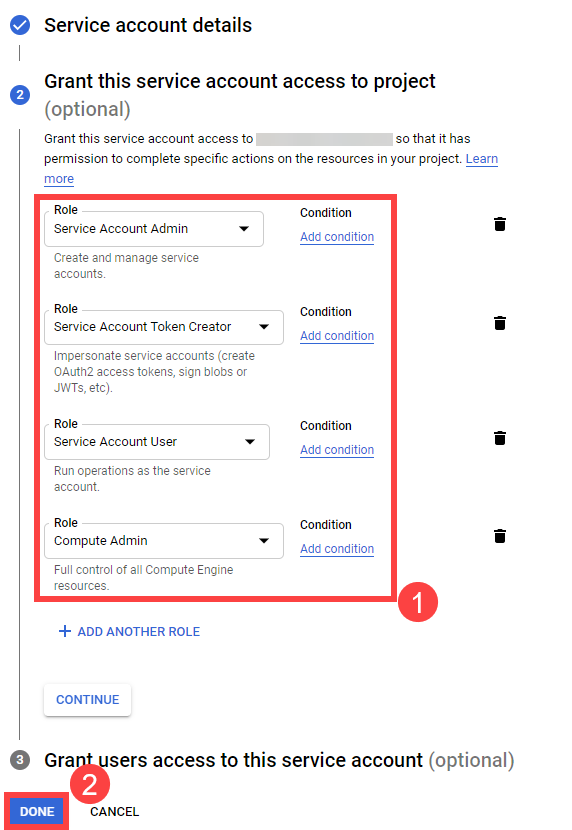
Users should now create a Service Account that is going to be impersonated by the federated identity.
Make sure to enable the Google Identity and Access Management (IAM) API.
Create a Service Account that shall be used for the Shoot cluster.
Grant at least the following IAM roles to the Service Account.
- Service Account Token Creator
- Service Account User
- Compute Admin
As a next step a resource of type WorkloadIdentity should be created in the Garden cluster and configured with the information from the already downloaded credential configuration file.
This identity will be used to impersonate the Service Account in order to call GCP APIs.
Mind that the service_account_impersonation_url is probably not present in the downloaded credential configuration file.
You can use the example template or download a new credential configuration file once we grant the permission to the federated identity to impersonate the Service Account.
A sample of such resource is shown below:
apiVersion: security.gardener.cloud/v1alpha1
kind: WorkloadIdentity
metadata:
name: gcp
namespace: garden-myproj
spec:
audiences:
# This is the audience that you configure during workload identity pool creation
- https://iam.googleapis.com/projects/<project_number>/locations/global/workloadIdentityPools/<pool_name>/providers/<provider_name>
targetSystem:
type: gcp
providerConfig:
apiVersion: gcp.provider.extensions.gardener.cloud/v1alpha1
kind: WorkloadIdentityConfig
projectID: gcp-project-name # This is the name of the project which the workload identity will access
# Use the downloaded credential configuration file to set this field. The credential_source field is not important to Gardener and should be omitted.
credentialsConfig:
universe_domain: "googleapis.com"
type: "external_account"
audience: "//iam.googleapis.com/projects/<project_number>/locations/global/workloadIdentityPools/<pool_name>/providers/<provider_name>"
subject_token_type: "urn:ietf:params:oauth:token-type:jwt"
service_account_impersonation_url: "https://iamcredentials.googleapis.com/v1/projects/-/serviceAccounts/<service_account_email>:generateAccessToken"
token_url: "https://sts.googleapis.com/v1/token"
Now users should give permissions to the WorkloadIdentity to impersonate the Service Account.
In order to construct the principal that will be used for impersonation retrieve the subject of the created WorkloadIdentity.
SUBJECT=$(kubectl -n garden-myproj get workloadidentity gcp -o=jsonpath='{.status.sub}')
echo "principal://iam.googleapis.com/projects/<project_number>/locations/global/workloadIdentityPools/<pool_name>/subject/$SUBJECT"
The principal template is also shown in the Google Console Workload Identity Pool UI.
Users should give this principal the Role Workload Identity User so that it can impersonate the Service Account.
One can do this through the Service Account Permissions tab, through the Google Console Workload Identity Pool UI or by using the gcloud cli.
As a final step create a CredentialsBinding referencing the GCP WorkloadIdentity and use it in your Shoot definitions.
apiVersion: security.gardener.cloud/v1alpha1
kind: CredentialsBinding
metadata:
name: gcp
namespace: garden-myproj
credentialsRef:
apiVersion: security.gardener.cloud/v1alpha1
kind: WorkloadIdentity
name: gcp
namespace: garden-myproj
provider:
type: gcp
apiVersion: core.gardener.cloud/v1beta1
kind: Shoot
metadata:
name: gcp
namespace: garden-myproj
spec:
credentialsBindingName: gcp
...
One can omit the creation of Service Account and directly grant access to the federated identity’s principal, skipping the Service Account impersonation.
This although recommended, will not always work because federated identities do not fall under the allAuthenticatedUsers category and cannot access machine images that are not made available to allUsers.
This means that machine images should be made available to allUsers or permissions should be explicitly given to the federated identity in order for this to work.
GCP imposes some restrictions on which images can be accessible to allUsers.
As of now, Gardenlinux images are not published in a way that they can be accessed by allUsers.
See the following issue for more details https://github.com/gardenlinux/glci/issues/148.
InfrastructureConfig
The infrastructure configuration mainly describes how the network layout looks like in order to create the shoot worker nodes in a later step, thus, prepares everything relevant to create VMs, load balancers, volumes, etc.
An example InfrastructureConfig for the GCP extension looks as follows:
apiVersion: gcp.provider.extensions.gardener.cloud/v1alpha1
kind: InfrastructureConfig
networks:
# vpc:
# name: my-vpc
# cloudRouter:
# name: my-cloudrouter
workers: 10.250.0.0/16
# internal: 10.251.0.0/16
# cloudNAT:
# minPortsPerVM: 2048
# maxPortsPerVM: 65536
# endpointIndependentMapping:
# enabled: false
# enableDynamicPortAllocation: false
# natIPNames:
# - name: manualnat1
# - name: manualnat2
# udpIdleTimeoutSec: 30
# icmpIdleTimeoutSec: 30
# tcpEstablishedIdleTimeoutSec: 1200
# tcpTransitoryIdleTimeoutSec: 30
# tcpTimeWaitTimeoutSec: 120
# flowLogs:
# aggregationInterval: INTERVAL_5_SEC
# flowSampling: 0.2
# metadata: INCLUDE_ALL_METADATA
The networks.vpc section describes whether you want to create the shoot cluster in an already existing VPC or whether to create a new one:
If networks.vpc.name is given then you have to specify the VPC name of the existing VPC that was created by other means (manually, other tooling, …).
If you want to get a fresh VPC for the shoot then just omit the networks.vpc field.
If a VPC name is not given then we will create the cloud router + NAT gateway to ensure that worker nodes don’t get external IPs.
If a VPC name is given then a cloud router name must also be given, failure to do so would result in validation errors
and possibly clusters without egress connectivity.
If a VPC name is given and calico shoot clusters are created without a network overlay within one VPC make sure that the pod CIDR specified in shoot.spec.networking.pods is not overlapping with any other pod CIDR used in that VPC.
Overlapping pod CIDRs will lead to disfunctional shoot clusters.
The networks.workers section describes the CIDR for a subnet that is used for all shoot worker nodes, i.e., VMs which later run your applications.
The networks.internal section is optional and can describe a CIDR for a subnet that is used for internal load balancers,
The networks.cloudNAT.minPortsPerVM is optional and is used to define the minimum number of ports allocated to a VM for the CloudNAT
The networks.cloudNAT.natIPNames is optional and is used to specify the names of the manual ip addresses which should be used by the nat gateway
The networks.cloudNAT.endpointIndependentMapping is optional and is used to define the endpoint mapping behavior. You can enable it or disable it at any point by toggling networks.cloudNAT.endpointIndependentMapping.enabled. By default, it is disabled.
networks.cloudNAT.enableDynamicPortAllocation is optional (default: false) and allows one to enable dynamic port allocation (https://cloud.google.com/nat/docs/ports-and-addresses#dynamic-port). Note that enabling this puts additional restrictions on the permitted values for networks.cloudNAT.minPortsPerVM and networks.cloudNAT.minPortsPerVM, namely that they now both are required to be powers of two. Also, maxPortsPerVM may not be given if dynamic port allocation is disabled.
networks.cloudNAT.udpIdleTimeoutSec, networks.cloudNAT.icmpIdleTimeoutSec, networks.cloudNAT.tcpEstablishedIdleTimeoutSec, networks.cloudNAT.tcpTransitoryIdleTimeoutSec, and networks.cloudNAT.tcpTimeWaitTimeoutSec give more fine-granular control over various timeout-values. For more details see https://cloud.google.com/nat/docs/public-nat#specs-timeouts.
The specified CIDR ranges must be contained in the VPC CIDR specified above, or the VPC CIDR of your already existing VPC.
You can freely choose these CIDRs and it is your responsibility to properly design the network layout to suit your needs.
The networks.flowLogs section describes the configuration for the VPC flow logs. In order to enable the VPC flow logs at least one of the following parameters needs to be specified in the flow log section:
networks.flowLogs.aggregationInterval an optional parameter describing the aggregation interval for collecting flow logs. For more details, see aggregation_interval reference.
networks.flowLogs.flowSampling an optional parameter describing the sampling rate of VPC flow logs within the subnetwork where 1.0 means all collected logs are reported and 0.0 means no logs are reported. For more details, see flow_sampling reference.
networks.flowLogs.metadata an optional parameter describing whether metadata fields should be added to the reported VPC flow logs. For more details, see metadata reference.
Apart from the VPC and the subnets the GCP extension will also create a dedicated service account for this shoot, and firewall rules.
ControlPlaneConfig
The control plane configuration mainly contains values for the GCP-specific control plane components.
Today, the only component deployed by the GCP extension is the cloud-controller-manager.
An example ControlPlaneConfig for the GCP extension looks as follows:
apiVersion: gcp.provider.extensions.gardener.cloud/v1alpha1
kind: ControlPlaneConfig
zone: europe-west1-b
cloudControllerManager:
# featureGates:
# SomeKubernetesFeature: true
storage:
managedDefaultStorageClass: true
managedDefaultVolumeSnapshotClass: true
The zone field tells the cloud-controller-manager in which zone it should mainly operate.
You can still create clusters in multiple availability zones, however, the cloud-controller-manager requires one “main” zone.
⚠️ You always have to specify this field!
The cloudControllerManager.featureGates contains a map of explicitly enabled or disabled feature gates.
For production usage it’s not recommend to use this field at all as you can enable alpha features or disable beta/stable features, potentially impacting the cluster stability.
If you don’t want to configure anything for the cloudControllerManager simply omit the key in the YAML specification.
The members of the storage allows to configure the provided storage classes further. If storage.managedDefaultStorageClass is enabled (the default), the default StorageClass deployed will be marked as default (via storageclass.kubernetes.io/is-default-class annotation). Similarly, if storage.managedDefaultVolumeSnapshotClass is enabled (the default), the default VolumeSnapshotClass deployed will be marked as default.
In case you want to set a different StorageClass or VolumeSnapshotClass as default you need to set the corresponding option to false as at most one class should be marked as default in each case and the ResourceManager will prevent any changes from the Gardener managed classes to take effect.
WorkerConfig
The worker configuration contains:
Local SSD interface for the additional volumes attached to GCP worker machines.
If you attach the disk with SCRATCH type, either an NVMe interface or a SCSI interface must be specified.
It is only meaningful to provide this volume interface if only SCRATCH data volumes are used.
Volume Encryption config that specifies values for kmsKeyName and kmsKeyServiceAccountName.
Setting a volume image with dataVolumes.sourceImage.
However, this parameter should only be used with particular caution.
For example Gardenlinux works with filesystem LABELs only and creating another disk form the very same image causes the LABELs to be duplicated.
See: https://github.com/gardener/gardener-extension-provider-gcp/issues/323
Some hyperdisks allow adjustment of their default values for provisionedIops and provisionedThroughput.
Keep in mind though that Hyperdisk Extreme and Hyperdisk Throughput volumes can’t be used as boot disks.
Service Account with their specified scopes, authorized for this worker.
Service accounts created in advance that generate access tokens that can be accessed through the metadata server and used to authenticate applications on the instance.
Note: If you do not provide service accounts for your workers, the Compute Engine default service account will be used. For more details on the default account, see https://cloud.google.com/compute/docs/access/service-accounts#default_service_account.
If the DisableGardenerServiceAccountCreation feature gate is disabled, Gardener will create a shared service accounts to use for all instances. This feature gate is currently in beta and it will no longer be possible to re-enable the service account creation via feature gate flag.
GPU with its type and count per node. This will attach that GPU to all the machines in the worker grp
Note:
A rolling upgrade of the worker group would be triggered in case the acceleratorType or count is updated.
Some machineTypes like a2 family come with already attached gpu of a100 type and pre-defined count. If your workerPool consists of such machineTypes, please specify exact GPU configuration for the machine type as specified in Google cloud documentation. acceleratorType to use for families with attached gpu are stated below:
- a2 family ->
nvidia-tesla-a100 - g2 family ->
nvidia-l4
Sufficient quota of gpu is needed in the GCP project. This includes quota to support autoscaling if enabled.
GPU-attached machines can’t be live migrated during host maintenance events. Find out how to handle that in your application here
GPU count specified here is considered for forming node template during scale-from-zero in Cluster Autoscaler
The .nodeTemplate is used to specify resource information of the machine during runtime. This then helps in Scale-from-Zero.
Some points to note for this field:
- Currently only cpu, gpu and memory are configurable.
- a change in the value lead to a rolling update of the machine in the workerpool
- all the resources needs to be specified
An example WorkerConfig for the GCP looks as follows:
apiVersion: gcp.provider.extensions.gardener.cloud/v1alpha1
kind: WorkerConfig
volume:
interface: NVME
encryption:
kmsKeyName: "projects/projectId/locations/<zoneName>/keyRings/<keyRingName>/cryptoKeys/alpha"
kmsKeyServiceAccount: "user@projectId.iam.gserviceaccount.com"
dataVolumes:
- name: test
sourceImage: projects/sap-se-gcp-gardenlinux/global/images/gardenlinux-gcp-gardener-prod-amd64-1443-3-c261f887
provisionedIops: 3000
provisionedThroughput: 140
serviceAccount:
email: foo@bar.com
scopes:
- https://www.googleapis.com/auth/cloud-platform
gpu:
acceleratorType: nvidia-tesla-t4
count: 1
nodeTemplate: # (to be specified only if the node capacity would be different from cloudprofile info during runtime)
capacity:
cpu: 2
gpu: 1
memory: 50Gi
Example Shoot manifest
Please find below an example Shoot manifest:
apiVersion: core.gardener.cloud/v1beta1
kind: Shoot
metadata:
name: johndoe-gcp
namespace: garden-dev
spec:
cloudProfile:
name: gcp
region: europe-west1
credentialsBindingName: core-gcp
provider:
type: gcp
infrastructureConfig:
apiVersion: gcp.provider.extensions.gardener.cloud/v1alpha1
kind: InfrastructureConfig
networks:
workers: 10.250.0.0/16
controlPlaneConfig:
apiVersion: gcp.provider.extensions.gardener.cloud/v1alpha1
kind: ControlPlaneConfig
zone: europe-west1-b
workers:
- name: worker-xoluy
machine:
type: n1-standard-4
minimum: 2
maximum: 2
volume:
size: 50Gi
type: pd-standard
zones:
- europe-west1-b
networking:
nodes: 10.250.0.0/16
type: calico
kubernetes:
version: 1.28.2
maintenance:
autoUpdate:
kubernetesVersion: true
machineImageVersion: true
addons:
kubernetesDashboard:
enabled: true
nginxIngress:
enabled: true
CSI volume provisioners
Every GCP shoot cluster will be deployed with the GCP PD CSI driver.
It is compatible with the legacy in-tree volume provisioner that was deprecated by the Kubernetes community and will be removed in future versions of Kubernetes.
End-users might want to update their custom StorageClasses to the new pd.csi.storage.gke.io provisioner.
Support for VolumeAttributesClasses (Beta in k8s 1.31)
To have the CSI-driver configured to support the necessary features for VolumeAttributesClasses on GCP for shoots with a k8s-version greater than 1.31, use the gcp.provider.extensions.gardener.cloud/enable-volume-attributes-class annotation on the shoot. Keep in mind to also enable the required feature flags and runtime-config on the common kubernetes controllers (as outlined in the link above) in the shoot-spec.
Kubernetes Versions per Worker Pool
This extension supports gardener/gardener’s WorkerPoolKubernetesVersion feature gate, i.e., having worker pools with overridden Kubernetes versions since gardener-extension-provider-gcp@v1.21.
Shoot CA Certificate and ServiceAccount Signing Key Rotation
This extension supports gardener/gardener’s ShootCARotation and ShootSARotation feature gates since gardener-extension-provider-gcp@v1.23.
BackupBucket
Gardener manages etcd backups for Shoot clusters using provider-specific backup storage solutions. On GCP, this storage is implemented through Google Cloud Storage (GCS) buckets, which store snapshots of the cluster’s etcd data.
The BackupBucket resource abstracts the backup infrastructure, enabling Gardener and its extension controllers to manage it seamlessly. This abstraction allows Gardener to create, delete, and maintain backup buckets across various cloud providers in a standardized manner.
The BackupBucket resource includes a spec field, which defines the configuration details for the backup bucket. These details include:
- The region where the bucket should be created.
- A reference to the secret containing credentials for accessing the cloud provider.
- A
ProviderConfig field for provider-specific configurations.
BackupBucketConfig
The BackupBucketConfig represents the configuration for a backup bucket. It includes an optional immutability configuration that enforces retention policies on the backup bucket.
The Gardener extension provider for GCP supports creating and managing immutable backup buckets by leveraging the bucket lock feature. Immutability ensures that once data is written to the bucket, it cannot be modified or deleted for a specified period. This feature is crucial for protecting backups from accidental or malicious deletion, ensuring data safety and availability for restoration.
Here is an example configuration for BackupBucketConfig:
apiVersion: gcp.provider.extensions.gardener.cloud/v1alpha1
kind: BackupBucketConfig
immutability:
retentionType: bucket
retentionPeriod: "24h"
locked: false
retentionType: Specifies the type of retention policy. The allowed value is bucket, which applies the retention policy to the entire bucket. For more details, refer to the documentation.retentionPeriod: Defines the duration for which objects in the bucket will remain immutable. The value should follow GCP-supported formats, such as "24h" for 24 hours. Refer to retention period formats for more information. The minimum retention period is 24 hours.locked: A boolean indicating whether the retention policy is locked. Once locked, the policy cannot be removed or shortened, ensuring immutability. Learn more about locking policies here.
To configure a BackupBucket with immutability, include the BackupBucketConfig in the ProviderConfig of the BackupBucket resource. If the locked field is set to true, the retention policy will be locked, preventing the retention policy from being removed and the retention period from being reduced. However, it’s still possible to increase the retention period.
Here is an example of configuring a BackupBucket with immutability:
apiVersion: extensions.gardener.cloud/v1alpha1
kind: BackupBucket
metadata:
name: my-backup-bucket
spec:
provider:
region: europe-west1
secretRef:
name: my-gcp-secret
namespace: my-namespace
providerConfig:
apiVersion: gcp.provider.extensions.gardener.cloud/v1alpha1
kind: BackupBucketConfig
immutability:
retentionType: bucket
retentionPeriod: 24h
locked: true