Using the GCP provider extension with Gardener as end-user
The core.gardener.cloud/v1beta1.Shoot resource declares a few fields that are meant to contain provider-specific configuration.
This document describes the configurable options for GCP and provides an example Shoot manifest with minimal configuration that can be used to create a GCP cluster (modulo the landscape-specific information like cloud profile names, secret binding names, etc.).
Accessing GCP APIs
In order for Gardener to create a Kubernetes cluster using GCP infrastructure components, a Shoot has to provide an authentication mechanism giving sufficient permissions to the desired GCP project. Every shoot cluster references a SecretBinding or a CredentialsBinding.
IMPORTANT
While SecretBindings can only reference Secrets, CredentialsBindings can also reference WorkloadIdentitys which provide an alternative authentication method. WorkloadIdentitys do not directly contain credentials but are rather a representation of the workload that is going to access the user's account. If the user has configured Workload Identity Federation with Gardener's Workload Identity Issuer then the GCP infrastructure components can access the user's account without the need of preliminary exchange of credentials.
IMPORTANT
The SecretBinding/CredentialsBinding is configurable in the Shoot cluster with the field secretBindingName/credentialsBindingName. SecretBindings are considered legacy and will be deprecated in the future. It is advised to use CredentialsBindings instead.
GCP Service Account Credentials
The required credentials for the GCP project are a Service Account Key to authenticate as a GCP Service Account. A service account is a special account that can be used by services and applications to interact with Google Cloud Platform APIs. Applications can use service account credentials to authorize themselves to a set of APIs and perform actions within the permissions granted to the service account.
Make sure to enable the Google Identity and Access Management (IAM) API. Create a Service Account that shall be used for the Shoot cluster. Grant at least the following IAM roles to the Service Account.
- Service Account Admin
- Service Account Token Creator
- Service Account User
- Compute Admin
Create a JSON Service Account key for the Service Account. Provide it in the Secret (base64 encoded for field serviceaccount.json), that is being referenced by the SecretBinding in the Shoot cluster configuration.
This Secret must look as follows:
apiVersion: v1
kind: Secret
metadata:
name: core-gcp
namespace: garden-dev
type: Opaque
data:
serviceaccount.json: base64(serviceaccount-json)WARNING
Depending on your API usage it can be problematic to reuse the same Service Account Key for different Shoot clusters due to rate limits. Please consider spreading your Shoots over multiple Service Accounts on different GCP projects if you are hitting those limits, see https://cloud.google.com/compute/docs/api-rate-limits.
GCP Workload Identity Federation
Users can choose to trust Gardener's Workload Identity Issuer and eliminate the need for providing GCP Service Account credentials.
As a first step users should configure Workload Identity Federation with Gardener's Workload Identity Issuer.
TIP
You can retrieve Gardener's Workload Identity Issuer URL directly from the Garden cluster by reading the contents of the Gardener Info ConfigMap.
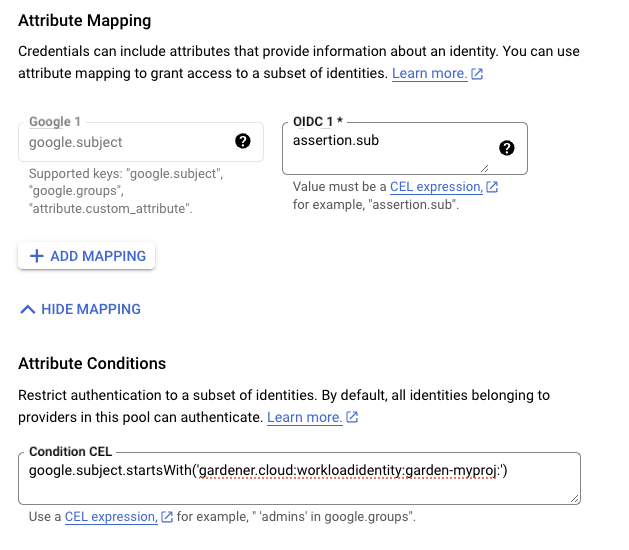
kubectl -n gardener-system-public get configmap gardener-info -o yamlIn the example attribute mapping shown below all WorkloadIdentitys that are created in the garden-myproj namespace will be authenticated. Now that the Workload Identity Federation is configured the user should download the credential configuration file.
IMPORTANT
If required, users can use a stricter mapping to authenticate only certain WorkloadIdentitys. Please, refer to the attribute mappings documentation for more information.
Users should now create a Service Account that is going to be impersonated by the federated identity. Make sure to enable the Google Identity and Access Management (IAM) API. Create a Service Account that shall be used for the Shoot cluster. Grant at least the following IAM roles to the Service Account.
- Service Account Token Creator
- Service Account User
- Compute Admin
As a next step a resource of type WorkloadIdentity should be created in the Garden cluster and configured with the information from the already downloaded credential configuration file. This identity will be used to impersonate the Service Account in order to call GCP APIs.
Mind that the service_account_impersonation_url is probably not present in the downloaded credential configuration file. You can use the example template or download a new credential configuration file once we grant the permission to the federated identity to impersonate the Service Account.
A sample of such resource is shown below:
apiVersion: security.gardener.cloud/v1alpha1
kind: WorkloadIdentity
metadata:
name: gcp
namespace: garden-myproj
spec:
audiences:
# This is the audience that you configure during workload identity pool creation
- https://iam.googleapis.com/projects/<project_number>/locations/global/workloadIdentityPools/<pool_name>/providers/<provider_name>
targetSystem:
type: gcp
providerConfig:
apiVersion: gcp.provider.extensions.gardener.cloud/v1alpha1
kind: WorkloadIdentityConfig
projectID: gcp-project-name # This is the name of the project which the workload identity will access
# Use the downloaded credential configuration file to set this field. The credential_source field is not important to Gardener and should be omitted.
credentialsConfig:
universe_domain: "googleapis.com"
type: "external_account"
audience: "//iam.googleapis.com/projects/<project_number>/locations/global/workloadIdentityPools/<pool_name>/providers/<provider_name>"
subject_token_type: "urn:ietf:params:oauth:token-type:jwt"
service_account_impersonation_url: "https://iamcredentials.googleapis.com/v1/projects/-/serviceAccounts/<service_account_email>:generateAccessToken"
token_url: "https://sts.googleapis.com/v1/token"Now users should give permissions to the WorkloadIdentity to impersonate the Service Account. In order to construct the principal that will be used for impersonation retrieve the subject of the created WorkloadIdentity.
SUBJECT=$(kubectl -n garden-myproj get workloadidentity gcp -o=jsonpath='{.status.sub}')
echo "principal://iam.googleapis.com/projects/<project_number>/locations/global/workloadIdentityPools/<pool_name>/subject/$SUBJECT"The principal template is also shown in the Google Console Workload Identity Pool UI.
Users should give this principal the Role Workload Identity User so that it can impersonate the Service Account. One can do this through the Service Account Permissions tab, through the Google Console Workload Identity Pool UI or by using the gcloud cli.
As a final step create a CredentialsBinding referencing the GCP WorkloadIdentity and use it in your Shoot definitions.
apiVersion: security.gardener.cloud/v1alpha1
kind: CredentialsBinding
metadata:
name: gcp
namespace: garden-myproj
credentialsRef:
apiVersion: security.gardener.cloud/v1alpha1
kind: WorkloadIdentity
name: gcp
namespace: garden-myproj
provider:
type: gcpapiVersion: core.gardener.cloud/v1beta1
kind: Shoot
metadata:
name: gcp
namespace: garden-myproj
spec:
credentialsBindingName: gcp
...WARNING
One can omit the creation of Service Account and directly grant access to the federated identity's principal, skipping the Service Account impersonation. This although recommended, will not always work because federated identities do not fall under the allAuthenticatedUsers category and cannot access machine images that are not made available to allUsers. This means that machine images should be made available to allUsers or permissions should be explicitly given to the federated identity in order for this to work.
GCP imposes some restrictions on which images can be accessible to allUsers. As of now, Gardenlinux images are not published in a way that they can be accessed by allUsers. See the following issue for more details https://github.com/gardenlinux/glci/issues/148.
InfrastructureConfig
The infrastructure configuration mainly describes how the network layout looks like in order to create the shoot worker nodes in a later step, thus, prepares everything relevant to create VMs, load balancers, volumes, etc.
An example InfrastructureConfig for the GCP extension looks as follows:
apiVersion: gcp.provider.extensions.gardener.cloud/v1alpha1
kind: InfrastructureConfig
networks:
# vpc:
# name: my-vpc
# cloudRouter:
# name: my-cloudrouter
workers: 10.250.0.0/16
# internal: 10.251.0.0/16
# cloudNAT:
# minPortsPerVM: 2048
# maxPortsPerVM: 65536
# endpointIndependentMapping:
# enabled: false
# enableDynamicPortAllocation: false
# natIPNames:
# - name: manualnat1
# - name: manualnat2
# udpIdleTimeoutSec: 30
# icmpIdleTimeoutSec: 30
# tcpEstablishedIdleTimeoutSec: 1200
# tcpTransitoryIdleTimeoutSec: 30
# tcpTimeWaitTimeoutSec: 120
# flowLogs:
# aggregationInterval: INTERVAL_5_SEC
# flowSampling: 0.2
# metadata: INCLUDE_ALL_METADATAThe networks.vpc section describes whether you want to create the shoot cluster in an already existing VPC or whether to create a new one:
If
networks.vpc.nameis given then you have to specify the VPC name of the existing VPC that was created by other means (manually, other tooling, ...). If you want to get a fresh VPC for the shoot then just omit thenetworks.vpcfield.If a VPC name is not given then we will create the cloud router + NAT gateway to ensure that worker nodes don't get external IPs.
If a VPC name is given then a cloud router name must also be given, failure to do so would result in validation errors and possibly clusters without egress connectivity.
If a VPC name is given and calico shoot clusters are created without a network overlay within one VPC make sure that the pod CIDR specified in
shoot.spec.networking.podsis not overlapping with any other pod CIDR used in that VPC. Overlapping pod CIDRs will lead to disfunctional shoot clusters.
The networks.workers section describes the CIDR for a subnet that is used for all shoot worker nodes, i.e., VMs which later run your applications.
The networks.internal section is optional and can describe a CIDR for a subnet that is used for internal load balancers. If it is omitted, no internal Loadbalancers can be created.
The networks.cloudNAT.minPortsPerVM is optional and is used to define the minimum number of ports allocated to a VM for the CloudNAT
The networks.cloudNAT.natIPNames is optional and is used to specify the names of the manual ip addresses which should be used by the nat gateway. If you bring your own IP addresses, the shoot’s status.networking.egressCIDRs field will be populated with those addresses. If you don’t, the field remains empty because GCP uses automatically allocated external IPs. During autoscaling, GCP may add more nodes and assign additional ephemeral IPs as needed. Since the set of egress IPs cannot be determined in advance in this scenario, we intentionally leave the field empty.
The networks.cloudNAT.endpointIndependentMapping is optional and is used to define the endpoint mapping behavior. You can enable it or disable it at any point by toggling networks.cloudNAT.endpointIndependentMapping.enabled. By default, it is disabled.
networks.cloudNAT.enableDynamicPortAllocation is optional (default: false) and allows one to enable dynamic port allocation (https://cloud.google.com/nat/docs/ports-and-addresses#dynamic-port). Note that enabling this puts additional restrictions on the permitted values for networks.cloudNAT.minPortsPerVM and networks.cloudNAT.minPortsPerVM, namely that they now both are required to be powers of two. Also, maxPortsPerVM may not be given if dynamic port allocation is disabled.
networks.cloudNAT.udpIdleTimeoutSec, networks.cloudNAT.icmpIdleTimeoutSec, networks.cloudNAT.tcpEstablishedIdleTimeoutSec, networks.cloudNAT.tcpTransitoryIdleTimeoutSec, and networks.cloudNAT.tcpTimeWaitTimeoutSec give more fine-granular control over various timeout-values. For more details see https://cloud.google.com/nat/docs/public-nat#specs-timeouts.
The specified CIDR ranges must be contained in the VPC CIDR specified above, or the VPC CIDR of your already existing VPC. You can freely choose these CIDRs and it is your responsibility to properly design the network layout to suit your needs.
The networks.flowLogs section describes the configuration for the VPC flow logs. In order to enable the VPC flow logs at least one of the following parameters needs to be specified in the flow log section:
networks.flowLogs.aggregationIntervalan optional parameter describing the aggregation interval for collecting flow logs. For more details, see aggregation_interval reference.networks.flowLogs.flowSamplingan optional parameter describing the sampling rate of VPC flow logs within the subnetwork where 1.0 means all collected logs are reported and 0.0 means no logs are reported. For more details, see flow_sampling reference.networks.flowLogs.metadataan optional parameter describing whether metadata fields should be added to the reported VPC flow logs. For more details, see metadata reference.
Apart from the VPC and the subnets the GCP extension will also create a dedicated service account for this shoot, and firewall rules.
ControlPlaneConfig
The control plane configuration mainly contains values for the GCP-specific control plane components. Today, the only component deployed by the GCP extension is the cloud-controller-manager.
An example ControlPlaneConfig for the GCP extension looks as follows:
apiVersion: gcp.provider.extensions.gardener.cloud/v1alpha1
kind: ControlPlaneConfig
zone: europe-west1-b
cloudControllerManager:
# featureGates:
# SomeKubernetesFeature: true
storage:
managedDefaultStorageClass: true
managedDefaultVolumeSnapshotClass: true
# defaultStorageClass: gce-sc-hd-balanced # allowed: default, gce-sc-hdd, gce-sc-fast, gce-sc-hd-balanced, gce-sc-hd-throughput, gce-sc-hd-extreme
# hyperDiskBalanced:
# enabled: true
# provisionedIopsOnCreate: 3000 # required when enabled
# provisionedThroughputOnCreate: "140Mi" # required when enabled
# hyperDiskThroughput:
# enabled: true
# provisionedThroughputOnCreate: "250Mi" # required when enabled
# hyperDiskExtreme:
# enabled: true
# provisionedIopsOnCreate: 10000 # required when enabled
# csiFilestore:
# enabled: trueThe zone field tells the cloud-controller-manager in which zone it should mainly operate. You can still create clusters in multiple availability zones, however, the cloud-controller-manager requires one "main" zone. ⚠️ You always have to specify this field!
The cloudControllerManager.featureGates contains a map of explicitly enabled or disabled feature gates. For production usage it's not recommend to use this field at all as you can enable alpha features or disable beta/stable features, potentially impacting the cluster stability. If you don't want to configure anything for the cloudControllerManager simply omit the key in the YAML specification.
The members of the storage allows to configure the provided storage classes further. If storage.managedDefaultStorageClass is enabled (the default), the default StorageClass deployed will be marked as default (via storageclass.kubernetes.io/is-default-class annotation). Similarly, if storage.managedDefaultVolumeSnapshotClass is enabled (the default), the default VolumeSnapshotClass deployed will be marked as default. In case you want to set a different StorageClass or VolumeSnapshotClass as default you need to set the corresponding option to false as at most one class should be marked as default in each case and the ResourceManager will prevent any changes from the Gardener managed classes to take effect.
The storage.defaultStorageClass field allows selecting which of the Gardener-managed storage classes is marked as default. The following values are supported:
| Value | Disk type |
|---|---|
default | pd-balanced (default if unset) |
gce-sc-hdd | pd-standard |
gce-sc-fast | pd-ssd |
gce-sc-hd-balanced | Hyperdisk Balanced |
gce-sc-hd-throughput | Hyperdisk Throughput |
gce-sc-hd-extreme | Hyperdisk Extreme |
Setting storage.defaultStorageClass has no effect when storage.managedDefaultStorageClass is false.
The storage.hyperDiskBalanced, storage.hyperDiskThroughput, and storage.hyperDiskExtreme fields allow deploying and configuring hyperdisk StorageClasses. Each field must have enabled: true to deploy the corresponding StorageClass; omitting the field or setting enabled: false skips deployment. When enabled is true, the required performance parameters for that disk type must be provided. The following parameters are supported per disk type:
| Field | hyperDiskBalanced | hyperDiskThroughput | hyperDiskExtreme |
|---|---|---|---|
enabled | required | required | required |
provisionedIopsOnCreate | required when enabled | not supported | required when enabled |
provisionedThroughputOnCreate | required when enabled | required when enabled | not supported |
provisionedIopsOnCreate is a positive integer (e.g. 3000). provisionedThroughputOnCreate is a quantity string (e.g. "140Mi").
Furthermore, the storage.csiFilestore.enabled field can be set to true to enable the GCP Filestore CSI driver. Additionally, you have to make sure that your IAM user has the permission roles/file.editor and that the filestore API is enabled in your GCP project.
WorkerConfig
The worker configuration contains:
Optional general volume configuration that applies to all your volumes (boot volume as well as data volumes).
Local SSD interface for the additional volumes attached to GCP worker machines. If you attach the disk with
SCRATCHtype, either anNVMeinterface or aSCSIinterface must be specified. It is only meaningful to provide this volume interface if onlySCRATCHdata volumes are used.Volume Encryption config that specifies values for
kmsKeyNameandkmsKeyServiceAccountName.- The
kmsKeyNameis the key name of the cloud kms disk encryption key and must be specified if CMEK disk encryption is needed. - The
kmsKeyServiceAccountis the service account granted theroles/cloudkms.cryptoKeyEncrypterDecrypteron thekmsKeyNameIf empty, then the role should be given to the Compute Engine Service Agent Account. This CESA account usually has the name:service-PROJECT_NUMBER@compute-system.iam.gserviceaccount.com. See: https://cloud.google.com/iam/docs/service-agents#compute-engine-service-agent - Prior to use, the operator should add IAM policy binding using the gcloud CLI:
gcloud projects add-iam-policy-binding projectId --member serviceAccount:name@projectIdgserviceaccount.com --role roles/cloudkms.cryptoKeyEncrypterDecrypter
- The
Here is an example how the volume configuration may look like:
yamlproviderConfig: apiVersion: gcp.provider.extensions.gardener.cloud/v1alpha1 kind: WorkerConfig volume: # provider specific volume configuration interface: "SCSI" # applies only for scratch disks, the local SSD Interface. encryption: # Encryption Details kmsKeyName: "projects/projectId/locations/<zoneName>/keyRings/<keyRingName>/cryptoKeys/alpha" kmsKeyServiceAccount: "user@projectId.iam.gserviceaccount.comSetting
.spec.provider.workers[].(data)Volumes[].encryptedhas no impact because GCP disks are encrypted by default.
Optional specific configuration for your
bootVolume.Some hyperdisks allow adjustment of their default values for
provisionedIopsandprovisionedThroughput. Keep in mind though that Hyperdisk Extreme and Hyperdisk Throughput volumes can't be used as boot disks.In order to create the disk into a storage pool, define the storage pool in
dataVolumes.storagePoolandbootVolume.storagePool. The storage pool must be created in advance and must be in the same region and zone as your worker.Here is an example how the
bootVolumeconfiguration may look like:yamlproviderConfig: apiVersion: gcp.provider.extensions.gardener.cloud/v1alpha1 kind: WorkerConfig bootVolume: storagePool: projects/<projectName>/zones/<zoneName>/storagePools/<storagePoolName> provisionedIops: 3000 # applies only for certain volume types provisionedThroughput: 140 # applies only for certain volume types
Optional specific configuration for your
dataVolume.All fields that are available for the boot volume are also available for the data volume.
Setting a volume image with
dataVolumes.sourceImage. However, this parameter should only be used with particular caution. For example Gardenlinux works with filesystem LABELs only and creating another disk form the very same image causes the LABELs to be duplicated. See: https://github.com/gardener/gardener-extension-provider-gcp/issues/323Here is an example how the
dataVolumeconfiguration may look like:yamlproviderConfig: apiVersion: gcp.provider.extensions.gardener.cloud/v1alpha1 kind: WorkerConfig dataVolume: # provider specific dataVolume configuration name: "alpha" sourceImage: "projects/sap-se-gcp-gardenlinux/global/images/..." provisionedIops: 3000 # applies only for certain volume types provisionedThroughput: 140 # applies only for certain volume types
Service Account with their specified scopes, authorized for this worker.
Service accounts created in advance that generate access tokens that can be accessed through the metadata server and used to authenticate applications on the instance.
Note: If you do not provide service accounts for your workers, the Compute Engine default service account will be used. For more details on the default account, see https://cloud.google.com/compute/docs/access/service-accounts#default_service_account. If the
DisableGardenerServiceAccountCreationfeature gate is disabled, Gardener will create a shared service account to use for all instances. The feature gateDisableGardenerServiceAccountCreationhas been marked as deprecated and will be removed in v1.52. It is recommended to always create dedicated service accounts for each shoot cluster.GPU with its type and count per node. This will attach that GPU to all the machines in the worker grp
Note:
A rolling upgrade of the worker group would be triggered in case the
acceleratorTypeorcountis updated.Some machineTypes like a2 family come with already attached gpu of
a100type and pre-defined count. If your workerPool consists of such machineTypes, please specify exact GPU configuration for the machine type as specified in Google cloud documentation.acceleratorTypeto use for families with attached gpu are stated below:- a2 family ->
nvidia-tesla-a100 - g2 family ->
nvidia-l4
- a2 family ->
Sufficient quota of gpu is needed in the GCP project. This includes quota to support autoscaling if enabled.
GPU-attached machines can't be live migrated during host maintenance events. Find out how to handle that in your application here
GPU count specified here is considered for forming node template during scale-from-zero in Cluster Autoscaler
The
.nodeTemplateis used to specify resource information of the machine during runtime. This then helps in Scale-from-Zero. Some points to note for this field:- Currently only cpu, gpu and memory are configurable.
- a change in the value lead to a rolling update of the machine in the workerpool
- all the resources needs to be specified
An example
WorkerConfigfor the GCP looks as follows:
apiVersion: gcp.provider.extensions.gardener.cloud/v1alpha1
kind: WorkerConfig
volume:
interface: NVME
encryption:
kmsKeyName: "projects/projectId/locations/<zoneName>/keyRings/<keyRingName>/cryptoKeys/alpha"
kmsKeyServiceAccount: "user@projectId.iam.gserviceaccount.com"
dataVolumes:
- name: test
sourceImage: projects/sap-se-gcp-gardenlinux/global/images/gardenlinux-gcp-gardener-prod-amd64-1443-3-c261f887
provisionedIops: 3000
provisionedThroughput: 140
serviceAccount:
email: foo@bar.com
scopes:
- https://www.googleapis.com/auth/cloud-platform
gpu:
acceleratorType: nvidia-tesla-t4
count: 1
nodeTemplate: # (to be specified only if the node capacity would be different from cloudprofile info during runtime)
capacity:
cpu: 2
gpu: 1
memory: 50GiThe nodeTemplate.virtualCapacity can be used to specify node extended resources that are hot-updated on nodes belonging to the pool. There are currently some caveats wrt rollouts
- If the
providerConfigsection has not yet been defined for the pool, then a rollout is un-avoidable. - If the
providerConfigis already present for the pool, thennodeTemplate.virtualCapacitycan be added without triggering a rollout as long as thevirtualCapacityis either the only element of thenodeTemplateor the last element. - If the
providerConfigis already present for the pool along with a previously definednodeTemplate.virtualCapacity, then further extended resource attributes may be freely added/modified withinvirtualCapacitywithout triggering a rollout.
Example Shoot manifest
Please find below an example Shoot manifest:
apiVersion: core.gardener.cloud/v1beta1
kind: Shoot
metadata:
name: johndoe-gcp
namespace: garden-dev
spec:
cloudProfile:
name: gcp
region: europe-west1
credentialsBindingName: core-gcp
provider:
type: gcp
infrastructureConfig:
apiVersion: gcp.provider.extensions.gardener.cloud/v1alpha1
kind: InfrastructureConfig
networks:
workers: 10.250.0.0/16
controlPlaneConfig:
apiVersion: gcp.provider.extensions.gardener.cloud/v1alpha1
kind: ControlPlaneConfig
zone: europe-west1-b
workers:
- name: worker-xoluy
machine:
type: n1-standard-4
minimum: 2
maximum: 2
volume:
size: 50Gi
type: pd-standard
zones:
- europe-west1-b
networking:
nodes: 10.250.0.0/16
type: calico
kubernetes:
version: 1.33.3
maintenance:
autoUpdate:
kubernetesVersion: true
machineImageVersion: true
addons:
kubernetesDashboard:
enabled: true
nginxIngress:
enabled: trueCSI volume provisioners
Every GCP shoot cluster will be deployed with the GCP PD CSI driver. It is compatible with the legacy in-tree volume provisioner that was deprecated by the Kubernetes community and will be removed in future versions of Kubernetes. End-users might want to update their custom StorageClasses to the new pd.csi.storage.gke.io provisioner.
Support for VolumeAttributesClasses (Beta in k8s 1.31)
To have the CSI-driver configured to support the necessary features for VolumeAttributesClasses on GCP for shoots with a k8s-version greater than 1.31, use the gcp.provider.extensions.gardener.cloud/enable-volume-attributes-class=true annotation on the shoot.
Support for CSI-driver data cache feature
To enable data caching for the CSI-driver use the gcp.provider.extensions.gardener.cloud/enable-csi-data-cache annotation on the shoot. This feature is currently experimental and not yet fully documented.
Kubernetes Versions per Worker Pool
This extension supports gardener/gardener's WorkerPoolKubernetesVersion feature gate, i.e., having worker pools with overridden Kubernetes versions since gardener-extension-provider-gcp@v1.21.
Shoot CA Certificate and ServiceAccount Signing Key Rotation
This extension supports gardener/gardener's ShootCARotation and ShootSARotation feature gates since gardener-extension-provider-gcp@v1.23.