This is the multi-page printable view of this section. Click here to print.
Concepts
1 - APIServer Admission Plugins
Overview
Similar to the kube-apiserver, the gardener-apiserver comes with a few in-tree managed admission plugins. If you want to get an overview of the what and why of admission plugins then this document might be a good start.
This document lists all existing admission plugins with a short explanation of what it is responsible for.
BackupBucketValidator
(enabled by default)
This admission controller reacts on CREATE and UPDATE operations for BackupBucketss.
When the backup bucket is using WorkloadIdentity as backup credentials, the plugin ensures the backup bucket and the workload identity have the same provider type, i.e. backupBucket.spec.provider.type and workloadIdentity.spec.targetSystem.type have the same value.
ClusterOpenIDConnectPreset, OpenIDConnectPreset
(both enabled by default)
These admission controllers react on CREATE operations for Shoots.
If the Shoot does not specify any OIDC configuration (.spec.kubernetes.kubeAPIServer.oidcConfig=nil), then it tries to find a matching ClusterOpenIDConnectPreset or OpenIDConnectPreset, respectively.
If there are multiple matches, then the one with the highest weight “wins”.
In this case, the admission controller will default the OIDC configuration in the Shoot.
ControllerRegistrationResources
(enabled by default)
This admission controller reacts on CREATE and UPDATE operations for ControllerRegistrations.
It validates that there exists only one ControllerRegistration in the system that is primarily responsible for a given kind/type resource combination.
This prevents misconfiguration by the Gardener administrator/operator.
CustomVerbAuthorizer
(enabled by default)
This admission controller reacts on CREATE and UPDATE operations for Projects and NamespacedCloudProfiles.
For Projects it validates whether the user is bound to an RBAC role with the modify-spec-tolerations-whitelist verb in case the user tries to change the .spec.tolerations.whitelist field of the respective Project resource.
Usually, regular project members are not bound to this custom verb, allowing the Gardener administrator to manage certain toleration whitelists on Project basis.
For NamespacedCloudProfiles, the modification of specific fields also require the user to be bound to an RBAC role with custom verbs.
Please see this document for more information.
DeletionConfirmation
(enabled by default)
This admission controller reacts on DELETE operations for Projects, Shoots, and ShootStates.
It validates that the respective resource is annotated with a deletion confirmation annotation, namely confirmation.gardener.cloud/deletion=true.
Only if this annotation is present it allows the DELETE operation to pass.
This prevents users from accidental/undesired deletions.
In addition, it applies the “four-eyes principle for deletion” concept if the Project is configured accordingly.
Find all information about it in this document.
Furthermore, this admission controller reacts on CREATE or UPDATE operations for Shoots.
It makes sure that the deletion.gardener.cloud/confirmed-by annotation is properly maintained in case the Shoot deletion is confirmed with above mentioned annotation.
ExposureClass
(enabled by default)
This admission controller reacts on Create operations for Shoots.
It mutates Shoot resources which have an ExposureClass referenced by merging both their shootSelectors and/or tolerations into the Shoot resource.
ExtensionValidator
(enabled by default)
This admission controller reacts on CREATE and UPDATE operations for BackupEntrys, BackupBuckets, Seeds, and Shoots.
For all the various extension types in the specifications of these objects, it validates whether there exists a ControllerRegistration in the system that is primarily responsible for the stated extension type(s).
This prevents misconfigurations that would otherwise allow users to create such resources with extension types that don’t exist in the cluster, effectively leading to failing reconciliation loops.
ExtensionLabels
(enabled by default)
This admission controller reacts on CREATE and UPDATE operations for BackupBuckets, BackupEntrys, CloudProfiles, NamespacedCloudProfiles, Seeds, SecretBindings, CredentialsBindings, WorkloadIdentitys and Shoots. For all the various extension types in the specifications of these objects, it adds a corresponding label in the resource. This would allow extension admission webhooks to filter out the resources they are responsible for and ignore all others. This label is of the form <extension-type>.extensions.gardener.cloud/<extension-name> : "true". For example, an extension label for provider extension type aws, looks like provider.extensions.gardener.cloud/aws : "true".
FinalizerRemoval
(enabled by default)
This admission controller reacts on UPDATE operations for CredentialsBindings, SecretBindings, Shoots.
It ensures that the finalizers of these resources are not removed by users, as long as the affected resource is still in use.
For CredentialsBindings and SecretBindings this means, that the gardener finalizer can only be removed if the binding is not referenced by any Shoot.
In case of Shoots, the gardener finalizer can only be removed if the last operation of the Shoot indicates a successful deletion.
ProjectValidator
(enabled by default)
This admission controller reacts on CREATE and UPDATE operations for Projects.
It prevents creating Projects with a non-empty .spec.namespace if the value in .spec.namespace does not start with garden-.
In addition, the project specification is initialized during creation:
.spec.createdByis set to the user creating the project..spec.ownerdefaults to the value of.spec.createdByif it is not specified.
During subsequent updates, it ensures that the project owner is included in the .spec.members list.
ResourceQuota
(enabled by default)
This admission controller enables object count ResourceQuotas for Gardener resources, e.g. Shoots, SecretBindings, Projects, etc.
⚠️ In addition to this admission plugin, the ResourceQuota controller must be enabled for the Kube-Controller-Manager of your Garden cluster.
ResourceReferenceManager
(enabled by default)
This admission controller reacts on CREATE and UPDATE operations for CloudProfiles, Projects, SecretBindings, Seeds, and Shoots.
Generally, it checks whether referred resources stated in the specifications of these objects exist in the system (e.g., if a referenced Secret exists).
However, it also has some special behaviours for certain resources:
CloudProfiles: It rejects removing Kubernetes or machine image versions if there is at least oneShootthat refers to them.
SeedValidator
(enabled by default)
This admission controller reacts on CREATE, UPDATE, and DELETE operations for Seeds.
Rejects the deletion if Shoot(s) reference the seed cluster.
While the seed is still used by Shoot(s), the plugin disallows removal of entries from the seed.spec.provider.zones field.
When the seed is using WorkloadIdentity as backup credentials, the plugin ensures the seed backup and the workload identity have the same provider type, i.e. seed.spec.backup.provider and workloadIdentity.spec.targetSystem.type have the same value.
SeedMutator
(enabled by default)
This admission controller reacts on CREATE and UPDATE operations for Seeds.
It maintains the name.seed.gardener.cloud/<name> labels for it.
More specifically, it adds that the name.seed.gardener.cloud/<name>=true label where <name> is
- the name of the
Seedresource (aSeednamedfoowill get labelname.seed.gardener.cloud/foo=true). - the name of the parent
Seedresource in case it is aManagedSeed(aSeednamedfoothat is created by aManagedSeedwhich references aShootrunning aSeedcalledbarwill get labelname.seed.gardener.cloud/bar=true).
ShootDNS
(enabled by default)
This admission controller reacts on CREATE and UPDATE operations for Shoots.
It tries to assign a default domain to the Shoot.
It also validates the DNS configuration (.spec.dns) for shoots.
ShootNodeLocalDNSEnabledByDefault
(disabled by default)
This admission controller reacts on CREATE operations for Shoots.
If enabled, it will enable node local dns within the shoot cluster (for more information, see NodeLocalDNS Configuration) by setting spec.systemComponents.nodeLocalDNS.enabled=true for newly created Shoots.
Already existing Shoots and new Shoots that explicitly disable node local dns (spec.systemComponents.nodeLocalDNS.enabled=false)
will not be affected by this admission plugin.
ShootQuotaValidator
(enabled by default)
This admission controller reacts on CREATE and UPDATE operations for Shoots.
It validates the resource consumption declared in the specification against applicable Quota resources.
Only if the applicable Quota resources admit the configured resources in the Shoot then it allows the request.
Applicable Quotas are referred in the SecretBinding that is used by the Shoot.
ShootResourceReservation
(enabled by default)
This admission controller reacts on CREATE and UPDATE operations for Shoots.
It injects the Kubernetes.Kubelet.KubeReserved setting for kubelet either as global setting for a shoot or on a per worker pool basis.
If the admission configuration (see this example) for the ShootResourceReservation plugin contains useGKEFormula: false (the default), then it sets a static default resource reservation for the shoot.
If useGKEFormula: true is set, then the plugin injects resource reservations based on the machine type similar to GKE’s formula for resource reservation into each worker pool.
Already existing resource reservations are not modified; this also means that resource reservations are not automatically updated if the machine type for a worker pool is changed.
If a shoot contains global resource reservations, then no per worker pool resource reservations are injected.
By default, useGKEFormula: true applies to all Shoots.
Operators can provide an optional label selector via the selector field to limit which Shoots get worker specific resource reservations injected.
ShootVPAEnabledByDefault
(disabled by default)
This admission controller reacts on CREATE operations for Shoots.
If enabled, it will enable the managed VerticalPodAutoscaler components (for more information, see Vertical Pod Auto-Scaling)
by setting spec.kubernetes.verticalPodAutoscaler.enabled=true for newly created Shoots.
Already existing Shoots and new Shoots that explicitly disable VPA (spec.kubernetes.verticalPodAutoscaler.enabled=false)
will not be affected by this admission plugin.
ShootTolerationRestriction
(enabled by default)
This admission controller reacts on CREATE and UPDATE operations for Shoots.
It validates the .spec.tolerations used in Shoots against the whitelist of its Project, or against the whitelist configured in the admission controller’s configuration, respectively.
Additionally, it defaults the .spec.tolerations in Shoots with those configured in its Project, and those configured in the admission controller’s configuration, respectively.
ShootValidator
(enabled by default)
This admission controller reacts on CREATE, UPDATE and DELETE operations for Shoots.
It validates certain configurations in the specification against the referred CloudProfile (e.g., machine images, machine types, used Kubernetes version, …).
Generally, it performs validations that cannot be handled by the static API validation due to their dynamic nature (e.g., when something needs to be checked against referred resources).
Additionally, it takes over certain defaulting tasks (e.g., default machine image for worker pools, default Kubernetes version) and setting the gardener.cloud/created-by=<username> annotation for newly created Shoot resources.
ShootManagedSeed
(enabled by default)
This admission controller reacts on UPDATE and DELETE operations for Shoots.
It validates certain configuration values in the specification that are specific to ManagedSeeds (e.g. the nginx-addon of the Shoot has to be disabled, the Shoot VPA has to be enabled).
It rejects the deletion if the Shoot is referred to by a ManagedSeed.
ManagedSeedValidator
(enabled by default)
This admission controller reacts on CREATE and UPDATE operations for ManagedSeedss.
It validates certain configuration values in the specification against the referred Shoot, for example Seed provider, network ranges, DNS domain, etc.
Similar to ShootValidator, it performs validations that cannot be handled by the static API validation due to their dynamic nature.
Additionally, it performs certain defaulting tasks, making sure that configuration values that are not specified are defaulted to the values of the referred Shoot, for example Seed provider, network ranges, DNS domain, etc.
ManagedSeedShoot
(enabled by default)
This admission controller reacts on DELETE operations for ManagedSeeds.
It rejects the deletion if there are Shoots that are scheduled onto the Seed that is registered by the ManagedSeed.
ShootDNSRewriting
(disabled by default)
This admission controller reacts on CREATE operations for Shoots.
If enabled, it adds a set of common suffixes configured in its admission plugin configuration to the Shoot (spec.systemComponents.coreDNS.rewriting.commonSuffixes) (for more information, see DNS Search Path Optimization).
Already existing Shoots will not be affected by this admission plugin.
NamespacedCloudProfileValidator
(enabled by default)
This admission controller reacts on CREATE and UPDATE operations for NamespacedCloudProfiles.
It primarily validates if the referenced parent CloudProfile exists in the system. In addition, the admission controller ensures that the NamespacedCloudProfile only configures new machine types, and does not overwrite those from the parent CloudProfile.
2 - Architecture
Official Definition - What is Kubernetes?
“Kubernetes is an open-source system for automating deployment, scaling, and management of containerized applications.”
Introduction - Basic Principle
The foundation of the Gardener (providing Kubernetes Clusters as a Service) is Kubernetes itself, because Kubernetes is the go-to solution to manage software in the Cloud, even when it’s Kubernetes itself (see also OpenStack which is provisioned more and more on top of Kubernetes as well).
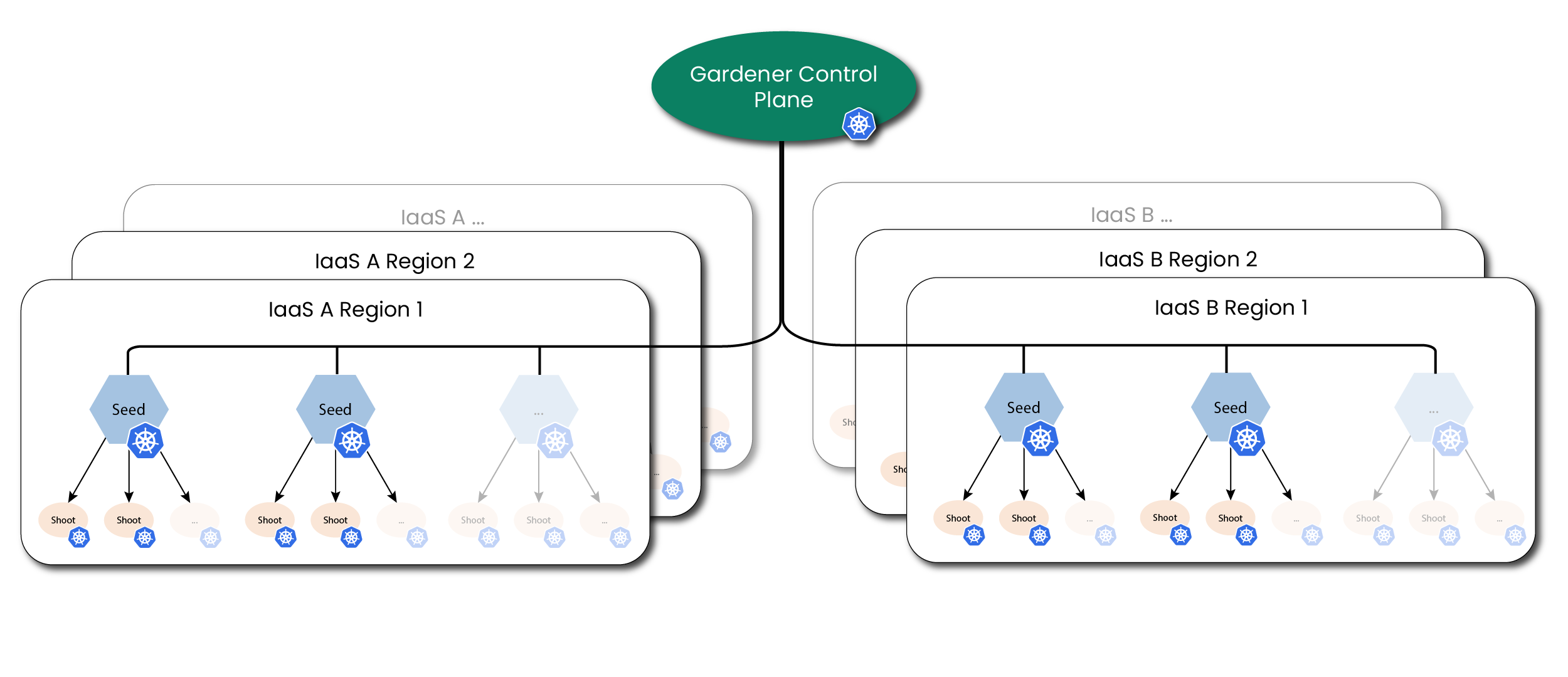
While self-hosting, meaning to run Kubernetes components inside Kubernetes, is a popular topic in the community, we apply a special pattern catering to the needs of our cloud platform to provision hundreds or even thousands of clusters. We take a so-called “seed” cluster and seed the control plane (such as the API server, scheduler, controllers, etcd persistence and others) of an end-user cluster, which we call “shoot” cluster, as pods into the “seed” cluster. That means that one “seed” cluster, of which we will have one per IaaS and region, hosts the control planes of multiple “shoot” clusters. That allows us to avoid dedicated hardware/virtual machines for the “shoot” cluster control planes. We simply put the control plane into pods/containers and since the “seed” cluster watches them, they can be deployed with a replica count of 1 and only need to be scaled out when the control plane gets under pressure, but no longer for HA reasons. At the same time, the deployments get simpler (standard Kubernetes deployment) and easier to update (standard Kubernetes rolling update). The actual “shoot” cluster consists only of the worker nodes (no control plane) and therefore the users may get full administrative access to their clusters.
Setting The Scene - Components and Procedure
We provide a central operator UI, which we call the “Gardener Dashboard”. It talks to a dedicated cluster, which we call the “Garden” cluster, and uses custom resources managed by an aggregated API server (one of the general extension concepts of Kubernetes) to represent “shoot” clusters. In this “Garden” cluster runs the “Gardener”, which is basically a Kubernetes controller that watches the custom resources and acts upon them, i.e. creates, updates/modifies, or deletes “shoot” clusters. The creation follows basically these steps:
- Create a namespace in the “seed” cluster for the “shoot” cluster, which will host the “shoot” cluster control plane.
- Generate secrets and credentials, which the worker nodes will need to talk to the control plane.
- Create the infrastructure (using Terraform), which basically consists out of the network setup.
- Deploy the “shoot” cluster control plane into the “shoot” namespace in the “seed” cluster, containing the “machine-controller-manager” pod.
- Create machine CRDs in the “seed” cluster, describing the configuration and the number of worker machines for the “shoot” (the machine-controller-manager watches the CRDs and creates virtual machines out of it).
- Wait for the “shoot” cluster API server to become responsive (pods will be scheduled, persistent volumes and load balancers are created by Kubernetes via the respective cloud provider).
- Finally, we deploy
kube-systemdaemons likekube-proxyand further add-ons like thedashboardinto the “shoot” cluster and the cluster becomes active.
Overview Architecture Diagram
Detailed Architecture Diagram
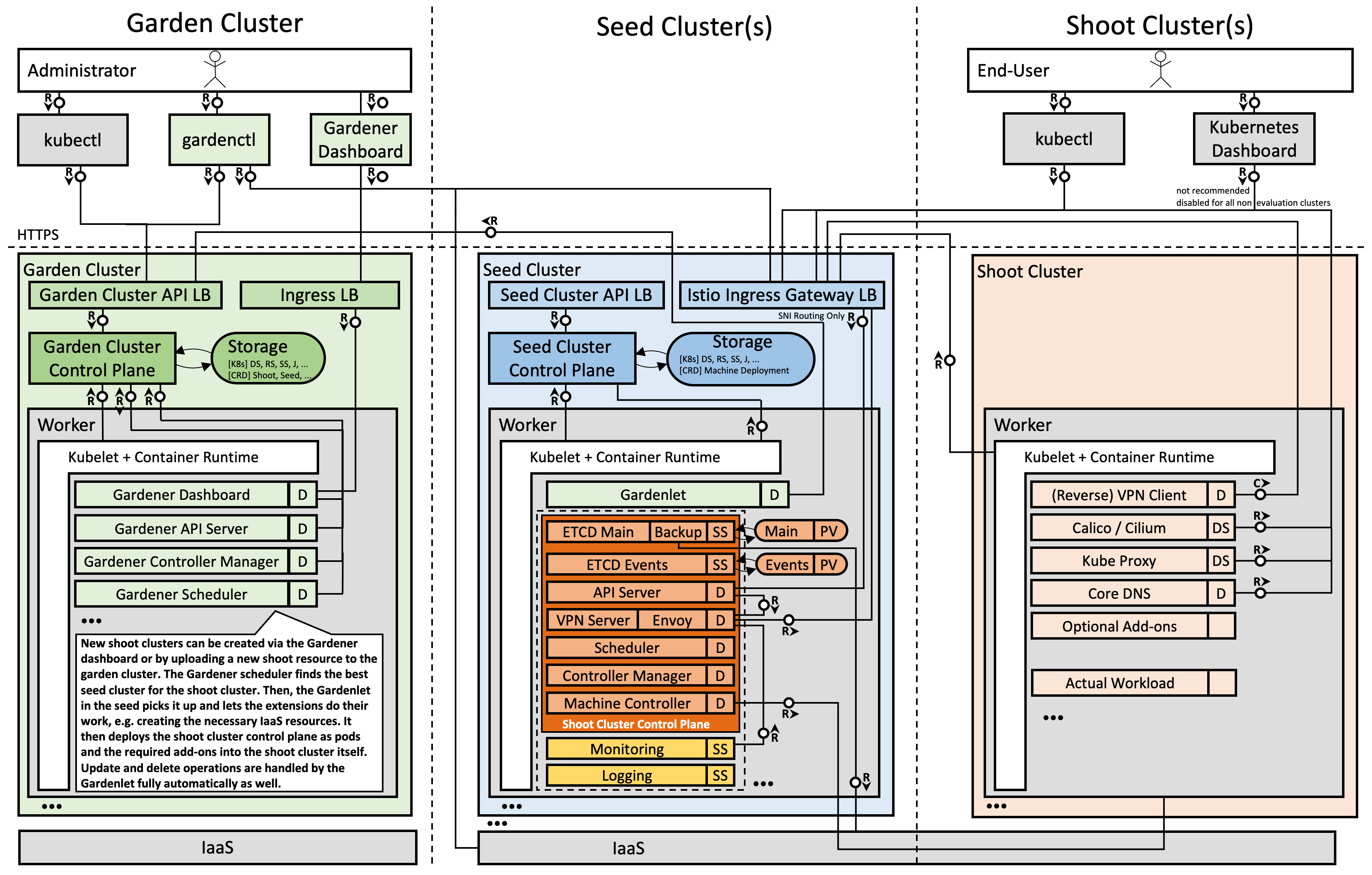
Note: The kubelet, as well as the pods inside the “shoot” cluster, talks through the front-door (load balancer IP; public Internet) to its “shoot” cluster API server running in the “seed” cluster. The reverse communication from the API server to the pod, service, and node networks happens through a VPN connection that we deploy into the “seed” and “shoot” clusters.
3 - Backup and Restore
Overview
Kubernetes uses etcd as the key-value store for its resource definitions. Gardener supports the backup and restore of etcd. It is the responsibility of the shoot owners to backup the workload data.
Gardener uses an etcd-backup-restore component to backup the etcd backing the Shoot cluster regularly and restore it in case of disaster. It is deployed as sidecar via etcd-druid. This doc mainly focuses on the backup and restore configuration used by Gardener when deploying these components. For more details on the design and internal implementation details, please refer to GEP-06 and the documentation on individual repositories.
Bucket Provisioning
Refer to the backup bucket extension document to find out details about configuring the backup bucket.
Backup Policy
etcd-backup-restore supports full snapshot and delta snapshots over full snapshot. In Gardener, this configuration is currently hard-coded to the following parameters:
- Full Snapshot schedule:
- Daily,
24hrinterval. - For each Shoot, the schedule time in a day is randomized based on the configured Shoot maintenance window.
- Daily,
- Delta Snapshot schedule:
- At
5mininterval. - If aggregated events size since last snapshot goes beyond
100Mib.
- At
- Backup History / Garbage backup deletion policy:
- Gardener configures backup restore to have
Exponentialgarbage collection policy. - As per policy, the following backups are retained:
- All full backups and delta backups for the previous hour.
- Latest full snapshot of each previous hour for the day.
- Latest full snapshot of each previous day for 7 days.
- Latest full snapshot of the previous 4 weeks.
- Garbage Collection is configured at
12hrinterval.
- Gardener configures backup restore to have
- Listing:
- Gardener doesn’t have any API to list out the backups.
- To find the backups list, an admin can checkout the
BackupEntryresource associated with the Shoot which holds the bucket and prefix details on the object store.
Restoration
The restoration process of etcd is automated through the etcd-backup-restore component from the latest snapshot. Gardener doesn’t support Point-In-Time-Recovery (PITR) of etcd. In case of an etcd disaster, the etcd is recovered from the latest backup automatically. For further details, please refer the Restoration topic. Post restoration of etcd, the Shoot reconciliation loop brings the cluster back to its previous state.
Again, the Shoot owner is responsible for maintaining the backup/restore of his workload. Gardener only takes care of the cluster’s etcd.
4 - Cluster API
Relation Between Gardener API and Cluster API (SIG Cluster Lifecycle)
The Cluster API (CAPI) and Gardener approach Kubernetes cluster management with different, albeit related, philosophies. In essence, Cluster API primarily harmonizes how to get to clusters, while Gardener goes a significant step further by also harmonizing the clusters themselves.
Gardener already provides a declarative, Kubernetes-native API to manage the full lifecycle of conformant Kubernetes clusters. This is a key distinction, as many other managed Kubernetes services are often exposed via proprietary REST APIs or imperative CLIs, whereas Gardener’s API is Kubernetes. Gardener is inherently multi-cloud and, by design, unifies far more aspects of a cluster’s make-up and operational behavior than Cluster API currently aims to.
Gardener’s Homogeneity vs. CAPI’s Provider Model
The Cluster API delegates the specifics of cluster creation and management to providers for infrastructures (e.g., AWS, Azure, GCP) and control planes, each with their own Custom Resource Definitions (CRDs). This means that different Cluster API providers can result in vastly different Kubernetes clusters in terms of their configuration (see, e.g., AKS vs GKE), available Kubernetes versions, operating systems, control plane setup, included add-ons, and operational behavior.
In stark contrast, Gardener provides homogeneous clusters. Regardless of the underlying infrastructure (AWS, Azure, GCP, OpenStack, etc.), you get clusters with the exact same Kubernetes version, operating system choices, control plane configuration (API server, kubelet, etc.), core add-ons (overlay network, DNS, metrics, logging, etc.), and consistent behavior for updates, auto-scaling, self-healing, credential rotation, you name it. This deep harmonization is a core design goal of Gardener, aimed at simplifying operations for teams developing and shipping software on Kubernetes across diverse environments. Gardener’s extensive coverage in the official Kubernetes conformance test grid underscores this commitment.
Historical Context and Evolution
Gardener has actively followed and contributed to Cluster API. Notably, Gardener heavily influenced the Machine API concepts within Cluster API through its Machine Controller Manager and was the first to adopt it. A joint KubeCon talk between SIG Cluster Lifecycle and Gardener further details this collaboration.
Cluster API has evolved significantly, especially from v1alpha1 to v1alpha2, which put a strong emphasis on a machine-based paradigm (The Cluster API Book - Updating a v1alpha1 provider to a v1alpha2 infrastructure provider). This “demoted” v1alpha1 providers to mere infrastructure providers, creating an “impedance mismatch” for fully managed services like GKE (which runs on Borg), Gardener (which uses a “kubeception” model — running control planes as pods in a seed cluster, a.k.a. “hosted control planes”) and others, making direct adoption difficult.
Challenges of Integrating Fully Managed Services with Cluster API
Despite the recent improvements, integrating fully managed Kubernetes services with Cluster API presents inherent challenges:
Opinionated Structure: Cluster API’s
Cluster/ControlPlane/MachineDeployment/MachinePoolstructure is opinionated and doesn’t always align naturally with how fully managed services architect their offerings. In particular, the separation betweenControlPlaneandInfraClusterobjects can be difficult to map cleanly. Fully managed services often abstract away the details of how control planes are provisioned and operated, making the distinction between these two components less meaningful or even redundant in those contexts.Provider-Specific CRDs: While CAPI provides a common
Clusterresource, the crucialControlPlaneand infrastructure-specific resources (e.g.,AWSManagedControlPlane,GCPManagedCluster,AzureManagedControlPlane) are entirely different for each provider. This means you cannot simply swapprovider: foowithprovider: barin a CAPI manifest and expect it to work. Users still need to understand the unique CRDs and capabilities of each CAPI provider.Limited Unification: CAPI unifies the act of requesting a cluster, but not the resulting cluster’s features, available Kubernetes versions, release cycles, supported operating systems, specific add-ons, or nuanced operational behaviors like credential rotation procedures and their side effects.
Experimental or Limited Support: For some managed services, CAPI provider support is still experimental or limited. For example:
- The CAPI provider for AKS notes that the
AzureManagedClusterTemplateis “basically a no-op,” with most configuration inAzureManagedControlPlaneTemplate(CAPZ Docs). - The CAPI provider for GKE states: “Provisioning managed clusters (GKE) is an experimental feature…” and is disabled by default (CAPG Docs).
- The CAPI provider for AKS notes that the
Platform Governance and Lifecycle Management: While Cluster API standardizes the request for a cluster, it doesn’t inherently provide the comprehensive governance and lifecycle management features that platform operators require, especially in enterprise settings. A platform solution needs to go beyond provisioning and offer robust mechanisms for:
- Defining and Enforcing Policies: Platform administrators need to control which Kubernetes versions, machine images, operating systems, and add-on versions are available to end-users. This includes classifying them (e.g., “preview,” “supported,” “deprecated”) and setting clear expiration dates.
- Communicating Lifecycle Changes: End-users must be informed about upcoming deprecations or required upgrades to plan their own application maintenance and avoid disruptions.
- Automated Maintenance and Compliance: The platform should facilitate or even automate updates and compliance checks based on these defined policies.
Gardener is designed with these enterprise platform needs at its core. It provides a rich API and control plane that allows administrators to manage the entire lifecycle of these components. For instance, Gardener enables platform teams to:
- Clearly mark Kubernetes versions or machine images as “supported,” “preview,” or “deprecated,” complete with expiration dates.
- Offer end-users the ability to opt-into automated maintenance schedules or provide them with the necessary information to build their own automated update logic for their workloads before underlying components are deprecated.
This level of granular control, policy enforcement, and lifecycle communication is crucial for maintaining stability, security, and operational efficiency across a large number of clusters. For organizations adopting Cluster API directly, implementing such a comprehensive governance layer becomes an additional, significant development and operational burden that they must address on top of CAPI’s provisioning capabilities.
Gardener’s Perspective on a Cluster API Provider
Given that Gardener already offers a robust, Kubernetes-native API for homogenous multi-cloud cluster management, a Cluster API provider for Gardener could still act as a bridge for users transitioning from CAPI to Gardener, enabling them to gradually adopt Gardener’s capabilities while maintaining compatibility with existing CAPI workflows.
- For users exclusively using Gardener: Wrapping Gardener’s comprehensive API within CAPI’s structure offers limited additional value other than maintaining compatibility with existing CAPI workflows, as Gardener’s native API is already declarative and Kubernetes-centric, meaning any tool or language binding that can handle Kubernetes CRDs will work with Gardener.
- For users managing diverse clusters (e.g., ACK, AKS, EKS, GKE, Gardener,
kubeadm) via CAPI: Cluster API offers a unified interface for initiating cluster provisioning across diverse managed services, but it does not harmonize the differences in provider-specific CRDs, capabilities, or operational behaviors. This can limit its ability to leverage the unique strengths of each service. However, we understand that a CAPI provider for Gardener could open doors for users familiar with CAPI’s workflows. It would allow them to explore Gardener’s enterprise-grade, homogeneous cluster management while maintaining compatibility with existing CAPI workflows, fostering a smoother transition to Gardener.
The mapping from the Gardener API to a potential Cluster API provider for Gardener would be mostly syntactic. However, the fundamental value proposition of Gardener — providing homogeneous Kubernetes clusters across all supported infrastructures — extends beyond what Cluster API currently aims to achieve.
We follow Cluster API’s development with great interest and remain active members of the community.
5 - etcd
etcd - Key-Value Store for Kubernetes
etcd is a strongly consistent key-value store and the most prevalent choice for the Kubernetes
persistence layer. All API cluster objects like Pods, Deployments, Secrets, etc., are stored in etcd, which
makes it an essential part of a Kubernetes control plane.
Garden or Shoot Cluster Persistence
Each garden or shoot cluster gets its very own persistence for the control plane.
It runs in the shoot namespace on the respective seed cluster (or in the garden namespace in the garden cluster, respectively).
Concretely, there are two etcd instances per shoot cluster, which the kube-apiserver is configured to use in the following way:
etcd-main
A store that contains all “cluster critical” or “long-term” objects. These object kinds are typically considered for a backup to prevent any data loss.
etcd-events
A store that contains all Event objects (events.k8s.io) of a cluster.
Events usually have a short retention period and occur frequently, but are not essential for a disaster recovery.
The setup above prevents both, the critical etcd-main is not flooded by Kubernetes Events, as well as backup space is not occupied by non-critical data.
This separation saves time and resources.
etcd Operator
Configuring, maintaining, and health-checking etcd is outsourced to a dedicated operator called etcd Druid.
When a gardenlet reconciles a Shoot resource or a gardener-operator reconciles a Garden resource, they manage an Etcd resource in the seed or garden cluster, containing necessary information (backup information, defragmentation schedule, resources, etc.).
etcd-druid needs to manage the lifecycle of the desired etcd instance (today main or events).
Likewise, when the Shoot or Garden is deleted, gardenlet or gardener-operator deletes the Etcd resources and etcd Druid takes care of cleaning up all related objects, e.g. the backing StatefulSets.
Backup
If Seeds specify backups for etcd (example), then Gardener and the respective provider extensions are responsible for creating a bucket on the cloud provider’s side (modelled through a BackupBucket resource).
The bucket stores backups of Shoots scheduled on that Seed.
Furthermore, Gardener creates a BackupEntry, which subdivides the bucket and thus makes it possible to store backups of multiple shoot clusters.
How long backups are stored in the bucket after a shoot has been deleted depends on the configured retention period in the Seed resource.
Please see this example configuration for more information.
For Gardens specifying backups for etcd (example), the bucket must be pre-created externally and provided via the Garden specification.
Both etcd instances are configured to run with a special backup-restore sidecar. It takes care about regularly backing up etcd data and restoring it in case of data loss (in the main etcd only). The sidecar also performs defragmentation and other house-keeping tasks. More information can be found in the component’s GitHub repository.
Housekeeping
etcd maintenance tasks must be performed from time to time in order to re-gain database storage and to ensure the system’s reliability. The backup-restore sidecar takes care about this job as well.
For both Shoots and Gardens, a random time within the shoot’s maintenance time is chosen for scheduling these tasks.
6 - gardenadm
Caution
This tool is currently under development and considered highly experimental. Do not use it in production environments. Read more about it in GEP-28.

Overview
gardenadm is a command line tool for bootstrapping Kubernetes clusters called “Autonomous Shoot Clusters”.
In contrast to usual Gardener-managed clusters (called Shoot Clusters), the Kubernetes control plane components run as static pods on a dedicated control plane worker pool in the cluster itself (instead of running them as pods on another Kubernetes cluster (called Seed Cluster)).
Autonomous shoot clusters can be bootstrapped without an existing Gardener installation.
Hence, they can host a Gardener installation itself and/or serve as the initial seed cluster of a Gardener installation.
Furthermore, autonomous shoot clusters can only be created by the gardenadm tool and not via an API of an existing Gardener system.
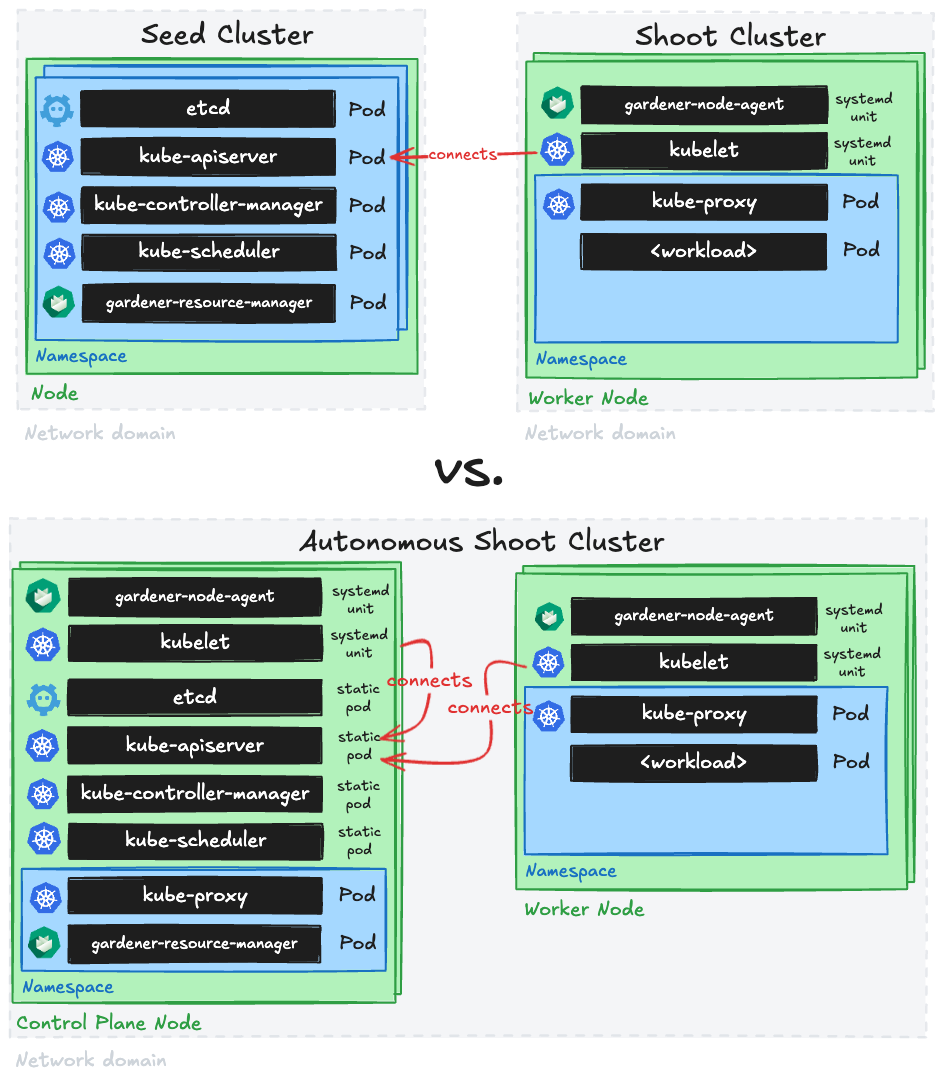
Such autonomous shoot clusters are meant to operate autonomously, but not to exist completely independently of Gardener.
Hence, after their initial creation, they are connected to an existing Gardener system such that the established cluster management functionality via the Shoot API can be applied.
I.e., day-2 operations for autonomous shoot clusters are only supported after connecting them to a Gardener system.
This Gardener system could also run in an autonomous shoot cluster itself (in this case, you would first need to deploy it before being able to connect the autonomous shoot cluster to it).
Furthermore, autonomous shoot clusters are not considered a replacement or alternative for regular shoot clusters. They should be only used for special use-cases or requirements as creating them is more complex and as their costs will most likely be higher (since control plane nodes are typically not fully utilized in such architecture). In this light, a high cluster creation/deletion churn rate is neither expected nor in scope.
Getting Started Locally
This document walks you through deploying Autonomous Shoot Clusters using gardenadm on your local machine.
This setup can be used for trying out and developing gardenadm locally without additional infrastructure.
The setup is also used for running e2e tests for gardenadm in CI.
Scenarios
We distinguish between two different scenarios for bootstrapping autonomous shoot clusters:
- High Touch, meaning that there is no programmable infrastructure available. We consider this the “bare metal” or “edge” use-case, where at first machines must be (often manually) prepared by human operators. In this case, network setup (e.g., VPCs, subnets, route tables, etc.) and machine management are out of scope.
- Medium Touch, meaning that there is programmable infrastructure available where we can leverage provider extensions and
machine-controller-managerin order to manage the network setup and the machines.
The general procedure of bootstrapping an autonomous shoot cluster is similar in both scenarios.
7 - Gardener Admission Controller
Overview
While the Gardener API server works with admission plugins to validate and mutate resources belonging to Gardener related API groups, e.g. core.gardener.cloud, the same is needed for resources belonging to non-Gardener API groups as well, e.g. secrets in the core API group.
Therefore, the Gardener Admission Controller runs a http(s) server with the following handlers which serve as validating/mutating endpoints for admission webhooks.
It is also used to serve http(s) handlers for authorization webhooks.
Admission Webhook Handlers
This section describes the admission webhook handlers that are currently served.
Authentication Configuration Validator
In Shoots, it is possible to reference structured authentication configurations.
This validation handler validates that such configurations are valid.
Authorization Configuration Validator
In Shoots, it is possible to reference structured authorization configurations.
This validation handler validates that such configurations are valid.
Admission Plugin Secret Validator
In Shoots, AdmissionPlugin can have reference to other files. This validation handler validates the referred admission plugin secret and ensures that the secret always contains the required data kubeconfig.
Kubeconfig Secret Validator
Malicious Kubeconfigs applied by end users may cause a leakage of sensitive data.
This handler checks if the incoming request contains a Kubernetes secret with a .data.kubeconfig field and denies the request if the Kubeconfig structure violates Gardener’s security standards.
Namespace Validator
Namespaces are the backing entities of Gardener projects in which shoot cluster objects reside.
This validation handler protects active namespaces against premature deletion requests.
Therefore, it denies deletion requests if a namespace still contains shoot clusters or if it belongs to a non-deleting Gardener project (without .metadata.deletionTimestamp).
Resource Size Validator
Since users directly apply Kubernetes native objects to the Garden cluster, it also involves the risk of being vulnerable to DoS attacks because these resources are continuously watched and read by controllers. One example is the creation of shoot resources with large annotation values (up to 256 kB per value), which can cause severe out-of-memory issues for the gardenlet component. Vertical autoscaling can help to mitigate such situations, but we cannot expect to scale infinitely, and thus need means to block the attack itself.
The Resource Size Validator checks arbitrary incoming admission requests against a configured maximum size for the resource’s group-version-kind combination. It denies the request if the object exceeds the quota.
Note
The contents of
statussubresources andmetadata.managedFieldsare not taken into account for the resource size calculation.
Example for Gardener Admission Controller configuration:
server:
resourceAdmissionConfiguration:
limits:
- apiGroups: ["core.gardener.cloud"]
apiVersions: ["*"]
resources: ["shoots"]
size: 100k
- apiGroups: [""]
apiVersions: ["v1"]
resources: ["secrets"]
size: 100k
unrestrictedSubjects:
- kind: Group
name: gardener.cloud:system:seeds
apiGroup: rbac.authorization.k8s.io
# - kind: User
# name: admin
# apiGroup: rbac.authorization.k8s.io
# - kind: ServiceAccount
# name: "*"
# namespace: garden
# apiGroup: ""
operationMode: block #log
With the configuration above, the Resource Size Validator denies requests for shoots with Gardener’s core API group which exceed a size of 100 kB. The same is done for Kubernetes secrets.
As this feature is meant to protect the system from malicious requests sent by users, it is recommended to exclude trusted groups, users or service accounts from the size restriction via resourceAdmissionConfiguration.unrestrictedSubjects.
For example, the backing user for the gardenlet should always be capable of changing the shoot resource instead of being blocked due to size restrictions.
This is because the gardenlet itself occasionally changes the shoot specification, labels or annotations, and might violate the quota if the existing resource is already close to the quota boundary.
Also, operators are supposed to be trusted users and subjecting them to a size limitation can inhibit important operational tasks.
Wildcard ("*") in subject name is supported.
Size limitations depend on the individual Gardener setup and choosing the wrong values can affect the availability of your Gardener service.
resourceAdmissionConfiguration.operationMode allows to control if a violating request is actually denied (default) or only logged.
It’s recommended to start with log, check the logs for exceeding requests, adjust the limits if necessary and finally switch to block.
SeedRestriction
Please refer to Scoped API Access for Gardenlets for more information.
UpdateRestriction
Gardener stores public data regarding shoot clusters, i.e. certificate authority bundles, OIDC discovery documents, etc.
This information can be used by third parties so that they establish trust to specific authorities, making the integrity of the stored data extremely important in a way that any unwanted modifications can be considered a security risk.
This handler protects secrets and configmaps against tampering.
It denies CREATE, UPDATE and DELETE requests if the resource is labeled with gardener.cloud/update-restriction=true and the request is not made by a gardenlet.
In addition, the following service accounts are allowed to perform certain operations:
system:serviceaccount:kube-system:generic-garbage-collectoris allowed toDELETErestricted resources.system:serviceaccount:kube-system:gardener-internalis allowed toUPDATErestricted resources.
Authorization Webhook Handlers
This section describes the authorization webhook handlers that are currently served.
SeedAuthorization
Please refer to Scoped API Access for Gardenlets for more information.
8 - Gardener API Server
Overview
The Gardener API server is a Kubernetes-native extension based on its aggregation layer.
It is registered via an APIService object and designed to run inside a Kubernetes cluster whose API it wants to extend.
After registration, it exposes the following resources:
CloudProfiles
CloudProfiles are resources that describe a specific environment of an underlying infrastructure provider, e.g. AWS, Azure, etc.
Each shoot has to reference a CloudProfile to declare the environment it should be created in.
In a CloudProfile, the gardener operator specifies certain constraints like available machine types, regions, which Kubernetes versions they want to offer, etc.
End-users can read CloudProfiles to see these values, but only operators can change the content or create/delete them.
When a shoot is created or updated, then an admission plugin checks that only allowed values are used via the referenced CloudProfile.
Additionally, a CloudProfile may contain a providerConfig, which is a special configuration dedicated for the infrastructure provider.
Gardener does not evaluate or understand this config, but extension controllers might need it for declaration of provider-specific constraints, or global settings.
Please see this example manifest and consult the documentation of your provider extension controller to get information about its providerConfig.
NamespacedCloudProfiles
In addition to CloudProfiles, NamespacedCloudProfiles exist to enable project-level customizations of CloudProfiles.
Project administrators can create and manage cloud profiles with overrides or extensions specific to their project.
Please see this example manifest and this usage documentation for further information.
InternalSecrets
End-users can read and/or write Secrets in their project namespaces in the garden cluster. This prevents Gardener components from storing such “Gardener-internal” secrets in the respective project namespace.
InternalSecrets are resources that contain shoot or project-related secrets that are “Gardener-internal”, i.e., secrets used and managed by the system that end-users don’t have access to.
InternalSecrets are defined like plain Kubernetes Secrets, behave exactly like them, and can be used in the same manners. The only difference is, that the InternalSecret resource is a dedicated API resource (exposed by gardener-apiserver).
This allows separating access to “normal” secrets and internal secrets by the usual RBAC means.
Gardener uses an InternalSecret per Shoot for syncing the client CA to the project namespace in the garden cluster (named <shoot-name>.ca-client). The shoots/adminkubeconfig subresource signs short-lived client certificates by retrieving the CA from the InternalSecret.
Operators should configure gardener-apiserver to encrypt the internalsecrets.core.gardener.cloud resource in etcd.
Please see this example manifest.
Seeds
Seeds are resources that represent seed clusters.
Gardener does not care about how a seed cluster got created - the only requirement is that it is of at least Kubernetes v1.27 and passes the Kubernetes conformance tests.
The Gardener operator has to either deploy the gardenlet into the cluster they want to use as seed (recommended, then the gardenlet will create the Seed object itself after bootstrapping) or provide the kubeconfig to the cluster inside a secret (that is referenced by the Seed resource) and create the Seed resource themselves.
Please see this, this, and optionally this example manifests.
Shoot Quotas
To allow end-users not having their dedicated infrastructure account to try out Gardener, the operator can register an account owned by them that they allow to be used for trial clusters. Trial clusters can be put under quota so that they don’t consume too many resources (resulting in costs) and that one user cannot consume all resources on their own. These clusters are automatically terminated after a specified time, but end-users may extend the lifetime manually if needed.
Please see this example manifest.
Projects
The first thing before creating a shoot cluster is to create a Project.
A project is used to group multiple shoot clusters together.
End-users can invite colleagues to the project to enable collaboration, and they can either make them admin or viewer.
After an end-user has created a project, they will get a dedicated namespace in the garden cluster for all their shoots.
Please see this example manifest.
SecretBindings
Now that the end-user has a namespace the next step is registering their infrastructure provider account.
Please see this example manifest and consult the documentation of the extension controller for the respective infrastructure provider to get information about which keys are required in this secret.
After the secret has been created, the end-user has to create a special SecretBinding resource that binds this secret.
Later, when creating shoot clusters, they will reference such binding.
Please see this example manifest.
Shoots
Shoot cluster contain various settings that influence how end-user Kubernetes clusters will look like in the end. As Gardener heavily relies on extension controllers for operating system configuration, networking, and infrastructure specifics, the end-user has the possibility (and responsibility) to provide these provider-specific configurations as well. Such configurations are not evaluated by Gardener (because it doesn’t know/understand them), but they are only transported to the respective extension controller.
⚠️ This means that any configuration issues/mistake on the end-user side that relates to a provider-specific flag or setting cannot be caught during the update request itself but only later during the reconciliation (unless a validator webhook has been registered in the garden cluster by an operator).
Please see this example manifest and consult the documentation of the provider extension controller to get information about its spec.provider.controlPlaneConfig, .spec.provider.infrastructureConfig, and .spec.provider.workers[].providerConfig.
(Cluster)OpenIDConnectPresets
Please see this separate documentation file.
Overview Data Model

9 - Gardener Controller Manager
Overview
The gardener-controller-manager (often referred to as “GCM”) is a component that runs next to the Gardener API server, similar to the Kubernetes Controller Manager.
It runs several controllers that do not require talking to any seed or shoot cluster.
Also, as of today, it exposes an HTTP server that is serving several health check endpoints and metrics.
This document explains the various functionalities of the gardener-controller-manager and their purpose.
Controllers
Bastion Controller
Bastion resources have a limited lifetime which can be extended up to a certain amount by performing a heartbeat on them.
The Bastion controller is responsible for deleting expired or rotten Bastions.
- “expired” means a
Bastionhas exceeded itsstatus.expirationTimestamp. - “rotten” means a
Bastionis older than the configuredmaxLifetime.
The maxLifetime defaults to 24 hours and is an option in the BastionControllerConfiguration which is part of gardener-controller-managers ControllerManagerControllerConfiguration, see the example config file for details.
The controller also deletes Bastions in case the referenced Shoot:
- no longer exists
- is marked for deletion (i.e., have a non-
nil.metadata.deletionTimestamp) - was migrated to another seed (i.e.,
Shoot.spec.seedNameis different thanBastion.spec.seedName).
The deletion of Bastions triggers the gardenlet to perform the necessary cleanups in the Seed cluster, so some time can pass between deletion and the Bastion actually disappearing.
Clients like gardenctl are advised to not re-use Bastions whose deletion timestamp has been set already.
Refer to GEP-15 for more information on the lifecycle of
Bastion resources.
CertificateSigningRequest Controller
After the gardenlet gets deployed on the Seed cluster, it needs to establish itself as a trusted party to communicate with the Gardener API server. It runs through a bootstrap flow similar to the kubelet bootstrap process.
On startup, the gardenlet uses a kubeconfig with a bootstrap token which authenticates it as being part of the system:bootstrappers group. This kubeconfig is used to create a CertificateSigningRequest (CSR) against the Gardener API server.
The controller in gardener-controller-manager checks whether the CertificateSigningRequest has the expected organization, common name and usages which the gardenlet would request.
It only auto-approves the CSR if the client making the request is allowed to “create” the
certificatesigningrequests/seedclient subresource. Clients with the system:bootstrappers group are bound to the gardener.cloud:system:seed-bootstrapper ClusterRole, hence, they have such privileges. As the bootstrap kubeconfig for the gardenlet contains a bootstrap token which is authenticated as being part of the systems:bootstrappers group, its created CSR gets auto-approved.
CloudProfile Controller
CloudProfiles are essential when it comes to reconciling Shoots since they contain constraints (like valid machine types, Kubernetes versions, or machine images) and sometimes also some global configuration for the respective environment (typically via provider-specific configuration in .spec.providerConfig).
Consequently, to ensure that CloudProfiles in-use are always present in the system until the last referring Shoot or NamespacedCloudProfile gets deleted, the controller adds a finalizer which is only released when there is no Shoot or NamespacedCloudProfile referencing the CloudProfile anymore.
NamespacedCloudProfile Controller
NamespacedCloudProfiles provide a project-scoped extension to CloudProfiles, allowing for adjustments of a parent CloudProfile (e.g. by overriding expiration dates of Kubernetes versions or machine images). This allows for modifications without global project visibility. Like CloudProfiles do in their spec, NamespacedCloudProfiles also expose the resulting Shoot constraints as a CloudProfileSpec in their status.
The controller ensures that NamespacedCloudProfiles in-use remain present in the system until the last referring Shoot is deleted by adding a finalizer that is only released when there is no Shoot referencing the NamespacedCloudProfile anymore.
ControllerDeployment Controller
Extensions are registered in the garden cluster via ControllerRegistration and deployment of respective extensions are specified via ControllerDeployment. For more info refer to Registering Extension Controllers.
This controller ensures that ControllerDeployment in-use always exists until the last ControllerRegistration referencing them gets deleted. The controller adds a finalizer which is only released when there is no ControllerRegistration referencing the ControllerDeployment anymore.
ControllerRegistration Controller
The ControllerRegistration controller makes sure that the required Gardener Extensions specified by the ControllerRegistration resources are present in the seed clusters.
It also takes care of the creation and deletion of ControllerInstallation objects for a given seed cluster.
The controller has three reconciliation loops.
“Main” Reconciler
This reconciliation loop watches the Seed objects and determines which ControllerRegistrations are required for them and reconciles the corresponding ControllerInstallation resources to reach the determined state.
To begin with, it computes the kind/type combinations of extensions required for the seed.
For this, the controller examines a live list of ControllerRegistrations, ControllerInstallations, BackupBuckets, BackupEntrys, Shoots, and Secrets from the garden cluster.
For example, it examines the shoots running on the seed and deducts the kind/type, like Infrastructure/gcp.
The seed (seed.spec.provider.type) and DNS (seed.spec.dns.provider.type) provider types are considered when calculating the list of required ControllerRegistrations, as well.
It also decides whether they should always be deployed based on the .spec.deployment.policy.
For the configuration options, please see this section.
Based on these required combinations, each of them are mapped to ControllerRegistration objects and then to their corresponding ControllerInstallation objects (if existing).
The controller then creates or updates the required ControllerInstallation objects for the given seed.
It also deletes every existing ControllerInstallation whose referenced ControllerRegistration is not part of the required list.
For example, if the shoots in the seed are no longer using the DNS provider aws-route53, then the controller proceeds to delete the respective ControllerInstallation object.
"ControllerRegistration Finalizer" Reconciler
This reconciliation loop watches the ControllerRegistration resource and adds finalizers to it when they are created.
In case a deletion request comes in for the resource, i.e., if a .metadata.deletionTimestamp is set, it actively scans for a ControllerInstallation resource using this ControllerRegistration, and decides whether the deletion can be allowed.
In case no related ControllerInstallation is present, it removes the finalizer and marks it for deletion.
"Seed Finalizer" Reconciler
This loop also watches the Seed object and adds finalizers to it at creation.
If a .metadata.deletionTimestamp is set for the seed, then the controller checks for existing ControllerInstallation objects which reference this seed.
If no such objects exist, then it removes the finalizer and allows the deletion.
“Extension ClusterRole” Reconciler
This reconciler watches two resources in the garden cluster:
ClusterRoles labelled withauthorization.gardener.cloud/custom-extensions-permissions=trueServiceAccounts in seed namespaces matching the selector provided via theauthorization.gardener.cloud/extensions-serviceaccount-selectorannotation of suchClusterRoles.
Its core task is to maintain a ClusterRoleBinding resource referencing the respective ClusterRole.
This gets bound to all ServiceAccounts in seed namespaces whose labels match the selector provided via the authorization.gardener.cloud/extensions-serviceaccount-selector annotation of such ClusterRoles.
You can read more about the purpose of this reconciler in this document.
CredentialsBinding Controller
CredentialsBindings reference Secrets, WorkloadIdentitys and Quotas and are themselves referenced by Shoots.
The controller adds finalizers to the referenced objects to ensure they don’t get deleted while still being referenced.
Similarly, to ensure that CredentialsBindings in-use are always present in the system until the last referring Shoot gets deleted, the controller adds a finalizer which is only released when there is no Shoot referencing the CredentialsBinding anymore.
Referenced Secrets and WorkloadIdentitys will also be labeled with provider.shoot.gardener.cloud/<type>=true, where <type> is the value of the .provider.type of the CredentialsBinding.
Also, all referenced Secrets and WorkloadIdentitys, as well as Quotas, will be labeled with reference.gardener.cloud/credentialsbinding=true to allow for easily filtering for objects referenced by CredentialsBindings.
Event Controller
With the Gardener Event Controller, you can prolong the lifespan of events related to Shoot clusters. This is an optional controller which will become active once you provide the below mentioned configuration.
All events in K8s are deleted after a configurable time-to-live (controlled via a kube-apiserver argument called --event-ttl (defaulting to 1 hour)).
The need to prolong the time-to-live for Shoot cluster events frequently arises when debugging customer issues on live systems.
This controller leaves events involving Shoots untouched, while deleting all other events after a configured time.
In order to activate it, provide the following configuration:
concurrentSyncs: The amount of goroutines scheduled for reconciling events.ttlNonShootEvents: When an event reaches this time-to-live it gets deleted unless it is a Shoot-related event (defaults to1h, equivalent to theevent-ttldefault).
⚠️ In addition, you should also configure the
--event-ttlfor the kube-apiserver to define an upper-limit of how long Shoot-related events should be stored. The--event-ttlshould be larger than thettlNonShootEventsor this controller will have no effect.
ExposureClass Controller
ExposureClass abstracts the ability to expose a Shoot clusters control plane in certain network environments (e.g. corporate networks, DMZ, internet) on all Seeds or a subset of the Seeds. For more information, see ExposureClasses.
Consequently, to ensure that ExposureClasses in-use are always present in the system until the last referring Shoot gets deleted, the controller adds a finalizer which is only released when there is no Shoot referencing the ExposureClass anymore.
ManagedSeedSet Controller
ManagedSeedSet objects maintain a stable set of replicas of ManagedSeeds, i.e. they guarantee the availability of a specified number of identical ManagedSeeds on an equal number of identical Shoots.
The ManagedSeedSet controller creates and deletes ManagedSeeds and Shoots in response to changes to the replicas and selector fields. For more information, refer to the ManagedSeedSet proposal document.
- The reconciler first gets all the replicas of the given
ManagedSeedSetin theManagedSeedSet’s namespace and with the matching selector. Each replica is a struct that contains aManagedSeed, its correspondingSeedandShootobjects. - Then the pending replica is retrieved, if it exists.
- Next it determines the ready, postponed, and deletable replicas.
- A replica is considered
readywhen aSeedowned by aManagedSeedhas been registered either directly or by deployinggardenletinto aShoot, theSeedisReadyand theShoot’s status isHealthy. - If a replica is not ready and it is not pending, i.e. it is not specified in the
ManagedSeed’sstatus.pendingReplicafield, then it is added to thepostponedreplicas. - A replica is deletable if it has no scheduled
Shoots and the replica’sShootandManagedSeeddo not have theseedmanagement.gardener.cloud/protect-from-deletionannotation.
- A replica is considered
- Finally, it checks the actual and target replica counts. If the actual count is less than the target count, the controller scales up the replicas by creating new replicas to match the desired target count. If the actual count is more than the target, the controller deletes replicas to match the desired count. Before scale-out or scale-in, the controller first reconciles the pending replica (there can always only be one) and makes sure the replica is ready before moving on to the next one.
Scale-out(actual count < target count)- During the scale-out phase, the controller first creates the
Shootobject from theManagedSeedSet’sspec.shootTemplatefield and adds the replica to thestatus.pendingReplicaof theManagedSeedSet. - For the subsequent reconciliation steps, the controller makes sure that the pending replica is ready before proceeding to the next replica. Once the
Shootis created successfully, theManagedSeedobject is created from theManagedSeedSet’sspec.template. TheManagedSeedobject is reconciled by theManagedSeedcontroller and aSeedobject is created for the replica. Once the replica’sSeedbecomes ready and theShootbecomes healthy, the replica also becomes ready.
- During the scale-out phase, the controller first creates the
Scale-in(actual count > target count)- During the scale-in phase, the controller first determines the replica that can be deleted. From the deletable replicas, it chooses the one with the lowest priority and deletes it. Priority is determined in the following order:
- First, compare replica statuses. Replicas with “less advanced” status are considered lower priority. For example, a replica with
StatusShootReconcilingstatus has a lower value than a replica withStatusShootReconciledstatus. Hence, in this case, a replica with aStatusShootReconcilingstatus will have lower priority and will be considered for deletion. - Then, the replicas are compared with the readiness of their
Seeds. Replicas with non-readySeeds are considered lower priority. - Then, the replicas are compared with the health statuses of their
Shoots. Replicas with “worse” statuses are considered lower priority. - Finally, the replica ordinals are compared. Replicas with lower ordinals are considered lower priority.
- First, compare replica statuses. Replicas with “less advanced” status are considered lower priority. For example, a replica with
- During the scale-in phase, the controller first determines the replica that can be deleted. From the deletable replicas, it chooses the one with the lowest priority and deletes it. Priority is determined in the following order:
Quota Controller
Quota object limits the resources consumed by shoot clusters either per provider secret or per project/namespace.
Consequently, to ensure that Quotas in-use are always present in the system until the last SecretBinding or CredentialsBinding that references them gets deleted, the controller adds a finalizer which is only released when there is no SecretBinding or CredentialsBinding referencing the Quota anymore.
Project Controller
There are multiple controllers responsible for different aspects of Project objects.
Please also refer to the Project documentation.
“Main” Reconciler
This reconciler manages a dedicated Namespace for each Project.
The namespace name can either be specified explicitly in .spec.namespace (must be prefixed with garden-) or it will be determined by the controller.
If .spec.namespace is set, it tries to create it. If it already exists, it tries to adopt it.
This will only succeed if the Namespace was previously labeled with gardener.cloud/role=project and project.gardener.cloud/name=<project-name>.
This is to prevent end-users from being able to adopt arbitrary namespaces and escalate their privileges, e.g. the kube-system namespace.
After the namespace was created/adopted, the controller creates several ClusterRoles and ClusterRoleBindings that allow the project members to access related resources based on their roles.
These RBAC resources are prefixed with gardener.cloud:system:project{-member,-viewer}:<project-name>.
Gardener administrators and extension developers can define their own roles. For more information, see Extending Project Roles for more information.
In addition, operators can configure the Project controller to maintain a default ResourceQuota for project namespaces.
Quotas can especially limit the creation of user facing resources, e.g. Shoots, SecretBindings, CredentialsBinding, Secrets and thus protect the garden cluster from massive resource exhaustion but also enable operators to align quotas with respective enterprise policies.
⚠️ Gardener itself is not exempted from configured quotas. For example, Gardener creates
Secretsfor every shoot cluster in the project namespace and at the same time increases the available quota count. Please mind this additional resource consumption.
The controller configuration provides a template section controllers.project.quotas where such a ResourceQuota (see the example below) can be deposited.
controllers:
project:
quotas:
- config:
apiVersion: v1
kind: ResourceQuota
spec:
hard:
count/shoots.core.gardener.cloud: "100"
count/secretbindings.core.gardener.cloud: "10"
count/credentialsbindings.security.gardener.cloud: "10"
count/secrets: "800"
projectSelector: {}
The Project controller takes the specified config and creates a ResourceQuota with the name gardener in the project namespace.
If a ResourceQuota resource with the name gardener already exists, the controller will only update fields in spec.hard which are unavailable at that time.
This is done to configure a default Quota in all projects but to allow manual quota increases as the projects’ demands increase.
spec.hard fields in the ResourceQuota object that are not present in the configuration are removed from the object.
Labels and annotations on the ResourceQuota config get merged with the respective fields on existing ResourceQuotas.
An optional projectSelector narrows down the amount of projects that are equipped with the given config.
If multiple configs match for a project, then only the first match in the list is applied to the project namespace.
The .status.phase of the Project resources is set to Ready or Failed by the reconciler to indicate whether the reconciliation loop was performed successfully.
Also, it generates Events to provide further information about its operations.
When a Project is marked for deletion, the controller ensures that there are no Shoots left in the project namespace.
Once all Shoots are gone, the Namespace and Project are released.
“Stale Projects” Reconciler
As Gardener is a large-scale Kubernetes as a Service, it is designed for being used by a large amount of end-users.
Over time, it is likely to happen that some of the hundreds or thousands of Project resources are no longer actively used.
Gardener offers the “stale projects” reconciler which will take care of identifying such stale projects, marking them with a “warning”, and eventually deleting them after a certain time period. This reconciler is enabled by default and works as follows:
- Projects are considered as “stale”/not actively used when all of the following conditions apply: The namespace associated with the
Projectdoes not have any…Shootresources.BackupEntryresources.Secretresources that are referenced by aSecretBindingor aCredentialsBindingthat is in use by aShoot(not necessarily in the same namespace).WorkloadIdentityresources that are referenced by aCredentialsBindingthat is in use by aShoot(not necessarily in the same namespace).Quotaresources that are referenced by aSecretBindingor aCredentialsBindingthat is in use by aShoot(not necessarily in the same namespace).- The time period when the project was used for the last time (
status.lastActivityTimestamp) is longer than the configuredminimumLifetimeDays
If a project is considered “stale”, then its .status.staleSinceTimestamp will be set to the time when it was first detected to be stale.
If it gets actively used again, this timestamp will be removed.
After some time, the .status.staleAutoDeleteTimestamp will be set to a timestamp after which Gardener will auto-delete the Project resource if it still is not actively used.
The component configuration of the gardener-controller-manager offers to configure the following options:
minimumLifetimeDays: Don’t consider newly createdProjects as “stale” too early to give people/end-users some time to onboard and get familiar with the system. The “stale project” reconciler won’t set any timestamp forProjects younger thanminimumLifetimeDays. When you change this value, then projects marked as “stale” may be no longer marked as “stale” in case they are young enough, or vice versa.staleGracePeriodDays: Don’t compute auto-delete timestamps for staleProjects that are unused for less thanstaleGracePeriodDays. This is to not unnecessarily make people/end-users nervous “just because” they haven’t actively used theirProjectfor a given amount of time. When you change this value, then already assigned auto-delete timestamps may be removed if the new grace period is not yet exceeded.staleExpirationTimeDays: Expiration time after which staleProjects are finally auto-deleted (after.status.staleSinceTimestamp). If this value is changed and an auto-delete timestamp got already assigned to the projects, then the new value will only take effect if it’s increased. Hence, decreasing thestaleExpirationTimeDayswill not decrease already assigned auto-delete timestamps.
Gardener administrators/operators can exclude specific
Projects from the stale check by annotating the relatedNamespaceresource withproject.gardener.cloud/skip-stale-check=true.
“Activity” Reconciler
Since the other two reconcilers are unable to actively monitor the relevant objects that are used in a Project (Shoot, Secret, etc.), there could be a situation where the user creates and deletes objects in a short period of time. In that case, the Stale Project Reconciler could not see that there was any activity on that project and it will still mark it as a Stale, even though it is actively used.
The Project Activity Reconciler is implemented to take care of such cases. An event handler will notify the reconciler for any activity and then it will update the status.lastActivityTimestamp. This update will also trigger the Stale Project Reconciler.
SecretBinding Controller
SecretBindings reference Secrets and Quotas and are themselves referenced by Shoots.
The controller adds finalizers to the referenced objects to ensure they don’t get deleted while still being referenced.
Similarly, to ensure that SecretBindings in-use are always present in the system until the last referring Shoot gets deleted, the controller adds a finalizer which is only released when there is no Shoot referencing the SecretBinding anymore.
Referenced Secrets will also be labeled with provider.shoot.gardener.cloud/<type>=true, where <type> is the value of the .provider.type of the SecretBinding.
Also, all referenced Secrets, as well as Quotas, will be labeled with reference.gardener.cloud/secretbinding=true to allow for easily filtering for objects referenced by SecretBindings.
Seed Controller
The Seed controller in the gardener-controller-manager reconciles Seed objects with the help of the following reconcilers.
“Main” Reconciler
This reconciliation loop takes care of seed related operations in the garden cluster. When a new Seed object is created,
the reconciler creates a new Namespace in the garden cluster seed-<seed-name>. Namespaces dedicated to single
seed clusters allow us to segregate access permissions i.e., a gardenlet must not have permissions to access objects in
all Namespaces in the garden cluster.
There are objects in a Garden environment which are created once by the operator e.g., default domain secret,
alerting credentials, and are required for operations happening in the gardenlet. Therefore, we not only need a seed specific
Namespace but also a copy of these “shared” objects.
The “main” reconciler takes care about this replication:
| Kind | Namespace | Label Selector |
|---|---|---|
| Secret | garden | gardener.cloud/role |
“Backup Buckets Check” Reconciler
Every time a BackupBucket object is created or updated, the referenced Seed object is enqueued for reconciliation.
It’s the reconciler’s task to check the status subresource of all existing BackupBuckets that reference this Seed.
If at least one BackupBucket has .status.lastError != nil, the BackupBucketsReady condition on the Seed will be set to False, and consequently the Seed is considered as NotReady.
If the SeedBackupBucketsCheckControllerConfiguration (which is part of gardener-controller-managers component configuration) contains a conditionThreshold for the BackupBucketsReady, the condition will instead first be set to Progressing and eventually to False once the conditionThreshold expires. See the example config file for details.
Once the BackupBucket is healthy again, the seed will be re-queued and the condition will turn true.
“Extensions Check” Reconciler
This reconciler reconciles Seed objects and checks whether all ControllerInstallations referencing them are in a healthy state.
Concretely, all three conditions Valid, Installed, and Healthy must have status True and the Progressing condition must have status False.
Based on this check, it maintains the ExtensionsReady condition in the respective Seed’s .status.conditions list.
“Lifecycle” Reconciler
The “Lifecycle” reconciler processes Seed objects which are enqueued every 10 seconds in order to check if the responsible
gardenlet is still responding and operable. Therefore, it checks renewals via Lease objects of the seed in the garden cluster
which are renewed regularly by the gardenlet.
In case a Lease is not renewed for the configured amount in config.controllers.seed.monitorPeriod.duration:
- The reconciler assumes that the
gardenletstopped operating and updates theGardenletReadycondition toUnknown. - Additionally, the conditions and constraints of all
Shootresources scheduled on the affected seed are set toUnknownas well, because a strikinggardenletwon’t be able to maintain these conditions any more. - If the gardenlet’s client certificate has expired (identified based on the
.status.clientCertificateExpirationTimestampfield in theSeedresource) and if it is managed by aManagedSeed, then this will be triggered for a reconciliation. This will trigger the bootstrapping process again and allows gardenlets to obtain a fresh client certificate.
“Reference” Reconciler
Seed objects may specify references to other objects in the garden namespace in the garden cluster which are required for certain features.
For example, operators can configure additional data for extensions via .spec.resources[].
Such objects need a special protection against deletion requests as long as they are still being referenced by one or multiple seeds.
Therefore, this reconciler checks Seeds for referenced objects and adds the finalizer gardener.cloud/reference-protection to their .metadata.finalizers list.
The reconciled Seed also gets this finalizer to enable a proper garbage collection in case the gardener-controller-manager is offline at the moment of an incoming deletion request.
When an object is not actively referenced anymore because the Seed specification has changed or all related seeds were deleted (are in deletion), the controller will remove the added finalizer again so that the object can safely be deleted or garbage collected.
This reconciler inspects the following references:
Secrets andConfigMaps from.spec.resources[]
The checks naturally grow with the number of references that are added to the Seed specification.
Shoot Controller
“Conditions” Reconciler
In case the reconciled Shoot is registered via a ManagedSeed as a seed cluster, this reconciler merges the conditions in the respective Seed’s .status.conditions into the .status.conditions of the Shoot.
This is to provide a holistic view on the status of the registered seed cluster by just looking at the Shoot resource.
“Hibernation” Reconciler
This reconciler is responsible for hibernating or awakening shoot clusters based on the schedules defined in their .spec.hibernation.schedules.
It ignores failed Shoots and those marked for deletion.
“Maintenance” Reconciler
This reconciler is responsible for maintaining shoot clusters based on the time window defined in their .spec.maintenance.timeWindow.
It might auto-update the Kubernetes version or the operating system versions specified in the worker pools (.spec.provider.workers).
It could also add some operation or task annotations. For more information, see Shoot Maintenance.
“Quota” Reconciler
This reconciler might auto-delete shoot clusters in case their referenced SecretBinding or CredentialsBinding is itself referencing a Quota with .spec.clusterLifetimeDays != nil.
If the shoot cluster is older than the configured lifetime, then it gets deleted.
It maintains the expiration time of the Shoot in the value of the shoot.gardener.cloud/expiration-timestamp annotation.
This annotation might be overridden, however only by at most twice the value of the .spec.clusterLifetimeDays.
“Reference” Reconciler
Shoot objects may specify references to other objects in the garden cluster which are required for certain features.
For example, users can configure various DNS providers via .spec.dns.providers and usually need to refer to a corresponding Secret with valid DNS provider credentials inside.
Such objects need a special protection against deletion requests as long as they are still being referenced by one or multiple shoots.
Therefore, this reconciler checks Shoots for referenced objects and adds the finalizer gardener.cloud/reference-protection to their .metadata.finalizers list.
The reconciled Shoot also gets this finalizer to enable a proper garbage collection in case the gardener-controller-manager is offline at the moment of an incoming deletion request.
When an object is not actively referenced anymore because the Shoot specification has changed or all related shoots were deleted (are in deletion), the controller will remove the added finalizer again so that the object can safely be deleted or garbage collected.
This reconciler inspects the following references:
- Admission plugin kubeconfig
Secrets (.spec.kubernetes.kubeAPIServer.admissionPlugins[].kubeconfigSecretName) - Audit policy
ConfigMaps (.spec.kubernetes.kubeAPIServer.auditConfig.auditPolicy.configMapRef) - DNS provider
Secrets (.spec.dns.providers[].secretName) - Structured authentication
ConfigMaps (.spec.kubernetes.kubeAPIServer.structuredAuthentication.configMapName) - Structured authorization
ConfigMaps (.spec.kubernetes.kubeAPIServer.structuredAuthorization.configMapName) - Structured authorization kubeconfig
Secrets (.spec.kubernetes.kubeAPIServer.structuredAuthorization.kubeconfigs[].secretName) Secrets andConfigMaps from.spec.resources[]
The checks naturally grow with the number of references that are added to the Shoot specification.
“Retry” Reconciler
This reconciler is responsible for retrying certain failed Shoots.
Currently, the reconciler retries only failed Shoots with an error code ERR_INFRA_RATE_LIMITS_EXCEEDED. See Shoot Status for more details.
“Status Label” Reconciler
This reconciler is responsible for maintaining the shoot.gardener.cloud/status label on Shoots. See Shoot Status for more details.
“Migration” Reconciler
This reconciler is triggered for Shoots currently in migration (i.e., .spec.seedName != .status.seedName).
It maintains the ReadyForMigration constraint in the .status.constraints[] list.
A Shoot is considered ready for migration if the destination Seed is up-to-date and healthy.
The main purpose of this constraint is to allow the gardenlet running in the source seed cluster to check if it can start with the migration flow without that it needs to directly read the destination Seed resource (for which it won’t have permissions).
“ShootState Finalizer” Reconciler
This reconciler is responsible for managing a finalizer (core.gardener.cloud/shootstate) on a ShootState. The finalizer ensures the ShootState will exist during migration of Shoot’s control plane to another Seed.
The ShootState has to be present until the Migrate and Restore operations finish successfully. Otherwise, in corner cases of prior deletion, subsequent Restore operations of the Shoot will fail due to the missing ShootState resource.
10 - Gardener Node Agent
Overview
The goal of the gardener-node-agent is to bootstrap a machine into a worker node and maintain node-specific components, which run on the node and are unmanaged by Kubernetes (e.g. the kubelet service, systemd units, …).
It effectively is a Kubernetes controller deployed onto the worker node.
Architecture and Basic Design

This figure visualizes the overall architecture of the gardener-node-agent. On the left side, it starts with an OperatingSystemConfig resource (OSC) with a corresponding worker pool specific cloud-config-<worker-pool> secret being passed by reference through the userdata to a machine by the machine-controller-manager (MCM).
On the right side, the cloud-config secret will be extracted and used by the gardener-node-agent after being installed. Details on this can be found in the next section.
Finally, the gardener-node-agent runs a systemd service watching on secret resources located in the kube-system namespace like our cloud-config secret that contains the OperatingSystemConfig. When gardener-node-agent applies the OSC, it installs the kubelet + configuration on the worker node.
Installation and Bootstrapping
This section describes how the gardener-node-agent is initially installed onto the worker node.
In the beginning, there is a very small bash script called gardener-node-init.sh, which will be copied to /var/lib/gardener-node-agent/init.sh on the node with cloud-init data.
This script’s sole purpose is downloading and starting the gardener-node-agent.
The binary artifact is extracted from an OCI artifact and lives at /opt/bin/gardener-node-agent.
Along with the init script, a configuration for the gardener-node-agent is carried over to the worker node at /var/lib/gardener-node-agent/config.yaml.
This configuration contains things like the shoot’s kube-apiserver endpoint, the according certificates to communicate with it, and controller configuration.
In a bootstrapping phase, the gardener-node-agent sets itself up as a systemd service.
It also executes tasks that need to be executed before any other components are installed, e.g. formatting the data device for the kubelet.
Controllers
This section describes the controllers in more details.
Lease Controller
This controller creates a Lease for gardener-node-agent in kube-system namespace of the shoot cluster.
Each instance of gardener-node-agent creates its own Lease when its corresponding Node was created.
It renews the Lease resource every 10 seconds. This indicates a heartbeat to the external world.
Node Controller
This controller watches the Node object for the machine it runs on.
The correct Node is identified based on the hostname of the machine (Nodes have the kubernetes.io/hostname label).
Whenever the worker.gardener.cloud/restart-systemd-services annotation changes, the controller performs the desired changes by restarting the specified systemd unit files.
See also this document for more information.
After restarting all units, the annotation is removed.
ℹ️ When the
gardener-node-agentsystemd service itself is requested to be restarted, the annotation is removed first to ensure it does not restart itself indefinitely.
Operating System Config Controller
This controller contains the main logic of gardener-node-agent.
It watches Secrets whose data map contains the OperatingSystemConfig which consists of all systemd units and files that are relevant for the node configuration.
Amongst others, a prominent example is the configuration file for kubelet and its unit file for the kubelet.service.
It also watches Nodes and requeues the corresponding Secret when the reason of the node condition InPlaceUpdate changes to ReadyForUpdate.
The controller decodes the configuration and computes the files and units that have changed since its last reconciliation. It writes or update the files and units to the file system, removes no longer needed files and units, reloads the systemd daemon, and starts or stops the units accordingly.
After successful reconciliation, it persists the just applied OperatingSystemConfig into a file on the host.
This file will be used for future reconciliations to compute file/unit changes.
The controller also maintains two annotations on the Node:
worker.gardener.cloud/kubernetes-version, describing the version of the installedkubelet.checksum/cloud-config-data, describing the checksum of the appliedOperatingSystemConfig(used in future reconciliations to determine whether it needs to reconcile, and to report that this node is up-to-date).
Token Controller
This controller watches the access token Secrets in the kube-system namespace configured via the gardener-node-agent’s component configuration (.controllers.token.syncConfigs[] field).
Whenever the .data.token field changes, it writes the new content to a file on the configured path on the host file system.
This mechanism is used to download its own access token for the shoot cluster, but also the access tokens of other systemd components (e.g., valitail).
Since the underlying client is based on k8s.io/client-go and the kubeconfig points to this token file, it is dynamically reloaded without the necessity of explicit configuration or code changes.
This procedure ensures that the most up-to-date tokens are always present on the host and used by the gardener-node-agent and the other systemd components.
The controller is also triggered via a source channel, which is done by the Operating System Config controller during an in-place service account key rotation.
Reasoning
The gardener-node-agent is a replacement for what was called the cloud-config-downloader and the cloud-config-executor, both written in bash. The gardener-node-agent implements this functionality as a regular controller and feels more uniform in terms of maintenance.
With the new architecture we gain a lot, let’s describe the most important gains here.
Developer Productivity
Since the Gardener community develops in Go day by day, writing business logic in bash is difficult, hard to maintain, almost impossible to test. Getting rid of almost all bash scripts which are currently in use for this very important part of the cluster creation process will enhance the speed of adding new features and removing bugs.
Speed
Until now, the cloud-config-downloader runs in a loop every 60s to check if something changed on the shoot which requires modifications on the worker node. This produces a lot of unneeded traffic on the API server and wastes time, it will sometimes take up to 60s until a desired modification is started on the worker node.
By writing a “real” Kubernetes controller, we can watch for the Node, the OSC in the Secret, and the shoot-access token in the secret. If any of these object changed, and only then, the required action will take effect immediately.
This will speed up operations and will reduce the load on the API server of the shoot especially for large clusters.
Scalability
The cloud-config-downloader adds a random wait time before restarting the kubelet in case the kubelet was updated or a configuration change was made to it. This is required to reduce the load on the API server and the traffic on the internet uplink. It also reduces the overall downtime of the services in the cluster because every kubelet restart transforms a node for several seconds into NotReady state which potentially interrupts service availability.
Decision was made to keep the existing jitter mechanism which calculates the kubelet-download-and-restart-delay-seconds on the controller itself.
Correctness
The configuration of the cloud-config-downloader is actually done by placing a file for every configuration item on the disk on the worker node. This was done because parsing the content of a single file and using this as a value in bash reduces to something like VALUE=$(cat /the/path/to/the/file). Simple, but it lacks validation, type safety and whatnot.
With the gardener-node-agent we introduce a new API which is then stored in the gardener-node-agent secret and stored on disk in a single YAML file for comparison with the previous known state. This brings all benefits of type safe configuration.
Because actual and previous configuration are compared, removed files and units are also removed and stopped on the worker if removed from the OSC.
Availability
Previously, the cloud-config-downloader simply restarted the systemd units on every change to the OSC, regardless which of the services changed. The gardener-node-agent first checks which systemd unit was changed, and will only restart these. This will prevent unneeded kubelet restarts.
11 - Gardener Operator
Overview
The gardener-operator is responsible for the garden cluster environment.
Without this component, users must deploy ETCD, the Gardener control plane, etc., manually and with separate mechanisms (not maintained in this repository).
This is quite unfortunate since this requires separate tooling, processes, etc.
A lot of production- and enterprise-grade features were built into Gardener for managing the seed and shoot clusters, so it makes sense to re-use them as much as possible also for the garden cluster.
Deployment
There is a Helm chart which can be used to deploy the gardener-operator.
Once deployed and ready, you can create a Garden resource.
Note that there can only be one Garden resource per system at a time.
ℹ️ Similar to seed clusters, garden runtime clusters require a VPA, see this section. By default,
gardener-operatordeploys the VPA components. However, when there already is a VPA available, then set.spec.runtimeCluster.settings.verticalPodAutoscaler.enabled=falsein theGardenresource.
Garden Resources
Please find an exemplary Garden resource here.
Configuration For Runtime Cluster
Settings
The Garden resource offers a few settings that are used to control the behaviour of gardener-operator in the runtime cluster.
This section provides an overview over the available settings in .spec.runtimeCluster.settings:
Load Balancer Services
gardener-operator deploys Istio and relevant resources to the runtime cluster in order to expose the virtual-garden-kube-apiserver service (similar to how the kube-apiservers of shoot clusters are exposed).
In most cases, the cloud-controller-manager (responsible for managing these load balancers on the respective underlying infrastructure) supports certain customization and settings via annotations.
This document provides a good overview and many examples.
By setting the .spec.runtimeCluster.settings.loadBalancerServices.annotations field the Gardener administrator can specify a list of annotations which will be injected into the Services of type LoadBalancer.
Vertical Pod Autoscaler
gardener-operator heavily relies on the Kubernetes vertical-pod-autoscaler component.
By default, the Garden controller deploys the VPA components into the garden namespace of the respective runtime cluster.
In case you want to manage the VPA deployment on your own or have a custom one, then you might want to disable the automatic deployment of gardener-operator.
Otherwise, you might end up with two VPAs which will cause erratic behaviour.
By setting the .spec.runtimeCluster.settings.verticalPodAutoscaler.enabled=false you can disable the automatic deployment.
⚠️ In any case, there must be a VPA available for your runtime cluster. Using a runtime cluster without VPA is not supported.
Topology-Aware Traffic Routing
Refer to the Topology-Aware Traffic Routing documentation as this document contains the documentation for the topology-aware routing setting for the garden runtime cluster.
Volumes
It is possible to define the minimum size for PersistentVolumeClaims in the runtime cluster created by gardener-operator via the .spec.runtimeCluster.volume.minimumSize field.
This can be relevant in case the runtime cluster runs on an infrastructure that does only support disks of at least a certain size.
Configuration For Virtual Cluster
ETCD Encryption Config
The spec.virtualCluster.kubernetes.kubeAPIServer.encryptionConfig field in the Garden API allows operators to customize encryption configurations for the kube-apiserver of the virtual cluster. It provides options to specify additional resources for encryption. Similarly spec.virtualCluster.gardener.gardenerAPIServer.encryptionConfig field allows operators to customize encryption configurations for the gardener-apiserver.
- The resources field can be used to specify resources that should be encrypted in addition to secrets. Secrets are always encrypted for the
kube-apiserver. For thegardener-apiserver, the following resources are always encrypted:controllerdeployments.core.gardener.cloudcontrollerregistrations.core.gardener.cloudinternalsecrets.core.gardener.cloudshootstates.core.gardener.cloud
- Adding an item to any of the lists will cause patch requests for all the resources of that kind to encrypt them in the etcd. See Encrypting Confidential Data at Rest for more details.
- Removing an item from any of these lists will cause patch requests for all the resources of that type to decrypt and rewrite the resource as plain text. See Decrypt Confidential Data that is Already Encrypted at Rest for more details.
Extension Resource
A Gardener installation relies on extensions to provide support for new cloud providers or to add new capabilities. You can find out more about Gardener extensions and how they can be used here.
The Extension resource is intended to automate the installation and management of extensions in a Gardener landscape.
It contains configuration for the following scenarios:
- The deployment of the extension chart in the garden runtime cluster.
- The deployment of
ControllerRegistrationandControllerDeploymentresources in the (virtual) garden cluster. - The deployment of extension admissions charts in runtime and virtual clusters.
With regard to the Garden reconciliation process, there are specific types of extensions that are of key interest, namely the BackupBucket, DNSRecord, and Extension types.
The BackupBucket extension is utilized to manage the backup bucket dedicated to the garden’s main etcd.
The DNSRecord extension type is essential to manage the API server and ingress DNS records.
Lastly, the Extension type plays a crucial role in managing generic Gardener extensions which deploy various components within the runtime cluster. These extensions can be activated and configured in the .spec.extensions field of the Garden resource. These extensions can supplement functionality and provide new capabilities.
Please find an exemplary Extension resource here.
Extension Deployment
The .spec.deployment specifies how an extension can be installed for a Gardener landscape and consists of the following parts:
.spec.deployment.extensioncontains the deployment specification of an extension..spec.deployment.admissioncontains the deployment specification of an extension admission.
Each one is described in more details below.
Configuration for Extension Deployment
.spec.deployment.extension contains configuration for the registration of an extension in the garden cluster.
gardener-operator follows the same principles described by this document:
.spec.deployment.extension.helmand.spec.deployment.extension.valuesare used when creating theControllerDeploymentin the garden cluster..spec.deployment.extension.policyand.spec.deployment.extension.seedSelectordefine the extension’s installation policy as per theControllerDeployment'srespective fields
Runtime
Extensions can manage resources required by the Garden resource (e.g. BackupBucket, DNSRecord, Extension) in the runtime cluster.
Since the environment in the runtime cluster may differ from that of a Seed, the extension is installed in the runtime cluster with a distinct set of Helm chart values specified in .spec.deployment.extension.runtimeValues.
If no runtimeValues are provided, the extension deployment for the runtime garden is considered superfluous and the deployment is uninstalled.
The configuration allows for precise control over various extension parameters, such as requested resources, priority classes, and more.
Besides the values configured in .spec.deployment.extension.runtimeValues, a runtime deployment flag and a priority class are merged into the values:
gardener:
runtimeCluster:
enabled: true # indicates the extension is enabled for the Garden cluster, e.g. for handling `BackupBucket`, `DNSRecord` and `Extension` objects.
priorityClassName: gardener-garden-system-200
As soon as a Garden object is created and runtimeValues are configured, the extension is deployed in the runtime cluster.
Extension Registration
When the virtual garden cluster is available, the Extension controller manages ControllerRegistration/ControllerDeployment resources
to register extensions for shoots. The fields of .spec.deployment.extension include their configuration options.
Configuration for Admission Deployment
The .spec.deployment.admission defines how an extension admission may be deployed by the gardener-operator.
This deployment is optional and may be omitted.
Typically, the admission are split in two parts:
Runtime
The runtime part contains deployment relevant manifests, required to run the admission service in the runtime cluster.
The following values are passed to the chart during reconciliation:
gardener:
runtimeCluster:
priorityClassName: <Class to be used for extension admission>
Virtual
The virtual part includes the webhook registration (MutatingWebhookConfiguration/Validatingwebhookconfiguration) and RBAC configuration.
The following values are passed to the chart during reconciliation:
gardener:
virtualCluster:
serviceAccount:
name: <Name of the service account used to connect to the garden cluster>
namespace: <Namespace of the service account>
Extension admissions often need to retrieve additional context from the garden cluster in order to process validating or mutating requests.
For example, the corresponding CloudProfile might be needed to perform a provider specific shoot validation.
Therefore, Gardener automatically injects a kubeconfig into the admission deployment to interact with the (virtual) garden cluster (see this document for more information).
Configuration for Extension Resources
The .spec.resources field refers to the extension resources as defined by Gardener in the extensions.gardener.cloud/v1alpha1 API.
These include both well-known types such as Infrastructure, Worker etc. and generic resources.
The field will be used to populate the respective field in the resulting ControllerRegistration in the garden cluster.
Controllers
The gardener-operator controllers are now described in more detail.
Garden Controller
The Garden controller in the operator reconciles Garden objects with the help of the following reconcilers.
Main Reconciler
The reconciler first generates a general CA certificate which is valid for ~30d and auto-rotated when 80% of its lifetime is reached.
Afterwards, it brings up the so-called “garden system components”.
The gardener-resource-manager is deployed first since its ManagedResource controller will be used to bring up the remainders.
Other system components are:
- runtime garden system resources (
PriorityClasses for the workload resources) - virtual garden system resources (RBAC rules)
- Vertical Pod Autoscaler (if enabled via
.spec.runtimeCluster.settings.verticalPodAutoscaler.enabled=truein theGarden) - ETCD Druid
- Istio
As soon as all system components are up, the reconciler deploys the virtual garden cluster.
It comprises out of two ETCDs (one “main” etcd, one “events” etcd) which are managed by ETCD Druid via druid.gardener.cloud/v1alpha1.Etcd custom resources.
The whole management works similar to how it works for Shoots, so you can take a look at this document for more information in general.
The virtual garden control plane components are:
virtual-garden-etcd-mainvirtual-garden-etcd-eventsvirtual-garden-kube-apiservervirtual-garden-kube-controller-managervirtual-garden-gardener-resource-manager
If the .spec.virtualCluster.controlPlane.highAvailability={} is set then these components will be deployed in a “highly available” mode.
For ETCD, this means that there will be 3 replicas each.
This works similar like for Shoots (see this document) except for the fact that there is no failure tolerance type configurability.
The gardener-resource-manager’s HighAvailabilityConfig webhook makes sure that all pods with multiple replicas are spread on nodes, and if there are at least two zones in .spec.runtimeCluster.provider.zones then they also get spread across availability zones.
If once set, removing
.spec.virtualCluster.controlPlane.highAvailabilityagain is not supported.
The virtual-garden-kube-apiserver Deployment is exposed via Istio, similar to how the kube-apiservers of shoot clusters are exposed.
Similar to the Shoot API, the version of the virtual garden cluster is controlled via .spec.virtualCluster.kubernetes.version.
Likewise, specific configuration for the control plane components can be provided in the same section, e.g. via .spec.virtualCluster.kubernetes.kubeAPIServer for the kube-apiserver or .spec.virtualCluster.kubernetes.kubeControllerManager for the kube-controller-manager.
The kube-controller-manager only runs a few controllers that are necessary in the scenario of the virtual garden.
Most prominently, the serviceaccount-token controller is unconditionally disabled.
Hence, the usage of static ServiceAccount secrets is not supported generally.
Instead, the TokenRequest API should be used.
Third-party components that need to communicate with the virtual cluster can leverage the gardener-resource-manager’s TokenRequestor controller and the generic kubeconfig, just like it works for Shoots.
Please note, that this functionality is restricted to the garden namespace. The current Secret name of the generic kubeconfig can be found in the annotations (key: generic-token-kubeconfig.secret.gardener.cloud/name) of the Garden resource.
For the virtual cluster, it is essential to provide at least one DNS domain via .spec.virtualCluster.dns.domains.
The respective DNS records are not managed by gardener-operator and should be created manually.
They should point to the load balancer IP of the istio-ingressgateway Service in namespace virtual-garden-istio-ingress.
The DNS records must be prefixed with both gardener. and api. for all domains in .spec.virtualCluster.dns.domains.
The first DNS domain in this list is used for the server in the kubeconfig, and for configuring the --external-hostname flag of the API server.
Apart from the control plane components of the virtual cluster, the reconcile also deploys the control plane components of Gardener.
gardener-apiserver reuses the same ETCDs like the virtual-garden-kube-apiserver, so all data related to the “the garden cluster” is stored together and “isolated” from ETCD data related to the runtime cluster.
This drastically simplifies backup and restore capabilities (e.g., moving the virtual garden cluster from one runtime cluster to another).
The Gardener control plane components are:
gardener-apiservergardener-admission-controllergardener-controller-managergardener-scheduler
Besides those, the gardener-operator is able to deploy the following optional components:
- Gardener Dashboard (and the controller for web terminals) when
.spec.virtualCluster.gardener.gardenerDashboard(or.spec.virtualCluster.gardener.gardenerDashboard.terminal, respectively) is set. You can read more about it and its configuration in this section. - Gardener Discovery Server when
.spec.virtualCluster.gardener.gardenerDiscoveryServeris set. The service account issuer of shoots will be calculated in the formathttps://discovery.<.spec.runtimeCluster.ingress.domains[0]>/projects/<project-name>/shoots/<shoot-uid>/issuer. This configuration applies for all seeds registered with the Garden cluster. Once set it should not be modified.
The reconciler also manages a few observability-related components:
fluent-operatorfluent-bitgardener-metrics-exporterkube-state-metricsplutonovaliprometheus-operatoropentelemetry-operatoralertmanager-garden(read more here)prometheus-garden(read more here)prometheus-longterm(read more here)blackbox-exporterperses-operator
It is also mandatory to provide an IPv4 CIDR for the service network of the virtual cluster via .spec.virtualCluster.networking.services.
This range is used by the API server to compute the cluster IPs of Services.
The controller maintains the .status.lastOperation which indicates the status of an operation.
Gardener Dashboard
.spec.virtualCluster.gardener.gardenerDashboard serves a few configuration options for the dashboard.
This section highlights the most prominent fields:
oidcConfig: The general OIDC configuration is part of.spec.virtualCluster.kubernetes.kubeAPIServer.oidcConfig(deprecated). Since Kubernetes 1.30 the general OIDC configuration happens via the Structured Authentication feature.spec.virtualCluster.kubernetes.kubeAPIServer.structuredAuthentication. This section allows you to define a few specific settings for the dashboard.clientIDPublicis the public ID of the OIDC client.issuerURLis the URL of the JWT issuer.sessionLifetimeis the duration after which a session is terminated (i.e., after which a user is automatically logged out).additionalScopesallows to extend the list of scopes of the JWT token that are to be recognized.certificateAuthoritySecretRefallows you to specify a secret containing a custom CA certificate for communicating with the OIDC issuer.
You must reference aSecretin thegardennamespace containing the client and, if applicable, the client secret for the dashboard:If using a public client, a client secret is not required. The dashboard can function as a public OIDC client, allowing for improved flexibility in environments where secret storage is not feasible.apiVersion: v1 kind: Secret metadata: name: gardener-dashboard-oidc namespace: garden type: Opaque stringData: client_id: <client_id> client_secret: <optional>enableTokenLogin: This is enabled by default and allows logging into the dashboard with a JWT token. You can disable it in case you want to only allow OIDC-based login. However, at least one of the both login methods must be enabled.frontendConfigMapRef: Reference aConfigMapin thegardennamespace containing the frontend configuration in the data with keyfrontend-config.yaml, for examplePlease take a look at this file to get an idea of which values are configurable. This configuration can also include branding, themes, and colors. Read more about it here. Assets (logos/icons) are configured in a separateapiVersion: v1 kind: ConfigMap metadata: name: gardener-dashboard-frontend namespace: garden data: frontend-config.yaml: | helpMenuItems: - title: Homepage icon: mdi-file-document url: https://gardener.cloudConfigMap, see below.assetsConfigMapRef: Reference aConfigMapin thegardennamespace containing the assets, for exampleNote that the assets must be provided base64-encoded, henceapiVersion: v1 kind: ConfigMap metadata: name: gardener-dashboard-assets namespace: garden binaryData: favicon-16x16.png: base64(favicon-16x16.png) favicon-32x32.png: base64(favicon-32x32.png) favicon-96x96.png: base64(favicon-96x96.png) favicon.ico: base64(favicon.ico) logo.svg: base64(logo.svg)binaryData(instead ofdata) must be used. Please take a look at this file to get more information.gitHub: You can connect a GitHub repository that can be used to create issues for shoot clusters in the cluster details page. You have to reference aSecretin thegardennamespace that contains the GitHub credentials, for example:Note that you can also set up a GitHub webhook to the dashboard such that it receives updates when somebody changes the GitHub issue. TheapiVersion: v1 kind: Secret metadata: name: gardener-dashboard-github namespace: garden type: Opaque stringData: # This is for GitHub token authentication: authentication.token: <secret> # Alternatively, this is for GitHub app authentication: authentication.appId: <secret> authentication.clientId: <secret> authentication.clientSecret: <secret> authentication.installationId: <secret> authentication.privateKey: <secret> # This is the webhook secret, see explanation below webhookSecret: <secret>webhookSecretfield is the secret that you enter in GitHub in the webhook configuration. The dashboard uses it to verify that received traffic is indeed originated from GitHub. If you don’t want to set up such webhook, or if the dashboard is not reachable by the GitHub webhook (e.g., in restricted environments) you can also configuregitHub.pollInterval. It is the interval of how often the GitHub API is polled for issue updates. This field is used as a fallback mechanism to ensure state synchronization, even when there is a GitHub webhook configuration. If a webhook event is missed or not successfully delivered, the polling will help catch up on any missed updates. If this field is not provided and there is nowebhookSecretkey in the referenced secret, it will be implicitly defaulted to15m. The dashboard will use this to regularly poll the GitHub API for updates on issues.terminal: This enables the web terminal feature, read more about it here. When set, theterminal-controller-managerwill be deployed to the runtime cluster. TheallowedHostsfield is explained here. Thecontainersection allows you to specify a container image and a description that should be used for the web terminals.ingress: This allows you to customize theIngressresource of the dashboard. Theenabledfield allows you to control whether to deploy theIngressresource to the cluster.
Observability
Garden Prometheus
gardener-operator deploys a Prometheus instance in the garden namespace (called “Garden Prometheus”) which fetches metrics and data from garden system components, cAdvisors, the virtual cluster control plane, and the Seeds’ aggregate Prometheus instances.
Its purpose is to provide an entrypoint for operators when debugging issues with components running in the garden cluster.
It also serves as the top-level aggregator of metering across a Gardener landscape.
To extend the configuration of the Garden Prometheus, you can create the prometheus-operator’s custom resources and label them with prometheus=garden, for example:
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
labels:
prometheus: garden
name: garden-my-component
namespace: garden
spec:
selector:
matchLabels:
app: my-component
endpoints:
- metricRelabelings:
- action: keep
regex: ^(metric1|metric2|...)$
sourceLabels:
- __name__
port: metrics
Long-Term Prometheus
gardener-operator deploys another Prometheus instance in the garden namespace (called “Long-Term Prometheus”) which federates metrics from Garden Prometheus.
Its purpose is to store those with a longer retention than Garden Prometheus would. It is not possible to define different retention periods for different metrics in Prometheus, hence, using another Prometheus instance is the only option.
This Long-term Prometheus also has an additional Cortex sidecar container for caching some queries to achieve faster processing times.
To extend the configuration of the Long-term Prometheus, you can create the prometheus-operator’s custom resources and label them with prometheus=longterm, for example:
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
labels:
prometheus: longterm
name: longterm-my-component
namespace: garden
spec:
selector:
matchLabels:
app: my-component
endpoints:
- metricRelabelings:
- action: keep
regex: ^(metric1|metric2|...)$
sourceLabels:
- __name__
port: metrics
Alertmanager
By default, the alertmanager-garden deployed by gardener-operator does not come with any configuration.
It is the responsibility of the human operators to design and provide it.
This can be done by creating monitoring.coreos.com/v1alpha1.AlertmanagerConfig resources labeled with alertmanager=garden (read more about them here), for example:
apiVersion: monitoring.coreos.com/v1alpha1
kind: AlertmanagerConfig
metadata:
name: config
namespace: garden
labels:
alertmanager: garden
spec:
route:
receiver: dev-null
groupBy:
- alertname
- landscape
routes:
- continue: true
groupWait: 3m
groupInterval: 5m
repeatInterval: 12h
routes:
- receiver: ops
matchers:
- name: severity
value: warning
matchType: =
- name: topology
value: garden
matchType: =
receivers:
- name: dev-null
- name: ops
slackConfigs:
- apiURL: https://<slack-api-url>
channel: <channel-name>
username: Gardener-Alertmanager
iconEmoji: ":alert:"
title: "[{{ .Status | toUpper }}] Gardener Alert(s)"
text: "{{ range .Alerts }}*{{ .Annotations.summary }} ({{ .Status }})*\n{{ .Annotations.description }}\n\n{{ end }}"
sendResolved: true
Plutono
A Plutono instance is deployed by gardener-operator into the garden namespace for visualizing monitoring metrics and logs via dashboards.
In order to provide custom dashboards, create a ConfigMap in the garden namespace labelled with dashboard.monitoring.gardener.cloud/garden=true that contains the respective JSON documents, for example:
apiVersion: v1
kind: ConfigMap
metadata:
labels:
dashboard.monitoring.gardener.cloud/garden: "true"
name: my-custom-dashboard
namespace: garden
data:
my-custom-dashboard.json: <dashboard-JSON-document>
Care Reconciler
This reconciler performs four “care” actions related to Gardens.
It maintains the following conditions:
VirtualGardenAPIServerAvailable: The/healthzendpoint of the garden’svirtual-garden-kube-apiserveris called and considered healthy when it responds with200 OK.RuntimeComponentsHealthy: The conditions of theManagedResources applied to the runtime cluster are checked (e.g.,ResourcesApplied).VirtualComponentsHealthy: The virtual components are considered healthy when the respectiveDeployments (for examplevirtual-garden-kube-apiserver,virtual-garden-kube-controller-manager), andEtcds (for examplevirtual-garden-etcd-main) exist and are healthy. Additionally, the conditions of theManagedResources applied to the virtual cluster are checked (e.g.,ResourcesApplied).ObservabilityComponentsHealthy: This condition is considered healthy when the respectiveDeployments (for exampleplutono) andStatefulSets (for exampleprometheus,vali) exist and are healthy.
If all checks for a certain condition are succeeded, then its status will be set to True.
Otherwise, it will be set to False or Progressing.
If at least one check fails and there is threshold configuration for the conditions (in .controllers.gardenCare.conditionThresholds), then the status will be set:
- to
Progressingif it wasTruebefore. - to
Progressingif it wasProgressingbefore and thelastUpdateTimeof the condition does not exceed the configured threshold duration yet. - to
Falseif it wasProgressingbefore and thelastUpdateTimeof the condition exceeds the configured threshold duration.
The condition thresholds can be used to prevent reporting issues too early just because there is a rollout or a short disruption.
Only if the unhealthiness persists for at least the configured threshold duration, then the issues will be reported (by setting the status to False).
In order to compute the condition statuses, this reconciler considers ManagedResources (in the garden and istio-system namespace) and their status, see this document for more information.
The following table explains which ManagedResources are considered for which condition type:
| Condition Type | ManagedResources are considered when |
|---|---|
RuntimeComponentsHealthy | .spec.class=seed and care.gardener.cloud/condition-type label either unset, or set to RuntimeComponentsHealthy |
VirtualComponentsHealthy | .spec.class unset or care.gardener.cloud/condition-type label set to VirtualComponentsHealthy |
ObservabilityComponentsHealthy | care.gardener.cloud/condition-type label set to ObservabilityComponentsHealthy |
Reference Reconciler
Garden objects may specify references to other objects in the Garden cluster which are required for certain features.
For example, operators can configure a secret for ETCD backup via .spec.virtualCluster.etcd.main.backup.secretRef.name or an audit policy ConfigMap via .spec.virtualCluster.kubernetes.kubeAPIServer.auditConfig.auditPolicy.configMapRef.name.
Such objects need a special protection against deletion requests as long as they are still being referenced by the Garden.
Therefore, this reconciler checks Gardens for referenced objects and adds the finalizer gardener.cloud/reference-protection to their .metadata.finalizers list.
The reconciled Garden also gets this finalizer to enable a proper garbage collection in case the gardener-operator is offline at the moment of an incoming deletion request.
When an object is not actively referenced anymore because the Garden specification has changed is in deletion, the controller will remove the added finalizer again so that the object can safely be deleted or garbage collected.
This reconciler inspects the following references:
- Admission plugin kubeconfig
Secrets (.spec.virtualCluster.kubernetes.kubeAPIServer.admissionPlugins[].kubeconfigSecretNameand.spec.virtualCluster.gardener.gardenerAPIServer.admissionPlugins[].kubeconfigSecretName) - Audit policy
ConfigMaps (.spec.virtualCluster.kubernetes.kubeAPIServer.auditConfig.auditPolicy.configMapRef.nameand.spec.virtualCluster.gardener.gardenerAPIServer.auditConfig.auditPolicy.configMapRef.name) - Audit webhook kubeconfig
Secrets (.spec.virtualCluster.kubernetes.kubeAPIServer.auditWebhook.kubeconfigSecretNameand.spec.virtualCluster.gardener.gardenerAPIServer.auditWebhook.kubeconfigSecretName) - Authentication webhook kubeconfig
Secrets (.spec.virtualCluster.kubernetes.kubeAPIServer.authentication.webhook.kubeconfigSecretName) - DNS
Secrets (.spec.dns.providers[].secretRef) - ETCD backup
Secrets (.spec.virtualCluster.etcd.main.backup.secretRef) - Structured authentication
ConfigMaps (.spec.virtualCluster.kubernetes.kubeAPIServer.structuredAuthentication.configMapName) - Structured authorization
ConfigMaps (.spec.virtualCluster.kubernetes.kubeAPIServer.structuredAuthorization.configMapName) - Structured authorization kubeconfig
Secrets (.spec.virtualCluster.kubernetes.kubeAPIServer.structuredAuthorization.kubeconfigs[].secretName) - SNI
Secrets (.spec.virtualCluster.kubernetes.kubeAPIServer.sni.secretName)
The checks naturally grow with the number of references that are added to the Garden specification.
Controller Registrar Controller
Some controllers may only be instantiated or added later, because they need the Garden resource to be available (e.g. network configuration) or even the entire virtual garden cluster to run:
NetworkPolicycontrollerVPA EvictionRequirementscontrollerRequired RuntimereconcilerRequired VirtualreconcilerAccesscontrollerVirtual-Cluster-RegistrarcontrollerGardenletcontroller
Note
Some of the listed controllers are part of
gardenlet, as well. If the garden cluster is a seed cluster at the same time,gardenletwill skip running theNetworkPolicyandVPA EvictionRequirementscontrollers to avoid interferences.
Extension Controller
Gardener relies on extensions to provide various capabilities, such as supporting cloud providers. This controller automates the management of extensions by managing all necessary resources in the runtime and virtual garden clusters.
Extension Care Reconciler
This reconciler performs three “care” actions related to Extensionss.
It maintains the following conditions:
ControllerInstallationsHealthy: The conditions of theControllerInstallations which belong to this extension are checked (e.g.,Healthy).RuntimeHealthy: The conditions of theManagedResources applied to the runtime cluster are checked (e.g.,ResourcesApplied).AdmissionHealthy: The conditions of theManagedResources applied to the runtime and the virtual cluster are checked (e.g.,ResourcesApplied).
If all checks for a certain condition are succeeded, then its status will be set to True.
Otherwise, it will be set to False or Progressing.
If at least one check fails and there is threshold configuration for the conditions (in .controllers.extensionCare.conditionThresholds), then the status will be set:
- to
Progressingif it wasTruebefore. - to
Progressingif it wasProgressingbefore and thelastUpdateTimeof the condition does not exceed the configured threshold duration yet. - to
Falseif it wasProgressingbefore and thelastUpdateTimeof the condition exceeds the configured threshold duration.
The condition thresholds can be used to prevent reporting issues too early just because there is a rollout or a short disruption.
Only if the unhealthiness persists for at least the configured threshold duration, then the issues will be reported (by setting the status to False).
Main Reconciler
Currently, this logic handles the following scenarios:
- Extension deployment in the runtime cluster, based on the
RequiredRuntimecondition. - Extension admission deployment for the virtual garden cluster.
ControllerDeploymentandControllerRegistrationreconciliation in the virtual garden cluster.
Required Runtime Reconciler
This reconciler reacts on Garden and Extension events.
It is checked if the extension deployment is required in the garden runtime cluster based on the existing Garden specification.
The result is then put into the RequiredRuntime condition and added to the Extension status.
Required Virtual Reconciler
This reconciler reacts on events from ControllerInstallation and Extension resources.
It updates the RequiredVirtual condition of Extension objects, based on the existence of related ControllerInstallations and whether they are marked as required.
Access Controller
This controller performs actions related to the garden access secret (gardener or gardener-internal) for the virtual garden cluster.
It extracts the included Kubeconfig, and prepares a dedicated REST config, where the inline bearer token is replaced by a bearer token file.
Any subsequent reconciliation run, mostly triggered by a token replacement, causes the content of the bearer token file to be updated with the token found in the access secret.
At the end, the prepared REST config is passed to the Virtual-Cluster-Registrar controller.
Together with the adjusted config and the token file, related controllers can continuously run their operations, even after credentials rotation.
Virtual-Cluster-Registrar Controller
The Virtual-Cluster-Registrar controller watches for events on a dedicated channel that is shared with the Access controller.
Once a REST config is sent to the channel, the reconciliation loop picks up the request, creates a Cluster object and stores in memory.
This Cluster object points to the virtual garden cluster and is used to register further controllers, e.g. Gardenlet controller.
Gardenlet Controller
The Gardenlet controller reconciles a seedmanagement.gardener.cloud/v1alpha1.Gardenlet resource in case there is no Seed yet with the same name.
This is used to allow easy deployments of gardenlets into unmanaged seed clusters.
For a general overview, see this document.
On Gardenlet reconciliation, the controller deploys the gardenlet to the cluster (either its own, or the one provided via the .spec.kubeconfigSecretRef) after downloading the Helm chart specified in .spec.deployment.helm.ociRepository and rendering it with the provided values/configuration.
On Gardenlet deletion, nothing happens: gardenlets must always be deleted manually (by deleting the Seed and, once gone, then the gardenlet Deployment).
Note
This controller only takes care of the very first
gardenletdeployment (since it only reacts when there is noSeedresource yet). After thegardenletis running, it uses the self-upgrade mechanism by watching theseedmanagement.gardener.cloud/v1alpha1.Gardenlet(see this for more details.)After a successful
Gardenreconciliation,gardener-operatoralso updates the.spec.deployment.helm.ociRepository.refto its own version in allGardenletresources labeled withoperator.gardener.cloud/auto-update-gardenlet-helm-chart-ref=true.gardenlets then updates themselves.⚠️ If you prefer to manage the
Gardenletresources via GitOps, Flux, or similar tools, then you should better manage the.spec.deployment.helm.ociRepository.reffield yourself and not label the resources as mentioned above (to preventgardener-operatorfrom interfering with your desired state). Make sure to apply yourGardenletresources (potentially containing a new version) after theGardenresource was successfully reconciled (i.e., after Gardener control plane was successfully rolled out, see this for more information.)
Webhooks
As of today, the gardener-operator only has one webhook handler which is now described in more detail.
Validation
The validation webhook consists of the following handlers.
Garden
This webhook handler validates CREATE/UPDATE/DELETE operations on Garden resources.
Simple validation is performed via standard CRD validation.
However, more advanced validation is hard to express via these means and is performed by this webhook handler.
Furthermore, for deletion requests, it is validated that the Garden is annotated with a deletion confirmation annotation, namely confirmation.gardener.cloud/deletion=true.
Only if this annotation is present it allows the DELETE operation to pass.
This prevents users from accidental/undesired deletions.
Another validation is to check that there is only one Garden resource at a time.
It prevents creating a second Garden when there is already one in the system.
Extension
This webhook handler validates UPDATE and DELETE operations on Extension resources.
In an UPDATE request, the configured .spec.resources are validated to ensure the primary field remains immutable.
DELETE requests for Extension resources are denied if they are reported as required (also see required-runtime and required-virtual).
These deletions often happen accidentally, and this handler safeguards the system from such actions.
Defaulting
This webhook handler mutates Garden resources on CREATE/UPDATE/DELETE operations.
Extension resources are mutated in the scope of CREATE/UPDATE requests.
Simple defaulting is performed via standard CRD defaulting.
However, more advanced defaulting is hard to express via these means and is performed by this webhook handler.
Using Garden Runtime Cluster As Seed Cluster
In production scenarios, you probably wouldn’t use the Kubernetes cluster running gardener-operator and the Gardener control plane (called “runtime cluster”) as seed cluster at the same time.
However, such setup is technically possible and might simplify certain situations (e.g., development, evaluation, …).
If the runtime cluster is a seed cluster at the same time, gardenlet’s Seed controller will not manage the components which were already deployed (and reconciled) by gardener-operator.
As of today, this applies to:
gardener-resource-managervpa-{admission-controller,recommender,updater}etcd-druidistiocontrol-planenginx-ingress-controller
Those components are so-called “seed system components”. In addition, there are a few observability components:
fluent-operatorfluent-bitvaliplutonokube-state-metricsprometheus-operatorperses-operatoropentelemetry-operator
As all of these components are managed by gardener-operator in this scenario, the gardenlet just skips them.
ℹ️ There is no need to configure anything - the
gardenletwill automatically detect when its seed cluster is the garden runtime cluster at the same time.
⚠️ Note that such setup requires that you upgrade the versions of gardener-operator and gardenlet in lock-step.
Otherwise, you might experience unexpected behaviour or issues with your seed or shoot clusters.
Credentials Rotation
The credentials rotation works in the same way as it does for Shoot resources, i.e. there are gardener.cloud/operation annotation values for starting or completing the rotation procedures.
For certificate authorities, gardener-operator generates one which is automatically rotated roughly each month (ca-garden-runtime) and several CAs which are NOT automatically rotated but only on demand.
🚨 Hence, it is the responsibility of the (human) operator to regularly perform the credentials rotation.
Please refer to this document for more details. As of today, gardener-operator only creates the following types of credentials (i.e., some sections of the document don’t apply for Gardens and can be ignored):
- certificate authorities (and related server and client certificates)
- ETCD encryption key
- observability password for Plutono
ServiceAccounttoken signing keyWorkloadIdentitytoken signing key
⚠️ Rotation of static ServiceAccount secrets is not supported since the kube-controller-manager does not enable the serviceaccount-token controller.
When the ServiceAccount token signing key rotation is in Preparing phase, then gardener-operator annotates all Seeds with gardener.cloud/operation=renew-garden-access-secrets.
This causes gardenlet to populate new ServiceAccount tokens for the garden cluster to all extensions, which are now signed with the new signing key.
Read more about it here.
Similarly, when the CA certificate rotation is in Preparing phase, then gardener-operator annotates all Seeds with gardener.cloud/operation=renew-kubeconfig.
This causes gardenlet to request a new client certificate for its garden cluster kubeconfig, which is now signed with the new client CA, and which also contains the new CA bundle for the server certificate verification.
Read more about it here.
Also, when the WorkloadIdentity token signing key rotation is in Preparing phase, then gardener-operator annotates all Seeds with gardener.cloud/operation=renew-workload-identity-tokens.
This causes gardenlet to renew all workload identity tokens in the seed cluster with new tokens now signed with the new signing key.
Migrating an Existing Gardener Landscape to gardener-operator
Since gardener-operator was only developed in 2023, six years after the Gardener project initiation, most users probably already have an existing Gardener landscape.
The most prominent installation procedure is garden-setup, however experience shows that most community members have developed their own tooling for managing the garden cluster and the Gardener control plane components.
Consequently, providing a general migration guide is not possible since the detailed steps vary heavily based on how the components were set up previously. As a result, this section can only highlight the most important caveats and things to know, while the concrete migration steps must be figured out individually based on the existing installation.
Please test your migration procedure thoroughly. Note that in some cases it can be easier to set up a fresh landscape with
gardener-operator, restore the ETCD data, switch the DNS records, and issue new credentials for all clients.
Please make sure that you configure all your desired fields in the Garden resource.
ETCD
gardener-operator leverages etcd-druid for managing the virtual-garden-etcd-main and virtual-garden-etcd-events, similar to how shoot cluster control planes are handled.
The PersistentVolumeClaim names differ slightly - for virtual-garden-etcd-events it’s virtual-garden-etcd-events-virtual-garden-etcd-events-0, while for virtual-garden-etcd-main it’s main-virtual-garden-etcd-virtual-garden-etcd-main-0.
The easiest approach for the migration is to make your existing ETCD volumes follow the same naming scheme.
Alternatively, backup your data, let gardener-operator take over ETCD, and then restore your data to the new volume.
The backup bucket must be created separately, and its name as well as the respective credentials must be provided via the Garden resource in .spec.virtualCluster.etcd.main.backup.
virtual-garden-kube-apiserver Deployment
gardener-operator deploys a virtual-garden-kube-apiserver into the runtime cluster.
This virtual-garden-kube-apiserver spans a new cluster, called the virtual cluster.
There are a few certificates and other credentials that should not change during the migration.
You have to prepare the environment accordingly by leveraging the secret’s manager capabilities.
- The existing Cluster CA
Secretshould be labeled withsecrets-manager-use-data-for-name=ca. - The existing Client CA
Secretshould be labeled withsecrets-manager-use-data-for-name=ca-client. - The existing Front Proxy CA
Secretshould be labeled withsecrets-manager-use-data-for-name=ca-front-proxy. - The existing Service Account Signing Key
Secretshould be labeled withsecrets-manager-use-data-for-name=service-account-key. - The existing ETCD Encryption Key
Secretshould be labeled withsecrets-manager-use-data-for-name=kube-apiserver-etcd-encryption-key.
virtual-garden-kube-apiserver Exposure
The virtual-garden-kube-apiserver is exposed via a dedicated istio-ingressgateway deployed to namespace virtual-garden-istio-ingress.
The virtual-garden-kube-apiserver Service in the garden namespace is only of type ClusterIP.
Consequently, DNS records for this API server must target the load balancer IP of the istio-ingressgateway.
Virtual Garden Kubeconfig
gardener-operator does not generate any static token or likewise for access to the virtual cluster.
Ideally, human users access it via OIDC only.
Alternatively, you can create an auto-rotated token that you can use for automation like CI/CD pipelines:
apiVersion: v1
kind: Secret
type: Opaque
metadata:
name: shoot-access-virtual-garden
namespace: garden
labels:
resources.gardener.cloud/purpose: token-requestor
resources.gardener.cloud/class: shoot
annotations:
serviceaccount.resources.gardener.cloud/name: virtual-garden-user
serviceaccount.resources.gardener.cloud/namespace: kube-system
serviceaccount.resources.gardener.cloud/token-expiration-duration: 3h
---
apiVersion: v1
kind: Secret
metadata:
name: managedresource-virtual-garden-access
namespace: garden
type: Opaque
stringData:
clusterrolebinding____gardener.cloud.virtual-garden-access.yaml: |
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: gardener.cloud.sap:virtual-garden
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: virtual-garden-user
namespace: kube-system
---
apiVersion: resources.gardener.cloud/v1alpha1
kind: ManagedResource
metadata:
name: virtual-garden-access
namespace: garden
spec:
secretRefs:
- name: managedresource-virtual-garden-access
The shoot-access-virtual-garden Secret will get a .data.token field which can be used to authenticate against the virtual garden cluster.
See also this document for more information about the TokenRequestor.
gardener-apiserver
Similar to the virtual-garden-kube-apiserver, the gardener-apiserver also uses a few certificates and other credentials that should not change during the migration.
Again, you have to prepare the environment accordingly by leveraging the secret’s manager capabilities.
- The existing ETCD Encryption Key
Secretshould be labeled withsecrets-manager-use-data-for-name=gardener-apiserver-etcd-encryption-key.
Also note that gardener-operator manages the Service and Endpoints resources for the gardener-apiserver in the virtual cluster within the kube-system namespace (garden-setup uses the garden namespace).
Local Development
The easiest setup is using a local KinD cluster and the Skaffold based approach to deploy and develop the gardener-operator.
Setting Up the KinD Cluster (runtime cluster)
make kind-multi-zone-up
This command sets up a new KinD cluster named gardener-local and stores the kubeconfig in the ./example/gardener-local/kind/multi-zone/kubeconfig file.
It might be helpful to copy this file to
$HOME/.kube/config, since you will need to target this KinD cluster multiple times. Alternatively, make sure to set yourKUBECONFIGenvironment variable to./example/gardener-local/kind/multi-zone/kubeconfigfor all future steps viaexport KUBECONFIG=$PWD/example/gardener-local/kind/multi-zone/kubeconfig.
All the following steps assume that you are using this kubeconfig.
Setting Up Gardener Operator
make operator-up
This will first build the base images (which might take a bit if you do it for the first time). Afterwards, the Gardener Operator resources will be deployed into the cluster.
Developing Gardener Operator (Optional)
make operator-dev
This is similar to make operator-up but additionally starts a skaffold dev loop.
After the initial deployment, skaffold starts watching source files.
Once it has detected changes, press any key to trigger a new build and deployment of the changed components.
Debugging Gardener Operator (Optional)
make operator-debug
This is similar to make gardener-debug but for Gardener Operator component. Please check Debugging Gardener for details.
Creating a Garden
In order to create a garden, just run:
kubectl apply -f example/operator/20-garden.yaml
You can wait for the Garden to be ready by running:
./hack/usage/wait-for.sh garden local VirtualGardenAPIServerAvailable VirtualComponentsHealthy
Alternatively, you can run kubectl get garden and wait for the RECONCILED status to reach True:
NAME LAST OPERATION RUNTIME VIRTUAL API SERVER OBSERVABILITY AGE
local Processing False False False False 1s
(Optional): Instead of creating above Garden resource manually, you could execute the e2e tests by running:
make test-e2e-local-operator
Accessing the Virtual Garden Cluster
⚠️ Please note that in this setup, the virtual garden cluster is not accessible by default when you download the kubeconfig and try to communicate with it.
The reason is that your host most probably cannot resolve the DNS name of the cluster.
Hence, if you want to access the virtual garden cluster, you have to run the following command which will extend your /etc/hosts file with the required information to make the DNS names resolvable:
cat <<EOF | sudo tee -a /etc/hosts
# Manually created to access local Gardener virtual garden cluster.
# TODO: Remove this again when the virtual garden cluster access is no longer required.
172.18.255.3 api.virtual-garden.local.gardener.cloud
EOF
To access the virtual garden, you can generate a kubeconfig by running
hack/usage/generate-virtual-garden-admin-kubeconf.sh > /tmp/virtual-garden-kubeconfig
kubectl --kubeconfig /tmp/virtual-garden-kubeconfig get namespaces
Creating Seeds and Shoots
You can also create Seeds and Shoots from your local development setup. Please see here for details.
Deleting the Garden
./hack/usage/delete garden local
Tear Down the Gardener Operator Environment
make operator-down
make kind-multi-zone-down
12 - Gardener Resource Manager
Overview
Initially, the gardener-resource-manager was a project similar to the kube-addon-manager.
It manages Kubernetes resources in a target cluster which means that it creates, updates, and deletes them.
Also, it makes sure that manual modifications to these resources are reconciled back to the desired state.
In the Gardener project we were using the kube-addon-manager since more than two years.
While we have progressed with our extensibility story (moving cloud providers out-of-tree), we had decided that the kube-addon-manager is no longer suitable for this use-case.
The problem with it is that it needs to have its managed resources on its file system.
This requires storing the resources in ConfigMaps or Secrets and mounting them to the kube-addon-manager pod during deployment time.
The gardener-resource-manager uses CustomResourceDefinitions which allows to dynamically add, change, and remove resources with immediate action and without the need to reconfigure the volume mounts/restarting the pod.
Meanwhile, the gardener-resource-manager has evolved to a more generic component comprising several controllers and webhook handlers.
It is deployed by gardenlet once per seed (in the garden namespace) and once per shoot (in the respective shoot namespaces in the seed).
Component Configuration
Similar to other Gardener components, the gardener-resource-manager uses a so-called component configuration file.
It allows specifying certain central settings like log level and formatting, client connection configuration, server ports and bind addresses, etc.
In addition, controllers and webhooks can be configured and sometimes even disabled.
Note that the very basic ManagedResource and health controllers cannot be disabled.
You can find an example configuration file here.
Controllers
ManagedResource Controller
This controller watches custom objects called ManagedResources in the resources.gardener.cloud/v1alpha1 API group.
These objects contain references to secrets, which itself contain the resources to be managed.
The reason why a Secret is used to store the resources is that they could contain confidential information like credentials.
---
apiVersion: v1
kind: Secret
metadata:
name: managedresource-example1
namespace: default
type: Opaque
data:
objects.yaml: YXBpVmVyc2lvbjogdjEKa2luZDogQ29uZmlnTWFwCm1ldGFkYXRhOgogIG5hbWU6IHRlc3QtMTIzNAogIG5hbWVzcGFjZTogZGVmYXVsdAotLS0KYXBpVmVyc2lvbjogdjEKa2luZDogQ29uZmlnTWFwCm1ldGFkYXRhOgogIG5hbWU6IHRlc3QtNTY3OAogIG5hbWVzcGFjZTogZGVmYXVsdAo=
# apiVersion: v1
# kind: ConfigMap
# metadata:
# name: test-1234
# namespace: default
# ---
# apiVersion: v1
# kind: ConfigMap
# metadata:
# name: test-5678
# namespace: default
---
apiVersion: resources.gardener.cloud/v1alpha1
kind: ManagedResource
metadata:
name: example
namespace: default
spec:
secretRefs:
- name: managedresource-example1
In the above example, the controller creates two ConfigMaps in the default namespace.
When a user is manually modifying them, they will be reconciled back to the desired state stored in the managedresource-example secret.
It is also possible to inject labels into all the resources:
---
apiVersion: v1
kind: Secret
metadata:
name: managedresource-example2
namespace: default
type: Opaque
data:
other-objects.yaml: YXBpVmVyc2lvbjogYXBwcy92MSAjIGZvciB2ZXJzaW9ucyBiZWZvcmUgMS45LjAgdXNlIGFwcHMvdjFiZXRhMgpraW5kOiBEZXBsb3ltZW50Cm1ldGFkYXRhOgogIG5hbWU6IG5naW54LWRlcGxveW1lbnQKc3BlYzoKICBzZWxlY3RvcjoKICAgIG1hdGNoTGFiZWxzOgogICAgICBhcHA6IG5naW54CiAgcmVwbGljYXM6IDIgIyB0ZWxscyBkZXBsb3ltZW50IHRvIHJ1biAyIHBvZHMgbWF0Y2hpbmcgdGhlIHRlbXBsYXRlCiAgdGVtcGxhdGU6CiAgICBtZXRhZGF0YToKICAgICAgbGFiZWxzOgogICAgICAgIGFwcDogbmdpbngKICAgIHNwZWM6CiAgICAgIGNvbnRhaW5lcnM6CiAgICAgIC0gbmFtZTogbmdpbngKICAgICAgICBpbWFnZTogbmdpbng6MS43LjkKICAgICAgICBwb3J0czoKICAgICAgICAtIGNvbnRhaW5lclBvcnQ6IDgwCg==
# apiVersion: apps/v1
# kind: Deployment
# metadata:
# name: nginx-deployment
# spec:
# selector:
# matchLabels:
# app: nginx
# replicas: 2 # tells deployment to run 2 pods matching the template
# template:
# metadata:
# labels:
# app: nginx
# spec:
# containers:
# - name: nginx
# image: nginx:1.7.9
# ports:
# - containerPort: 80
---
apiVersion: resources.gardener.cloud/v1alpha1
kind: ManagedResource
metadata:
name: example
namespace: default
spec:
secretRefs:
- name: managedresource-example2
injectLabels:
foo: bar
In this example, the label foo=bar will be injected into the Deployment, as well as into all created ReplicaSets and Pods.
Preventing Reconciliations
If a ManagedResource is annotated with resources.gardener.cloud/ignore=true, then it will be skipped entirely by the controller (no reconciliations or deletions of managed resources at all).
However, when the ManagedResource itself is deleted (for example when a shoot is deleted), then the annotation is not respected and all resources will be deleted as usual.
This feature can be helpful to temporarily patch/change resources managed as part of such ManagedResource.
Condition checks will be skipped for such ManagedResources.
Modes
The gardener-resource-manager can manage a resource in the following supported modes:
Ignore- The corresponding resource is removed from the
ManagedResourcestatus (.status.resources). No action is performed on the cluster. - The resource is no longer “managed” (updated or deleted).
- The primary use case is a migration of a resource from one
ManagedResourceto another one.
- The corresponding resource is removed from the
The mode for a resource can be specified with the resources.gardener.cloud/mode annotation. The annotation should be specified in the encoded resource manifest in the Secret that is referenced by the ManagedResource.
Resource Class and Reconciliation Scope
By default, the gardener-resource-manager controller watches for ManagedResources in all namespaces.
The .sourceClientConnection.namespace field in the component configuration restricts the watch to ManagedResources in a single namespace only.
Note that this setting also affects all other controllers and webhooks since it’s a central configuration.
A ManagedResource has an optional .spec.class field that allows it to indicate that it belongs to a given class of resources.
The .controllers.resourceClass field in the component configuration restricts the watch to ManagedResources with the given .spec.class.
A default class is assumed if no class is specified.
For instance, the gardener-resource-manager which is deployed in the Shoot’s control plane namespace in the Seed does not specify a .spec.class and watches only for resources in the control plane namespace by specifying it in the .sourceClientConnection.namespace field.
If the .spec.class changes this means that the resources have to be handled by a different Gardener Resource Manager. That is achieved by:
- Cleaning all referenced resources by the Gardener Resource Manager that was responsible for the old class in its target cluster.
- Creating all referenced resources by the Gardener Resource Manager that is responsible for the new class in its target cluster.
Conditions
A ManagedResource has a ManagedResourceStatus, which has an array of Conditions. Conditions currently include:
| Condition | Description |
|---|---|
ResourcesApplied | True if all resources are applied to the target cluster |
ResourcesHealthy | True if all resources are present and healthy |
ResourcesProgressing | False if all resources have been fully rolled out |
ResourcesApplied may be False when:
- the resource
apiVersionis not known to the target cluster - the resource spec is invalid (for example the label value does not match the required regex for it)
- …
ResourcesHealthy may be False when:
- the resource is not found
- the resource is a Deployment and the Deployment does not have the minimum availability.
- …
ResourcesProgressing may be True when:
- a
Deployment,StatefulSetorDaemonSethas not been fully rolled out yet, i.e. not all replicas have been updated with the latest changes tospec.template. - there are still old
Pods belonging to an olderReplicaSetof aDeploymentwhich are not terminated yet.
Each Kubernetes resources has different notion for being healthy. For example, a Deployment is considered healthy if the controller observed its current revision and if the number of updated replicas is equal to the number of replicas.
The following status.conditions section describes a healthy ManagedResource:
conditions:
- lastTransitionTime: "2022-05-03T10:55:39Z"
lastUpdateTime: "2022-05-03T10:55:39Z"
message: All resources are healthy.
reason: ResourcesHealthy
status: "True"
type: ResourcesHealthy
- lastTransitionTime: "2022-05-03T10:55:36Z"
lastUpdateTime: "2022-05-03T10:55:36Z"
message: All resources have been fully rolled out.
reason: ResourcesRolledOut
status: "False"
type: ResourcesProgressing
- lastTransitionTime: "2022-05-03T10:55:18Z"
lastUpdateTime: "2022-05-03T10:55:18Z"
message: All resources are applied.
reason: ApplySucceeded
status: "True"
type: ResourcesApplied
Ignoring Updates
In some cases, it is not desirable to update or re-apply some of the cluster components (for example, if customization is required or needs to be applied by the end-user). For these resources, the annotation “resources.gardener.cloud/ignore” needs to be set to “true” or a truthy value (Truthy values are “1”, “t”, “T”, “true”, “TRUE”, “True”) in the corresponding managed resource secrets. This can be done from the components that create the managed resource secrets, for example Gardener extensions or Gardener. Once this is done, the resource will be initially created and later ignored during reconciliation.
Finalizing Deletion of Resources After Grace Period
When a ManagedResource is deleted, the controller deletes all managed resources from the target cluster.
In case the resources still have entries in their .metadata.finalizers[] list, they will remain stuck in the system until another entity removes the finalizers.
If you want the controller to forcefully finalize the deletion after some grace period (i.e., setting .metadata.finalizers=null), you can annotate the managed resources with resources.gardener.cloud/finalize-deletion-after=<duration>, e.g., resources.gardener.cloud/finalize-deletion-after=1h.
Preserving replicas or resources in Workload Resources
The objects which are part of the ManagedResource can be annotated with:
resources.gardener.cloud/preserve-replicas=truein case the.spec.replicasfield of workload resources likeDeployments,StatefulSets, etc., shall be preserved during updates.resources.gardener.cloud/preserve-resources=truein case the.spec.containers[*].resourcesfields of all containers of workload resources likeDeployments,StatefulSets, etc., shall be preserved during updates.
This can be useful if there are non-standard horizontal/vertical auto-scaling mechanisms in place. Standard mechanisms like
HorizontalPodAutoscalerorVerticalPodAutoscalerwill be auto-recognized bygardener-resource-manager, i.e., in such cases the annotations are not needed.
Origin
All the objects managed by the resource manager get a dedicated annotation
resources.gardener.cloud/origin describing the ManagedResource object that describes
this object. The default format is <namespace>/<objectname>.
In multi-cluster scenarios (the ManagedResource objects are maintained in a
cluster different from the one the described objects are managed), it might
be useful to include the cluster identity, as well.
This can be enforced by setting the .controllers.clusterID field in the component configuration.
Here, several possibilities are supported:
- given a direct value: use this as id for the source cluster.
<cluster>: read the cluster identity from acluster-identityconfig map in thekube-systemnamespace (attributecluster-identity). This is automatically maintained in all clusters managed or involved in a gardener landscape.<default>: try to read the cluster identity from the config map. If not found, no identity is used.- empty string: no cluster identity is used (completely cluster local scenarios).
By default, cluster id is not used. If cluster id is specified, the format is <cluster id>:<namespace>/<objectname>.
In addition to the origin annotation, all objects managed by the resource manager get a dedicated label resources.gardener.cloud/managed-by. This label can be used to describe these objects with a selector. By default it is set to “gardener”, but this can be overwritten by setting the .conrollers.managedResources.managedByLabelValue field in the component configuration.
Compression
The number and size of manifests for a ManagedResource can accumulate to a considerable amount which leads to increased Secret data.
A decent compression algorithm helps to reduce the footprint of such Secrets and the load they put on etcd, the kube-apiserver, and client caches.
We found Brotli to be a suitable candidate for most use cases (see comparison table here).
When the gardener-resource-manager detects a data key with the known suffix .br, it automatically un-compresses the data first before processing the contained manifest.
To decompress a ManagedResource Secret use:
kubectl -n <namespace> get secret <managed-resource-secret> -o jsonpath='{.data.data\.yaml\.br}' | base64 -d | brotli -d
On macOS, the brotli binary can be installed via homebrew using the brotli formula.
health Controller
This controller processes ManagedResources that were reconciled by the main ManagedResource Controller at least once.
Its main job is to perform checks for maintaining the well known conditions ResourcesHealthy and ResourcesProgressing.
Progressing Checks
In Kubernetes, applied changes must usually be rolled out first, e.g. when changing the base image in a Deployment.
Progressing checks detect ongoing roll-outs and report them in the ResourcesProgressing condition of the corresponding ManagedResource.
The following object kinds are considered for progressing checks:
DaemonSetDeploymentStatefulSetPrometheusAlertmanagerCertificateIssuer
Health Checks
gardener-resource-manager can evaluate the health of specific resources, often by consulting their conditions.
Health check results are regularly updated in the ResourcesHealthy condition of the corresponding ManagedResource.
The following object kinds are considered for health checks:
CustomResourceDefinitionDaemonSetDeploymentJobPodReplicaSetReplicationControllerServiceStatefulSetVerticalPodAutoscalerPrometheusAlertmanagerCertificateIssuer
Skipping Health Check
If a resource owned by a ManagedResource is annotated with resources.gardener.cloud/skip-health-check=true, then the resource will be skipped during health checks by the health controller. The ManagedResource conditions will not reflect the health condition of this resource anymore. The ResourcesProgressing condition will also be set to False.
Garbage Collector For Immutable ConfigMaps/Secrets
In Kubernetes, workload resources (e.g., Pods) can mount ConfigMaps or Secrets or reference them via environment variables in containers.
Typically, when the content of such a ConfigMap/Secret gets changed, then the respective workload is usually not dynamically reloading the configuration, i.e., a restart is required.
The most commonly used approach is probably having the so-called checksum annotations in the pod template, which makes Kubernetes recreate the pod if the checksum changes.
However, it has the downside that old, still running versions of the workload might not be able to properly work with the already updated content in the ConfigMap/Secret, potentially causing application outages.
In order to protect users from such outages (and also to improve the performance of the cluster), the Kubernetes community provides the “immutable ConfigMaps/Secrets feature”.
Enabling immutability requires ConfigMaps/Secrets to have unique names.
Having unique names requires the client to delete ConfigMaps/Secrets no longer in use.
In order to provide a similarly lightweight experience for clients (compared to the well-established checksum annotation approach), the gardener-resource-manager features an optional garbage collector controller (disabled by default).
The purpose of this controller is cleaning up such immutable ConfigMaps/Secrets if they are no longer in use.
How Does the Garbage Collector Work?
The following algorithm is implemented in the GC controller:
- List all
ConfigMaps andSecrets labeled withresources.gardener.cloud/garbage-collectable-reference=true. - List all
Deployments,StatefulSets,DaemonSets,Jobs,CronJobs,Pods,ManagedResources and for each of them:- iterate over the
.metadata.annotationsand for each of them:- If the annotation key follows the
reference.resources.gardener.cloud/{configmap,secret}-<hash>scheme and the value equals<name>, then consider it as “in-use”.
- If the annotation key follows the
- iterate over the
- Delete all
ConfigMaps andSecrets not considered as “in-use”.
Consequently, clients need to:
Create immutable
ConfigMaps/Secrets with unique names (e.g., a checksum suffix based on the.data).Label such
ConfigMaps/Secrets withresources.gardener.cloud/garbage-collectable-reference=true.Annotate their workload resources with
reference.resources.gardener.cloud/{configmap,secret}-<hash>=<name>for allConfigMaps/Secrets used by the containers of the respectivePods.⚠️ Add such annotations to
.metadata.annotations, as well as to all templates of other resources (e.g.,.spec.template.metadata.annotationsinDeployments or.spec.jobTemplate.metadata.annotationsand.spec.jobTemplate.spec.template.metadata.annotationsforCronJobs. This ensures that the GC controller does not unintentionally considerConfigMaps/Secrets as “not in use” just because there isn’t aPodreferencing them anymore (e.g., they could still be used by aDeploymentscaled down to0).
ℹ️ For the last step, there is a helper function InjectAnnotations in the pkg/controller/garbagecollector/references, which you can use for your convenience.
Example:
---
apiVersion: v1
kind: ConfigMap
metadata:
name: test-1234
namespace: default
labels:
resources.gardener.cloud/garbage-collectable-reference: "true"
---
apiVersion: v1
kind: ConfigMap
metadata:
name: test-5678
namespace: default
labels:
resources.gardener.cloud/garbage-collectable-reference: "true"
---
apiVersion: v1
kind: Pod
metadata:
name: example
namespace: default
annotations:
reference.resources.gardener.cloud/configmap-82a3537f: test-5678
spec:
containers:
- name: nginx
image: nginx:1.14.2
terminationGracePeriodSeconds: 2
The GC controller would delete the ConfigMap/test-1234 because it is considered as not “in-use”.
ℹ️ If the GC controller is activated then the ManagedResource controller will no longer delete ConfigMaps/Secrets having the above label.
How to Activate the Garbage Collector?
The GC controller can be activated by setting the .controllers.garbageCollector.enabled field to true in the component configuration.
TokenRequestor Controller
This controller provides the service to create and auto-renew tokens via the TokenRequest API.
It provides a functionality similar to the kubelet’s Service Account Token Volume Projection. It was created to handle the special case of issuing tokens to pods that run in a different cluster than the API server they communicate with (hence, using the native token volume projection feature is not possible).
The controller differentiates between source cluster and target cluster.
The source cluster hosts the gardener-resource-manager pod. Secrets in this cluster are watched and modified by the controller.
The target cluster can be configured to point to another cluster. The existence of ServiceAccounts are ensured and token requests are issued against the target.
When the gardener-resource-manager is deployed next to the Shoot’s controlplane in the Seed, the source cluster is the Seed while the target cluster points to the Shoot.
Reconciliation Loop
This controller reconciles Secrets in all namespaces in the source cluster with the label: resources.gardener.cloud/purpose=token-requestor.
See this YAML file for an example of the secret.
The controller ensures a ServiceAccount exists in the target cluster as specified in the annotations of the Secret in the source cluster:
serviceaccount.resources.gardener.cloud/name: <sa-name>
serviceaccount.resources.gardener.cloud/namespace: <sa-namespace>
You can optionally annotate the Secret with serviceaccount.resources.gardener.cloud/labels, e.g. serviceaccount.resources.gardener.cloud/labels={"some":"labels","foo":"bar"}.
This will make the ServiceAccount getting labelled accordingly.
The requested tokens will act with the privileges which are assigned to this ServiceAccount.
The controller will then request a token via the TokenRequest API and populate it into the .data.token field to the Secret in the source cluster.
Alternatively, the client can provide a raw kubeconfig (in YAML or JSON format) via the Secret’s .data.kubeconfig field.
The controller will then populate the requested token in the kubeconfig for the user used in the .current-context.
For example, if .data.kubeconfig is
apiVersion: v1
clusters:
- cluster:
certificate-authority-data: AAAA
server: some-server-url
name: shoot--foo--bar
contexts:
- context:
cluster: shoot--foo--bar
user: shoot--foo--bar-token
name: shoot--foo--bar
current-context: shoot--foo--bar
kind: Config
preferences: {}
users:
- name: shoot--foo--bar-token
user:
token: ""
then the .users[0].user.token field of the kubeconfig will be updated accordingly.
The TokenRequestor can also optionally inject the current CA bundle if the secret is annotated with
serviceaccount.resources.gardener.cloud/inject-ca-bundle: "true"
If a kubeconfig is present in the secret, the CA bundle is set in the in the cluster.certificate-authority-data field of the cluster of the current context.
Otherwise, the bundle is stored in an additional secret key bundle.crt.
The controller also adds an annotation to the Secret to keep track when to renew the token before it expires.
By default, the tokens are issued to expire after 12 hours. The expiration time can be set with the following annotation:
serviceaccount.resources.gardener.cloud/token-expiration-duration: 6h
It automatically renews once 80% of the lifetime is reached, or after 24h.
Optionally, the controller can also populate the token into a Secret in the target cluster. This can be requested by annotating the Secret in the source cluster with:
token-requestor.resources.gardener.cloud/target-secret-name: "foo"
token-requestor.resources.gardener.cloud/target-secret-namespace: "bar"
Overall, the TokenRequestor controller provides credentials with limited lifetime (JWT tokens) used by Shoot control plane components running in the Seed to talk to the Shoot API Server. Please see the graphic below:
ℹ️ Generally, the controller can run with multiple instances in different components. For example,
gardener-resource-managermight run theTokenRequestorcontroller, butgardenletmight run it, too. In order to differentiate which instance of the controller is responsible for aSecret, it can be labeled withresources.gardener.cloud/class=<class>. The<class>must be configured in the respective controller, otherwise it will be responsible for allSecrets no matter whether they have the label or not.
CertificateSigningRequest Approver
Kubelet Server
Gardener configures the kubelets such that they request two certificates via the CertificateSigningRequest API:
- client certificate for communicating with the
kube-apiserver - server certificate for serving its HTTPS server
For client certificates, the kubernetes.io/kube-apiserver-client-kubelet signer is used (see Certificate Signing Requests for more details).
The kube-controller-manager’s csrapprover controller is responsible for auto-approving such CertificateSigningRequests so that the respective certificates can be issued.
For server certificates, the kubernetes.io/kubelet-serving signer is used.
Unfortunately, the kube-controller-manager is not able to auto-approve such CertificateSigningRequests (see kubernetes/kubernetes#73356 for details).
That’s the motivation for having this controller as part of gardener-resource-manager.
It watches CertificateSigningRequests with the kubernetes.io/kubelet-serving signer and auto-approves them when all the following conditions are met:
- The
.spec.usernameis prefixed withsystem:node:. - There must be at least one DNS name or IP address as part of the certificate SANs.
- The common name in the CSR must match the
.spec.username. - The organization in the CSR must only contain
system:nodes. - There must be a
Nodeobject with the same name in the shoot cluster. - There must be exactly one
Machinefor the node in the seed cluster. - The DNS names part of the SANs must be equal to all
.status.addresses[]of typeHostnamein theNode. - The IP addresses part of the SANs must be equal to all
.status.addresses[]of typeInternalIPin theNode.
If any one of these requirements is violated, the CertificateSigningRequest will be denied.
Otherwise, once approved, the kube-controller-manager’s csrsigner controller will issue the requested certificate.
Gardener Node Agent
There is a second use case for CSR Approver, because Gardener Node Agent is able to use client certificates for communication with kube-apiserver.
These certificates are requested via the CertificateSigningRequest API. They are using the kubernetes.io/kube-apiserver-client signer.
Three use cases are covered:
- Bootstrap a new
node. - Renew certificates.
- Migrate nodes using
gardener-node-agentservice account.
There is no auto-approve for these CertificateSigningRequests either.
As there are more users of kubernetes.io/kube-apiserver-client signer this controller handles only CertificateSigningRequests when the common name in the CSR is prefixed with gardener.cloud:node-agent:machine:.
The prefix is followed by the username which must be equal to the machine.Name.
It auto-approves them when the following conditions are met.
Bootstrapping:
- The
.spec.usernameis prefixed withsystem:node:. - A
Machinefor common name patterngardener.cloud:node-agent:machine:<machine-name>in the CSR exists. - The
Machinedoes not have alabelwith keynode.
Certificate renewal:
- The
.spec.usernameis prefixed withgardener.cloud:node-agent:machine:. - A
Machinefor common name patterngardener.cloud:node-agent:machine:<machine-name>in the CSR exists. - The common name in the CSR must match the
.spec.username.
Migration:
- The
.spec.usernameis equal tosystem:serviceaccount:kube-system:gardener-node-agent. - A
Machinefor common name patterngardener.cloud:node-agent:machine:<machine-name>in the CSR exists. - The
Machinehas alabelwith keynode.
If the common name in the CSR is not prefixed with gardener.cloud:node-agent:machine:, the CertificateSigningRequest will be ignored.
If any one of these requirements is violated, the CertificateSigningRequest will be denied.
Otherwise, once approved, the kube-controller-manager’s csrsigner controller will issue the requested certificate.
NetworkPolicy Controller
This controller reconciles Services with a non-empty .spec.podSelector.
It creates two NetworkPolicys for each port in the .spec.ports[] list.
For example:
apiVersion: v1
kind: Service
metadata:
name: gardener-resource-manager
namespace: a
spec:
selector:
app: gardener-resource-manager
ports:
- name: server
port: 443
protocol: TCP
targetPort: 10250
leads to
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
annotations:
gardener.cloud/description: Allows ingress TCP traffic to port 10250 for pods
selected by the a/gardener-resource-manager service selector from pods running
in namespace a labeled with map[networking.resources.gardener.cloud/to-gardener-resource-manager-tcp-10250:allowed].
name: ingress-to-gardener-resource-manager-tcp-10250
namespace: a
spec:
ingress:
- from:
- podSelector:
matchLabels:
networking.resources.gardener.cloud/to-gardener-resource-manager-tcp-10250: allowed
ports:
- port: 10250
protocol: TCP
podSelector:
matchLabels:
app: gardener-resource-manager
policyTypes:
- Ingress
---
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
annotations:
gardener.cloud/description: Allows egress TCP traffic to port 10250 from pods
running in namespace a labeled with map[networking.resources.gardener.cloud/to-gardener-resource-manager-tcp-10250:allowed]
to pods selected by the a/gardener-resource-manager service selector.
name: egress-to-gardener-resource-manager-tcp-10250
namespace: a
spec:
egress:
- to:
- podSelector:
matchLabels:
app: gardener-resource-manager
ports:
- port: 10250
protocol: TCP
podSelector:
matchLabels:
networking.resources.gardener.cloud/to-gardener-resource-manager-tcp-10250: allowed
policyTypes:
- Egress
A component that initiates the connection to gardener-resource-manager’s tcp/10250 port can now be labeled with networking.resources.gardener.cloud/to-gardener-resource-manager-tcp-10250=allowed.
That’s all this component needs to do - it does not need to create any NetworkPolicys itself.
Cross-Namespace Communication
Apart from this “simple” case where both communicating components run in the same namespace a, there is also the cross-namespace communication case.
With above example, let’s say there are components running in another namespace b, and they would like to initiate the communication with gardener-resource-manager in a.
To cover this scenario, the Service can be annotated with networking.resources.gardener.cloud/namespace-selectors='[{"matchLabels":{"kubernetes.io/metadata.name":"b"}}]'.
Note that you can specify multiple namespace selectors in this annotation which are OR-ed.
This will make the controller create additional NetworkPolicys as follows:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
annotations:
gardener.cloud/description: Allows ingress TCP traffic to port 10250 for pods selected
by the a/gardener-resource-manager service selector from pods running in namespace b
labeled with map[networking.resources.gardener.cloud/to-a-gardener-resource-manager-tcp-10250:allowed].
name: ingress-to-gardener-resource-manager-tcp-10250-from-b
namespace: a
spec:
ingress:
- from:
- namespaceSelector:
matchLabels:
kubernetes.io/metadata.name: b
podSelector:
matchLabels:
networking.resources.gardener.cloud/to-a-gardener-resource-manager-tcp-10250: allowed
ports:
- port: 10250
protocol: TCP
podSelector:
matchLabels:
app: gardener-resource-manager
policyTypes:
- Ingress
---
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
annotations:
gardener.cloud/description: Allows egress TCP traffic to port 10250 from pods running in
namespace b labeled with map[networking.resources.gardener.cloud/to-a-gardener-resource-manager-tcp-10250:allowed]
to pods selected by the a/gardener-resource-manager service selector.
name: egress-to-a-gardener-resource-manager-tcp-10250
namespace: b
spec:
egress:
- to:
- namespaceSelector:
matchLabels:
kubernetes.io/metadata.name: a
podSelector:
matchLabels:
app: gardener-resource-manager
ports:
- port: 10250
protocol: TCP
podSelector:
matchLabels:
networking.resources.gardener.cloud/to-a-gardener-resource-manager-tcp-10250: allowed
policyTypes:
- Egress
The components in namespace b now need to be labeled with networking.resources.gardener.cloud/to-a-gardener-resource-manager-tcp-10250=allowed, but that’s already it.
Obviously, this approach also works for namespace selectors different from
kubernetes.io/metadata.nameto cover scenarios where the namespace name is not known upfront or where multiple namespaces with a similar label are relevant. The controller creates two dedicated policies for each namespace matching the selectors.
Service Targets In Multiple Namespaces
Finally, let’s say there is a Service called example which exists in different namespaces whose names are not static (e.g., foo-1, foo-2), and a component in namespace bar wants to initiate connections with all of them.
The example Services in these namespaces can now be annotated with networking.resources.gardener.cloud/namespace-selectors='[{"matchLabels":{"kubernetes.io/metadata.name":"bar"}}]'.
As a consequence, the component in namespace bar now needs to be labeled with networking.resources.gardener.cloud/to-foo-1-example-tcp-8080=allowed, networking.resources.gardener.cloud/to-foo-2-example-tcp-8080=allowed, etc.
This approach does not work in practice, however, since the namespace names are neither static nor known upfront.
To overcome this, it is possible to specify an alias for the concrete namespace in the pod label selector via the networking.resources.gardener.cloud/pod-label-selector-namespace-alias annotation.
In above case, the example Service in the foo-* namespaces could be annotated with networking.resources.gardener.cloud/pod-label-selector-namespace-alias=all-foos.
This would modify the label selector in all NetworkPolicys related to cross-namespace communication, i.e. instead of networking.resources.gardener.cloud/to-foo-{1,2,...}-example-tcp-8080=allowed, networking.resources.gardener.cloud/to-all-foos-example-tcp-8080=allowed would be used.
Now the component in namespace bar only needs this single label and is able to talk to all such Services in the different namespaces.
Real-world examples for this scenario are the
kube-apiserverService(which exists in all shoot namespaces), or theistio-ingressgatewayService(which exists in allistio-ingress*namespaces). In both cases, the names of the namespaces are not statically known and depend on user input.
Overwriting The Pod Selector Label
For a component which initiates the connection to many other components, it’s sometimes impractical to specify all the respective labels in its pod template.
For example, let’s say a component foo talks to bar{0..9} on ports tcp/808{0..9}.
foo would need to have the ten networking.resources.gardener.cloud/to-bar{0..9}-tcp-808{0..9}=allowed labels.
As an alternative and to simplify this, it is also possible to annotate the targeted Services with networking.resources.gardener.cloud/from-<some-alias>-allowed-ports.
For our example, <some-alias> could be all-bars.
As a result, component foo just needs to have the label networking.resources.gardener.cloud/to-all-bars=allowed instead of all the other ten explicit labels.
⚠️ Note that this also requires to specify the list of allowed container ports as annotation value since the pod selector label will no longer be specific for a dedicated service/port.
For our example, the Service for barX with X in {0..9} needs to be annotated with networking.resources.gardener.cloud/from-all-bars-allowed-ports=[{"port":808X,"protocol":"TCP"}] in addition.
Real-world examples for this scenario are the
Prometheisin seed clusters which initiate the communication to a lot of components in order to scrape their metrics. Another example is thekube-apiserverwhich initiates the communication to webhook servers (potentially of extension components that are not known by Gardener itself).
Ingress From Everywhere
All above scenarios are about components initiating connections to some targets. However, some components also receive incoming traffic from sources outside the cluster. This traffic requires adequate ingress policies so that it can be allowed.
To cover this scenario, the Service can be annotated with networking.resources.gardener.cloud/from-world-to-ports=[{"port":"10250","protocol":"TCP"}].
As a result, the controller creates the following NetworkPolicy:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: ingress-to-gardener-resource-manager-from-world
namespace: a
spec:
ingress:
- ports:
- port: 10250
protocol: TCP
podSelector:
matchLabels:
app: gardener-resource-manager
policyTypes:
- Ingress
The respective pods don’t need any additional labels.
If the annotation’s value is empty ([]) then all ports are allowed.
Services Exposed via Ingress Resources
The controller can optionally be configured to watch Ingress resources by specifying the pod and namespace selectors for the Ingress controller.
If this information is provided, it automatically creates NetworkPolicy resources allowing the respective ingress/egress traffic for the backends exposed by the Ingresses.
This way, neither custom NetworkPolicys nor custom labels must be provided.
The needed configuration is part of the component configuration:
controllers:
networkPolicy:
enabled: true
concurrentSyncs: 5
# namespaceSelectors:
# - matchLabels:
# kubernetes.io/metadata.name: default
ingressControllerSelector:
namespace: default
podSelector:
matchLabels:
foo: bar
As an example, let’s assume that above gardener-resource-manager Service was exposed via the following Ingress resource:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: gardener-resource-manager
namespace: a
spec:
rules:
- host: grm.foo.example.com
http:
paths:
- backend:
service:
name: gardener-resource-manager
port:
number: 443
path: /
pathType: Prefix
As a result, the controller would automatically create the following NetworkPolicys:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
annotations:
gardener.cloud/description: Allows ingress TCP traffic to port 10250 for pods
selected by the a/gardener-resource-manager service selector from ingress controller
pods running in the default namespace labeled with map[foo:bar].
name: ingress-to-gardener-resource-manager-tcp-10250-from-ingress-controller
namespace: a
spec:
ingress:
- from:
- podSelector:
matchLabels:
foo: bar
namespaceSelector:
matchLabels:
kubernetes.io/metadata.name: default
ports:
- port: 10250
protocol: TCP
podSelector:
matchLabels:
app: gardener-resource-manager
policyTypes:
- Ingress
---
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
annotations:
gardener.cloud/description: Allows egress TCP traffic to port 10250 from pods
running in the default namespace labeled with map[foo:bar] to pods selected by
the a/gardener-resource-manager service selector.
name: egress-to-a-gardener-resource-manager-tcp-10250-from-ingress-controller
namespace: default
spec:
egress:
- to:
- podSelector:
matchLabels:
app: gardener-resource-manager
namespaceSelector:
matchLabels:
kubernetes.io/metadata.name: a
ports:
- port: 10250
protocol: TCP
podSelector:
matchLabels:
foo: bar
policyTypes:
- Egress
ℹ️ Note that
Ingressresources reference the service port whileNetworkPolicys reference the target port/container port. The controller automatically translates this when reconciling theNetworkPolicyresources.
Node Controller
Critical Components Controller
Gardenlet configures kubelet of shoot worker nodes to register the Node object with the node.gardener.cloud/critical-components-not-ready taint (effect NoSchedule).
This controller watches newly created Node objects in the shoot cluster and removes the taint once all node-critical components are scheduled and ready.
If the controller finds node-critical components that are not scheduled or not ready yet, it checks the Node again after the duration configured in ResourceManagerConfiguration.controllers.node.backoff
Please refer to the feature documentation or proposal issue for more details.
Node Agent Reconciliation Delay Controller
This controller computes a reconciliation delay per node by using a simple linear mapping approach based on the index of the nodes in the list of all nodes in the shoot cluster.
This approach ensures that the delays of all instances of gardener-node-agent are distributed evenly.
The minimum and maximum delays can be configured, but they are defaulted to 0s and 5m, respectively.
This approach works well as long as the number of nodes in the cluster is not higher than the configured maximum delay in seconds.
In this case, the delay is still computed linearly, however, the more nodes exist in the cluster, the closer the delay times become (which might be of limited use then).
Consider increasing the maximum delay by annotating the Shoot with shoot.gardener.cloud/cloud-config-execution-max-delay-seconds=<value>.
The highest possible value is 1800.
The controller adds the node-agent.gardener.cloud/reconciliation-delay annotation to nodes whose value is read by the node-agents.
Webhooks
Mutating Webhooks
High Availability Config
This webhook is used to conveniently apply the configuration to make components deployed to seed or shoot clusters highly available. The details and scenarios are described in High Availability Of Deployed Components.
The webhook reacts on creation/update of Deployments, StatefulSets and HorizontalPodAutoscalers in namespaces labeled with high-availability-config.resources.gardener.cloud/consider=true.
The webhook performs the following actions:
The
.spec.replicas(orspec.minReplicasrespectively) field is mutated based on thehigh-availability-config.resources.gardener.cloud/typelabel of the resource and thehigh-availability-config.resources.gardener.cloud/failure-tolerance-typeannotation of the namespace:Failure Tolerance Type ➡️
/
⬇️ Component Type️ ️unset empty non-empty controller212server222- The replica count values can be overwritten by the
high-availability-config.resources.gardener.cloud/replicasannotation. - It does NOT mutate the replicas when:
- the replicas are already set to
0(hibernation case), or - when the resource is scaled horizontally by
HorizontalPodAutoscaler, and the current replica count is higher than what was computed above.
- the replicas are already set to
- The replica count values can be overwritten by the
When the
high-availability-config.resources.gardener.cloud/zonesannotation is NOT empty and either thehigh-availability-config.resources.gardener.cloud/failure-tolerance-typeannotation is set or thehigh-availability-config.resources.gardener.cloud/zone-pinningannotation is set totrue, then it adds a node affinity to the pod template spec:spec: affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: topology.kubernetes.io/zone operator: In values: - <zone1> # - ...This ensures that all pods are pinned to only nodes in exactly those concrete zones.
Topology Spread Constraints are added to the pod template spec when the
.spec.replicasare greater than1. When thehigh-availability-config.resources.gardener.cloud/zonesannotation …… contains only one zone, then the following is added:
spec: topologySpreadConstraints: - topologyKey: kubernetes.io/hostname minDomains: 3 # lower value of max replicas or 3 maxSkew: 1 whenUnsatisfiable: ScheduleAnyway # or DoNotSchedule matchLabelKeys: - pod-template-hash labelSelector: ...This ensures that the (multiple) pods are scheduled across nodes.
minDomainsis set when failure tolerance is configured or annotationhigh-availability-config.resources.gardener.cloud/host-spread="true"is given.… contains at least two zones, then the following is added:
spec: topologySpreadConstraints: - topologyKey: kubernetes.io/hostname maxSkew: 1 whenUnsatisfiable: ScheduleAnyway # or DoNotSchedule matchLabelKeys: - pod-template-hash labelSelector: ... - topologyKey: topology.kubernetes.io/zone minDomains: 2 # lower value of max replicas or number of zones maxSkew: 1 whenUnsatisfiable: DoNotSchedule matchLabelKeys: - pod-template-hash labelSelector: ...This enforces that the (multiple) pods are scheduled across zones. The
minDomainscalculation is based on whatever value is lower - (maximum) replicas or number of zones. This is the number of minimum domains required to schedule pods in a highly available manner.
Independent on the number of zones, when one of the following conditions is true, then the field
whenUnsatisfiableis set toDoNotSchedulefor the constraint withtopologyKey=kubernetes.io/hostname(which enforces the node-spread):- The
high-availability-config.resources.gardener.cloud/host-spreadannotation is set totrue. - The
high-availability-config.resources.gardener.cloud/failure-tolerance-typeannotation is set and NOT empty.
Adds default tolerations for taint-based evictions:
Tolerations for taints
node.kubernetes.io/not-readyandnode.kubernetes.io/unreachableare added to the handledDeploymentandStatefulSetif theirpodTemplates do not already specify them. TheTolerationSecondsare taken from the respective configuration section of the webhook’s configuration (see example)).We consider fine-tuned values for those tolerations a matter of high-availability because they often help to reduce recovery times in case of node or zone outages, also see High-Availability Best Practices. In addition, this webhook handling helps to set defaults for many but not all workload components in a cluster. For instance, Gardener can use this webhook to set defaults for nearly every component in seed clusters but only for the system components in shoot clusters. Any customer workload remains unchanged.
Kubernetes Service Host Injection
By default, when Pods are created, Kubernetes implicitly injects the KUBERNETES_SERVICE_HOST environment variable into all containers.
The value of this variable points it to the default Kubernetes service (i.e., kubernetes.default.svc.cluster.local).
This allows pods to conveniently talk to the API server of their cluster.
In shoot clusters, this network path involves the apiserver-proxy DaemonSet which eventually forwards the traffic to the API server.
Hence, it results in additional network hop.
The purpose of this webhook is to explicitly inject the KUBERNETES_SERVICE_HOST environment variable into all containers and setting its value to the FQDN of the API server.
This way, the additional network hop is avoided.
Auto-Mounting Projected ServiceAccount Tokens
When this webhook is activated, then it automatically injects projected ServiceAccount token volumes into Pods and all its containers if all of the following preconditions are fulfilled:
- The
Podis NOT labeled withprojected-token-mount.resources.gardener.cloud/skip=true. - The
Pod’s.spec.serviceAccountNamefield is NOT empty and NOT set todefault. - The
ServiceAccountspecified in thePod’s.spec.serviceAccountNamesets.automountServiceAccountToken=false. - The
Pod’s.spec.volumes[]DO NOT already contain a volume with a name prefixed withkube-api-access-.
The projected volume will look as follows:
spec:
volumes:
- name: kube-api-access-gardener
projected:
defaultMode: 420
sources:
- serviceAccountToken:
expirationSeconds: 43200
path: token
- configMap:
items:
- key: ca.crt
path: ca.crt
name: kube-root-ca.crt
- downwardAPI:
items:
- fieldRef:
apiVersion: v1
fieldPath: metadata.namespace
path: namespace
The
expirationSecondsare defaulted to12hand can be overwritten with the.webhooks.projectedTokenMount.expirationSecondsfield in the component configuration, or with theprojected-token-mount.resources.gardener.cloud/expiration-secondsannotation on aPodresource.
The volume will be mounted into all containers specified in the Pod to the path /var/run/secrets/kubernetes.io/serviceaccount.
This is the default location where client libraries expect to find the tokens and mimics the upstream ServiceAccount admission plugin. See Managing Service Accounts for more information.
Overall, this webhook is used to inject projected service account tokens into pods running in the Shoot and the Seed cluster. Hence, it is served from the Seed GRM and each Shoot GRM. Please find an overview below for pods deployed in the Shoot cluster:
Pod Topology Spread Constraints
When this webhook is enabled, then it mimics the topologyKey feature for Topology Spread Constraints (TSC) on the label pod-template-hash.
Concretely, when a pod is labelled with pod-template-hash, the handler of this webhook extends any topology spread constraint in the pod:
metadata:
labels:
pod-template-hash: 123abc
spec:
topologySpreadConstraints:
- maxSkew: 1
topologyKey: topology.kubernetes.io/zone
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
pod-template-hash: 123abc # added by webhook
The procedure circumvents a known limitation with TSCs which leads to imbalanced deployments after rolling updates.
Gardener enables this webhook to schedule pods of deployments across nodes and zones. This webhook is enabled only when the MatchLabelKeysInPodTopologySpread feature gate (beta since v1.27) is explicitly disabled in the kube-apiserver and kube-scheduler.
Please note that the gardener-resource-manager itself as well as pods labelled with topology-spread-constraints.resources.gardener.cloud/skip are excluded from any mutations.
System Components Webhook
If enabled, this webhook handles scheduling concerns for system components Pods (except those managed by DaemonSets).
The following tasks are performed by this webhook:
- Add
pod.spec.nodeSelectoras given in the webhook configuration. - Add
pod.spec.tolerationsas given in the webhook configuration. - Add
pod.spec.tolerationsfor any existing nodes matching the node selector given in the webhook configuration. Known taints and tolerations used for taint based evictions are disregarded.
Gardener enables this webhook for kube-system and kubernetes-dashboard namespaces in shoot clusters, selecting Pods being labelled with resources.gardener.cloud/managed-by: gardener.
It adds a configuration, so that Pods will get the worker.gardener.cloud/system-components: true node selector (step 1) as well as tolerate any custom taint (step 2) that is added to system component worker nodes (shoot.spec.provider.workers[].systemComponents.allow: true).
In addition, the webhook merges these tolerations with the ones required for at that time available system component Nodes in the cluster (step 3).
Both is required to ensure system component Pods can be scheduled or executed during an active shoot reconciliation that is happening due to any modifications to shoot.spec.provider.workers[].taints, e.g. Pods must be scheduled while there are still Nodes not having the updated taint configuration.
You can opt-out of this behaviour for
Pods by labeling them withsystem-components-config.resources.gardener.cloud/skip=true.
EndpointSlice Hints
This webhook mutates EndpointSlices. For each endpoint in the EndpointSlice, it sets the endpoint’s hints to the endpoint’s zone.
apiVersion: discovery.k8s.io/v1
kind: EndpointSlice
metadata:
name: example-hints
endpoints:
- addresses:
- "10.1.2.3"
conditions:
ready: true
hostname: pod-1
zone: zone-a
hints:
forZones:
- name: "zone-a" # added by webhook
- addresses:
- "10.1.2.4"
conditions:
ready: true
hostname: pod-2
zone: zone-b
hints:
forZones:
- name: "zone-b" # added by webhook
The webhook aims to circumvent issues with the Kubernetes TopologyAwareHints feature that currently does not allow to achieve a deterministic topology-aware traffic routing. For more details, see the following issue kubernetes/kubernetes#113731 that describes drawbacks of the TopologyAwareHints feature for our use case.
If the above-mentioned issue gets resolved and there is a native support for deterministic topology-aware traffic routing in Kubernetes, then this webhook can be dropped in favor of the native Kubernetes feature.
The EndpointSlice Hints webhook is disabled when the runtime Kubernetes version is >= 1.32. Instead, the
ServiceTrafficDistributionfeature is used. See more details in Topology-Aware Traffic Routing.
Pod Kube API Server Load Balancing
This webhook is used in the context of L7 load balancing for kube-apiservers. It facilitates access of control plane components to the kube-apiserver via istio ingress gateway which is the Gardener l7 load balancer.
For those control plane pods which use the generic token kubeconfig the webhook adds these items:
- It adds a network policy label to allow the pods to access the internal istio ingress gateway service which is responsible for “its” kube-apiserver.
- It adds a host alias which resolves the cluster externally resolvable kube-apiserver host to the internal istio ingress gateway service cluster IP address.
apiVersion: v1
kind: Pod
metadata:
labels:
networking.resources.gardener.cloud/to-istio-ingress-istio-ingressgateway-internal-tcp-9443: allowed # added by webhook
spec:
hostAliases:
- hostnames: # added by webhook
- api.local.local.internal.local.gardener.cloud # added by webhook
ip: 10.2.15.178 # added by webhook
For mutating pods, the webhook needs to know the namespace of the istio ingress gateway responsible for the kube-apiserver and its host names.
These values are stored in istio-internal-load-balancing configmap in the same namespace as the pod being mutated.
Validating Webhooks
Unconfirmed Deletion Prevention For Custom Resources And Definitions
As part of Gardener’s extensibility concepts, a lot of CustomResourceDefinitions are deployed to the seed clusters that serve as extension points for provider-specific controllers.
For example, the Infrastructure CRD triggers the provider extension to prepare the IaaS infrastructure of the underlying cloud provider for a to-be-created shoot cluster.
Consequently, these extension CRDs have a lot of power and control large portions of the end-user’s shoot cluster.
Accidental or undesired deletions of those resource can cause tremendous and hard-to-recover-from outages and should be prevented.
When this webhook is activated, it reacts for CustomResourceDefinitions and most of the custom resources in the extensions.gardener.cloud/v1alpha1 API group.
It also reacts for the druid.gardener.cloud/v1alpha1.Etcd resources.
The webhook prevents DELETE requests for those CustomResourceDefinitions labeled with gardener.cloud/deletion-protected=true, and for all mentioned custom resources if they were not previously annotated with the confirmation.gardener.cloud/deletion=true.
This prevents that undesired kubectl delete <...> requests are accepted.
Extension Resource Validation
When this webhook is activated, it reacts for most of the custom resources in the extensions.gardener.cloud/v1alpha1 API group.
It also reacts for the druid.gardener.cloud/v1alpha1.Etcd resources.
The webhook validates the resources specifications for CREATE and UPDATE requests.
Authorization Webhooks
node-agent-authorizer webhook
gardener-resource-manager serves an authorization webhook for shoot kube-apiservers which authorizes requests made by the gardener-node-agent.
It works similar to SeedAuthorizer. However, the logic used to make decisions is much simpler so it does not implement a decision graph.
In many cases, the objects gardener-node-agent is allowed to access depend on the Node it is running on.
The username of the gardener-node-agent used for authorization requests is derived from the name of the Machine resource responsible for the node that the gardener-node-agent is running on. It follows the pattern gardener.cloud:node-agent:machine:<machine-name>.
The name of the Node which runs on a Machine is read from node label of the Machine.
All gardener-node-agent users are assigned to gardener.cloud:node-agents group.
Today, the following rules are implemented:
| Resource | Verbs | Description |
|---|---|---|
CertificateSigningRequests | get , create | Allow create requests for all CertificateSigningRequests s. Allow get requests for CertificateSigningRequests s created by the same user. |
Events | create , patch | Allow to create and patch all Event s. |
Leases | get , list , watch , create , update | Allow get , list , watch , create , update requests for Leases with the name gardener-node-agent-<node-name> in kube-system namespace. |
Nodes | get , list , watch , patch , update | Allow get , watch , patch , update requests for the Node where gardener-node-agent is running. Allow list requests for all nodes. |
Secrets | get , list , watch | Allow get , list , watch request to gardener-valitail secret and the gardener-node-agent-secret of the worker group of the Node where gardener-node-agent is running. |
Pods | get , list , watch , delete | Allow list and watch permissions on Pods . For Shoot clusters running Kubernetes v1.31 or later, where the AuthorizeWithSelectors feature gate is enabled (it’s beta and enabled by default in v1.32+), allow list and watch only if the request contains a field selector spec.nodeName=<node-on-which-gardener-node-agent-is-running> . Allow get and delete requests if the .spec.nodeName of the Pod matches the Node on which gardener-node-agent is running. |
13 - Gardener Scheduler
Overview
The Gardener Scheduler is in essence a controller that watches newly created shoots and assigns a seed cluster to them. Conceptually, the task of the Gardener Scheduler is very similar to the task of the Kubernetes Scheduler: finding a seed for a shoot instead of a node for a pod.
Either the scheduling strategy or the shoot cluster purpose hereby determines how the scheduler is operating. The following sections explain the configuration and flow in greater detail.
Why Is the Gardener Scheduler Needed?
1. Decoupling
Previously, an admission plugin in the Gardener API server conducted the scheduling decisions. This implies changes to the API server whenever adjustments of the scheduling are needed. Decoupling the API server and the scheduler comes with greater flexibility to develop these components independently.
2. Extensibility
It should be possible to easily extend and tweak the scheduler in the future. Possibly, similar to the Kubernetes scheduler, hooks could be provided which influence the scheduling decisions. It should be also possible to completely replace the standard Gardener Scheduler with a custom implementation.
Algorithm Overview
The following sequence describes the steps involved to determine a seed candidate:
- Determine usable seeds with “usable” defined as follows:
- no
.metadata.deletionTimestamp .spec.settings.scheduling.visibleistrue.status.lastOperationis notnil- conditions
GardenletReady,BackupBucketsReady(if available) aretrue
- no
- Filter seeds:
- matching
.spec.seedSelectorinCloudProfileused by theShoot - matching
.spec.seedSelectorinShoot - having no network intersection with the
Shoot’s networks (due to the VPN connectivity between seeds and shoots their networks must be disjoint) - whose taints (
.spec.taints) are tolerated by theShoot(.spec.tolerations) - whose access restrictions (
.spec.accessRestrictions) are supporting those configured in theShoot(.spec.accessRestrictions) - whose capacity for shoots would not be exceeded if the shoot is scheduled onto the seed, see Ensuring seeds capacity for shoots is not exceeded
- which have at least three zones in
.spec.provider.zonesif shoot requests a high available control plane with failure tolerance typezone.
- matching
- Apply active strategy e.g., Minimal Distance strategy
- Choose least utilized seed, i.e., the one with the least number of shoot control planes, will be the winner and written to the
.spec.seedNamefield of theShoot.
In order to put the scheduling decision into effect, the scheduler sends an update request for the Shoot resource to
the API server. After validation, the gardener-apiserver updates the Shoot to have the spec.seedName field set.
Subsequently, the gardenlet picks up and starts to create the cluster on the specified seed.
Configuration
The Gardener Scheduler configuration has to be supplied on startup. It is a mandatory and also the only available flag. This yaml file holds an example scheduler configuration.
Most of the configuration options are the same as in the Gardener Controller Manager (leader election, client connection, …). However, the Gardener Scheduler on the other hand does not need a TLS configuration, because there are currently no webhooks configurable.
Strategies
The scheduling strategy is defined in the candidateDeterminationStrategy of the scheduler’s configuration and can have the possible values SameRegion and MinimalDistance.
The SameRegion strategy is the default strategy.
Same Region strategy
The Gardener Scheduler reads the spec.provider.type and .spec.region fields from the Shoot resource.
It tries to find a seed that has the identical .spec.provider.type and .spec.provider.region fields set.
If it cannot find a suitable seed, it adds an event to the shoot stating that it is unschedulable.
Minimal Distance strategy
The Gardener Scheduler tries to find a valid seed with minimal distance to the shoot’s intended region.
Distances are configured via ConfigMap(s), usually per cloud provider in a Gardener landscape.
The configuration is structured like this:
- It refers to one or multiple
CloudProfiles via annotationscheduling.gardener.cloud/cloudprofiles. - It contains the declaration as
region-configvia labelscheduling.gardener.cloud/purpose. - If a
CloudProfileis referred by multipleConfigMaps, only the first one is considered. - The
datafields configure actual distances, where key relates to theShootregion and value contains distances toSeedregions.
apiVersion: v1
kind: ConfigMap
metadata:
name: <name>
namespace: garden
annotations:
scheduling.gardener.cloud/cloudprofiles: cloudprofile-name-1{,optional-cloudprofile-name-2,...}
labels:
scheduling.gardener.cloud/purpose: region-config
data:
region-1: |
region-2: 10
region-3: 20
...
region-2: |
region-1: 10
region-3: 10
...
Gardener provider extensions for public cloud providers usually have an example weight
ConfigMapin their repositories. We suggest to check them out before defining your own data.
If a valid seed candidate cannot be found after consulting the distance configuration, the scheduler will fall back to
the Levenshtein distance to find the closest region. Therefore, the region name
is split into a base name and an orientation. Possible orientations are north, south, east, west and central.
The distance then is twice the Levenshtein distance of the region’s base name plus a correction value based on the
orientation and the provider.
If the orientations of shoot and seed candidate match, the correction value is 0, if they differ it is 2 and if either the seed’s or the shoot’s region does not have an orientation it is 1. If the provider differs, the correction value is additionally incremented by 2.
Because of this, a matching region with a matching provider is always preferred.
Special handling based on shoot cluster purpose
Every shoot cluster can have a purpose that describes what the cluster is used for, and also influences how the cluster is setup (see Shoot Cluster Purpose for more information).
In case the shoot has the testing purpose, then the scheduler only reads the .spec.provider.type from the Shoot resource and tries to find a Seed that has the identical .spec.provider.type.
The region does not matter, i.e., testing shoots may also be scheduled on a seed in a complete different region if it is better for balancing the whole Gardener system.
shoots/binding Subresource
The shoots/binding subresource is used to bind a Shoot to a Seed. On creation of a shoot cluster/s, the scheduler updates the binding automatically if an appropriate seed cluster is available.
Only an operator with the necessary RBAC can update this binding manually. This can be done by changing the .spec.seedName of the shoot. However, if a different seed is already assigned to the shoot, this will trigger a control-plane migration. For required steps, please see Triggering the Migration.
spec.schedulerName Field in the Shoot Specification
Similar to the spec.schedulerName field in Pods, the Shoot specification has an optional .spec.schedulerName field. If this field is set on creation, only the scheduler which relates to the configured name is responsible for scheduling the shoot.
The default-scheduler name is reserved for the default scheduler of Gardener.
Affected Shoots will remain in Pending state if the mentioned scheduler is not present in the landscape.
spec.seedName Field in the Shoot Specification
Similar to the .spec.nodeName field in Pods, the Shoot specification has an optional .spec.seedName field. If this field is set on creation, the shoot will be scheduled to this seed. However, this field can only be set by users having RBAC for the shoots/binding subresource. If this field is not set, the scheduler will assign a suitable seed automatically and populate this field with the seed name.
seedSelector Field in the Shoot Specification
Similar to the .spec.nodeSelector field in Pods, the Shoot specification has an optional .spec.seedSelector field.
It allows the user to provide a label selector that must match the labels of the Seeds in order to be scheduled to one of them.
The labels on the Seeds are usually controlled by Gardener administrators/operators - end users cannot add arbitrary labels themselves.
If provided, the Gardener Scheduler will only consider as “suitable” those seeds whose labels match those provided in the .spec.seedSelector of the Shoot.
By default, only seeds with the same provider as the shoot are selected. By adding a providerTypes field to the seedSelector,
a dedicated set of possible providers (* means all provider types) can be selected.
Ensuring a Seed’s Capacity for Shoots Is Not Exceeded
Seeds have a practical limit of how many shoots they can accommodate. Exceeding this limit is undesirable, as the system performance will be noticeably impacted. Therefore, the scheduler ensures that a seed’s capacity for shoots is not exceeded by taking into account a maximum number of shoots that can be scheduled onto a seed.
This mechanism works as follows:
- The
gardenletis configured with certain resources and their total capacity (and, for certain resources, the amount reserved for Gardener), see /example/20-componentconfig-gardenlet.yaml. Currently, the only such resource is the maximum number of shoots that can be scheduled onto a seed. - The
gardenletseed controller updates thecapacityandallocatablefields in the Seed status with the capacity of each resource and how much of it is actually available to be consumed by shoots. Theallocatablevalue of a resource is equal tocapacityminusreserved. - When scheduling shoots, the scheduler filters out all candidate seeds whose allocatable capacity for shoots would be exceeded if the shoot is scheduled onto the seed.
Failure to Determine a Suitable Seed
In case the scheduler fails to find a suitable seed, the operation is being retried with exponential backoff.
The reason for the failure will be reported in the Shoot’s .status.lastOperation field as well as a Kubernetes event (which can be retrieved via kubectl -n <namespace> describe shoot <shoot-name>).
Current Limitation / Future Plans
- Azure unfortunately has a geographically non-hierarchical naming pattern and does not start with the continent. This is the reason why we will exchange the implementation of the
MinimalDistancestrategy with a more suitable one in the future.
14 - gardenlet
Overview
Gardener is implemented using the operator pattern: It uses custom controllers that act on our own custom resources, and apply Kubernetes principles to manage clusters instead of containers. Following this analogy, you can recognize components of the Gardener architecture as well-known Kubernetes components, for example, shoot clusters can be compared with pods, and seed clusters can be seen as worker nodes.
The following Gardener components play a similar role as the corresponding components in the Kubernetes architecture:
| Gardener Component | Kubernetes Component |
|---|---|
gardener-apiserver | kube-apiserver |
gardener-controller-manager | kube-controller-manager |
gardener-scheduler | kube-scheduler |
gardenlet | kubelet |
Similar to how the kube-scheduler of Kubernetes finds an appropriate node
for newly created pods, the gardener-scheduler of Gardener finds an appropriate seed cluster
to host the control plane for newly ordered clusters.
By providing multiple seed clusters for a region or provider, and distributing the workload,
Gardener also reduces the blast radius of potential issues.
Kubernetes runs a primary “agent” on every node, the kubelet, which is responsible for managing pods and containers on its particular node. Decentralizing the responsibility to the kubelet has the advantage that the overall system is scalable. Gardener achieves the same for cluster management by using a gardenlet as a primary “agent” on every seed cluster, and is only responsible for shoot clusters located in its particular seed cluster:
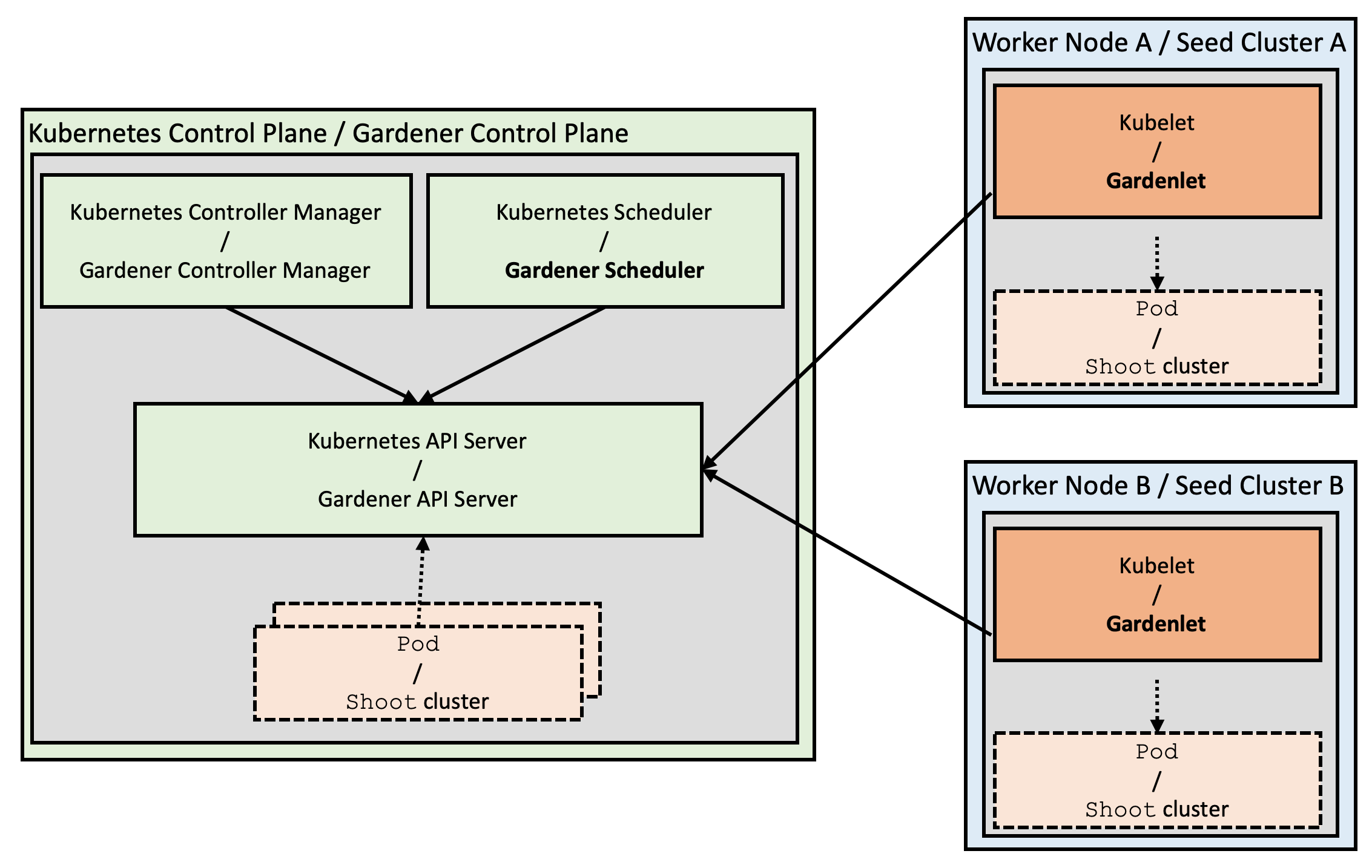
The gardener-controller-manager has controllers to manage resources of the Gardener API. However, instead of letting the gardener-controller-manager talk directly to seed clusters or shoot clusters, the responsibility isn’t only delegated to the gardenlet, but also managed using a reversed control flow: It’s up to the gardenlet to contact the Gardener API server, for example, to share a status for its managed seed clusters.
Reversing the control flow allows placing seed clusters or shoot clusters behind firewalls without the necessity of direct access via VPN tunnels anymore.
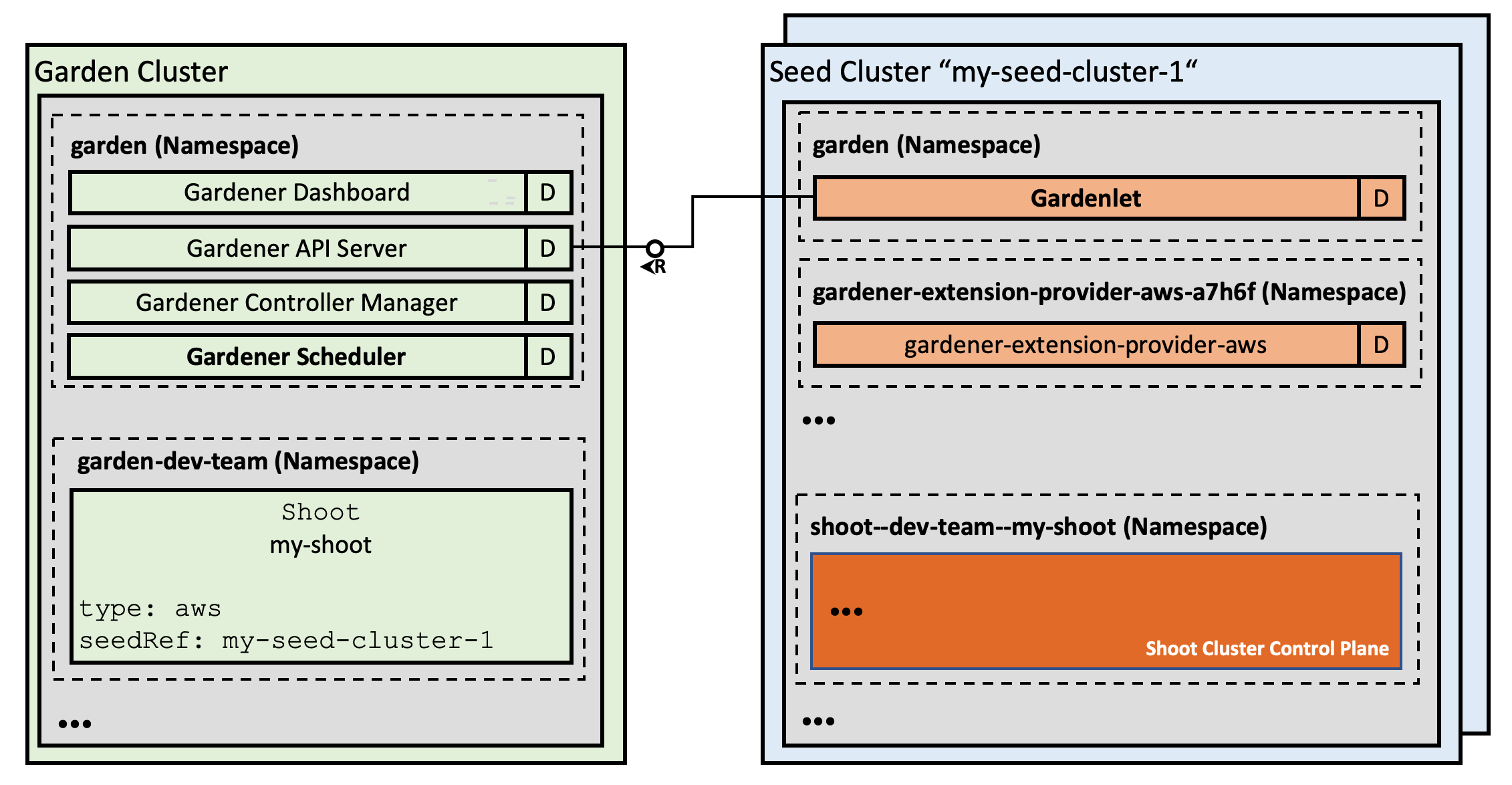
TLS Bootstrapping
Kubernetes doesn’t manage worker nodes itself, and it’s also not responsible for the lifecycle of the kubelet running on the workers. Similarly, Gardener doesn’t manage seed clusters itself, so it is also not responsible for the lifecycle of the gardenlet running on the seeds. As a consequence, both the gardenlet and the kubelet need to prepare a trusted connection to the Gardener API server and the Kubernetes API server correspondingly.
To prepare a trusted connection between the gardenlet and the Gardener API server, the gardenlet initializes a bootstrapping process after you deployed it into your seed clusters:
The gardenlet starts up with a bootstrap
kubeconfighaving a bootstrap token that allows to createCertificateSigningRequest(CSR) resources.After the CSR is signed, the gardenlet downloads the created client certificate, creates a new
kubeconfigwith it, and stores it inside aSecretin the seed cluster.The gardenlet deletes the bootstrap
kubeconfigsecret, and starts up with its newkubeconfig.The gardenlet starts normal operation.
The gardener-controller-manager runs a control loop
that automatically signs CSRs created by gardenlets.
The gardenlet bootstrapping process is based on the kubelet bootstrapping process. More information: Kubelet’s TLS bootstrapping.
If you don’t want to run this bootstrap process, you can create
a kubeconfig pointing to the garden cluster for the gardenlet yourself,
and use the field gardenClientConnection.kubeconfig in the
gardenlet configuration to share it with the gardenlet.
gardenlet Certificate Rotation
The certificate used to authenticate the gardenlet against the API server
has a certain validity based on the configuration of the garden cluster
(--cluster-signing-duration flag of the kube-controller-manager (default 1y)).
You can also configure the validity for the client certificate by specifying
.gardenClientConnection.kubeconfigValidity.validityin the gardenlet’s component configuration. Note that changing this value will only take effect when the kubeconfig is rotated again (it is not picked up immediately). The minimum validity is10m(that’s what is enforced by theCertificateSigningRequestAPI in Kubernetes which is used by the gardenlet).
By default, after about 70-90% of the validity has expired, the gardenlet tries to automatically replace the current certificate with a new one (certificate rotation).
You can change these boundaries by specifying
.gardenClientConnection.kubeconfigValidity.autoRotationJitterPercentage{Min,Max}in the gardenlet’s component configuration.
To use a certificate rotation, you need to specify the secret to store
the kubeconfig with the rotated certificate in the field
.gardenClientConnection.kubeconfigSecret of the
gardenlet component configuration.
Rotate Certificates Using Bootstrap kubeconfig
If the gardenlet created the certificate during the initial TLS Bootstrapping
using the Bootstrap kubeconfig, certificates can be rotated automatically.
The same control loop in the gardener-controller-manager that signs
the CSRs during the initial TLS Bootstrapping also automatically signs
the CSR during a certificate rotation.
ℹ️ You can trigger an immediate renewal by annotating the Secret in the seed
cluster stated in the .gardenClientConnection.kubeconfigSecret field with
gardener.cloud/operation=renew. Within 10s, gardenlet detects this and terminates
itself to request new credentials. After it has booted up again, gardenlet will issue a
new certificate independent of the remaining validity of the existing one.
ℹ️ Alternatively, annotate the respective Seed with gardener.cloud/operation=renew-kubeconfig.
This will make gardenlet annotate its own kubeconfig secret with gardener.cloud/operation=renew
and triggers the process described in the previous paragraph.
Rotate Certificates Using Custom kubeconfig
When trying to rotate a custom certificate that wasn’t created by gardenlet
as part of the TLS Bootstrap, the x509 certificate’s Subject field
needs to conform to the following:
- the Common Name (CN) is prefixed with
gardener.cloud:system:seed: - the Organization (O) equals
gardener.cloud:system:seeds
Otherwise, the gardener-controller-manager doesn’t automatically
sign the CSR.
In this case, an external component or user needs to approve the CSR manually,
for example, using the command kubectl certificate approve seed-csr-<...>).
If that doesn’t happen within 15 minutes,
the gardenlet repeats the process and creates another CSR.
Configuring the Seed to Work with gardenlet
The gardenlet works with a single seed, which must be configured in the
GardenletConfiguration under .seedConfig. This must be a copy of the
Seed resource, for example:
apiVersion: gardenlet.config.gardener.cloud/v1alpha1
kind: GardenletConfiguration
seedConfig:
metadata:
name: my-seed
spec:
provider:
type: aws
# ...
settings:
scheduling:
visible: true
(see this yaml file for a more complete example)
On startup, gardenlet registers a Seed resource using the given template
in the seedConfig if it’s not present already.
Component Configuration
In the component configuration for the gardenlet, it’s possible to define:
- settings for the Kubernetes clients interacting with the various clusters
- settings for the controllers inside the gardenlet
- settings for leader election and log levels, feature gates, and seed selection or seed configuration.
More information: Example gardenlet Component Configuration.
Heartbeats
Similar to how Kubernetes uses Lease objects for node heart beats
(see KEP),
the gardenlet is using Lease objects for heart beats of the seed cluster.
Every two seconds, the gardenlet checks that the seed cluster’s /healthz
endpoint returns HTTP status code 200.
If that is the case, the gardenlet renews the lease in the Garden cluster in the gardener-system-seed-lease namespace and updates
the GardenletReady condition in the status.conditions field of the Seed resource. For more information, see this section.
Similar to the node-lifecycle-controller inside the kube-controller-manager,
the gardener-controller-manager features a seed-lifecycle-controller that sets
the GardenletReady condition to Unknown in case the gardenlet fails to renew the lease.
As a consequence, the gardener-scheduler doesn’t consider this seed cluster for newly created shoot clusters anymore.
/healthz Endpoint
The gardenlet includes an HTTP server that serves a /healthz endpoint.
It’s used as a liveness probe in the Deployment of the gardenlet.
If the gardenlet fails to renew its lease,
then the endpoint returns 500 Internal Server Error, otherwise it returns 200 OK.
Please note that the /healthz only indicates whether the gardenlet
could successfully probe the Seed’s API server and renew the lease with
the Garden cluster.
It does not show that the Gardener extension API server (with the Gardener resource groups)
is available.
However, the gardenlet is designed to withstand such connection outages and
retries until the connection is reestablished.
Controllers
The gardenlet consists out of several controllers which are now described in more detail.
BackupBucket Controller
The BackupBucket controller reconciles those core.gardener.cloud/v1beta1.BackupBucket resources whose .spec.seedName value is equal to the name of the Seed the respective gardenlet is responsible for.
A core.gardener.cloud/v1beta1.BackupBucket resource is created by the Seed controller if .spec.backup is defined in the Seed.
The controller adds finalizers to the BackupBucket and the secret mentioned in the .spec.secretRef of the BackupBucket. The controller also copies this secret to the seed cluster. Additionally, it creates an extensions.gardener.cloud/v1alpha1.BackupBucket resource (non-namespaced) in the seed cluster and waits until the responsible extension controller reconciles it (see Contract: BackupBucket Resource for more details).
The status from the reconciliation is reported in the .status.lastOperation field. Once the extension resource is ready and the .status.generatedSecretRef is set by the extension controller, the gardenlet copies the referenced secret to the garden namespace in the garden cluster. An owner reference to the core.gardener.cloud/v1beta1.BackupBucket is added to this secret.
If the core.gardener.cloud/v1beta1.BackupBucket is deleted, the controller deletes the generated secret in the garden cluster and the extensions.gardener.cloud/v1alpha1.BackupBucket resource in the seed cluster and it waits for the respective extension controller to remove its finalizers from the extensions.gardener.cloud/v1alpha1.BackupBucket. Then it deletes the secret in the seed cluster and finally removes the finalizers from the core.gardener.cloud/v1beta1.BackupBucket and the referred secret.
BackupEntry Controller
The BackupEntry controller reconciles those core.gardener.cloud/v1beta1.BackupEntry resources whose .spec.seedName value is equal to the name of a Seed the respective gardenlet is responsible for.
Those resources are created by the Shoot controller (only if backup is enabled for the respective Seed) and there is exactly one BackupEntry per Shoot.
The controller creates an extensions.gardener.cloud/v1alpha1.BackupEntry resource (non-namespaced) in the seed cluster and waits until the responsible extension controller reconciled it (see Contract: BackupEntry Resource for more details).
The status is populated in the .status.lastOperation field.
The core.gardener.cloud/v1beta1.BackupEntry resource has an owner reference pointing to the corresponding Shoot.
Hence, if the Shoot is deleted, the BackupEntry resource also gets deleted.
In this case, the controller deletes the extensions.gardener.cloud/v1alpha1.BackupEntry resource in the seed cluster and waits until the responsible extension controller has deleted it.
Afterwards, the finalizer of the core.gardener.cloud/v1beta1.BackupEntry resource is released so that it finally disappears from the system.
If the spec.seedName and .status.seedName of the core.gardener.cloud/v1beta1.BackupEntry are different, the controller will migrate it by annotating the extensions.gardener.cloud/v1alpha1.BackupEntry in the Source Seed with gardener.cloud/operation: migrate, waiting for it to be migrated successfully and eventually deleting it from the Source Seed cluster. Afterwards, the controller will recreate the extensions.gardener.cloud/v1alpha1.BackupEntry in the Destination Seed, annotate it with gardener.cloud/operation: restore and wait for the restore operation to finish. For more details about control plane migration, please read Shoot Control Plane Migration.
Keep Backup for Deleted Shoots
In some scenarios it might be beneficial to not immediately delete the BackupEntrys (and with them, the etcd backup) for deleted Shoots.
In this case you can configure the .controllers.backupEntry.deletionGracePeriodHours field in the component configuration of the gardenlet.
For example, if you set it to 48, then the BackupEntrys for deleted Shoots will only be deleted 48 hours after the Shoot was deleted.
Additionally, you can limit the shoot purposes for which this applies by setting .controllers.backupEntry.deletionGracePeriodShootPurposes[].
For example, if you set it to [production] then only the BackupEntrys for Shoots with .spec.purpose=production will be deleted after the configured grace period. All others will be deleted immediately after the Shoot deletion.
In case a BackupEntry is scheduled for future deletion but you want to delete it immediately, add the annotation backupentry.core.gardener.cloud/force-deletion=true.
Bastion Controller
The Bastion controller reconciles those operations.gardener.cloud/v1alpha1.Bastion resources whose .spec.seedName value is equal to the name of a Seed the respective gardenlet is responsible for.
The controller creates an extensions.gardener.cloud/v1alpha1.Bastion resource in the seed cluster in the shoot namespace with the same name as operations.gardener.cloud/v1alpha1.Bastion. Then it waits until the responsible extension controller has reconciled it (see Contract: Bastion Resource for more details). The status is populated in the .status.conditions and .status.ingress fields.
During the deletion of operations.gardener.cloud/v1alpha1.Bastion resources, the controller first sets the Ready condition to False and then deletes the extensions.gardener.cloud/v1alpha1.Bastion resource in the seed cluster.
Once this resource is gone, the finalizer of the operations.gardener.cloud/v1alpha1.Bastion resource is released, so it finally disappears from the system.
ControllerInstallation Controller
The ControllerInstallation controller in the gardenlet reconciles ControllerInstallation objects with the help of the following reconcilers.
“Main” Reconciler
This reconciler is responsible for ControllerInstallations referencing a ControllerDeployment whose type=helm.
For each ControllerInstallation, it creates a namespace on the seed cluster named extension-<controller-installation-name>.
Then, it creates a generic garden kubeconfig and garden access secret for the extension for accessing the garden cluster.
After that, it unpacks the Helm chart tarball in the ControllerDeployments .providerConfig.chart field and deploys the rendered resources to the seed cluster.
The Helm chart values in .providerConfig.values will be used and extended with some information about the Gardener environment and the seed cluster:
gardener:
version: <gardenlet-version>
garden:
clusterIdentity: <identity-of-garden-cluster>
genericKubeconfigSecretName: <secret-name>
gardenlet:
featureGates:
Foo: true
Bar: false
# ...
seed:
name: <seed-name>
clusterIdentity: <identity-of-seed-cluster>
annotations: <seed-annotations>
labels: <seed-labels>
spec: <seed-specification>
As of today, there are a few more fields in .gardener.seed, but it is recommended to use the .gardener.seed.spec if the Helm chart needs more information about the seed configuration.
The rendered chart will be deployed via a ManagedResource created in the garden namespace of the seed cluster.
It is labeled with controllerinstallation-name=<name> so that one can easily find the owning ControllerInstallation for an existing ManagedResource.
The reconciler maintains the Installed condition of the ControllerInstallation and sets it to False if the rendering or deployment fails.
“Care” Reconciler
This reconciler reconciles ControllerInstallation objects and checks whether they are in a healthy state.
It checks the .status.conditions of the backing ManagedResource created in the garden namespace of the seed cluster.
- If the
ResourcesAppliedcondition of theManagedResourceisTrue, then theInstalledcondition of theControllerInstallationwill be set toTrue. - If the
ResourcesHealthycondition of theManagedResourceisTrue, then theHealthycondition of theControllerInstallationwill be set toTrue. - If the
ResourcesProgressingcondition of theManagedResourceisTrue, then theProgressingcondition of theControllerInstallationwill be set toTrue.
A ControllerInstallation is considered “healthy” if Applied=Healthy=True and Progressing=False.
“Required” Reconciler
This reconciler watches all resources in the extensions.gardener.cloud API group in the seed cluster.
It is responsible for maintaining the Required condition on ControllerInstallations.
Concretely, when there is at least one extension resource in the seed cluster a ControllerInstallation is responsible for, then the status of the Required condition will be True.
If there are no extension resources anymore, its status will be False.
This condition is taken into account by the ControllerRegistration controller part of gardener-controller-manager when it computes which extensions have to be deployed to which seed cluster. See Gardener Controller Manager for more details.
Gardenlet Controller
The Gardenlet controller reconciles a Gardenlet resource with the same name as the Seed the gardenlet is responsible for.
This is used to implement self-upgrades of gardenlet based on information pulled from the garden cluster.
For a general overview, see this document.
On Gardenlet reconciliation, the controller deploys the gardenlet within its own cluster which after downloading the Helm chart specified in .spec.deployment.helm.ociRepository and rendering it with the provided values/configuration.
On Gardenlet deletion, nothing happens: The gardenlet does not terminate itself - deleting a Gardenlet object effectively means that self-upgrades are stopped.
ManagedSeed Controller
The ManagedSeed controller in the gardenlet reconciles ManagedSeeds that refers to Shoot scheduled on Seed the gardenlet is responsible for.
Additionally, the controller monitors Seeds, which are owned by ManagedSeeds for which the gardenlet is responsible.
On ManagedSeed reconciliation, the controller first waits for the referenced Shoot to undergo a reconciliation process.
Once the Shoot is successfully reconciled, the controller sets the ShootReconciled status of the ManagedSeed to true.
Then, it creates garden namespace within the target shoot cluster.
The controller also manages secrets related to Seeds, such as the backup and kubeconfig secrets.
It ensures that these secrets are created and updated according to the ManagedSeed spec.
Finally, it deploys the gardenlet within the specified shoot cluster which registers the Seed cluster.
On ManagedSeed deletion, the controller first deletes the corresponding Seed that was originally created by the controller.
Subsequently, it deletes the gardenlet instance within the shoot cluster.
The controller also ensures the deletion of related Seed secrets.
Finally, the dedicated garden namespace within the shoot cluster is deleted.
NetworkPolicy Controller
The NetworkPolicy controller reconciles NetworkPolicys in all relevant namespaces in the seed cluster and provides so-called “general” policies for access to the runtime cluster’s API server, DNS, public networks, etc.
The controller resolves the IP address of the Kubernetes service in the default namespace and creates an egress NetworkPolicys for it.
For more details about NetworkPolicys in Gardener, please see NetworkPolicys In Garden, Seed, Shoot Clusters.
Seed Controller
The Seed controller in the gardenlet reconciles Seed objects with the help of the following reconcilers.
“Main Reconciler”
This reconciler is responsible for managing the seed’s system components.
Those comprise CA certificates, the various CustomResourceDefinitions, the logging and monitoring stacks, and few central components like gardener-resource-manager, etcd-druid, istio, etc.
The reconciler also deploys a BackupBucket resource in the garden cluster in case the Seed's .spec.backup is set.
It also checks whether the seed cluster’s Kubernetes version is at least the minimum supported version and errors in case this constraint is not met.
This reconciler maintains the .status.lastOperation field, i.e. it sets it:
- to
state=Progressingbefore it executes its reconciliation flow. - to
state=Errorin case an error occurs. - to
state=Succeededin case the reconciliation succeeded.
“Care” Reconciler
This reconciler checks whether the seed system components (deployed by the “main” reconciler) are healthy.
It checks the .status.conditions of the backing ManagedResource created in the garden namespace of the seed cluster.
A ManagedResource is considered “healthy” if the conditions ResourcesApplied=ResourcesHealthy=True and ResourcesProgressing=False.
If all ManagedResources are healthy, then the SeedSystemComponentsHealthy condition of the Seed will be set to True.
Otherwise, it will be set to False.
If at least one ManagedResource is unhealthy and there is threshold configuration for the conditions (in .controllers.seedCare.conditionThresholds), then the status of the SeedSystemComponentsHealthy condition will be set:
- to
Progressingif it wasTruebefore. - to
Progressingif it wasProgressingbefore and thelastUpdateTimeof the condition does not exceed the configured threshold duration yet. - to
Falseif it wasProgressingbefore and thelastUpdateTimeof the condition exceeds the configured threshold duration.
The condition thresholds can be used to prevent reporting issues too early just because there is a rollout or a short disruption.
Only if the unhealthiness persists for at least the configured threshold duration, then the issues will be reported (by setting the status to False).
In order to compute the condition statuses, this reconciler considers ManagedResources (in the garden and istio-system namespace) and their status, see this document for more information.
The following table explains which ManagedResources are considered for which condition type:
| Condition Type | ManagedResources are considered when |
|---|---|
SeedSystemComponentsHealthy | .spec.class is set |
“Lease” Reconciler
This reconciler checks whether the connection to the seed cluster’s /healthz endpoint works.
If this succeeds, then it renews a Lease resource in the garden cluster’s gardener-system-seed-lease namespace.
This indicates a heartbeat to the external world, and internally the gardenlet sets its health status to true.
In addition, the GardenletReady condition in the status of the Seed is set to True.
The whole process is similar to what the kubelet does to report heartbeats for its Node resource and its KubeletReady condition. For more information, see this section.
If the connection to the /healthz endpoint or the update of the Lease fails, then the internal health status of gardenlet is set to false.
Also, this internal health status is set to false automatically after some time, in case the controller gets stuck for whatever reason.
This internal health status is available via the gardenlet’s /healthz endpoint and is used for the livenessProbe in the gardenlet pod.
Shoot Controller
The Shoot controller in the gardenlet reconciles Shoot objects with the help of the following reconcilers.
“Main” Reconciler
This reconciler is responsible for managing all shoot cluster components and implements the core logic for creating, updating, hibernating, deleting, and migrating shoot clusters.
It is also responsible for syncing the Cluster cluster to the seed cluster before and after each successful shoot reconciliation.
The main reconciliation logic is performed in 3 different task flows dedicated to specific operation types:
reconcile(operations: create, reconcile, restore): this is the main flow responsible for creation and regular reconciliation of shoots. Hibernating a shoot also triggers this flow. It is also used for restoration of the shoot control plane on the new seed (second half of a Control Plane Migration)migrate: this flow is triggered whenspec.seedNamespecifies a different seed thanstatus.seedName. It performs the first half of the Control Plane Migration, i.e., a backup (migrateoperation) of all control plane components followed by a “shallow delete”.delete: this flow is triggered when the shoot’sdeletionTimestampis set, i.e., when it is deleted.
The gardenlet takes special care to prevent unnecessary shoot reconciliations. This is important for several reasons, e.g., to not overload the seed API servers and to not exhaust infrastructure rate limits too fast. The gardenlet performs shoot reconciliations according to the following rules:
- If
status.observedGenerationis less thanmetadata.generation: this is the case, e.g., when the spec was changed, a manual reconciliation operation was triggered, or the shoot was deleted. - If the last operation was not successful.
- If the shoot is in a failed state, the gardenlet does not perform any reconciliation on the shoot (unless the retry operation was triggered). However, it syncs the
Clusterresource to the seed in order to inform the extension controllers about the failed state. - Regular reconciliations are performed with every
GardenletConfiguration.controllers.shoot.syncPeriod(defaults to1h). - Shoot reconciliations are not performed if the assigned seed cluster is not healthy or has not been reconciled by the current gardenlet version yet (determined by the
Seed.status.gardenersection). This is done to make sure that shoots are reconciled with fully rolled out seed system components after a Gardener upgrade. Otherwise, the gardenlet might perform operations of the new version that doesn’t match the old version of the deployed seed system components, which might lead to unspecified behavior.
There are a few special cases that overwrite or confine how often and under which circumstances periodic shoot reconciliations are performed:
- In case the gardenlet config allows it (
controllers.shoot.respectSyncPeriodOverwrite, disabled by default), the sync period for a shoot can be increased individually by setting theshoot.gardener.cloud/sync-periodannotation. This is always allowed for shoots in thegardennamespace. Shoots are not reconciled with a higher frequency than specified inGardenletConfiguration.controllers.shoot.syncPeriod. - In case the gardenlet config allows it (
controllers.shoot.respectSyncPeriodOverwrite, disabled by default), shoots can be marked as “ignored” by setting theshoot.gardener.cloud/ignoreannotation. In this case, the gardenlet does not perform any reconciliation for the shoot. - In case
GardenletConfiguration.controllers.shoot.reconcileInMaintenanceOnlyis enabled (disabled by default), the gardenlet performs regular shoot reconciliations only once in the respective maintenance time window (GardenletConfiguration.controllers.shoot.syncPeriodis ignored). The gardenlet randomly distributes shoot reconciliations over the maintenance time window to avoid high bursts of reconciliations (see Shoot Maintenance). - In case
Shoot.spec.maintenance.confineSpecUpdateRolloutis enabled (disabled by default), changes to the shoot specification are not rolled out immediately but only during the respective maintenance time window (see Shoot Maintenance).
“Care” Reconciler
This reconciler performs three “care” actions related to Shoots.
Conditions
It maintains the following conditions:
APIServerAvailable: The/healthzendpoint of the shoot’skube-apiserveris called and considered healthy when it responds with200 OK.ControlPlaneHealthy: The control plane is considered healthy when the respectiveDeployments (for examplekube-apiserver,kube-controller-manager), andEtcds (for exampleetcd-main) exist and are healthy.ObservabilityComponentsHealthy: This condition is considered healthy when the respectiveDeployments (for exampleplutono) andStatefulSets (for exampleprometheus,vali) exist and are healthy.EveryNodeReady: The conditions of the worker nodes are checked (e.g.,Ready,MemoryPressure). Also, it’s checked whether the Kubernetes version of the installedkubeletmatches the desired version specified in theShootresource.SystemComponentsHealthy: The conditions of theManagedResources are checked (e.g.,ResourcesApplied). Also, it is verified whether the VPN tunnel connection is established (which is required for thekube-apiserverto communicate with the worker nodes).
Sometimes, ManagedResources can have both Healthy and Progressing conditions set to True (e.g., when a DaemonSet rolls out one-by-one on a large cluster with many nodes) while this is not reflected in the Shoot status. In order to catch issues where the rollout gets stuck, one can set .controllers.shootCare.managedResourceProgressingThreshold in the gardenlet’s component configuration. If the Progressing condition is still True for more than the configured duration, the SystemComponentsHealthy condition in the Shoot is set to False, eventually.
Each condition can optionally also have error codes in order to indicate which type of issue was detected (see Shoot Status for more details).
Apart from the above, extension controllers can also contribute to the status or error codes of these conditions (see Contributing to Shoot Health Status Conditions for more details).
If all checks for a certain conditions are succeeded, then its status will be set to True.
Otherwise, it will be set to False.
If at least one check fails and there is threshold configuration for the conditions (in .controllers.seedCare.conditionThresholds), then the status will be set:
- to
Progressingif it wasTruebefore. - to
Progressingif it wasProgressingbefore and thelastUpdateTimeof the condition does not exceed the configured threshold duration yet. - to
Falseif it wasProgressingbefore and thelastUpdateTimeof the condition exceeds the configured threshold duration.
The condition thresholds can be used to prevent reporting issues too early just because there is a rollout or a short disruption.
Only if the unhealthiness persists for at least the configured threshold duration, then the issues will be reported (by setting the status to False).
Besides directly checking the status of Deployments, Etcds, StatefulSets in the shoot namespace, this reconciler also considers ManagedResources (in the shoot namespace) and their status in order to compute the condition statuses, see this document for more information.
The following table explains which ManagedResources are considered for which condition type:
| Condition Type | ManagedResources are considered when |
|---|---|
ControlPlaneHealthy | .spec.class=seed and care.gardener.cloud/condition-type label either unset, or set to ControlPlaneHealthy |
ObservabilityComponentsHealthy | care.gardener.cloud/condition-type label set to ObservabilityComponentsHealthy |
SystemComponentsHealthy | .spec.class unset or care.gardener.cloud/condition-type label set to SystemComponentsHealthy |
Constraints And Automatic Webhook Remediation
Please see Shoot Status for more details.
Garbage Collection
Stale pods in the shoot namespace in the seed cluster and in the kube-system namespace in the shoot cluster are deleted.
A pod is considered stale when:
- it was terminated with reason
Evicted. - it was terminated with reason starting with
OutOf(e.g.,OutOfCpu). - it was terminated with reason
NodeAffinity. - it is stuck in termination (i.e., if its
deletionTimestampis more than5mago).
“State” Reconciler
This reconciler periodically (default: every 6h) performs backups of the state of Shoot clusters and persists them into ShootState resources into the same namespace as the Shoots in the garden cluster.
It is only started in case the gardenlet is responsible for an unmanaged Seed, i.e. a Seed which is not backed by a seedmanagement.gardener.cloud/v1alpha1.ManagedSeed object.
Alternatively, it can be disabled by setting the concurrentSyncs=0 for the controller in the gardenlet’s component configuration.
Please refer to GEP-22: Improved Usage of the ShootState API for all information.
“Status” Reconciler
This reconciler watches for the extensionsv1alpha1.Worker resource in the control plane namespace of the Shoot and if its status.inPlaceUpdates.workerPoolToHashMap has changed, it requeues the corresponding Shoot. A worker pool is removed from status.inPlaceUpdates.pendingWorkersRollouts.manualInPlaceUpdate field in the Shoot if the hash of the worker pool in the Shoot spec and the Worker status field matches. This indicates that all the nodes of that worker pool are successfully updated and are no longer pending manual in-place updates.
TokenRequestor Controller For ServiceAccounts
The gardenlet uses an instance of the TokenRequestor controller which initially was developed in the context of the gardener-resource-manager, please read this document for further information.
gardenlet uses it for requesting tokens for components running in the seed cluster that need to communicate with the garden cluster.
The mechanism works the same way as for shoot control plane components running in the seed which need to communicate with the shoot cluster.
However, gardenlet’s instance of the TokenRequestor controller is restricted to Secrets labeled with resources.gardener.cloud/class=garden.
Furthermore, it doesn’t respect the serviceaccount.resources.gardener.cloud/namespace annotation. Instead, it always uses the seed’s namespace in the garden cluster for managing ServiceAccounts and their tokens.
TokenRequestor Controller For WorkloadIdentitys
The TokenRequestorWorkloadIdentity controller in the gardenlet reconciles Secrets labeled with security.gardener.cloud/purpose=workload-identity-token-requestor.
When it encounters such Secret, it associates the Secret with a specific WorkloadIdentity using the annotations workloadidentity.security.gardener.cloud/name and workloadidentity.security.gardener.cloud/namespace.
Any workload creating such Secrets is responsible to label and annotate the Secrets accordingly.
After the association is made, the gardenlet requests a token for the specific WorkloadIdentity from the Gardener API Server and writes it back in the Secret’s data against the token key.
The gardenlet is responsible to keep this token valid by refreshing it periodically.
The token is then used by components running in the seed cluster in order to present the said WorkloadIdentity before external systems, e.g. by calling cloud provider APIs.
Please refer to GEP-26: Workload Identity - Trust Based Authentication for more details.
VPAEvictionRequirements Controller
The VPAEvictionRequirements controller in the gardenlet reconciles VerticalPodAutoscaler objects labeled with autoscaling.gardener.cloud/eviction-requirements: managed-by-controller. It manages the EvictionRequirements on a VPA object, which are used to restrict when and how a Pod can be evicted to apply a new resource recommendation.
Specifically, the following actions will be taken for the respective label and annotation configuration:
- If the VPA has the annotation
eviction-requirements.autoscaling.gardener.cloud/downscale-restriction: never, anEvictionRequirementis added to the VPA object that allows evictions for upscaling only - If the VPA has the annotation
eviction-requirements.autoscaling.gardener.cloud/downscale-restriction: in-maintenance-window-only, the sameEvictionRequirementis added to the VPA object when the Shoot is currently outside of its maintenance window. When the Shoot is inside its maintenance window, theEvictionRequirementis removed. Information about the Shoot maintenance window times are stored in the annotationshoot.gardener.cloud/maintenance-windowon the VPA
Managed Seeds
Gardener users can use shoot clusters as seed clusters, so-called “managed seeds” (aka “shooted seeds”),
by creating ManagedSeed resources.
By default, the gardenlet that manages this shoot cluster then automatically
creates a clone of itself with the same version and the same configuration
that it currently has.
Then it deploys the gardenlet clone into the managed seed cluster.
For more information, see ManagedSeeds: Register Shoot as Seed.
Migrating from Previous Gardener Versions
If your Gardener version doesn’t support gardenlets yet, no special migration is required, but the following prerequisites must be met:
- Your Gardener version is at least 0.31 before upgrading to v1.
- You have to make sure that your garden cluster is exposed in a way that it’s reachable from all your seed clusters.
With previous Gardener versions, you had deployed the Gardener Helm chart
(incorporating the API server, controller-manager, and scheduler).
With v1, this stays the same, but you now have to deploy the gardenlet Helm chart as well
into all of your seeds (if they aren’t managed, as mentioned earlier).
See Deploy a gardenlet for all instructions.