Backup and Restore of Kubernetes Objects

TL;DR
NOTE
Details of the description might change in the near future since Heptio was taken over by VMWare which might result in different GitHub repositories or other changes. Please don't hesitate to inform us in case you encounter any issues.
In general, Backup and Restore (BR) covers activities enabling an organization to bring a system back in a consistent state, e.g., after a disaster or to setup a new system. These activities vary in a very broad way depending on the applications and its persistency.
Kubernetes objects like Pods, Deployments, NetworkPolicies, etc. configure Kubernetes internal components and might as well include external components like load balancer and persistent volumes of the cloud provider. The BR of external components and their configurations might be difficult to handle in case manual configurations were needed to prepare these components.
To set the expectations right from the beginning, this tutorial covers the BR of Kubernetes deployments which might use persistent volumes. The BR of any manual configuration of external components, e.g., via the cloud providers console, is not covered here, as well as the BR of a whole Kubernetes system.
This tutorial puts the focus on the open source tool Velero (formerly Heptio Ark) and its functionality to explain the BR process.
Basically, Velero allows you to:
- backup and restore your Kubernetes cluster resources and persistent volumes (on-demand or scheduled)
- backup or restore all objects in your cluster, or filter resources by type, namespace, and/or label
- by default, all persistent volumes are backed up (configurable)
- replicate your production environment for development and testing environments
- define an expiration date per backup
- execute pre- and post-activities in a container of a pod when a backup is created (see Hooks)
- extend Velero by Plugins, e.g., for Object and Block store (see Plugins)
Velero consists of a server-side component and a client tool. The server components consists of Custom Resource Definitions (CRD) and controllers to perform the activities. The client tool communicates with the K8s API server to, e.g., create objects like a Backup object.
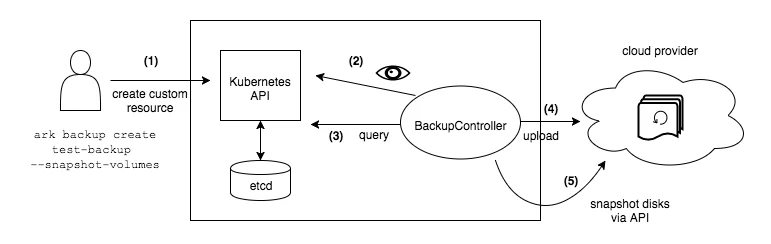
The diagram below explains the backup process. When creating a backup, Velero client makes a call to the Kubernetes API server to create a Backup object (1). The BackupController notices the new Backup object, validates the object (2) and begins the backup process (3). Based on the filter settings provided by the Velero client it collects the resources in question (3). The BackupController creates a tar ball with the Kubernetes objects and stores it in the backup location, e.g., AWS S3 (4) as well as snapshots of persistent volumes (5).
The size of the backup tar ball corresponds to the number of objects in etcd. The gzipped archive contains the Json representations of the objects.
NOTE
As of the writing of this tutorial, Velero or any other BR tool for Shoot clusters is not provided by Gardener.
Getting Started
At first, clone the Velero GitHub repository and get the Velero client from the releases or build it from source via make all in the main directory of the cloned GitHub repository.
To use an AWS S3 bucket as storage for the backup files and the persistent volumes, you need to:
- create a S3 bucket as the backup target
- create an AWS IAM user for Velero
- configure the Velero server
- create a secret for your AWS credentials
For details about this setup, check the Set Permissions for Velero documentation. Moreover, it is possible to use other supported storage providers.
NOTE
Per default, Velero is installed in the namespace velero. To change the namespace, check the documentation.
Velero offers a wide range of filter possibilities for Kubernetes resources, e.g filter by namespaces, labels or resource types. The filter settings can be combined and used as include or exclude, which gives a great flexibility for selecting resources.
NOTE
Carefully set labels and/or use namespaces for your deployments to make the selection of the resources to be backed up easier. The best practice would be to check in advance which resources are selected with the defined filter.
Exemplary Use Cases
Below are some use cases which could give you an idea on how to use Velero. You can also check Velero's documentation for other introductory examples.
Helm Based Deployments
To be able to use Helm charts in your Kubernetes cluster, you need to install the Helm client helm and the server component tiller. Per default the server component is installed in the namespace kube-system. Even if it is possible to select single deployments via the filter settings of Velero, you should consider to install tiller in a separate namespace via helm init --tiller-namespace <your namespace>. This approach applies as well for all Helm charts to be deployed - consider separate namespaces for your deployments as well by using the parameter --namespace.
To backup a Helm based deployment, you need to backup both Tiller and the deployment. Only then the deployments could be managed via Helm. As mentioned above, the selection of resources would be easier in case they are separated in namespaces.
Separate Backup Locations
In case you run all your Kubernetes clusters on a single cloud provider, there is probably no need to store the backups in a bucket of a different cloud provider. However, if you run Kubernetes clusters on different cloud provider, you might consider to use a bucket on just one cloud provider as the target for the backups, e.g., to benefit from a lower price tag for the storage.
Per default, Velero assumes that both the persistent volumes and the backup location are on the same cloud provider. During the setup of Velero, a secret is created using the credentials for a cloud provider user who has access to both objects (see the policies, e.g., for the AWS configuration).
Now, since the backup location is different from the volume location, you need to follow these steps (described here for AWS):
configure as documented the volume storage location in
examples/aws/06-volumesnapshotlocation.yamland provide the user credentials. In this case, the S3 related settings like the policies can be omittedcreate the bucket for the backup in the cloud provider in question and a user with the appropriate credentials and store them in a separate file similar to
credentials-arkcreate a secret which contains two credentials, one for the volumes and one for the backup target, e.g., by using the command
kubectl create secret generic cloud-credentials --namespace heptio-ark --from-file cloud=credentials-ark --from-file backup-target=backup-arkconfigure in the deployment manifest
examples/aws/10-deployment.yamlthe entries involumeMounts,envandvolumesaccordingly, e.g., for a cluster running on AWS and the backup target bucket on GCP a configuration could look similar to:Some links might get broken in the near future since Heptio was taken over by VMWare which might result in different GitHub repositories or other changes. Please don't hesitate to inform us in case you encounter any issues.Example Velero deployment
yaml# Copyright 2017 the Heptio Ark contributors. # # Licensed under the Apache License, Version 2.0 (the "License"); # you may not use this file except in compliance with the License. # You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. --- apiVersion: apps/v1beta1 kind: Deployment metadata: namespace: velero name: velero spec: replicas: 1 template: metadata: labels: component: velero annotations: prometheus.io/scrape: "true" prometheus.io/port: "8085" prometheus.io/path: "/metrics" spec: restartPolicy: Always serviceAccountName: velero containers: - name: velero image: gcr.io/heptio-images/velero:latest command: - /velero args: - server volumeMounts: - name: cloud-credentials mountPath: /credentials - name: plugins mountPath: /plugins - name: scratch mountPath: /scratch env: - name: AWS_SHARED_CREDENTIALS_FILE value: /credentials/cloud - name: GOOGLE_APPLICATION_CREDENTIALS value: /credentials/backup-target - name: VELERO_SCRATCH_DIR value: /scratch volumes: - name: cloud-credentials secret: secretName: cloud-credentials - name: plugins emptyDir: {} - name: scratch emptyDir: {}finally, configure the backup storage location in
examples/aws/05-backupstoragelocation.yamlto use, in this case, a GCP bucket
Limitations
Below is a potentially incomplete list of limitations. You can also consult Velero's documentation to get up to date information.
- Only full backups of selected resources are supported. Incremental backups are not (yet) supported. However, by using filters it is possible to restrict the backup to specific resources
- Inconsistencies might occur in case of changes during the creation of the backup
- Application specific actions are not considered by default. However, they might be handled by using Velero's Hooks or Plugins