Gardener Shoots
Overview
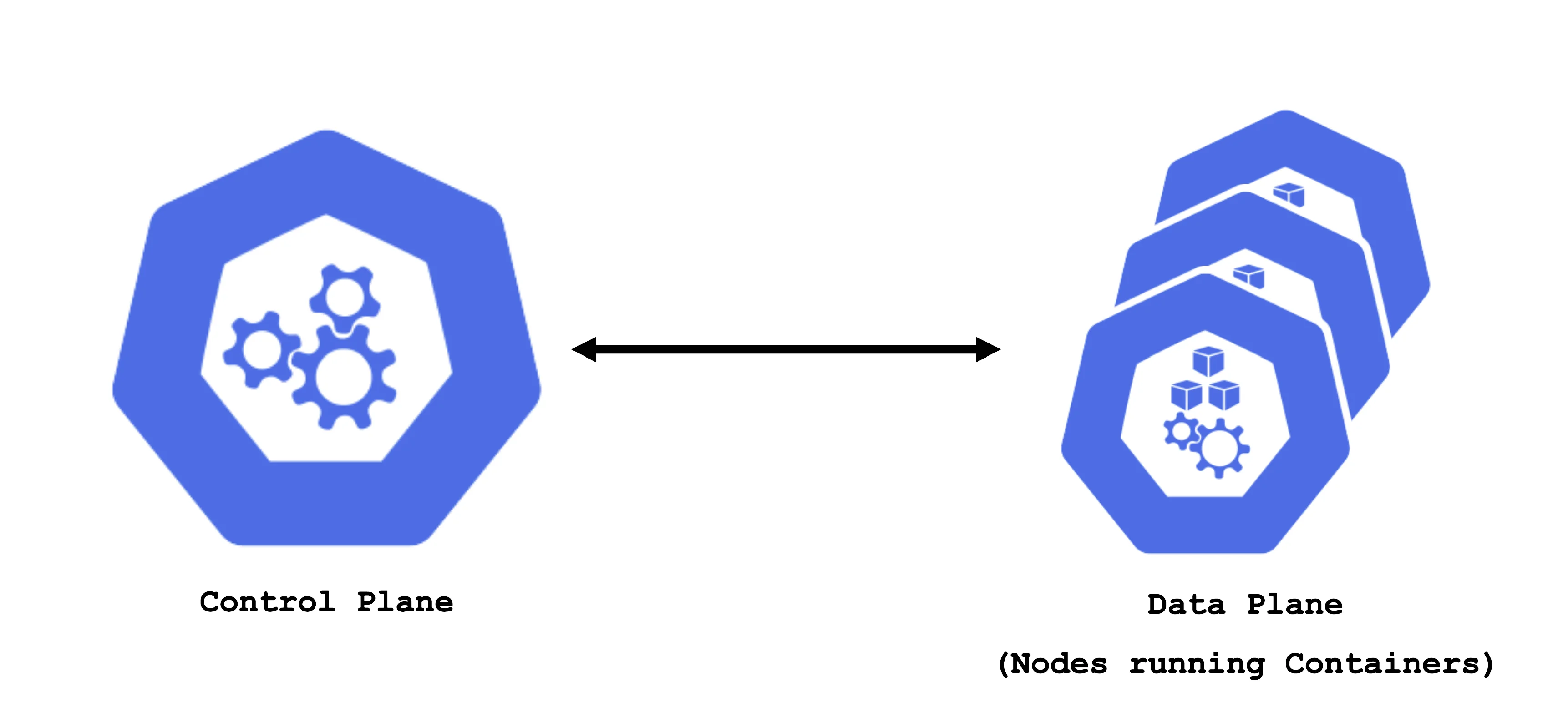
A Kubernetes cluster consists of a control plane and a data plane. The data plane runs the actual containers on worker nodes (which translate to physical or virtual machines). For the control and data plane to work together properly, lots of components need matching configuration.
Some configurations are standardized but some are also very specific to the needs of a cluster's user / workload. Ideally, you want a properly configured cluster with the possibility to fine-tune some settings.
Concept of a "Shoot"
In Gardener, Kubernetes clusters (with their control plane and their data plane) are called shoot clusters or simply shoots. For Gardener, a shoot is just another Kubernetes resource. Gardener components watch it and act upon changes (e.g., creation). It comes with reasonable default settings but also allows fine-tuned configuration. And on top of it, you get a status providing health information, information about ongoing operations, and so on.
Luckily there is a dashboard to get started.
Basic Configuration Options

Every cluster needs a name - after all, it is a Kubernetes resource and therefore unique within a namespace.
The Kubernetes version will be used as a starting point. Once a newer version is available, you can always update your existing clusters (but not downgrade, as this is not supported by Kubernetes in general).
The "purpose" affects some configuration (like automatic deployment of a monitoring stack or setting up certain alerting rules) and generally indicates the importance of a cluster.

Start by selecting the infrastructure you want to use. The choice will be mapped to a cloud profile that contains provider specific information like the available (actual) OS images, zones and regions or machine types.
Each data plane runs in an infrastructure account owned by the end user. By selecting the infrastructure secret containing the accounts credentials, you are granting Gardener access to the respective account to create / manage resources.
NOTE
Changing the account after the creation of a cluster is not possible. The credentials can be updated with a new key or even user but have to stay within the same account.
Currently, there is no way to move a single cluster to a different account. You would rather have to re-create a cluster and migrate workloads by different means.
As part of the infrastructure you chose, the region for data plane has to be chosen as well. The Gardener scheduler will try to place the control plane on a seed cluster based on a minimal distance strategy. See Gardener Scheduler for more details.
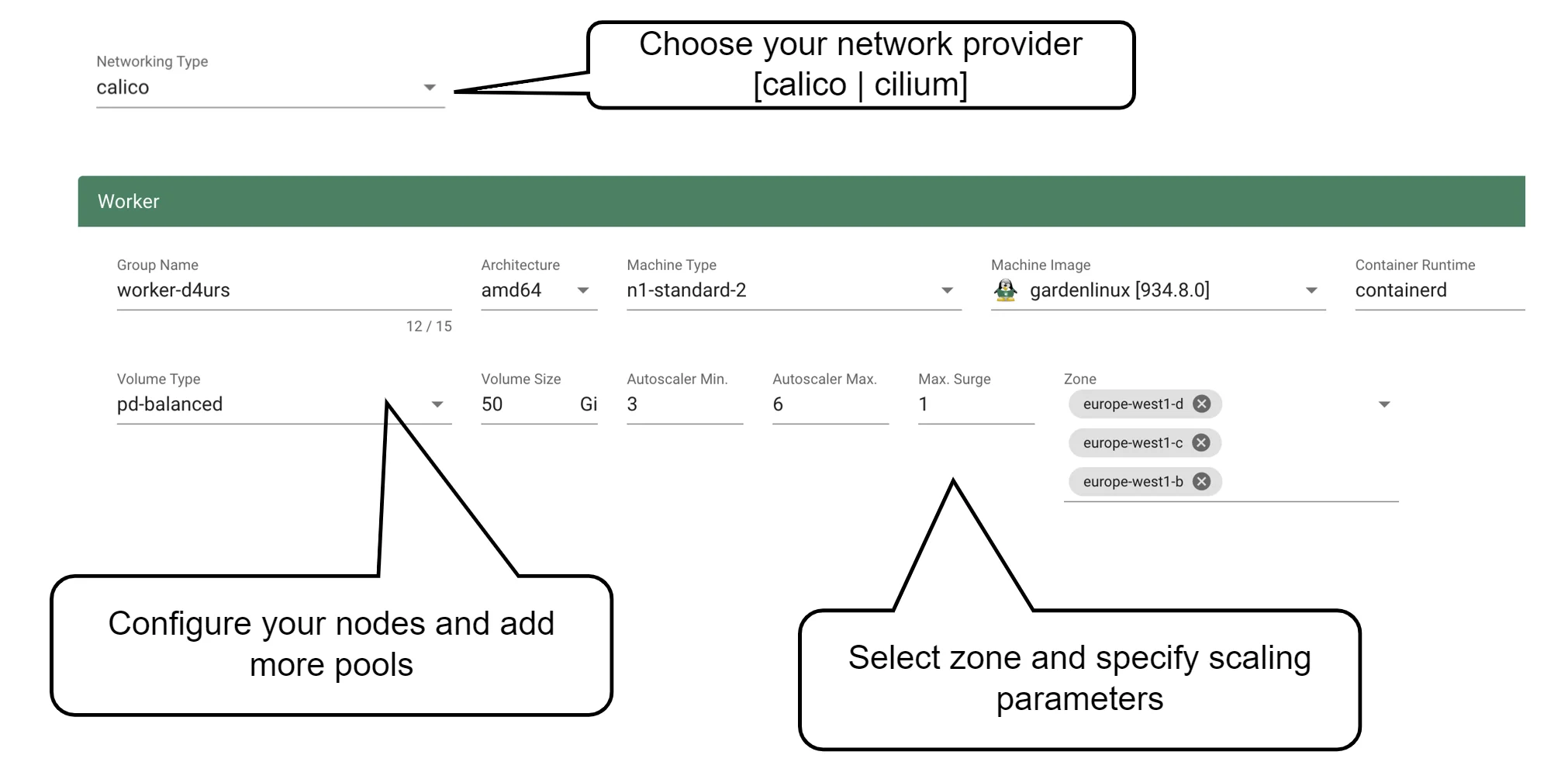
Up next, the networking provider (CNI) for the cluster has to be selected. At the point of writing, it is possible to choose between Calico and Cilium. If not specified in the shoot's manifest, default CIDR ranges for nodes, services, and pods will be used.
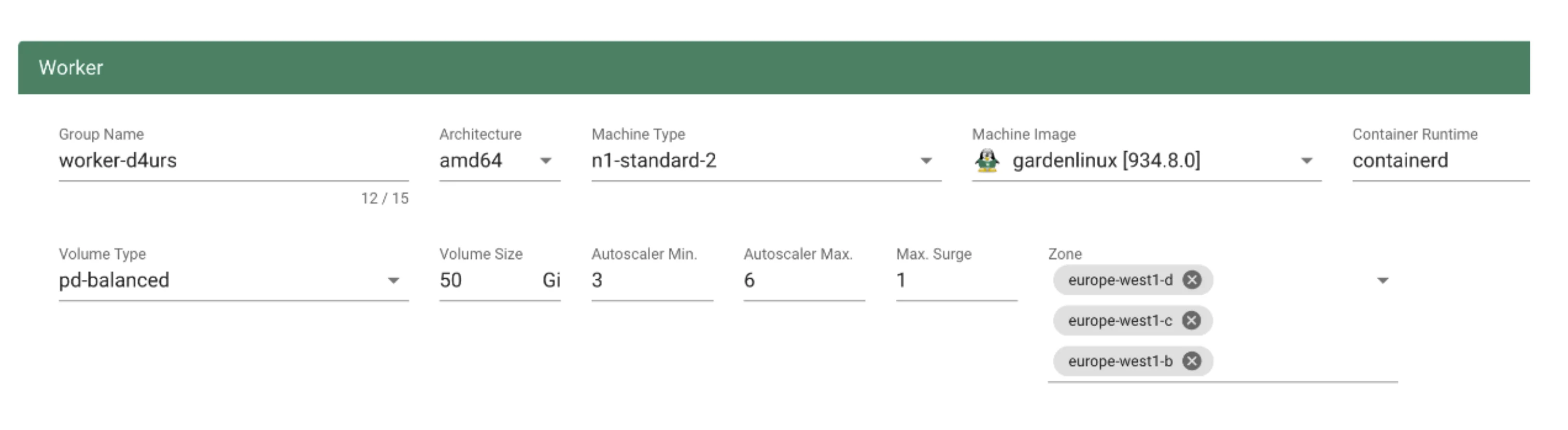
In order to run any workloads in your cluster, you need nodes. The worker section lets you specify the most important configuration options. For beginners, the machine type is probably the most relevant field, together with the machine image (operating system).
The machine type is provider-specific and configured in the cloud profile. Check your respective cloud profile if you're missing a machine type. Maybe it is available in general but unavailable in your selected region.
The operating system your machines will run is the next thing to choose. Debian-based GardenLinux is the best choice for most use cases.
Other specifications for the workers include the volume type and size. These settings affect the root disk of each node. Therefore we would always recommend to use an SSD-based type to avoid i/o issues.
Caveat
Some machine types (e.g., bare-metal machine types on OpenStack) require you to omit the volume type and volume size settings.
The autoscaler parameter defines the initial elasticity / scalability of your cluster. The cluster-autoscaler will add more nodes up to the maximum defined here when your workload grows and remove nodes in case your workload shrinks. The minimum number of nodes should be equal to or higher than the number of zones. You can distribute the nodes of a worker pool among all zones available to your cluster. This is the first step in running HA workloads.
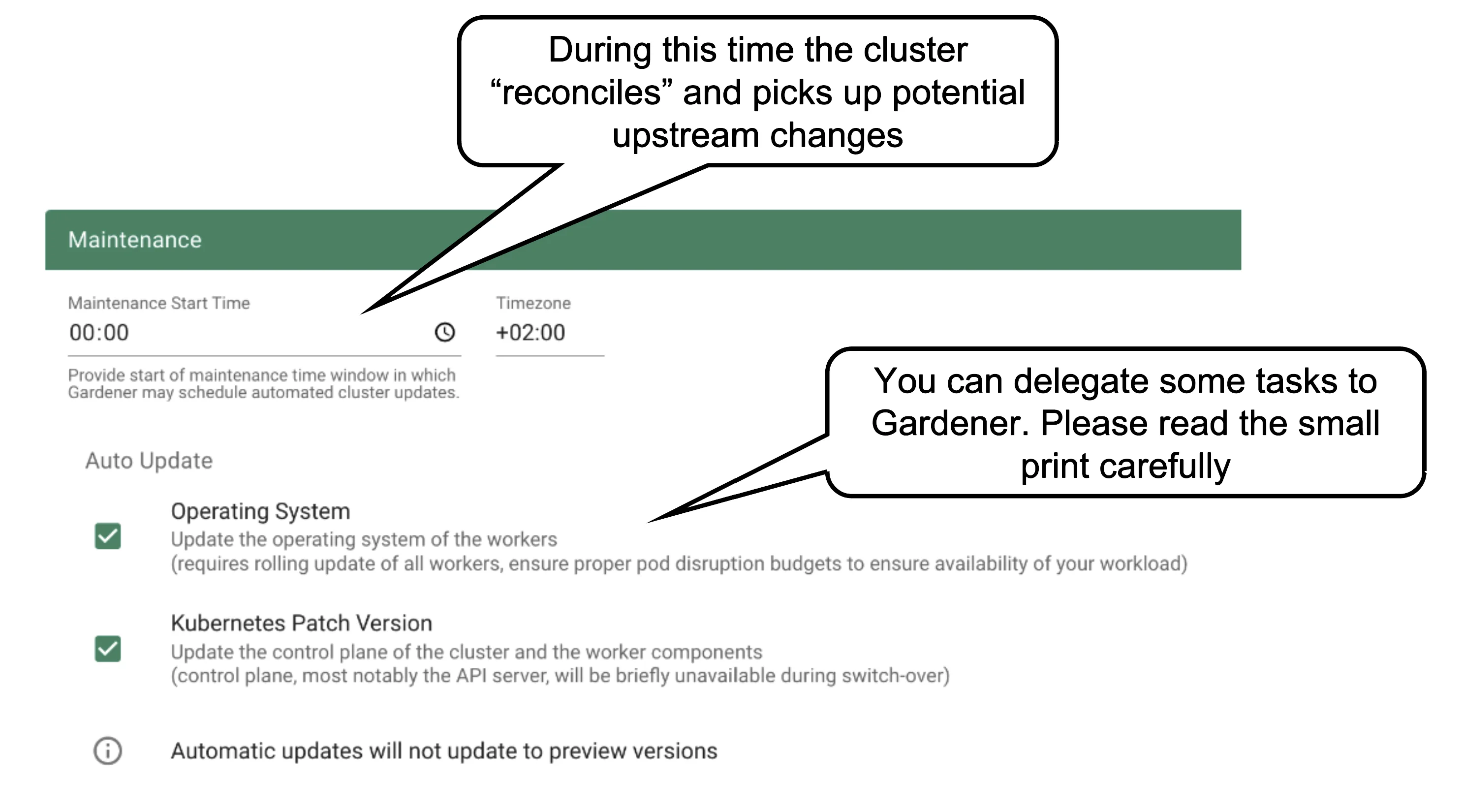
Once per day, all clusters reconcile. This means all controllers will check if there are any updates they have to apply (e.g., new image version for ETCD). The maintenance window defines when this daily operation will be triggered. It is important to understand that there is no opt-out for reconciliation.
It is also possible to confine updates to the shoot spec to be applied only during this time. This can come in handy when you want to bundle changes or prevent changes to be applied outside a well-known time window.
You can allow Gardener to automatically update your cluster's Kubernetes patch version and/or OS version (of the nodes). Take this decision consciously! Whenever a new Kubernetes patch version or OS version is set to supported in the respective cloud profile, auto update will upgrade your cluster during the next maintenance window. If you fail to (manually) upgrade the Kubernetes or OS version before they expire, force-upgrades will take place during the maintenance window.
Result
The result of your provided inputs and a set of conscious default values is a shoot resource that, once applied, will be acted upon by various Gardener components. The status section represents the intermediate steps / results of these operations. A typical shoot creation flow would look like this:
- Assign control plane to a seed.
- Create infrastructure resources in the data plane account (e.g., VPC, gateways, ...)
- Deploy control plane incl. DNS records.
- Create nodes (VMs) and bootstrap kubelets.
- Deploy kube-system components to nodes.
How to Access a Shoot

Static credentials for shoots were discontinued in Gardener with Kubernetes v1.27. Short lived credentials need to be used instead. You can create/request tokens directly via Gardener or delegate authentication to an identity provider.
A short-lived admin kubeconfig can be requested by using kubectl. If this is something you do frequently, consider switching to gardenlogin, which helps you with it.
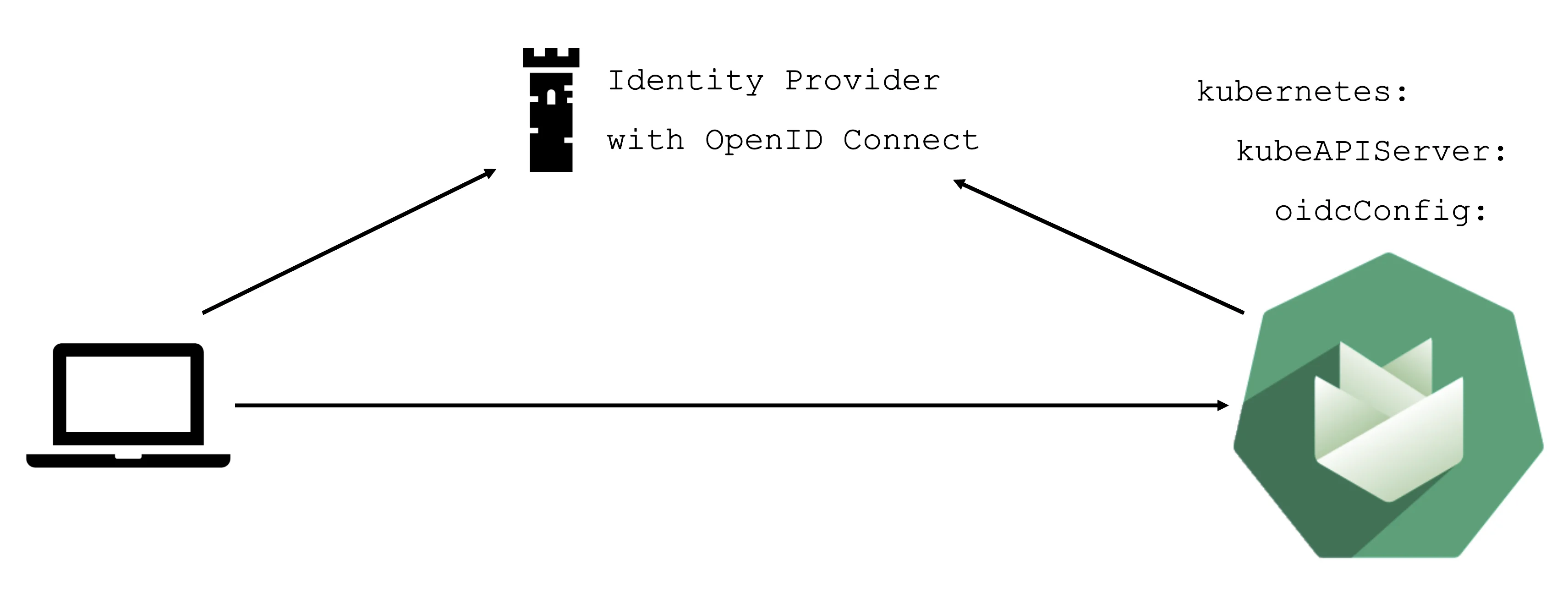
An alternative is to use an identity provider and issue OIDC tokens.
What can you configure?
With the basic configuration options having been introduced, it is time to discuss more possibilities. Gardener offers a variety of options to tweak the control plane's behavior - like defining an event TTL (default 1h), adding an OIDC configuration or activating some feature gates. You could alter the scheduling profile and define an audit logging policy. In addition, the control plane can be configured to run in HA mode (applied on a node or zone level), but keep in mind that once you enable HA, you cannot go back.
In case you have specific requirements for the cluster internal DNS, Gardener offers a plugin mechanism for custom core DNS rules or optimization with node-local DNS. For more information, see Custom DNS Configuration and NodeLocalDNS Configuration.
Another category of configuration options is dedicated to the nodes and the infrastructure they are running on. Every provider has their own perks and some of them are exposed. Check the detailed documentation of the relevant extension for your infrastructure provider.
You can fine-tune the cluster-autoscaler or help the kubelet to cope better with your workload.
Worker Pools
There are a couple of ways to configure a worker pool. One of them is to set everything in the Gardener dashboard. However, only a subset of options is presented there.
A slightly more complex way is to set the configuration through the yaml file itself.
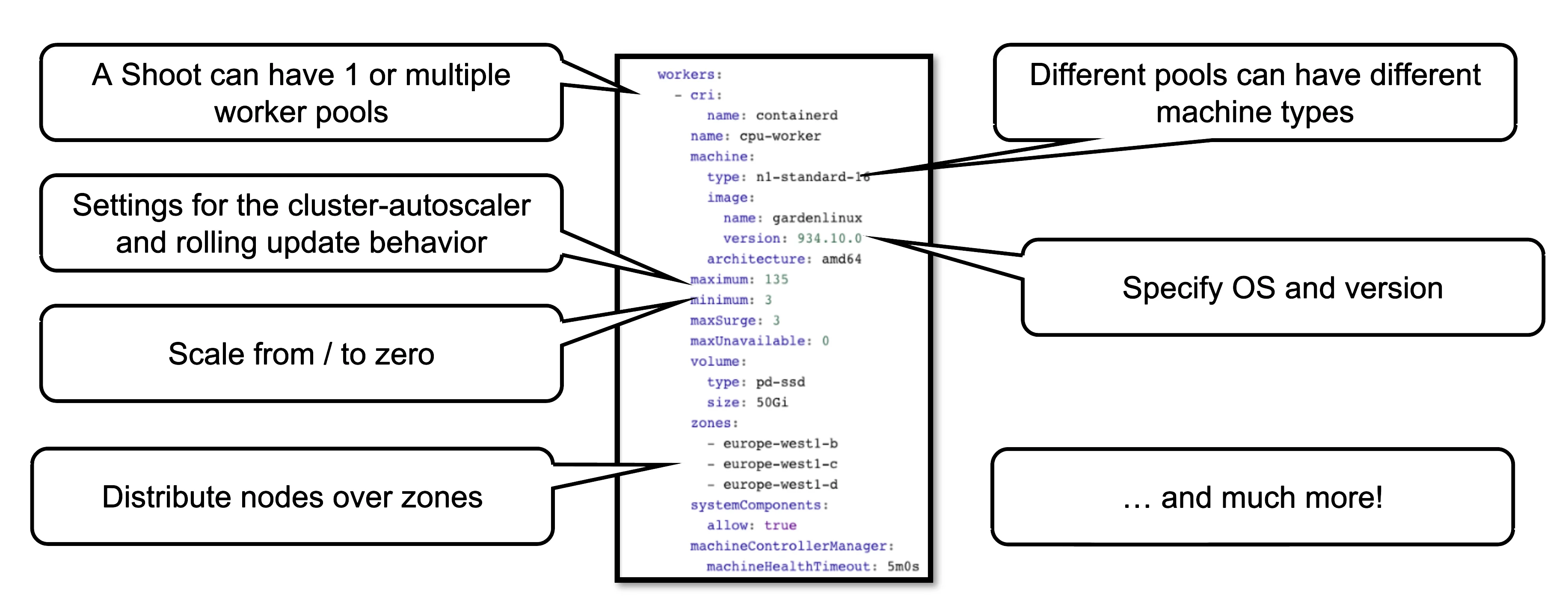
This allows you to configure much more properties of a worker pool, like the timeout after which an unhealthy machine is getting replaced. For more options, see the Worker API reference.
How to Change Things
Since a shoot is just another Kubernetes resource, changes can be applied via kubectl. For convenience, the basic settings are configurable via the dashboard's UI. It also has a "yaml" tab where you can alter all of the shoot's specification in your browser. Once applied, the cluster will reconcile eventually and your changes become active (or cause an error).
Immutability in a Shoot
While Gardener allows you to modify existing shoot clusters, it is important to remember that not all properties of a shoot can be changed after it is created.
For example, it is not possible to move a shoot to a different infrastructure account. This is mainly rooted in the fact that discs and network resources are bound to your account.
Another set of options that become immutable are most of the network aspects of a cluster. On an infrastructure level the VPC cannot be changed and on a cluster level things like the pod / service cidr ranges, together with the nodeCIDRmask, are set for the lifetime of the cluster.
Some other things can be changed, but not reverted. While it is possible to add more zones to a cluster on an infrastructure level (assuming that an appropriate CIDR range is available), removing zones is not supported. Similarly, upgrading Kubernetes versions is comparable to a one-way ticket. As of now, Kubernetes does not support downgrading. Lastly, the HA setting of the control plane is immutable once specified.
Crazy Botany
Since remembering all these options can be quite challenging, here is very helpful resource - an example shoot with all the latest options 🎉