When a shoot cluster is deleted then Gardener tries to gracefully remove most of the Kubernetes resources inside the cluster.
This is to prevent that any infrastructure or other artifacts remain after the shoot deletion.
The cleanup is performed in four steps.
Some resources are deleted with a grace period, and all resources are forcefully deleted (by removing blocking finalizers) after some time to not block the cluster deletion entirely.
Cleanup steps:
All ValidatingWebhookConfigurations and MutatingWebhookConfigurations are deleted with a 5m grace period. Forceful finalization happens after 5m.
All APIServices and CustomResourceDefinitions are deleted with a 5m grace period. Forceful finalization happens after 1h.
All CronJobs, DaemonSets, Deployments, Ingresss, Jobs, Pods, ReplicaSets, ReplicationControllers, Services, StatefulSets, PersistentVolumeClaims are deleted with a 5m grace period. Forceful finalization happens after 5m.
If the Shoot is annotated with shoot.gardener.cloud/skip-cleanup=true, then only Services and PersistentVolumeClaims are considered.
All VolumeSnapshots and VolumeSnapshotContents are deleted with a 5m grace period. Forceful finalization happens after 1h.
It is possible to override the finalization grace periods via annotations on the Shoot:
shoot.gardener.cloud/cleanup-webhooks-finalize-grace-period-seconds (for the resources handled in step 1)
shoot.gardener.cloud/cleanup-extended-apis-finalize-grace-period-seconds (for the resources handled in step 2)
shoot.gardener.cloud/cleanup-kubernetes-resources-finalize-grace-period-seconds (for the resources handled in step 3)
⚠️ If "0" is provided, then all resources are finalized immediately without waiting for any graceful deletion.
Please be aware that this might lead to orphaned infrastructure artifacts.
1.2 - containerd Registry Configuration
containerd Registry Configuration
containerd supports configuring registries and mirrors. Using this native containerd feature, Shoot owners can configure containerd to use public or private mirrors for a given upstream registry. More details about the registry configuration can be found in the corresponding upstream documentation.
containerd Registry Configuration Patterns
At the time of writing this document, containerd support two patterns for configuring registries/mirrors.
Note: Trying to use both of the patterns at the same time is not supported by containerd. Only one of the configuration patterns has to be followed strictly.
Old and Deprecated Pattern
The old and deprecated pattern is specifying registry.mirrors and registry.configs in the containerd’s config.toml file. See the upstream documentation.
Example of the old and deprecated pattern:
version = 2
[plugins."io.containerd.grpc.v1.cri".registry]
[plugins."io.containerd.grpc.v1.cri".registry.mirrors]
[plugins."io.containerd.grpc.v1.cri".registry.mirrors."docker.io"]
endpoint = ["https://public-mirror.example.com"]
In the above example, containerd is configured to first try to pull docker.io images from a configured endpoint (https://public-mirror.example.com). If the image is not available in https://public-mirror.example.com, then containerd will fall back to the upstream registry (docker.io) and will pull the image from there.
Hosts Directory Pattern
The hosts directory pattern is the new and recommended pattern for configuring registries. It is available starting containerd@v1.5.0. See the upstream documentation.
The above example in the hosts directory pattern looks as follows.
The /etc/containerd/config.toml file has the following section:
version = 2
[plugins."io.containerd.grpc.v1.cri".registry]
config_path = "/etc/containerd/certs.d"
The following hosts directory structure has to be created:
$ tree /etc/containerd/certs.d
/etc/containerd/certs.d
└── docker.io
└── hosts.toml
Finally, for the docker.io upstream registry, we configure a hosts.toml file as follows:
server = "https://registry-1.docker.io"[host."http://public-mirror.example.com"]
capabilities = ["pull", "resolve"]
Configuring containerd Registries for a Shoot
Gardener supports configuring containerd registries on a Shoot using the new hosts directory pattern. For each Shoot Node, Gardener creates the /etc/containerd/certs.d directory and adds the following section to the containerd’s /etc/containerd/config.toml file:
This allows Shoot owners to use the hosts directory pattern to configure registries for containerd. To do this, the Shoot owners need to create a directory under /etc/containerd/certs.d that is named with the upstream registry host name. In the newly created directory, a hosts.toml file needs to be created. For more details, see the hosts directory pattern section and the upstream documentation.
The registry-cache Extension
There is a Gardener-native extension named registry-cache that supports:
Configuring containerd registry mirrors based on the above-described contract. The feature is added in registry-cache@v0.6.0.
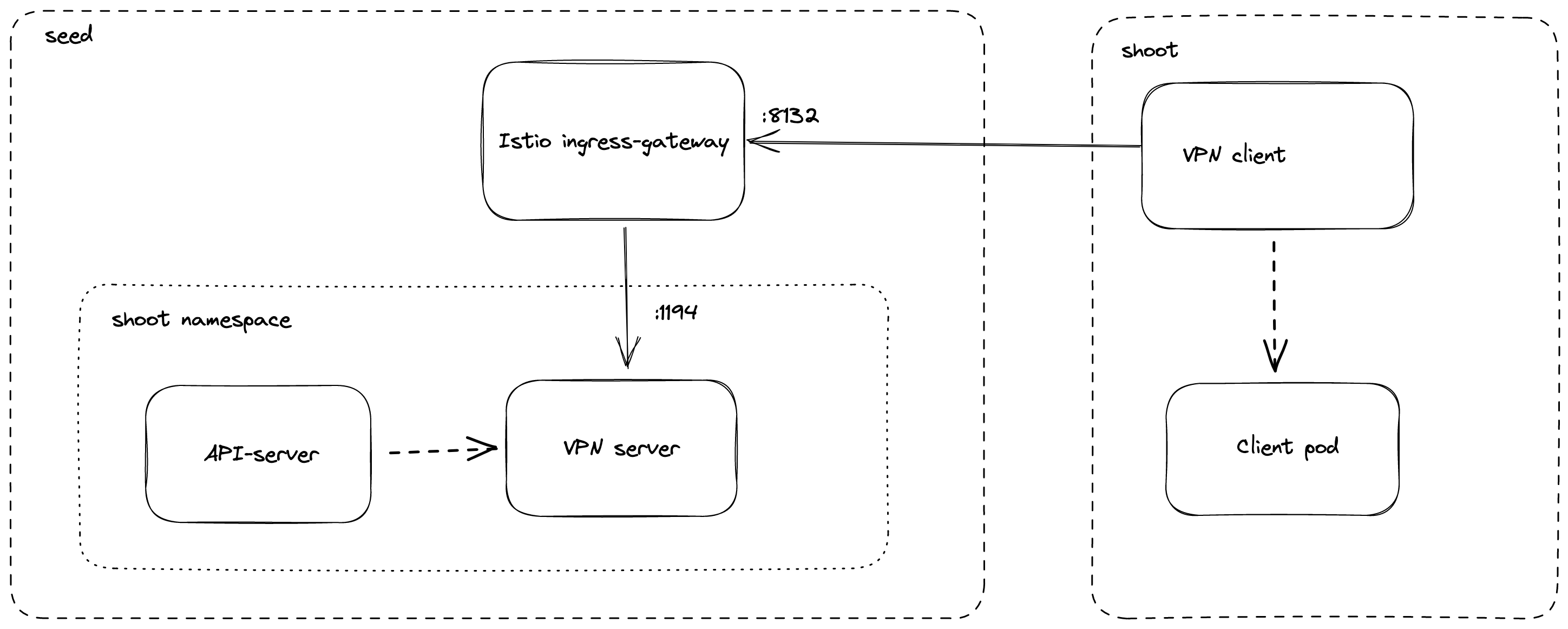
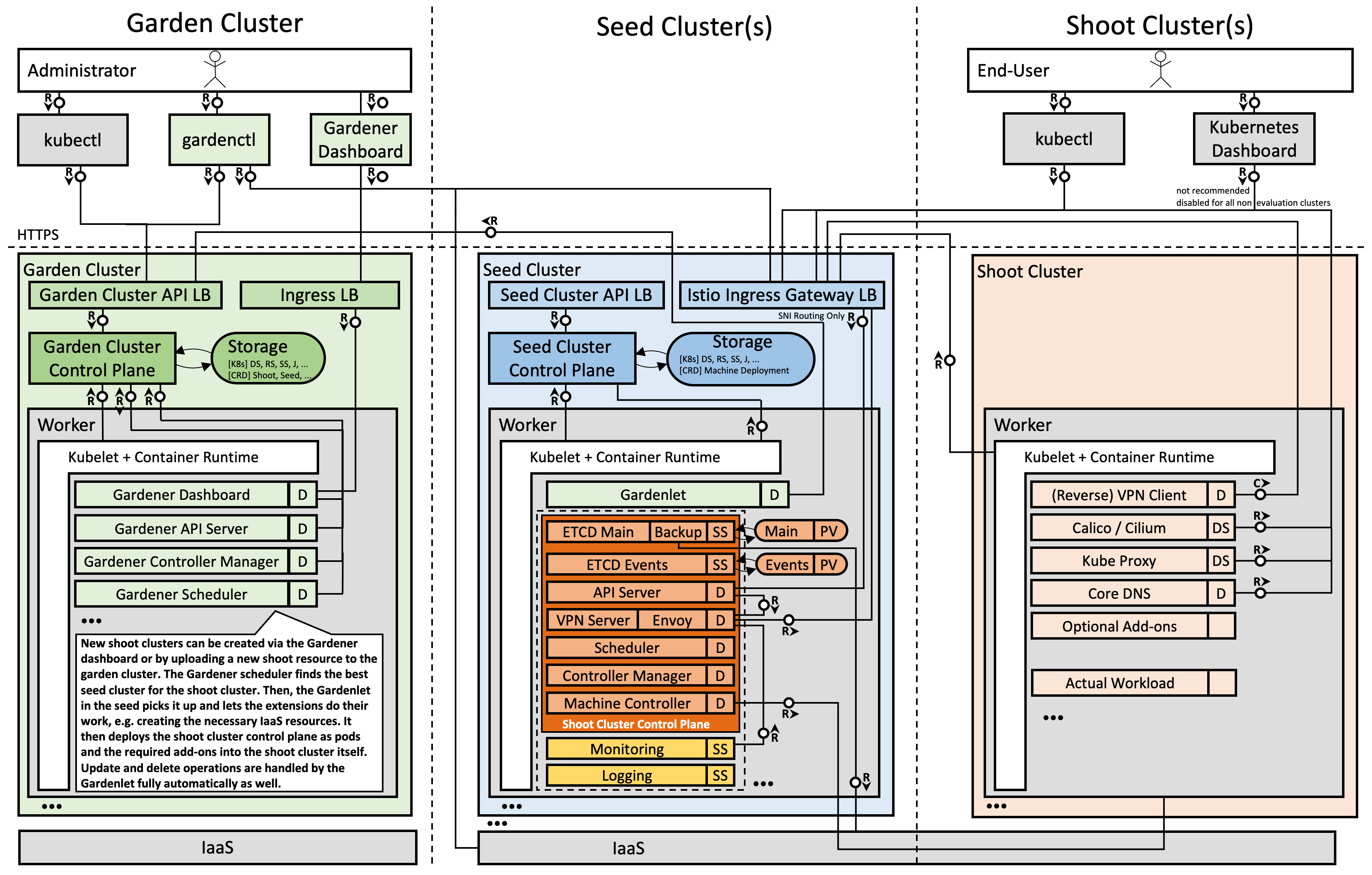
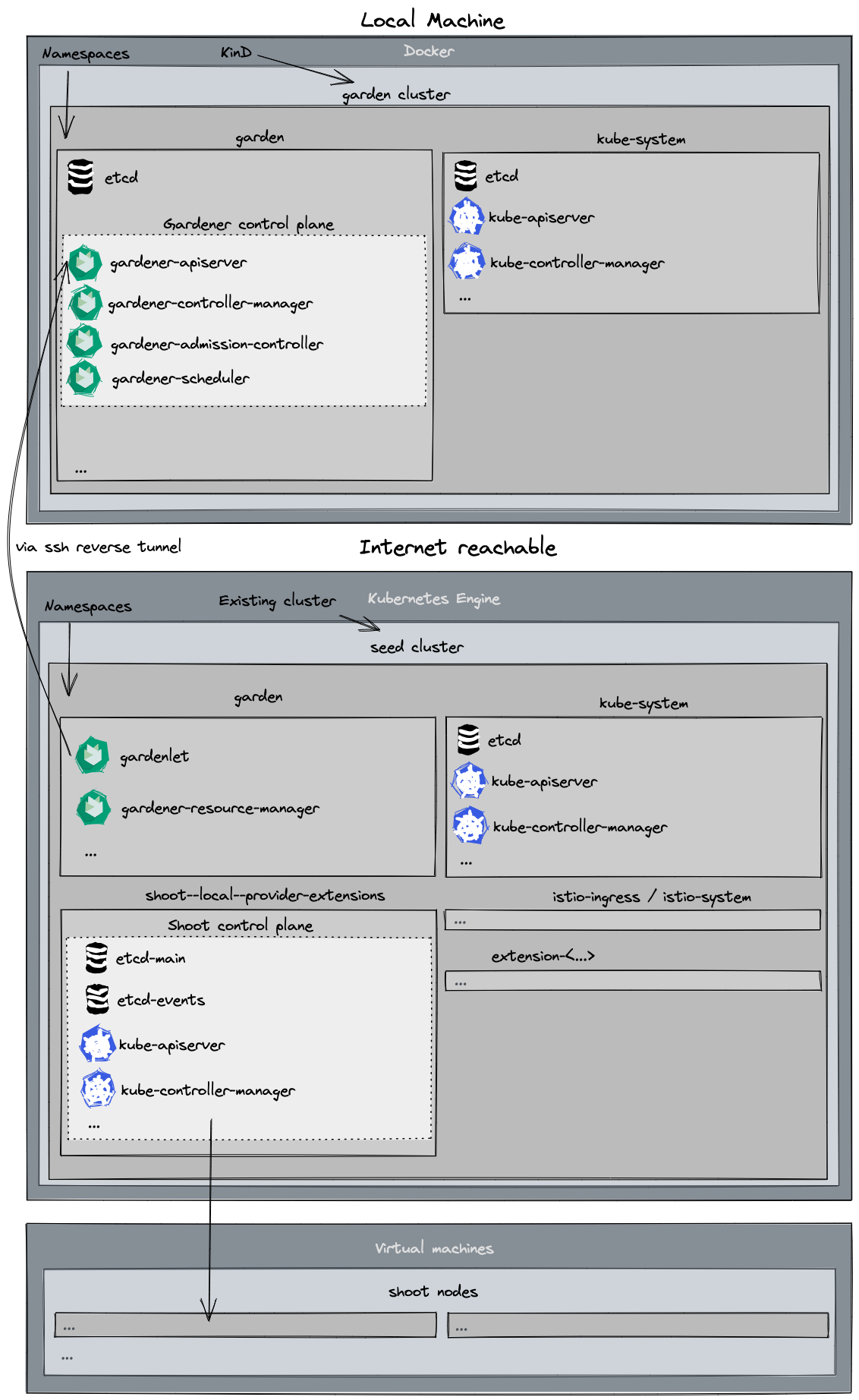
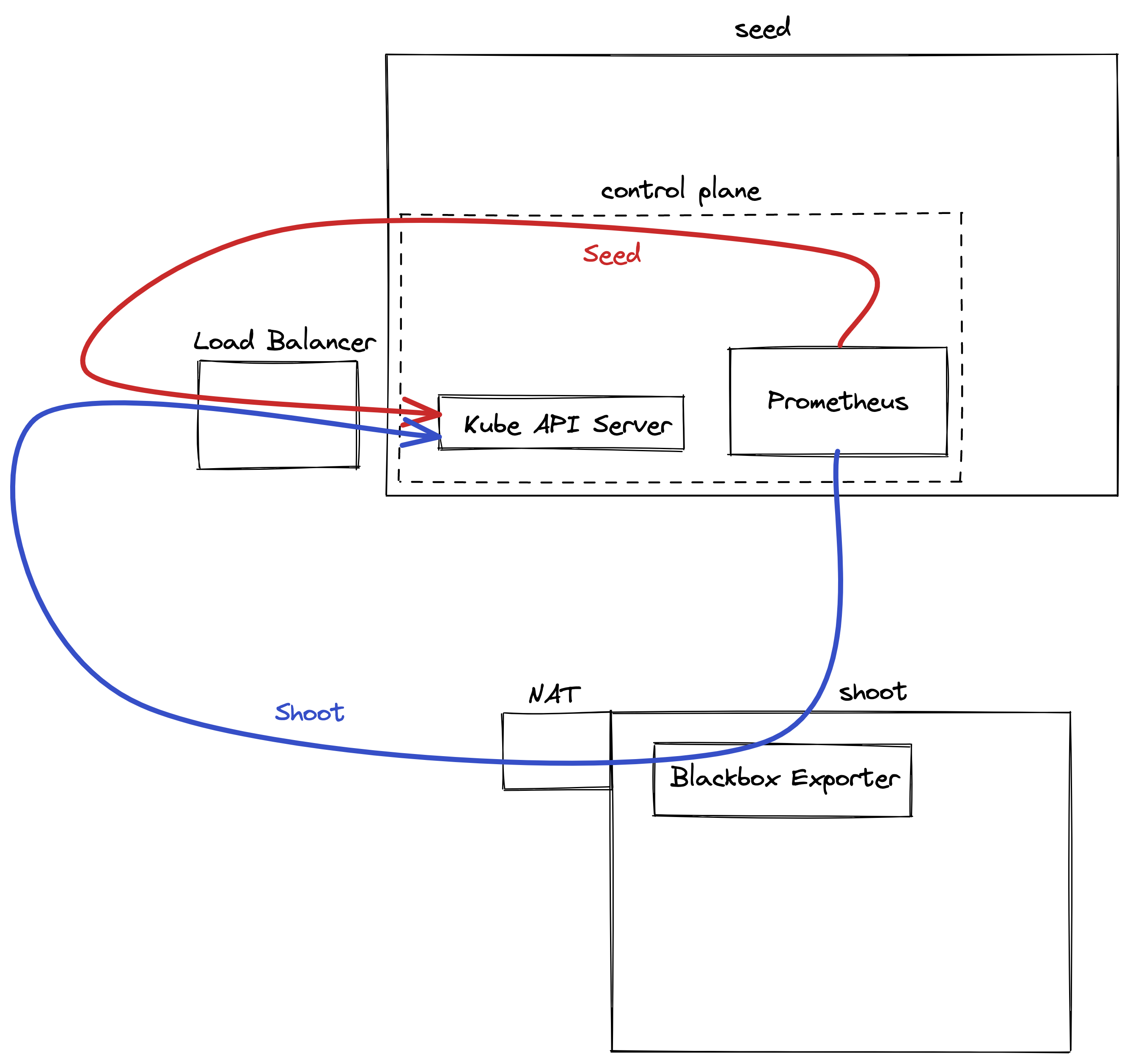
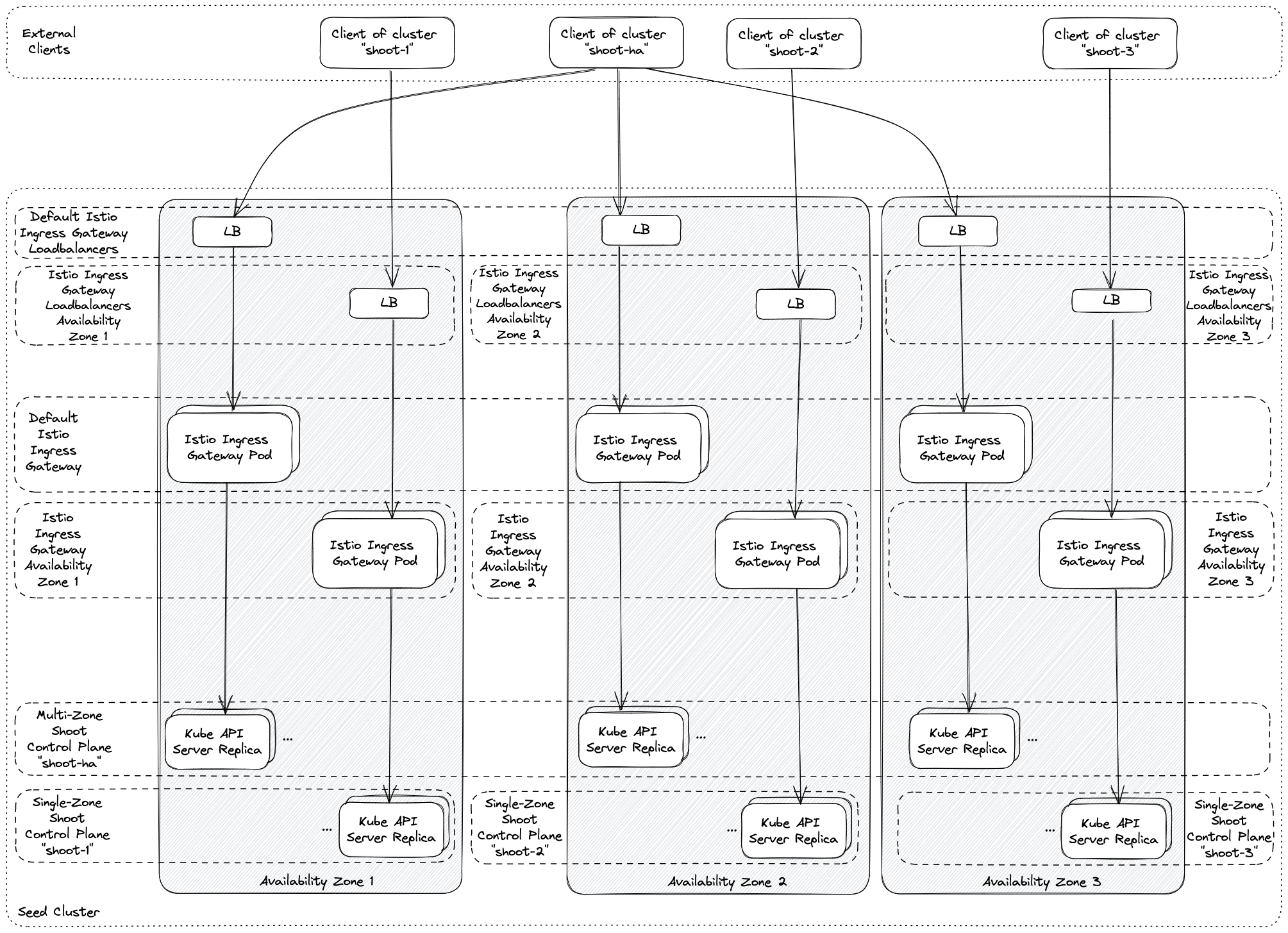
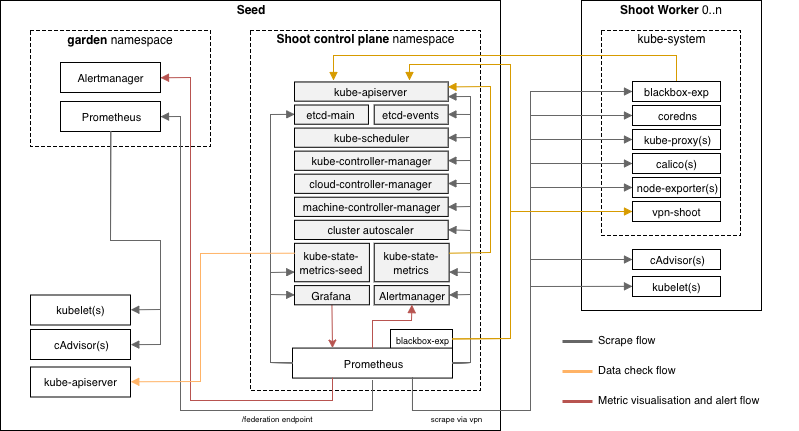
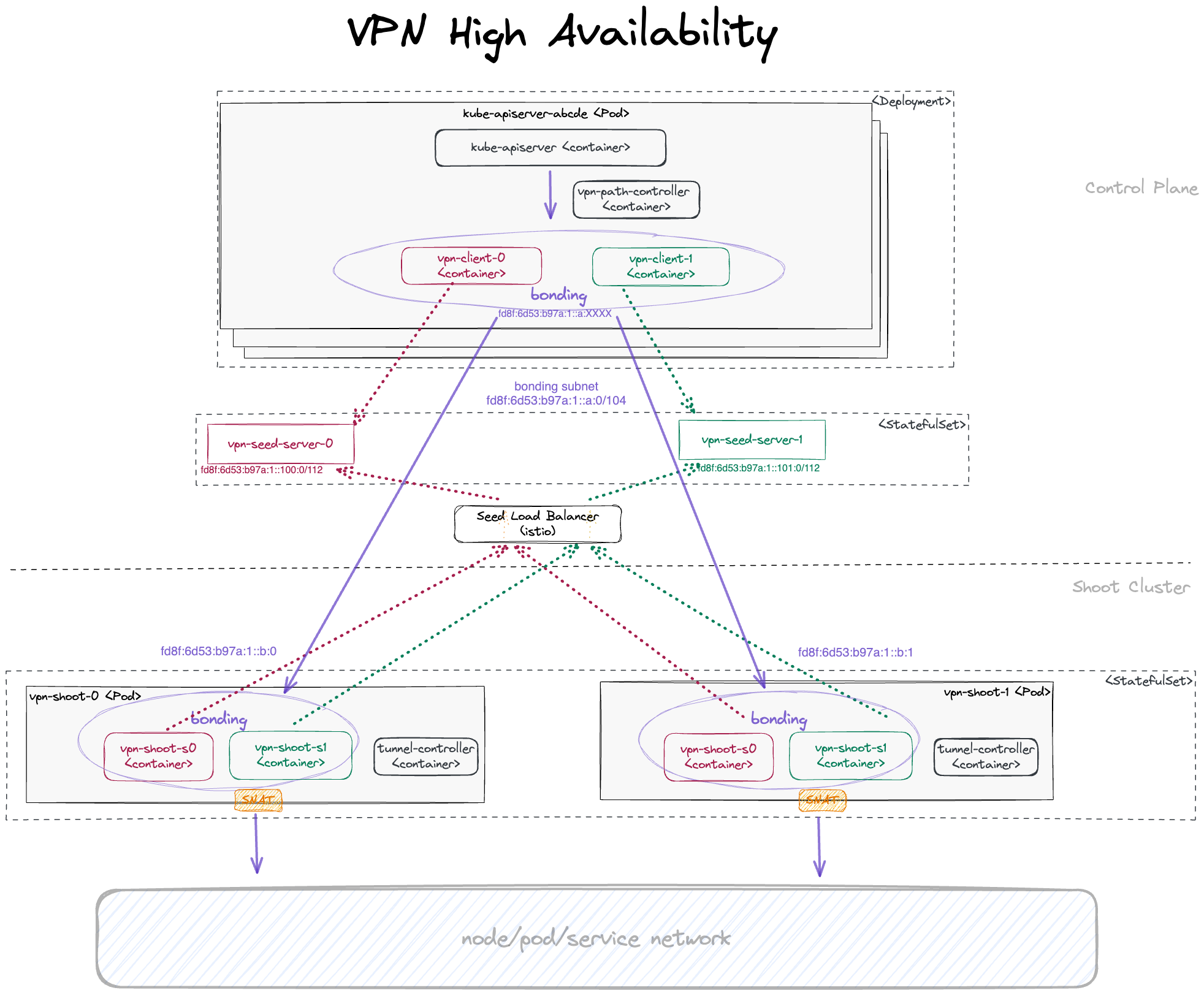
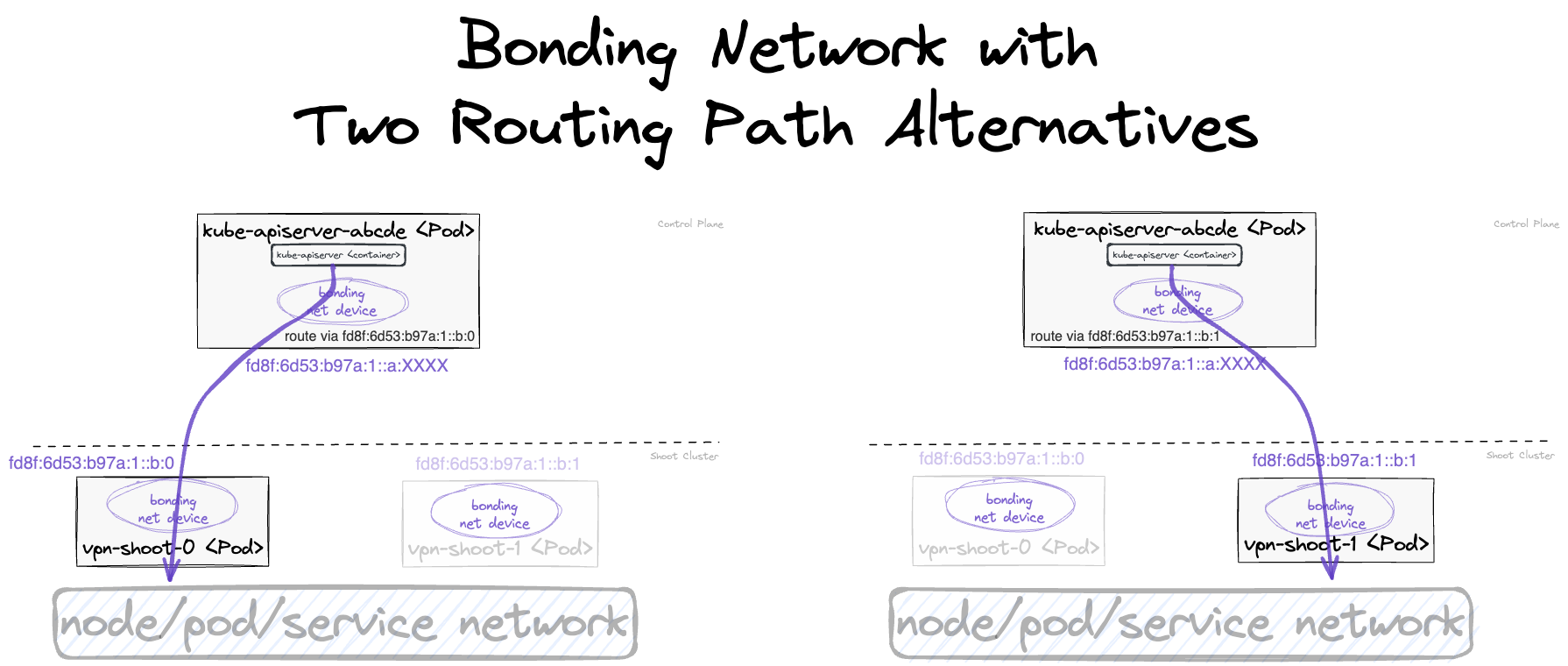
With the reversed VPN tunnel, there are no endpoints with open ports in the shoot cluster required by Gardener.
In order to allow communication to the shoots control-plane in the seed cluster, there are endpoints shared by multiple shoots of a seed cluster.
Depending on the configured zones or exposure classes, there are different endpoints in a seed cluster. The IP address(es) can be determined by a DNS query for the API Server URL.
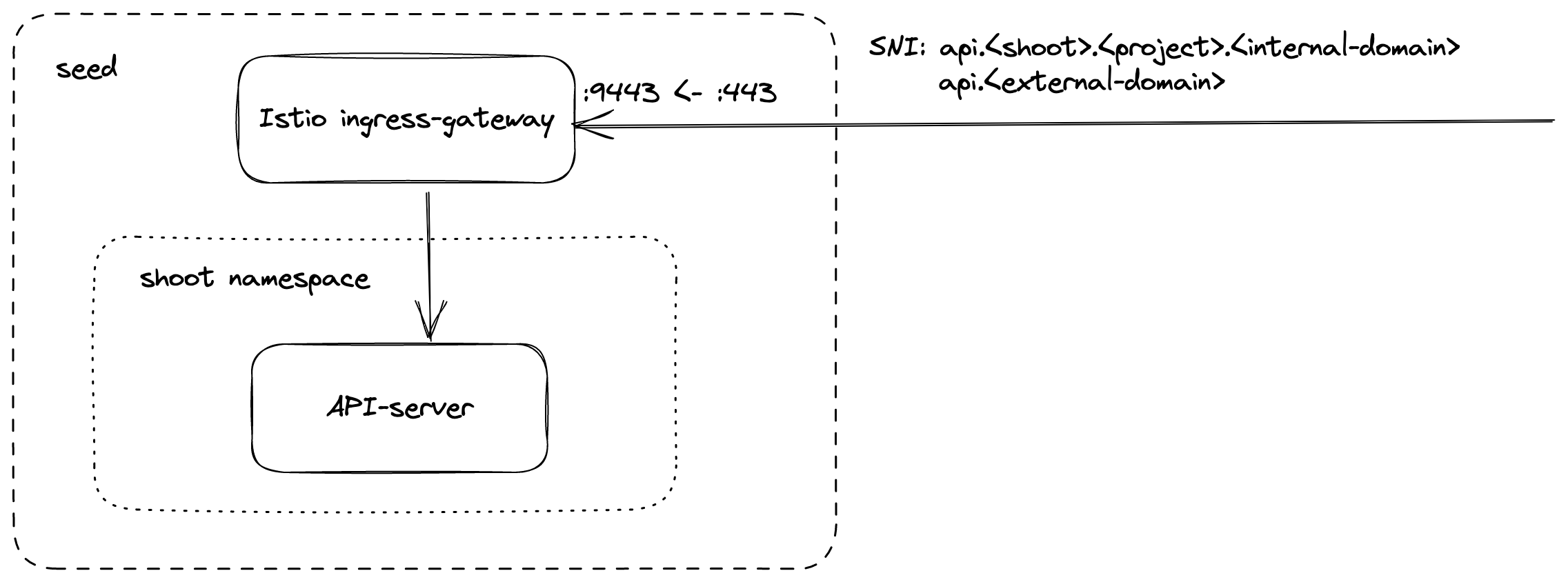
The main entry-point into the seed cluster is the load balancer of the Istio ingress-gateway service. Depending on the infrastructure provider, there can be one IP address per zone.
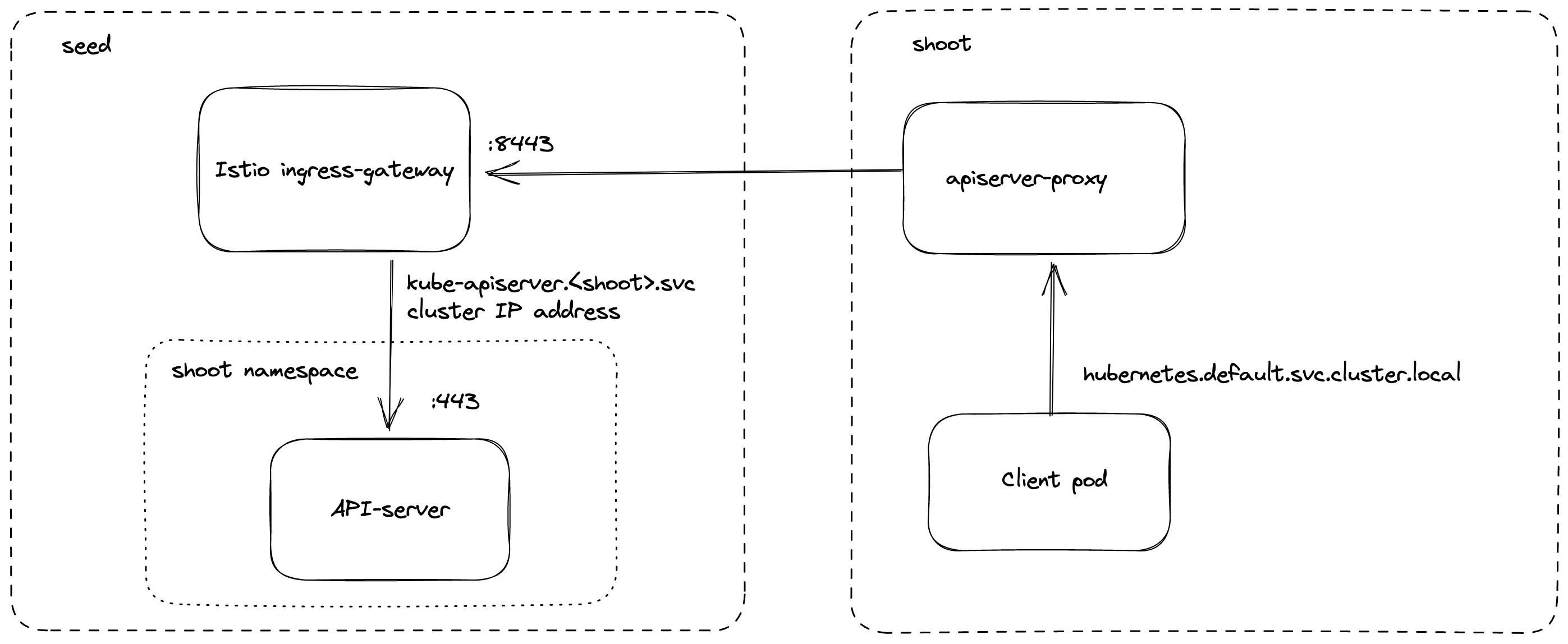
The load balancer of the Istio ingress-gateway service exposes the following TCP ports:
443 for requests to the shoot API Server. The request is dispatched according to the set TLS SNI extension.
8443 for requests to the shoot API Server via api-server-proxy, dispatched based on the proxy protocol target, which is the IP address of kubernetes.default.svc.cluster.local in the shoot.
8132 to establish the reversed VPN connection. It’s dispatched according to an HTTP header value.
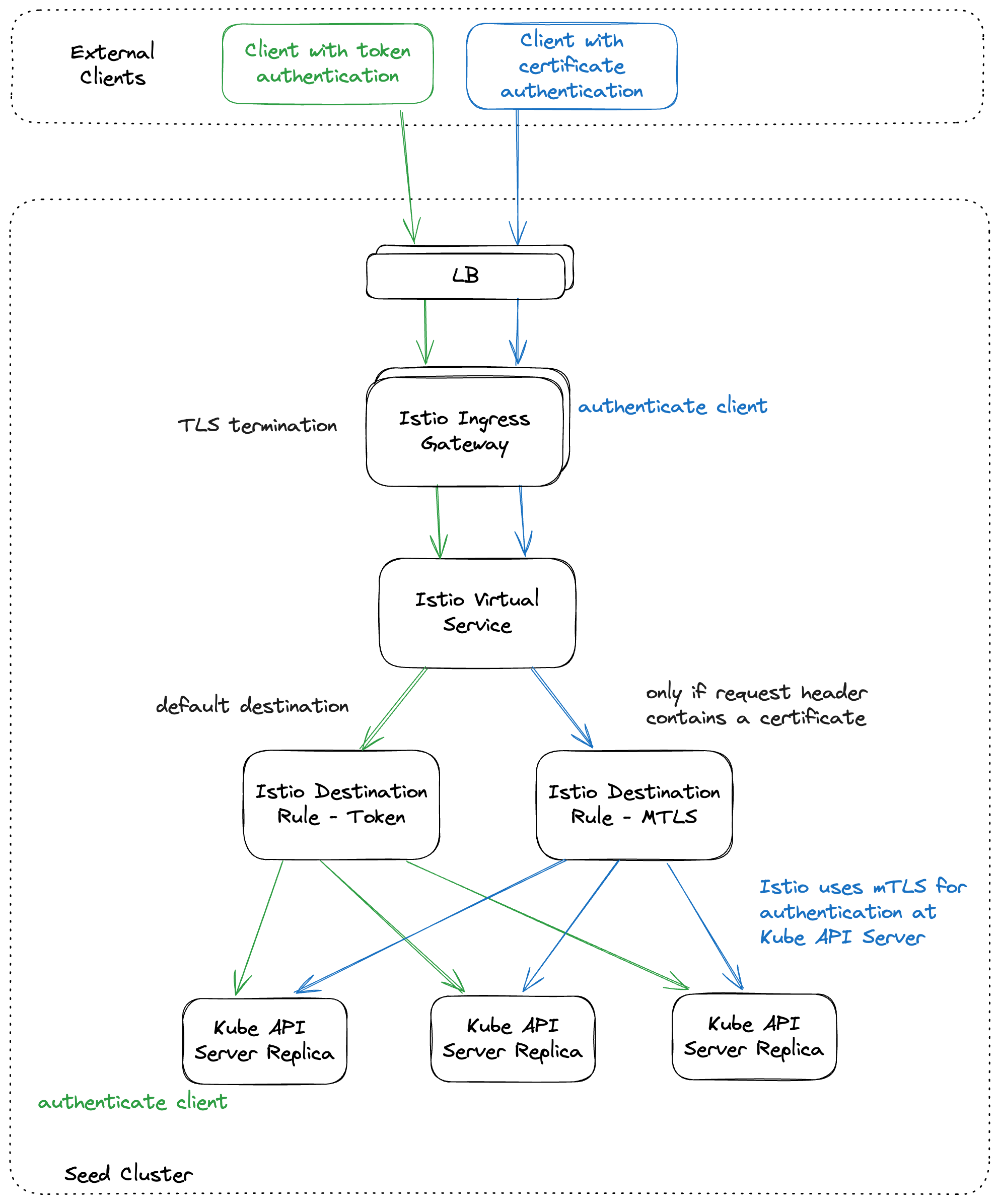
kube-apiserver via SNI
DNS entries for api.<external-domain> and api.<shoot>.<project>.<internal-domain> point to the load balancer of an Istio ingress-gateway service.
The Kubernetes client sets the server name to api.<external-domain> or api.<shoot>.<project>.<internal-domain>.
Based on SNI, the connection is forwarded to the respective API Server at TCP layer. There is no TLS termination at the Istio ingress-gateway.
TLS termination happens on the shoots API Server. Traffic is end-to-end encrypted between the client and the API Server. The certificate authority and authentication are defined in the corresponding kubeconfig.
Details can be found in GEP-08.
kube-apiserver via apiserver-proxy
Inside the shoot cluster, the API Server can also be reached by the cluster internal name kubernetes.default.svc.cluster.local.
The pods apiserver-proxy are deployed in the host network as daemonset and intercept connections to the Kubernetes service IP address.
The destination address is changed to the cluster IP address of the service kube-apiserver.<shoot-namespace>.svc.cluster.local in the seed cluster.
The connections are forwarded via the HaProxy Proxy Protocol to the Istio ingress-gateway in the seed cluster.
The Istio ingress-gateway forwards the connection to the respective shoot API Server by it’s cluster IP address.
As TLS termination happens at the API Server, the traffic is end-to-end encrypted the same way as with SNI.
As the API Server has to be able to connect to endpoints in the shoot cluster, a VPN connection is established.
This VPN connection is initiated from a VPN client in the shoot cluster.
The VPN client connects to the Istio ingress-gateway and is forwarded to the VPN server in the control-plane namespace of the shoot.
Once the VPN tunnel between the VPN client in the shoot and the VPN server in the seed cluster is established, the API Server can connect to nodes, services and pods in the shoot cluster.
In case a Shoot cluster uses containerd, it is possible to make the containerd process load custom configuration files.
Gardener initializes containerd with the following statement:
imports = ["/etc/containerd/conf.d/*.toml"]
This means that all *.toml files in the /etc/containerd/conf.d directory will be imported and merged with the default configuration.
To prevent unintended configuration overwrites, please be aware that containerd merges config sections, not individual keys (see here and here).
Please consult the upstream containerd documentation for more information.
⚠️ Note that this only applies to nodes which were newly created after gardener/gardener@v1.51 was deployed. Existing nodes are not affected.
1.5 - Immutable Backup Buckets
Immutable Backup Buckets
Overview
Immutable backup buckets ensure that etcd backups cannot be modified or deleted before the configured retention period expires, by leveraging immutability features provided by supported cloud providers.
This capability is critical for:
Security: Protecting against accidental or malicious deletion of backups.
Compliance: Meeting regulatory requirements for data retention.
Operational integrity: Ensuring recoverable state of your Kubernetes clusters.
When immutability is enabled via a supported Gardener provider extension:
The provider extension will:
✅ Create the backup bucket with the desired immutability policy (if it does not already exist).
🔄 Reconcile the policy on existing buckets to match the current configuration.
🚫 Prevent changes that would weaken the policy (reduce retention period or disable immutability).
🕑 Manage deletion lifecycle: If retention lock prevents immediate deletion of objects, a deletion policy will apply when allowed.
Important
Once a bucket’s immutability is locked at the cloud provider level, it cannot be removed or shortened—even by administrators or operators.
Provider Support
Warning
Not all Gardener provider extensions currently support immutable buckets.
Support and configuration options vary between providers.
Please check your cloud provider’s extension documentation (see References) for up-to-date support and syntax.
How It Works: Admission Webhook Enforcement
To ensure backup integrity, an admission webhook enforces:
🔒 Immutability lock: Once the policy is locked, it cannot be disabled.
📅 Retention period: Once the policy is locked, the retention period cannot be shortened.
This protects clusters from accidental misconfiguration or policy drift.
How to Enable Immutable Backup Buckets
To enable immutable backup buckets:
1️⃣ Set the immutability options in .spec.backup.providerConfig of your Seed resource.
2️⃣ The Gardenlet and the provider extension will collaborate to provision and manage the bucket.
Example Configuration
Below is a generic example; adjust according to your cloud provider’s API:
When using immutable backup buckets, you may encounter situations where certain snapshots cannot be deleted due to immutability constraints. In such cases, you can configure the etcd-backup-restore tool to ignore problematic snapshots during restoration.
This allows you to proceed with restoring the etcd cluster without being blocked by snapshots that cannot be deleted.
Warning
Ignoring snapshots should be used with caution. It is recommended to only ignore snapshots that you are certain are not needed for recovery, as this may lead to data loss if critical snapshots are skipped.
1.6 - Necessary Labeling for Custom CSI Components
Necessary Labeling for Custom CSI Components
Some provider extensions for Gardener are using CSI components to manage persistent volumes in the shoot clusters.
Additionally, most of the provider extensions are deploying controllers for taking volume snapshots (CSI snapshotter).
End-users can deploy their own CSI components and controllers into shoot clusters.
In such situations, there are multiple controllers acting on the VolumeSnapshot custom resources (each responsible for those instances associated with their respective driver provisioner types).
However, this might lead to operational conflicts that cannot be overcome by Gardener alone.
Concretely, Gardener cannot know which custom CSI components were installed by end-users which can lead to issues, especially during shoot cluster deletion.
You can add a label to your custom CSI components indicating that Gardener should not try to remove them during shoot cluster deletion. This means you have to take care of the lifecycle for these components yourself!
Recommendations
Custom CSI components are typically regular Deployments running in the shoot clusters.
Please label them with the shoot.gardener.cloud/no-cleanup=true label.
Background Information
When a shoot cluster is deleted, Gardener deletes most Kubernetes resources (Deployments, DaemonSets, StatefulSets, etc.). Gardener will also try to delete CSI components if they are not marked with the above mentioned label.
This can result in VolumeSnapshot resources still having finalizers that will never be cleaned up.
Consequently, manual intervention is required to clean them up before the cluster deletion can continue.
1.7 - Readiness of Shoot Worker Nodes
Implementation in Gardener for readiness of Shoot worker Nodes. How to mark components as node-critical
Readiness of Shoot Worker Nodes
Background
When registering new Nodes, kubelet adds the node.kubernetes.io/not-ready taint to prevent scheduling workload Pods to the Node until the Ready condition gets True.
However, the kubelet does not consider the readiness of node-critical Pods.
Hence, the Ready condition might get True and the node.kubernetes.io/not-ready taint might get removed, for example, before the CNI daemon Pod (e.g., calico-node) has successfully placed the CNI binaries on the machine.
This problem has been discussed extensively in kubernetes, e.g., in kubernetes/kubernetes#75890.
However, several proposals have been rejected because the problem can be solved by using the --register-with-taints kubelet flag and dedicated controllers (ref).
Implementation in Gardener
Gardener makes sure that workload Pods are only scheduled to Nodes where all node-critical components required for running workload Pods are ready.
For this, Gardener follows the proposed solution by the Kubernetes community and registers new Node objects with the node.gardener.cloud/critical-components-not-ready taint (effect NoSchedule).
gardener-resource-manager’s Node controller reacts on newly created Node objects that have this taint.
The controller removes the taint once all node-critical Pods are ready (determined by checking the Pods’ Ready conditions).
The Node controller considers all DaemonSets and Pods as node-critical which run in the kube-system namespace and are labeled with node.gardener.cloud/critical-component=true.
If there are DaemonSets that contain the node.gardener.cloud/critical-component=true label in their metadata and in their Pod template, the Node controller waits for corresponding daemon Pods to be scheduled and to get ready before removing the taint.
Additionally, the Node controller checks for the readiness of csi-driver-node components if a respective Pod indicates that it uses such a driver.
This is achieved through a well-defined annotation prefix (node.gardener.cloud/wait-for-csi-node-).
For example, the csi-driver-node Pod for Openstack Cinder is annotated with node.gardener.cloud/wait-for-csi-node-cinder=cinder.csi.openstack.org.
A key prefix is used instead of a “regular” annotation to allow for multiple CSI drivers being registered by one csi-driver-node Pod.
The annotation key’s suffix can be chosen arbitrarily (in this case cinder) and the annotation value needs to match the actual driver name as specified in the CSINode object.
The Node controller will verify that the used driver is properly registered in this object before removing the node.gardener.cloud/critical-components-not-ready taint.
Note that the csi-driver-node Pod still needs to be labelled and tolerate the taint as described above to be considered in this additional check.
Marking Node-Critical Components
To make use of this feature, node-critical DaemonSets and Pods need to:
Tolerate the node.gardener.cloud/critical-components-not-readyNoSchedule taint.
Be labelled with node.gardener.cloud/critical-component=true.
Be placed in the kube-system namespace.
csi-driver-node Pods additionally need to:
Be annotated with node.gardener.cloud/wait-for-csi-node-<name>=<full-driver-name>.
It’s required that these Pods fulfill the above criteria (label and toleration) as well.
Gardener already marks components like kube-proxy, apiserver-proxy and node-local-dns as node-critical.
Provider extensions mark components like csi-driver-node as node-critical and add the wait-for-csi-node annotation.
Network extensions mark components responsible for setting up CNI on worker Nodes (e.g., calico-node) as node-critical.
If shoot owners manage any additional node-critical components, they can make use of this feature as well.
1.8 - Taints and Tolerations for Seeds and Shoots
Taints and Tolerations for Seeds and Shoots
Similar to taints and tolerations for Nodes and Pods in Kubernetes, the Seed resource supports specifying taints (.spec.taints, see this example) while the Shoot resource supports specifying tolerations (.spec.tolerations, see this example).
The feature is used to control scheduling to seeds as well as decisions whether a shoot can use a certain seed.
Compared to Kubernetes, Gardener’s taints and tolerations are very much down-stripped right now and have some behavioral differences.
Please read the following explanations carefully if you plan to use them.
Scheduling
When scheduling a new shoot, the gardener-scheduler will filter all seed candidates whose taints are not tolerated by the shoot.
As Gardener’s taints/tolerations don’t support effects yet, you can compare this behaviour with using a NoSchedule effect taint in Kubernetes.
Be reminded that taints/tolerations are no means to define any affinity or selection for seeds - please use .spec.seedSelector in the Shoot to state such desires.
⚠️ Please note that - unlike how it’s implemented in Kubernetes - a certain seed cluster may only be used when the shoot tolerates all the seed’s taints.
This means that specifying .spec.seedName for a seed whose taints are not tolerated will make the gardener-apiserver reject the request.
Consequently, the taints/tolerations feature can be used as means to restrict usage of certain seeds.
Toleration Defaults and Whitelist
The Project resource features a .spec.tolerations object that may carry defaults and a whitelist (see this example).
The corresponding ShootTolerationRestriction admission plugin (cf. Kubernetes’ PodTolerationRestriction admission plugin) is responsible for evaluating these settings during creation/update of Shoots.
Whitelist
If a shoot gets created or updated with tolerations, then it is validated that only those tolerations may be used that were added to either a) the Project’s .spec.tolerations.whitelist, or b) to the global whitelist in the ShootTolerationRestriction’s admission config (see this example).
⚠️ Please note that the tolerations whitelist of Projects can only be changed if the user trying to change it is bound to the modify-spec-tolerations-whitelist custom RBAC role, e.g., via the following ClusterRole:
If a shoot gets created, then the default tolerations specified in both the Project’s .spec.tolerations.defaults and the global default list in the ShootTolerationRestriction admission plugin’s configuration will be added to the .spec.tolerations of the Shoot (unless it already specifies a certain key).
Package v1alpha1 is a version of the API.
“authentication.gardener.cloud/v1alpha1” API is already used for CRD registration and must not be served by the API server.
Resource Types:
AdminKubeconfigRequest
AdminKubeconfigRequest can be used to request a kubeconfig with admin credentials
for a Shoot cluster.
Spec is the specification of the AdminKubeconfigRequest.
expirationSecondsint64
(Optional)
ExpirationSeconds is the requested validity duration of the credential. The
credential issuer may return a credential with a different validity duration so a
client needs to check the ‘expirationTimestamp’ field in a response.
Defaults to 1 hour.
AdminKubeconfigRequestSpec contains the expiration time of the kubeconfig.
Field
Description
expirationSecondsint64
(Optional)
ExpirationSeconds is the requested validity duration of the credential. The
credential issuer may return a credential with a different validity duration so a
client needs to check the ‘expirationTimestamp’ field in a response.
Defaults to 1 hour.
Spec is the specification of the ViewerKubeconfigRequest.
expirationSecondsint64
(Optional)
ExpirationSeconds is the requested validity duration of the credential. The
credential issuer may return a credential with a different validity duration so a
client needs to check the ‘expirationTimestamp’ field in a response.
Defaults to 1 hour.
ViewerKubeconfigRequestSpec contains the expiration time of the kubeconfig.
Field
Description
expirationSecondsint64
(Optional)
ExpirationSeconds is the requested validity duration of the credential. The
credential issuer may return a credential with a different validity duration so a
client needs to check the ‘expirationTimestamp’ field in a response.
Defaults to 1 hour.
SecretRef is a reference to a secret that contains the credentials to access object store.
Deprecated: This field will be removed after v1.123.0 has been released. Use CredentialsRef instead.
Until removed, this field is synced with the CredentialsRef field when it refers to a secret.
seedNamestring
(Optional)
SeedName holds the name of the seed allocated to BackupBucket for running controller.
This field is immutable.
CredentialsRef is reference to a resource holding the credentials used for
authentication with the object store service where the backups are stored.
Supported referenced resources are v1.Secrets and
security.gardener.cloud/v1alpha1.WorkloadIdentity
SeedSelector contains an optional list of labels on Seed resources that marks those seeds whose shoots may use this provider profile.
An empty list means that all seeds of the same provider type are supported.
This is useful for environments that are of the same type (like openstack) but may have different “instances”/landscapes.
Optionally a list of possible providers can be added to enable cross-provider scheduling. By default, the provider
type of the seed must match the shoot’s provider.
Capabilities contains the definition of all possible capabilities in the CloudProfile.
Only capabilities and values defined here can be used to describe MachineImages and MachineTypes.
The order of values for a given capability is relevant. The most important value is listed first.
During maintenance upgrades, the image that matches most capabilities will be selected.
ControllerDeployment
ControllerDeployment contains information about how this controller is deployed.
Refer to the Kubernetes API documentation for the fields of the
metadata field.
immutablebool
(Optional)
Immutable, if set to true, ensures that data stored in the Secret cannot
be updated (only object metadata can be modified).
If not set to true, the field can be modified at any time.
Defaulted to nil.
datamap[string][]byte
(Optional)
Data contains the secret data. Each key must consist of alphanumeric
characters, ‘-’, ‘_’ or ‘.’. The serialized form of the secret data is a
base64 encoded string, representing the arbitrary (possibly non-string)
data value here. Described in https://tools.ietf.org/html/rfc4648#section-4
stringDatamap[string]string
(Optional)
stringData allows specifying non-binary secret data in string form.
It is provided as a write-only input field for convenience.
All keys and values are merged into the data field on write, overwriting any existing values.
The stringData field is never output when reading from the API.
Owner is a subject representing a user name, an email address, or any other identifier of a user owning
the project.
IMPORTANT: Be aware that this field will be removed in the v1 version of this API in favor of the owner
role. The only way to change the owner will be by moving the owner role. In this API version the only way
to change the owner is to use this field.
TODO: Remove this field in favor of the owner role in v1.
purposestring
(Optional)
Purpose is a human-readable explanation of the project’s purpose.
Members is a list of subjects representing a user name, an email address, or any other identifier of a user,
group, or service account that has a certain role.
namespacestring
(Optional)
Namespace is the name of the namespace that has been created for the Project object.
A nil value means that Gardener will determine the name of the namespace.
If set, its value must be prefixed with garden-.
This field is immutable.
Backup holds the object store configuration for the backups of shoot (currently only etcd).
If it is not specified, then there won’t be any backups taken for shoots associated with this seed.
If backup field is present in seed, then backups of the etcd from shoot control plane will be stored
under the configured object store.
Addons contains information about enabled/disabled addons and their configuration.
cloudProfileNamestring
(Optional)
CloudProfileName is a name of a CloudProfile object.
Deprecated: This field will be removed in a future version of Gardener. Use CloudProfile instead.
Until removed, this field is synced with the CloudProfile field.
Region is a name of a region. This field is immutable.
secretBindingNamestring
(Optional)
SecretBindingName is the name of a SecretBinding that has a reference to the provider secret.
The credentials inside the provider secret will be used to create the shoot in the respective account.
The field is mutually exclusive with CredentialsBindingName.
This field is immutable.
seedNamestring
(Optional)
SeedName is the name of the seed cluster that runs the control plane of the Shoot.
ControlPlane contains general settings for the control plane of the shoot.
schedulerNamestring
(Optional)
SchedulerName is the name of the responsible scheduler which schedules the shoot.
If not specified, the default scheduler takes over.
This field is immutable.
CloudProfile contains a reference to a CloudProfile or a NamespacedCloudProfile.
credentialsBindingNamestring
(Optional)
CredentialsBindingName is the name of a CredentialsBinding that has a reference to the provider credentials.
The credentials will be used to create the shoot in the respective account. The field is mutually exclusive with SecretBindingName.
CredentialsRef is reference to a resource holding the credentials used for
authentication with the object store service where the backups are stored.
Supported referenced resources are v1.Secrets and
security.gardener.cloud/v1alpha1.WorkloadIdentity
SecretRef is a reference to a secret that contains the credentials to access object store.
Deprecated: This field will be removed after v1.123.0 has been released. Use CredentialsRef instead.
Until removed, this field is synced with the CredentialsRef field when it refers to a secret.
seedNamestring
(Optional)
SeedName holds the name of the seed allocated to BackupBucket for running controller.
This field is immutable.
CredentialsRef is reference to a resource holding the credentials used for
authentication with the object store service where the backups are stored.
Supported referenced resources are v1.Secrets and
security.gardener.cloud/v1alpha1.WorkloadIdentity
LastError holds information about the last occurred error during an operation.
observedGenerationint64
(Optional)
ObservedGeneration is the most recent generation observed for this BackupBucket. It corresponds to the
BackupBucket’s generation, which is updated on mutation by the API Server.
LastError holds information about the last occurred error during an operation.
observedGenerationint64
(Optional)
ObservedGeneration is the most recent generation observed for this BackupEntry. It corresponds to the
BackupEntry’s generation, which is updated on mutation by the API Server.
seedNamestring
(Optional)
SeedName is the name of the seed to which this BackupEntry is currently scheduled. This field is populated
at the beginning of a create/reconcile operation. It is used when moving the BackupEntry between seeds.
SeedSelector contains an optional list of labels on Seed resources that marks those seeds whose shoots may use this provider profile.
An empty list means that all seeds of the same provider type are supported.
This is useful for environments that are of the same type (like openstack) but may have different “instances”/landscapes.
Optionally a list of possible providers can be added to enable cross-provider scheduling. By default, the provider
type of the seed must match the shoot’s provider.
Capabilities contains the definition of all possible capabilities in the CloudProfile.
Only capabilities and values defined here can be used to describe MachineImages and MachineTypes.
The order of values for a given capability is relevant. The most important value is listed first.
During maintenance upgrades, the image that matches most capabilities will be selected.
MaxNodeProvisionTime defines how long CA waits for node to be provisioned (default: 20 mins).
maxGracefulTerminationSecondsint32
(Optional)
MaxGracefulTerminationSeconds is the number of seconds CA waits for pod termination when trying to scale down a node (default: 600).
ignoreTaints[]string
(Optional)
IgnoreTaints specifies a list of taint keys to ignore in node templates when considering to scale a node group.
Deprecated: Ignore taints are deprecated as of K8S 1.29 and treated as startup taints
NewPodScaleUpDelay specifies how long CA should ignore newly created pods before they have to be considered for scale-up (default: 0s).
maxEmptyBulkDeleteint32
(Optional)
MaxEmptyBulkDelete specifies the maximum number of empty nodes that can be deleted at the same time (default: MaxScaleDownParallelism when that is set).
Deprecated: This field is deprecated. Setting this field will be forbidden starting from Kubernetes 1.33 and will be removed once gardener drops support for kubernetes v1.32.
This cluster-autoscaler field is deprecated upstream, use –max-scale-down-parallelism instead.
TODO(Kostov6): Drop this field after support for Kubernetes 1.32 is dropped.
ignoreDaemonsetsUtilizationbool
(Optional)
IgnoreDaemonsetsUtilization allows CA to ignore DaemonSet pods when calculating resource utilization for scaling down (default: false).
verbosityint32
(Optional)
Verbosity allows CA to modify its log level (default: 2).
startupTaints[]string
(Optional)
StartupTaints specifies a list of taint keys to ignore in node templates when considering to scale a node group.
Cluster Autoscaler treats nodes tainted with startup taints as unready, but taken into account during scale up logic, assuming they will become ready shortly.
statusTaints[]string
(Optional)
StatusTaints specifies a list of taint keys to ignore in node templates when considering to scale a node group.
Cluster Autoscaler internally treats nodes tainted with status taints as ready, but filtered out during scale up logic.
maxScaleDownParallelismint32
(Optional)
MaxScaleDownParallelism specifies the maximum number of nodes (both empty and needing drain) that can be deleted in parallel.
Default: 10 or MaxEmptyBulkDelete when that is set
maxDrainParallelismint32
(Optional)
MaxDrainParallelism specifies the maximum number of nodes needing drain, that can be drained and deleted in parallel.
Default: 1
MinAllowed configures the minimum allowed resource requests for vertical pod autoscaling..
Configuration of minAllowed resources is an advanced feature that can help clusters to overcome scale-up delays.
Default values are not applied to this field.
SeedSelector contains an optional label selector for seeds. Only if the labels match then this controller will be
considered for a deployment.
An empty list means that all seeds are selected.
ControllerResource is a combination of a kind (DNSProvider, Infrastructure, Generic, …) and the actual type for this
kind (aws-route53, gcp, auditlog, …).
Field
Description
kindstring
Kind is the resource kind, for example “OperatingSystemConfig”.
typestring
Type is the resource type, for example “coreos” or “ubuntu”.
ReconcileTimeout defines how long Gardener should wait for the resource reconciliation.
This field is defaulted to 3m0s when kind is “Extension”.
primarybool
(Optional)
Primary determines if the controller backed by this ControllerRegistration is responsible for the extension
resource’s lifecycle. This field defaults to true. There must be exactly one primary controller for this kind/type
combination. This field is immutable.
Lifecycle defines a strategy that determines when different operations on a ControllerResource should be performed.
This field is defaulted in the following way when kind is “Extension”.
Reconcile: “AfterKubeAPIServer”
Delete: “BeforeKubeAPIServer”
Migrate: “BeforeKubeAPIServer”
workerlessSupportedbool
(Optional)
WorkerlessSupported specifies whether this ControllerResource supports Workerless Shoot clusters.
This field is only relevant when kind is “Extension”.
AutoEnable determines if this resource is automatically enabled for shoot or seed clusters, or both.
This field can only be set for resources of kind “Extension”.
ClusterCompatibility defines the compatibility of this resource with different cluster types.
If compatibility is not specified, it will be defaulted to ‘shoot’.
This field can only be set for resources of kind “Extension”.
The mode of the autoscaling to be used for the Core DNS components running in the data plane of the Shoot cluster.
Supported values are horizontal and cluster-proportional.
CoreDNSRewriting contains the setting related to rewriting requests, which are obviously incorrect due to the unnecessary application of the search path.
Field
Description
commonSuffixes[]string
(Optional)
CommonSuffixes are expected to be the suffix of a fully qualified domain name. Each suffix should contain at least one or two dots (‘.’) to prevent accidental clashes.
DNS holds information about the provider, the hosted zone id and the domain.
Field
Description
domainstring
(Optional)
Domain is the external available domain of the Shoot cluster. This domain will be written into the
kubeconfig that is handed out to end-users. This field is immutable.
Providers is a list of DNS providers that shall be enabled for this shoot cluster. Only relevant if
not a default domain is used.
Deprecated: Configuring multiple DNS providers is deprecated and will be forbidden in a future release.
Please use the DNS extension provider config (e.g. shoot-dns-service) for additional providers.
Domains contains information about which domains shall be included/excluded for this provider.
Deprecated: This field is deprecated and will be removed in a future release.
Please use the DNS extension provider config (e.g. shoot-dns-service) for additional configuration.
primarybool
(Optional)
Primary indicates that this DNSProvider is used for shoot related domains.
Deprecated: This field is deprecated and will be removed in a future release.
Please use the DNS extension provider config (e.g. shoot-dns-service) for additional and non-primary providers.
secretNamestring
(Optional)
SecretName is a name of a secret containing credentials for the stated domain and the
provider. When not specified, the Gardener will use the cloud provider credentials referenced
by the Shoot and try to find respective credentials there (primary provider only). Specifying this field may override
this behavior, i.e. forcing the Gardener to only look into the given secret.
Zones contains information about which hosted zones shall be included/excluded for this provider.
Deprecated: This field is deprecated and will be removed in a future release.
Please use the DNS extension provider config (e.g. shoot-dns-service) for additional configuration.
Classification defines the state of a version (preview, supported, deprecated).
To get the currently valid classification, use CurrentLifecycleClassification().
Data contains the payload required to generate resources
labelsmap[string]string
(Optional)
Labels are labels of the object
HelmControllerDeployment
HelmControllerDeployment configures how an extension controller is deployed using helm.
This is the legacy structure that used to be defined in gardenlet’s ControllerInstallation controller for
ControllerDeployment’s with type=helm.
While this is not a proper API type, we need to define the structure in the API package so that we can convert it
to the internal API version in the new representation.
Hibernation contains information whether the Shoot is suspended or not.
Field
Description
enabledbool
(Optional)
Enabled specifies whether the Shoot needs to be hibernated or not. If it is true, the Shoot’s desired state is to be hibernated.
If it is false or nil, the Shoot’s desired state is to be awakened.
HibernationSchedule determines the hibernation schedule of a Shoot.
A Shoot will be regularly hibernated at each start time and will be woken up at each end time.
Start or End can be omitted, though at least one of each has to be specified.
Field
Description
startstring
(Optional)
Start is a Cron spec at which time a Shoot will be hibernated.
endstring
(Optional)
End is a Cron spec at which time a Shoot will be woken up.
locationstring
(Optional)
Location is the time location in which both start and shall be evaluated.
HighAvailability specifies the configuration settings for high availability for a resource. Typical
usages could be to configure HA for shoot control plane or for seed system components.
HorizontalPodAutoscalerConfig contains horizontal pod autoscaler configuration settings for the kube-controller-manager.
Note: Descriptions were taken from the Kubernetes documentation.
The configurable period at which the horizontal pod autoscaler considers a Pod “not yet ready” given that it’s unready and it has transitioned to unready during that time.
Ingress configures the Ingress specific settings of the cluster
Field
Description
domainstring
Domain specifies the IngressDomain of the cluster pointing to the ingress controller endpoint. It will be used
to construct ingress URLs for system applications running in Shoot/Garden clusters. Once set this field is immutable.
AdmissionPlugins contains the list of user-defined admission plugins (additional to those managed by Gardener), and, if desired, the corresponding
configuration.
apiAudiences[]string
(Optional)
APIAudiences are the identifiers of the API. The service account token authenticator will
validate that tokens used against the API are bound to at least one of these audiences.
Defaults to [“kubernetes”].
OIDCConfig contains configuration settings for the OIDC provider.
Deprecated: This field is deprecated and will be forbidden starting from Kubernetes 1.32.
Please configure and use structured authentication instead of oidc flags.
For more information check https://github.com/gardener/gardener/issues/9858
TODO(AleksandarSavchev): Drop this field after support for Kubernetes 1.31 is dropped.
runtimeConfigmap[string]bool
(Optional)
RuntimeConfig contains information about enabled or disabled APIs.
WatchCacheSizes contains configuration of the API server’s watch cache sizes.
Configuring these flags might be useful for large-scale Shoot clusters with a lot of parallel update requests
and a lot of watching controllers (e.g. large ManagedSeed clusters). When the API server’s watch cache’s
capacity is too small to cope with the amount of update requests and watchers for a particular resource, it
might happen that controller watches are permanently stopped with too old resource version errors.
Starting from kubernetes v1.19, the API server’s watch cache size is adapted dynamically and setting the watch
cache size flags will have no effect, except when setting it to 0 (which disables the watch cache).
Logging contains configuration for the log level and HTTP access logs.
defaultNotReadyTolerationSecondsint64
(Optional)
DefaultNotReadyTolerationSeconds indicates the tolerationSeconds of the toleration for notReady:NoExecute
that is added by default to every pod that does not already have such a toleration (flag --default-not-ready-toleration-seconds).
The field has effect only when the DefaultTolerationSeconds admission plugin is enabled.
Defaults to 300.
defaultUnreachableTolerationSecondsint64
(Optional)
DefaultUnreachableTolerationSeconds indicates the tolerationSeconds of the toleration for unreachable:NoExecute
that is added by default to every pod that does not already have such a toleration (flag --default-unreachable-toleration-seconds).
The field has effect only when the DefaultTolerationSeconds admission plugin is enabled.
Defaults to 300.
StructuredAuthentication contains configuration settings for structured authentication for the kube-apiserver.
This field is only available for Kubernetes v1.30 or later.
StructuredAuthorization contains configuration settings for structured authorization for the kube-apiserver.
This field is only available for Kubernetes v1.30 or later.
PodEvictionTimeout defines the grace period for deleting pods on failed nodes. Defaults to 2m.
Deprecated: The corresponding kube-controller-manager flag --pod-eviction-timeout is deprecated
in favor of the kube-apiserver flags --default-not-ready-toleration-seconds and --default-unreachable-toleration-seconds.
The --pod-eviction-timeout flag does not have effect when the taint based eviction is enabled. The taint
based eviction is beta (enabled by default) since Kubernetes 1.13 and GA since Kubernetes 1.18. Hence,
instead of setting this field, set the spec.kubernetes.kubeAPIServer.defaultNotReadyTolerationSeconds and
spec.kubernetes.kubeAPIServer.defaultUnreachableTolerationSeconds. Setting this field is forbidden starting
from Kubernetes 1.33.
TODO(plkokanov): Drop this field after support for Kubernetes 1.32 is dropped.
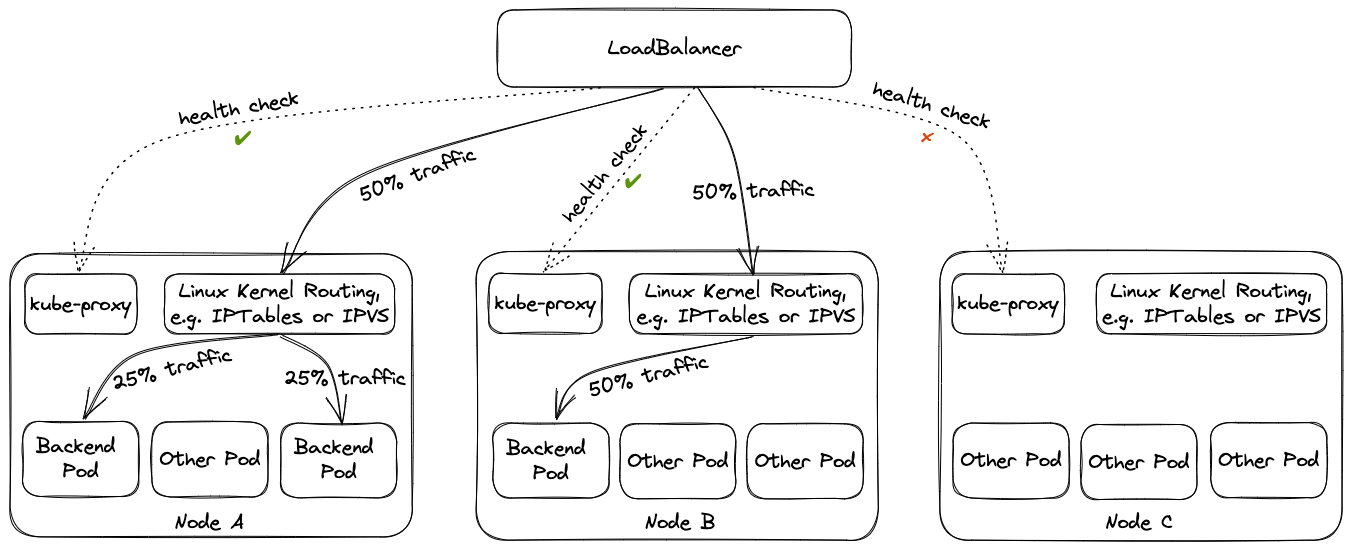
Mode specifies which proxy mode to use.
defaults to IPTables.
enabledbool
(Optional)
Enabled indicates whether kube-proxy should be deployed or not.
Depending on the networking extensions switching kube-proxy off might be rejected. Consulting the respective documentation of the used networking extension is recommended before using this field.
defaults to true if not specified.
(Members of KubernetesConfig are embedded into this type.)
kubeMaxPDVolsstring
(Optional)
KubeMaxPDVols allows to configure the KUBE_MAX_PD_VOLS environment variable for the kube-scheduler.
Please find more information here: https://kubernetes.io/docs/concepts/storage/storage-limits/#custom-limits
Note that using this field is considered alpha-/experimental-level and is on your own risk. You should be aware
of all the side-effects and consequences when changing it.
Profile configures the scheduling profile for the cluster.
If not specified, the used profile is “balanced” (provides the default kube-scheduler behavior).
EvictionHard describes a set of eviction thresholds (e.g. memory.available<1Gi) that if met would trigger a Pod eviction.
Default:
memory.available: “100Mi/1Gi/5%”
nodefs.available: “5%”
nodefs.inodesFree: “5%”
imagefs.available: “5%”
imagefs.inodesFree: “5%”
evictionMaxPodGracePeriodint32
(Optional)
EvictionMaxPodGracePeriod describes the maximum allowed grace period (in seconds) to use when terminating pods in response to a soft eviction threshold being met.
Default: 90
EvictionMinimumReclaim configures the amount of resources below the configured eviction threshold that the kubelet attempts to reclaim whenever the kubelet observes resource pressure.
Default: 0 for each resource
EvictionPressureTransitionPeriod is the duration for which the kubelet has to wait before transitioning out of an eviction pressure condition.
Default: 4m0s
EvictionSoft describes a set of eviction thresholds (e.g. memory.available<1.5Gi) that if met over a corresponding grace period would trigger a Pod eviction.
Default:
memory.available: “200Mi/1.5Gi/10%”
nodefs.available: “10%”
nodefs.inodesFree: “10%”
imagefs.available: “10%”
imagefs.inodesFree: “10%”
EvictionSoftGracePeriod describes a set of eviction grace periods (e.g. memory.available=1m30s) that correspond to how long a soft eviction threshold must hold before triggering a Pod eviction.
Default:
memory.available: 1m30s
nodefs.available: 1m30s
nodefs.inodesFree: 1m30s
imagefs.available: 1m30s
imagefs.inodesFree: 1m30s
maxPodsint32
(Optional)
MaxPods is the maximum number of Pods that are allowed by the Kubelet.
Default: 110
podPidsLimitint64
(Optional)
PodPIDsLimit is the maximum number of process IDs per pod allowed by the kubelet.
failSwapOnbool
(Optional)
FailSwapOn makes the Kubelet fail to start if swap is enabled on the node. (default true).
KubeReserved is the configuration for resources reserved for kubernetes node components (mainly kubelet and container runtime).
When updating these values, be aware that cgroup resizes may not succeed on active worker nodes. Look for the NodeAllocatableEnforced event to determine if the configuration was applied.
Default: cpu=80m,memory=1Gi,pid=20k
SystemReserved is the configuration for resources reserved for system processes not managed by kubernetes (e.g. journald).
When updating these values, be aware that cgroup resizes may not succeed on active worker nodes. Look for the NodeAllocatableEnforced event to determine if the configuration was applied.
Deprecated: Separately configuring resource reservations for system processes is deprecated in Gardener and will be forbidden starting from Kubernetes 1.31.
Please merge existing resource reservations into the kubeReserved field.
TODO(MichaelEischer): Drop this field after support for Kubernetes 1.30 is dropped.
imageGCHighThresholdPercentint32
(Optional)
ImageGCHighThresholdPercent describes the percent of the disk usage which triggers image garbage collection.
Default: 50
imageGCLowThresholdPercentint32
(Optional)
ImageGCLowThresholdPercent describes the percent of the disk to which garbage collection attempts to free.
Default: 40
serializeImagePullsbool
(Optional)
SerializeImagePulls describes whether the images are pulled one at a time.
Default: true
registryPullQPSint32
(Optional)
RegistryPullQPS is the limit of registry pulls per second. The value must not be a negative number.
Setting it to 0 means no limit.
Default: 5
registryBurstint32
(Optional)
RegistryBurst is the maximum size of bursty pulls, temporarily allows pulls to burst to this number,
while still not exceeding registryPullQPS. The value must not be a negative number.
Only used if registryPullQPS is greater than 0.
Default: 10
seccompDefaultbool
(Optional)
SeccompDefault enables the use of RuntimeDefault as the default seccomp profile for all workloads.
StreamingConnectionIdleTimeout is the maximum time a streaming connection can be idle before the connection is automatically closed.
This field cannot be set lower than “30s” or greater than “4h”.
Default: “5m”.
MemorySwap configures swap memory available to container workloads.
maxParallelImagePullsint32
(Optional)
MaxParallelImagePulls describes the maximum number of image pulls in parallel. The value must be a positive number.
This field cannot be set if SerializeImagePulls (pull one image at a time) is set to true.
Setting it to nil means no limit.
Default: nil
Kubelet contains configuration settings for the kubelet.
versionstring
(Optional)
Version is the semantic Kubernetes version to use for the Shoot cluster.
Defaults to the highest supported minor and patch version given in the referenced cloud profile.
The version can be omitted completely or partially specified, e.g. <major>.<minor>.
LoadBalancerServicesProxyProtocol controls whether ProxyProtocol is (optionally) allowed for the load balancer services.
Field
Description
allowedbool
Allowed controls whether the ProxyProtocol is optionally allowed for the load balancer services.
This should only be enabled if the load balancer services are already using ProxyProtocol or will be reconfigured to use it soon.
Until the load balancers are configured with ProxyProtocol, enabling this setting may allow clients to spoof their source IP addresses.
The option allows a migration from non-ProxyProtocol to ProxyProtocol without downtime (depending on the infrastructure).
Defaults to false.
Image holds information about the machine image to use for all nodes of this pool. It will default to the
latest version of the first image stated in the referenced CloudProfile if no value has been provided.
architecturestring
(Optional)
Architecture is CPU architecture of machines in this worker pool.
MachineInPlaceUpdateTimeout is the timeout after which in-place update is declared failed.
disableHealthTimeoutbool
(Optional)
DisableHealthTimeout if set to true, health timeout will be ignored. Leading to machine never being declared failed.
This is intended to be used only for in-place updates.
UpdateStrategy is the update strategy to use for the machine image. Possible values are:
- patch: update to the latest patch version of the current minor version.
- minor: update to the latest minor and patch version.
- major: always update to the overall latest version (default).
CRI list of supported container runtime and interfaces supported by this version
architectures[]string
(Optional)
Architectures is the list of CPU architectures of the machine image in this version.
kubeletVersionConstraintstring
(Optional)
KubeletVersionConstraint is a constraint describing the supported kubelet versions by the machine image in this version.
If the field is not specified, it is assumed that the machine image in this version supports all kubelet versions.
Examples:
- ‘>= 1.26’ - supports only kubelet versions greater than or equal to 1.26
- ‘< 1.26’ - supports only kubelet versions less than 1.26
TimeWindow contains information about the time window for maintenance operations.
confineSpecUpdateRolloutbool
(Optional)
ConfineSpecUpdateRollout prevents that changes/updates to the shoot specification will be rolled out immediately.
Instead, they are rolled out during the shoot’s maintenance time window. There is one exception that will trigger
an immediate roll out which is changes to the Spec.Hibernation.Enabled field.
MaintenanceTimeWindow contains information about the time window for maintenance operations.
Field
Description
beginstring
Begin is the beginning of the time window in the format HHMMSS+ZONE, e.g. “220000+0100”.
If not present, a random value will be computed.
endstring
End is the end of the time window in the format HHMMSS+ZONE, e.g. “220000+0100”.
If not present, the value will be computed based on the “Begin” value.
NetworkingStatus contains information about cluster networking such as CIDRs.
Field
Description
pods[]string
(Optional)
Pods are the CIDRs of the pod network.
nodes[]string
(Optional)
Nodes are the CIDRs of the node network.
services[]string
(Optional)
Services are the CIDRs of the service network.
egressCIDRs[]string
(Optional)
EgressCIDRs is a list of CIDRs used by the shoot as the source IP for egress traffic as reported by the used
Infrastructure extension controller. For certain environments the egress IPs may not be stable in which case the
extension controller may opt to not populate this field.
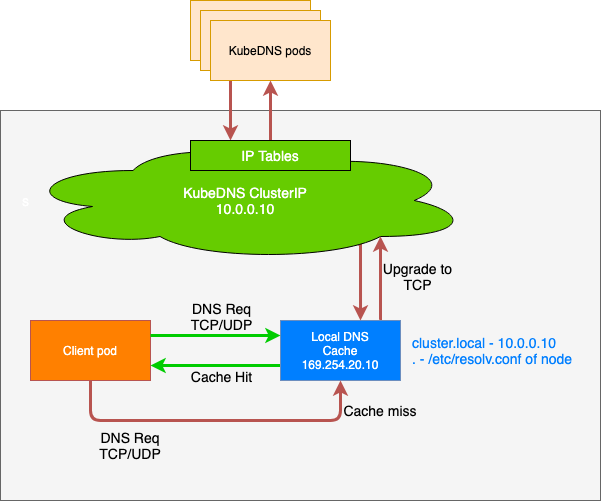
NodeLocalDNS contains the settings of the node local DNS components running in the data plane of the Shoot cluster.
Field
Description
enabledbool
Enabled indicates whether node local DNS is enabled or not.
forceTCPToClusterDNSbool
(Optional)
ForceTCPToClusterDNS indicates whether the connection from the node local DNS to the cluster DNS (Core DNS) will be forced to TCP or not.
Default, if unspecified, is to enforce TCP.
forceTCPToUpstreamDNSbool
(Optional)
ForceTCPToUpstreamDNS indicates whether the connection from the node local DNS to the upstream DNS (infrastructure DNS) will be forced to TCP or not.
Default, if unspecified, is to enforce TCP.
disableForwardToUpstreamDNSbool
(Optional)
DisableForwardToUpstreamDNS indicates whether requests from node local DNS to upstream DNS should be disabled.
Default, if unspecified, is to forward requests for external domains to upstream DNS
PullSecretRef is a reference to a secret containing the pull secret.
The secret must be of type kubernetes.io/dockerconfigjson and must be located in the garden namespace.
ClientAuthentication can optionally contain client configuration used for kubeconfig generation.
Deprecated: This field has no implemented use and will be forbidden starting from Kubernetes 1.31.
It’s use was planned for genereting OIDC kubeconfig https://github.com/gardener/gardener/issues/1433
TODO(AleksandarSavchev): Drop this field after support for Kubernetes 1.30 is dropped.
clientIDstring
(Optional)
The client ID for the OpenID Connect client, must be set.
groupsClaimstring
(Optional)
If provided, the name of a custom OpenID Connect claim for specifying user groups. The claim value is expected to be a string or array of strings. This flag is experimental, please see the authentication documentation for further details.
groupsPrefixstring
(Optional)
If provided, all groups will be prefixed with this value to prevent conflicts with other authentication strategies.
issuerURLstring
(Optional)
The URL of the OpenID issuer, only HTTPS scheme will be accepted. Used to verify the OIDC JSON Web Token (JWT).
requiredClaimsmap[string]string
(Optional)
key=value pairs that describes a required claim in the ID Token. If set, the claim is verified to be present in the ID Token with a matching value.
signingAlgs[]string
(Optional)
List of allowed JOSE asymmetric signing algorithms. JWTs with a ‘alg’ header value not in this list will be rejected. Values are defined by RFC 7518 https://tools.ietf.org/html/rfc7518#section-3.1
usernameClaimstring
(Optional)
The OpenID claim to use as the user name. Note that claims other than the default (‘sub’) is not guaranteed to be unique and immutable. This flag is experimental, please see the authentication documentation for further details. (default “sub”)
usernamePrefixstring
(Optional)
If provided, all usernames will be prefixed with this value. If not provided, username claims other than ‘email’ are prefixed by the issuer URL to avoid clashes. To skip any prefixing, provide the value ‘-’.
OpenIDConnectClientAuthentication contains configuration for OIDC clients.
Field
Description
extraConfigmap[string]string
(Optional)
Extra configuration added to kubeconfig’s auth-provider.
Must not be any of idp-issuer-url, client-id, client-secret, idp-certificate-authority, idp-certificate-authority-data, id-token or refresh-token
Subject is representing a user name, an email address, or any other identifier of a user, group, or service
account that has a certain role.
rolestring
Role represents the role of this member.
IMPORTANT: Be aware that this field will be removed in the v1 version of this API in favor of the roles
list.
TODO: Remove this field in favor of the roles list in v1.
roles[]string
(Optional)
Roles represents the list of roles of this member.
Owner is a subject representing a user name, an email address, or any other identifier of a user owning
the project.
IMPORTANT: Be aware that this field will be removed in the v1 version of this API in favor of the owner
role. The only way to change the owner will be by moving the owner role. In this API version the only way
to change the owner is to use this field.
TODO: Remove this field in favor of the owner role in v1.
purposestring
(Optional)
Purpose is a human-readable explanation of the project’s purpose.
Members is a list of subjects representing a user name, an email address, or any other identifier of a user,
group, or service account that has a certain role.
namespacestring
(Optional)
Namespace is the name of the namespace that has been created for the Project object.
A nil value means that Gardener will determine the name of the namespace.
If set, its value must be prefixed with garden-.
This field is immutable.
Whitelist contains a list of tolerations that are allowed to be added to the shoots in this project. Please note
that this list may only be added by users having the spec-tolerations-whitelist verb for project resources.
ControlPlaneConfig contains the provider-specific control plane config blob. Please look up the concrete
definition in the documentation of your provider extension.
InfrastructureConfig contains the provider-specific infrastructure config blob. Please look up the concrete
definition in the documentation of your provider extension.
ProxyMode available in Linux platform: ‘userspace’ (older, going to be EOL), ‘iptables’
(newer, faster), ‘ipvs’ (newest, better in performance and scalability).
As of now only ‘iptables’ and ‘ipvs’ is supported by Gardener.
In Linux platform, if the iptables proxy is selected, regardless of how, but the system’s kernel or iptables versions are
insufficient, this always falls back to the userspace proxy. IPVS mode will be enabled when proxy mode is set to ‘ipvs’,
and the fall back path is firstly iptables and then userspace.
Zones is a list of availability zones in this region.
labelsmap[string]string
(Optional)
Labels is an optional set of key-value pairs that contain certain administrator-controlled labels for this region.
It can be used by Gardener administrators/operators to provide additional information about a region, e.g. wrt
quality, reliability, etc.
ResourceWatchCacheSize contains configuration of the API server’s watch cache size for one specific resource.
Field
Description
apiGroupstring
(Optional)
APIGroup is the API group of the resource for which the watch cache size should be configured.
An unset value is used to specify the legacy core API (e.g. for secrets).
resourcestring
Resource is the name of the resource for which the watch cache size should be configured
(in lowercase plural form, e.g. secrets).
sizeint32
CacheSize specifies the watch cache size that should be configured for the specified resource.
SecretBindingProvider defines the provider type of the SecretBinding.
Field
Description
typestring
Type is the type of the provider.
For backwards compatibility, the field can contain multiple providers separated by a comma.
However the usage of single SecretBinding (hence Secret) for different cloud providers is strongly discouraged.
SeedSettingDependencyWatchdogProber controls the prober settings for the dependency-watchdog for the seed.
Field
Description
enabledbool
Enabled controls whether the probe controller(prober) of the dependency-watchdog should be enabled. This controller
scales down the kube-controller-manager, machine-controller-manager and cluster-autoscaler of shoot clusters in case their respective kube-apiserver is not
reachable via its external ingress in order to avoid melt-down situations.
SeedSettingDependencyWatchdogWeeder controls the weeder settings for the dependency-watchdog for the seed.
Field
Description
enabledbool
Enabled controls whether the endpoint controller(weeder) of the dependency-watchdog should be enabled. This controller
helps to alleviate the delay where control plane components remain unavailable by finding the respective pods in
CrashLoopBackoff status and restarting them once their dependants become ready and available again.
ExternalTrafficPolicy describes how nodes distribute service traffic they
receive on one of the service’s “externally-facing” addresses.
Defaults to “Cluster”.
Zones controls settings, which are specific to the single-zone load balancers in a multi-zonal setup.
Can be empty for single-zone seeds. Each specified zone has to relate to one of the zones in seed.spec.provider.zones.
ProxyProtocol controls whether ProxyProtocol is (optionally) allowed for the load balancer services.
Defaults to nil, which is equivalent to not allowing ProxyProtocol.
ExternalTrafficPolicy describes how nodes distribute service traffic they
receive on one of the service’s “externally-facing” addresses.
Defaults to “Cluster”.
ProxyProtocol controls whether ProxyProtocol is (optionally) allowed for the load balancer services.
Defaults to nil, which is equivalent to not allowing ProxyProtocol.
Enabled controls whether certain Services deployed in the seed cluster should be topology-aware.
These Services are etcd-main-client, etcd-events-client, kube-apiserver, gardener-resource-manager and vpa-webhook.
SeedSettingVerticalPodAutoscaler controls certain settings for the vertical pod autoscaler components deployed in the
seed.
Field
Description
enabledbool
Enabled controls whether the VPA components shall be deployed into the garden namespace in the seed cluster. It
is enabled by default because Gardener heavily relies on a VPA being deployed. You should only disable this if
your seed cluster already has another, manually/custom managed VPA deployment.
Backup holds the object store configuration for the backups of shoot (currently only etcd).
If it is not specified, then there won’t be any backups taken for shoots associated with this seed.
If backup field is present in seed, then backups of the etcd from shoot control plane will be stored
under the configured object store.
Conditions represents the latest available observations of a Seed’s current state.
observedGenerationint64
(Optional)
ObservedGeneration is the most recent generation observed for this Seed. It corresponds to the
Seed’s generation, which is updated on mutation by the API Server.
clusterIdentitystring
(Optional)
ClusterIdentity is the identity of the Seed cluster. This field is immutable.
Backup holds the object store configuration for the backups of shoot (currently only etcd).
If it is not specified, then there won’t be any backups taken for shoots associated with this seed.
If backup field is present in seed, then backups of the etcd from shoot control plane will be stored
under the configured object store.
ServiceAccountConfig is the kube-apiserver configuration for service accounts.
Field
Description
issuerstring
(Optional)
Issuer is the identifier of the service account token issuer. The issuer will assert this
identifier in “iss” claim of issued tokens. This value is used to generate new service account tokens.
This value is a string or URI. Defaults to URI of the API server.
extendTokenExpirationbool
(Optional)
ExtendTokenExpiration turns on projected service account expiration extension during token generation, which
helps safe transition from legacy token to bound service account token feature. If this flag is enabled,
admission injected tokens would be extended up to 1 year to prevent unexpected failure during transition,
ignoring value of service-account-max-token-expiration.
MaxTokenExpiration is the maximum validity duration of a token created by the service account token issuer. If an
otherwise valid TokenRequest with a validity duration larger than this value is requested, a token will be issued
with a validity duration of this value.
This field must be within [30d,90d].
acceptedIssuers[]string
(Optional)
AcceptedIssuers is an additional set of issuers that are used to determine which service account tokens are accepted.
These values are not used to generate new service account tokens. Only useful when service account tokens are also
issued by another external system or a change of the current issuer that is used for generating tokens is being performed.
Addons contains information about enabled/disabled addons and their configuration.
cloudProfileNamestring
(Optional)
CloudProfileName is a name of a CloudProfile object.
Deprecated: This field will be removed in a future version of Gardener. Use CloudProfile instead.
Until removed, this field is synced with the CloudProfile field.
Region is a name of a region. This field is immutable.
secretBindingNamestring
(Optional)
SecretBindingName is the name of a SecretBinding that has a reference to the provider secret.
The credentials inside the provider secret will be used to create the shoot in the respective account.
The field is mutually exclusive with CredentialsBindingName.
This field is immutable.
seedNamestring
(Optional)
SeedName is the name of the seed cluster that runs the control plane of the Shoot.
ControlPlane contains general settings for the control plane of the shoot.
schedulerNamestring
(Optional)
SchedulerName is the name of the responsible scheduler which schedules the shoot.
If not specified, the default scheduler takes over.
This field is immutable.
CloudProfile contains a reference to a CloudProfile or a NamespacedCloudProfile.
credentialsBindingNamestring
(Optional)
CredentialsBindingName is the name of a CredentialsBinding that has a reference to the provider credentials.
The credentials will be used to create the shoot in the respective account. The field is mutually exclusive with SecretBindingName.
LastErrors holds information about the last occurred error(s) during an operation.
observedGenerationint64
(Optional)
ObservedGeneration is the most recent generation observed for this Shoot. It corresponds to the
Shoot’s generation, which is updated on mutation by the API Server.
RetryCycleStartTime is the start time of the last retry cycle (used to determine how often an operation
must be retried until we give up).
seedNamestring
(Optional)
SeedName is the name of the seed cluster that runs the control plane of the Shoot. This value is only written
after a successful create/reconcile operation. It will be used when control planes are moved between Seeds.
technicalIDstring
TechnicalID is a unique technical ID for this Shoot. It is used for the infrastructure resources, and
basically everything that is related to this particular Shoot. For regular shoot clusters, this is also the name
of the namespace in the seed cluster running the shoot’s control plane. This field is immutable.
UID is a unique identifier for the Shoot cluster to avoid portability between Kubernetes clusters.
It is used to compute unique hashes. This field is immutable.
clusterIdentitystring
(Optional)
ClusterIdentity is the identity of the Shoot cluster. This field is immutable.
Addons contains information about enabled/disabled addons and their configuration.
cloudProfileNamestring
(Optional)
CloudProfileName is a name of a CloudProfile object.
Deprecated: This field will be removed in a future version of Gardener. Use CloudProfile instead.
Until removed, this field is synced with the CloudProfile field.
Region is a name of a region. This field is immutable.
secretBindingNamestring
(Optional)
SecretBindingName is the name of a SecretBinding that has a reference to the provider secret.
The credentials inside the provider secret will be used to create the shoot in the respective account.
The field is mutually exclusive with CredentialsBindingName.
This field is immutable.
seedNamestring
(Optional)
SeedName is the name of the seed cluster that runs the control plane of the Shoot.
ControlPlane contains general settings for the control plane of the shoot.
schedulerNamestring
(Optional)
SchedulerName is the name of the responsible scheduler which schedules the shoot.
If not specified, the default scheduler takes over.
This field is immutable.
CloudProfile contains a reference to a CloudProfile or a NamespacedCloudProfile.
credentialsBindingNamestring
(Optional)
CredentialsBindingName is the name of a CredentialsBinding that has a reference to the provider credentials.
The credentials will be used to create the shoot in the respective account. The field is mutually exclusive with SecretBindingName.
EvictAfterOOMThreshold defines the threshold that will lead to pod eviction in case it OOMed in less than the given
threshold since its start and if it has only one container (default: 10m0s).
evictionRateBurstint32
(Optional)
EvictionRateBurst defines the burst of pods that can be evicted (default: 1)
evictionRateLimitfloat64
(Optional)
EvictionRateLimit defines the number of pods that can be evicted per second. A rate limit set to 0 or -1 will
disable the rate limiter (default: -1).
evictionTolerancefloat64
(Optional)
EvictionTolerance defines the fraction of replica count that can be evicted for update in case more than one
pod can be evicted (default: 0.5).
recommendationMarginFractionfloat64
(Optional)
RecommendationMarginFraction is the fraction of usage added as the safety margin to the recommended request
(default: 0.15).
RecommenderInterval is the interval how often metrics should be fetched (default: 1m0s).
targetCPUPercentilefloat64
(Optional)
TargetCPUPercentile is the usage percentile that will be used as a base for CPU target recommendation.
Doesn’t affect CPU lower bound, CPU upper bound nor memory recommendations.
(default: 0.9)
recommendationLowerBoundCPUPercentilefloat64
(Optional)
RecommendationLowerBoundCPUPercentile is the usage percentile that will be used for the lower bound on CPU recommendation.
(default: 0.5)
recommendationUpperBoundCPUPercentilefloat64
(Optional)
RecommendationUpperBoundCPUPercentile is the usage percentile that will be used for the upper bound on CPU recommendation.
(default: 0.95)
targetMemoryPercentilefloat64
(Optional)
TargetMemoryPercentile is the usage percentile that will be used as a base for memory target recommendation.
Doesn’t affect memory lower bound nor memory upper bound.
(default: 0.9)
recommendationLowerBoundMemoryPercentilefloat64
(Optional)
RecommendationLowerBoundMemoryPercentile is the usage percentile that will be used for the lower bound on memory recommendation.
(default: 0.5)
recommendationUpperBoundMemoryPercentilefloat64
(Optional)
RecommendationUpperBoundMemoryPercentile is the usage percentile that will be used for the upper bound on memory recommendation.
(default: 0.95)
MemoryAggregationInterval is the length of a single interval, for which the peak memory usage is computed.
(default: 24h)
memoryAggregationIntervalCountint64
(Optional)
MemoryAggregationIntervalCount is the number of consecutive memory-aggregation-intervals which make up the
MemoryAggregationWindowLength which in turn is the period for memory usage aggregation by VPA. In other words,
MemoryAggregationWindowLength = memory-aggregation-interval * memory-aggregation-interval-count.
(default: 8)
MaxSurge is maximum number of machines that are created during an update.
This value is divided by the number of configured zones for a fair distribution.
Defaults to 0 in case of an in-place update.
Defaults to 1 in case of a rolling update.
MaxUnavailable is the maximum number of machines that can be unavailable during an update.
This value is divided by the number of configured zones for a fair distribution.
Defaults to 1 in case of an in-place update.
Defaults to 0 in case of a rolling update.
DataVolumes contains a list of additional worker volumes.
kubeletDataVolumeNamestring
(Optional)
KubeletDataVolumeName contains the name of a dataVolume that should be used for storing kubelet state.
zones[]string
(Optional)
Zones is a list of availability zones that are used to evenly distribute this worker pool. Optional
as not every provider may support availability zones.
ControlPlane specifies that the shoot cluster control plane components should be running in this worker pool.
This is only relevant for autonomous shoot clusters.
Backup holds the object store configuration for the backups of shoot (currently only etcd).
If it is not specified, then there won’t be any backups taken.
Kubelet contains configuration settings for all kubelets of this worker pool.
If set, all spec.kubernetes.kubelet settings will be overwritten for this worker pool (no merge of settings).
versionstring
(Optional)
Version is the semantic Kubernetes version to use for the Kubelet in this Worker Group.
If not specified the kubelet version is derived from the global shoot cluster kubernetes version.
version must be equal or lower than the version of the shoot kubernetes version.
Only one minor version difference to other worker groups and global kubernetes version is allowed.
PullSecretRef is a reference to a secret containing the pull secret.
The secret must be of type kubernetes.io/dockerconfigjson and must be located in the garden namespace.
For usage in the gardenlet, the secret must have the label gardener.cloud/role=helm-pull-secret.
(Members of DefaultSpec are embedded into this type.)
DefaultSpec is a structure containing common fields used by all extension resources.
userData[]byte
UserData is the base64-encoded user data for the bastion instance. This should
contain code to provision the SSH key on the bastion instance.
This field is immutable.
SecretRef is a reference to a secret that contains the cloud provider specific credentials.
regionstring
(Optional)
Region is the region of this DNS record. If not specified, the region specified in SecretRef will be used.
If that is also not specified, the extension controller will use its default region.
zonestring
(Optional)
Zone is the DNS hosted zone of this DNS record. If not specified, it will be determined automatically by
getting all hosted zones of the account and searching for the longest zone name that is a suffix of Name.
namestring
Name is the fully qualified domain name, e.g. “api.”. This field is immutable.
Purpose describes how the result of this OperatingSystemConfig is used by Gardener. Either it
gets sent to the Worker extension controller to bootstrap a VM, or it is downloaded by the
gardener-node-agent already running on a bootstrapped VM.
This field is immutable.
InfrastructureProviderStatus is a raw extension field that contains the provider status that has
been generated by the controller responsible for the Infrastructure resource.
regionstring
Region is the name of the region where the worker pool should be deployed to. This field is immutable.
(Members of DefaultSpec are embedded into this type.)
DefaultSpec is a structure containing common fields used by all extension resources.
userData[]byte
UserData is the base64-encoded user data for the bastion instance. This should
contain code to provision the SSH key on the bastion instance.
This field is immutable.
CloudConfig contains the generated output for the given operating system
config spec. It contains a reference to a secret as the result may contain confidential data.
CredentialsRotation is a structure containing information about the last initiation time of the certificate authority and service account key rotation.
SecretRef is a reference to a secret that contains the cloud provider specific credentials.
regionstring
(Optional)
Region is the region of this DNS record. If not specified, the region specified in SecretRef will be used.
If that is also not specified, the extension controller will use its default region.
zonestring
(Optional)
Zone is the DNS hosted zone of this DNS record. If not specified, it will be determined automatically by
getting all hosted zones of the account and searching for the longest zone name that is a suffix of Name.
namestring
Name is the fully qualified domain name, e.g. “api.”. This field is immutable.
File is a file that should get written to the host’s file system. The content can either be inlined or
referenced from a secret in the same namespace.
Field
Description
pathstring
Path is the path of the file system where the file should get written to.
permissionsuint32
(Optional)
Permissions describes with which permissions the file should get written to the file system.
If no permissions are set, the operating system’s defaults are used.
Inline is a struct that contains information about the inlined data.
transmitUnencodedbool
(Optional)
TransmitUnencoded set to true will ensure that the os-extension does not encode the file content when sent to the node.
This for example can be used to manipulate the clear-text content before it reaches the node.
CredentialsRotation is a structure containing information about the last initiation time of the certificate authority and service account key rotation.
(Members of DefaultStatus are embedded into this type.)
DefaultStatus is a structure containing common fields used by all extension resources.
nodesCIDRstring
(Optional)
NodesCIDR is the CIDR of the node network that was optionally created by the acting extension controller.
This might be needed in environments in which the CIDR for the network for the shoot worker node cannot
be statically defined in the Shoot resource but must be computed dynamically.
egressCIDRs[]string
(Optional)
EgressCIDRs is a list of CIDRs used by the shoot as the source IP for egress traffic. For certain environments the egress
IPs may not be stable in which case the extension controller may opt to not populate this field.
MachineImage contains logical information about the name and the version of the machie image that
should be used. The logical information must be mapped to the provider-specific information (e.g.,
AMIs, …) by the provider itself.
IPFamilies specifies the IP protocol versions that actually are used for shoot networking.
During dual-stack migration, this field may differ from the spec.
Purpose describes how the result of this OperatingSystemConfig is used by Gardener. Either it
gets sent to the Worker extension controller to bootstrap a VM, or it is downloaded by the
gardener-node-agent already running on a bootstrapped VM.
This field is immutable.
CloudConfig is a structure for containing the generated output for the given operating system
config spec. It contains a reference to a secret as the result may contain confidential data.
After Gardener v1.112, this will be only set for OperatingSystemConfigs with purpose ‘provision’.
Values are the values configured at the given path. If defined, it is expected as json format:
- A given json object will be put to the given path.
- If not configured, only the table entry to be created.
FilePaths is a list of files the unit depends on. If any file changes a restart of the dependent unit will be
triggered. For each FilePath there must exist a File with matching Path in OperatingSystemConfig.Spec.Files.
MachineImage contains logical information about the name and the version of the machie image that
should be used. The logical information must be mapped to the provider-specific information (e.g.,
AMIs, …) by the provider itself.
minimumint32
Minimum is the minimum size of the worker pool.
namestring
Name is the name of this worker pool.
nodeAgentSecretNamestring
(Optional)
NodeAgentSecretName is uniquely identifying selected aspects of the OperatingSystemConfig. If it changes, then the
worker pool must be rolled.
UserDataSecretRef references a Secret and a data key containing the data that is sent to the provider’s APIs when
a new machine/VM that is part of this worker pool shall be spawned.
InfrastructureProviderStatus is a raw extension field that contains the provider status that has
been generated by the controller responsible for the Infrastructure resource.
regionstring
Region is the name of the region where the worker pool should be deployed to. This field is immutable.
ShootRef defines the target shoot for a Bastion. The name field of the ShootRef is immutable.
seedNamestring
(Optional)
SeedName is the name of the seed to which this Bastion is currently scheduled. This field is populated
at the beginning of a create/reconcile operation.
providerTypestring
(Optional)
ProviderType is cloud provider used by the referenced Shoot.
sshPublicKeystring
SSHPublicKey is the user’s public key. This field is immutable.
ShootRef defines the target shoot for a Bastion. The name field of the ShootRef is immutable.
seedNamestring
(Optional)
SeedName is the name of the seed to which this Bastion is currently scheduled. This field is populated
at the beginning of a create/reconcile operation.
providerTypestring
(Optional)
ProviderType is cloud provider used by the referenced Shoot.
sshPublicKeystring
SSHPublicKey is the user’s public key. This field is immutable.
LastHeartbeatTimestamp is the time when the bastion was last marked as
not to be deleted. When this is set, the ExpirationTimestamp is advanced
as well.
ExpirationTimestamp is the time after which a Bastion is supposed to be
garbage collected.
observedGenerationint64
(Optional)
ObservedGeneration is the most recent generation observed for this Bastion. It corresponds to the
Bastion’s generation, which is updated on mutation by the API Server.
RuntimeCluster is the deployment configuration for the admission in the runtime cluster. The runtime deployment
is responsible for creating the admission controller in the runtime cluster.
VirtualCluster is the deployment configuration for the admission deployment in the garden cluster. The garden deployment
installs necessary resources in the virtual garden cluster e.g. RBAC that are necessary for the admission controller.
Backup contains the object store configuration for backups for the virtual garden etcd.
Field
Description
providerstring
Provider is a provider name. This field is immutable.
bucketNamestring
(Optional)
BucketName is the name of the backup bucket. If not provided, gardener-operator attempts to manage a new bucket.
In this case, the cloud provider credentials provided in the SecretRef must have enough privileges for creating
and deleting buckets.
SecretRef is a reference to a Secret object containing the cloud provider credentials for the object store where
backups should be stored. It should have enough privileges to manipulate the objects as well as buckets.
DNSDomain defines a DNS domain with optional provider.
Field
Description
namestring
Name is the domain name.
providerstring
(Optional)
Provider is the name of the DNS provider as declared in the ‘.spec.dns.providers’ section.
It is only optional, if the .spec.dns section is not provided at all.
PollInterval is the interval of how often the GitHub API is polled for issue updates. This field is used as a
fallback mechanism to ensure state synchronization, even when there is a GitHub webhook configuration. If a
webhook event is missed or not successfully delivered, the polling will help catch up on any missed updates.
If this field is not provided and there is no ‘webhookSecret’ key in the referenced secret, it will be
implicitly defaulted to 15m.
DashboardOIDC contains configuration for the OIDC settings.
Field
Description
clientIDPublicstring
(Optional)
ClientIDPublic is the public client ID.
Falls back to the API server’s OIDC client ID configuration if not set here.
issuerURLstring
(Optional)
The URL of the OpenID issuer, only HTTPS scheme will be accepted. Used to verify the OIDC JSON Web Token (JWT).
Falls back to the API server’s OIDC issuer URL configuration if not set here.
Container contains configuration for the dashboard terminal container.
allowedHosts[]string
(Optional)
AllowedHosts should consist of permitted hostnames (without the scheme) for terminal connections.
It is important to consider that the usage of wildcards follows the rules defined by the content security policy.
‘.seed.local.gardener.cloud’, or ‘.other-seeds.local.gardener.cloud’. For more information, see
https://github.com/gardener/dashboard/blob/master/docs/operations/webterminals.md#allowlist-for-hosts.
Deployment specifies how an extension can be installed for a Gardener landscape. It includes the specification
for installing an extension and/or an admission controller.
ExtensionDeploymentSpec specifies how to install the extension in a gardener landscape. The installation is split into two parts:
- installing the extension in the virtual garden cluster by creating the ControllerRegistration and ControllerDeployment
- installing the extension in the runtime cluster (if necessary).
SeedSelector contains an optional label selector for seeds. Only if the labels match then this controller will be
considered for a deployment.
An empty list means that all seeds are selected.
injectGardenKubeconfigbool
(Optional)
InjectGardenKubeconfig controls whether a kubeconfig to the garden cluster should be injected into workload
resources.
AdmissionPlugins contains the list of user-defined admission plugins (additional to those managed by Gardener),
and, if desired, the corresponding configuration.
WatchCacheSizes contains configuration of the API server’s watch cache sizes.
Configuring these flags might be useful for large-scale Garden clusters with a lot of parallel update requests
and a lot of watching controllers (e.g. large ManagedSeed clusters). When the API server’s watch cache’s
capacity is too small to cope with the amount of update requests and watchers for a particular resource, it
might happen that controller watches are permanently stopped with too old resource version errors.
Starting from kubernetes v1.19, the API server’s watch cache size is adapted dynamically and setting the watch
cache size flags will have no effect, except when setting it to 0 (which disables the watch cache).
EncryptionConfig contains customizable encryption configuration of the Gardener API server.
goAwayChancefloat64
(Optional)
GoAwayChance can be used to prevent HTTP/2 clients from getting stuck on a single apiserver, randomly close a
connection (GOAWAY). The client’s other in-flight requests won’t be affected, and the client will reconnect,
likely landing on a different apiserver after going through the load balancer again. This field sets the fraction
of requests that will be sent a GOAWAY. Min is 0 (off), Max is 0.02 (1⁄50 requests); 0.001 (1⁄1000) is a
recommended starting point.
ShootAdminKubeconfigMaxExpiration is the maximum validity duration of a credential requested to a Shoot by an AdminKubeconfigRequest.
If an otherwise valid AdminKubeconfigRequest with a validity duration larger than this value is requested,
a credential will be issued with a validity duration of this value.
Domains specify the ingress domains of the cluster pointing to the ingress controller endpoint. They will be used
to construct ingress URLs for system applications running in runtime cluster.
ResourcesToStoreInETCDEvents contains a list of resources which should be stored in etcd-events instead of
etcd-main. The ‘events’ resource is always stored in etcd-events. Note that adding or removing resources from
this list will not migrate them automatically from the etcd-main to etcd-events or vice versa.
CertificateSigningDuration is the maximum length of duration signed certificates will be given. Individual CSRs
may request shorter certs by setting spec.expirationSeconds.
SNI contains configuration options for the TLS SNI settings.
Field
Description
secretNamestring
(Optional)
SecretName is the name of a secret containing the TLS certificate and private key.
If not configured, Gardener falls back to a secret labelled with ‘gardener.cloud/role=garden-cert’.
domainPatterns[]string
(Optional)
DomainPatterns is a list of fully qualified domain names, possibly with prefixed wildcard segments. The domain
patterns also allow IP addresses, but IPs should only be used if the apiserver has visibility to the IP address
requested by a client. If no domain patterns are provided, the names of the certificate are extracted.
Non-wildcard matches trump over wildcard matches, explicit domain patterns trump over extracted names.
Enabled controls whether certain Services deployed in the cluster should be topology-aware.
These Services are virtual-garden-etcd-main-client, virtual-garden-etcd-events-client and virtual-garden-kube-apiserver.
Additionally, other components that are deployed to the runtime cluster via other means can read this field and
according to its value enable/disable topology-aware routing for their Services.
SettingVerticalPodAutoscaler controls certain settings for the vertical pod autoscaler components deployed in the
seed.
Field
Description
enabledbool
(Optional)
Enabled controls whether the VPA components shall be deployed into this cluster. It is true by default because
the operator (and Gardener) heavily rely on a VPA being deployed. You should only disable this if your runtime
cluster already has another, manually/custom managed VPA deployment. If this is not the case, but you still
disable it, then reconciliation will fail.
MachineImages is the list of machine images that are understood by the controller. It maps
logical names and versions to provider-specific identifiers.
WorkerStatus
WorkerStatus contains information about created worker resources.
MachineImages is a list of machine images that have been used in this worker. Usually, the extension controller
gets the mapping from name/version to the provider-specific machine image data from the CloudProfile. However, if
a version that is still in use gets removed from this componentconfig it cannot reconcile anymore existing Worker
resources that are still using this version. Hence, it stores the used versions in the provider status to ensure
reconciliation is possible.
Equivalences specifies possible group/kind equivalences for objects.
deletePersistentVolumeClaimsbool
(Optional)
DeletePersistentVolumeClaims specifies if PersistentVolumeClaims created by StatefulSets, which are managed by this
resource, should also be deleted when the corresponding StatefulSet is deleted (defaults to false).
Equivalences specifies possible group/kind equivalences for objects.
deletePersistentVolumeClaimsbool
(Optional)
DeletePersistentVolumeClaims specifies if PersistentVolumeClaims created by StatefulSets, which are managed by this
resource, should also be deleted when the corresponding StatefulSet is deleted (defaults to false).
CredentialsRef is a reference to a resource holding the credentials.
Accepted resources are core/v1.Secret and security.gardener.cloud/v1alpha1.WorkloadIdentity
This field is immutable.
Quotas is a list of references to Quota objects in the same or another namespace.
This field is immutable.
WorkloadIdentity
WorkloadIdentity is resource that allows workloads to be presented before external systems
by giving them identities managed by the Gardener API server.
The identity of such workload is represented by JSON Web Token issued by the Gardener API server.
Workload identities are designed to be used by components running in the Gardener environment,
seed or runtime cluster, that make use of identity federation inspired by the OIDC protocol.
KubeconfigSecretRef is a reference to a secret containing a kubeconfig for the cluster to which gardenlet should
be deployed. This is only used by gardener-operator for a very first gardenlet deployment. After that, gardenlet
will continuously upgrade itself. If this field is empty, gardener-operator deploys it into its own runtime
cluster.
Gardenlet specifies that the ManagedSeed controller should deploy a gardenlet into the cluster
with the given deployment parameters and GardenletConfiguration.
Selector is a label query over ManagedSeeds and Shoots that should match the replica count.
It must match the ManagedSeeds and Shoots template’s labels. This field is immutable.
Template describes the ManagedSeed that will be created if insufficient replicas are detected.
Each ManagedSeed created / updated by the ManagedSeedSet will fulfill this template.
ShootTemplate describes the Shoot that will be created if insufficient replicas are detected for hosting the corresponding ManagedSeed.
Each Shoot created / updated by the ManagedSeedSet will fulfill this template.
UpdateStrategy specifies the UpdateStrategy that will be
employed to update ManagedSeeds / Shoots in the ManagedSeedSet when a revision is made to
Template / ShootTemplate.
revisionHistoryLimitint32
(Optional)
RevisionHistoryLimit is the maximum number of revisions that will be maintained
in the ManagedSeedSet’s revision history. Defaults to 10. This field is immutable.
Bootstrap is the mechanism that should be used for bootstrapping gardenlet connection to the Garden cluster. One of ServiceAccount, BootstrapToken, None.
If set to ServiceAccount or BootstrapToken, a service account or a bootstrap token will be created in the garden cluster and used to compute the bootstrap kubeconfig.
If set to None, the gardenClientConnection.kubeconfig field will be used to connect to the Garden cluster. Defaults to BootstrapToken.
This field is immutable.
mergeWithParentbool
(Optional)
MergeWithParent specifies whether the GardenletConfiguration of the parent gardenlet
should be merged with the specified GardenletConfiguration. Defaults to true. This field is immutable.
KubeconfigSecretRef is a reference to a secret containing a kubeconfig for the cluster to which gardenlet should
be deployed. This is only used by gardener-operator for a very first gardenlet deployment. After that, gardenlet
will continuously upgrade itself. If this field is empty, gardener-operator deploys it into its own runtime
cluster.
Conditions represents the latest available observations of a Gardenlet’s current state.
observedGenerationint64
(Optional)
ObservedGeneration is the most recent generation observed for this Gardenlet. It corresponds to the Gardenlet’s
generation, which is updated on mutation by the API Server.
Selector is a label query over ManagedSeeds and Shoots that should match the replica count.
It must match the ManagedSeeds and Shoots template’s labels. This field is immutable.
Template describes the ManagedSeed that will be created if insufficient replicas are detected.
Each ManagedSeed created / updated by the ManagedSeedSet will fulfill this template.
ShootTemplate describes the Shoot that will be created if insufficient replicas are detected for hosting the corresponding ManagedSeed.
Each Shoot created / updated by the ManagedSeedSet will fulfill this template.
UpdateStrategy specifies the UpdateStrategy that will be
employed to update ManagedSeeds / Shoots in the ManagedSeedSet when a revision is made to
Template / ShootTemplate.
revisionHistoryLimitint32
(Optional)
RevisionHistoryLimit is the maximum number of revisions that will be maintained
in the ManagedSeedSet’s revision history. Defaults to 10. This field is immutable.
ManagedSeedSetStatus represents the current state of a ManagedSeedSet.
Field
Description
observedGenerationint64
ObservedGeneration is the most recent generation observed for this ManagedSeedSet. It corresponds to the
ManagedSeedSet’s generation, which is updated on mutation by the API Server.
replicasint32
Replicas is the number of replicas (ManagedSeeds and their corresponding Shoots) created by the ManagedSeedSet controller.
readyReplicasint32
ReadyReplicas is the number of ManagedSeeds created by the ManagedSeedSet controller that have a Ready Condition.
nextReplicaNumberint32
NextReplicaNumber is the ordinal number that will be assigned to the next replica of the ManagedSeedSet.
currentReplicasint32
CurrentReplicas is the number of ManagedSeeds created by the ManagedSeedSet controller from the ManagedSeedSet version
indicated by CurrentRevision.
updatedReplicasint32
UpdatedReplicas is the number of ManagedSeeds created by the ManagedSeedSet controller from the ManagedSeedSet version
indicated by UpdateRevision.
currentRevisionstring
CurrentRevision, if not empty, indicates the version of the ManagedSeedSet used to generate ManagedSeeds with smaller
ordinal numbers during updates.
updateRevisionstring
UpdateRevision, if not empty, indicates the version of the ManagedSeedSet used to generate ManagedSeeds with larger
ordinal numbers during updates
collisionCountint32
(Optional)
CollisionCount is the count of hash collisions for the ManagedSeedSet. The ManagedSeedSet controller
uses this field as a collision avoidance mechanism when it needs to create the name for the
newest ControllerRevision.
PendingReplica, if not empty, indicates the replica that is currently pending creation, update, or deletion.
This replica is in a state that requires the controller to wait for it to change before advancing to the next replica.
Gardenlet specifies that the ManagedSeed controller should deploy a gardenlet into the cluster
with the given deployment parameters and GardenletConfiguration.
Conditions represents the latest available observations of a ManagedSeed’s current state.
observedGenerationint64
ObservedGeneration is the most recent generation observed for this ManagedSeed. It corresponds to the
ManagedSeed’s generation, which is updated on mutation by the API Server.
Gardenlet specifies that the ManagedSeed controller should deploy a gardenlet into the cluster
with the given deployment parameters and GardenletConfiguration.
Since is the moment in time since the replica is pending with the specified reason.
retriesint32
(Optional)
Retries is the number of times the shoot operation (reconcile or delete) has been retried after having failed.
Only applicable if Reason is ShootReconciling or ShootDeleting.
UpdateStrategy specifies the strategy that the ManagedSeedSet
controller will use to perform updates. It includes any additional parameters
necessary to perform the update for the indicated strategy.
Project decides whether to apply the configuration if the
Shoot is in a specific Project matching the label selector.
Use the selector only if the OIDC Preset is opt-in, because end
users may skip the admission by setting the labels.
Defaults to the empty LabelSelector, which matches everything.
OpenIDConnectPreset
OpenIDConnectPreset is a OpenID Connect configuration that is applied
to a Shoot in a namespace.
Server contains the kube-apiserver’s OpenID Connect configuration.
This configuration is not overwriting any existing OpenID Connect
configuration already set on the Shoot object.
Client contains the configuration used for client OIDC authentication
of Shoot clusters.
This configuration is not overwriting any existing OpenID Connect
client authentication already set on the Shoot object.
Deprecated: The OpenID Connect configuration this field specifies is not used and will be forbidden starting from Kubernetes 1.31.
It’s use was planned for genereting OIDC kubeconfig https://github.com/gardener/gardener/issues/1433
TODO(AleksandarSavchev): Drop this field after support for Kubernetes 1.30 is dropped.
ShootSelector decides whether to apply the configuration if the
Shoot has matching labels.
Use the selector only if the OIDC Preset is opt-in, because end
users may skip the admission by setting the labels.
Default to the empty LabelSelector, which matches everything.
weightint32
Weight associated with matching the corresponding preset,
in the range 1-100.
Required.
Project decides whether to apply the configuration if the
Shoot is in a specific Project matching the label selector.
Use the selector only if the OIDC Preset is opt-in, because end
users may skip the admission by setting the labels.
Defaults to the empty LabelSelector, which matches everything.
KubeAPIServerOpenIDConnect contains configuration settings for the OIDC provider.
Note: Descriptions were taken from the Kubernetes documentation.
Field
Description
caBundlestring
(Optional)
If set, the OpenID server’s certificate will be verified by one of the authorities in the oidc-ca-file, otherwise the host’s root CA set will be used.
clientIDstring
The client ID for the OpenID Connect client.
Required.
groupsClaimstring
(Optional)
If provided, the name of a custom OpenID Connect claim for specifying user groups. The claim value is expected to be a string or array of strings. This field is experimental, please see the authentication documentation for further details.
groupsPrefixstring
(Optional)
If provided, all groups will be prefixed with this value to prevent conflicts with other authentication strategies.
issuerURLstring
The URL of the OpenID issuer, only HTTPS scheme will be accepted. If set, it will be used to verify the OIDC JSON Web Token (JWT).
Required.
requiredClaimsmap[string]string
(Optional)
key=value pairs that describes a required claim in the ID Token. If set, the claim is verified to be present in the ID Token with a matching value.
signingAlgs[]string
(Optional)
List of allowed JOSE asymmetric signing algorithms. JWTs with a ‘alg’ header value not in this list will be rejected. Values are defined by RFC 7518 https://tools.ietf.org/html/rfc7518#section-3.1
Defaults to [RS256]
usernameClaimstring
(Optional)
The OpenID claim to use as the user name. Note that claims other than the default (‘sub’) is not guaranteed to be unique and immutable. This field is experimental, please see the authentication documentation for further details.
Defaults to “sub”.
usernamePrefixstring
(Optional)
If provided, all usernames will be prefixed with this value. If not provided, username claims other than ‘email’ are prefixed by the issuer URL to avoid clashes. To skip any prefixing, provide the value ‘-’.
OpenIDConnectClientAuthentication contains configuration for OIDC clients.
Field
Description
secretstring
(Optional)
The client Secret for the OpenID Connect client.
extraConfigmap[string]string
(Optional)
Extra configuration added to kubeconfig’s auth-provider.
Must not be any of idp-issuer-url, client-id, client-secret, idp-certificate-authority, idp-certificate-authority-data, id-token or refresh-token
Server contains the kube-apiserver’s OpenID Connect configuration.
This configuration is not overwriting any existing OpenID Connect
configuration already set on the Shoot object.
Client contains the configuration used for client OIDC authentication
of Shoot clusters.
This configuration is not overwriting any existing OpenID Connect
client authentication already set on the Shoot object.
Deprecated: The OpenID Connect configuration this field specifies is not used and will be forbidden starting from Kubernetes 1.31.
It’s use was planned for genereting OIDC kubeconfig https://github.com/gardener/gardener/issues/1433
TODO(AleksandarSavchev): Drop this field after support for Kubernetes 1.30 is dropped.
ShootSelector decides whether to apply the configuration if the
Shoot has matching labels.
Use the selector only if the OIDC Preset is opt-in, because end
users may skip the admission by setting the labels.
Default to the empty LabelSelector, which matches everything.
weightint32
Weight associated with matching the corresponding preset,
in the range 1-100.
Required.
This is a short guide describing different options how to automatically scale CoreDNS in the shoot cluster.
Background
Currently, Gardener uses CoreDNS as DNS server. Per default, it is installed as a deployment into the shoot cluster that is auto-scaled horizontally to cover for QPS-intensive applications. However, doing so does not seem to be enough to completely circumvent DNS bottlenecks such as:
Cloud provider limits for DNS lookups.
Unreliable UDP connections that forces a period of timeout in case packets are dropped.
Unnecessary node hopping since CoreDNS is not deployed on all nodes, and as a result DNS queries end-up traversing multiple nodes before reaching the destination server.
Inefficient load-balancing of services (e.g., round-robin might not be enough when using IPTables mode).
Overload of the CoreDNS replicas as the maximum amount of replicas is fixed.
and more …
As an alternative with extended configuration options, Gardener provides cluster-proportional autoscaling of CoreDNS. This guide focuses on the configuration of cluster-proportional autoscaling of CoreDNS and its advantages/disadvantages compared to the horizontal
autoscaling.
Please note that there is also the option to use a node-local DNS cache, which helps mitigate potential DNS bottlenecks (see Trade-offs in conjunction with NodeLocalDNS for considerations regarding using NodeLocalDNS together with one of the CoreDNS autoscaling approaches).
Configuring Cluster-Proportional DNS Autoscaling
All that needs to be done to enable the usage of cluster-proportional autoscaling of CoreDNS is to set the corresponding option (spec.systemComponents.coreDNS.autoscaling.mode) in the Shoot resource to cluster-proportional:
To switch back to horizontal DNS autoscaling, you can set the spec.systemComponents.coreDNS.autoscaling.mode to horizontal (or remove the coreDNS section).
Once the cluster-proportional autoscaling of CoreDNS has been enabled and the Shoot cluster has been reconciled afterwards, a ConfigMap called coredns-autoscaler will be created in the kube-system namespace with the default settings. The content will be similar to the following:
It is possible to adapt the ConfigMap according to your needs in case the defaults do not work as desired. The number of CoreDNS replicas is calculated according to the following formula:
Depending on your needs, you can adjust coresPerReplica or nodesPerReplica, but it is also possible to override min if required.
Trade-Offs of Horizontal and Cluster-Proportional DNS Autoscaling
The horizontal autoscaling of CoreDNS as implemented by Gardener is fully managed, i.e., you do not need to perform any configuration changes. It scales according to the CPU usage of CoreDNS replicas, meaning that it will create new replicas if the existing ones are under heavy load. This approach scales between 2 and 5 instances, which is sufficient for most workloads. In case this is not enough, the cluster-proportional autoscaling approach can be used instead, with its more flexible configuration options.
The cluster-proportional autoscaling of CoreDNS as implemented by Gardener is fully managed, but allows more configuration options to adjust the default settings to your individual needs. It scales according to the cluster size, i.e., if your cluster grows in terms of cores/nodes so will the amount of CoreDNS replicas. However, it does not take the actual workload, e.g., CPU consumption, into account.
Experience shows that the horizontal autoscaling of CoreDNS works for a variety of workloads. It does reach its limits if a cluster has a high amount of DNS requests, though. The cluster-proportional autoscaling approach allows to fine-tune the amount of CoreDNS replicas. It helps to scale in clusters of changing size. However, please keep in mind that you need to cater for the maximum amount of DNS requests as the replicas will not be adapted according to the workload, but only according to the cluster size (cores/nodes).
Trade-Offs in Conjunction with NodeLocalDNS
Using a node-local DNS cache can mitigate a lot of the potential DNS related problems. It works fine with a DNS workload that can be handle through the cache and reduces the inter-node DNS communication. As node-local DNS cache reduces the amount of traffic being sent to the cluster’s CoreDNS replicas, it usually works fine with horizontally scaled CoreDNS. Nevertheless, it also works with CoreDNS scaled in a cluster-proportional approach. In this mode, though, it might make sense to adapt the default settings as the CoreDNS workload is likely significantly reduced.
Overall, you can view the DNS options on a scale. Horizontally scaled DNS provides a small amount of DNS servers. Especially for bigger clusters, a cluster-proportional approach will yield more CoreDNS instances and hence may yield a more balanced DNS solution. By adapting the settings you can further increase the amount of CoreDNS replicas. On the other end of the spectrum, a node-local DNS cache provides DNS on every node and allows to reduce the amount of (backend) CoreDNS instances regardless if they are horizontally or cluster-proportionally scaled.
3.2 - Shoot Autoscaling
The basics of horizontal Node and vertical Pod auto-scaling
Auto-Scaling in Shoot Clusters
There are three auto-scaling scenarios of relevance in Kubernetes clusters in general and Gardener shoot clusters in particular:
Horizontal node auto-scaling, i.e., dynamically adding and removing worker nodes.
Horizontal pod auto-scaling, i.e., dynamically adding and removing pod replicas.
Vertical pod auto-scaling, i.e., dynamically raising or shrinking the resource requests/limits of pods.
This document provides an overview of these scenarios and how the respective auto-scaling components can be enabled and configured. For more details, please see our pod auto-scaling best practices.
Horizontal Node Auto-Scaling
Every shoot cluster that has at least one worker pool with minimum < maximum nodes configuration will get a cluster-autoscaler deployment.
Gardener is leveraging the upstream community Kubernetes cluster-autoscaler component.
We have forked it to gardener/autoscaler so that it supports the way how Gardener manages the worker nodes (leveraging gardener/machine-controller-manager).
However, we have not touched the logic how it performs auto-scaling decisions.
Consequently, please refer to the official documentation for this component.
The Shoot API allows to configure a few flags of the cluster-autoscaler:
Only some cluster-autoscaler flags can be configured per worker pool, and is limited by NodeGroupAutoscalingOptions of the upstream community Kubernetes repository. This list can be found here.
Horizontal Pod Auto-Scaling
This functionality (HPA) is a standard functionality of any Kubernetes cluster (implemented as part of the kube-controller-manager that all Kubernetes clusters have). It is always enabled.
This form of auto-scaling (VPA) is enabled by default, but it can be switched off in the Shoot by setting .spec.kubernetes.verticalPodAutoscaler.enabled=false in case you deploy your own VPA into your cluster (having more than one VPA on the same set of pods will lead to issues, eventually).
Gardener is leveraging the upstream community Kubernetes vertical-pod-autoscaler.
If enabled, Gardener will deploy it as part of the control plane into the seed cluster.
It will also be used for the vertical autoscaling of Gardener’s system components deployed into the kube-system namespace of shoot clusters, for example, kube-proxy or metrics-server.
You might want to refer to the official documentation for this component to get more information how to use it.
⚠️ Please note that if you disable VPA, the related CustomResourceDefinitions (ours and yours) will remain in your shoot cluster (whether someone acts on them or not).
You can delete these CustomResourceDefinitions yourself using kubectl delete crd if you want to get rid of them (in case you statically size all resources, which we do not recommend).
There are two types of pod autoscaling in Kubernetes: Horizontal Pod Autoscaling (HPA) and Vertical Pod Autoscaling (VPA). HPA (implemented as part of the kube-controller-manager) scales the number of pod replicas, while VPA (implemented as independent community project) adjusts the CPU and memory requests for the pods. Both types of autoscaling aim to optimize resource usage/costs and maintain the performance and (high) availability of applications running on Kubernetes.
Horizontal Pod Autoscaling involves increasing or decreasing the number of pod replicas in a deployment, replica set, stateful set, or anything really with a scale subresource that manages pods. HPA adjusts the number of replicas based on specified metrics, such as CPU or memory average utilization (usage divided by requests; most common) or average value (usage; less common). When the demand on your application increases, HPA automatically scales out the number of pods to meet the demand. Conversely, when the demand decreases, it scales in the number of pods to reduce resource usage.
HPA targets (mostly stateless) applications where adding more instances of the application can linearly increase the ability to handle additional load. It is very useful for applications that experience variable traffic patterns, as it allows for real-time scaling without the need for manual intervention.
Note
HPA continuously monitors the metrics of the targeted pods and adjusts the number of replicas based on the observed metrics. It operates solely on the current metrics when it calculates the averages across all pods, meaning it reacts to the immediate resource usage without considering past trends or patterns. Also, all pods are treated equally based on the average metrics. This could potentially lead to situations where some pods are under high load while others are underutilized. Therefore, particular care must be applied to (fair) load-balancing (connection vs. request vs. actual resource load balancing are crucial).
Besides HPA and VPA, CPA and CPVA are further options for scaling horizontally or vertically (neither is deployed by Gardener and must be deployed by the user). Unlike HPA and VPA, CPA and CPVA do not monitor the actual pod metrics, but scale solely on the number of nodes or CPU cores in the cluster. While this approach may be helpful and sufficient in a few rare cases, it is often a risky and crude scaling scheme that we do not recommend. More often than not, cluster-proportional scaling results in either under- or over-reserving your resources.
Vertical Pod Autoscaling, on the other hand, focuses on adjusting the CPU and memory resources allocated to the pods themselves. Instead of changing the number of replicas, VPA tweaks the resource requests (and limits, but only proportionally, if configured) for the pods in a deployment, replica set, stateful set, daemon set, or anything really with a scale subresource that manages pods. This means that each pod can be given more, or fewer resources as needed.
VPA is very useful for optimizing the resource requests of pods that have dynamic resource needs over time. It does so by mutating pod requests (unfortunately, not in-place). Therefore, in order to apply new recommendations, pods that are “out of bounds” (i.e. below a configured/computed lower or above a configured/computed upper recommendation percentile) will be evicted proactively, but also pods that are “within bounds” may be evicted after a grace period. The corresponding higher-level replication controller will then recreate a new pod that VPA will then mutate to set the currently recommended requests (and proportional limits, if configured).
Note
VPA continuously monitors all targeted pods and calculates recommendations based on their usage (one recommendation for the entire target). This calculation is influenced by configurable percentiles, with a greater emphasis on recent usage data and a gradual decrease (=decay) in the relevance of older data. However, this means, that VPA doesn’t take into account individual needs of single pods - eventually, all pods will receive the same recommendation, which may lead to considerable resource waste. Ideally, VPA would update pods in-place depending on their individual needs, but that’s (individual recommendations) not in its design, even if in-place updates get implemented, which may be years away for VPA based on current activity on the component.
Selecting the Appropriate Autoscaler
Before deciding on an autoscaling strategy, it’s important to understand the characteristics of your application:
Interruptibility: Most importantly, if the clients of your workload are too sensitive to disruptions/cannot cope well with terminating pods, then maybe neither HPA nor VPA is an option (both, HPA and VPA cause pods and connections to be terminated, though VPA even more frequently). Clients must retry on disruptions, which is a reasonable ask in a highly dynamic (and self-healing) environment such as Kubernetes, but this is often not respected (or expected) by your clients (they may not know or care you run the workload in a Kubernetes cluster and have different expectations to the stability of the workload unless you communicated those through SLIs/SLOs/SLAs).
Statelessness: Is your application stateless or stateful? Stateless applications are typically better candidates for HPA as they can be easily scaled out by adding more replicas without worrying about maintaining state.
Traffic Patterns: Does your application experience variable traffic? If so, HPA can help manage these fluctuations by adjusting the number of replicas to handle the load.
Resource Usage: Does your application’s resource usage change over time? VPA can adjust the CPU and memory reservations dynamically, which is beneficial for applications with non-uniform resource requirements.
Scalability: Can your application handle increased load by scaling vertically (more resources per pod) or does it require horizontal scaling (more pod instances)?
HPA is the right choice if:
Your application is stateless and can handle increased load by adding more instances.
You experience short-term fluctuations in traffic that require quick scaling responses.
You want to maintain a specific performance metric, such as requests per second per pod.
VPA is the right choice if:
Your application’s resource requirements change over time, and you want to optimize resource usage without manual intervention.
You want to avoid the complexity of managing resource requests for each pod, especially when they run code where it’s impossible for you to suggest static requests.
In essence:
For applications that can handle increased load by simply adding more replicas, HPA should be used to handle short-term fluctuations in load by scaling the number of replicas.
For applications that require more resources per pod to handle additional work, VPA should be used to adjust the resource allocation for longer-term trends in resource usage.
Consequently, if both cases apply (VPA often applies), HPA and VPA can also be combined. However, combining both, especially on the same metrics (CPU and memory), requires understanding and care to avoid conflicts and ensure that the autoscaling actions do not interfere with and rather complement each other. For more details, see Combining HPA and VPA.
Horizontal Pod Autoscaler (HPA)
HPA operates by monitoring resource metrics for all pods in a target. It computes the desired number of replicas from the current average metrics and the desired user-defined metrics as follows:
HPA checks the metrics at regular intervals, which can be configured by the user. Several types of metrics are supported (classical resource metrics like CPU and memory, but also custom and external metrics like requests per second or queue length can be configured, if available). If a scaling event is necessary, HPA adjusts the replica count for the targeted resource.
Defining an HPA Resource
To configure HPA, you need to create an HPA resource in your cluster. This resource specifies the target to scale, the metrics to be used for scaling decisions, and the desired thresholds. Here’s an example of an HPA configuration:
In this example, HPA is configured to scale foo-deployment based on pod average CPU and memory usage. It will maintain an average CPU and memory usage (not utilization, which is usage divided by requests!) across all replicas of 2 CPUs and 8G or lower with as few replicas as possible. The number of replicas will be scaled between a minimum of 1 and a maximum of 10 based on this target.
In the official documentation ([1] and [2]) you will find examples with average utilization (averageUtilization), not average usage (averageValue), but this is not particularly helpful, especially if you plan to combine HPA together with VPA on the same metrics (generally discouraged in the documentation). If you want to safely combine both on the same metrics, you should scale on average usage (averageValue) as shown above. For more details, see Combining HPA and VPA.
Finally, the behavior section influences how fast you scale up and down. Most of the time (depends on your workload), you like to scale out faster than you scale in. In this example, the configuration will trigger a scale-out only after observing the need to scale out for 30s (stabilizationWindowSeconds) and will then only scale out at most 100% (value + type) of the current number of replicas every 60s (periodSeconds). The configuration will trigger a scale-in only after observing the need to scale in for 1800s (stabilizationWindowSeconds) and will then only scale in at most 1 pod (value + type) every 300s (periodSeconds). As you can see, scale-out happens quicker than scale-in in this example.
HPA (actually KCM) Options
HPA is a function of the kube-controller-manager (KCM).
downscaleStabilization (default 5m): HPA will scale out whenever the formula (in accordance with the behavior section, if present in the HPA resource) yields a higher replica count, but it won’t scale in just as eagerly. This option lets you define a trailing time window that HPA must check and only if the recommended replica count is consistently lower throughout the entire time window, HPA will scale in (in accordance with the behavior section, if present in the HPA resource). If at any point in time in that trailing time window the recommended replica count isn’t lower, scale-in won’t happen. This setting is just a default, if nothing is defined in the behavior section of an HPA resource. The default for the upscale stabilization is 0s and it cannot be set via a KCM option (downscale stabilization was historically more important than upscale stabilization and when later the behavior sections were added to the HPA resources, upscale stabilization remained missing from the KCM options).
tolerance (default +/-10%): HPA will not scale out or in if the desired replica count is (mathematically as a float) near the actual replica count (see source code for details), which is a form of hysteresis to avoid replica flapping around a threshold.
There are a few more configurable options of lesser interest:
syncPeriod (default 15s): How often HPA retrieves the pods and metrics respectively how often it recomputes and sets the desired replica count.
cpuInitializationPeriod (default 30s) and initialReadinessDelay (default 5m): Both settings only affect whether or not CPU metrics are considered for scaling decisions. They can be easily misinterpreted as the official docs are somewhat hard to read (see source code for details, which is more readable, if you ignore the comments). Normally, you have little reason to modify them, but here is what they do:
cpuInitializationPeriod: Defines a grace period after a pod starts during which HPA won’t consider CPU metrics of the pod for scaling if the pod is either not ready or it is ready, but a given CPU metric is older than the last state transition (to ready). This is to ignore CPU metrics that predate the current readiness while still in initialization to not make scaling decisions based on potentially misleading data. If the pod is ready and a CPU metric was collected after it became ready, it is considered also within this grace period.
initialReadinessDelay: Defines another grace period after a pod starts during which HPA won’t consider CPU metrics of the pod for scaling if the pod is not ready and it became not ready within this grace period (the docs/comments want to check whether the pod was ever ready, but the code only checks whether the pod condition last transition time to not ready happened within that grace period which it could have from being ready or simply unknown before). This is to ignore not (ever have been) ready pods while still in initialization to not make scaling decisions based on potentially misleading data. If the pod is ready, it is considered also within this grace period.
So, regardless of the values of these settings, if a pod is reporting ready and it has a CPU metric from the time after it became ready, that pod and its metric will be considered. This holds true even if the pod becomes ready very early into its initialization. These settings cannot be used to “black-out” pods for a certain duration before being considered for scaling decisions. Instead, if it is your goal to ignore a potentially resource-intensive initialization phase that could wrongly lead to further scale-out, you would need to configure your pods to not report as ready until that resource-intensive initialization phase is over.
Considerations When Using HPA
Selection of metrics: Besides CPU and memory, HPA can also target custom or external metrics. Pick those (in addition or exclusively), if you guarantee certain SLOs in your SLAs.
Targeting usage or utilization: HPA supports usage (absolute) and utilization (relative). Utilization is often preferred in simple examples, but usage is more precise and versatile.
Compatibility with VPA: Care must be taken when using HPA in conjunction with VPA, as they can potentially interfere with each other’s scaling decisions.
Vertical Pod Autoscaler (VPA)
VPA operates by monitoring resource metrics for all pods in a target. It computes a resource requests recommendation from the historic and current resource metrics. VPA checks the metrics at regular intervals, which can be configured by the user. Only CPU and memory are supported. If VPA detects that a pod’s resource allocation is too high or too low, it may evict pods (if within the permitted disruption budget), which will trigger the creation of a new pod by the corresponding higher-level replication controller, which will then be mutated by VPA to match resource requests recommendation. This happens in three different components that work together:
VPA Recommender: The Recommender observes the historic and current resource metrics of pods and generates recommendations based on this data.
VPA Updater: The Updater component checks the recommendations from the Recommender and decides whether any pod’s resource requests need to be updated. If an update is needed, the Updater will evict the pod.
VPA Admission Controller: When a pod is (re-)created, the Admission Controller modifies the pod’s resource requests based on the recommendations from the Recommender. This ensures that the pod starts with the optimal amount of resources.
Since VPA doesn’t support in-place updates, pods will be evicted. You will want to control voluntary evictions by means of Pod Disruption Budgets (PDBs). Please make yourself familiar with those and use them.
Note
PDBs will not always work as expected and can also get in your way, e.g. if the PDB is violated or would be violated, it may possibly block evictions that would actually help your workload, e.g. to get a pod out of an OOMKilledCrashLoopBackoff (if the PDB is or would be violated, not even unhealthy pods would be evicted as they could theoretically become healthy again, which VPA doesn’t know). In order to overcome this issue, it is now possible (alpha since Kubernetes v1.26 in combination with the feature gate PDBUnhealthyPodEvictionPolicy on the API server, beta and enabled by default since Kubernetes v1.27) to configure the so-called unhealthy pod eviction policy. The default is still IfHealthyBudget as a change in default would have changed the behavior (as described above), but you can now also set AlwaysAllow at the PDB (spec.unhealthyPodEvictionPolicy). For more information, please check out this discussion, the PR and this document and balance the pros and cons for yourself. In short, the new AlwaysAllow option is probably the better choice in most of the cases while IfHealthyBudget is useful only if you have frequent temporary transitions or for special cases where you have already implemented controllers that depend on the old behavior.
Defining a VPA Resource
To configure VPA, you need to create a VPA resource in your cluster. This resource specifies the target to scale, the metrics to be used for scaling decisions, and the policies for resource updates. Here’s an example of an VPA configuration:
In this example, VPA is configured to scale foo-deployment requests (RequestsOnly) from 50m cores (minAllowed) up to 4 cores (maxAllowed) and 200M memory (minAllowed) up to 16G memory (maxAllowed) automatically (updateMode). VPA doesn’t support in-place updates, so in updateModeAuto it will evict pods under certain conditions and then mutate the requests (and possibly limits if you omit controlledValues or set it to RequestsAndLimits, which is the default) of upcoming new pods.
Off: In this mode, recommendations are computed, but never applied. This mode is useful, if you want to learn more about your workload or if you have a custom controller that depends on VPA’s recommendations but shall act instead of VPA.
Initial: In this mode, recommendations are computed and applied, but pods are never proactively evicted to enforce new recommendations over time. This mode is useful, if you want to control pod evictions yourself (similar to the StatefulSetupdateStrategyOnDelete) or your workload is sensitive to evictions, e.g. some brownfield singleton application or a daemon set pod that is critical for the node.
Auto (default): In this mode, recommendations are computed, applied, and pods are even proactively evicted to enforce new recommendations over time. This applies recommendations continuously without you having to worry too much.
As mentioned, controlledValues influences whether only requests or requests and limits are scaled:
RequestsOnly: Updates only requests and doesn’t change limits. Useful if you have defined absolute limits (unrelated to the requests).
RequestsAndLimits (default): Updates requests and proportionally scales limits along with the requests. Useful if you have defined relative limits (related to the requests). In this case, the gap between requests and limits should be either zero for QoS Guaranteed or small for QoS Burstable to avoid useless (way beyond the threshold of unhealthy behavior) or absurd (larger than node capacity) values.
VPA doesn’t offer many more settings that can be tuned per VPA resource than you see above (different than HPA’s behavior section). However, there is one more that isn’t shown above, which allows to scale only up or only down (evictionRequirements[].changeRequirement), in case you need that, e.g. to provide resources when needed, but avoid disruptions otherwise.
VPA Options
VPA is an independent community project that consists of a recommender (computing target recommendations and bounds), an updater (evicting pods that are out of recommendation bounds), and an admission controller (mutating webhook applying the target recommendation to newly created pods). As such, they have independent options.
recommendationMarginFraction (default 15%): Safety margin that will be added to the recommended requests.
targetCPUPercentile (default 90%): CPU usage percentile that will be targeted with the CPU recommendation (i.e. recommendation will “fit” e.g. 90% of the observed CPU usages). This setting is relevant for balancing your requests reservations vs. your costs. If you want to reduce costs, you can reduce this value (higher risk because of potential under-reservation, but lower costs), because CPU is compressible, but then VPA may lack the necessary signals for scale-up as throttling on an otherwise fully utilized node will go unnoticed by VPA. If you want to err on the safe side, you can increase this value, but you will then target more and more a worst case scenario, quickly (maybe even exponentially) increasing the costs.
targetMemoryPercentile (default 90%): Memory usage percentile that will be targeted with the memory recommendation (i.e. recommendation will “fit” e.g. 90% of the observed memory usages). This setting is relevant for balancing your requests reservations vs. your costs. If you want to reduce costs, you can reduce this value (higher risk because of potential under-reservation, but lower costs), because OOMs will trigger bump-ups, but those will disrupt the workload. If you want to err on the safe side, you can increase this value, but you will then target more and more a worst case scenario, quickly (maybe even exponentially) increasing the costs.
There are a few more configurable options of lesser interest:
recommenderInterval (default 1m): How often VPA retrieves the pods and metrics respectively how often it recomputes the recommendations and bounds.
There are many more options that you can only configure if you deploy your own VPA and which we will not discuss here, but you can check them out here.
Note
Due to an implementation detail (smallest bucket size), VPA cannot create recommendations below 10m cores and 10M memory even if minAllowed is lower.
evictAfterOOMThreshold (default 10m): Pods where at least one container OOMs within this time period since its start will be actively evicted, which will implicitly apply the new target recommendation that will have been bumped up after OOMKill. Please note, the kubelet may evict pods even before an OOM, but only if kube-reserved is underrun, i.e. node-level resources are running low. In these cases, eviction will happen first by pod priority and second by how much the usage overruns the requests.
evictionTolerance (default 50%): Defines a threshold below which no further eligible pod will be evited anymore, i.e. limits how many eligible pods may be in eviction in parallel (but at least 1). The threshold is computed as follows: running - evicted > replicas - tolerance. Example: 10 replicas, 9 running, 8 eligible for eviction, 20% tolerance with 10 replicas which amounts to 2 pods, and no pod evicted in this round yet, then 9 - 0 > 10 - 2 is true and a pod would be evicted, but the next one would be in violation as 9 - 1 = 10 - 2 and no further pod would be evicted anymore in this round.
evictionRateBurst (default 1): Defines how many eligible pods may be evicted in one go.
evictionRateLimit (default disabled): Defines how many eligible pods may be evicted per second (a value of 0 or -1 disables the rate limiting).
There are a few more configurable options of lesser interest:
updaterInterval (default 1m): How often VPA evicts the pods.
There are many more options that you can only configure if you deploy your own VPA and which we will not discuss here, but you can check them out here.
Considerations When Using VPA
Initial Resource Estimates: VPA requires historical resource usage data to base its recommendations on. Until they kick in, your initial resource requests apply and should be sensible.
Pod Disruption: When VPA adjusts the resources for a pod, it may need to “recreate” the pod, which can cause temporary disruptions. This should be taken into account.
Compatibility with HPA: Care must be taken when using VPA in conjunction with HPA, as they can potentially interfere with each other’s scaling decisions.
Combining HPA and VPA
HPA and VPA serve different purposes and operate on different axes of scaling. HPA increases or decreases the number of pod replicas based on metrics like CPU or memory usage, effectively scaling the application out or in. VPA, on the other hand, adjusts the CPU and memory reservations of individual pods, scaling the application up or down.
When used together, these autoscalers can provide both horizontal and vertical scaling. However, they can also conflict with each other if used on the same metrics (e.g. both on CPU or both on memory). In particular, if VPA adjusts the requests, the utilization, i.e. the ratio between usage and requests, will approach 100% (for various reasons not exactly right, but for this consideration, close enough), which may trigger HPA to scale out, if it’s configured to scale on utilization below 100% (often seen in simple examples), which will spread the load across more pods, which may trigger VPA again to adjust the requests to match the new pod usages.
If desiredMetricValue is utilization and VPA adjusts the requests, which changes the utilization, this may inadvertently trigger HPA and create said feedback loop. On the other hand, if desiredMetricValue is usage and VPA adjusts the requests now, this will have no impact on HPA anymore (HPA will always influence VPA, but we can control whether VPA influences HPA).
Therefore, to safely combine HPA and VPA, consider the following strategies:
Configure HPA and VPA on different metrics: One way to avoid conflicts is to use HPA and VPA based on different metrics. For instance, you could configure HPA to scale based on requests per seconds (or another representative custom/external metric) and VPA to adjust CPU and memory requests. This way, each autoscaler operates independently based on its specific metric(s).
Configure HPA to scale on usage, not utilization, when used with VPA: Another way to avoid conflicts is to use HPA not on average utilization (averageUtilization), but instead on average usage (averageValue) as replicas driver, which is an absolute metric (requests don’t affect usage). This way, you can combine both autoscalers even on the same metrics.
Pod Autoscaling and Cluster Autoscaler
Autoscaling within Kubernetes can be implemented at different levels: pod autoscaling (HPA and VPA) and cluster autoscaling (CA). While pod autoscaling adjusts the number of pod replicas or their resource reservations, cluster autoscaling focuses on the number of nodes in the cluster, so that your pods can be hosted. If your workload isn’t static and especially if you make use of pod autoscaling, it only works if you have sufficient node capacity available. The most effective way to do that, without running a worst-case number of nodes, is to configure burstable worker pools in your shoot spec, i.e. define a true minimum node count and a worst-case maximum node count and leave the node autoscaling to Gardener that internally uses the Cluster Autoscaler to provision and deprovision nodes as needed.
Cluster Autoscaler automatically adjusts the number of nodes by adding or removing nodes based on the demands of the workloads and the available resources. It interacts with the cloud provider’s APIs to provision or deprovision nodes as needed. Cluster Autoscaler monitors the utilization of nodes and the scheduling of pods. If it detects that pods cannot be scheduled due to a lack of resources, it will trigger the addition of new nodes to the cluster. Conversely, if nodes are underutilized for some time and their pods can be placed on other nodes, it will remove those nodes to reduce costs and improve resource efficiency.
Pod Disruption Budgets (PDBs): Use PDBs to ensure that during scale-down events, the availability of applications is maintained as the Cluster Autoscaler will not voluntarily evict a pod if a PDB would be violated.
expander (default least-waste): Defines the “expander” algorithm to use during scale-up, see FAQ.
scaleDownDelayAfterAdd (default 1h): Defines how long after scaling up a node, a node may be scaled down.
scaleDownDelayAfterFailure (default 3m): Defines how long after scaling down a node failed, scaling down will be resumed.
scaleDownDelayAfterDelete (default 0s): Defines how long after scaling down a node, another node may be scaled down.
Can be configured globally and also overwritten individually per worker pool:
scaleDownUtilizationThreshold (default 50%): Defines the threshold below which a node becomes eligible for scaling down.
scaleDownUnneededTime (default 30m): Defines the trailing time window the node must be consistently below a certain utilization threshold before it can finally be scaled down.
There are many more options that you can only configure if you deploy your own CA and which we will not discuss here, but you can check them out here.
Importance of Monitoring
Monitoring is a critical component of autoscaling for several reasons:
Performance Insights: It provides insights into how well your autoscaling strategy is meeting the performance requirements of your applications.
Resource Utilization: It helps you understand resource utilization patterns, enabling you to optimize resource allocation and reduce waste.
Cost Management: It allows you to track the cost implications of scaling actions, helping you to maintain control over your cloud spending.
Troubleshooting: It enables you to quickly identify and address issues with autoscaling, such as unexpected scaling behavior or resource bottlenecks.
To effectively monitor autoscaling, you should leverage the following tools and metrics:
Kubernetes Metrics Server: Collects resource metrics from kubelets and provides them to HPA and VPA for autoscaling decisions (automatically provided by Gardener).
Prometheus: An open-source monitoring system that can collect and store custom metrics, providing a rich dataset for autoscaling decisions.
Grafana/Plutono: A visualization tool that integrates with Prometheus to create dashboards for monitoring autoscaling metrics and events.
Cloud Provider Tools: Most cloud providers offer native monitoring solutions that can be used to track the performance and costs associated with autoscaling.
Key metrics to monitor include:
CPU and Memory Utilization: Track the resource utilization of your pods and nodes to understand how they correlate with scaling events.
Pod Count: Monitor the number of pod replicas over time to see how HPA is responding to changes in load.
Scaling Events: Keep an eye on scaling events triggered by HPA and VPA to ensure they align with expected behavior.
Application Performance Metrics: Track application-specific metrics such as response times, error rates, and throughput.
Based on the insights gained from monitoring, you may need to adjust your autoscaling configurations:
Refine Thresholds: If you notice frequent scaling actions or periods of underutilization or overutilization, adjust the thresholds used by HPA and VPA to better match the workload patterns.
Update Policies: Modify VPA update policies if you observe that the current settings are causing too much or too little pod disruption.
Custom Metrics: If using custom metrics, ensure they accurately reflect the load on your application and adjust them if they do not.
Scaling Limits: Review and adjust the minimum and maximum scaling limits to prevent over-scaling or under-scaling based on the capacity of your cluster and the criticality of your applications.
BestEffort, i.e. pods where no container has CPU or memory requests or limits: Avoid them unless you have really good reasons. The kube-scheduler will place them just anywhere according to its policy, e.g. balanced or bin-packing, but whatever resources these pods consume, may bring other pods into trouble or even the kubelet and the container runtime itself, if it happens very suddenly.
Burstable, i.e. pods where at least one container has CPU or memory requests and at least one has no limits or limits that don’t match the requests: Prefer them unless you have really good reasons for the other QoS classes. Always specify proper requests or use VPA to recommend those. This helps the kube-scheduler to make the right scheduling decisions. Not having limits will additionally provide upward resource flexibility, if the node is not under pressure.
Guaranteed, i.e. pods where all containers have CPU and memory requests and equal limits: Avoid them unless you really know the limits or throttling/killing is intended. While “Guaranteed” sounds like something “positive” in the English language, this class comes with the downside, that pods will be actively CPU-throttled and will actively go OOM, even if the node is not under pressure and has excess capacity left. Worse, if containers in the pod are under VPA, their CPU requests/limits will often not be scaled up as CPU throttling will go unnoticed by VPA.
Summary
As a rule of thumb, always set CPU and memory requests (or let VPA do that) and always avoid CPU and memory limits.
CPU limits aren’t helpful on an under-utilized node (=may result in needless outages) and even suppress the signals for VPA to act. On a nearly or fully utilized node, CPU limits are practically irrelevant as only the requests matter, which are translated into CPU shares that provide a fair use of the CPU anyway (see CFS). Therefore, if you do not know the healthy range, do not set CPU limits. If you as author of the source code know its healthy range, set them to the upper threshold of that healthy range (everything above, from your knowledge of that code, is definitely an unbound busy loop or similar, which is the main reason for CPU limits, besides batch jobs where throttling is acceptable or even desired).
Memory limits may be more useful, but suffer a similar, though not as negative downside. As with CPU limits, memory limits aren’t helpful on an under-utilized node (=may result in needless outages), but different than CPU limits, they result in an OOM, which triggers VPA to provide more memory suddenly (modifies the currently computed recommendations by a configurable factor, defaulting to +20%, see docs). Therefore, if you do not know the healthy range, do not set memory limits. If you as author of the source code know its healthy range, set them to the upper threshold of that healthy range (everything above, from your knowledge of that code, is definitely an unbound memory leak or similar, which is the main reason for memory limits)
Horizontal Pod Autoscaling (HPA): Use for pods that support horizontal scaling. Prefer scaling on usage, not utilization, as this is more predictable (not dependent on a second variable, namely the current requests) and conflict-free with vertical pod autoscaling (VPA).
As a rule of thumb, set the initial replicas to the 5th percentile of the actually observed replica count in production. Since HPA reacts fast, this is not as critical, but may help reduce initial load on the control plane early after deployment. However, be cautious when you update the higher-level resource not to inadvertently reset the current HPA-controlled replica count (very easy to make mistake that can lead to catastrophic loss of pods). HPA modifies the replica count directly in the spec and you do not want to overwrite that. Even if it reacts fast, it is not instant (not via a mutating webhook as VPA operates) and the damage may already be done.
As for minimum and maximum, let your high availability requirements determine the minimum and your theoretical maximum load determine the maximum, flanked with alerts to detect erroneous run-away out-scaling or the actual nearing of your practical maximum load, so that you can intervene.
Vertical Pod Autoscaling (VPA): Use for containers that have a significant usage (e.g. any container above 50m CPU or 100M memory) and a significant usage spread over time (by more than 2x), i.e. ignore small (e.g. side-cars) or static (e.g. Java statically allocated heap) containers, but otherwise use it to provide the resources needed on the one hand and keep the costs in check on the other hand.
As a rule of thumb, set the initial requests to the 5th percentile of the actually observed CPU resp. memory usage in production. Since VPA may need some time at first to respond and evict pods, this is especially critical early after deployment. The lower bound, below which pods will be immediately evicted, converges much faster than the upper bound, above which pods will be immediately evicted, but it isn’t instant, e.g. after 5 minutes the lower bound is just at 60% of the computed lower bound; after 12 hours the upper bound is still at 300% of the computed upper bound (see code). Unlike with HPA, you don’t need to be as cautious when updating the higher-level resource in the case of VPA. As long as VPA’s mutating webhook (VPA Admission Controller) is operational (which also the VPA Updater checks before evicting pods), it’s generally safe to update the higher-level resource. However, if it’s not up and running, any new pods that are spawned (e.g. as a consequence of a rolling update of the higher-level resource or for any other reason) will not be mutated. Instead, they will receive whatever requests are currently configured at the higher-level resource, which can lead to catastrophic resource under-reservation. Gardener deploys the VPA Admission Controller in HA - if unhealthy, it is reported under the ControlPlaneHealthy shoot status condition.
As a rule of thumb, for a container under VPA always specify initial resource requests for the resources which are controlled by VPA (the controlledResources field; by default both cpu and memory are controlled). vpa-updater evicts immediately if a container does not specify initial resource requests for a resource controlled by VPA (see code).
As a rule of thumb, for a container under VPA do not set initial requests less than VPA’s minAllowed or vpa-recommender’s Pod minimum recommendation (10m and 10Mi). In Gardener, vpa-recommender is configured to run with --pod-recommendation-min-cpu-millicores=10 and --pod-recommendation-min-memory-mb=10 (see code). These values are synced with the smallest histogram bucket sizes - 10m and 10M (see VPA Recommender Options). Note that the --pod-recommendation-min-memory-mb flag is in mebibytes, not megabytes (see code). If a Pod has a container under VPA with resource requests less than the VPA’s minAllowed or 10m and 10Mi, the Pod will be evicted immediately. The reason is that the VPA’s lower bound recommendation is set to minAllowed or 10m and 10Mi. vpa-updater evicts immediately if the container’s resource requests are “out of bounds” (in this particular case - less than the lower bound).
If you have defined absolute limits (unrelated to the requests), configure VPA to only scale the requests or else it will proportionally scale the limits as well, which can easily become useless (way beyond the threshold of unhealthy behavior) or absurd (larger than node capacity):
If you have defined relative limits (related to the requests), the default policy to scale the limits proportionally with the requests is fine, but the gap between requests and limits must be zero for QoS Guaranteed and should best be small for QoS Burstable to avoid useless or absurd limits either, e.g. prefer limits being 5 to at most 20% larger than requests as opposed to being 100% larger or more.
As a rule of thumb, set minAllowed to the highest observed VPA recommendation (usually during the initialization phase or during any periodical activity) for an otherwise practically idle container, so that you avoid needless trashing (e.g. resource usage calms down over time and recommendations drop consecutively until eviction, which will then lead again to initialization or later periodical activity and higher recommendations and new evictions). ⚠️ You may want to provide higher minAllowed values, if you observe that up-scaling takes too long for CPU or memory for a too large percentile of your workload. This will get you out of the danger zone of too few resources for too many pods at the expense of providing too many resources for a few pods. Memory may react faster than CPU, because CPU throttling is not visible and memory gets aided by OOM bump-up incidents, but still, if you observe that up-scaling takes too long, you may want to increase minAllowed accordingly.
As a rule of thumb, set maxAllowed to your theoretical maximum load, flanked with alerts to detect erroneous run-away usage or the actual nearing of your practical maximum load, so that you can intervene. However, VPA can easily recommend requests larger than what is allocatable on a node, so you must either ensure large enough nodes (Gardener can scale up from zero, in case you like to define a low-priority worker pool with more resources for very large pods) and/or cap VPA’s target recommendations using maxAllowed at the node allocatable remainder (after daemon set pods) of the largest eligible machine type (may result in under-provisioning resources for a pod). Use your monitoring and check maximum pod usage to decide about the maximum machine type.
Recommendations in a Box
Container
When to use
Value
Requests
- Set them (recommended) unless: - Do not set requests for QoS BestEffort; useful only if pod can be evicted as often as needed and pod can pick up where it left off without any penalty
Set requests to 95th percentile (w/o VPA) of the actually observed CPU resp. memory usage in production resp. 5th percentile (w/ VPA) (see below)
Limits
- Avoid them (recommended) unless: - Set limits for QoS Guaranteed; useful only if pod has strictly static resource requirements - Set CPU limits if you want to throttle CPU usage for containers that can be throttled w/o any other disadvantage than processing time (never do that when time-critical operations like leases are involved) - Set limits if you know the healthy range and want to shield against unbound busy loops, unbound memory leaks, or similar
If you really can (otherwise not), set limits to healthy theoretical max load
Scaler
When to use
Initial
Minimum
Maximum
HPA
Use for pods that support horizontal scaling
Set initial replicas to 5th percentile of the actually observed replica count in production (prefer scaling on usage, not utilization) and make sure to never overwrite it later when controlled by HPA
Set minReplicas to 0 (requires feature gate and custom/external metrics), to 1 (regular HPA minimum), or whatever the high availability requirements of the workload demand
Set maxReplicas to healthy theoretical max load
VPA
Use for containers that have a significant usage (>50m/100M) and a significant usage spread over time (>2x)
Set initial requests to 5th percentile of the actually observed CPU resp. memory usage in production
Set minAllowed to highest observed VPA recommendation (includes start-up phase) for an otherwise practically idle container (avoids pod trashing when pod gets evicted after idling)
Set maxAllowed to fresh node allocatable remainder after daemonset pods (avoids pending pods when requests exceed fresh node allocatable remainder) or, if you really can (otherwise not), to healthy theoretical max load (less disruptive than limits as no throttling or OOM happens on under-utilized nodes)
CA
Use for dynamic workloads, definitely if you use HPA and/or VPA
N/A
Set minimum to 0 or number of nodes required right after cluster creation or wake-up
Set maximum to healthy theoretical max load
Note
Theoretical max load may be very difficult to ascertain, especially with modern software that consists of building blocks you do not own or know in detail. If you have comprehensive monitoring in place, you may be tempted to pick the observed maximum and add a safety margin or even factor on top (2x, 4x, or any other number), but this is not to be confused with “theoretical max load” (solely depending on the code, not observations from the outside). At any point in time, your numbers may change, e.g. because you updated a software component or your usage increased. If you decide to use numbers that are set based only on observations, make sure to flank those numbers with monitoring alerts, so that you have sufficient time to investigate, revise, and readjust if necessary.
Conclusion
Pod autoscaling is a dynamic and complex aspect of Kubernetes, but it is also one of the most powerful tools at your disposal for maintaining efficient, reliable, and cost-effective applications. By carefully selecting the appropriate autoscaler, setting well-considered thresholds, and continuously monitoring and adjusting your strategies, you can ensure that your Kubernetes deployments are well-equipped to handle your resource demands while not over-paying for the provided resources at the same time.
As Kubernetes continues to evolve (e.g. in-place updates) and as new patterns and practices emerge, the approaches to autoscaling may also change. However, the principles discussed above will remain foundational to creating scalable and resilient Kubernetes workloads. Whether you’re a developer or operations engineer, a solid understanding of pod autoscaling will be instrumental in the successful deployment and management of containerized applications.
4 - Concepts
4.1 - APIServer Admission Plugins
A list of all gardener managed admission plugins together with their responsibilities
Overview
Similar to the kube-apiserver, the gardener-apiserver comes with a few in-tree managed admission plugins.
If you want to get an overview of the what and why of admission plugins then this document might be a good start.
This document lists all existing admission plugins with a short explanation of what it is responsible for.
BackupBucketValidator
(enabled by default)
This admission controller reacts on CREATE and UPDATE operations for BackupBucketss.
When the backup bucket is using WorkloadIdentity as backup credentials, the plugin ensures the backup bucket and the workload identity have the same provider type, i.e. backupBucket.spec.provider.type and workloadIdentity.spec.targetSystem.type have the same value.
ClusterOpenIDConnectPreset, OpenIDConnectPreset
(both enabled by default)
These admission controllers react on CREATE operations for Shoots.
If the Shoot does not specify any OIDC configuration (.spec.kubernetes.kubeAPIServer.oidcConfig=nil), then it tries to find a matching ClusterOpenIDConnectPreset or OpenIDConnectPreset, respectively.
If there are multiple matches, then the one with the highest weight “wins”.
In this case, the admission controller will default the OIDC configuration in the Shoot.
ControllerRegistrationResources
(enabled by default)
This admission controller reacts on CREATE and UPDATE operations for ControllerRegistrations.
It validates that there exists only one ControllerRegistration in the system that is primarily responsible for a given kind/type resource combination.
This prevents misconfiguration by the Gardener administrator/operator.
CustomVerbAuthorizer
(enabled by default)
This admission controller reacts on CREATE and UPDATE operations for Projects and NamespacedCloudProfiles.
For Projects it validates whether the user is bound to an RBAC role with the modify-spec-tolerations-whitelist verb in case the user tries to change the .spec.tolerations.whitelist field of the respective Project resource.
Usually, regular project members are not bound to this custom verb, allowing the Gardener administrator to manage certain toleration whitelists on Project basis.
For NamespacedCloudProfiles, the modification of specific fields also require the user to be bound to an RBAC role with custom verbs.
Please see this document for more information.
DeletionConfirmation
(enabled by default)
This admission controller reacts on DELETE operations for Projects, Shoots, and ShootStates.
It validates that the respective resource is annotated with a deletion confirmation annotation, namely confirmation.gardener.cloud/deletion=true.
Only if this annotation is present it allows the DELETE operation to pass.
This prevents users from accidental/undesired deletions.
In addition, it applies the “four-eyes principle for deletion” concept if the Project is configured accordingly.
Find all information about it in this document.
Furthermore, this admission controller reacts on CREATE or UPDATE operations for Shoots.
It makes sure that the deletion.gardener.cloud/confirmed-by annotation is properly maintained in case the Shoot deletion is confirmed with above mentioned annotation.
ExposureClass
(enabled by default)
This admission controller reacts on Create operations for Shoots.
It mutates Shoot resources which have an ExposureClass referenced by merging both their shootSelectors and/or tolerations into the Shoot resource.
ExtensionValidator
(enabled by default)
This admission controller reacts on CREATE and UPDATE operations for BackupEntrys, BackupBuckets, Seeds, and Shoots.
For all the various extension types in the specifications of these objects, it validates whether there exists a ControllerRegistration in the system that is primarily responsible for the stated extension type(s).
This prevents misconfigurations that would otherwise allow users to create such resources with extension types that don’t exist in the cluster, effectively leading to failing reconciliation loops.
ExtensionLabels
(enabled by default)
This admission controller reacts on CREATE and UPDATE operations for BackupBuckets, BackupEntrys, CloudProfiles, NamespacedCloudProfiles, Seeds, SecretBindings, CredentialsBindings, WorkloadIdentitys and Shoots. For all the various extension types in the specifications of these objects, it adds a corresponding label in the resource. This would allow extension admission webhooks to filter out the resources they are responsible for and ignore all others. This label is of the form <extension-type>.extensions.gardener.cloud/<extension-name> : "true". For example, an extension label for provider extension type aws, looks like provider.extensions.gardener.cloud/aws : "true".
FinalizerRemoval
(enabled by default)
This admission controller reacts on UPDATE operations for CredentialsBindings, SecretBindings, Shoots.
It ensures that the finalizers of these resources are not removed by users, as long as the affected resource is still in use.
For CredentialsBindings and SecretBindings this means, that the gardener finalizer can only be removed if the binding is not referenced by any Shoot.
In case of Shoots, the gardener finalizer can only be removed if the last operation of the Shoot indicates a successful deletion.
ProjectValidator
(enabled by default)
This admission controller reacts on CREATE and UPDATE operations for Projects.
It prevents creating Projects with a non-empty .spec.namespace if the value in .spec.namespace does not start with garden-.
In addition, the project specification is initialized during creation:
.spec.createdBy is set to the user creating the project.
.spec.owner defaults to the value of .spec.createdBy if it is not specified.
During subsequent updates, it ensures that the project owner is included in the .spec.members list.
ResourceQuota
(enabled by default)
This admission controller enables object count ResourceQuotas for Gardener resources, e.g. Shoots, SecretBindings, Projects, etc.
⚠️ In addition to this admission plugin, the ResourceQuota controller must be enabled for the Kube-Controller-Manager of your Garden cluster.
ResourceReferenceManager
(enabled by default)
This admission controller reacts on CREATE and UPDATE operations for CloudProfiles, Projects, SecretBindings, Seeds, and Shoots.
Generally, it checks whether referred resources stated in the specifications of these objects exist in the system (e.g., if a referenced Secret exists).
However, it also has some special behaviours for certain resources:
CloudProfiles: It rejects removing Kubernetes or machine image versions if there is at least one Shoot that refers to them.
SeedValidator
(enabled by default)
This admission controller reacts on CREATE, UPDATE, and DELETE operations for Seeds.
Rejects the deletion if Shoot(s) reference the seed cluster.
While the seed is still used by Shoot(s), the plugin disallows removal of entries from the seed.spec.provider.zones field.
When the seed is using WorkloadIdentity as backup credentials, the plugin ensures the seed backup and the workload identity have the same provider type, i.e. seed.spec.backup.provider and workloadIdentity.spec.targetSystem.type have the same value.
SeedMutator
(enabled by default)
This admission controller reacts on CREATE and UPDATE operations for Seeds.
It maintains the name.seed.gardener.cloud/<name> labels for it.
More specifically, it adds that the name.seed.gardener.cloud/<name>=true label where <name> is
the name of the Seed resource (a Seed named foo will get label name.seed.gardener.cloud/foo=true).
the name of the parent Seed resource in case it is a ManagedSeed (a Seed named foo that is created by a ManagedSeed which references a Shoot running a Seed called bar will get label name.seed.gardener.cloud/bar=true).
ShootDNS
(enabled by default)
This admission controller reacts on CREATE and UPDATE operations for Shoots.
It tries to assign a default domain to the Shoot.
It also validates the DNS configuration (.spec.dns) for shoots.
ShootNodeLocalDNSEnabledByDefault
(disabled by default)
This admission controller reacts on CREATE operations for Shoots.
If enabled, it will enable node local dns within the shoot cluster (for more information, see NodeLocalDNS Configuration) by setting spec.systemComponents.nodeLocalDNS.enabled=true for newly created Shoots.
Already existing Shoots and new Shoots that explicitly disable node local dns (spec.systemComponents.nodeLocalDNS.enabled=false)
will not be affected by this admission plugin.
ShootQuotaValidator
(enabled by default)
This admission controller reacts on CREATE and UPDATE operations for Shoots.
It validates the resource consumption declared in the specification against applicable Quota resources.
Only if the applicable Quota resources admit the configured resources in the Shoot then it allows the request.
Applicable Quotas are referred in the SecretBinding that is used by the Shoot.
ShootResourceReservation
(enabled by default)
This admission controller reacts on CREATE and UPDATE operations for Shoots.
It injects the Kubernetes.Kubelet.KubeReserved setting for kubelet either as global setting for a shoot or on a per worker pool basis.
If the admission configuration (see this example) for the ShootResourceReservation plugin contains useGKEFormula: false (the default), then it sets a static default resource reservation for the shoot.
If useGKEFormula: true is set, then the plugin injects resource reservations based on the machine type similar to GKE’s formula for resource reservation into each worker pool.
Already existing resource reservations are not modified; this also means that resource reservations are not automatically updated if the machine type for a worker pool is changed.
If a shoot contains global resource reservations, then no per worker pool resource reservations are injected.
By default, useGKEFormula: true applies to all Shoots.
Operators can provide an optional label selector via the selector field to limit which Shoots get worker specific resource reservations injected.
ShootVPAEnabledByDefault
(disabled by default)
This admission controller reacts on CREATE operations for Shoots.
If enabled, it will enable the managed VerticalPodAutoscaler components (for more information, see Vertical Pod Auto-Scaling)
by setting spec.kubernetes.verticalPodAutoscaler.enabled=true for newly created Shoots.
Already existing Shoots and new Shoots that explicitly disable VPA (spec.kubernetes.verticalPodAutoscaler.enabled=false)
will not be affected by this admission plugin.
ShootTolerationRestriction
(enabled by default)
This admission controller reacts on CREATE and UPDATE operations for Shoots.
It validates the .spec.tolerations used in Shoots against the whitelist of its Project, or against the whitelist configured in the admission controller’s configuration, respectively.
Additionally, it defaults the .spec.tolerations in Shoots with those configured in its Project, and those configured in the admission controller’s configuration, respectively.
ShootValidator
(enabled by default)
This admission controller reacts on CREATE, UPDATE and DELETE operations for Shoots.
It validates certain configurations in the specification against the referred CloudProfile (e.g., machine images, machine types, used Kubernetes version, …).
Generally, it performs validations that cannot be handled by the static API validation due to their dynamic nature (e.g., when something needs to be checked against referred resources).
Additionally, it takes over certain defaulting tasks (e.g., default machine image for worker pools, default Kubernetes version) and setting the gardener.cloud/created-by=<username> annotation for newly created Shoot resources.
ShootManagedSeed
(enabled by default)
This admission controller reacts on UPDATE and DELETE operations for Shoots.
It validates certain configuration values in the specification that are specific to ManagedSeeds (e.g. the nginx-addon of the Shoot has to be disabled, the Shoot VPA has to be enabled).
It rejects the deletion if the Shoot is referred to by a ManagedSeed.
ManagedSeedValidator
(enabled by default)
This admission controller reacts on CREATE and UPDATE operations for ManagedSeedss.
It validates certain configuration values in the specification against the referred Shoot, for example Seed provider, network ranges, DNS domain, etc.
Similar to ShootValidator, it performs validations that cannot be handled by the static API validation due to their dynamic nature.
Additionally, it performs certain defaulting tasks, making sure that configuration values that are not specified are defaulted to the values of the referred Shoot, for example Seed provider, network ranges, DNS domain, etc.
ManagedSeedShoot
(enabled by default)
This admission controller reacts on DELETE operations for ManagedSeeds.
It rejects the deletion if there are Shoots that are scheduled onto the Seed that is registered by the ManagedSeed.
ShootDNSRewriting
(disabled by default)
This admission controller reacts on CREATE operations for Shoots.
If enabled, it adds a set of common suffixes configured in its admission plugin configuration to the Shoot (spec.systemComponents.coreDNS.rewriting.commonSuffixes) (for more information, see DNS Search Path Optimization).
Already existing Shoots will not be affected by this admission plugin.
NamespacedCloudProfileValidator
(enabled by default)
This admission controller reacts on CREATE and UPDATE operations for NamespacedCloudProfiles.
It primarily validates if the referenced parent CloudProfile exists in the system. In addition, the admission controller ensures that the NamespacedCloudProfile only configures new machine types, and does not overwrite those from the parent CloudProfile.
4.2 - Architecture
The concepts behind the Gardener architecture
Official Definition - What is Kubernetes?
“Kubernetes is an open-source system for automating deployment, scaling, and management of containerized applications.”
Introduction - Basic Principle
The foundation of the Gardener (providing Kubernetes Clusters as a Service) is Kubernetes itself, because Kubernetes is the go-to solution to manage software in the Cloud, even when it’s Kubernetes itself (see also OpenStack which is provisioned more and more on top of Kubernetes as well).
While self-hosting, meaning to run Kubernetes components inside Kubernetes, is a popular topic in the community, we apply a special pattern catering to the needs of our cloud platform to provision hundreds or even thousands of clusters. We take a so-called “seed” cluster and seed the control plane (such as the API server, scheduler, controllers, etcd persistence and others) of an end-user cluster, which we call “shoot” cluster, as pods into the “seed” cluster. That means that one “seed” cluster, of which we will have one per IaaS and region, hosts the control planes of multiple “shoot” clusters. That allows us to avoid dedicated hardware/virtual machines for the “shoot” cluster control planes. We simply put the control plane into pods/containers and since the “seed” cluster watches them, they can be deployed with a replica count of 1 and only need to be scaled out when the control plane gets under pressure, but no longer for HA reasons. At the same time, the deployments get simpler (standard Kubernetes deployment) and easier to update (standard Kubernetes rolling update). The actual “shoot” cluster consists only of the worker nodes (no control plane) and therefore the users may get full administrative access to their clusters.
Setting The Scene - Components and Procedure
We provide a central operator UI, which we call the “Gardener Dashboard”. It talks to a dedicated cluster, which we call the “Garden” cluster, and uses custom resources managed by an aggregated API server (one of the general extension concepts of Kubernetes) to represent “shoot” clusters. In this “Garden” cluster runs the “Gardener”, which is basically a Kubernetes controller that watches the custom resources and acts upon them, i.e. creates, updates/modifies, or deletes “shoot” clusters. The creation follows basically these steps:
Create a namespace in the “seed” cluster for the “shoot” cluster, which will host the “shoot” cluster control plane.
Generate secrets and credentials, which the worker nodes will need to talk to the control plane.
Create the infrastructure (using Terraform), which basically consists out of the network setup.
Deploy the “shoot” cluster control plane into the “shoot” namespace in the “seed” cluster, containing the “machine-controller-manager” pod.
Create machine CRDs in the “seed” cluster, describing the configuration and the number of worker machines for the “shoot” (the machine-controller-manager watches the CRDs and creates virtual machines out of it).
Wait for the “shoot” cluster API server to become responsive (pods will be scheduled, persistent volumes and load balancers are created by Kubernetes via the respective cloud provider).
Finally, we deploy kube-system daemons like kube-proxy and further add-ons like the dashboard into the “shoot” cluster and the cluster becomes active.
Overview Architecture Diagram
Detailed Architecture Diagram
Note: The kubelet, as well as the pods inside the “shoot” cluster, talks through the front-door (load balancer IP; public Internet) to its “shoot” cluster API server running in the “seed” cluster. The reverse communication from the API server to the pod, service, and node networks happens through a VPN connection that we deploy into the “seed” and “shoot” clusters.
4.3 - Backup and Restore
Understand the etcd backup and restore capabilities of Gardener
Overview
Kubernetes uses etcd as the key-value store for its resource definitions. Gardener supports the backup and restore of etcd. It is the responsibility of the shoot owners to backup the workload data.
Gardener uses an etcd-backup-restore component to backup the etcd backing the Shoot cluster regularly and restore it in case of disaster. It is deployed as sidecar via etcd-druid. This doc mainly focuses on the backup and restore configuration used by Gardener when deploying these components. For more details on the design and internal implementation details, please refer to GEP-06 and the documentation on individual repositories.
etcd-backup-restore supports full snapshot and delta snapshots over full snapshot. In Gardener, this configuration is currently hard-coded to the following parameters:
Full Snapshot schedule:
Daily, 24hr interval.
For each Shoot, the schedule time in a day is randomized based on the configured Shoot maintenance window.
Delta Snapshot schedule:
At 5min interval.
If aggregated events size since last snapshot goes beyond 100Mib.
Backup History / Garbage backup deletion policy:
Gardener configures backup restore to have Exponential garbage collection policy.
As per policy, the following backups are retained:
All full backups and delta backups for the previous hour.
Latest full snapshot of each previous hour for the day.
Latest full snapshot of each previous day for 7 days.
Latest full snapshot of the previous 4 weeks.
Garbage Collection is configured at 12hr interval.
Listing:
Gardener doesn’t have any API to list out the backups.
To find the backups list, an admin can checkout the BackupEntry resource associated with the Shoot which holds the bucket and prefix details on the object store.
Restoration
The restoration process of etcd is automated through the etcd-backup-restore component from the latest snapshot. Gardener doesn’t support Point-In-Time-Recovery (PITR) of etcd. In case of an etcd disaster, the etcd is recovered from the latest backup automatically. For further details, please refer the Restoration topic. Post restoration of etcd, the Shoot reconciliation loop brings the cluster back to its previous state.
Again, the Shoot owner is responsible for maintaining the backup/restore of his workload. Gardener only takes care of the cluster’s etcd.
4.4 - Cluster API
Understand the evolution of the Gardener API and its relation to the Cluster API
Relation Between Gardener API and Cluster API (SIG Cluster Lifecycle)
The Cluster API (CAPI) and Gardener approach Kubernetes cluster management with different, albeit related, philosophies. In essence, Cluster API primarily harmonizes how to get to clusters, while Gardener goes a significant step further by also harmonizing the clusters themselves.
Gardener already provides a declarative, Kubernetes-native API to manage the full lifecycle of conformant Kubernetes clusters. This is a key distinction, as many other managed Kubernetes services are often exposed via proprietary REST APIs or imperative CLIs, whereas Gardener’s API is Kubernetes. Gardener is inherently multi-cloud and, by design, unifies far more aspects of a cluster’s make-up and operational behavior than Cluster API currently aims to.
Gardener’s Homogeneity vs. CAPI’s Provider Model
The Cluster API delegates the specifics of cluster creation and management to providers for infrastructures (e.g., AWS, Azure, GCP) and control planes, each with their own Custom Resource Definitions (CRDs). This means that different Cluster API providers can result in vastly different Kubernetes clusters in terms of their configuration (see, e.g., AKS vs GKE), available Kubernetes versions, operating systems, control plane setup, included add-ons, and operational behavior.
In stark contrast, Gardener provides homogeneous clusters. Regardless of the underlying infrastructure (AWS, Azure, GCP, OpenStack, etc.), you get clusters with the exact same Kubernetes version, operating system choices, control plane configuration (API server, kubelet, etc.), core add-ons (overlay network, DNS, metrics, logging, etc.), and consistent behavior for updates, auto-scaling, self-healing, credential rotation, you name it. This deep harmonization is a core design goal of Gardener, aimed at simplifying operations for teams developing and shipping software on Kubernetes across diverse environments. Gardener’s extensive coverage in the official Kubernetes conformance test grid underscores this commitment.
Cluster API has evolved significantly, especially from v1alpha1 to v1alpha2, which put a strong emphasis on a machine-based paradigm (The Cluster API Book - Updating a v1alpha1 provider to a v1alpha2 infrastructure provider). This “demoted” v1alpha1 providers to mere infrastructure providers, creating an “impedance mismatch” for fully managed services like GKE (which runs on Borg), Gardener (which uses a “kubeception” model — running control planes as pods in a seed cluster, a.k.a. “hosted control planes”) and others, making direct adoption difficult.
Challenges of Integrating Fully Managed Services with Cluster API
Despite the recent improvements, integrating fully managed Kubernetes services with Cluster API presents inherent challenges:
Opinionated Structure: Cluster API’s Cluster / ControlPlane / MachineDeployment / MachinePool structure is opinionated and doesn’t always align naturally with how fully managed services architect their offerings. In particular, the separation between ControlPlane and InfraCluster objects can be difficult to map cleanly. Fully managed services often abstract away the details of how control planes are provisioned and operated, making the distinction between these two components less meaningful or even redundant in those contexts.
Provider-Specific CRDs: While CAPI provides a common Cluster resource, the crucial ControlPlane and infrastructure-specific resources (e.g., AWSManagedControlPlane, GCPManagedCluster, AzureManagedControlPlane) are entirely different for each provider. This means you cannot simply swap provider: foo with provider: bar in a CAPI manifest and expect it to work. Users still need to understand the unique CRDs and capabilities of each CAPI provider.
Limited Unification: CAPI unifies the act of requesting a cluster, but not the resulting cluster’s features, available Kubernetes versions, release cycles, supported operating systems, specific add-ons, or nuanced operational behaviors like credential rotation procedures and their side effects.
Experimental or Limited Support: For some managed services, CAPI provider support is still experimental or limited. For example:
The CAPI provider for AKS notes that the AzureManagedClusterTemplate is “basically a no-op,” with most configuration in AzureManagedControlPlaneTemplate (CAPZ Docs).
The CAPI provider for GKE states: “Provisioning managed clusters (GKE) is an experimental feature…” and is disabled by default (CAPG Docs).
Platform Governance and Lifecycle Management: While Cluster API standardizes the request for a cluster, it doesn’t inherently provide the comprehensive governance and lifecycle management features that platform operators require, especially in enterprise settings. A platform solution needs to go beyond provisioning and offer robust mechanisms for:
Defining and Enforcing Policies: Platform administrators need to control which Kubernetes versions, machine images, operating systems, and add-on versions are available to end-users. This includes classifying them (e.g., “preview,” “supported,” “deprecated”) and setting clear expiration dates.
Communicating Lifecycle Changes: End-users must be informed about upcoming deprecations or required upgrades to plan their own application maintenance and avoid disruptions.
Automated Maintenance and Compliance: The platform should facilitate or even automate updates and compliance checks based on these defined policies.
Gardener is designed with these enterprise platform needs at its core. It provides a rich API and control plane that allows administrators to manage the entire lifecycle of these components. For instance, Gardener enables platform teams to:
Clearly mark Kubernetes versions or machine images as “supported,” “preview,” or “deprecated,” complete with expiration dates.
Offer end-users the ability to opt-into automated maintenance schedules or provide them with the necessary information to build their own automated update logic for their workloads before underlying components are deprecated.
This level of granular control, policy enforcement, and lifecycle communication is crucial for maintaining stability, security, and operational efficiency across a large number of clusters. For organizations adopting Cluster API directly, implementing such a comprehensive governance layer becomes an additional, significant development and operational burden that they must address on top of CAPI’s provisioning capabilities.
Gardener’s Perspective on a Cluster API Provider
Given that Gardener already offers a robust, Kubernetes-native API for homogenous multi-cloud cluster management, a Cluster API provider for Gardener could still act as a bridge for users transitioning from CAPI to Gardener, enabling them to gradually adopt Gardener’s capabilities while maintaining compatibility with existing CAPI workflows.
For users exclusively using Gardener: Wrapping Gardener’s comprehensive API within CAPI’s structure offers limited additional value other than maintaining compatibility with existing CAPI workflows, as Gardener’s native API is already declarative and Kubernetes-centric, meaning any tool or language binding that can handle Kubernetes CRDs will work with Gardener.
For users managing diverse clusters (e.g., ACK, AKS, EKS, GKE, Gardener, kubeadm) via CAPI: Cluster API offers a unified interface for initiating cluster provisioning across diverse managed services, but it does not harmonize the differences in provider-specific CRDs, capabilities, or operational behaviors. This can limit its ability to leverage the unique strengths of each service. However, we understand that a CAPI provider for Gardener could open doors for users familiar with CAPI’s workflows. It would allow them to explore Gardener’s enterprise-grade, homogeneous cluster management while maintaining compatibility with existing CAPI workflows, fostering a smoother transition to Gardener.
The mapping from the Gardener API to a potential Cluster API provider for Gardener would be mostly syntactic. However, the fundamental value proposition of Gardener — providing homogeneous Kubernetes clusters across all supported infrastructures — extends beyond what Cluster API currently aims to achieve.
We follow Cluster API’s development with great interest and remain active members of the community.
4.5 - etcd
How Gardener uses the etcd key-value store
etcd - Key-Value Store for Kubernetes
etcd is a strongly consistent key-value store and the most prevalent choice for the Kubernetes
persistence layer. All API cluster objects like Pods, Deployments, Secrets, etc., are stored in etcd, which
makes it an essential part of a Kubernetes control plane.
Garden or Shoot Cluster Persistence
Each garden or shoot cluster gets its very own persistence for the control plane.
It runs in the shoot namespace on the respective seed cluster (or in the garden namespace in the garden cluster, respectively).
Concretely, there are two etcd instances per shoot cluster, which the kube-apiserver is configured to use in the following way:
etcd-main
A store that contains all “cluster critical” or “long-term” objects.
These object kinds are typically considered for a backup to prevent any data loss.
etcd-events
A store that contains all Event objects (events.k8s.io) of a cluster.
Events usually have a short retention period and occur frequently, but are not essential for a disaster recovery.
The setup above prevents both, the critical etcd-main is not flooded by Kubernetes Events, as well as backup space is not occupied by non-critical data.
This separation saves time and resources.
etcd Operator
Configuring, maintaining, and health-checking etcd is outsourced to a dedicated operator called etcd Druid.
When a gardenlet reconciles a Shoot resource or a gardener-operator reconciles a Garden resource, they manage an Etcd resource in the seed or garden cluster, containing necessary information (backup information, defragmentation schedule, resources, etc.).
etcd-druid needs to manage the lifecycle of the desired etcd instance (today main or events).
Likewise, when the Shoot or Garden is deleted, gardenlet or gardener-operator deletes the Etcd resources and etcd Druid takes care of cleaning up all related objects, e.g. the backing StatefulSets.
Backup
If Seeds specify backups for etcd (example), then Gardener and the respective provider extensions are responsible for creating a bucket on the cloud provider’s side (modelled through a BackupBucket resource).
The bucket stores backups of Shoots scheduled on that Seed.
Furthermore, Gardener creates a BackupEntry, which subdivides the bucket and thus makes it possible to store backups of multiple shoot clusters.
How long backups are stored in the bucket after a shoot has been deleted depends on the configured retention period in the Seed resource.
Please see this example configuration for more information.
For Gardens specifying backups for etcd (example), the bucket must be pre-created externally and provided via the Garden specification.
Both etcd instances are configured to run with a special backup-restore sidecar.
It takes care about regularly backing up etcd data and restoring it in case of data loss (in the main etcd only).
The sidecar also performs defragmentation and other house-keeping tasks.
More information can be found in the component’s GitHub repository.
Housekeeping
etcd maintenance tasks must be performed from time to time in order to re-gain database storage and to ensure the system’s reliability.
The backup-restoresidecar takes care about this job as well.
For both Shoots and Gardens, a random time within the shoot’s maintenance time is chosen for scheduling these tasks.
4.6 - gardenadm
Bootstrapping and management of autonomous shoot clusters.
Caution
This tool is currently under development and considered highly experimental.
Do not use it in production environments.
Read more about it in GEP-28.
Overview
gardenadm is a command line tool for bootstrapping Kubernetes clusters called “Autonomous Shoot Clusters”.
In contrast to usual Gardener-managed clusters (called Shoot Clusters), the Kubernetes control plane components run as static pods on a dedicated control plane worker pool in the cluster itself (instead of running them as pods on another Kubernetes cluster (called Seed Cluster)).
Autonomous shoot clusters can be bootstrapped without an existing Gardener installation.
Hence, they can host a Gardener installation itself and/or serve as the initial seed cluster of a Gardener installation.
Furthermore, autonomous shoot clusters can only be created by the gardenadm tool and not via an API of an existing Gardener system.
Such autonomous shoot clusters are meant to operate autonomously, but not to exist completely independently of Gardener.
Hence, after their initial creation, they are connected to an existing Gardener system such that the established cluster management functionality via the Shoot API can be applied.
I.e., day-2 operations for autonomous shoot clusters are only supported after connecting them to a Gardener system.
This Gardener system could also run in an autonomous shoot cluster itself (in this case, you would first need to deploy it before being able to connect the autonomous shoot cluster to it).
Furthermore, autonomous shoot clusters are not considered a replacement or alternative for regular shoot clusters.
They should be only used for special use-cases or requirements as creating them is more complex and as their costs will most likely be higher (since control plane nodes are typically not fully utilized in such architecture).
In this light, a high cluster creation/deletion churn rate is neither expected nor in scope.
Getting Started Locally
This document walks you through deploying Autonomous Shoot Clusters using gardenadm on your local machine.
This setup can be used for trying out and developing gardenadm locally without additional infrastructure.
The setup is also used for running e2e tests for gardenadm in CI.
Scenarios
We distinguish between two different scenarios for bootstrapping autonomous shoot clusters:
High Touch, meaning that there is no programmable infrastructure available.
We consider this the “bare metal” or “edge” use-case, where at first machines must be (often manually) prepared by human operators.
In this case, network setup (e.g., VPCs, subnets, route tables, etc.) and machine management are out of scope.
Medium Touch, meaning that there is programmable infrastructure available where we can leverage provider extensions and machine-controller-manager in order to manage the network setup and the machines.
The general procedure of bootstrapping an autonomous shoot cluster is similar in both scenarios.
4.7 - Gardener Admission Controller
Functions and list of handlers for the Gardener Admission Controller
Overview
While the Gardener API server works with admission plugins to validate and mutate resources belonging to Gardener related API groups, e.g. core.gardener.cloud, the same is needed for resources belonging to non-Gardener API groups as well, e.g. secrets in the core API group.
Therefore, the Gardener Admission Controller runs a http(s) server with the following handlers which serve as validating/mutating endpoints for admission webhooks.
It is also used to serve http(s) handlers for authorization webhooks.
Admission Webhook Handlers
This section describes the admission webhook handlers that are currently served.
In Shoots, AdmissionPlugin can have reference to other files. This validation handler validates the referred admission plugin secret and ensures that the secret always contains the required data kubeconfig.
Kubeconfig Secret Validator
Malicious Kubeconfigs applied by end users may cause a leakage of sensitive data.
This handler checks if the incoming request contains a Kubernetes secret with a .data.kubeconfig field and denies the request if the Kubeconfig structure violates Gardener’s security standards.
Namespace Validator
Namespaces are the backing entities of Gardener projects in which shoot cluster objects reside.
This validation handler protects active namespaces against premature deletion requests.
Therefore, it denies deletion requests if a namespace still contains shoot clusters or if it belongs to a non-deleting Gardener project (without .metadata.deletionTimestamp).
Resource Size Validator
Since users directly apply Kubernetes native objects to the Garden cluster, it also involves the risk of being vulnerable to DoS attacks because these resources are continuously watched and read by controllers.
One example is the creation of shoot resources with large annotation values (up to 256 kB per value), which can cause severe out-of-memory issues for the gardenlet component.
Vertical autoscaling can help to mitigate such situations, but we cannot expect to scale infinitely, and thus need means to block the attack itself.
The Resource Size Validator checks arbitrary incoming admission requests against a configured maximum size for the resource’s group-version-kind combination. It denies the request if the object exceeds the quota.
Note
The contents of status subresources and metadata.managedFields are not taken into account for the resource size calculation.
Example for Gardener Admission Controller configuration:
With the configuration above, the Resource Size Validator denies requests for shoots with Gardener’s core API group which exceed a size of 100 kB. The same is done for Kubernetes secrets.
As this feature is meant to protect the system from malicious requests sent by users, it is recommended to exclude trusted groups, users or service accounts from the size restriction via resourceAdmissionConfiguration.unrestrictedSubjects.
For example, the backing user for the gardenlet should always be capable of changing the shoot resource instead of being blocked due to size restrictions.
This is because the gardenlet itself occasionally changes the shoot specification, labels or annotations, and might violate the quota if the existing resource is already close to the quota boundary.
Also, operators are supposed to be trusted users and subjecting them to a size limitation can inhibit important operational tasks.
Wildcard ("*") in subject name is supported.
Size limitations depend on the individual Gardener setup and choosing the wrong values can affect the availability of your Gardener service.
resourceAdmissionConfiguration.operationMode allows to control if a violating request is actually denied (default) or only logged.
It’s recommended to start with log, check the logs for exceeding requests, adjust the limits if necessary and finally switch to block.
Gardener stores public data regarding shoot clusters, i.e. certificate authority bundles, OIDC discovery documents, etc.
This information can be used by third parties so that they establish trust to specific authorities, making the integrity of the stored data extremely important in a way that any unwanted modifications can be considered a security risk.
This handler protects secrets and configmaps against tampering.
It denies CREATE, UPDATE and DELETE requests if the resource is labeled with gardener.cloud/update-restriction=true and the request is not made by a gardenlet.
In addition, the following service accounts are allowed to perform certain operations:
system:serviceaccount:kube-system:generic-garbage-collector is allowed to DELETE restricted resources.
system:serviceaccount:kube-system:gardener-internal is allowed to UPDATE restricted resources.
Authorization Webhook Handlers
This section describes the authorization webhook handlers that are currently served.
Understand the Gardener API server extension and the resources it exposes
Overview
The Gardener API server is a Kubernetes-native extension based on its aggregation layer.
It is registered via an APIService object and designed to run inside a Kubernetes cluster whose API it wants to extend.
After registration, it exposes the following resources:
CloudProfiles
CloudProfiles are resources that describe a specific environment of an underlying infrastructure provider, e.g. AWS, Azure, etc.
Each shoot has to reference a CloudProfile to declare the environment it should be created in.
In a CloudProfile, the gardener operator specifies certain constraints like available machine types, regions, which Kubernetes versions they want to offer, etc.
End-users can read CloudProfiles to see these values, but only operators can change the content or create/delete them.
When a shoot is created or updated, then an admission plugin checks that only allowed values are used via the referenced CloudProfile.
Additionally, a CloudProfile may contain a providerConfig, which is a special configuration dedicated for the infrastructure provider.
Gardener does not evaluate or understand this config, but extension controllers might need it for declaration of provider-specific constraints, or global settings.
Please see this example manifest and consult the documentation of your provider extension controller to get information about its providerConfig.
NamespacedCloudProfiles
In addition to CloudProfiles, NamespacedCloudProfiles exist to enable project-level customizations of CloudProfiles.
Project administrators can create and manage cloud profiles with overrides or extensions specific to their project.
Please see this example manifest and this usage documentation for further information.
InternalSecrets
End-users can read and/or write Secrets in their project namespaces in the garden cluster. This prevents Gardener components from storing such “Gardener-internal” secrets in the respective project namespace.
InternalSecrets are resources that contain shoot or project-related secrets that are “Gardener-internal”, i.e., secrets used and managed by the system that end-users don’t have access to.
InternalSecrets are defined like plain Kubernetes Secrets, behave exactly like them, and can be used in the same manners. The only difference is, that the InternalSecret resource is a dedicated API resource (exposed by gardener-apiserver).
This allows separating access to “normal” secrets and internal secrets by the usual RBAC means.
Gardener uses an InternalSecret per Shoot for syncing the client CA to the project namespace in the garden cluster (named <shoot-name>.ca-client). The shoots/adminkubeconfig subresource signs short-lived client certificates by retrieving the CA from the InternalSecret.
Operators should configure gardener-apiserver to encrypt the internalsecrets.core.gardener.cloud resource in etcd.
Seeds are resources that represent seed clusters.
Gardener does not care about how a seed cluster got created - the only requirement is that it is of at least Kubernetes v1.27 and passes the Kubernetes conformance tests.
The Gardener operator has to either deploy the gardenlet into the cluster they want to use as seed (recommended, then the gardenlet will create the Seed object itself after bootstrapping) or provide the kubeconfig to the cluster inside a secret (that is referenced by the Seed resource) and create the Seed resource themselves.
Please see this, this, and optionally this example manifests.
Shoot Quotas
To allow end-users not having their dedicated infrastructure account to try out Gardener, the operator can register an account owned by them that they allow to be used for trial clusters.
Trial clusters can be put under quota so that they don’t consume too many resources (resulting in costs) and that one user cannot consume all resources on their own.
These clusters are automatically terminated after a specified time, but end-users may extend the lifetime manually if needed.
The first thing before creating a shoot cluster is to create a Project.
A project is used to group multiple shoot clusters together.
End-users can invite colleagues to the project to enable collaboration, and they can either make them admin or viewer.
After an end-user has created a project, they will get a dedicated namespace in the garden cluster for all their shoots.
Now that the end-user has a namespace the next step is registering their infrastructure provider account.
Please see this example manifest and consult the documentation of the extension controller for the respective infrastructure provider to get information about which keys are required in this secret.
After the secret has been created, the end-user has to create a special SecretBinding resource that binds this secret.
Later, when creating shoot clusters, they will reference such binding.
Shoot cluster contain various settings that influence how end-user Kubernetes clusters will look like in the end.
As Gardener heavily relies on extension controllers for operating system configuration, networking, and infrastructure specifics, the end-user has the possibility (and responsibility) to provide these provider-specific configurations as well.
Such configurations are not evaluated by Gardener (because it doesn’t know/understand them), but they are only transported to the respective extension controller.
⚠️ This means that any configuration issues/mistake on the end-user side that relates to a provider-specific flag or setting cannot be caught during the update request itself but only later during the reconciliation (unless a validator webhook has been registered in the garden cluster by an operator).
Please see this example manifest and consult the documentation of the provider extension controller to get information about its spec.provider.controlPlaneConfig, .spec.provider.infrastructureConfig, and .spec.provider.workers[].providerConfig.
Understand where the gardener-controller-manager runs and its functionalities
Overview
The gardener-controller-manager (often referred to as “GCM”) is a component that runs next to the Gardener API server, similar to the Kubernetes Controller Manager.
It runs several controllers that do not require talking to any seed or shoot cluster.
Also, as of today, it exposes an HTTP server that is serving several health check endpoints and metrics.
This document explains the various functionalities of the gardener-controller-manager and their purpose.
Bastion resources have a limited lifetime which can be extended up to a certain amount by performing a heartbeat on them.
The Bastion controller is responsible for deleting expired or rotten Bastions.
“expired” means a Bastion has exceeded its status.expirationTimestamp.
“rotten” means a Bastion is older than the configured maxLifetime.
The maxLifetime defaults to 24 hours and is an option in the BastionControllerConfiguration which is part of gardener-controller-managers ControllerManagerControllerConfiguration, see the example config file for details.
The controller also deletes Bastions in case the referenced Shoot:
no longer exists
is marked for deletion (i.e., have a non-nil.metadata.deletionTimestamp)
was migrated to another seed (i.e., Shoot.spec.seedName is different than Bastion.spec.seedName).
The deletion of Bastions triggers the gardenlet to perform the necessary cleanups in the Seed cluster, so some time can pass between deletion and the Bastion actually disappearing.
Clients like gardenctl are advised to not re-use Bastions whose deletion timestamp has been set already.
Refer to GEP-15 for more information on the lifecycle of
Bastion resources.
After the gardenlet gets deployed on the Seed cluster, it needs to establish itself as a trusted party to communicate with the Gardener API server. It runs through a bootstrap flow similar to the kubelet bootstrap process.
On startup, the gardenlet uses a kubeconfig with a bootstrap token which authenticates it as being part of the system:bootstrappers group. This kubeconfig is used to create a CertificateSigningRequest (CSR) against the Gardener API server.
The controller in gardener-controller-manager checks whether the CertificateSigningRequest has the expected organization, common name and usages which the gardenlet would request.
It only auto-approves the CSR if the client making the request is allowed to “create” the
certificatesigningrequests/seedclient subresource. Clients with the system:bootstrappers group are bound to the gardener.cloud:system:seed-bootstrapperClusterRole, hence, they have such privileges. As the bootstrap kubeconfig for the gardenlet contains a bootstrap token which is authenticated as being part of the systems:bootstrappers group, its created CSR gets auto-approved.
CloudProfiles are essential when it comes to reconciling Shoots since they contain constraints (like valid machine types, Kubernetes versions, or machine images) and sometimes also some global configuration for the respective environment (typically via provider-specific configuration in .spec.providerConfig).
Consequently, to ensure that CloudProfiles in-use are always present in the system until the last referring Shoot or NamespacedCloudProfile gets deleted, the controller adds a finalizer which is only released when there is no Shoot or NamespacedCloudProfile referencing the CloudProfile anymore.
NamespacedCloudProfiles provide a project-scoped extension to CloudProfiles, allowing for adjustments of a parent CloudProfile (e.g. by overriding expiration dates of Kubernetes versions or machine images). This allows for modifications without global project visibility. Like CloudProfiles do in their spec, NamespacedCloudProfiles also expose the resulting Shoot constraints as a CloudProfileSpec in their status.
The controller ensures that NamespacedCloudProfiles in-use remain present in the system until the last referring Shoot is deleted by adding a finalizer that is only released when there is no Shoot referencing the NamespacedCloudProfile anymore.
Extensions are registered in the garden cluster via ControllerRegistration and deployment of respective extensions are specified via ControllerDeployment. For more info refer to Registering Extension Controllers.
This controller ensures that ControllerDeployment in-use always exists until the last ControllerRegistration referencing them gets deleted. The controller adds a finalizer which is only released when there is no ControllerRegistration referencing the ControllerDeployment anymore.
The ControllerRegistration controller makes sure that the required Gardener Extensions specified by the ControllerRegistration resources are present in the seed clusters.
It also takes care of the creation and deletion of ControllerInstallation objects for a given seed cluster.
The controller has three reconciliation loops.
This reconciliation loop watches the Seed objects and determines which ControllerRegistrations are required for them and reconciles the corresponding ControllerInstallation resources to reach the determined state.
To begin with, it computes the kind/type combinations of extensions required for the seed.
For this, the controller examines a live list of ControllerRegistrations, ControllerInstallations, BackupBuckets, BackupEntrys, Shoots, and Secrets from the garden cluster.
For example, it examines the shoots running on the seed and deducts the kind/type, like Infrastructure/gcp.
The seed (seed.spec.provider.type) and DNS (seed.spec.dns.provider.type) provider types are considered when calculating the list of required ControllerRegistrations, as well.
It also decides whether they should always be deployed based on the .spec.deployment.policy.
For the configuration options, please see this section.
Based on these required combinations, each of them are mapped to ControllerRegistration objects and then to their corresponding ControllerInstallation objects (if existing).
The controller then creates or updates the required ControllerInstallation objects for the given seed.
It also deletes every existing ControllerInstallation whose referenced ControllerRegistration is not part of the required list.
For example, if the shoots in the seed are no longer using the DNS provider aws-route53, then the controller proceeds to delete the respective ControllerInstallation object.
This reconciliation loop watches the ControllerRegistration resource and adds finalizers to it when they are created.
In case a deletion request comes in for the resource, i.e., if a .metadata.deletionTimestamp is set, it actively scans for a ControllerInstallation resource using this ControllerRegistration, and decides whether the deletion can be allowed.
In case no related ControllerInstallation is present, it removes the finalizer and marks it for deletion.
This loop also watches the Seed object and adds finalizers to it at creation.
If a .metadata.deletionTimestamp is set for the seed, then the controller checks for existing ControllerInstallation objects which reference this seed.
If no such objects exist, then it removes the finalizer and allows the deletion.
This reconciler watches two resources in the garden cluster:
ClusterRoles labelled with authorization.gardener.cloud/custom-extensions-permissions=true
ServiceAccounts in seed namespaces matching the selector provided via the authorization.gardener.cloud/extensions-serviceaccount-selector annotation of such ClusterRoles.
Its core task is to maintain a ClusterRoleBinding resource referencing the respective ClusterRole.
This gets bound to all ServiceAccounts in seed namespaces whose labels match the selector provided via the authorization.gardener.cloud/extensions-serviceaccount-selector annotation of such ClusterRoles.
You can read more about the purpose of this reconciler in this document.
CredentialsBindings reference Secrets, WorkloadIdentitys and Quotas and are themselves referenced by Shoots.
The controller adds finalizers to the referenced objects to ensure they don’t get deleted while still being referenced.
Similarly, to ensure that CredentialsBindings in-use are always present in the system until the last referring Shoot gets deleted, the controller adds a finalizer which is only released when there is no Shoot referencing the CredentialsBinding anymore.
Referenced Secrets and WorkloadIdentitys will also be labeled with provider.shoot.gardener.cloud/<type>=true, where <type> is the value of the .provider.type of the CredentialsBinding.
Also, all referenced Secrets and WorkloadIdentitys, as well as Quotas, will be labeled with reference.gardener.cloud/credentialsbinding=true to allow for easily filtering for objects referenced by CredentialsBindings.
With the Gardener Event Controller, you can prolong the lifespan of events related to Shoot clusters.
This is an optional controller which will become active once you provide the below mentioned configuration.
All events in K8s are deleted after a configurable time-to-live (controlled via a kube-apiserver argument called --event-ttl (defaulting to 1 hour)).
The need to prolong the time-to-live for Shoot cluster events frequently arises when debugging customer issues on live systems.
This controller leaves events involving Shoots untouched, while deleting all other events after a configured time.
In order to activate it, provide the following configuration:
concurrentSyncs: The amount of goroutines scheduled for reconciling events.
ttlNonShootEvents: When an event reaches this time-to-live it gets deleted unless it is a Shoot-related event (defaults to 1h, equivalent to the event-ttl default).
⚠️ In addition, you should also configure the --event-ttl for the kube-apiserver to define an upper-limit of how long Shoot-related events should be stored. The --event-ttl should be larger than the ttlNonShootEvents or this controller will have no effect.
ExposureClass abstracts the ability to expose a Shoot clusters control plane in certain network environments (e.g. corporate networks, DMZ, internet) on all Seeds or a subset of the Seeds. For more information, see ExposureClasses.
Consequently, to ensure that ExposureClasses in-use are always present in the system until the last referring Shoot gets deleted, the controller adds a finalizer which is only released when there is no Shoot referencing the ExposureClass anymore.
ManagedSeedSet objects maintain a stable set of replicas of ManagedSeeds, i.e. they guarantee the availability of a specified number of identical ManagedSeeds on an equal number of identical Shoots.
The ManagedSeedSet controller creates and deletes ManagedSeeds and Shoots in response to changes to the replicas and selector fields. For more information, refer to the ManagedSeedSet proposal document.
The reconciler first gets all the replicas of the given ManagedSeedSet in the ManagedSeedSet’s namespace and with the matching selector. Each replica is a struct that contains a ManagedSeed, its corresponding Seed and Shoot objects.
Then the pending replica is retrieved, if it exists.
Next it determines the ready, postponed, and deletable replicas.
A replica is considered ready when a Seed owned by a ManagedSeed has been registered either directly or by deploying gardenlet into a Shoot, the Seed is Ready and the Shoot’s status is Healthy.
If a replica is not ready and it is not pending, i.e. it is not specified in the ManagedSeed’s status.pendingReplica field, then it is added to the postponed replicas.
A replica is deletable if it has no scheduled Shoots and the replica’s Shoot and ManagedSeed do not have the seedmanagement.gardener.cloud/protect-from-deletion annotation.
Finally, it checks the actual and target replica counts. If the actual count is less than the target count, the controller scales up the replicas by creating new replicas to match the desired target count. If the actual count is more than the target, the controller deletes replicas to match the desired count. Before scale-out or scale-in, the controller first reconciles the pending replica (there can always only be one) and makes sure the replica is ready before moving on to the next one.
Scale-out(actual count < target count)
During the scale-out phase, the controller first creates the Shoot object from the ManagedSeedSet’s spec.shootTemplate field and adds the replica to the status.pendingReplica of the ManagedSeedSet.
For the subsequent reconciliation steps, the controller makes sure that the pending replica is ready before proceeding to the next replica. Once the Shoot is created successfully, the ManagedSeed object is created from the ManagedSeedSet’s spec.template. The ManagedSeed object is reconciled by the ManagedSeed controller and a Seed object is created for the replica. Once the replica’s Seed becomes ready and the Shoot becomes healthy, the replica also becomes ready.
Scale-in(actual count > target count)
During the scale-in phase, the controller first determines the replica that can be deleted. From the deletable replicas, it chooses the one with the lowest priority and deletes it. Priority is determined in the following order:
First, compare replica statuses. Replicas with “less advanced” status are considered lower priority. For example, a replica with StatusShootReconciling status has a lower value than a replica with StatusShootReconciled status. Hence, in this case, a replica with a StatusShootReconciling status will have lower priority and will be considered for deletion.
Then, the replicas are compared with the readiness of their Seeds. Replicas with non-ready Seeds are considered lower priority.
Then, the replicas are compared with the health statuses of their Shoots. Replicas with “worse” statuses are considered lower priority.
Finally, the replica ordinals are compared. Replicas with lower ordinals are considered lower priority.
Quota object limits the resources consumed by shoot clusters either per provider secret or per project/namespace.
Consequently, to ensure that Quotas in-use are always present in the system until the last SecretBinding or CredentialsBinding that references them gets deleted, the controller adds a finalizer which is only released when there is no SecretBinding or CredentialsBinding referencing the Quota anymore.
This reconciler manages a dedicated Namespace for each Project.
The namespace name can either be specified explicitly in .spec.namespace (must be prefixed with garden-) or it will be determined by the controller.
If .spec.namespace is set, it tries to create it. If it already exists, it tries to adopt it.
This will only succeed if the Namespace was previously labeled with gardener.cloud/role=project and project.gardener.cloud/name=<project-name>.
This is to prevent end-users from being able to adopt arbitrary namespaces and escalate their privileges, e.g. the kube-system namespace.
After the namespace was created/adopted, the controller creates several ClusterRoles and ClusterRoleBindings that allow the project members to access related resources based on their roles.
These RBAC resources are prefixed with gardener.cloud:system:project{-member,-viewer}:<project-name>.
Gardener administrators and extension developers can define their own roles. For more information, see Extending Project Roles for more information.
In addition, operators can configure the Project controller to maintain a default ResourceQuota for project namespaces.
Quotas can especially limit the creation of user facing resources, e.g. Shoots, SecretBindings, CredentialsBinding, Secrets and thus protect the garden cluster from massive resource exhaustion but also enable operators to align quotas with respective enterprise policies.
⚠️ Gardener itself is not exempted from configured quotas. For example, Gardener creates Secrets for every shoot cluster in the project namespace and at the same time increases the available quota count. Please mind this additional resource consumption.
The controller configuration provides a template section controllers.project.quotas where such a ResourceQuota (see the example below) can be deposited.
The Project controller takes the specified config and creates a ResourceQuota with the name gardener in the project namespace.
If a ResourceQuota resource with the name gardener already exists, the controller will only update fields in spec.hard which are unavailable at that time.
This is done to configure a default Quota in all projects but to allow manual quota increases as the projects’ demands increase.
spec.hard fields in the ResourceQuota object that are not present in the configuration are removed from the object.
Labels and annotations on the ResourceQuotaconfig get merged with the respective fields on existing ResourceQuotas.
An optional projectSelector narrows down the amount of projects that are equipped with the given config.
If multiple configs match for a project, then only the first match in the list is applied to the project namespace.
The .status.phase of the Project resources is set to Ready or Failed by the reconciler to indicate whether the reconciliation loop was performed successfully.
Also, it generates Events to provide further information about its operations.
When a Project is marked for deletion, the controller ensures that there are no Shoots left in the project namespace.
Once all Shoots are gone, the Namespace and Project are released.
As Gardener is a large-scale Kubernetes as a Service, it is designed for being used by a large amount of end-users.
Over time, it is likely to happen that some of the hundreds or thousands of Project resources are no longer actively used.
Gardener offers the “stale projects” reconciler which will take care of identifying such stale projects, marking them with a “warning”, and eventually deleting them after a certain time period.
This reconciler is enabled by default and works as follows:
Projects are considered as “stale”/not actively used when all of the following conditions apply: The namespace associated with the Project does not have any…
Shoot resources.
BackupEntry resources.
Secret resources that are referenced by a SecretBinding or a CredentialsBinding that is in use by a Shoot (not necessarily in the same namespace).
WorkloadIdentity resources that are referenced by a CredentialsBinding that is in use by a Shoot (not necessarily in the same namespace).
Quota resources that are referenced by a SecretBinding or a CredentialsBinding that is in use by a Shoot (not necessarily in the same namespace).
The time period when the project was used for the last time (status.lastActivityTimestamp) is longer than the configured minimumLifetimeDays
If a project is considered “stale”, then its .status.staleSinceTimestamp will be set to the time when it was first detected to be stale.
If it gets actively used again, this timestamp will be removed.
After some time, the .status.staleAutoDeleteTimestamp will be set to a timestamp after which Gardener will auto-delete the Project resource if it still is not actively used.
The component configuration of the gardener-controller-manager offers to configure the following options:
minimumLifetimeDays: Don’t consider newly created Projects as “stale” too early to give people/end-users some time to onboard and get familiar with the system. The “stale project” reconciler won’t set any timestamp for Projects younger than minimumLifetimeDays. When you change this value, then projects marked as “stale” may be no longer marked as “stale” in case they are young enough, or vice versa.
staleGracePeriodDays: Don’t compute auto-delete timestamps for stale Projects that are unused for less than staleGracePeriodDays. This is to not unnecessarily make people/end-users nervous “just because” they haven’t actively used their Project for a given amount of time. When you change this value, then already assigned auto-delete timestamps may be removed if the new grace period is not yet exceeded.
staleExpirationTimeDays: Expiration time after which stale Projects are finally auto-deleted (after .status.staleSinceTimestamp). If this value is changed and an auto-delete timestamp got already assigned to the projects, then the new value will only take effect if it’s increased. Hence, decreasing the staleExpirationTimeDays will not decrease already assigned auto-delete timestamps.
Gardener administrators/operators can exclude specific Projects from the stale check by annotating the related Namespace resource with project.gardener.cloud/skip-stale-check=true.
Since the other two reconcilers are unable to actively monitor the relevant objects that are used in a Project (Shoot, Secret, etc.), there could be a situation where the user creates and deletes objects in a short period of time. In that case, the Stale Project Reconciler could not see that there was any activity on that project and it will still mark it as a Stale, even though it is actively used.
The Project Activity Reconciler is implemented to take care of such cases. An event handler will notify the reconciler for any activity and then it will update the status.lastActivityTimestamp. This update will also trigger the Stale Project Reconciler.
SecretBindings reference Secrets and Quotas and are themselves referenced by Shoots.
The controller adds finalizers to the referenced objects to ensure they don’t get deleted while still being referenced.
Similarly, to ensure that SecretBindings in-use are always present in the system until the last referring Shoot gets deleted, the controller adds a finalizer which is only released when there is no Shoot referencing the SecretBinding anymore.
Referenced Secrets will also be labeled with provider.shoot.gardener.cloud/<type>=true, where <type> is the value of the .provider.type of the SecretBinding.
Also, all referenced Secrets, as well as Quotas, will be labeled with reference.gardener.cloud/secretbinding=true to allow for easily filtering for objects referenced by SecretBindings.
This reconciliation loop takes care of seed related operations in the garden cluster. When a new Seed object is created,
the reconciler creates a new Namespace in the garden cluster seed-<seed-name>. Namespaces dedicated to single
seed clusters allow us to segregate access permissions i.e., a gardenlet must not have permissions to access objects in
all Namespaces in the garden cluster.
There are objects in a Garden environment which are created once by the operator e.g., default domain secret,
alerting credentials, and are required for operations happening in the gardenlet. Therefore, we not only need a seed specific
Namespace but also a copy of these “shared” objects.
The “main” reconciler takes care about this replication:
Every time a BackupBucket object is created or updated, the referenced Seed object is enqueued for reconciliation.
It’s the reconciler’s task to check the status subresource of all existing BackupBuckets that reference this Seed.
If at least one BackupBucket has .status.lastError != nil, the BackupBucketsReady condition on the Seed will be set to False, and consequently the Seed is considered as NotReady.
If the SeedBackupBucketsCheckControllerConfiguration (which is part of gardener-controller-managers component configuration) contains a conditionThreshold for the BackupBucketsReady, the condition will instead first be set to Progressing and eventually to False once the conditionThreshold expires. See the example config file for details.
Once the BackupBucket is healthy again, the seed will be re-queued and the condition will turn true.
This reconciler reconciles Seed objects and checks whether all ControllerInstallations referencing them are in a healthy state.
Concretely, all three conditions Valid, Installed, and Healthy must have status True and the Progressing condition must have status False.
Based on this check, it maintains the ExtensionsReady condition in the respective Seed’s .status.conditions list.
The “Lifecycle” reconciler processes Seed objects which are enqueued every 10 seconds in order to check if the responsible
gardenlet is still responding and operable. Therefore, it checks renewals via Lease objects of the seed in the garden cluster
which are renewed regularly by the gardenlet.
In case a Lease is not renewed for the configured amount in config.controllers.seed.monitorPeriod.duration:
The reconciler assumes that the gardenlet stopped operating and updates the GardenletReady condition to Unknown.
Additionally, the conditions and constraints of all Shoot resources scheduled on the affected seed are set to Unknown as well,
because a striking gardenlet won’t be able to maintain these conditions any more.
If the gardenlet’s client certificate has expired (identified based on the .status.clientCertificateExpirationTimestamp field in the Seed resource) and if it is managed by a ManagedSeed, then this will be triggered for a reconciliation. This will trigger the bootstrapping process again and allows gardenlets to obtain a fresh client certificate.
Seed objects may specify references to other objects in the garden namespace in the garden cluster which are required for certain features.
For example, operators can configure additional data for extensions via .spec.resources[].
Such objects need a special protection against deletion requests as long as they are still being referenced by one or multiple seeds.
Therefore, this reconciler checks Seeds for referenced objects and adds the finalizer gardener.cloud/reference-protection to their .metadata.finalizers list.
The reconciled Seed also gets this finalizer to enable a proper garbage collection in case the gardener-controller-manager is offline at the moment of an incoming deletion request.
When an object is not actively referenced anymore because the Seed specification has changed or all related seeds were deleted (are in deletion), the controller will remove the added finalizer again so that the object can safely be deleted or garbage collected.
This reconciler inspects the following references:
Secrets and ConfigMaps from .spec.resources[]
The checks naturally grow with the number of references that are added to the Seed specification.
In case the reconciled Shoot is registered via a ManagedSeed as a seed cluster, this reconciler merges the conditions in the respective Seed’s .status.conditions into the .status.conditions of the Shoot.
This is to provide a holistic view on the status of the registered seed cluster by just looking at the Shoot resource.
This reconciler is responsible for hibernating or awakening shoot clusters based on the schedules defined in their .spec.hibernation.schedules.
It ignores failed Shoots and those marked for deletion.
This reconciler is responsible for maintaining shoot clusters based on the time window defined in their .spec.maintenance.timeWindow.
It might auto-update the Kubernetes version or the operating system versions specified in the worker pools (.spec.provider.workers).
It could also add some operation or task annotations. For more information, see Shoot Maintenance.
This reconciler might auto-delete shoot clusters in case their referenced SecretBinding or CredentialsBinding is itself referencing a Quota with .spec.clusterLifetimeDays != nil.
If the shoot cluster is older than the configured lifetime, then it gets deleted.
It maintains the expiration time of the Shoot in the value of the shoot.gardener.cloud/expiration-timestamp annotation.
This annotation might be overridden, however only by at most twice the value of the .spec.clusterLifetimeDays.
Shoot objects may specify references to other objects in the garden cluster which are required for certain features.
For example, users can configure various DNS providers via .spec.dns.providers and usually need to refer to a corresponding Secret with valid DNS provider credentials inside.
Such objects need a special protection against deletion requests as long as they are still being referenced by one or multiple shoots.
Therefore, this reconciler checks Shoots for referenced objects and adds the finalizer gardener.cloud/reference-protection to their .metadata.finalizers list.
The reconciled Shoot also gets this finalizer to enable a proper garbage collection in case the gardener-controller-manager is offline at the moment of an incoming deletion request.
When an object is not actively referenced anymore because the Shoot specification has changed or all related shoots were deleted (are in deletion), the controller will remove the added finalizer again so that the object can safely be deleted or garbage collected.
This reconciler inspects the following references:
This reconciler is responsible for retrying certain failed Shoots.
Currently, the reconciler retries only failed Shoots with an error code ERR_INFRA_RATE_LIMITS_EXCEEDED. See Shoot Status for more details.
This reconciler is triggered for Shoots currently in migration (i.e., .spec.seedName != .status.seedName).
It maintains the ReadyForMigration constraint in the .status.constraints[] list.
A Shoot is considered ready for migration if the destination Seed is up-to-date and healthy.
The main purpose of this constraint is to allow the gardenlet running in the source seed cluster to check if it can start with the migration flow without that it needs to directly read the destination Seed resource (for which it won’t have permissions).
This reconciler is responsible for managing a finalizer (core.gardener.cloud/shootstate) on a ShootState. The finalizer ensures the ShootState will exist during migration of Shoot’s control plane to another Seed.
The ShootState has to be present until the Migrate and Restore operations finish successfully. Otherwise, in corner cases of prior deletion, subsequent Restore operations of the Shoot will fail due to the missing ShootState resource.
4.10 - Gardener Node Agent
How Gardener bootstraps machines into worker nodes and how it installs and maintains gardener-managed node-specific components
Overview
The goal of the gardener-node-agent is to bootstrap a machine into a worker node and maintain node-specific components, which run on the node and are unmanaged by Kubernetes (e.g. the kubelet service, systemd units, …).
It effectively is a Kubernetes controller deployed onto the worker node.
Architecture and Basic Design
This figure visualizes the overall architecture of the gardener-node-agent. On the left side, it starts with an OperatingSystemConfig resource (OSC) with a corresponding worker pool specific cloud-config-<worker-pool> secret being passed by reference through the userdata to a machine by the machine-controller-manager (MCM).
On the right side, the cloud-config secret will be extracted and used by the gardener-node-agent after being installed. Details on this can be found in the next section.
Finally, the gardener-node-agent runs a systemd service watching on secret resources located in the kube-system namespace like our cloud-config secret that contains the OperatingSystemConfig. When gardener-node-agent applies the OSC, it installs the kubelet + configuration on the worker node.
Installation and Bootstrapping
This section describes how the gardener-node-agent is initially installed onto the worker node.
In the beginning, there is a very small bash script called gardener-node-init.sh, which will be copied to /var/lib/gardener-node-agent/init.sh on the node with cloud-init data.
This script’s sole purpose is downloading and starting the gardener-node-agent.
The binary artifact is extracted from an OCI artifact and lives at /opt/bin/gardener-node-agent.
Along with the init script, a configuration for the gardener-node-agent is carried over to the worker node at /var/lib/gardener-node-agent/config.yaml.
This configuration contains things like the shoot’s kube-apiserver endpoint, the according certificates to communicate with it, and controller configuration.
In a bootstrapping phase, the gardener-node-agent sets itself up as a systemd service.
It also executes tasks that need to be executed before any other components are installed, e.g. formatting the data device for the kubelet.
Controllers
This section describes the controllers in more details.
This controller creates a Lease for gardener-node-agent in kube-system namespace of the shoot cluster.
Each instance of gardener-node-agent creates its own Lease when its corresponding Node was created.
It renews the Lease resource every 10 seconds. This indicates a heartbeat to the external world.
This controller watches the Node object for the machine it runs on.
The correct Node is identified based on the hostname of the machine (Nodes have the kubernetes.io/hostname label).
Whenever the worker.gardener.cloud/restart-systemd-services annotation changes, the controller performs the desired changes by restarting the specified systemd unit files.
See also this document for more information.
After restarting all units, the annotation is removed.
ℹ️ When the gardener-node-agent systemd service itself is requested to be restarted, the annotation is removed first to ensure it does not restart itself indefinitely.
This controller contains the main logic of gardener-node-agent.
It watches Secrets whose data map contains the OperatingSystemConfig which consists of all systemd units and files that are relevant for the node configuration.
Amongst others, a prominent example is the configuration file for kubelet and its unit file for the kubelet.service.
It also watches Nodes and requeues the corresponding Secret when the reason of the node condition InPlaceUpdate changes to ReadyForUpdate.
The controller decodes the configuration and computes the files and units that have changed since its last reconciliation.
It writes or update the files and units to the file system, removes no longer needed files and units, reloads the systemd daemon, and starts or stops the units accordingly.
After successful reconciliation, it persists the just applied OperatingSystemConfig into a file on the host.
This file will be used for future reconciliations to compute file/unit changes.
The controller also maintains two annotations on the Node:
worker.gardener.cloud/kubernetes-version, describing the version of the installed kubelet.
checksum/cloud-config-data, describing the checksum of the applied OperatingSystemConfig (used in future reconciliations to determine whether it needs to reconcile, and to report that this node is up-to-date).
This controller watches the access token Secrets in the kube-system namespace configured via the gardener-node-agent’s component configuration (.controllers.token.syncConfigs[] field).
Whenever the .data.token field changes, it writes the new content to a file on the configured path on the host file system.
This mechanism is used to download its own access token for the shoot cluster, but also the access tokens of other systemd components (e.g., valitail).
Since the underlying client is based on k8s.io/client-go and the kubeconfig points to this token file, it is dynamically reloaded without the necessity of explicit configuration or code changes.
This procedure ensures that the most up-to-date tokens are always present on the host and used by the gardener-node-agent and the other systemd components.
The controller is also triggered via a source channel, which is done by the Operating System Config controller during an in-place service account key rotation.
Reasoning
The gardener-node-agent is a replacement for what was called the cloud-config-downloader and the cloud-config-executor, both written in bash. The gardener-node-agent implements this functionality as a regular controller and feels more uniform in terms of maintenance.
With the new architecture we gain a lot, let’s describe the most important gains here.
Developer Productivity
Since the Gardener community develops in Go day by day, writing business logic in bash is difficult, hard to maintain, almost impossible to test. Getting rid of almost all bash scripts which are currently in use for this very important part of the cluster creation process will enhance the speed of adding new features and removing bugs.
Speed
Until now, the cloud-config-downloader runs in a loop every 60s to check if something changed on the shoot which requires modifications on the worker node. This produces a lot of unneeded traffic on the API server and wastes time, it will sometimes take up to 60s until a desired modification is started on the worker node.
By writing a “real” Kubernetes controller, we can watch for the Node, the OSC in the Secret, and the shoot-access token in the secret. If any of these object changed, and only then, the required action will take effect immediately.
This will speed up operations and will reduce the load on the API server of the shoot especially for large clusters.
Scalability
The cloud-config-downloader adds a random wait time before restarting the kubelet in case the kubelet was updated or a configuration change was made to it. This is required to reduce the load on the API server and the traffic on the internet uplink. It also reduces the overall downtime of the services in the cluster because every kubelet restart transforms a node for several seconds into NotReady state which potentially interrupts service availability.
Decision was made to keep the existing jitter mechanism which calculates the kubelet-download-and-restart-delay-seconds on the controller itself.
Correctness
The configuration of the cloud-config-downloader is actually done by placing a file for every configuration item on the disk on the worker node. This was done because parsing the content of a single file and using this as a value in bash reduces to something like VALUE=$(cat /the/path/to/the/file). Simple, but it lacks validation, type safety and whatnot.
With the gardener-node-agent we introduce a new API which is then stored in the gardener-node-agentsecret and stored on disk in a single YAML file for comparison with the previous known state. This brings all benefits of type safe configuration.
Because actual and previous configuration are compared, removed files and units are also removed and stopped on the worker if removed from the OSC.
Availability
Previously, the cloud-config-downloader simply restarted the systemd units on every change to the OSC, regardless which of the services changed. The gardener-node-agent first checks which systemd unit was changed, and will only restart these. This will prevent unneeded kubelet restarts.
4.11 - Gardener Operator
Understand the component responsible for the garden cluster environment and its various features
Overview
The gardener-operator is responsible for the garden cluster environment.
Without this component, users must deploy ETCD, the Gardener control plane, etc., manually and with separate mechanisms (not maintained in this repository).
This is quite unfortunate since this requires separate tooling, processes, etc.
A lot of production- and enterprise-grade features were built into Gardener for managing the seed and shoot clusters, so it makes sense to re-use them as much as possible also for the garden cluster.
Deployment
There is a Helm chart which can be used to deploy the gardener-operator.
Once deployed and ready, you can create a Garden resource.
Note that there can only be one Garden resource per system at a time.
ℹ️ Similar to seed clusters, garden runtime clusters require a VPA, see this section.
By default, gardener-operator deploys the VPA components.
However, when there already is a VPA available, then set .spec.runtimeCluster.settings.verticalPodAutoscaler.enabled=false in the Garden resource.
The Garden resource offers a few settings that are used to control the behaviour of gardener-operator in the runtime cluster.
This section provides an overview over the available settings in .spec.runtimeCluster.settings:
Load Balancer Services
gardener-operator deploys Istio and relevant resources to the runtime cluster in order to expose the virtual-garden-kube-apiserver service (similar to how the kube-apiservers of shoot clusters are exposed).
In most cases, the cloud-controller-manager (responsible for managing these load balancers on the respective underlying infrastructure) supports certain customization and settings via annotations.
This document provides a good overview and many examples.
By setting the .spec.runtimeCluster.settings.loadBalancerServices.annotations field the Gardener administrator can specify a list of annotations which will be injected into the Services of type LoadBalancer.
Vertical Pod Autoscaler
gardener-operator heavily relies on the Kubernetes vertical-pod-autoscaler component.
By default, the Garden controller deploys the VPA components into the garden namespace of the respective runtime cluster.
In case you want to manage the VPA deployment on your own or have a custom one, then you might want to disable the automatic deployment of gardener-operator.
Otherwise, you might end up with two VPAs which will cause erratic behaviour.
By setting the .spec.runtimeCluster.settings.verticalPodAutoscaler.enabled=false you can disable the automatic deployment.
⚠️ In any case, there must be a VPA available for your runtime cluster.
Using a runtime cluster without VPA is not supported.
It is possible to define the minimum size for PersistentVolumeClaims in the runtime cluster created by gardener-operator via the .spec.runtimeCluster.volume.minimumSize field.
This can be relevant in case the runtime cluster runs on an infrastructure that does only support disks of at least a certain size.
Configuration For Virtual Cluster
ETCD Encryption Config
The spec.virtualCluster.kubernetes.kubeAPIServer.encryptionConfig field in the Garden API allows operators to customize encryption configurations for the kube-apiserver of the virtual cluster. It provides options to specify additional resources for encryption. Similarly spec.virtualCluster.gardener.gardenerAPIServer.encryptionConfig field allows operators to customize encryption configurations for the gardener-apiserver.
The resources field can be used to specify resources that should be encrypted in addition to secrets. Secrets are always encrypted for the kube-apiserver. For the gardener-apiserver, the following resources are always encrypted:
controllerdeployments.core.gardener.cloud
controllerregistrations.core.gardener.cloud
internalsecrets.core.gardener.cloud
shootstates.core.gardener.cloud
Adding an item to any of the lists will cause patch requests for all the resources of that kind to encrypt them in the etcd. See Encrypting Confidential Data at Rest for more details.
A Gardener installation relies on extensions to provide support for new cloud providers or to add new capabilities.
You can find out more about Gardener extensions and how they can be used here.
The Extension resource is intended to automate the installation and management of extensions in a Gardener landscape.
It contains configuration for the following scenarios:
The deployment of the extension chart in the garden runtime cluster.
The deployment of ControllerRegistration and ControllerDeployment resources in the (virtual) garden cluster.
With regard to the Garden reconciliation process, there are specific types of extensions that are of key interest, namely the BackupBucket, DNSRecord, and Extension types.
The BackupBucket extension is utilized to manage the backup bucket dedicated to the garden’s main etcd.
The DNSRecord extension type is essential to manage the API server and ingress DNS records.
Lastly, the Extension type plays a crucial role in managing generic Gardener extensions which deploy various components within the runtime cluster. These extensions can be activated and configured in the .spec.extensions field of the Garden resource. These extensions can supplement functionality and provide new capabilities.
The .spec.deployment specifies how an extension can be installed for a Gardener landscape and consists of the following parts:
.spec.deployment.extension contains the deployment specification of an extension.
.spec.deployment.admission contains the deployment specification of an extension admission.
Each one is described in more details below.
Configuration for Extension Deployment
.spec.deployment.extension contains configuration for the registration of an extension in the garden cluster.
gardener-operator follows the same principles described by this document:
.spec.deployment.extension.helm and .spec.deployment.extension.values are used when creating the ControllerDeployment in the garden cluster.
.spec.deployment.extension.policy and .spec.deployment.extension.seedSelector define the extension’s installation policy as per the ControllerDeployment's respective fields
Runtime
Extensions can manage resources required by the Garden resource (e.g. BackupBucket, DNSRecord, Extension) in the runtime cluster.
Since the environment in the runtime cluster may differ from that of a Seed, the extension is installed in the runtime cluster with a distinct set of Helm chart values specified in .spec.deployment.extension.runtimeValues.
If no runtimeValues are provided, the extension deployment for the runtime garden is considered superfluous and the deployment is uninstalled.
The configuration allows for precise control over various extension parameters, such as requested resources, priority classes, and more.
Besides the values configured in .spec.deployment.extension.runtimeValues, a runtime deployment flag and a priority class are merged into the values:
gardener:
runtimeCluster:
enabled: true# indicates the extension is enabled for the Garden cluster, e.g. for handling `BackupBucket`, `DNSRecord` and `Extension` objects. priorityClassName: gardener-garden-system-200
As soon as a Garden object is created and runtimeValues are configured, the extension is deployed in the runtime cluster.
Extension Registration
When the virtual garden cluster is available, the Extension controller manages ControllerRegistration/ControllerDeployment resources
to register extensions for shoots. The fields of .spec.deployment.extension include their configuration options.
Configuration for Admission Deployment
The .spec.deployment.admission defines how an extension admission may be deployed by the gardener-operator.
This deployment is optional and may be omitted.
Typically, the admission are split in two parts:
Runtime
The runtime part contains deployment relevant manifests, required to run the admission service in the runtime cluster.
The following values are passed to the chart during reconciliation:
gardener:
runtimeCluster:
priorityClassName: <Class to be used for extension admission>
gardener:
virtualCluster:
serviceAccount:
name: <Name of the service account used to connect to the garden cluster>
namespace: <Namespace of the service account>
Extension admissions often need to retrieve additional context from the garden cluster in order to process validating or mutating requests.
For example, the corresponding CloudProfile might be needed to perform a provider specific shoot validation.
Therefore, Gardener automatically injects a kubeconfig into the admission deployment to interact with the (virtual) garden cluster (see this document for more information).
Configuration for Extension Resources
The .spec.resources field refers to the extension resources as defined by Gardener in the extensions.gardener.cloud/v1alpha1 API.
These include both well-known types such as Infrastructure, Worker etc. and generic resources.
The field will be used to populate the respective field in the resulting ControllerRegistration in the garden cluster.
Controllers
The gardener-operator controllers are now described in more detail.
The reconciler first generates a general CA certificate which is valid for ~30d and auto-rotated when 80% of its lifetime is reached.
Afterwards, it brings up the so-called “garden system components”.
The gardener-resource-manager is deployed first since its ManagedResource controller will be used to bring up the remainders.
Other system components are:
runtime garden system resources (PriorityClasses for the workload resources)
virtual garden system resources (RBAC rules)
Vertical Pod Autoscaler (if enabled via .spec.runtimeCluster.settings.verticalPodAutoscaler.enabled=true in the Garden)
ETCD Druid
Istio
As soon as all system components are up, the reconciler deploys the virtual garden cluster.
It comprises out of two ETCDs (one “main” etcd, one “events” etcd) which are managed by ETCD Druid via druid.gardener.cloud/v1alpha1.Etcd custom resources.
The whole management works similar to how it works for Shoots, so you can take a look at this document for more information in general.
The virtual garden control plane components are:
virtual-garden-etcd-main
virtual-garden-etcd-events
virtual-garden-kube-apiserver
virtual-garden-kube-controller-manager
virtual-garden-gardener-resource-manager
If the .spec.virtualCluster.controlPlane.highAvailability={} is set then these components will be deployed in a “highly available” mode.
For ETCD, this means that there will be 3 replicas each.
This works similar like for Shoots (see this document) except for the fact that there is no failure tolerance type configurability.
The gardener-resource-manager’s HighAvailabilityConfig webhook makes sure that all pods with multiple replicas are spread on nodes, and if there are at least two zones in .spec.runtimeCluster.provider.zones then they also get spread across availability zones.
If once set, removing .spec.virtualCluster.controlPlane.highAvailability again is not supported.
The virtual-garden-kube-apiserverDeployment is exposed via Istio, similar to how the kube-apiservers of shoot clusters are exposed.
Similar to the Shoot API, the version of the virtual garden cluster is controlled via .spec.virtualCluster.kubernetes.version.
Likewise, specific configuration for the control plane components can be provided in the same section, e.g. via .spec.virtualCluster.kubernetes.kubeAPIServer for the kube-apiserver or .spec.virtualCluster.kubernetes.kubeControllerManager for the kube-controller-manager.
The kube-controller-manager only runs a few controllers that are necessary in the scenario of the virtual garden.
Most prominently, the serviceaccount-token controller is unconditionally disabled.
Hence, the usage of static ServiceAccount secrets is not supported generally.
Instead, the TokenRequest API should be used.
Third-party components that need to communicate with the virtual cluster can leverage the gardener-resource-manager’s TokenRequestor controller and the generic kubeconfig, just like it works for Shoots.
Please note, that this functionality is restricted to the garden namespace. The current Secret name of the generic kubeconfig can be found in the annotations (key: generic-token-kubeconfig.secret.gardener.cloud/name) of the Garden resource.
For the virtual cluster, it is essential to provide at least one DNS domain via .spec.virtualCluster.dns.domains.
The respective DNS records are not managed by gardener-operator and should be created manually.
They should point to the load balancer IP of the istio-ingressgatewayService in namespace virtual-garden-istio-ingress.
The DNS records must be prefixed with both gardener. and api. for all domains in .spec.virtualCluster.dns.domains.
The first DNS domain in this list is used for the server in the kubeconfig, and for configuring the --external-hostname flag of the API server.
Apart from the control plane components of the virtual cluster, the reconcile also deploys the control plane components of Gardener.
gardener-apiserver reuses the same ETCDs like the virtual-garden-kube-apiserver, so all data related to the “the garden cluster” is stored together and “isolated” from ETCD data related to the runtime cluster.
This drastically simplifies backup and restore capabilities (e.g., moving the virtual garden cluster from one runtime cluster to another).
The Gardener control plane components are:
gardener-apiserver
gardener-admission-controller
gardener-controller-manager
gardener-scheduler
Besides those, the gardener-operator is able to deploy the following optional components:
Gardener Dashboard (and the controller for web terminals) when .spec.virtualCluster.gardener.gardenerDashboard (or .spec.virtualCluster.gardener.gardenerDashboard.terminal, respectively) is set.
You can read more about it and its configuration in this section.
Gardener Discovery Server when .spec.virtualCluster.gardener.gardenerDiscoveryServer is set.
The service account issuer of shoots will be calculated in the format https://discovery.<.spec.runtimeCluster.ingress.domains[0]>/projects/<project-name>/shoots/<shoot-uid>/issuer.
This configuration applies for all seeds registered with the Garden cluster. Once set it should not be modified.
The reconciler also manages a few observability-related components:
It is also mandatory to provide an IPv4 CIDR for the service network of the virtual cluster via .spec.virtualCluster.networking.services.
This range is used by the API server to compute the cluster IPs of Services.
The controller maintains the .status.lastOperation which indicates the status of an operation.
.spec.virtualCluster.gardener.gardenerDashboard serves a few configuration options for the dashboard.
This section highlights the most prominent fields:
oidcConfig: The general OIDC configuration is part of .spec.virtualCluster.kubernetes.kubeAPIServer.oidcConfig (deprecated). Since Kubernetes 1.30 the general OIDC configuration happens via the Structured Authentication feature .spec.virtualCluster.kubernetes.kubeAPIServer.structuredAuthentication.
This section allows you to define a few specific settings for the dashboard.
clientIDPublic is the public ID of the OIDC client.
issuerURL is the URL of the JWT issuer.
sessionLifetime is the duration after which a session is terminated (i.e., after which a user is automatically logged out).
additionalScopes allows to extend the list of scopes of the JWT token that are to be recognized.
certificateAuthoritySecretRef allows you to specify a secret containing a custom CA certificate for communicating with the OIDC issuer. You must reference a Secret in the garden namespace containing the client and, if applicable, the client secret for the dashboard:
If using a public client, a client secret is not required. The dashboard can function as a public OIDC client, allowing for improved flexibility in environments where secret storage is not feasible.
enableTokenLogin: This is enabled by default and allows logging into the dashboard with a JWT token.
You can disable it in case you want to only allow OIDC-based login.
However, at least one of the both login methods must be enabled.
frontendConfigMapRef: Reference a ConfigMap in the garden namespace containing the frontend configuration in the data with key frontend-config.yaml, for example
Please take a look at this file to get an idea of which values are configurable.
This configuration can also include branding, themes, and colors.
Read more about it here.
Assets (logos/icons) are configured in a separate ConfigMap, see below.
assetsConfigMapRef: Reference a ConfigMap in the garden namespace containing the assets, for example
Note that the assets must be provided base64-encoded, hence binaryData (instead of data) must be used.
Please take a look at this file to get more information.
gitHub: You can connect a GitHub repository that can be used to create issues for shoot clusters in the cluster details page.
You have to reference a Secret in the garden namespace that contains the GitHub credentials, for example:
apiVersion: v1
kind: Secret
metadata:
name: gardener-dashboard-github
namespace: garden
type: Opaque
stringData:
# This is for GitHub token authentication: authentication.token: <secret>
# Alternatively, this is for GitHub app authentication: authentication.appId: <secret>
authentication.clientId: <secret>
authentication.clientSecret: <secret>
authentication.installationId: <secret>
authentication.privateKey: <secret>
# This is the webhook secret, see explanation below webhookSecret: <secret>
Note that you can also set up a GitHub webhook to the dashboard such that it receives updates when somebody changes the GitHub issue.
The webhookSecret field is the secret that you enter in GitHub in the webhook configuration.
The dashboard uses it to verify that received traffic is indeed originated from GitHub.
If you don’t want to set up such webhook, or if the dashboard is not reachable by the GitHub webhook (e.g., in restricted environments) you can also configure gitHub.pollInterval.
It is the interval of how often the GitHub API is polled for issue updates.
This field is used as a fallback mechanism to ensure state synchronization, even when there is a GitHub webhook configuration.
If a webhook event is missed or not successfully delivered, the polling will help catch up on any missed updates.
If this field is not provided and there is no webhookSecret key in the referenced secret, it will be implicitly defaulted to 15m.
The dashboard will use this to regularly poll the GitHub API for updates on issues.
terminal: This enables the web terminal feature, read more about it here.
When set, the terminal-controller-manager will be deployed to the runtime cluster.
The allowedHosts field is explained here.
The container section allows you to specify a container image and a description that should be used for the web terminals.
ingress: This allows you to customize the Ingress resource of the dashboard.
The enabled field allows you to control whether to deploy the Ingress resource to the cluster.
Observability
Garden Prometheus
gardener-operator deploys a Prometheus instance in the garden namespace (called “Garden Prometheus”) which fetches metrics and data from garden system components, cAdvisors, the virtual cluster control plane, and the Seeds’ aggregate Prometheus instances.
Its purpose is to provide an entrypoint for operators when debugging issues with components running in the garden cluster.
It also serves as the top-level aggregator of metering across a Gardener landscape.
To extend the configuration of the Garden Prometheus, you can create the prometheus-operator’s custom resources and label them with prometheus=garden, for example:
gardener-operator deploys another Prometheus instance in the garden namespace (called “Long-Term Prometheus”) which federates metrics from Garden Prometheus.
Its purpose is to store those with a longer retention than Garden Prometheus would. It is not possible to define different retention periods for different metrics in Prometheus, hence, using another Prometheus instance is the only option.
This Long-term Prometheus also has an additional Cortex sidecar container for caching some queries to achieve faster processing times.
To extend the configuration of the Long-term Prometheus, you can create the prometheus-operator’s custom resources and label them with prometheus=longterm, for example:
By default, the alertmanager-garden deployed by gardener-operator does not come with any configuration.
It is the responsibility of the human operators to design and provide it.
This can be done by creating monitoring.coreos.com/v1alpha1.AlertmanagerConfig resources labeled with alertmanager=garden (read more about them here), for example:
A Plutono instance is deployed by gardener-operator into the garden namespace for visualizing monitoring metrics and logs via dashboards.
In order to provide custom dashboards, create a ConfigMap in the garden namespace labelled with dashboard.monitoring.gardener.cloud/garden=true that contains the respective JSON documents, for example:
This reconciler performs four “care” actions related to Gardens.
It maintains the following conditions:
VirtualGardenAPIServerAvailable: The /healthz endpoint of the garden’s virtual-garden-kube-apiserver is called and considered healthy when it responds with 200 OK.
RuntimeComponentsHealthy: The conditions of the ManagedResources applied to the runtime cluster are checked (e.g., ResourcesApplied).
VirtualComponentsHealthy: The virtual components are considered healthy when the respective Deployments (for example virtual-garden-kube-apiserver,virtual-garden-kube-controller-manager), and Etcds (for example virtual-garden-etcd-main) exist and are healthy. Additionally, the conditions of the ManagedResources applied to the virtual cluster are checked (e.g., ResourcesApplied).
ObservabilityComponentsHealthy: This condition is considered healthy when the respective Deployments (for example plutono) and StatefulSets (for example prometheus, vali) exist and are healthy.
If all checks for a certain condition are succeeded, then its status will be set to True.
Otherwise, it will be set to False or Progressing.
If at least one check fails and there is threshold configuration for the conditions (in .controllers.gardenCare.conditionThresholds), then the status will be set:
to Progressing if it was True before.
to Progressing if it was Progressing before and the lastUpdateTime of the condition does not exceed the configured threshold duration yet.
to False if it was Progressing before and the lastUpdateTime of the condition exceeds the configured threshold duration.
The condition thresholds can be used to prevent reporting issues too early just because there is a rollout or a short disruption.
Only if the unhealthiness persists for at least the configured threshold duration, then the issues will be reported (by setting the status to False).
In order to compute the condition statuses, this reconciler considers ManagedResources (in the garden and istio-system namespace) and their status, see this document for more information.
The following table explains which ManagedResources are considered for which condition type:
Condition Type
ManagedResources are considered when
RuntimeComponentsHealthy
.spec.class=seed and care.gardener.cloud/condition-type label either unset, or set to RuntimeComponentsHealthy
VirtualComponentsHealthy
.spec.class unset or care.gardener.cloud/condition-type label set to VirtualComponentsHealthy
ObservabilityComponentsHealthy
care.gardener.cloud/condition-type label set to ObservabilityComponentsHealthy
Garden objects may specify references to other objects in the Garden cluster which are required for certain features.
For example, operators can configure a secret for ETCD backup via .spec.virtualCluster.etcd.main.backup.secretRef.name or an audit policy ConfigMap via .spec.virtualCluster.kubernetes.kubeAPIServer.auditConfig.auditPolicy.configMapRef.name.
Such objects need a special protection against deletion requests as long as they are still being referenced by the Garden.
Therefore, this reconciler checks Gardens for referenced objects and adds the finalizer gardener.cloud/reference-protection to their .metadata.finalizers list.
The reconciled Garden also gets this finalizer to enable a proper garbage collection in case the gardener-operator is offline at the moment of an incoming deletion request.
When an object is not actively referenced anymore because the Garden specification has changed is in deletion, the controller will remove the added finalizer again so that the object can safely be deleted or garbage collected.
This reconciler inspects the following references:
Admission plugin kubeconfig Secrets (.spec.virtualCluster.kubernetes.kubeAPIServer.admissionPlugins[].kubeconfigSecretName and .spec.virtualCluster.gardener.gardenerAPIServer.admissionPlugins[].kubeconfigSecretName)
Audit policy ConfigMaps (.spec.virtualCluster.kubernetes.kubeAPIServer.auditConfig.auditPolicy.configMapRef.name and .spec.virtualCluster.gardener.gardenerAPIServer.auditConfig.auditPolicy.configMapRef.name)
Audit webhook kubeconfig Secrets (.spec.virtualCluster.kubernetes.kubeAPIServer.auditWebhook.kubeconfigSecretName and .spec.virtualCluster.gardener.gardenerAPIServer.auditWebhook.kubeconfigSecretName)
Some controllers may only be instantiated or added later, because they need the Garden resource to be available (e.g. network configuration) or even the entire virtual garden cluster to run:
Some of the listed controllers are part of gardenlet, as well.
If the garden cluster is a seed cluster at the same time, gardenlet will skip running the NetworkPolicy and VPA EvictionRequirements controllers to avoid interferences.
Gardener relies on extensions to provide various capabilities, such as supporting cloud providers.
This controller automates the management of extensions by managing all necessary resources in the runtime and virtual garden clusters.
This reconciler performs three “care” actions related to Extensionss.
It maintains the following conditions:
ControllerInstallationsHealthy: The conditions of the ControllerInstallations which belong to this extension are checked (e.g., Healthy).
RuntimeHealthy: The conditions of the ManagedResources applied to the runtime cluster are checked (e.g., ResourcesApplied).
AdmissionHealthy: The conditions of the ManagedResources applied to the runtime and the virtual cluster are checked (e.g., ResourcesApplied).
If all checks for a certain condition are succeeded, then its status will be set to True.
Otherwise, it will be set to False or Progressing.
If at least one check fails and there is threshold configuration for the conditions (in .controllers.extensionCare.conditionThresholds), then the status will be set:
to Progressing if it was True before.
to Progressing if it was Progressing before and the lastUpdateTime of the condition does not exceed the configured threshold duration yet.
to False if it was Progressing before and the lastUpdateTime of the condition exceeds the configured threshold duration.
The condition thresholds can be used to prevent reporting issues too early just because there is a rollout or a short disruption.
Only if the unhealthiness persists for at least the configured threshold duration, then the issues will be reported (by setting the status to False).
This reconciler reacts on Garden and Extension events.
It is checked if the extension deployment is required in the garden runtime cluster based on the existing Garden specification.
The result is then put into the RequiredRuntime condition and added to the Extension status.
This reconciler reacts on events from ControllerInstallation and Extension resources.
It updates the RequiredVirtual condition of Extension objects, based on the existence of related ControllerInstallations and whether they are marked as required.
This controller performs actions related to the garden access secret (gardener or gardener-internal) for the virtual garden cluster.
It extracts the included Kubeconfig, and prepares a dedicated REST config, where the inline bearer token is replaced by a bearer token file.
Any subsequent reconciliation run, mostly triggered by a token replacement, causes the content of the bearer token file to be updated with the token found in the access secret.
At the end, the prepared REST config is passed to the Virtual-Cluster-Registrar controller.
Together with the adjusted config and the token file, related controllers can continuously run their operations, even after credentials rotation.
The Virtual-Cluster-Registrar controller watches for events on a dedicated channel that is shared with the Access controller.
Once a REST config is sent to the channel, the reconciliation loop picks up the request, creates a Cluster object and stores in memory.
This Cluster object points to the virtual garden cluster and is used to register further controllers, e.g. Gardenlet controller.
The Gardenlet controller reconciles a seedmanagement.gardener.cloud/v1alpha1.Gardenlet resource in case there is no Seed yet with the same name.
This is used to allow easy deployments of gardenlets into unmanaged seed clusters.
For a general overview, see this document.
On Gardenlet reconciliation, the controller deploys the gardenlet to the cluster (either its own, or the one provided via the .spec.kubeconfigSecretRef) after downloading the Helm chart specified in .spec.deployment.helm.ociRepository and rendering it with the provided values/configuration.
On Gardenlet deletion, nothing happens: gardenlets must always be deleted manually (by deleting the Seed and, once gone, then the gardenletDeployment).
Note
This controller only takes care of the very first gardenlet deployment (since it only reacts when there is no Seed resource yet).
After the gardenlet is running, it uses the self-upgrade mechanism by watching the seedmanagement.gardener.cloud/v1alpha1.Gardenlet (see this for more details.)
After a successful Garden reconciliation, gardener-operator also updates the .spec.deployment.helm.ociRepository.ref to its own version in all Gardenlet resources labeled with operator.gardener.cloud/auto-update-gardenlet-helm-chart-ref=true.
gardenlets then updates themselves.
⚠️ If you prefer to manage the Gardenlet resources via GitOps, Flux, or similar tools, then you should better manage the .spec.deployment.helm.ociRepository.ref field yourself and not label the resources as mentioned above (to prevent gardener-operator from interfering with your desired state).
Make sure to apply your Gardenlet resources (potentially containing a new version) after the Garden resource was successfully reconciled (i.e., after Gardener control plane was successfully rolled out, see this for more information.)
Webhooks
As of today, the gardener-operator only has one webhook handler which is now described in more detail.
Validation
The validation webhook consists of the following handlers.
Garden
This webhook handler validates CREATE/UPDATE/DELETE operations on Garden resources.
Simple validation is performed via standard CRD validation.
However, more advanced validation is hard to express via these means and is performed by this webhook handler.
Furthermore, for deletion requests, it is validated that the Garden is annotated with a deletion confirmation annotation, namely confirmation.gardener.cloud/deletion=true.
Only if this annotation is present it allows the DELETE operation to pass.
This prevents users from accidental/undesired deletions.
Another validation is to check that there is only one Garden resource at a time.
It prevents creating a second Garden when there is already one in the system.
Extension
This webhook handler validates UPDATE and DELETE operations on Extension resources.
In an UPDATE request, the configured .spec.resources are validated to ensure the primary field remains immutable.
DELETE requests for Extension resources are denied if they are reported as required (also see required-runtime and required-virtual).
These deletions often happen accidentally, and this handler safeguards the system from such actions.
Defaulting
This webhook handler mutates Garden resources on CREATE/UPDATE/DELETE operations.
Extension resources are mutated in the scope of CREATE/UPDATE requests.
Simple defaulting is performed via standard CRD defaulting.
However, more advanced defaulting is hard to express via these means and is performed by this webhook handler.
Using Garden Runtime Cluster As Seed Cluster
In production scenarios, you probably wouldn’t use the Kubernetes cluster running gardener-operator and the Gardener control plane (called “runtime cluster”) as seed cluster at the same time.
However, such setup is technically possible and might simplify certain situations (e.g., development, evaluation, …).
If the runtime cluster is a seed cluster at the same time, gardenlet’s Seed controller will not manage the components which were already deployed (and reconciled) by gardener-operator.
As of today, this applies to:
gardener-resource-manager
vpa-{admission-controller,recommender,updater}
etcd-druid
istio control-plane
nginx-ingress-controller
Those components are so-called “seed system components”.
In addition, there are a few observability components:
fluent-operator
fluent-bit
vali
plutono
kube-state-metrics
prometheus-operator
perses-operator
opentelemetry-operator
As all of these components are managed by gardener-operator in this scenario, the gardenlet just skips them.
ℹ️ There is no need to configure anything - the gardenlet will automatically detect when its seed cluster is the garden runtime cluster at the same time.
⚠️ Note that such setup requires that you upgrade the versions of gardener-operator and gardenlet in lock-step.
Otherwise, you might experience unexpected behaviour or issues with your seed or shoot clusters.
Credentials Rotation
The credentials rotation works in the same way as it does for Shoot resources, i.e. there are gardener.cloud/operation annotation values for starting or completing the rotation procedures.
For certificate authorities, gardener-operator generates one which is automatically rotated roughly each month (ca-garden-runtime) and several CAs which are NOT automatically rotated but only on demand.
🚨 Hence, it is the responsibility of the (human) operator to regularly perform the credentials rotation.
Please refer to this document for more details. As of today, gardener-operator only creates the following types of credentials (i.e., some sections of the document don’t apply for Gardens and can be ignored):
certificate authorities (and related server and client certificates)
ETCD encryption key
observability password for Plutono
ServiceAccount token signing key
WorkloadIdentity token signing key
⚠️ Rotation of static ServiceAccount secrets is not supported since the kube-controller-manager does not enable the serviceaccount-token controller.
When the ServiceAccount token signing key rotation is in Preparing phase, then gardener-operator annotates all Seeds with gardener.cloud/operation=renew-garden-access-secrets.
This causes gardenlet to populate new ServiceAccount tokens for the garden cluster to all extensions, which are now signed with the new signing key.
Read more about it here.
Similarly, when the CA certificate rotation is in Preparing phase, then gardener-operator annotates all Seeds with gardener.cloud/operation=renew-kubeconfig.
This causes gardenlet to request a new client certificate for its garden cluster kubeconfig, which is now signed with the new client CA, and which also contains the new CA bundle for the server certificate verification.
Read more about it here.
Also, when the WorkloadIdentity token signing key rotation is in Preparing phase, then gardener-operator annotates all Seeds with gardener.cloud/operation=renew-workload-identity-tokens.
This causes gardenlet to renew all workload identity tokens in the seed cluster with new tokens now signed with the new signing key.
Migrating an Existing Gardener Landscape to gardener-operator
Since gardener-operator was only developed in 2023, six years after the Gardener project initiation, most users probably already have an existing Gardener landscape.
The most prominent installation procedure is garden-setup, however experience shows that most community members have developed their own tooling for managing the garden cluster and the Gardener control plane components.
Consequently, providing a general migration guide is not possible since the detailed steps vary heavily based on how the components were set up previously.
As a result, this section can only highlight the most important caveats and things to know, while the concrete migration steps must be figured out individually based on the existing installation.
Please test your migration procedure thoroughly.
Note that in some cases it can be easier to set up a fresh landscape with gardener-operator, restore the ETCD data, switch the DNS records, and issue new credentials for all clients.
Please make sure that you configure all your desired fields in the Garden resource.
ETCD
gardener-operator leverages etcd-druid for managing the virtual-garden-etcd-main and virtual-garden-etcd-events, similar to how shoot cluster control planes are handled.
The PersistentVolumeClaim names differ slightly - for virtual-garden-etcd-events it’s virtual-garden-etcd-events-virtual-garden-etcd-events-0, while for virtual-garden-etcd-main it’s main-virtual-garden-etcd-virtual-garden-etcd-main-0.
The easiest approach for the migration is to make your existing ETCD volumes follow the same naming scheme.
Alternatively, backup your data, let gardener-operator take over ETCD, and then restore your data to the new volume.
The backup bucket must be created separately, and its name as well as the respective credentials must be provided via the Garden resource in .spec.virtualCluster.etcd.main.backup.
virtual-garden-kube-apiserver Deployment
gardener-operator deploys a virtual-garden-kube-apiserver into the runtime cluster.
This virtual-garden-kube-apiserver spans a new cluster, called the virtual cluster.
There are a few certificates and other credentials that should not change during the migration.
You have to prepare the environment accordingly by leveraging the secret’s manager capabilities.
The existing Cluster CA Secret should be labeled with secrets-manager-use-data-for-name=ca.
The existing Client CA Secret should be labeled with secrets-manager-use-data-for-name=ca-client.
The existing Front Proxy CA Secret should be labeled with secrets-manager-use-data-for-name=ca-front-proxy.
The existing Service Account Signing Key Secret should be labeled with secrets-manager-use-data-for-name=service-account-key.
The existing ETCD Encryption Key Secret should be labeled with secrets-manager-use-data-for-name=kube-apiserver-etcd-encryption-key.
virtual-garden-kube-apiserver Exposure
The virtual-garden-kube-apiserver is exposed via a dedicated istio-ingressgateway deployed to namespace virtual-garden-istio-ingress.
The virtual-garden-kube-apiserverService in the garden namespace is only of type ClusterIP.
Consequently, DNS records for this API server must target the load balancer IP of the istio-ingressgateway.
Virtual Garden Kubeconfig
gardener-operator does not generate any static token or likewise for access to the virtual cluster.
Ideally, human users access it via OIDC only.
Alternatively, you can create an auto-rotated token that you can use for automation like CI/CD pipelines:
The shoot-access-virtual-gardenSecret will get a .data.token field which can be used to authenticate against the virtual garden cluster.
See also this document for more information about the TokenRequestor.
gardener-apiserver
Similar to the virtual-garden-kube-apiserver, the gardener-apiserver also uses a few certificates and other credentials that should not change during the migration.
Again, you have to prepare the environment accordingly by leveraging the secret’s manager capabilities.
The existing ETCD Encryption Key Secret should be labeled with secrets-manager-use-data-for-name=gardener-apiserver-etcd-encryption-key.
Also note that gardener-operator manages the Service and Endpoints resources for the gardener-apiserver in the virtual cluster within the kube-system namespace (garden-setup uses the garden namespace).
Local Development
The easiest setup is using a local KinD cluster and the Skaffold based approach to deploy and develop the gardener-operator.
Setting Up the KinD Cluster (runtime cluster)
make kind-multi-zone-up
This command sets up a new KinD cluster named gardener-local and stores the kubeconfig in the ./example/gardener-local/kind/multi-zone/kubeconfig file.
It might be helpful to copy this file to $HOME/.kube/config, since you will need to target this KinD cluster multiple times.
Alternatively, make sure to set your KUBECONFIG environment variable to ./example/gardener-local/kind/multi-zone/kubeconfig for all future steps via export KUBECONFIG=$PWD/example/gardener-local/kind/multi-zone/kubeconfig.
All the following steps assume that you are using this kubeconfig.
Setting Up Gardener Operator
make operator-up
This will first build the base images (which might take a bit if you do it for the first time).
Afterwards, the Gardener Operator resources will be deployed into the cluster.
Developing Gardener Operator (Optional)
make operator-dev
This is similar to make operator-up but additionally starts a skaffold dev loop.
After the initial deployment, skaffold starts watching source files.
Once it has detected changes, press any key to trigger a new build and deployment of the changed components.
Debugging Gardener Operator (Optional)
make operator-debug
This is similar to make gardener-debug but for Gardener Operator component. Please check Debugging Gardener for details.
Creating a Garden
In order to create a garden, just run:
kubectl apply -f example/operator/20-garden.yaml
You can wait for the Garden to be ready by running:
./hack/usage/wait-for.sh garden local VirtualGardenAPIServerAvailable VirtualComponentsHealthy
Alternatively, you can run kubectl get garden and wait for the RECONCILED status to reach True:
NAME LAST OPERATION RUNTIME VIRTUAL API SERVER OBSERVABILITY AGE
local Processing False False False False 1s
(Optional): Instead of creating above Garden resource manually, you could execute the e2e tests by running:
make test-e2e-local-operator
Accessing the Virtual Garden Cluster
⚠️ Please note that in this setup, the virtual garden cluster is not accessible by default when you download the kubeconfig and try to communicate with it.
The reason is that your host most probably cannot resolve the DNS name of the cluster.
Hence, if you want to access the virtual garden cluster, you have to run the following command which will extend your /etc/hosts file with the required information to make the DNS names resolvable:
cat <<EOF | sudo tee -a /etc/hosts
# Manually created to access local Gardener virtual garden cluster.
# TODO: Remove this again when the virtual garden cluster access is no longer required.
172.18.255.3 api.virtual-garden.local.gardener.cloud
EOF
To access the virtual garden, you can generate a kubeconfig by running
hack/usage/generate-virtual-garden-admin-kubeconf.sh > /tmp/virtual-garden-kubeconfig
kubectl --kubeconfig /tmp/virtual-garden-kubeconfig get namespaces
Creating Seeds and Shoots
You can also create Seeds and Shoots from your local development setup.
Please see here for details.
Deleting the Garden
./hack/usage/delete garden local
Tear Down the Gardener Operator Environment
make operator-down
make kind-multi-zone-down
4.12 - Gardener Resource Manager
Set of controllers with different responsibilities running once per seed and once per shoot
Overview
Initially, the gardener-resource-manager was a project similar to the kube-addon-manager.
It manages Kubernetes resources in a target cluster which means that it creates, updates, and deletes them.
Also, it makes sure that manual modifications to these resources are reconciled back to the desired state.
In the Gardener project we were using the kube-addon-manager since more than two years.
While we have progressed with our extensibility story (moving cloud providers out-of-tree), we had decided that the kube-addon-manager is no longer suitable for this use-case.
The problem with it is that it needs to have its managed resources on its file system.
This requires storing the resources in ConfigMaps or Secrets and mounting them to the kube-addon-manager pod during deployment time.
The gardener-resource-manager uses CustomResourceDefinitions which allows to dynamically add, change, and remove resources with immediate action and without the need to reconfigure the volume mounts/restarting the pod.
Meanwhile, the gardener-resource-manager has evolved to a more generic component comprising several controllers and webhook handlers.
It is deployed by gardenlet once per seed (in the garden namespace) and once per shoot (in the respective shoot namespaces in the seed).
Component Configuration
Similar to other Gardener components, the gardener-resource-manager uses a so-called component configuration file.
It allows specifying certain central settings like log level and formatting, client connection configuration, server ports and bind addresses, etc.
In addition, controllers and webhooks can be configured and sometimes even disabled.
Note that the very basic ManagedResource and health controllers cannot be disabled.
This controller watches custom objects called ManagedResources in the resources.gardener.cloud/v1alpha1 API group.
These objects contain references to secrets, which itself contain the resources to be managed.
The reason why a Secret is used to store the resources is that they could contain confidential information like credentials.
In the above example, the controller creates two ConfigMaps in the default namespace.
When a user is manually modifying them, they will be reconciled back to the desired state stored in the managedresource-example secret.
It is also possible to inject labels into all the resources:
In this example, the label foo=bar will be injected into the Deployment, as well as into all created ReplicaSets and Pods.
Preventing Reconciliations
If a ManagedResource is annotated with resources.gardener.cloud/ignore=true, then it will be skipped entirely by the controller (no reconciliations or deletions of managed resources at all).
However, when the ManagedResource itself is deleted (for example when a shoot is deleted), then the annotation is not respected and all resources will be deleted as usual.
This feature can be helpful to temporarily patch/change resources managed as part of such ManagedResource.
Condition checks will be skipped for such ManagedResources.
Modes
The gardener-resource-manager can manage a resource in the following supported modes:
Ignore
The corresponding resource is removed from the ManagedResource status (.status.resources). No action is performed on the cluster.
The resource is no longer “managed” (updated or deleted).
The primary use case is a migration of a resource from one ManagedResource to another one.
The mode for a resource can be specified with the resources.gardener.cloud/mode annotation. The annotation should be specified in the encoded resource manifest in the Secret that is referenced by the ManagedResource.
Resource Class and Reconciliation Scope
By default, the gardener-resource-manager controller watches for ManagedResources in all namespaces.
The .sourceClientConnection.namespace field in the component configuration restricts the watch to ManagedResources in a single namespace only.
Note that this setting also affects all other controllers and webhooks since it’s a central configuration.
A ManagedResource has an optional .spec.class field that allows it to indicate that it belongs to a given class of resources.
The .controllers.resourceClass field in the component configuration restricts the watch to ManagedResources with the given .spec.class.
A default class is assumed if no class is specified.
For instance, the gardener-resource-manager which is deployed in the Shoot’s control plane namespace in the Seed does not specify a .spec.class and watches only for resources in the control plane namespace by specifying it in the .sourceClientConnection.namespace field.
If the .spec.class changes this means that the resources have to be handled by a different Gardener Resource Manager. That is achieved by:
Cleaning all referenced resources by the Gardener Resource Manager that was responsible for the old class in its target cluster.
Creating all referenced resources by the Gardener Resource Manager that is responsible for the new class in its target cluster.
A ManagedResource has a ManagedResourceStatus, which has an array of Conditions. Conditions currently include:
Condition
Description
ResourcesApplied
True if all resources are applied to the target cluster
ResourcesHealthy
True if all resources are present and healthy
ResourcesProgressing
False if all resources have been fully rolled out
ResourcesApplied may be False when:
the resource apiVersion is not known to the target cluster
the resource spec is invalid (for example the label value does not match the required regex for it)
…
ResourcesHealthy may be False when:
the resource is not found
the resource is a Deployment and the Deployment does not have the minimum availability.
…
ResourcesProgressing may be True when:
a Deployment, StatefulSet or DaemonSet has not been fully rolled out yet, i.e. not all replicas have been updated with the latest changes to spec.template.
there are still old Pods belonging to an older ReplicaSet of a Deployment which are not terminated yet.
Each Kubernetes resources has different notion for being healthy. For example, a Deployment is considered healthy if the controller observed its current revision and if the number of updated replicas is equal to the number of replicas.
The following status.conditions section describes a healthy ManagedResource:
conditions:
- lastTransitionTime: "2022-05-03T10:55:39Z" lastUpdateTime: "2022-05-03T10:55:39Z" message: All resources are healthy.
reason: ResourcesHealthy
status: "True" type: ResourcesHealthy
- lastTransitionTime: "2022-05-03T10:55:36Z" lastUpdateTime: "2022-05-03T10:55:36Z" message: All resources have been fully rolled out.
reason: ResourcesRolledOut
status: "False" type: ResourcesProgressing
- lastTransitionTime: "2022-05-03T10:55:18Z" lastUpdateTime: "2022-05-03T10:55:18Z" message: All resources are applied.
reason: ApplySucceeded
status: "True" type: ResourcesApplied
Ignoring Updates
In some cases, it is not desirable to update or re-apply some of the cluster components (for example, if customization is required or needs to be applied by the end-user).
For these resources, the annotation “resources.gardener.cloud/ignore” needs to be set to “true” or a truthy value (Truthy values are “1”, “t”, “T”, “true”, “TRUE”, “True”) in the corresponding managed resource secrets.
This can be done from the components that create the managed resource secrets, for example Gardener extensions or Gardener. Once this is done, the resource will be initially created and later ignored during reconciliation.
Finalizing Deletion of Resources After Grace Period
When a ManagedResource is deleted, the controller deletes all managed resources from the target cluster.
In case the resources still have entries in their .metadata.finalizers[] list, they will remain stuck in the system until another entity removes the finalizers.
If you want the controller to forcefully finalize the deletion after some grace period (i.e., setting .metadata.finalizers=null), you can annotate the managed resources with resources.gardener.cloud/finalize-deletion-after=<duration>, e.g., resources.gardener.cloud/finalize-deletion-after=1h.
Preserving replicas or resources in Workload Resources
The objects which are part of the ManagedResource can be annotated with:
resources.gardener.cloud/preserve-replicas=true in case the .spec.replicas field of workload resources like Deployments, StatefulSets, etc., shall be preserved during updates.
resources.gardener.cloud/preserve-resources=true in case the .spec.containers[*].resources fields of all containers of workload resources like Deployments, StatefulSets, etc., shall be preserved during updates.
This can be useful if there are non-standard horizontal/vertical auto-scaling mechanisms in place.
Standard mechanisms like HorizontalPodAutoscaler or VerticalPodAutoscaler will be auto-recognized by gardener-resource-manager, i.e., in such cases the annotations are not needed.
Origin
All the objects managed by the resource manager get a dedicated annotation
resources.gardener.cloud/origin describing the ManagedResource object that describes
this object. The default format is <namespace>/<objectname>.
In multi-cluster scenarios (the ManagedResource objects are maintained in a
cluster different from the one the described objects are managed), it might
be useful to include the cluster identity, as well.
This can be enforced by setting the .controllers.clusterID field in the component configuration.
Here, several possibilities are supported:
given a direct value: use this as id for the source cluster.
<cluster>: read the cluster identity from a cluster-identity config map
in the kube-system namespace (attribute cluster-identity). This is
automatically maintained in all clusters managed or involved in a gardener landscape.
<default>: try to read the cluster identity from the config map. If not found,
no identity is used.
empty string: no cluster identity is used (completely cluster local scenarios).
By default, cluster id is not used. If cluster id is specified, the format is <cluster id>:<namespace>/<objectname>.
In addition to the origin annotation, all objects managed by the resource manager get a dedicated label resources.gardener.cloud/managed-by. This label can be used to describe these objects with a selector. By default it is set to “gardener”, but this can be overwritten by setting the .conrollers.managedResources.managedByLabelValue field in the component configuration.
Compression
The number and size of manifests for a ManagedResource can accumulate to a considerable amount which leads to increased Secret data.
A decent compression algorithm helps to reduce the footprint of such Secrets and the load they put on etcd, the kube-apiserver, and client caches.
We found Brotli to be a suitable candidate for most use cases (see comparison table here).
When the gardener-resource-manager detects a data key with the known suffix .br, it automatically un-compresses the data first before processing the contained manifest.
This controller processes ManagedResources that were reconciled by the main ManagedResource Controller at least once.
Its main job is to perform checks for maintaining the well known conditionsResourcesHealthy and ResourcesProgressing.
Progressing Checks
In Kubernetes, applied changes must usually be rolled out first, e.g. when changing the base image in a Deployment.
Progressing checks detect ongoing roll-outs and report them in the ResourcesProgressing condition of the corresponding ManagedResource.
The following object kinds are considered for progressing checks:
gardener-resource-manager can evaluate the health of specific resources, often by consulting their conditions.
Health check results are regularly updated in the ResourcesHealthy condition of the corresponding ManagedResource.
The following object kinds are considered for health checks:
If a resource owned by a ManagedResource is annotated with resources.gardener.cloud/skip-health-check=true, then the resource will be skipped during health checks by the health controller. The ManagedResource conditions will not reflect the health condition of this resource anymore. The ResourcesProgressing condition will also be set to False.
In Kubernetes, workload resources (e.g., Pods) can mount ConfigMaps or Secrets or reference them via environment variables in containers.
Typically, when the content of such a ConfigMap/Secret gets changed, then the respective workload is usually not dynamically reloading the configuration, i.e., a restart is required.
The most commonly used approach is probably having the so-called checksum annotations in the pod template, which makes Kubernetes recreate the pod if the checksum changes.
However, it has the downside that old, still running versions of the workload might not be able to properly work with the already updated content in the ConfigMap/Secret, potentially causing application outages.
In order to protect users from such outages (and also to improve the performance of the cluster), the Kubernetes community provides the “immutable ConfigMaps/Secrets feature”.
Enabling immutability requires ConfigMaps/Secrets to have unique names.
Having unique names requires the client to delete ConfigMaps/Secrets no longer in use.
In order to provide a similarly lightweight experience for clients (compared to the well-established checksum annotation approach), the gardener-resource-manager features an optional garbage collector controller (disabled by default).
The purpose of this controller is cleaning up such immutable ConfigMaps/Secrets if they are no longer in use.
How Does the Garbage Collector Work?
The following algorithm is implemented in the GC controller:
List all ConfigMaps and Secrets labeled with resources.gardener.cloud/garbage-collectable-reference=true.
List all Deployments, StatefulSets, DaemonSets, Jobs, CronJobs, Pods, ManagedResources and for each of them:
iterate over the .metadata.annotations and for each of them:
If the annotation key follows the reference.resources.gardener.cloud/{configmap,secret}-<hash> scheme and the value equals <name>, then consider it as “in-use”.
Delete all ConfigMaps and Secrets not considered as “in-use”.
Consequently, clients need to:
Create immutable ConfigMaps/Secrets with unique names (e.g., a checksum suffix based on the .data).
Label such ConfigMaps/Secrets with resources.gardener.cloud/garbage-collectable-reference=true.
Annotate their workload resources with reference.resources.gardener.cloud/{configmap,secret}-<hash>=<name> for all ConfigMaps/Secrets used by the containers of the respective Pods.
⚠️ Add such annotations to .metadata.annotations, as well as to all templates of other resources (e.g., .spec.template.metadata.annotations in Deployments or .spec.jobTemplate.metadata.annotations and .spec.jobTemplate.spec.template.metadata.annotations for CronJobs.
This ensures that the GC controller does not unintentionally consider ConfigMaps/Secrets as “not in use” just because there isn’t a Pod referencing them anymore (e.g., they could still be used by a Deployment scaled down to 0).
ℹ️ For the last step, there is a helper function InjectAnnotations in the pkg/controller/garbagecollector/references, which you can use for your convenience.
This controller provides the service to create and auto-renew tokens via the TokenRequest API.
It provides a functionality similar to the kubelet’s Service Account Token Volume Projection.
It was created to handle the special case of issuing tokens to pods that run in a different cluster than the API server they communicate with (hence, using the native token volume projection feature is not possible).
The controller differentiates between source cluster and target cluster.
The source cluster hosts the gardener-resource-manager pod. Secrets in this cluster are watched and modified by the controller.
The target clustercan be configured to point to another cluster. The existence of ServiceAccounts are ensured and token requests are issued against the target.
When the gardener-resource-manager is deployed next to the Shoot’s controlplane in the Seed, the source cluster is the Seed while the target cluster points to the Shoot.
Reconciliation Loop
This controller reconciles Secrets in all namespaces in the source cluster with the label: resources.gardener.cloud/purpose=token-requestor.
See this YAML file for an example of the secret.
The controller ensures a ServiceAccount exists in the target cluster as specified in the annotations of the Secret in the source cluster:
You can optionally annotate the Secret with serviceaccount.resources.gardener.cloud/labels, e.g. serviceaccount.resources.gardener.cloud/labels={"some":"labels","foo":"bar"}.
This will make the ServiceAccount getting labelled accordingly.
The requested tokens will act with the privileges which are assigned to this ServiceAccount.
The controller will then request a token via the TokenRequest API and populate it into the .data.token field to the Secret in the source cluster.
Alternatively, the client can provide a raw kubeconfig (in YAML or JSON format) via the Secret’s .data.kubeconfig field.
The controller will then populate the requested token in the kubeconfig for the user used in the .current-context.
For example, if .data.kubeconfig is
If a kubeconfig is present in the secret, the CA bundle is set in the in the cluster.certificate-authority-data field of the cluster of the current context.
Otherwise, the bundle is stored in an additional secret key bundle.crt.
The controller also adds an annotation to the Secret to keep track when to renew the token before it expires.
By default, the tokens are issued to expire after 12 hours. The expiration time can be set with the following annotation:
It automatically renews once 80% of the lifetime is reached, or after 24h.
Optionally, the controller can also populate the token into a Secret in the target cluster. This can be requested by annotating the Secret in the source cluster with:
Overall, the TokenRequestor controller provides credentials with limited lifetime (JWT tokens)
used by Shoot control plane components running in the Seed to talk to the Shoot API Server.
Please see the graphic below:
ℹ️ Generally, the controller can run with multiple instances in different components.
For example, gardener-resource-manager might run the TokenRequestor controller, but gardenlet might run it, too.
In order to differentiate which instance of the controller is responsible for a Secret, it can be labeled with resources.gardener.cloud/class=<class>.
The <class> must be configured in the respective controller, otherwise it will be responsible for all Secrets no matter whether they have the label or not.
Gardener configures the kubelets such that they request two certificates via the CertificateSigningRequest API:
client certificate for communicating with the kube-apiserver
server certificate for serving its HTTPS server
For client certificates, the kubernetes.io/kube-apiserver-client-kubelet signer is used (see Certificate Signing Requests for more details).
The kube-controller-manager’s csrapprover controller is responsible for auto-approving such CertificateSigningRequests so that the respective certificates can be issued.
For server certificates, the kubernetes.io/kubelet-serving signer is used.
Unfortunately, the kube-controller-manager is not able to auto-approve such CertificateSigningRequests (see kubernetes/kubernetes#73356 for details).
That’s the motivation for having this controller as part of gardener-resource-manager.
It watches CertificateSigningRequests with the kubernetes.io/kubelet-serving signer and auto-approves them when all the following conditions are met:
The .spec.username is prefixed with system:node:.
There must be at least one DNS name or IP address as part of the certificate SANs.
The common name in the CSR must match the .spec.username.
The organization in the CSR must only contain system:nodes.
There must be a Node object with the same name in the shoot cluster.
There must be exactly one Machine for the node in the seed cluster.
The DNS names part of the SANs must be equal to all .status.addresses[] of type Hostname in the Node.
The IP addresses part of the SANs must be equal to all .status.addresses[] of type InternalIP in the Node.
If any one of these requirements is violated, the CertificateSigningRequest will be denied.
Otherwise, once approved, the kube-controller-manager’s csrsigner controller will issue the requested certificate.
Gardener Node Agent
There is a second use case for CSR Approver, because Gardener Node Agent is able to use client certificates for communication with kube-apiserver.
These certificates are requested via the CertificateSigningRequest API. They are using the kubernetes.io/kube-apiserver-client signer.
Three use cases are covered:
Bootstrap a new node.
Renew certificates.
Migrate nodes using gardener-node-agent service account.
There is no auto-approve for these CertificateSigningRequests either.
As there are more users of kubernetes.io/kube-apiserver-client signer this controller handles only CertificateSigningRequests when the common name in the CSR is prefixed with gardener.cloud:node-agent:machine:.
The prefix is followed by the username which must be equal to the machine.Name.
It auto-approves them when the following conditions are met.
Bootstrapping:
The .spec.username is prefixed with system:node:.
A Machine for common name pattern gardener.cloud:node-agent:machine:<machine-name> in the CSR exists.
The Machine does not have a label with key node.
Certificate renewal:
The .spec.username is prefixed with gardener.cloud:node-agent:machine:.
A Machine for common name pattern gardener.cloud:node-agent:machine:<machine-name> in the CSR exists.
The common name in the CSR must match the .spec.username.
Migration:
The .spec.username is equal to system:serviceaccount:kube-system:gardener-node-agent.
A Machine for common name pattern gardener.cloud:node-agent:machine:<machine-name> in the CSR exists.
The Machine has a label with key node.
If the common name in the CSR is not prefixed with gardener.cloud:node-agent:machine:, the CertificateSigningRequest will be ignored.
If any one of these requirements is violated, the CertificateSigningRequest will be denied.
Otherwise, once approved, the kube-controller-manager’s csrsigner controller will issue the requested certificate.
This controller reconciles Services with a non-empty .spec.podSelector.
It creates two NetworkPolicys for each port in the .spec.ports[] list.
For example:
apiVersion: v1
kind: Service
metadata:
name: gardener-resource-manager
namespace: a
spec:
selector:
app: gardener-resource-manager
ports:
- name: server
port: 443
protocol: TCP
targetPort: 10250
leads to
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
annotations:
gardener.cloud/description: Allows ingress TCP traffic to port 10250 for pods
selected by the a/gardener-resource-manager service selector from pods running
in namespace a labeled with map[networking.resources.gardener.cloud/to-gardener-resource-manager-tcp-10250:allowed].
name: ingress-to-gardener-resource-manager-tcp-10250
namespace: a
spec:
ingress:
- from:
- podSelector:
matchLabels:
networking.resources.gardener.cloud/to-gardener-resource-manager-tcp-10250: allowed
ports:
- port: 10250
protocol: TCP
podSelector:
matchLabels:
app: gardener-resource-manager
policyTypes:
- Ingress
---
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
annotations:
gardener.cloud/description: Allows egress TCP traffic to port 10250 from pods
running in namespace a labeled with map[networking.resources.gardener.cloud/to-gardener-resource-manager-tcp-10250:allowed]
to pods selected by the a/gardener-resource-manager service selector.
name: egress-to-gardener-resource-manager-tcp-10250
namespace: a
spec:
egress:
- to:
- podSelector:
matchLabels:
app: gardener-resource-manager
ports:
- port: 10250
protocol: TCP
podSelector:
matchLabels:
networking.resources.gardener.cloud/to-gardener-resource-manager-tcp-10250: allowed
policyTypes:
- Egress
A component that initiates the connection to gardener-resource-manager’s tcp/10250 port can now be labeled with networking.resources.gardener.cloud/to-gardener-resource-manager-tcp-10250=allowed.
That’s all this component needs to do - it does not need to create any NetworkPolicys itself.
Cross-Namespace Communication
Apart from this “simple” case where both communicating components run in the same namespace a, there is also the cross-namespace communication case.
With above example, let’s say there are components running in another namespace b, and they would like to initiate the communication with gardener-resource-manager in a.
To cover this scenario, the Service can be annotated with networking.resources.gardener.cloud/namespace-selectors='[{"matchLabels":{"kubernetes.io/metadata.name":"b"}}]'.
Note that you can specify multiple namespace selectors in this annotation which are OR-ed.
This will make the controller create additional NetworkPolicys as follows:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
annotations:
gardener.cloud/description: Allows ingress TCP traffic to port 10250 for pods selected
by the a/gardener-resource-manager service selector from pods running in namespace b
labeled with map[networking.resources.gardener.cloud/to-a-gardener-resource-manager-tcp-10250:allowed].
name: ingress-to-gardener-resource-manager-tcp-10250-from-b
namespace: a
spec:
ingress:
- from:
- namespaceSelector:
matchLabels:
kubernetes.io/metadata.name: b
podSelector:
matchLabels:
networking.resources.gardener.cloud/to-a-gardener-resource-manager-tcp-10250: allowed
ports:
- port: 10250
protocol: TCP
podSelector:
matchLabels:
app: gardener-resource-manager
policyTypes:
- Ingress
---
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
annotations:
gardener.cloud/description: Allows egress TCP traffic to port 10250 from pods running in
namespace b labeled with map[networking.resources.gardener.cloud/to-a-gardener-resource-manager-tcp-10250:allowed]
to pods selected by the a/gardener-resource-manager service selector.
name: egress-to-a-gardener-resource-manager-tcp-10250
namespace: b
spec:
egress:
- to:
- namespaceSelector:
matchLabels:
kubernetes.io/metadata.name: a
podSelector:
matchLabels:
app: gardener-resource-manager
ports:
- port: 10250
protocol: TCP
podSelector:
matchLabels:
networking.resources.gardener.cloud/to-a-gardener-resource-manager-tcp-10250: allowed
policyTypes:
- Egress
The components in namespace b now need to be labeled with networking.resources.gardener.cloud/to-a-gardener-resource-manager-tcp-10250=allowed, but that’s already it.
Obviously, this approach also works for namespace selectors different from kubernetes.io/metadata.name to cover scenarios where the namespace name is not known upfront or where multiple namespaces with a similar label are relevant.
The controller creates two dedicated policies for each namespace matching the selectors.
Service Targets In Multiple Namespaces
Finally, let’s say there is a Service called example which exists in different namespaces whose names are not static (e.g., foo-1, foo-2), and a component in namespace bar wants to initiate connections with all of them.
The exampleServices in these namespaces can now be annotated with networking.resources.gardener.cloud/namespace-selectors='[{"matchLabels":{"kubernetes.io/metadata.name":"bar"}}]'.
As a consequence, the component in namespace bar now needs to be labeled with networking.resources.gardener.cloud/to-foo-1-example-tcp-8080=allowed, networking.resources.gardener.cloud/to-foo-2-example-tcp-8080=allowed, etc.
This approach does not work in practice, however, since the namespace names are neither static nor known upfront.
To overcome this, it is possible to specify an alias for the concrete namespace in the pod label selector via the networking.resources.gardener.cloud/pod-label-selector-namespace-alias annotation.
In above case, the exampleService in the foo-* namespaces could be annotated with networking.resources.gardener.cloud/pod-label-selector-namespace-alias=all-foos.
This would modify the label selector in all NetworkPolicys related to cross-namespace communication, i.e. instead of networking.resources.gardener.cloud/to-foo-{1,2,...}-example-tcp-8080=allowed, networking.resources.gardener.cloud/to-all-foos-example-tcp-8080=allowed would be used.
Now the component in namespace bar only needs this single label and is able to talk to all such Services in the different namespaces.
Real-world examples for this scenario are the kube-apiserverService (which exists in all shoot namespaces), or the istio-ingressgatewayService (which exists in all istio-ingress* namespaces).
In both cases, the names of the namespaces are not statically known and depend on user input.
Overwriting The Pod Selector Label
For a component which initiates the connection to many other components, it’s sometimes impractical to specify all the respective labels in its pod template.
For example, let’s say a component foo talks to bar{0..9} on ports tcp/808{0..9}.
foo would need to have the ten networking.resources.gardener.cloud/to-bar{0..9}-tcp-808{0..9}=allowed labels.
As an alternative and to simplify this, it is also possible to annotate the targeted Services with networking.resources.gardener.cloud/from-<some-alias>-allowed-ports.
For our example, <some-alias> could be all-bars.
As a result, component foo just needs to have the label networking.resources.gardener.cloud/to-all-bars=allowed instead of all the other ten explicit labels.
⚠️ Note that this also requires to specify the list of allowed container ports as annotation value since the pod selector label will no longer be specific for a dedicated service/port.
For our example, the Service for barX with X in {0..9} needs to be annotated with networking.resources.gardener.cloud/from-all-bars-allowed-ports=[{"port":808X,"protocol":"TCP"}] in addition.
Real-world examples for this scenario are the Prometheis in seed clusters which initiate the communication to a lot of components in order to scrape their metrics.
Another example is the kube-apiserver which initiates the communication to webhook servers (potentially of extension components that are not known by Gardener itself).
Ingress From Everywhere
All above scenarios are about components initiating connections to some targets.
However, some components also receive incoming traffic from sources outside the cluster.
This traffic requires adequate ingress policies so that it can be allowed.
To cover this scenario, the Service can be annotated with networking.resources.gardener.cloud/from-world-to-ports=[{"port":"10250","protocol":"TCP"}].
As a result, the controller creates the following NetworkPolicy:
The respective pods don’t need any additional labels.
If the annotation’s value is empty ([]) then all ports are allowed.
Services Exposed via Ingress Resources
The controller can optionally be configured to watch Ingress resources by specifying the pod and namespace selectors for the Ingress controller.
If this information is provided, it automatically creates NetworkPolicy resources allowing the respective ingress/egress traffic for the backends exposed by the Ingresses.
This way, neither custom NetworkPolicys nor custom labels must be provided.
The needed configuration is part of the component configuration:
As a result, the controller would automatically create the following NetworkPolicys:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
annotations:
gardener.cloud/description: Allows ingress TCP traffic to port 10250 for pods
selected by the a/gardener-resource-manager service selector from ingress controller
pods running in the default namespace labeled with map[foo:bar].
name: ingress-to-gardener-resource-manager-tcp-10250-from-ingress-controller
namespace: a
spec:
ingress:
- from:
- podSelector:
matchLabels:
foo: bar
namespaceSelector:
matchLabels:
kubernetes.io/metadata.name: default
ports:
- port: 10250
protocol: TCP
podSelector:
matchLabels:
app: gardener-resource-manager
policyTypes:
- Ingress
---
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
annotations:
gardener.cloud/description: Allows egress TCP traffic to port 10250 from pods
running in the default namespace labeled with map[foo:bar] to pods selected by
the a/gardener-resource-manager service selector.
name: egress-to-a-gardener-resource-manager-tcp-10250-from-ingress-controller
namespace: default
spec:
egress:
- to:
- podSelector:
matchLabels:
app: gardener-resource-manager
namespaceSelector:
matchLabels:
kubernetes.io/metadata.name: a
ports:
- port: 10250
protocol: TCP
podSelector:
matchLabels:
foo: bar
policyTypes:
- Egress
ℹ️ Note that Ingress resources reference the service port while NetworkPolicys reference the target port/container port.
The controller automatically translates this when reconciling the NetworkPolicy resources.
Gardenlet configures kubelet of shoot worker nodes to register the Node object with the node.gardener.cloud/critical-components-not-ready taint (effect NoSchedule).
This controller watches newly created Node objects in the shoot cluster and removes the taint once all node-critical components are scheduled and ready.
If the controller finds node-critical components that are not scheduled or not ready yet, it checks the Node again after the duration configured in ResourceManagerConfiguration.controllers.node.backoff
Please refer to the feature documentation or proposal issue for more details.
This controller computes a reconciliation delay per node by using a simple linear mapping approach based on the index of the nodes in the list of all nodes in the shoot cluster.
This approach ensures that the delays of all instances of gardener-node-agent are distributed evenly.
The minimum and maximum delays can be configured, but they are defaulted to 0s and 5m, respectively.
This approach works well as long as the number of nodes in the cluster is not higher than the configured maximum delay in seconds.
In this case, the delay is still computed linearly, however, the more nodes exist in the cluster, the closer the delay times become (which might be of limited use then).
Consider increasing the maximum delay by annotating the Shoot with shoot.gardener.cloud/cloud-config-execution-max-delay-seconds=<value>.
The highest possible value is 1800.
The controller adds the node-agent.gardener.cloud/reconciliation-delay annotation to nodes whose value is read by the node-agents.
Webhooks
Mutating Webhooks
High Availability Config
This webhook is used to conveniently apply the configuration to make components deployed to seed or shoot clusters highly available.
The details and scenarios are described in High Availability Of Deployed Components.
The webhook reacts on creation/update of Deployments, StatefulSets and HorizontalPodAutoscalers in namespaces labeled with high-availability-config.resources.gardener.cloud/consider=true.
The webhook performs the following actions:
The .spec.replicas (or spec.minReplicas respectively) field is mutated based on the high-availability-config.resources.gardener.cloud/type label of the resource and the high-availability-config.resources.gardener.cloud/failure-tolerance-type annotation of the namespace:
Failure Tolerance Type ➡️ / ⬇️ Component Type️ ️
unset
empty
non-empty
controller
2
1
2
server
2
2
2
The replica count values can be overwritten by the high-availability-config.resources.gardener.cloud/replicas annotation.
It does NOT mutate the replicas when:
the replicas are already set to 0 (hibernation case), or
when the resource is scaled horizontally by HorizontalPodAutoscaler, and the current replica count is higher than what was computed above.
When the high-availability-config.resources.gardener.cloud/zones annotation is NOT empty and either the high-availability-config.resources.gardener.cloud/failure-tolerance-type annotation is set or the high-availability-config.resources.gardener.cloud/zone-pinning annotation is set to true, then it adds a node affinity to the pod template spec:
This ensures that all pods are pinned to only nodes in exactly those concrete zones.
Topology Spread Constraints are added to the pod template spec when the .spec.replicas are greater than 1. When the high-availability-config.resources.gardener.cloud/zones annotation …
… contains only one zone, then the following is added:
spec:
topologySpreadConstraints:
- topologyKey: kubernetes.io/hostname
minDomains: 3 # lower value of max replicas or 3 maxSkew: 1
whenUnsatisfiable: ScheduleAnyway # or DoNotSchedule matchLabelKeys:
- pod-template-hash
labelSelector: ...
This ensures that the (multiple) pods are scheduled across nodes. minDomains is set when failure tolerance is configured or annotation high-availability-config.resources.gardener.cloud/host-spread="true" is given.
… contains at least two zones, then the following is added:
spec:
topologySpreadConstraints:
- topologyKey: kubernetes.io/hostname
maxSkew: 1
whenUnsatisfiable: ScheduleAnyway # or DoNotSchedule matchLabelKeys:
- pod-template-hash
labelSelector: ...
- topologyKey: topology.kubernetes.io/zone
minDomains: 2 # lower value of max replicas or number of zones maxSkew: 1
whenUnsatisfiable: DoNotSchedule
matchLabelKeys:
- pod-template-hash
labelSelector: ...
This enforces that the (multiple) pods are scheduled across zones.
The minDomains calculation is based on whatever value is lower - (maximum) replicas or number of zones. This is the number of minimum domains required to schedule pods in a highly available manner.
Independent on the number of zones, when one of the following conditions is true, then the field whenUnsatisfiable is set to DoNotSchedule for the constraint with topologyKey=kubernetes.io/hostname (which enforces the node-spread):
The high-availability-config.resources.gardener.cloud/host-spread annotation is set to true.
The high-availability-config.resources.gardener.cloud/failure-tolerance-type annotation is set and NOT empty.
Tolerations for taints node.kubernetes.io/not-ready and node.kubernetes.io/unreachable are added to the handled Deployment and StatefulSet if their podTemplates do not already specify them.
The TolerationSeconds are taken from the respective configuration section of the webhook’s configuration (see example)).
We consider fine-tuned values for those tolerations a matter of high-availability because they often help to reduce recovery times in case of node or zone outages, also see High-Availability Best Practices.
In addition, this webhook handling helps to set defaults for many but not all workload components in a cluster. For instance, Gardener can use this webhook to set defaults for nearly every component in seed clusters but only for the system components in shoot clusters. Any customer workload remains unchanged.
Kubernetes Service Host Injection
By default, when Pods are created, Kubernetes implicitly injects the KUBERNETES_SERVICE_HOST environment variable into all containers.
The value of this variable points it to the default Kubernetes service (i.e., kubernetes.default.svc.cluster.local).
This allows pods to conveniently talk to the API server of their cluster.
In shoot clusters, this network path involves the apiserver-proxyDaemonSet which eventually forwards the traffic to the API server.
Hence, it results in additional network hop.
The purpose of this webhook is to explicitly inject the KUBERNETES_SERVICE_HOST environment variable into all containers and setting its value to the FQDN of the API server.
This way, the additional network hop is avoided.
Auto-Mounting Projected ServiceAccount Tokens
When this webhook is activated, then it automatically injects projected ServiceAccount token volumes into Pods and all its containers if all of the following preconditions are fulfilled:
The Pod is NOT labeled with projected-token-mount.resources.gardener.cloud/skip=true.
The Pod’s .spec.serviceAccountName field is NOT empty and NOT set to default.
The ServiceAccount specified in the Pod’s .spec.serviceAccountName sets .automountServiceAccountToken=false.
The Pod’s .spec.volumes[] DO NOT already contain a volume with a name prefixed with kube-api-access-.
The expirationSeconds are defaulted to 12h and can be overwritten with the .webhooks.projectedTokenMount.expirationSeconds field in the component configuration, or with the projected-token-mount.resources.gardener.cloud/expiration-seconds annotation on a Pod resource.
The volume will be mounted into all containers specified in the Pod to the path /var/run/secrets/kubernetes.io/serviceaccount.
This is the default location where client libraries expect to find the tokens and mimics the upstream ServiceAccount admission plugin. See Managing Service Accounts for more information.
Overall, this webhook is used to inject projected service account tokens into pods running in the Shoot and the Seed cluster.
Hence, it is served from the Seed GRM and each Shoot GRM.
Please find an overview below for pods deployed in the Shoot cluster:
Pod Topology Spread Constraints
When this webhook is enabled, then it mimics the topologyKey feature for Topology Spread Constraints (TSC) on the label pod-template-hash.
Concretely, when a pod is labelled with pod-template-hash, the handler of this webhook extends any topology spread constraint in the pod:
The procedure circumvents a known limitation with TSCs which leads to imbalanced deployments after rolling updates.
Gardener enables this webhook to schedule pods of deployments across nodes and zones. This webhook is enabled only when the MatchLabelKeysInPodTopologySpread feature gate (beta since v1.27) is explicitly disabled in the kube-apiserver and kube-scheduler.
Please note that the gardener-resource-manager itself as well as pods labelled with topology-spread-constraints.resources.gardener.cloud/skip are excluded from any mutations.
System Components Webhook
If enabled, this webhook handles scheduling concerns for system components Pods (except those managed by DaemonSets).
The following tasks are performed by this webhook:
Add pod.spec.nodeSelector as given in the webhook configuration.
Add pod.spec.tolerations as given in the webhook configuration.
Add pod.spec.tolerations for any existing nodes matching the node selector given in the webhook configuration. Known taints and tolerations used for taint based evictions are disregarded.
Gardener enables this webhook for kube-system and kubernetes-dashboard namespaces in shoot clusters, selecting Pods being labelled with resources.gardener.cloud/managed-by: gardener.
It adds a configuration, so that Pods will get the worker.gardener.cloud/system-components: true node selector (step 1) as well as tolerate any custom taint (step 2) that is added to system component worker nodes (shoot.spec.provider.workers[].systemComponents.allow: true).
In addition, the webhook merges these tolerations with the ones required for at that time available system component Nodes in the cluster (step 3).
Both is required to ensure system component Pods can be scheduled or executed during an active shoot reconciliation that is happening due to any modifications to shoot.spec.provider.workers[].taints, e.g. Pods must be scheduled while there are still Nodes not having the updated taint configuration.
You can opt-out of this behaviour for Pods by labeling them with system-components-config.resources.gardener.cloud/skip=true.
EndpointSlice Hints
This webhook mutates EndpointSlices. For each endpoint in the EndpointSlice, it sets the endpoint’s hints to the endpoint’s zone.
The webhook aims to circumvent issues with the Kubernetes TopologyAwareHints feature that currently does not allow to achieve a deterministic topology-aware traffic routing. For more details, see the following issue kubernetes/kubernetes#113731 that describes drawbacks of the TopologyAwareHints feature for our use case.
If the above-mentioned issue gets resolved and there is a native support for deterministic topology-aware traffic routing in Kubernetes, then this webhook can be dropped in favor of the native Kubernetes feature.
The EndpointSlice Hints webhook is disabled when the runtime Kubernetes version is >= 1.32. Instead, the ServiceTrafficDistribution feature is used. See more details in Topology-Aware Traffic Routing.
Pod Kube API Server Load Balancing
This webhook is used in the context of L7 load balancing for kube-apiservers.
It facilitates access of control plane components to the kube-apiserver via istio ingress gateway which is the Gardener l7 load balancer.
For those control plane pods which use the generic token kubeconfig the webhook adds these items:
It adds a network policy label to allow the pods to access the internal istio ingress gateway service which is responsible for “its” kube-apiserver.
It adds a host alias which resolves the cluster externally resolvable kube-apiserver host to the internal istio ingress gateway service cluster IP address.
apiVersion: v1
kind: Pod
metadata:
labels:
networking.resources.gardener.cloud/to-istio-ingress-istio-ingressgateway-internal-tcp-9443: allowed # added by webhookspec:
hostAliases:
- hostnames: # added by webhook - api.local.local.internal.local.gardener.cloud # added by webhook ip: 10.2.15.178 # added by webhook
For mutating pods, the webhook needs to know the namespace of the istio ingress gateway responsible for the kube-apiserver and its host names.
These values are stored in istio-internal-load-balancing configmap in the same namespace as the pod being mutated.
Validating Webhooks
Unconfirmed Deletion Prevention For Custom Resources And Definitions
As part of Gardener’s extensibility concepts, a lot of CustomResourceDefinitions are deployed to the seed clusters that serve as extension points for provider-specific controllers.
For example, the Infrastructure CRD triggers the provider extension to prepare the IaaS infrastructure of the underlying cloud provider for a to-be-created shoot cluster.
Consequently, these extension CRDs have a lot of power and control large portions of the end-user’s shoot cluster.
Accidental or undesired deletions of those resource can cause tremendous and hard-to-recover-from outages and should be prevented.
When this webhook is activated, it reacts for CustomResourceDefinitions and most of the custom resources in the extensions.gardener.cloud/v1alpha1 API group.
It also reacts for the druid.gardener.cloud/v1alpha1.Etcd resources.
The webhook prevents DELETE requests for those CustomResourceDefinitions labeled with gardener.cloud/deletion-protected=true, and for all mentioned custom resources if they were not previously annotated with the confirmation.gardener.cloud/deletion=true.
This prevents that undesired kubectl delete <...> requests are accepted.
Extension Resource Validation
When this webhook is activated, it reacts for most of the custom resources in the extensions.gardener.cloud/v1alpha1 API group.
It also reacts for the druid.gardener.cloud/v1alpha1.Etcd resources.
The webhook validates the resources specifications for CREATE and UPDATE requests.
Authorization Webhooks
node-agent-authorizer webhook
gardener-resource-manager serves an authorization webhook for shoot kube-apiservers which authorizes requests made by the gardener-node-agent.
It works similar to SeedAuthorizer. However, the logic used to make decisions is much simpler so it does not implement a decision graph.
In many cases, the objects gardener-node-agent is allowed to access depend on the Node it is running on.
The username of the gardener-node-agent used for authorization requests is derived from the name of the Machine resource responsible for the node that the gardener-node-agent is running on. It follows the pattern gardener.cloud:node-agent:machine:<machine-name>.
The name of the Node which runs on a Machine is read from node label of the Machine.
All gardener-node-agent users are assigned to gardener.cloud:node-agents group.
Today, the following rules are implemented:
Resource
Verbs
Description
CertificateSigningRequests
get , create
Allow create requests for all CertificateSigningRequests s. Allow get requests for CertificateSigningRequests s created by the same user.
Events
create , patch
Allow to create and patch all Event s.
Leases
get , list , watch , create , update
Allow get , list , watch , create , update requests for Leases with the name gardener-node-agent-<node-name> in kube-system namespace.
Nodes
get , list , watch , patch , update
Allow get , watch , patch , update requests for the Node where gardener-node-agent is running. Allow list requests for all nodes.
Secrets
get , list , watch
Allow get , list , watch request to gardener-valitail secret and the gardener-node-agent-secret of the worker group of the Node where gardener-node-agent is running.
Pods
get , list , watch , delete
Allow list and watch permissions on Pods . For Shoot clusters running Kubernetes v1.31 or later, where the AuthorizeWithSelectors feature gate is enabled (it’s beta and enabled by default in v1.32+), allow list and watch only if the request contains a field selector spec.nodeName=<node-on-which-gardener-node-agent-is-running> . Allow get and delete requests if the .spec.nodeName of the Pod matches the Node on which gardener-node-agent is running.
4.13 - Gardener Scheduler
Understand the configuration and flow of the controller that assigns a seed cluster to newly created shoots
Overview
The Gardener Scheduler is in essence a controller that watches newly created shoots and assigns a seed cluster to them.
Conceptually, the task of the Gardener Scheduler is very similar to the task of the Kubernetes Scheduler: finding a seed for a shoot instead of a node for a pod.
Either the scheduling strategy or the shoot cluster purpose hereby determines how the scheduler is operating.
The following sections explain the configuration and flow in greater detail.
Why Is the Gardener Scheduler Needed?
1. Decoupling
Previously, an admission plugin in the Gardener API server conducted the scheduling decisions.
This implies changes to the API server whenever adjustments of the scheduling are needed.
Decoupling the API server and the scheduler comes with greater flexibility to develop these components independently.
2. Extensibility
It should be possible to easily extend and tweak the scheduler in the future.
Possibly, similar to the Kubernetes scheduler, hooks could be provided which influence the scheduling decisions.
It should be also possible to completely replace the standard Gardener Scheduler with a custom implementation.
Algorithm Overview
The following sequence describes the steps involved to determine a seed candidate:
Determine usable seeds with “usable” defined as follows:
no .metadata.deletionTimestamp
.spec.settings.scheduling.visible is true
.status.lastOperation is not nil
conditions GardenletReady, BackupBucketsReady (if available) are true
Filter seeds:
matching .spec.seedSelector in CloudProfile used by the Shoot
matching .spec.seedSelector in Shoot
having no network intersection with the Shoot’s networks (due to the VPN connectivity between seeds and shoots their networks must be disjoint)
whose taints (.spec.taints) are tolerated by the Shoot (.spec.tolerations)
whose access restrictions (.spec.accessRestrictions) are supporting those configured in the Shoot (.spec.accessRestrictions)
which have at least three zones in .spec.provider.zones if shoot requests a high available control plane with failure tolerance type zone.
Apply active strategy e.g., Minimal Distance strategy
Choose least utilized seed, i.e., the one with the least number of shoot control planes, will be the winner and written to the .spec.seedName field of the Shoot.
In order to put the scheduling decision into effect, the scheduler sends an update request for the Shoot resource to
the API server. After validation, the gardener-apiserver updates the Shoot to have the spec.seedName field set.
Subsequently, the gardenlet picks up and starts to create the cluster on the specified seed.
Configuration
The Gardener Scheduler configuration has to be supplied on startup. It is a mandatory and also the only available flag.
This yaml file holds an example scheduler configuration.
Most of the configuration options are the same as in the Gardener Controller Manager (leader election, client connection, …).
However, the Gardener Scheduler on the other hand does not need a TLS configuration, because there are currently no webhooks configurable.
Strategies
The scheduling strategy is defined in the candidateDeterminationStrategy of the scheduler’s configuration and can have the possible values SameRegion and MinimalDistance.
The SameRegion strategy is the default strategy.
Same Region strategy
The Gardener Scheduler reads the spec.provider.type and .spec.region fields from the Shoot resource.
It tries to find a seed that has the identical .spec.provider.type and .spec.provider.region fields set.
If it cannot find a suitable seed, it adds an event to the shoot stating that it is unschedulable.
Minimal Distance strategy
The Gardener Scheduler tries to find a valid seed with minimal distance to the shoot’s intended region.
Distances are configured via ConfigMap(s), usually per cloud provider in a Gardener landscape.
The configuration is structured like this:
It refers to one or multiple CloudProfiles via annotation scheduling.gardener.cloud/cloudprofiles.
It contains the declaration as region-config via label scheduling.gardener.cloud/purpose.
If a CloudProfile is referred by multiple ConfigMaps, only the first one is considered.
The data fields configure actual distances, where key relates to the Shoot region and value contains distances to Seed regions.
Gardener provider extensions for public cloud providers usually have an example weight ConfigMap in their repositories.
We suggest to check them out before defining your own data.
If a valid seed candidate cannot be found after consulting the distance configuration, the scheduler will fall back to
the Levenshtein distance to find the closest region. Therefore, the region name
is split into a base name and an orientation. Possible orientations are north, south, east, west and central.
The distance then is twice the Levenshtein distance of the region’s base name plus a correction value based on the
orientation and the provider.
If the orientations of shoot and seed candidate match, the correction value is 0, if they differ it is 2 and if
either the seed’s or the shoot’s region does not have an orientation it is 1.
If the provider differs, the correction value is additionally incremented by 2.
Because of this, a matching region with a matching provider is always preferred.
Special handling based on shoot cluster purpose
Every shoot cluster can have a purpose that describes what the cluster is used for, and also influences how the cluster is setup (see Shoot Cluster Purpose for more information).
In case the shoot has the testing purpose, then the scheduler only reads the .spec.provider.type from the Shoot resource and tries to find a Seed that has the identical .spec.provider.type.
The region does not matter, i.e., testing shoots may also be scheduled on a seed in a complete different region if it is better for balancing the whole Gardener system.
shoots/binding Subresource
The shoots/binding subresource is used to bind a Shoot to a Seed. On creation of a shoot cluster/s, the scheduler updates the binding automatically if an appropriate seed cluster is available.
Only an operator with the necessary RBAC can update this binding manually. This can be done by changing the .spec.seedName of the shoot. However, if a different seed is already assigned to the shoot, this will trigger a control-plane migration. For required steps, please see Triggering the Migration.
spec.schedulerName Field in the Shoot Specification
Similar to the spec.schedulerName field in Pods, the Shoot specification has an optional .spec.schedulerName field. If this field is set on creation, only the scheduler which relates to the configured name is responsible for scheduling the shoot.
The default-scheduler name is reserved for the default scheduler of Gardener.
Affected Shoots will remain in Pending state if the mentioned scheduler is not present in the landscape.
spec.seedName Field in the Shoot Specification
Similar to the .spec.nodeName field in Pods, the Shoot specification has an optional .spec.seedName field. If this field is set on creation, the shoot will be scheduled to this seed. However, this field can only be set by users having RBAC for the shoots/binding subresource. If this field is not set, the scheduler will assign a suitable seed automatically and populate this field with the seed name.
seedSelector Field in the Shoot Specification
Similar to the .spec.nodeSelector field in Pods, the Shoot specification has an optional .spec.seedSelector field.
It allows the user to provide a label selector that must match the labels of the Seeds in order to be scheduled to one of them.
The labels on the Seeds are usually controlled by Gardener administrators/operators - end users cannot add arbitrary labels themselves.
If provided, the Gardener Scheduler will only consider as “suitable” those seeds whose labels match those provided in the .spec.seedSelector of the Shoot.
By default, only seeds with the same provider as the shoot are selected. By adding a providerTypes field to the seedSelector,
a dedicated set of possible providers (* means all provider types) can be selected.
Ensuring a Seed’s Capacity for Shoots Is Not Exceeded
Seeds have a practical limit of how many shoots they can accommodate. Exceeding this limit is undesirable, as the system performance will be noticeably impacted. Therefore, the scheduler ensures that a seed’s capacity for shoots is not exceeded by taking into account a maximum number of shoots that can be scheduled onto a seed.
This mechanism works as follows:
The gardenlet is configured with certain resources and their total capacity (and, for certain resources, the amount reserved for Gardener), see /example/20-componentconfig-gardenlet.yaml. Currently, the only such resource is the maximum number of shoots that can be scheduled onto a seed.
The gardenlet seed controller updates the capacity and allocatable fields in the Seed status with the capacity of each resource and how much of it is actually available to be consumed by shoots. The allocatable value of a resource is equal to capacity minus reserved.
When scheduling shoots, the scheduler filters out all candidate seeds whose allocatable capacity for shoots would be exceeded if the shoot is scheduled onto the seed.
Failure to Determine a Suitable Seed
In case the scheduler fails to find a suitable seed, the operation is being retried with exponential backoff.
The reason for the failure will be reported in the Shoot’s .status.lastOperation field as well as a Kubernetes event (which can be retrieved via kubectl -n <namespace> describe shoot <shoot-name>).
Current Limitation / Future Plans
Azure unfortunately has a geographically non-hierarchical naming pattern and does not start with the continent. This is the reason why we will exchange the implementation of the MinimalDistance strategy with a more suitable one in the future.
4.14 - gardenlet
Understand how the gardenlet, the primary “agent” on every seed cluster, works and learn more about the different Gardener components
Overview
Gardener is implemented using the operator pattern:
It uses custom controllers that act on our own custom resources,
and apply Kubernetes principles to manage clusters instead of containers.
Following this analogy, you can recognize components of the Gardener architecture
as well-known Kubernetes components, for example, shoot clusters can be compared with pods,
and seed clusters can be seen as worker nodes.
The following Gardener components play a similar role as the corresponding components
in the Kubernetes architecture:
Gardener Component
Kubernetes Component
gardener-apiserver
kube-apiserver
gardener-controller-manager
kube-controller-manager
gardener-scheduler
kube-scheduler
gardenlet
kubelet
Similar to how the kube-scheduler of Kubernetes finds an appropriate node
for newly created pods, the gardener-scheduler of Gardener finds an appropriate seed cluster
to host the control plane for newly ordered clusters.
By providing multiple seed clusters for a region or provider, and distributing the workload,
Gardener also reduces the blast radius of potential issues.
Kubernetes runs a primary “agent” on every node, the kubelet,
which is responsible for managing pods and containers on its particular node.
Decentralizing the responsibility to the kubelet has the advantage that the overall system
is scalable. Gardener achieves the same for cluster management by using a gardenlet
as a primary “agent” on every seed cluster, and is only responsible for shoot clusters
located in its particular seed cluster:
The gardener-controller-manager has controllers to manage resources of the Gardener API. However, instead of letting the gardener-controller-manager talk directly to seed clusters or shoot clusters, the responsibility isn’t only delegated to the gardenlet, but also managed using a reversed control flow: It’s up to the gardenlet to contact the Gardener API server, for example, to share a status for its managed seed clusters.
Reversing the control flow allows placing seed clusters or shoot clusters behind firewalls without the necessity of direct access via VPN tunnels anymore.
TLS Bootstrapping
Kubernetes doesn’t manage worker nodes itself, and it’s also not
responsible for the lifecycle of the kubelet running on the workers.
Similarly, Gardener doesn’t manage seed clusters itself,
so it is also not responsible for the lifecycle of the gardenlet running on the seeds.
As a consequence, both the gardenlet and the kubelet need to prepare
a trusted connection to the Gardener API server
and the Kubernetes API server correspondingly.
To prepare a trusted connection between the gardenlet
and the Gardener API server, the gardenlet initializes
a bootstrapping process after you deployed it into your seed clusters:
The gardenlet starts up with a bootstrap kubeconfig
having a bootstrap token that allows to create CertificateSigningRequest (CSR) resources.
After the CSR is signed, the gardenlet downloads
the created client certificate, creates a new kubeconfig with it,
and stores it inside a Secret in the seed cluster.
The gardenlet deletes the bootstrap kubeconfig secret,
and starts up with its new kubeconfig.
The gardenlet starts normal operation.
The gardener-controller-manager runs a control loop
that automatically signs CSRs created by gardenlets.
The gardenlet bootstrapping process is based on the
kubelet bootstrapping process. More information:
Kubelet’s TLS bootstrapping.
If you don’t want to run this bootstrap process, you can create
a kubeconfig pointing to the garden cluster for the gardenlet yourself,
and use the field gardenClientConnection.kubeconfig in the
gardenlet configuration to share it with the gardenlet.
gardenlet Certificate Rotation
The certificate used to authenticate the gardenlet against the API server
has a certain validity based on the configuration of the garden cluster
(--cluster-signing-duration flag of the kube-controller-manager (default 1y)).
You can also configure the validity for the client certificate by specifying .gardenClientConnection.kubeconfigValidity.validity in the gardenlet’s component configuration.
Note that changing this value will only take effect when the kubeconfig is rotated again (it is not picked up immediately).
The minimum validity is 10m (that’s what is enforced by the CertificateSigningRequest API in Kubernetes which is used by the gardenlet).
By default, after about 70-90% of the validity has expired, the gardenlet tries to automatically replace
the current certificate with a new one (certificate rotation).
You can change these boundaries by specifying .gardenClientConnection.kubeconfigValidity.autoRotationJitterPercentage{Min,Max} in the gardenlet’s component configuration.
To use a certificate rotation, you need to specify the secret to store
the kubeconfig with the rotated certificate in the field
.gardenClientConnection.kubeconfigSecret of the
gardenlet component configuration.
Rotate Certificates Using Bootstrap kubeconfig
If the gardenlet created the certificate during the initial TLS Bootstrapping
using the Bootstrap kubeconfig, certificates can be rotated automatically.
The same control loop in the gardener-controller-manager that signs
the CSRs during the initial TLS Bootstrapping also automatically signs
the CSR during a certificate rotation.
ℹ️ You can trigger an immediate renewal by annotating the Secret in the seed
cluster stated in the .gardenClientConnection.kubeconfigSecret field with
gardener.cloud/operation=renew. Within 10s, gardenlet detects this and terminates
itself to request new credentials. After it has booted up again, gardenlet will issue a
new certificate independent of the remaining validity of the existing one.
ℹ️ Alternatively, annotate the respective Seed with gardener.cloud/operation=renew-kubeconfig.
This will make gardenlet annotate its own kubeconfig secret with gardener.cloud/operation=renew
and triggers the process described in the previous paragraph.
Rotate Certificates Using Custom kubeconfig
When trying to rotate a custom certificate that wasn’t created by gardenlet
as part of the TLS Bootstrap, the x509 certificate’s Subject field
needs to conform to the following:
the Common Name (CN) is prefixed with gardener.cloud:system:seed:
the Organization (O) equals gardener.cloud:system:seeds
Otherwise, the gardener-controller-manager doesn’t automatically
sign the CSR.
In this case, an external component or user needs to approve the CSR manually,
for example, using the command kubectl certificate approve seed-csr-<...>).
If that doesn’t happen within 15 minutes,
the gardenlet repeats the process and creates another CSR.
Configuring the Seed to Work with gardenlet
The gardenlet works with a single seed, which must be configured in the
GardenletConfiguration under .seedConfig. This must be a copy of the
Seed resource, for example:
Similar to how Kubernetes uses Lease objects for node heart beats
(see KEP),
the gardenlet is using Lease objects for heart beats of the seed cluster.
Every two seconds, the gardenlet checks that the seed cluster’s /healthz
endpoint returns HTTP status code 200.
If that is the case, the gardenlet renews the lease in the Garden cluster in the gardener-system-seed-lease namespace and updates
the GardenletReady condition in the status.conditions field of the Seed resource. For more information, see this section.
Similar to the node-lifecycle-controller inside the kube-controller-manager,
the gardener-controller-manager features a seed-lifecycle-controller that sets
the GardenletReady condition to Unknown in case the gardenlet fails to renew the lease.
As a consequence, the gardener-scheduler doesn’t consider this seed cluster for newly created shoot clusters anymore.
/healthz Endpoint
The gardenlet includes an HTTP server that serves a /healthz endpoint.
It’s used as a liveness probe in the Deployment of the gardenlet.
If the gardenlet fails to renew its lease,
then the endpoint returns 500 Internal Server Error, otherwise it returns 200 OK.
Please note that the /healthz only indicates whether the gardenlet
could successfully probe the Seed’s API server and renew the lease with
the Garden cluster.
It does not show that the Gardener extension API server (with the Gardener resource groups)
is available.
However, the gardenlet is designed to withstand such connection outages and
retries until the connection is reestablished.
Controllers
The gardenlet consists out of several controllers which are now described in more detail.
The BackupBucket controller reconciles those core.gardener.cloud/v1beta1.BackupBucket resources whose .spec.seedName value is equal to the name of the Seed the respective gardenlet is responsible for.
A core.gardener.cloud/v1beta1.BackupBucket resource is created by the Seed controller if .spec.backup is defined in the Seed.
The controller adds finalizers to the BackupBucket and the secret mentioned in the .spec.secretRef of the BackupBucket. The controller also copies this secret to the seed cluster. Additionally, it creates an extensions.gardener.cloud/v1alpha1.BackupBucket resource (non-namespaced) in the seed cluster and waits until the responsible extension controller reconciles it (see Contract: BackupBucket Resource for more details).
The status from the reconciliation is reported in the .status.lastOperation field. Once the extension resource is ready and the .status.generatedSecretRef is set by the extension controller, the gardenlet copies the referenced secret to the garden namespace in the garden cluster. An owner reference to the core.gardener.cloud/v1beta1.BackupBucket is added to this secret.
If the core.gardener.cloud/v1beta1.BackupBucket is deleted, the controller deletes the generated secret in the garden cluster and the extensions.gardener.cloud/v1alpha1.BackupBucket resource in the seed cluster and it waits for the respective extension controller to remove its finalizers from the extensions.gardener.cloud/v1alpha1.BackupBucket. Then it deletes the secret in the seed cluster and finally removes the finalizers from the core.gardener.cloud/v1beta1.BackupBucket and the referred secret.
The BackupEntry controller reconciles those core.gardener.cloud/v1beta1.BackupEntry resources whose .spec.seedName value is equal to the name of a Seed the respective gardenlet is responsible for.
Those resources are created by the Shoot controller (only if backup is enabled for the respective Seed) and there is exactly one BackupEntry per Shoot.
The controller creates an extensions.gardener.cloud/v1alpha1.BackupEntry resource (non-namespaced) in the seed cluster and waits until the responsible extension controller reconciled it (see Contract: BackupEntry Resource for more details).
The status is populated in the .status.lastOperation field.
The core.gardener.cloud/v1beta1.BackupEntry resource has an owner reference pointing to the corresponding Shoot.
Hence, if the Shoot is deleted, the BackupEntry resource also gets deleted.
In this case, the controller deletes the extensions.gardener.cloud/v1alpha1.BackupEntry resource in the seed cluster and waits until the responsible extension controller has deleted it.
Afterwards, the finalizer of the core.gardener.cloud/v1beta1.BackupEntry resource is released so that it finally disappears from the system.
If the spec.seedName and .status.seedName of the core.gardener.cloud/v1beta1.BackupEntry are different, the controller will migrate it by annotating the extensions.gardener.cloud/v1alpha1.BackupEntry in the Source Seed with gardener.cloud/operation: migrate, waiting for it to be migrated successfully and eventually deleting it from the Source Seed cluster. Afterwards, the controller will recreate the extensions.gardener.cloud/v1alpha1.BackupEntry in the Destination Seed, annotate it with gardener.cloud/operation: restore and wait for the restore operation to finish. For more details about control plane migration, please read Shoot Control Plane Migration.
Keep Backup for Deleted Shoots
In some scenarios it might be beneficial to not immediately delete the BackupEntrys (and with them, the etcd backup) for deleted Shoots.
In this case you can configure the .controllers.backupEntry.deletionGracePeriodHours field in the component configuration of the gardenlet.
For example, if you set it to 48, then the BackupEntrys for deleted Shoots will only be deleted 48 hours after the Shoot was deleted.
Additionally, you can limit the shoot purposes for which this applies by setting .controllers.backupEntry.deletionGracePeriodShootPurposes[].
For example, if you set it to [production] then only the BackupEntrys for Shoots with .spec.purpose=production will be deleted after the configured grace period. All others will be deleted immediately after the Shoot deletion.
In case a BackupEntry is scheduled for future deletion but you want to delete it immediately, add the annotation backupentry.core.gardener.cloud/force-deletion=true.
The Bastion controller reconciles those operations.gardener.cloud/v1alpha1.Bastion resources whose .spec.seedName value is equal to the name of a Seed the respective gardenlet is responsible for.
The controller creates an extensions.gardener.cloud/v1alpha1.Bastion resource in the seed cluster in the shoot namespace with the same name as operations.gardener.cloud/v1alpha1.Bastion. Then it waits until the responsible extension controller has reconciled it (see Contract: Bastion Resource for more details). The status is populated in the .status.conditions and .status.ingress fields.
During the deletion of operations.gardener.cloud/v1alpha1.Bastion resources, the controller first sets the Ready condition to False and then deletes the extensions.gardener.cloud/v1alpha1.Bastion resource in the seed cluster.
Once this resource is gone, the finalizer of the operations.gardener.cloud/v1alpha1.Bastion resource is released, so it finally disappears from the system.
This reconciler is responsible for ControllerInstallations referencing a ControllerDeployment whose type=helm.
For each ControllerInstallation, it creates a namespace on the seed cluster named extension-<controller-installation-name>.
Then, it creates a generic garden kubeconfig and garden access secret for the extension for accessing the garden cluster.
After that, it unpacks the Helm chart tarball in the ControllerDeployments .providerConfig.chart field and deploys the rendered resources to the seed cluster.
The Helm chart values in .providerConfig.values will be used and extended with some information about the Gardener environment and the seed cluster:
As of today, there are a few more fields in .gardener.seed, but it is recommended to use the .gardener.seed.spec if the Helm chart needs more information about the seed configuration.
The rendered chart will be deployed via a ManagedResource created in the garden namespace of the seed cluster.
It is labeled with controllerinstallation-name=<name> so that one can easily find the owning ControllerInstallation for an existing ManagedResource.
The reconciler maintains the Installed condition of the ControllerInstallation and sets it to False if the rendering or deployment fails.
This reconciler reconciles ControllerInstallation objects and checks whether they are in a healthy state.
It checks the .status.conditions of the backing ManagedResource created in the garden namespace of the seed cluster.
If the ResourcesApplied condition of the ManagedResource is True, then the Installed condition of the ControllerInstallation will be set to True.
If the ResourcesHealthy condition of the ManagedResource is True, then the Healthy condition of the ControllerInstallation will be set to True.
If the ResourcesProgressing condition of the ManagedResource is True, then the Progressing condition of the ControllerInstallation will be set to True.
A ControllerInstallation is considered “healthy” if Applied=Healthy=True and Progressing=False.
This reconciler watches all resources in the extensions.gardener.cloud API group in the seed cluster.
It is responsible for maintaining the Required condition on ControllerInstallations.
Concretely, when there is at least one extension resource in the seed cluster a ControllerInstallation is responsible for, then the status of the Required condition will be True.
If there are no extension resources anymore, its status will be False.
This condition is taken into account by the ControllerRegistration controller part of gardener-controller-manager when it computes which extensions have to be deployed to which seed cluster. See Gardener Controller Manager for more details.
The Gardenlet controller reconciles a Gardenlet resource with the same name as the Seed the gardenlet is responsible for.
This is used to implement self-upgrades of gardenlet based on information pulled from the garden cluster.
For a general overview, see this document.
On Gardenlet reconciliation, the controller deploys the gardenlet within its own cluster which after downloading the Helm chart specified in .spec.deployment.helm.ociRepository and rendering it with the provided values/configuration.
On Gardenlet deletion, nothing happens: The gardenlet does not terminate itself - deleting a Gardenlet object effectively means that self-upgrades are stopped.
The ManagedSeed controller in the gardenlet reconciles ManagedSeeds that refers to Shoot scheduled on Seed the gardenlet is responsible for.
Additionally, the controller monitors Seeds, which are owned by ManagedSeeds for which the gardenlet is responsible.
On ManagedSeed reconciliation, the controller first waits for the referenced Shoot to undergo a reconciliation process.
Once the Shoot is successfully reconciled, the controller sets the ShootReconciled status of the ManagedSeed to true.
Then, it creates garden namespace within the target shoot cluster.
The controller also manages secrets related to Seeds, such as the backup and kubeconfig secrets.
It ensures that these secrets are created and updated according to the ManagedSeed spec.
Finally, it deploys the gardenlet within the specified shoot cluster which registers the Seed cluster.
On ManagedSeed deletion, the controller first deletes the corresponding Seed that was originally created by the controller.
Subsequently, it deletes the gardenlet instance within the shoot cluster.
The controller also ensures the deletion of related Seed secrets.
Finally, the dedicated garden namespace within the shoot cluster is deleted.
The NetworkPolicy controller reconciles NetworkPolicys in all relevant namespaces in the seed cluster and provides so-called “general” policies for access to the runtime cluster’s API server, DNS, public networks, etc.
The controller resolves the IP address of the Kubernetes service in the default namespace and creates an egress NetworkPolicys for it.
This reconciler is responsible for managing the seed’s system components.
Those comprise CA certificates, the various CustomResourceDefinitions, the logging and monitoring stacks, and few central components like gardener-resource-manager, etcd-druid, istio, etc.
The reconciler also deploys a BackupBucket resource in the garden cluster in case the Seed's .spec.backup is set.
It also checks whether the seed cluster’s Kubernetes version is at least the minimum supported version and errors in case this constraint is not met.
This reconciler maintains the .status.lastOperation field, i.e. it sets it:
to state=Progressing before it executes its reconciliation flow.
to state=Error in case an error occurs.
to state=Succeeded in case the reconciliation succeeded.
This reconciler checks whether the seed system components (deployed by the “main” reconciler) are healthy.
It checks the .status.conditions of the backing ManagedResource created in the garden namespace of the seed cluster.
A ManagedResource is considered “healthy” if the conditions ResourcesApplied=ResourcesHealthy=True and ResourcesProgressing=False.
If all ManagedResources are healthy, then the SeedSystemComponentsHealthy condition of the Seed will be set to True.
Otherwise, it will be set to False.
If at least one ManagedResource is unhealthy and there is threshold configuration for the conditions (in .controllers.seedCare.conditionThresholds), then the status of the SeedSystemComponentsHealthy condition will be set:
to Progressing if it was True before.
to Progressing if it was Progressing before and the lastUpdateTime of the condition does not exceed the configured threshold duration yet.
to False if it was Progressing before and the lastUpdateTime of the condition exceeds the configured threshold duration.
The condition thresholds can be used to prevent reporting issues too early just because there is a rollout or a short disruption.
Only if the unhealthiness persists for at least the configured threshold duration, then the issues will be reported (by setting the status to False).
In order to compute the condition statuses, this reconciler considers ManagedResources (in the garden and istio-system namespace) and their status, see this document for more information.
The following table explains which ManagedResources are considered for which condition type:
This reconciler checks whether the connection to the seed cluster’s /healthz endpoint works.
If this succeeds, then it renews a Lease resource in the garden cluster’s gardener-system-seed-lease namespace.
This indicates a heartbeat to the external world, and internally the gardenlet sets its health status to true.
In addition, the GardenletReady condition in the status of the Seed is set to True.
The whole process is similar to what the kubelet does to report heartbeats for its Node resource and its KubeletReady condition. For more information, see this section.
If the connection to the /healthz endpoint or the update of the Lease fails, then the internal health status of gardenlet is set to false.
Also, this internal health status is set to false automatically after some time, in case the controller gets stuck for whatever reason.
This internal health status is available via the gardenlet’s /healthz endpoint and is used for the livenessProbe in the gardenlet pod.
This reconciler is responsible for managing all shoot cluster components and implements the core logic for creating, updating, hibernating, deleting, and migrating shoot clusters.
It is also responsible for syncing the Cluster cluster to the seed cluster before and after each successful shoot reconciliation.
The main reconciliation logic is performed in 3 different task flows dedicated to specific operation types:
reconcile (operations: create, reconcile, restore): this is the main flow responsible for creation and regular reconciliation of shoots. Hibernating a shoot also triggers this flow. It is also used for restoration of the shoot control plane on the new seed (second half of a Control Plane Migration)
migrate: this flow is triggered when spec.seedName specifies a different seed than status.seedName. It performs the first half of the Control Plane Migration, i.e., a backup (migrate operation) of all control plane components followed by a “shallow delete”.
delete: this flow is triggered when the shoot’s deletionTimestamp is set, i.e., when it is deleted.
The gardenlet takes special care to prevent unnecessary shoot reconciliations.
This is important for several reasons, e.g., to not overload the seed API servers and to not exhaust infrastructure rate limits too fast.
The gardenlet performs shoot reconciliations according to the following rules:
If status.observedGeneration is less than metadata.generation: this is the case, e.g., when the spec was changed, a manual reconciliation operation was triggered, or the shoot was deleted.
If the shoot is in a failed state, the gardenlet does not perform any reconciliation on the shoot (unless the retry operation was triggered). However, it syncs the Cluster resource to the seed in order to inform the extension controllers about the failed state.
Regular reconciliations are performed with every GardenletConfiguration.controllers.shoot.syncPeriod (defaults to 1h).
Shoot reconciliations are not performed if the assigned seed cluster is not healthy or has not been reconciled by the current gardenlet version yet (determined by the Seed.status.gardener section). This is done to make sure that shoots are reconciled with fully rolled out seed system components after a Gardener upgrade. Otherwise, the gardenlet might perform operations of the new version that doesn’t match the old version of the deployed seed system components, which might lead to unspecified behavior.
There are a few special cases that overwrite or confine how often and under which circumstances periodic shoot reconciliations are performed:
In case the gardenlet config allows it (controllers.shoot.respectSyncPeriodOverwrite, disabled by default), the sync period for a shoot can be increased individually by setting the shoot.gardener.cloud/sync-period annotation. This is always allowed for shoots in the garden namespace. Shoots are not reconciled with a higher frequency than specified in GardenletConfiguration.controllers.shoot.syncPeriod.
In case the gardenlet config allows it (controllers.shoot.respectSyncPeriodOverwrite, disabled by default), shoots can be marked as “ignored” by setting the shoot.gardener.cloud/ignore annotation. In this case, the gardenlet does not perform any reconciliation for the shoot.
In case GardenletConfiguration.controllers.shoot.reconcileInMaintenanceOnly is enabled (disabled by default), the gardenlet performs regular shoot reconciliations only once in the respective maintenance time window (GardenletConfiguration.controllers.shoot.syncPeriod is ignored). The gardenlet randomly distributes shoot reconciliations over the maintenance time window to avoid high bursts of reconciliations (see Shoot Maintenance).
In case Shoot.spec.maintenance.confineSpecUpdateRollout is enabled (disabled by default), changes to the shoot specification are not rolled out immediately but only during the respective maintenance time window (see Shoot Maintenance).
This reconciler performs three “care” actions related to Shoots.
Conditions
It maintains the following conditions:
APIServerAvailable: The /healthz endpoint of the shoot’s kube-apiserver is called and considered healthy when it responds with 200 OK.
ControlPlaneHealthy: The control plane is considered healthy when the respective Deployments (for example kube-apiserver,kube-controller-manager), and Etcds (for example etcd-main) exist and are healthy.
ObservabilityComponentsHealthy: This condition is considered healthy when the respective Deployments (for example plutono) and StatefulSets (for example prometheus,vali) exist and are healthy.
EveryNodeReady: The conditions of the worker nodes are checked (e.g., Ready, MemoryPressure). Also, it’s checked whether the Kubernetes version of the installed kubelet matches the desired version specified in the Shoot resource.
SystemComponentsHealthy: The conditions of the ManagedResources are checked (e.g., ResourcesApplied). Also, it is verified whether the VPN tunnel connection is established (which is required for the kube-apiserver to communicate with the worker nodes).
Sometimes, ManagedResources can have both Healthy and Progressing conditions set to True (e.g., when a DaemonSet rolls out one-by-one on a large cluster with many nodes) while this is not reflected in the Shoot status. In order to catch issues where the rollout gets stuck, one can set .controllers.shootCare.managedResourceProgressingThreshold in the gardenlet’s component configuration. If the Progressing condition is still True for more than the configured duration, the SystemComponentsHealthy condition in the Shoot is set to False, eventually.
Each condition can optionally also have error codes in order to indicate which type of issue was detected (see Shoot Status for more details).
If all checks for a certain conditions are succeeded, then its status will be set to True.
Otherwise, it will be set to False.
If at least one check fails and there is threshold configuration for the conditions (in .controllers.seedCare.conditionThresholds), then the status will be set:
to Progressing if it was True before.
to Progressing if it was Progressing before and the lastUpdateTime of the condition does not exceed the configured threshold duration yet.
to False if it was Progressing before and the lastUpdateTime of the condition exceeds the configured threshold duration.
The condition thresholds can be used to prevent reporting issues too early just because there is a rollout or a short disruption.
Only if the unhealthiness persists for at least the configured threshold duration, then the issues will be reported (by setting the status to False).
Besides directly checking the status of Deployments, Etcds, StatefulSets in the shoot namespace, this reconciler also considers ManagedResources (in the shoot namespace) and their status in order to compute the condition statuses, see this document for more information.
The following table explains which ManagedResources are considered for which condition type:
Condition Type
ManagedResources are considered when
ControlPlaneHealthy
.spec.class=seed and care.gardener.cloud/condition-type label either unset, or set to ControlPlaneHealthy
ObservabilityComponentsHealthy
care.gardener.cloud/condition-type label set to ObservabilityComponentsHealthy
SystemComponentsHealthy
.spec.class unset or care.gardener.cloud/condition-type label set to SystemComponentsHealthy
Stale pods in the shoot namespace in the seed cluster and in the kube-system namespace in the shoot cluster are deleted.
A pod is considered stale when:
it was terminated with reason Evicted.
it was terminated with reason starting with OutOf (e.g., OutOfCpu).
it was terminated with reason NodeAffinity.
it is stuck in termination (i.e., if its deletionTimestamp is more than 5m ago).
This reconciler periodically (default: every 6h) performs backups of the state of Shoot clusters and persists them into ShootState resources into the same namespace as the Shoots in the garden cluster.
It is only started in case the gardenlet is responsible for an unmanaged Seed, i.e. a Seed which is not backed by a seedmanagement.gardener.cloud/v1alpha1.ManagedSeed object.
Alternatively, it can be disabled by setting the concurrentSyncs=0 for the controller in the gardenlet’s component configuration.
This reconciler watches for the extensionsv1alpha1.Worker resource in the control plane namespace of the Shoot and if its status.inPlaceUpdates.workerPoolToHashMap has changed, it requeues the corresponding Shoot. A worker pool is removed from status.inPlaceUpdates.pendingWorkersRollouts.manualInPlaceUpdate field in the Shoot if the hash of the worker pool in the Shoot spec and the Worker status field matches. This indicates that all the nodes of that worker pool are successfully updated and are no longer pending manual in-place updates.
The gardenlet uses an instance of the TokenRequestor controller which initially was developed in the context of the gardener-resource-manager, please read this document for further information.
gardenlet uses it for requesting tokens for components running in the seed cluster that need to communicate with the garden cluster.
The mechanism works the same way as for shoot control plane components running in the seed which need to communicate with the shoot cluster.
However, gardenlet’s instance of the TokenRequestor controller is restricted to Secrets labeled with resources.gardener.cloud/class=garden.
Furthermore, it doesn’t respect the serviceaccount.resources.gardener.cloud/namespace annotation. Instead, it always uses the seed’s namespace in the garden cluster for managing ServiceAccounts and their tokens.
The TokenRequestorWorkloadIdentity controller in the gardenlet reconciles Secrets labeled with security.gardener.cloud/purpose=workload-identity-token-requestor.
When it encounters such Secret, it associates the Secret with a specific WorkloadIdentity using the annotations workloadidentity.security.gardener.cloud/name and workloadidentity.security.gardener.cloud/namespace.
Any workload creating such Secrets is responsible to label and annotate the Secrets accordingly.
After the association is made, the gardenlet requests a token for the specific WorkloadIdentity from the Gardener API Server and writes it back in the Secret’s data against the token key.
The gardenlet is responsible to keep this token valid by refreshing it periodically.
The token is then used by components running in the seed cluster in order to present the said WorkloadIdentity before external systems, e.g. by calling cloud provider APIs.
The VPAEvictionRequirements controller in the gardenlet reconciles VerticalPodAutoscaler objects labeled with autoscaling.gardener.cloud/eviction-requirements: managed-by-controller. It manages the EvictionRequirements on a VPA object, which are used to restrict when and how a Pod can be evicted to apply a new resource recommendation.
Specifically, the following actions will be taken for the respective label and annotation configuration:
If the VPA has the annotation eviction-requirements.autoscaling.gardener.cloud/downscale-restriction: never, an EvictionRequirement is added to the VPA object that allows evictions for upscaling only
If the VPA has the annotation eviction-requirements.autoscaling.gardener.cloud/downscale-restriction: in-maintenance-window-only, the same EvictionRequirement is added to the VPA object when the Shoot is currently outside of its maintenance window. When the Shoot is inside its maintenance window, the EvictionRequirement is removed. Information about the Shoot maintenance window times are stored in the annotation shoot.gardener.cloud/maintenance-window on the VPA
Managed Seeds
Gardener users can use shoot clusters as seed clusters, so-called “managed seeds” (aka “shooted seeds”),
by creating ManagedSeed resources.
By default, the gardenlet that manages this shoot cluster then automatically
creates a clone of itself with the same version and the same configuration
that it currently has.
Then it deploys the gardenlet clone into the managed seed cluster.
If your Gardener version doesn’t support gardenlets yet,
no special migration is required, but the following prerequisites must be met:
Your Gardener version is at least 0.31 before upgrading to v1.
You have to make sure that your garden cluster is exposed in a way
that it’s reachable from all your seed clusters.
With previous Gardener versions, you had deployed the Gardener Helm chart
(incorporating the API server, controller-manager, and scheduler).
With v1, this stays the same, but you now have to deploy the gardenlet Helm chart as well
into all of your seeds (if they aren’t managed, as mentioned earlier).
Initially, everything was developed in-tree in the Gardener project. All cloud providers and the configuration for all the supported operating systems were released together with the Gardener core itself.
But as the project grew, it got more and more difficult to add new providers and maintain the existing code base.
As a consequence and in order to become agile and flexible again, we proposed GEP-1 (Gardener Enhancement Proposal) and later gardener/gardener#9635 as an enhancement.
The document describes an out-of-tree extension architecture that keeps the Gardener core logic independent of provider-specific knowledge (similar to what Kubernetes has achieved with out-of-tree cloud providers or with CSI volume plugins).
Basic Concepts
Gardener components run in the garden and seed clusters, implementing the core logic for garden, seed, and shoot cluster reconciliation and deletion.
Extensions are Kubernetes controllers themselves (like Gardener) and run in the garden runtime and seed clusters.
As usual, we try to use Kubernetes wherever applicable.
We rely on Kubernetes extension concepts in order to enable extensibility for Gardener.
Building Blocks
Extensions consist of the following building blocks:
A Helm chart as the vehicle to generally deploy extension controllers to a Kubernetes clusters
Extension controllers that reconcile objects of the API group extensions.gardener.cloud. These controllers take over outsourced tasks, like creating the shoot infrastructure or deploying components to the control-plane. Optionally, extensions can bring their own webhooks to mutate resources deployed by Gardener.
Optionally, a Helm chart with an admission component inside. The admission controller runs in the garden runtime cluster and validates extension specific settings of the Shoot (given in providerConfig fields). See admission for more details.
Registration
Before an extension can be used, it needs to be made known to the system. The gardener-operator automates much of the registration process, making Extension resources (group operator.gardener.cloud) the preferred method for registering extensions. For more information, see the Registration documentation.
Practically, many extensions provide basic example manifests to start with the registration in their example directory (example1, example2).
Kinds and Types
Extensions are defined by their Kinds (defined by Gardener - see resources) and Types.
For example, the following is an extension resource of Kind Infrastructure and Type local, which means we need a Gardener extension local that reconciles Infrastructure resources.
A Gardener landscape consists of various cluster types which extension controllers may consider during reconciliation.
The .spec.class field identifies the different deployment cases.
Garden
Extension controllers serve the garden (run in garden runtime), e.g., installing certificates for API and ingress endpoints.
In the course of the Garden reconciliation, the gardener-operator creates BackupBucket, DNSRecord and Extension resources (group extensions.gardener.cloud) which triggers the responsible extension controllers to reconcile them.
Seed
Extension controllers serve the seed (run in seed), e.g., requesting a wildcard certificate for the seed’s ingress domain.
In the course of the Seed reconciliation, the gardenlet creates DNSRecord and Extension resources (group extensions.gardener.cloud) which triggers the responsible extension controllers to reconcile them.
Shoot
Extension controllers serve the shoot (run in seed), e.g., deploying a certificate controller into the control-plane namespace.
In the course of the Shoot reconciliation, the gardenlet creates various extension resources (group extensions.gardener.cloud) which triggers the responsible extension controllers to reconcile them.
gardenlet Reconciliation Walkthrough
Resources of group extensions.gardener.cloud are always created by Gardener itself, either in the garden runtime or in the seed cluster.
To get a better understanding of how the concept works, we will walk through the reconciliation process of a Shoot resource in the seed cluster.
During the shoot reconciliation process, Gardener will write CRDs into the seed cluster that are watched and managed by the extension controllers. They will reconcile (based on the .spec) and report whether everything went well or errors occurred in the CRD’s .status field.
Gardener keeps deploying the provider-independent control plane components (etcd, kube-apiserver, etc.). However, some of these components might still need little customization by providers, e.g., additional configuration, flags, etc. In this case, the extension controllers register webhooks in order to manipulate the manifests.
Example 1:
Gardener creates a new AWS shoot cluster and requires the preparation of infrastructure in order to proceed (networks, security groups, etc.).
It writes the following CRD into the seed cluster:
Please note that the .spec.providerConfig is a raw blob and not evaluated or known in any way by Gardener.
Instead, it was specified by the user (in the Shoot resource) and just “forwarded” to the extension controller.
Only the AWS controller understands this configuration and will now start provisioning/reconciling the infrastructure.
It reports in the .status field the result:
Gardener waits until the .status.lastOperation / .status.lastError indicates that the operation reached a final state and either continuous with the next step, or stops and reports the potential error.
The extension-specific output in .status.providerStatus is - similar to .spec.providerConfig - not evaluated, and simply forwarded to CRDs in subsequent steps.
Example 2:
Gardener deploys the control plane components into the seed cluster, e.g., the kube-controller-manager deployment with the following flags:
The AWS controller requires some additional flags in order to make the cluster functional.
It needs to provide a Kubernetes cloud-config and also some cloud-specific flags.
Consequently, it registers a MutatingWebhookConfiguration on Deployments and adds these flags to the container:
Of course, it would have needed to create a ConfigMap containing the cloud config and to add the proper volume and volumeMounts to the manifest as well.
(Please note for this special example: The Kubernetes community is also working on making the kube-controller-manager provider-independent.
However, there will most probably be still components other than the kube-controller-manager which need to be adapted by extensions.)
If you are interested in writing an extension, or generally in digging deeper to find out the nitty-gritty details of the extension concepts, please read GEP-1.
We are truly looking forward to your feedback!
Gardener offers different means to provide or equip registered extensions with a kubeconfig which may be used to connect to the garden cluster.
Admission Controllers
For extensions with an admission controller deployment, gardener-operator injects a token-based kubeconfig as a volume and volume mount.
The token is valid for 12h, automatically renewed, and associated with a dedicated ServiceAccount in the garden cluster.
The path to this kubeconfig is revealed under the GARDEN_KUBECONFIG environment variable, also added to the pod spec(s).
Extensions on Seed Clusters
Extensions that are installed on seed clusters via a ControllerInstallation can request gardenlet to inject a kubeconfig and a token for the garden cluster.
In order to do so, injectGardenKubeconfig must be set to true in the referenced ControllerDeployment.
If it should still be disabled for an individual workload resource (Deployment, StatefulSet, etc.), they must be labeled with extensions.gardener.cloud/inject-garden-kubeconfig=false.
When enabled, extensions can then simply read the kubeconfig file specified by the GARDEN_KUBECONFIG environment variable to create a garden cluster client.
With this, they use a short-lived token (valid for 12h) associated with a dedicated ServiceAccount in the seed-<seed-name> namespace to securely access the garden cluster.
The used ServiceAccounts are granted permissions in the garden cluster similar to gardenlet clients.
Background
Historically, gardenlet has been the only component running in the seed cluster that has access to both the seed cluster and the garden cluster.
Accordingly, extensions running on the seed cluster didn’t have access to the garden cluster.
Starting from Gardener v1.74.0, there is a new mechanism for components running on seed clusters to get access to the garden cluster.
For this, gardenlet runs an instance of the TokenRequestor for requesting tokens that can be used to communicate with the garden cluster.
Using Gardenlet-Managed Garden Access
By default, extensions are equipped with secure access to the garden cluster using a dedicated ServiceAccount without requiring any additional action.
They can simply read the file specified by the GARDEN_KUBECONFIG and construct a garden client with it.
When installing a ControllerInstallation, gardenlet creates two secrets in the installation’s namespace: a generic garden kubeconfig (generic-garden-kubeconfig-<hash>) and a garden access secret (garden-access-extension).
Note that the ServiceAccount created based on this access secret will be created in the respective seed-* namespace in the garden cluster and labelled with controllerregistration.core.gardener.cloud/name=<name>.
Additionally, gardenlet injects volume, volumeMounts, and two environment variables into all (init) containers in all objects in the apps and batch API groups:
GARDEN_KUBECONFIG: points to the path where the generic garden kubeconfig is mounted.
SEED_NAME: set to the name of the Seed where the extension is installed.
This is useful for restricting watches in the garden cluster to relevant objects.
If an object already contains the GARDEN_KUBECONFIG environment variable, it is not overwritten and injection of volume and volumeMounts is skipped.
For example, a Deployment deployed via a ControllerInstallation will be mutated as follows:
Manually Requesting a Token for the Garden Cluster
Seed components that need to communicate with the garden cluster can request a token in the garden cluster by creating a garden access secret.
This secret has to be labelled with resources.gardener.cloud/purpose=token-requestor and resources.gardener.cloud/class=garden, e.g.:
apiVersion: v1
kind: Secret
metadata:
name: garden-access-example
namespace: example
labels:
resources.gardener.cloud/purpose: token-requestor
resources.gardener.cloud/class: garden
annotations:
serviceaccount.resources.gardener.cloud/name: example
type: Opaque
This will instruct gardenlet to create a new ServiceAccount named example in its own seed-<seed-name> namespace in the garden cluster, request a token for it, and populate the token in the secret’s data under the token key.
Permissions in the Garden Cluster
Both the SeedAuthorizer and the SeedRestriction plugin handle extensions clients and generally grant the same permissions in the garden cluster to them as to gardenlet clients.
With this, extensions are restricted to work with objects in the garden cluster that are related to seed they are running one just like gardenlet.
Note that if the plugins are not enabled, extension clients are only granted read access to global resources like CloudProfiles (this is granted to all authenticated users).
There are a few exceptions to the granted permissions as documented here.
Additional Permissions
If an extension needs access to additional resources in the garden cluster (e.g., extension-specific custom resources), permissions need to be granted via the usual RBAC means.
Let’s consider the following example: An extension requires the privileges to create authorization.k8s.io/v1.SubjectAccessReviews (which is not covered by the “default” permissions mentioned above).
This requires a human Gardener operator to create a ClusterRole in the garden cluster with the needed rules:
Note the label authorization.gardener.cloud/extensions-serviceaccount-selector which contains a label selector for ServiceAccounts.
There is a controller part of gardener-controller-manager which takes care of maintaining the respective ClusterRoleBinding resources.
It binds all ServiceAccounts in the seed namespaces in the garden cluster (i.e., all extension clients) whose labels match.
You can read more about this controller here.
Custom Permissions
If an extension wants to create a dedicated ServiceAccount for accessing the garden cluster without automatically inheriting all permissions of the gardenlet, it first needs to create a garden access secret in its extension namespace in the seed cluster:
❗️️Do not prefix the service account name with extension- to prevent inheriting the gardenlet permissions! It is still recommended to add the extension name (e.g., as a suffix) for easier identification where this ServiceAccount comes from.
Next, you can follow the same approach described above.
However, the authorization.gardener.cloud/extensions-serviceaccount-selector annotation should not contain controllerregistration.core.gardener.cloud/name=<extension-name> but rather custom labels, e.g. foo=bar.
This way, the created ServiceAccount will only get the permissions of above ClusterRole and nothing else.
Renewing All Garden Access Secrets
Operators can trigger an automatic renewal of all garden access secrets in a given Seed and their requested ServiceAccount tokens, e.g., when rotating the garden cluster’s ServiceAccount signing key.
For this, the Seed has to be annotated with gardener.cloud/operation=renew-garden-access-secrets.
5.2 - CA Rotation
CA Rotation in Extensions
GEP-18 proposes adding support for automated rotation of Shoot cluster certificate authorities (CAs).
This document outlines all the requirements that Gardener extensions need to fulfill in order to support the CA rotation feature.
Requirements for Shoot Cluster CA Rotation
Extensions must not rely on static CA Secret names managed by the gardenlet, because their names are changing during CA rotation.
Extensions cannot issue or use client certificates for authenticating against shoot API servers. Instead, they should use short-lived auto-rotated ServiceAccount tokens via gardener-resource-manager’s TokenRequestor. Also see Conventions and TokenRequestor documents.
Extensions need to generate dedicated CAs for signing server certificates (e.g. cloud-controller-manager). There should be one CA per controller and purpose in order to bind the lifecycle to the reconciliation cycle of the respective object for which it is created.
CAs managed by extensions should be rotated in lock-step with the shoot cluster CA.
When the user triggers a rotation, the gardenlet writes phase and initiation time to Shoot.status.credentials.rotation.certificateAuthorities.{phase,lastInitiationTime}. See GEP-18 for a detailed description on what needs to happen in each phase.
Extensions can retrieve this information from Cluster.shoot.status.
Utilities for Secrets Management
In order to fulfill the requirements listed above, extension controllers can reuse the SecretsManager that the gardenlet uses to manage all shoot cluster CAs, certificates, and other secrets as well.
It implements the core logic for managing secrets that need to be rotated, auto-renewed, etc.
Additionally, there are utilities for reusing SecretsManager in extension controllers.
They already implement the above requirements based on the Cluster resource and allow focusing on the extension controllers’ business logic.
For example, a simple SecretsManager usage in an extension controller could look like this:
const (
// identity for SecretsManager instance in ControlPlane controller identity = "provider-foo-controlplane"// secret config name of the dedicated CA caControlPlaneName = "ca-provider-foo-controlplane")
func Reconcile() {
var (
cluster *extensionscontroller.Cluster
client client.Client
// define wanted secrets with options secretConfigs = []extensionssecretsmanager.SecretConfigWithOptions{
{
// dedicated CA for ControlPlane controller Config: &secretutils.CertificateSecretConfig{
Name: caControlPlaneName,
CommonName: "ca-provider-foo-controlplane",
CertType: secretutils.CACert,
},
// persist CA so that it gets restored on control plane migration Options: []secretsmanager.GenerateOption{secretsmanager.Persist()},
},
{
// server cert for control plane component Config: &secretutils.CertificateSecretConfig{
Name: "cloud-controller-manager",
CommonName: "cloud-controller-manager",
DNSNames: kutil.DNSNamesForService("cloud-controller-manager", namespace),
CertType: secretutils.ServerCert,
},
// sign with our dedicated CA Options: []secretsmanager.GenerateOption{secretsmanager.SignedByCA(caControlPlaneName)},
},
}
)
// initialize SecretsManager based on Cluster object sm, err := extensionssecretsmanager.SecretsManagerForCluster(ctx, logger.WithName("secretsmanager"), clock.RealClock{}, client, cluster, identity, secretConfigs)
// generate all wanted secrets (first CAs, then the rest) secrets, err := extensionssecretsmanager.GenerateAllSecrets(ctx, sm, secretConfigs)
// cleanup any secrets that are not needed any more (e.g. after rotation) err = sm.Cleanup(ctx)
}
Please pay attention to the following points:
There should be one SecretsManager identity per controller in order to prevent conflicts between different instances.
E.g., there should be different identities for Infrastructrue, Worker, ControlPlane controller, etc.
As part of the extensibility epic, a lot of responsibility that was previously taken over by Gardener directly has now been shifted to extension controllers running in the seed clusters.
These extensions often serve a well-defined purpose (e.g., the management of DNS records, infrastructure).
We have introduced a couple of extension CRDs in the seeds whose specification is written by Gardener, and which are acted up by the extensions.
However, the extensions sometimes require more information that is not directly part of the specification.
One example of that is the GCP infrastructure controller which needs to know the shoot’s pod and service network.
Another example is the Azure infrastructure controller which requires some information out of the CloudProfile resource.
The problem is that Gardener does not know which extension requires which information so that it can write it into their specific CRDs.
In order to deal with this problem we have introduced the Cluster extension resource.
This CRD is written into the seeds, however, it does not contain a status, so it is not expected that something acts upon it.
Instead, you can treat it like a ConfigMap which contains data that might be interesting for you.
In the context of Gardener, seeds and shoots, and extensibility the Cluster resource contains the CloudProfile, Seed, and Shoot manifest.
Extension controllers can take whatever information they want out of it that might help completing their individual tasks.
The resource is written by Gardener before it starts the reconciliation flow of the shoot.
⚠️ All Gardener components use the core.gardener.cloud/v1beta1 version, i.e., the Cluster resource will contain the objects in this version.
Important Information that Should Be Taken into Account
There are some fields in the Shoot specification that might be interesting to take into account.
.spec.hibernation.enabled={true,false}: Extension controllers might want to behave differently if the shoot is hibernated or not (probably they might want to scale down their control plane components, for example).
.status.lastOperation.state=Failed: If Gardener sets the shoot’s last operation state to Failed, it means that Gardener won’t automatically retry to finish the reconciliation/deletion flow because an error occurred that could not be resolved within the last 24h (default). In this case, end-users are expected to manually re-trigger the reconciliation flow in case they want Gardener to try again. Extension controllers are expected to follow the same principle. This means they have to read the shoot state out of the Cluster resource.
Extension Resources Not Associated with a Shoot
In some cases, Gardener may create extension resources that are not associated with a shoot, but are needed to support some functionality internal to Gardener. Such resources will be created in the garden namespace of a seed cluster.
For example, if the managed ingress controller is active on the seed, Gardener will create a DNSRecord resource(s) in the garden namespace of the seed cluster for the ingress DNS record.
Extension controllers that may be expected to reconcile extension resources in the garden namespace should make sure that they can tolerate the absence of a cluster resource. This means that they should not attempt to read the cluster resource in such cases, or if they do they should ignore the “not found” error.
Gardener creates the Shoot controlplane in several steps of the Shoot flow. At different point of this flow, it:
Deploys standard controlplane components such as kube-apiserver, kube-controller-manager, and kube-scheduler by creating the corresponding deployments, services, and other resources in the Shoot namespace.
Initiates the deployment of custom controlplane components by ControlPlane controllers by creating a ControlPlane resource in the Shoot namespace.
In order to apply any provider-specific changes to the configuration provided by Gardener for the standard controlplane components, cloud extension providers can install mutating admission webhooks for the resources created by Gardener in the Shoot namespace.
What needs to be implemented to support a new cloud provider?
In order to support a new cloud provider, you should install “controlplane” mutating webhooks for any of the following resources:
Deployment with name kube-apiserver, kube-controller-manager, or kube-scheduler
Service with name kube-apiserver
OperatingSystemConfig with any name, and purpose reconcile
See Contract Specification for more details on the contract that Gardener and webhooks should adhere to regarding the content of the above resources.
You can install 2 different kinds of controlplane webhooks:
Shoot, or controlplane webhooks apply changes needed by the Shoot cloud provider, for example the --cloud-provider command line flag of kube-apiserver and kube-controller-manager. Such webhooks should only operate on Shoot namespaces labeled with shoot.gardener.cloud/provider=<provider>.
Seed, or seedprovider webhooks apply changes needed by the Seed cloud provider, for example adapting the storage class and capacity on Etcd objects. Such webhooks should only operate on Shoot namespaces labeled with seed.gardener.cloud/provider=<provider>.
The labels shoot.gardener.cloud/provider and seed.gardener.cloud/provider are added by Gardener when it creates the Shoot namespace.
The resources mutated by the “controlplane” mutating webhooks are labeled with provider.extensions.gardener.cloud/mutated-by-controlplane-webhook: true by gardenlet. The provider extensions can add an object selector to their “controlplane” mutating webhooks to not intercept requests for unrelated objects.
Contract Specification
This section specifies the contract that Gardener and webhooks should adhere to in order to ensure smooth interoperability. Note that this contract can’t be specified formally and is therefore easy to violate, especially by Gardener. The Gardener team will nevertheless do its best to adhere to this contract in the future and to ensure via additional measures (tests, validations) that it’s not unintentionally broken. If it needs to be changed intentionally, this can only happen after proper communication has taken place to ensure that the affected provider webhooks could be adapted to work with the new version of the contract.
Note: The contract described below may not necessarily be what Gardener does currently (as of May 2019). Rather, it reflects the target state after changes for Gardener extensibility have been introduced.
kube-apiserver
To deploy kube-apiserver, Gardener shall create a deployment and a service both named kube-apiserver in the Shoot namespace. They can be mutated by webhooks to apply any provider-specific changes to the standard configuration provided by Gardener.
The pod template of the kube-apiserver deployment shall contain a container named kube-apiserver.
The command field of the kube-apiserver container shall contain the kube-apiserver command line. It shall contain a number of provider-independent flags that should be ignored by webhooks, such as:
The kube-apiserver command line shall not contain any provider-specific flags, such as:
--cloud-provider
--cloud-config
These flags can be added by webhooks if needed.
The kube-apiserver command line may contain a number of additional provider-independent flags. In general, webhooks should ignore these unless they are known to interfere with the desired kube-apiserver behavior for the specific provider. Among the flags to be considered are:
--endpoint-reconciler-type
--advertise-address
--feature-gates
Gardener uses SNI to expose the apiserver. In this case, Gardener expects that the --endpoint-reconciler-type and --advertise-address flags of the kube-apiserver’s Deployment are not modified.
The --enable-admission-plugins flag may contain admission plugins that are not compatible with CSI plugins such as PersistentVolumeLabel. Webhooks should therefore ensure that such admission plugins are either explicitly enabled (if CSI plugins are not used) or disabled (otherwise).
The env field of the kube-apiserver container shall not contain any provider-specific environment variables (so it will be empty). If any provider-specific environment variables are needed, they should be added by webhooks.
The volumes field of the pod template of the kube-apiserver deployment, and respectively the volumeMounts field of the kube-apiserver container shall not contain any provider-specific Secret or ConfigMap resources. If such resources should be mounted as volumes, this should be done by webhooks.
The kube-apiserverServicewill be of type ClusterIP. In this case, Gardener expects that for this Service no mutations happen.
kube-controller-manager
To deploy kube-controller-manager, Gardener shall create a deployment named kube-controller-manager in the Shoot namespace. It can be mutated by webhooks to apply any provider-specific changes to the standard configuration provided by Gardener.
The pod template of the kube-controller-manager deployment shall contain a container named kube-controller-manager.
The command field of the kube-controller-manager container shall contain the kube-controller-manager command line. It shall contain a number of provider-independent flags that should be ignored by webhooks, such as:
horizontal pod autoscaler (--horizontal-pod-autoscaler-*)
ports (--port, --secure-port)
The kube-controller-manager command line shall not contain any provider-specific flags, such as:
--cloud-provider
--cloud-config
--configure-cloud-routes
--external-cloud-volume-plugin
These flags can be added by webhooks if needed.
The kube-controller-manager command line may contain a number of additional provider-independent flags. In general, webhooks should ignore these unless they are known to interfere with the desired kube-controller-manager behavior for the specific provider. Among the flags to be considered are:
--feature-gates
The env field of the kube-controller-manager container shall not contain any provider-specific environment variables (so it will be empty). If any provider-specific environment variables are needed, they should be added by webhooks.
The volumes field of the pod template of the kube-controller-manager deployment, and respectively the volumeMounts field of the kube-controller-manager container shall not contain any provider-specific Secret or ConfigMap resources. If such resources should be mounted as volumes, this should be done by webhooks.
kube-scheduler
To deploy kube-scheduler, Gardener shall create a deployment named kube-scheduler in the Shoot namespace. It can be mutated by webhooks to apply any provider-specific changes to the standard configuration provided by Gardener.
The pod template of the kube-scheduler deployment shall contain a container named kube-scheduler.
The command field of the kube-scheduler container shall contain the kube-scheduler command line. It shall contain a number of provider-independent flags that should be ignored by webhooks, such as:
The kube-scheduler command line may contain additional provider-independent flags. In general, webhooks should ignore these unless they are known to interfere with the desired kube-controller-manager behavior for the specific provider. Among the flags to be considered are:
--feature-gates
The kube-scheduler command line can’t contain provider-specific flags, and it makes no sense to specify provider-specific environment variables or mount provider-specific Secret or ConfigMap resources as volumes.
etcd-main and etcd-events
To deploy etcd, Gardener shall create 2 Etcd named etcd-main and etcd-events in the Shoot namespace. They can be mutated by webhooks to apply any provider-specific changes to the standard configuration provided by Gardener.
Gardener shall configure the Etcd resource completely to set up an etcd cluster which uses the default storage class of the seed cluster.
cloud-controller-manager
Gardener shall not deploy a cloud-controller-manager. If it is needed, it should be added by a ControlPlane controller
CSI Controllers
Gardener shall not deploy a CSI controller. If it is needed, it should be added by a ControlPlane controller
kubelet
To specify the kubelet configuration, Gardener shall create a OperatingSystemConfig resource with any name and purpose reconcile in the Shoot namespace. It can therefore also be mutated by webhooks to apply any provider-specific changes to the standard configuration provided by Gardener. Gardener may write multiple such resources with different type to the same Shoot namespaces if multiple OSs are used.
The OSC resource shall contain a unit named kubelet.service, containing the corresponding systemd unit configuration file. The [Service] section of this file shall contain a single ExecStart option having the kubelet command line as its value.
The OSC resource shall contain a file with path /var/lib/kubelet/config/kubelet, which contains a KubeletConfiguration resource in YAML format. Most of the flags that can be specified in the kubelet command line can alternatively be specified as options in this configuration as well.
The kubelet command line shall contain a number of provider-independent flags that should be ignored by webhooks, such as:
--config
--bootstrap-kubeconfig, --kubeconfig
--network-plugin (and, if it equals cni, also --cni-bin-dir and --cni-conf-dir)
--node-labels
The kubelet command line shall not contain any provider-specific flags, such as:
--cloud-provider
--cloud-config
--provider-id
These flags can be added by webhooks if needed.
The kubelet command line / configuration may contain a number of additional provider-independent flags / options. In general, webhooks should ignore these unless they are known to interfere with the desired kubelet behavior for the specific provider. Among the flags / options to be considered are:
--enable-controller-attach-detach (enableControllerAttachDetach) - should be set to true if CSI plugins are used, but in general can also be ignored since its default value is also true, and this should work both with and without CSI plugins.
--feature-gates (featureGates) - should contain a list of specific feature gates if CSI plugins are used. If CSI plugins are not used, the corresponding feature gates can be ignored since enabling them should not harm in any way.
5.5 - Conventions
General Conventions
All the extensions that are registered to Gardener are deployed to the garden runtime and seed clusters on which they are required (also see extension registration documentation).
Some of these extensions might need to create global resources in the seed (e.g., ClusterRoles), i.e., it’s important to have a naming scheme to avoid conflicts as it cannot be checked or validated upfront that two extensions don’t use the same names.
Consequently, this page should help answering some general questions that might come up when it comes to developing an extension.
Extension Classes
Each extension resource has a .spec.class field that is used to distinguish between different instances of the same extension type.
For extensions configured in Shoots the class is named shoot (or unspecified for backwards compatibility), for Seeds the class is named seed.
Extension controllers ought to use the class field for event filtering (see HasClass Predicate) and during reconciliation.
PriorityClasses
Extensions are not supposed to create and use self-defined PriorityClasses.
Instead, they can and should rely on well-known PriorityClasses managed by gardenlet.
High Availability of Deployed Components
Extensions might deploy components via Deployments, StatefulSets, etc., as part of the shoot control plane, or the seed or shoot system components.
In case a seed or shoot cluster is highly available, there are various failure tolerance types. For more information, see Highly Available Shoot Control Plane.
Accordingly, the replicas, topologySpreadConstraints or affinity settings of the deployed components might need to be adapted.
Instead of doing this one-by-one for each and every component, extensions can rely on a mutating webhook provided by Gardener.
Please refer to High Availability of Deployed Components for details.
To reduce costs and to improve the network traffic latency in multi-zone clusters, extensions can make a Service topology-aware.
Please refer to this document for details.
Is there a naming scheme for (global) resources?
As there is no formal process to validate non-existence of conflicts between two extensions, please follow these naming schemes when creating resources (especially, when creating global resources, but it’s in general a good idea for most created resources):
The resource name should be prefixed with extensions.gardener.cloud:<extension-type>-<extension-name>:<resource-name>, for example:
Some extensions might not only create resources in the seed cluster itself but also in the shoot cluster. Usually, every extension comes with a ServiceAccount and the required RBAC permissions when it gets installed to the seed.
However, there are no credentials for the shoot for every extension.
Extensions are supposed to use ManagedResources to manage resources in shoot clusters.
gardenlet deploys gardener-resource-manager instances into all shoot control planes, that will reconcile ManagedResources without a specified class (spec.class=null) in shoot clusters. Mind that Gardener acts on ManagedResources with the origin=gardener label. In order to prevent unwanted behavior, extensions should omit the origin label or provide their own unique value for it when creating such resources.
If you need to deploy a non-DaemonSet resource, Gardener automatically ensures that it only runs on nodes that are allowed to host system components and extensions. For more information, see System Components Webhook.
How to create kubeconfigs for the shoot cluster?
Historically, Gardener extensions used to generate kubeconfigs with client certificates for components they deploy into the shoot control plane.
For this, they reused the shoot cluster CA secret (ca) to issue new client certificates.
With gardener/gardener#4661 we moved away from using client certificates in favor of short-lived, auto-rotated ServiceAccount tokens. These tokens are managed by gardener-resource-manager’s TokenRequestor.
Extensions are supposed to reuse this mechanism for requesting tokens and a generic-token-kubeconfig for authenticating against shoot clusters.
With GEP-18 (Shoot cluster CA rotation), a dedicated CA will be used for signing client certificates (gardener/gardener#5779) which will be rotated when triggered by the shoot owner.
With this, extensions cannot reuse the ca secret anymore to issue client certificates.
Hence, extensions must switch to short-lived ServiceAccount tokens in order to support the CA rotation feature.
The generic-token-kubeconfig secret contains the CA bundle for establishing trust to shoot API servers. However, as the secret is immutable, its name changes with the rotation of the cluster CA.
Extensions need to look up the generic-token-kubeconfig.secret.gardener.cloud/name annotation on the respective Cluster object in order to determine which secret contains the current CA bundle.
The helper function extensionscontroller.GenericTokenKubeconfigSecretNameFromCluster can be used for this task.
You can take a look at CA Rotation in Extensions for more details on the CA rotation feature in regard to extensions.
How to create certificates for the shoot cluster?
Gardener creates several certificate authorities (CA) that are used to create server certificates for various components.
For example, the shoot’s etcd has its own CA, the kube-aggregator has its own CA as well, and both are different to the actual cluster’s CA.
With GEP-18 (Shoot cluster CA rotation), extensions are required to do the same and generate dedicated CAs for their components (e.g. for signing a server certificate for cloud-controller-manager). They must not depend on the CA secrets managed by gardenlet.
Please see CA Rotation in Extensions for the exact requirements that extensions need to fulfill in order to support the CA rotation feature.
How to enforce a Pod Security Standard for extension namespaces?
The pod-security.kubernetes.io/enforce namespace label enforces the Pod Security Standards.
You can set the pod-security.kubernetes.io/enforce label for extension namespace by adding the security.gardener.cloud/pod-security-enforce annotation to your ControllerRegistration. The value of the annotation would be the value set for the pod-security.kubernetes.io/enforce label. It is advised to set the annotation with the most restrictive pod security standard that your extension pods comply with.
If you are using the ./hack/generate-controller-registration.sh script to generate your ControllerRegistration you can use the -e, –pod-security-enforce option to set the security.gardener.cloud/pod-security-enforce annotation. If the option is not set, it defaults to baseline.
5.6 - Force Deletion
Force Deletion
From v1.81, Gardener supports Shoot Force Deletion. All extension controllers should also properly support it. This document outlines some important points that extension maintainers should keep in mind to support force deletion in their extensions.
Overall Principles
The following principles should always be upheld:
All resources pertaining to the extension and managed by it should be appropriately handled and cleaned up by the extension when force deletion is initiated.
Implementation Details
ForceDelete Actuator Methods
Most extension controller implementations follow a common pattern where a generic Reconciler implementation delegates to an Actuator interface that contains the methods Reconcile, Delete, Migrate and Restore provided by the extension. A new method, ForceDelete has been added to all such Actuator interfaces; see the infrastructure Actuator interface as an example. The generic reconcilers call this method if the Shoot has annotation confirmation.gardener.cloud/force-deletion=true. Thus, it should be implemented by the extension controller to forcefully delete resources if not possible to delete them gracefully. If graceful deletion is possible, then in the ForceDelete, they can simply call the Delete method.
Extension Controllers Based on Generic Actuators
In practice, the implementation of many extension controllers (for example, the controlplane and worker controllers in most provider extensions) are based on a generic Actuator implementation that only delegates to extension methods for behavior that is truly provider-specific. In all such cases, the ForceDelete method has already been implemented with a method that should suit most of the extensions. If it doesn’t suit your extension, then the ForceDelete method needs to be overridden; see the Azure controlplane controller as an example.
Extension Controllers Not Based on Generic Actuators
The implementation of some extension controllers (for example, the infrastructure controllers in all provider extensions) are not based on a generic Actuator implementation. Such extension controllers must always provide a proper implementation of the ForceDelete method according to the above guidelines; see the AWS infrastructure controller as an example. In practice, this might result in code duplication between the different extensions, since the ForceDelete code is usually not OS-specific.
If the extension deploys resources which are backed by infrastructure in third-party systems:
If the resource is in the Seed cluster, the extension should remove the finalizers and delete the resource. This is needed especially if the resource is a custom resource since gardenlet will not be aware of this resource and cannot take action.
If the resource is in the Shoot and if it’s deployed by a ManagedResource, then gardenlet will take care to forcefully delete it in a later step of force-deletion. If the resource is not deployed via a ManagedResource, then it wouldn’t block the deletion flow anyway since it is in the Shoot cluster. In both cases, the extension controller can ignore the resource and return nil.
5.7 - Healthcheck Library
Health Check Library
Goal
Typically, an extension reconciles a specific resource (Custom Resource Definitions (CRDs)) and creates / modifies resources in the cluster (via helm, managed resources, kubectl, …).
We call these API Objects ‘dependent objects’ - as they are bound to the lifecycle of the extension.
The goal of this library is to enable extensions to setup health checks for their ‘dependent objects’ with minimal effort.
Usage
The library provides a generic controller with the ability to register any resource that satisfies the extension object interface.
An example is the Worker CRD.
Health check functions for commonly used dependent objects can be reused and registered with the controller, such as:
This creates a health check controller that reconciles the extensions.gardener.cloud/v1alpha1.Worker resource with the spec.type ‘aws’.
Three health check functions are registered that are executed during reconciliation.
Each health check is mapped to a single HealthConditionType that results in conditions with the same condition.type (see below).
To contribute to the Shoot’s health, the following conditions can be used: SystemComponentsHealthy, EveryNodeReady, ControlPlaneHealthy, ObservabilityComponentsHealthy. In case of workerless Shoot the EveryNodeReady condition is not present, so it can’t be used.
The Gardener/Gardenlet checks each extension for conditions matching these types.
However, extensions are free to choose any HealthConditionType.
For more information, see Contributing to Shoot Health Status Conditions.
type HealthCheck interface {
// Check is the function that executes the actual health check Check(context.Context, types.NamespacedName) (*SingleCheckResult, error)
// InjectSeedClient injects the seed client InjectSeedClient(client.Client)
// InjectShootClient injects the shoot client InjectShootClient(client.Client)
// SetLoggerSuffix injects the logger SetLoggerSuffix(string, string)
// DeepCopy clones the healthCheck DeepCopy() HealthCheck
}
The health check controller regularly (default: 30s) reconciles the extension resource and executes the registered health checks for the dependent objects.
As a result, the controller writes condition(s) to the status of the extension containing the health check result.
In our example, two checks are mapped to ShootEveryNodeReady and one to ShootSystemComponentsHealthy, leading to conditions with two distinct HealthConditionTypes (condition.type):
Please note that there are four statuses: True, False, Unknown, and Progressing.
True should be used for successful health checks.
False should be used for unsuccessful/failing health checks.
Unknown should be used when there was an error trying to determine the health status.
Progressing should be used to indicate that the health status did not succeed but for expected reasons (e.g., a cluster scale up/down could make the standard health check fail because something is wrong with the Machines, however, it’s actually an expected situation and known to be completed within a few minutes.)
Health checks that report Progressing should also provide a timeout, after which this “progressing situation” is expected to be completed.
The health check library will automatically transition the status to False if the timeout was exceeded.
Additional Considerations
It is up to the extension to decide how to conduct health checks, though it is recommended to make use of the build-in health check functionality of managedresources for trivial checks.
By deploying the depending resources via managed resources, the gardener resource manager conducts basic checks for different API objects out-of-the-box (e.g Deployments, DaemonSets, …) - and writes health conditions.
By default, Gardener performs health checks for all the ManagedResources created in the shoot namespaces.
Their status will be aggregated to the Shoot conditions according to the following rules:
Health checks of ManagedResource with .spec.class=nil are aggregated to the SystemComponentsHealthy condition
Health checks of ManagedResource with .spec.class!=nil are aggregated to the ControlPlaneHealthy condition unless the ManagedResource is labeled with care.gardener.cloud/condition-type=<other-condition-type>. In such case, it is aggregated to the <other-condition-type>.
More sophisticated health checks should be implemented by the extension controller itself (implementing the HealthCheck interface).
5.8 - Heartbeat
Heartbeat Controller
The heartbeat controller renews a dedicated Lease object named gardener-extension-heartbeat at regular 30 second intervals by default. This Lease is used for heartbeats similar to how gardenlet uses Lease objects for seed heartbeats (see gardenlet heartbeats).
The gardener-extension-heartbeatLease can be checked by other controllers to verify that the corresponding extension controller is still running. Currently, gardenlet checks this Lease when performing shoot health checks and expects to find the Lease inside the namespace where the extension controller is deployed by the corresponding ControllerInstallation. For each extension resource deployed in the Shoot control plane, gardenlet finds the corresponding gardener-extension-heartbeatLease resource and checks whether the Lease’s .spec.renewTime is older than the allowed threshold for stale extension health checks - in this case, gardenlet considers the health check report for an extension resource as “outdated” and reflects this in the Shoot status.
5.9 - Logging And Monitoring
Logging and Monitoring for Extensions
Gardener provides an integrated logging and monitoring stack for alerting, monitoring, and troubleshooting of its managed components by operators or end users. For further information how to make use of it in these roles, refer to the corresponding guides for exploring logs and for monitoring with Plutono.
The components that constitute the logging and monitoring stack are managed by Gardener. By default, it deploys Prometheus and Alertmanager (managed via prometheus-operator, and Plutono into the garden namespace of all seed clusters. If the logging is enabled in the gardenlet configuration (logging.enabled), it will deploy fluent-operator and Vali in the garden namespace too.
Each shoot namespace hosts managed logging and monitoring components. As part of the shoot reconciliation flow, Gardener deploys a shoot-specific Prometheus, blackbox-exporter, Plutono, and, if configured, an Alertmanager into the shoot namespace, next to the other control plane components. If the logging is enabled in the gardenlet configuration (logging.enabled) and the shoot purpose is not testing, it deploys a shoot-specific Vali in the shoot namespace too.
The logging and monitoring stack is extensible by configuration. Gardener extensions can take advantage of that and contribute monitoring configurations encoded in ConfigMaps for their own, specific dashboards, alerts and other supported assets and integrate with it. As with other Gardener resources, they will be continuously reconciled. The extensions can also deploy directly fluent-operator custom resources which will be created in the seed cluster and plugged into the fluent-bit instance.
This guide is about the roles and extensibility options of the logging and monitoring stack components, and how to integrate extensions with:
The central Prometheus instance in the garden namespace (called “cache Prometheus”) fetches metrics and data from all seed cluster nodes and all seed cluster pods.
It uses the federation concept to allow the shoot-specific instances to scrape only the metrics for the pods of the control plane they are responsible for.
This mechanism allows to scrape the metrics for the nodes/pods once for the whole cluster, and to have them distributed afterwards.
For more details, continue reading here.
Typically, this is not necessary, but in case an extension wants to extend the configuration for this cache Prometheus, they can create the prometheus-operator’s custom resources and label them with prometheus=cache, for example:
Another Prometheus instance in the garden namespace (called “seed Prometheus”) fetches metrics and data from seed system components, kubelets, cAdvisors, and extensions.
If you want your extension pods to be scraped then they must be annotated with prometheus.io/scrape=true and prometheus.io/port=<metrics-port>.
For more details, continue reading here.
Typically, this is not necessary, but in case an extension wants to extend the configuration for this seed Prometheus, they can create the prometheus-operator’s custom resources and label them with prometheus=seed, for example:
Another Prometheus instance in the garden namespace (called “aggregate Prometheus”) stores pre-aggregated data from the cache Prometheus and shoot Prometheus.
An ingress exposes this Prometheus instance allowing it to be scraped from another cluster.
For more details, continue reading here.
Typically, this is not necessary, but in case an extension wants to extend the configuration for this aggregate Prometheus, they can create the prometheus-operator’s custom resources and label them with prometheus=aggregate, for example:
A Plutono instance is deployed by gardenlet into the seed cluster’s garden namespace for visualizing monitoring metrics and logs via dashboards.
In order to provide custom dashboards, create a ConfigMap in the garden namespace labelled with dashboard.monitoring.gardener.cloud/seed=true that contains the respective JSON documents, for example:
The shoot-specific metrics are then made available to operators and users in the shoot Plutono, using the shoot Prometheus as data source.
Extension controllers might deploy components as part of their reconciliation next to the shoot’s control plane.
Examples for this would be a cloud-controller-manager or CSI controller deployments. Extensions that want to have their managed control plane components integrated with monitoring can contribute their per-shoot configuration for scraping Prometheus metrics, Alertmanager alerts or Plutono dashboards.
Extensions Monitoring Integration
In case an extension wants to extend the configuration for the shoot Prometheus, they can create the prometheus-operator’s custom resources and label them with prometheus=shoot.
ServiceMonitor
When the component runs in the seed cluster (e.g., as part of the shoot control plane), ServiceMonitor resources should be used:
If the component delegates authorization to the kube-apiserver of the shoot cluster, you can use the shoot-access-prometheus-shoot secret:
spec:
authorization:
credentials:
name: shoot-access-prometheus-shoot
key: token
# in case the component's server certificate is signed by the cluster CA: scheme: HTTPS
tlsConfig:
ca:
secret:
name: <name-of-ca-bundle-secret>
key: bundle.crt
ScrapeConfigs
If the component runs in the shoot cluster itself, metrics are scraped via the kube-apiserver proxy.
In this case, Prometheus needs to authenticate itself with the API server.
This can be done like this:
Developers can make use of the pkg/component/observability/monitoring/prometheus/shoot.ClusterComponentScrapeConfigSpec function in order to generate a ScrapeConfig like above.
PrometheusRule
Similar to ServiceMonitors, PrometheusRules can be created with the prometheus=shoot label:
A Plutono instance is deployed by gardenlet into the shoot cluster’s namespace for visualizing monitoring metrics and logs via dashboards.
In order to provide custom dashboards, create a ConfigMap in the shoot cluster’s namespace labelled with dashboard.monitoring.gardener.cloud/shoot=true that contains the respective JSON documents, for example:
In Kubernetes clusters, container logs are non-persistent and do not survive stopped and destroyed containers. Gardener addresses this problem for the components hosted in a seed cluster by introducing its own managed logging solution. It is integrated with the Gardener monitoring stack to have all troubleshooting context in one place.
Gardener logging consists of components in three roles - log collectors and forwarders, log persistency and exploration/consumption interfaces. All of them live in the seed clusters in multiple instances:
Logs are persisted by Vali instances deployed as StatefulSets - one per shoot namespace, if the logging is enabled in the gardenlet configuration (logging.enabled) and the shoot purpose is not testing, and one in the garden namespace. The shoot instances store logs from the control plane components hosted there. The garden Vali instance is responsible for logs from the rest of the seed namespaces - kube-system, garden, extension-*, and others.
Fluent-bit DaemonSets deployed by the fluent-operator on each seed node collect logs from it. A custom plugin takes care to distribute the collected log messages to the Vali instances that they are intended for. This allows to fetch the logs once for the whole cluster, and to distribute them afterwards.
Plutono is the UI component used to explore monitoring and log data together for easier troubleshooting and in context. Plutono instances are configured to use the corresponding Vali instances, sharing the same namespace as data providers. There is one Plutono Deployment in the garden namespace and one Deployment per shoot namespace (exposed to the end users and to the operators).
Logs can be produced from various sources, such as containers or systemd, and in different formats. The fluent-bit design supports configurable data pipeline to address that problem. Gardener provides such configuration for logs produced by all its core managed components as ClusterFilters and ClusterParsers . Extensions can contribute their own, specific configurations as fluent-operator custom resources too. See for example the logging configuration for the Gardener AWS provider extension.
Fluent-bit Log Parsers and Filters
To integrate with Gardener logging, extensions can and should specify how fluent-bit will handle the logs produced by the managed components that they contribute to Gardener. Normally, that would require to configure a parser for the specific logging format, if none of the available is applicable, and a filter defining how to apply it. For a complete reference for the configuration options, refer to fluent-bit’s documentation.
To contribute its own configuration to the fluent-bit agents data pipelines, an extension must deploy a fluent-operator custom resource labeled with fluentbit.gardener/type: seed in the seed cluster.
Note: Take care to provide the correct data pipeline elements in the corresponding fields and not to mix them.
Example: Logging configuration for provider-specific cloud-controller-manager deployed into shoot namespaces that reuses the kube-apiserver-parser defined in logging.go to parse the component logs:
If the type of logs exposed in the Plutono instances needs to be changed, it is necessary to update the corresponding instance dashboard configurations.
Tips
Be careful to create ClusterFilters and ClusterParsers with unique names because they are not namespaced. We use pod_name for filters with one container and pod_name--container_name for pods with multiple containers.
Be careful to match exactly the log names that you need for a particular parser in your filters configuration. The regular expression you will supply will match names in the form kubernetes.pod_name.<metadata>.container_name. If there are extensions with the same container and pod names, they will all match the same parser in a filter. That may be a desired effect, if they all share the same log format. But it will be a problem if they don’t. To solve it, either the pod or container names must be unique, and the regular expression in the filter has to match that unique pattern. A recommended approach is to prefix containers with the extension name and tune the regular expression to match it. For example, using myextension-container as container name and a regular expression kubernetes.mypod.*myextension-container will guarantee match of the right log name. Make sure that the regular expression does not match more than you expect. For example, kubernetes.systemd.*systemd.* will match both systemd-service and systemd-monitor-service. You will want to be as specific as possible.
It’s a good idea to put the logging configuration into the Helm chart that also deploys the extension controller, while the monitoring configuration can be part of the Helm chart/deployment routine that deploys the component managed by the controller.
We have introduced a component called gardener-resource-manager that is deployed as part of every shoot control plane in the seed.
One of its tasks is to manage CRDs, so called ManagedResources.
Managed resources contain Kubernetes resources that shall be created, reconciled, updated, and deleted by the gardener-resource-manager.
Extension controllers may create these ManagedResources in the shoot namespace if they need to create any resource in the shoot cluster itself, for example RBAC roles (or anything else).
Where can I find more examples and more information how to use ManagedResources?
Control Plane Migration is a new Gardener feature that has been recently implemented as proposed in GEP-7 Shoot Control Plane Migration. It should be properly supported by all extensions controllers. This document outlines some important points that extension maintainers should keep in mind to properly support migration in their extensions.
Overall Principles
The following principles should always be upheld:
All states maintained by the extension that is external from the seed cluster, for example infrastructure resources in a cloud provider, DNS entries, etc., should be kept during the migration. No such state should be deleted and then recreated, as this might cause disruption in the availability of the shoot cluster.
All Kubernetes resources maintained by the extension in the shoot cluster itself should also be kept during the migration. No such resources should be deleted and then recreated.
Migrate and Restore Operations
Two new operations have been introduced in Gardener. They can be specified as values of the gardener.cloud/operation annotation on an extension resource to indicate that an operation different from a normal reconcile should be performed by the corresponding extension controller:
The migrate operation is used to ask the extension controller in the source seed to stop reconciling extension resources (in case they are requeued due to errors) and perform cleanup activities, if such are required. These cleanup activities might involve removing finalizers on resources in the shoot namespace that have been previously created by the extension controller and deleting them without actually deleting any resources external to the seed cluster. This is also the last opportunity for extensions to persist their state into the .status.state field of the reconciled extension resource before its restored in the new destination seed cluster.
The restore operation is used to ask the extension controller in the destination seed to restore any state saved in the extension resource status, before performing the actual reconciliation.
Unlike the reconcile operation, extension controllers must remove the gardener.cloud/operation annotation at the end of a successful reconciliation when the current operation is migrate or restore, not at the beginning of a reconciliation.
Cleaning-Up Source Seed Resources
All resources in the source seed that have been created by an extension controller, for example secrets, config maps, managed resources, etc., should be properly cleaned up by the extension controller when the current operation is migrate. As mentioned above, such resources should be deleted without actually deleting any resources external to the seed cluster.
There is one exception to this: Secrets labeled with persist=true created via the secrets manager. They should be kept (i.e., the Cleanup function of secrets manager should not be called) and will be garbage collected automatically at the end of the migrate operation. This ensures that they can be properly persisted in the ShootState resource and get restored on the new destination seed cluster.
For many custom resources, for example MCM resources, the above requirement means in practice that any finalizers should be removed before deleting the resource, in addition to ensuring that the resource deletion is not reconciled by its respective controller if there is no finalizer. For managed resources, the above requirement means in practice that the spec.keepObjects field should be set to true before deleting the extension resource.
Here it is assumed that any resources that contain state needed by the extension controller can be safely deleted, since any such state has been saved as described in Saving and Restoring Extension States at the end of the last successful reconciliation.
Saving and Restoring Extension States
Some extension controllers create and maintain their own state when reconciling extension resources. For example, most infrastructure controllers use Terraform and maintain the terraform state in a special config map in the shoot namespace. This state must be properly migrated to the new seed cluster during control plane migration, so that subsequent reconciliations in the new seed could find and use it appropriately.
All extension controllers that require such state migration must save their state in the status.state field of their extension resource at the end of a successful reconciliation. They must also restore their state from that same field upon reconciling an extension resource when the current operation is restore, as specified by the gardener.cloud/operation annotation, before performing the actual reconciliation.
As an example, an infrastructure controller that uses Terraform must save the terraform state in the status.state field of the Infrastructure resource. An Infrastructure resource with a properly saved state might look as follows:
Extension controllers that do not use a saved state and therefore do not require state migration could leave the status.state field as nil at the end of a successful reconciliation, and just perform a normal reconciliation when the current operation is restore.
In addition, extension controllers that use referenced resources (usually secrets) must also make sure that these resources are added to the status.resources field of their extension resource at the end of a successful reconciliation, so they could be properly migrated by Gardener to the destination seed.
Implementation Details
Migrate and Restore Actuator Methods
Most extension controller implementations follow a common pattern where a generic Reconciler implementation delegates to an Actuator interface that contains the methods Reconcile and Delete, provided by the extension.
Two methods Migrate and Restore are available in all such Actuator interfaces, see the infrastructure Actuator interface as an example.
These methods are called by the generic reconcilers for the migrate and restore operations respectively, and should be implemented by the extension according to the above guidelines.
Extension Controllers Based on Generic Actuators
In practice, the implementation of many extension controllers (for example, the ControlPlane and Worker controllers in most provider extensions) are based on a generic Actuator implementation that only delegates to extension methods for behavior that is truly provider specific.
In all such cases, the Migrate and Restore methods have already been implemented properly in the generic actuators and there is nothing more to do in the extension itself.
In some rare cases, extension controllers based on a generic actuator might still introduce a custom Actuator implementation to override some of the generic actuator methods in order to enhance or change their behavior in a certain way.
In such cases, the Migrate and Restore methods might need to be overridden as well, see the Azure controlplane controller as an example.
Worker State
Note that the machine state is handled specially by gardenlet (i.e., all relevant objects in the machine.sapcloud.io/v1alpha1 API are directly persisted by gardenlet and NOT by the generic actuators).
In the past, they were persisted to the Worker’s .status.state field by the so-called “worker state reconciler”, however, this reconciler was dropped and changed as part of GEP-22.
Nowadays, gardenlet directly writes the state to the ShootState resource during the Migrate phase of a Shoot (without the detour of the Worker’s .status.state field).
On restoration, unlike for other extension kinds, gardenlet no longer populates the machine state into the Worker’s .status.state field.
Instead, the extension controller should read the machine state directly from the ShootState in the garden cluster (see this document for information how to access the garden cluster) and use it to subsequently restore the relevant machine.sapcloud.io/v1alpha1 resources.
This flow is implemented in the generic Worker actuator.
As a result, Extension controllers using this generic actuator do not need to implement any custom logic.
Extension Controllers Not Based on Generic Actuators
The implementation of some extension controllers (for example, the infrastructure controllers in all provider extensions) are not based on a generic Actuator implementation.
Such extension controllers must always provide a proper implementation of the Migrate and Restore methods according to the above guidelines, see the AWS infrastructure controller as an example.
In practice, this might result in code duplication between the different extensions, since the Migrate and Restore code is usually not provider or OS-specific.
If you do not use the generic Worker actuator, see this section for information how to handle the machine state related to the Worker resource.
5.12 - Project Roles
Extending Project Roles
The Project resource allows to specify a list of roles for every member (.spec.members[*].roles).
There are a few standard roles defined by Gardener itself.
Please consult Projects for further information.
However, extension controllers running in the garden cluster may also create CustomResourceDefinitions that project members might be able to CRUD.
For this purpose, Gardener also allows to specify extension roles.
An extension role is prefixed with extension:, e.g.
The project controller will, for every extension role, create a ClusterRole with name gardener.cloud:extension:project:<projectName>:<roleName>, i.e., for the above example: gardener.cloud:extension:project:dev:foo.
This ClusterRole aggregates other ClusterRoles that are labeled with rbac.gardener.cloud/aggregate-to-extension-role=foo which might be created by extension controllers.
An extension that might want to contribute to the core admin or viewer roles can use the labels rbac.gardener.cloud/aggregate-to-project-member=true or rbac.gardener.cloud/aggregate-to-project-viewer=true, respectively.
Please note that the names of the extension roles are restricted to 20 characters!
Moreover, the project controller will also create a corresponding RoleBinding with the same name in the project namespace.
It will automatically assign all members that are assigned to this extension role.
5.13 - Provider Local
Local Provider Extension
The “local provider” extension is used to allow the usage of seed and shoot clusters which run entirely locally without any real infrastructure or cloud provider involved.
It implements Gardener’s extension contract (GEP-1) and thus comprises several controllers and webhooks acting on resources in seed and shoot clusters.
The motivation for maintaining such extension is the following:
🛡 Output Qualification: Run fast and cost-efficient end-to-end tests, locally and in CI systems (increased confidence ⛑ before merging pull requests)
⚙️ Development Experience: Develop Gardener entirely on a local machine without any external resources involved (improved costs 💰 and productivity 🚀)
🤝 Open Source: Quick and easy setup for a first evaluation of Gardener and a good basis for first contributions
Current Limitations
The following enlists the current limitations of the implementation.
Please note that all of them are not technical limitations/blockers, but simply advanced scenarios that we haven’t had invested yet into.
No load balancers for Shoot clusters.
We have not yet developed a cloud-controller-manager which could reconcile load balancer Services in the shoot cluster.
In case a seed cluster with multiple availability zones, i.e. multiple entries in .spec.provider.zones, is used in conjunction with a single-zone shoot control plane, i.e. a shoot cluster without .spec.controlPlane.highAvailability or with .spec.controlPlane.highAvailability.failureTolerance.type set to node, the local address of the API server endpoint needs to be determined manually or via the in-cluster coredns.
As the different istio ingress gateway loadbalancers have individual external IP addresses, single-zone shoot control planes can end up in a random availability zone. Having the local host use the coredns in the cluster as name resolver would form a name resolution cycle. The tests mitigate the issue by adapting the DNS configuration inside the affected test.
The images locally built by Skaffold for the Gardener components which are deployed to this shoot cluster are managed by a container registry in the registry namespace in the kind cluster.
provider-local configures this registry as mirror for the shoot by mutating the OperatingSystemConfig and using the default contract for extending the containerd configuration.
In order to bootstrap a seed cluster, the gardenlet deploys PersistentVolumeClaims and Services of type LoadBalancer.
While storage is supported in shoot clusters by using the local-path-provisioner, load balancers are not supported yet.
However, provider-local runs a Service controller which specifically reconciles the seed-related Services of type LoadBalancer.
This way, they get an IP and gardenlet can finish its bootstrapping process.
Note that these IPs are not reachable, however for the sake of developing ManagedSeeds this is sufficient for now.
Also, please note that the provider-local extension only gets deployed because of the Always deployment policy in its corresponding ControllerRegistration and because the DNS provider type of the seed is set to local.
Implementation Details
This section contains information about how the respective controllers and webhooks in provider-local are implemented and what their purpose is.
Bootstrapping
The Helm chart of the provider-local extension defined in its Extension contains a special deployment for a CoreDNS instance in a gardener-extension-provider-local-coredns namespace in the seed cluster.
This CoreDNS instance is responsible for enabling the components running in the shoot clusters to be able to resolve the DNS names when they communicate with their kube-apiservers.
It contains a static configuration to resolve the DNS names based on local.gardener.cloud to istio-ingressgateway.istio-ingress.svc.
Controllers
There are controllers for all resources in the extensions.gardener.cloud/v1alpha1 API group except for BackupBucket and BackupEntrys.
ControlPlane
This controller is deploying the local-path-provisioner as well as a related StorageClass in order to support PersistentVolumeClaims in the local shoot cluster.
Additionally, it creates a few (currently unused) dummy secrets (CA, server and client certificate, basic auth credentials) for the sake of testing the secrets manager integration in the extensions library.
DNSRecord
The controller adapts the cluster internal DNS configuration by extending the coredns configuration for every observed DNSRecord. It will add two corresponding entries in the custom DNS configuration per shoot cluster:
data:
api.local.local.external.local.gardener.cloud.override: |
rewrite stop name regex api.local.local.external.local.gardener.cloud istio-ingressgateway.istio-ingress.svc.cluster.local answer auto
api.local.local.internal.local.gardener.cloud.override: |
rewrite stop name regex api.local.local.internal.local.gardener.cloud istio-ingressgateway.istio-ingress.svc.cluster.local answer auto
Infrastructure
This controller generates a NetworkPolicy which allows the control plane pods (like kube-apiserver) to communicate with the worker machine pods (see Worker section).
It also deploys a NetworkPolicy which allows the bastion pods to communicate with the worker machine pods (see Bastion section).
Network
This controller is not implemented anymore. In the initial version of provider-local, there was a Network controller deploying kindnetd (see release v1.44.1).
However, we decided to drop it because this setup prevented us from using NetworkPolicys (kindnetd does not ship a NetworkPolicy controller).
In addition, we had issues with shoot clusters having more than one node (hence, we couldn’t support rolling updates, see PR #5666).
OperatingSystemConfig
This controller renders a simple cloud-init template which can later be executed by the shoot worker nodes.
The shoot worker nodes are Pods with a container based on the kindest/node image. This is maintained in the gardener/machine-controller-manager-provider-local repository and has a special run-userdata systemd service which executes the cloud-init generated earlier by the OperatingSystemConfig controller.
Additionally, it generates the MachineClasses and the MachineDeployments based on the specification of the Worker resources.
Bastion
This controller implements the Bastion.extensions.gardener.cloud resource by deploying a pod with the local machine image along with a LoadBalancer service.
Note that this controller does not respect the Bastion.spec.ingress configuration as there is no way to perform client IP restrictions in the local setup.
Ingress
The gardenlet creates a wildcard DNS record for the Seed’s ingress domain pointing to the nginx-ingress-controller’s LoadBalancer.
This domain is commonly used by all Ingress objects created in the Seed for Seed and Shoot components.
As provider-local implements the DNSRecord extension API (see the DNSRecordsection), this controller reconciles all Ingresss and creates DNSRecords of type local for each host included in spec.rules.
This only happens for shoot namespaces (gardener.cloud/role=shoot label) to make Ingress domains resolvable on the machine pods.
Service
This controller reconciles Services of type LoadBalancer in the local Seed cluster.
Since the local Kubernetes clusters used as Seed clusters typically don’t support such services, this controller sets the .status.ingress.loadBalancer.ip[0] to the IP of the host.
It makes important LoadBalancer Services (e.g. istio-ingress/istio-ingressgateway and shoot--*--*/bastion-*) available to the host by setting spec.ports[].nodePort to well-known ports that are mapped to hostPorts in the kind cluster configuration.
istio-ingress/istio-ingressgateway is set to be exposed on nodePort30433 by this controller.
The bastion services are exposed on nodePort30022.
In case the seed has multiple availability zones (.spec.provider.zones) and it uses SNI, the different zone-specific istio-ingressgateway loadbalancers are exposed via different IP addresses. Per default, IP addresses 172.18.255.10, 172.18.255.11, and 172.18.255.12 are used for the zones 0, 1, and 2 respectively.
ETCD Backups
This controller reconciles the BackupBucket and BackupEntry of the shoot allowing the etcd-backup-restore to create and copy backups using the local provider functionality. The backups are stored on the host file system. This is achieved by mounting that directory to the etcd-backup-restore container.
Extension Seed
This controller reconciles Extensions of type local-ext-seed. It creates a single serviceaccount named local-ext-seed in the shoot’s namespace in the seed. The extension is reconciled before the kube-apiserver. More on extension lifecycle strategies can be read in Registering Extension Controllers.
Extension Shoot
This controller reconciles Extensions of type local-ext-shoot. It creates a single serviceaccount named local-ext-shoot in the kube-system namespace of the shoot. The extension is reconciled after the kube-apiserver. More on extension lifecycle strategies can be read Registering Extension Controllers.
Extension Shoot After Worker
This controller reconciles Extensions of type local-ext-shoot-after-worker. It creates a deployment named local-ext-shoot-after-worker in the kube-system namespace of the shoot. The extension is reconciled after the workers and waits until the deployment is ready. More on extension lifecycle strategies can be read Registering Extension Controllers.
check the health of the ManagedResource/extension-controlplane-shoot-webhooks and populate the SystemComponentsHealthy condition in the ControlPlane resource.
check the health of the ManagedResource/extension-networking-local and populate the SystemComponentsHealthy condition in the Network resource.
check the health of the ManagedResource/extension-worker-mcm-shoot and populate the SystemComponentsHealthy condition in the Worker resource.
check the health of the Deployment/machine-controller-manager and populate the ControlPlaneHealthy condition in the Worker resource.
check the health of the Nodes and populate the EveryNodeReady condition in the Worker resource.
Webhooks
Control Plane
This webhook reacts on the OperatingSystemConfig containing the configuration of the kubelet and sets the failSwapOn to false (independent of what is configured in the Shoot spec) (ref).
DNS Config
This webhook reacts on events for the dependency-watchdog-probeDeployment, the blackbox-exporterDeployment, as well as on events for Pods created when the machine-controller-manager reconciles Machines.
All these pods need to be able to resolve the DNS names for shoot clusters.
It sets the .spec.dnsPolicy=None and .spec.dnsConfig.nameServers to the cluster IP of the corednsService created in the gardener-extension-provider-local-coredns namespaces so that these pods can resolve the DNS records for shoot clusters (see the Bootstrapping section for more details).
Machine Controller Manager
This webhook mutates the global ClusterRole related to machine-controller-manager and injects permissions for Service resources.
The machine-controller-manager-provider-local deploys Pods for each Machine (while real infrastructure provider obviously deploy VMs, so no Kubernetes resources directly).
It also deploys a Service for these machine pods, and in order to do so, the ClusterRole must allow the needed permissions for Service resources.
Node
This webhook reacts on updates to nodes/status in both seed and shoot clusters and sets the .status.{allocatable,capacity}.cpu="100" and .status.{allocatable,capacity}.memory="100Gi" fields.
Background: Typically, the .status.{capacity,allocatable} values are determined by the resources configured for the Docker daemon (see for example the docker Quick Start Guide for Mac).
Since many of the Pods deployed by Gardener have quite high .spec.resources.requests, the Nodes easily get filled up and only a few Pods can be scheduled (even if they barely consume any of their reserved resources).
In order to improve the user experience, on startup/leader election the provider-local extension submits an empty patch which triggers the “node webhook” (see the below section) for the seed cluster.
The webhook will increase the capacity of the Nodes to allow all Pods to be scheduled.
For the shoot clusters, this empty patch trigger is not needed since the MutatingWebhookConfiguration is reconciled by the ControlPlane controller and exists before the Node object gets registered.
Shoot
This webhook reacts on the ConfigMap used by the kube-proxy and sets the maxPerCore field to 0 since other values don’t work well in conjunction with the kindest/node image which is used as base for the shoot worker machine pods (ref).
DNS Configuration for Multi-Zonal Seeds
In case a seed cluster has multiple availability zones as specified in .spec.provider.zones, multiple istio ingress gateways are deployed, one per availability zone in addition to the default deployment. The result is that single-zone shoot control planes, i.e. shoot clusters with .spec.controlPlane.highAvailability set or with .spec.controlPlane.highAvailability.failureTolerance.type set to node, may be exposed via any of the zone-specific istio ingress gateways. Previously, the endpoints were statically mapped via /etc/hosts. Unfortunately, this is no longer possible due to the aforementioned dynamic in the endpoint selection.
For multi-zonal seed clusters, there is an additional configuration following coredns’s view plugin mapping the external IP addresses of the zone-specific loadbalancers to the corresponding internal istio ingress gateway domain names. This configuration is only in place for requests from outside of the seed cluster. Those requests are currently being identified by the protocol. UDP requests are interpreted as originating from within the seed cluster while TCP requests are assumed to come from outside the cluster via the docker hostport mapping.
The corresponding test sets the DNS configuration accordingly so that the name resolution during the test use coredns in the cluster.
machine-controller-manager-provider-local
Out of tree (controller-based) implementation for local as a new provider.
The local out-of-tree provider implements the interface defined at MCM OOT driver.
Fundamental Design Principles
Following are the basic principles kept in mind while developing the external plugin.
Communication between this Machine Controller (MC) and Machine Controller Manager (MCM) is achieved using the Kubernetes native declarative approach.
Machine Controller (MC) behaves as the controller used to interact with the local provider and manage the VMs corresponding to the machine objects.
Machine Controller Manager (MCM) deals with higher level objects such as machine-set and machine-deployment objects.
Future Work
Future work could mostly focus on resolving the above listed limitations, i.e.:
Properly implement .spec.machineTypes in the CloudProfiles (i.e., configure .spec.resources properly for the created shoot worker machine pods).
5.14 - Reconcile Trigger
Reconcile Trigger
Gardener dictates the time of reconciliation for resources of the API group extensions.gardener.cloud.
It does that by annotating the respected resource with gardener.cloud/operation=reconcile.
Extension controllers shall react to this annotation and start reconciling the resource.
They have to remove this annotation as soon as they begin with their reconcile operation and maintain the status of the extension resource accordingly.
The reason for this behaviour is that it is possible to configure Gardener to reconcile only in the shoots’ maintenance time windows.
In order to avoid that, extension controllers reconcile outside of the shoot’s maintenance time window we have introduced this contract.
This way extension controllers don’t need to care about when the shoot maintenance time window happens.
Gardener keeps control and decides when the shoot shall be reconciled/updated.
Shoots and Seeds can include a list of resources (usually secrets) that can be referenced by name in the extension providerConfig and other Shoot sections, for example:
Gardener expects these referenced resources to be located in the project namespace (e.g., garden-dev) for Shoots and in the garden namespace for Seeds.
Seed resources are copied to the garden namespace in the seed cluster, while Shoot resources are copied to the control-plane namespace in the shoot cluster.
To avoid conflicts with other resources in the shoot, all resources in the seed are prefixed with a static value.
Extension controllers can resolve the references to these resources by accessing the Shoot via the Cluster resource. To properly read a referenced resources, extension controllers should use the utility function GetObjectByReference from the extensions/pkg/controller package, for example:
Before Gardener can manage shoot clusters, it needs to know which required and optional extensions are available in the landscape.
The following sections explain the general registration process for extensions.
Extensions
The registration starts by creating Extension resources in the garden runtime cluster.
They represent the single source for all deployment aspects an extension may offer (garden, seed, shoot, admission).
The gardener-operator takes these resources to deploy the extension controllers to the garden runtime cluster, as well as creating corresponding ControllerRegistration and ControllerDeployment resources in the virtual garden cluster.
Please see the following example of an Extension resource which mainly configures:
The resource kinds and types the extension is responsible for
A Reference the OCI Helm chart(s) for the extension admission and optional values
A Reference the OCI Helm chart for the extension controller
Optional values for the extension in the garden runtime cluster
Optional values for the deployment in the seed clusters
Operators may use Extensions to observe their status conditions, regularly updated by gardener-operator.
They provide more information about whether an extension is currently in use and if their installation was successful.
In the virtual garden cluster, the native extension registration resource kinds are ControllerRegistration and ControllerDeployment.
These resources are usually created by the gardener-operator based on Extensions in the runtime cluster.
They provide the gardenlets in the seed clusters with information about which extensions are available and how to deploy them.
Note
Before gardener/gardener#9635, the only option to register extensions was via ControllerRegistration/ControllerDeployment resources.
In the meantime, they became an implementation detail of the extension registration and should be treated as a gardener internal object.
While it’s still possible to create them manually (without Extensions), operators should only consider this option for advanced use cases.
Once created, gardener evaluates the registrations and deployments and creates ControllerInstallation resources which describe the request “please install this controller X to this seed Y”.
The specification mainly describes which of Gardener’s extension CRDs are managed, for example:
This information tells Gardener that there is an extension controller that can handle BackupBucket, BackupEntry, DNSRecord, Infrastructure, ControlPlane and Worker resources of type local.
A reference to the shown ControllerDeployment specifies how the deployment of the extension controller is accomplished.
Deploying Extension Controllers
In the garden runtime cluster gardener-operator deploys the extension controllers directly, as soon as it is considered as required.
Deployments in the seed clusters are represented by another resource called ControllerInstallation.
This resource expresses that Gardener requires the provider-local extension controller to run on the local-1 seed cluster.
gardener-controller-manager automatically determines which extension controller is required on which seed cluster and will only create ControllerInstallation objects for those.
Also, it will automatically delete ControllerInstallations referencing extension controllers that are no longer required on a seed (e.g., because all shoots on it have been deleted).
There are additional configuration options, please see the Deployment Configuration Options section.
After gardener-controller-manager has written the ControllerInstallation resource, gardenlet picks it up and installs the controller on the respective Seed using the referenced ControllerDeployment.
Helm Charts
Extensions and ControllerDeployments both need to specify a reference to an OCI Helm chart that contains the extension controller.
Those charts are usually provided by the extension and allow their deployment to the garden runtime or seed clusters.
Note
Due to legacy reasons, a ControllerDeployment can work with a rawChart instead of an OCI image reference.
If your extension does not yet offer an OCI image, you may consider using this option as a temporary workaround.
Please note, that rawChart is not supported in Extensions and thus cannot be used for a deployment in the garden runtime cluster.
helm:
ociRepository:
# full ref with either tag or digest, or both ref: registry.example.com/foo:1.0.0@sha256:abc
---
helm:
ociRepository:
# repository and tag repository: registry.example.com
tag: 1.0.0
---
helm:
ociRepository:
# repository and digest repository: registry.example.com
digest: sha256:abc
---
helm:
ociRepository:
# when specifying both tag and digest, the tag is ignored. repository: registry.example.com
tag: 1.0.0
digest: sha256:abc
If needed, a pull secret can be referenced in the ControllerDeployment.helm.ociRepository.pullSecretRef field.
The pull secret must be available in the garden namespace of the cluster where the ControllerDeployment is created and must contain the data key .dockerconfigjson with the base64-encoded Docker configuration JSON.
The downloaded chart is cached in memory. It is recommended to always specify a digest, because if it is not specified, the manifest is fetched in every reconciliation to compare the digest with the local cache.
Helm Values
No matter where the chart originates from, gardener-operator and gardenlet deploy it with the provided Helm values.
The chart and the values can be updated at any time - Gardener will recognize it and re-trigger the deployment process.
In order to allow extension controller deployments to get information about the garden and the seed cluster, additional properties are mixed into the values (root level) of every deployed Helm chart:
If the extension is deployed in an autonomous shoot cluster, then the .gardener.autonomousShootCluster field is additionally propagated and set to true.
Extension controller deployments can use this information in their Helm chart in case they require knowledge about the garden and the seed environment.
The list might be extended in the future.
Deployment Configuration Options
The .spec.extension structure allows to configure a deployment policy.
There are the following policies:
OnDemand (default): Gardener will demand the deployment and deletion of the extension controller to/from seed clusters dynamically. It will automatically determine (based on other resources like Shoots) whether it is required and decide accordingly.
Always: Gardener will demand the deployment of the extension controller to seed clusters independent of whether it is actually required or not. This might be helpful if you want to add a new component/controller to all seed clusters by default. Another use-case is to minimize the durations until extension controllers get deployed and ready in case you have highly fluctuating seed clusters.
AlwaysExceptNoShoots: Similar to Always, but if the seed does not have any shoots, then the extension controller is not being deployed. It will be deleted from a seed after the last shoot has been removed from it.
Also, the .spec.extension.seedSelector allows to specify a label selector for seed clusters.
Only if it matches the labels of a seed, then it will be deployed to it.
Please note that a seed selector can only be specified for secondary controllers (primary=false for all .spec.resources[]).
Extension Resource Configurations
The extensibility contract allows the following configuration options per registered extension resource (see resources below):
The autoEnable=[shoot] option specifies that the Extension/foo object shall be created by default for all shoots (unless they opted out by setting .spec.extensions[].enabled=false in the Shoot spec).
The autoEnable=[seed,shoot] option specifies that the Extension/foo can be enabled in seed and shoot clusters.
The reconcileTimeout tells Gardener how long it should wait during its reconciliation flow for the Extension/foo’s reconciliation to finish.
primary specifies whether the extension controller is the main one responsible for the lifecycle of the Extension resource.
Setting primary to false would allow to register additional, secondary controllers that may also watch/react on the Extension/foo resources, however, only the primary controller may change/update the main status of the extension object.
Particularly, only the primary controller may set .status.lastOperation, .status.lastError, .status.observedGeneration, and .status.state.
Secondary controllers may contribute to the .status.conditions[] if they like, of course.
Secondary controllers might be helpful in scenarios where additional tasks need to be completed which are not part of the reconciliation logic of the primary controller but separated out into a dedicated extension.
⚠️ There must be exactly one primary controller for every registered kind/type combination.
Also, please note that the primary field cannot be changed after creation of the Extension.
Extension Lifecycle
The lifecycle field tells Gardener when to perform a certain action on the Extension (extensions.gardener.cloud/v1alpha1) resource during the reconciliation flows. If omitted, then the default behaviour will be applied. Please find more information on the defaults in the explanation below. Possible values for each control flow are AfterKubeAPIServer, BeforeKubeAPIServer, and AfterWorker. Let’s take the following configuration and explain it.
reconcile: AfterKubeAPIServer means that the extension resource will be reconciled after the successful reconciliation of the kube-apiserver during shoot reconciliation. This is also the default behaviour if this value is not specified. During shoot hibernation, the opposite rule is applied, meaning that in this case the reconciliation of the extension will happen before the kube-apiserver is scaled to 0 replicas. On the other hand, if the extension needs to be reconciled before the kube-apiserver and scaled down after it, then the value BeforeKubeAPIServer should be used.
delete: BeforeKubeAPIServer means that the extension resource will be deleted before the kube-apiserver is destroyed during shoot deletion. This is the default behaviour if this value is not specified.
migrate: BeforeKubeAPIServer means that the extension resource will be migrated before the kube-apiserver is destroyed in the source cluster during control plane migration. This is the default behaviour if this value is not specified. The restoration of the control plane follows the reconciliation control flow.
Due to technical reasons, exceptions apply for different reconcile flows, for example:
The garden reconciliation doesn’t distinguish between AfterKubeAPIServer and AfterWorker.
The seed reconciliation completely ignores the lifecycle field.
The lifecycle value AfterWorker is only available during reconcile. When specified, the extension resource will be reconciled after the workers are deployed. This is useful for extensions that want to deploy a workload in the shoot control plane and want to wait for the workload to run and get ready on a node. During shoot creation the extension will start its reconciliation before the first workers have joined the cluster, they will become available at some later point.
5.17 - Resource Admission in the Garden Cluster
Resource Admission in the Garden Cluster
The Shoot resource itself can contain some extension-specific data blobs (see providerConfig):
In the above example, Gardener itself does not understand the AWS-specific provider configuration for the infrastructure. However, if this part of the Shoot resource should be validated, then you should run an AWS-specific component in the garden cluster that registers a webhook. The same is true for values defaulting via MutatingWebhookConfiguration. Similarly to how Gardener is deployed to the garden cluster, these components must be deployed and managed by the Gardener administrator.
Examples of extensions performing validation:
provider extensions would validate spec.provider.infrastructureConfig and spec.provider.controlPlaneConfig in the Shoot resource and spec.providerConfig in the CloudProfile resource.
networking extensions would validate spec.networking.providerConfig in the Shoot resource.
As a best practice, the validation should be performed only if there is a change in the spec of the resource. Please find an exemplary implementation in the gardener/gardener-extension-provider-aws repository.
extensions.gardener.cloud Labeling
When an admission relevant resource (e.g., BackupEntrys, BackupBuckets, CloudProfiles, Seeds, SecretBindings, and Shoots) is newly created or updated in the garden cluster, Gardener adds an extension label to it. This label is of the form <extension-type>.extensions.gardener.cloud/<extension-name> : "true". For example, an extension label for a provider extension type aws looks like provider.extensions.gardener.cloud/aws : "true". The extensions should add object selectors in their admission webhooks for these labels to filter out the objects they are responsible for. Please see the types_constants.go file for the full list of extension labels.
5.18 - Resources
5.18.1 - BackupBucket
Contract: BackupBucket Resource
The Gardener project features a sub-project called etcd-backup-restore to take periodic backups of etcd backing Shoot clusters. It demands the bucket (or its equivalent in different object store providers) to be created and configured externally with appropriate credentials. The BackupBucket resource takes this responsibility in Gardener.
Before introducing the BackupBucket extension resource, Gardener was using Terraform in order to create and manage these provider-specific resources (e.g., see AWS Backup).
Now, Gardener commissions an external, provider-specific controller to take over this task. You can also refer to backupInfra proposal documentation to get an idea about how the transition was done and understand the resource in a broader scope.
What Is the Scope of a Bucket?
A bucket will be provisioned per Seed. So, a backup of every Shoot created on that Seed will be stored under a different shoot specific prefix under the bucket.
For the backup of the Shoot rescheduled on different Seed, it will continue to use the same bucket.
What Is the Lifespan of a BackupBucket?
The bucket associated with BackupBucket will be created at the creation of the Seed. And as per current implementation, it will also be deleted on deletion of the Seed, if there isn’t any BackupEntry resource associated with it.
In the future, we plan to introduce a schedule for BackupBucket - the deletion logic for the BackupBucket resource, which will reschedule it on different available Seeds on deletion or failure of a health check for the currently associated seed. In that case, the BackupBucket will be deleted only if there isn’t any schedulable Seed available and there isn’t any associated BackupEntry resource.
What Needs to Be Implemented to Support a New Infrastructure Provider?
As part of the seed flow, Gardener will create a special CRD in the seed cluster that needs to be reconciled by an extension controller, for example:
The .spec.secretRef contains a reference to the provider secret pointing to the account that shall be used to create the needed resources. This provider secret will be configured by the Gardener operator in the Seed resource and propagated over there by the seed controller.
After your controller has created the required bucket, if required, it generates the secret to access the objects in the bucket and put a reference to it in status.generatedSecretRef.
The secret should be created in the namespace specified in the backupbucket.extensions.gardener.cloud/generated-secret-namespace annotation.
In case the annotation is not present, the garden namespace should be used.
This secret is supposed to be used by Gardener, or eventually a BackupEntry resource and etcd-backup-restore component, for backing up the etcd.
In order to support a new infrastructure provider, you need to write a controller that watches all BackupBuckets with .spec.type=<my-provider-name>. You can take a look at the below referenced example implementation for the Azure provider.
The Gardener project features a sub-project called etcd-backup-restore to take periodic backups of etcd backing Shoot clusters. It demands the bucket (or its equivalent in different object store providers) access credentials to be created and configured externally with appropriate credentials. The BackupEntry resource takes this responsibility in Gardener to provide this information by creating a secret specific to the component.
That being said, the core motivation for introducing this resource was to support retention of backups post deletion of Shoot. The etcd-backup-restore components take responsibility of garbage collecting old backups out of the defined period. Once a shoot is deleted, we need to persist the backups for few days. Hence, Gardener uses the BackupEntry resource for this housekeeping work post deletion of a Shoot. The BackupEntry resource is responsible for shoot specific prefix under referred bucket.
Before introducing the BackupEntry extension resource, Gardener was using Terraform in order to create and manage these provider-specific resources (e.g., see AWS Backup).
Now, Gardener commissions an external, provider-specific controller to take over this task. You can also refer to backupInfra proposal documentation to get idea about how the transition was done and understand the resource in broader scope.
What Is the Lifespan of a BackupEntry?
The bucket associated with BackupEntry will be created by using a BackupBucket resource. The BackupEntry resource will be created as a part of the Shoot creation. But resources might continue to exist post deletion of a Shoot (see gardenlet for more details).
What Needs to be Implemented to Support a New Infrastructure Provider?
As part of the shoot flow, Gardener will create a special CRD in the seed cluster that needs to be reconciled by an extension controller, for example:
The .spec.secretRef contains a reference to the provider secret pointing to the account that shall be used to create the needed resources. This provider secret will be propagated from the BackupBucket resource by the shoot controller.
Your controller is supposed to create the etcd-backup secret in the control plane namespace of a shoot. This secret is supposed to be used by Gardener or eventually by the etcd-backup-restore component to backup the etcd. The controller implementation should clean up the objects created under the shoot specific prefix in the bucket equivalent to the name of the BackupEntry resource.
In order to support a new infrastructure provider, you need to write a controller that watches all the BackupBuckets with .spec.type=<my-provider-name>. You can take a look at the below referenced example implementation for the Azure provider.
The Gardener project allows users to connect to Shoot worker nodes via SSH. As nodes are usually firewalled and not directly accessible from the public internet, GEP-15 introduced the concept of “Bastions”. A bastion is a dedicated server that only serves to allow SSH ingress to the worker nodes.
Bastion resources contain the user’s public SSH key and IP address, in order to provision the server accordingly: The public key is put onto the Bastion and SSH ingress is only authorized for the given IP address (in fact, it’s not a single IP address, but a set of IP ranges, however for most purposes a single IP is be used).
What Is the Lifespan of a Bastion?
Once a Bastion has been created in the garden, it will be replicated to the appropriate seed cluster, where a controller then reconciles a server and firewall rules etc., on the cloud provider used by the target Shoot. When the Bastion is ready (i.e. has a public IP), that IP is stored in the Bastion’s status and from there it is picked up by the garden cluster and gardenctl eventually.
To make multiple SSH sessions possible, the existence of the Bastion is not directly tied to the execution of gardenctl: users can exit out of gardenctl and use ssh manually to connect to the bastion and worker nodes.
However, Bastions have an expiry date, after which they will be garbage collected.
When SSH access is set to false for the Shoot in the workers settings (see Shoot Worker Nodes Settings), Bastion resources are deleted during Shoot reconciliation and new Bastions are prevented from being created.
What Needs to Be Implemented to Support a New Infrastructure Provider?
As part of the shoot flow, Gardener will create a special CRD in the seed cluster that needs to be reconciled by an extension controller, for example:
---
apiVersion: extensions.gardener.cloud/v1alpha1
kind: Bastion
metadata:
name: mybastion
namespace: shoot--foo--bar
spec:
type: aws
# userData is base64-encoded cloud provider user data; this contains the# user's SSH key userData: IyEvYmluL2Jhc2ggL....Nlcgo=
ingress:
- ipBlock:
cidr: 192.88.99.0/32 # this is most likely the user's IP address
Your controller is supposed to create a new instance at the given cloud provider, firewall it to only allow SSH (TCP port 22) from the given IP blocks, and then configure the firewall for the worker nodes to allow SSH from the bastion instance. When a Bastion is deleted, all these changes need to be reverted.
Implementation Details
ConfigValidator Interface
For bastion controllers, the generic Reconciler also delegates to a ConfigValidator interface that contains a single Validate method. This method is called by the generic Reconciler at the beginning of every reconciliation, and can be implemented by the extension to validate the .spec.providerConfig part of the Bastion resource with the respective cloud provider, typically the existence and validity of cloud provider resources such as VPCs, images, etc.
The Validate method returns a list of errors. If this list is non-empty, the generic Reconciler will fail with an error. This error will have the error code ERR_CONFIGURATION_PROBLEM, unless there is at least one error in the list that has its ErrorType field set to field.ErrorTypeInternal.
At the lowest layers of a Kubernetes node is the software that, among other things, starts and stops containers. It is called “Container Runtime”.
The most widely known container runtime is Docker, but it is not alone in this space. In fact, the container runtime space has been rapidly evolving.
Kubernetes supports different container runtimes using Container Runtime Interface (CRI) – a plugin interface which enables kubelet to use a wide variety of container runtimes.
Gardener supports creation of Worker machines using CRI. For more information, see CRI Support.
Motivation
Prior to the Container Runtime Extensibility concept, Gardener used Docker as the only
container runtime to use in shoot worker machines. Because of the wide variety of different container runtimes
offering multiple important features (for example, enhanced security concepts), it is important to enable end users to use other container runtimes as well.
The ContainerRuntime Extension Resource
Here is what a typical ContainerRuntime resource would look like:
Gardener deploys one ContainerRuntime resource per worker pool per CRI.
To exemplify this, consider a Shoot having two worker pools (worker-one, worker-two) using containerd as the CRI as well as gvisor and kata as enabled container runtimes.
Gardener would deploy four ContainerRuntime resources. For worker-one: one ContainerRuntime for type gvisor and one for type kata. The same resource are being deployed for worker-two.
Supporting a New Container Runtime Provider
To add support for another container runtime (e.g., gvisor, kata-containers), a container runtime extension controller needs to be implemented. It should support Gardener’s supported CRI plugins.
The container runtime extension should install the necessary resources into the shoot cluster (e.g., RuntimeClasses), and it should copy the runtime binaries to the relevant worker machines in path: spec.binaryPath.
Gardener labels the shoot nodes according to the CRI configured: worker.gardener.cloud/cri-name=<value> (e.g., worker.gardener.cloud/cri-name=containerd) and multiple labels for each of the container runtimes configured for the shoot Worker machine:
containerruntime.worker.gardener.cloud/<container-runtime-type-value>=true (e.g., containerruntime.worker.gardener.cloud/gvisor=true).
The way to install the binaries is by creating a daemon set which copies the binaries from an image in a docker registry to the relevant labeled Worker’s nodes (avoid downloading binaries from the internet to also cater with isolated environments).
For additional reference, please have a look at the runtime-gvsior provider extension, which provides more information on how to configure the necessary charts, as well as the actuators required to reconcile container runtime inside the Shoot cluster to the desired state.
5.18.5 - ControlPlane
Contract: ControlPlane Resource
Most Kubernetes clusters require a cloud-controller-manager or CSI drivers in order to work properly.
Before introducing the ControlPlane extension resource Gardener was having several different Helm charts for the cloud-controller-manager deployments for the various providers.
Now, Gardener commissions an external, provider-specific controller to take over this task.
Which control plane resources are required?
As mentioned in the controlplane customization webhooks document, Gardener shall not deploy any cloud-controller-manager or any other provider-specific component.
Instead, it creates a ControlPlane CRD that should be picked up by provider extensions.
Its purpose is to trigger the deployment of such provider-specific components in the shoot namespace in the seed cluster.
What needs to be implemented to support a new infrastructure provider?
As part of the shoot flow Gardener will create a special CRD in the seed cluster that needs to be reconciled by an extension controller, for example:
The .spec.secretRef contains a reference to the provider secret pointing to the account that shall be used for the shoot cluster.
However, the most important section is the .spec.providerConfig and the .spec.infrastructureProviderStatus.
The first one contains an embedded declaration of the provider specific configuration for the control plane (that cannot be known by Gardener itself).
You are responsible for designing how this configuration looks like.
Gardener does not evaluate it but just copies this part from what has been provided by the end-user in the Shoot resource.
The second one contains the output of the Infrastructure resource (that might be relevant for the CCM config).
In order to support a new control plane provider, you need to write a controller that watches all ControlPlanes with .spec.type=<my-provider-name>.
You can take a look at the below referenced example implementation for the Alicloud provider.
The control plane controller as part of the ControlPlane reconciliation often deploys resources (e.g. pods/deployments) into the Shoot namespace in the Seed as part of its ControlPlane reconciliation loop.
Because the namespace contains network policies that per default deny all ingress and egress traffic,
the pods may need to have proper labels matching to the selectors of the network policies in order to allow the required network traffic.
Otherwise, they won’t be allowed to talk to certain other components (e.g., the kube-apiserver of the shoot).
For more information, see NetworkPolicys In Garden, Seed, Shoot Clusters.
Non-Provider Specific Information Required for Infrastructure Creation
Most providers might require further information that is not provider specific but already part of the shoot resource.
One example for this is the GCP control plane controller, which needs the Kubernetes version of the shoot cluster (because it already uses the in-tree Kubernetes cloud-controller-manager).
As Gardener cannot know which information is required by providers, it simply mirrors the Shoot, Seed, and CloudProfile resources into the seed.
They are part of the Cluster extension resource and can be used to extract information that is not part of the Infrastructure resource itself.
Every shoot cluster requires external DNS records that are publicly resolvable.
The management of these DNS records requires provider-specific knowledge which is to be developed outside the Gardener’s core repository.
Currently, Gardener uses DNSProvider and DNSEntry resources. However, this introduces undesired coupling of Gardener to a controller that does not adhere to the Gardener extension contracts. Because of this, we plan to stop using DNSProvider and DNSEntry resources for Gardener DNS records in the future and use the DNSRecord resources described here instead.
What does Gardener create DNS records for?
Internal Domain Name
Every shoot cluster’s kube-apiserver running in the seed is exposed via a load balancer that has a public endpoint (IP or hostname).
This endpoint is used by end-users and also by system components (that are running in another network, e.g., the kubelet or kube-proxy) to talk to the cluster.
In order to be robust against changes of this endpoint (e.g., caused due to re-creation of the load balancer or move of the DNS record to another seed cluster), Gardener creates a so-called internal domain name for every shoot cluster.
The internal domain name is a publicly resolvable DNS record that points to the load balancer of the kube-apiserver.
Gardener uses this domain name in the kubeconfigs of all system components, instead of using directly the load balancer endpoint.
This way Gardener does not need to recreate all kubeconfigs if the endpoint changes - it just needs to update the DNS record.
External Domain Name
The internal domain name is not configurable by end-users directly but configured by the Gardener administrator.
However, end-users usually prefer to have another DNS name, maybe even using their own domain sometimes, to access their Kubernetes clusters.
Gardener supports that by creating another DNS record, named external domain name, that actually points to the internal domain name.
The kubeconfig handed out to end-users does contain this external domain name, i.e., users can access their clusters with the DNS name they like to.
As not every end-user has an own domain, it is possible for Gardener administrators to configure so-called default domains.
If configured, shoots that do not specify a domain explicitly get an external domain name based on a default domain (unless explicitly stated that this shoot should not get an external domain name (.spec.dns.provider=unmanaged)).
Ingress Domain Name (Deprecated)
Gardener allows to deploy a nginx-ingress-controller into a shoot cluster (deprecated).
This controller is exposed via a public load balancer (again, either IP or hostname).
Gardener creates a wildcard DNS record pointing to this load balancer.
Ingress resources can later use this wildcard DNS record to expose underlying applications.
Seed Ingress
If .spec.ingress is configured in the Seed, Gardener deploys the ingress controller mentioned in .spec.ingress.controller.kind to the seed cluster. Currently, the only supported kind is “nginx”. If the ingress field is set, then .spec.dns.provider must also be set. Gardener creates a wildcard DNS record pointing to the load balancer of the ingress controller. The Ingress resources of components like Plutono and Prometheus in the garden namespace and the shoot namespaces use this wildcard DNS record to expose their underlying applications.
What needs to be implemented to support a new DNS provider?
As part of the shoot flow, Gardener will create a number of DNSRecord resources in the seed cluster (one for each of the DNS records mentioned above) that need to be reconciled by an extension controller.
These resources contain the following information:
The DNS provider type (e.g., aws-route53, google-clouddns, …)
A reference to a Secret object that contains the provider-specific credentials used to communicate with the provider’s API.
The fully qualified domain name (FQDN) of the DNS record, e.g. “api.<shoot domain>”.
The DNS record type, one of A, AAAA, CNAME, or TXT.
The DNS record values, that is a list of IP addresses for A records, a single hostname for CNAME records, or a list of texts for TXT records.
Optionally, the DNSRecord resource may contain also the following information:
The region of the DNS record. If not specified, the region specified in the referenced Secret shall be used. If that is also not specified, the extension controller shall use a certain default region.
The DNS hosted zone of the DNS record. If not specified, it shall be determined automatically by the extension controller by getting all hosted zones of the account and searching for the longest zone name that is a suffix of the fully qualified domain name (FQDN) mentioned above.
The TTL of the DNS record in seconds. If not specified, it shall be set by the extension controller to 120.
In order to support a new DNS record provider, you need to write a controller that watches all DNSRecords with .spec.type=<my-provider-name>.
You can take a look at the below referenced example implementation for the AWS route53 provider.
Key Names in Secrets Containing Provider-Specific Credentials
For compatibility with existing setups, extension controllers shall support two different namings of keys in secrets containing provider-specific credentials:
The naming used by the external-dns-management DNS controller. For example, on AWS the key names are AWS_ACCESS_KEY_ID, AWS_SECRET_ACCESS_KEY, and AWS_REGION.
The naming used by other provider-specific extension controllers, e.g., for infrastructure. For example, on AWS the key names are accessKeyId, secretAccessKey, and region.
Avoiding Reading the DNS Hosted Zones
If the DNS hosted zone is not specified in the DNSRecord resource, during the first reconciliation the extension controller shall determine the correct DNS hosted zone for the specified FQDN and write it to the status of the resource:
On subsequent reconciliations, the extension controller shall use the zone from the status and avoid reading the DNS hosted zones from the provider.
If the DNSRecord resource specifies a zone in .spec.zone and the extension controller has written a value to .status.zone, the first one shall be considered with higher priority by the extension controller.
Non-Provider Specific Information Required for DNS Record Creation
Some providers might require further information that is not provider specific but already part of the shoot resource.
As Gardener cannot know which information is required by providers, it simply mirrors the Shoot, Seed, and CloudProfile resources into the seed.
They are part of the Cluster extension resource and can be used to extract information that is not part of the DNSRecord resource itself.
Using DNSRecord Resources
gardenlet manages DNSRecord resources for all three DNS records mentioned above (internal, external, and ingress).
In order to successfully reconcile a shoot with the feature gate enabled, extension controllers for DNSRecord resources for types used in the default, internal, and custom domain secrets should be registered via ControllerRegistration resources.
Note: For compatibility reasons, the spec.dns.providers section is still used to specify additional providers. Only the one marked as primary: true will be used for DNSRecord. All others are considered by the shoot-dns-service extension only (if deployed).
Support for DNSRecord Resources in the Provider Extensions
The following table contains information about the provider extension version that adds support for DNSRecord resources:
Extension
Version
provider-alicloud
v1.26.0
provider-aws
v1.27.0
provider-azure
v1.21.0
provider-gcp
v1.18.0
provider-openstack
v1.21.0
provider-vsphere
N/A
provider-equinix-metal
N/A
provider-kubevirt
N/A
provider-openshift
N/A
Support for DNSRecord IPv6 recordType: AAAA in the Provider Extensions
The following table contains information about the provider extension version that adds support for DNSRecord IPv6 recordType: AAAA:
Gardener defines common procedures which must be passed to create a functioning shoot cluster. Well known steps are represented by special resources like Infrastructure, OperatingSystemConfig or DNS. These resources are typically reconciled by dedicated controllers setting up the infrastructure on the hyperscaler or managing DNS entries, etc.
But, some requirements don’t match with those special resources or don’t depend on being proceeded at a specific step in the creation / deletion flow of the shoot. They require a more generic hook. Therefore, Gardener offers the Extension resource.
What is required to register and support an Extension type?
Gardener creates one Extension resource per registered extension type in ControllerRegistration per shoot.
If spec.resources[].autoEnable is set to shoot, then the Extension resources of the given type is created for every shoot cluster. Set to none (default), the Extension resource is only created if configured in the Shoot manifest. In case of workerless Shoot, an automatically enabled Extension resource is created only if spec.resources[].workerlessSupported is also set to true. If an extension configured in the spec of a workerless Shoot is not supported yet, the admission request will be rejected.
Another valid value is seed, which means the extension is automatically enabled for all seeds.
The Extension resources are created in the shoot namespace of the seed cluster.
---
apiVersion: extensions.gardener.cloud/v1alpha1
kind: Extension
metadata:
name: example
namespace: shoot--foo--bar
spec:
type: example
providerConfig: {}
Your controller needs to reconcile extensions.extensions.gardener.cloud. Since there can exist multiple Extension resources per shoot, each one holds a spec.type field to let controllers check their responsibility (similar to all other extension resources of Gardener).
ProviderConfig
It is possible to provide data in the Shoot resource which is copied to spec.providerConfig of the Extension resource.
---
apiVersion: core.gardener.cloud/v1beta1
kind: Shoot
metadata:
name: bar
namespace: garden-foo
spec:
extensions:
- type: example
providerConfig:
foo: bar
...
results in
---
apiVersion: extensions.gardener.cloud/v1alpha1
kind: Extension
metadata:
name: example
namespace: shoot--foo--bar
spec:
type: example
providerConfig:
foo: bar
Shoot Reconciliation Flow and Extension Status
Gardener creates Extension resources as part of the Shoot reconciliation. Moreover, it is guaranteed that the Cluster resource exists before the Extension resource is created. Extensions can be reconciled at different stages during Shoot reconciliation depending on the defined extension lifecycle strategy in the respective ControllerRegistration resource. Please consult the Extension Lifecycle section for more information.
For an Extension controller it is crucial to maintain the Extension’s status correctly. At the end Gardener checks the status of each Extension and only reports a successful shoot reconciliation if the state of the last operation is Succeeded.
apiVersion: extensions.gardener.cloud/v1alpha1
kind: Extension
metadata:
generation: 1
name: example
namespace: shoot--foo--bar
spec:
type: example
status:
lastOperation:
state: Succeeded
observedGeneration: 1
5.18.8 - Infrastructure
Contract: Infrastructure Resource
Every Kubernetes cluster requires some low-level infrastructure to be setup in order to work properly.
Examples for that are networks, routing entries, security groups, IAM roles, etc.
Before introducing the Infrastructure extension resource Gardener was using Terraform in order to create and manage these provider-specific resources (e.g., see here).
Now, Gardener commissions an external, provider-specific controller to take over this task.
Which infrastructure resources are required?
Unfortunately, there is no general answer to this question as it is highly provider specific.
Consider the above mentioned resources, i.e., VPC, subnets, route tables, security groups, IAM roles, SSH key pairs.
Most of the resources are required in order to create VMs (the shoot cluster worker nodes), load balancers, and volumes.
What needs to be implemented to support a new infrastructure provider?
As part of the shoot flow Gardener will create a special CRD in the seed cluster that needs to be reconciled by an extension controller, for example:
The .spec.secretRef contains a reference to the provider secret pointing to the account that shall be used to create the needed resources.
However, the most important section is the .spec.providerConfig.
It contains an embedded declaration of the provider specific configuration for the infrastructure (that cannot be known by Gardener itself).
You are responsible for designing how this configuration looks like.
Gardener does not evaluate it but just copies this part from what has been provided by the end-user in the Shoot resource.
After your controller has created the required resources in your provider’s infrastructure it needs to generate an output that can be used by other controllers in subsequent steps.
An example for that is the Worker extension resource controller.
It is responsible for creating virtual machines (shoot worker nodes) in this prepared infrastructure.
Everything that it needs to know in order to do that (e.g. the network IDs, security group names, etc. (again: provider-specific)) needs to be provided as output in the Infrastructure resource:
In order to support a new infrastructure provider you need to write a controller that watches all Infrastructures with .spec.type=<my-provider-name>.
You can take a look at the below referenced example implementation for the Azure provider.
Dynamic nodes network for shoot clusters
Some environments do not allow end-users to statically define a CIDR for the network that shall be used for the shoot worker nodes.
In these cases it is possible for the extension controllers to dynamically provision a network for the nodes (as part of their reconciliation loops), and to provide the CIDR in the status of the Infrastructure resource:
Gardener will pick this nodesCIDR and use it to configure the VPN components to establish network connectivity between the control plane and the worker nodes.
If the Shoot resource already specifies a nodes CIDR in .spec.networking.nodes and the extension controller provides also a value in .status.nodesCIDR in the Infrastructure resource then the latter one will always be considered with higher priority by Gardener.
Non-provider specific information required for infrastructure creation
Some providers might require further information that is not provider specific but already part of the shoot resource.
One example for this is the GCP infrastructure controller which needs the pod and the service network of the cluster in order to prepare and configure the infrastructure correctly.
As Gardener cannot know which information is required by providers it simply mirrors the Shoot, Seed, and CloudProfile resources into the seed.
They are part of the Cluster extension resource and can be used to extract information that is not part of the Infrastructure resource itself.
Implementation details
Actuator interface
Most existing infrastructure controller implementations follow a common pattern where a generic Reconciler delegates to an Actuator interface that contains the methods Reconcile, Delete, Migrate, and Restore. These methods are called by the generic Reconciler for the respective operations, and should be implemented by the extension according to the contract described here and the migration guidelines.
ConfigValidator interface
For infrastructure controllers, the generic Reconciler also delegates to a ConfigValidator interface that contains a single Validate method. This method is called by the generic Reconciler at the beginning of every reconciliation, and can be implemented by the extension to validate the .spec.providerConfig part of the Infrastructure resource with the respective cloud provider, typically the existence and validity of cloud provider resources such as AWS VPCs or GCP Cloud NAT IPs.
The Validate method returns a list of errors. If this list is non-empty, the generic Reconciler will fail with an error. This error will have the error code ERR_CONFIGURATION_PROBLEM, unless there is at least one error in the list that has its ErrorType field set to field.ErrorTypeInternal.
Gardener is an open-source project that provides a nested user model. Basically, there are two types of services provided by Gardener to its users:
Managed: end-users only request a Kubernetes cluster (Clusters-as-a-Service)
Hosted: operators utilize Gardener to provide their own managed version of Kubernetes (Cluster-Provisioner-as-a-service)
Whether a user is an operator or an end-user, it makes sense to provide choice. For example, for an end-user it might make sense to
choose a network-plugin that would support enforcing network policies (some plugins does not come with network-policy support by default).
For operators however, choice only matters for delegation purposes, i.e., when providing an own managed-service, it becomes important to also provide choice over which network-plugins to use.
Furthermore, Gardener provisions clusters on different cloud-providers with different networking requirements. For example, Azure does not support Calico overlay networking with IP in IP [1], this leads to the introduction of manual exceptions in static add-on charts which is error prone and can lead to failures during upgrades.
Finally, every provider is different, and thus the network always needs to adapt to the infrastructure needs to provide better performance. Consistency does not necessarily lie in the implementation but in the interface.
Motivation
Prior to the Network Extensibility concept, Gardener followed a mono network-plugin support model (i.e., Calico). Although this seemed to be the easier approach, it did not completely reflect the real use-case.
The goal of the Gardener Network Extensions is to support different network plugins, therefore, the specification for the network resource won’t be fixed and will be customized based on the underlying network plugin.
To do so, a ProviderConfig field in the spec will be provided where each plugin will define. Below is an example for how to deploy Calico as the cluster network plugin.
The Network Extensions Resource
Here is what a typical Network resource would look-like:
global configuration (e.g., podCIDR, serviceCIDR, and type)
provider specific config (e.g., for calico we can choose to configure a bird backend)
Note: Certain cloud-provider extensions might have webhooks that would modify the network-resource to fit into their network specific context. As previously mentioned, Azure does not support IPIP, as a result, the Azure provider extension implements a webhook to mutate the backend and set it to None instead of bird.
Supporting a New Network Extension Provider
To add support for another networking provider (e.g., weave, Cilium, Flannel) a network extension controller needs to be implemented which would optionally have its own custom configuration specified in the spec.providerConfig in the Network resource. For example, if support for a network plugin named gardenet is required, the following Network resource would be created:
Once applied, the presumably implemented Gardenet extension controller would pick the configuration up, parse the providerConfig, and create the necessary resources in the shoot.
For additional reference, please have a look at the networking-calico provider extension, which provides more information on how to configure the necessary charts, as well as the actuators required to reconcile networking inside the Shoot cluster to the desired state.
Supporting kube-proxy-less Service Routing
Some networking extensions support service routing without the kube-proxy component. This is why Gardener supports disabling of kube-proxy for service routing by setting .spec.kubernetes.kubeproxy.enabled to false in the Shoot specification. The implicit contract of the flag is:
If kube-proxy is disabled, then the networking extension is responsible for the service routing.
The networking extensions need to handle this twofold:
During the reconciliation of the networking resources, the extension needs to check whether kube-proxy takes care of the service routing or the networking extension itself should handle it. In case the networking extension should be responsible according to .spec.kubernetes.kubeproxy.enabled (but is unable to perform the service routing), it should raise an error during the reconciliation. If the networking extension should handle the service routing, it may reconfigure itself accordingly.
(Optional) In case the networking extension does not support taking over the service routing (in some scenarios), it is recommended to also provide a validating admission webhook to reject corresponding changes early on. The validation may take the current operating mode of the networking extension into consideration.
Supporting Migration of ipFamilies
To enable the migration from a shoot cluster with single-stack networking to a cluster with dual-stack networking, the status field of the Network resource includes the ipFamilies field.
This field reflects the currently deployed configuration and is used to verify whether the migration process has been completed successfully. To support the migration from single-stack to dual-stack networking, a network extension provider must ensure that this field is properly maintained and updated during the migration process.
Gardener uses the machine API and leverages the functionalities of the machine-controller-manager (MCM) in order to manage the worker nodes of a shoot cluster.
The machine-controller-manager itself simply takes a reference to an OS-image and (optionally) some user-data (a script or configuration that is executed when a VM is bootstrapped), and forwards both to the provider’s API when creating VMs.
MCM does not have any restrictions regarding supported operating systems as it does not modify or influence the machine’s configuration in any way - it just creates/deletes machines with the provided metadata.
Consequently, Gardener needs to provide this information when interacting with the machine-controller-manager.
This means that basically every operating system is possible to be used, as long as there is some implementation that generates the OS-specific configuration in order to provision/bootstrap the machines.
⚠️ Currently, there are a few requirements of pre-installed components that must be present in all OS images:
What does the user-data bootstrapping the machines contain?
Gardener installs a few components onto every worker machine in order to allow it to join the shoot cluster.
There is the kubelet process and also configuration for log rotation, CA certificates, etc.
You can find the complete configuration at the components folder. We are calling this the “original” user-data.
How does Gardener bootstrap the machines?
gardenlet makes use of gardener-node-agent to perform the bootstrapping and reconciliation of systemd units and files on the machine.
Please refer to this document for a first overview.
Usually, you would submit all the components you want to install onto the machine as part of the user-data during creation time.
However, some providers do have a size limitation (around ~16KB) for that user-data.
That’s why we do not send the “original” user-data to the machine-controller-manager (who then forwards it to the provider’s API).
Instead, we only send a small “init” script that bootstrap the gardener-node-agent.
It fetches the “original” content from a Secret and applies it on the machine directly.
This way we can extend the “original” user-data without any size restrictions (except for the 1 MB limit for Secrets).
The high-level flow is as follows:
For every worker pool X in the Shoot specification, Gardener creates a Secret named cloud-config-<X> in the kube-system namespace of the shoot cluster. The secret contains the “original” OperatingSystemConfig (i.e., systemd units and files for kubelet).
Gardener generates a kubeconfig with minimal permissions just allowing reading these secrets. It is used by the gardener-node-agent later.
Gardener provides the gardener-node-init.sh bash script and the machine image stated in the Shoot specification to the machine-controller-manager.
Based on this information, the machine-controller-manager creates the VM.
After the VM has been provisioned, the gardener-node-init.sh script starts, fetches the gardener-node-agent binary, and starts it.
The gardener-node-agent will read the gardener-node-agent-<X>Secret for its worker pool (containing the “original” OperatingSystemConfig), and reconciles it.
The gardener-node-agent can update itself in case of newer Gardener versions, and it performs a continuous reconciliation of the systemd units and files in the provided OperatingSystemConfig (just like any other Kubernetes controller).
What needs to be implemented to support a new operating system?
As part of the Shoot reconciliation flow, gardenlet will create a special CRD in the seed cluster that needs to be reconciled by an extension controller, for example:
---
apiVersion: extensions.gardener.cloud/v1alpha1
kind: OperatingSystemConfig
metadata:
name: pool-01-original
namespace: default
spec:
type: <my-operating-system>
purpose: reconcile
units:
- name: containerd.service
dropIns:
- name: 10-containerd-opts.conf
content: | [Service]
Environment="SOME_OPTS=--foo=bar" files:
- path: /var/lib/kubelet/ca.crt
permissions: 0644
encoding: b64
content:
secretRef:
name: default-token-5dtjz
dataKey: token
- path: /etc/sysctl.d/99-k8s-general.conf
permissions: 0644
content:
inline:
data: | # A higher vm.max_map_count is great for elasticsearch, mongo, or other mmap users
# See https://github.com/kubernetes/kops/issues/1340
vm.max_map_count = 135217728
In order to support a new operating system, you need to write a controller that watches all OperatingSystemConfigs with .spec.type=<my-operating-system>.
For those it shall generate a configuration blob that fits to your operating system.
OperatingSystemConfigs can have two purposes: either provision or reconcile.
provision Purpose
The provision purpose is used by gardenlet for the user-data that it later passes to the machine-controller-manager (and then to the provider’s API) when creating new VMs.
It contains the gardener-node-init.sh script and systemd unit.
The OS controller has to translate the .spec.units and .spec.files into configuration that fits to the operating system.
For example, a Flatcar controller might generate a CoreOS cloud-config or Ignition, SLES might generate cloud-init, and others might simply generate a bash script translating the .spec.units into systemd units, and .spec.files into real files on the disk.
⚠️ Please avoid mixing in additional systemd units or files - this step should just translate what gardenlet put into .spec.units and .spec.files.
After generation, extension controllers are asked to store their OS config inside a Secret (as it might contain confidential data) in the same namespace.
The secret’s .data could look like this:
The reconcile purpose contains the “original” OperatingSystemConfig (which is later stored in Secrets in the shoot’s kube-system namespace (see step 1)). This is downloaded and applies late (see step 5).
The OS controller does not need to translate anything here, but it has the option to provide additional systemd units or files via the .status field:
As described above, the “original” user-data must be re-applicable to allow in-place updates.
The way how this is done is specific to the generated operating system config (e.g., for CoreOS cloud-init the command is /usr/bin/coreos-cloudinit --from-file=<path>, whereas SLES would run cloud-init --file <path> single -n write_files --frequency=once).
Consequently, besides the generated OS config, the extension controller must also provide a command for re-application an updated version of the user-data.
As visible in the mentioned examples, the command requires a path to the user-data file.
As soon as Gardener detects that the user data has changed it will reload the systemd daemon and restart all the units provided in the .status.units[] list (see the below example). The same logic applies during the very first application of the whole configuration.
After generation, extension controllers are asked to store their OS config inside a Secret (as it might contain confidential data) in the same namespace.
The secret’s .data could look like this:
Finally, the secret’s metadata, the OS-specific command to re-apply the configuration, and the list of systemd units that shall be considered to be restarted if an updated version of the user-data is re-applied must be provided in the OperatingSystemConfig’s .status field:
Once the .status indicates that the extension controller finished reconciling Gardener will continue with the next step of the shoot reconciliation flow.
Bootstrap Tokens
gardenlet adds a file with the content <<BOOTSTRAP_TOKEN>> to the OperatingSystemConfig with purpose provision and sets transmitUnencoded=true.
This instructs the responsible OS extension to pass this file (with its content in clear-text) to the corresponding Worker resource.
machine-controller-manager makes sure that:
a bootstrap token gets created per machine
the <<BOOTSTRAP_TOKEN>> string in the user data of the machine gets replaced by the generated token
After the machine has been bootstrapped, the token secret in the shoot cluster gets deleted again.
Gardener enables in-place OS updates for worker nodes, allowing OS updates without replacing the node. This feature executes a predefined command on the node to perform the update.
For an OS to support in-place updates, it must meet the following prerequisites:
The machine image or operating system must support in-place updates with a tool or utility to initiate the process.
The update mechanism should ensure reliability by:
Booting into the updated version if successful.
Reverting to the previous version in case of failure.
The update tool may also provide configuration options, including:
Retry Configuration: The ability to define the number of retries for the update.
Registry Configuration: The option to specify the registry from which the OS image is pulled.
An OS supporting in-place updates must define the update configuration in .status.inPlaceUpdates as follows:
status:
inPlaceUpdates:
osUpdate:
command: /update-me
args:
- foo
- bar
command: Specifies the path to the OS update utility or script to be executed on the node.
args: Provides optional flags or arguments to customize the update behavior.
CRI Support
Gardener supports specifying a Container Runtime Interface (CRI) configuration in the OperatingSystemConfig resource. If the .spec.cri section exists, then the name property is mandatory. The only supported value for cri.name at the moment is: containerd.
For example:
containerd must listen on its default socket path: unix:///run/containerd/containerd.sock
containerd must be configured to work with the default configuration file in: /etc/containerd/config.toml (Created by Gardener).
For a convenient handling, gardener-node-agent can manage various aspects of containerd’s config, e.g. the registry configuration, if given in the OperatingSystemConfig.
Any Gardener extension which needs to modify the config, should check the functionality exposed through this API first.
If applicable, adjustments can be implemented through mutating webhooks, acting on the created or updated OperatingSystemConfig resource.
If CRI configurations are not supported, it is recommended to create a validating webhook running in the garden cluster that prevents specifying the .spec.providers.workers[].cri section in the Shoot objects.
cgroup driver
For Shoot clusters using Kubernetes < 1.31, Gardener is setting the kubelet’s cgroup driver to cgroupfs and containerd’s cgroup driver is unmanaged. For Shoot clusters using Kubernetes 1.31+, Gardener is setting both kubelet’s and containerd’s cgroup driver to systemd.
The systemd cgroup driver is a requirement for operating systems using cgroup v2. It’s important to ensure that both kubelet and the container runtime (containerd) are using the same cgroup driver to avoid potential issues.
OS extensions might also overwrite the cgroup driver for containerd and kubelet.
While the control plane of a shoot cluster is living in the seed and deployed as native Kubernetes workload, the worker nodes of the shoot clusters are normal virtual machines (VMs) in the end-users infrastructure account.
The Gardener project features a sub-project called machine-controller-manager.
This controller is extending the Kubernetes API using custom resource definitions to represent actual VMs as Machine objects inside a Kubernetes system.
This approach unlocks the possibility to manage virtual machines in the Kubernetes style and benefit from all its design principles.
What is the machine-controller-manager doing exactly?
Generally, there are provider-specific MachineClass objects (AWSMachineClass, AzureMachineClass, etc.; similar to StorageClass), and MachineDeployment, MachineSet, and Machine objects (similar to Deployment, ReplicaSet, and Pod).
A machine class describes where and how to create virtual machines (in which networks, region, availability zone, SSH key, user-data for bootstrapping, etc.), while a Machine results in an actual virtual machine.
You can read up more information in the machine-controller-manager’s repository.
The gardenlet deploys the machine-controller-manager, hence, provider extensions only have to inject their specific out-of-tree machine-controller-manager sidecar container into the Deployment.
What needs to be implemented to support a new worker provider?
As part of the shoot flow Gardener will create a special CRD in the seed cluster that needs to be reconciled by an extension controller, for example:
The .spec.secretRef contains a reference to the provider secret pointing to the account that shall be used to create the needed virtual machines.
Also, as you can see, Gardener copies the output of the infrastructure creation (.spec.infrastructureProviderStatus, see Infrastructure resource), into the .spec.
In the .spec.pools[] field, the desired worker pools are listed.
In the above example, one pool with machine type m4.large and min=3, max=5 machines shall be spread over two availability zones (eu-west-1b, eu-west-1c).
This information together with the infrastructure status must be used to determine the proper configuration for the machine classes.
The spec.pools[].labels map contains all labels that should be added to all nodes of the corresponding worker pool.
Gardener configures kubelet’s --node-labels flag to contain all labels that are mentioned here and allowed by the NodeRestriction admission plugin.
This makes sure that kubelet adds all user-specified and gardener-managed labels to the new Node object when registering a new machine with the API server.
Nevertheless, this is only effective when bootstrapping new nodes.
The provider extension (respectively, machine-controller-manager) is still responsible for updating the labels of existing Nodes when the worker specification changes.
The spec.pools[].nodeTemplate.capacity field contains the resource information of the machine like cpu, gpu, and memory. This info is used by Cluster Autoscaler to generate nodeTemplate during scaling the nodeGroup from zero.
The spec.pools[].nodeTemplate.virtualCapacity field contains the virtual resource information associated with the machine and used to specify extended resources that are virtual in nature (for specifying real, provisionable resources, nodeTemplate.capacity should be used). This will be applied to the machine class nodeTemplate without triggering a rollout of the cluster and will be used by Cluster Autoscaler for scaling the nodeGroup.
The spec.pools[].machineControllerManager field allows to configure the settings for machine-controller-manager component. Providers must populate these settings on worker-pool to the related fields in MachineDeployment.
The spec.pools[].clusterAutoscaler field contains cluster-autoscaler settings that are to be applied only to specific worker group. cluster-autoscaler expects to find these settings as annotations on the MachineDeployment, and so providers must pass these values to the corresponding MachineDeployment via annotations. The keys for these annotations can be found here and the values for the corresponding annotations should be the same as what is passed into the field. Providers can use the helper function extensionsv1alpha1helper.GetMachineDeploymentClusterAutoscalerAnnotations that returns the annotation map to be used.
The controller must only inject its provider-specific sidecar container into the machine-controller-managerDeployment managed by gardenlet.
After that, it must compute the desired machine classes and the desired machine deployments.
Typically, one class maps to one deployment, and one class/deployment is created per availability zone.
Following this convention, the created resource would look like this:
Another convention is the 5-letter hash at the end of the machine class names.
Most controllers compute a checksum out of the specification of the machine class.
Any change to the value of the nodeAgentSecretName field must result in a change of the machine class name.
The checksum in the machine class name helps to trigger a rolling update of the worker nodes if, for example, the machine image version changes.
In this case, a new checksum will be generated which results in the creation of a new machine class.
The MachineDeployment’s machine class reference (.spec.template.spec.class.name) is updated, which triggers the rolling update process in the machine-controller-manager.
However, all of this is only a convention that eases writing the controller, but you can do it completely differently if you desire - as long as you make sure that the described behaviours are implemented correctly.
After the machine classes and machine deployments have been created, the machine-controller-manager will start talking to the provider’s IaaS API and create the virtual machines.
Gardener makes sure that the content of the Secret referenced in the userDataSecretRef field that is used to bootstrap the machines contains the required configuration for installation of the kubelet and registering the VM as worker node in the shoot cluster.
The Worker extension controller shall wait until all the created MachineDeployments indicate healthiness/readiness before it ends the control loop.
Does Gardener need some information that must be returned back?
Another important benefit of the machine-controller-manager’s design principles (extending the Kubernetes API using CRDs) is that the cluster-autoscaler can be used without any provider-specific implementation.
We have forked the upstream Kubernetes community’s cluster-autoscaler and extended it so that it understands the machine API.
Definitely, we will merge it back into the community’s versions once it has been adapted properly.
Our cluster-autoscaler only needs to know the minimum and maximum number of replicas perMachineDeployment and is ready to act. Without knowing that, it needs to talk to the provider APIs (it just modifies the .spec.replicas field in the MachineDeployment object).
Gardener deploys this autoscaler if there is at least one worker pool that specifies max>min.
In order to know how it needs to configure it, the provider-specific Worker extension controller must expose which MachineDeployments it has created and how the min/max numbers should look like.
Consequently, your controller should write this information into the Worker resource’s .status.machineDeployments field. It should also update the .status.machineDeploymentsLastUpdateTime field along with .status.machineDeployments, so that gardener is able to deploy Cluster-Autoscaler right after the status is updated with the latest MachineDeployments and does not wait for the reconciliation to be completed:
In order to support a new worker provider, you need to write a controller that watches all Workers with .spec.type=<my-provider-name>.
You can take a look at the below referenced example implementation for the AWS provider.
That sounds like a lot that needs to be done, can you help me?
All of the described behaviour is mostly the same for every provider.
The only difference is maybe the version/configuration of the provider-specific machine-controller-manager sidecar container, and the machine class specification itself.
You can take a look at our extension library, especially the worker controller part where you will find a lot of utilities that you can use.
Note that there are also utility functions for getting the default sidecar container specification or corresponding VPA container policy in the machinecontrollermanager package called ProviderSidecarContainer and ProviderSidecarVPAContainerPolicy.
Also, using the library you only need to implement your provider specifics - all the things that can be handled generically can be taken for free and do not need to be re-implemented.
Take a look at the AWS worker controller for finding an example.
Non-provider specific information required for worker creation
All the providers require further information that is not provider specific but already part of the shoot resource.
One example for such information is whether the shoot is hibernated or not.
In this case, all the virtual machines should be deleted/terminated, and after that the machine controller-manager should be scaled down.
You can take a look at the AWS worker controller to see how it reads this information and how it is used.
As Gardener cannot know which information is required by providers, it simply mirrors the Shoot, Seed, and CloudProfile resources into the seed.
They are part of the Cluster extension resource and can be used to extract information that is not part of the Worker resource itself.
Gardener checks regularly (every minute by default) the health status of all shoot clusters.
It categorizes its checks into five different types:
APIServerAvailable: This type indicates whether the shoot’s kube-apiserver is available or not.
ControlPlaneHealthy: This type indicates whether the core components of the Shoot controlplane (ETCD, KAPI, KCM..) are healthy.
EveryNodeReady: This type indicates whether all Nodes and all Machine objects report healthiness.
ObservabilityComponentsHealthy: This type indicates whether the observability components of the Shoot control plane (Prometheus, Vali, Plutono..) are healthy.
SystemComponentsHealthy: This type indicates whether all system components deployed to the kube-system namespace in the shoot do exist and are running fine.
In case of workerless Shoot, EveryNodeReady condition is not present in the Shoot’s conditions since there are no nodes in the cluster.
Every Shoot resource has a status.conditions[] list that contains the mentioned types, together with a status (True/False) and a descriptive message/explanation of the status.
Most extension controllers are deploying components and resources as part of their reconciliation flows into the seed or shoot cluster.
A prominent example for this is the ControlPlane controller that usually deploys a cloud-controller-manager or CSI controllers as part of the shoot control plane.
Now that the extensions deploy resources into the cluster, especially resources that are essential for the functionality of the cluster, they might want to contribute to Gardener’s checks mentioned above.
What can extensions do to contribute to Gardener’s health checks?
Every extension resource in Gardener’s extensions.gardener.cloud/v1alpha1 API group also has a status.conditions[] list (like the Shoot).
Extension controllers can write conditions to the resource they are acting on and use a type that also exists in the shoot’s conditions.
One exception is that APIServerAvailable can’t be used, as Gardener clearly can identify the status of this condition and it doesn’t make sense for extensions to try to contribute/modify it.
As an example for the ControlPlane controller, let’s take a look at the following resource:
apiVersion: extensions.gardener.cloud/v1alpha1
kind: ControlPlane
metadata:
name: control-plane
namespace: shoot--foo--bar
spec:
...
status:
conditions:
- type: ControlPlaneHealthy
status: "False" reason: DeploymentUnhealthy
message: 'Deployment cloud-controller-manager is unhealthy: condition "Available" has
invalid status False (expected True) due to MinimumReplicasUnavailable: Deployment
does not have minimum availability.'
lastUpdateTime: "2014-05-25T12:44:27Z" - type: ConfigComputedSuccessfully
status: "True" reason: ConfigCreated
message: The cloud-provider-config has been successfully computed.
lastUpdateTime: "2014-05-25T12:43:27Z"
The extension controller has declared in its extension resource that one of the deployments it is responsible for is unhealthy.
Also, it has written a second condition using a type that is unknown by Gardener.
Gardener will pick the list of conditions and recognize that there is one with a type ControlPlaneHealthy.
It will merge it with its own ControlPlaneHealthy condition and report it back to the Shoot’s status:
apiVersion: core.gardener.cloud/v1beta1
kind: Shoot
metadata:
labels:
shoot.gardener.cloud/status: unhealthy
name: some-shoot
namespace: garden-core
spec:
status:
conditions:
- type: APIServerAvailable
status: "True" reason: HealthzRequestSucceeded
message: API server /healthz endpoint responded with success status code. [response_time:31ms]
lastUpdateTime: "2014-05-23T08:26:52Z" lastTransitionTime: "2014-05-25T12:45:13Z" - type: ControlPlaneHealthy
status: "False" reason: ControlPlaneUnhealthyReport
message: 'Deployment cloud-controller-manager is unhealthy: condition "Available" has
invalid status False (expected True) due to MinimumReplicasUnavailable: Deployment
does not have minimum availability.'
lastUpdateTime: "2014-05-25T12:45:13Z" lastTransitionTime: "2014-05-25T12:45:13Z" ...
Hence, the only duty extensions have is to maintain the health status of their components in the extension resource they are managing.
This can be accomplished using the health check library for extensions.
Error Codes
The Gardener API includes some well-defined error codes, e.g., ERR_INFRA_UNAUTHORIZED, ERR_INFRA_DEPENDENCIES, etc.
Extension may set these error codes in the .status.conditions[].codes[] list in case it makes sense.
Gardener will pick them up and will similarly merge them into the .status.conditions[].codes[] list in the Shoot:
status:
conditions:
- type: ControlPlaneHealthy
status: "False" reason: DeploymentUnhealthy
message: 'Deployment cloud-controller-manager is unhealthy: condition "Available" has
invalid status False (expected True) due to MinimumReplicasUnavailable: Deployment
does not have minimum availability.'
lastUpdateTime: "2014-05-25T12:44:27Z" codes:
- ERR_INFRA_UNAUTHORIZED
5.20 - Shoot Maintenance
Shoot Maintenance
There is a general document about shoot maintenance that you might want to read.
Here, we describe how you can influence certain operations that happen during a shoot maintenance.
Restart Control Plane Controllers
As outlined in the above linked document, Gardener offers to restart certain control plane controllers running in the seed during a shoot maintenance.
Extension controllers can extend the amount of pods being affected by these restarts.
If your Gardener extension manages pods of a shoot’s control plane (shoot namespace in seed) and it could potentially profit from a regular restart, please consider labeling it with maintenance.gardener.cloud/restart=true.
5.21 - Shoot Webhooks
Shoot Resource Customization Webhooks
Gardener deploys several components/resources into the shoot cluster.
Some of these resources are essential (like the kube-proxy), others are optional addons (like the kubernetes-dashboard or the nginx-ingress-controller).
In either case, some provider extensions might need to mutate these resources and inject provider-specific bits into it.
What’s the approach to implement such mutations?
Similar to how control plane components in the seed are modified, we are using MutatingWebhookConfigurations to achieve the same for resources in the shoot.
Both the provider extension and the kube-apiserver of the shoot cluster are running in the same seed.
Consequently, the kube-apiserver can talk cluster-internally to the provider extension webhook, which makes such operations even faster.
How is the MutatingWebhookConfiguration object created in the shoot?
The preferred approach is to use a ManagedResource (see also Deploy Resources to the Shoot Cluster) in the seed cluster.
This way the gardener-resource-manager ensures that end-users cannot delete/modify the webhook configuration.
The provider extension doesn’t need to care about the same.
What else is needed?
The shoot’s kube-apiserver must be allowed to talk to the provider extension.
To achieve this, you need to make sure that the relevant NetworkPolicy get created for allowing the network traffic.
Please refer to this guide for more information.
Autonomous Shoot Clusters
If running in an autonomous shoot cluster, the shoot webhooks should be merged into the seed webhooks.
You can do so by setting the mergeShootWebhooksIntoSeedWebhooks to true in the extensions/pkg/webhook/cmd.AddToManager function.
Take a look at this document in order to determine whether the extension runs in an autonomous shoot cluster.
6 - High Availability
6.1 - Implementing High Availability and Tolerating Zone Outages
Implementing High Availability and Tolerating Zone Outages
Developing highly available workload that can tolerate a zone outage is no trivial task. You will find here various recommendations to get closer to that goal. While many recommendations are general enough, the examples are specific in how to achieve this in a Gardener-managed cluster and where/how to tweak the different control plane components. If you do not use Gardener, it may be still a worthwhile read.
First however, what is a zone outage? It sounds like a clear-cut “thing”, but it isn’t. There are many things that can go haywire. Here are some examples:
Elevated cloud provider API error rates for individual or multiple services
Network bandwidth reduced or latency increased, usually also effecting storage sub systems as they are network attached
No networking at all, no DNS, machines shutting down or restarting, …
Functional issues, of either the entire service (e.g. all block device operations) or only parts of it (e.g. LB listener registration)
All services down, temporarily or permanently (the proverbial burning down data center 🔥)
This and everything in between make it hard to prepare for such events, but you can still do a lot. The most important recommendation is to not target specific issues exclusively - tomorrow another service will fail in an unanticipated way. Also, focus more on meaningful availability than on internal signals (useful, but not as relevant as the former). Always prefer automation over manual intervention (e.g. leader election is a pretty robust mechanism, auto-scaling may be required as well, etc.).
Also remember that HA is costly - you need to balance it against the cost of an outage as silly as this may sound, e.g. running all this excess capacity “just in case” vs. “going down” vs. a risk-based approach in between where you have means that will kick in, but they are not guaranteed to work (e.g. if the cloud provider is out of resource capacity). Maybe some of your components must run at the highest possible availability level, but others not - that’s a decision only you can make.
Control Plane
The Kubernetes cluster control plane is managed by Gardener (as pods in separate infrastructure clusters to which you have no direct access) and can be set up with no failure tolerance (control plane pods will be recreated best-effort when resources are available) or one of the failure tolerance types node or zone.
Strictly speaking, static workload does not depend on the (high) availability of the control plane, but static workload doesn’t rhyme with Cloud and Kubernetes and also means, that when you possibly need it the most, e.g. during a zone outage, critical self-healing or auto-scaling functionality won’t be available to you and your workload, if your control plane is down as well. That’s why, even though the resource consumption is significantly higher, we generally recommend to use the failure tolerance type zone for the control planes of productive clusters, at least in all regions that have 3+ zones. Regions that have only 1 or 2 zones don’t support the failure tolerance type zone and then your second best option is the failure tolerance type node, which means a zone outage can still take down your control plane, but individual node outages won’t.
In the shoot resource it’s merely only this what you need to add:
apiVersion: core.gardener.cloud/v1beta1
kind: Shoot
spec:
controlPlane:
highAvailability:
failureTolerance:
type: zone # valid values are `node` and `zone` (only available if your control plane resides in a region with 3+ zones)
This setting will scale out all control plane components for a Gardener cluster as necessary, so that no single zone outage can take down the control plane for longer than just a few seconds for the fail-over to take place (e.g. lease expiration and new leader election or readiness probe failure and endpoint removal). Components run highly available in either active-active (servers) or active-passive (controllers) mode at all times, the persistence (ETCD), which is consensus-based, will tolerate the loss of one zone and still maintain quorum and therefore remain operational. These are all patterns that we will revisit down below also for your own workload.
Worker Pools
Now that you have configured your Kubernetes cluster control plane in HA, i.e. spread it across multiple zones, you need to do the same for your own workload, but in order to do so, you need to spread your nodes across multiple zones first.
Prefer regions with at least 2, better 3+ zones and list the zones in the zones section for each of your worker pools. Whether you need 2 or 3 zones at a minimum depends on your fail-over concept:
Consensus-based software components (like ETCD) depend on maintaining a quorum of (n/2)+1, so you need at least 3 zones to tolerate the outage of 1 zone.
Primary/Secondary-based software components need just 2 zones to tolerate the outage of 1 zone.
Then there are software components that can scale out horizontally. They are probably fine with 2 zones, but you also need to think about the load-shift and that the remaining zone must then pick up the work of the unhealthy zone. With 2 zones, the remaining zone must cope with an increase of 100% load. With 3 zones, the remaining zones must only cope with an increase of 50% load (per zone).
In general, the question is also whether you have the fail-over capacity already up and running or not. If not, i.e. you depend on re-scheduling to a healthy zone or auto-scaling, be aware that during a zone outage, you will see a resource crunch in the healthy zones. If you have no automation, i.e. only human operators (a.k.a. “red button approach”), you probably will not get the machines you need and even with automation, it may be tricky. But holding the capacity available at all times is costly. In the end, that’s a decision only you can make. If you made that decision, please adapt the minimum, maximum, maxSurge and maxUnavailable settings for your worker pools accordingly (visit this section for more information).
In addition to that, it is also possible to configure the cluster-autoscaler priority expander by adding priorities to the worker groups like this:
apiVersion: core.gardener.cloud/v1beta1
kind: Shoot
spec:
provider:
workers:
- name: worker1
priority: 40 # priority of this worker group machine:
type: local
- name: worker2
machine:
type: local
When at least one worker group has a priority defined, the respective ConfigMap will be generated and deployed, which the cluster-autoscaler uses.
When only a part of the worker groups have priorities configured, those who do not have these configured, will be defaulted to 0.
If you want to be ready for a sudden spike or have some buffer in general, over-provision nodes by means of “placeholder” pods with low priority and appropriate resource requests. This way, they will demand nodes to be provisioned for them, but if any pod comes up with a regular/higher priority, the low priority pods will be evicted to make space for the more important ones. Strictly speaking, this is not related to HA, but it may be important to keep this in mind as you generally want critical components to be rescheduled as fast as possible and if there is no node available, it may take 3 minutes or longer to do so (depending on the cloud provider). Besides, not only zones can fail, but also individual nodes.
Replicas (Horizontal Scaling)
Now let’s talk about your workload. In most cases, this will mean to run multiple replicas. If you cannot do that (a.k.a. you have a singleton), that’s a bad situation to be in. Maybe you can run a spare (secondary) as backup? If you cannot, you depend on quick detection and rescheduling of your singleton (more on that below).
Obviously, things get messier with persistence. If you have persistence, you should ideally replicate your data, i.e. let your spare (secondary) “follow” your main (primary). If your software doesn’t support that, you have to deploy other means, e.g. volume snapshotting or side-backups (specific to the software you deploy; keep the backups regional, so that you can switch to another zone at all times). If you have to do those, your HA scenario becomes more a DR scenario and terms like RPO and RTO become relevant to you:
Recovery Point Objective (RPO): Potential data loss, i.e. how much data will you lose at most (time between backups)
Recovery Time Objective (RTO): Time until recovery, i.e. how long does it take you to be operational again (time to restore)
Also, keep in mind that your persistent volumes are usually zonal, i.e. once you have a volume in one zone, it’s bound to that zone and you cannot get up your pod in another zone w/o first recreating the volume yourself (Kubernetes won’t help you here directly).
Anyway, best avoid that, if you can (from technical and cost perspective). The best solution (and also the most costly one) is to run multiple replicas in multiple zones and keep your data replicated at all times, so that your RPO is always 0 (best). That’s what we do for Gardener-managed cluster HA control planes (ETCD) as any data loss may be disastrous and lead to orphaned resources (in addition, we deploy side cars that do side-backups for disaster recovery, with full and incremental snapshots with an RPO of 5m).
So, how to run with multiple replicas? That’s the easiest part in Kubernetes and the two most important resources, Deployments and StatefulSet, support that out of the box:
The problem comes with the number of replicas. It’s easy only if the number is static, e.g. 2 for active-active/passive or 3 for consensus-based software components, but what with software components that can scale out horizontally? Here you usually do not set the number of replicas statically, but make use of the horizontal pod autoscaler or HPA for short (built-in; part of the kube-controller-manager). There are also other options like the cluster proportional autoscaler, but while the former works based on metrics, the latter is more a guesstimate approach that derives the number of replicas from the number of nodes/cores in a cluster. Sometimes useful, but often blind to the actual demand.
So, HPA it is then for most of the cases. However, what is the resource (e.g. CPU or memory) that drives the number of desired replicas? Again, this is up to you, but not always are CPU or memory the best choices. In some cases, custom metrics may be more appropriate, e.g. requests per second (it was also for us).
You will have to create specific HorizontalPodAutoscaler resources for your scale target and can tweak the general HPA knobs for Gardener-managed clusters like this:
While it is important to set a sufficient number of replicas, it is also important to give the pods sufficient resources (CPU and memory). This is especially true when you think about HA. When a zone goes down, you might need to get up replacement pods, if you don’t have them running already to take over the load from the impacted zone. Likewise, e.g. with active-active software components, you can expect the remaining pods to receive more load. If you cannot scale them out horizontally to serve the load, you will probably need to scale them out (or rather up) vertically. This is done by the vertical pod autoscaler or VPA for short (not built-in; part of the kubernetes/autoscaler repository).
A few caveats though:
You cannot use HPA and VPA on the same metrics as they would influence each other, which would lead to pod trashing (more replicas require fewer resources; fewer resources require more replicas)
Scaling horizontally doesn’t cause downtimes (at least not when out-scaling and only one replica is affected when in-scaling), but scaling vertically does (if the pod runs OOM anyway, but also when new recommendations are applied, resource requests for existing pods may be changed, which causes the pods to be rescheduled). Although the discussion is going on for a very long time now, that is still not supported in-place yet (see KEP 1287, implementation in Kubernetes, implementation in VPA).
VPA is a useful tool and Gardener-managed clusters deploy a VPA by default for you (HPA is supported anyway as it’s built into the kube-controller-manager). You will have to create specific VerticalPodAutoscaler resources for your scale target and can tweak the general VPA knobs for Gardener-managed clusters like this:
While horizontal pod autoscaling is relatively straight-forward, it takes a long time to master vertical pod autoscaling. We saw performance issues, hard-coded behavior (on OOM, memory is bumped by +20% and it may take a few iterations to reach a good level), unintended pod disruptions by applying new resource requests (after 12h all targeted pods will receive new requests even though individually they would be fine without, which also drives active-passive resource consumption up), difficulties to deal with spiky workload in general (due to the algorithmic approach it takes), recommended requests may exceed node capacity, limit scaling is proportional and therefore often questionable, and more. VPA is a double-edged sword: useful and necessary, but not easy to handle.
For the Gardener-managed components, we mostly removed limits. Why?
CPU limits have almost always only downsides. They cause needless CPU throttling, which is not even easily visible. CPU requests turn into cpu shares, so if the node has capacity, the pod may consume the freely available CPU, but not if you have set limits, which curtail the pod by means of cpu quota. There are only certain scenarios in which they may make sense, e.g. if you set requests=limits and thereby define a pod with guaranteedQoS, which influences your cgroup placement. However, that is difficult to do for the components you implement yourself and practically impossible for the components you just consume, because what’s the correct value for requests/limits and will it hold true also if the load increases and what happens if a zone goes down or with the next update/version of this component? If anything, CPU limits caused outages, not helped prevent them.
As for memory limits, they are slightly more useful, because CPU is compressible and memory is not, so if one pod runs berserk, it may take others down (with CPU, cpu shares make it as fair as possible), depending on which OOM killer strikes (a complicated topic by itself). You don’t want the operating system OOM killer to strike as the result is unpredictable. Better, it’s the cgroup OOM killer or even the kubelet’s eviction, if the consumption is slow enough as it takes priorities into consideration even. If your component is critical and a singleton (e.g. node daemon set pods), you are better off also without memory limits, because letting the pod go OOM because of artificial/wrong memory limits can mean that the node becomes unusable. Hence, such components also better run only with no or a very high memory limit, so that you can catch the occasional memory leak (bug) eventually, but under normal operation, if you cannot decide about a true upper limit, rather not have limits and cause endless outages through them or when you need the pods the most (during a zone outage) where all your assumptions went out of the window.
The downside of having poor or no limits and poor and no requests is that nodes may “die” more often. Contrary to the expectation, even for managed services, the managed service is not responsible or cannot guarantee the health of a node under all circumstances, since the end user defines what is run on the nodes (shared responsibility). If the workload exhausts any resource, it will be the end of the node, e.g. by compressing the CPU too much (so that the kubelet fails to do its work), exhausting the main memory too fast, disk space, file handles, or any other resource.
The kubelet allows for explicit reservation of resources for operating system daemons (system-reserved) and Kubernetes daemons (kube-reserved) that are subtracted from the actual node resources and become the allocatable node resources for your workload/pods. All managed services configure these settings “by rule of thumb” (a balancing act), but cannot guarantee that the values won’t waste resources or always will be sufficient. You will have to fine-tune them eventually and adapt them to your needs. In addition, you can configure soft and hard eviction thresholds to give the kubelet some headroom to evict “greedy” pods in a controlled way. These settings can be configured for Gardener-managed clusters like this:
apiVersion: core.gardener.cloud/v1beta1
kind: Shoot
spec:
kubernetes:
kubelet:
kubeReserved: # explicit resource reservation for Kubernetes daemons cpu: 100m
memory: 1Gi
ephemeralStorage: 1Gi
pid: 1000
evictionSoft: # soft, i.e. graceful eviction (used if the node is about to run out of resources, avoiding hard evictions) memoryAvailable: 200Mi
imageFSAvailable: 10%
imageFSInodesFree: 10%
nodeFSAvailable: 10%
nodeFSInodesFree: 10%
evictionSoftGracePeriod: # caps pod's `terminationGracePeriodSeconds` value during soft evictions (specific grace periods) memoryAvailable: 1m30s
imageFSAvailable: 1m30s
imageFSInodesFree: 1m30s
nodeFSAvailable: 1m30s
nodeFSInodesFree: 1m30s
evictionHard: # hard, i.e. immediate eviction (used if the node is out of resources, avoiding the OS generally run out of resources fail processes indiscriminately) memoryAvailable: 100Mi
imageFSAvailable: 5%
imageFSInodesFree: 5%
nodeFSAvailable: 5%
nodeFSInodesFree: 5%
evictionMinimumReclaim: # additional resources to reclaim after hitting the hard eviction thresholds to not hit the same thresholds soon after again memoryAvailable: 0Mi
imageFSAvailable: 0Mi
imageFSInodesFree: 0Mi
nodeFSAvailable: 0Mi
nodeFSInodesFree: 0Mi
evictionMaxPodGracePeriod: 90 # caps pod's `terminationGracePeriodSeconds` value during soft evictions (general grace periods) evictionPressureTransitionPeriod: 5m0s # stabilization time window to avoid flapping of node eviction state
You can tweak these settings also individually per worker pool (spec.provider.workers.kubernetes.kubelet...), which makes sense especially with different machine types (and also workload that you may want to schedule there).
Physical memory is not compressible, but you can overcome this issue to some degree (alpha since Kubernetes v1.22 in combination with the feature gate NodeSwap on the kubelet) with swap memory. You can read more in this introductory blog and the docs. If you chose to use it (still only alpha at the time of this writing) you may want to consider also the risks associated with swap memory:
Reduced performance predictability
Reduced performance up to page trashing
Reduced security as secrets, normally held only in memory, could be swapped out to disk
That said, the various options mentioned above are only remotely related to HA and will not be further explored throughout this document, but just to remind you: if a zone goes down, load patterns will shift, existing pods will probably receive more load and will require more resources (especially because it is often practically impossible to set “proper” resource requests, which drive node allocation - limits are always ignored by the scheduler) or more pods will/must be placed on the existing and/or new nodes and then these settings, which are generally critical (especially if you switch on bin-packing for Gardener-managed clusters as a cost saving measure), will become even more critical during a zone outage.
Probes
Before we go down the rabbit hole even further and talk about how to spread your replicas, we need to talk about probes first, as they will become relevant later. Kubernetes supports three kinds of probes: startup, liveness, and readiness probes. If you are a visual thinker, also check out this slide deck by Tim Hockin (Kubernetes networking SIG chair).
Basically, the startupProbe and the livenessProbe help you restart the container, if it’s unhealthy for whatever reason, by letting the kubelet that orchestrates your containers on a node know, that it’s unhealthy. The former is a special case of the latter and only applied at the startup of your container, if you need to handle the startup phase differently (e.g. with very slow starting containers) from the rest of the lifetime of the container.
Now, the readinessProbe helps you manage the ready status of your container and thereby pod (any container that is not ready turns the pod not ready). This again has impact on endpoints and pod disruption budgets:
If the pod is not ready, the endpoint will be removed and the pod will not receive traffic anymore
If the pod is not ready, the pod counts into the pod disruption budget and if the budget is exceeded, no further voluntary pod disruptions will be permitted for the remaining ready pods (e.g. no eviction, no voluntary horizontal or vertical scaling, if the pod runs on a node that is about to be drained or in draining, draining will be paused until the max drain timeout passes)
As you can see, all of these probes are (also) related to HA (mostly the readinessProbe, but depending on your workload, you can also leverage livenessProbe and startupProbe into your HA strategy). If Kubernetes doesn’t know about the individual status of your container/pod, it won’t do anything for you (right away). That said, later/indirectly something might/will happen via the node status that can also be ready or not ready, which influences the pods and load balancer listener registration (a not ready node will not receive cluster traffic anymore), but this process is worker pool global and reacts delayed and also doesn’t discriminate between the containers/pods on a node.
In addition, Kubernetes also offers pod readiness gates to amend your pod readiness with additional custom conditions (normally, only the sum of the container readiness matters, but pod readiness gates additionally count into the overall pod readiness). This may be useful if you want to block (by means of pod disruption budgets that we will talk about next) the roll-out of your workload/nodes in case some (possibly external) condition fails.
Pod Disruption Budgets
One of the most important resources that help you on your way to HA are pod disruption budgets or PDB for short. They tell Kubernetes how to deal with voluntary pod disruptions, e.g. during the deployment of your workload, when the nodes are rolled, or just in general when a pod shall be evicted/terminated. Basically, if the budget is reached, they block all voluntary pod disruptions (at least for a while until possibly other timeouts act or things happen that leave Kubernetes no choice anymore, e.g. the node is forcefully terminated). You should always define them for your workload.
Very important to note is that they are based on the readinessProbe, i.e. even if all of your replicas are lively, but not enough of them are ready, this blocks voluntary pod disruptions, so they are very critical and useful. Here an example (you can specify either minAvailable or maxUnavailable in absolute numbers or as percentage):
And please do not specify a PDB of maxUnavailable being 0 or similar. That’s pointless, even detrimental, as it blocks then even useful operations, forces always the hard timeouts that are less graceful and it doesn’t make sense in the context of HA. You cannot “force” HA by preventing voluntary pod disruptions, you must work with the pod disruptions in a resilient way. Besides, PDBs are really only about voluntary pod disruptions - something bad can happen to a node/pod at any time and PDBs won’t make this reality go away for you.
PDBs will not always work as expected and can also get in your way, e.g. if the PDB is violated or would be violated, it may possibly block whatever you are trying to do to salvage the situation, e.g. drain a node or deploy a patch version (if the PDB is or would be violated, not even unhealthy pods would be evicted as they could theoretically become healthy again, which Kubernetes doesn’t know). In order to overcome this issue, it is now possible (alpha since Kubernetes v1.26 in combination with the feature gate PDBUnhealthyPodEvictionPolicy on the API server, beta and enabled by default since Kubernetes v1.27) to configure the so-called unhealthy pod eviction policy. The default is still IfHealthyBudget as a change in default would have changed the behavior (as described above), but you can now also set AlwaysAllow at the PDB (spec.unhealthyPodEvictionPolicy). For more information, please check out this discussion, the PR and this document and balance the pros and cons for yourself. In short, the new AlwaysAllow option is probably the better choice in most of the cases while IfHealthyBudget is useful only if you have frequent temporary transitions or for special cases where you have already implemented controllers that depend on the old behavior.
Pod Topology Spread Constraints
Pod topology spread constraints or PTSC for short (no official abbreviation exists, but we will use this in the following) are enormously helpful to distribute your replicas across multiple zones, nodes, or any other user-defined topology domain. They complement and improve on pod (anti-)affinities that still exist and can be used in combination.
PTSCs are an improvement, because they allow for maxSkew and minDomains. You can steer the “level of tolerated imbalance” with maxSkew, e.g. you probably want that to be at least 1, so that you can perform a rolling update, but this all depends on your deployment (maxUnavailable and maxSurge), etc. Stateful sets are a bit different (maxUnavailable) as they are bound to volumes and depend on them, so there usually cannot be 2 pods requiring the same volume. minDomains is a hint to tell the scheduler how far to spread, e.g. if all nodes in one zone disappeared because of a zone outage, it may “appear” as if there are only 2 zones in a 3 zones cluster and the scheduling decisions may end up wrong, so a minDomains of 3 will tell the scheduler to spread to 3 zones before adding another replica in one zone. Be careful with this setting as it also means, if one zone is down the “spread” is already at least 1, if pods run in the other zones. This is useful where you have exactly as many replicas as you have zones and you do not want any imbalance. Imbalance is critical as if you end up with one, nobody is going to do the (active) re-balancing for you (unless you deploy and configure additional non-standard components such as the descheduler). So, for instance, if you have something like a DBMS that you want to spread across 2 zones (active-passive) or 3 zones (consensus-based), you better specify minDomains of 2 respectively 3 to force your replicas into at least that many zones before adding more replicas to another zone (if supported).
Anyway, PTSCs are critical to have, but not perfect, so we saw (unsurprisingly, because that’s how the scheduler works), that the scheduler may block the deployment of new pods because it takes the decision pod-by-pod (see for instance #109364).
Pod Affinities and Anti-Affinities
As said, you can combine PTSCs with pod affinities and/or anti-affinities. Especially inter-pod (anti-)affinities may be helpful to place pods apart, e.g. because they are fall-backs for each other or you do not want multiple potentially resource-hungry “best-effort” or “burstable” pods side-by-side (noisy neighbor problem), or together, e.g. because they form a unit and you want to reduce the failure domain, reduce the network latency, and reduce the costs.
Topology Aware Hints
While topology aware hints are not directly related to HA, they are very relevant in the HA context. Spreading your workload across multiple zones may increase network latency and cost significantly, if the traffic is not shaped. Topology aware hints (beta since Kubernetes v1.23, replacing the now deprecated topology aware traffic routing with topology keys) help to route the traffic within the originating zone, if possible. Basically, they tell kube-proxy how to setup your routing information, so that clients can talk to endpoints that are located within the same zone.
Be aware however, that there are some limitations. Those are called safeguards and if they strike, the hints are off and traffic is routed again randomly. Especially controversial is the balancing limitation as there is the assumption, that the load that hits an endpoint is determined by the allocatable CPUs in that topology zone, but that’s not always, if even often, the case (see for instance #113731 and #110714). So, this limitation hits far too often and your hints are off, but then again, it’s about network latency and cost optimization first, so it’s better than nothing.
Networking
We have talked about networking only to some small degree so far (readiness probes, pod disruption budgets, topology aware hints). The most important component is probably your ingress load balancer - everything else is managed by Kubernetes. AWS, Azure, GCP, and also OpenStack offer multi-zonal load balancers, so make use of them. In Azure and GCP, LBs are regional whereas in AWS and OpenStack, they need to be bound to a zone, which the cloud-controller-manager does by observing the zone labels at the nodes (please note that this behavior is not always working as expected, see #570 where the AWS cloud-controller-manager is not readjusting to newly observed zones).
Please be reminded that even if you use a service mesh like Istio, the off-the-shelf installation/configuration usually never comes with productive settings (to simplify first-time installation and improve first-time user experience) and you will have to fine-tune your installation/configuration, much like the rest of your workload.
Relevant Cluster Settings
Following now a summary/list of the more relevant settings you may like to tune for Gardener-managed clusters:
apiVersion: core.gardener.cloud/v1beta1
kind: Shoot
spec:
controlPlane:
highAvailability:
failureTolerance:
type: zone # valid values are `node` and `zone` (only available if your control plane resides in a region with 3+ zones) kubernetes:
kubeAPIServer:
defaultNotReadyTolerationSeconds: 300
defaultUnreachableTolerationSeconds: 300
kubelet:
...
kubeScheduler:
featureGates:
MinDomainsInPodTopologySpread: true kubeControllerManager:
nodeMonitorGracePeriod: 40s
horizontalPodAutoscaler:
syncPeriod: 15s
tolerance: 0.1
downscaleStabilization: 5m0s
initialReadinessDelay: 30s
cpuInitializationPeriod: 5m0s
verticalPodAutoscaler:
enabled: true evictAfterOOMThreshold: 10m0s
evictionRateBurst: 1
evictionRateLimit: -1
evictionTolerance: 0.5
recommendationMarginFraction: 0.15
updaterInterval: 1m0s
recommenderInterval: 1m0s
clusterAutoscaler:
expander: "least-waste" scanInterval: 10s
scaleDownDelayAfterAdd: 60m
scaleDownDelayAfterDelete: 0s
scaleDownDelayAfterFailure: 3m
scaleDownUnneededTime: 30m
scaleDownUtilizationThreshold: 0.5
provider:
workers:
- name: ...
minimum: 6
maximum: 60
maxSurge: 3
maxUnavailable: 0
zones:
- ... # list of zones you want your worker pool nodes to be spread across, see above kubernetes:
kubelet:
... # similar to `kubelet` above (cluster-wide settings), but here per worker pool (pool-specific settings), see above machineControllerManager: # optional, it allows to configure the machine-controller settings. machineCreationTimeout: 20m
machineHealthTimeout: 10m
machineDrainTimeout: 60h
systemComponents:
coreDNS:
autoscaling:
mode: horizontal # valid values are `horizontal` (driven by CPU load) and `cluster-proportional` (driven by number of nodes/cores)
On spec.controlPlane.highAvailability.failureTolerance.type
If set, determines the degree of failure tolerance for your control plane. zone is preferred, but only available if your control plane resides in a region with 3+ zones. See above and the docs.
On spec.kubernetes.kubeAPIServer.defaultUnreachableTolerationSeconds and defaultNotReadyTolerationSeconds
This is a very interesting API server setting that lets Kubernetes decide how fast to evict pods from nodes whose status condition of type Ready is either Unknown (node status unknown, a.k.a unreachable) or False (kubelet not ready) (see node status conditions; please note that kubectl shows both values as NotReady which is a somewhat “simplified” visualization).
You can also override the cluster-wide API server settings individually per pod:
This will evict pods on unreachable or not-ready nodes immediately, but be cautious: 0 is very aggressive and may lead to unnecessary disruptions. Again, you must decide for your own workload and balance out the pros and cons (e.g. long startup time).
Please note, these settings replace spec.kubernetes.kubeControllerManager.podEvictionTimeout that was deprecated with Kubernetes v1.26 (and acted as an upper bound).
On spec.kubernetes.kubeScheduler.featureGates.MinDomainsInPodTopologySpread
Required to be enabled for minDomains to work with PTSCs (beta since Kubernetes v1.25, but off by default). See above and the docs. This tells the scheduler, how many topology domains to expect (=zones in the context of this document).
On spec.kubernetes.kubeControllerManager.nodeMonitorGracePeriod
This is another very interesting kube-controller-manager setting that can help you speed up or slow down how fast a node shall be considered Unknown (node status unknown, a.k.a unreachable) when the kubelet is not updating its status anymore (see node status conditions), which effects eviction (see spec.kubernetes.kubeAPIServer.defaultUnreachableTolerationSeconds and defaultNotReadyTolerationSeconds above). The shorter the time window, the faster Kubernetes will act, but the higher the chance of flapping behavior and pod trashing, so you may want to balance that out according to your needs, otherwise stick to the default which is a reasonable compromise.
On spec.kubernetes.kubeControllerManager.horizontalPodAutoscaler...
This configures horizontal pod autoscaling in Gardener-managed clusters. See above and the docs for the detailed fields.
On spec.kubernetes.verticalPodAutoscaler...
This configures vertical pod autoscaling in Gardener-managed clusters. See above and the docs for the detailed fields.
On spec.kubernetes.clusterAutoscaler...
This configures node auto-scaling in Gardener-managed clusters. See above and the docs for the detailed fields, especially about expanders, which may become life-saving in case of a zone outage when a resource crunch is setting in and everybody rushes to get machines in the healthy zones.
In case of a zone outage, it is critical to understand how the cluster autoscaler will put a worker pool in one zone into “back-off” and what the consequences for your workload will be. Unfortunately, the official cluster autoscaler documentation does not explain these details, but you can find hints in the source code:
If a node fails to come up, the node group (worker pool in that zone) will go into “back-off”, at first 5m, then exponentially longer until the maximum of 30m is reached. The “back-off” is reset after 3 hours. This in turn means, that nodes must be first considered Unknown, which happens when spec.kubernetes.kubeControllerManager.nodeMonitorGracePeriod lapses (e.g. at the beginning of a zone outage). Then they must either remain in this state until spec.provider.workers.machineControllerManager.machineHealthTimeout lapses for them to be recreated, which will fail in the unhealthy zone, or spec.kubernetes.kubeAPIServer.defaultUnreachableTolerationSeconds lapses for the pods to be evicted (usually faster than node replacements, depending on your configuration), which will trigger the cluster autoscaler to create more capacity, but very likely in the same zone as it tries to balance its node groups at first, which will fail in the unhealthy zone. It will be considered failed only when maxNodeProvisionTime lapses (usually close to spec.provider.workers.machineControllerManager.machineCreationTimeout) and only then put the node group into “back-off” and not retry for 5m (at first and then exponentially longer). Only then you can expect new node capacity to be brought up somewhere else.
During the time of ongoing node provisioning (before a node group goes into “back-off”), the cluster autoscaler may have “virtually scheduled” pending pods onto those new upcoming nodes and will not reevaluate these pods anymore unless the node provisioning fails (which will fail during a zone outage, but the cluster autoscaler cannot know that and will therefore reevaluate its decision only after it has given up on the new nodes).
It’s critical to keep that in mind and accommodate for it. If you have already capacity up and running, the reaction time is usually much faster with leases (whatever you set) or endpoints (spec.kubernetes.kubeControllerManager.nodeMonitorGracePeriod), but if you depend on new/fresh capacity, the above should inform you how long you will have to wait for it and for how long pods might be pending (because capacity is generally missing and pending pods may have been “virtually scheduled” to new nodes that won’t come up until the node group goes eventually into “back-off” and nodes in the healthy zones come up).
On spec.provider.workers.minimum, maximum, maxSurge, maxUnavailable, zones, and machineControllerManager
Each worker pool in Gardener may be configured differently. Among many other settings like machine type, root disk, Kubernetes version, kubelet settings, and many more you can also specify the lower and upper bound for the number of machines (minimum and maximum), how many machines may be added additionally during a rolling update (maxSurge) and how many machines may be in termination/recreation during a rolling update (maxUnavailable), and of course across how many zones the nodes shall be spread (zones).
Gardener divides minimum, maximum, maxSurge, maxUnavailable values by the number of zones specified for this worker pool. This fact must be considered when you plan the sizing of your worker pools.
The resulting MachineDeployments per zone will get minimum: 2, maximum: 20, maxSurge: 1, maxUnavailable: 0.
If another zone is added all values will be divided by 4, resulting in:
Less workers per zone.
⚠️ One MachineDeployment with maxSurge: 0, i.e. there will be a replacement of nodes without rolling updates.
Interesting is also the configuration for Gardener’s machine-controller-manager or MCM for short that provisions, monitors, terminates, replaces, or updates machines that back your nodes:
The shorter machineCreationTimeout is, the faster MCM will retry to create a machine/node, if the process is stuck on cloud provider side. It is set to useful/practical timeouts for the different cloud providers and you probably don’t want to change those (in the context of HA at least). Please align with the cluster autoscaler’s maxNodeProvisionTime.
The shorter machineHealthTimeout is, the faster MCM will replace machines/nodes in case the kubelet isn’t reporting back, which translates to Unknown, or reports back with NotReady, or the node-problem-detector that Gardener deploys for you reports a non-recoverable issue/condition (e.g. read-only file system). If it is too short however, you risk node and pod trashing, so be careful.
The shorter machineDrainTimeout is, the faster you can get rid of machines/nodes that MCM decided to remove, but this puts a cap on the grace periods and PDBs. They are respected up until the drain timeout lapses - then the machine/node will be forcefully terminated, whether or not the pods are still in termination or not even terminated because of PDBs. Those PDBs will then be violated, so be careful here as well. Please align with the cluster autoscaler’s maxGracefulTerminationSeconds.
Especially the last two settings may help you recover faster from cloud provider issues.
On spec.systemComponents.coreDNS.autoscaling
DNS is critical, in general and also within a Kubernetes cluster. Gardener-managed clusters deploy CoreDNS, a graduated CNCF project. Gardener supports 2 auto-scaling modes for it, horizontal (using HPA based on CPU) and cluster-proportional (using cluster proportional autoscaler that scales the number of pods based on the number of nodes/cores, not to be confused with the cluster autoscaler that scales nodes based on their utilization). Check out the docs, especially the trade-offs why you would chose one over the other (cluster-proportional gives you more configuration options, if CPU-based horizontal scaling is insufficient to your needs). Consider also Gardener’s feature node-local DNS to decouple you further from the DNS pods and stabilize DNS. Again, that’s not strictly related to HA, but may become important during a zone outage, when load patterns shift and pods start to initialize/resolve DNS records more frequently in bulk.
More Caveats
Unfortunately, there are a few more things of note when it comes to HA in a Kubernetes cluster that may be “surprising” and hard to mitigate:
If the kubelet restarts, it will report all pods as NotReady on startup until it reruns its probes (#100277), which leads to temporary endpoint and load balancer target removal (#102367). This topic is somewhat controversial. Gardener uses rolling updates and a jitter to spread necessary kubelet restarts as good as possible.
If a kube-proxy pod on a node turns NotReady, all load balancer traffic to all pods (on this node) under services with externalTrafficPolicylocal will cease as the load balancer will then take this node out of serving. This topic is somewhat controversial as well. So, please remember that externalTrafficPolicylocal not only has the disadvantage of imbalanced traffic spreading, but also a dependency to the kube-proxy pod that may and will be unavailable during updates. Gardener uses rolling updates to spread necessary kube-proxy updates as good as possible.
These are just a few additional considerations. They may or may not affect you, but other intricacies may. It’s a reminder to be watchful as Kubernetes may have one or two relevant quirks that you need to consider (and will probably only find out over time and with extensive testing).
Meaningful Availability
Finally, let’s go back to where we started. We recommended to measure meaningful availability. For instance, in Gardener, we do not trust only internal signals, but track also whether Gardener or the control planes that it manages are externally available through the external DNS records and load balancers, SNI-routing Istio gateways, etc. (the same path all users must take). It’s a huge difference whether the API server’s internal readiness probe passes or the user can actually reach the API server and it does what it’s supposed to do. Most likely, you will be in a similar spot and can do the same.
What you do with these signals is another matter. Maybe there are some actionable metrics and you can trigger some active fail-over, maybe you can only use it to improve your HA setup altogether. In our case, we also use it to deploy mitigations, e.g. via our dependency-watchdog that watches, for instance, Gardener-managed API servers and shuts down components like the controller managers to avert cascading knock-off effects (e.g. melt-down if the kubelets cannot reach the API server, but the controller managers can and start taking down nodes and pods).
Either way, understanding how users perceive your service is key to the improvement process as a whole. Even if you are not struck by a zone outage, the measures above and tracking the meaningful availability will help you improve your service.
Thank you for your interest.
6.2 - Shoot High Availability
Failure tolerance types node and zone. Possible mitigations for zone or node outages
Highly Available Shoot Control Plane
Shoot resource offers a way to request for a highly available control plane.
Failure Tolerance Types
A highly available shoot control plane can be setup with either a failure tolerance of zone or node.
Node Failure Tolerance
The failure tolerance of a node will have the following characteristics:
Control plane components will be spread across different nodes within a single availability zone. There will not be
more than one replica per node for each control plane component which has more than one replica.
Worker pool should have a minimum of 3 nodes.
A multi-node etcd (quorum size of 3) will be provisioned, offering zero-downtime capabilities with each member in a
different node within a single availability zone.
Zone Failure Tolerance
The failure tolerance of a zone will have the following characteristics:
Control plane components will be spread across different availability zones. There will be at least
one replica per zone for each control plane component which has more than one replica.
Gardener scheduler will automatically select a seed which has a minimum of 3 zones to host the shoot control plane.
A multi-node etcd (quorum size of 3) will be provisioned, offering zero-downtime capabilities with each member in a
different zone.
Shoot Spec
To request for a highly available shoot control plane Gardener provides the following configuration in the shoot spec:
If you already have a shoot cluster with non-HA control plane, then the following upgrades are possible:
Upgrade of non-HA shoot control plane to HA shoot control plane with node failure tolerance.
Upgrade of non-HA shoot control plane to HA shoot control plane with zone failure tolerance. However, it is essential that the seed which is currently hosting the shoot control plane should be multi-zonal. If it is not, then the request to upgrade will be rejected.
Note: There will be a small downtime during the upgrade, especially for etcd, which will transition from a single node etcd cluster to a multi-node etcd cluster.
Disallowed Transitions
If you already have a shoot cluster with HA control plane, then the following transitions are not possible:
Upgrade of HA shoot control plane from node failure tolerance to zone failure tolerance is currently not supported, mainly because already existing volumes are bound to the zone they were created in originally.
Downgrade of HA shoot control plane with zone failure tolerance to node failure tolerance is currently not supported, mainly because of the same reason as above, that already existing volumes are bound to the respective zones they were created in originally.
Downgrade of HA shoot control plane with either node or zone failure tolerance, to a non-HA shoot control plane is currently not supported, mainly because etcd-druid does not currently support scaling down of a multi-node etcd cluster to a single-node etcd cluster.
Zone Outage Situation
Implementing highly available software that can tolerate even a zone outage unscathed is no trivial task. You may find our HA Best Practices helpful to get closer to that goal. In this document, we collected many options and settings for you that also Gardener internally uses to provide a highly available service.
During a zone outage, you may be forced to change your cluster setup on short notice in order to compensate for failures and shortages resulting from the outage.
For instance, if the shoot cluster has worker nodes across three zones where one zone goes down, the computing power from these nodes is also gone during that time.
Changing the worker pool (shoot.spec.provider.workers[]) and infrastructure (shoot.spec.provider.infrastructureConfig) configuration can eliminate this disbalance, having enough machines in healthy availability zones that can cope with the requests of your applications.
Gardener relies on a sophisticated reconciliation flow with several dependencies for which various flow steps wait for the readiness of prior ones.
During a zone outage, this can block the entire flow, e.g., because all three etcd replicas can never be ready when a zone is down, and required changes mentioned above can never be accomplished.
For this, a special one-off annotation shoot.gardener.cloud/skip-readiness helps to skip any readiness checks in the flow.
The shoot.gardener.cloud/skip-readiness annotation serves as a last resort if reconciliation is stuck because of important changes during an AZ outage. Use it with caution, only in exceptional cases and after a case-by-case evaluation with your Gardener landscape administrator. If used together with other operations like Kubernetes version upgrades or credential rotation, the annotation may lead to a severe outage of your shoot control plane.
7 - Deployment
7.1 - Authentication Gardener Control Plane
Authentication of Gardener Control Plane Components Against the Garden Cluster
Note: This document refers to Gardener’s API server, admission controller, controller manager and scheduler components. Any reference to the term Gardener control plane component can be replaced with any of the mentioned above.
Virtual Garden is not used, i.e., the runtime Garden cluster is also the target Garden cluster.
Automounted Service Account Token
The easiest way to deploy a Gardener control plane component is to not provide a kubeconfig at all. This way in-cluster configuration and an automounted service account token will be used. The drawback of this approach is that the automounted token will not be automatically rotated.
This will allow for automatic rotation of the service account token by the kubelet. The configuration can be achieved by setting both .Values.global.<GardenerControlPlaneComponent>.serviceAccountTokenVolumeProjection.enabled: true and .Values.global.<GardenerControlPlaneComponent>.kubeconfig in the respective chart’s values.yaml file.
Virtual Garden is used, i.e., the runtime Garden cluster is different from the target Garden cluster.
Service Account
The easiest way to setup the authentication is to create a service account and the respective roles will be bound to this service account in the target cluster. Then use the generated service account token and craft a kubeconfig, which will be used by the workload in the runtime cluster. This approach does not provide a solution for the rotation of the service account token. However, this setup can be achieved by setting .Values.global.deployment.virtualGarden.enabled: true and following these steps:
Deploy the application part of the charts in the target cluster.
Get the service account token and craft the kubeconfig.
Set the crafted kubeconfig and deploy the runtime part of the charts in the runtime cluster.
Client Certificate
Another solution is to bind the roles in the target cluster to a User subject instead of a service account and use a client certificate for authentication. This approach does not provide a solution for the client certificate rotation. However, this setup can be achieved by setting both .Values.global.deployment.virtualGarden.enabled: true and .Values.global.deployment.virtualGarden.<GardenerControlPlaneComponent>.user.name, then following these steps:
Generate a client certificate for the target cluster for the respective user.
Deploy the application part of the charts in the target cluster.
Craft a kubeconfig using the already generated client certificate.
Set the crafted kubeconfig and deploy the runtime part of the charts in the runtime cluster.
Projected Service Account Token
This approach requires an already deployed and configured oidc-webhook-authenticator for the target cluster. Also, the runtime cluster should be registered as a trusted identity provider in the target cluster. Then, projected service accounts tokens from the runtime cluster can be used to authenticate against the target cluster. The needed steps are as follows:
Set .Values.global.deployment.virtualGarden.enabled: true and .Values.global.deployment.virtualGarden.<GardenerControlPlaneComponent>.user.name.
Note: username value will depend on the trust configuration, e.g., <prefix>:system:serviceaccount:<namespace>:<serviceaccount>
Set .Values.global.<GardenerControlPlaneComponent>.serviceAccountTokenVolumeProjection.enabled: true and .Values.global.<GardenerControlPlaneComponent>.serviceAccountTokenVolumeProjection.audience.
Note: audience value will depend on the trust configuration, e.g., <client-id-from-trust-config>.
Craft a kubeconfig (see the example below).
Deploy the application part of the charts in the target cluster.
Deploy the runtime part of the charts in the runtime cluster.
Configuring the Logging Stack via gardenlet Configurations
Enable the Logging
In order to install the Gardener logging stack, the logging.enabled configuration option has to be enabled in the Gardenlet configuration:
logging:
enabled: true
From now on, each Seed is going to have a logging stack which will collect logs from all pods and some systemd services. Logs related to Shoots with testing purpose are dropped in the fluent-bit output plugin. Shoots with a purpose different than testing have the same type of log aggregator (but different instance) as the Seed. The logs can be viewed in the Plutono in the garden namespace for the Seed components and in the respective shoot control plane namespaces.
Enable Logs from the Shoot’s Node systemd Services
The logs from the systemd services on each node can be retrieved by enabling the logging.shootNodeLogging option in the gardenlet configuration:
Under the shootPurpose section, just list all the shoot purposes for which the Shoot node logging feature will be enabled. Specifying the testing purpose has no effect because this purpose prevents the logging stack installation.
Logs can be viewed in the operator Plutono!
The dedicated labels are unit, syslog_identifier, and nodename in the Explore menu.
Configuring Central Vali Storage Capacity
By default, the central Vali has 100Gi of storage capacity.
To overwrite the current central Vali storage capacity, the logging.vali.garden.storage setting in the gardenlet’s component configuration should be altered.
If you need to increase it, you can do so without losing the current data by specifying a higher capacity. By doing so, the Vali’s PersistentVolume capacity will be increased instead of deleting the current PV.
However, if you specify less capacity, then the PersistentVolume will be deleted and with it the logs, too.
Gardenlets act as decentralized agents to manage the shoot clusters of a seed cluster.
Procedure
After you have deployed the Gardener control plane, you need one or more seed clusters in order to be able to create shoot clusters.
You can either register an existing cluster as “seed” (this could also be the cluster in which the control plane runs), or you can create new clusters (typically shoots, i.e., this approach registers at least one first initial seed) and then register them as “seeds”.
The following sections describe the scenarios.
Register A First Seed Cluster
If you have not registered a seed cluster yet (thus, you need to deploy a first, so-called “unmanaged seed”), your approach depends on how you deployed the Gardener control plane.
If you want to register the same cluster in which gardener-operator runs, or if you want to register another cluster that is reachable (network-wise) for gardener-operator, you can follow Deploy gardenlet via gardener-operator.
If you want to register a cluster that is not reachable (network-wise) (e.g., because it runs behind a firewall), you can follow Deploy a gardenlet Manually.
Register Further Seed Clusters
If you already have a seed cluster, and you want to deploy further seed clusters (so-called “managed seeds”), you can follow Deploy a gardenlet Automatically.
7.4 - Deploy Gardenlet Automatically
Deploy a gardenlet Automatically
The gardenlet can automatically deploy itself into shoot clusters, and register them as seed clusters.
These clusters are called “managed seeds” (aka “shooted seeds”).
This procedure is the preferred way to add additional seed clusters, because shoot clusters already come with production-grade qualities that are also demanded for seed clusters.
Prerequisites
The only prerequisite is to register an initial cluster as a seed cluster that already has a deployed gardenlet (for available options see Deploying Gardenlets).
Tip
The initial seed cluster can be the garden cluster itself, but for better separation of concerns, it is recommended to only register other clusters as seeds.
Auto-Deployment of Gardenlets into Shoot Clusters
For a better scalability of your Gardener landscape (e.g., when the total number of Shoots grows), you usually need more seed clusters that you can create, as follows:
Use the initial seed cluster (“unmanaged seed”) to create shoot clusters that you later register as seed clusters.
The gardenlet deployed in the initial cluster can deploy itself into the shoot clusters (which eventually makes them getting registered as seeds) if ManagedSeed resources are created.
The advantage of this approach is that there’s only one initial gardenlet installation required.
Every other managed seed cluster gets an automatically deployed gardenlet.
Manually deploying a gardenlet is usually only required if the Kubernetes cluster to be registered as a seed cluster is managed via third-party tooling (i.e., the Kubernetes cluster is not a shoot cluster, so Deploy a gardenlet Automatically cannot be used).
In this case, gardenlet needs to be deployed manually, meaning that its Helm chart must be installed.
Tip
Once you’ve deployed a gardenlet manually, you can deploy new gardenlets automatically.
The manually deployed gardenlet is then used as a template for the new gardenlets.
For more information, see Deploy a gardenlet Automatically.
Prerequisites
Kubernetes Cluster that Should Be Registered as a Seed Cluster
Determine the nodes, pods, and services CIDR of the cluster.
You need to configure this information in the Seed configuration.
Gardener uses this information to check that the shoot cluster isn’t created with overlapping CIDR ranges.
Every seed cluster needs an Ingress controller which distributes external requests to internal components like Plutono and Prometheus.
For this, configure the following lines in your Seed resource:
The client credentials required for the gardenlet’s TLS bootstrapping process need to be either token or certificate (OIDC isn’t supported) and have permissions to create a Certificate Signing Request (CSR).
It’s recommended to use bootstrap tokens due to their desirable security properties (such as a limited token lifetime).
Therefore, first create a bootstrap token secret for the garden cluster:
apiVersion: v1
kind: Secret
metadata:
# Name MUST be of form "bootstrap-token-<token id>" name: bootstrap-token-07401b
namespace: kube-system
# Type MUST be 'bootstrap.kubernetes.io/token'type: bootstrap.kubernetes.io/token
stringData:
# Human readable description. Optional. description: "Token to be used by the gardenlet for Seed `sweet-seed`."# Token ID and secret. Required. token-id: 07401b # 6 characters token-secret: f395accd246ae52d # 16 characters# Expiration. Optional.# expiration: 2017-03-10T03:22:11Z# Allowed usages. usage-bootstrap-authentication: "true" usage-bootstrap-signing: "true"
When you later prepare the gardenlet Helm chart, a kubeconfig based on this token is shared with the gardenlet upon deployment.
Prepare the gardenlet Helm Chart
This section only describes the minimal configuration, using the global configuration values of the gardenlet Helm chart.
For an overview over all values, see the configuration values.
We refer to the global configuration values as gardenlet configuration in the following procedure.
Create a gardenlet configuration gardenlet-values.yaml based on this template.
Create a bootstrap kubeconfig based on the bootstrap token created in the garden cluster.
Replace the <bootstrap-token> with token-id.token-secret (from our previous example: 07401b.f395accd246ae52d) from the bootstrap token secret.
In the gardenClientConnection.bootstrapKubeconfig section of your gardenlet configuration, provide the bootstrap kubeconfig together with a name and namespace to the gardenlet Helm chart.
gardenClientConnection:
bootstrapKubeconfig:
name: gardenlet-kubeconfig-bootstrap
namespace: garden
kubeconfig: | <bootstrap-kubeconfig> # will be base64 encoded by helm
The bootstrap kubeconfig is stored in the specified secret.
In the gardenClientConnection.kubeconfigSecret section of your gardenlet configuration, define a name and a namespace where the gardenlet stores the real kubeconfig that it creates during the bootstrap process.
If the secret doesn’t exist, the gardenlet creates it for you.
The kubeconfig created by the gardenlet in step 4 will not be recreated as long as it exists, even if a new bootstrap kubeconfig is provided.
To enable rotation of the garden cluster CA certificate, a new bundle can be provided via the gardenClientConnection.gardenClusterCACert field.
If the provided bundle differs from the one currently in the gardenlet’s kubeconfig secret then it will be updated.
To remove the CA completely (e.g. when switching to a publicly trusted endpoint), this field can be set to either none or null.
Prepare Seed Specification
When gardenlet starts, it tries to register a Seed resource in the garden cluster based on the specification provided in seedConfig in its configuration.
This procedure doesn’t describe all the possible configurations for the Seed resource.
For more information, see:
Supply the Seed resource in the seedConfig section of your gardenlet configuration gardenlet-values.yaml.
Add the seedConfig to your gardenlet configuration gardenlet-values.yaml.
The field seedConfig.spec.provider.type specifies the infrastructure provider type (for example, aws) of the seed cluster.
For all supported infrastructure providers, see Known Extension Implementations.
Apart from the seed’s name, seedConfig.metadata can optionally contain labels and annotations.
gardenlet will set the labels of the registered Seed object to the labels given in the seedConfig plus gardener.cloud/role=seed.
Any custom labels on the Seed object will be removed on the next restart of gardenlet.
If a label is removed from the seedConfig it is removed from the Seed object as well.
In contrast to labels, annotations in the seedConfig are added to existing annotations on the Seed object.
Thus, custom annotations that are added to the Seed object during runtime are not removed by gardenlet on restarts.
Furthermore, if an annotation is removed from the seedConfig, gardenlet does not remove it from the Seed object.
Optional: Enable HA Mode
You may consider running gardenlet with multiple replicas, especially if the seed cluster is configured to host HA shoot control planes.
Therefore, the following Helm chart values define the degree of high availability you want to achieve for the gardenlet deployment.
replicaCount: 2 # or more if a higher failure tolerance is required.failureToleranceType: zone # One of `zone` or `node` - defines how replicas are spread.
Optional: Enable Backup and Restore
The seed cluster can be set up with backup and restore for the main etcds of shoot clusters.
Create a secret in the garden cluster with client credentials for the storage provider.
The format of the secret is cloud provider specific and can be found in the repository of the respective Gardener extension.
For example, the secret for AWS S3 can be found in the AWS provider extension (30-etcd-backup-secret.yaml).
apiVersion: v1
kind: Secret
metadata:
name: sweet-seed-backup
namespace: garden
type: Opaque
data:
# client credentials format is provider specific
Configure the Seed resource in the seedConfig section of your gardenlet configuration to use backup and restore:
In order to take off the continuous task of deploying gardenlet’s Helm chart in case you want to upgrade its version, it supports self-upgrades.
The way this works is that it pulls information (its configuration and deployment values) from a seedmanagement.gardener.cloud/v1alpha1.Gardenlet resource in the garden cluster.
This resource must be in the garden namespace and must have the same name as the Seed the gardenlet is responsible for.
For more information, see this section.
In order to make gardenlet automatically create a corresponding seedmanagement.gardener.cloud/v1alpha1.Gardenlet resource, you must provide
in your gardenlet-values.yaml file.
Please replace the ref placeholder with the URL to the OCI repository containing the gardenlet Helm chart you are installing.
Note
If you don’t configure this selfUpgrade section in the initial deployment, you can also do it later, or you directly create the corresponding seedmanagement.gardener.cloud/v1alpha1.Gardenlet resource in the garden cluster.
Deploy the gardenlet
The gardenlet-values.yaml looks something like this (with backup for shoot clusters enabled):
In order to keep your gardenlets in such “unmanaged seeds” up-to-date (i.e., in seeds which are no shoot clusters), its Helm chart must be regularly deployed.
This requires network connectivity to such clusters which can be challenging if they reside behind a firewall or in restricted environments.
It is much simpler if gardenlet could keep itself up-to-date, based on configuration read from the garden cluster.
This approach greatly reduces operational complexity.
gardenlet runs a controller which watches for seedmanagement.gardener.cloud/v1alpha1.Gardenlet resources in the garden cluster in the garden namespace having the same name as the Seed the gardenlet is responsible for.
Such resources contain its component configuration and deployment values.
Most notably, a URL to an OCI repository containing gardenlet’s Helm chart is included.
On reconciliation, gardenlet downloads the Helm chart, renders it with the provided values, and then applies it to its own cluster.
Hence, in order to keep a gardenlet up-to-date, it is enough to update the tag/digest of the OCI repository ref for the Helm chart:
This way, network connectivity to the cluster in which gardenlet runs is not required at all (at least for deployment purposes).
When you delete this resource, nothing happens: gardenlet remains running with the configuration as before.
However, self-upgrades are obviously not possible anymore.
In order to upgrade it, you have to either recreate the Gardenlet object, or redeploy the Helm chart.
The initial seed cluster can be the garden cluster itself, but for better separation of concerns, it is recommended to only register other clusters as seeds.
Deployment of gardenlets
Using this method, gardener-operator is only taking care of the very first deployment of gardenlet.
Once running, the gardenlet leverages the self-upgrade strategy in order to keep itself up-to-date.
Concretely, gardener-operator only acts when there is no respective Seed resource yet.
In order to request a gardenlet deployment, create following resource in the (virtual) garden cluster:
This causes gardener-operator to deploy gardenlet to the same cluster where it is running.
Once it comes up, gardenlet will create a Seed resource with the same name and uses the Gardenlet resource for self-upgrades (see this document).
Remote Clusters
If you want gardener-operator to deploy gardenlet into some other cluster, create a kubeconfig Secret and reference it in the Gardenlet resource:
After successful deployment of gardenlet, gardener-operator will delete the remote-cluster-kubeconfigSecret and set .spec.kubeconfigSecretRef to nil.
This is because the kubeconfig will never ever be needed anymore (gardener-operator is only responsible for initial deployment, and gardenlet updates itself with an in-cluster kubeconfig).
In case your landscape is managed via a GitOps approach, you might want to reflect this change in your repository.
Forceful Re-Deployment
In certain scenarios, it might be necessary to forcefully re-deploy the gardenlet.
For example, in case the gardenlet client certificate has been expired or is “lost”, or the gardenlet Deployment has been “accidentally” (😉) deleted from the seed cluster.
You can trigger the forceful re-deployment by annotating the Gardenlet with
gardener.cloud/operation=force-redeploy
Tip
Do not forget to create the kubeconfig Secret and re-add the .spec.kubeconfigSecretRef to the Gardenlet specification if this is a remote cluster.
gardener-operator will remove the operation annotation after it’s done.
Just like after the initial deployment, it’ll also delete the kubeconfig Secret and set .spec.kubeconfigSecretRef to nil, see above.
Configuring the connection to garden cluster
The garden cluster connection of your seeds are configured automatically by gardener-operator.
You could also specify the gardenClusterAddress and gardenClusterCACert in the Gardenlet resource manually, but this is not recommended.
If GardenClusterAddress is unset gardener-operator will determine the address automatically based on the Garden resource.
It is set to "api." + garden.spec.virtualCluster.dns.domains[0] which should cover most use cases since this is the immutable address of the garden cluster. If the runtime cluster is used as a seed cluster and IstioTLSTermination feature is not active, gardenlet overwrites the address with the internal service address of the garden cluster at runtime.
This happens for this single seed cluster only, so any managed seed running on this seed cluster will still use the default address of the garden cluster.
gardenClusterCACert is deprecated and should not be set. In this case, gardenlet will update the garden cluster CA certificate automatically from the garden cluster.
If a seed managed by a Gardenlet resource loses permanent access to the garden cluster for some reason, you can re-establish the connection by using the Forceful Re-Deployment feature.
7.7 - Feature Gates
Feature Gates in Gardener
This page contains an overview of the various feature gates an administrator can specify on different Gardener components.
Overview
Feature gates are a set of key=value pairs that describe Gardener features. You can turn these features on or off using the component configuration file for a specific component.
Each Gardener component lets you enable or disable a set of feature gates that are relevant to that component. For example, this is the configuration of the gardenlet component.
The following tables are a summary of the feature gates that you can set on different Gardener components.
The “Since” column contains the Gardener release when a feature is introduced or its release stage is changed.
The “Until” column, if not empty, contains the last Gardener release in which you can still use a feature gate.
If a feature is in the Alpha or Beta state, you can find the feature listed in the Alpha/Beta feature gate table.
If a feature is stable you can find all stages for that feature listed in the Graduated/Deprecated feature gate table.
The Graduated/Deprecated feature gate table also lists deprecated and withdrawn features.
Feature Gates for Alpha or Beta Features
Feature
Default
Stage
Since
Until
DefaultSeccompProfile
false
Alpha
1.54
UseNamespacedCloudProfile
false
Alpha
1.92
1.111
UseNamespacedCloudProfile
true
Beta
1.112
ShootCredentialsBinding
false
Alpha
1.98
1.106
ShootCredentialsBinding
true
Beta
1.107
NewWorkerPoolHash
false
Alpha
1.98
CredentialsRotationWithoutWorkersRollout
false
Alpha
1.112
1.120
CredentialsRotationWithoutWorkersRollout
true
Beta
1.121
InPlaceNodeUpdates
false
Alpha
1.113
IstioTLSTermination
false
Alpha
1.114
CloudProfileCapabilities
false
Alpha
1.117
DoNotCopyBackupCredentials
false
Alpha
1.121
1.122
DoNotCopyBackupCredentials
true
Beta
1.123
Feature Gates for Graduated or Deprecated Features
Feature
Default
Stage
Since
Until
NodeLocalDNS
false
Alpha
1.7
1.25
NodeLocalDNS
Removed
1.26
KonnectivityTunnel
false
Alpha
1.6
1.26
KonnectivityTunnel
Removed
1.27
MountHostCADirectories
false
Alpha
1.11
1.25
MountHostCADirectories
true
Beta
1.26
1.27
MountHostCADirectories
true
GA
1.27
1.29
MountHostCADirectories
Removed
1.30
DisallowKubeconfigRotationForShootInDeletion
false
Alpha
1.28
1.31
DisallowKubeconfigRotationForShootInDeletion
true
Beta
1.32
1.35
DisallowKubeconfigRotationForShootInDeletion
true
GA
1.36
1.37
DisallowKubeconfigRotationForShootInDeletion
Removed
1.38
Logging
false
Alpha
0.13
1.40
Logging
Removed
1.41
AdminKubeconfigRequest
false
Alpha
1.24
1.38
AdminKubeconfigRequest
true
Beta
1.39
1.41
AdminKubeconfigRequest
true
GA
1.42
1.49
AdminKubeconfigRequest
Removed
1.50
UseDNSRecords
false
Alpha
1.27
1.38
UseDNSRecords
true
Beta
1.39
1.43
UseDNSRecords
true
GA
1.44
1.49
UseDNSRecords
Removed
1.50
CachedRuntimeClients
false
Alpha
1.7
1.33
CachedRuntimeClients
true
Beta
1.34
1.44
CachedRuntimeClients
true
GA
1.45
1.49
CachedRuntimeClients
Removed
1.50
DenyInvalidExtensionResources
false
Alpha
1.31
1.41
DenyInvalidExtensionResources
true
Beta
1.42
1.44
DenyInvalidExtensionResources
true
GA
1.45
1.49
DenyInvalidExtensionResources
Removed
1.50
RotateSSHKeypairOnMaintenance
false
Alpha
1.28
1.44
RotateSSHKeypairOnMaintenance
true
Beta
1.45
1.47
RotateSSHKeypairOnMaintenance (deprecated)
false
Beta
1.48
1.50
RotateSSHKeypairOnMaintenance (deprecated)
Removed
1.51
ShootForceDeletion
false
Alpha
1.81
1.90
ShootForceDeletion
true
Beta
1.91
1.110
ShootForceDeletion
true
GA
1.111
1.119
ShootForceDeletion
Removed
1.120
ShootMaxTokenExpirationOverwrite
false
Alpha
1.43
1.44
ShootMaxTokenExpirationOverwrite
true
Beta
1.45
1.47
ShootMaxTokenExpirationOverwrite
true
GA
1.48
1.50
ShootMaxTokenExpirationOverwrite
Removed
1.51
ShootMaxTokenExpirationValidation
false
Alpha
1.43
1.45
ShootMaxTokenExpirationValidation
true
Beta
1.46
1.47
ShootMaxTokenExpirationValidation
true
GA
1.48
1.50
ShootMaxTokenExpirationValidation
Removed
1.51
WorkerPoolKubernetesVersion
false
Alpha
1.35
1.45
WorkerPoolKubernetesVersion
true
Beta
1.46
1.49
WorkerPoolKubernetesVersion
true
GA
1.50
1.51
WorkerPoolKubernetesVersion
Removed
1.52
DisableDNSProviderManagement
false
Alpha
1.41
1.49
DisableDNSProviderManagement
true
Beta
1.50
1.51
DisableDNSProviderManagement
true
GA
1.52
1.59
DisableDNSProviderManagement
Removed
1.60
SecretBindingProviderValidation
false
Alpha
1.38
1.50
SecretBindingProviderValidation
true
Beta
1.51
1.52
SecretBindingProviderValidation
true
GA
1.53
1.54
SecretBindingProviderValidation
Removed
1.55
SeedKubeScheduler
false
Alpha
1.15
1.54
SeedKubeScheduler
false
Deprecated
1.55
1.60
SeedKubeScheduler
Removed
1.61
ShootCARotation
false
Alpha
1.42
1.50
ShootCARotation
true
Beta
1.51
1.56
ShootCARotation
true
GA
1.57
1.59
ShootCARotation
Removed
1.60
ShootSARotation
false
Alpha
1.48
1.50
ShootSARotation
true
Beta
1.51
1.56
ShootSARotation
true
GA
1.57
1.59
ShootSARotation
Removed
1.60
ReversedVPN
false
Alpha
1.22
1.41
ReversedVPN
true
Beta
1.42
1.62
ReversedVPN
true
GA
1.63
1.69
ReversedVPN
Removed
1.70
ForceRestore
Removed
1.66
SeedChange
false
Alpha
1.12
1.52
SeedChange
true
Beta
1.53
1.68
SeedChange
true
GA
1.69
1.72
SeedChange
Removed
1.73
CopyEtcdBackupsDuringControlPlaneMigration
false
Alpha
1.37
1.52
CopyEtcdBackupsDuringControlPlaneMigration
true
Beta
1.53
1.68
CopyEtcdBackupsDuringControlPlaneMigration
true
GA
1.69
1.72
CopyEtcdBackupsDuringControlPlaneMigration
Removed
1.73
ManagedIstio
false
Alpha
1.5
1.18
ManagedIstio
true
Beta
1.19
1.47
ManagedIstio
true
Deprecated
1.48
1.69
ManagedIstio
Removed
1.70
APIServerSNI
false
Alpha
1.7
1.18
APIServerSNI
true
Beta
1.19
1.47
APIServerSNI
true
Deprecated
1.48
1.72
APIServerSNI
Removed
1.73
HAControlPlanes
false
Alpha
1.49
1.70
HAControlPlanes
true
Beta
1.71
1.72
HAControlPlanes
true
GA
1.73
1.73
HAControlPlanes
Removed
1.74
FullNetworkPoliciesInRuntimeCluster
false
Alpha
1.66
1.70
FullNetworkPoliciesInRuntimeCluster
true
Beta
1.71
1.72
FullNetworkPoliciesInRuntimeCluster
true
GA
1.73
1.73
FullNetworkPoliciesInRuntimeCluster
Removed
1.74
DisableScalingClassesForShoots
false
Alpha
1.73
1.78
DisableScalingClassesForShoots
true
Beta
1.79
1.80
DisableScalingClassesForShoots
true
GA
1.81
1.81
DisableScalingClassesForShoots
Removed
1.82
ContainerdRegistryHostsDir
false
Alpha
1.77
1.85
ContainerdRegistryHostsDir
true
Beta
1.86
1.86
ContainerdRegistryHostsDir
true
GA
1.87
1.87
ContainerdRegistryHostsDir
Removed
1.88
WorkerlessShoots
false
Alpha
1.70
1.78
WorkerlessShoots
true
Beta
1.79
1.85
WorkerlessShoots
true
GA
1.86
1.87
WorkerlessShoots
Removed
1.88
MachineControllerManagerDeployment
false
Alpha
1.73
1.80
MachineControllerManagerDeployment
true
Beta
1.81
1.81
MachineControllerManagerDeployment
true
GA
1.82
1.91
MachineControllerManagerDeployment
Removed
1.92
APIServerFastRollout
true
Beta
1.82
1.89
APIServerFastRollout
true
GA
1.90
1.91
APIServerFastRollout
Removed
1.92
UseGardenerNodeAgent
false
Alpha
1.82
1.88
UseGardenerNodeAgent
true
Beta
1.89
1.89
UseGardenerNodeAgent
true
GA
1.90
1.91
UseGardenerNodeAgent
Removed
1.92
CoreDNSQueryRewriting
false
Alpha
1.55
1.95
CoreDNSQueryRewriting
true
Beta
1.96
1.96
CoreDNSQueryRewriting
true
GA
1.97
1.100
CoreDNSQueryRewriting
Removed
1.101
MutableShootSpecNetworkingNodes
false
Alpha
1.64
1.95
MutableShootSpecNetworkingNodes
true
Beta
1.96
1.96
MutableShootSpecNetworkingNodes
true
GA
1.97
1.100
MutableShootSpecNetworkingNodes
Removed
1.101
VPAForETCD
false
Alpha
1.94
1.96
VPAForETCD
true
Beta
1.97
1.104
VPAForETCD
true
GA
1.105
1.108
VPAForETCD
Removed
1.109
VPAAndHPAForAPIServer
false
Alpha
1.95
1.100
VPAAndHPAForAPIServer
true
Beta
1.101
1.104
VPAAndHPAForAPIServer
true
GA
1.105
1.108
VPAAndHPAForAPIServer
Removed
1.109
HVPA
false
Alpha
0.31
1.105
HVPA
false
Deprecated
1.106
1.108
HVPA
Removed
1.109
HVPAForShootedSeed
false
Alpha
0.32
1.105
HVPAForShootedSeed
false
Deprecated
1.106
1.108
HVPAForShootedSeed
Removed
1.109
IPv6SingleStack
false
Alpha
1.63
1.106
IPv6SingleStack
Removed
1.107
ShootManagedIssuer
false
Alpha
1.93
1.110
ShootManagedIssuer
Removed
1.111
NewVPN
false
Alpha
1.104
1.114
NewVPN
true
Beta
1.115
1.115
NewVPN
true
GA
1.116
RemoveAPIServerProxyLegacyPort
false
Alpha
1.113
1.118
RemoveAPIServerProxyLegacyPort
true
Beta
1.119
1.121
RemoveAPIServerProxyLegacyPort
true
GA
1.122
1.122
RemoveAPIServerProxyLegacyPort
Removed
1.123
NodeAgentAuthorizer
false
Alpha
1.109
1.115
NodeAgentAuthorizer
true
Beta
1.116
1.122
NodeAgentAuthorizer
true
GA
1.123
Using a Feature
A feature can be in Alpha, Beta or GA stage.
An Alpha feature means:
Disabled by default.
Might be buggy. Enabling the feature may expose bugs.
Support for feature may be dropped at any time without notice.
The API may change in incompatible ways in a later software release without notice.
Recommended for use only in short-lived testing clusters, due to increased
risk of bugs and lack of long-term support.
A Beta feature means:
Enabled by default.
The feature is well tested. Enabling the feature is considered safe.
Support for the overall feature will not be dropped, though details may change.
The schema and/or semantics of objects may change in incompatible ways in a
subsequent beta or stable release. When this happens, we will provide instructions
for migrating to the next version. This may require deleting, editing, and
re-creating API objects. The editing process may require some thought.
This may require downtime for applications that rely on the feature.
Recommended for only non-critical uses because of potential for
incompatible changes in subsequent releases.
Please do try Beta features and give feedback on them!
After they exit beta, it may not be practical for us to make more changes.
A General Availability (GA) feature is also referred to as a stable feature. It means:
The feature is always enabled; you cannot disable it.
The corresponding feature gate is no longer needed.
Stable versions of features will appear in released software for many subsequent versions.
List of Feature Gates
Note: All feature gates that are relevant for gardenlet, are also relevant for gardenadm.
Feature
Relevant Components
Description
DefaultSeccompProfile
gardenlet, gardener-operator
Enables the defaulting of the seccomp profile for Gardener managed workload in the garden or seed to RuntimeDefault.
UseNamespacedCloudProfile
gardener-apiserver
Enables usage of NamespacedCloudProfiles in Shoots.
ShootManagedIssuer
gardenlet
Enables the shoot managed issuer functionality described in GEP 24.
ShootCredentialsBinding
gardener-apiserver
Enables usage of CredentialsBindingName in Shoots.
NewWorkerPoolHash
gardenlet
Enables usage of the new worker pool hash calculation. The new calculation supports rolling worker pools if kubeReserved, systemReserved, evictionHard or cpuManagerPolicy in the kubelet configuration are changed. All provider extensions must be upgraded to support this feature first. Existing worker pools are not immediately migrated to the new hash variant, since this would trigger the replacement of all nodes. The migration happens when a rolling update is triggered according to the old or new hash version calculation.
NewVPN
gardenlet
Enables usage of the new implementation of the VPN (go rewrite) using an IPv6 transfer network.
NodeAgentAuthorizer
gardenlet, gardener-node-agent
Enables authorization of gardener-node-agent to kube-apiserver of shoot clusters using an authorization webhook. It restricts the permissions of each gardener-node-agent instance to the objects belonging to its own node only.
CredentialsRotationWithoutWorkersRollout
gardener-apiserver
CredentialsRotationWithoutWorkersRollout enables starting the credentials rotation without immediately causing a rolling update of all worker nodes. Instead, the rolling update can be triggered manually by the user at a later point in time of their convenience. This should only be enabled when all deployed provider extensions vendor at least gardener/gardener@v1.111+.
InPlaceNodeUpdates
gardener-apiserver
Enables setting the update strategy of worker pools to AutoInPlaceUpdate or ManualInPlaceUpdate in the Shoot API.
IstioTLSTermination
gardenlet, gardener-operator
Enables TLS termination for the Istio Ingress Gateway instead of TLS termination at the kube-apiserver. It allows load-balancing of requests to the kube-apiserver on request level instead of connection level.
CloudProfileCapabilities
gardener-apiserver
Enables the usage of capabilities in the CloudProfile. Capabilities are used to create a relation between machineTypes and machineImages. It allows to validate worker groups of a shoot ensuring the selected image and machine combination will boot up successfully. Capabilities are also used to determine valid upgrade paths during automated maintenance operation.
DoNotCopyBackupCredentials
gardenlet
Disables the copying of Shoot infrastructure credentials as backup credentials when the Shoot is used as a ManagedSeed. Operators are responsible for providing the credentials for backup explicitly. Credentials that were already copied will be labeled with secret.backup.gardener.cloud/status=previously-managed and would have to be cleaned up by operators.
7.8 - Getting Started Locally
Deploying Gardener Locally
This document will walk you through deploying Gardener on your local machine.
If you encounter difficulties, please open an issue so that we can make this process easier.
Overview
Gardener runs in any Kubernetes cluster.
In this guide, we will start a KinD cluster which is used as both garden and seed cluster (please refer to the architecture overview) for simplicity.
Based on Skaffold, the container images for all required components will be built and deployed into the cluster (via their Helm charts).
Alternatives
When deploying Gardener on your local machine you might face several limitations:
Your machine doesn’t have enough compute resources (see prerequisites) for hosting a second seed cluster or multiple shoot clusters.
Testing Gardener’s IPv6 features requires a Linux machine and native IPv6 connectivity to the internet, but you’re on macOS or don’t have IPv6 connectivity in your office environment or via your home ISP.
In these cases, you might want to check out one of the following options that run the setup described in this guide elsewhere for circumventing these limitations:
Make sure your Docker daemon is up-to-date, up and running and has enough resources (at least 8 CPUs and 8Gi memory; see here how to configure the resources for Docker for Mac).
Please note that 8 CPU / 8Gi memory might not be enough for more than two Shoot clusters, i.e., you might need to increase these values if you want to run additional Shoots.
If you plan on following the optional steps to create a second seed cluster, the required resources will be more - at least 10 CPUs and 18Gi memory.
Additionally, please configure at least 120Gi of disk size for the Docker daemon.
Tip: You can clean up unused data with docker system df and docker system prune -a.
Setting Up the KinD Cluster (Garden and Seed)
make kind-up
If you want to setup an IPv6 KinD cluster, use make kind-up IPFAMILY=ipv6 instead.
This command sets up a new KinD cluster named gardener-local and stores the kubeconfig in the ./example/gardener-local/kind/local/kubeconfig file.
It might be helpful to copy this file to $HOME/.kube/config, since you will need to target this KinD cluster multiple times.
Alternatively, make sure to set your KUBECONFIG environment variable to ./example/gardener-local/kind/local/kubeconfig for all future steps via export KUBECONFIG=$PWD/example/gardener-local/kind/local/kubeconfig.
All following steps assume that you are using this kubeconfig.
Additionally, this command also deploys a local container registry to the cluster, as well as a few registry mirrors, that are set up as a pull-through cache for all upstream registries Gardener uses by default.
This is done to speed up image pulls across local clusters.
You will need to add 127.0.0.1 garden.local.gardener.cloud to your /etc/hosts.
The local registry can now be accessed either via localhost:5001 or garden.local.gardener.cloud:5001 for pushing and pulling.
The storage directories of the registries are mounted to the host machine under dev/local-registry.
With this, mirrored images don’t have to be pulled again after recreating the cluster.
The command also deploys a default calico installation as the cluster’s CNI implementation with NetworkPolicy support (the default kindnet CNI doesn’t provide NetworkPolicy support).
Furthermore, it deploys the metrics-server in order to support HPA and VPA on the seed cluster.
Setting Up IPv6 Single-Stack Networking (optional)
First, ensure that your /etc/hosts file contains an entry resolving garden.local.gardener.cloud to the IPv6 loopback address:
::1 garden.local.gardener.cloud
Typically, only ip6-localhost is mapped to ::1 on linux machines.
However, we need garden.local.gardener.cloud to resolve to both 127.0.0.1 and ::1 so that we can talk to our registry via a single address (garden.local.gardener.cloud:5001).
Next, we need to configure NAT for outgoing traffic from the kind network to the internet.
After executing make kind-up IPFAMILY=ipv6, execute the following command to set up the corresponding iptables rules:
ip6tables -t nat -A POSTROUTING -o $(ip route show default | awk '{print $5}') -s fd00:10::/64 -j MASQUERADE
Setting Up Gardener
make gardener-up
If you want to setup an IPv6 ready Gardener, use make gardener-up IPFAMILY=ipv6 instead.
This will first build the base images (which might take a bit if you do it for the first time).
Afterwards, the Gardener resources will be deployed into the cluster.
Developing Gardener
make gardener-dev
This is similar to make gardener-up but additionally starts a skaffold dev loop.
After the initial deployment, skaffold starts watching source files.
Once it has detected changes, press any key to trigger a new build and deployment of the changed components.
Tip: you can set the SKAFFOLD_MODULE environment variable to select specific modules of the skaffold configuration (see skaffold.yaml) that skaffold should watch, build, and deploy.
This significantly reduces turnaround times during development.
For example, if you want to develop changes to gardenlet:
# initial deployment of all componentsmake gardener-up
# start iterating on gardenlet without deploying other componentsmake gardener-dev SKAFFOLD_MODULE=gardenlet
Debugging Gardener
make gardener-debug
This is using skaffold debugging features. In the Gardener case, Go debugging using Delve is the most relevant use case.
Please see the skaffold debugging documentation how to set up your IDE accordingly or check the examples below (GoLand, VS Code).
SKAFFOLD_MODULE environment variable is working the same way as described for Developing Gardener. However, skaffold is not watching for changes when debugging,
because it would like to avoid interrupting your debugging session.
For example, if you want to debug gardenlet:
# initial deployment of all componentsmake gardener-up
# start debugging gardenlet without deploying other componentsmake gardener-debug SKAFFOLD_MODULE=gardenlet
In debugging flow, skaffold builds your container images, reconfigures your pods and creates port forwardings for the Delve debugging ports to your localhost.
The default port is 56268. If you debug multiple pods at the same time, the port of the second pod will be forwarded to 56269 and so on.
Please check your console output for the concrete port-forwarding on your machine.
Note: Resuming or stopping only a single goroutine (Go Issue 25578, 31132) is currently not supported, so the action will cause all the goroutines to get activated or paused.
(vscode-go wiki)
This means that when a goroutine of gardenlet (or any other gardener-core component you try to debug) is paused on a breakpoint, all the other goroutines are paused. Hence, when the whole gardenlet process is paused, it can not renew its lease and can not respond to the liveness and readiness probes. Skaffold automatically increases timeoutSeconds of liveness and readiness probes to 600. Anyway, we were facing problems when debugging that pods have been killed after a while.
Thus, leader election, health and readiness checks for gardener-admission-controller, gardener-apiserver, gardener-controller-manager, gardener-scheduler,gardenlet and operator are disabled when debugging.
If you have similar problems with other components which are not deployed by skaffold, you could temporarily turn off the leader election and disable liveness and readiness probes there too.
Debugging in GoLand
Edit your Run/Debug Configurations.
Add a new Go Remote configuration.
Set the port to 56268 (or any increment of it when debugging multiple components).
Recommended: Change the behavior of On disconnect to Leave it running.
Debugging in VS Code
Create or edit your .vscode/launch.json configuration.
Add the following configuration:
{
"name": "go remote",
"type": "go",
"request": "attach",
"mode": "remote",
"port": 56268, // or any increment of it when debugging multiple components
"host": "127.0.0.1"
}
Since the ko builder is used in Skaffold to build the images, it’s not necessary to specify the cwd and remotePath options as they match the workspace folder (ref).
Creating a Shoot Cluster
You can wait for the Seed to be ready by running:
./hack/usage/wait-for.sh seed local GardenletReady SeedSystemComponentsHealthy ExtensionsReady
Alternatively, you can run kubectl get seed local and wait for the STATUS to indicate readiness:
NAME STATUS PROVIDER REGION AGE VERSION K8S VERSION
local Ready local local 4m42s vX.Y.Z-dev v1.28.1
In order to create a first shoot cluster, just run:
You can wait for the Shoot to be ready by running:
NAMESPACE=garden-local ./hack/usage/wait-for.sh shoot local APIServerAvailable ControlPlaneHealthy ObservabilityComponentsHealthy EveryNodeReady SystemComponentsHealthy
Alternatively, you can run kubectl -n garden-local get shoot local and wait for the LAST OPERATION to reach 100%:
NAME CLOUDPROFILE PROVIDER REGION K8S VERSION HIBERNATION LAST OPERATION STATUS AGE
local local local local 1.28.1 Awake Create Processing (43%) healthy 94s
If you don’t need any worker pools, you can create a workerless Shoot by running:
(Optional): You could also execute a simple e2e test (creating and deleting a shoot) by running:
make test-e2e-local-simple KUBECONFIG="$PWD/example/gardener-local/kind/local/kubeconfig"
Accessing the Shoot Cluster
⚠️ Please note that in this setup, shoot clusters are not accessible by default when you download the kubeconfig and try to communicate with them.
The reason is that your host most probably cannot resolve the DNS names of the clusters since provider-local extension runs inside the KinD cluster (for more details, see DNSRecord).
Hence, if you want to access the shoot cluster, you have to run the following command which will extend your /etc/hosts file with the required information to make the DNS names resolvable:
For convenience a helper script is provided in the hack directory. By default the script will generate a kubeconfig for a Shoot named “local” in the garden-local namespace valid for one hour.
To access an Ingress resource from the Seed, use the Ingress host with port 8448 (https://<ingress-host>:8448, for example https://gu-local--local.ingress.local.seed.local.gardener.cloud:8448).
(Optional): Setting Up a Second Seed Cluster
There are cases where you would want to create a second seed cluster in your local setup.
For example, if you want to test the control plane migration feature.
The following steps describe how to do that.
Start by setting up the second KinD cluster:
make kind2-up
This command sets up a new KinD cluster named gardener-local2 and stores its kubeconfig in the ./example/gardener-local/kind/local2/kubeconfig file.
It adds another IP address (172.18.255.2) to your loopback device which is necessary for you to reach the new cluster locally.
In order to deploy required resources in the KinD cluster that you just created, run:
make gardenlet-kind2-up
The following steps assume that you are using the kubeconfig that points to the gardener-local cluster (first KinD cluster): export KUBECONFIG=$PWD/example/gardener-local/kind/local/kubeconfig.
You can wait for the local2Seed to be ready by running:
Alternatively, you can run kubectl get seed local2 and wait for the STATUS to indicate readiness:
NAME STATUS PROVIDER REGION AGE VERSION K8S VERSION
local2 Ready local local 4m42s vX.Y.Z-dev v1.25.1
If you want to perform control plane migration, you can follow the steps outlined in Control Plane Migration to migrate the shoot cluster to the second seed you just created.
Deleting the Shoot Cluster
./hack/usage/delete shoot local garden-local
(Optional): Tear Down the Second Seed Cluster
make kind2-down
On macOS, if you want to remove the additional IP address on your loopback device run the following script:
sudo ip addr del 172.18.255.2 dev lo0
Tear Down the Gardener Environment
make kind-down
Alternative Way to Set Up Garden and Seed Leveraging gardener-operator
Instead of starting Garden and Seed via make kind-up gardener-up, you can also use gardener-operator to create your local dev landscape.
In this setup, the virtual garden cluster has its own load balancer, so you have to create an own DNS entry in your /etc/hosts:
cat <<EOF | sudo tee -a /etc/hosts
# Begin of Gardener Operator local setup section
172.18.255.3 api.virtual-garden.local.gardener.cloud
172.18.255.3 plutono-garden.ingress.runtime-garden.local.gardener.cloud
# End of Gardener Operator local setup section
EOF
You can bring up gardener-operator with this command:
make kind-multi-zone-up operator-up
Afterwards, you can create your local Garden and install gardenlet into the KinD cluster with this command:
make operator-seed-up
You find the kubeconfig for the KinD cluster at ./example/gardener-local/kind/multi-zone/kubeconfig.
The one for the virtual garden is accessible at ./dev-setup/kubeconfigs/virtual-garden/kubeconfig.
Important
When you create non-HA shoot clusters (i.e., Shoots with .spec.controlPlane.highAvailability.failureTolerance != zone), then they are not exposed via 172.18.255.1 (ref).
Instead, you need to find out under which Istio instance they got exposed, and put the corresponding IP address into your /etc/hosts file:
# replace <shoot-namespace> with your shoot namespace (e.g., `shoot--foo--bar`):kubectl -n "$(kubectl -n <shoot-namespace> get gateway kube-apiserver -o jsonpath={.spec.selector.istio} | sed 's/.*--/istio-ingress--/')" get svc istio-ingressgateway -o jsonpath={.status.loadBalancer.ingress..ip}
When the shoot cluster is HA (i.e., .spec.controlPlane.highAvailability.failureTolerance == zone), then you can access it via 172.18.255.1.
Finally, please use this command to tear down your environment:
make kind-multi-zone-down
This setup supports creating shoots and managed seeds the same way as explained in the previous chapters.
However, the development loop has limitations and the debugging setup is not working yet.
Remote Local Setup
Just like Prow is executing the KinD-based e2e tests in a K8s pod, it is
possible to interactively run this KinD based Gardener development environment,
aka “local setup”, in a “remote” K8s pod.
k apply -f docs/deployment/content/remote-local-setup.yaml
k exec -it remote-local-setup-0 -- sh
tmux a
Caveats
Please refer to the TMUX documentation for
working effectively inside the remote-local-setup pod.
To access Plutono, Prometheus or other components in a browser, two port forwards are needed:
The port forward from the laptop to the pod:
k port-forward remote-local-setup-0 3000
The port forward in the remote-local-setup pod to the respective component:
k port-forward -n shoot--local--local deployment/plutono 3000
Deploying Gardener Locally and Enabling Provider-Extensions
This document will walk you through deploying Gardener on your local machine and bootstrapping your own seed clusters on an existing Kubernetes cluster.
It is supposed to run your local Gardener developments on a real infrastructure. For running Gardener only entirely local, please check the getting started locally documentation.
If you encounter difficulties, please open an issue so that we can make this process easier.
Overview
Gardener runs in any Kubernetes cluster.
In this guide, we will start a KinD cluster which is used as garden cluster. Any Kubernetes cluster could be used as seed clusters in order to support provider extensions (please refer to the architecture overview). This guide is tested for using Kubernetes clusters provided by Gardener, AWS, Azure, and GCP as seed so far.
Based on Skaffold, the container images for all required components will be built and deployed into the clusters (via their Helm charts).
Make sure your Docker daemon is up-to-date, up and running and has enough resources (at least 8 CPUs and 8Gi memory; see the Docker documentation for how to configure the resources for Docker for Mac).
Additionally, please configure at least 120Gi of disk size for the Docker daemon.
Tip: You can clean up unused data with docker system df and docker system prune -a.
Make sure that you have access to a Kubernetes cluster you can use as a seed cluster in this setup.
The seed cluster requires at least 16 CPUs in total to run one shoot cluster
You could use any Kubernetes cluster for your seed cluster. However, using a Gardener shoot cluster for your seed simplifies some configuration steps.
When bootstrapping gardenlet to the cluster, your new seed will have the same provider type as the shoot cluster you use - an AWS shoot will become an AWS seed, a GCP shoot will become a GCP seed, etc. (only relevant when using a Gardener shoot as seed).
Provide Infrastructure Credentials and Configuration
As this setup is running on a real infrastructure, you have to provide credentials for DNS, the infrastructure, and the kubeconfig for the Kubernetes cluster you want to use as seed.
There are .gitignore entries for all files and directories which include credentials. Nevertheless, please double check and make sure that credentials are not committed to the version control system.
DNS
Gardener control plane requires DNS for default and internal domains. Thus, you have to configure a valid DNS provider for your setup.
Please maintain your DNS provider configuration and credentials at ./example/provider-extensions/garden/controlplane/domain-secrets.yaml.
You can find a template for the file at ./example/provider-extensions/garden/controlplane/domain-secrets.yaml.tmpl.
Infrastructure
Infrastructure secrets and the corresponding secret bindings should be maintained at:
There are templates with .tmpl suffixes for the files in the same folder.
Projects
The projects and the namespaces associated with them should be maintained at ./example/provider-extensions/garden/project/project.yaml.
You can find a template for the file at ./example/provider-extensions/garden/project/project.yaml.tmpl.
Seed Cluster Preparation
The kubeconfig of your Kubernetes cluster you would like to use as seed should be placed at ./example/provider-extensions/seed/kubeconfig.
Additionally, please maintain the configuration of your seed in ./example/provider-extensions/gardenlet/values.yaml. It is automatically copied from values.yaml.tmpl in the same directory when you run make gardener-extensions-up for the first time. It also includes explanations of the properties you should set.
Using a Gardener Shoot cluster as seed simplifies the process, because some configuration options can be taken from shoot-info and creating DNS entries and TLS certificates is automated.
However, you can use different Kubernetes clusters for your seed too and configure these things manually. Please configure the options of ./example/provider-extensions/gardenlet/values.yaml upfront. For configuring DNS and TLS certificates, make gardener-extensions-up, which is explained later, will pause and tell you what to do.
External Controllers
You might plan to deploy and register external controllers for networking, operating system, providers, etc. Please put ControllerDeployments and ControllerRegistrations into the ./example/provider-extensions/garden/controllerregistrations directory. The whole content of this folder will be applied to your KinD cluster.
CloudProfiles
There are no demo CloudProfiles yet. Thus, please copy CloudProfiles from another landscape to the ./example/provider-extensions/garden/cloudprofiles directory or create your own CloudProfiles based on the gardener examples. Please check the GitHub repository of your desired provider-extension. Most of them include example CloudProfiles. All files you place in this folder will be applied to your KinD cluster.
Setting Up the KinD Cluster
make kind-extensions-up
This command sets up a new KinD cluster named gardener-extensions and stores the kubeconfig in the ./example/gardener-local/kind/extensions/kubeconfig file.
It might be helpful to copy this file to $HOME/.kube/config, since you will need to target this KinD cluster multiple times.
Alternatively, make sure to set your KUBECONFIG environment variable to ./example/gardener-local/kind/extensions/kubeconfig for all future steps via export KUBECONFIG=$PWD/example/gardener-local/kind/extensions/kubeconfig.
All of the following steps assume that you are using this kubeconfig.
Additionally, this command deploys a local container registry to the cluster as well as a few registry mirrors that are set up as a pull-through cache for all upstream registries Gardener uses by default.
This is done to speed up image pulls across local clusters.
You will need to add 127.0.0.1 garden.local.gardener.cloud to your /etc/hosts.
The local registry can now be accessed either via localhost:5001 or garden.local.gardener.cloud:5001 for pushing and pulling.
The storage directories of the registries are mounted to your machine under dev/local-registry.
With this, mirrored images don’t have to be pulled again after recreating the cluster.
The command also deploys a default calico installation as the cluster’s CNI implementation with NetworkPolicy support (the default kindnet CNI doesn’t provide NetworkPolicy support).
Furthermore, it deploys the metrics-server in order to support HPA and VPA on the seed cluster.
Setting Up Gardener (Garden on KinD, Seed on Gardener Cluster)
make gardener-extensions-up
This will first prepare the basic configuration of your KinD and Gardener clusters.
Afterwards, the images for the Garden cluster are built and deployed into the KinD cluster.
Finally, the images for the Seed cluster are built, pushed to a container registry on the Seed, and the gardenlet is started.
If support for workload identity is required you can invoke the top command with DEV_SETUP_WITH_WORKLOAD_IDENTITY_SUPPORT variable set to true.
This will cause the Gardener Discovery Server to be deployed and exposed through the seed cluster.
External systems can be then configured to trust the workload identity issuer of the local Garden cluster.
DEV_SETUP_WITH_WORKLOAD_IDENTITY_SUPPORT=true make gardener-extensions-up
Important
The Gardener Discovery Server is started with a token which is valid for 48 hours.
Rerun DEV_SETUP_WITH_WORKLOAD_IDENTITY_SUPPORT=true make gardener-extensions-up in order to renew the token.
When working with multiple seed clusters you need to only pass DEV_SETUP_WITH_WORKLOAD_IDENTITY_SUPPORT=true for the one seed cluster that will be used to expose the workload identity documents.
A single Garden cluster needs only one Gardener Discovery Server.
To setup workload identity with your provider please refer to the provider extension specific docs:
The seed cluster preparations are similar to the first seed:
The kubeconfig of your Kubernetes cluster you would like to use as seed should be placed at ./example/provider-extensions/seed/kubeconfig-<seed-name>.
Additionally, please maintain the configuration of your seed in ./example/provider-extensions/gardenlet/values-<seed-name>.yaml. It is automatically copied from values.yaml.tmpl in the same directory when you run make gardener-extensions-up SEED_NAME=<seed-name> for the first time. It also includes explanations of the properties you should set.
Removing a Seed
If you have multiple seeds and want to remove one, just use
make gardener-extensions-down SEED_NAME=<seed-name>
If it is not the last seed, this command will only remove the seed, but leave the local Gardener cluster and the other seeds untouched.
To remove all seeds and to cleanup the local Gardener cluster, you have to run the command for each seed.
Tip
If using development setup that supports workload identity pass DEV_SETUP_WITH_WORKLOAD_IDENTITY_SUPPORT=true when removing the seed that was used to host the Gardener Discovery Server.
DEV_SETUP_WITH_WORKLOAD_IDENTITY_SUPPORT=true make gardener-extensions-down SEED_NAME=<seed-name>
Rotate credentials of container image registry in a Seed
There is a container image registry in each Seed cluster where Gardener images required for the Seed and the Shoot nodes are pushed to. This registry is password protected.
The password is generated when the Seed is deployed via make gardener-extensions-up. Afterward, it is not rotated automatically.
Otherwise, this could break the update of gardener-node-agent, because it might not be able to pull its own new image anymore
This is no general issue of gardener-node-agent, but a limitation provider-extensions setup. Gardener does not support protected container images out of the box. The function was added for this scenario only.
However, if you want to rotate the credentials for any reason, there are two options for it.
run make gardener-extensions-up (to ensure that your images are up-to-date)
reconcile all shoots on the seed where you want to rotate the registry password
run kubectl delete secrets -n registry registry-password on your seed cluster
run make gardener-extensions-up
reconcile the shoots again
or
reconcile all shoots on the seed where you want to rotate the registry password
run kubectl delete secrets -n registry registry-password on your seed cluster
run ./example/provider-extensions/registry-seed/deploy-registry.sh <path to seed kubeconfig> <seed registry hostname>
reconcile the shoots again
Pause and Unpause the KinD Cluster
The KinD cluster can be paused by stopping and keeping its docker container. This can be done by running:
make kind-extensions-down
When you run make kind-extensions-up again, you will start the docker container with your previous Gardener configuration again.
This provides the option to switch off your local KinD cluster fast without leaving orphaned infrastructure elements behind.
make kind-extensions-up already includes such a check. However, it might be useful when you wake up your Seed from hibernation or unpause you KinD cluster.
Alternatively, you can run kubectl get seed provider-extensions and wait for the STATUS to indicate readiness:
NAME STATUS PROVIDER REGION AGE VERSION K8S VERSION
provider-extensions Ready gcp europe-west1 111m v1.61.0-dev v1.24.7
In order to create a first shoot cluster, please create your own Shoot definition and apply it to your KinD cluster. gardener-scheduler includes candidateDeterminationStrategy: MinimalDistance configuration so you are able to run schedule Shoots of different providers on your Seed.
You can wait for your Shoots to be ready by running kubectl -n garden-local get shoots and wait for the LAST OPERATION to reach 100%. The output depends on your Shoot definition. This is an example output:
NAME CLOUDPROFILE PROVIDER REGION K8S VERSION HIBERNATION LAST OPERATION STATUS AGE
aws aws aws eu-west-1 1.24.3 Awake Create Processing (43%) healthy 84s
aws-arm64 aws aws eu-west-1 1.24.3 Awake Create Processing (43%) healthy 65s
azure az azure westeurope 1.24.2 Awake Create Processing (43%) healthy 57s
gcp gcp gcp europe-west1 1.24.3 Awake Create Processing (43%) healthy 94s
Accessing the Shoot Cluster
Your shoot clusters will have a public DNS entries for their API servers, so that they could be reached via the Internet via kubectl after you have created their kubeconfig.
Before tearing down your environment, you have to delete your shoot clusters. This is highly recommended because otherwise you would leave orphaned items on your infrastructure accounts.
Before you delete your local KinD cluster, you should shut down your Shoots and Seed in a clean way to avoid orphaned infrastructure elements in your projects.
Please ensure that your KinD and Seed clusters are online (not paused or hibernated) and run:
make gardener-extensions-down
This will delete all Shoots first (this could take a couple of minutes), then uninstall gardenlet from the Seed and the gardener components from the KinD. Finally, the additional components like container registry, etc., are deleted from both clusters.
When this is done, you can securely delete your local KinD cluster by running:
make kind-extensions-clean
7.10 - Getting Started Locally With Gardenadm
Deploying Autonomous Shoot Clusters Locally
Caution
The gardenadm tool is currently under development and considered highly experimental.
Do not use it in production environments.
Read more about it in GEP-28.
This document walks you through deploying Autonomous Shoot Clusters using gardenadm on your local machine.
This setup can be used for trying out and developing gardenadm locally without additional infrastructure.
The setup is also used for running e2e tests for gardenadm in CI (Prow).
If you encounter difficulties, please open an issue so that we can make this process easier.
Overview
gardenadm is a command line tool for bootstrapping Kubernetes clusters called “Autonomous Shoot Clusters”. Read the gardenadm documentation for more details on its concepts.
In this guide, we will start a KinD cluster which hosts pods serving as machines for the autonomous shoot cluster – just as for shoot clusters of provider-local.
The setup supports both the high-touch and medium-touch scenario of gardenadm.
Based on Skaffold, the container images for all required components will be built and deployed into the cluster.
This also includes the gardenadm CLI, which is installed on the machine pods by pulling the container image and extracting the binary.
Make sure your Docker daemon is up-to-date, up and running and has enough resources (at least 8 CPUs and 8Gi memory; see here how to configure the resources for Docker for Mac).
Additionally, please configure at least 120Gi of disk size for the Docker daemon.
Tip
You can clean up unused data with docker system df and docker system prune -a.
Use the following command to prepare the gardenadm high-touch scenario:
make gardenadm-up
This will first build the needed images, deploy 2 machine pods using the gardener-extension-provider-local-node image, install the gardenadm binary on both of them, and copy the needed manifests to the /gardenadm/resources directory.
Afterward, you can use kubectl exec to execute gardenadm commands on the machines.
Let’s start with exec’ing into the machine-0 pod:
$ kubectl -n gardenadm-high-touch exec -it machine-0 -- bash
root@machine-0:/# gardenadm -h
gardenadm bootstraps and manages autonomous shoot clusters in the Gardener project.
...
root@machine-0:/# cat /gardenadm/resources/manifests.yaml
apiVersion: core.gardener.cloud/v1beta1
kind: CloudProfile
metadata:
name: local
...
Bootstrapping a Single-Node Control Plane
Use gardenadm init to bootstrap the first control plane node using the provided manifests:
root@machine-0:/# gardenadm init -d /gardenadm/resources
...
Your Shoot cluster control-plane has initialized successfully!
...
Connecting to the Autonomous Shoot Cluster
The machine pod’s shell environment is configured for easily connecting to the autonomous shoot cluster.
Just execute kubectl within a bash shell in the machine pod:
$ kubectl -n gardenadm-high-touch exec -it machine-0 -- bash
root@machine-0:/# kubectl get node
NAME STATUS ROLES AGE VERSION
machine-0 Ready <none> 4m11s v1.32.0
You can also copy the kubeconfig to your local machine and use a port-forward to connect to the cluster’s API server:
$ kubectl -n gardenadm-high-touch exec -it machine-0 -- cat /etc/kubernetes/admin.conf | sed 's/api.root.garden.internal.gardenadm.local/localhost:6443/' > /tmp/shoot--garden--root.conf
$ kubectl -n gardenadm-high-touch port-forward pod/machine-0 6443:443
# in a new terminal$ export KUBECONFIG=/tmp/shoot--garden--root.conf
$ kubectl get no
NAME STATUS ROLES AGE VERSION
machine-0 Ready <none> 10m v1.32.0
Joining a Worker Node
If you would like to join a worker node to the cluster, generate a bootstrap token and the corresponding gardenadm join command on machine-0 (the control plane node).
Then exec into the machine-1 pod to run the command:
root@machine-0:/# gardenadm token create --print-join-command
# now copy the output, terminate the exec session and start a new one for machine-1$ kubectl -n gardenadm-high-touch exec -it machine-1 -- bash
# paste the copied 'gardenadm join' command here and execute itroot@machine-1:/# gardenadm join ...
...
Your node has successfully been instructed to join the cluster as a worker!
...
Using the kubeconfig as described in this section, you should now be able to see the new node in the cluster:
$ kubectl get no
NAME STATUS ROLES AGE VERSION
machine-0 Ready <none> 10m v1.32.0
machine-1 Ready <none> 37s v1.32.0
Medium-Touch Scenario
Use the following command to prepare the gardenadm medium-touch scenario:
Afterward, you can use go run to execute gardenadm commands on your machine:
$ export IMAGEVECTOR_OVERWRITE=$PWD/dev-setup/gardenadm/resources/generated/.imagevector-overwrite.yaml
$ go run ./cmd/gardenadm bootstrap -d ./dev-setup/gardenadm/resources/generated/medium-touch
...
Command is work in progress
Connecting the Autonomous Shoot Cluster to Gardener
After you have successfully bootstrapped an autonomous shoot cluster (either via the high touch or the medium touch scenario), you can connect it to an existing Gardener system.
For this, you need to have a Gardener running locally in your KinD cluster.
In order to deploy it, you can run
make gardenadm-up SCENARIO=connect
This will deploy gardener-operator and create a Garden resource (which will then be reconciled and results in a full Gardener deployment).
Find all information about it here.
Note, that in this setup, no Seed will be registered in the Gardener - it’s just a plain garden cluster without the ability to create regular shoot clusters.
Once above command is finished, you can connect the autonomous shoot cluster to this Gardener instance:
$ kubectl -n gardenadm-high-touch exec -it machine-0 -- bash
root@machine-0:/# gardenadm connect
2025-07-03T12:21:49.586Z INFO Command is work in progress
Running E2E Tests for gardenadm
Based on the described setup, you can execute the e2e test suite for gardenadm:
make gardenadm-up SCENARIO=high-touch
make gardenadm-up SCENARIO=medium-touch
make test-e2e-local-gardenadm
You can also selectively run the e2e tests for one of the scenarios:
make gardenadm-up SCENARIO=high-touch
./hack/test-e2e-local.sh gardenadm --label-filter="high-touch" ./test/e2e/gardenadm/...
Tear Down the KinD Cluster
make kind-down
7.11 - Image Vector
Image Vector
The Gardener components are deploying several different container images into the garden, seed, and the shoot clusters.
The image repositories and tags are defined in a central image vector file.
Obviously, the image versions defined there must fit together with the deployment manifests (e.g., some command-line flags do only exist in certain versions).
That means that Gardener will use the pause-container with tag 3.4 for all clusters with Kubernetes version 1.20.x, and the image with ref registry.k8s.io/pause:3.5 for all clusters with Kubernetes >= 1.21.
Note
As you can see, it is possible to provide the full image reference via the ref field.
Another option is to use the repository and tag fields. tag may also be a digest only (starting with sha256:...), or it can contain both tag and digest (v1.2.3@sha256:...).
architectures is an optional field of image. It is a list of strings specifying CPU architecture of machines on which this image can be used. The valid options for the architectures field are as follows:
amd64 : This specifies that the image can run only on machines having CPU architecture amd64.
arm64 : This specifies that the image can run only on machines having CPU architecture arm64.
If an image doesn’t specify any architectures, then by default it is considered to support both amd64 and arm64 architectures.
Overwriting Image Vector
In some environments it is not possible to use these “pre-defined” images that come with a Gardener release.
A prominent example for that is Alicloud in China, which does not allow access to Google’s GCR.
In these cases, you might want to overwrite certain images, e.g., point the pause-container to a different registry.
⚠️ If you specify an image that does not fit to the resource manifest, then the reconciliations might fail.
In order to overwrite the images, you must provide a similar file to the Gardener component:
When the overwriting file contains ref for an image but the source file doesn’t, then this invalidates both repository and tag of the source.
When it contains repository for an image but the source file uses ref, then this invalidates ref of the source.
For gardenlet, you can create a ConfigMap containing the above content and mount it as a volume into the gardenlet pod.
Next, specify the environment variable IMAGEVECTOR_OVERWRITE, whose value must be the path to the file you just mounted.
The approach works similarly for gardener-operator.
Gardener is deploying a lot of different components that might deploy other images themselves.
These components might use an image vector as well.
Operators might want to customize the image locations for these transitive images as well, hence, they might need to specify an image vector overwrite for the components directly deployed by Gardener.
It is possible to specify the IMAGEVECTOR_OVERWRITE_COMPONENTS environment variable to Gardener that points to a file with the following content:
Gardener will, if supported by the directly deployed component (etcd-druid in this example), inject the given imageVectorOverwrite into the Deployment manifest.
The respective component is responsible for using the overwritten images instead of its defaults.
Helm Chart Image Vector
Some Gardener components might also deploy packaged Helm charts which are pulled from an OCI repository.
The concepts are the very same as for the container images.
The only difference is that the environment variable for overwriting this chart image vector is called IMAGEVECTOR_OVERWRITE_CHARTS.
7.13 - Scoped API Access for gardenlets and Extensions
Scoped API Access for gardenlets and Extensions
By default, gardenlets have administrative access in the garden cluster.
They are able to execute any API request on any object independent of whether the object is related to the seed cluster the gardenlet is responsible for.
As RBAC is not powerful enough for fine-grained checks and for the sake of security, Gardener provides two optional but recommended configurations for your environments that scope the API access for gardenlets.
Similar to the Node authorization mode in Kubernetes, Gardener features a SeedAuthorizer plugin.
It is a special-purpose authorization plugin that specifically authorizes API requests made by the gardenlets.
Likewise, similar to the NodeRestriction admission plugin in Kubernetes, Gardener features a SeedRestriction plugin.
It is a special-purpose admission plugin that specifically limits the Kubernetes objects gardenlets can modify.
📚 You might be interested to look into the design proposal for scoped Kubelet API access from the Kubernetes community.
It can be translated to Gardener and Gardenlets with their Seed and Shoot resources.
Historically, gardenlet has been the only component running in the seed cluster that has access to both the seed cluster and the garden cluster.
Starting from Gardener v1.74.0, extensions running on seed clusters can also get access to the garden cluster using a token for a dedicated ServiceAccount.
Extensions using this mechanism only get permission to read global resources like CloudProfiles (this is granted to all authenticated users) unless the plugins described in this document are enabled.
Generally, the plugins handle extension clients exactly like gardenlet clients with some minor exceptions.
Extension clients in the sense of the plugins are clients authenticated as a ServiceAccount with the extension- name prefix in a seed- namespace of the garden cluster.
Other ServiceAccounts are not considered as seed clients, not handled by the plugins, and only get the described read access to global resources.
Flow Diagram
The following diagram shows how the two plugins are included in the request flow of a gardenlet.
When they are not enabled, then the kube-apiserver is internally authorizing the request via RBAC before forwarding the request directly to the gardener-apiserver, i.e., the gardener-admission-controller would not be consulted (this is not entirely correct because it also serves other admission webhook handlers, but for simplicity reasons this document focuses on the API access scope only).
When enabling the plugins, there is one additional step for each before the gardener-apiserver responds to the request.
Please note that the example shows a request to an object (Shoot) residing in one of the API groups served by gardener-apiserver.
However, the gardenlet is also interacting with objects in API groups served by the kube-apiserver (e.g., Secret,ConfigMap).
In this case, the consultation of the SeedRestriction admission plugin is performed by the kube-apiserver itself before it forwards the request to the gardener-apiserver.
Implemented Rules
Today, the following rules are implemented:
Resource
Verbs
Path(s)
Description
BackupBucket
get, list, watch, create, update, patch, delete
BackupBucket -> Seed
Allow get, list, watch requests for all BackupBuckets. Allow only create, update, patch, delete requests for BackupBuckets assigned to the gardenlet’s Seed.
BackupEntry
get, list, watch, create, update, patch
BackupEntry -> Seed
Allow get, list, watch requests for all BackupEntrys. Allow only create, update, patch requests for BackupEntrys assigned to the gardenlet’s Seed and referencing BackupBuckets assigned to the gardenlet’s Seed.
Bastion
get, list, watch, create, update, patch
Bastion -> Seed
Allow get, list, watch requests for all Bastions. Allow only create, update, patch requests for Bastions assigned to the gardenlet’s Seed.
CertificateSigningRequest
get, create
CertificateSigningRequest -> Seed
Allow only get, create requests for CertificateSigningRequests related to the gardenlet’s Seed.
CloudProfile
get
CloudProfile -> Shoot -> Seed
Allow only get requests for CloudProfiles referenced by Shoots that are assigned to the gardenlet’s Seed.
Allow create, get, update, patch requests for ManagedSeeds in the bootstrapping phase assigned to the gardenlet’s Seeds. Allow delete requests from gardenlets bootstrapped via ManagedSeeds.
ConfigMap
get
ConfigMap -> Seed, ConfigMap -> Shoot -> Seed
Allow only get requests for ConfigMaps referenced by Seeds, or Shoots that are assigned to the gardenlet’s Seed. Allow reading the kube-system/cluster-identityConfigMap.
Allow get requests for ControllerDeploymentss referenced by ControllerInstallations assigned to the gardenlet’s Seed.
ControllerInstallation
get, list, watch, update, patch
ControllerInstallation -> Seed
Allow get, list, watch requests for all ControllerInstallations. Allow only update, patch requests for ControllerInstallations assigned to the gardenlet’s Seed.
CredentialsBinding
get
CredentialsBinding -> Shoot -> Seed
Allow only get requests for CredentialsBindings referenced by Shoots that are assigned to the gardenlet’s Seed.
Event
create, patch
none
Allow to create or patch all kinds of Events.
ExposureClass
get
ExposureClass -> Shoot -> Seed
Allow get requests for ExposureClasses referenced by Shoots that are assigned to the gardenlet’s Seed. Deny get requests to other ExposureClasses.
Gardenlet
get, list, watch, update, patch, create
Gardenlet -> Seed
Allow get, list, watch requests for all Gardenlets. Allow only create, update, and patch requests for Gardenlets belonging to the gardenlet’s Seed.
Lease
create, get, watch, update
Lease -> Seed
Allow create, get, update, and delete requests for Leases of the gardenlet’s Seed.
ManagedSeed
get, list, watch, update, patch
ManagedSeed -> Shoot -> Seed
Allow get, list, watch requests for all ManagedSeeds. Allow only update, patch requests for ManagedSeeds referencing a Shoot assigned to the gardenlet’s Seed.
Namespace
get
Namespace -> Shoot -> Seed
Allow get requests for Namespaces of Shoots that are assigned to the gardenlet’s Seed. Always allow get requests for the gardenNamespace.
NamespacedCloudProfile
get
NamespacedCloudProfile -> Shoot -> Seed
Allow only get requests for NamespacedCloudProfiles referenced by Shoots that are assigned to the gardenlet’s Seed.
Project
get
Project -> Namespace -> Shoot -> Seed
Allow get requests for Projects referenced by the Namespace of Shoots that are assigned to the gardenlet’s Seed.
SecretBinding
get
SecretBinding -> Shoot -> Seed
Allow only get requests for SecretBindings referenced by Shoots that are assigned to the gardenlet’s Seed.
Allow get, list, watch requests for all Secrets in the seed-<name> namespace. Allow only create, get, update, patch, delete requests for the Secrets related to resources assigned to the gardenlet’s Seeds.
Seed
get, list, watch, create, update, patch, delete
Seed
Allow get, list, watch requests for all Seeds. Allow only create, update, patch, delete requests for the gardenlet’s Seeds. [1]
Allow create, get, update, patch requests for ManagedSeeds in the bootstrapping phase assigned to the gardenlet’s Seeds. Allow delete requests from gardenlets bootstrapped via ManagedSeeds. Allow all verbs on ServiceAccounts in seed-specific namespace.
Shoot
get, list, watch, update, patch
Shoot -> Seed
Allow get, list, watch requests for all Shoots. Allow only update, patch requests for Shoots assigned to the gardenlet’s Seed.
ShootState
get, create, update, patch
ShootState -> Shoot -> Seed
Allow only get, create, update, patch requests for ShootStates belonging by Shoots that are assigned to the gardenlet’s Seed.
Allow only get requests for WorkloadIdentities referenced by CredentialsBindings referenced by Shoots that are assigned to the gardenlet’s Seed.
[1] If you use ManagedSeed resources then the gardenlet reconciling them (“parent gardenlet”) may be allowed to submit certain requests for the Seed resources resulting out of such ManagedSeed reconciliations (even if the “parent gardenlet” is not responsible for them):
ℹ️ It is allowed to delete the Seed resources if the corresponding ManagedSeed objects already have a deletionTimestamp (this is secure as gardenlets themselves don’t have permissions for deleting ManagedSeeds).
Rule Exceptions for Extension Clients
Extension clients are allowed to perform the same operations as gardenlet clients with the following exceptions:
Extension clients are granted the read-only subset of verbs for CertificateSigningRequests, ClusterRoleBindings, and ServiceAccounts (to prevent privilege escalation).
Extension clients are granted full access to Lease objects but only in the seed-specific namespace.
When the need arises, more exceptions might be added to the access rules for resources that are already handled by the plugins.
E.g., if an extension needs to populate additional shoot-specific InternalSecrets, according handling can be introduced.
Permissions for resources that are not handled by the plugins can be granted using additional RBAC rules (independent of the plugins).
🎛 In order to activate it, you have to follow these steps:
Set the following flags for the kube-apiserver of the garden cluster (i.e., the kube-apiserver whose API is extended by Gardener):
--authorization-mode=RBAC,Node,Webhook (please note that Webhook should appear after RBAC in the list [1]; Node might not be needed if you use a virtual garden cluster)
When deploying the Gardener controlplane Helm chart, set .global.rbac.seedAuthorizer.enabled=true. This will ensure that the RBAC resources granting global access for all gardenlets will be deployed.
Delete the existing RBAC resources granting global access for all gardenlets by running:
Please note that you should activate the SeedRestriction admission handler as well.
[1] The reason for the fact that Webhook authorization plugin should appear after RBAC is that the kube-apiserver will be depending on the gardener-admission-controller (serving the webhook). However, the gardener-admission-controller can only start when gardener-apiserver runs, but gardener-apiserver itself can only start when kube-apiserver runs. If Webhook is before RBAC, then gardener-apiserver might not be able to start, leading to a deadlock.
Authorizer Decisions
As mentioned earlier, it’s the authorizer’s job to evaluate API requests and return one of the following decisions:
DecisionAllow: The request is allowed, further configured authorizers won’t be consulted.
DecisionDeny: The request is denied, further configured authorizers won’t be consulted.
DecisionNoOpinion: A decision cannot be made, further configured authorizers will be consulted.
For backwards compatibility, no requests are denied at the moment, so that they are still deferred to a subsequent authorizer like RBAC.
Though, this might change in the future.
First, the SeedAuthorizer extracts the Seed name from the API request.
This step considers the following two cases:
If the authenticated user belongs to the gardener.cloud:system:seeds group, it is considered a gardenlet client.
This requires a proper TLS certificate that the gardenlet uses to contact the API server and is automatically given if TLS bootstrapping is used.
The authorizer extracts the seed name from the username by stripping the gardener.cloud:system:seed: prefix.
In cases where this information is missing e.g., when a custom Kubeconfig is used, the authorizer cannot make any decision. Thus, RBAC is still a considerable option to restrict the gardenlet’s access permission if the above explained preconditions are not given.
If the authenticated user belongs to the system:serviceaccounts group, it is considered an extension client under the following conditions:
The ServiceAccount must be located in a seed- namespace. I.e., the user has to belong to a group with the system:serviceaccounts:seed- prefix. The seed name is extracted from this group by stripping the prefix.
The ServiceAccount must have the extension- prefix. I.e., the username must have the system:serviceaccount:seed-<seed-name>:extension- prefix.
With the Seed name at hand, the authorizer checks for an existing path from the resource that a request is being made for to the Seed belonging to the gardenlet/extension.
Take a look at the Implementation Details section for more information.
Implementation Details
Internally, the SeedAuthorizer uses a directed, acyclic graph data structure in order to efficiently respond to authorization requests for gardenlets/extensions:
A vertex in this graph represents a Kubernetes resource with its kind, namespace, and name (e.g., Shoot:garden-my-project/my-shoot).
An edge from vertex u to vertex v in this graph exists when
(1) v is referred by u and v is a Seed, or when
(2) u is referred by v, or when
(3) u is strictly associated with v.
For example, a Shoot refers to a Seed, a CloudProfile, a SecretBinding, etc., so it has an outgoing edge to the Seed (1) and incoming edges from the CloudProfile and SecretBinding vertices (2).
However, there might also be a ShootState or a BackupEntry resource strictly associated with this Shoot, hence, it has incoming edges from these vertices (3).
In the above picture, the resources that are actively watched are shaded.
Gardener resources are green, while Kubernetes resources are blue.
It shows the dependencies between the resources and how the graph is built based on the above rules.
ℹ️ The above picture shows all resources that may be accessed by gardenlets/extensions, except for the Quota resource which is only included for completeness.
Now, when a gardenlet/extension wants to access certain resources, then the SeedAuthorizer uses a Depth-First traversal starting from the vertex representing the resource in question, e.g., from a Project vertex.
If there is a path from the Project vertex to the vertex representing the Seed the gardenlet/extension is responsible for. then it allows the request.
Metrics
The SeedAuthorizer registers the following metrics related to the mentioned graph implementation:
Histogram of duration of resource dependency graph updates in seed authorizer, i.e., how long does it take to update the graph’s vertices/edges when a resource is created, changed, or deleted.
Histogram of duration of checks whether a path exists in the resource dependency graph in seed authorizer.
Debug Handler
When the .server.enableDebugHandlers field in the gardener-admission-controller’s component configuration is set to true, then it serves a handler that can be used for debugging the resource dependency graph under /debug/resource-dependency-graph.
🚨 Only use this setting for development purposes, as it enables unauthenticated users to view all data if they have access to the gardener-admission-controller component.
The handler renders an HTML page displaying the current graph with a list of vertices and its associated incoming and outgoing edges to other vertices.
Depending on the size of the Gardener landscape (and consequently, the size of the graph), it might not be possible to render it in its entirety.
If there are more than 2000 vertices, then the default filtering will selected for kind=Seed to prevent overloading the output.
There are anchor links to easily jump from one resource to another, and the page provides means for filtering the results based on the kind, namespace, and/or name.
Pitfalls
When there is a relevant update to an existing resource, i.e., when a reference to another resource is changed, then the corresponding vertex (along with all associated edges) is first deleted from the graph before it gets added again with the up-to-date edges.
However, this does only work for vertices belonging to resources that are only created in exactly one “watch handler”.
For example, the vertex for a SecretBinding can either be created in the SecretBinding handler itself or in the Shoot handler.
In such cases, deleting the vertex before (re-)computing the edges might lead to race conditions and potentially renders the graph invalid.
Consequently, instead of deleting the vertex, only the edges the respective handler is responsible for are deleted.
If the vertex ends up with no remaining edges, then it also gets deleted automatically.
Afterwards, the vertex can either be added again or the updated edges can be created.
🎛 In order to activate it, you have to set .global.admission.seedRestriction.enabled=true when using the Gardener controlplane Helm chart.
This will add an additional webhook in the existing ValidatingWebhookConfiguration of the gardener-admission-controller which contains the configuration for the SeedRestriction handler.
Please note that it should only be activated when the SeedAuthorizer is active as well.
Admission Decisions
The admission’s purpose is to perform extended validation on requests which require the body of the object in question.
Additionally, it handles CREATE requests of gardenlets/extensions (the above discussed resource dependency graph cannot be used in such cases because there won’t be any vertex/edge for non-existing resources).
Gardenlets/extensions are restricted to only create new resources which are somehow related to the seed clusters they are responsible for.
7.14 - Secret Binding Provider Controller
SecretBinding Provider Controller
This page describes the process on how to enable the SecretBinding provider controller.
Overview
With Gardener v1.38.0, the SecretBinding resource now contains a new optional field .provider.type (details about the motivation can be found in https://github.com/gardener/gardener/issues/4888). To make the process of setting the new field automated and afterwards to enforce validation on the new field in backwards compatible manner, Gardener features the SecretBinding provider controller and a feature gate - SecretBindingProviderValidation.
Process
A Gardener landscape operator can follow the following steps:
Enable the SecretBinding provider controller of Gardener Controller Manager.
The SecretBinding provider controller is responsible for populating the .provider.type field of a SecretBinding based on its current usage by Shoot resources. For example, if a Shoot crazy-botany with .provider.type=aws is using a SecretBinding my-secret-binding, then the SecretBinding provider controller will take care to set the .provider.type field of the SecretBinding to the same provider type (aws).
To enable the SecretBinding provider controller, set the controller.secretBindingProvider.concurrentSyncs field in the ControllerManagerConfiguration (e.g set it to 5).
Although that it is not recommended, the API allows Shoots from different provider types to reference the same SecretBinding (assuming that the backing Secret contains data for both of the provider types). To preserve the backwards compatibility for such SecretBindings, the provider controller will maintain the multiple provider types in the field (it will join them with the separator , - for example aws,gcp).
Disable the SecretBinding provider controller and enable the SecretBindingProviderValidation feature gate of Gardener API server.
The SecretBindingProviderValidation feature gate of Gardener API server enables a set of validations for the SecretBinding provider field. It forbids creating a Shoot that has a different provider type from the referenced SecretBinding’s one. It also enforces immutability on the field.
After making sure that SecretBinding provider controller is enabled and it populated the .provider.type field of a majority of the SecretBindings on a Gardener landscape (the SecretBindings that are unused will have their provider type unset), a Gardener landscape operator has to disable the SecretBinding provider controller and to enable the SecretBindingProviderValidation feature gate of Gardener API server. To disable the SecretBinding provider controller, set the controller.secretBindingProvider.concurrentSyncs field in the ControllerManagerConfiguration to 0.
Implementation History
Gardener v1.38: The SecretBinding resource has a new optional field .provider.type. The SecretBinding provider controller is disabled by default. The SecretBindingProviderValidation feature gate of Gardener API server is disabled by default.
Gardener v1.42: The SecretBinding provider controller is enabled by default.
Gardener v1.51: The SecretBindingProviderValidation feature gate of Gardener API server is enabled by default and the SecretBinding provider controller is disabled by default.
Gardener v1.53: The SecretBindingProviderValidation feature gate of Gardener API server is unconditionally enabled (can no longer be disabled).
Gardener v1.55: The SecretBindingProviderValidation feature gate of Gardener API server and the SecretBinding provider controller are removed.
7.15 - Setup Gardener
How to Set Up a Gardener Landscape
Important
DISCLAIMER
This document outlines the building blocks used to set up a Gardener landscape. It is not meant as a comprehensive configuration guide but rather as a starting point. Setting up a landscape requires careful planning and consideration of dimensions like the number of providers, geographical distribution, and envisioned size.
To make it more tangible, some choices are made to provide examples - specifically this guide uses OpenStack as infrastructure provider, Garden Linux to run any worker nodes, and Calico as CNI.
Providing working examples for all combinations of components is out of scope. For a detailed descriptions of components, please refer to the documentation and API reference.
Target Picture
A Gardener landscape consists of several building blocks. The basis is an existing Kubernetes cluster which is referred to as runtime cluster.
Within this cluster another Kubernetes cluster is hosted, which is referred to as virtual Garden cluster. It is nodeless, meaning it does not host any pods as workload. The virtual Garden cluster is the management plane for the Gardener landscape and contains resources like Shoots, Seeds and so on.
Any new Gardener landscape starts with the deployment of the Gardener Operator and the creation of a garden namespace on the designated runtime cluster.
With the operator in place, the Garden resource can be deployed. It is reconciled by the Gardener Operator, which will create the “virtual” Garden cluster with its etcd, kube-apiserver, gardener-apiserver, and so on.
The API server is exposed through an Istio Gateway and a DNS record pointing to the Gateway’s external IP address is created.
Once the Garden reports readiness, basic building blocks like CloudProfiles, ControllerDeployments, and ControllerRegistrations, as well as Secrets granting access to DNS management for the internal domain and external default domain, are deployed to the virtual Garden cluster.
To be able to host any Shoots, at least one Seed is required. The very first Seed is created via a Gardenlet resource (more precisely gardenlets.seedmanagement.gardener.cloud) deployed to the virtual Garden cluster. The actual gardenlet Pods run on the runtime cluster or another Kubernetes cluster not managed by Gardener. Typically, this is referred to as an unmanaged Seed and is considered part of the Gardener infrastructure.
In this setup, the very first Seed will be reserved for one or several “infrastructure” Shoots. Those will be turned into Seeds again through a ManagedSeed resource. These Gardener-managedSeeds will then host control planes of any users’ Shoot clusters.
In order to install and run Gardener an already existing Kubernetes cluster is required. It serves as the root cluster hosting all the components required for the virtual Garden cluster - like a kube-apiserver and etcd but also admission webhooks or the gardener-controller-manager.
In this example, the runtime cluster is also used to host the very first gardenlet, which will register this cluster as a Seed as well. The gardenlet can be deployed to another Kubernetes cluster (recommended for productive setups). Here, using the runtime cluster keeps the amount of unmanaged clusters at a bare minimum.
DNS Zone
The virtual Garden API endpoint (kube-apiserver) is exposed through an Istio Gateway. This in turn is reachable via a LoadBalancer Service. The IP address is made discoverable through DNS. Hence, a zone where an A record can be created is required.
Additionally, Gardener advertises kube-apiservers of Shoots through two DNS records, which requires at least one DNS zone and credentials to interact with it through automation.
Assuming the base domain for a Gardener landscape is crazy-botany.gardener.cloud, the following example shows a possible way to structure DNS records:
The virtual Garden cluster’s etcd is governed by etcd-druid. If configured, backups are created continuously and stored to a supported object store. This requires credentials to manage an object store on the chosen infrastructure.
It is recommended for any productive installation of Gardener.
Infrastructure
For each infrastructure supported by Gardener a so-called provider-extension exists. It implements the required interfaces. For this example, the OpenStack extension will be used.
Access to the respective infrastructure is required and needs to be handed over to Gardener in the provider-specific format (e.g., OpenStack application credentials).
This section focuses on the individual building blocks of a Gardener landscape and their deployment / options.
Gardener Operator
The Gardener Operator is provided as a helm chart, which is also published as an OCI artifact and attached to each release of the gardener/gardener repository.
When setting up a new Gardener landscape, choose the latest version and either install the chart or render the templates e.g.:
The Gardener Operator reconciles the so-called Garden resource, which contains a detailed configuration of the Garden landscape to be created. Specify the domain name for the Garden’s API endpoint, CIDR blocks for the virtual cluster, high availability, and other options here.
To get familiar with the available options, check the Garden example.
While most operations are carried out in the realm of the runtime cluster, two external services are required. To automate both the creation of DNSRecords and a BackupBucket, a provider-extension needs to be deployed to the runtime cluster as well.
To facilitate the extension’s deployment, the API group operator.gardener.cloud/v1alpha1 contains an Extension resources, which is reconciled by the Gardener Operator. Such an Extension resource specifies how to install it into the runtime cluster, as well as the virtual Garden cluster. More details can be found in the Extensions section.
The below example shows how an Extension is used to deploy the provider-extension for OpenStack. Please note, it advertises to support resources of kind: BackupBucket and type: openstack as well as kind: DNSrecord and type: openstack-designate.
To make use of the automated DNS management, the Garden resource has to contain a primary provider. Here is an example for an OpenStack-based setup, where the actual credentials are stored in the referenced Secret:
Additionally, the BackupBucket and credentials to access it are configured alongside. The easiest way to get started is by using and customizing the example linked below.
Upon the first reconciliation of the Garden resource, a Kubernetes control plane will be bootstrapped in the garden namespace. etcd-main and etcd-events are managed by etcd-druid and use the BackupBucket created by the provider-extension.
To be able to serve any Gardener resource, the gardener-apiserver is deployed and registered through an APIService resource with the kube-apiserver of the virtual Garden cluster. Components like gardener-scheduler and gardener-controller-manager are deployed to act on Gardener’s resources.
Once the Garden resource reports readiness, the virtual Garden cluster can be targeted.
kubectl get garden crazy-botany
NAME K8S VERSION GARDENER VERSION LAST OPERATION RUNTIME VIRTUAL API SERVER OBSERVABILITY AGE
crazy-botany 1.31.1 v1.110.0 Succeeded True True True True 1d
In case the automatic DNS record creation is not supported, a record with the external address of the virtual-garden-istio-ingress (found in namespace istio-ingressgateway) service has to be created manually.
To obtain credentials and interact with the virtual Garden cluster, please follow this guide.
Gardener is provider-agnostic and relies on a growing set of extensions. An extension can provide support for an infrastructure (required) or add a desired feature to a Kubernetes cluster (often optional).
There are a few extensions considered essential to any Gardener installation:
An extension often consists of two components - a controller implementing the Gardener’s extension contract and an admission controller. The latter is deployed to the runtime cluster and prevents misconfiguration of Shoots.
In order to make an extension known to a Gardener landscape, two resources have to be applied to the virtual Garden cluster - firstly, a ControllerDeployment and secondly, a matching ControllerRegistration. With both in place, Gardener-managed ControllerInstallations take care of the actual deployment of the extension to the target environment.
Now, the classical way of installing ControllerDeployment and ControllerRegistration is to prepare the resources and apply them to the virtual Garden cluster. The ControllerDeployment references an OCI repository containing the extension’s helm chart.
To simplify this procedure, extensions can be registered through Extension resources in the runtime cluster. The Gardener Operator will take care of deploying the required resources to the virtual Garden cluster.
In addition, this approach allows the extensions and their admission controllers to be deployed to the runtime cluster as well. There, they can provide additional functionality like managing DNSRecords or BackupBuckets.
More details can be found in the Extension Resource documentation.
Cloud Profile
In order to host any Shoot cluster, at least one CloudProfile is required. The CloudProfile resource describes supported Kubernetes and OS versions, as well as infrastructure capabilities like regions and their availability zones.
Hence, the next step is to craft a CloudProfile for each infrastructure provider and combine it with the information where the operating system images can be found. The resulting CloudProfile resource has to be deployed to the virtual Garden cluster.
The following list provides the high-level steps to build a CloudProfile:
add at least one supported minor version to .spec.kubernetes.versions[].
add at least one region including the availability zone to .spec.regions[].
add at least one operating system to .spec.machineImages[] and define at least on supported version.
add one or several machine types to .spec.machineTypes[].
specify a .spec.providerConfig according to the extension’s documentation. Typically, this includes a list of MachineImages. Garden Linux, for example, publishes images and provides a list of location as part of the release notes. In case of private infrastructure, copying the images might be required.
Here is a simplified example manifest:
apiVersion: core.gardener.cloud/v1beta1
kind: CloudProfile
metadata:
name: openstack-example
spec:
caBundle: | # CA Bundle installed on all nodes of the shoot clusters using this CloudProfile <redacted>
kubernetes:
versions:
- classification: preview
version: 1.31.3
- classification: supported
expirationDate: "2025-07-30T23:59:59Z" version: 1.31.2
machineImages:
- name: gardenlinux
updateStrategy: minor
versions:
- architectures:
- amd64
- arm64
classification: supported
cri:
- containerRuntimes:
- type: gvisor
name: containerd
version: 1592.3.0
machineTypes:
- architecture: amd64
cpu: "2" gpu: "0" memory: 4Gi
name: small_machine
storage:
class: standard
size: 64Gi
type: default
usable: true regions:
- name: my-region-1
zones:
- name: my-region-1a
- name: my-region-1b
providerConfig:
apiVersion: openstack.provider.extensions.gardener.cloud/v1alpha1
kind: CloudProfileConfig
machineImages:
- name: gardenlinux
versions:
- version: 1592.3.0
regions:
- id: abcd-1234 # The ID of the image in the given OpenStack installation for the specified region. name: my-region-1
# ...
Gardener maintains DNS records for a Shoot which requires a DNS zone and credentials to manage records in this zone. Provide the credentials alongside with information about the zone. The secrets are deployed to the virtual Garden cluster.
Before the first Shoot can be created in a new Gardener landscape, at least one Seed is required. Typically, the very first Seed is created by deploying a properly configured gardenlet to an existing Kubernetes cluster. In this example, the gardenlet will be deployed to the runtime cluster - effectively turning it into a Seed as well.
Thus, the runtime cluster serves two purposes now - it hosts the virtual Garden cluster and control planes. It is possible, and strongly recommended for larger installations, to deploy a gardenlet to another Kubernetes cluster. This separates the virtual Garden cluster from the first Seed with the control planes hosted there.
A Seed requires a provider-extension matching the target infrastructure to manage DNSRecords for the Seed’s ingress domain and if configured, the BackupBucket. A Secret with the credentials to interact with the infrastructure needs to be created in the virtual Garden cluster and linked in the gardenlet’s configuration.
The easiest way to deploy a gardenlet is to create a Gardenlet resource in the virtual Garden cluster. Make sure to configure the CIDR blocks properly to avoid conflicts or overlaps with the runtime cluster.
A common pattern is to protect this very first Seed, in a sense that no control planes of user Shoot clusters will be scheduled to it. Instead, this Seed should host control planes of Gardener-managed Seed clusters exclusively. These in turn host the control planes of user Shoots.
This pattern allows to scale out the capacity of a Gardener landscape, as creating new seeds is simple and fast. More details can be found in the Shoot & Managed Seed section.
To achieve this protection, the gardenlet resource should contain the following configuration:
With the very first Seed in place, the Gardener landscape can scale by the means of Gardener-managed infrastructure. To get started, a Shoot needs to be created in the virtual Garden cluster. This requires infrastructure credentials to be provided in the form of a Secret and CredentialsBinding. This Shoot should have a toleration for the above taint:
Up next, a gardenlet has to be installed on to this Shoot and it needs to be registered as a Seed. The recommended way is to create a ManagedSeed resource in the virtual Garden. The configuration for the Seed needs to be crafted carefully to avoid overlapping CIDR ranges etc. Additionally, the virtual Garden’s API endpoint needs to be added. When deploying a gardenlet to the runtime cluster, cluster-internal communication through the Service’s cluster DNS record works well. Now with the new gardenlet running on a different Kubernetes cluster, the public endpoint is required in the gardenlet’s configuration within the ManagedSeed resource.
Setting up a new Gardener landscape is much easier today - thanks to the evolution of the Gardener Operator and Garden resource. Utilizing the Extension resource reduces manual efforts significantly.
A single Gardener landscape can support multiple infrastructures for Shoots. To onboard an infrastructure, the relevant extensions need to be deployed as well.
Due to the vast amount of configuration options it is highly recommended to spend some time to derive a meaningful setup initially.
In this example, the runtime cluster serves two purposes - it hosts the virtual Garden cluster and runs a gardenlet which registers the runtime cluster itself as a seed with the virtual Garden cluster. This first seed is reserved to host the control planes of “infrastructure” Shoots only. Those Shoots will be turned into seeds using the ManagedSeed resource and allow for proper scaling.
This document describes the maximum version skew supported between various Gardener components.
Supported Gardener Versions
Gardener versions are expressed as x.y.z, where x is the major version, y is the minor version, and z is the patch version, following Semantic Versioning terminology.
The Gardener project maintains release branches for the three most recent minor releases.
Applicable fixes, including security fixes, may be backported to those three release branches, depending on severity and feasibility.
Patch releases are cut from those branches at a regular cadence, plus additional urgent releases when required.
Technically, we follow the same policy as the Kubernetes project.
However, given that our release cadence is much more frequent compared to Kubernetes (every 14d vs. every 120d), in many cases it might be possible to skip versions, though we do not test these upgrade paths.
Consequently, in general it might not work, and to be on the safe side, it is highly recommended to follow the described policy.
🚨 Note that downgrading Gardener versions is generally not tested during development and should be considered unsupported.
gardener-apiserver
In multi-instance setups of Gardener, the newest and oldest gardener-apiserver instances must be within one minor version.
Example:
newest gardener-apiserver is at 1.37
other gardener-apiserver instances are supported at 1.37 and 1.36
gardener-controller-manager, gardener-scheduler, and gardener-admission-controller must not be newer than the gardener-apiserver instances they communicate with.
They are expected to match the gardener-apiserver minor version, but may be up to one minor version older (to allow live upgrades).
Example:
gardener-apiserver is at 1.37
gardener-controller-manager, gardener-scheduler, and gardener-admission-controller are supported at 1.37 and 1.36
gardenlet
gardenlet must not be newer than gardener-apiserver
gardenlet may be up to two minor versions older than gardener-apiserver
Example:
gardener-apiserver is at 1.37
gardenlet is supported at 1.37, 1.36, and 1.35
gardener-operator
Since gardener-operator manages the Gardener control plane components (gardener-apiserver, gardener-controller-manager, gardener-scheduler, gardener-admission-controller), it follows the same policy as for gardener-apiserver.
It implements additional start-up checks to ensure adherence to this policy.
Concretely, gardener-operator will crash when
its gets downgraded.
its version gets upgraded and skips at least one minor version.
Supported Component Upgrade Order
The supported version skew between components has implications on the order in which components must be upgraded.
This section describes the order in which components must be upgraded to transition an existing Gardener installation from version 1.37 to version 1.38.
gardener-apiserver
Prerequisites:
In a single-instance setup, the existing gardener-apiserver instance is 1.37.
In a multi-instance setup, all gardener-apiserver instances are at 1.37 or 1.38 (this ensures maximum skew of 1 minor version between the oldest and newest gardener-apiserver instance).
The gardener-controller-manager, gardener-scheduler, and gardener-admission-controller instances that communicate with this gardener-apiserver are at version 1.37 (this ensures they are not newer than the existing API server version and are within 1 minor version of the new API server version).
gardenlet instances on all seeds are at version 1.37 or 1.36 (this ensures they are not newer than the existing API server version and are within 2 minor versions of the new API server version).
The gardener-apiserver instances these components communicate with are at 1.38 (in multi-instance setups in which these components can communicate with any gardener-apiserver instance in the cluster, all gardener-apiserver instances must be upgraded before upgrading these components).
Actions:
Upgrade gardener-controller-manager, gardener-scheduler, and gardener-admission-controller to 1.38
gardenlet
Prerequisites:
The gardener-apiserver instances the gardenlet communicates with are at 1.38.
Actions:
Optionally upgrade gardenlet instances to 1.38 (or they can be left at 1.37 or 1.36).
Warning
Running a landscape with gardenlet instances that are persistently two minor versions behind gardener-apiserver means they must be upgraded before the Gardener control plane can be upgraded.
gardener-operator
Prerequisites:
All gardener-operator instances are at 1.37.
Actions:
Upgrade gardener-operator to 1.38.
Supported Gardener Extension Versions
Extensions are maintained and released separately and independently of the gardener/gardener repository.
Consequently, providing version constraints is not possible in this document.
Sometimes, the documentation of extensions contains compatibility information (e.g., “this extension version is only compatible with Gardener versions higher than 1.80”, see this example).
However, since all extensions typically make use of the extensions library (example), a general constraint is that no extension must depend on a version of the extensions library higher than the version of gardenlet.
Example 1:
gardener-apiserver and other Gardener control plane components are at 1.37.
All gardenlets are at 1.37.
Only extensions are supported which depend on 1.37 or lower of the extensions library.
Example 2:
gardener-apiserver and other Gardener control plane components are at 1.37.
Some gardenlets are at 1.37, others are at 1.36.
Only extensions are supported which depend on 1.36 or lower of the extensions library.
Gardener provides Kubernetes-Clusters-As-A-Service where all the system components (e.g., kube-proxy, networking, dns) are managed.
As a result, Gardener needs to ensure and auto-correct additional configuration to those system components to avoid unnecessary down-time.
In some cases, auto-correcting system components can prevent users from deploying applications on top of the cluster that requires bits of customization, DNS configuration can be a good example.
To allow for customizations for DNS configuration (that could potentially lead to downtime) while having the option to “undo”, we utilize the import plugin from CoreDNS [1].
which enables in-line configuration changes.
How to use
To customize your CoreDNS cluster config, you can simply edit a ConfigMap named coredns-custom in the kube-system namespace.
By editing, this ConfigMap, you are modifying CoreDNS configuration, therefore care is advised.
For example, to apply new config to CoreDNS that would point all .global DNS requests to another DNS pod, simply edit the configuration as follows:
The port number 8053 in global:8053 is the specific port that CoreDNS is bound to and cannot be changed to any other port if it should act on ordinary name resolution requests from pods. Otherwise, CoreDNS will open a second port, but you are responsible to direct the traffic to this port. kube-dns service in kube-system namespace will direct name resolution requests within the cluster to port 8053 on the CoreDNS pods.
Moreover, additional network policies are needed to allow corresponding ingress traffic to CoreDNS pods.
In order for the destination DNS server to be reachable, it must listen on port 53 as it is required by network policies. Other ports are only possible if additional network policies allow corresponding egress traffic from CoreDNS pods.
It is important to have the ConfigMap keys ending with *.server (if you would like to add a new server) or *.override
if you want to customize the current server configuration (it is optional setting both).
Warning
Be careful when overriding plugins log, forward or cache.
Increasing log level can lead to increased load/reduced throughput.
Changing the forward target may lead to unexpected results.
Playing with the cache settings can impact the timeframe how long it takes for changes to become visible.
*.override and *.server data points from coredns-customConfigMap are imported into Corefile as follows.
Please consult corednsplugin documentation for potential side-effects.
As Gardener is configuring the reloadplugin of CoreDNS a restart of the CoreDNS components is typically not necessary to propagate ConfigMap changes. However, if you don’t want to wait for the default (30s) to kick in, you can roll-out your CoreDNS deployment using:
The approach we follow here was inspired by AKS’s approach [2].
Anti-Pattern
Applying a configuration that is in-compatible with the running version of CoreDNS is an anti-pattern (sometimes plugin configuration changes,
simply applying a configuration can break DNS).
If incompatible changes are applied by mistake, simply delete the content of the ConfigMap and re-apply.
This should bring the cluster DNS back to functioning state.
Node Local DNS
Custom DNS configuration] may not work as expected in conjunction with NodeLocalDNS.
With NodeLocalDNS, ordinary DNS queries targeted at the upstream DNS servers, i.e. non-kubernetes domains,
will not end up at CoreDNS, but will instead be directly sent to the upstream DNS server. Therefore, configuration
applying to non-kubernetes entities, e.g. the istio.server block in the
custom DNS configuration example, may not have any effect with NodeLocalDNS enabled.
If this kind of custom configuration is required, forwarding to upstream DNS has to be disabled.
This can be done by setting the option (spec.systemComponents.nodeLocalDNS.disableForwardToUpstreamDNS) in the Shoot resource to true:
Using fully qualified names has some downsides, e.g., it may become harder to move deployments from one landscape to the
next. It is far easier and simple to rely on short/local names, which may have different meaning depending on the context
they are used in.
The DNS search path allows for the usage of short/local names. It is an ordered list of DNS suffixes to append to short/local
names to create a fully qualified name.
If a short/local name should be resolved, each entry is appended to it one by one to check whether it can be resolved. The
process stops when either the name could be resolved or the DNS search path ends. As the last step after trying the search
path, the short/local name is attempted to be resolved on it own.
DNS Option ndots
As explained in the section above, the DNS search path is used for short/local names to create fully
qualified names. The DNS option ndots specifies how many dots (.) a name needs to have to be considered fully qualified.
For names with less than ndots dots (.), the DNS search path will be applied.
DNS Search Path, ndots, and Kubernetes
Kubernetes tries to make it easy/convenient for developers to use name resolution. It provides several means to address a
service, most notably by its name directly, using the namespace as suffix, utilizing <namespace>.svc as suffix or as a
fully qualified name as <service>.<namespace>.svc.cluster.local (assuming cluster.local to be the cluster domain).
This is why the DNS search path is fairly long in Kubernetes, usually consisting of <namespace>.svc.cluster.local,
svc.cluster.local, cluster.local, and potentially some additional entries coming from the local network of the cluster.
For various reasons, the default ndots value in the context of Kubernetes is with 5, also fairly large. See
this comment for a more detailed description.
DNS Search Path/ndots Problem in Kubernetes
As the DNS search path is long and ndots is large, a lot of DNS queries might traverse the DNS search path. This results
in an explosion of DNS requests.
For example, consider the name resolution of the default kubernetes service kubernetes.default.svc.cluster.local. As this
name has only four dots, it is not considered a fully qualified name according to the default ndots=5 setting. Therefore,
the DNS search path is applied, resulting in the following queries being created
In IPv4/IPv6 dual stack systems, the amount of DNS requests may even double as each name is resolved for IPv4 and IPv6.
General Workarounds/Mitigations
Kubernetes provides the capability to set the DNS options for each pod (see
Pod DNS config for details).
However, this has to be applied for every pod (doing name resolution) to resolve the problem. A mutating webhook may be
useful in this regard. Unfortunately, the DNS requirements may be different depending on the workload. Therefore, a general
solution may difficult to impossible.
Another approach is to use always fully qualified names and append a dot (.) to the name to prevent the name resolution
system from using the DNS search path. This might be somewhat counterintuitive as most developers are not used to the
trailing dot (.). Furthermore, it makes moving to different landscapes more difficult/error-prone.
Gardener Specific Workarounds/Mitigations
Gardener allows users to customize their DNS configuration. CoreDNS allows several approaches to deal with
the requests generated by the DNS search path. Caching is possible as well as
query rewriting. There are also several other plugins
available, which may mitigate the situation.
Gardener DNS Query Rewriting
As explained above, the application of the DNS search path may lead to the undesired
creation of DNS requests. Especially with the default setting of ndots=5, seemingly fully qualified names pointing to
services in the cluster may trigger the DNS search path application.
Gardener allows to automatically rewrite some obviously incorrect DNS names, which stem from an application of the DNS search
path to the most likely desired name. This will automatically rewrite requests like service.namespace.svc.cluster.local.svc.cluster.local to
service.namespace.svc.cluster.local.
In case the applications also target services for name resolution, which are outside of the cluster and have less than ndots dots,
it might be helpful to prevent search path application for them as well. One way to achieve it is by adding them to the
commonSuffixes:
DNS requests containing a common suffix and ending in .svc.cluster.local are assumed to be incorrect application of the DNS
search path. Therefore, they are rewritten to everything ending in the common suffix. For example, www.gardener.cloud.svc.cluster.local
would be rewritten to www.gardener.cloud.
Please note that the common suffixes should be long enough and include enough dots (.) to prevent random overlap with
other DNS queries. For example, it would be a bad idea to simply put com on the list of common suffixes, as there may be
services/namespaces which have com as part of their name. The effect would be seemingly random DNS requests. Gardener
requires that common suffixes contain at least one dot (.) and adds a second dot at the beginning. For instance, a common
suffix of example.com in the configuration would match *.example.com.
Since some clients verify the host in the response of a DNS query, the host must also be rewritten.
For that reason, we can’t rewrite a query for service.dst-namespace.svc.cluster.local.src-namespace.svc.cluster.local or
www.example.com.src-namespace.svc.cluster.local, as for an answer rewrite src-namespace would not be known.
8.3 - Dual-stack network migration
Migrate IPv4 shoots to dual-stack IPv4,IPv6 network
Dual-Stack Network Migration
This document provides a guide for migrating IPv4-only or IPv6-only Gardener shoot clusters to dual-stack networking (IPv4 and IPv6).
Overview
Dual-stack networking allows clusters to operate with both IPv4 and IPv6 protocols. This configuration is controlled via the spec.networking.ipFamilies field, which accepts the following values:
[IPv4]
[IPv6]
[IPv4, IPv6]
[IPv6, IPv4]
Key Considerations
Adding a new protocol is only allowed as the second element in the array, ensuring the primary protocol remains unchanged.
Migration involves multiple reconciliation runs to ensure a smooth transition without disruptions.
Preconditions
Gardener supports multiple different network configurations, including running with pod overlay network or native routing. Currently, there is only native routing as supported operating mode for dual-stack networking in Gardener. This means that the pod overlay network needs to be disabled before starting the dual-stack migration. Otherwise, pod-to-pod cross-node communication may not work as expected after the migration.
At the moment, this only affects IPv4-only clusters, which should be migrated to dual-stack networking. IPv6-only clusters always use native routing.
You can check whether your cluster uses overlay network or native routing by looking for spec.networking.providerConfig.overlay.enabled in your cluster’s manifest. If it is set to true or not present, the cluster is using the pod overlay network. If it is set to false, the cluster is using native routing.
Please note that there are infrastructure-specific limitations with regards to cluster size due to one route being added per node. Therefore, please consult the documentation of your infrastructure if your cluster should grow beyond 50 nodes and adapt the route limit quotas accordingly before switching to native routing.
To disable the pod overlay network and thereby switch to native routing, adjust your cluster specification as follows:
The migration process should usually take place during the corresponding shoot maintenance time window. If you wish to run the migration process earlier, then you need to roll the nodes yourself and then trigger a reconcile so that the status of the DualStackNodesMigrationReady constraint is set to true. Once this is the case a new reconcile needs to be triggered to update the final components as described in step 5.
Step 1: Update Networking Configuration
Modify the spec.networking.ipFamilies field to include the desired dual-stack configuration. For example, change [IPv4] to [IPv4, IPv6].
Step 2: Infrastructure Reconciliation
Changing the ipFamilies field triggers an infrastructure reconciliation. This step applies necessary changes to the underlying infrastructure to support dual-stack networking.
Step 3: Control Plane Updates
Depending on the infrastructure, control plane components will be updated or reconfigured to support dual-stack networking.
Step 4: Node Rollout
Nodes must support the new network protocol. However, node rollout is a manual step and is not triggered automatically. It should be performed during a maintenance window to minimize disruptions. Over time, this step may occur automatically, for example, during Kubernetes minor version updates that involve node replacements.
Cluster owners can monitor the progress of this step by checking the DualStackNodesMigrationReady constraint in the shoot status. During shoot reconciliation, the system verifies if all nodes support dual-stack networking and updates the migration state accordingly.
Step 5: Final Reconciliation
Once all nodes are migrated, the remaining control plane components and the Container Network Interface (CNI) are configured for dual-stack networking. The migration constraint is removed at the end of this step.
Post-Migration Behavior
After completing the migration:
The shoot cluster supports dual-stack networking.
New pods will receive IP addresses from both address families.
Existing pods will only receive a second IP address upon recreation.
If full dual-stack networking is required all pods need to be rolled.
8.4 - ExposureClasses
ExposureClasses
The Gardener API server provides a cluster-scoped ExposureClass resource.
This resource is used to allow exposing the control plane of a Shoot cluster in various network environments like restricted corporate networks, DMZ, etc.
Background
The ExposureClass resource is based on the concept for the RuntimeClass resource in Kubernetes.
A RuntimeClass abstracts the installation of a certain container runtime (e.g., gVisor, Kata Containers) on all nodes or a subset of the nodes in a Kubernetes cluster.
See Runtime Class for more information.
In contrast, an ExposureClass abstracts the ability to expose a Shoot clusters control plane in certain network environments (e.g., corporate networks, DMZ, internet) on all Seeds or a subset of the Seeds.
Similar to RuntimeClasses, ExposureClasses also define a .handler field reflecting the name reference for the corresponding CRI configuration of the RuntimeClass and the control plane exposure configuration for the ExposureClass.
The CRI handler for RuntimeClasses is usually installed by an administrator (e.g., via a DaemonSet which installs the corresponding container runtime on the nodes).
The control plane exposure configuration for ExposureClasses will be also provided by an administrator.
This exposure configuration is part of the gardenlet configuration, as this component is responsible to configure the control plane accordingly.
See the gardenlet Configuration ExposureClass Handlers section for more information.
The RuntimeClass also supports the selection of a node subset (which have the respective controller runtime binaries installed) for pod scheduling via its .scheduling section.
The ExposureClass also supports the selection of a subset of available Seed clusters whose gardenlet is capable of applying the exposure configuration for the Shoot control plane accordingly via its .scheduling section.
Usage by a Shoot
A Shoot can reference an ExposureClass via the .spec.exposureClassName field.
⚠️ When creating a Shoot resource, the Gardener scheduler will try to assign the Shoot to a Seed which will host its control plane.
The scheduling behaviour can be influenced via the .spec.seedSelectors and/or .spec.tolerations fields in the Shoot.
ExposureClasses can also contain scheduling instructions.
If a Shoot is referencing an ExposureClass, then the scheduling instructions of both will be merged into the Shoot.
Those unions of scheduling instructions might lead to a selection of a Seed which is not able to deal with the handler of the ExposureClass and the Shoot creation might end up in an error.
In such case, the Shoot scheduling instructions should be revisited to check that they are not interfering with the ones from the ExposureClass.
If this is not feasible, then the combination with the ExposureClass might not be possible and you need to contact your Gardener administrator.
Example: Shoot and ExposureClass scheduling instructions merge flow
Assuming there is the following Shoot which is referencing the ExposureClass below:
Now the Gardener Scheduler would try to find a Seed with those labels.
If there are no Seeds with matching labels for the seed selector, then the Shoot will be unschedulable.
If there are Seeds with matching labels for the seed selector, then the Shoot will be assigned to the best candidate after the scheduling strategy is applied, see Gardener Scheduler.
If the Seed is not able to serve the ExposureClass handler abc, then the Shoot will end up in error state.
If the Seed is able to serve the ExposureClass handler abc, then the Shoot will be created.
gardenlet Configuration ExposureClass Handlers
The gardenlet is responsible to realize the control plane exposure strategy defined in the referenced ExposureClass of a Shoot.
Therefore, the GardenletConfiguration can contain an .exposureClassHandlers list with the respective configuration.
Each gardenlet can define how the handler of a certain ExposureClass needs to be implemented for the Seed(s) where it is responsible for.
The .name is the name of the handler config and it must match to the .handler in the ExposureClass.
All control planes on a Seed are exposed via a load balancer, either a dedicated one or a central shared one.
The load balancer service needs to be configured in a way that it is reachable from the target network environment.
Therefore, the configuration of load balancer service need to be specified, which can be done via the .loadBalancerService section.
The common way to influence load balancer service behaviour is via annotations where the respective cloud-controller-manager will react on and configure the infrastructure load balancer accordingly.
The control planes on a Seed will be exposed via a central load balancer and with Envoy via TLS SNI passthrough proxy.
In this case, the gardenlet will install a dedicated ingress gateway (Envoy + load balancer + respective configuration) for each handler on the Seed.
The configuration of the ingress gateways can be controlled via the .sni section in the same way like for the default ingress gateways.
In each Shoot cluster’s kube-system namespace a DaemonSet called apiserver-proxy is deployed. It routes traffic to the upstream Shoot Kube APIServer. See the APIServer SNI GEP for more details.
To skip this extra network hop, a mutating webhook called apiserver-proxy.networking.gardener.cloud is deployed next to the API server in the Seed. It adds a KUBERNETES_SERVICE_HOST environment variable to each container and init container that do not specify it. See the webhook repository for more information.
Opt-Out of Pod Injection
In some cases it’s desirable to opt-out of Pod injection:
DNS is disabled on that individual Pod, but it still needs to talk to the kube-apiserver.
Want to test the kube-proxy and kubelet in-cluster discovery.
Opt-Out of Pod Injection for Specific Pods
To opt out of the injection, the Pod should be labeled with apiserver-proxy.networking.gardener.cloud/inject: disable, e.g.:
To opt out of the injection of all Pods in a namespace, you should label your namespace with apiserver-proxy.networking.gardener.cloud/inject: disable, e.g.:
Note: Please be aware that it’s not possible to disable injection on a namespace level and enable it for individual pods in it.
Opt-Out of Pod Injection for the Entire Cluster
If the injection is causing problems for different workloads and ignoring individual pods or namespaces is not possible, then the feature could be disabled for the entire cluster with the alpha.featuregates.shoot.gardener.cloud/apiserver-sni-pod-injector annotation with value disable on the Shoot resource itself:
Note: Please be aware that it’s not possible to disable injection on a cluster level and enable it for individual pods in it.
8.6 - NodeLocalDNS Configuration
NodeLocalDNS Configuration
This is a short guide describing how to enable DNS caching on the shoot cluster nodes.
Background
Currently in Gardener we are using CoreDNS as a deployment that is auto-scaled horizontally to cover for QPS-intensive applications. However, doing so does not seem to be enough to completely circumvent DNS bottlenecks such as:
Cloud provider limits for DNS lookups.
Unreliable UDP connections that forces a period of timeout in case packets are dropped.
Unnecessary node hopping since CoreDNS is not deployed on all nodes, and as a result DNS queries end-up traversing multiple nodes before reaching the destination server.
Inefficient load-balancing of services (e.g., round-robin might not be enough when using IPTables mode)
and more …
To workaround the issues described above, node-local-dns was introduced. The architecture is described below. The idea is simple:
For new queries, the connection is upgraded from UDP to TCP and forwarded towards the cluster IP for the original CoreDNS server.
For previously resolved queries, an immediate response from the same node where the requester workload / pod resides is provided.
Configuring NodeLocalDNS
All that needs to be done to enable the usage of the node-local-dns feature is to set the corresponding option (spec.systemComponents.nodeLocalDNS.enabled) in the Shoot resource to true:
When migrating from IPVS to IPTables, existing pods will continue to leverage the node-local-dns cache.
When migrating from IPtables to IPVS, only newer pods will be switched to the node-local-dns cache.
During the reconfiguration of the node-local-dns there might be a short disruption in terms of domain name resolution depending on the setup. Usually, DNS requests are repeated for some time as UDP is an unreliable protocol, but that strictly depends on the application/way the domain name resolution happens. It is recommended to let the shoot be reconciled during the next maintenance period.
Enabling or disabling node-local-dns triggers a rollout of all shoot worker nodes, see also this document.
For more information about node-local-dns, please refer to the KEP or to the usage documentation.
Known Issues
Custom DNS configuration may not work as expected in conjunction with NodeLocalDNS.
Please refer to Custom DNS Configuration.
8.7 - Shoot Networking Configurations
Configuring Pod network. Maximum number of Nodes and Pods per Node
Shoot Networking Configurations
This document contains network related information for Shoot clusters.
Pod Network
A Pod network is imperative for any kind of cluster communication with Pods not started within the Node’s host network.
More information about the Kubernetes network model can be found in the Cluster Networking topic.
Gardener allows users to configure the Pod network’s CIDR during Shoot creation:
⚠️ The networking.pods IP configuration is immutable and cannot be changed afterwards.
Please consider the following paragraph to choose a configuration which will meet your demands.
One of the network plugin’s (CNI) tasks is to assign IP addresses to Pods started in the Pod network.
Different network plugins come with different IP address management (IPAM) features, so we can’t give any definite advice how IP ranges should be configured.
Nevertheless, we want to outline the standard configuration.
Information in .spec.networking.pods matches the –cluster-cidr flag of the Kube-Controller-Manager of your Shoot cluster.
This IP range is divided into smaller subnets, also called podCIDRs (default mask /24) and assigned to Node objects .spec.podCIDR.
Pods get their IP address from this smaller node subnet in a default IPAM setup.
Thus, it must be guaranteed that enough of these subnets can be created for the maximum amount of nodes you expect in the cluster.
Example 1
Pod network: 100.96.0.0/16
nodeCIDRMaskSize: /24
-------------------------
Number of podCIDRs: 256 --> max. Node count
Number of IPs per podCIDRs: 256
With the configuration above a Shoot cluster can at most have 256 nodes which are ready to run workload in the Pod network.
Example 2
Pod network: 100.96.0.0/20
nodeCIDRMaskSize: /24
-------------------------
Number of podCIDRs: 16 --> max. Node count
Number of IPs per podCIDRs: 256
With the configuration above a Shoot cluster can at most have 16 nodes which are ready to run workload in the Pod network.
Beside the configuration in .spec.networking.pods, users can tune the nodeCIDRMaskSize used by Kube-Controller-Manager on shoot creation.
A smaller IP range per node means more podCIDRs and thus the ability to provision more nodes in the cluster, but less available IPs for Pods running on each of the nodes.
⚠️ The nodeCIDRMaskSize configuration is immutable and cannot be changed afterwards.
Example 3
Pod network: 100.96.0.0/20
nodeCIDRMaskSize: /25
-------------------------
Number of podCIDRs: 32 --> max. Node count
Number of IPs per podCIDRs: 128
With the configuration above, a Shoot cluster can at most have 32 nodes which are ready to run workload in the Pod network.
Reserved Networks
Some network ranges are reserved for specific use-cases in the communication between seeds and shoots.
IPv
CIDR
Name
Purpose
IPv6
fd8f:6d53:b97a:1::/96
Default VPN Range
IPv4
240.0.0.0/8
Kube-ApiServer Mapping Range
Used for the kubernetes.default.svc.cluster.local service in a shoot
IPv4
241.0.0.0/8
Seed Pod Mapping Range
Used for allowing overlapping IPv4 networks between shoot and seed. Requires non-HA control plane. Only used within the vpn pods
IPv4
242.0.0.0/8
Shoot Node Mapping Range
Used for allowing overlapping IPv4 networks between shoot and seed. Requires non-HA control plane. Only used within the vpn pods
IPv4
243.0.0.0/8
Shoot Service Mapping Range
Used for allowing overlapping IPv4 networks between shoot and seed. Requires non-HA control plane. Only used within the vpn pods
IPv4
244.0.0.0/8
Shoot Pod Mapping Range
Used for allowing overlapping IPv4 networks between shoot and seed. Requires non-HA control plane. Only used within the vpn pods
⚠️ Do not use any of the CIDR ranges mentioned above for any of the node, pod or service networks.
Gardener will prevent their creation. Pre-existing shoots using reserved ranges will still work, though it is recommended
to recreate them with compatible network ranges.
Overlapping IPv4 Networks between Seed and Shoot
By default, the seed and shoot clusters must have non-overlapping IPv4 network ranges and gardener will enforce disjunct ranges.
However, under certain conditions it is possible to allow overlapping IPv4 network ranges:
The shoot cluster must have a non-highly-available VPN, usually implicitly selected by having a non-highly-available control plane.
The shoot cluster need be either single-stack IPv4 or dual-stack IPv4/IPv6.
The shoot cluster networks don’t use the reserved ranges mentioned above.
Note: single-stack IPv6 shoots are usually not affected due to the vastly larger address space. However,
Gardener still enforces the non-overlapping condition for IPv6 networks to avoid any potential issues.
If all conditions are met, the seed and shoot clusters can have overlapping (IPv4) network ranges.
The potentially overlapping ranges are mapped to the reserved ranges mentioned above within the VPN network, i.e., double network address translation (NAT) is used .
9 - Monitoring
Monitoring
Roles of the different Prometheus instances
Cache Prometheus
Deployed in the garden namespace. Important scrape targets:
cadvisor
node-exporter
kube-state-metrics
Purpose: Act as a reverse proxy that supports server-side filtering, which is not supported by Prometheus exporters but by federation. Metrics in this Prometheus are kept for a short amount of time (~1 day) since other Prometheus instances are expected to federate from it and move metrics over. For example, the shoot Prometheus queries this Prometheus to retrieve metrics corresponding to the shoot’s control plane. This way, we achieve isolation so that shoot owners are only able to query metrics for their shoots. Please note Prometheus does not support isolation features. Another example is if another Prometheus needs access to cadvisor metrics, which does not support server-side filtering, so it will query this Prometheus instead of the cadvisor. This strategy also reduces load on the kubelets and API Server.
Note some of these Prometheus’ metrics have high cardinality (e.g., metrics related to all shoots managed by the seed). Some of these are aggregated with recording rules. These pre-aggregated metrics are scraped by the aggregate Prometheus.
This Prometheus is not used for alerting.
Aggregate Prometheus
Deployed in the garden namespace. Important scrape targets:
other Prometheus instances
logging components
Purpose: Store pre-aggregated data from the cache Prometheus and shoot Prometheus. An ingress exposes this Prometheus allowing it to be scraped from another cluster. Such pre-aggregated data is also used for alerting.
Seed Prometheus
Deployed in the garden namespace. Important scrape targets:
Purpose: Monitor all relevant components belonging to a shoot cluster managed by Gardener. Shoot owners can view the metrics in Plutono dashboards and receive alerts based on these metrics. For alerting internals refer to this document.
Federate from the Shoot Prometheus to an External Prometheus
Shoot owners that are interested in collecting metrics for their shoot’s control-planes can do so by federating from their shoot Prometheus instances. This allows shoot owners to selectively pull metrics from the shoot Prometheus into their own Prometheus instance. Collecting shoot’s control-plane metrics by directly scraping control-plane resources will not work because such resources are managed by Gardener and are either not accessible to shoot owners or are behind a load balancer.
Note Gardener is working on an OpenTelemetry-based approach for observability, but there is no official timeline for its release yet.
Step 1: Retrieve Prometheus Credentials and URL
Gardener provides access to the shoot control plane Prometheus instance through a monitoring secret stored in the virtual garden cluster. The necessary credentials can be found in the dashboard or by following these steps:
Replace <prometheus-username>, <prometheus-password>, and <prometheus-url> with the values obtained earlier. In this example, the federation job is configured to federate metrics scraped by the kube-apiserver job, but match[] entry should be adjusted to the specific use-case.
Restart Prometheus to apply the configuration.
Collect all shoot Prometheus with remote write
An optional collection of all shoot Prometheus metrics to a central Prometheus (or cortex) instance is possible with the monitoring.shoot setting in GardenletConfiguration:
monitoring:
shoot:
remoteWrite:
url: https://remoteWriteUrl # remote write URL
keep:# metrics that should be forwarded to the external write endpoint. If empty all metrics get forwarded
- kube_pod_container_info
externalLabels: # add additional labels to metrics to identify it on the central instance
additional: label
If basic auth is needed it can be set via secret in garden namespace (Gardener API Server). Example secret
Disable Gardener Monitoring
If you wish to disable metric collection for every shoot and roll your own then you can simply set.
monitoring:
shoot:
enabled: false
9.1 - Alerting
Alerting
Gardener uses Prometheus to gather metrics from each component. A Prometheus is deployed in each shoot control plane (on the seed) which is responsible for gathering control plane and cluster metrics. Prometheus can be configured to fire alerts based on these metrics and send them to an Alertmanager. The Alertmanager is responsible for sending the alerts to users and operators. This document describes how to setup alerting for:
Gardener provides the option to deploy an Alertmanager into each seed. This Alertmanager is responsible for sending out alerts to operators for each shoot cluster in the seed. Only email alerts are supported by the Alertmanager managed by Gardener. This is configurable by setting the Gardener controller manager configuration values alerting. See Gardener Configuration and Usage on how to configure the Gardener’s SMTP secret. If the values are set, a secret with the label gardener.cloud/role: alerting will be created in the garden namespace of the garden cluster. This secret will be used by each Alertmanager in each seed.
External Alertmanager
The Alertmanager supports different kinds of alerting configurations. The Alertmanager provided by Gardener only supports email alerts. If email is not sufficient, then alerts can be sent to an external Alertmanager. Prometheus will send alerts to a URL and then alerts will be handled by the external Alertmanager. This external Alertmanager is operated and configured by the operator (i.e. Gardener does not configure or deploy this Alertmanager). To configure sending alerts to an external Alertmanager, create a secret in the virtual garden cluster in the garden namespace with the label: gardener.cloud/role: alerting. This secret needs to contain a URL to the external Alertmanager and information regarding authentication. Supported authentication types are:
No Authentication (none)
Basic Authentication (basic)
Mutual TLS (certificate)
Remote Alertmanager Examples
Note: The url value cannot be prepended with http or https.
Please refer to the Alertmanager documentation on how to configure an Alertmanager.
We recommend you use at least the following inhibition rules in your Alertmanager configuration to prevent excessive alerts:
inhibit_rules:
# Apply inhibition if the alert name is the same.- source_match:
severity: critical
target_match:
severity: warning
equal: ['alertname', 'service', 'cluster']
# Stop all alerts for type=shoot if there are VPN problems.- source_match:
service: vpn
target_match_re:
type: shoot
equal: ['type', 'cluster']
# Stop warning and critical alerts if there is a blocker- source_match:
severity: blocker
target_match_re:
severity: ^(critical|warning)$
equal: ['cluster']
# If the API server is down inhibit no worker nodes alert. No worker nodes depends on kube-state-metrics which depends on the API server.- source_match:
service: kube-apiserver
target_match_re:
service: nodes
equal: ['cluster']
# If API server is down inhibit kube-state-metrics alerts.- source_match:
service: kube-apiserver
target_match_re:
severity: info
equal: ['cluster']
# No Worker nodes depends on kube-state-metrics. Inhibit no worker nodes if kube-state-metrics is down.- source_match:
service: kube-state-metrics-shoot
target_match_re:
service: nodes
equal: ['cluster']
Below is a graph visualizing the inhibition rules:
9.2 - Connectivity
Connectivity
Shoot Connectivity
We measure the connectivity from the shoot to the API Server. This is done via the blackbox exporter which is deployed in the shoot’s kube-system namespace. Prometheus will scrape the blackbox exporter and then the exporter will try to access the API Server. Metrics are exposed if the connection was successful or not. This can be seen in the Kubernetes Control Plane Status dashboard under the API Server Connectivity panel. The shoot line represents the connectivity from the shoot.
Seed Connectivity
In addition to the shoot connectivity, we also measure the seed connectivity. This means trying to reach the API Server from the seed via the external fully qualified domain name of the API server. The connectivity is also displayed in the above panel as the seed line. Both seed and shoot connectivity are shown below.
9.3 - Profiling
Profiling Gardener Components
Similar to Kubernetes, Gardener components support profiling using standard Go tools for analyzing CPU and memory usage by different code sections and more.
This document shows how to enable and use profiling handlers with Gardener components.
Enabling profiling handlers and the ports on which they are exposed differs between components.
However, once the handlers are enabled, they provide profiles via the same HTTP endpoint paths, from which you can retrieve them via curl/wget or directly using go tool pprof.
(You might need to use kubectl port-forward in order to access HTTP endpoints of Gardener components running in clusters.)
$ go tool pprof http://localhost:2718/debug/pprof/heap
Fetching profile over HTTP from http://localhost:2718/debug/pprof/heap
Saved profile in /Users/timebertt/pprof/pprof.alloc_objects.alloc_space.inuse_objects.inuse_space.008.pb.gz
Type: inuse_space
Time: Sep 3, 2021 at 10:05am (CEST)
Entering interactive mode (type "help"for commands, "o"for options)
(pprof)
gardener-apiserver
gardener-apiserver provides the same flags as kube-apiserver for enabling profiling handlers (enabled by default):
--contention-profiling Enable lock contention profiling, if profiling is enabled
--profiling Enable profiling via web interface host:port/debug/pprof/ (default true)
The handlers are served on the same port as the API endpoints (configured via --secure-port).
This means that you will also have to authenticate against the API server according to the configured authentication and authorization policy.
gardener-controller-manager, gardener-admission-controller, gardener-scheduler, gardener-resource-manager and gardenlet also allow enabling profiling handlers via their respective component configs (currently disabled by default).
Here is an example for the gardener-admission-controller’s configuration and how to enable it (it looks similar for the other components):
However, the handlers are served on the same port as configured in server.metrics.port via HTTP.
For example (gardener-admission-controller):
$ curl http://localhost:2723/debug/pprof/heap > /tmp/heap
$ go tool pprof /tmp/heap
10 - Observability
10.1 - Logging
Logging Stack
Motivation
Kubernetes uses the underlying container runtime logging, which does not persist logs for stopped and destroyed containers. This makes it difficult to investigate issues in the very common case of not running containers. Gardener provides a solution to this problem for the managed cluster components by introducing its own logging stack.
Components
A Fluent-bit daemonset which works like a log collector and custom Golang plugin which spreads log messages to their Vali instances.
One Vali Statefulset in the garden namespace which contains logs for the seed cluster and one per shoot namespace which contains logs for shoot’s controlplane.
One Plutono Deployment in garden namespace and two Deployments per shoot namespace (one exposed to the end users and one for the operators). Plutono is the UI component used in the logging stack.
Container Logs Rotation and Retention in kubelet
It is possible to configure the containerLogMaxSize and containerLogMaxFiles fields in the Shoot specification. Both fields are optional and if nothing is specified, then the kubelet rotates on the size 100M. Those fields are part of provider’s workers definition. Here is an example:
spec:
provider:
workers:
- cri:
name: containerd
kubernetes:
kubelet:
# accepted values are of resource.Quantity containerLogMaxSize: 150Mi
containerLogMaxFiles: 10
The values of the containerLogMaxSize and containerLogMaxFiles fields need to be considered with care since container log files claim disk space from the host. On the opposite side, log rotations on too small sizes may result in frequent rotations which can be missed by other components (log shippers) observing these rotations.
In the majority of the cases, the defaults should do just fine. Custom configuration might be of use under rare conditions.
Logs Retention in Vali
Logs in Vali are preserved for a maximum of 14 days. Note that the retention period is also restricted to the Vali’s persistent volume size and in some cases, it can be less than 14 days. The oldest logs are deleted when a configured threshold of free disk space is crossed.
Extension of the Logging Stack
The logging stack is extended to scrape logs from the systemd services of each shoots’ nodes and from all Gardener components in the shoot kube-system namespace. These logs are exposed only to the Gardener operators.
Also, in the shoot control plane an event-logger pod is deployed, which scrapes events from the shoot kube-system namespace and shoot control-plane namespace in the seed. The event-logger logs the events to the standard output. Then the fluent-bit gets these events as container logs and sends them to the Vali in the shoot control plane (similar to how it works for any other control plane component).
How to Access the Logs
The logs are accessible via Plutono. To access them:
Authenticate via basic auth to gain access to Plutono. The secret containing the credentials is stored in the project namespace following the naming pattern <shoot-name>.monitoring.
In this secret you can also find the Plutono URL in the plutono-url annotation.
For Gardener operators, the credentials are also stored in the control-plane (shoot--<project-name>--<shoot-name>) namespace in the observability-ingress-users-<hash> secret in the seed.
Plutono contains several dashboards that aim to facilitate the work of operators and users.
From the Explore tab, users and operators have unlimited abilities to extract and manipulate logs.
Note: Gardener Operators are people part of the Gardener team with operator permissions, not operators of the end-user cluster!
How to Use the Explore Tab
If you click on the Log browser > button, you will see all of the available labels.
Clicking on the label, you can see all of its available values for the given period of time you have specified.
If you are searching for logs for the past one hour, do not expect to see labels or values for which there were no logs for that period of time.
By clicking on a value, Plutono automatically eliminates all other labels and/or values with which no valid log stream can be made.
After choosing the right labels and their values, click on the Show logs button.
This will build Log query and execute it.
This approach is convenient when you don’t know the labels names or they values.
Once you feel comfortable, you can start to use the LogQL language to search for logs.
Next to the Log browser > button is the place where you can type log queries.
Examples:
If you want to get logs for calico-node-<hash> pod in the cluster kube-system:
The name of the node on which calico-node was running is known, but not the hash suffix of the calico-node pod.
Also we want to search for errors in the logs.
Note:{job="systemd-combine-journal",nodename="<node name>"} stream pack all logs from systemd services except docker, containerd, kubelet, and kernel. To filter those log by unit, you have to unpack them first.
Retrieving events:
If you want to get the events from the shoot kube-system namespace generated by kubelet and related to the node-problem-detector:
Note: In order to group events by origin, one has to specify origin_extracted because the origin label is reserved for all of the logs from the seed and the event-logger resides in the seed, so all of its logs are coming as they are only from the seed. The actual origin is embedded in the unpacked event. When unpacked, the embedded origin becomes origin_extracted.
11 - Project
11.1 - NamespacedCloudProfiles
NamespacedCloudProfiles
NamespacedCloudProfiles are resources in Gardener that allow project-level customization of CloudProfiles.
They enable project administrators to create and manage cloud profiles specific to their projects and reduce the operational burden on central Gardener operators.
As opposed to CloudProfiles, NamespacedCloudProfiles are namespaced and thus limit configuration options for Shoots, such as special machine types, to the associated project only.
These profiles inherit from a parent CloudProfile and can override or extend certain fields while maintaining backward compatibility.
Project viewers have the permission to see NamespacedCloudProfiles associated with a particular project.
Project administrators can generally create, edit, or delete NamespacedCloudProfiles but with some exceptions (see the restrictions outlined below).
When creating or updating a Shoot, the cloud profile reference can be set to point to a NamespacedCloudProfile, allowing for more granular and project-specific configurations.
The modification of a Shoot’s cloud profile reference is restricted to switching within the same profile hierarchy, i.e. from a CloudProfile to a descendant NamespacedCloudProfile, from a NamespacedCloudProfile to its parent CloudProfile and between NamespacedCloudProfiles having the same CloudProfile parent.
Changing the reference from one CloudProfile or descendant NamespacedCloudProfile to another CloudProfile or descendant NamespacedCloudProfile is not allowed.
The usage of NamespacedCloudProfiles is currently subject to a beta feature gate and is enabled by default.
It requires the enabled provider extensions to support the feature as well.
The feature gate can be disabled by passing the --feature-gates=NamespacedCloudProfiles=false flag to the Gardener API server.
Please see this example manifest and GEP-25 for additional information.
Field Modification Restrictions
In order to make changes to specific fields in the NamespacedCloudProfile, a user must be granted custom RBAC verbs.
Modifications of these fields need to be performed with caution and might require additional validation steps or accompanying changes.
By default, only landscape operators have the permission to change these fields, as they are usually able to judge the implications.
Changing the following fields require the corresponding custom verbs:
For changing the .spec.kubernetes field, the custom verb modify-spec-kubernetes is required.
For changing the .spec.machineImages field, the custom verb modify-spec-machineimages is required.
For changing the .spec.providerConfig field, the custom verb modify-spec-providerconfig is required.
For raising limits in .spec.limits field above values in the parent CloudProfile .spec.limits, the custom verb raise-spec-limits is required.
The assignment of these custom verbs can be achieved by creating a ClusterRole and a RoleBinding like in the following example:
Project operations and roles. Four-Eyes-Principle for resource deletion
Projects
The Gardener API server supports a cluster-scoped Project resource which is used for data isolation between individual Gardener consumers. For example, each development team has its own project to manage its own shoot clusters.
Each Project is backed by a Kubernetes Namespace that contains the actual related Kubernetes resources, like Secrets or Shoots.
Example resource:
apiVersion: core.gardener.cloud/v1beta1
kind: Project
metadata:
name: dev
spec:
namespace: garden-dev
description: "This is my first project" purpose: "Experimenting with Gardener" owner:
apiGroup: rbac.authorization.k8s.io
kind: User
name: john.doe@example.com
members:
- apiGroup: rbac.authorization.k8s.io
kind: User
name: alice.doe@example.com
role: admin
# roles:# - viewer # - uam# - serviceaccountmanager# - extension:foo - apiGroup: rbac.authorization.k8s.io
kind: User
name: bob.doe@example.com
role: viewer
# tolerations:# defaults:# - key: <some-key># whitelist:# - key: <some-key>
The .spec.namespace field is optional and is initialized if unset.
The name of the resulting namespace will be determined based on the Project name and UID, e.g., garden-dev-5aef3.
It’s also possible to adopt existing namespaces by labeling them gardener.cloud/role=project and project.gardener.cloud/name=dev beforehand (otherwise, they cannot be adopted).
When deleting a Project resource, the corresponding namespace is also deleted.
To keep a namespace after project deletion, an administrator/operator (not Project members!) can annotate the project-namespace with namespace.gardener.cloud/keep-after-project-deletion.
The spec.description and .spec.purpose fields can be used to describe to fellow team members and Gardener operators what this project is used for.
Each project has one dedicated owner, configured in .spec.owner using the rbac.authorization.k8s.io/v1.Subject type.
The owner is the main contact person for Gardener operators.
Please note that the .spec.owner field is deprecated and will be removed in future API versions in favor of the owner role, see below.
The list of members (again a list in .spec.members[] using the rbac.authorization.k8s.io/v1.Subject type) contains all the people that are associated with the project in any way.
Each project member must have at least one role (currently described in .spec.members[].role, additional roles can be added to .spec.members[].roles[]). The following roles exist:
admin: This allows to fully manage resources inside the project (e.g., secrets, shoots, configmaps, and similar). Mind that the admin role has read only access to service accounts.
serviceaccountmanager: This allows to fully manage service accounts inside the project namespace and request tokens for them. The permissions of the created service accounts are instead managed by the admin role. Please refer to Service Account Manager.
uam: This allows to add/modify/remove human users or groups to/from the project member list.
viewer: This allows to read all resources inside the project except secrets.
owner: This combines the admin, uam, and serviceaccountmanager roles.
The project controller inside the Gardener Controller Manager is managing RBAC resources that grant the described privileges to the respective members.
There are three central ClusterRoles gardener.cloud:system:project-member, gardener.cloud:system:project-viewer, and gardener.cloud:system:project-serviceaccountmanager that grant the permissions for namespaced resources (e.g., Secrets, Shoots, ServiceAccounts).
Via referring RoleBindings created in the respective namespace the project members get bound to these ClusterRoles and, thus, the needed permissions.
There are also project-specific ClusterRoles granting the permissions for cluster-scoped resources, e.g., the Namespace or Project itself. For each role, the following ClusterRoles, ClusterRoleBindings, and RoleBindings are created:
For Projects created before Gardener v1.8, all admins were allowed to manage other members.
Beginning with v1.8, the new uam role is being introduced.
It is backed by the manage-members custom RBAC verb which allows to add/modify/remove human users or groups to/from the project member list.
Human users are subjects with kind=User and name!=system:serviceaccount:*, and groups are subjects with kind=Group.
The management of service account subjects (kind=ServiceAccount or name=system:serviceaccount:*) is not controlled via the uam custom verb but with the standard update/patch verbs for projects.
All newly created projects will only bind the owner to the uam role.
The owner can still grant the uam role to other members if desired.
For projects created before Gardener v1.8, the Gardener Controller Manager will migrate all projects to also assign the uam role to all admin members (to not break existing use-cases). The corresponding migration logic is present in Gardener Controller Manager from v1.8 to v1.13.
The project owner can gradually remove these roles if desired.
Stale Projects
When a project is not actively used for some period of time, it is marked as “stale”. This is done by a controller called “Stale Projects Reconciler”. Once the project is marked as stale, there is a time frame in which if not used it will be deleted by that controller.
Four-Eyes-Principle For Resource Deletion
In order to delete a Shoot, the deletion must be confirmed upfront with the confirmation.gardener.cloud/deletion=true annotation.
Without this annotation being set, gardener-apiserver denies any DELETE request.
Still, users sometimes accidentally shot themselves in the foot, meaning that they accidentally deleted a Shoot despite the confirmation requirement.
To prevent that (or make it harder, at least), the Project can be configured to apply the dual approval concept for Shoot deletion.
This means that the subject confirming the deletion must not be the same as the subject sending the DELETE request.
As of today, core.gardener.cloud/v1beta1.Shoot is the only resource for which this concept is implemented.
As usual, .spec.dualApprovalForDeletion[].selector.matchLabels={} matches all resources, .spec.dualApprovalForDeletion[].selector.matchLabels=null matches none at all.
It can also be decided to specify an individual label selector if this concept shall only apply to a subset of the Shoots in the project (e.g., CI/development clusters shall be excluded).
The includeServiceAccounts (default: true) controls whether the concept also applies when the Shoot deletion confirmation and actual deletion is triggered via ServiceAccounts.
This is to prevent that CI jobs have to follow this concept as well, adding additional complexity/overhead.
Alternatively, you could also use two ServiceAccounts, one for confirming the deletion, and another one for actually sending the DELETE request, if desired.
Important
Project members can still change the labels of Shoots (or the selector itself) to circumvent the dual approval concept.
This concern is intentionally excluded/ignored for now since the principle is not a “security feature” but shall just help preventing accidental deletion.
11.3 - Service Account Manager
The role that allows a user to manage ServiceAccounts in the project namespace
Service Account Manager
Overview
With Gardener v1.47, a new role called serviceaccountmanager was introduced. This role allows to fully manage ServiceAccount’s in the project namespace and request tokens for them. This is the preferred way of managing the access to a project namespace, as it aims to replace the usage of the default ServiceAccount secrets that will no longer be generated automatically.
Actions
Once assigned the serviceaccountmanager role, a user can create/update/delete ServiceAccounts in the project namespace.
Create a Service Account
In order to create a ServiceAccount named “robot-user”, run the following kubectl command:
kubectl -n project-abc create sa robot-user
Request a Token for a Service Account
A token for the “robot-user” ServiceAccount can be requested via the TokenRequest API in several ways:
Mind that the returned token is not stored within the Kubernetes cluster, will be valid for 3600 seconds, and will be invalidated if the “robot-user” ServiceAccount is deleted. Although expirationSeconds can be modified depending on the needs, the returned token’s validity will not exceed the configured service-account-max-token-expiration duration for the garden cluster. It is advised that the actual expirationTimestamp is verified so that expectations are met. This can be done by asserting the expirationTimestamp in the TokenRequestStatus or the exp claim in the token itself.
Delete a Service Account
In order to delete the ServiceAccount named “robot-user”, run the following kubectl command:
kubectl -n project-abc delete sa robot-user
This will invalidate all existing tokens for the “robot-user” ServiceAccount.
12 - Security
12.1 - Admission Configuration for the `PodSecurity` Admission Plugin
Adding custom configuration for the PodSecurity plugin in .spec.kubernetes.kubeAPIServer.admissionPlugins
Admission Configuration for the PodSecurity Admission Plugin
If you wish to add your custom configuration for the PodSecurity plugin, you can do so in the Shoot spec under .spec.kubernetes.kubeAPIServer.admissionPlugins by adding:
admissionPlugins:
- name: PodSecurity
config:
apiVersion: pod-security.admission.config.k8s.io/v1
kind: PodSecurityConfiguration
# Defaults applied when a mode label is not set.## Level label values must be one of:# - "privileged" (default)# - "baseline"# - "restricted"## Version label values must be one of:# - "latest" (default) # - specific version like "v1.25" defaults:
enforce: "privileged" enforce-version: "latest" audit: "privileged" audit-version: "latest" warn: "privileged" warn-version: "latest" exemptions:
# Array of authenticated usernames to exempt. usernames: []
# Array of runtime class names to exempt. runtimeClasses: []
# Array of namespaces to exempt. namespaces: []
For proper functioning of Gardener, kube-system namespace will also be automatically added to the exemptions.namespaces list.
12.2 - Audit a Kubernetes Cluster
How to define a custom audit policy through a ConfigMap and reference it in the shoot spec
Audit a Kubernetes Cluster
The shoot cluster is a Kubernetes cluster and its kube-apiserver handles the audit events. In order to define which audit events must be logged, a proper audit policy file must be passed to the Kubernetes API server. You could find more information about auditing a kubernetes cluster in the Auditing topic.
Default Audit Policy
By default, the Gardener will deploy the shoot cluster with audit policy defined in the kube-apiserver package.
Custom Audit Policy
If you need specific audit policy for your shoot cluster, then you could deploy the required audit policy in the garden cluster as ConfigMap resource and set up your shoot to refer this ConfigMap. Note that the policy must be stored under the key policy in the data section of the ConfigMap.
For example, deploy the auditpolicy ConfigMap in the same namespace as your Shoot resource:
Gardener validate the Shoot resource to refer only existing ConfigMap containing valid audit policy, and rejects the Shoot on failure.
If you want to switch back to the default audit policy, you have to remove the section
auditPolicy:
configMapRef:
name: <configmap-name>
from the shoot spec.
Rolling Out Changes to the Audit Policy
Gardener is not automatically rolling out changes to the Audit Policy to minimize the amount of Shoot reconciliations in order to prevent cloud provider rate limits, etc.
Gardener will pick up the changes on the next reconciliation of Shoots referencing the Audit Policy ConfigMap.
If users want to immediately rollout Audit Policy changes, they can manually trigger a Shoot reconciliation as described in triggering an immediate reconciliation.
This is similar to changes to the cloud provider secret referenced by Shoots.
12.3 - Default Seccomp Profile
Enable the use of RuntimeDefault as the default seccomp profile through spec.kubernetes.kubelet.seccompDefault
Default Seccomp Profile and Configuration
This is a short guide describing how to enable the defaulting of seccomp profiles for Gardener managed workloads in the seed. Running pods in Unconfined (seccomp disabled) mode is undesirable since this is the least restrictive profile. Also, mind that any privileged container will always run as Unconfined. More information about seccomp can be found in this Kubernetes tutorial.
Setting the Seccomp Profile to RuntimeDefault for Seed Clusters
To address the above issue, Gardener provides a webhook that is capable of mutating pods in the seed clusters, explicitly providing them with a seccomp profile type of RuntimeDefault. This profile is defined by the container runtime and represents a set of default syscalls that are allowed or not.
A Pod is mutated when all of the following preconditions are fulfilled:
The Pod is created in a Gardener managed namespace.
The Pod is NOT labeled with seccompprofile.resources.gardener.cloud/skip.
The Pod does NOT explicitly specify .spec.securityContext.seccompProfile.type.
How to Configure
To enable this feature, the gardenlet DefaultSeccompProfile feature gate must be set to true.
featureGates:
DefaultSeccompProfile: true
Please refer to the examples in this yaml file for more information.
Once the feature gate is enabled, the webhook will be registered and configured for the seed cluster. Newly created pods will be mutated to have their seccomp profile set to RuntimeDefault.
Note: Please note that this feature is still in Alpha, so you might see instabilities every now and then.
Setting the Seccomp Profile to RuntimeDefault for Shoot Clusters
You can enable the use of RuntimeDefault as the default seccomp profile for all workloads. If enabled, the kubelet will use the RuntimeDefault seccomp profile by default, which is defined by the container runtime, instead of using the Unconfined mode. More information for this feature can be found in the Kubernetes documentation.
To use seccomp profile defaulting, you must run the kubelet with the SeccompDefault feature gate enabled (this is the default).
How to Configure
To enable this feature, the kubelet seccompDefault configuration parameter must be set to true in the shoot’s spec.
Please refer to the examples in this yaml file for more information.
12.4 - ETCD Encryption Config
Specifying resource types for encryption with spec.kubernetes.kubeAPIServer.encryptionConfig
ETCD Encryption Config
The spec.kubernetes.kubeAPIServer.encryptionConfig field in the Shoot API allows users to customize encryption configurations for the API server. It provides options to specify additional resources for encryption beyond secrets.
Usage Guidelines
The resources field can be used to specify resources that should be encrypted in addition to secrets. Secrets are always encrypted.
Each item is a Kubernetes resource name in plural (resource or resource.group). Wild cards are not supported.
Adding an item to this list will cause patch requests for all the resources of that kind to encrypt them in the etcd. See Encrypting Confidential Data at Rest for more details.
ClusterOpenIDConnectPreset and OpenIDConnectPreset
Warning
OpenID Connect is deprecated in favor of Structured Authentication configuration. Setting OpenID Connect configurations is forbidden for clusters with Kubernetes version >= 1.32.
This page provides an overview of ClusterOpenIDConnectPresets and OpenIDConnectPresets, which are objects for injecting OpenIDConnect Configuration into Shoot at creation time. The injected information contains configuration for the Kube API Server and optionally configuration for kubeconfig generation using said configuration.
OpenIDConnectPreset
An OpenIDConnectPreset is an API resource for injecting additional runtime OIDC requirements into a Shoot at creation time. You use label selectors to specify the Shoot to which a given OpenIDConnectPreset applies.
Using a OpenIDConnectPresets allows project owners to not have to explicitly provide the same OIDC configuration for every Shoot in their Project.
For more information about the background, see the issue for OpenIDConnectPreset.
How OpenIDConnectPreset Works
Gardener provides an admission controller (OpenIDConnectPreset) which, when enabled, applies OpenIDConnectPresets to incoming Shoot creation requests. When a Shoot creation request occurs, the system does the following:
Retrieve all OpenIDConnectPreset available for use in the Shoot namespace.
Check if the shoot label selectors of any OpenIDConnectPreset matches the labels on the Shoot being created.
If multiple presets are matched then only one is chosen and results are sorted based on:
.spec.weight value.
lexicographically ordering their names (e.g., 002preset > 001preset)
If the Shoot already has a .spec.kubernetes.kubeAPIServer.oidcConfig, then no mutation occurs.
Simple OpenIDConnectPreset Example
This is a simple example to show how a Shoot is modified by the OpenIDConnectPreset:
The OpenIDConnectPreset admission control is enabled by default. To disable it, use the --disable-admission-plugins flag on the gardener-apiserver.
For example:
--disable-admission-plugins=OpenIDConnectPreset
ClusterOpenIDConnectPreset
A ClusterOpenIDConnectPreset is an API resource for injecting additional runtime OIDC requirements into a Shoot at creation time. In contrast to OpenIDConnect, it’s a cluster-scoped resource. You use label selectors to specify the Project and Shoot to which a given OpenIDCConnectPreset applies.
Using a OpenIDConnectPresets allows cluster owners to not have to explicitly provide the same OIDC configuration for every Shoot in specific Project.
For more information about the background, see the issue for ClusterOpenIDConnectPreset.
How ClusterOpenIDConnectPreset Works
Gardener provides an admission controller (ClusterOpenIDConnectPreset) which, when enabled, applies ClusterOpenIDConnectPresets to incoming Shoot creation requests. When a Shoot creation request occurs, the system does the following:
Retrieve all ClusterOpenIDConnectPresets available.
Check if the project label selector of any ClusterOpenIDConnectPreset matches the labels of the Project in which the Shoot is being created.
Check if the shoot label selectors of any ClusterOpenIDConnectPreset matches the labels on the Shoot being created.
If multiple presets are matched then only one is chosen and results are sorted based on:
.spec.weight value.
lexicographically ordering their names ( e.g. 002preset > 001preset )
If the Shoot already has a .spec.kubernetes.kubeAPIServer.oidcConfig then no mutation occurs.
Note: Due to the previous requirement, if a Shoot is matched by both OpenIDConnectPreset and ClusterOpenIDConnectPreset, then OpenIDConnectPreset takes precedence over ClusterOpenIDConnectPreset.
Simple ClusterOpenIDConnectPreset Example
This is a simple example to show how a Shoot is modified by the ClusterOpenIDConnectPreset:
The ClusterOpenIDConnectPreset admission control is enabled by default. To disable it, use the --disable-admission-plugins flag on the gardener-apiserver.
The .spec.kubernetes.kubeAPIServer.serviceAccountConfig.{issuer,acceptedIssuers} fields are translated to the --service-account-issuer flag for the kube-apiserver.
The issuer will assert its identifier in the iss claim of the issued tokens.
According to the upstream specification, values need to meet the following requirements:
This value is a string or URI. If this option is not a valid URI per the OpenID Discovery 1.0 spec, the ServiceAccountIssuerDiscovery feature will remain disabled, even if the feature gate is set to true. It is highly recommended that this value comply with the OpenID spec: https://openid.net/specs/openid-connect-discovery-1_0.html. In practice, this means that service-account-issuer must be an https URL. It is also highly recommended that this URL be capable of serving OpenID discovery documents at {service-account-issuer}/.well-known/openid-configuration.
By default, Gardener uses the internal cluster domain as issuer (e.g., https://api.foo.bar.example.com).
If you specify the issuer, then this default issuer will always be part of the list of accepted issuers (you don’t need to specify it yourself).
Caution
If you change from the default issuer to a custom issuer, all previously issued tokens will still be valid/accepted.
However, if you change from a custom issuerA to another issuerB (custom or default), then you have to add A to the acceptedIssuers so that previously issued tokens are not invalidated.
Otherwise, the control plane components as well as system components and your workload pods might fail.
You can remove A from the acceptedIssuers when all currently active tokens have been issued solely by B.
This can be ensured by using projected token volumes with a short validity, or by rolling out all pods.
Additionally, all ServiceAccount token secrets should be recreated.
Apart from this, you should wait for at least 12h to make sure the control plane and system components have received a new token from Gardener.
Token Expirations
The .spec.kubernetes.kubeAPIServer.serviceAccountConfig.extendTokenExpiration configures the --service-account-extend-token-expiration flag of the kube-apiserver.
It is enabled by default and has the following specification:
Turns on projected service account expiration extension during token generation, which helps safe transition from legacy token to bound service account token feature. If this flag is enabled, admission injected tokens would be extended up to 1 year to prevent unexpected failure during transition, ignoring value of service-account-max-token-expiration.
The .spec.kubernetes.kubeAPIServer.serviceAccountConfig.maxTokenExpiration configures the --service-account-max-token-expiration flag of the kube-apiserver.
It has the following specification:
The maximum validity duration of a token created by the service account token issuer. If an otherwise valid TokenRequest with a validity duration larger than this value is requested, a token will be issued with a validity duration of this value.
Note
The value for this field must be in the [30d,90d] range.
The background for this limitation is that all Gardener components rely on the TokenRequest API and the Kubernetes service account token projection feature with short-lived, auto-rotating tokens.
Any values lower than 30d risk impacting the SLO for shoot clusters, and any values above 90d violate security best practices with respect to maximum validity of credentials before they must be rotated.
Given that the field just specifies the upper bound, end-users can still use lower values for their individual workload by specifying the .spec.volumes[].projected.sources[].serviceAccountToken.expirationSeconds in the PodSpecs.
Managed Service Account Issuer
Gardener also provides a way to manage the service account issuer of a shoot cluster as well as serving its OIDC discovery documents from a centrally managed server called Gardener Discovery Server.
This ability removes the need for changing the .spec.kubernetes.kubeAPIServer.serviceAccountConfig.issuer and exposing it separately.
Prerequisites
Note
The following prerequisites are responsibility of the Gardener Administrators and are not something that end users can configure by themselves.
If uncertain that these requirements are met, please contact your Gardener Administrator.
Prerequisites:
The Garden Cluster should have the Gardener Discovery Server deployed and configured.
The easiest way to handle this is by using the gardener-operator.
Enablement
If the prerequisites are met then the feature can be enabled for a shoot cluster by annotating it with authentication.gardener.cloud/issuer=managed.
Mind that once enabled, this feature cannot be disabled.
Note
After annotating the shoot with authentication.gardener.cloud/issuer=managed the reconciliation will not be triggered immediately.
One can wait for the shoot maintenance window or trigger reconciliation by annotating the shoot with gardener.cloud/operation=reconcile.
After the shoot is reconciled, you can retrieve the new shoot service account issuer value from the shoot’s status.
A sample query that will retrieve the managed issuer looks like this:
kubectl -n my-project get shoot my-shoot -o jsonpath='{.status.advertisedAddresses[?(@.name=="service-account-issuer")].url}'
Once retrieved, the shoot’s OIDC discovery documents can be explored by querying the /.well-known/openid-configuration endpoint of the issuer.
Mind that this annotation is incompatible with the .spec.kubernetes.kubeAPIServer.serviceAccountConfig.issuer field, so if you want to enable it then the issuer field should not be set in the shoot specification.
Caution
If you change from the default issuer to a managed issuer, all previously issued tokens will still be valid/accepted.
However, if you change from a custom issuerA to a managed issuer, then you have to add A to the .spec.kubernetes.kubeAPIServer.serviceAccountConfig.acceptedIssuers so that previously issued tokens are not invalidated.
Otherwise, the control plane components as well as system components and your workload pods might fail.
You can remove A from the acceptedIssuers when all currently active tokens have been issued solely by the managed issuer.
This can be ensured by using projected token volumes with a short validity, or by rolling out all pods.
Additionally, all ServiceAccount token secrets should be recreated.
Apart from this, you should wait for at least 12h to make sure the control plane and system components have received a new token from Gardener.
13 - Shoot
13.1 - Access Restrictions
Access Restrictions
Access restrictions can be configured in the CloudProfile, Seed, and Shoot APIs.
They can be used to implement access restrictions for seed and shoot clusters (e.g., if you want to ensure “EU access”-only or similar policies).
CloudProfile
The .spec.regions list contains all regions that can be selected by Shoots.
Operators can configure them with a list of access restrictions that apply for each region, for example:
This configuration means that Shoots selecting the europe-central-1 region can configure an eu-access-only access restriction.
Shoots running in other regions cannot configure this access restriction in their specification.
Seed
The Seed specification also allows to configure access restrictions that apply for this specific seed cluster, for example:
spec:
accessRestrictions:
- name: eu-access-only
This configuration means that this seed cluster can host shoot clusters that also have the eu-access-only access restriction.
In addition, this seed cluster can also host shoot clusters without any access restrictions at all.
Shoot
If the CloudProfile allows to configure access restrictions for the selected .spec.region in the Shoot (see above), then they can also be provided in the specification of the Shoot, for example:
In addition, it is possible to specify arbitrary options (key-value pairs) for the access restriction.
These options are not interpreted by Gardener, but can be helpful when evaluated by other tools (e.g., gardenctl implements some of them).
Above configuration means that the Shoot shall only be accessible by operators in the EU.
When configured for
a newly created Shoot, gardener-scheduler will automatically filter for Seeds also supporting this access restriction.
All other Seeds are not considered for scheduling.
an existing Shoot, gardener-apiserver will allow removing access restrictions, but adding them is only possible if the currently selected Seed supports them.
If it does not support them, the Shoot must first be migrated to another eligible Seed before they can be added.
an existing Shoot that is migrated, gardener-apiserver will only allow the migration in case the targeted Seed also supports the access restrictions configured on the Shoot.
Important
There is no technical enforcement of these access restrictions - they are purely informational.
Hence, it is the responsibility of the operator to ensure that they enforce the configured access restrictions.
13.2 - Accessing Shoot Clusters
Accessing Shoot Clusters
After creation of a shoot cluster, end-users require a kubeconfig to access it. There are several options available to get to such kubeconfig.
shoots/adminkubeconfig Subresource
The shoots/adminkubeconfig subresource allows users to dynamically generate temporary kubeconfigs that can be used to access shoot cluster with cluster-admin privileges. The credentials associated with this kubeconfig are client certificates which have a very short validity and must be renewed before they expire (by calling the subresource endpoint again).
The username associated with such kubeconfig will be the same which is used for authenticating to the Gardener API. Apart from this advantage, the created kubeconfig will not be persisted anywhere.
In order to request such a kubeconfig, you can run the following commands (targeting the garden cluster):
export NAMESPACE=garden-my-namespace
export SHOOT_NAME=my-shoot
export KUBECONFIG=<kubeconfig for garden cluster> # can be set using "gardenctl target --garden <landscape>"kubectl create \
-f <(printf '{"spec":{"expirationSeconds":600}}') \
--raw /apis/core.gardener.cloud/v1beta1/namespaces/${NAMESPACE}/shoots/${SHOOT_NAME}/adminkubeconfig | \
jq -r ".status.kubeconfig" | \
base64 -d
You also can use controller-runtime client (>= v0.14.3) to create such a kubeconfig from your go code like so:
In Python, you can use the native kubernetes client to create such a kubeconfig like this:
# This script first loads an existing kubeconfig from your system, and then sends a request to the Gardener API to create a new kubeconfig for a shoot cluster. # The received kubeconfig is then decoded and a new API client is created for interacting with the shoot cluster.import base64
import json
from kubernetes import client, config
import yaml
# Set configuration optionsshoot_name="my-shoot"# Name of the shootproject_namespace="garden-my-namespace"# Namespace of the project# Load kubeconfig from default ~/.kube/configconfig.load_kube_config()
api = client.ApiClient()
# Create kubeconfig requestkubeconfig_request = {
'apiVersion': 'authentication.gardener.cloud/v1alpha1',
'kind': 'AdminKubeconfigRequest',
'spec': {
'expirationSeconds': 600
}
}
response = api.call_api(resource_path=f'/apis/core.gardener.cloud/v1beta1/namespaces/{project_namespace}/shoots/{shoot_name}/adminkubeconfig',
method='POST',
body=kubeconfig_request,
auth_settings=['BearerToken'],
_preload_content=False,
_return_http_data_only=True,
)
decoded_kubeconfig = base64.b64decode(json.loads(response.data)["status"]["kubeconfig"]).decode('utf-8')
print(decoded_kubeconfig)
# Create an API client to interact with the shoot clustershoot_api_client = config.new_client_from_config_dict(yaml.safe_load(decoded_kubeconfig))
v1 = client.CoreV1Api(shoot_api_client)
Note: The gardenctl-v2 tool simplifies targeting shoot clusters. It automatically downloads a kubeconfig that uses the gardenlogin kubectl auth plugin. This transparently manages authentication and certificate renewal without containing any credentials.
shoots/viewerkubeconfig Subresource
The shoots/viewerkubeconfig subresource works similar to the shoots/adminkubeconfig.
The difference is that it returns a kubeconfig with read-only access for all APIs except the core/v1.Secret API and the resources which are specified in the spec.kubernetes.kubeAPIServer.encryptionConfig field in the Shoot (see this document).
In order to request such a kubeconfig, you can run follow almost the same code as above - the only difference is that you need to use the viewerkubeconfig subresource.
For example, in bash this looks like this:
The examples for other programming languages are similar to the above and can be adapted accordingly.
Tip
If the Gardener operator has configured a “control plane wildcard certificate”, the issued kubeconfigs have a dedicated Cluster entry containing an endpoint that is served with this wildcard certificate.
This could be a generally trusted certificate, e.g. from Let’s Encrypt or a similar certificate authority, i.e., it does not require you to specify the certificate authority bundle.
⚠️ This endpoint is specific to the seed cluster your Shoot is scheduled to, i.e., if the seed cluster changes (.spec.seedName, for example because of a control plane migration), the endpoint changes as well. Have this in mind in case you consider using it!
Structured Authentication
For shoots with Kubernetes version >= 1.30, which have StructuredAuthenticationConfiguration feature gate enabled (enabled by default), kube-apiserver of shoot clusters can be provided with Structured Authentication configuration via the Shoot spec:
The configMapName references a user created ConfigMap in the project namespace containing the AuthenticationConfiguration in it’s config.yaml data field.
Here is an example of such ConfigMap:
The user is responsible for the validity of the configured JWTAuthenticators.
Be aware that changing the configuration in the ConfigMap will be applied in the next Shoot reconciliation, but this is not automatically triggered.
If you want the changes to roll out immediately, trigger a reconciliation explicitly.
Migrating from OIDC to Structured Authentication Config
If you would like to migrate from OIDC to Structured Authentication Config and your Shoot spec has the spec.kubernetes.kubeAPIServer.oidcConfig field set, for example:
Create a ConfigMap in your project namespace containing an equivalent AuthenticationConfiguration to your current OIDC config. It should look similar to:
Remove the spec.kubernetes.kubeAPIServer.oidcConfig field from the Shoot spec (or the (Cluster)OpenIDConnectPreset resources if it does not target any other Shoot cluster) and replace it with a reference to the newly created ConfigMap in spec.kubernetes.kubeAPIServer.structuredAuthentication.configMapName:
For shoots with Kubernetes version >= 1.30, which have StructuredAuthorizationConfiguration feature gate enabled (enabled by default), kube-apiserver of shoot clusters can be provided with Structured Authorization configuration via the Shoot spec:
The configMapName references a user created ConfigMap in the project namespace containing the AuthorizationConfiguration in it’s config.yaml data field.
Here is an example of such ConfigMap:
In addition, it is required to provide a Secret for each authorizer.
This Secret should contain a kubeconfig with the server address of the webhook server, and optionally credentials for authentication:
The user is responsible for the validity of the configured authorizers.
Be aware that changing the configuration in the ConfigMap will be applied in the next Shoot reconciliation, but this is not automatically triggered.
If you want the changes to roll out immediately, trigger a reconciliation explicitly.
Note
You can have one or more authorizers of type Webhook (no other types are supported).
You are not allowed to specify the authorizers[].webhook.connectionInfo field.
Instead, as mentioned above, provide a kubeconfig file containing the server address (and optionally, credentials that can be used by kube-apiserver in order to authenticate with the webhook server) by creating a Secret containing the kubeconfig (in the .data.kubeconfig key).
Reference this Secret by adding it to .spec.kubernetes.kubeAPIServer.structuredAuthorization.kubeconfigs[] (choose the proper authorizerName, see example above).
Be aware of the fact that all webhook authorizers are added only after the RBAC/Node authorizers.
Hence, if RBAC already allows a request, your webhook authorizer might not get called.
OpenID Connect
Warning
OpenID Connect is deprecated in favor of Structured Authentication configuration. Setting OpenID Connect configurations is forbidden for clusters with Kubernetes version >= 1.32. The configuration and the related API resources (Cluster)OpenIDConnectPreset will be removed when Gardener no longer supports clusters with Kubernetes version < 1.32.
It is the end-user’s responsibility to incorporate the OpenID Connect configurations in the kubeconfig for accessing the cluster (i.e., Gardener will not automatically generate the kubeconfig based on these OIDC settings).
The recommended way is using the kubectl plugin called kubectl oidc-login for OIDC authentication.
If you want to use the same OIDC configuration for all your shoots by default, then you can use the ClusterOpenIDConnectPreset and OpenIDConnectPreset API resources. They allow defaulting the .spec.kubernetes.kubeAPIServer.oidcConfig fields for newly created Shoots such that you don’t have to repeat yourself every time (similar to PodPreset resources in Kubernetes).
ClusterOpenIDConnectPreset specified OIDC configuration applies to Projects and Shoots cluster-wide (hence, only available to Gardener operators), while OpenIDConnectPreset is Project-scoped.
Shoots have to “opt-in” for such defaulting by using the oidc=enable label.
For shoots with Kubernetes version >= 1.30, which have StructuredAuthenticationConfiguration feature gate enabled (enabled by default), it is advised to use Structured Authentication instead of configuring .spec.kubernetes.kubeAPIServer.oidcConfig and/or (Cluster)OpenIDConnectPreset.
Gardener operators can configure limits for shoot clusters in the CloudProfile.spec.limits section, where they can also be looked up by shoot owners.
The limits are enforced on all shoot clusters using the respective CloudProfile.
If a certain limit is not configured, no limit is enforced.
The configured limits of a CloudProfile can be overridden by configuring limits in a NamespacedCloudProfile.
To increase a CloudProfile limit, a user must have permission by the appropriate custom verbs.
Setting a stricter limit is always allowed without requiring special permissions.
For more information, see the NamespacedCloudProfile documentation.
This document explains the limits that can be configured in the CloudProfile.
Maximum Node Count
The CloudProfile.spec.limits.maxNodesTotal configures the maximum supported node count of shoot clusters in a Gardener installation.
If this limit is set, Gardener ensures that
the total minimum node count of all worker pools (i.e., the total initial node count) does not exceed the configured limit
the maximum node count of an individual worker pool does not exceed the configured limit
cluster-autoscaler does not provision more nodes than the configured limit (--max-nodes-total flag)
The maximum node count of a shoot cluster can be lower than the configured limit, if the cluster’s networking configurations don’t allow it (see this doc page).
Gardener operators must ensure that no existing shoot cluster exceeds the limit when adding it.
Because Gardener API server itself cannot verify that all shoot clusters would comply with a given limit set in an API request, it does not allow decreasing the limit, which could be disruptive for existing shoots.
Increasing and removing the limits is allowed.
Note that the node count limit during runtime is applied by the cluster-autoscaler only.
E.g., performing a rolling update can cause shoots to exceed maxNodesTotal by the total maxSurge of all worker pools.
Also, when a shoot owner adds another worker pool to a cluster that has already reached the maximum node count via cluster autoscaling, Gardener would initially deploy the new worker pool with the minimum number of nodes.
This would cause the shoot to temporarily exceed the configured limit until cluster-autoscaler scales the cluster down again.
In other words, CloudProfile.spec.limits.maxNodesTotal doesn’t enforce a hard limit, but rather ensures that shoot clusters stay within a reasonable size that the Gardener operator can and wants to support.
Shoot owners should keep the limit configured in the CloudProfile in mind when configuring the initial node count of new worker pools.
13.4 - Shoot Cluster Purposes
Available Shoot cluster purposes and the behavioral differences between them
Shoot Cluster Purpose
The Shoot resource contains a .spec.purpose field indicating how the shoot is used, whose allowed values are as follows:
evaluation (default): Indicates that the shoot cluster is for evaluation scenarios.
development: Indicates that the shoot cluster is for development scenarios.
testing: Indicates that the shoot cluster is for testing scenarios.
production: Indicates that the shoot cluster is for production scenarios.
infrastructure: Indicates that the shoot cluster is for infrastructure scenarios (only allowed for shoots in the garden namespace).
Behavioral Differences
The following enlists the differences in the way the shoot clusters are set up based on the selected purpose:
testing shoot clusters do not get a monitoring or a logging stack as part of their control planes.
for production and infrastructure shoot clusters auto-scaling scale down of the main ETCD is disabled.
shoot addons like nginxIngress and kubernetesDashboard can only be enabled for evaluation shoot clusters.
There are also differences with respect to how testing shoots are scheduled after creation, please consult the Scheduler documentation.
Future Steps
We might introduce more behavioral difference depending on the shoot purpose in the future.
As of today, there are no plans yet.
13.5 - Shoot cluster supported Kubernetes versions and specifics
Defining the differences and requirements for upgrading to a supported Kubernetes version
Shoot Kubernetes Minor Version Upgrades
Breaking changes may be introduced with new Kubernetes versions.
This documentation describes the Gardener specific differences and requirements for upgrading to a supported Kubernetes version.
For Kubernetes specific upgrade notes the upstream Kubernetes release notes, changelogs and release blogs should be considered before upgrade.
Upgrading to Kubernetes v1.33
A new deny-allNetworkPolicy is deployed into the kube-system namespace of the Shoot cluster. Shoot owners that run workloads in the kube-system namespace are required to explicitly allow their expected Ingress and Egress traffic in kube-system via NetworkPolicies.
The Shoot’s field .spec.kubernetes.kubeControllerManager.podEvictionTimeout is forbidden. Shoot owners should use the .spec.kubernetes.kubeAPIServer.defaultNotReadyTolerationSeconds and .spec.kubernetes.kubeAPIServer.defaultUnreachableTolerationSeconds fields.
The Shoot’s field .spec.kubernetes.clusterAutoscaler.maxEmptyBulkDelete is forbidden. Shoot owners should use the .spec.kubernetes.clusterAutoscaler.maxScaleDownParallelism field.
The Shoot’s spec.kubernetes.kubeAPIServer.oidcConfig.clientAuthentication field is forbidden.
The Shoot’s .spec.kubernetes.kubelet.systemReserved and .spec.provider.workers[].kubernetes.kubelet.systemReserved fields are forbidden. Shoot owners should use the .spec.kubernetes.kubelet.kubeReserved and .spec.provider.workers[].kubernetes.kubelet.kubeReserved fields.
Upgrading to Kubernetes v1.30
The kubeletUnlimitedSwap behavior, configured in the Shoot’s .spec.{kubernetes,provider.workers[]}.kubelet.memorySwap.swapBehavior fields, can no longer be used.
13.6 - Shoot Hibernation
What is hibernation? Manual hibernation/wake up and specifying a hibernation schedule
Shoot Hibernation
Clusters are only needed 24 hours a day if they run productive workload. So whenever you do development in a cluster, or just use it for tests or demo purposes, you can save a lot of money if you scale-down your Kubernetes resources whenever you don’t need them. However, scaling them down manually can become time-consuming the more resources you have.
Gardener offers a clever way to automatically scale-down all resources to zero: cluster hibernation. You can either hibernate a cluster by pushing a button, or by defining a hibernation schedule.
To save costs, it’s recommended to define a hibernation schedule before the creation of a cluster. You can hibernate your cluster or wake up your cluster manually even if there’s a schedule for its hibernation.
When a cluster is hibernated, Gardener scales down the worker nodes and the cluster’s control plane to free resources at the IaaS provider. This affects:
Your workload, for example, pods, deployments, custom resources.
The virtual machines running your workload.
The resources of the control plane of your cluster.
What Isn’t Affected by the Hibernation?
To scale up everything where it was before hibernation, Gardener doesn’t delete state-related information, that is, information stored in persistent volumes. The cluster state as persistent in etcd is also preserved.
Hibernate Your Cluster Manually
The .spec.hibernation.enabled field specifies whether the cluster needs to be hibernated or not. If the field is set to true, the cluster’s desired state is to be hibernated. If it is set to false or not specified at all, the cluster’s desired state is to be awakened.
To hibernate your cluster, you can run the following kubectl command:
You can specify a hibernation schedule to automatically hibernate/wake up a cluster.
Let’s have a look into the following example:
hibernation:
enabled: false schedules:
- start: "0 20 * * *"# Start hibernation every day at 8PM end: "0 6 * * *"# Stop hibernation every day at 6AM location: "America/Los_Angeles"# Specify a location for the cron to run in
The above section configures a hibernation schedule that hibernates the cluster every day at 08:00 PM and wakes it up at 06:00 AM. The start or end fields can be omitted, though at least one of them has to be specified. Hence, it is possible to configure a hibernation schedule that only hibernates or wakes up a cluster. The location field is the time location used to evaluate the cron expressions.
13.7 - Shoot Info Configmap
Shoot Info ConfigMap
Overview
The gardenlet maintains a ConfigMap inside the Shoot cluster that contains information about the cluster itself. The ConfigMap is named shoot-info and located in the kube-system namespace.
Fields
The following fields are provided:
apiVersion: v1
kind: ConfigMap
metadata:
name: shoot-info
namespace: kube-system
data:
domain: crazy-botany.core.my-custom-domain.com # .spec.dns.domain field from the Shoot resource extensions: foobar,foobaz # List of extensions that are enabled kubernetesVersion: 1.25.4 # .spec.kubernetes.version field from the Shoot resource maintenanceBegin: 220000+0100 # .spec.maintenance.timeWindow.begin field from the Shoot resource maintenanceEnd: 230000+0100 # .spec.maintenance.timeWindow.end field from the Shoot resource nodeNetwork: 10.250.0.0/16 # .spec.networking.nodes field from the Shoot resource podNetwork: 100.96.0.0/11 # .spec.networking.pods field from the Shoot resource projectName: dev # .metadata.name of the Project provider: <some-provider-name> # .spec.provider.type field from the Shoot resource region: europe-central-1 # .spec.region field from the Shoot resource serviceNetwork: 100.64.0.0/13 # .spec.networking.services field from the Shoot resource shootName: crazy-botany # .metadata.name from the Shoot resource
13.8 - Shoot Maintenance
Defining the maintenance time window, configuring automatic version updates, confining reconciliations to only happen during maintenance, adding an additional maintenance operation, etc.
Shoot Maintenance
Shoots configure a maintenance time window in which Gardener performs certain operations that may restart the control plane, roll out the nodes, result in higher network traffic, etc. A summary of what was changed in the last maintenance time window in shoot specification is kept in the shoot status .status.lastMaintenance field.
This document outlines what happens during a shoot maintenance.
Time Window
Via the .spec.maintenance.timeWindow field in the shoot specification, end-users can configure the time window in which maintenance operations are executed.
Gardener runs one maintenance operation per day in this time window:
The offset (+0100) is considered with respect to UTC time.
The minimum time window is 30m and the maximum is 6h.
⚠️ Please note that there is no guarantee that a maintenance operation that, e.g., starts a node roll-out will finish within the time window.
Especially for large clusters, it may take several hours until a graceful rolling update of the worker nodes succeeds (also depending on the workload and the configured pod disruption budgets/termination grace periods).
Internally, Gardener is subtracting 15m from the end of the time window to (best-effort) try to finish the maintenance until the end is reached, however, this might not work in all cases.
If you don’t specify a time window, then Gardener will randomly compute it.
You can change it later, of course.
Automatic Version Updates
The .spec.maintenance.autoUpdate field in the shoot specification allows you to control how/whether automatic updates of Kubernetes patch and machine image versions are performed.
Machine image versions are updated per worker pool.
During the daily maintenance, the Gardener Controller Manager updates the Shoot’s Kubernetes and machine image version if any of the following criteria applies:
There is a higher version available and the Shoot opted-in for automatic version updates.
The currently used version is expired.
The target version for machine image upgrades is controlled by the updateStrategy field for the machine image in the CloudProfile. Allowed update strategies are patch, minor and major.
Gardener (gardener-controller-manager) populates the lastMaintenance field in the Shoot status with the maintenance results.
Last Maintenance:
Description: "All maintenance operations successful. Control Plane: Updated Kubernetes version from 1.26.4 to 1.27.1. Reason: Kubernetes version expired - force update required" State: Succeeded
Triggered Time: 2023-07-28T09:07:27Z
Additionally, Gardener creates events with the type MachineImageVersionMaintenance or KubernetesVersionMaintenance on the Shoot describing the action performed during maintenance, including the reason why an update has been triggered.
LAST SEEN TYPE REASON OBJECT MESSAGE
30m Normal MachineImageVersionMaintenance shoot/local Worker pool "local": Updated image from 'gardenlinux' version 'xy' to version 'abc'. Reason: Automatic update of the machine image version is configured (image update strategy: major).
30m Normal KubernetesVersionMaintenance shoot/local Control Plane: Updated Kubernetes version from "1.26.4" to "1.27.1". Reason: Kubernetes version expired - force update required.
15m Normal KubernetesVersionMaintenance shoot/local Worker pool "local": Updated Kubernetes version '1.26.3' to version '1.27.1'. Reason: Kubernetes version expired - force update required.
If at least one maintenance operation fails, the lastMaintenance field in the Shoot status is set to Failed:
Last Maintenance:
Description: "(1/2) maintenance operations successful: Control Plane: Updated Kubernetes version from 1.26.4 to 1.27.1. Reason: Kubernetes version expired - force update required, Worker pool x: 'gardenlinux' machine image version maintenance failed. Reason for update: machine image version expired" FailureReason: "Worker pool x: either the machine image 'gardenlinux' is reaching end of life and migration to another machine image is required or there is a misconfiguration in the CloudProfile." State: Failed
Triggered Time: 2023-07-28T09:07:27Z
Gardener administrators/operators can configure the gardenlet in a way that it only reconciles shoot clusters during their maintenance time windows.
This behaviour is not controllable by end-users but might make sense for large Gardener installations.
Concretely, your shoot will be reconciled regularly during its maintenance time window.
Outside of the maintenance time window it will only reconcile if you change the specification or if you explicitly trigger it, see also Trigger Shoot Operations.
Confine Specification Changes/Updates Roll Out
Via the .spec.maintenance.confineSpecUpdateRollout field you can control whether you want to make Gardener roll out changes/updates to your shoot specification only during the maintenance time window.
It is false by default, i.e., any change to your shoot specification triggers a reconciliation (even outside of the maintenance time window).
This is helpful if you want to update your shoot but don’t want the changes to be applied immediately. One example use-case would be a Kubernetes version upgrade that you want to roll out during the maintenance time window.
Any update to the specification will not increase the .metadata.generation of the Shoot, which is something you should be aware of.
Also, even if Gardener administrators/operators have not enabled the “reconciliation in maintenance time window only” configuration (as mentioned above), then your shoot will only reconcile in the maintenance time window.
The reason is that Gardener cannot differentiate between create/update/reconcile operations.
⚠️ If confineSpecUpdateRollout=true, please note that if you change the maintenance time window itself, then it will only be effective after the upcoming maintenance.
⚠️ As exceptions to the above rules, manually triggered reconciliations and changes to the .spec.hibernation.enabled field trigger immediate rollouts.
I.e., if you hibernate or wake-up your shoot, or you explicitly tell Gardener to reconcile your shoot, then Gardener gets active right away.
Shoot Operations
In case you would like to perform a shoot credential rotation or a reconcile operation during your maintenance time window, you can annotate the Shoot with
maintenance.gardener.cloud/operation=<operation>
This will execute the specified <operation> during the next maintenance reconciliation.
Note that Gardener will remove this annotation after it has been performed in the maintenance reconciliation.
⚠️ This is skipped when the Shoot’s .status.lastOperation.state=Failed. Make sure to retry your shoot reconciliation beforehand.
Special Operations During Maintenance
The shoot maintenance controller triggers special operations that are performed as part of the shoot reconciliation.
Infrastructure and DNSRecord Reconciliation
The reconciliation of the Infrastructure and DNSRecord extension resources is only demanded during the shoot’s maintenance time window.
The rationale behind it is to prevent sending too many requests against the cloud provider APIs, especially on large landscapes or if a user has many shoot clusters in the same cloud provider account.
Restart Control Plane Controllers
Gardener operators can make Gardener restart/delete certain control plane pods during a shoot maintenance.
This feature helps to automatically solve service denials of controllers due to stale caches, dead-locks or starving routines.
Please note that these are exceptional cases but they are observed from time to time.
Gardener, for example, takes this precautionary measure for kube-controller-manager pods.
See Shoot Maintenance to see how extension developers can extend this behaviour.
Restart Some Core Addons
Gardener operators can make Gardener restart some core addons (at the moment only CoreDNS) during a shoot maintenance.
CoreDNS benefits from this feature as it automatically solve problems with clients stuck to single replica of the deployment and thus overloading it.
Please note that these are exceptional cases but they are observed from time to time.
13.9 - Shoot Scheduling Profiles
Introducing balanced and bin-packing scheduling profiles
Shoot Scheduling Profiles
This guide describes the available scheduling profiles and how they can be configured in the Shoot cluster. It also clarifies how a custom scheduling profile can be configured.
Scheduling Profiles
The scheduling process in the kube-scheduler happens in a series of stages. A scheduling profile allows configuring the different stages of the scheduling.
As of today, Gardener supports two predefined scheduling profiles:
balanced (default)
Overview
The balanced profile attempts to spread Pods evenly across Nodes to obtain a more balanced resource usage. This profile provides the default kube-scheduler behavior.
How it works?
The kube-scheduler is started without any profiles. In such case, by default, one profile with the scheduler name default-scheduler is created. This profile includes the default plugins. If a Pod doesn’t specify the .spec.schedulerName field, kube-apiserver sets it to default-scheduler. Then, the Pod gets scheduled by the default-scheduler accordingly.
bin-packing
Overview
The bin-packing profile scores Nodes based on the allocation of resources. It prioritizes Nodes with the most allocated resources. By favoring the Nodes with the most allocation, some of the other Nodes become under-utilized over time (because new Pods keep being scheduled to the most allocated Nodes). Then, the cluster-autoscaler identifies such under-utilized Nodes and removes them from the cluster. In this way, this profile provides a greater overall resource utilization (compared to the balanced profile).
Note: The decision of when to remove a Node is a trade-off between optimizing for utilization or the availability of resources. Removing under-utilized Nodes improves cluster utilization, but new workloads might have to wait for resources to be provisioned again before they can run.
How it works?
The kube-scheduler is configured with the following bin packing profile:
To impose the new profile, a MutatingWebhookConfiguration is deployed in the Shoot cluster. The MutatingWebhookConfiguration intercepts CREATE operations for Pods and sets the .spec.schedulerName field to bin-packing-scheduler. Then, the Pod gets scheduled by the bin-packing-scheduler accordingly. Pods that specify a custom scheduler (i.e., having .spec.schedulerName different from default-scheduler and bin-packing-scheduler) are not affected.
Configuring the Scheduling Profile
The scheduling profile can be configured via the .spec.kubernetes.kubeScheduler.profile field in the Shoot:
spec:
# ... kubernetes:
kubeScheduler:
profile: "balanced"# or "bin-packing"
Custom Scheduling Profiles
The kube-scheduler’s component configs allows configuring custom scheduling profiles to match the cluster needs. As of today, Gardener supports only two predefined scheduling profiles. The profile configuration in the component config is quite expressive and it is not possible to easily define profiles that would match the needs of every cluster. Because of these reasons, there are no plans to add support for new predefined scheduling profiles. If a cluster owner wants to use a custom scheduling profile, then they have to deploy (and maintain) a dedicated kube-scheduler deployment in the cluster itself.
13.10 - Shoot Status
Shoot conditions, constraints, and error codes
Shoot Status
This document provides an overview of the ShootStatus.
Conditions
The Shoot status consists of a set of conditions. A Condition has the following fields:
Field name
Description
type
Name of the condition.
status
Indicates whether the condition is applicable, with possible values True, False, Unknown or Progressing.
lastTransitionTime
Timestamp for when the condition last transitioned from one status to another.
lastUpdateTime
Timestamp for when the condition was updated. Usually changes when reason or message in condition is updated.
reason
Machine-readable, UpperCamelCase text indicating the reason for the condition’s last transition.
message
Human-readable message indicating details about the last status transition.
codes
Well-defined error codes in case the condition reports a problem.
Currently, the available Shoot condition types are:
The condition checks are executed periodically at an interval which is configurable in the GardenletConfiguration (.controllers.shootCare.syncPeriod, defaults to 1m).
Condition Thresholds
The GardenletConfiguration also allows configuring condition thresholds (controllers.shootCare.conditionThresholds). A condition threshold is the amount of time to consider a condition as Processing on condition status changes.
Let’s check the following example to get a better understanding. Let’s say that the APIServerAvailable condition of our Shoot is with status True. If the next condition check fails (for example kube-apiserver becomes unreachable), then the condition first goes to Processing state. Only if this state remains for condition threshold amount of time, then the condition is finally updated to False.
Constraints
Constraints represent conditions of a Shoot’s current state that constraint some operations on it.
The current constraints are:
HibernationPossible:
This constraint indicates whether a Shoot is allowed to be hibernated.
The rationale behind this constraint is that a Shoot can have ValidatingWebhookConfigurations or MutatingWebhookConfigurations acting on resources that are critical for waking up a cluster.
For example, if a webhook has rules for CREATE/UPDATE Pods or Nodes and failurePolicy=Fail, the webhook will block joining Nodes and creating critical system component Pods and thus block the entire wakeup operation, because the server backing the webhook is not running.
Even if the failurePolicy is set to Ignore, high timeouts (>15s) can lead to blocking requests of control plane components.
That’s because most control-plane API calls are made with a client-side timeout of 30s, so if a webhook has timeoutSeconds=30
the overall request might still fail as there is overhead in communication with the API server and potential other webhooks.
Generally, it’s best practice to specify low timeouts in WebhookConfigs.
As an effort to correct this common problem, the webhook remediator has been created. This is enabled by setting .controllers.shootCare.webhookRemediatorEnabled=true in the gardenlet’s configuration. This feature simply checks whether webhook configurations in shoot clusters match a set of rules described here. If at least one of the rules matches, it will change set status=False for the .status.constraints of type HibernationPossible and MaintenancePreconditionsSatisfied in the Shoot resource. In addition, the failurePolicy in the affected webhook configurations will be set from Fail to Ignore. Gardenlet will also add an annotation to make it visible to end-users that their webhook configurations were mutated and should be fixed/adapted according to the rules and best practices.
In most cases, you can avoid this by simply excluding the kube-system namespace from your webhook via the namespaceSelector:
However, some other resources (some of them cluster-scoped) might still trigger the remediator, namely:
endpoints
nodes
clusterroles
clusterrolebindings
customresourcedefinitions
apiservices
certificatesigningrequests
priorityclasses
If one of the above resources triggers the remediator, the preferred solution is to remove that particular resource from your webhook’s rules. You can also use the objectSelector to reduce the scope of webhook’s rules. However, in special cases where a webhook is absolutely needed for the workload, it is possible to add the remediation.webhook.shoot.gardener.cloud/exclude=true label to your webhook so that the remediator ignores it. This label should not be used to silence an alert, but rather to confirm that a webhook won’t cause problems. Note that all of this is no perfect solution and just done on a best effort basis, and only the owner of the webhook can know whether it indeed is problematic and configured correctly.
In a special case, if a webhook has a rule for CREATE/UPDATE lease resources in kube-system namespace, its timeoutSeconds is updated to 3 seconds. This is required to ensure the proper functioning of the leader election of essential control plane controllers.
This constraint indicates whether all preconditions for a safe maintenance operation are satisfied (see Shoot Maintenance for more information about what happens during a shoot maintenance).
As of today, the same checks as in the HibernationPossible constraint are being performed (user-deployed webhooks that might interfere with potential rolling updates of shoot worker nodes).
There is no further action being performed on this constraint’s status (maintenance is still being performed).
It is meant to make the user aware of potential problems that might occur due to his configurations.
CACertificateValiditiesAcceptable:
This constraint indicates that there is at least one CA certificate which expires in less than 1y.
It will not be added to the .status.constraints if there is no such CA certificate.
However, if it’s visible, then a credentials rotation operation should be considered.
CRDsWithProblematicConversionWebhooks:
This constraint indicates that there is at least one CustomResourceDefinition in the cluster which has multiple stored versions and a conversion webhook configured. This could break the reconciliation flow of a Shoot cluster in some cases. See https://github.com/gardener/gardener/issues/7471 for more details.
It will not be added to the .status.constraints if there is no such CRD.
However, if it’s visible, then you should consider upgrading the existing objects to the current stored version. See Upgrade existing objects to a new stored version for detailed steps.
ManualInPlaceWorkersUpdated:
This constraint indicates that at least one worker pool with the update strategy ManualInPlaceUpdate is pending an update. Despite this, the Shoot reconciliation will still succeed.
The constraint is not added to .status.constraints if all such worker pools are already up-to-date.
Once the user manually labels all the relevant nodes with node.machine.sapcloud.io/selected-for-update and the update process completes, the constraint will be automatically removed.
Last Operation
The Shoot status holds information about the last operation that is performed on the Shoot. The last operation field reflects overall progress and the tasks that are currently being executed. Allowed operation types are Create, Reconcile, Delete, Migrate, and Restore. Allowed operation states are Processing, Succeeded, Error, Failed, Pending, and Aborted. An operation in Error state is an operation that will be retried for a configurable amount of time (controllers.shoot.retryDuration field in GardenletConfiguration, defaults to 12h). If the operation cannot complete successfully for the configured retry duration, it will be marked as Failed. An operation in Failed state is an operation that won’t be retried automatically (to retry such an operation, see Retry failed operation).
Last Errors
The Shoot status also contains information about the last occurred error(s) (if any) during an operation. A LastError consists of identifier of the task returned error, human-readable message of the error and error codes (if any) associated with the error.
Error Codes
Known error codes and their classification are:
Error code
User error
Description
ERR_INFRA_UNAUTHENTICATED
true
Indicates that the last error occurred due to the client request not being completed because it lacks valid authentication credentials for the requested resource. It is classified as a non-retryable error code.
ERR_INFRA_UNAUTHORIZED
true
Indicates that the last error occurred due to the server understanding the request but refusing to authorize it. It is classified as a non-retryable error code.
ERR_INFRA_QUOTA_EXCEEDED
true
Indicates that the last error occurred due to infrastructure quota limits. It is classified as a non-retryable error code.
ERR_INFRA_RATE_LIMITS_EXCEEDED
false
Indicates that the last error occurred due to exceeded infrastructure request rate limits.
ERR_INFRA_DEPENDENCIES
true
Indicates that the last error occurred due to dependent objects on the infrastructure level. It is classified as a non-retryable error code.
ERR_RETRYABLE_INFRA_DEPENDENCIES
false
Indicates that the last error occurred due to dependent objects on the infrastructure level, but the operation should be retried.
ERR_INFRA_RESOURCES_DEPLETED
true
Indicates that the last error occurred due to depleted resource in the infrastructure.
ERR_CLEANUP_CLUSTER_RESOURCES
true
Indicates that the last error occurred due to resources in the cluster that are stuck in deletion.
ERR_CONFIGURATION_PROBLEM
true
Indicates that the last error occurred due to a configuration problem. It is classified as a non-retryable error code.
ERR_RETRYABLE_CONFIGURATION_PROBLEM
true
Indicates that the last error occurred due to a retryable configuration problem. “Retryable” means that the occurred error is likely to be resolved in a ungraceful manner after given period of time.
ERR_PROBLEMATIC_WEBHOOK
true
Indicates that the last error occurred due to a webhook not following the Kubernetes best practices.
Please note: Errors classified as User error: true do not require a Gardener operator to resolve but can be remediated by the user (e.g. by refreshing expired infrastructure credentials).
Even though ERR_INFRA_RATE_LIMITS_EXCEEDED and ERR_RETRYABLE_INFRA_DEPENDENCIES is mentioned as User error: false` operator can’t provide any resolution because it is related to cloud provider issue.
Status Label
Shoots will be automatically labeled with the shoot.gardener.cloud/status label.
Its value might either be healthy, progressing, unhealthy or unknown depending on the .status.conditions, .status.lastOperation, and status.lastErrors of the Shoot.
This can be used as an easy filter method to find shoots based on their “health” status.
13.11 - Shoot Supported Architectures
Supported CPU Architectures for Shoot Worker Nodes
Users can create shoot clusters with worker groups having virtual machines of different architectures. CPU architecture of each worker pool can be specified in the Shoot specification as follows:
If no value is specified for the architecture field, it defaults to amd64. For a valid shoot object, a machine type should be present in the respective CloudProfile with the same CPU architecture as specified in the Shoot yaml. Also, a valid machine image should be present in the CloudProfile that supports the required architecture specified in the Shoot worker pool.
Currently, Gardener supports two of the most widely used CPU architectures:
amd64
arm64
13.12 - Shoot Worker Nodes Settings
Configuring SSH Access through ‘.spec.provider.workersSettings`
Shoot Worker Nodes Settings
Users can configure settings affecting all worker nodes via .spec.provider.workersSettings in the Shoot resource.
SSH Access
SSHAccess indicates whether the sshd.service should be running on the worker nodes. This is ensured by a systemd service called sshd-ensurer.service which runs every 15 seconds on each worker node. When set to true, the systemd service ensures that the sshd.service is unmasked, enabled and running. If it is set to false, the systemd service ensures that sshd.service is disabled, masked and stopped. This also terminates all established SSH connections on the host. In addition, when this value is set to false, existing Bastion resources are deleted during Shoot reconciliation and new ones are prevented from being created, SSH keypairs are not created/rotated, SSH keypair secrets are deleted from the Garden cluster, and the gardener-user.service is not deployed to the worker nodes.
Configure access to infrastructure accounts via workload identity instead of static credentials
Shoot Workload Identity
WorkloadIdentity is a resource that allows workloads to be presented before external systems by giving them identities managed by Gardener.
As WorkloadIdentitys do not directly contain credentials we gain the ability to create Shoots without the need of preliminary exchange of credentials.
For that to work users should establish trust to the Gardener Workload Identity Issuer in advance.
The issuer URL can be read from the Gardener Info ConfigMap.
Tip
Shoots that were previously using Secrets as authentication method can also be migrated to use WorkloadIdentity.
As the credentialsRef field of CredentialsBinding is immutable,
one would have to create a new CredentialsBinding that references a WorkloadIdentity and set the .spec.credentialsBindingName field of the Shoot
to refer to the newly created CredentialsBinding.
As of now WorkloadIdentity is supported for AWS, Azure and GCP. For detailed explanation on how to enable the feature, please consult the provider extension specific documentation:
Starting from v1.71, users can create a Shoot without any workers, known as a “workerless Shoot”. Previously, worker nodes had to always be included even if users only needed the Kubernetes control plane. With workerless Shoots, Gardener will not create any worker nodes or anything related to them.
Here’s an example manifest for a local workerless Shoot:
apiVersion: core.gardener.cloud/v1beta1
kind: Shoot
metadata:
name: local
namespace: garden-local
spec:
cloudProfile:
name: local
region: local
provider:
type: local
kubernetes:
version: 1.31.1
⚠️ It’s important to note that a workerless Shoot cannot be converted to a Shoot with workers or vice versa.
As part of the control plane, the following components are deployed in the seed cluster for workerless Shoot:
etcds
kube-apiserver
kube-controller-manager
gardener-resource-manager
logging and monitoring components
extension components (if they support workerless Shoots, see here)
14 - Shoot Operations
14.1 - Controlling the Kubernetes Versions for Specific Worker Pools
Controlling the Kubernetes Versions for Specific Worker Pools
Since Gardener v1.36, worker pools can have different Kubernetes versions specified than the control plane.
In earlier Gardener versions, all worker pools inherited the Kubernetes version of the control plane. Once the Kubernetes version of the control plane was modified, all worker pools have been updated as well (either by rolling the nodes in case of a minor version change, or in-place for patch version changes).
In order to gracefully perform Kubernetes upgrades (triggering a rolling update of the nodes) with workloads sensitive to restarts (e.g., those dealing with lots of data), it might be required to be able to gradually perform the upgrade process.
In such cases, the Kubernetes version for the worker pools can be pinned (.spec.provider.workers[].kubernetes.version) while the control plane Kubernetes version (.spec.kubernetes.version) is updated.
This results in the nodes being untouched while the control plane is upgraded.
Now a new worker pool (with the version equal to the control plane version) can be added.
Administrators can then reschedule their workloads to the new worker pool according to their upgrade requirements and processes.
If .kubernetes.version is not specified in a worker pool, then the Kubernetes version of the kubelet is inherited from the control plane (.spec.kubernetes.version), i.e., in the above example, the data2 pool will use 1.26.8.
If .kubernetes.version is specified in a worker pool, then it must meet the following constraints:
It must be at most two minor versions lower than the control plane version.
If it was not specified before, then no downgrade is possible (you cannot set it to 1.26.8 while .spec.kubernetes.version is already 1.27.4). The “two minor version skew” is only possible if the worker pool version is set to the control plane version and then the control plane was updated gradually by two minor versions.
If the version is removed from the worker pool, only one minor version difference is allowed to the control plane (you cannot upgrade a pool from version 1.25.0 to 1.27.0 in one go).
Automatic updates of Kubernetes versions (see Shoot Maintenance) also apply to worker pool Kubernetes versions.
14.2 - SecretBinding to CredentialsBinding Migration
SecretBinding to CredentialsBinding Migration
With the introduction of the CredentialsBinding resource a new way of referencing credentials through the Shoot was created.
While SecretBindings can only reference Secrets, CredentialsBindings can also reference WorkloadIdentitys which provide an alternative authentication method.
WorkloadIdentitys do not directly contain credentials but are rather a representation of the workload that is going to access the user’s account.
As CredentialsBindings cover the functionality of SecretBindings, the latter are considered legacy and will be deprecated in the future.
This incurs the need for migration from SecretBinding to CredentialsBinding resources.
Note
Mind that the migration will be allowed only if the old SecretBinding and the new CredentialsBinding refer to the same exact Secret.
One cannot do a direct migration to a CredentialsBinding that reference a WorkloadIdentity.
For information on how to use WorkloadIdentity, please refer to the following document.
Migration Path
A standard use of SecretBinding can look like the following example.
In order to migrate to CredentialsBinding one should:
Create a CredentialsBinding resource corresponding to the existing SecretBinding. The main difference is that we set the kind and apiVersion of the credentials that the CredentialsBinding is referencing.
There are a lot of different credentials for Shoots to make sure that the various components can communicate with each other and to make sure it is usable and operable.
This page explains how the varieties of credentials can be rotated so that the cluster can be considered secure.
User-Provided Credentials
Cloud Provider Keys
End-users must provide credentials such that Gardener and Kubernetes controllers can communicate with the respective cloud provider APIs in order to perform infrastructure operations.
For example, Gardener uses them to set up and maintain the networks, security groups, subnets, etc., while the cloud-controller-manager uses them to reconcile load balancers and routes, and the CSI controller uses them to reconcile volumes and disks.
Depending on the cloud provider, the required data keys of the Secret differ.
Please consult the documentation of the respective provider extension documentation to get to know the concrete data keys (e.g., this document for AWS).
It is the responsibility of the end-user to regularly rotate those credentials.
The following steps are required to perform the rotation:
Update the data in the Secret with new credentials.
⚠️ Wait until all Shoots using the Secret are reconciled before you disable the old credentials in your cloud provider account! Otherwise, the Shoots will no longer work as expected. Check out this document to learn how to trigger a reconciliation of your Shoots.
(Optional) If you want to verify that the new credentials are valid you can trigger immediate maintenance operation for the corresponding shoot cluster(s) and wait for to subsequent reconciliation(s) to complete successfully. The maintenance operation triggers infrastructure reconciliation during the subsequent shoot reconciliation which makes use of the new cloud provider credentials.
After all Shoots using the Secret were reconciled, you can go ahead and deactivate the old credentials in your provider account.
Gardener-Provided Credentials
The below credentials are generated by Gardener when shoot clusters are being created.
Those include:
certificate authorities (and related server and client certificates)
observability passwords for Plutono
SSH key pair for worker nodes
ETCD encryption key
ServiceAccount token signing key
…
🚨 There is no auto-rotation of those credentials, and it is the responsibility of the end-user to regularly rotate them.
While it is possible to rotate them one by one, there is also a convenient method to combine the rotation of all of those credentials.
The rotation happens in two phases since it might be required to update some API clients (e.g., when CAs are rotated).
Prepare Rotation of All Credentials
In order to start the rotation (first phase), you have to annotate the shoot with the rotate-credentials-start operation:
You can check the .status.credentials.rotation field in the Shoot to see when the rotation was last initiated and last completed.
Kindly consider the detailed descriptions below to learn how the rotation is performed and what your responsibilities are.
Please note that all respective individual actions apply for this combined rotation as well (e.g., worker nodes are rolled out in the first phase).
Tip
If you don’t want the worker nodes to roll out immediately in this phase (and rather trigger it individually at a later time of your convenience), you can use the rotate-credentials-start-without-workers-rollout and rotate-rollout-workers operations instead.
Read up all about it here.
Complete Rotation of All Credentials
You can complete the rotation (second phase) by annotating the shoot with the rotate-credentials-complete operation:
Gardener generates several certificate authorities (CAs) to ensure secured communication between the various components and actors.
Most of those CAs are used for internal communication (e.g., kube-apiserver talks to etcd, vpn-shoot talks to the vpn-seed-server, kubelet talks to kube-apiserver).
However, there is also the “cluster CA” which is part of all kubeconfigs and used to sign the server certificate exposed by the kube-apiserver.
Gardener populates a ConfigMap with the name <shoot-name>.ca-cluster in the project namespace in the garden cluster which contains the following data keys:
ca.crt: the CA bundle of the cluster
This bundle contains one or multiple CAs which are used for signing serving certificates of the Shoot’s API server.
Hence, the certificates contained in this ConfigMap can be used to verify the API server’s identity when communicating with its public endpoint (e.g., as certificate-authority-data in a kubeconfig).
This is the same certificate that is also contained in the kubeconfig’s certificate-authority-data field.
Shoots created with Gardener >= v1.45 have a dedicated client CA which verifies the legitimacy of client certificates. For older Shoots, the client CA is equal to the cluster CA. With the first CA rotation, such clusters will get a dedicated client CA as well.
All the certificates are valid for 10 years.
Since it requires adaptation for the consumers of the Shoot, there is no automatic rotation, and it is the responsibility of the end-user to regularly rotate the CA certificates.
The rotation happens in three stages (see also GEP-18 for the full details):
In stage one, new CAs are created and added to the bundle (together with the old CAs). Client certificates are re-issued immediately.
In stage two, end-users update all cluster API clients that communicate with the control plane.
In stage three, the old CAs are dropped from the bundle and server certificate are re-issued.
Technically, the Preparing phase indicates stage one.
Once it is completed, the Prepared phase indicates readiness for stage two.
The Completing phase indicates stage three, and the Completed phase states that the rotation process has finished.
You can check the .status.credentials.rotation.certificateAuthorities field in the Shoot to see when the rotation was last initiated, last completed, and in which phase it currently is.
In order to start the rotation (stage one), you have to annotate the shoot with the rotate-ca-start operation:
This will trigger a Shoot reconciliation and performs stage one.
After it is completed, the .status.credentials.rotation.certificateAuthorities.phase is set to Prepared.
Now you must update all API clients outside the cluster (such as the kubeconfigs on developer machines) to use the newly issued CA bundle in the <shoot-name>.ca-clusterConfigMap.
Please also note that client certificates must be re-issued now.
After updating all API clients, you can complete the rotation by annotating the shoot with the rotate-ca-complete operation:
This will trigger another Shoot reconciliation and performs stage three.
After it is completed, the .status.credentials.rotation.certificateAuthorities.phase is set to Completed.
You could update your API clients again and drop the old CA from their bundle.
Note that the CA rotation also rotates all internal CAs and signed certificates.
Hence, most of the components need to be restarted (including etcd and kube-apiserver).
⚠️ In stage one, all worker nodes of the Shoot will be rolled out to ensure that the Pods as well as the kubelets get the updated credentials as well.
Triggering Worker Node Rollout Individually
If you don’t want that all worker nodes of the Shoot get rolled out in phase one, you can start the rotation with rotate-ca-start-without-workers-rollout instead of rotate-ca-start.
This allows you to trigger the worker node rollout individually (per worker pool) whenever you are ready for it.
Using this annotation will trigger a Shoot reconciliation and performs stage one.
While it’s running, .status.credentials.rotation.certificateAuthorities.phase is set to PreparingWithoutWorkersRollout.
Once completed, the phase transitions to WaitingForWorkersRollout.
Now you can update all API clients outside the cluster (see above) and also trigger the rollout of your worker pools like this:
You can check which worker pools still need to be rolled by reading .status.credentials.rotation.certificateAuthorities.pendingWorkersRollouts[].name.
Once this list is empty, the phase transitions to Prepared.
Now you can just complete the rotation as usual (see above).
Worker Node with ManualInPlaceUpdate Update Strategy
In case of manual in-place update, shoot CA rotation phase will be at Preparing until all the worker pools are successfully in-place updated and there are no pending worker pools with strategy ManualInPlaceUpdate.
You can check which worker pools still need to be updated by reading .status.inPlaceUpdates.pendingWorkerUpdates.manualInPlaceUpdate.
Once this list is empty, the phase transitions to Prepared.
After this rotation will be completed as usual (see above).
Observability Password(s) For Plutono and Prometheus
For Shoots with .spec.purpose!=testing, Gardener deploys an observability stack with Prometheus for monitoring, Alertmanager for alerting (optional), Vali for logging, and Plutono for visualization.
The Plutono instance is exposed via Ingress and accessible for end-users via basic authentication credentials generated and managed by Gardener.
Those credentials are stored in a Secret with the name <shoot-name>.monitoring in the project namespace in the garden cluster and has multiple data keys:
username: the username
password: the password
auth: the username with SHA-1 representation of the password
It is the responsibility of the end-user to regularly rotate those credentials.
In order to rotate the password, annotate the Shoot with gardener.cloud/operation=rotate-observability-credentials.
This operation is not allowed for Shoots that are already marked for deletion.
You can check the .status.credentials.rotation.observability field in the Shoot to see when the rotation was last initiated and last completed.
SSH Key Pair for Worker Nodes
Gardener generates an SSH key pair whose public key is propagated to all worker nodes of the Shoot.
The private key can be used to establish an SSH connection to the workers for troubleshooting purposes.
It is recommended to use gardenctl-v2 and its gardenctl ssh command since it is required to first open up the security groups and create a bastion VM (no direct SSH access to the worker nodes is possible).
The private key is stored in a Secret with the name <shoot-name>.ssh-keypair in the project namespace in the garden cluster and has multiple data keys:
id_rsa: the private key
id_rsa.pub: the public key for SSH
In order to rotate the keys, annotate the Shoot with gardener.cloud/operation=rotate-ssh-keypair.
This will propagate a new key to all worker nodes while keeping the old key active and valid as well (it will only be invalidated/removed with the next rotation).
You can check the .status.credentials.rotation.sshKeypair field in the Shoot to see when the rotation was last initiated or last completed.
The old key is stored in a Secret with the name <shoot-name>.ssh-keypair.old in the project namespace in the garden cluster and has the same data keys as the regular Secret.
The encryption key has no expiration date.
There is no automatic rotation, and it is the responsibility of the end-user to regularly rotate the encryption key.
The rotation happens in three stages:
In stage one, a new encryption key is created and added to the bundle (together with the old encryption key).
In stage two, all Secrets in the cluster and resources configured in the spec.kubernetes.kubeAPIServer.encryptionConfig of the Shoot (see ETCD Encryption Config) are rewritten by the kube-apiserver so that they become encrypted with the new encryption key.
In stage three, the old encryption is dropped from the bundle.
Technically, the Preparing phase indicates the stages one and two.
Once it is completed, the Prepared phase indicates readiness for stage three.
The Completing phase indicates stage three, and the Completed phase states that the rotation process has finished.
You can check the .status.credentials.rotation.etcdEncryptionKey field in the Shoot to see when the rotation was last initiated, last completed, and in which phase it currently is.
In order to start the rotation (stage one), you have to annotate the shoot with the rotate-etcd-encryption-key-start operation:
This will trigger a Shoot reconciliation and performs the stages one and two.
After it is completed, the .status.credentials.rotation.etcdEncryptionKey.phase is set to Prepared.
Now you can complete the rotation by annotating the shoot with the rotate-etcd-encryption-key-complete operation:
This will trigger another Shoot reconciliation and performs stage three.
After it is completed, the .status.credentials.rotation.etcdEncryptionKey.phase is set to Completed.
ServiceAccount Token Signing Key
Gardener generates a key which is used to sign the tokens for ServiceAccounts.
Those tokens are typically used by workload Pods running inside the cluster in order to authenticate themselves with the kube-apiserver.
This also includes system components running in the kube-system namespace.
The token signing key has no expiration date.
Since it might require adaptation for the consumers of the Shoot, there is no automatic rotation, and it is the responsibility of the end-user to regularly rotate the signing key.
The rotation happens in three stages, similar to how the CA certificates are rotated:
In stage one, a new signing key is created and added to the bundle (together with the old signing key).
In stage two, end-users update all out-of-cluster API clients that communicate with the control plane via ServiceAccount tokens.
In stage three, the old signing key is dropped from the bundle.
Technically, the Preparing phase indicates stage one.
Once it is completed, the Prepared phase indicates readiness for stage two.
The Completing phase indicates stage three, and the Completed phase states that the rotation process has finished.
You can check the .status.credentials.rotation.serviceAccountKey field in the Shoot to see when the rotation was last initiated, last completed, and in which phase it currently is.
In order to start the rotation (stage one), you have to annotate the shoot with the rotate-serviceaccount-key-start operation:
This will trigger a Shoot reconciliation and performs stage one.
After it is completed, the .status.credentials.rotation.serviceAccountKey.phase is set to Prepared.
Now you must update all API clients outside the cluster using a ServiceAccount token (such as the kubeconfigs on developer machines) to use a token issued by the new signing key.
Gardener already generates new secrets for those ServiceAccounts in the cluster, whose static token was automatically created by Kubernetes (typically before v1.22 - ref)
However, if you need to create it manually, you can check out this document for instructions.
After updating all API clients, you can complete the rotation by annotating the shoot with the rotate-serviceaccount-key-complete operation:
This will trigger another Shoot reconciliation and performs stage three.
After it is completed, the .status.credentials.rotation.serviceAccountKey.phase is set to Completed.
⚠️ In stage one, all worker nodes of the Shoot will be rolled out to ensure that the Pods use a new token.
Triggering Worker Node Rollout Individually
Similar to the rotation of the certificate authorities, you can control the worker node rollout individually.
Please read this section to get more information.
It works the same way for the ServiceAccount token signing key (using rotate-serviceaccount-key-start-without-workers-rollout).
Worker Node with ManualInPlaceUpdate Update Strategy
Similar to the rotation of the certificate authorities, in case of manual in-place update, ServiceAccount token signing key rotation phase will be at Preparing until all the worker pools are successfully in-place updated and there are no pending worker pools with strategy ManualInPlaceUpdate.
Please read this section for more information.
OpenVPN TLS Auth Keys
This key is used to ensure encrypted communication for the VPN connection between the control plane in the seed cluster and the shoot cluster.
It is currently not rotated automatically and there is no way to trigger it manually.
14.4 - Shoot Kubernetes and Operating System Versioning in Gardener
Shoot Kubernetes and Operating System Versioning in Gardener
Motivation
On the one hand-side, Gardener is responsible for managing the Kubernetes and the Operating System (OS) versions of its Shoot clusters.
On the other hand-side, Gardener needs to be configured and updated based on the availability and support of the Kubernetes and Operating System version it provides.
For instance, the Kubernetes community releases minor versions roughly every three months and usually maintains three minor versions (the current and the last two) with bug fixes and security updates.
Patch releases are done more frequently.
When using the term Machine image in the following, we refer to the OS version that comes with the machine image of the node/worker pool of a Gardener Shoot cluster.
As such, we are not referring to the CloudProvider specific machine image like the AMI for AWS.
For more information on how Gardener maps machine image versions to CloudProvider specific machine images, take a look at the individual gardener extension providers, such as the provider for AWS.
Gardener should be configured accordingly to reflect the “logical state” of a version.
It should be possible to define the Kubernetes or Machine image versions that still receive bug fixes and security patches, and also vice-versa to define the version that are out-of-maintenance and are potentially vulnerable.
Moreover, this allows Gardener to “understand” the current state of a version and act upon it (more information in the following sections).
Overview
As a Gardener operator:
I can classify a version based on it’s logical state (preview, supported, deprecated, and expired; see Version Classification).
I can define which Machine image and Kubernetes versions are eligible for the auto update of clusters during the maintenance time.
I can define a moment in time when Shoot clusters are forcefully migrated off a certain version (through an expirationDate).
I can disallow the creation of clusters having a certain version (think of severe security issues).
As an end-user/Shoot owner of Gardener:
I can get information about which Kubernetes and Machine image versions exist and their classification.
I can determine the time when my Shoot clusters Machine image and Kubernetes version will be forcefully updated to the next patch or minor version (in case the cluster is running a deprecated version with an expiration date).
I can get this information via API from the CloudProfile.
Version Classifications
Administrators can classify versions into four distinct “logical states”: preview, supported, deprecated, and expired.
The version classification serves as a “point-of-reference” for end-users and also has implications during shoot creation and the maintenance time.
If a version is unclassified, Gardener cannot make those decision based on the “logical state”.
Nevertheless, Gardener can operate without version classifications and can be added at any time to the Kubernetes and machine image versions in the CloudProfile.
As a best practice, versions usually start with the classification preview, then are promoted to supported, eventually deprecated and finally expired.
This information is programmatically available in the CloudProfiles of the Garden cluster.
preview: A preview version is a new version that has not yet undergone thorough testing, possibly a new release, and needs time to be validated.
Due to its short early age, there is a higher probability of undiscovered issues and is therefore not yet recommended for production usage.
A Shoot does not update (neither auto-update or force-update) to a preview version during the maintenance time.
Also, preview versions are not considered for the defaulting to the highest available version when deliberately omitting the patch version during Shoot creation.
Typically, after a fresh release of a new Kubernetes (e.g., v1.25.0) or Machine image version (e.g., suse-chost 15.4.20220818), the operator tags it as preview until they have gained sufficient experience and regards this version to be reliable.
After the operator has gained sufficient trust, the version can be manually promoted to supported.
supported: A supported version is the recommended version for new and existing Shoot clusters. This is the version that new Shoot clusters should use and existing clusters should update to.
Typically for Kubernetes versions, the latest Kubernetes patch versions of the actual (if not still in preview) and the last 3 minor Kubernetes versions are maintained by the community. An operator could define these versions as being supported (e.g., v1.27.6, v1.26.10, and v1.25.12).
deprecated: A deprecated version is a version that approaches the end of its lifecycle and can contain issues which are probably resolved in a supported version.
New Shoots should not use this version anymore.
Existing Shoots will be updated to a newer version if auto-update is enabled (.spec.maintenance.autoUpdate.kubernetesVersion for Kubernetes version auto-update, or .spec.maintenance.autoUpdate.machineImageVersion for machine image version auto-update).
Using automatic upgrades, however, does not guarantee that a Shoot runs a non-deprecated version, as the latest version (overall or of the minor version) can be deprecated as well.
Deprecated versions should have an expiration date set for eventual expiration.
expired: An expired versions has an expiration date (based on the Golang time package) in the past.
New clusters with that version cannot be created and existing clusters are forcefully migrated to a higher version during the maintenance time.
Below is an example how the relevant section of the CloudProfile might look like:
There are two ways, the Kubernetes version of the control plane as well as the Kubernetes and machine image version of a worker pool can be upgraded: auto update and forceful update.
See Automatic Version Updates for how to enable auto updates for Kubernetes or machine image versions on the Shoot cluster.
If a Shoot is running a version after its expiration date has passed, it will be forcefully updated during its maintenance time.
This happens even if the owner has opted out of automatic cluster updates!
When an auto update is triggered?:
The Shoot has auto-update enabled and the version is not the latest eligible version for the auto-update. Please note that this latest version that qualifies for an auto-update is not necessarily the overall latest version in the CloudProfile:
For Kubernetes version, the latest eligible version for auto-updates is the latest patch version of the current minor.
For machine image version, the latest eligible version for auto-updates is controlled by the updateStrategy field of the machine image in the CloudProfile.
The Shoot has auto-update disabled and the version is either expired or does not exist.
The auto update can fail if the version is already on the latest eligible version for the auto-update. A failed auto update triggers a force update.
The force and auto update path for Kubernetes and machine image versions differ slightly and are described in more detail below.
Update rules for both Kubernetes and machine image versions
Both auto and force update first try to update to the latest patch version of the same minor.
An auto update prefers supported versions over deprecated versions. If there is a lower supported version and a higher deprecated version, auto update will pick the supported version. If all qualifying versions are deprecated, update to the latest deprecated version.
An auto update never updates to an expired version.
A force update prefers to update to not-expired versions. If all qualifying versions are expired, update to the latest expired version. Please note that therefore multiple consecutive version upgrades are possible. In this case, the version is again upgraded in the next maintenance time.
Update path for machine image versions
Administrators can define three different update strategies (field updateStrategy) for machine images in the CloudProfile: patch, minor, major (default). This is to accommodate the different version schemes of Operating Systems (e.g. Gardenlinux only updates major and minor versions with occasional patches).
patch: update to the latest patch version of the current minor version. When using an expired version: force update to the latest patch of the current minor. If already on the latest patch version, then force update to the next higher (not necessarily +1) minor version.
minor: update to the latest minor and patch version. When using an expired version: force update to the latest minor and patch of the current major. If already on the latest minor and patch of the current major, then update to the next higher (not necessarily +1) major version.
major: always update to the overall latest version. This is the legacy behavior for automatic machine image version upgrades. Force updates are not possible and will fail if the latest version in the CloudProfile for that image is expired (EOL scenario).
Please note that force updates for machine images can skip minor versions (strategy: patch) or major versions (strategy: minor) if the next minor/major version has no qualifying versions (only preview versions).
Update path for Kubernetes versions
For Kubernetes versions, the auto update picks the latest non-preview patch version of the current minor version.
If the cluster is already on the latest patch version and the latest patch version is also expired,
it will continue with the latest patch version of the next consecutive minor (minor +1) Kubernetes version,
so it will result in an update of a minor Kubernetes version!
Kubernetes “minor version jumps” are not allowed - meaning to skip the update to the consecutive minor version and directly update to any version after that.
For instance, the version 1.24.x can only update to a version 1.25.x, not to 1.26.x or any other version.
This is because Kubernetes does not guarantee upgradability in this case, leading to possibly broken Shoot clusters.
The administrator has to set up the CloudProfile in such a way that consecutive Kubernetes minor versions are available.
Otherwise, Shoot clusters will fail to upgrade during the maintenance time.
Consider the CloudProfile below with a Shoot using the Kubernetes version 1.24.12.
Even though the version is expired, due to missing 1.25.x versions, the Gardener Controller Manager cannot upgrade the Shoot’s Kubernetes version.
spec:
kubernetes:
versions:
- version: 1.26.10
- version: 1.26.9
- version: 1.24.12
expirationDate: "<expiration date in the past>"
The CloudProfile must specify versions 1.25.x of the consecutive minor version.
Configuring the CloudProfile in such a way, the Shoot’s Kubernetes version will be upgraded to version 1.25.10 in the next maintenance time.
spec:
kubernetes:
versions:
- version: 1.26.9
- version: 1.25.10
- version: 1.25.9
- version: 1.24.12
expirationDate: "<expiration date in the past>"
Version Requirements (Kubernetes and Machine Image)
The Gardener API server enforces the following requirements for versions:
A version that is in use by a Shoot cannot be deleted from the CloudProfile.
Creating a new version with expiration date in the past is not allowed.
There can be only one supported version per minor version.
The latest Kubernetes version cannot have an expiration date.
NOTE: The latest version for a machine image can have an expiration date. [*]
[*] Useful for cases in which support for a given machine image needs to be deprecated and removed (for example, the machine image reaches end of life).
Related Documentation
You might want to read about the Shoot Updates and Upgrades procedures to get to know the effects of such operations.
14.5 - Shoot Updates and Upgrades
Shoot Updates and Upgrades
This document describes what happens during shoot updates (changes incorporated in a newly deployed Gardener version) and during shoot upgrades (changes for version controllable by end-users).
Updates
Updates to all aspects of the shoot cluster happen when the gardenlet reconciles the Shoot resource.
When are Reconciliations Triggered
Generally, when you change the specification of your Shoot the reconciliation will start immediately, potentially updating your cluster.
Please note that you can also confine the reconciliation triggered due to your specification updates to the cluster’s maintenance time window. Please find more information in Confine Specification Changes/Updates Roll Out.
You can also annotate your shoot with special operation annotations (for more information, see Trigger Shoot Operations), which will cause the reconciliation to start due to your actions.
There is also an automatic reconciliation by Gardener.
The period, i.e., how often it is performed, depends on the configuration of the Gardener administrators/operators.
In some Gardener installations the operators might enable “reconciliation in maintenance time window only” (for more information, see Cluster Reconciliation), which will result in at least one reconciliation during the time configured in the Shoot’s .spec.maintenance.timeWindow field.
Which Updates are Applied
As end-users can only control the Shoot resource’s specification but not the used Gardener version, they don’t have any influence on which of the updates are rolled out (other than those settings configurable in the Shoot).
A Gardener operator can deploy a new Gardener version at any point in time.
Any subsequent reconciliation of Shoots will update them by rolling out the changes incorporated in this new Gardener version.
Some examples for such shoot updates are:
Add a new/remove an old component to/from the shoot’s control plane running in the seed, or to/from the shoot’s system components running on the worker nodes.
Change the configuration of an existing control plane/system component.
Restart of existing control plane/system components (this might result in a short unavailability of the Kubernetes API server, e.g., when etcd or a kube-apiserver itself is being restarted)
Behavioural Changes
Generally, some of such updates (e.g., configuration changes) could theoretically result in different behaviour of controllers.
If such changes would be backwards-incompatible, then we usually follow one of those approaches (depends on the concrete change):
Only apply the change for new clusters.
Expose a new field in the Shoot resource that lets users control this changed behaviour to enable it at a convenient point in time.
Put the change behind an alpha feature gate (disabled by default) in the gardenlet (only controllable by Gardener operators), which will be promoted to beta (enabled by default) in subsequent releases (in this case, end-users have no influence on when the behaviour changes - Gardener operators should inform their end-users and provide clear timelines when they will enable the feature gate).
Upgrades
We consider shoot upgrades to change either the:
Kubernetes version (.spec.kubernetes.version)
Kubernetes version of the worker pool if specified (.spec.provider.workers[].kubernetes.version)
Machine image version of at least one worker pool (.spec.provider.workers[].machine.image.version)
Generally, an upgrade is also performed through a reconciliation of the Shoot resource, i.e., the same concepts as for shoot updates apply.
If an end-user triggers an upgrade (e.g., by changing the Kubernetes version) after a new Gardener version was deployed but before the shoot was reconciled again, then this upgrade might incorporate the changes delivered with this new Gardener version.
The UpdateStrategy field in the Shoot specification (.spec.provider.workers[].updateStrategy) gives users the flexibility to define how the machine-controller-manager handles worker pool updates during the upgrade process. Currently gardener support three update strategies:
AutoRollingUpdate
AutoInPlaceUpdate
ManualInPlaceUpdate
⚠️ The above strategies generally require draining the node when changes are made to the Shoot specification. The specific changes that trigger this behavior will be discussed in later sections.
For all other spec changes like Kubernetes patch version update, the upgrade is executed without draining the node and the shoot worker nodes remain unchanged. In case of Kubernetes patch version, only the kubelet process is restarted with the updated Kubernetes version binary.
Rolling Updates
The upgrade is performed in a “rolling update” manner, during which nodes in the worker pool are replaced. Similar to how pods in Kubernetes are updated when backed by a Deployment.
Worker nodes are terminated one after another and replaced by new nodes.
The existing workload is gracefully drained and evicted from the old worker nodes to new worker nodes, respecting the configured PodDisruptionBudgets (see Specifying a Disruption Budget for your Application).
Automatic Rolling Updates
When the auto rolling update strategy is selected, the update process is fully orchestrated by the Gardener and the machine-controller-manager. The machine-controller-manager sequentially terminates the worker nodes and replaces them with new nodes.
ℹ️ This is the default update strategy.
To create workers with AutoRollingUpdate, either omit the Shoot's .spec.provider.workers[].updateStrategy field (it will default to AutoRollingUpdate) or explicitly set the field to AutoRollingUpdate.
Customize Rolling Update Behaviour of Shoot Worker Nodes
The .spec.provider.workers[] list exposes two fields that you might configure based on your workload’s needs: maxSurge and maxUnavailable.
The same concepts like in Kubernetes apply.
Additionally, you might customize how the machine-controller-manager is behaving. You can configure the following fields in .spec.provider.worker[].machineControllerManager:
machineDrainTimeout: Timeout (in duration) used while draining of machine before deletion, beyond which machine-controller-manager forcefully deletes the machine (default: 2h).
machineHealthTimeout: Timeout (in duration) used while re-joining (in case of temporary health issues) of a machine before it is declared as failed (default: 10m).
machineCreationTimeout: Timeout (in duration) used while joining (during creation) of a machine before it is declared as failed (default: 10m).
maxEvictRetries: Maximum number of times evicts would be attempted on a pod before it is forcibly deleted during the draining of a machine (default: 10).
nodeConditions: List of case-sensitive node-conditions which will change a machine to a Failed state after the machineHealthTimeout duration. It may further be replaced with a new machine if the machine is backed by a machine-set object (defaults: KernelDeadlock, ReadonlyFilesystem , DiskPressure).
Rolling Update Triggers
A rolling update of the shoot worker nodes is triggered for some changes to your worker pool specification (.spec.provider.workers[], even if you don’t change the Kubernetes or machine image version).
The complete list of fields that trigger a rolling update:
.spec.kubernetes.version (except for patch version changes)
.spec.provider.workers[].machine.image.name
.spec.provider.workers[].machine.image.version
.spec.provider.workers[].machine.type
.spec.provider.workers[].volume.type
.spec.provider.workers[].volume.size
.spec.provider.workers[].providerConfig (provider extension dependent with feature gate NewWorkerPoolHash)
.spec.provider.workers[].cri.name
.spec.provider.workers[].kubernetes.version (except for patch version changes)
.spec.systemComponents.nodeLocalDNS.enabled
.status.credentials.rotation.certificateAuthorities.lastInitiationTime (changed by Gardener when a shoot CA rotation is initiated) when worker pool is not part of .status.credentials.rotation.certificateAuthorities.pendingWorkersRollouts[]
.status.credentials.rotation.serviceAccountKey.lastInitiationTime (changed by Gardener when a shoot service account signing key rotation is initiated) when worker pool is not part of .status.credentials.rotation.serviceAccountKey.pendingWorkersRollouts[]
If feature gate NewWorkerPoolHash is enabled:
.spec.kubernetes.kubelet.kubeReserved (unless a worker pool-specific value is set)
.spec.kubernetes.kubelet.systemReserved (unless a worker pool-specific value is set)
.spec.kubernetes.kubelet.evictionHard (unless a worker pool-specific value is set)
.spec.kubernetes.kubelet.cpuManagerPolicy (unless a worker pool-specific value is set)
Changes to kubeReserved or systemReserved do not trigger a node roll if their sum does not change.
Generally, the provider extension controllers might have additional constraints for changes leading to rolling updates, so please consult the respective documentation as well.
In particular, if the feature gate NewWorkerPoolHash is enabled and a worker pool uses the new hash, then the providerConfig as a whole is not included. Instead only fields selected by the provider extension are considered.
In-Place Updates
For scenarios where users want to retain the current nodes and avoid deletion during updates, Gardener provides the option of in-place updates. The upgrade is performed without replacing the underlying machines. Although there is an exception where new nodes are created with the updated configuration and old ones are terminated. One such exception is discussed in Automatic inplace update section.
ℹ️ Currently, in-place updates are controlled by the InPlaceNodeUpdates feature gate in the gardener-apiserver.
For in-place updates, the first requirement is that the operating system must support them. For a specific machine image version, the configuration for in-place updates must be defined in the CloudProfile under spec.machineImages[].versions[].inPlaceUpdates:
The inPlaceUpdates.supported field must be set to true.
The inPlaceUpdates.minVersionForUpdate field specifies the minimum version from which an in-place update to the target machine image version can be performed.
The inPlaceUpdates field in the Shoot status provides details about in-place updates for the Shoot workers. It includes the pendingWorkerUpdates field, which lists the worker pools that are awaiting in-place updates.
Customize In-Place Update Behaviour of Shoot Worker Nodes
In addition to customisable fields mentioned in section, you can configure the following fields in .spec.provider.worker[].machineControllerManager:
MachineInPlaceUpdateTimeout: Timeout (in duration) after which an in-place update is declared as failed.
DisableHealthTimeout: A boolean value that, when set to true, ignores the health timeout. As a result, machines are never marked as failed, and unhealthy machines are not deleted. The default value is true for in-place updates.
In-Place Update Triggers
An in-place update of the shoot worker nodes is triggered for rolling update triggers listed under Rolling Update Triggers except for the following:
.spec.provider.workers[].machine.image.name
.spec.provider.workers[].machine.type
.spec.provider.workers[].volume.type
.spec.provider.workers[].volume.size
.spec.provider.workers[].cri.name
.spec.systemComponents.nodeLocalDNS.enabled
There are validations which restricts changing the above mentioned exception fields when in-place updates strategy is configured.
When a worker pool is undergoing an in-place update, applying subsequent updates to the same worker pool is restricted.
If an in-place update fails and nodes are left in a problematic state, user intervention is required to manually fix the nodes. In cases where a subsequent update is necessary to resolve the issue, users can update the worker pool after adding the force update annotation gardener.cloud/operation=force-in-place-update on the Shoot. Refer to Force-update a worker pool with InPlace update strategy for more details.
⚠️ Changing the update strategy from AutoRollingUpdate to AutoInPlaceUpdate/ManualInPlaceUpdate (and vice versa) is not allowed. However, switching between AutoInPlaceUpdate and ManualInPlaceUpdate is permitted.
Automatic In-Place Updates
In case of AutoInPlaceUpdate update strategy, the update process is fully orchestrated by Gardener and the machine-controller-manager. No user intervention is required.
Set .spec.provider.workers[].updateStrategy field in the Shoot spec to AutoInPlaceUpdate.
During automatic in-place updates, if the maxSurge value is set to greater than 0, the machine-controller-manager creates new nodes equal to the maxSurge value. All old nodes, except for those equal to the maxSurge value, are updated in place, and the old nodes corresponding to the maxSurge value are terminated. If maxSurge is set to 0, no new nodes are created and all old nodes are updated in-place.
The inPlaceUpdates.pendingWorkerUpdates.autoInPlaceUpdate field in the Shoot status lists the names of worker pools that are pending updates with this strategy.
Manual In-Place Updates
The ManualInPlaceUpdate strategy allows users to control and orchestrate the update process manually.
Set .spec.provider.workers[].updateStrategy field in the Shoot spec to ManualInPlaceUpdate.
Once machine-controller-manager labels nodes with node.machine.sapcloud.io/candidate-for-update, user can select the candidate nodes for update by labeling them with node.machine.sapcloud.io/selected-for-update=true:
The ManualInPlaceWorkersUpdatedconstraint in the shoot status indicates that at least one worker pool with the ManualInPlaceUpdate strategy is pending an update. Shoot reconciliation will still succeed even if there are worker pools pending updates.
The inPlaceUpdates.pendingWorkerUpdates.manualInPlaceUpdate field in the Shoot status lists the names of worker pools that are pending updates with this strategy.
Currently, Gardener supports the following Kubernetes versions:
Garden Clusters
The minimum version of a garden cluster that can be used to run Gardener is 1.27.x.
Seed Clusters
The minimum version of a seed cluster that can be connected to Gardener is 1.27.x.
Shoot Clusters
Gardener itself is capable of spinning up clusters with Kubernetes versions 1.27 up to 1.33.
However, the concrete versions that can be used for shoot clusters depend on the installed provider extension.
Consequently, please consult the documentation of your provider extension to see which Kubernetes versions are supported for shoot clusters.
14.7 - Trigger Shoot Operations Through Annotations
Trigger Shoot Operations Through Annotations
You can trigger a few explicit operations by annotating the Shoot with an operation annotation.
This might allow you to induct certain behavior without the need to change the Shoot specification.
Some of the operations can also not be caused by changing something in the shoot specification because they can’t properly be reflected here.
Note that once the triggered operation is considered by the controllers, the annotation will be automatically removed and you have to add it each time you want to trigger the operation.
Please note: If .spec.maintenance.confineSpecUpdateRollout=true, then the only way to trigger a shoot reconciliation is by setting the reconcile operation, see below.
Immediate Reconciliation
Annotate the shoot with gardener.cloud/operation=reconcile to make the gardenlet start a reconciliation operation without changing the shoot spec and possibly without being in its maintenance time window:
Annotate the shoot with gardener.cloud/operation=maintain to make the gardener-controller-manager start maintaining your shoot immediately (possibly without being in its maintenance time window).
If no reconciliation starts, then nothing needs to be maintained:
Annotate the shoot with gardener.cloud/operation=retry to make the gardenlet start a new reconciliation loop on a failed shoot.
Failed shoots are only reconciled again if a new Gardener version is deployed, the shoot specification is changed or this annotation is set:
Force-update a worker pool with InPlace update strategy
Annotate the shoot with gardener.cloud/operation=force-in-place-update to force an update for worker pools using the update strategy AutoInPlaceUpdate or ManualInPlaceUpdate. Without this annotation, any subsequent updates to the same worker pool are denied until the Shoot has been successfully reconciled following the current in-place update.
Restart systemd Services on Particular Worker Nodes
It is possible to make Gardener restart particular systemd services on your shoot worker nodes if needed.
The annotation is not set on the Shoot resource but directly on the Node object you want to target.
For example, the following will restart both the kubelet and the containerd services:
It may take up to a minute until the service is restarted.
The annotation will be removed from the Node object after all specified systemd services have been restarted.
It will also be removed even if the restart of one or more services failed.
ℹ️ In the example mentioned above, you could additionally verify when/whether the kubelet restarted by using kubectl describe node <node-name> and looking for such a Starting kubelet event.
Force Deletion
When a Shoot fails to be deleted normally, users can force-delete the Shoot if it meets the following conditions:
Shoot has a deletion timestamp.
Shoot status contains at least one of the following ErrorCodes:
ERR_CLEANUP_CLUSTER_RESOURCES
ERR_CONFIGURATION_PROBLEM
ERR_INFRA_DEPENDENCIES
ERR_INFRA_UNAUTHENTICATED
ERR_INFRA_UNAUTHORIZED
If the above conditions are satisfied, you can annotate the Shoot with confirmation.gardener.cloud/force-deletion=true, and Gardener will cleanup the Shoot controlplane and the Shoot metadata.
⚠️ You MUST ensure that all the resources created in the IaaS account are cleaned up to prevent orphaned resources. Gardener will NOT delete any resources in the underlying infrastructure account. Hence, use this annotation at your own risk and only if you are fully aware of these consequences.
15 - Autoscaling Specifics for Components
Overview
This document describes the used autoscaling mechanism for several components.
Garden or Shoot Cluster etcd
The etcd is scaled by a native VPA resource.
Downscaling is handled more pessimistically to prevent many subsequent etcd restarts. Thus, for production and infrastructure Shoot clusters (or all Garden clusters), downscaling is deactivated for the main etcd. For all other Shoot clusters, lower advertised requests/limits are only applied during the Shoot’s maintenance time window.
Shoot Kubernetes API Server
The Shoot Kubernetes API server is scaled simultaneously by VPA and HPA on the same metric (CPU and memory usage).
The pod-trashing cycle between VPA and HPA scaling on the same metric is avoided by configuring the HPA to scale on average usage (not on average utilization).
This makes possible VPA to first scale vertically on CPU/memory usage.
Once all Pods’ average CPU/memory usage exceeds the HPA’s target average usage, HPA is scaling horizontally (by adding a new replica). HPA’s average target usage values are 6 CPU and 24G.
The initial API server resource requests are 250m and 500Mi.
The gardenlet sets the initial API server resource requests only when the Deployment is not found. When the Deployment exists, it is not overwriting the kube-apiserver container resources.
Disabling Scale Down for Components in the Shoot Control Plane
Some Shoot clusters’ control plane components can be overloaded and can have very high resource usage. The existing autoscaling solution could be imperfect to cover these cases. Scale down actions for such overloaded components could be disruptive.
To prevent such disruptive scale-down actions it is possible to disable scale down of the etcd, Kubernetes API server and Kubernetes controller manager in the Shoot control plane by annotating the Shoot with alpha.control-plane.scaling.shoot.gardener.cloud/scale-down-disabled=true.
There is the following specific for when disabling scale-down for the Kubernetes API server component:
If the HPA resource exists and HPA’s spec.minReplicas is not nil then the min replica count is max(spec.minReplicas, status.desiredReplicas). When scale-down is disabled, this allows operators to specify a custom value for HPA spec.minReplicas and this value not to be reverted by gardenlet. I.e, HPA does scale down to min replicas but not below min replicas. HPA’s max replica count is 6.
Note
The alpha.control-plane.scaling.shoot.gardener.cloud/scale-down-disabled annotation is alpha and can be removed anytime without further notice. Only use it if you know what you do.
Virtual Kubernetes API Server and Gardener API Server
The virtual Kubernetes API server’s autoscaling is same as the Shoot Kubernetes API server’s with the following differences:
The initial API server resource requests are 600m and 512Mi.
The min replica count is 2 for a non-HA virtual cluster and 3 for an HA virtual cluster. The max replica count is 6.
The Gardener API server’s autoscaling is the same as the Shoot Kubernetes API server’s with the following differences:
The initial API server resource requests are 600m and 512Mi.
The replica count is 2 for a non-HA virtual cluster and 3 for an HA virtual cluster.
Gardener API server is not scaled by HPA.
Virtual Kubernetes API servers use one single HTTP2 connection to a Gardener API server. Thus, in case Gardener API server have more replicas its additional pods would not receive any requests.
Configure minAllowed Resources for Control Plane Components
It is possible to configure minimum allowed resources (minAllowed) for CPU/memory for ETCD instances and the Kubernetes API server.
This configuration is available for both Shoot clusters and the Garden cluster, see examples below:
A primary use-case for configuring minAllowed resources arises from the need to alleviate delays during consecutive scale-up activities.
Typically, in longer-running clusters, resource usage patterns evolve gradually, and the control plane can scale vertically in an adequate manner.
However, in the case of newly spun-up clusters requiring immediate heavy usage, setting a minAllowed threshold for CPU and memory ensures that the control plane components are provisioned with sufficient resources to handle abrupt load increases without substantial delay.
Note
To use this feature effectively, users should thoroughly analyze their cluster usage patterns in advance to identify appropriate resource values.
16 - Changing the API
Changing the API
This document describes the steps that need to be performed when changing the API.
It provides guidance for API changes to both (Gardener system in general or component configurations).
Generally, as Gardener is a Kubernetes-native extension, it follows the same API conventions and guidelines like Kubernetes itself. The Kubernetes
API Conventions as well as Changing the API topics already provide a good overview and general explanation of the basic concepts behind it.
We are following the same approaches.
Gardener API
The Gardener API is defined in the pkg/apis/{core,extensions,settings} directories and is the main point of interaction with the system.
It must be ensured that the API is always backwards-compatible.
Changing the API
Checklist when changing the API:
Modify the field(s) in the respective Golang files of all external versions and the internal version.
Make sure new fields are being added as “optional” fields, i.e., they are of pointer types, they have the // +optional comment, and they have the omitempty JSON tag.
Make sure that the existing field numbers in the protobuf tags are not changed.
Do not copy protobuf tags from other fields but create them with make generate WHAT="protobuf".
If necessary, implement/adapt the conversion logic defined in the versioned APIs (e.g., pkg/apis/core/v1beta1/conversions*.go).
If necessary, implement/adapt defaulting logic defined in the versioned APIs (e.g., pkg/apis/core/v1beta1/defaults*.go).
Run the code generation: make generate
If necessary, implement/adapt validation logic defined in the internal API (e.g., pkg/apis/core/validation/validation*.go).
If necessary, adapt the exemplary YAML manifests of the Gardener resources defined in example/*.yaml.
In most cases, it makes sense to add/adapt the documentation for administrators/operators and/or end-users in the docs folder to provide information on purpose and usage of the added/changed fields.
When opening the pull request, always add a release note so that end-users are becoming aware of the changes.
Removing a Field
If fields shall be removed permanently from the API, then a proper deprecation period must be adhered to so that end-users have enough time to adapt their clients.
Once the deprecation period is over, the field should be dropped from the API in a two-step process, i.e., in two release cycles. In the first step, all the usages in the code base should be dropped. In the second step, the field should be dropped from API. We need to follow this two-step process cause there can be the case where gardener-apiserver is upgraded to a new version in which the field has been removed but other controllers are still on the old version of Gardener. This can lead to nil pointer exceptions or other unexpected behaviour.
The steps for removing a field from the code base is:
The field in the external version(s) has to be commented out with appropriate doc string that the protobuf number of the corresponding field is reserved. Example:
- SeedTemplate *gardencorev1beta1.SeedTemplate `json:"seedTemplate,omitempty" protobuf:"bytes,2,opt,name=seedTemplate"`
+ // SeedTemplate is tombstoned to show why 2 is reserved protobuf tag.
+ // SeedTemplate *gardencorev1beta1.SeedTemplate `json:"seedTemplate,omitempty" protobuf:"bytes,2,opt,name=seedTemplate"`
The reasoning behind this is to prevent the same protobuf number being used by a new field. Introducing a new field with the same protobuf number would be a breaking change for clients still using the old protobuf definitions that have the old field for the given protobuf number.
The field in the internal version can be removed.
A unit test has to be added to make sure that a new field does not reuse the already reserved protobuf tag.
Most Gardener components have a component configuration that follows similar principles to the Gardener API.
Those component configurations are defined in pkg/{controllermanager,gardenlet,scheduler},pkg/apis/config.
Hence, the above checklist also applies for changes to those APIs.
However, since these APIs are only used internally and only during the deployment of Gardener, the guidelines with respect to changes and backwards-compatibility are slightly relaxed.
If necessary, it is allowed to remove fields without a proper deprecation period if the release note uses the breaking operator keywords.
In addition to the above checklist:
If necessary, then adapt the Helm chart of Gardener defined in charts/gardener. Adapt the values.yaml file as well as the manifest templates.
17 - Component Checklist
Checklist For Adding New Components
Adding new components that run in the garden, seed, or shoot cluster is theoretically quite simple - we just need a Deployment (or other similar workload resource), the respective container image, and maybe a bit of configuration.
In practice, however, there are a couple of things to keep in mind in order to make the deployment production-ready.
This document provides a checklist for them that you can walk through.
Nowadays, we use Golang components instead of Helm charts for deploying components to a cluster.
Please find a typical structure of such components in the provided metrics_server.go file (configuration values are typically managed in a Values structure).
There are a few exceptions (e.g., Istio) still using charts, however the default should be using a Golang-based implementation.
For the exceptional cases, use Golang’s embed package to embed the Helm chart directory (example 1, example 2).
For historic reasons, resources related to shoot control plane components are applied directly with the client.
All other resources (seed or shoot system components) are deployed via gardener-resource-manager’s Resource controller (ManagedResources) since it performs health checks out-of-the-box and has a lot of other features (see its documentation for more information).
Components that can run as both seed system component or shoot control plane component (e.g., VPA or kube-state-metrics) can make use of these utility functions.
Unique ConfigMaps/Secrets are immutable for modification and have a unique name.
This has a couple of benefits, e.g. the kubelet doesn’t watch these resources, and it is always clear which resource contains which data since it cannot be changed.
As a consequence, unique/immutable ConfigMaps/Secret are superior to checksum annotations on the pod templates.
Stale/unused ConfigMaps/Secrets are garbage-collected by gardener-resource-manager’s GarbageCollector.
There are utility functions (see examples above) for using unique ConfigMaps/Secrets in Golang components.
It is essential to inject the annotations into the workload resource to make the garbage-collection work. Note that some ConfigMaps/Secrets should not be unique (e.g., those containing monitoring or logging configuration).
The reason is that the old revision stays in the cluster even if unused until the garbage-collector acts.
During this time, they would be wrongly aggregated to the full configuration.
You should use the secrets manager for the management of any kind of credentials.
This makes sure that credentials rotation works out-of-the-box without you requiring to think about it.
Generally, do not use client certificates (see the Security section).
Consider hibernation when calculating replica count (example)
Shoot clusters can be hibernated meaning that all control plane components in the shoot namespace in the seed cluster are scaled down to zero and all worker nodes are terminated.
If your component runs in the seed cluster then you have to consider this case and provide the proper replica count.
There is a utility function available (see example).
Ensure task dependencies are as precise as possible in shoot flows (example 1, example 2)
Shoot system components deployed by gardener-resource-manager are labelled with resource.gardener.cloud/managed-by: gardener. This makes Gardener adding required label selectors and tolerations so that non-DaemonSet managed Pods will exclusively run on selected nodes (for more information, see System Components Webhook).
DaemonSets on the other hand, should generally tolerate any NoSchedule or NoExecute taints so that they can run on any Node, regardless of user added taints.
We define all image references centrally in the imagevector/containers.yaml file.
Hence, the image references must not be hard-coded in the pod template spec but read from this so-called image vector instead.
Registries such as ECR, GHCR (ghcr.io), MCR (mcr.microsoft.com) don’t support pulling images over IPv6.
Check if the upstream image is being also maintained in a registry that support IPv6 natively such as Artifact Registry, Quay (quay.io). If there is such image, use the image from registry with IPv6 support.
If the image is not available in a registry with IPv6 then copy the image to the gardener GCR. There is a prow job copying images that are needed in gardener components from a source registry to the gardener GCR under the prefix europe-docker.pkg.dev/gardener-project/releases/3rd/ (see the documentation or gardener/ci-infra#619).
If you want to use a new image from a registry without IPv6 support or upgrade an already used image to a newer tag, please open a PR to the ci-infra repository that modifies the job’s list of images to copy: images.yaml.
There is a strict rate-limit that applies to the Docker Hub registry. As described in 2., use another registry (if possible) or copy the image to the gardener GCR.
Do not use Shoot container images that are not multi-arch
Gardener supports Shoot clusters with both amd64 and arm64 based worker Nodes. amd64 container images cannot run on arm64 worker Nodes and vice-versa.
Components that need to talk to the API server of their runtime cluster must always use a dedicated ServiceAccount (do not use default), with automountServiceAccountToken set to false.
This makes gardener-resource-manager’s ProjectedTokenMount webhook inject a projected token automatically.
Use shoot access tokens instead of a client certificates (example)
For components that need to talk to a target cluster different from their runtime cluster (e.g., running in seed cluster but talking to shoot) the gardener-resource-manager’s TokenRequestor should be used to manage a so-called “shoot access token”.
Define RBAC roles with minimal privileges (example)
The component’s ServiceAccount (if it exists) should have as little privileges as possible.
Consequently, please define proper RBAC roles for it.
This might include a combination of ClusterRoles and Roles.
Please do not provide elevated privileges due to laziness (e.g., because there is already a ClusterRole that can be extended vs. creating a Role only when access to a single namespace is needed).
Please avoid using wildcards * where possible.
You should restrict both ingress and egress traffic to/from your component as much as possible to ensure that it only gets access to/from other components if really needed.
Gardener provides a few default policies for typical usage scenarios. For more information, see NetworkPolicys In Garden, Seed, Shoot Clusters.
Avoid running containers with privileged=true. Instead, define the needed Linux capabilities.
Do not allow privilege escalation for containers (example)
Explicitly set securityContext.allowPrivilegeEscalation=false, in cases when possible. There is an issue in Kubernetes about this configuration being true by default.
Avoid running containers as root. Usually, components such as Kubernetes controllers and admission webhook servers don’t need root user capabilities to do their jobs.
The problem with running as root, starts with how the container is first built. Unless a non-privileged user is configured in the Dockerfile, container build systems by default set up the container with the root user. Add a non-privileged user to your Dockerfile or use a base image with a non-root user (for example the nonroot images from distroless such as gcr.io/distroless/static-debian12:nonroot).
If the image is an upstream one, then consider configuring a securityContext for the container/Pod with a non-privileged user. For more information, see Configure a Security Context for a Pod or Container.
For components deployed in the Seed cluster, the Seccomp profile will be defaulted to RuntimeDefault by gardener-resource-manager’s SeccompProfile webhook which works well for the majority of components. However, in some special cases you might need to overwrite it.
The gardener-resource-manager’s SeccompProfile webhook is not enabled for a Shoot cluster. For components deployed in the Shoot cluster, it is required [*] to explicitly specify the Seccomp profile.
[*] It is required because if a component deployed in the Shoot cluster does not specify a Seccomp profile and cannot run with the RuntimeDefault Seccomp profile, then enabling the .spec.kubernetes.kubelet.seccompDefault field in the Shoot spec would break the corresponding component.
High Availability / Stability
Specify the component type label for high availability (example)
To support high-availability deployments, gardener-resource-managers HighAvailabilityConfig webhook injects the proper specification like replica or topology spread constraints.
You only need to specify the type label. For more information, see High Availability Of Deployed Components.
Closely related to high availability but also to stability in general: The definition of a PodDisruptionBudget with maxUnavailable=1 should be provided by default.
Each cluster runs many components with different priorities.
Gardener provides a set of default PriorityClasses. For more information, see Priority Classes.
Consider defining liveness and readiness probes (example)
To ensure user workload pods are only scheduled to Nodes where all node-critical components are ready, these components need to tolerate the node.gardener.cloud/critical-components-not-ready taint (NoSchedule effect).
Also, such DaemonSets and the included PodTemplates need to be labelled with node.gardener.cloud/critical-component=true.
For more information, see Readiness of Shoot Worker Nodes.
Consider making a Service topology-aware (example)
To reduce costs and to improve the network traffic latency in multi-zone Seed clusters, consider making a Service topology-aware, if applicable. In short, when a Service is topology-aware, Kubernetes routes network traffic to the Endpoints (Pods) which are located in the same zone where the traffic originated from. In this way, the cross availability zone traffic is avoided. See Topology-Aware Traffic Routing.
Enable leader election unconditionally for controllers independently from the number of replicas or from the high availability configurations. Having leader election enabled even for a single replica Deployment prevents having two Pods active at the same time. Otherwise, there are some corner cases that can result in two active Pods - Deployment rolling update or kubelet stops running on a Node and is not able to terminate the old replica while kube-controller-manager creates a new replica to match the Deployment’s desired replicas count.
Do not set a pod{Anti}Affinity for spreading across nodes or zones
Spread across nodes and zones is handled by the HighAvailabilityConfig webhook. Specifying another pod{Anti}Affinity makes it harder to run the component locally or in smaller setups with only a single node.
All components should define reasonable (initial) CPU and memory requests and avoid limits (especially CPU limits) unless you know the healthy range for your component (almost impossible with most components today), but no more than the node allocatable remainder (after daemonset pods) of the largest eligible machine type. Scheduling only takes requests into account!
We typically (need to) perform vertical auto-scaling for containers that have a significant usage (>50m/100M) and a significant usage spread over time (>2x) by defining a VerticalPodAutoscaler with updatePolicy.updateModeAuto, containerPolicies[].controlledValuesRequestsOnly, reasonable minAllowed configuration and no maxAllowed configuration (will be taken care of in Gardener environments for you/capped at the largest eligible machine type).
Define a HorizontalPodAutoscaler if needed (example)
If your component is capable of scaling horizontally, you should consider defining a HorizontalPodAutoscaler.
Provide monitoring scrape config and alerting rules (example 1, example 2)
Components should provide scrape configuration and alerting rules for Prometheus/Alertmanager if appropriate.
This should be done inside a dedicated monitoring.go file.
Extensions should follow the guidelines described in Extensions Monitoring Integration.
Components should provide parsers and filters for fluent-bit, if appropriate.
This should be done inside a dedicated logging.go file.
Extensions should follow the guidelines described in Fluent-bit log parsers and filters.
Set the revisionHistoryLimit to 2 for Deployments and DaemonSets (example)
In order to allow easy inspection of two ReplicaSets / ControllerRevisions to quickly find the changes that lead to a rolling update, the revision history limit should be set to 2.
This also helps to not flood the API server with too many revisions.
gardener-operators’s and gardenlet’s care controllers regularly check the health status of components relevant to the respective cluster (garden/seed/shoot).
For shoot control plane components, you need to enhance the lists of components to make sure your component is checked, see example above.
For components deployed via ManagedResource, please consult the respective care controller documentation for more information (garden, seed, shoot).
Configure automatic restarts in shoot maintenance time window (example 1, example 2)
Gardener offers to restart components during the maintenance time window. For more information, see Restart Control Plane Controllers and Restart Some Core Addons.
You can consider adding the needed label to your control plane component to get this automatic restart (probably not needed for most components).
18 - Configuration
Gardener Configuration and Usage
Gardener automates the full lifecycle of Kubernetes clusters as a service.
Additionally, it has several extension points allowing external controllers to plug-in to the lifecycle.
As a consequence, there are several configuration options for the various custom resources that are partially required.
Configuration and Usage of Gardener as Operator/Administrator
When we use the terms “operator/administrator”, we refer to both the people deploying and operating Gardener.
Gardener consists of the following components:
gardener-apiserver, a Kubernetes-native API extension that serves custom resources in the Kubernetes-style (like Seeds and Shoots), and a component that contains multiple admission plugins.
gardener-controller-manager, a component consisting of multiple controllers that implement reconciliation and deletion flows for some of the custom resources (e.g., it contains the logic for maintaining Shoots, reconciling Projects).
gardener-scheduler, a component that assigns newly created Shoot clusters to appropriate Seed clusters.
gardenlet, a component running in seed clusters and consisting out of multiple controllers that implement reconciliation and deletion flows for some of the custom resources (e.g., it contains the logic for reconciliation and deletion of Shoots).
Each of these components have various configuration options.
The gardener-apiserver uses the standard API server library maintained by the Kubernetes community, and as such it mainly supports command line flags.
Other components use so-called componentconfig files that describe their configuration in a Kubernetes-style versioned object.
Configuration File for Gardener Admission Controller
The Gardener admission controller only supports one command line flag, which should be a path to a valid admission-controller configuration file.
Please take a look at this example configuration.
Configuration File for Gardener Controller Manager
The Gardener controller manager only supports one command line flag, which should be a path to a valid controller-manager configuration file.
Please take a look at this example configuration.
Configuration File for Gardener Scheduler
The Gardener scheduler also only supports one command line flag, which should be a path to a valid scheduler configuration file.
Please take a look at this example configuration.
Information about the concepts of the Gardener scheduler can be found at Gardener Scheduler.
Configuration File for gardenlet
The gardenlet also only supports one command line flag, which should be a path to a valid gardenlet configuration file.
Please take a look at this example configuration.
Information about the concepts of the Gardenlet can be found at gardenlet.
System Configuration
After successful deployment of the four components, you need to setup the system.
Let’s first focus on some “static” configuration.
When the gardenlet starts, it scans the garden namespace of the garden cluster for Secrets that have influence on its reconciliation loops, mainly the Shoot reconciliation:
Internal domain secret - contains the DNS provider credentials (having appropriate privileges) which will be used to create/delete the so-called “internal” DNS records for the Shoot clusters, please see this yaml file for an example.
This secret is used in order to establish a stable endpoint for shoot clusters, which is used internally by all control plane components.
The DNS records are normal DNS records but called “internal” in our scenario because only the kubeconfigs for the control plane components use this endpoint when talking to the shoot clusters.
It is forbidden to change the internal domain secret if there are existing shoot clusters.
Default domain secrets (optional) - contain the DNS provider credentials (having appropriate privileges) which will be used to create/delete DNS records for a default domain for shoots (e.g., example.com), please see this yaml file for an example.
Not every end-user/stakeholder/customer has its own domain, however, Gardener needs to create a DNS record for every shoot cluster.
As landscape operator you might want to define a default domain owned and controlled by you that is used for all shoot clusters that don’t specify their own domain.
If you have multiple default domain secrets defined you can add a priority as an annotation (dns.gardener.cloud/domain-default-priority) to select which domain should be used for new shoots during creation. The domain with the highest priority is selected during shoot creation. If there is no annotation defined, the default priority is 0, also all non integer values are considered as priority 0.
Alerting secrets (optional) - contain the alerting configuration and credentials for the AlertManager to send email alerts. It is also possible to configure the monitoring stack to send alerts to an AlertManager not deployed by Gardener to handle alerting. Please see this yaml file for an example.
If email alerting is configured:
An AlertManager is deployed into each seed cluster that handles the alerting for all shoots on the seed cluster.
Gardener will inject the SMTP credentials into the configuration of the AlertManager.
The AlertManager will send emails to the configured email address in case any alerts are firing.
If an external AlertManager is configured:
Each shoot has a Prometheus responsible for monitoring components and sending out alerts. The alerts will be sent to a URL configured in the alerting secret.
This external AlertManager is not managed by Gardener and can be configured however the operator sees fit.
Supported authentication types are no authentication, basic, or mutual TLS.
Global monitoring secrets (optional) - contains basic authentication credentials for the Prometheus aggregating metrics for all clusters.
These secrets are synced to each seed cluster and used to gain access to the aggregate monitoring components.
Shoot Service Account Issuer secret (optional) - contains the configuration needed to centrally configure gardenlets in order to implement GEP-24. Please see the example configuration for more details.
This secret contains the hostname which will be used to configure the shoot’s managed issuer, therefore the value of the hostname should not be changed once configured.
Caution
Gardener Operator manages this field automatically if Gardener Discovery Server is enabled and does not provide a way to change the default value of it as of now.
It calculates it based on the first ingress domain for the runtime Garden cluster. The domain is prefixed with “discovery.” using the formula discovery.{garden.spec.runtimeCluster.ingress.domains[0]}.
If you are not yet using Gardener Operator it is EXTREMELY important to follow the same convention as Gardener Operator,
so that during migration to Gardener Operator the hostname can stay the same and avoid disruptions for shoots that already have a managed service account issuer.
Apart from this “static” configuration there are several custom resources extending the Kubernetes API and used by Gardener.
As an operator/administrator, you have to configure some of them to make the system work.
Configuration and Usage of Gardener as End-User/Stakeholder/Customer
As an end-user/stakeholder/customer, you are using a Gardener landscape that has been setup for you by another team.
You don’t need to care about how Gardener itself has to be configured or how it has to be deployed.
Take a look at Gardener API Server - the topic describes which resources are offered by Gardener.
You may want to have a more detailed look for Projects, SecretBindings, Shoots, and (Cluster)OpenIDConnectPresets.
19 - Control Plane Migration
Control Plane Migration
Prerequisites
The Seeds involved in the control plane migration must have backups enabled - their .spec.backup fields cannot be nil.
ShootState
ShootState is an API resource which stores non-reconstructible state and data required to completely recreate a Shoot’s control plane on a new Seed. The ShootState resource is created on Shoot creation in its Project namespace and the required state/data is persisted during Shoot creation or reconciliation.
Shoot Control Plane Migration
Triggering the migration is done by changing the Shoot’s .spec.seedName to a Seed that differs from the .status.seedName, we call this Seed a "Destination Seed". This action can only be performed by an operator (see Triggering the Migration). If the Destination Seed does not have a backup and restore configuration, the change to spec.seedName is rejected. Additionally, this Seed must not be set for deletion and must be healthy.
If the Shoot has different .spec.seedName and .status.seedName, a process is started to prepare the Control Plane for migration:
.status.lastOperation is changed to Migrate.
Kubernetes API Server is stopped and the extension resources are annotated with gardener.cloud/operation=migrate.
Full snapshot of the ETCD is created and terminating of the Control Plane in the Source Seed is initiated.
If the process is successful, we update the status of the Shoot by setting the .status.seedName to the null value. That way, a restoration is triggered in the Destination Seed and .status.lastOperation is changed to Restore. The control plane migration is completed when the Restore operation has completed successfully.
The etcd backups will be copied over to the BackupBucket of the Destination Seed during control plane migration and any future backups will be uploaded there.
Triggering the Migration
For control plane migration, operators with the necessary RBAC can use the shoots/binding subresource to change the .spec.seedName, with the following commands:
When migrating Shoots to a Destination Seed with different provider type from the Source Seed, make sure of the following:
Pods running in the Destination Seed must have network connectivity to the backup storage provider of the Source Seed so that etcd backups can be copied successfully. Otherwise, the Restore operation will get stuck at the Waiting until etcd backups are copied step. However, if you do end up in this case, you can still finish the control plane migration by following the guide to manually copy etcd backups.
The nodes of your Shoot cluster must have network connectivity to the Shoot’s kube-apiserver and the vpn-seed-server once they are migrated to the Destination Seed. Otherwise, the Restore operation will get stuck at the Waiting until the Kubernetes API server can connect to the Shoot workers step. However, if you do end up in this case and cannot allow network traffic from the nodes to the Shoot’s control plane, you can annotate the Shoot with the shoot.gardener.cloud/skip-readiness annotation so that the Restore operation finishes, and then use the shoots/binding subresource to migrate the control plane back to the Source Seed.
Copying ETCD Backups Manually During the Restore Operation
Following is a workaround that can be used to copy etcd backups manually in situations where a Shoot’s control plane has been moved to a Destination Seed and the pods running in it lack network connectivity to the Source Seed’s storage provider:
Follow the instructions in the passing-credentials guide on how to set up the required credentials for the copy operation depending on the storage providers for which you want to perform it.
Use the etcdbrctl copy command to copy the backups by following the instructions in the etcdbrctl copy guide
After you have successfully copied the etcd backups, wait for the EtcdCopyBackupsTask custom resource to be created in the Shoot’s control plane on the Destination Seed, if it does not already exist. Afterwards, mark it as successful by patching it using the following command:
After the main-etcd becomes Ready, and the source-etcd-backup secret is deleted from the Shoot’s control plane, remove the finalizer on the source extensions.gardener.cloud/v1alpha1.BackupEntry in the Destination Seed so that it can be deleted successfully (the resource name uses the following format: source-shoot--<project-name>--<shoot-name>--<uid>). This is necessary as the Destination Seed will not have network connectivity to the Source Seed’s storage provider and the deletion will fail.
Once the control plane migration has finished successfully, make sure to manually clean up the source backup directory in the Source Seed’s storage provider.
20 - Defaulting
Defaulting Strategy and Developer Guidelines
This document walks you through:
Conventions to be followed when writing defaulting functions
How to write a test for a defaulting function
The document is aimed towards developers who want to contribute code and need to write defaulting code and unit tests covering the defaulting functions, as well as maintainers and reviewers who review code.
It serves as a common guide that we commit to follow in our project to ensure consistency in our defaulting code, good coverage for high confidence, and good maintainability.
Writing defaulting code
Every kubernetes type should have a dedicated defaults_*.go file. For instance, if you have a Shoot type, there should be a corresponding defaults_shoot.go file containing all defaulting logic for that type.
If there is only one type under an api group then we can just have types.go and a corresponding defaults.go. For instance, resourcemanager api has only one types.go, hence in this case only defaults.go file would suffice.
Aim to segregate each struct type into its own SetDefaults_* function. These functions encapsulate the defaulting logic specific to the corresponding struct type, enhancing modularity and maintainability. For example, ServerConfiguration struct in resourcemanager api has corresponding SetDefaults_ServerConfiguration() function.
⚠️ Ensure to run the make generate WHAT=codegen command when new SetDefaults_* function is added, which generates the zz_generated.defaults.go file containing the overall defaulting function.
We are using go modules for dependency management.
In order to add a new package dependency to the project, you can perform go get <PACKAGE>@<VERSION> or edit the go.mod file and append the package along with the version you want to use.
Updating Dependencies
The Makefile contains a rule called tidy which performs go mod tidy:
go mod tidy makes sure go.mod matches the source code in the module. It adds any missing modules necessary to build the current module’s packages and dependencies, and it removes unused modules that don’t provide any relevant packages.
make tidy
⚠️ Make sure that you test the code after you have updated the dependencies!
Exported Packages
This repository contains several packages that could be considered “exported packages”, in a sense that they are supposed to be reused in other Go projects.
For example:
Gardener’s API packages: pkg/apis
Library for building Gardener extensions: extensions
Gardener’s Test Framework: test/framework
There are a few more folders in this repository (non-Go sources) that are reused across projects in the Gardener organization:
GitHub templates: .github
Concourse / cc-utils related helpers: hack/.ci
Development, build and testing helpers: hack
These packages feature a dummy doc.go file to allow other Go projects to pull them in as go mod dependencies.
These packages are explicitly not supposed to be used in other projects (consider them as “non-exported”):
API validation packages: pkg/apis/*/*/validation
Operation package (main Gardener business logic regarding Seed and Shoot clusters): pkg/gardenlet/operation
Third party code: third_party
Currently, we don’t have a mechanism yet for selectively syncing out these exported packages into dedicated repositories like kube’s staging mechanism (publishing-bot).
Import Restrictions
We want to make sure that other projects can depend on this repository’s “exported” packages without pulling in the entire repository (including “non-exported” packages) or a high number of other unwanted dependencies.
Hence, we have to be careful when adding new imports or references between our packages.
ℹ️ General rule of thumb: the mentioned “exported” packages should be as self-contained as possible and depend on as few other packages in the repository and other projects as possible.
In order to support that rule and automatically check compliance with that goal, we leverage import-boss.
The tool checks all imports of the given packages (including transitive imports) against rules defined in .import-restrictions files in each directory.
An import is allowed if it matches at least one allowed prefix and does not match any forbidden prefixes.
Note: '' (the empty string) is a prefix of everything.
For more details, see the import-boss topic.
import-boss is executed on every pull request and blocks the PR if it doesn’t comply with the defined import restrictions.
You can also run it locally using make check.
Import restrictions should be changed in the following situations:
We spot a new pattern of imports across our packages that was not restricted before but makes it more difficult for other projects to depend on our “exported” packages.
In that case, the imports should be further restricted to disallow such problematic imports, and the code/package structure should be reworked to comply with the newly given restrictions.
We want to share code between packages, but existing import restrictions prevent us from doing so.
In that case, please consider what additional dependencies it will pull in, when loosening existing restrictions.
Also consider possible alternatives, like code restructurings or extracting shared code into dedicated packages for minimal impact on dependent projects.
22 - Gardener Info Configmap
Gardener Info ConfigMap
Overview
The Gardener Operator maintains a ConfigMap inside the Garden cluster that contains information about the Garden landscape.
The ConfigMap is named gardener-info and located in the gardener-system-public namespace. It is visible to all authenticated users.
Fields
The following fields are provided:
apiVersion: v1
kind: ConfigMap
metadata:
name: gardener-info
namespace: gardener-system-public
data:
gardenerAPIServer: | # key name of the gardener-apiserver section version: v1.111.0 # version of the gardener-apiserver workloadIdentityIssuerURL: https://issuer.gardener.cloud.local # the URL of the authority that issues workload identity tokens
23 - Getting Started Locally
Developing Gardener Locally
This document explains how to setup a kind based environment for developing Gardener locally.
For the best development experience you should especially check the Developing Gardener section.
In case you plan a debugging session please check the Debugging Gardener section.
24 - High Availability Of Components
High Availability of Deployed Components
gardenlets and extension controllers are deploying components via Deployments, StatefulSets, etc., as part of the shoot control plane, or the seed or shoot system components.
Some of the above component deployments must be further tuned to improve fault tolerance / resilience of the service. This document outlines what needs to be done to achieve this goal.
Please be forwarded to the Convenient Application Of These Rules section, if you want to take a shortcut to the list of actions that require developers’ attention.
Seed Clusters
The worker nodes of seed clusters can be deployed to one or multiple availability zones.
The Seed specification allows you to provide the information which zones are available:
Independent of the number of zones, seed system components like the gardenlet or the extension controllers themselves, or others like etcd-druid, dependency-watchdog, etc., should always be running with multiple replicas.
Concretely, all seed system components should respect the following conventions:
Replica Counts
Component Type
< 3 Zones
>= 3 Zones
Comment
Observability (Monitoring, Logging)
1
1
Downtimes accepted due to cost reasons
Controllers
2
2
/
(Webhook) Servers
2
2
/
Apart from the above, there might be special cases where these rules do not apply, for example:
istio-ingressgateway is scaled horizontally, hence the above numbers are the minimum values.
nginx-ingress-controller in the seed cluster is used to advertise all shoot observability endpoints, so due to performance reasons it runs with 2 replicas at all times. In the future, this component might disappear in favor of the istio-ingressgateway anyways.
Topology Spread Constraints
When the component has >= 2 replicas …
… then it should also have a topologySpreadConstraint, ensuring the replicas are spread over the nodes:
spec:
topologySpreadConstraints:
- topologyKey: kubernetes.io/hostname
minDomains: 3 # lower value of max replicas or 3 maxSkew: 1
whenUnsatisfiable: ScheduleAnyway
matchLabels: ...
minDomains is set when failure tolerance is configured or annotation high-availability-config.resources.gardener.cloud/host-spread="true" is given.
… and the seed cluster has >= 2 zones, then the component should also have a second topologySpreadConstraint, ensuring the replicas are spread over the zones:
spec:
topologySpreadConstraints:
- topologyKey: topology.kubernetes.io/zone
minDomains: 2 # lower value of max replicas or number of zones maxSkew: 1
whenUnsatisfiable: DoNotSchedule
matchLabels: ...
According to these conventions, even seed clusters with only one availability zone try to be highly available “as good as possible” by spreading the replicas across multiple nodes.
Hence, while such seed clusters obviously cannot handle zone outages, they can at least handle node failures.
Shoot Clusters
The Shoot specification allows configuring “high availability” as well as the failure tolerance type for the control plane components, see Highly Available Shoot Control Plane for details.
Regarding the seed cluster selection, the only constraint is that shoot clusters with failure tolerance type zone are only allowed to run on seed clusters with at least three zones.
All other shoot clusters (non-HA or those with failure tolerance type node) can run on seed clusters with any number of zones.
Control Plane Components
All control plane components should respect the following conventions:
Replica Counts
Component Type
w/o HA
w/ HA (node)
w/ HA (zone)
Comment
Observability (Monitoring, Logging)
1
1
1
Downtimes accepted due to cost reasons
Controllers
1
2
2
/
(Webhook) Servers
2
2
2
/
Apart from the above, there might be special cases where these rules do not apply, for example:
etcd is a server, though the most critical component of a cluster requiring a quorum to survive failures. Hence, it should have 3 replicas even when the failure tolerance is node only.
kube-apiserver is scaled horizontally, hence the above numbers are the minimum values (even when the shoot cluster is not HA, there might be multiple replicas).
Topology Spread Constraints
When the component has >= 2 replicas …
… then it should also have a topologySpreadConstraint ensuring the replicas are spread over the nodes:
Hence, the node spread is done on best-effort basis only.
However, if the shoot cluster has defined a failure tolerance type, the whenUnsatisfiable field should be set to DoNotSchedule.
… and the failure tolerance type of the shoot cluster is zone, then the component should also have a second topologySpreadConstraint ensuring the replicas are spread over the zones:
spec:
topologySpreadConstraints:
- maxSkew: 1
minDomains: 2 # lower value of max replicas or number of zones topologyKey: topology.kubernetes.io/zone
whenUnsatisfiable: DoNotSchedule
matchLabels: ...
Node Affinity
The gardenlet annotates the shoot namespace in the seed cluster with the high-availability-config.resources.gardener.cloud/zones annotation.
If the shoot cluster is non-HA or has failure tolerance type node, then the value will be always exactly one zone (e.g., high-availability-config.resources.gardener.cloud/zones=europe-1b).
If the shoot cluster has failure tolerance type zone, then the value will always contain exactly three zones (e.g., high-availability-config.resources.gardener.cloud/zones=europe-1a,europe-1b,europe-1c).
For backwards-compatibility, this annotation might contain multiple zones for shoot clusters created before gardener/gardener@v1.60 and not having failure tolerance type zone.
This is because their volumes might already exist in multiple zones, hence pinning them to only one zone would not work.
Hence, in case this annotation is present, the components should have the following node affinity:
This is to ensure all pods are running in the same (set of) availability zone(s) such that cross-zone network traffic is avoided as much as possible (such traffic is typically charged by the underlying infrastructure provider).
System Components
The availability of system components is independent of the control plane since they run on the shoot worker nodes while the control plane components run on the seed worker nodes (for more information, see the Kubernetes architecture overview).
Hence, it only depends on the number of availability zones configured in the shoot worker pools via .spec.provider.workers[].zones.
Concretely, the highest number of zones of a worker pool with systemComponents.allow=true is considered.
All system components should respect the following conventions:
Replica Counts
Component Type
1 or 2 Zones
>= 3 Zones
Controllers
2
2
(Webhook) Servers
2
2
Apart from the above, there might be special cases where these rules do not apply, for example:
coredns is scaled horizontally (today), hence the above numbers are the minimum values (possibly, scaling these components vertically may be more appropriate, but that’s unrelated to the HA subject matter).
Optional addons like nginx-ingress or kubernetes-dashboard are only provided on best-effort basis for evaluation purposes, hence they run with 1 replica at all times.
Topology Spread Constraints
When the component has >= 2 replicas …
… then it should also have a topologySpreadConstraint ensuring the replicas are spread over the nodes:
Hence, the node spread is done on best-effort basis only.
… and the cluster has >= 2 zones, then the component should also have a second topologySpreadConstraint ensuring the replicas are spread over the zones:
spec:
topologySpreadConstraints:
- maxSkew: 1
minDomains: 2 # lower value of max replicas or number of zones topologyKey: topology.kubernetes.io/zone
whenUnsatisfiable: DoNotSchedule
matchLabels: ...
Convenient Application of These Rules
According to above scenarios and conventions, the replicas, topologySpreadConstraints or affinity settings of the deployed components might need to be adapted.
In order to apply those conveniently and easily for developers, Gardener installs a mutating webhook into both seed and shoot clusters which reacts on Deployments and StatefulSets deployed to namespaces with the high-availability-config.resources.gardener.cloud/consider=true label set.
The following actions have to be taken by developers:
Check if components are prepared to run concurrently with multiple replicas, e.g. controllers usually use leader election to achieve this.
All components should be generally equipped with PodDisruptionBudgets with .spec.maxUnavailable=1 and unhealthyPodEvictionPolicy=AlwaysAllow:
Add the label high-availability-config.resources.gardener.cloud/type to deployments or statefulsets, as well as optionally involved horizontalpodautoscalers where the following two values are possible:
controller
server
Type server is also preferred if a component is a controller and (webhook) server at the same time.
Make sure you have read the above document about the webhook internals before continuing reading this section.
Seed Controller
The gardenlet performs the following changes on all namespaces running seed system components:
adds the label high-availability-config.resources.gardener.cloud/consider=true.
adds the annotation high-availability-config.resources.gardener.cloud/zones=<zones>, where <zones> is the list provided in .spec.provider.zones[] in the Seed specification.
Note that neither the high-availability-config.resources.gardener.cloud/failure-tolerance-type, nor the high-availability-config.resources.gardener.cloud/zone-pinning annotations are set, hence the node affinity would never be touched by the webhook.
The only exception to this rule are the istio ingress gateway namespaces. This includes the default istio ingress gateway when SNI is enabled, as well as analogous namespaces for exposure classes and zone-specific istio ingress gateways. Those namespaces
will additionally be annotated with high-availability-config.resources.gardener.cloud/zone-pinning set to true, resulting in the node affinities and the topology spread constraints being set. The replicas are not touched, as the istio ingress gateways
are scaled by a horizontal autoscaler instance.
Shoot Controller
Control Plane
The gardenlet performs the following changes on the namespace running the shoot control plane components:
adds the label high-availability-config.resources.gardener.cloud/consider=true. This makes the webhook mutate the replica count and the topology spread constraints.
adds the annotation high-availability-config.resources.gardener.cloud/failure-tolerance-type with value equal to .spec.controlPlane.highAvailability.failureTolerance.type (or "", if .spec.controlPlane.highAvailability=nil). This makes the webhook mutate the node affinity according to the specified zone(s).
adds the annotation high-availability-config.resources.gardener.cloud/zones=<zones>, where <zones> is a …
… random zone chosen from the .spec.provider.zones[] list in the Seed specification (always only one zone (even if there are multiple available in the seed cluster)) in case the Shoot has no HA setting (i.e., spec.controlPlane.highAvailability=nil) or when the Shoot has HA setting with failure tolerance type node.
… list of three randomly chosen zones from the .spec.provider.zones[] list in the Seed specification in case the Shoot has HA setting with failure tolerance type zone.
System Components
The gardenlet performs the following changes on all namespaces running shoot system components:
adds the label high-availability-config.resources.gardener.cloud/consider=true. This makes the webhook mutate the replica count and the topology spread constraints.
adds the annotation high-availability-config.resources.gardener.cloud/zones=<zones> where <zones> is the merged list of zones provided in .zones[] with systemComponents.allow=true for all worker pools in .spec.provider.workers[] in the Shoot specification.
Note that neither the high-availability-config.resources.gardener.cloud/failure-tolerance-type, nor the high-availability-config.resources.gardener.cloud/zone-pinning annotations are set, hence the node affinity would never be touched by the webhook.
25 - Ipv6
IPv6 in Gardener Clusters
🚧 IPv6 networking is currently under development.
IPv6 Single-Stack Networking
GEP-21 proposes IPv6 Single-Stack Support in the local Gardener environment.
This documentation will be enhanced while implementing GEP-21, see gardener/gardener#7051.
For real infrastructure providers, please check the corresponding provider documentation for IPv6 support.
Furthermore, please check the documentation of your preferred networking extension for IPv6 support.
Development/Testing Setup
Developing or testing IPv6-related features requires a Linux machine (docker only supports IPv6 on Linux) and native IPv6 connectivity to the internet.
If you’re on a different OS or don’t have IPv6 connectivity in your office environment or via your home ISP, make sure to check out gardener-community/dev-box-gcp, which allows you to circumvent these limitations.
To get started with the IPv6 setup and create a local IPv6 single-stack shoot cluster, run the following commands:
make kind-up gardener-up IPFAMILY=ipv6
k apply -f example/provider-local/shoot-ipv6.yaml
Please also take a look at the guide on Deploying Gardener Locally for more details on setting up an IPv6 gardener for testing or development purposes.
Container Images
If you plan on using custom images, make sure your registry supports IPv6 access.
Check the component checklist for tips concerning container registries and how to handle their IPv6 support.
26 - Istio
Istio
Istio offers a service mesh implementation with focus on several important features - traffic, observability, security, and policy.
The default profile which is recommended for production deployment, is not suitable for the Gardener use case, as it offers more functionality than desired. The current installation goes through heavy refactorings due to the IstioOperator and the mixture of Helm values + Kubernetes API specification makes configuring and fine-tuning it very hard. A more simplistic deployment is used by Gardener. The differences are the following:
Telemetry is not deployed.
istiod is deployed.
istio-ingress-gateway is deployed in a separate istio-ingress namespace.
istio-egress-gateway is not deployed.
None of the Istio addons are deployed.
Mixer (deprecated) is not deployed.
Mixer CDRs are not deployed.
Kubernetes Service, Istio’s VirtualService and ServiceEntry are NOT advertised in the service mesh. This means that if a Service needs to be accessed directly from the Istio Ingress Gateway, it should have networking.istio.io/exportTo: "*" annotation. VirtualService and ServiceEntry must have .spec.exportTo: ["*"] set on them respectively.
Istio injector is not enabled.
mTLS is enabled by default.
Handling Multiple Availability Zones with Istio
For various reasons, e.g., improved resiliency to certain failures, it may be beneficial to use multiple availability zones in a seed cluster. While availability zones have advantages in being able to cover some failure domains, they also come with some additional challenges. Most notably, the latency across availability zone boundaries is higher than within an availability zone. Furthermore, there might be additional cost implied by network traffic crossing an availability zone boundary. Therefore, it may be useful to try to keep traffic within an availability zone if possible. The istio deployment as part of Gardener has been adapted to allow this.
A seed cluster spanning multiple availability zones may be used for highly-available shoot control planes. Those control planes may use a single or multiple availability zones. In addition to that, ordinary non-highly-available shoot control planes may be scheduled to such a seed cluster as well. The result is that the seed cluster may have control planes spanning multiple availability zones and control planes that are pinned to exactly one availability zone. These two types need to be handled differently when trying to prevent unnecessary cross-zonal traffic.
The goal is achieved by using multiple istio ingress gateways. The default istio ingress gateway spans all availability zones. It is used for multi-zonal shoot control planes. For each availability zone, there is an additional istio ingress gateway, which is utilized only for single-zone shoot control planes pinned to this availability zone. This is illustrated in the following diagram.
Please note that operators may need to perform additional tuning to prevent cross-zonal traffic completely. The loadbalancer settings in the seed specification offer various options, e.g., by setting the external traffic policy to local or using infrastructure specific loadbalancer annotations.
Furthermore, note that this approach is also taken in case ExposureClasses are used. For each exposure class, additional zonal istio ingress gateways may be deployed to cover for single-zone shoot control planes using the exposure class.
In default mode Istio performs L4 load balancing. Istio distributes connections to Kube API servers preferably in the
same zone (Topology-Aware Traffic Routing).
Requests are not taken into account for a load balancing decisions. TLS is terminated by Kube API server instances.
There is a second mode which can be activated via IstioTLSTermination feature gate in gardenlet and gardener-operator.
This mode introduces L7 load balancing and distributes requests among the Kube API server instances.
It does not use Topology-Aware Traffic Routing since it contradicts the load balancing goal.
In this mode TLS is terminated in Istio. However, Istio creates a TLS connection to Kube API servers, too, so the
traffic within the cluster remains encrypted.
This document is focused on the second mode.
On seeds where the feature gate is activated L7 load balancing can still be deactivated for single shoots by annotating
them with shoot.gardener.cloud/disable-istio-tls-termination: "true".
How it works
L7 load balancing works for the externally resolvable Kube API server endpoints, for connections which use
apiserver-proxy like endpoint kubernetes.default.svc.cluster.local and for control plane components running in shoot
namespaces.
Clients might authenticate at Kube API server using client certificates, tokens or might connect unauthenticated. In the
first case Istio ingress gateway must validate client certificates because it terminates the TLS connection. Thus, it is
configured with an optional mutual TLS authentication. It is optional because in case of the authentication via token,
the token is validated by Kube API server. Unauthenticated requests are handled by Kube API server too. For TLS
termination and client certificate validation Kube API server certificate (including the private key) and the client CA
bundle must be synchronized into the namespace where istio ingress gateway is running.
While token authentication and unauthenticated requests are still handled by Kube API server itself, it requires
dedicated request headers
if an authentication proxy is used. Based on these headers Kube API server identifies the user and group of a request.
They are added with a lua script running in an envoy filter in istio ingress gateway. Kube API server trusts the headers
set by the authentication proxy so it requires an mTLS connection to the proxy. Istio uses the front proxy CA
(including private key) and the server CA bundle to establish the mTLS connection. These secrets again must be synchronized
into the namespace where istio ingress gateway is running. There is an own istio destination rule for the mTLS connection.
The destination host of the istio virtual service has an istio destination rule which does not use mTLS so that Kube API
server authenticates requests by itself. It is used for the token based authentication. The istio destination rule for
the mTLS connection is set by the lua script mentioned above only. This is a safety net to prevent that requests can
reach Kube API server via the trusted connection in case the lua scripts fails for some reason.
Cluster internal control plane components like kube-controller-manager, kube-scheduler and gardener-resource-manager
use L7 load balancing too. They connect to the Kube API server via a cluster IP service for istio ingress gateway.
The generic token kubeconfig uses the public Kube API server endpoint. In order to avoid external traffic, the control
plane components use host aliases in their pod specifications. For convenience, the host aliases are automatically added
by the pod-kube-apiserver-load-balancing webhook
in gardener-resource-manager. It also adds a label to create a network policy allowing egress traffic to the istio
ingress gateway pods.
This works for control plane components running in shoot namespaces and for the virtual garden control plane.
The flow for L7 load balancing is shown in the following illustration.
28 - Kubernetes Clients
Kubernetes Clients in Gardener
This document aims at providing a general developer guideline on different aspects of using Kubernetes clients in a large-scale distributed system and project like Gardener.
The points included here are not meant to be consulted as absolute rules, but rather as general rules of thumb that allow developers to get a better feeling about certain gotchas and caveats.
It should be updated with lessons learned from maintaining the project and running Gardener in production.
Prerequisites:
Please familiarize yourself with the following basic Kubernetes API concepts first, if you’re new to Kubernetes. A good understanding of these basics will help you better comprehend the following document.
For historical reasons, you will find different kinds of Kubernetes clients in Gardener:
Client-Go Clients
client-go is the default/official client for talking to the Kubernetes API in Golang.
It features the so called “client sets” for all built-in Kubernetes API groups and versions (e.g. v1 (aka core/v1), apps/v1).
client-go clients are generated from the built-in API types using client-gen and are composed of interfaces for every known API GroupVersionKind.
A typical client-go usage looks like this:
var (
ctx context.Context
c kubernetes.Interface // "k8s.io/client-go/kubernetes" deployment *appsv1.Deployment // "k8s.io/api/apps/v1")
updatedDeployment, err := c.AppsV1().Deployments("default").Update(ctx, deployment, metav1.UpdateOptions{})
Important characteristics of client-go clients:
clients are specific to a given API GroupVersionKind, i.e., clients are hard-coded to corresponding API-paths (don’t need to use the discovery API to map GVK to a REST endpoint path).
client’s don’t modify the passed in-memory object (e.g. deployment in the above example). Instead, they return a new in-memory object.
This means that controllers have to continue working with the new in-memory object or overwrite the shared object to not lose any state updates.
Generated Client Sets for Gardener APIs
Gardener’s APIs extend the Kubernetes API by registering an extension API server (in the garden cluster) and CustomResourceDefinitions (on Seed clusters), meaning that the Kubernetes API will expose additional REST endpoints to manage Gardener resources in addition to the built-in API resources.
In order to talk to these extended APIs in our controllers and components, client-gen is used to generate client-go-style clients to pkg/client/{core,extensions,seedmanagement,...}.
Usage of these clients is equivalent to client-go clients, and the same characteristics apply. For example:
var (
ctx context.Context
c gardencoreclientset.Interface // "github.com/gardener/gardener/pkg/client/core/clientset/versioned" shoot *gardencorev1beta1.Shoot // "github.com/gardener/gardener/pkg/apis/core/v1beta1")
updatedShoot, err := c.CoreV1beta1().Shoots("garden-my-project").Update(ctx, shoot, metav1.UpdateOptions{})
Controller-Runtime Clients
controller-runtime is a Kubernetes community project (kubebuilder subproject) for building controllers and operators for custom resources.
Therefore, it features a generic client that follows a different approach and does not rely on generated client sets. Instead, the client can be used for managing any Kubernetes resources (built-in or custom) homogeneously.
For example:
A brief introduction to controller-runtime and its basic constructs can be found at the official Go documentation.
Important characteristics of controller-runtime clients:
The client functions take a generic client.Object or client.ObjectList value. These interfaces are implemented by all Golang types, that represent Kubernetes API objects or lists respectively which can be interacted with via usual API requests. [1]
The client first consults a runtime.Scheme (configured during client creation) for recognizing the object’s GroupVersionKind (this happens on the client-side only).
A runtime.Scheme is basically a registry for Golang API types, defaulting and conversion functions. Schemes are usually provided per GroupVersion (see this example for apps/v1) and can be combined to one single scheme for further usage (example). In controller-runtime clients, schemes are used only for mapping a typed API object to its GroupVersionKind.
It then consults a meta.RESTMapper (also configured during client creation) for mapping the GroupVersionKind to a RESTMapping, which contains the GroupVersionResource and Scope (namespaced or cluster-scoped). From these values, the client can unambiguously determine the REST endpoint path of the corresponding API resource. For instance: appsv1.DeploymentList is available at /apis/apps/v1/deployments or /apis/apps/v1/namespaces/<namespace>/deployments respectively.
There are different RESTMapper implementations, but generally they are talking to the API server’s discovery API for retrieving RESTMappings for all API resources known to the API server (either built-in, registered via API extension or CustomResourceDefinitions).
The default implementation of a controller-runtime (which Gardener uses as well) is the dynamic RESTMapper. It caches discovery results (i.e. RESTMappings) in-memory and only re-discovers resources from the API server when a client tries to use an unknown GroupVersionKind, i.e., when it encounters a No{Kind,Resource}MatchError.
The client writes back results from the API server into the passed in-memory object.
This means that controllers don’t have to worry about copying back the results and should just continue to work on the given in-memory object.
This is a nice and flexible pattern, and helper functions should try to follow it wherever applicable. Meaning, if possible accept an object param, pass it down to clients and keep working on the same in-memory object instead of creating a new one in your helper function.
The benefit is that you don’t lose updates to the API object and always have the last-known state in memory. Therefore, you don’t have to read it again, e.g., for getting the current resourceVersion when working with optimistic locking, and thus minimize the chances for running into conflicts.
However, controllers must not use the same in-memory object concurrently in multiple goroutines. For example, decoding results from the API server in multiple goroutines into the same maps (e.g., labels, annotations) will cause panics because of “concurrent map writes”. Also, reading from an in-memory API object in one goroutine while decoding into it in another goroutine will yield non-atomic reads, meaning data might be corrupt and represent a non-valid/non-existing API object.
Therefore, if you need to use the same in-memory object in multiple goroutines concurrently (e.g., shared state), remember to leverage proper synchronization techniques like channels, mutexes, atomic.Value and/or copy the object prior to use. The average controller however, will not need to share in-memory API objects between goroutines, and it’s typically an indicator that the controller’s design should be improved.
The client decoder erases the object’s TypeMeta (apiVersion and kind fields) after retrieval from the API server, see kubernetes/kubernetes#80609, kubernetes-sigs/controller-runtime#1517.
Unstructured and metadata-only requests objects are an exception to this because the contained TypeMeta is the only way to identify the object’s type.
Because of this behavior, obj.GetObjectKind().GroupVersionKind() is likely to return an empty GroupVersionKind.
I.e., you must not rely on TypeMeta being set or GetObjectKind() to return something usable.
If you need to identify an object’s GroupVersionKind, use a scheme and its ObjectKinds function instead (or the helper function apiutil.GVKForObject).
This is not specific to controller-runtime clients and applies to client-go clients as well.
[1] Other lower level, config or internal API types (e.g., such as AdmissionReview) don’t implement client.Object. However, you also can’t interact with such objects via the Kubernetes API and thus also not via a client, so this can be disregarded at this point.
Metadata-Only Clients
Additionally, controller-runtime clients can be used to easily retrieve metadata-only objects or lists.
This is useful for efficiently checking if at least one object of a given kind exists, or retrieving metadata of an object, if one is not interested in the rest (e.g., spec/status).
The Accept header sent to the API server then contains application/json;as=PartialObjectMetadataList;g=meta.k8s.io;v=v1, which makes the API server only return metadata of the retrieved object(s).
This saves network traffic and CPU/memory load on the API server and client side.
If the client fully lists all objects of a given kind including their spec/status, the resulting list can be quite large and easily exceed the controllers available memory.
That’s why it’s important to carefully check if a full list is actually needed, or if metadata-only list can be used instead.
For example:
var (
ctx context.Context
c client.Client // "sigs.k8s.io/controller-runtime/pkg/client" shootList = &metav1.PartialObjectMetadataList{} // "k8s.io/apimachinery/pkg/apis/meta/v1")
shootList.SetGroupVersionKind(gardencorev1beta1.SchemeGroupVersion.WithKind("ShootList"))
if err := c.List(ctx, shootList, client.InNamespace("garden-my-project"), client.Limit(1)); err != nil {
return err
}
if len(shootList.Items) > 0 {
// project has at least one shoot} else {
// project doesn't have any shoots}
Gardener’s Client Collection, ClientMaps
The Gardener codebase has a collection of clients (kubernetes.Interface), which can return all the above mentioned client types.
Additionally, it contains helpers for rendering and applying helm charts (ChartRender, ChartApplier) and retrieving the API server’s version (Version).
Client sets are managed by so called ClientMaps, which are a form of registry for all client set for a given type of cluster, i.e., Garden, Seed and Shoot.
ClientMaps manage the whole lifecycle of clients: they take care of creating them if they don’t exist already, running their caches, refreshing their cached server version and invalidating them when they are no longer needed.
var (
ctx context.Context
cm clientmap.ClientMap // "github.com/gardener/gardener/pkg/client/kubernetes/clientmap" shoot *gardencorev1beta1.Shoot
)
cs, err := cm.GetClient(ctx, keys.ForShoot(shoot)) // kubernetes.Interfaceif err != nil {
return err
}
c := cs.Client() // client.Client
The client collection mainly exist for historical reasons (there used to be a lot of code using the client-go style clients).
However, Gardener is in the process of moving more towards controller-runtime and only using their clients, as they provide many benefits and are much easier to use.
Also, gardener/gardener#4251 aims at refactoring our controller and admission components to native controller-runtime components.
⚠️ Please always prefer controller-runtime clients over other clients when writing new code or refactoring existing code.
Similar to the different types of client(set)s, there are also different kinds of Kubernetes client caches.
However, all of them are based on the same concept: Informers.
An Informer is a watch-based cache implementation, meaning it opens watch connections to the API server and continuously updates cached objects based on the received watch events (ADDED, MODIFIED, DELETED).
Informers offer to add indices to the cache for efficient object lookup (e.g., by name or labels) and to add EventHandlers for the watch events.
The latter is used by controllers to fill queues with objects that should be reconciled on watch events.
Informers are used in and created via several higher-level constructs:
SharedInformerFactories, Listers
The generated clients (built-in as well as extended) feature a SharedInformerFactory for every API group, which can be used to create and retrieve Informers for all GroupVersionKinds.
Similarly, it can be used to retrieve Listers that allow getting and listing objects from the Informer’s cache.
However, both of these constructs are only used for historical reasons, and we are in the process of migrating away from them in favor of cached controller-runtime clients (see gardener/gardener#2414, gardener/gardener#2822). Thus, they are described only briefly here.
Important characteristics of Listers:
Objects read from Informers and Listers can always be slightly out-out-date (i.e., stale) because the client has to first observe changes to API objects via watch events (which can intermittently lag behind by a second or even more).
Thus, don’t make any decisions based on data read from Listers if the consequences of deciding wrongfully based on stale state might be catastrophic (e.g. leaking infrastructure resources). In such cases, read directly from the API server via a client instead.
Objects retrieved from Informers or Listers are pointers to the cached objects, so they must not be modified without copying them first, otherwise the objects in the cache are also modified.
Controller-Runtime Caches
controller-runtime features a cache implementation that can be used equivalently as their clients. In fact, it implements a subset of the client.Client interface containing the Get and List functions.
Under the hood, a cache.Cache dynamically creates Informers (i.e., opens watches) for every object GroupVersionKind that is being retrieved from it.
Note that the underlying Informers of a controller-runtime cache (cache.Cache) and the ones of a SharedInformerFactory (client-go) are not related in any way.
Both create Informers and watch objects on the API server individually.
This means that if you read the same object from different cache implementations, you may receive different versions of the object because the watch connections of the individual Informers are not synced.
⚠️ Because of this, controllers/reconcilers should get the object from the same cache in the reconcile loop, where the EventHandler was also added to set up the controller. For example, if a SharedInformerFactory is used for setting up the controller then read the object in the reconciler from the Lister instead of from a cached controller-runtime client.
By default, the client.Client created by a controller-runtime Manager is a DelegatingClient. It delegates Get and List calls to a Cache, and all other calls to a client that talks directly to the API server. Exceptions are requests with *unstructured.Unstructured objects and object kinds that were configured to be excluded from the cache in the DelegatingClient.
ℹ️
kubernetes.Interface.Client() returns a DelegatingClient that uses the cache returned from kubernetes.Interface.Cache() under the hood. This means that all Client() usages need to be ready for cached clients and should be able to cater with stale cache reads.
Important characteristics of cached controller-runtime clients:
Like for Listers, objects read from a controller-runtime cache can always be slightly out of date. Hence, don’t base any important decisions on data read from the cache (see above).
In contrast to Listers, controller-runtime caches fill the passed in-memory object with the state of the object in the cache (i.e., they perform something like a “deep copy into”). This means that objects read from a controller-runtime cache can safely be modified without unintended side effects.
Reading from a controller-runtime cache or a cached controller-runtime client implicitly starts a watch for the given object kind under the hood. This has important consequences:
Reading a given object kind from the cache for the first time can take up to a few seconds depending on size and amount of objects as well as API server latency. This is because the cache has to do a full list operation and wait for an initial watch sync before returning results.
⚠️ Controllers need appropriate RBAC permissions for the object kinds they retrieve via cached clients (i.e., list and watch).
⚠️ By default, watches started by a controller-runtime cache are cluster-scoped, meaning it watches and caches objects across all namespaces. Thus, be careful which objects to read from the cache as it might significantly increase the controller’s memory footprint.
There is no interaction with the cache on writing calls (Create, Update, Patch and Delete), see below.
Uncached objects, filtered caches, APIReaders:
In order to allow more granular control over which object kinds should be cached and which calls should bypass the cache, controller-runtime offers a few mechanisms to further tweak the client/cache behavior:
When creating a DelegatingClient, certain object kinds can be configured to always be read directly from the API instead of from the cache. Note that this does not prevent starting a new Informer when retrieving them directly from the cache.
Watches can be restricted to a given (set of) namespace(s) by setting cache.Options.Namespaces.
Watches can be filtered (e.g., by label) per object kind by configuring cache.Options.SelectorsByObject on creation of the cache.
Retrieving metadata-only objects or lists from a cache results in a metadata-only watch/cache for that object kind.
The APIReader can be used to always talk directly to the API server for a given Get or List call (use with care and only as a last resort!).
To Cache or Not to Cache
Although watch-based caches are an important factor for the immense scalability of Kubernetes, it definitely comes at a price (mainly in terms of memory consumption).
Thus, developers need to be careful when introducing new API calls and caching new object kinds.
Here are some general guidelines on choosing whether to read from a cache or not:
Always try to use the cache wherever possible and make your controller able to tolerate stale reads.
Leverage optimistic locking: use deterministic naming for objects you create (this is what the Deployment controller does [2]).
Leverage optimistic locking / concurrency control of the API server: send updates/patches with the last-known resourceVersion from the cache (see below). This will make the request fail, if there were concurrent updates to the object (conflict error), which indicates that we have operated on stale data and might have made wrong decisions. In this case, let the controller handle the error with exponential backoff. This will make the controller eventually consistent.
Track the actions you took, e.g., when creating objects with generateName (this is what the ReplicaSet controller does [3]). The actions can be tracked in memory and repeated if the expected watch events don’t occur after a given amount of time.
Always try to write controllers with the assumption that data will only be eventually correct and can be slightly out of date (even if read directly from the API server!).
If there is already some other code that needs a cache (e.g., a controller watch), reuse it instead of doing extra direct reads.
Don’t read an object again if you just sent a write request. Write requests (Create, Update, Patch and Delete) don’t interact with the cache. Hence, use the current state that the API server returned (filled into the passed in-memory object), which is basically a “free direct read” instead of reading the object again from a cache, because this will probably set back the object to an older resourceVersion.
If you are concerned about the impact of the resulting cache, try to minimize that by using filtered or metadata-only watches.
If watching and caching an object type is not feasible, for example because there will be a lot of updates, and you are only interested in the object every ~5m, or because it will blow up the controllers memory footprint, fallback to a direct read. This can either be done by disabling caching the object type generally or doing a single request via an APIReader. In any case, please bear in mind that every direct API call results in a quorum read from etcd, which can be costly in a heavily-utilized cluster and impose significant scalability limits. Thus, always try to minimize the impact of direct calls by filtering results by namespace or labels, limiting the number of results and/or using metadata-only calls.
[2] The Deployment controller uses the pattern <deployment-name>-<podtemplate-hash> for naming ReplicaSets. This means, the name of a ReplicaSet it tries to create/update/delete at any given time is deterministically calculated based on the Deployment object. By this, it is insusceptible to stale reads from its ReplicaSets cache.
[3] In simple terms, the ReplicaSet controller tracks its CREATE pod actions as follows: when creating new Pods, it increases a counter of expected ADDED watch events for the corresponding ReplicaSet. As soon as such events arrive, it decreases the counter accordingly. It only creates new Pods for a given ReplicaSet once all expected events occurred (counter is back to zero) or a timeout has occurred. This way, it prevents creating more Pods than desired because of stale cache reads and makes the controller eventually consistent.
Conflicts, Concurrency Control, and Optimistic Locking
Every Kubernetes API object contains the metadata.resourceVersion field, which identifies an object’s version in the backing data store, i.e., etcd. Every write to an object in etcd results in a newer resourceVersion.
This field is mainly used for concurrency control on the API server in an optimistic locking fashion, but also for efficient resumption of interrupted watch connections.
Optimistic locking in the Kubernetes API sense means that when a client wants to update an API object, then it includes the object’s resourceVersion in the request to indicate the object’s version the modifications are based on.
If the resourceVersion in etcd has not changed in the meantime, the update request is accepted by the API server and the updated object is written to etcd.
If the resourceVersion sent by the client does not match the one of the object stored in etcd, there were concurrent modifications to the object. Consequently, the request is rejected with a conflict error (status code 409, API reason Conflict), for example:
{
"kind": "Status",
"apiVersion": "v1",
"metadata": {},
"status": "Failure",
"message": "Operation cannot be fulfilled on configmaps \"foo\": the object has been modified; please apply your changes to the latest version and try again",
"reason": "Conflict",
"details": {
"name": "foo",
"kind": "configmaps" },
"code": 409
}
This concurrency control is an important mechanism in Kubernetes as there are typically multiple clients acting on API objects at the same time (humans, different controllers, etc.). If a client receives a conflict error, it should read the object’s latest version from the API server, make the modifications based on the newest changes, and retry the update.
The reasoning behind this is that a client might choose to make different decisions based on the concurrent changes made by other actors compared to the outdated version that it operated on.
Important points about concurrency control and conflicts:
The resourceVersion field carries a string value and clients must not assume numeric values (the type and structure of versions depend on the backing data store). This means clients may compare resourceVersion values to detect whether objects were changed. But they must not compare resourceVersions to figure out which one is newer/older, i.e., no greater/less-than comparisons are allowed.
By default, update calls (e.g. via client-go and controller-runtime clients) use optimistic locking as the passed in-memory usually object contains the latest resourceVersion known to the controller, which is then also sent to the API server.
API servers can also choose to accept update calls without optimistic locking (i.e., without a resourceVersion in the object’s metadata) for any given resource. However, sending update requests without optimistic locking is strongly discouraged, as doing so overwrites the entire object, discarding any concurrent changes made to it.
On the other side, patch requests can always be executed either with or without optimistic locking, by (not) including the resourceVersion in the patched object’s metadata. Sending patch requests without optimistic locking might be safe and even desirable as a patch typically updates only a specific section of the object. However, there are also situations where patching without optimistic locking is not safe (see below).
Don’t Retry on Conflict
Similar to how a human would typically handle a conflict error, there are helper functions implementing RetryOnConflict-semantics, i.e., try an update call, then re-read the object if a conflict occurs, apply the modification again and retry the update.
However, controllers should generally not use RetryOnConflict-semantics. Instead, controllers should abort their current reconciliation run and let the queue handle the conflict error with exponential backoff.
The reasoning behind this is that a conflict error indicates that the controller has operated on stale data and might have made wrong decisions earlier on in the reconciliation.
When using a helper function that implements RetryOnConflict-semantics, the controller doesn’t check which fields were changed and doesn’t revise its previous decisions accordingly.
Instead, retrying on conflict basically just ignores any conflict error and blindly applies the modification.
To properly solve the conflict situation, controllers should immediately return with the error from the update call. This will cause retries with exponential backoff so that the cache has a chance to observe the latest changes to the object.
In a later run, the controller will then make correct decisions based on the newest version of the object, not run into conflict errors, and will then be able to successfully reconcile the object. This way, the controller becomes eventually consistent.
The other way to solve the situation is to modify objects without optimistic locking in order to avoid running into a conflict in the first place (only if this is safe).
This can be a preferable solution for controllers with long-running reconciliations (which is actually an anti-pattern but quite unavoidable in some of Gardener’s controllers).
Aborting the entire reconciliation run is rather undesirable in such cases, as it will add a lot of unnecessary waiting time for end users and overhead in terms of compute and network usage.
However, in any case, retrying on conflict is probably not the right option to solve the situation (there are some correct use cases for it, though, they are very rare). Hence, don’t retry on conflict.
To Lock or Not to Lock
As explained before, conflicts are actually important and prevent clients from doing wrongful concurrent updates. This means that conflicts are not something we generally want to avoid or ignore.
However, in many cases controllers are exclusive owners of the fields they want to update and thus it might be safe to run without optimistic locking.
For example, the gardenlet is the exclusive owner of the spec section of the Extension resources it creates on behalf of a Shoot (e.g., the Infrastructure resource for creating VPC). Meaning, it knows the exact desired state and no other actor is supposed to update the Infrastructure’s spec fields.
When the gardenlet now updates the Infrastructures spec section as part of the Shoot reconciliation, it can simply issue a PATCH request that only updates the spec and runs without optimistic locking.
If another controller concurrently updated the object in the meantime (e.g., the status section), the resourceVersion got changed, which would cause a conflict error if running with optimistic locking.
However, concurrent status updates would not change the gardenlet’s mind on the desired spec of the Infrastructure resource as it is determined only by looking at the Shoot’s specification.
If the spec section was changed concurrently, it’s still fine to overwrite it because the gardenlet should reconcile the spec back to its desired state.
Generally speaking, if a controller is the exclusive owner of a given set of fields and they are independent of concurrent changes to other fields in that object, it can patch these fields without optimistic locking.
This might ignore concurrent changes to other fields or blindly overwrite changes to the same fields, but this is fine if the mentioned conditions apply.
Obviously, this applies only to patch requests that modify only a specific set of fields but not to update requests that replace the entire object.
In such cases, it’s even desirable to run without optimistic locking as it will be more performant and save retries.
If certain requests are made with high frequency and have a good chance of causing conflicts, retries because of optimistic locking can cause a lot of additional network traffic in a large-scale Gardener installation.
Updates, Patches, Server-Side Apply
There are different ways of modifying Kubernetes API objects.
The following snippet demonstrates how to do a given modification with the most frequently used options using a controller-runtime client:
Important characteristics of the shown request types:
Update requests always send the entire object to the API server and update all fields accordingly. By default, optimistic locking is used (resourceVersion is included).
Both patch types run without optimistic locking by default. However, it can be enabled explicitly if needed:
Patch requests only contain the changes made to the in-memory object between the copy passed to client.*MergeFrom and the object passed to Client.Patch(). The diff is calculated on the client-side based on the in-memory objects only. This means that if in the meantime some fields were changed on the API server to a different value than the one on the client-side, the fields will not be changed back as long as they are not changed on the client-side as well (there will be no diff in memory).
Thus, if you want to ensure a given state using patch requests, always read the object first before patching it, as there will be no diff otherwise, meaning the patch will be empty. For more information, see gardener/gardener#4057 and the comments in gardener/gardener#4027.
Also, always send updates and patch requests even if your controller hasn’t made any changes to the current state on the API server. I.e., don’t make any optimization for preventing empty patches or no-op updates. There might be mutating webhooks in the system that will modify the object and that rely on update/patch requests being sent (even if they are no-op). Gardener’s extension concept makes heavy use of mutating webhooks, so it’s important to keep this in mind.
JSON merge patches always replace lists as a whole and don’t merge them. Keep this in mind when operating on lists with merge patch requests. If the controller is the exclusive owner of the entire list, it’s safe to run without optimistic locking. Though, if you want to prevent overwriting concurrent changes to the list or its items made by other actors (e.g., additions/removals to the metadata.finalizers list), enable optimistic locking.
Strategic merge patches are able to make more granular modifications to lists and their elements without replacing the entire list. It uses Golang struct tags of the API types to determine which and how lists should be merged. See Update API Objects in Place Using kubectl patch or the strategic merge patch documentation for more in-depth explanations and comparison with JSON merge patches.
With this, controllers might be able to issue patch requests for individual list items without optimistic locking, even if they are not exclusive owners of the entire list. Remember to check the patchStrategy and patchMergeKey struct tags of the fields you want to modify before blindly adding patch requests without optimistic locking.
Strategic merge patches are only supported by built-in Kubernetes resources and custom resources served by Extension API servers. Strategic merge patches are not supported by custom resources defined by CustomResourceDefinitions (see this comparison). In that case, fallback to JSON merge patches.
Server-side Apply is yet another mechanism to modify API objects, which is supported by all API resources (in newer Kubernetes versions). However, it has a few problems and more caveats preventing us from using it in Gardener at the time of writing. See gardener/gardener#4122 for more details.
Generally speaking, patches are often the better option compared to update requests because they can save network traffic, encoding/decoding effort, and avoid conflicts under the presented conditions.
If choosing a patch type, consider which type is supported by the resource you’re modifying and what will happen in case of a conflict. Consider whether your modification is safe to run without optimistic locking.
However, there is no simple rule of thumb on which patch type to choose.
On Helper Functions
Here is a note on some helper functions, that should be avoided and why:
controllerutil.CreateOrUpdate does a basic get, mutate and create or update call chain, which is often used in controllers. We should avoid using this helper function in Gardener, because it is likely to cause conflicts for cached clients and doesn’t send no-op requests if nothing was changed, which can cause problems because of the heavy use of webhooks in Gardener extensions (see above).
That’s why usage of this function was completely replaced in gardener/gardener#4227 and similar PRs.
controllerutil.CreateOrPatch is similar to CreateOrUpdate but does a patch request instead of an update request. It has the same drawback as CreateOrUpdate regarding no-op updates.
Also, controllers can’t use optimistic locking or strategic merge patches when using CreateOrPatch.
Another reason for avoiding use of this function is that it also implicitly patches the status section if it was changed, which is confusing for others reading the code. To accomplish this, the func does some back and forth conversion, comparison and checks, which are unnecessary in most of our cases and simply wasted CPU cycles and complexity we want to avoid.
There were some Try{Update,UpdateStatus,Patch,PatchStatus} helper functions in Gardener that were already removed by gardener/gardener#4378 but are still used in some extension code at the time of writing.
The reason for eliminating these functions is that they implement RetryOnConflict-semantics. Meaning, they first get the object, mutate it, then try to update and retry if a conflict error occurs.
As explained above, retrying on conflict is a controller anti-pattern and should be avoided in almost every situation.
The other problem with these functions is that they read the object first from the API server (always do a direct call), although in most cases we already have a recent version of the object at hand. So, using this function generally does unnecessary API calls and therefore causes unwanted compute and network load.
For the reasons explained above, there are similar helper functions that accomplish similar things but address the mentioned drawbacks: controllerutils.{GetAndCreateOrMergePatch,GetAndCreateOrStrategicMergePatch}.
These can be safely used as replacements for the aforementioned helper funcs.
If they are not fitting for your use case, for example because you need to use optimistic locking, just do the appropriate calls in the controller directly.
These resources are only partially related to the topics covered in this doc, but might still be interesting for developer seeking a deeper understanding of Kubernetes API machinery, architecture and foundational concepts.
Conceptually, all Gardener components are designed to run as a Pod inside a Kubernetes cluster.
The Gardener API server extends the Kubernetes API via the user-aggregated API server concepts.
However, if you want to develop it, you may want to work locally with the Gardener without building a Docker image and deploying it to a cluster each and every time.
That means that the Gardener runs outside a Kubernetes cluster which requires providing a Kubeconfig in your local filesystem and point the Gardener to it when starting it (see below).
iproute2 provides a collection of utilities for network administration and configuration. On macOS run
brew install iproute2mac
Installing jq
jq is a lightweight and flexible command-line JSON processor. On macOS run
brew install jq
Installing yq
yq is a lightweight and portable command-line YAML processor. On macOS run
brew install yq
Installing GNU Parallel
GNU Parallel is a shell tool for executing jobs in parallel, used by the code generation scripts (make generate). On macOS run
brew install parallel
[macOS only] Install GNU Core Utilities
When running on macOS, install the GNU core utilities and friends:
brew install coreutils gnu-sed gnu-tar grep gzip
This will create symbolic links for the GNU utilities with g prefix on your PATH, e.g., gsed or gbase64.
To allow using them without the g prefix, add the gnubin directories to the beginning of your PATH environment variable (brew install and brew info will print out instructions for each formula):
The Gardener repository and all the above-mentioned tools (git, golang, kubectl, …) should be installed in your WSL2 distro, according to the distribution-specific Linux installation instructions.
Get the Sources
Clone the repository from GitHub into your $GOPATH.
mkdir -p $(go env GOPATH)/src/github.com/gardener
cd $(go env GOPATH)/src/github.com/gardener
git clone git@github.com:gardener/gardener.git
cd gardener
Note: Gardener is using Go modules and cloning the repository into $GOPATH is not a hard requirement. However it is still recommended to clone into $GOPATH because k8s.io/code-generator does not work yet outside of $GOPATH - kubernetes/kubernetes#86753.
{
"log":"{
\"level\":\"info\",\"ts\":\"2020-06-01T11:23:26.679Z\",\"logger\":\"gardener-resource-manager.health-reconciler\",\"msg\":\"Finished ManagedResource health checks\",\"object\":\"garden/provider-aws-dsm9r\"
}\n" }
}
Create a Custom Parser
First of all, we need to know how the log for the specific container looks like (for example, lets take a log from the alertmanager :
level=info ts=2019-01-28T12:33:49.362015626Z caller=main.go:175 build_context="(go=go1.11.2, user=root@4ecc17c53d26, date=20181109-15:40:48))
We can see that this log contains 4 subfields(severity=info, timestamp=2019-01-28T12:33:49.362015626Z, source=main.go:175 and the actual message).
So we have to write a regex which matches this log in 4 groups(We can use https://regex101.com/ like helping tool). So, for this purpose our regex looks like this:
It’s time to apply our new regex into fluent-bit configuration. To achieve that we can just deploy in the cluster where the fluent-operator is deployed the following custom resources:
EXAMPLE
apiVersion: fluentbit.fluent.io/v1alpha2
kind: ClusterParser
metadata:
name: alermanager-parser
labels:
fluentbit.gardener/type: "seed"spec:
regex:
timeKey: time
timeFormat: "%Y-%m-%dT%H:%M:%S.%L" regex: "^level=(?<severity>\\w+)\\s+ts=(?<time>\\d{4}-\\d{2}-\\d{2}[Tt].*[zZ])\\s+caller=(?<source>[^\\s]*+)\\s+(?<log>.*)"
Follow your development setup to validate that the parsers are working correctly.
31 - Logging Guidelines
Logging Guidelines in Gardener Components
This document aims at providing a general developer guideline on different aspects of logging practices and conventions used in the Gardener codebase.
It contains mostly Gardener-specific points, and references other existing and commonly accepted logging guidelines for general advice.
Developers and reviewers should consult this guide when writing, refactoring, and reviewing Gardener code.
If parts are unclear or new learnings arise, this guide should be adapted accordingly.
Logging Libraries / Implementations
Historically, Gardener components have been using logrus.
There is a global logrus logger (logger.Logger) that is initialized by components on startup and used across the codebase.
In most places, it is used as a printf-style logger and only in some instances we make use of logrus’ structured logging functionality.
In the process of migrating our components to native controller-runtime components (see gardener/gardener#4251), we also want to make use of controller-runtime’s built-in mechanisms for streamlined logging.
controller-runtime uses logr, a simple structured logging interface, for library-internal logging and logging in controllers.
logr itself is only an interface and doesn’t provide an implementation out of the box.
Instead, it needs to be backed by a logging implementation like zapr. Code that uses the logr interface is thereby not tied to a specific logging implementation and makes the implementation easily exchangeable.
controller-runtime already provides a set of helpers for constructing zapr loggers, i.e., logr loggers backed by zap, which is a popular logging library in the go community.
Hence, we are migrating our component logging from logrus to logr (backed by zap) as part of gardener/gardener#4251.
⚠️ logger.Logger (logrus logger) is deprecated in Gardener and shall not be used in new code – use logr loggers when writing new code! (also see Migration from logrus to logr)
ℹ️ Don’t use zap loggers directly, always use the logr interface in order to avoid tight coupling to a specific logging implementation.
gardener-apiserver differs from the other components as it is based on the apiserver library and therefore uses klog – just like kube-apiserver.
As gardener-apiserver writes (almost) no logs in our coding (outside the apiserver library), there is currently no plan for switching the logging implementation.
Hence, the following sections focus on logging in the controller and admission components only.
logcheck Tool
To ensure a smooth migration to logr and make logging in Gardener components more consistent, the logcheck tool was added.
It enforces (parts of) this guideline and detects programmer-level errors early on in order to prevent bugs.
Please check out the tool’s documentation for a detailed description.
Structured Logging
Similar to efforts in the Kubernetes project, we want to migrate our component logs to structured logging.
As motivated above, we will use the logr interface instead of klog though.
You can read more about the motivation behind structured logging in logr’s background and FAQ (also see this blog post by Dave Cheney).
Also, make sure to check out controller-runtime’s logging guideline with specifics for projects using the library.
The following sections will focus on the most important takeaways from those guidelines and give general instructions on how to apply them to Gardener and its controller-runtime components.
Note: Some parts in this guideline differ slightly from controller-runtime’s document.
TL;DR of Structured Logging
❌ Stop using printf-style logging:
var logger *logrus.Logger
logger.Infof("Scaling deployment %s/%s to %d replicas", deployment.Namespace, deployment.Name, replicaCount)
✅ Instead, write static log messages and enrich them with additional structured information in form of key-value pairs:
var logger logr.Logger
logger.Info("Scaling deployment", "deployment", client.ObjectKeyFromObject(deployment), "replicas", replicaCount)
Log Configuration
Gardener components can be configured to either log in json (default) or text format:
json format is supposed to be used in production, while text format might be nicer for development.
# json
{"level":"info","ts":"2021-12-16T08:32:21.059+0100","msg":"Hello botanist","garden":"eden"}
# text
2021-12-16T08:32:21.059+0100 INFO Hello botanist {"garden": "eden"}
Components can be set to one of the following log levels (with increasing verbosity): error, info (default), debug.
Log Levels
logr uses V-levels (numbered log levels), higher V-level means higher verbosity.
V-levels are relative (in contrast to klog’s absolute V-levels), i.e., V(1) creates a logger, that is one level more verbose than its parent logger.
In Gardener components, the mentioned log levels in the component config (error, info, debug) map to the zap levels with the same names (see here).
Hence, our loggers follow the same mapping from numerical logr levels to named zap levels like described in zapr, i.e.:
component config specifies debug ➡️ both V(0) and V(1) are enabled
component config specifies info ➡️ V(0) is enabled, V(1) will not be shown
component config specifies error ➡️ neither V(0) nor V(1) will be shown
Error() logs will always be shown
This mapping applies to the components’ root loggers (the ones that are not “derived” from any other logger; constructed on component startup).
If you derive a new logger with e.g. V(1), the mapping will shift by one. For example, V(0) will then log at zap’s debug level.
There is no warning level (see Dave Cheney’s post).
If there is an error condition (e.g., unexpected error received from a called function), the error should either be handled or logged at error if it is neither handled nor returned.
If you have an error value at hand that doesn’t represent an actual error condition, but you still want to log it as an informational message, log it at info level with key err.
We might consider to make use of a broader range of log levels in the future when introducing more logs and common command line flags for our components (comparable to --v of Kubernetes components).
For now, we stick to the mentioned two log levels like controller-runtime: info (V(0)) and debug (V(1)).
Logging in Controllers
Named Loggers
Controllers should use named loggers that include their name, e.g.:
2021-12-16T09:27:56.550+0100 INFO controller.shoot Deploying kube-apiserver
Logger names are hierarchical. You can make use of it, where controllers are composed of multiple “subcontrollers”, e.g., controller.shoot.hibernation or controller.shoot.maintenance.
Using the global logger logf.Log directly is discouraged and should be rather exceptional because it makes correlating logs with code harder.
Preferably, all parts of the code should use some named logger.
Reconciler Loggers
In your Reconcile function, retrieve a logger from the given context.Context.
It inherits from the controller’s logger (i.e., is already named) and is preconfigured with name and namespace values for the reconciliation request:
2021-12-16T09:35:59.099+0100 INFO controller.shoot Reconciling Shoot {"name": "sunflower", "namespace": "garden-greenhouse"}
The logger is injected by controller-runtime’s Controller implementation. The logger returned by logf.FromContext is never nil. If the context doesn’t carry a logger, it falls back to the global logger (logf.Log), which might discard logs if not configured, but is also never nil.
⚠️ Make sure that you don’t overwrite the name or namespace value keys for such loggers, otherwise you will lose information about the reconciled object.
The controller implementation (controller-runtime) itself takes care of logging the error returned by reconcilers.
Hence, don’t log an error that you are returning.
Generally, functions should not return an error, if they already logged it, because that means the error is already handled and not an error anymore.
See Dave Cheney’s post for more on this.
Messages
Log messages should be static. Don’t put variable content in there, i.e., no fmt.Sprintf or string concatenation (+). Use key-value pairs instead.
Log messages should be capitalized. Note: This contrasts with error messages, that should not be capitalized. However, both should not end with a punctuation mark.
Keys and Values
Use WithValues instead of repeatedly adding key-value pairs for multiple log statements. WithValues creates a new logger from the parent, that carries the given key-value pairs. E.g., use it when acting on one object in multiple steps and logging something for each step:
log := parentLog.WithValues("infrastructure", client.ObjectKeyFromObject(infrastructure))
// ...log.Info("Creating Infrastructure")
// ...log.Info("Waiting for Infrastructure to be reconciled")
// ...
Note: WithValues bypasses controller-runtime’s special zap encoder that nicely encodes ObjectKey/NamespacedName and runtime.Object values, see kubernetes-sigs/controller-runtime#1290.
Thus, the end result might look different depending on the value and its Stringer implementation.
Use lowerCamelCase for keys. Don’t put spaces in keys, as it will make log processing with simple tools like jq harder.
Keys should be constant, human-readable, consistent across the codebase and naturally match parts of the log message, see logr guideline.
When logging object keys (name and namespace), use the object’s type as the log key and a client.ObjectKey/types.NamespacedName value as value, e.g.:
var deployment *appsv1.Deployment
log.Info("Creating Deployment", "deployment", client.ObjectKeyFromObject(deployment))
There are cases where you don’t have the full object key or the object itself at hand, e.g., if an object references another object (in the same namespace) by name (think secretRef or similar).
In such a cases, either construct the full object key including the implied namespace or log the object name under a key ending in Name, e.g.:
var (
// object to reconcile shoot *gardencorev1beta1.Shoot
// retrieved via logf.FromContext, preconfigured by controller with namespace and name of reconciliation request log logr.Logger
)
// option a: full object key, manually constructedlog.Info("Shoot uses SecretBinding", "secretBinding", client.ObjectKey{Namespace: shoot.Namespace, Name: *shoot.Spec.SecretBindingName})
// option b: only name under respective *Name log keylog.Info("Shoot uses SecretBinding", "secretBindingName", *shoot.Spec.SecretBindingName)
Both options result in well-structured logs, that are easy to interpret and process:
When handling generic client.Object values (e.g. in helper funcs), use object as key.
When adding timestamps to key-value pairs, use time.Time values. By this, they will be encoded in the same format as the log entry’s timestamp. Don’t use metav1.Time values, as they will be encoded in a different format by their Stringer implementation. Pass <someTimestamp>.Time to loggers in case you have a metav1.Time value at hand.
Same applies to durations. Use time.Duration values instead of *metav1.Duration. Durations can be handled specially by zap just like timestamps.
Event recorders not only create Event objects but also log them.
However, both Gardener’s manually instantiated event recorders and the ones that controller-runtime provides log to debug level and use generic formats, that are not very easy to interpret or process (no structured logs).
Hence, don’t use event recorders as replacements for well-structured logs.
If a controller records an event for a completed action or important information, it should probably log it as well, e.g.:
If the tested production code requires a logger, you can pass logr.Discard() or logf.NullLogger{} in your test, which simply discards all logs.
logf.Log is safe to use in tests and will not cause a nil pointer deref, even if it’s not initialized via logf.SetLogger.
It is initially set to a NullLogger by default, which means all logs are discarded, unless logf.SetLogger is called in the first 30 seconds of execution.
Pass zap.WriteTo(GinkgoWriter) in tests where you want to see the logs on test failure but not on success, for example:
The Fluent-bit configurations can be found on pkg/component/observability/logging/fluentoperator/customresources
There are six different specifications:
FluentBit: Defines the fluent-bit DaemonSet specifications
ClusterFluentBitConfig: Defines the labelselectors of the resources which fluent-bit will match
ClusterInput: Defines the location of the input stream of the logs
ClusterOutput: Defines the location of the output source (Vali for example)
ClusterFilter: Defines filters which match specific keys
ClusterParser: Defines parsers which are used by the filters
Vali
The Vali configurations can be found on charts/seed-bootstrap/charts/vali/templates/vali-configmap.yaml
The main specifications there are:
Index configuration: Currently the following one is used:
from: Is the date from which logs collection is started. Using a date in the past is okay.
store: The DB used for storing the index.
object_store: Where the data is stored.
schema: Schema version which should be used (v11 is currently recommended).
index.prefix: The prefix for the index.
index.period: The period for updating the indices.
Adding a new index happens with new config block definition. The from field should start from the current day + previous index.period and should not overlap with the current index. The prefix also should be different.
table_manager.retention_period is the living time for each log message. Vali will keep messages for (table_manager.retention_period - index.period) time due to specification in the Vali implementation.
jsonData.maxLines: The limit of the log messages which Plutono will show to the users.
Decrease this value if the browser works slowly!
33 - Managed Seed
ManagedSeeds: Register Shoot as Seed
An existing shoot can be registered as a seed by creating a ManagedSeed resource. This resource contains:
The name of the shoot that should be registered as seed.
A gardenlet section that contains:
gardenlet deployment parameters, such as the number of replicas, the image, etc.
The GardenletConfiguration resource that contains controllers configuration, feature gates, and a seedConfig section that contains the Seed spec and parts of its metadata.
Additional configuration parameters, such as the garden connection bootstrap mechanism (see TLS Bootstrapping), and whether to merge the provided configuration with the configuration of the parent gardenlet.
gardenlet is deployed to the shoot, and it registers a new seed upon startup based on the seedConfig section.
Note: Earlier Gardener allowed specifying a seedTemplate directly in the ManagedSeed resource. This feature is discontinued, any seed configuration must be via the GardenletConfiguration.
Note the following important aspects:
Unlike the Seed resource, the ManagedSeed resource is namespaced. Currently, managed seeds are restricted to the garden namespace.
The newly created Seed resource always has the same name as the ManagedSeed resource. Attempting to specify a different name in the seedConfig will fail.
The ManagedSeed resource must always refer to an existing shoot. Attempting to create a ManagedSeed referring to a non-existing shoot will fail.
A shoot that is being referred to by a ManagedSeed cannot be deleted. Attempting to delete such a shoot will fail.
You can omit practically everything from the gardenlet section, including all or most of the Seed spec fields. Proper defaults will be supplied in all cases, based either on the most common use cases or the information already available in the Shoot resource.
Also, if your seed is configured to host HA shoot control planes, then gardenlet will be deployed with multiple replicas across nodes or availability zones by default.
Some Seed spec fields, for example the provider type and region, networking CIDRs for pods, services, and nodes, etc., must be the same as the corresponding Shoot spec fields of the shoot that is being registered as seed. Attempting to use different values (except empty ones, so that they are supplied by the defaulting mechanism) will fail.
Deploying gardenlet to the Shoot
To register a shoot as a seed and deploy gardenlet to the shoot using a default configuration, create a ManagedSeed resource similar to the following:
In order to make the ManagedSeed controller renew the gardenlet’s kubeconfig secret, annotate the ManagedSeed with gardener.cloud/operation=renew-kubeconfig. This will trigger a reconciliation during which the kubeconfig secret is deleted and the bootstrapping is performed again (during which gardenlet obtains a new client certificate).
The following configuration options are enforced by Gardener API server for the ManagedSeed resources:
The vertical pod autoscaler should be enabled from the Shoot specification.
The vertical pod autoscaler is a prerequisite for a Seed cluster. It is possible to enable the VPA feature for a Seed (using the Seed spec) and for a Shoot (using the Shoot spec). In context of ManagedSeeds, enabling the VPA in the Seed spec (instead of the Shoot spec) offers less flexibility and increases the network transfer and cost. Due to these reasons, the Gardener API server enforces the vertical pod autoscaler to be enabled from the Shoot specification.
The nginx-ingress addon should not be enabled for a Shoot referred by a ManagedSeed.
An Ingress controller is also a prerequisite for a Seed cluster. For a Seed cluster, it is possible to enable Gardener managed Ingress controller or to deploy self-managed Ingress controller. There is also the nginx-ingress addon that can be enabled for a Shoot (using the Shoot spec). However, the Shoot nginx-ingress addon is in deprecated mode and it is not recommended for production clusters. Due to these reasons, the Gardener API server does not allow the Shoot nginx-ingress addon to be enabled for ManagedSeeds.
34 - Monitoring Stack
Extending the Monitoring Stack
This document provides instructions to extend the Shoot cluster monitoring stack by integrating new scrape targets, alerts and dashboards.
Please ensure that you have understood the basic principles of Prometheus and its ecosystem before you continue.
‼️ The purpose of the monitoring stack is to observe the behaviour of the control plane and the system components deployed by Gardener onto the worker nodes. Monitoring of custom workloads running in the cluster is out of scope.
Overview
Each Shoot cluster comes with its own monitoring stack. The following components are deployed into the seed and shoot:
In each Seed cluster there is a Prometheus in the garden namespace responsible for collecting metrics from the Seed kubelets and cAdvisors. These metrics are provided to each Shoot Prometheus via federation.
The alerts for all Shoot clusters hosted on a Seed are routed to a central Alertmanger running in the garden namespace of the Seed. The purpose of this central Alertmanager is to forward all important alerts to the operators of the Gardener setup.
The Alertmanager in the Shoot namespace on the Seed is only responsible for forwarding alerts from its Shoot cluster to a cluster owner/cluster alert receiver via email. The Alertmanager is optional and the conditions for a deployment are already described in Alerting.
The node-exporter’s textfile collector is enabled and configured to parse all *.prom files in the /var/lib/node-exporter/textfile-collector directory on each Shoot node. Scripts and programs which run on Shoot nodes and cannot expose an endpoint to be scraped by prometheus can use this directory to export metrics in files that match the glob *.prom using the text format.
Adding New Monitoring Targets
After exploring the metrics which your component provides or adding new metrics, you should be aware which metrics are required to write the needed alerts and dashboards.
Prometheus prefers a pull based metrics collection approach and therefore the targets to observe need to be defined upfront. The targets are defined in charts/seed-monitoring/charts/core/charts/prometheus/templates/config.yaml.
New scrape jobs can be added in the section scrape_configs. Detailed information how to configure scrape jobs and how to use the kubernetes service discovery are available in the Prometheus documentation.
The job_name of a scrape job should be the name of the component e.g. kube-apiserver or vpn. The collection interval should be the default of 30s. You do not need to specify this in the configuration.
Please do not ingest all metrics which are provided by a component. Rather, collect only those metrics which are needed to define the alerts and dashboards (i.e. whitelist). This can be achieved by adding the following metric_relabel_configs statement to your scrape jobs (replace exampleComponent with component name).
The whitelist for the metrics of your job can be maintained in charts/seed-monitoring/charts/core/charts/prometheus/values.yaml in section allowedMetrics.exampleComponent (replace exampleComponent with component name). Check the following example:
groups:
* name: example.rules
rules:
* alert: ExampleAlert
expr: absent(up{job="exampleJob"} == 1)
for: 20m
labels:
service: example
severity: critical # How severe is the alert? (blocker|critical|info|warning) type: shoot # For which topology is the alert relevant? (seed|shoot) visibility: all # Who should receive the alerts? (all|operator|owner) annotations:
description: A longer description of the example alert that should also explain the impact of the alert.
summary: Short summary of an example alert.
If the deployment of component is optional then the alert definitions needs to be added to charts/seed-monitoring/charts/core/charts/prometheus/optional-rules instead. Furthermore the alerts for component need to be activatable in charts/seed-monitoring/charts/core/charts/prometheus/values.yaml via rules.optional.example-component.enabled. The default should be true.
The Alertmanager is grouping incoming alerts based on labels into buckets. Each bucket has its own configuration like alert receivers, initial delaying duration or resending frequency, etc. You can find more information about Alertmanager routing in the Prometheus/Alertmanager documentation. The routing trees for the Alertmanagers deployed by Gardener are depicted below.
Central Seed Alertmanager
∟ main route (all alerts for all shoots on the seed will enter)
∟ group by project and shoot name
∟ group by visibility "all" and "operator"
∟ group by severity "blocker", "critical", and "info" → route to Garden operators
∟ group by severity "warning" (dropped)
∟ group by visibility "owner" (dropped)
Shoot Alertmanager
∟ main route (only alerts for one Shoot will enter)
∟ group by visibility "all" and "owner"
∟ group by severity "blocker", "critical", and "info" → route to cluster alert receiver
∟ group by severity "warning" (dropped, will change soon → route to cluster alert receiver)
∟ group by visibility "operator" (dropped)
Alert Inhibition
All alerts related to components running on the Shoot workers are inhibited in case of an issue with the vpn connection, because those components can’t be scraped anymore and Prometheus will fire alerts in consequence. The components running on the workers are probably healthy and the alerts are presumably false positives. The inhibition flow is shown in the figure below. If you add a new alert, make sure to add it to the diagram.
Alert Attributes
Each alert rule definition has to contain the following annotations:
summary: A short description of the issue.
description: A detailed explanation of the issue with hints to the possible root causes and the impact assessment of the issue.
In addition, each alert must contain the following labels:
type
shoot: Components running on the Shoot worker nodes in the kube-system namespace.
seed: Components running on the Seed in the Shoot namespace as part of/next to the control plane.
service
Name of the component (in lowercase) e.g. kube-apiserver, alertmanager or vpn.
severity
blocker: All issues which make the cluster entirely unusable, e.g. KubeAPIServerDown or KubeSchedulerDown
critical: All issues which affect single functionalities/components but do not affect the cluster in its core functionality e.g. VPNDown or KubeletDown.
info: All issues that do not affect the cluster or its core functionality, but if this component is down we cannot determine if a blocker alert is firing. (i.e. A component with an info level severity is a dependency for a component with a blocker severity)
warning: No current existing issue, rather a hint for situations which could lead to real issue in the close future e.g. HighLatencyApiServerToWorkers or ApiServerResponseSlow.
Adding Plutono Dashboards
The dashboard definition files are located in charts/seed-monitoring/charts/plutono/dashboards. Every dashboard needs its own file.
If you are adding a new component dashboard please also update the overview dashboard by adding a chart for its current up/down status and with a drill down option to the component dashboard.
Dashboard Structure
The dashboards should be structured in the following way. The assignment of the component dashboards to the categories should be handled via dashboard tags.
Kubernetes control plane components (Tag: control-plane)
All components which are part of the Kubernetes control plane e. g. Kube API Server, Kube Controller Manager, Kube Scheduler and Cloud Controller Manager
ETCD + Backup/Restore
Kubernetes Addon Manager
Node/Machine components (Tag: node/machine)
All metrics which are related to the behaviour/control of the Kubernetes nodes and kubelets
Machine-Controller-Manager + Cluster Autoscaler
Networking components (Tag: network)
CoreDNS, KubeProxy, Calico, VPN, Nginx Ingress
Addon components (Tag: addon)
Cert Broker
Monitoring components (Tag: monitoring)
Logging components (Tag: logging)
Mandatory Charts for Component Dashboards
For each new component, its corresponding dashboard should contain the following charts in the first row, before adding custom charts for the component in the subsequent rows.
Pod up/down status up{job="example-component"}
Pod/containers cpu utilization
Pod/containers memory consumption
Pod/containers network i/o
That information is provided by the cAdvisor metrics. These metrics are already integrated. Please check the other dashboards for detailed information on how to query.
Chart Requirements
Each chart needs to contain:
a meaningful name
a detailed description (for non trivial charts)
appropriate x/y axis descriptions
appropriate scaling levels for the x/y axis
proper units for the x/y axis
Dashboard Parameters
The following parameters should be added to all dashboards to ensure a homogeneous experience across all dashboards.
Dashboards have to:
contain a title which refers to the component name(s)
contain a timezone statement which should be the browser time
contain tags which express where the component is running (seed or shoot) and to which category the component belong (see dashboard structure)
Allows egress traffic from pods labeled with networking.gardener.cloud/to-dns=allowed to DNS pods running in the kube-system namespace. In practice, most of the pods performing network egress traffic need this label.
allow-to-runtime-apiserver
Allows egress traffic from pods labeled with networking.gardener.cloud/to-runtime-apiserver=allowed to the API server of the runtime cluster.
allow-to-blocked-cidrs
Allows egress traffic from pods labeled with networking.gardener.cloud/to-blocked-cidrs=allowed to explicitly blocked addresses configured by human operators (configured via .spec.networking.blockedCIDRs in the Seed). For instance, this can be used to block the cloud provider’s metadata service.
allow-to-public-networks
Allows egress traffic from pods labeled with networking.gardener.cloud/to-public-networks=allowed to all public network IPs, except for private networks (RFC1918), carrier-grade NAT (RFC6598), and explicitly blocked addresses configured by human operators for all pods labeled with networking.gardener.cloud/to-public-networks=allowed. In practice, this blocks egress traffic to all networks in the cluster and only allows egress traffic to public IPv4 addresses.
allow-to-private-networks
Allows egress traffic from pods labeled with networking.gardener.cloud/to-private-networks=allowed to the private networks (RFC1918) and carrier-grade NAT (RFC6598) except for cluster-specific networks (configured via .spec.networks in the Seed).
Apart from those, the gardener-operator also enables the NetworkPolicy controller of gardener-resource-manager.
Please find more information in the linked document.
In summary, most of the pods that initiate connections with other pods will have labels with networking.resources.gardener.cloud/ prefixes.
This way, they leverage the automatically created NetworkPolicys by the controller.
As a result, in most cases no special/custom-crafted NetworkPolicys must be created anymore.
Logging & Monitoring
As part of the garden reconciliation flow, the gardener-operator deploys various Prometheus instances into the garden namespace.
Each pod that should be scraped for metrics by these instances must have a Service which is annotated with
annotations:
networking.resources.gardener.cloud/from-all-garden-scrape-targets-allowed-ports: '[{"port":<metrics-port-on-pod>,"protocol":"<protocol, typically TCP>"}]'
If the respective pod is not running in the garden namespace, the Service needs these annotations in addition:
This automatically allows the needed network traffic from the respective Prometheus pods.
Seed Cluster
(via gardenlet and gardener-resource-manager)
In seed clusters it works the same way as in the garden cluster managed by gardener-operator.
When a seed cluster is the garden cluster at the same time, gardenlet does not enable the NetworkPolicy controller (since gardener-operator already runs it).
Otherwise, it uses the exact same controller and code like gardener-operator, resulting in the same behaviour in both garden and seed clusters.
Logging & Monitoring
Seed System Namespaces
As part of the seed reconciliation flow, the gardenlet deploys various Prometheus instances into the garden namespace.
See also this document for more information.
Each pod that should be scraped for metrics by these instances must have a Service which is annotated with
annotations:
networking.resources.gardener.cloud/from-all-seed-scrape-targets-allowed-ports: '[{"port":<metrics-port-on-pod>,"protocol":"<protocol, typically TCP>"}]'
If the respective pod is not running in the garden namespace, the Service needs these annotations in addition:
This automatically allows the needed network traffic from the respective Prometheus pods.
Shoot Namespaces
As part of the shoot reconciliation flow, the gardenlet deploys a shoot-specific Prometheus into the shoot namespace.
Each pod that should be scraped for metrics must have a Service which is annotated with
annotations:
networking.resources.gardener.cloud/from-all-scrape-targets-allowed-ports: '[{"port":<metrics-port-on-pod>,"protocol":"<protocol, typically TCP>"}]'
This automatically allows the network traffic from the Prometheus pod.
Webhook Servers
Components serving webhook handlers that must be reached by kube-apiservers of the virtual garden cluster or shoot clusters just need to annotate their Service as follows:
annotations:
networking.resources.gardener.cloud/from-all-webhook-targets-allowed-ports: '[{"port":<server-port-on-pod>,"protocol":"<protocol, typically TCP>"}]'
This automatically allows the network traffic from the API server pods.
In case the servers run in a different namespace than the kube-apiservers, the following annotations are needed:
annotations:
networking.resources.gardener.cloud/from-all-webhook-targets-allowed-ports: '[{"port":<server-port-on-pod>,"protocol":"<protocol, typically TCP>"}]' networking.resources.gardener.cloud/pod-label-selector-namespace-alias: extensions
# for the virtual garden cluster: networking.resources.gardener.cloud/namespace-selectors: '[{"matchLabels":{"kubernetes.io/metadata.name":"garden"}}]'# for shoot clusters: networking.resources.gardener.cloud/namespace-selectors: '[{"matchLabels":{"gardener.cloud/role":"shoot"}}]'
Additional Namespace Coverage in Garden/Seed Cluster
In some cases, garden or seed clusters might run components in dedicated namespaces which are not covered by the controller by default (see list above).
Still, it might(/should) be desired to also include such “custom namespaces” into the control of the NetworkPolicy controllers.
In order to do so, human operators can adapt the component configs of gardener-operator or gardenlet by providing label selectors for additional namespaces:
controllers:
networkPolicy:
additionalNamespaceSelectors:
- matchLabels:
foo: bar
Communication With kube-apiserver For Components In Custom Namespaces
Egress Traffic
Component running in such custom namespaces might need to initiate the communication with the kube-apiservers of the virtual garden cluster or a shoot cluster.
In order to achieve this, their custom namespace must be labeled with networking.gardener.cloud/access-target-apiserver=allowed.
This will make the NetworkPolicy controllers automatically provisioning the required policies into their namespace.
As a result, the respective component pods just need to be labeled with
Components running in such custom namespaces might serve webhook handlers that must be reached by the kube-apiservers of the virtual garden cluster or a shoot cluster.
In order to achieve this, their Service must be annotated.
Please refer to this section for more information.
Shoot Cluster
(via gardenlet)
For shoot clusters, the concepts mentioned above don’t apply and are not enabled.
Instead, gardenlet only deploys a few “custom” NetworkPolicys for the shoot system components running in the kube-system namespace.
All other namespaces in the shoot cluster do not contain network policies deployed by gardenlet.
As a best practice, every pod deployed into the kube-system namespace should use appropriate NetworkPolicy in order to only allow required network traffic.
Therefore, pods should have labels matching to the selectors of the available network policies.
gardenlet deploys the following NetworkPolicys:
NAME POD-SELECTOR
gardener.cloud--allow-dns k8s-app in (kube-dns)
gardener.cloud--allow-from-seed networking.gardener.cloud/from-seed=allowed
gardener.cloud--allow-to-dns networking.gardener.cloud/to-dns=allowed
gardener.cloud--allow-to-apiserver networking.gardener.cloud/to-apiserver=allowed
gardener.cloud--allow-to-from-nginx app=nginx-ingress
gardener.cloud--allow-to-kubelet networking.gardener.cloud/to-kubelet=allowed
gardener.cloud--allow-to-public-networks networking.gardener.cloud/to-public-networks=allowed
gardener.cloud--allow-vpn app=vpn-shoot
Note that a deny-all policy will not be created by gardenlet.
Shoot owners can create it manually if needed/desired.
Above listed NetworkPolicys ensure that the traffic for the shoot system components is allowed in case such deny-all policies is created.
Webhook Servers in Shoot Clusters
Shoot components serving webhook handlers must be reached by kube-apiservers of the shoot cluster.
However, the control plane components, e.g. kube-apiserver, run on the seed cluster decoupled by a VPN connection.
Therefore, shoot components serving webhook handlers need to allow the VPN endpoints in the shoot cluster as clients to allow kube-apiservers to call them.
For the kube-system namespace, the network policy gardener.cloud--allow-from-seed fulfils the purpose to allow pods to mark themselves as targets for such calls, allowing corresponding traffic to pass through.
For custom namespaces, operators can use the network policy gardener.cloud--allow-from-seed as a template.
Please note that the label selector may change over time, i.e. with Gardener version updates.
This is why a simpler variant with a reduced label selector like the example below is recommended:
Gardener extensions sometimes need to deploy additional components into the shoot namespace in the seed cluster hosting the control plane.
For example, the gardener-extension-provider-aws deploys the cloud-controller-manager into the shoot namespace.
In most cases, such pods require network policy labels to allow the traffic they are initiating.
For components deployed in the kube-system namespace of the shoots (e.g., CNI plugins or CSI drivers, etc.), custom NetworkPolicys might be required to ensure the respective components can still communicate in case the user creates a deny-all policy.
36 - New Cloud Provider
Adding Cloud Providers
This document provides an overview of how to integrate a new cloud provider into Gardener. Each component that requires integration has a detailed description of how to integrate it and the steps required.
Cloud Components
Gardener is composed of 2 or more Kubernetes clusters:
Shoot: These are the end-user clusters, the regular Kubernetes clusters you have seen. They provide places for your workloads to run.
Seed: This is the “management” cluster. It manages the control planes of shoots by running them as native Kubernetes workloads.
These two clusters can run in the same cloud provider, but they do not need to. For example, you could run your Seed in AWS, while having one shoot in Azure, two in Google, two in Alicloud, and three in Equinix Metal.
The Seed cluster deploys and manages the Shoot clusters. Importantly, for this discussion, the etcd data store backing each Shoot runs as workloads inside the Seed. Thus, to use the above example, the clusters in Azure, Google, Alicloud and Equinix Metal will have their worker nodes and master nodes running in those clouds, but the etcd clusters backing them will run as separate deployments in the Seed Kubernetes cluster on AWS.
This distinction becomes important when preparing the integration to a new cloud provider.
Gardener Cloud Integration
Gardener and its related components integrate with cloud providers at the following key lifecycle elements:
Create/destroy/get/list machines for the Shoot.
Create/destroy/get/list infrastructure components for the Shoot, e.g. VPCs, subnets, routes, etc.
Backup/restore etcd for the Seed via writing files to and reading them from object storage.
Thus, the integrations you need for your cloud provider depend on whether you want to deploy Shoot clusters to the provider, Seed or both.
In addition to the requirements to integrate with the cloud provider, you also need to enable the core Gardener app to receive, validate, and process requests to use that cloud provider.
Expose the cloud provider to the consumers of the Gardener API, so it can be told to use that cloud provider as an option.
Validate that API as requests come in.
Write cloud provider specific implementation (called “provider extension”).
Cloud Provider API Requirements
In order for a cloud provider to integrate with Gardener, the provider must have an API to perform machine lifecycle events, specifically:
Create a machine
Destroy a machine
Get information about a machine and its state
List machines
In addition, if the Seed is to run on the given provider, it also must have an API to save files to block storage and retrieve them, for etcd backup/restore.
The current integration with cloud providers is to add their API calls to Gardener and the Machine Controller Manager. As both Gardener and the Machine Controller Manager are written in go, the cloud provider should have a go SDK. However, if it has an API that is wrappable in go, e.g. a REST API, then you can use that to integrate.
The Gardener team is working on bringing cloud provider integrations out-of-tree, making them pluggable, which should simplify the process and make it possible to use other SDKs.
Summary
To add a new cloud provider, you need some or all of the following. Each repository contains instructions on how to extend it to a new cloud provider.
This document describes the steps needed to perform in order to confidently add support for a new Kubernetes minor version.
Kubernetes Release Responsible Plan
Tasks:
Ensure Gardener and extensions are updated to support the new Kubernetes version (example)
Bump Golang dependencies for k8s.io/* and sigs.k8s.io/controller-runtime (example) [ref]
Prepare a short (~30-60 min) session for a special edition of Gardener’s Review Meeting on new key features and changes in the release
Drop support for all but the greatest/latest 5 Kubernetes minor versions (the newly added plus four prior). Drop all lower/older versions and adapt accordingly (example)
⚠️ Typically, once a minor Kubernetes version vX.Y is supported by Gardener, then all patch versions vX.Y.Z are also automatically supported without any required action.
This is because patch versions do not introduce any new feature or API changes, so there is nothing that needs to be adapted in gardener/gardener code.
The Kubernetes community release a new minor version roughly every 4 months.
Please refer to the official documentation about their release cycles for any additional information.
Shortly before a new release, an “umbrella” issue should be opened which is used to collect the required adaptations and to track the work items.
For example, #5102 can be used as a template for the issue description.
As you can see, the task of supporting a new Kubernetes version also includes the provider extensions maintained in the gardener GitHub organization and is not restricted to gardener/gardener only.
Generally, the work items can be split into two groups:
The first group contains tasks specific to the changes in the given Kubernetes release, the second group contains Kubernetes release-independent tasks.
ℹ️ Upgrading the k8s.io/* and sigs.k8s.io/controller-runtime Golang dependencies is typically tracked and worked on separately (see e.g. #4772 or #5282), however, it is in the responsibility of the Kubernetes Release Responsibles to make sure the libraries get updated (see the respective section below).
Preparation
Once a new Kubernetes version is released, two issues should be created and assigned according to the release responsible plan.
Use the most recent previous issue as a template for the new issue:
Most new minor Kubernetes releases incorporate API changes, deprecations, or new features.
The community announces them via their change logs.
In order to derive the release-specific tasks, the respective change log for the new version vX.Y has to be read and understood (for example, the changelog for v1.24).
As already mentioned, typical changes to watch out for are:
API version promotions or deprecations
Feature gate promotions or deprecations
CLI flag changes for Kubernetes components
New default values in resources
New available fields in resources
New features potentially relevant for the Gardener system
Changes of labels or annotations Gardener relies on
…
Obviously, this requires a certain experience and understanding of the Gardener project so that all “relevant changes” can be identified.
While reading the change log, add the tasks (along with the respective PR in kubernetes/kubernetes to the umbrella issue).
ℹ️ Some of the changes might be specific to certain cloud providers. Pay attention to those as well and add related tasks to the issue.
List Of Release-Independent Tasks
The following paragraphs describe recurring tasks that need to be performed for each new release.
Make Sure a New hyperkube Image Is Released
The gardener/hyperkube repository is used to release container images consisting of the kubectl and kubelet binaries.
There is a CI/CD job that runs periodically and releases a new hyperkube image when there is a new Kubernetes release. Before proceeding with the next steps, make sure that a new hyperkube image is released for the corresponding new Kubernetes minor version. Make sure that container image is present in GCR.
Adapting Gardener
Allow instantiation of a Kubernetes client for the new minor version and update the README.md:
Search the page for the current Kubernetes version, e.g. if the new version is “1.32”, search for “1.31”.
Set RemovedInVersion to the new Kubernetes version for feature gates that have been removed after the current Kubernetes version according to the “To” column.
To maintain this list for new Kubernetes versions, run hack/compare-k8s-admission-plugins.sh <old-version> <new-version> (e.g. hack/compare-k8s-admission-plugins.sh 1.26 1.27).
It will present 2 lists of admission plugins: those added and those removed in <new-version> compared to <old-version>.
Add all added admission plugins to the admissionPluginsVersionRanges map with <new-version> as AddedInVersion and no RemovedInVersion.
For any removed admission plugins, add <new-version> as RemovedInVersion to the already existing admission plugin in the map.
In local setup, create a shoot with all of the newly added admission plugins disabled. Make sure that the shoot creation and deletion will succeed. If it fails, that means some of the admission plugins are required. Flag any admission plugins that are required (plugins that must not be disabled in the Shoot spec) by setting the Required boolean variable to true for the admission plugin in the map.
Check the Kubernetes documentation for admission controllers if any newly added admission plugin is not recommended for production usage. Example: The Kubernetes project recommends that you do not use the SecurityContextDeny admission controller. Note that this admission controller was removed in Kubernetes 1.30 in this PR and that’s why it is not mentioned in the latest Kubernetes documentation. Flag those admission plugins by setting the Forbidden boolean variable to true for the admission plugin in the map.
Maintain the Kubernetes kube-apiserver API groups used for validation of Shoot resources:
To maintain this list for new Kubernetes versions, run hack/compare-k8s-api-groups.sh <old-version> <new-version> (e.g. hack/compare-k8s-api-groups.sh 1.26 1.27).
It will present 2 lists of API GroupVersions and 2 lists of API GroupVersionResources: those added and those removed in <new-version> compared to <old-version>.
Add all added group versions to the apiGroupVersionRanges map and group version resources to the apiGVRVersionRanges map with <new-version> as AddedInVersion and no RemovedInVersion.
For any removed APIs, add <new-version> as RemovedInVersion to the already existing API in the corresponding map.
In local setup, create a shoot and a workerless shoot with all of the newly added API groups disabled. Make sure that the shoot creation and deletion will succeed. If it fails, that means some of the API groups are required. Flag any APIs that are required (APIs that must not be disabled in the Shoot spec) by setting the Required boolean variable to true for the API in the apiGVRVersionRanges map. If this API also should not be disabled for Workerless Shoots, then set RequiredForWorkerless boolean variable also to true. If the API is required for both Shoot types, then both of these booleans need to be set to true. If the whole API Group is required, then mark it correspondingly in the apiGroupVersionRanges map.
Maintain the Kubernetes kube-controller-manager controllers for each API group used in deploying required KCM controllers based on active APIs:
To maintain this list for new Kubernetes versions, run hack/compute-k8s-controllers.sh <old-version> <new-version> (e.g. hack/compute-k8s-controllers.sh 1.28 1.29).
If it complains that the path for the controller is not present in the map, check the release branch of the new Kubernetes version and find the correct path for the missing/wrong controller. You can do so by checking the file cmd/kube-controller-manager/app/controllermanager.go and where the controller is initialized from. As of now, there is no straight-forward way to map each controller to its file. If this has improved, please enhance the script.
If the paths are correct, it will present 2 lists of controllers: those added and those removed for each API group in <new-version> compared to <old-version>.
Add all added controllers to the APIGroupControllerMap map and under the corresponding API group with <new-version> as AddedInVersion and no RemovedInVersion.
For any removed controllers, add <new-version> as RemovedInVersion to the already existing controller in the corresponding API group map. If you are unable to find the removed controller name, then check for its alias. Either in the staging/src/k8s.io/cloud-provider/names/controller_names.go file (example) or in the cmd/kube-controller-manager/app/* files (example for apps API group). This is because for kubernetes versions starting from v1.28, we don’t maintain the aliases in the controller, but the controller names itself since some controllers can be initialized without aliases as well (example). The old alias should still be working since it should be backwards compatible as explained here. Once the support for kubernetes version < v1.28 is dropped, we can drop the usages of these aliases and move completely to controller names.
Make sure that the API groups in this file are in sync with the groups in this file. Please note that, for example, core/v1 is replaced by the script as v1 and apiserverinternal as internal. This is because the API groups registered by the apiserver (example) and the file path imported by the controllers (example) might be slightly different in some cases.
Maintain the names of controllers used for workerless Shoots, here after carefully evaluating whether they are needed if there are no workers. The Kubernetes documentation might not always explain what a specific controller does. In such cases, you may need to search the kubernetes/kubernetes repository for the controller’s name and find the pull request that introduced it.
Maintain copies of the DaemonSet controller’s scheduling logic:
gardener-resource-manager’s Node controller uses a copy of parts of the DaemonSet controller’s logic for determining whether a specific Node should run a daemon pod of a given DaemonSet: see this file.
Check the referenced upstream files for changes to the DaemonSet controller’s logic and adapt our copies accordingly. This might include introducing version-specific checks in our codebase to handle different shoot cluster versions.
Handle breaking changes that require adjustments to update the Shoot to the new Kubernetes minor version:
Removal of functionalities from the Shoot API is usually connected to a Kubernetes minor version upgrade. For more details, see the Deprecations and Backwards-Compatibility section. Check if there are breaking changes to the Shoot API that require the Shoot spec to be adapted in order to update to the new Kubernetes minor version.
Maintain version specific defaulting logic in shoot admission plugin. Sometimes default values for shoots are intentionally changed with the introduction of a new Kubernetes version. The final Kubernetes version for a shoot is determined in the Shoot Validator Admission Plugin. Any defaulting logic that depends on the version should be placed in this admission plugin (example).
Ensure that maintenance-controller is able to auto-update shoots to the new Kubernetes version. Changes to the shoot spec required for the Kubernetes update should be enforced in such cases (examples).
Maintain the Shoot Kubernetes Minor Version Upgrades documentation file. Add breaking and/or behavioral changes related to Gardener, introduced with the new Kubernetes version.
Add the new Kubernetes version to the CloudProfile in local setup.
In the next Gardener release, file a PR that bumps the used Kubernetes version for local e2e test.
This step must be performed in a PR that targets the next Gardener release because of the e2e upgrade tests. The e2e upgrade tests deploy the previous Gardener version where the new Kubernetes version is not present in the CloudProfile. If the e2e tests are adapted in the same PR that adds the support for the Kubernetes version, then the e2e upgrade tests for that PR will fail because the newly added Kubernetes version in missing in the local CloudProfile from the old release.
Work on all the tasks you have collected and validate them using the local provider.
Execute the e2e tests and if everything looks good, then go ahead and file the PR (example PR).
Generally, it is great if you add the PRs also to the umbrella issue so that they can be tracked more easily.
Adapting Provider Extensions
After the PR in gardener/gardener for the support of the new version has been merged, you can go ahead and work on the provider extensions.
Actually, you can already start even if the PR is not yet merged and use the branch of your fork.
Update the github.com/gardener/gardener dependency in the extension and update the README.md.
Work on release-specific tasks related to this provider.
Maintaining the cloud-controller-manager Images
Provider extensions are using upstream cloud-controller-manager images.
Make sure to adopt the new cloud-controller-manager release for the new Kubernetes minor version (example PR).
Some of the cloud providers are not using upstream cloud-controller-manager images for some of the supported Kubernetes versions.
Instead, we build and maintain the images ourselves:
Update the VERSION to vX.Y.Z-dev where Z is the latest available Kubernetes patch version for the vX.Y minor version.
Update the k8s.io/* dependencies in the go.mod file to vX.Y.Z and run go mod tidy (example commit).
Checkout a new release-vX.Y branch and release it (example)
As you are already on it, it is great if you also bump the k8s.io/* dependencies for the last three minor releases as well.
In this case, you need to check out the release-vX.{Y-{1,2,3}} branches and only perform the last three steps (example branch, example commit).
Now you need to update the new releases in the imagevector/images.yaml of the respective provider extension so that they are used (see this example commit for reference).
Maintaining Additional Images
Provider extensions might also deploy additional images other than cloud-controller-manager that are specific for a given Kubernetes minor version.
Make sure to use a new image for the following components:
The ecr-credential-provider image for the provider-aws extension.
We are building the ecr-credential-provider image ourselves because the upstream community does not provide an OCI image for the corresponding component. For more details, see this upstream issue.
Use the following steps to prepare a release of the ecr-credential-provider image for the new Kubernetes minor version:
Once the PR is merged, trigger a new release from the CI/CD.
The csi-driver-cinder and csi-driver-manila images for the provider-openstack extension.
The upstream community is providing csi-driver-cinder and csi-driver-manila releases per Kubernetes minor version. Make sure to adopt the new csi-driver-cinder and csi-driver-manila releases for the new Kubernetes minor version (example PR).
Filing the Pull Request
Again, work on all the tasks you have collected.
This time, you cannot use the local provider for validation but should create real clusters on the various infrastructures.
Typically, the following validations should be performed:
Create new clusters with versions < vX.Y
Create new clusters with version = vX.Y
Upgrade old clusters from version vX.{Y-1} to version vX.Y
Delete clusters with versions < vX.Y
Delete clusters with version = vX.Y
If everything looks good, then go ahead and file the PR (example PR).
Generally, it is again great if you add the PRs also to the umbrella issue so that they can be tracked more easily.
Bump Golang dependencies for k8s.io/* and sigs.k8s.io/controller-runtime
The versions of the upstream Go dependencies k8s.io/* and sigs.k8s.io/controller-runtime should be updated to the latest version that is compatible with the new Kubernetes version.
This is handled via a separate issue (example) and pull request (example).
Bump the k8s.io/* dependencies in the go.mod file to the latest version that is compatible with the new Kubernetes version.
Bump the sigs.k8s.io/controller-runtime dependency in the go.mod file to the latest version that is compatible with the new Kubernetes version.
Ensure that the major version of gomodules.xyz/jsonpatch/v2 that we use (go.mod) matches the major version of the same dependency in the updated version of sigs.k8s.io/controller-runtime (go.mod).
38 - Priority Classes
PriorityClasses in Gardener Clusters
Gardener makes use of PriorityClasses to improve the overall robustness of the system.
In order to benefit from the full potential of PriorityClasses, the gardenlet manages a set of well-known PriorityClasses with fine-granular priority values.
All components of the system should use these well-known PriorityClasses instead of creating and using separate ones with arbitrary values, which would compromise the overall goal of using PriorityClasses in the first place.
The gardenlet manages the well-known PriorityClasses listed in this document, so that third parties (e.g., Gardener extensions) can rely on them to be present when deploying components to Seed and Shoot clusters.
The listed well-known PriorityClasses follow this rough concept:
Values are close to the maximum that can be declared by the user. This is important to ensure that Shoot system components have higher priority than the workload deployed by end-users.
Values have a bit of headroom in between to ensure flexibility when the need for intermediate priority values arises.
Values of PriorityClasses created on Seed clusters are lower than the ones on Shoots to ensure that Shoot system components have higher priority than Seed components, if the Seed is backed by a Shoot (ManagedSeed), e.g. coredns should have higher priority than gardenlet.
Names simply include the last digits of the value to minimize confusion caused by many (similar) names like critical, importance-high, etc.
Garden Clusters
When using the gardener-operator for managing the garden runtime and virtual cluster, the following PriorityClasses are available:
PriorityClasses for Garden Control Plane Components
The @gardener-maintainers are trying to provide a new release roughly every other week (depending on their capacity and the stability/robustness of the master branch).
Hotfixes are usually maintained for the latest three minor releases, though, there are no fixed release dates.
Apart from the release of the next version, the release responsible is also taking care of potential hotfix releases of the last three minor versions.
The release responsible is the main contact person for coordinating new feature PRs for the next minor versions or cherry-pick PRs for the last three minor versions.
Click to expand the archived release responsible associations!
Click here to view the Kubernetes Release Responsible plan.
Release Validation
The release phase for a new minor version lasts two weeks.
Typically, the first week is used for the validation of the release.
This phase includes the following steps:
master (or latest release-* branch) is deployed to a development landscape that already hosts some existing seed and shoot clusters.
An extended test suite is triggered by the “release responsible” which:
executes the Gardener integration tests for different Kubernetes versions, infrastructures, and Shoot settings.
executes the Kubernetes conformance tests.
executes further tests like Kubernetes/OS patch/minor version upgrades.
Additionally, every four hours (or on demand) more tests (e.g., including the Kubernetes e2e test suite) are executed for different infrastructures.
The “release responsible” is verifying new features or other notable changes (derived of the draft release notes) in this development system.
Usually, the new release is triggered in the beginning of the second week if all tests are green, all checks were successful, and if all of the planned verifications were performed by the release responsible.
Contributing New Features or Fixes
Please refer to the Gardener contributor guide.
Besides a lot of general information, it also provides a checklist for newly created pull requests that may help you to prepare your changes for an efficient review process.
If you are contributing a fix or major improvement, please take care to open cherry-pick PRs to all affected and still supported versions once the change is approved and merged in the master branch.
⚠️ Please ensure that your modifications pass the verification checks (linting, formatting, static code checks, tests, etc.) by executing
make verify
before filing your pull request.
The guide applies for both changes to the master and to any release-* branch.
All changes must be submitted via a pull request and be reviewed and approved by at least one code owner.
TODO Statements
Sometimes, TODO statements are being introduced when one cannot follow up immediately with certain tasks or when temporary migration code is required.
In order to properly follow-up with such TODOs and to prevent them from piling up without getting attention, the following rules should be followed:
Each TODO statement should have an associated person and state when it can be removed.
Example:
// TODO(<github-username>): Remove this code after v1.75 has been released.
When the task depends on a certain implementation, a GitHub issue should be opened and referenced in the statement.
Example:
// TODO(<github-username>): Remove this code after https://github.com/gardener/gardener/issues/<issue-number> has been implemented.
The associated person should actively drive the implementation of the referenced issue (unless it cannot be done because of third-party dependencies or conditions) so that the TODO statement does not get stale.
TODO statements without actionable tasks or those that are unlikely to ever be implemented (maybe because of very low priorities) should not be specified in the first place. If a TODO is specified, the associated person should make sure to actively follow-up.
Deprecations and Backwards-Compatibility
In case you have to remove functionality relevant to end-users (e.g., a field or default value in the Shoot API), please connect it with a Kubernetes minor version upgrade.
This way, end-users are forced to actively adapt their manifests when they perform their Kubernetes upgrades.
For example, the .spec.kubernetes.enableStaticTokenKubeconfig field in the Shoot API is no longer allowed to be set for Kubernetes versions >= 1.27.
In case you have to remove or change functionality which cannot be directly connected with a Kubernetes version upgrade, please consider introducing a feature gate.
This way, landscape operators can announce the planned changes to their users and communicate a timeline when they plan to activate the feature gate.
End-users can then prepare for it accordingly.
For example, the fact that changes to kubelet.kubeReserved in the Shoot API will lead to a rolling update of the worker nodes (previously, these changes were updated in-place) is controlled via the NewWorkerPoolHash feature gate.
In case you have to remove functionality relevant to Gardener extensions, please deprecate it first, and add a TODO statement to remove it only after at least 9 releases.
Do not forget to write a proper release note as part of your pull request.
This gives extension developers enough time (~18 weeks) to adapt to the changes (and to release a new version of their extension) before Gardener finally removes the functionality.
Examples are removing a field in the extensions.gardener.cloud/v1alpha1 API group, or removing a controller in the extensions library.
In case you have to run migration code (which is mostly internal), please add a TODO statement to remove it only after 3 releases.
This way, we can ensure that the Gardener version skew policy is not violated.
For example, the migration code for moving the Prometheus instances under management of prometheus-operator was running for three releases.
Be aware the cherry pick script assumes you have a git remote called
upstream that points at the Gardener GitHub org.
You will need to run the cherry pick script separately for each patch
release you want to cherry pick to. Cherry picks should be applied to all
active release branches where the fix is applicable.
The Reversed VPN Tunnel is enabled by default.
A highly available VPN connection is automatically deployed in all shoots that configure an HA control-plane.
Reversed VPN Tunnel
In the first VPN solution, connection establishment was initiated by a VPN client in the seed cluster.
Due to several issues with this solution, the tunnel establishment direction has been reverted.
The client is deployed in the shoot and initiates the connection from there. This way, there is no need to deploy a special purpose
loadbalancer for the sake of addressing the data-plane, in addition to saving costs, this is considered the more secure alternative.
For more information on how this is achieved, please have a look at the following GEP.
Connection establishment with a reversed tunnel:
APIServer --> Envoy-Proxy | VPN-Seed-Server <-- Istio/Envoy-Proxy <-- SNI API Server Endpoint <-- LB (one for all clusters of a seed) <--- internet <--- VPN-Shoot-Client --> Pods | Nodes | Services
High Availability for Reversed VPN Tunnel
Shoots which define spec.controlPlane.highAvailability.failureTolerance: {node, zone} get an HA control-plane, including a
highly available VPN connection by deploying redundant VPN servers and clients.
Please note that it is not possible to move an open connection to another VPN tunnel. Especially long-running
commands like kubectl exec -it ... or kubectl logs -f ... will still break if the routing path must be switched
because either VPN server or client are not reachable anymore. A new request should be possible within seconds.
HA Architecture for VPN
Establishing a connection from the VPN client on the shoot to the server in the control plane works nearly the same
way as in the non-HA case. The only difference is that the VPN client targets one of two VPN servers, represented by two services
vpn-seed-server-0 and vpn-seed-server-1 with endpoints in pods with the same name.
The VPN tunnel is used by a kube-apiserver to reach nodes, services, or pods in the shoot cluster.
In the non-HA case, a kube-apiserver uses an HTTP proxy running as a side-car in the VPN server to address
the shoot networks via the VPN tunnel and the vpn-shoot acts as a router.
In the HA case, the setup is more complicated. Instead of an HTTP proxy in the VPN server, the kube-apiserver has
additional side-cars, one side-car for each VPN client to connect to the corresponding VPN server.
On the shoot side, there are now two vpn-shoot pods, each with two VPN clients for each VPN server.
With this setup, there would be four possible routes, but only one can be used. Switching the route kills all
open connections. Therefore, another layer is introduced: link aggregation, also named bonding.
In Linux, you can create a network link by using several other links as slaves. Bonding here is used with
active-backup mode. This means the traffic only goes through the active sublink and is only changed if the active one
becomes unavailable. Switching happens in the bonding network driver without changing any routes. So with this layer,
vpn-seed-server pods can be rolled without disrupting open connections.
With bonding, there are 2 possible routing paths, ensuring that there is at least one routing path intact even if
one vpn-seed-server pod and one vpn-shoot pod are unavailable at the same time.
As multi-path routing is not available on the worker nodes, one routing path must be configured explicitly.
For this purpose, the path-controller app is running in another side-car of the kube-apiserver pod.
It pings all shoot-side VPN clients regularly every few seconds. If the active routing path is not responsive anymore,
the routing is switched to the other responsive routing path.
Using an IPv6 transport network for communication between the bonding devices of the VPN clients, additional
tunnel devices are needed on both ends to allow transport of both IPv4 and IPv6 packets.
For this purpose, ip6tnl type tunnel devices are in place (an IPv4/IPv6 over IPv6 tunnel interface).
The connection establishment with a reversed tunnel in HA case is:
APIServer[k] --> ip6tnl-device[j] --> bond-device --> tap-device[i] | VPN-Seed-Server[i] <-- Istio/Envoy-Proxy <-- SNI API Server Endpoint <-- LB (one for all clusters of a seed) <--- internet <--- VPN-Shoot-Client[j] --> tap-device[i] --> bond-device --> ip6tnl-device[k] --> Pods | Nodes | Services
Here, [k] is the index of the kube-apiserver instance, [j] of the VPN shoot instance, and [i] of VPN seed server.
For each kube-apiserver instance, an own ip6tnl tunnel device is needed on the shoot side.
Additionally, the back routes from the VPN shoot to any new kube-apiserver instance must be set dynamically.
Both tasks are managed by the tunnel-controller running in each VPN shoot client.
It listens for UDP6 packets sent periodically from the path-controller running in the kube-apiserver pods.
These UDP6 packets contain the IPv6 address of the bond device.
If the tunnel controller detects a new kube-apiserver this way, it creates a new tunnel device and route to it.
For general information about HA control-plane, see GEP-20.
41 - Secrets Management
Secrets Management for Seed and Shoot Cluster
The gardenlet needs to create quite some amount of credentials (certificates, private keys, passwords) for seed and shoot clusters in order to ensure secure deployments.
Such credentials typically should be renewed automatically when their validity expires, rotated regularly, and they potentially need to be persisted such that they don’t get lost in case of a control plane migration or a lost seed cluster.
SecretsManager Introduction
These requirements can be covered by using the SecretsManager package maintained in pkg/utils/secrets/manager.
It is built on top of the ConfigInterface and DataInterface interfaces part of pkg/utils/secrets and provides the following functions:
This method either retrieves the current secret for the given configuration or it (re)generates it in case the configuration changed, the signing CA changed (for certificate secrets), or when proactive rotation was triggered.
If the configuration describes a certificate authority secret then this method automatically generates a bundle secret containing the current and potentially the old certificate.
Available GenerateOptions:
SignedByCA(string, ...SignedByCAOption): This is only valid for certificate secrets and automatically retrieves the correct certificate authority in order to sign the provided server or client certificate.
There are two SignedByCAOptions:
UseCurrentCA. This option will sign server certificates with the new/current CA in case of a CA rotation. For more information, please refer to the “Certificate Signing” section below.
UseOldCA. This option will sign client certificates with the old CA in case of a CA rotation. For more information, please refer to the “Certificate Signing” section below.
Persist(): This marks the secret such that it gets persisted in the ShootState resource in the garden cluster. Consequently, it should only be used for secrets related to a shoot cluster.
Rotate(rotationStrategy): This specifies the strategy in case this secret is to be rotated or regenerated (either InPlace which immediately forgets about the old secret, or KeepOld which keeps the old secret in the system).
IgnoreOldSecrets(): This specifies that old secrets should not be considered and loaded (contrary to the default behavior). It should be used when old secrets are no longer important and can be “forgotten” (e.g. in “phase 2” (t2) of the CA certificate rotation). Such old secrets will be deleted on Cleanup().
IgnoreOldSecretsAfter(time.Duration): This specifies that old secrets should not be considered and loaded once a given duration after rotation has passed. It can be used to clean up old secrets after automatic rotation (e.g. the Seed cluster CA is automatically rotated when its validity will soon end and the old CA will be cleaned up 24 hours after triggering the rotation).
Validity(time.Duration): This specifies how long the secret should be valid. For certificate secret configurations, the manager will automatically deduce this information from the generated certificate.
RenewAfterValidityPercentage(int): This specifies the percentage of validity for renewal. The secret will be renewed based on whichever comes first: The specified percentage of validity or 10 days before end of validity. If not specified, the default percentage is 80.
Get(string, ...GetOption) (*corev1.Secret, bool)
This method retrieves the current secret for the given name.
In case the secret in question is a certificate authority secret then it retrieves the bundle secret by default.
It is important that this method only knows about secrets for which there were prior Generate calls.
Available GetOptions:
Bundle (default): This retrieves the bundle secret.
Current: This retrieves the current secret.
Old: This retrieves the old secret.
Cleanup(context.Context) error
This method deletes secrets which are no longer required.
No longer required secrets are those still existing in the system which weren’t detected by prior Generate calls.
Consequently, only call Cleanup after you have executed Generate calls for all desired secrets.
As explained above, the caller does not need to care about the renewal, rotation or the persistence of this secret - all of these concerns are handled by the secrets manager.
Automatic renewal of secrets happens when their validity approaches 80% or less than 10d are left until expiration.
In case a CA certificate is needed by some component, then it can be retrieved as follows:
caSecret, found := k.secretsManager.Get("my-ca")
if !found {
return fmt.Errorf("secret my-ca not found")
}
As explained above, this returns the bundle secret for the CA my-ca which might potentially contain both the current and the old CA (in case of rotation/regeneration).
Certificate Signing
Default Behaviour
By default, client certificates are signed by the current CA while server certificate are signed by the old CA (if it exists).
This is to ensure a smooth exchange of certificate during a CA rotation (typically has two phases, ref GEP-18):
Client certificates:
In phase 1, clients get new certificates as soon as possible to ensure that all clients have been adapted before phase 2.
In phase 2, the respective server drops accepting certificates signed by the old CA.
Server certificates:
In phase 1, servers still use their old/existing certificates to allow clients to update their CA bundle used for verification of the servers’ certificates.
In phase 2, the old CA is dropped, hence servers need to get a certificate signed by the new/current CA. At this point in time, clients have already adapted their CA bundles.
Alternative: Sign Server Certificates with Current CA
In case you control all clients and update them at the same time as the server, it is possible to make the secrets manager generate even server certificates with the new/current CA.
This can help to prevent certificate mismatches when the CA bundle is already exchanged while the server still serves with a certificate signed by a CA no longer part of the bundle.
Let’s consider the two following examples:
gardenlet deploys a webhook server (gardener-resource-manager) and a corresponding MutatingWebhookConfiguration at the same time. In this case, the server certificate should be generated with the new/current CA to avoid above mentioned certificate mismatches during a CA rotation.
gardenlet deploys a server (etcd) in one step, and a client (kube-apiserver) in a subsequent step. In this case, the default behaviour should apply (server certificate should be signed by old/existing CA).
Alternative: Sign Client Certificate with Old CA
In the unusual case where the client is deployed before the server, it might be useful to always use the old CA for signing the client’s certificate.
This can help to prevent certificate mismatches when the client already gets a new certificate while the server still only accepts certificates signed by the old CA.
Let’s consider the two following examples:
gardenlet deploys the kube-apiserver before the kubelet. However, the kube-apiserver has a client certificate signed by the ca-kubelet in order to communicate with it (e.g., when retrieving logs or forwarding ports). In this case, the client certificate should be generated with the old CA to avoid above mentioned certificate mismatches during a CA rotation.
gardenlet deploys a server (etcd) in one step, and a client (kube-apiserver) in a subsequent step. In this case, the default behaviour should apply (client certificate should be signed by new/current CA).
Reusing the SecretsManager in Other Components
While the SecretsManager is primarily used by gardenlet, it can be reused by other components (e.g. extensions) as well for managing secrets that are specific to the component or extension. For example, provider extensions might use their own SecretsManager instance for managing the serving certificate of cloud-controller-manager.
External components that want to reuse the SecretsManager should consider the following aspects:
On initialization of a SecretsManager, pass an identity specific to the component and controller. For example, gardenlet’s shoot controller uses gardenlet as the SecretsManager’s identity, the Worker controller in provider-foo should use provider-foo-worker, and the ControlPlane controller should use provider-foo-controlplane for ControlPlane objects.
The given identity is added as a value for the manager-identity label on managed Secrets.
This label is used by the Cleanup function to select only those Secrets that are actually managed by the particular SecretManager instance. This is done to prevent removing still needed Secrets that are managed by other instances.
Generate dedicated CAs for signing certificates instead of depending on CAs managed by gardenlet.
Names of Secrets managed by external SecretsManager instances must not conflict with Secret names from other instances (e.g. gardenlet).
For CAs that should be rotated in lock-step with the Shoot CAs managed by gardenlet, components need to pass information about the last rotation initiation time and the current rotation phase to the SecretsManager upon initialization.
The relevant information can be retrieved from the Cluster resource under .spec.shoot.status.credentials.rotation.certificateAuthorities.
Independent of the specific identity, secrets marked with the Persist option are automatically saved in the ShootState resource by the gardenlet and are also restored by the gardenlet on Control Plane Migration to the new Seed.
Migrating Existing Secrets To SecretsManager
If you already have existing secrets which were not created with SecretsManager, then you can (optionally) migrate them by labeling them with secrets-manager-use-data-for-name=<config-name>.
For example, if your SecretsManager generates a CertificateConfigSecret with name foo like this
and you already have an existing secret in your system whose data should be kept instead of regenerated, then labeling it with secrets-manager-use-data-for-name=foo will instruct SecretsManager accordingly.
⚠️ Caveat: You have to make sure that the existing data keys match with what SecretsManager uses:
Secret Type
Data Keys
Basic Auth
username, password, auth
CA Certificate
ca.crt, ca.key
Non-CA Certificate
tls.crt, tls.key
Control Plane Secret
ca.crt, username, password, token, kubeconfig
ETCD Encryption Key
key, secret
Kubeconfig
kubeconfig
RSA Private Key
id_rsa, id_rsa.pub
Static Token
static_tokens.csv
VPN TLS Auth
vpn.tlsauth
Implementation Details
The source of truth for the secrets manager is the list of Secrets in the Kubernetes cluster it acts upon (typically, the seed cluster).
The persisted secrets in the ShootState are only used if and only if the shoot is in the Restore phase - in this case all secrets are just synced to the seed cluster so that they can be picked up by the secrets manager.
In order to prevent kubelets from unneeded watches (thus, causing some significant traffic against the kube-apiserver), the Secrets are marked as immutable.
Consequently, they have a unique, deterministic name which is computed as follows:
For CA secrets, the name is just exactly the name specified in the configuration (e.g., ca). This is for backwards-compatibility and will be dropped in a future release once all components depending on the static name have been adapted.
For all other secrets, the name specified in the configuration is used as prefix followed by an 8-digit hash. This hash is computed out of the checksum of the secret configuration and the checksum of the certificate of the signing CA (only for certificate configurations).
In all cases, the name of the secrets is suffixed with a 5-digit hash computed out of the time when the rotation for this secret was last started.
42 - Seed Bootstrapping
Seed Bootstrapping
Whenever the gardenlet is responsible for a new Seed resource its “seed controller” is being activated.
One part of this controller’s reconciliation logic is deploying certain components into the garden namespace of the seed cluster itself.
These components are required to spawn and manage control planes for shoot clusters later on.
This document is providing an overview which actions are performed during this bootstrapping phase, and it explains the rationale behind them.
Dependency Watchdog
The dependency watchdog (abbreviation: DWD) is a component developed separately in the gardener/dependency-watchdog GitHub repository.
Gardener is using it for two purposes:
Prevention of melt-down situations when the load balancer used to expose the kube-apiserver of shoot clusters goes down while the kube-apiserver itself is still up and running.
Fast recovery times for crash-looping pods when depending pods are again available.
For the sake of separating these concerns, two instances of the DWD are deployed by the seed controller.
Prober
The dependency-watchdog-prober deployment is responsible for above-mentioned first point.
The kube-apiserver of shoot clusters is exposed via a load balancer, usually with an attached public IP, which serves as the main entry point when it comes to interaction with the shoot cluster (e.g., via kubectl).
While end-users are talking to their clusters via this load balancer, other control plane components like the kube-controller-manager or kube-scheduler run in the same namespace/same cluster, so they can communicate via the in-cluster Service directly instead of using the detour with the load balancer.
However, the worker nodes of shoot clusters run in isolated, distinct networks.
This means that the kubelets and kube-proxys also have to talk to the control plane via the load balancer.
The kube-controller-manager has a special control loop called nodelifecycle which will set the status of Nodes to NotReady in case the kubelet stops to regularly renew its lease/to send its heartbeat.
This will trigger other self-healing capabilities of Kubernetes, for example, the eviction of pods from such “unready” nodes to healthy nodes.
Similarly, the cloud-controller-manager has a control loop that will disconnect load balancers from “unready” nodes, i.e., such workload would no longer be accessible until moved to a healthy node.
Furthermore, the machine-controller-manager removes “unready” nodes after health-timeout (default 10min).
While these are awesome Kubernetes features on their own, they have a dangerous drawback when applied in the context of Gardener’s architecture:
When the kube-apiserver load balancer fails for whatever reason, then the kubelets can’t talk to the kube-apiserver to renew their lease anymore.
After a minute or so the kube-controller-manager will get the impression that all nodes have died and will mark them as NotReady.
This will trigger above mentioned eviction as well as detachment of load balancers.
As a result, the customer’s workload will go down and become unreachable.
This is exactly the situation that the DWD prevents:
It regularly tries to talk to the kube-apiservers of the shoot clusters, once by using their load balancer, and once by talking via the in-cluster Service.
If it detects that the kube-apiserver is reachable internally but not externally, it scales down machine-controller-manager, cluster-autoscaler (if enabled) and kube-controller-manager to 0.
This will prevent it from marking the shoot worker nodes as “unready”. This will also prevent the machine-controller-manager from deleting potentially healthy nodes.
As soon as the kube-apiserver is reachable externally again, kube-controller-manager, machine-controller-manager and cluster-autoscaler are restored to the state prior to scale-down.
Weeder
The dependency-watchdog-weeder deployment is responsible for above mentioned second point.
Kubernetes is restarting failing pods with an exponentially increasing backoff time.
While this is a great strategy to prevent system overloads, it has the disadvantage that the delay between restarts is increasing up to multiple minutes very fast.
In the Gardener context, we are deploying many components that are depending on other components.
For example, the kube-apiserver is depending on a running etcd, or the kube-controller-manager and kube-scheduler are depending on a running kube-apiserver.
In case such a “higher-level” component fails for whatever reason, the dependent pods will fail and end-up in crash-loops.
As Kubernetes does not know anything about these hierarchies, it won’t recognize that such pods can be restarted faster as soon as their dependents are up and running again.
This is exactly the situation in which the DWD will become active:
If it detects that a certain Service is available again (e.g., after the etcd was temporarily down while being moved to another seed node), then DWD will restart all crash-looping dependant pods.
These dependant pods are detected via a pre-configured label selector.
As of today, the DWD is configured to restart a crash-looping kube-apiserver after etcd became available again, or any pod depending on the kube-apiserver that has a gardener.cloud/role=controlplane label (e.g., kube-controller-manager, kube-scheduler).
43 - Seed Settings
Settings for Seeds
The Seed resource offers a few settings that are used to control the behaviour of certain Gardener components.
This document provides an overview over the available settings:
Dependency Watchdog
Gardenlet can deploy two instances of the dependency-watchdog into the garden namespace of the seed cluster.
One instance only activates the weeder while the second instance only activates the prober.
Weeder
The weeder helps to alleviate the delay where control plane components remain unavailable by finding the respective pods in CrashLoopBackoff status and restarting them once their dependents become ready and available again.
For example, if etcd goes down then also kube-apiserver goes down (and into a CrashLoopBackoff state). If etcd comes up again then (without the endpoint controller) it might take some time until kube-apiserver gets restarted as well.
⚠️ .spec.settings.dependencyWatchdog.endpoint.enabled is deprecated and will be removed in a future version of Gardener. Use .spec.settings.dependencyWatchdog.weeder.enabled instead.
It can be enabled/disabled via the .spec.settings.dependencyWatchdog.endpoint.enabled field.
It defaults to true.
Prober
The probe controller scales down the kube-controller-manager of shoot clusters in case their respective kube-apiserver is not reachable via its external ingress.
This is in order to avoid melt-down situations, since the kube-controller-manager uses in-cluster communication when talking to the kube-apiserver, i.e., it wouldn’t be affected if the external access to the kube-apiserver is interrupted for whatever reason.
The kubelets on the shoot worker nodes, however, would indeed be affected since they typically run in different networks and use the external ingress when talking to the kube-apiserver.
Hence, without scaling down kube-controller-manager, the nodes might be marked as NotReady and eventually replaced (since the kubelets cannot report their status anymore).
To prevent such unnecessary turbulence, kube-controller-manager is being scaled down until the external ingress becomes available again. In addition, as a precautionary measure, machine-controller-manager is also scaled down, along with cluster-autoscaler which depends on machine-controller-manager.
⚠️ .spec.settings.dependencyWatchdog.probe.enabled is deprecated and will be removed in a future version of Gardener. Use .spec.settings.dependencyWatchdog.prober.enabled instead.
It can be enabled/disabled via the .spec.settings.dependencyWatchdog.probe.enabled field.
It defaults to true.
Reserve Excess Capacity
If the excess capacity reservation is enabled, then the gardenlet will deploy a special Deployment into the garden namespace of the seed cluster.
This Deployment’s pod template has only one container, the pause container, which simply runs in an infinite loop.
The priority of the deployment is very low, so any other pod will preempt these pause pods.
This is especially useful if new shoot control planes are created in the seed.
In case the seed cluster runs at its capacity, then there is no waiting time required during the scale-up.
Instead, the low-priority pause pods will be preempted and allow newly created shoot control plane pods to be scheduled fast.
In the meantime, the cluster-autoscaler will trigger the scale-up because the preempted pause pods want to run again.
However, this delay doesn’t affect the important shoot control plane pods, which will improve the user experience.
Use .spec.settings.excessCapacityReservation.configs to create excess capacity reservation deployments which allow to specify custom values for resources, nodeSelector and tolerations. Each config creates a deployment with a minimum number of 2 replicas and a maximum equal to the number of zones configured for this seed.
It defaults to a config reserving 2 CPUs and 6Gi of memory for each pod with no nodeSelector and no tolerations.
Excess capacity reservation is enabled when .spec.settings.excessCapacityReservation.enabled is true or not specified while configs are present. It can be disabled by setting the field to false.
Scheduling
By default, the Gardener Scheduler will consider all seed clusters when a new shoot cluster shall be created.
However, administrators/operators might want to exclude some of them from being considered by the scheduler.
Therefore, seed clusters can be marked as “invisible”.
In this case, the scheduler simply ignores them as if they wouldn’t exist.
Shoots can still use the invisible seed but only by explicitly specifying the name in their .spec.seedName field.
Seed clusters can be marked visible/invisible via the .spec.settings.scheduling.visible field.
It defaults to true.
ℹ️ In previous Gardener versions (< 1.5) these settings were controlled via taint keys (seed.gardener.cloud/{disable-capacity-reservation,invisible}).
The taint keys are no longer supported and removed in version 1.12.
The rationale behind it is the implementation of tolerations similar to Kubernetes tolerations.
More information about it can be found in #2193.
Load Balancer Services
Gardener creates certain Kubernetes Service objects of type LoadBalancer in the seed cluster.
Most prominently, they are used for exposing the shoot control planes, namely the kube-apiserver of the shoot clusters.
In most cases, the cloud-controller-manager (responsible for managing these load balancers on the respective underlying infrastructure) supports certain customization and settings via annotations.
This document provides a good overview and many examples.
By setting the .spec.settings.loadBalancerServices.annotations field the Gardener administrator can specify a list of annotations, which will be injected into the Services of type LoadBalancer.
External Traffic Policy
Setting the external traffic policy to Local can be beneficial as it
preserves the source IP address of client requests. In addition to that, it removes one hop in the data path and hence reduces request latency. On some cloud infrastructures, it can furthermore be
used in conjunction with Service annotations as described above to prevent cross-zonal traffic from the load balancer to the backend pod.
The default external traffic policy is Cluster, meaning that all traffic from the load balancer will be sent to any cluster node, which then itself will redirect the traffic to the actual receiving pod.
This approach adds a node to the data path, may cross the zone boundaries twice, and replaces the source IP with one of the cluster nodes.
Using external traffic policy Local drops the additional node, i.e., only cluster nodes with corresponding backend pods will be in the list of backends of the load balancer. However, this has multiple implications.
The health check port in this scenario is exposed by kube-proxy , i.e., if kube-proxy is not working on a node a corresponding pod on the node will not receive traffic from
the load balancer as the load balancer will see a failing health check. (This is quite different from ordinary service routing where kube-proxy is only responsible for setup, but does not need to
run for its operation.) Furthermore, load balancing may become imbalanced if multiple pods run on the same node because load balancers will split the load equally among the nodes and not among the pods. This is mitigated by corresponding node anti affinities.
Operators need to take these implications into account when considering switching external traffic policy to Local.
Proxy Protocol
Traditionally, the client IP address can be used for security filtering measures, e.g. IP allow listing. However, for this to have any usefulness, the client IP address needs to be correctly transferred to the filtering entity.
Load balancers can either act transparently and simply pass the client IP on, or they terminate one connection and forward data on a new connection. The latter (intransparant) approach requires a separate way to propagate the client IP address. Common approaches are an HTTP header for TLS terminating load balancers or (HA) proxy protocol.
For level 3 load balancers, (HA) proxy protocol is the default way to preserve client IP addresses. As it prepends a small proxy protocol header before the actual workload data, the receiving server needs to be aware of it and handle it properly. This means that activating proxy protocol needs to happen on both load balancer and receiving server at/around the same time, as otherwise the receiving server will incorrectly interpret data as workload/proxy protocol header.
For disruption-free migration to proxy protocol, set .spec.settings.loadBalancerServices.proxyProtocol.allow to true. The migration path should be to enable the option and shortly thereafter also enable proxy protocol on the load balancer with infrastructure-specific means, e.g. a corresponding load balancer annotation.
When switching back from use of proxy protocol to no use of it, use the inverse order, i.e. disable proxy protocol first on the load balancer before disabling .spec.settings.loadBalancerServices.proxyProtocol.allow.
Zone-Specific Settings
In case a seed cluster is configured to use multiple zones via .spec.provider.zones, it may be necessary to configure the load balancers in individual zones in different way, e.g., by utilizing
different annotations. One reason may be to reduce cross-zonal traffic and have zone-specific load balancers in place. Zone-specific load balancers may then be bound to zone-specific subnets or
availability zones in the cloud infrastructure.
Gardener heavily relies on the Kubernetes vertical-pod-autoscaler component.
By default, the seed controller deploys the VPA components into the garden namespace of the respective seed clusters.
In case you want to manage the VPA deployment on your own or have a custom one, then you might want to disable the automatic deployment of Gardener.
Otherwise, you might end up with two VPAs, which will cause erratic behaviour.
By setting the .spec.settings.verticalPodAutoscaler.enabled=false, you can disable the automatic deployment.
⚠️ In any case, there must be a VPA available for your seed cluster. Using a seed without VPA is not supported.
VPA Pitfall: Excessive Resource Requests Making Pod Unschedulable
VPA is unaware of node capacity, and can increase the resource requests of a pod beyond the capacity of any single node.
Such pod is likely to become permanently unschedulable. That problem can be partly mitigated by using the
VerticalPodAutoscaler.Spec.ResourcePolicy.ContainerPolicies[].MaxAllowed field to constrain pod resource requests to
the level of nodes’ allocatable resources. The downside is that a pod constrained in such fashion would be using more
resources than it has requested, and can starve for resources and/or negatively impact neighbour pods with which it is
sharing a node.
As an alternative, in scenarios where MaxAllowed is not set, it is important to maintain a worker pool which can
accommodate the highest level of resources that VPA would actually request for the pods it controls.
Finally, the optimal strategy typically is to both ensure large enough worker pools, and, as an insurance,
use MaxAllowed aligned with the allocatable resources of the largest worker.
How to best write tests that are correct, stable, fast and maintainable
How to debug tests that are not working as expected
The document is aimed towards developers that want to contribute code and need to write tests, as well as maintainers and reviewers that review test code.
It serves as a common guide that we commit to follow in our project to ensure consistency in our tests, good coverage for high confidence, and good maintainability.
The guidelines are not meant to be absolute rules.
Always apply common sense and adapt the guideline if it doesn’t make much sense for some cases.
If in doubt, don’t hesitate to ask questions during a PR review (as an author, but also as a reviewer).
Add new learnings as soon as we make them!
Generally speaking, tests are a strict requirement for contributing new code.
If you touch code that is currently untested, you need to add tests for the new cases that you introduce as a minimum.
Ideally though, you would add the missing test cases for the current code as well (boy scout rule – “always leave the campground cleaner than you found it”).
Writing Tests (Relevant for All Kinds)
We follow BDD (behavior-driven development) testing principles and use Ginkgo, along with Gomega.
Make sure to check out their extensive guides for more information and how to best leverage all of their features
Use By to structure test cases with multiple steps, so that steps are easy to follow in the logs: example test
Call defer GinkgoRecover() if making assertions in goroutines: doc, example test
Use DeferCleanup instead of cleaning up manually (or use custom coding from the test framework): example test, example test
DeferCleanup makes sure to run the cleanup code in the right point in time, e.g., a DeferCleanup added in BeforeEach is executed with AfterEach.
Test results should point to locations that cause the failures, so that the CI output isn’t too difficult to debug/fix.
Consider using ExpectWithOffset if the test uses assertions made in a helper function, among other assertions defined directly in the test (e.g. expectSomethingWasCreated): example test
Make sure to add additional descriptions to Gomega matchers if necessary (e.g. in a loop): example test
Introduce helper functions for assertions to make test more readable where applicable: example test
Make sure that your test is actually asserting the right thing and it doesn’t pass if the exact bug is introduced that you want to prevent.
Use specific error matchers instead of asserting any error has happened, make sure that the corresponding branch in the code is tested, e.g., prefer
Expect(err).To(MatchError("foo"))
over
Expect(err).To(HaveOccurred())
If you’re unsure about your test’s behavior, attaching the debugger can sometimes be helpful to make sure your test is correct.
About overwriting global variables:
This is a common pattern (or hack?) in go for faking calls to external functions.
However, this can lead to races, when the global variable is used from a goroutine (e.g., the function is called).
Alternatively, set fields on structs (passed via parameter or set directly): this is not racy, as struct values are typically (and should be) only used for a single test case.
An alternative to dealing with function variables and fields:
Add an interface which your code depends on
Write a fake and a real implementation (similar to clock.Clock.Sleep)
The real implementation calls the actual function (clock.RealClock.Sleep calls time.Sleep)
The fake implementation does whatever you want it to do for your test (clock.FakeClock.Sleep waits until the test code advanced the time)
Use constants in test code with care.
Typically, you should not use constants from the same package as the tested code, instead use literals.
If the constant value is changed, tests using the constant will still pass, although the “specification” is not fulfilled anymore.
There are cases where it’s fine to use constants, but keep this caveat in mind when doing so.
Creating sample data for tests can be a high effort.
If valuable, add a package for generating common sample data, e.g. Shoot/Cluster objects.
Make use of the testdata directory for storing arbitrary sample data needed by tests (helm charts, YAML manifests, etc.), example PR
The go tool will ignore a directory named “testdata”, making it available to hold ancillary data needed by the tests.
Unit Tests
Running Unit Tests
Run all unit tests:
make test
Run all unit tests with test coverage:
make test-cov
open test.coverage.html
make test-cov-clean
Run unit tests of specific packages:
# run with same settings like in CI (race detector, timeout, ...)./hack/test.sh ./pkg/resourcemanager/controller/... ./pkg/utils/secrets/...
# freestylego test ./pkg/resourcemanager/controller/... ./pkg/utils/secrets/...
ginkgo run ./pkg/resourcemanager/controller/... ./pkg/utils/secrets/...
Debugging Unit Tests
Use ginkgo to focus on (a set of) test specs via code or via CLI flags.
Remember to unfocus specs before contributing code, otherwise your PR tests will fail.
$ ginkgo run --focus "should delete the unused resources" ./pkg/resourcemanager/controller/garbagecollector
...
Will run 1 of 3 specs
SS•
Ran 1 of 3 Specs in 0.003 seconds
SUCCESS! -- 1 Passed | 0 Failed | 0 Pending | 2 Skipped
PASS
Use ginkgo to run tests until they fail:
$ ginkgo run --until-it-fails ./pkg/resourcemanager/controller/garbagecollector
...
Ran 3 of 3 Specs in 0.004 seconds
SUCCESS! -- 3 Passed | 0 Failed | 0 Pending | 0 Skipped
PASS
All tests passed...
Will keep running them until they fail.
This was attempt #58No, seriously... you can probably stop now.
Use the stress tool for deflaking tests that fail sporadically in CI, e.g., due resource contention (CPU throttling):
# get the stress toolgo install golang.org/x/tools/cmd/stress@latest
# build a test binaryginkgo build ./pkg/resourcemanager/controller/garbagecollector
# alternativelygo test -c ./pkg/resourcemanager/controller/garbagecollector
# run the test in parallel and report any failuresstress -p 16 ./pkg/resourcemanager/controller/garbagecollector/garbagecollector.test -ginkgo.focus "should delete the unused resources"5s: 1077 runs so far, 0 failures
10s: 2160 runs so far, 0 failures
stress will output a path to a file containing the full failure message when a test run fails.
Purpose of Unit Tests
Unit tests prove the correctness of a single unit according to the specification of its interface.
Think: Is the unit that I introduced doing what it is supposed to do for all cases?
Unit tests protect against regressions caused by adding new functionality to or refactoring of a single unit.
Think: Is the unit that was introduced earlier (by someone else) and that I changed still doing what it was supposed to do for all cases?
Example units: functions (conversion, defaulting, validation, helpers), structs (helpers, basic building blocks like the Secrets Manager), predicates, event handlers.
For these purposes, unit tests need to cover all important cases of input for a single unit and cover edge cases / negative paths as well (e.g., errors).
Because of the possible high dimensionality of test input, unit tests need to be fast to execute: individual test cases should not take more than a few seconds, test suites not more than 2 minutes.
Fuzzing can be used as a technique in addition to usual test cases for covering edge cases.
Test coverage can be used as a tool during test development for covering all cases of a unit.
However, test coverage data can be a false safety net.
Full line coverage doesn’t mean you have covered all cases of valid input.
We don’t have strict requirements for test coverage, as it doesn’t necessarily yield the desired outcome.
Unit tests should not test too large components, e.g. entire controller Reconcile functions.
If a function/component does many steps, it’s probably better to split it up into multiple functions/components that can be unit tested individually
There might be special cases for very small Reconcile functions.
If there are a lot of edge cases, extract dedicated functions that cover them and use unit tests to test them.
Usual-sized controllers should rather be tested in integration tests.
Individual parts (e.g. helper functions) should still be tested in unit test for covering all cases, though.
Unit tests are especially easy to run with a debugger and can help in understanding concrete behavior of components.
Writing Unit Tests
For the sake of execution speed, fake expensive calls/operations, e.g. secret generation: example test
Generally, prefer fakes over mocks, e.g., use controller-runtime fake client over mock clients.
Mocks decrease maintainability because they expect the tested component to follow a certain way to reach the desired goal (e.g., call specific functions with particular arguments), example consequence
Generally, fakes should be used in “result-oriented” test code (e.g., that a certain object was labelled, but the test doesn’t care if it was via patch or update as both a valid ways to reach the desired goal).
Although rare, there are valid use cases for mocks, e.g. if the following aspects are important for correctness:
Asserting that an exact function is called
Asserting that functions are called in a specific order
Asserting that exact parameters/values/… are passed
Asserting that a certain function was not called
Many of these can also be verified with fakes, although mocks might be simpler
Only use mocks if the tested code directly calls the mock; never if the tested code only calls the mock indirectly (e.g., through a helper package/function).
Keep in mind the maintenance implications of using mocks:
Can you make a valid non-behavioral change in the code without breaking the test or dependent tests?
It’s valid to mix fakes and mocks in the same test or between test cases.
When using mocks, prefer Return over DoAndReturn whenever possible, e.g., prefer:
Helpers can also be exported if no one is supposed to import the containing package (e.g. controller package).
Integration Tests (envtests)
Integration tests in Gardener use the sigs.k8s.io/controller-runtime/pkg/envtest package.
It sets up a temporary control plane (etcd + kube-apiserver) and runs the test against it.
The test suites start their individual envtest environment before running the tested controller/webhook and executing test cases.
Before exiting, the test suites tear down the temporary test environment.
Package github.com/gardener/gardener/test/envtest augments the controller-runtime’s envtest package by starting and registering gardener-apiserver.
This is used to test controllers that act on resources in the Gardener APIs (aggregated APIs).
Historically, test machinery tests have also been called “integration tests”.
However, test machinery does not perform integration testing but rather executes a form of end-to-end tests against a real landscape.
Hence, we tried to sharpen the terminology that we use to distinguish between “real” integration tests and test machinery tests but you might still find “integration tests” referring to test machinery tests in old issues or outdated documents.
Running Integration Tests
The test-integration make rule prepares the environment automatically by downloading the respective binaries (if not yet present) and setting the necessary environment variables.
make test-integration
If you want to run a specific set of integration tests, you can also execute them using ./hack/test-integration.sh directly instead of using the test-integration rule. Prior to execution, the PATH environment variable needs to be set to also included the tools binary directory. For example:
The script takes care of preparing the environment for you.
If you want to execute the test suites directly via go test or ginkgo, you have to point the KUBEBUILDER_ASSETS environment variable to the path that contains the etcd and kube-apiserver binaries. Alternatively, you can install the binaries to /usr/local/kubebuilder/bin. Additionally, the environment variables from hack/test-integration.env should be sourced.
Debugging Integration Tests
You can configure envtest to use an existing cluster or control plane instead of starting a temporary control plane that is torn down immediately after executing the test.
This can be helpful for debugging integration tests because you can easily inspect what is going on in your test environment with kubectl.
While you can use an existing cluster (e.g., kind), some test suites expect that no controllers and no nodes are running in the test environment (as it is the case in envtest test environments).
Hence, using a full-blown cluster with controllers and nodes might sometimes be impractical, as you would need to stop cluster components for the tests to work.
You can use make start-envtest to start an envtest test environment that is managed separately from individual test suites.
This allows you to keep the test environment running for as long as you want, and to debug integration tests by executing multiple test runs in parallel or inspecting test runs using kubectl.
When you are finished, just hit CTRL-C for tearing down the test environment.
The kubeconfig for the test environment is placed in dev/envtest-kubeconfig.yaml.
make start-envtest brings up an envtest environment using the default configuration.
If your test suite requires a different control plane configuration (e.g., disabled admission plugins or enabled feature gates), feel free to locally modify the configuration in test/start-envtest while debugging.
Run an envtest suite (not using gardener-apiserver) against an existing test environment:
make start-envtest
# in another terminal session:export KUBECONFIG=$PWD/dev/envtest-kubeconfig.yaml
export USE_EXISTING_CLUSTER=true
# run test with verbose output./hack/test-integration.sh -v ./test/integration/resourcemanager/health -ginkgo.v
# in another terminal session:export KUBECONFIG=$PWD/dev/envtest-kubeconfig.yaml
# watch test objectsk get managedresource -A -w
Run a gardenerenvtest suite (using gardener-apiserver) against an existing test environment:
# modify GardenerTestEnvironment{} in test/start-envtest to disable admission plugins and enable feature gates like in test suite...make start-envtest ENVTEST_TYPE=gardener
# in another terminal session:export KUBECONFIG=$PWD/dev/envtest-kubeconfig.yaml
export USE_EXISTING_GARDENER=true
# run test with verbose output./hack/test-integration.sh -v ./test/integration/controllermanager/bastion -ginkgo.v
# in another terminal session:export KUBECONFIG=$PWD/dev/envtest-kubeconfig.yaml
# watch test objectsk get bastion -A -w
Similar to debugging unit tests, the stress tool can help hunting flakes in integration tests.
Though, you might need to run less tests in parallel though (specified via -p) and have a bit more patience.
Generally, reproducing flakes in integration tests is easier when stress-testing against an existing test environment instead of starting temporary individual control planes per test run.
Stress-test an envtest suite (not using gardener-apiserver):
# build a test binaryginkgo build ./test/integration/resourcemanager/health
# prepare a test environment to run the test againstmake start-envtest
# in another terminal session:export KUBECONFIG=$PWD/dev/envtest-kubeconfig.yaml
export USE_EXISTING_CLUSTER=true
# use same timeout settings like in CIsource ./hack/test-integration.env
# switch to test package directory like `go test`cd ./test/integration/resourcemanager/health
# run the test in parallel and report any failuresstress -ignore "unable to grab random port" -p 16 ./health.test
...
Stress-test a gardenerenvtest suite (using gardener-apiserver):
# modify test/start-envtest to disable admission plugins and enable feature gates like in test suite...# build a test binaryginkgo build ./test/integration/controllermanager/bastion
# prepare a test environment including gardener-apiserver to run the test againstmake start-envtest ENVTEST_TYPE=gardener
# in another terminal session:export KUBECONFIG=$PWD/dev/envtest-kubeconfig.yaml
export USE_EXISTING_GARDENER=true
# use same timeout settings like in CIsource ./hack/test-integration.env
# switch to test package directory like `go test`cd ./test/integration/controllermanager/bastion
# run the test in parallel and report any failuresstress -ignore "unable to grab random port" -p 16 ./bastion.test
...
Purpose of Integration Tests
Integration tests prove that multiple units are correctly integrated into a fully-functional component of the system.
Example components with multiple units:
A controller with its reconciler, watches, predicates, event handlers, queues, etc.
A webhook with its server, handler, decoder, and webhook configuration.
Integration tests set up a full component (including used libraries) and run it against a test environment close to the actual setup.
e.g., start controllers against a real Kubernetes control plane to catch bugs that can only happen when talking to a real API server.
Integration tests are generally more expensive to run (e.g., in terms of execution time).
Integration tests should not cover each and every detailed case.
Rather than that, cover a good portion of the “usual” cases that components will face during normal operation (positive and negative test cases).
Also, there is no need to cover all failure cases or all cases of predicates -> they should be covered in unit tests already.
Generally, not supposed to “generate test coverage” but to provide confidence that components work well.
As integration tests typically test only one component (or a cohesive set of components) isolated from others, they cannot catch bugs that occur when multiple controllers interact (could be discovered by e2e tests, though).
Rule of thumb: a new integration tests should be added for each new controller (an integration test doesn’t replace unit tests though).
Writing Integration Tests
Make sure to have a clean test environment on both test suite and test case level:
Set up dedicated test environments (envtest instances) per test suite.
Use dedicated namespaces per test suite:
Use GenerateName with a test-specific prefix: example test
Restrict the controller-runtime manager to the test namespace by setting manager.Options.Namespace: example test
Alternatively, use a test-specific prefix with a random suffix determined upfront: example test
This can be used to restrict webhooks to a dedicated test namespace: example test
This allows running a test in parallel against the same existing cluster for deflaking and stress testing: example PR
If the controller works on cluster-scoped resources:
Label the resources with a label specific to the test run, e.g. the test namespace’s name: example test
Restrict the manager’s cache for these objects with a corresponding label selector: example test
Alternatively, use a checksum of a random UUID using uuid.NewUUID() function: example test
This allows running a test in parallel against the same existing cluster for deflaking and stress testing, even if it works with cluster-scoped resources that are visible to all parallel test runs: example PR
Don’t use a cached client in test code (e.g., the one from a controller-runtime manager), always construct a dedicated test client (uncached): example test
When creating/updating an object with runtime.RawExtension field against a real cluster (not fake or mocked client), pass the field definition in the Raw field of the runtime.RawExtension. The Object field of runtime.RawExtension doesn’t have a protobuf tag, and the Raw field does, which allows it to be serialized.
Don’t forget to call {Eventually,Consistently}.Should(), otherwise the assertions always silently succeeds without errors: onsi/gomega#561
When using Gardener’s envtest (envtest.GardenerTestEnvironment):
Disable gardener-apiserver’s admission plugins that are not relevant to the integration test itself by passing --disable-admission-plugins: example test
This makes setup / teardown code simpler and ensures to only test code relevant to the tested component itself (but not the entire set of admission plugins)
e.g., you can disable the ShootValidator plugin to create Shoots that reference non-existing SecretBindings or disable the DeletionConfirmation plugin to delete Gardener resources without adding a deletion confirmation first.
Use a custom rate limiter for controllers in integration tests: example test
This can be used for limiting exponential backoff to shorten wait times.
Otherwise, if using the default rate limiter, exponential backoff might exceed the timeout of Eventually calls and cause flakes.
End-to-End (e2e) Tests (Using provider-local)
We run a suite of e2e tests on every pull request and periodically on the master branch.
It uses a KinD cluster and skaffold to bootstrap a full installation of Gardener based on the current revision, including provider-local.
This allows us to run e2e tests in an isolated test environment and fully locally without any infrastructure interaction.
The tests perform a set of operations on Shoot clusters, e.g. creating, deleting, hibernating and waking up.
You can also run these tests on your development machine, using the following commands:
make kind-up
export KUBECONFIG=$PWD/example/gardener-local/kind/local/kubeconfig
make gardener-up
make test-e2e-local # alternatively: make test-e2e-local-simple
If you want to run a specific set of e2e test cases, you can also execute them using ./hack/test-e2e-local.sh directly in combination with ginkgo label filters. For example:
If you want to use an existing shoot instead of creating a new one for the test case and deleting it afterwards, you can specify the existing shoot via the following flags.
This can be useful to speed up the development of e2e tests.
When debugging e2e test failures in CI, logs of the cluster components can be very helpful.
Our e2e test jobs export logs of all containers running in the kind cluster to prow’s artifacts storage.
You can find them by clicking the Artifacts link in the top bar in prow’s job view and navigating to artifacts.
This directory will contain all cluster component logs grouped by node.
Pull all artifacts using gsutil for searching and filtering the logs locally (use the path displayed in the artifacts view):
e2e tests provide a high level of confidence that our code runs as expected by users when deployed to production.
They are supposed to catch bugs resulting from interaction between multiple components.
Test cases should be as close as possible to real usage by end users:
You should test “from the perspective of the user” (or operator).
Example: I create a Shoot and expect to be able to connect to it via the provided kubeconfig.
Accordingly, don’t assert details of the system.
e.g., the user also wouldn’t expect that there is a kube-apiserver deployment in the seed, they rather expect that they can talk to it no matter how it is deployed
Only assert details of the system if the tested feature is not fully visible to the end-user and there is no other way of ensuring that the feature works reliably
e.g., the Shoot CA rotation is not fully visible to the user but is assertable by looking at the secrets in the Seed.
Pro: can be executed by developers and users without any real infrastructure (provider-local).
Con: they currently cannot be executed with real infrastructure (e.g., provider-aws), we will work on this as part of #6016.
Keep in mind that the tested scenario is still artificial in a sense of using default configuration, only a few objects, only a few config/settings combinations are covered.
We will never be able to cover the full “test matrix” and this should not be our goal.
Bugs will still be released and will still happen in production; we can’t avoid it.
Instead, we should add test cases for preventing bugs in features or settings that were frequently regressed: example PR
Usually e2e tests cover the “straight-forward cases”.
However, negative test cases can also be included, especially if they are important from the user’s perspective.
Writing e2e Tests
Tests must always use the Ordered decorator
Separate individual steps from each other with It statements
This makes debugging of the test and flake detection much easier
Make sure to always utilize the SpecContext when dealing with contexts inside of It statements, like here
Use the TestContext to store the current state of the test (Reference)
Do not share test contexts between test cases
Whenever possible, use the type-specific test contexts like: ShootContext, SeedContext
Always wrap API calls and similar things in Eventually blocks: example test
At this point, we are pretty much working with a distributed system and failures can happen anytime.
Wrapping calls in Eventually makes tests more stable and more realistic (usually, you wouldn’t call the system broken if a single API call fails because of a short connectivity issue).
Most of the points from writing integration tests are relevant for e2e tests as well (especially the points about asynchronous assertions).
In contrast to integration tests, in e2e tests, it might make sense to specify higher timeouts for Eventually calls, e.g., when waiting for a Shoot to be reconciled.
Generally, try to use the default settings for Eventually specified via the environment variables.
Only set higher timeouts if waiting for long-running reconciliations to be finished.
Gardener Upgrade Tests (Using provider-local)
Gardener upgrade tests setup a kind cluster and deploy Gardener version vX.X.X before upgrading it to a given version vY.Y.Y.
This allows verifying whether the current (unreleased) revision/branch (or a specific release) is compatible with the latest (or a specific other) release. The GARDENER_PREVIOUS_RELEASE and GARDENER_NEXT_RELEASE environment variables are used to specify the respective versions.
This helps understanding what happens or how the system reacts when Gardener upgrades from versions vX.X.X to vY.Y.Y for existing shoots in different states (creation/hibernation/wakeup/deletion). Gardener upgrade tests also help qualifying releases for all flavors (non-HA or HA with failure tolerance node/zone).
Just like E2E tests, upgrade tests also use a KinD cluster and skaffold for bootstrapping a full Gardener installation based on the current revision/branch, including provider-local.
This allows running e2e tests in an isolated test environment, fully locally without any infrastructure interaction.
The tests perform a set of operations on Shoot clusters, e.g. create, delete, hibernate and wake up.
Below is a sequence describing how the tests are performed.
Create a kind cluster.
Install Gardener version vX.X.X.
Run gardener pre-upgrade tests which are labeled with pre-upgrade.
Upgrade Gardener version from vX.X.X to vY.Y.Y.
Run gardener post-upgrade tests which are labeled with post-upgrade
Tear down seed and kind cluster.
How to Run Upgrade Tests Between Two Gardener Releases
Sometimes, we need to verify/qualify two Gardener releases when we upgrade from one version to another.
This can performed by fetching the two Gardener versions from the GitHub Gardener release page and setting appropriate env variables GARDENER_PREVIOUS_RELEASE, GARDENER_NEXT_RELEASE.
GARDENER_PREVIOUS_RELEASE – This env variable refers to a source revision/branch (or a specific release) which has to be installed first and then upgraded to version GARDENER_NEXT_RELEASE. By default, it fetches the latest release version from GitHub Gardener release page.
GARDENER_NEXT_RELEASE – This env variable refers to the target revision/branch (or a specific release) to be upgraded to after successful installation of GARDENER_PREVIOUS_RELEASE. By default, it considers the local HEAD revision, builds code, and installs Gardener from the current revision where the Gardener upgrade tests triggered.
make ci-e2e-kind-upgrade GARDENER_PREVIOUS_RELEASE=v1.60.0 GARDENER_NEXT_RELEASE=v1.61.0
make ci-e2e-kind-ha-multi-node-upgrade GARDENER_PREVIOUS_RELEASE=v1.60.0 GARDENER_NEXT_RELEASE=v1.61.0
make ci-e2e-kind-ha-multi-zone-upgrade GARDENER_PREVIOUS_RELEASE=v1.60.0 GARDENER_NEXT_RELEASE=v1.61.0
Purpose of Upgrade Tests
Tests will ensure that shoot clusters reconciled with the previous version of Gardener work as expected even with the next Gardener version.
This will reproduce or catch actual issues faced by end users.
One of the test cases ensures no downtime is faced by the end-users for shoots while upgrading Gardener if the shoot’s control-plane is configured as HA.
Writing Upgrade Tests
Tests are divided into two parts and labeled with pre-upgrade and post-upgrade labels.
An example test case which ensures a shoot which was hibernated in a previous Gardener release should wakeup as expected in next release:
Creating a shoot and hibernating a shoot is pre-upgrade test case which should be labeled pre-upgrade label.
Then wakeup a shoot and delete a shoot is post-upgrade test case which should be labeled post-upgrade label.
Test machinery tests have to be executed against full-blown Gardener installations.
They can provide a very high level of confidence that an installation is functional in its current state, this includes: all Gardener components, Extensions, the used Cloud Infrastructure, all relevant settings/configuration.
This brings the following benefits:
They test more realistic scenarios than e2e tests (real configuration, real infrastructure, etc.).
Tests run “where the users are”.
However, this also brings significant drawbacks:
Tests are difficult to develop and maintain.
Tests require a full Gardener installation and cannot be executed in CI (on PR-level or against master).
Tests require real infrastructure (think cloud provider credentials, cost).
Using TestDefinitions under .test-defs requires a full test machinery installation.
Accordingly, tests are heavyweight and expensive to run.
Testing against real infrastructure can cause flakes sometimes (e.g., in outage situations).
Failures are hard to debug, because clusters are deleted after the test (for obvious cost reasons).
Bugs can only be caught, once it’s “too late”, i.e., when code is merged and deployed.
Today, test machinery tests cover a bigger “test matrix” (e.g., Shoot creation across infrastructures, kubernetes versions, machine image versions).
Test machinery also runs Kubernetes conformance tests.
However, because of the listed drawbacks, we should rather focus on augmenting our e2e tests, as we can run them locally and in CI in order to catch bugs before they get merged.
It’s still a good idea to add test machinery tests if a feature that is depending on some installation-specific configuration needs to be tested.
However, test machinery tests contain a lot of technical debt and existing code doesn’t follow these best practices.
As test machinery tests are out of our general focus, we don’t intend on reworking the tests soon or providing more guidance on how to write new ones.
Manual Tests
Manual tests can be useful when the cost of trying to automatically test certain functionality are too high.
Useful for PR verification, if a reviewer wants to verify that all cases are properly tested by automated tests.
Currently, it’s the simplest option for testing upgrade scenarios.
e.g. migration coding is probably best tested manually, as it’s a high effort to write an automated test for little benefit
Obviously, the need for manual tests should be kept at a bare minimum.
Instead, we should add e2e tests wherever sensible/valuable.
We want to implement some form of general upgrade tests as part of #6016.
45 - Testmachinery Tests
Test Machinery Tests
In order to automatically qualify Gardener releases, we execute a set of end-to-end tests using Test Machinery.
This requires a full Gardener installation including infrastructure extensions, as well as a setup of Test Machinery itself.
These tests operate on Shoot clusters across different Cloud Providers, using different supported Kubernetes versions and various configuration options (huge test matrix).
This manual gives an overview about test machinery tests in Gardener.
Gardener test machinery tests are split into two test suites that can be found under test/testmachinery/suites:
The Gardener Test Suite contains all tests that only require a running gardener instance.
The Shoot Test Suite contains all tests that require a predefined running shoot cluster.
The corresponding tests of a test suite are defined in the import statement of the suite definition (see shoot/run_suite_test.go)
and their source code can be found under test/testmachinery.
The test directory is structured as follows:
test
├── e2e # end-to-end tests (using provider-local)
│ ├── gardener
│ │ ├── seed
│ │ ├── shoot
| | └── ...
| └──operator
├── framework # helper code shared across integration, e2e and testmachinery tests
├── integration # integration tests (envtests)
│ ├── controllermanager
│ ├── envtest
│ ├── resourcemanager
│ ├── scheduler
│ └── ...
└── testmachinery # test machinery tests
├── gardener # actual test cases imported by suites/gardener
│ └── security
├── shoots # actual test cases imported by suites/shoot
│ ├── applications
│ ├── care
│ ├── logging
│ ├── operatingsystem
│ ├── operations
│ └── vpntunnel
├── suites # suites that run against a running garden or shoot cluster
│ ├── gardener
│ └── shoot
└── system # suites that are used for building a full test flow
├── complete_reconcile
├── managed_seed_creation
├── managed_seed_deletion
├── shoot_cp_migration
├── shoot_creation
├── shoot_deletion
├── shoot_hibernation
├── shoot_hibernation_wakeup
└── shoot_update
A suite can be executed by running the suite definition with ginkgo’s focus and skip flags
to control the execution of specific labeled test. See the example below:
go test -timeout=0 ./test/testmachinery/suites/shoot \
--v -ginkgo.v -ginkgo.show-node-events -ginkgo.no-color \
--report-file=/tmp/report.json \ # write elasticsearch formatted output to a file
--disable-dump=false \ # disables dumping of the current state if a test fails
-kubecfg=/path/to/gardener/kubeconfig \
-shoot-name=<shoot-name> \ # Name of the shoot to test
-project-namespace=<gardener project namespace> \ # Name of the gardener project the test shoot resides
-ginkgo.focus="\[RELEASE\]" \ # Run all tests that are tagged as release
-ginkgo.skip="\[SERIAL\]|\[DISRUPTIVE\]" # Exclude all tests that are tagged SERIAL or DISRUPTIVE
Add a New Test
To add a new test the framework requires the following steps (step 1. and 2. can be skipped if the test is added to an existing package):
Create a new test file e.g. test/testmachinery/shoot/security/my-sec-test.go
Import the test into the appropriate test suite (gardener or shoot): import _ "github.com/gardener/gardener/test/testmachinery/shoot/security"
Define your test with the testframework. The framework will automatically add its initialization, cleanup and dump functions.
var _ = ginkgo.Describe("my suite", func(){
f := framework.NewShootFramework(nil)
f.Beta().CIt("my first test", func(ctx context.Context) {
f.ShootClient.Get(xx)
// testing ... })
})
The newly created test can be tested by focusing the test with the default ginkgo focus f.Beta().FCIt("my first test", func(ctx context.Context)
and running the shoot test suite with:
go test -timeout=0 ./test/testmachinery/suites/shoot \
--v -ginkgo.v -ginkgo.show-node-events -ginkgo.no-color \
--report-file=/tmp/report.json \ # write elasticsearch formatted output to a file
--disable-dump=false \ # disables dumping of the current state if a test fails
-kubecfg=/path/to/gardener/kubeconfig \
-shoot-name=<shoot-name> \ # Name of the shoot to test
-project-namespace=<gardener project namespace> \
-fenced=<true|false> # Tested shoot is running in a fenced environment and cannot be reached by gardener
or for the gardener suite with:
go test -timeout=0 ./test/testmachinery/suites/gardener \
--v -ginkgo.v -ginkgo.show-node-events -ginkgo.no-color \
--report-file=/tmp/report.json \ # write elasticsearch formatted output to a file
--disable-dump=false \ # disables dumping of the current state if a test fails
-kubecfg=/path/to/gardener/kubeconfig \
-project-namespace=<gardener project namespace>
⚠️ Make sure that you do not commit any focused specs as this feature is only intended for local development! Ginkgo will fail the test suite if there are any focused specs.
Alternatively, a test can be triggered by specifying a ginkgo focus regex with the name of the test e.g.
go test -timeout=0 ./test/testmachinery/suites/gardener \
--v -ginkgo.v -ginkgo.show-node-events -ginkgo.no-color \
--report-file=/tmp/report.json \ # write elasticsearch formatted output to a file
-kubecfg=/path/to/gardener/kubeconfig \
-project-namespace=<gardener project namespace> \
-ginkgo.focus="my first test" # regex to match test cases
Test Labels
Every test should be labeled by using the predefined labels available with every framework to have consistent labeling across
all test machinery tests.
The labels are applied to every new It()/CIt() definition by:
f := framework.NewCommonFramework()
f.Default().Serial().It("my test") => "[DEFAULT] [SERIAL] my test"f := framework.NewShootFramework()
f.Default().Serial().It("my test") => "[DEFAULT] [SERIAL] [SHOOT] my test"f := framework.NewGardenerFramework()
f.Default().Serial().It("my test") => "[DEFAULT] [GARDENER] [SERIAL] my test"
Labels:
Beta: Newly created tests with no experience on stableness should be first labeled as beta tests.
They should be watched (and probably improved) until stable enough to be promoted to Default.
Default: Tests that were Beta before and proved to be stable are promoted to Default eventually.
Default tests run more often, produce alerts and are considered during the release decision although they don’t necessarily block a release.
Release: Test are release relevant. A failing Release test blocks the release pipeline.
Therefore, these tests need to be stable. Only tests proven to be stable will eventually be promoted to Release.
Behavior Labels:
Serial: The test should always be executed in serial with no other tests running, as it may impact other tests.
Destructive: The test is destructive. Which means that is runs with no other tests and may break Gardener or the shoot.
Only create such tests if really necessary, as the execution will be expensive (neither Gardener nor the shoot can be reused in this case for other tests).
Framework
The framework directory contains all the necessary functions / utilities for running test machinery tests.
For example, there are methods for creation/deletion of shoots, waiting for shoot deletion/creation, downloading/installing/deploying helm charts, logging, etc.
The framework itself consists of 3 different frameworks that expect different prerequisites and offer context specific functionality.
CommonFramework: The common framework is the base framework that handles logging and setup of commonly needed resources like helm.
It also contains common functions for interacting with Kubernetes clusters like Waiting for resources to be ready or Exec into a running pod.
GardenerFramework contains all functions of the common framework and expects a running Gardener instance with the provided Gardener kubeconfig and a project namespace.
It also contains functions to interact with gardener like Waiting for a shoot to be reconciled or Patch a shoot or Get a seed.
ShootFramework: contains all functions of the common and the gardener framework.
It expects a running shoot cluster defined by the shoot’s name and namespace (project namespace).
This framework contains functions to directly interact with the specific shoot.
The whole framework also includes commonly used checks, ginkgo wrapper, etc., as well as commonly used tests.
Theses common application tests (like the guestbook test) can be used within multiple tests to have a default application (with ingress, deployment, stateful backend) to test external factors.
Config
Every framework commandline flag can also be defined by a configuration file (the value of the configuration file is only used if a flag is not specified by commandline).
The test suite searches for a configuration file (yaml is preferred) if the command line flag --config=/path/to/config/file is provided.
A framework can be defined in the configuration file by just using the flag name as root key e.g.
The framework automatically writes the ginkgo default report to stdout and a specifically structured elastichsearch bulk report file to a specified location.
The elastichsearch bulk report will write one json document per testcase and injects the metadata of the whole testsuite.
An example document for one test case would look like the following document:
This directory contains the system tests that have a special meaning for the testmachinery with their own Test Definition.
Currently, these system tests consist of:
Shoot creation
Shoot deletion
Shoot Kubernetes update
Gardener Full reconcile check
Shoot Creation Test
Create Shoot test is meant to test shoot creation.
Delete Shoot test is meant to test the deletion of a shoot.
Example Run
go test -timeout=0 -ginkgo.v -ginkgo.show-node-events \
./test/testmachinery/system/shoot_deletion \
-kubecfg=$HOME/.kube/config \
-shoot-name=$SHOOT_NAME \
-project-namespace=$PROJECT_NAMESPACE
Shoot Update Test
The Update Shoot test is meant to test the Kubernetes version update of a existing shoot.
If no specific version is provided, the next patch version is automatically selected.
If there is no available newer version, this test is a noop.
Example Run
go test -timeout=0 ./test/testmachinery/system/shoot_update \
--v -ginkgo.v -ginkgo.show-node-events \
-kubecfg=$HOME/.kube/config \
-shoot-name=$SHOOT_NAME \
-project-namespace=$PROJECT_NAMESPACE \
-version=$K8S_VERSION
Gardener Full Reconcile Test
The Gardener Full Reconcile test is meant to test if all shoots of a Gardener instance are successfully reconciled.
Example Run
go test -timeout=0 ./test/testmachinery/system/complete_reconcile \
--v -ginkgo.v -ginkgo.show-node-events \
-kubecfg=$HOME/.kube/config \
-project-namespace=$PROJECT_NAMESPACE \
-gardenerVersion=$GARDENER_VERSION # needed to validate the last acted gardener version of a shoot
Container Images
Test machinery tests usually deploy a workload to the Shoot cluster as part of the test execution. When introducing a new container image, consider the following:
Make sure the container image is multi-arch.
Tests are executed against amd64 and arm64 based worker Nodes.
Do not use container images from Docker Hub.
Docker Hub has rate limiting (see Download rate limit). For anonymous users, the rate limit is set to 100 pulls per 6 hours per IP address. In some fenced environments the network setup can be such that all egress connections are issued from single IP (or set of IPs). In such scenarios the allowed rate limit can be exhausted too fast. See https://github.com/gardener/gardener/issues/4160.
Avoid manually copying Docker Hub images to Gardener GCR (europe-docker.pkg.dev/gardener-project/releases/3rd/). Use the existing prow job for this (see Copy Images).
If possible, use a Kubernetes e2e image (registry.k8s.io/e2e-test-images/<image-name>).
In some cases, there is already a Kubernetes e2e image alternative of the Docker Hub image.
For example, use registry.k8s.io/e2e-test-images/busybox instead of europe-docker.pkg.dev/gardener-project/releases/3rd/busybox or docker.io/busybox.
The list of available Kubernetes e2e images and tags can be checked in this page.
46 - Topology Aware Routing
Topology-Aware Traffic Routing
Motivation
The enablement of highly available shoot control-planes requires multi-zone seed clusters. A garden runtime cluster can also be a multi-zone cluster. The topology-aware routing is introduced to reduce costs and to improve network performance by avoiding the cross availability zone traffic, if possible. The cross availability zone traffic is charged by the cloud providers and it comes with higher latency compared to the traffic within the same zone. The topology-aware routing feature enables topology-aware routing for Services deployed in a seed or garden runtime cluster. For the clients consuming these topology-aware services, kube-proxy favors the endpoints which are located in the same zone where the traffic originated from. In this way, the cross availability zone traffic is avoided.
For Kubernetes versions >= 1.31, the ServiceTrafficDistribution feature is being used on. The EndpointSlice hints mutating webhook is enabled for Kubernetes 1.31 to allow graceful migration from TopologyAwareHints to ServiceTrafficDistribution.
The component that is responsible for providing hints in the EndpointSlices resources is the kube-controller-manager, in particular this is the EndpointSlice controller. However, there are several drawbacks with the TopologyAwareHints feature that don’t allow us to use it in its native way:
The algorithm in the EndpointSlice controller is based on a CPU-balance heuristic. From the TopologyAwareHints documentation:
The controller allocates a proportional amount of endpoints to each zone. This proportion is based on the allocatable CPU cores for nodes running in that zone. For example, if one zone had 2 CPU cores and another zone only had 1 CPU core, the controller would allocate twice as many endpoints to the zone with 2 CPU cores.
In case it is not possible to achieve a balanced distribution of the endpoints, as a safeguard mechanism the controller removes hints from the EndpointSlice resource.
In our setup, the clients and the servers are well-known and usually the traffic a component receives does not depend on the zone’s allocatable CPU.
Many components deployed by Gardener are scaled automatically by VPA. In case of an overload of a replica, the VPA should provide and apply enhanced CPU and memory resources. Additionally, Gardener uses the cluster-autoscaler to upscale/downscale Nodes dynamically. Hence, it is not possible to ensure a balanced allocatable CPU across the zones.
The TopologyAwareHints feature does not work at low-endpoint counts. It falls apart for a Service with less than 10 Endpoints.
Hints provided by the EndpointSlice controller are not deterministic. With cluster-autoscaler running and load increasing, hints can be removed in the next moment. There is no option to enforce the zone-level topology.
To circumvent these issues with the EndpointSlice controller, a mutating webhook in the gardener-resource-manager assigns hints to EndpointSlice resources. For each endpoint in the EndpointSlice, it sets the endpoint’s hints to the endpoint’s zone. The webhook overwrites the hints provided by the EndpointSlice controller in kube-controller-manager. For more details, see the webhook’s documentation.
kube-proxy
By default, with kube-proxy running in iptables mode, traffic is distributed randomly across all endpoints, regardless of where it originates from. In a cluster with 3 zones, traffic is more likely to go to another zone than to stay in the current zone.
With the topology-aware routing feature, kube-proxy filters the endpoints it routes to based on the hints in the EndpointSlice resource. In most of the cases, kube-proxy will prefer the endpoint(s) in the same zone. For more details, see the Kubernetes documentation.
How ServiceTrafficDistribution works
We reported the drawbacks related to the TopologyAwareHints feature in kubernetes/kubernetes#113731. As result, the Kubernetes community implemented the ServiceTrafficDistribution feature.
The ServiceTrafficDistribution allows expressing preferences for how traffic should be routed to Service endpoints. For more details, see upstream documentation of the feature.
The PreferClose strategy allows traffic to be routed to Service endpoints in topology-aware and predictable manner.
It is simpler than service.kubernetes.io/topology-mode: auto - if there are Service endpoints which reside in the same zone as the client, traffic is routed to one of the endpoints within the same zone as the client. If the client’s zone does not have any available Service endpoints, traffic is routed to any available endpoint within the cluster.
How to make a Service topology-aware
How to make a Service topology-aware in Kubernetes < 1.31
In Kubernetes < 1.31, TopologyAwareHints and EndpointSlice Hints mutating webhook are being used to make a Service topology-aware. The following annotation and label have to be added to the Service:
The service.kubernetes.io/topology-mode=auto annotation is needed for kube-proxy. One of the prerequisites on kube-proxy side for using topology-aware routing is the corresponding Service to be annotated with the service.kubernetes.io/topology-mode=auto. For more details, see the following kube-proxy function.
The endpoint-slice-hints.resources.gardener.cloud/consider=true label is needed for gardener-resource-manager to prevent the EndpointSlice hints mutating webhook from selecting all EndpointSlice resources but only the ones that are labeled with the consider label.
The Gardener extensions can use this approach to make a Service they deploy topology-aware.
How to make a Service topology-aware in Kubernetes 1.31
In Kubernetes 1.31, ServiceTrafficDistribution and EndpointSlice Hints mutating webhook are being used to make a Service topology-aware. The .spec.trafficDistribution field has to be set to PreferClose and the label endpoint-slice-hints.resources.gardener.cloud/consider=true needs to be added:
apiVersion: v1
kind: Service
metadata:
labels:
endpoint-slice-hints.resources.gardener.cloud/consider: "true"spec:
trafficDistribution: PreferClose
How to make a Service topology-aware in Kubernetes >= 1.32
In Kubernetes >= 1.32, ServiceTrafficDistribution is being used to make a Service topology-aware. The .spec.trafficDistribution field has to be set to PreferClose:
apiVersion: v1
kind: Service
spec:
trafficDistribution: PreferClose
Prerequisites for making a Service topology-aware
The Pods backing the Service should be spread on most of the available zones. This constraint should be ensured with appropriate scheduling constraints (topology spread constraints, (anti-)affinity). Enabling the feature for a Service with a single backing Pod or Pods all located in the same zone does not lead to a benefit.
The component should be scaled up by VerticalPodAutoscaler. In case of an overload (a large portion of the of the traffic is originating from a given zone), the VerticalPodAutoscaler should provide better resource recommendations for the overloaded backing Pods.
Note: The topology-aware routing feature is considered as alpha feature. Use it only for evaluation purposes.
Topology-aware Services in the Seed cluster
etcd-main-client and etcd-events-client
The etcd-main-client and etcd-events-client Services are topology-aware. They are consumed by the kube-apiserver.
kube-apiserver
The kube-apiserver Service is topology-aware. It is consumed by the controllers running in the Shoot control plane.
Note: The istio-ingressgateway component routes traffic in topology-aware manner - if possible, it routes traffic to the target kube-apiserver Pods in the same zone. If there is no healthy kube-apiserver Pod available in the same zone, the traffic is routed to any of the healthy Pods in the other zones. This behaviour is unconditionally enabled.
gardener-resource-manager
The gardener-resource-manager Service that is part of the Shoot control plane is topology-aware. The resource-manager serves webhooks and the Service is consumed by the kube-apiserver for the webhook communication.
vpa-webhook
The vpa-webhook Service that is part of the Shoot control plane is topology-aware. It is consumed by the kube-apiserver for the webhook communication.
Topology-aware Services in the garden runtime cluster
virtual-garden-etcd-main-client and virtual-garden-etcd-events-client
The virtual-garden-etcd-main-client and virtual-garden-etcd-events-client Services are topology-aware. virtual-garden-etcd-main-client is consumed by virtual-garden-kube-apiserver and gardener-apiserver, virtual-garden-etcd-events-client is consumed by virtual-garden-kube-apiserver.
virtual-garden-kube-apiserver
The virtual-garden-kube-apiserver Service is topology-aware. It is consumed by virtual-garden-kube-controller-manager, gardener-controller-manager, gardener-scheduler, gardener-admission-controller, extension admission components, gardener-dashboard and other components.
Note: Unlike the other Services, the virtual-garden-kube-apiserver Service is of type LoadBalancer. In-cluster components consuming the virtual-garden-kube-apiserver Service by its Service name will have benefit from the topology-aware routing. However, the TopologyAwareHints feature cannot help with external traffic routed to load balancer’s address - such traffic won’t be routed in a topology-aware manner and will be routed according to the cloud-provider specific implementation.
gardener-apiserver
The gardener-apiserver Service is topology-aware. It is consumed by virtual-garden-kube-apiserver. The aggregation layer in virtual-garden-kube-apiserver proxies requests sent for the Gardener API types to the gardener-apiserver.
gardener-admission-controller
The gardener-admission-controller Service is topology-aware. It is consumed by virtual-garden-kube-apiserver and gardener-apiserver for the webhook communication.
How to enable the topology-aware routing for a Seed cluster?
For a Seed cluster the topology-aware routing functionality can be enabled in the Seed specification:
The topology-aware routing setting can be only enabled for a Seed cluster with more than one zone.
gardenlet enables topology-aware Services only for Shoot control planes with failure tolerance type zone (.spec.controlPlane.highAvailability.failureTolerance.type=zone). Control plane Pods of non-HA Shoots and HA Shoots with failure tolerance type node are pinned to single zone. For more details, see High Availability Of Deployed Components.
How to enable the topology-aware routing for a garden runtime cluster?
For a garden runtime cluster the topology-aware routing functionality can be enabled in the Garden resource specification:
The topology-aware routing setting can be only enabled for a garden runtime cluster with more than one zone.
47 - Trusted Tls For Control Planes
Trusted TLS Certificate for Shoot Control Planes
Shoot clusters are composed of several control plane components deployed by Gardener and its corresponding extensions.
Some components are exposed via Ingress resources, which make them addressable under the HTTPS protocol.
Examples:
Alertmanager
Plutono
Prometheus
Gardener generates the backing TLS certificates, which are signed by the shoot cluster’s CA by default (self-signed).
Unlike with a self-contained Kubeconfig file, common internet browsers or operating systems don’t trust a shoot’s cluster CA and adding it as a trusted root is often undesired in enterprise environments.
Therefore, Gardener operators can predefine trusted wildcard certificates under which the mentioned endpoints will be served instead.
Register a trusted wildcard certificate
Since control plane components are published under the ingress domain (core.gardener.cloud/v1beta1.Seed.spec.ingress.domain) a wildcard certificate is required.
For example:
Seed ingress domain: dev.my-seed.example.com
CN or SAN for a certificate: *.dev.my-seed.example.com
A wildcard certificate matches exactly one seed. It must be deployed as part of your landscape setup as a Kubernetes Secret inside the garden namespace of the corresponding seed cluster.
Please ensure that the secret has the gardener.cloud/role label shown below:
Gardener copies the secret during the reconciliation of shoot clusters to the shoot namespace in the seed. Afterwards, the Ingress resources in that namespace for the mentioned components will refer to the wildcard certificate.
Best Practice
While it is possible to create the wildcard certificates manually and deploy them to seed clusters, it is recommended to let certificate management components do this job. Often, a seed cluster is also a shoot cluster at the same time (ManagedSeed) and might already provide a certificate service extension.
Otherwise, a Gardener operator may use solutions like Cert-Management or Cert-Manager.
48 - Trusted Tls For Garden Runtime
Trusted TLS Certificate for Garden Runtime Cluster
In Garden Runtime Cluster components are exposed via Ingress resources, which make them addressable under the HTTPS protocol.
Examples:
Plutono
Gardener generates the backing TLS certificates, which are signed by the garden runtime cluster’s CA by default (self-signed).
Unlike with a self-contained Kubeconfig file, common internet browsers or operating systems don’t trust a garden runtime’s cluster CA and adding it as a trusted root is often undesired in enterprise environments.
Therefore, Gardener operators can predefine a trusted wildcard certificate under which the mentioned endpoints will be served instead.
Register a trusted wildcard certificate
Since Garden Runtime Cluster components are published under the ingress domain (operator.gardener.cloud/v1alpha1.Garden.spec.runtimeCluster.ingress.domains) a wildcard certificate is required.
In addition to the configured ingress domains, this wildcard certificate is considered for SNI domains (operator.gardener.cloud/v1alpha1.Garden.spec.virtualCluster.kubernetes.kubeAPIServer.sni.domainPatterns) if secretName is unspecified.
Best Practice
While it is possible to create the wildcard certificate manually and deploy it to the cluster, it is recommended to let certificate management components (e.g. gardener/cert-management) do this job.