This is the multi-page printable view of this section. Click here to print.
Advanced
1 - Cleanup of Shoot Clusters in Deletion
Cleanup of Shoot Clusters in Deletion
When a shoot cluster is deleted then Gardener tries to gracefully remove most of the Kubernetes resources inside the cluster. This is to prevent that any infrastructure or other artifacts remain after the shoot deletion.
The cleanup is performed in four steps. Some resources are deleted with a grace period, and all resources are forcefully deleted (by removing blocking finalizers) after some time to not block the cluster deletion entirely.
Cleanup steps:
- All
ValidatingWebhookConfigurations andMutatingWebhookConfigurations are deleted with a5mgrace period. Forceful finalization happens after5m. - All
APIServices andCustomResourceDefinitions are deleted with a5mgrace period. Forceful finalization happens after1h. - All
CronJobs,DaemonSets,Deployments,Ingresss,Jobs,Pods,ReplicaSets,ReplicationControllers,Services,StatefulSets,PersistentVolumeClaims are deleted with a5mgrace period. Forceful finalization happens after5m.If the
Shootis annotated withshoot.gardener.cloud/skip-cleanup=true, then onlyServices andPersistentVolumeClaims are considered. - All
VolumeSnapshots andVolumeSnapshotContents are deleted with a5mgrace period. Forceful finalization happens after1h.
It is possible to override the finalization grace periods via annotations on the Shoot:
shoot.gardener.cloud/cleanup-webhooks-finalize-grace-period-seconds(for the resources handled in step 1)shoot.gardener.cloud/cleanup-extended-apis-finalize-grace-period-seconds(for the resources handled in step 2)shoot.gardener.cloud/cleanup-kubernetes-resources-finalize-grace-period-seconds(for the resources handled in step 3)
⚠️ If "0" is provided, then all resources are finalized immediately without waiting for any graceful deletion.
Please be aware that this might lead to orphaned infrastructure artifacts.
2 - containerd Registry Configuration
containerd Registry Configuration
containerd supports configuring registries and mirrors. Using this native containerd feature, Shoot owners can configure containerd to use public or private mirrors for a given upstream registry. More details about the registry configuration can be found in the corresponding upstream documentation.
containerd Registry Configuration Patterns
At the time of writing this document, containerd support two patterns for configuring registries/mirrors.
Note: Trying to use both of the patterns at the same time is not supported by containerd. Only one of the configuration patterns has to be followed strictly.
Old and Deprecated Pattern
The old and deprecated pattern is specifying registry.mirrors and registry.configs in the containerd’s config.toml file. See the upstream documentation.
Example of the old and deprecated pattern:
version = 2
[plugins."io.containerd.grpc.v1.cri".registry]
[plugins."io.containerd.grpc.v1.cri".registry.mirrors]
[plugins."io.containerd.grpc.v1.cri".registry.mirrors."docker.io"]
endpoint = ["https://public-mirror.example.com"]
In the above example, containerd is configured to first try to pull docker.io images from a configured endpoint (https://public-mirror.example.com). If the image is not available in https://public-mirror.example.com, then containerd will fall back to the upstream registry (docker.io) and will pull the image from there.
Hosts Directory Pattern
The hosts directory pattern is the new and recommended pattern for configuring registries. It is available starting containerd@v1.5.0. See the upstream documentation.
The above example in the hosts directory pattern looks as follows.
The /etc/containerd/config.toml file has the following section:
version = 2
[plugins."io.containerd.grpc.v1.cri".registry]
config_path = "/etc/containerd/certs.d"
The following hosts directory structure has to be created:
$ tree /etc/containerd/certs.d
/etc/containerd/certs.d
└── docker.io
└── hosts.toml
Finally, for the docker.io upstream registry, we configure a hosts.toml file as follows:
server = "https://registry-1.docker.io"
[host."http://public-mirror.example.com"]
capabilities = ["pull", "resolve"]
Configuring containerd Registries for a Shoot
Gardener supports configuring containerd registries on a Shoot using the new hosts directory pattern. For each Shoot Node, Gardener creates the /etc/containerd/certs.d directory and adds the following section to the containerd’s /etc/containerd/config.toml file:
[plugins."io.containerd.grpc.v1.cri".registry] # gardener-managed
config_path = "/etc/containerd/certs.d"
This allows Shoot owners to use the hosts directory pattern to configure registries for containerd. To do this, the Shoot owners need to create a directory under /etc/containerd/certs.d that is named with the upstream registry host name. In the newly created directory, a hosts.toml file needs to be created. For more details, see the hosts directory pattern section and the upstream documentation.
The registry-cache Extension
There is a Gardener-native extension named registry-cache that supports:
- Configuring containerd registry mirrors based on the above-described contract. The feature is added in registry-cache@v0.6.0.
- Running pull through cache(s) in the Shoot.
For more details, see the registry-cache documentation.
3 - Control Plane Endpoints And Ports
Endpoints and Ports of a Shoot Control-Plane
With the reversed VPN tunnel, there are no endpoints with open ports in the shoot cluster required by Gardener. In order to allow communication to the shoots control-plane in the seed cluster, there are endpoints shared by multiple shoots of a seed cluster. Depending on the configured zones or exposure classes, there are different endpoints in a seed cluster. The IP address(es) can be determined by a DNS query for the API Server URL. The main entry-point into the seed cluster is the load balancer of the Istio ingress-gateway service. Depending on the infrastructure provider, there can be one IP address per zone.
The load balancer of the Istio ingress-gateway service exposes the following TCP ports:
- 443 for requests to the shoot API Server. The request is dispatched according to the set TLS SNI extension.
- 8443 for requests to the shoot API Server via
api-server-proxy, dispatched based on the proxy protocol target, which is the IP address ofkubernetes.default.svc.cluster.localin the shoot. - 8132 to establish the reversed VPN connection. It’s dispatched according to an HTTP header value.
kube-apiserver via SNI
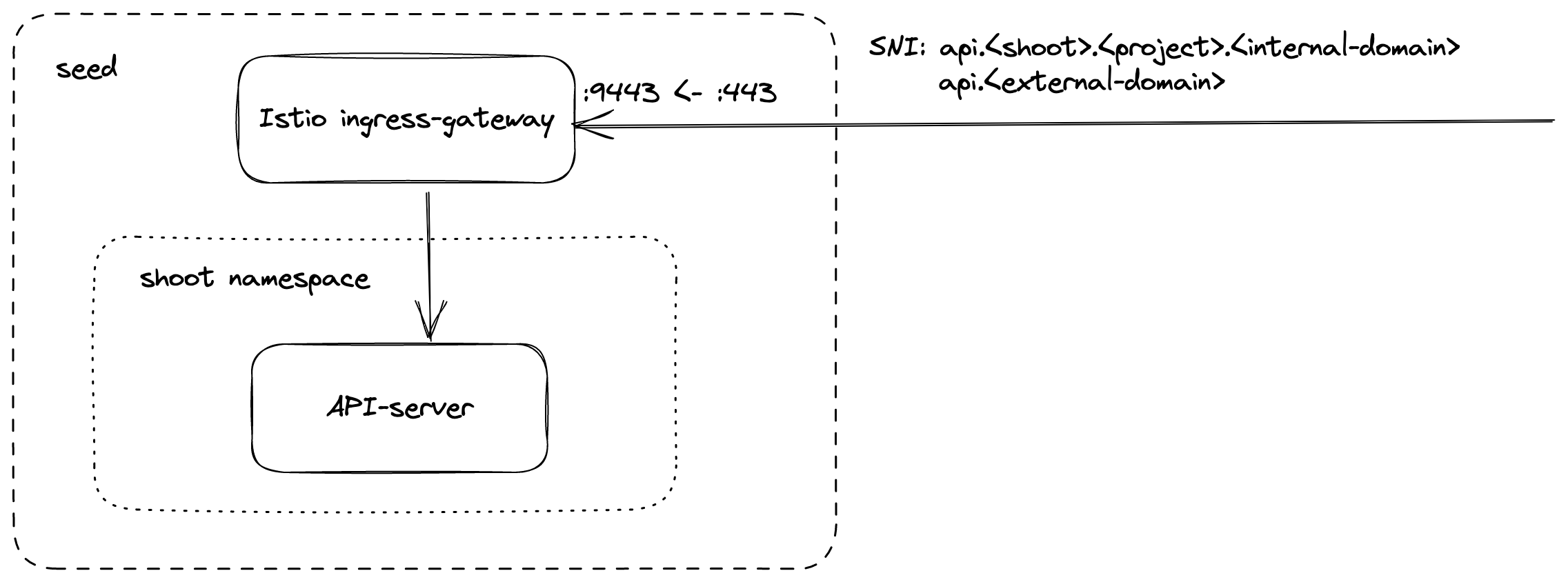
DNS entries for api.<external-domain> and api.<shoot>.<project>.<internal-domain> point to the load balancer of an Istio ingress-gateway service.
The Kubernetes client sets the server name to api.<external-domain> or api.<shoot>.<project>.<internal-domain>.
Based on SNI, the connection is forwarded to the respective API Server at TCP layer. There is no TLS termination at the Istio ingress-gateway.
TLS termination happens on the shoots API Server. Traffic is end-to-end encrypted between the client and the API Server. The certificate authority and authentication are defined in the corresponding kubeconfig.
Details can be found in GEP-08.
kube-apiserver via apiserver-proxy
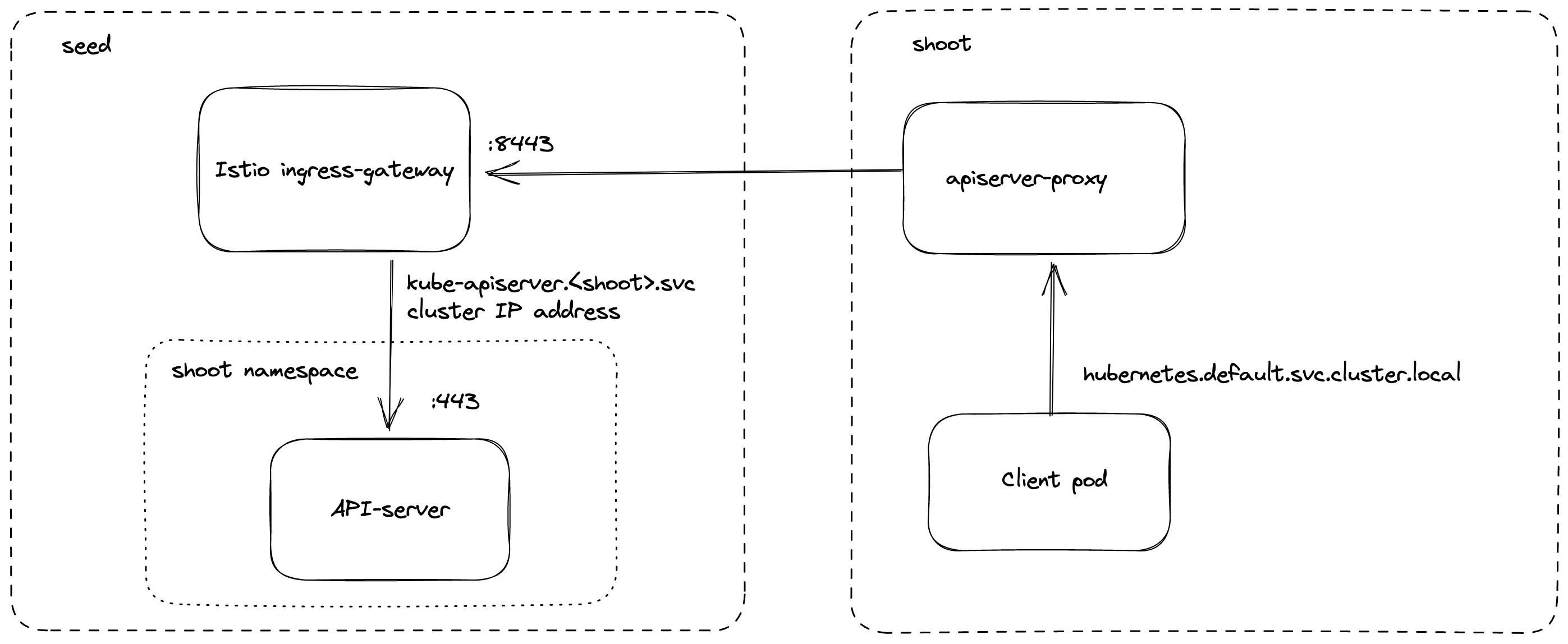
Inside the shoot cluster, the API Server can also be reached by the cluster internal name kubernetes.default.svc.cluster.local.
The pods apiserver-proxy are deployed in the host network as daemonset and intercept connections to the Kubernetes service IP address.
The destination address is changed to the cluster IP address of the service kube-apiserver.<shoot-namespace>.svc.cluster.local in the seed cluster.
The connections are forwarded via the HaProxy Proxy Protocol to the Istio ingress-gateway in the seed cluster.
The Istio ingress-gateway forwards the connection to the respective shoot API Server by it’s cluster IP address.
As TLS termination happens at the API Server, the traffic is end-to-end encrypted the same way as with SNI.
Details can be found in GEP-11.
Reversed VPN Tunnel
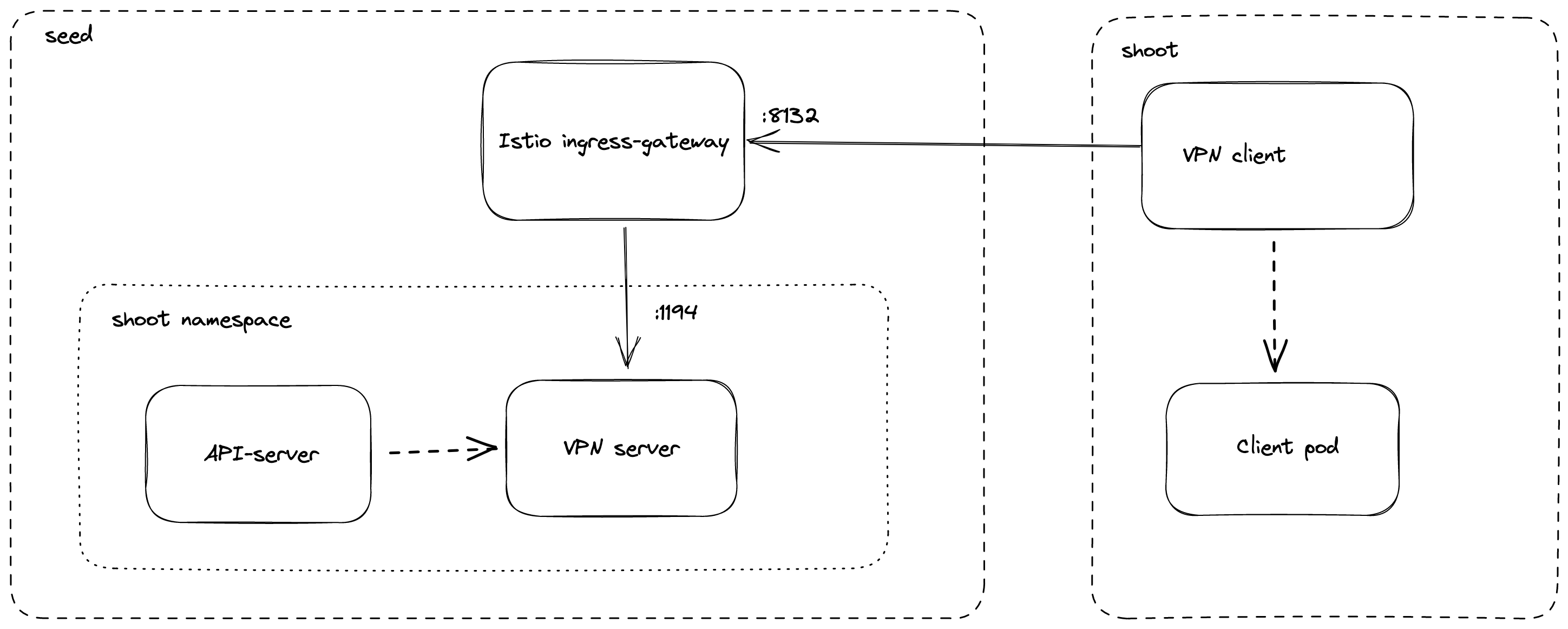
As the API Server has to be able to connect to endpoints in the shoot cluster, a VPN connection is established. This VPN connection is initiated from a VPN client in the shoot cluster. The VPN client connects to the Istio ingress-gateway and is forwarded to the VPN server in the control-plane namespace of the shoot. Once the VPN tunnel between the VPN client in the shoot and the VPN server in the seed cluster is established, the API Server can connect to nodes, services and pods in the shoot cluster.
More details can be found in the usage document and GEP-14.
4 - Custom containerd Configuration
Custom containerd Configuration
In case a Shoot cluster uses containerd, it is possible to make the containerd process load custom configuration files.
Gardener initializes containerd with the following statement:
imports = ["/etc/containerd/conf.d/*.toml"]
This means that all *.toml files in the /etc/containerd/conf.d directory will be imported and merged with the default configuration.
To prevent unintended configuration overwrites, please be aware that containerd merges config sections, not individual keys (see here and here).
Please consult the upstream containerd documentation for more information.
⚠️ Note that this only applies to nodes which were newly created after
gardener/gardener@v1.51was deployed. Existing nodes are not affected.
5 - Immutable Backup Buckets
Immutable Backup Buckets
Overview
Immutable backup buckets ensure that etcd backups cannot be modified or deleted before the configured retention period expires, by leveraging immutability features provided by supported cloud providers.
This capability is critical for:
- Security: Protecting against accidental or malicious deletion of backups.
- Compliance: Meeting regulatory requirements for data retention.
- Operational integrity: Ensuring recoverable state of your Kubernetes clusters.
Note
For background, see Gardener Issue #10866.
Core Concepts
When immutability is enabled via a supported Gardener provider extension:
The provider extension will:
- ✅ Create the backup bucket with the desired immutability policy (if it does not already exist).
- 🔄 Reconcile the policy on existing buckets to match the current configuration.
- 🚫 Prevent changes that would weaken the policy (reduce retention period or disable immutability).
- 🕑 Manage deletion lifecycle: If retention lock prevents immediate deletion of objects, a deletion policy will apply when allowed.
Important
Once a bucket’s immutability is locked at the cloud provider level, it cannot be removed or shortened—even by administrators or operators.
Provider Support
Warning
Not all Gardener provider extensions currently support immutable buckets. Support and configuration options vary between providers.
Please check your cloud provider’s extension documentation (see References) for up-to-date support and syntax.
How It Works: Admission Webhook Enforcement
To ensure backup integrity, an admission webhook enforces:
- 🔒 Immutability lock: Once the policy is locked, it cannot be disabled.
- 📅 Retention period: Once the policy is locked, the retention period cannot be shortened.
This protects clusters from accidental misconfiguration or policy drift.
How to Enable Immutable Backup Buckets
To enable immutable backup buckets:
1️⃣ Set the immutability options in .spec.backup.providerConfig of your Seed resource.
2️⃣ The Gardenlet and the provider extension will collaborate to provision and manage the bucket.
Example Configuration
Below is a generic example; adjust according to your cloud provider’s API:
apiVersion: core.gardener.cloud/v1beta1
kind: Seed
metadata:
name: example-seed
spec:
backup:
provider: <provider-name>
providerConfig:
apiVersion: <provider-extension-api-version>
kind: BackupBucketConfig
immutability:
retentionPeriod: 96h # Required: Retention duration (e.g., 96h)
retentionType: bucket # Bucket-level or object-level (provider-specific)
locked: false # Whether to lock policy on creation (recommended: true for production)
Note
See your provider’s documentation for specific fields and behavior:
Advanced: Ignoring Snapshots During Restoration
When using immutable backup buckets, you may encounter situations where certain snapshots cannot be deleted due to immutability constraints. In such cases, you can configure the etcd-backup-restore tool to ignore problematic snapshots during restoration. This allows you to proceed with restoring the etcd cluster without being blocked by snapshots that cannot be deleted.
Warning
Ignoring snapshots should be used with caution. It is recommended to only ignore snapshots that you are certain are not needed for recovery, as this may lead to data loss if critical snapshots are skipped.
👉 See: Ignoring Snapshots During Restoration.
References
6 - Necessary Labeling for Custom CSI Components
Necessary Labeling for Custom CSI Components
Some provider extensions for Gardener are using CSI components to manage persistent volumes in the shoot clusters. Additionally, most of the provider extensions are deploying controllers for taking volume snapshots (CSI snapshotter).
End-users can deploy their own CSI components and controllers into shoot clusters.
In such situations, there are multiple controllers acting on the VolumeSnapshot custom resources (each responsible for those instances associated with their respective driver provisioner types).
However, this might lead to operational conflicts that cannot be overcome by Gardener alone. Concretely, Gardener cannot know which custom CSI components were installed by end-users which can lead to issues, especially during shoot cluster deletion. You can add a label to your custom CSI components indicating that Gardener should not try to remove them during shoot cluster deletion. This means you have to take care of the lifecycle for these components yourself!
Recommendations
Custom CSI components are typically regular Deployments running in the shoot clusters.
Please label them with the shoot.gardener.cloud/no-cleanup=true label.
Background Information
When a shoot cluster is deleted, Gardener deletes most Kubernetes resources (Deployments, DaemonSets, StatefulSets, etc.). Gardener will also try to delete CSI components if they are not marked with the above mentioned label.
This can result in VolumeSnapshot resources still having finalizers that will never be cleaned up.
Consequently, manual intervention is required to clean them up before the cluster deletion can continue.
7 - Readiness of Shoot Worker Nodes
Readiness of Shoot Worker Nodes
Background
When registering new Nodes, kubelet adds the node.kubernetes.io/not-ready taint to prevent scheduling workload Pods to the Node until the Ready condition gets True.
However, the kubelet does not consider the readiness of node-critical Pods.
Hence, the Ready condition might get True and the node.kubernetes.io/not-ready taint might get removed, for example, before the CNI daemon Pod (e.g., calico-node) has successfully placed the CNI binaries on the machine.
This problem has been discussed extensively in kubernetes, e.g., in kubernetes/kubernetes#75890.
However, several proposals have been rejected because the problem can be solved by using the --register-with-taints kubelet flag and dedicated controllers (ref).
Implementation in Gardener
Gardener makes sure that workload Pods are only scheduled to Nodes where all node-critical components required for running workload Pods are ready.
For this, Gardener follows the proposed solution by the Kubernetes community and registers new Node objects with the node.gardener.cloud/critical-components-not-ready taint (effect NoSchedule).
gardener-resource-manager’s Node controller reacts on newly created Node objects that have this taint.
The controller removes the taint once all node-critical Pods are ready (determined by checking the Pods’ Ready conditions).
The Node controller considers all DaemonSets and Pods as node-critical which run in the kube-system namespace and are labeled with node.gardener.cloud/critical-component=true.
If there are DaemonSets that contain the node.gardener.cloud/critical-component=true label in their metadata and in their Pod template, the Node controller waits for corresponding daemon Pods to be scheduled and to get ready before removing the taint.
Additionally, the Node controller checks for the readiness of csi-driver-node components if a respective Pod indicates that it uses such a driver.
This is achieved through a well-defined annotation prefix (node.gardener.cloud/wait-for-csi-node-).
For example, the csi-driver-node Pod for Openstack Cinder is annotated with node.gardener.cloud/wait-for-csi-node-cinder=cinder.csi.openstack.org.
A key prefix is used instead of a “regular” annotation to allow for multiple CSI drivers being registered by one csi-driver-node Pod.
The annotation key’s suffix can be chosen arbitrarily (in this case cinder) and the annotation value needs to match the actual driver name as specified in the CSINode object.
The Node controller will verify that the used driver is properly registered in this object before removing the node.gardener.cloud/critical-components-not-ready taint.
Note that the csi-driver-node Pod still needs to be labelled and tolerate the taint as described above to be considered in this additional check.
Marking Node-Critical Components
To make use of this feature, node-critical DaemonSets and Pods need to:
- Tolerate the
node.gardener.cloud/critical-components-not-readyNoScheduletaint. - Be labelled with
node.gardener.cloud/critical-component=true. - Be placed in the
kube-systemnamespace.
csi-driver-node Pods additionally need to:
- Be annotated with
node.gardener.cloud/wait-for-csi-node-<name>=<full-driver-name>. It’s required that these Pods fulfill the above criteria (label and toleration) as well.
Gardener already marks components like kube-proxy, apiserver-proxy and node-local-dns as node-critical.
Provider extensions mark components like csi-driver-node as node-critical and add the wait-for-csi-node annotation.
Network extensions mark components responsible for setting up CNI on worker Nodes (e.g., calico-node) as node-critical.
If shoot owners manage any additional node-critical components, they can make use of this feature as well.
8 - Taints and Tolerations for Seeds and Shoots
Taints and Tolerations for Seeds and Shoots
Similar to taints and tolerations for Nodes and Pods in Kubernetes, the Seed resource supports specifying taints (.spec.taints, see this example) while the Shoot resource supports specifying tolerations (.spec.tolerations, see this example).
The feature is used to control scheduling to seeds as well as decisions whether a shoot can use a certain seed.
Compared to Kubernetes, Gardener’s taints and tolerations are very much down-stripped right now and have some behavioral differences. Please read the following explanations carefully if you plan to use them.
Scheduling
When scheduling a new shoot, the gardener-scheduler will filter all seed candidates whose taints are not tolerated by the shoot.
As Gardener’s taints/tolerations don’t support effects yet, you can compare this behaviour with using a NoSchedule effect taint in Kubernetes.
Be reminded that taints/tolerations are no means to define any affinity or selection for seeds - please use .spec.seedSelector in the Shoot to state such desires.
⚠️ Please note that - unlike how it’s implemented in Kubernetes - a certain seed cluster may only be used when the shoot tolerates all the seed’s taints.
This means that specifying .spec.seedName for a seed whose taints are not tolerated will make the gardener-apiserver reject the request.
Consequently, the taints/tolerations feature can be used as means to restrict usage of certain seeds.
Toleration Defaults and Whitelist
The Project resource features a .spec.tolerations object that may carry defaults and a whitelist (see this example).
The corresponding ShootTolerationRestriction admission plugin (cf. Kubernetes’ PodTolerationRestriction admission plugin) is responsible for evaluating these settings during creation/update of Shoots.
Whitelist
If a shoot gets created or updated with tolerations, then it is validated that only those tolerations may be used that were added to either a) the Project’s .spec.tolerations.whitelist, or b) to the global whitelist in the ShootTolerationRestriction’s admission config (see this example).
⚠️ Please note that the tolerations whitelist of Projects can only be changed if the user trying to change it is bound to the modify-spec-tolerations-whitelist custom RBAC role, e.g., via the following ClusterRole:
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: full-project-modification-access
rules:
- apiGroups:
- core.gardener.cloud
resources:
- projects
verbs:
- create
- patch
- update
- modify-spec-tolerations-whitelist
- delete
Defaults
If a shoot gets created, then the default tolerations specified in both the Project’s .spec.tolerations.defaults and the global default list in the ShootTolerationRestriction admission plugin’s configuration will be added to the .spec.tolerations of the Shoot (unless it already specifies a certain key).