This is the multi-page printable view of this section. Click here to print.
Other Components
1 - Dependency Watchdog
Dependency Watchdog


Overview
A watchdog which actively looks out for disruption and recovery of critical services. If there is a disruption then it will prevent cascading failure by conservatively scaling down dependent configured resources and if a critical service has just recovered then it will expedite the recovery of dependent services/pods.
Avoiding cascading failure is handled by Prober component and expediting recovery of dependent services/pods is handled by Weeder component. These are separately deployed as individual pods.
Current Limitation & Future Scope
Although in the current offering the Prober is tailored to handle one such use case of kube-apiserver connectivity, but the usage of prober can be extended to solve similar needs for other scenarios where the components involved might be different.
Start using or developing the Dependency Watchdog
See our documentation in the /docs repository, please find the index here.
Feedback and Support
We always look forward to active community engagement.
Please report bugs or suggestions on how we can enhance dependency-watchdog to address additional recovery scenarios on GitHub issues
1.1 - Concepts
1.1.1 - Prober
Prober
Overview
Prober starts asynchronous and periodic probes for every shoot cluster. The first probe is the api-server probe which checks the reachability of the API Server from the control plane. The second probe is the lease probe which is done after the api server probe is successful and checks if the number of expired node leases is below a certain threshold.
If the lease probe fails, it will scale down the dependent kubernetes resources. Once the connectivity to kube-apiserver is reestablished and the number of expired node leases are within the accepted threshold, the prober will then proactively scale up the dependent kubernetes resources it had scaled down earlier. The failure threshold fraction for lease probe
and dependent kubernetes resources are defined in configuration that is passed to the prober.
Origin
In a shoot cluster (a.k.a data plane) each node runs a kubelet which periodically renewes its lease. Leases serve as heartbeats informing Kube Controller Manager that the node is alive. The connectivity between the kubelet and the Kube ApiServer can break for different reasons and not recover in time.
As an example, consider a large shoot cluster with several hundred nodes. There is an issue with a NAT gateway on the shoot cluster which prevents the Kubelet from any node in the shoot cluster to reach its control plane Kube ApiServer. As a consequence, Kube Controller Manager transitioned the nodes of this shoot cluster to Unknown state.
Machine Controller Manager which also runs in the shoot control plane reacts to any changes to the Node status and then takes action to recover backing VMs/machine(s). It waits for a grace period and then it will begin to replace the unhealthy machine(s) with new ones.
This replacement of healthy machines due to a broken connectivity between the worker nodes and the control plane Kube ApiServer results in undesired downtimes for customer workloads that were running on these otherwise healthy nodes. It is therefore required that there be an actor which detects the connectivity loss between the the kubelet and shoot cluster’s Kube ApiServer and proactively scales down components in the shoot control namespace which could exacerbate the availability of nodes in the shoot cluster.
Dependency Watchdog Prober in Gardener
Prober is a central component which is deployed in the garden namespace in the seed cluster. Control plane components for a shoot are deployed in a dedicated shoot namespace for the shoot within the seed cluster.
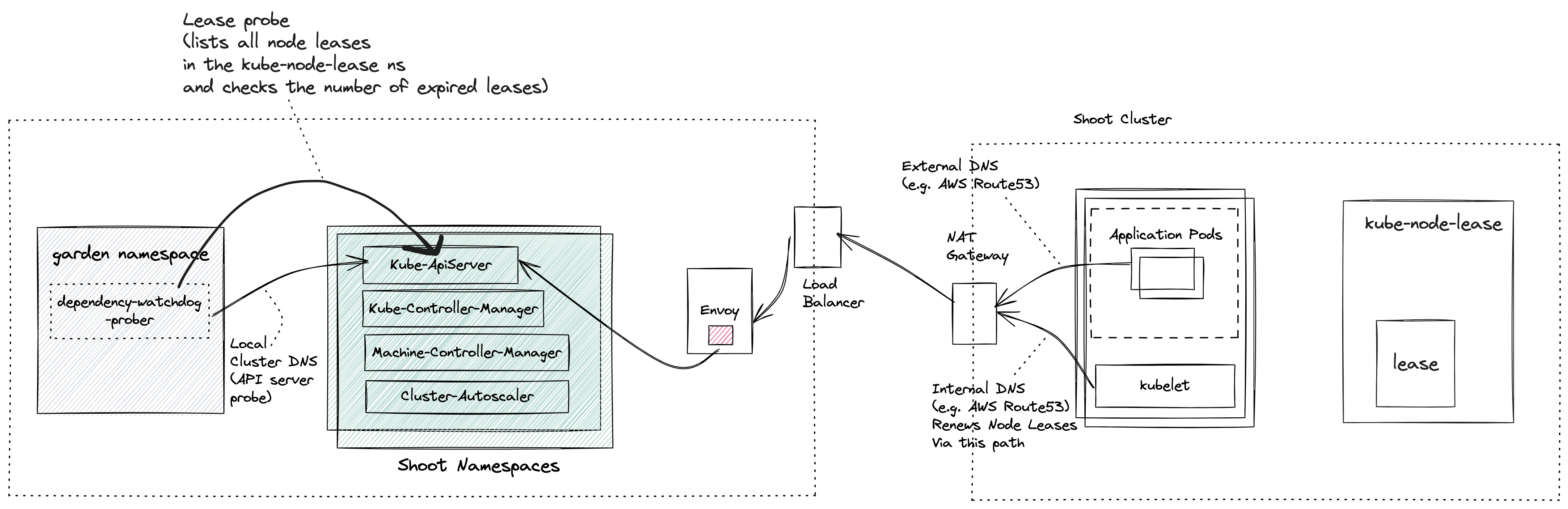
NOTE: If you are not familiar with what gardener components like seed, shoot then please see the appendix for links.
Prober periodically probes Kube ApiServer via two separate probes:
- API Server Probe: Local cluster DNS name which resolves to the ClusterIP of the Kube Apiserver
- Lease Probe: Checks for number of expired leases to be within the specified threshold. The threshold defines the limit after which DWD can say that the kubelets are not able to reach the API server.
Behind the scene
For all active shoot clusters (which have not been hibernated or deleted or moved to another seed via control-plane-migration), prober will schedule a probe to run periodically. During each run of a probe it will do the following:
- Checks if the Kube ApiServer is reachable via local cluster DNS. This should always succeed and will fail only when the Kube ApiServer has gone down. If the Kube ApiServer is down then there can be no further damage to the existing shoot cluster (barring new requests to the Kube Api Server).
- Only if the probe is able to reach the Kube ApiServer via local cluster DNS, will it attempt to check the number of expired node leases in the shoot. The node lease renewal is done by the Kubelet, and so we can say that the lease probe is checking if the kubelet is able to reach the API server. If the number of expired node leases reaches the threshold, then the probe fails.
- If and when a lease probe fails, then it will initiate a scale-down operation for dependent resources as defined in the prober configuration. While scaling down the resource prober will annotate the deployment of the resource with
dependency-watchdog.gardener.cloud/meltdown-protection-active. This annotation can be checked to ensure not to scale up these resources during a regular shoot maintenance or an out-of-band shoot reconciliation. - In subsequent runs it will keep performing the lease probe. If it is successful, then it will start the scale-up operation for dependent resources as defined in the configuration. It shall also remove the
dependency-watchdog.gardener.cloud/meltdown-protection-activefrom deployment metadata of all scaled up resources.
Manual Intervention/Override of DWD behavior: j In case where you don’t want DWD to act on a resource during a meltdown, you can annotate the said resource deployment with
"dependency-watchdog.gardener.cloud/ignore-scaling"annotation. This will ensure that prober will not act on such resource. When this ignore scaling annotation is put by an operator, thedependency-watchdog.gardener.cloud/meltdown-protection-activeannotation shall be removed to avoid any ambiguity.
Prober lifecycle
A reconciler is registered to listen to all events for Cluster resource.
When a Reconciler receives a request for a Cluster change, it will query the extension kube-api server to get the Cluster resource.
In the following cases it will either remove an existing probe for this cluster or skip creating a new probe:
- Cluster is marked for deletion.
- Hibernation has been enabled for the cluster.
- There is an ongoing seed migration for this cluster.
- If a new cluster is created with no workers.
- If an update is made to the cluster by removing all workers (in other words making it worker-less).
If none of the above conditions are true and there is no existing probe for this cluster then a new probe will be created, registered and started.
Probe failure identification
DWD probe can either be a success or it could return an error. If the API server probe fails, the lease probe is not done and the probes will be retried. If the error is a TooManyRequests error due to requests to the Kube-API-Server being throttled,
then the probes are retried after a backOff of backOffDurationForThrottledRequests.
If the lease probe fails, then the error could be due to failure in listing the leases. In this case, no scaling operations are performed. If the error in listing the leases is a TooManyRequests error due to requests to the Kube-API-Server being throttled,
then the probes are retried after a backOff of backOffDurationForThrottledRequests.
If there is no error in listing the leases, then the Lease probe fails if the number of expired leases reaches the threshold fraction specified in the configuration. A lease is considered expired in the following scenario:-
time.Now() >= lease.Spec.RenewTime + (p.config.KCMNodeMonitorGraceDuration.Duration * expiryBufferFraction)
Here, lease.Spec.RenewTime is the time when current holder of a lease has last updated the lease. config is the probe config generated from the configuration and
KCMNodeMonitorGraceDuration is amount of time which KCM allows a running Node to be unresponsive before marking it unhealthy (See ref)
. expiryBufferFraction is a hard coded value of 0.75. Using this fraction allows the prober to intervene before KCM marks a node as unknown, but at the same time allowing kubelet sufficient retries to renew the node lease (Kubelet renews the lease every 10s See ref).
Appendix
1.1.2 - Weeder
Weeder
Overview
Weeder watches for an update to service endpoints and on receiving such an event it will create a time-bound watch for all configured dependent pods that need to be actively recovered in case they have not yet recovered from CrashLoopBackoff state. In a nutshell it accelerates recovery of pods when an upstream service recovers.
An interference in automatic recovery for dependent pods is required because kubernetes pod restarts a container with an exponential backoff when the pod is in CrashLoopBackOff state. This backoff could become quite large if the service stays down for long. Presence of weeder would not let that happen as it’ll restart the pod.
Prerequisites
Before we understand how Weeder works, we need to be familiar with kubernetes services & endpoints.
NOTE: If a kubernetes service is created with selectors then kubernetes will create corresponding endpoint resource which will have the same name as that of the service. In weeder implementation service and endpoint name is used interchangeably.
Config
Weeder can be configured via command line arguments and a weeder configuration. See configure weeder.
Internals
Weeder keeps a watch on the events for the specified endpoints in the config. For every endpoints a list of podSelectors can be specified. It cretes a weeder object per endpoints resource when it receives a satisfactory Create or Update event. Then for every podSelector it creates a goroutine. This goroutine keeps a watch on the pods with labels as per the podSelector and kills any pod which turn into CrashLoopBackOff. Each weeder lives for watchDuration interval which has a default value of 5 mins if not explicitly set.
To understand the actions taken by the weeder lets use the following diagram as a reference.
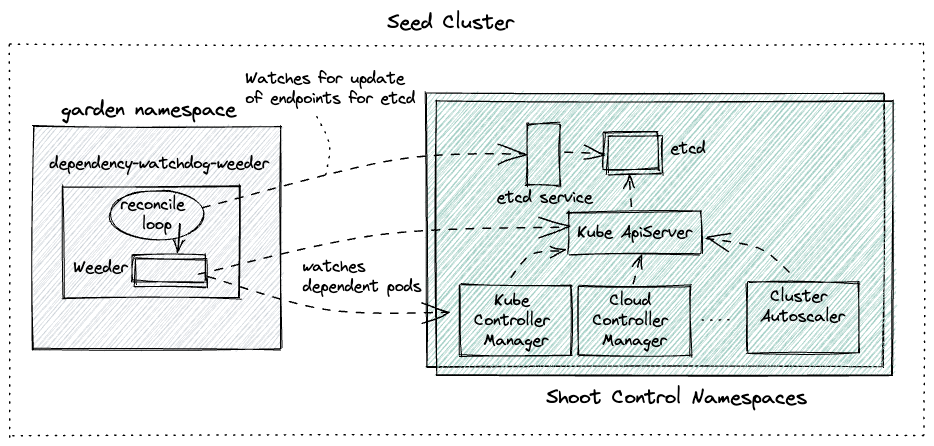 Let us also assume the following configuration for the weeder:
Let us also assume the following configuration for the weeder:
watchDuration: 2m0s
servicesAndDependantSelectors:
etcd-main-client: # name of the service/endpoint for etcd statefulset that weeder will receive events for.
podSelectors: # all pods matching the label selector are direct dependencies for etcd service
- matchExpressions:
- key: gardener.cloud/role
operator: In
values:
- controlplane
- key: role
operator: In
values:
- apiserver
kube-apiserver: # name of the service/endpoint for kube-api-server pods that weeder will receive events for.
podSelectors: # all pods matching the label selector are direct dependencies for kube-api-server service
- matchExpressions:
- key: gardener.cloud/role
operator: In
values:
- controlplane
- key: role
operator: NotIn
values:
- main
- apiserver
Only for the sake of demonstration lets pick the first service -> dependent pods tuple (etcd-main-client as the service endpoint).
- Assume that there are 3 replicas for etcd statefulset.
- Time here is just for showing the series of events
t=0-> all etcd pods go downt=10-> kube-api-server pods transition to CrashLoopBackOfft=100-> all etcd pods recover togethert=101-> Weeder seesUpdateevent foretcd-main-clientendpoints resourcet=102-> go routine created to keep watch on kube-api-server podst=103-> Since kube-api-server pods are still in CrashLoopBackOff, weeder deletes the pods to accelerate the recovery.t=104-> new kube-api-server pod created by replica-set controller in kube-controller-manager
Points to Note
- Weeder only respond on
Updateevents where anotReadyendpoints resource turn toReady. Thats why there was no weeder action at timet=10in the example above.notReady-> no backing pod is ReadyReady-> atleast one backing pod is Ready
- Weeder doesn’t respond on
Deleteevents - Weeder will always wait for the entire
watchDuration. If the dependent pods transition to CrashLoopBackOff after the watch duration or even after repeated deletion of these pods they do not recover then weeder will exit. Quality of service offered via a weeder is only Best-Effort.
1.2 - Deployment
1.2.1 - Configure
Configure Dependency Watchdog Components
Prober
Dependency watchdog prober command takes command-line-flags which are meant to fine-tune the prober. In addition a ConfigMap is also mounted to the container which provides tuning knobs for the all probes that the prober starts.
Command line arguments
Prober can be configured via the following flags:
| Flag Name | Type | Required | Default Value | Description |
|---|---|---|---|---|
| kube-api-burst | int | No | 10 | Burst to use while talking with kubernetes API server. The number must be >= 0. If it is 0 then a default value of 10 will be used |
| kube-api-qps | float | No | 5.0 | Maximum QPS (queries per second) allowed when talking with kubernetes API server. The number must be >= 0. If it is 0 then a default value of 5.0 will be used |
| concurrent-reconciles | int | No | 1 | Maximum number of concurrent reconciles |
| config-file | string | Yes | NA | Path of the config file containing the configuration to be used for all probes |
| metrics-bind-addr | string | No | “:9643” | The TCP address that the controller should bind to for serving prometheus metrics |
| health-bind-addr | string | No | “:9644” | The TCP address that the controller should bind to for serving health probes |
| enable-leader-election | bool | No | false | In case prober deployment has more than 1 replica for high availability, then it will be setup in a active-passive mode. Out of many replicas one will become the leader and the rest will be passive followers waiting to acquire leadership in case the leader dies. |
| leader-election-namespace | string | No | “garden” | Namespace in which leader election resource will be created. It should be the same namespace where DWD pods are deployed |
| leader-elect-lease-duration | time.Duration | No | 15s | The duration that non-leader candidates will wait after observing a leadership renewal until attempting to acquire leadership of a led but unrenewed leader slot. This is effectively the maximum duration that a leader can be stopped before it is replaced by another candidate. This is only applicable if leader election is enabled. |
| leader-elect-renew-deadline | time.Duration | No | 10s | The interval between attempts by the acting master to renew a leadership slot before it stops leading. This must be less than or equal to the lease duration. This is only applicable if leader election is enabled. |
| leader-elect-retry-period | time.Duration | No | 2s | The duration the clients should wait between attempting acquisition and renewal of a leadership. This is only applicable if leader election is enabled. |
You can view an example kubernetes prober deployment YAML to see how these command line args are configured.
Prober Configuration
A probe configuration is mounted as ConfigMap to the container. The path to the config file is configured via config-file command line argument as mentioned above. Prober will start one probe per Shoot control plane hosted within the Seed cluster. Each such probe will run asynchronously and will periodically connect to the Kube ApiServer of the Shoot. Configuration below will influence each such probe.
You can view an example YAML configuration provided as data in a ConfigMap here.
| Name | Type | Required | Default Value | Description |
|---|---|---|---|---|
| kubeConfigSecretName | string | Yes | NA | Name of the kubernetes Secret which has the encoded KubeConfig required to connect to the Shoot control plane Kube ApiServer via an internal domain. This typically uses the local cluster DNS. |
| probeInterval | metav1.Duration | No | 10s | Interval with which each probe will run. |
| initialDelay | metav1.Duration | No | 30s | Initial delay for the probe to become active. Only applicable when the probe is created for the first time. |
| probeTimeout | metav1.Duration | No | 30s | In each run of the probe it will attempt to connect to the Shoot Kube ApiServer. probeTimeout defines the timeout after which a single run of the probe will fail. |
| backoffJitterFactor | float64 | No | 0.2 | Jitter with which a probe is run. |
| dependentResourceInfos | []prober.DependentResourceInfo | Yes | NA | Detailed below. |
| kcmNodeMonitorGraceDuration | metav1.Duration | Yes | NA | It is the node-monitor-grace-period set in the kcm flags. Used to determine whether a node lease can be considered expired. |
| nodeLeaseFailureFraction | float64 | No | 0.6 | is used to determine the maximum number of leases that can be expired for a lease probe to succeed. |
DependentResourceInfo
If a lease probe fails, then it scales down the dependent resources defined by this property. Similarly, if the lease probe is now successful, then it scales up the dependent resources defined by this property.
Each dependent resource info has the following properties:
| Name | Type | Required | Default Value | Description |
|---|---|---|---|---|
| ref | autoscalingv1.CrossVersionObjectReference | Yes | NA | It is a collection of ApiVersion, Kind and Name for a kubernetes resource thus serving as an identifier. |
| optional | bool | Yes | NA | It is possible that a dependent resource is optional for a Shoot control plane. This property enables a probe to determine the correct behavior in case it is unable to find the resource identified via ref. |
| scaleUp | prober.ScaleInfo | No | Captures the configuration to scale up this resource. Detailed below. | |
| scaleDown | prober.ScaleInfo | No | Captures the configuration to scale down this resource. Detailed below. |
NOTE: Since each dependent resource is a target for scale up/down, therefore it is mandatory that the resource reference points a kubernetes resource which has a
scalesubresource.
ScaleInfo
How to scale a DependentResourceInfo is captured in ScaleInfo. It has the following properties:
| Name | Type | Required | Default Value | Description |
|---|---|---|---|---|
| level | int | Yes | NA | Detailed below. |
| initialDelay | metav1.Duration | No | 0s (No initial delay) | Once a decision is taken to scale a resource then via this property a delay can be induced before triggering the scale of the dependent resource. |
| timeout | metav1.Duration | No | 30s | Defines the timeout for the scale operation to finish for a dependent resource. |
Determining target replicas
Prober cannot assume any target replicas during a scale-up operation for the following reasons:
- Kubernetes resources could be set to provide highly availability and the number of replicas could wary from one shoot control plane to the other. In gardener the number of replicas of pods in shoot namespace are controlled by the shoot control plane configuration.
- If Horizontal Pod Autoscaler has been configured for a kubernetes dependent resource then it could potentially change the
spec.replicasfor a deployment/statefulset.
Given the above constraint lets look at how prober determines the target replicas during scale-down or scale-up operations.
Scale-Up: Primary responsibility of a probe while performing a scale-up is to restore the replicas of a kubernetes dependent resource prior to scale-down. In order to do that it updates the following for each dependent resource that requires a scale-up:spec.replicas: Checks ifdependency-watchdog.gardener.cloud/replicasis set. If it is, then it will take the value stored against this key as the target replicas. To be a valid value it should always be greater than 0.- If
dependency-watchdog.gardener.cloud/replicasannotation is not present then it falls back to the hard coded default value for scale-up which is set to 1. - Removes the annotation
dependency-watchdog.gardener.cloud/replicasif it exists.
Scale-Down: To scale down a dependent kubernetes resource it does the following:- Adds an annotation
dependency-watchdog.gardener.cloud/replicasand sets its value to the current value ofspec.replicas. - Updates
spec.replicasto 0.
- Adds an annotation
Level
Each dependent resource that should be scaled up or down is associated to a level. Levels are ordered and processed in ascending order (starting with 0 assigning it the highest priority). Consider the following configuration:
dependentResourceInfos:
- ref:
kind: "Deployment"
name: "kube-controller-manager"
apiVersion: "apps/v1"
scaleUp:
level: 1
scaleDown:
level: 0
- ref:
kind: "Deployment"
name: "machine-controller-manager"
apiVersion: "apps/v1"
scaleUp:
level: 1
scaleDown:
level: 1
- ref:
kind: "Deployment"
name: "cluster-autoscaler"
apiVersion: "apps/v1"
scaleUp:
level: 0
scaleDown:
level: 2
Let us order the dependent resources by their respective levels for both scale-up and scale-down. We get the following order:
Scale Up Operation
Order of scale up will be:
- cluster-autoscaler
- kube-controller-manager and machine-controller-manager will be scaled up concurrently after cluster-autoscaler has been scaled up.
Scale Down Operation
Order of scale down will be:
- kube-controller-manager
- machine-controller-manager after (1) has been scaled down.
- cluster-autoscaler after (2) has been scaled down.
Disable/Ignore Scaling
A probe can be configured to ignore scaling of configured dependent kubernetes resources.
To do that one must set dependency-watchdog.gardener.cloud/ignore-scaling annotation to true on the scalable resource for which scaling should be ignored.
Weeder
Dependency watchdog weeder command also (just like the prober command) takes command-line-flags which are meant to fine-tune the weeder. In addition a ConfigMap is also mounted to the container which helps in defining the dependency of pods on endpoints.
Command Line Arguments
Weeder can be configured with the same flags as that for prober described under command-line-arguments section You can find an example weeder deployment YAML to see how these command line args are configured.
Weeder Configuration
Weeder configuration is mounted as ConfigMap to the container. The path to the config file is configured via config-file command line argument as mentioned above. Weeder will start one go routine per podSelector per endpoint on an endpoint event as described in weeder internal concepts.
You can view the example YAML configuration provided as data in a ConfigMap here.
| Name | Type | Required | Default Value | Description |
|---|---|---|---|---|
| watchDuration | *metav1.Duration | No | 5m0s | The time duration for which watch is kept on dependent pods to see if anyone turns to CrashLoopBackoff |
| servicesAndDependantSelectors | map[string]DependantSelectors | Yes | NA | Endpoint name and its corresponding dependent pods. More info below. |
DependantSelectors
If the service recovers from downtime, then weeder starts to watch for CrashLoopBackOff pods. These pods are identified by info stored in this property.
| Name | Type | Required | Default Value | Description |
|---|---|---|---|---|
| podSelectors | []*metav1.LabelSelector | Yes | NA | This is a list of Label selector |
1.2.2 - Monitor
Monitoring
Work In Progress
We will be introducing metrics for Dependency-Watchdog-Prober and Dependency-Watchdog-Weeder. These metrics will be pushed to prometheus. Once that is completed we will provide details on all the metrics that will be supported here.
1.3 - Contribution
How to contribute?
Contributions are always welcome!
In order to contribute ensure that you have the development environment setup and you familiarize yourself with required steps to build, verify-quality and test.
Setting up development environment
Installing Go
Minimum Golang version required: 1.18.
On MacOS run:
brew install go
For other OS, follow the installation instructions.
Installing Git
Git is used as version control for dependency-watchdog. On MacOS run:
brew install git
If you do not have git installed already then please follow the installation instructions.
Installing Docker
In order to test dependency-watchdog containers you will need a local kubernetes setup. Easiest way is to first install Docker. This becomes a pre-requisite to setting up either a vanilla KIND/minikube cluster or a local Gardener cluster.
On MacOS run:
brew install -cash docker
For other OS, follow the installation instructions.
Installing Kubectl
To interact with the local Kubernetes cluster you will need kubectl. On MacOS run:
brew install kubernetes-cli
For other IS, follow the installation instructions.
Get the sources
Clone the repository from Github:
git clone https://github.com/gardener/dependency-watchdog.git
Using Makefile
For every change following make targets are recommended to run.
# build the code changes
> make build
# ensure that all required checks pass
> make verify # this will check formatting, linting and will run unit tests
# if you do not wish to run tests then you can use the following make target.
> make check
All tests should be run and the test coverage should ideally not reduce. Please ensure that you have read testing guidelines.
Before raising a pull request ensure that if you are introducing any new file then you must add licesence header to all new files. To add license header you can run this make target:
> make add-license-headers
# This will add license headers to any file which does not already have it.
NOTE: Also have a look at the Makefile as it has other targets that are not mentioned here.
Raising a Pull Request
To raise a pull request do the following:
- Create a fork of dependency-watchdog
- Add dependency-watchdog as upstream remote via
git remote add upstream https://github.com/gardener/dependency-watchdog
- It is recommended that you create a git branch and push all your changes for the pull-request.
- Ensure that while you work on your pull-request, you continue to rebase the changes from upstream to your branch. To do that execute the following command:
git pull --rebase upstream master
- We prefer clean commits. If you have multiple commits in the pull-request, then squash the commits to a single commit. You can do this via
interactive git rebasecommand. For example if your PR branch is ahead of remote origin HEAD by 5 commits then you can execute the following command and pick the first commit and squash the remaining commits.
git rebase -i HEAD~5 #actual number from the head will depend upon how many commits your branch is ahead of remote origin master
1.4 - Dwd Using Local Garden
Dependency Watchdog with Local Garden Cluster
Setting up Local Garden cluster
A convenient way to test local dependency-watchdog changes is to use a local garden cluster. To setup a local garden cluster you can follow the setup-guide.
Dependency Watchdog resources
As part of the local garden installation, a local seed will be available.
Dependency Watchdog resources created in the seed
Namespaced resources
In the garden namespace of the seed cluster, following resources will be created:
| Resource (GVK) | Name |
|---|---|
| {apiVersion: v1, Kind: ServiceAccount} | dependency-watchdog-prober |
| {apiVersion: v1, Kind: ServiceAccount} | dependency-watchdog-weeder |
| {apiVersion: apps/v1, Kind: Deployment} | dependency-watchdog-prober |
| {apiVersion: apps/v1, Kind: Deployment} | dependency-watchdog-weeder |
| {apiVersion: v1, Kind: ConfigMap} | dependency-watchdog-prober-* |
| {apiVersion: v1, Kind: ConfigMap} | dependency-watchdog-weeder-* |
| {apiVersion: rbac.authorization.k8s.io/v1, Kind: Role} | gardener.cloud:dependency-watchdog-prober:role |
| {apiVersion: rbac.authorization.k8s.io/v1, Kind: Role} | gardener.cloud:dependency-watchdog-weeder:role |
| {apiVersion: rbac.authorization.k8s.io/v1, Kind: RoleBinding} | gardener.cloud:dependency-watchdog-prober:role-binding |
| {apiVersion: rbac.authorization.k8s.io/v1, Kind: RoleBinding} | gardener.cloud:dependency-watchdog-weeder:role-binding |
| {apiVersion: resources.gardener.cloud/v1alpha1, Kind: ManagedResource} | dependency-watchdog-prober |
| {apiVersion: resources.gardener.cloud/v1alpha1, Kind: ManagedResource} | dependency-watchdog-weeder |
| {apiVersion: v1, Kind: Secret} | managedresource-dependency-watchdog-weeder |
| {apiVersion: v1, Kind: Secret} | managedresource-dependency-watchdog-prober |
Cluster resources
| Resource (GVK) | Name |
|---|---|
| {apiVersion: rbac.authorization.k8s.io/v1, Kind: ClusterRole} | gardener.cloud:dependency-watchdog-prober:cluster-role |
| {apiVersion: rbac.authorization.k8s.io/v1, Kind: ClusterRole} | gardener.cloud:dependency-watchdog-weeder:cluster-role |
| {apiVersion: rbac.authorization.k8s.io/v1, Kind: ClusterRoleBinding} | gardener.cloud:dependency-watchdog-prober:cluster-role-binding |
| {apiVersion: rbac.authorization.k8s.io/v1, Kind: ClusterRoleBinding} | gardener.cloud:dependency-watchdog-weeder:cluster-role-binding |
Dependency Watchdog resources created in Shoot control namespace
| Resource (GVK) | Name |
|---|---|
| {apiVersion: v1, Kind: Secret} | dependency-watchdog-prober |
| {apiVersion: resources.gardener.cloud/v1alpha1, Kind: ManagedResource} | shoot-core-dependency-watchdog |
Dependency Watchdog resources created in the kube-node-lease namespace of the shoot
| Resource (GVK) | Name |
|---|---|
| {apiVersion: rbac.authorization.k8s.io/v1, Kind: Role} | gardener.cloud:target:dependency-watchdog |
| {apiVersion: rbac.authorization.k8s.io/v1, Kind: RoleBinding} | gardener.cloud:target:dependency-watchdog |
These will be created by the GRM and will have a managed resource named shoot-core-dependency-watchdog in the shoot namespace in the seed.
Update Gardener with custom Dependency Watchdog Docker images
Build, Tag and Push docker images
To build dependency watchdog docker images run the following make target:
> make docker-build
Local gardener hosts a docker registry which can be access at localhost:5001. To enable local gardener to be able to access the custom docker images you need to tag and push these images to the embedded docker registry. To do that execute the following commands:
> docker images
# Get the IMAGE ID of the dependency watchdog images that were built using docker-build make target.
> docker tag <IMAGE-ID> localhost:5001/europe-docker.pkg.dev/gardener-project/public/gardener/dependency-watchdog-prober:<TAGNAME>
> docker push localhost:5001/europe-docker.pkg.dev/gardener-project/public/gardener/dependency-watchdog-prober:<TAGNAME>
Update ManagedResource
Garden resource manager will revert back any changes that are done to the kubernetes deployment for dependency watchdog. This is quite useful in live landscapes where only tested and qualified images are used for all gardener managed components. Any change therefore is automatically reverted.
However, during development and testing you will need to use custom docker images. To prevent garden resource manager from reverting the changes done to the kubernetes deployment for dependency watchdog components you must update the respective managed resources first.
# List the managed resources
> kubectl get mr -n garden | grep dependency
# Sample response
dependency-watchdog-weeder seed True True False 26h
dependency-watchdog-prober seed True True False 26h
# Lets assume that you are currently testing prober and would like to use a custom docker image
> kubectl edit mr dependency-watchdog-prober -n garden
# This will open the resource YAML for editing. Add the annotation resources.gardener.cloud/ignore=true
# Reference: https://github.com/gardener/gardener/blob/master/docs/concepts/resource-manager.md
# Save the YAML file.
When you are done with your testing then you can again edit the ManagedResource and remove the annotation. Garden resource manager will revert back to the image with which gardener was initially built and started.
Update Kubernetes Deployment
Find and update the kubernetes deployment for dependency watchdog.
> kubectl get deploy -n garden | grep dependency
# Sample response
dependency-watchdog-weeder 1/1 1 1 26h
dependency-watchdog-prober 1/1 1 1 26h
# Lets assume that you are currently testing prober and would like to use a custom docker image
> kubectl edit deploy dependency-watchdog-prober -n garden
# This will open the resource YAML for editing. Change the image or any other changes and save.
1.5 - Testing
Testing Strategy and Developer Guideline
Intent of this document is to introduce you (the developer) to the following:
- Category of tests that exists.
- Libraries that are used to write tests.
- Best practices to write tests that are correct, stable, fast and maintainable.
- How to run each category of tests.
For any new contributions tests are a strict requirement. Boy Scouts Rule is followed: If you touch a code for which either no tests exist or coverage is insufficient then it is expected that you will add relevant tests.
Tools Used for Writing Tests
These are the following tools that were used to write all the tests (unit + envtest + vanilla kind cluster tests), it is preferred not to introduce any additional tools / test frameworks for writing tests:
Gomega
We use gomega as our matcher or assertion library. Refer to Gomega’s official documentation for details regarding its installation and application in tests.
Testing Package from Standard Library
We use the Testing package provided by the standard library in golang for writing all our tests. Refer to its official documentation to learn how to write tests using Testing package. You can also refer to this example.
Writing Tests
Common for All Kinds
- For naming the individual tests (
TestXxxandtestXxxmethods) and helper methods, make sure that the name describes the implementation of the method. For eg:testScalingWhenMandatoryResourceNotFoundtests the behaviour of thescalerwhen a mandatory resource (KCM deployment) is not present. - Maintain proper logging in tests. Use
t.log()method to add appropriate messages wherever necessary to describe the flow of the test. See this for examples. - Make use of the
testdatadirectory for storing arbitrary sample data needed by tests (YAML manifests, etc.). See this package for examples.- From https://pkg.go.dev/cmd/go/internal/test:
The go tool will ignore a directory named “testdata”, making it available to hold ancillary data needed by the tests.
- From https://pkg.go.dev/cmd/go/internal/test:
Table-driven tests
We need a tabular structure in two cases:
- When we have multiple tests which require the same kind of setup:- In this case we have a
TestXxxSuitemethod which will do the setup and run all the tests. We have a slice ofteststruct which holds all the tests (typically atitleandrunmethod). We use aforloop to run all the tests one by one. See this for examples. - When we have the same code path and multiple possible values to check:- In this case we have the arguments and expectations in a struct. We iterate through the slice of all such structs, passing the arguments to appropriate methods and checking if the expectation is met. See this for examples.
Env Tests
Env tests in Dependency Watchdog use the sigs.k8s.io/controller-runtime/pkg/envtest package. It sets up a temporary control plane (etcd + kube-apiserver) and runs the test against it. The code to set up and teardown the environment can be checked out here.
These are the points to be followed while writing tests that use envtest setup:
All tests should be divided into two top level partitions:
- tests with common environment (
testXxxCommonEnvTests) - tests which need a dedicated environment for each one. (
testXxxDedicatedEnvTests)
They should be contained within the
TestXxxSuitemethod. See this for examples. If all tests are of one kind then this is not needed.- tests with common environment (
Create a method named
setUpXxxTestfor performing setup tasks before all/each test. It should either return a method or have a separate method to perform teardown tasks. See this for examples.The tests run by the suite can be table-driven as well.
Use the
envtestsetup when there is a need of an environment close to an actual setup. Eg: start controllers against a real Kubernetes control plane to catch bugs that can only happen when talking to a real API server.
NOTE: It is currently not possible to bring up more than one envtest environments. See issue#1363. We enforce running serial execution of test suites each of which uses a different envtest environments. See hack/test.sh.
Vanilla Kind Cluster Tests
There are some tests where we need a vanilla kind cluster setup, for eg:- The scaler.go code in the prober package uses the scale subresource to scale the deployments mentioned in the prober config. But the envtest setup does not support the scale subresource as of now. So we need this setup to test if the deployments are scaled as per the config or not.
You can check out the code for this setup here. You can add utility methods for different kubernetes and custom resources in there.
These are the points to be followed while writing tests that use Vanilla Kind Cluster setup:
- Use this setup only if there is a need of an actual Kubernetes cluster(api server + control plane + etcd) to write the tests. (Because this is slower than your normal
envTestsetup) - Create
setUpXxxTestsimilar to the one inenvTest. Follow the same structural pattern used inenvTestfor writing these tests. See this for examples.
Run Tests
To run unit tests, use the following Makefile target
make test
To run KIND cluster based tests, use the following Makefile target
make kind-tests # these tests will be slower as it brings up a vanilla KIND cluster
To view coverage after running the tests, run :
go tool cover -html=cover.out
Flaky tests
If you see that a test is flaky then you can use make stress target which internally uses stress tool
make stress test-package=<test-package> test-func=<test-func> tool-params="<tool-params>"
An example invocation:
make stress test-package=./internal/util test-func=TestRetryUntilPredicateWithBackgroundContext tool-params="-p 10"
The make target will do the following:
- It will create a test binary for the package specified via
test-packageat/tmp/pkg-stress.testdirectory. - It will run
stresstool passing thetool-paramsand targets the functiontest-func.
2 - etcd-druid
![]()
![]()

![]()
etcd-druid is an etcd operator which makes it easy to configure, provision, reconcile, monitor and delete etcd clusters. It enables management of etcd clusters through declarative Kubernetes API model.
In every etcd cluster managed by etcd-druid, each etcd member is a two container Pod which consists of:
- etcd-wrapper which manages the lifecycle (validation & initialization) of an etcd.
- etcd-backup-restore sidecar which currently provides the following capabilities (the list is not comprehensive):
- etcd DB validation.
- Scheduled etcd DB defragmentation.
- Backup - etcd DB snapshots are taken regularly and backed in an object store if one is configured.
- Restoration - In case of a DB corruption for a single-member cluster it helps in restoring from latest set of snapshots (full & delta).
- Member control operations.
etcd-druid additionally provides the following capabilities:
- Facilitates declarative scale-out of etcd clusters.
- Provides protection against accidental deletion/mutation of resources provisioned as part of an etcd cluster.
- Offers an asynchronous and threshold based capability to process backed up snapshots to:
- Potentially minimize the recovery time by leveraging restoration from backups followed by etcd’s compaction and defragmentation.
- Indirectly assert integrity of the backed up snaphots.
- Allows seamless copy of backups between any two object store buckets.
Start using or developing etcd-druid locally
If you are looking to try out druid then you can use a Kind cluster based setup.
https://github.com/user-attachments/assets/cfe0d891-f709-4d7f-b975-4300c6de67e4
For detailed documentation, see our docs.
Contributions
If you wish to contribute then please see our contributor guidelines.
Feedback and Support
We always look forward to active community engagement. Please report bugs or suggestions on how we can enhance etcd-druid on GitHub Issues.
License
Release under Apache-2.0 license.
2.1 - 01 Multi Node Etcd Clusters
DEP-01: Multi-node etcd cluster instances via etcd-druid
This document proposes an approach (along with some alternatives) to support provisioning and management of multi-node etcd cluster instances via etcd-druid and etcd-backup-restore.
Goal
- Enhance etcd-druid and etcd-backup-restore to support provisioning and management of multi-node etcd cluster instances within a single Kubernetes cluster.
- The etcd CRD interface should be simple to use. It should preferably work with just setting the
spec.replicasfield to the desired value and should not require any more configuration in the CRD than currently required for the single-node etcd instances. Thespec.replicasfield is part of thescalesub-resource implementation inEtcdCRD. - The single-node and multi-node scenarios must be automatically identified and managed by
etcd-druidandetcd-backup-restore. - The etcd clusters (single-node or multi-node) managed by
etcd-druidandetcd-backup-restoremust automatically recover from failures (even quorum loss) and disaster (e.g. etcd member persistence/data loss) as much as possible. - It must be possible to dynamically scale an etcd cluster horizontally (even between single-node and multi-node scenarios) by simply scaling the
Etcdscale sub-resource. - It must be possible to (optionally) schedule the individual members of an etcd clusters on different nodes or even infrastructure availability zones (within the hosting Kubernetes cluster).
Though this proposal tries to cover most aspects related to single-node and multi-node etcd clusters, there are some more points that are not goals for this document but are still in the scope of either etcd-druid/etcd-backup-restore and/or gardener. In such cases, a high-level description of how they can be addressed in the future are mentioned at the end of the document.
Background and Motivation
Single-node etcd cluster
At present, etcd-druid supports only single-node etcd cluster instances.
The advantages of this approach are given below.
- The problem domain is smaller. There are no leader election and quorum related issues to be handled. It is simpler to setup and manage a single-node etcd cluster.
- Single-node etcd clusters instances have less request latency than multi-node etcd clusters because there is no requirement to replicate the changes to the other members before committing the changes.
etcd-druidprovisions etcd cluster instances as pods (actually asstatefulsets) in a Kubernetes cluster and Kubernetes is quick (<20s) to restart container/pods if they go down.- Also,
etcd-druidis currently only used by gardener to provision etcd clusters to act as back-ends for Kubernetes control-planes and Kubernetes control-plane components (kube-apiserver,kubelet,kube-controller-manager,kube-scheduleretc.) can tolerate etcd going down and recover when it comes back up. - Single-node etcd clusters incur less cost (CPU, memory and storage)
- It is easy to cut-off client requests if backups fail by using
readinessProbeon theetcd-backup-restorehealthz endpoint to minimize the gap between the latest revision and the backup revision.
The disadvantages of using single-node etcd clusters are given below.
- The database verification step by
etcd-backup-restorecan introduce additional delays whenever etcd container/pod restarts (in total ~20-25s). This can be much longer if a database restoration is required. Especially, if there are incremental snapshots that need to be replayed (this can be mitigated by compacting the incremental snapshots in the background). - Kubernetes control-plane components can go into
CrashloopBackoffif etcd is down for some time. This is mitigated by the dependency-watchdog. But Kubernetes control-plane components require a lot of resources and create a lot of load on the etcd cluster and the apiserver when they come out ofCrashloopBackoff. Especially, in medium or large sized clusters (>20nodes). - Maintenance operations such as updates to etcd (and updates to
etcd-druidofetcd-backup-restore), rolling updates to the nodes of the underlying Kubernetes cluster and vertical scaling of etcd pods are disruptive because they cause etcd pods to be restarted. The vertical scaling of etcd pods is somewhat mitigated during scale down by doing it only during the target clusters’ maintenance window. But scale up is still disruptive. - We currently use some form of elastic storage (via
persistentvolumeclaims) for storing which have some upper-bounds on the I/O latency and throughput. This can be potentially be a problem for large clusters (>220nodes). Also, some cloud providers (e.g. Azure) take a long time to attach/detach volumes to and from machines which increases the down time to the Kubernetes components that depend on etcd. It is difficult to use ephemeral/local storage (to achieve better latency/throughput as well as to circumvent volume attachment/detachment) for single-node etcd cluster instances.
Multi-node etcd-cluster
The advantages of introducing support for multi-node etcd clusters via etcd-druid are below.
- Multi-node etcd cluster is highly-available. It can tolerate disruption to individual etcd pods as long as the quorum is not lost (i.e. more than half the etcd member pods are healthy and ready).
- Maintenance operations such as updates to etcd (and updates to
etcd-druidofetcd-backup-restore), rolling updates to the nodes of the underlying Kubernetes cluster and vertical scaling of etcd pods can be done non-disruptively by respectingpoddisruptionbudgetsfor the various multi-node etcd cluster instances hosted on that cluster. - Kubernetes control-plane components do not see any etcd cluster downtime unless quorum is lost (which is expected to be lot less frequent than current frequency of etcd container/pod restarts).
- We can consider using ephemeral/local storage for multi-node etcd cluster instances because individual member restarts can afford to take time to restore from backup before (re)joining the etcd cluster because the remaining members serve the requests in the meantime.
- High-availability across availability zones is also possible by specifying (anti)affinity for the etcd pods (possibly via
kupid).
Some disadvantages of using multi-node etcd clusters due to which it might still be desirable, in some cases, to continue to use single-node etcd cluster instances in the gardener context are given below.
- Multi-node etcd cluster instances are more complex to manage.
The problem domain is larger including the following.
- Leader election
- Quorum loss
- Managing rolling changes
- Backups to be taken from only the leading member.
- More complex to cut-off client requests if backups fail to minimize the gap between the latest revision and the backup revision is under control.
- Multi-node etcd cluster instances incur more cost (CPU, memory and storage).
Dynamic multi-node etcd cluster
Though it is not part of this proposal, it is conceivable to convert a single-node etcd cluster into a multi-node etcd cluster temporarily to perform some disruptive operation (etcd, etcd-backup-restore or etcd-druid updates, etcd cluster vertical scaling and perhaps even node rollout) and convert it back to a single-node etcd cluster once the disruptive operation has been completed. This will necessarily still involve a down-time because scaling from a single-node etcd cluster to a three-node etcd cluster will involve etcd pod restarts, it is still probable that it can be managed with a shorter down time than we see at present for single-node etcd clusters (on the other hand, converting a three-node etcd cluster to five node etcd cluster can be non-disruptive).
This is definitely not to argue in favour of such a dynamic approach in all cases (eventually, if/when dynamic multi-node etcd clusters are supported). On the contrary, it makes sense to make use of static (fixed in size) multi-node etcd clusters for production scenarios because of the high-availability.
Prior Art
ETCD Operator from CoreOS
This project is no longer actively developed or maintained. The project exists here for historical reference. If you are interested in the future of the project and taking over stewardship, please contact etcd-dev@googlegroups.com.
etcdadm from kubernetes-sigs
etcdadm is a command-line tool for operating an etcd cluster. It makes it easy to create a new cluster, add a member to, or remove a member from an existing cluster. Its user experience is inspired by kubeadm.
It is a tool more tailored for manual command-line based management of etcd clusters with no API’s. It also makes no assumptions about the underlying platform on which the etcd clusters are provisioned and hence, doesn’t leverage any capabilities of Kubernetes.
Etcd Cluster Operator from Improbable-Engineering
Etcd Cluster Operator is an Operator for automating the creation and management of etcd inside of Kubernetes. It provides a custom resource definition (CRD) based API to define etcd clusters with Kubernetes resources, and enable management with native Kubernetes tooling._
Out of all the alternatives listed here, this one seems to be the only possible viable alternative. Parts of its design/implementations are similar to some of the approaches mentioned in this proposal. However, we still don’t propose to use it as -
- The project is still in early phase and is not mature enough to be consumed as is in productive scenarios of ours.
- The resotration part is completely different which makes it difficult to adopt as-is and requries lot of re-work with the current restoration semantics with etcd-backup-restore making the usage counter-productive.
General Approach to ETCD Cluster Management
Bootstrapping
There are three ways to bootstrap an etcd cluster which are static, etcd discovery and DNS discovery. Out of these, the static way is the simplest (and probably faster to bootstrap the cluster) and has the least external dependencies. Hence, it is preferred in this proposal. But it requires that the initial (during bootstrapping) etcd cluster size (number of members) is already known before bootstrapping and that all of the members are already addressable (DNS,IP,TLS etc.). Such information needs to be passed to the individual members during startup using the following static configuration.
- ETCD_INITIAL_CLUSTER
- The list of peer URLs including all the members. This must be the same as the advertised peer URLs configuration. This can also be passed as
initial-clusterflag to etcd.
- The list of peer URLs including all the members. This must be the same as the advertised peer URLs configuration. This can also be passed as
- ETCD_INITIAL_CLUSTER_STATE
- This should be set to
newwhile bootstrapping an etcd cluster.
- This should be set to
- ETCD_INITIAL_CLUSTER_TOKEN
- This is a token to distinguish the etcd cluster from any other etcd cluster in the same network.
Assumptions
- ETCD_INITIAL_CLUSTER can use DNS instead of IP addresses. We need to verify this by deleting a pod (as against scaling down the statefulset) to ensure that the pod IP changes and see if the recreated pod (by the statefulset controller) re-joins the cluster automatically.
- DNS for the individual members is known or computable. This is true in the case of etcd-druid setting up an etcd cluster using a single statefulset. But it may not necessarily be true in other cases (multiple statefulset per etcd cluster or deployments instead of statefulsets or in the case of etcd cluster with members distributed across more than one Kubernetes cluster.
Adding a new member to an etcd cluster
A new member can be added to an existing etcd cluster instance using the following steps.
- If the latest backup snapshot exists, restore the member’s etcd data to the latest backup snapshot. This can reduce the load on the leader to bring the new member up to date when it joins the cluster.
- If the latest backup snapshot doesn’t exist or if the latest backup snapshot is not accessible (please see backup failure) and if the cluster itself is quorate, then the new member can be started with an empty data. But this will will be suboptimal because the new member will fetch all the data from the leading member to get up-to-date.
- The cluster is informed that a new member is being added using the
MemberAddAPI including information like the member name and its advertised peer URLs. - The new etcd member is then started with
ETCD_INITIAL_CLUSTER_STATE=existingapart from other required configuration.
This proposal recommends this approach.
Note
- If there are incremental snapshots (taken by
etcd-backup-restore), they cannot be applied because that requires the member to be started in isolation without joining the cluster which is not possible. This is acceptable if the amount of incremental snapshots are managed to be relatively small. This adds one more reason to increase the priority of the issue of incremental snapshot compaction. - There is a time window, between the
MemberAddcall and the new member joining the cluster and getting up to date, where the cluster is vulnerable to leader elections which could be disruptive.
Alternative
With v3.4, the new raft learner approach can be used to mitigate some of the possible disruptions mentioned above.
Then the steps will be as follows.
- If the latest backup snapshot exists, restore the member’s etcd data to the latest backup snapshot. This can reduce the load on the leader to bring the new member up to date when it joins the cluster.
- The cluster is informed that a new member is being added using the
MemberAddAsLearnerAPI including information like the member name and its advertised peer URLs. - The new etcd member is then started with
ETCD_INITIAL_CLUSTER_STATE=existingapart from other required configuration. - Once the new member (learner) is up to date, it can be promoted to a full voting member by using the
MemberPromoteAPI
This approach is new and involves more steps and is not recommended in this proposal. It can be considered in future enhancements.
Managing Failures
A multi-node etcd cluster may face failures of diffent kinds during its life-cycle. The actions that need to be taken to manage these failures depend on the failure mode.
Removing an existing member from an etcd cluster
If a member of an etcd cluster becomes unhealthy, it must be explicitly removed from the etcd cluster, as soon as possible.
This can be done by using the MemberRemove API.
This ensures that only healthy members participate as voting members.
A member of an etcd cluster may be removed not just for managing failures but also for other reasons such as -
- The etcd cluster is being scaled down. I.e. the cluster size is being reduced
- An existing member is being replaced by a new one for some reason (e.g. upgrades)
If the majority of the members of the etcd cluster are healthy and the member that is unhealthy/being removed happens to be the leader at that moment then the etcd cluster will automatically elect a new leader. But if only a minority of etcd clusters are healthy after removing the member then the the cluster will no longer be quorate and will stop accepting write requests. Such an etcd cluster needs to be recovered via some kind of disaster-recovery.
Restarting an existing member of an etcd cluster
If the existing member of an etcd cluster restarts and retains an uncorrupted data directory after the restart, then it can simply re-join the cluster as an existing member without any API calls or configuration changes. This is because the relevant metadata (including member ID and cluster ID) are maintained in the write ahead logs. However, if it doesn’t retain an uncorrupted data directory after the restart, then it must first be removed and added as a new member.
Recovering an etcd cluster from failure of majority of members
If a majority of members of an etcd cluster fail but if they retain their uncorrupted data directory then they can be simply restarted and they will re-form the existing etcd cluster when they come up. However, if they do not retain their uncorrupted data directory, then the etcd cluster must be recovered from latest snapshot in the backup. This is very similar to bootstrapping with the additional initial step of restoring the latest snapshot in each of the members. However, the same limitation about incremental snapshots, as in the case of adding a new member, applies here. But unlike in the case of adding a new member, not applying incremental snapshots is not acceptable in the case of etcd cluster recovery. Hence, if incremental snapshots are required to be applied, the etcd cluster must be recovered in the following steps.
- Restore a new single-member cluster using the latest snapshot.
- Apply incremental snapshots on the single-member cluster.
- Take a full snapshot which can now be used while adding the remaining members.
- Add new members using the latest snapshot created in the step above.
Kubernetes Context
- Users will provision an etcd cluster in a Kubernetes cluster by creating an etcd CRD resource instance.
- A multi-node etcd cluster is indicated if the
spec.replicasfield is set to any value greater than 1. The etcd-druid will add validation to ensure that thespec.replicasvalue is an odd number according to the requirements of etcd. - The etcd-druid controller will provision a statefulset with the etcd main container and the etcd-backup-restore sidecar container. It will pass on the
spec.replicasfield from the etcd resource to the statefulset. It will also supply the right pre-computed configuration to both the containers. - The statefulset controller will create the pods based on the pod template in the statefulset spec and these individual pods will be the members that form the etcd cluster.
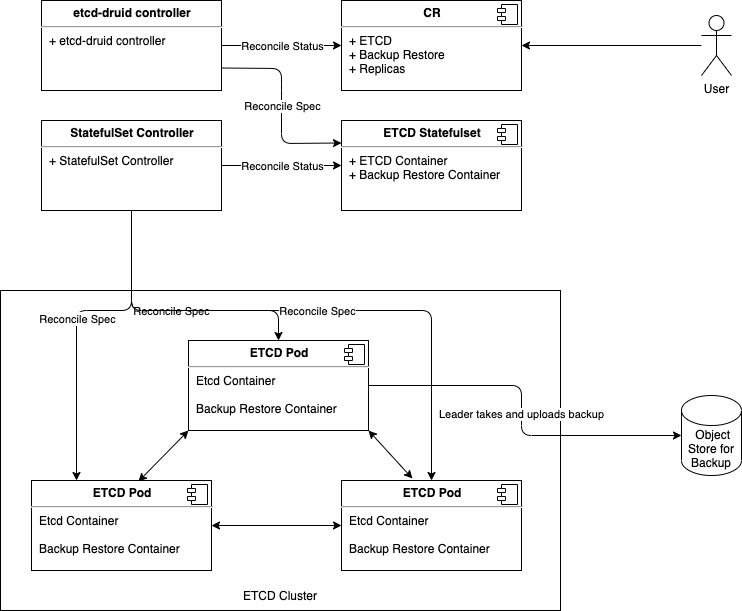
This approach makes it possible to satisfy the assumption that the DNS for the individual members of the etcd cluster must be known/computable.
This can be achieved by using a headless service (along with the statefulset) for each etcd cluster instance.
Then we can address individual pods/etcd members via the predictable DNS name of <statefulset_name>-{0|1|2|3|…|n}.<headless_service_name> from within the Kubernetes namespace (or from outside the Kubernetes namespace by appending .<namespace>.svc.<cluster_domain> suffix).
The etcd-druid controller can compute the above configurations automatically based on the spec.replicas in the etcd resource.
This proposal recommends this approach.
Alternative
One statefulset is used for each member (instead of one statefulset for all members). While this approach gives a flexibility to have different pod specifications for the individual members, it makes managing the individual members (e.g. rolling updates) more complicated. Hence, this approach is not recommended.
ETCD Configuration
As mentioned in the general approach section, there are differences in the configuration that needs to be passed to individual members of an etcd cluster in different scenarios such as bootstrapping, adding a new member, removing a member, restarting an existing member etc. Managing such differences in configuration for individual pods of a statefulset is tricky in the recommended approach of using a single statefulset to manage all the member pods of an etcd cluster. This is because statefulset uses the same pod template for all its pods.
The recommendation is for etcd-druid to provision the base configuration template in a ConfigMap which is passed to all the pods via the pod template in the StatefulSet.
The initialization flow of etcd-backup-restore (which is invoked every time the etcd container is (re)started) is then enhanced to generate the customized etcd configuration for the corresponding member pod (in a shared volume between etcd and the backup-restore containers) based on the supplied template configuration.
This will require that etcd-backup-restore will have to have a mechanism to detect which scenario listed above applies during any given member container/pod restart.
Alternative
As mentioned above, one statefulset is used for each member of the etcd cluster.
Then different configuration (generated directly by etcd-druid) can be passed in the pod templates of the different statefulsets.
Though this approach is advantageous in the context of managing the different configuration, it is not recommended in this proposal because it makes the rest of the management (e.g. rolling updates) more complicated.
Data Persistence
The type of persistence used to store etcd data (including the member ID and cluster ID) has an impact on the steps that are needed to be taken when the member pods or containers (minority of them or majority) need to be recovered.
Persistent
Like the single-node case, persistentvolumes can be used to persist ETCD data for all the member pods. The individual member pods then get their own persistentvolumes.
The advantage is that individual members retain their member ID across pod restarts and even pod deletion/recreation across Kubernetes nodes.
This means that member pods that crash (or are unhealthy) can be restarted automatically (by configuring livenessProbe) and they will re-join the etcd cluster using their existing member ID without any need for explicit etcd cluster management).
The disadvantages of this approach are as follows.
- The number of persistentvolumes increases linearly with the cluster size which is a cost-related concern.
- Network-mounted persistentvolumes might eventually become a performance bottleneck under heavy load for a latency-sensitive component like ETCD.
- Volume attach/detach issues when associated with etcd cluster instances cause downtimes to the target shoot clusters that are backed by those etcd cluster instances.
Ephemeral
The ephemeral volumes use-case is considered as an optimization and may be planned as a follow-up action.
Disk
Ephemeral persistence can be achieved in Kubernetes by using either emptyDir volumes or local persistentvolumes to persist ETCD data.
The advantages of this approach are as follows.
- Potentially faster disk I/O.
- The number of persistent volumes does not increase linearly with the cluster size (at least not technically).
- Issues related volume attachment/detachment can be avoided.
The main disadvantage of using ephemeral persistence is that the individual members may retain their identity and data across container restarts but not across pod deletion/recreation across Kubernetes nodes. If the data is lost then on restart of the member pod, the older member (represented by the container) has to be removed and a new member has to be added.
Using emptyDir ephemeral persistence has the disadvantage that the volume doesn’t have its own identity.
So, if the member pod is recreated but scheduled on the same node as before then it will not retain the identity as the persistence is lost.
But it has the advantage that scheduling of pods is unencumbered especially during pod recreation as they are free to be scheduled anywhere.
Using local persistentvolumes has the advantage that the volume has its own indentity and hence, a recreated member pod will retain its identity if scheduled on the same node.
But it has the disadvantage of tying down the member pod to a node which is a problem if the node becomes unhealthy requiring etcd druid to take additional actions (such as deleting the local persistent volume).
Based on these constraints, if ephemeral persistence is opted for, it is recommended to use emptyDir ephemeral persistence.
In-memory
In-memory ephemeral persistence can be achieved in Kubernetes by using emptyDir with medium: Memory.
In this case, a tmpfs (RAM-backed file-system) volume will be used.
In addition to the advantages of ephemeral persistence, this approach can achieve the fastest possible disk I/O.
Similarly, in addition to the disadvantages of ephemeral persistence, in-memory persistence has the following additional disadvantages.
- More memory required for the individual member pods.
- Individual members may not at all retain their data and identity across container restarts let alone across pod restarts/deletion/recreation across Kubernetes nodes. I.e. every time an etcd container restarts, the old member (represented by the container) will have to be removed and a new member has to be added.
How to detect if valid metadata exists in an etcd member
Since the likelyhood of a member not having valid metadata in the WAL files is much more likely in the ephemeral persistence scenario, one option is to pass the information that ephemeral persistence is being used to the etcd-backup-restore sidecar (say, via command-line flags or environment variables).
But in principle, it might be better to determine this from the WAL files directly so that the possibility of corrupted WAL files also gets handled correctly. To do this, the wal package has some functions that might be useful.
Recommendation
It might be possible that using the wal package for verifying if valid metadata exists might be performance intensive. So, the performance impact needs to be measured. If the performance impact is acceptable (both in terms of resource usage and time), it is recommended to use this way to verify if the member contains valid metadata. Otherwise, alternatives such as a simple check that WAL folder exists coupled with the static information about use of persistent or ephemeral storage might be considered.
How to detect if valid data exists in an etcd member
The initialization sequence in etcd-backup-restore already includes database verification.
This would suffice to determine if the member has valid data.
Recommendation
Though ephemeral persistence has performance and logistics advantages, it is recommended to start with persistent data for the member pods. In addition to the reasons and concerns listed above, there is also the additional concern that in case of backup failure, the risk of additional data loss is a bit higher if ephemeral persistence is used (simultaneous quoram loss is sufficient) when compared to persistent storage (simultaenous quorum loss with majority persistence loss is needed). The risk might still be acceptable but the idea is to gain experience about how frequently member containers/pods get restarted/recreated, how frequently leader election happens among members of an etcd cluster and how frequently etcd clusters lose quorum. Based on this experience, we can move towards using ephemeral (perhaps even in-memory) persistence for the member pods.
Separating peer and client traffic
The current single-node ETCD cluster implementation in etcd-druid and etcd-backup-restore uses a single service object to act as the entry point for the client traffic.
There is no separation or distinction between the client and peer traffic because there is not much benefit to be had by making that distinction.
In the multi-node ETCD cluster scenario, it makes sense to distinguish between and separate the peer and client traffic.
This can be done by using two services.
- peer
- To be used for peer communication. This could be a
headlessservice.
- To be used for peer communication. This could be a
- client
- To be used for client communication. This could be a normal
ClusterIPservice like it is in the single-node case.
- To be used for client communication. This could be a normal
The main advantage of this approach is that it makes it possible (if needed) to allow only peer to peer communication while blocking client communication. Such a thing might be required during some phases of some maintenance tasks (manual or automated).
Cutting off client requests
At present, in the single-node ETCD instances, etcd-druid configures the readinessProbe of the etcd main container to probe the healthz endpoint of the etcd-backup-restore sidecar which considers the status of the latest backup upload in addition to the regular checks about etcd and the side car being up and healthy. This has the effect of setting the etcd main container (and hence the etcd pod) as not ready if the latest backup upload failed. This results in the endpoints controller removing the pod IP address from the endpoints list for the service which eventually cuts off ingress traffic coming into the etcd pod via the etcd client service. The rationale for this is to fail early when the backup upload fails rather than continuing to serve requests while the gap between the last backup and the current data increases which might lead to unacceptably large amount of data loss if disaster strikes.
This approach will not work in the multi-node scenario because we need the individual member pods to be able to talk to each other to maintain the cluster quorum when backup upload fails but need to cut off only client ingress traffic.
It is recommended to separate the backup health condition tracking taking appropriate remedial actions.
With that, the backup health condition tracking is now separated to the BackupReady condition in the Etcd resource status and the cutting off of client traffic (which could now be done for more reasons than failed backups) can be achieved in a different way described below.
Manipulating Client Service podSelector
The client traffic can be cut off by updating (manually or automatically by some component) the podSelector of the client service to add an additional label (say, unhealthy or disabled) such that the podSelector no longer matches the member pods created by the statefulset.
This will result in the client ingress traffic being cut off.
The peer service is left unmodified so that peer communication is always possible.
Health Check
The etcd main container and the etcd-backup-restore sidecar containers will be configured with livenessProbe and readinessProbe which will indicate the health of the containers and effectively the corresponding ETCD cluster member pod.
Backup Failure
As described above using readinessProbe failures based on latest backup failure is not viable in the multi-node ETCD scenario.
Though cutting off traffic by manipulating client service podSelector is workable, it may not be desirable.
It is recommended that on backup failure, the leading etcd-backup-restore sidecar (the one that is responsible for taking backups at that point in time, as explained in the backup section below, updates the BackupReady condition in the Etcd status and raises a high priority alert to the landscape operators but does not cut off the client traffic.
The reasoning behind this decision to not cut off the client traffic on backup failure is to allow the Kubernetes cluster’s control plane (which relies on the ETCD cluster) to keep functioning as long as possible and to avoid bringing down the control-plane due to a missed backup.
The risk of this approach is that with a cascaded sequence of failures (on top of the backup failure), there is a chance of more data loss than the frequency of backup would otherwise indicate.
To be precise, the risk of such an additional data loss manifests only when backup failure as well as a special case of quorum loss (majority of the members are not ready) happen in such a way that the ETCD cluster needs to be re-bootstrapped from the backup. As described here, re-bootstrapping the ETCD cluster requires restoration from the latest backup only when a majority of members no longer have uncorrupted data persistence.
If persistent storage is used, this will happen only when backup failure as well as a majority of the disks/volumes backing the ETCD cluster members fail simultaneously. This would indeed be rare and might be an acceptable risk.
If ephemeral storage is used (especially, in-memory), the data loss will happen if a majority of the ETCD cluster members become NotReady (requiring a pod restart) at the same time as the backup failure.
This may not be as rare as majority members’ disk/volume failure.
The risk can be somewhat mitigated at least for planned maintenance operations by postponing potentially disruptive maintenance operations when BackupReady condition is false (vertical scaling, rolling updates, evictions due to node roll-outs).
But in practice (when ephemeral storage is used), the current proposal suggests restoring from the latest full backup even when a minority of ETCD members (even a single pod) restart both to speed up the process of the new member catching up to the latest revision but also to avoid load on the leading member which needs to supply the data to bring the new member up-to-date. But as described here, in case of a minority member failure while using ephemeral storage, it is possible to restart the new member with empty data and let it fetch all the data from the leading member (only if backup is not accessible). Though this is suboptimal, it is workable given the constraints and conditions. With this, the risk of additional data loss in the case of ephemeral storage is only if backup failure as well as quorum loss happens. While this is still less rare than the risk of additional data loss in case of persistent storage, the risk might be tolerable. Provided the risk of quorum loss is not too high. This needs to be monitored/evaluated before opting for ephemeral storage.
Given these constraints, it is better to dynamically avoid/postpone some potentially disruptive operations when BackupReady condition is false.
This has the effect of allowing n/2 members to be evicted when the backups are healthy and completely disabling evictions when backups are not healthy.
- Skip/postpone potentially disruptive maintenance operations (listed below) when the
BackupReadycondition isfalse. - Vertical scaling.
- Rolling updates, Basically, any updates to the
StatefulSetspec which includes vertical scaling. - Dynamically toggle the
minAvailablefield of thePodDisruptionBudgetbetweenn/2 + 1andn(wherenis the ETCD desired cluster size) whenever theBackupReadycondition toggles betweentrueandfalse.
This will mean that etcd-backup-restore becomes Kubernetes-aware. But there might be reasons for making etcd-backup-restore Kubernetes-aware anyway (e.g. to update the etcd resource status with latest full snapshot details).
This enhancement should keep etcd-backup-restore backward compatible.
I.e. it should be possible to use etcd-backup-restore Kubernetes-unaware as before this proposal.
This is possible either by auto-detecting the existence of kubeconfig or by an explicit command-line flag (such as --enable-client-service-updates which can be defaulted to false for backward compatibility).
Alternative
The alternative is for etcd-druid to implement the above functionality.
But etcd-druid is centrally deployed in the host Kubernetes cluster and cannot scale well horizontally.
So, it can potentially be a bottleneck if it is involved in regular health check mechanism for all the etcd clusters it manages.
Also, the recommended approach above is more robust because it can work even if etcd-druid is down when the backup upload of a particular etcd cluster fails.
Status
It is desirable (for the etcd-druid and landscape administrators/operators) to maintain/expose status of the etcd cluster instances in the status sub-resource of the Etcd CRD.
The proposed structure for maintaining the status is as shown in the example below.
apiVersion: druid.gardener.cloud/v1alpha1
kind: Etcd
metadata:
name: etcd-main
spec:
replicas: 3
...
...
status:
...
conditions:
- type: Ready # Condition type for the readiness of the ETCD cluster
status: "True" # Indicates of the ETCD Cluster is ready or not
lastHeartbeatTime: "2020-11-10T12:48:01Z"
lastTransitionTime: "2020-11-10T12:48:01Z"
reason: Quorate # Quorate|QuorumLost
- type: AllMembersReady # Condition type for the readiness of all the member of the ETCD cluster
status: "True" # Indicates if all the members of the ETCD Cluster are ready
lastHeartbeatTime: "2020-11-10T12:48:01Z"
lastTransitionTime: "2020-11-10T12:48:01Z"
reason: AllMembersReady # AllMembersReady|NotAllMembersReady
- type: BackupReady # Condition type for the readiness of the backup of the ETCD cluster
status: "True" # Indicates if the backup of the ETCD cluster is ready
lastHeartbeatTime: "2020-11-10T12:48:01Z"
lastTransitionTime: "2020-11-10T12:48:01Z"
reason: FullBackupSucceeded # FullBackupSucceeded|IncrementalBackupSucceeded|FullBackupFailed|IncrementalBackupFailed
...
clusterSize: 3
...
replicas: 3
...
members:
- name: etcd-main-0 # member pod name
id: 272e204152 # member Id
role: Leader # Member|Leader
status: Ready # Ready|NotReady|Unknown
lastTransitionTime: "2020-11-10T12:48:01Z"
reason: LeaseSucceeded # LeaseSucceeded|LeaseExpired|UnknownGracePeriodExceeded|PodNotRead
- name: etcd-main-1 # member pod name
id: 272e204153 # member Id
role: Member # Member|Leader
status: Ready # Ready|NotReady|Unknown
lastTransitionTime: "2020-11-10T12:48:01Z"
reason: LeaseSucceeded # LeaseSucceeded|LeaseExpired|UnknownGracePeriodExceeded|PodNotRead
This proposal recommends that etcd-druid (preferrably, the custodian controller in etcd-druid) maintains most of the information in the status of the Etcd resources described above.
One exception to this is the BackupReady condition which is recommended to be maintained by the leading etcd-backup-restore sidecar container.
This will mean that etcd-backup-restore becomes Kubernetes-aware. But there are other reasons for making etcd-backup-restore Kubernetes-aware anyway (e.g. to maintain health conditions).
This enhancement should keep etcd-backup-restore backward compatible.
But it should be possible to use etcd-backup-restore Kubernetes-unaware as before this proposal. This is possible either by auto-detecting the existence of kubeconfig or by an explicit command-line flag (such as --enable-etcd-status-updates which can be defaulted to false for backward compatibility).
Members
The members section of the status is intended to be maintained by etcd-druid (preferraby, the custodian controller of etcd-druid) based on the leases of the individual members.
Note
An earlier design in this proposal was for the individual etcd-backup-restore sidecars to update the corresponding status.members entries themselves. But this was redesigned to use member leases to avoid conflicts rising from frequent updates and the limitations in the support for Server-Side Apply in some versions of Kubernetes.
The spec.holderIdentity field in the leases is used to communicate the ETCD member id and role between the etcd-backup-restore sidecars and etcd-druid.
Member name as the key
In an ETCD cluster, the member id is the unique identifier for a member.
However, this proposal recommends using a single StatefulSet whose pods form the members of the ETCD cluster and Pods of a StatefulSet have uniquely indexed names as well as uniquely addressible DNS.
This proposal recommends that the name of the member (which is the same as the name of the member Pod) be used as the unique key to identify a member in the members array.
This can minimise the need to cleanup superfluous entries in the members array after the member pods are gone to some extent because the replacement pods for any member will share the same name and will overwrite the entry with a possibly new member id.
There is still the possibility of not only superfluous entries in the members array but also superfluous members in the ETCD cluster for which there is no corresponding pod in the StatefulSet anymore.
For example, if an ETCD cluster is scaled up from 3 to 5 and the new members were failing constantly due to insufficient resources and then if the ETCD client is scaled back down to 3 and failing member pods may not have the chance to clean up their member entries (from the members array as well as from the ETCD cluster) leading to superfluous members in the cluster that may have adverse effect on quorum of the cluster.
Hence, the superfluous entries in both members array as well as the ETCD cluster need to be cleaned up as appropriate.
Member Leases
One Kubernetes lease object per desired ETCD member is maintained by etcd-druid (preferrably, the custodian controller in etcd-druid).
The lease objects will be created in the same namespace as their owning Etcd object and will have the same name as the member to which they correspond (which, in turn would be the same as the pod name in which the member ETCD process runs).
The lease objects are created and deleted only by etcd-druid but are continually renewed within the leaseDurationSeconds by the individual etcd-backup-restore sidecars (corresponding to their members) if the the corresponding ETCD member is ready and is part of the ETCD cluster.
This will mean that etcd-backup-restore becomes Kubernetes-aware. But there are other reasons for making etcd-backup-restore Kubernetes-aware anyway (e.g. to maintain health conditions).
This enhancement should keep etcd-backup-restore backward compatible.
But it should be possible to use etcd-backup-restore Kubernetes-unaware as before this proposal. This is possible either by auto-detecting the existence of kubeconfig or by an explicit command-line flag (such as --enable-etcd-lease-renewal which can be defaulted to false for backward compatibility).
A member entry in the Etcd resource status would be marked as Ready (with reason: LeaseSucceeded) if the corresponding pod is ready and the corresponding lease has not yet expired.
The member entry would be marked as NotReady if the corresponding pod is not ready (with reason PodNotReady) or as Unknown if the corresponding lease has expired (with reason: LeaseExpired).
While renewing the lease, the etcd-backup-restore sidecars also maintain the ETCD member id and their role (Leader or Member) separated by : in the spec.holderIdentity field of the corresponding lease object since this information is only available to the ETCD member processes and the etcd-backup-restore sidecars (e.g. 272e204152:Leader or 272e204153:Member).
When the lease objects are created by etcd-druid, the spec.holderIdentity field would be empty.
The value in spec.holderIdentity in the leases is parsed and copied onto the id and role fields of the corresponding status.members by etcd-druid.
Conditions
The conditions section in the status describe the overall condition of the ETCD cluster.
The condition type Ready indicates if the ETCD cluster as a whole is ready to serve requests (i.e. the cluster is quorate) even though some minority of the members are not ready.
The condition type AllMembersReady indicates of all the members of the ETCD cluster are ready.
The distinction between these conditions could be significant for both external consumers of the status as well as etcd-druid itself.
Some maintenance operations might be safe to do (e.g. rolling updates) only when all members of the cluster are ready.
The condition type BackupReady indicates of the most recent backup upload (full or incremental) succeeded.
This information also might be significant because some maintenance operations might be safe to do (e.g. anything that involves re-bootstrapping the ETCD cluster) only when backup is ready.
The Ready and AllMembersReady conditions can be maintained by etcd-druid based on the status in the members section.
The BackupReady condition will be maintained by the leading etcd-backup-restore sidecar that is in charge of taking backups.
More condition types could be introduced in the future if specific purposes arise.
ClusterSize
The clusterSize field contains the current size of the ETCD cluster. It will be actively kept up-to-date by etcd-druid in all scenarios.
- Before bootstrapping the ETCD cluster (during cluster creation or later bootstrapping because of quorum failure),
etcd-druidwill clear thestatus.membersarray and setstatus.clusterSizeto be equal tospec.replicas. - While the ETCD cluster is quorate,
etcd-druidwill actively setstatus.clusterSizeto be equal to length of thestatus.memberswhenever the length of the array changes (say, due to scaling of the ETCD cluster).
Given that clusterSize reliably represents the size of the ETCD cluster, it can be used to calculate the Ready condition.
Alternative
The alternative is for etcd-druid to maintain the status in the Etcd status sub-resource.
But etcd-druid is centrally deployed in the host Kubernetes cluster and cannot scale well horizontally.
So, it can potentially be a bottleneck if it is involved in regular health check mechanism for all the etcd clusters it manages.
Also, the recommended approach above is more robust because it can work even if etcd-druid is down when the backup upload of a particular etcd cluster fails.
Decision table for etcd-druid based on the status
The following decision table describes the various criteria etcd-druid takes into consideration to determine the different etcd cluster management scenarios and the corresponding reconciliation actions it must take.
The general principle is to detect the scenario and take the minimum action to move the cluster along the path to good health.
The path from any one scenario to a state of good health will typically involve going through multiple reconciliation actions which probably take the cluster through many other cluster management scenarios.
Especially, it is proposed that individual members auto-heal where possible, even in the case of the failure of a majority of members of the etcd cluster and that etcd-druid takes action only if the auto-healing doesn’t happen for a configured period of time.
1. Pink of health
Observed state
- Cluster Size
- Desired:
n - Current:
n
- Desired:
StatefulSetreplicas- Desired:
n - Ready:
n
- Desired:
Etcdstatus- members
- Total:
n - Ready:
n - Members
NotReadyfor long enough to be evicted, i.e.lastTransitionTime > notReadyGracePeriod:0 - Members with readiness status
Unknownlong enough to be consideredNotReady, i.e.lastTransitionTime > unknownGracePeriod:0 - Members with expired
lease:0
- Total:
- conditions:
- Ready:
true - AllMembersReady:
true - BackupReady:
true
- Ready:
- members
Recommended Action
Nothing to do
2. Member status is out of sync with their leases
Observed state
- Cluster Size
- Desired:
n - Current:
n
- Desired:
StatefulSetreplicas- Desired:
n - Ready:
n
- Desired:
Etcdstatus- members
- Total:
n - Ready:
r - Members
NotReadyfor long enough to be evicted, i.e.lastTransitionTime > notReadyGracePeriod:0 - Members with readiness status
Unknownlong enough to be consideredNotReady, i.e.lastTransitionTime > unknownGracePeriod:0 - Members with expired
lease:l
- Total:
- conditions:
- Ready:
true - AllMembersReady:
true - BackupReady:
true
- Ready:
- members
Recommended Action
Mark the l members corresponding to the expired leases as Unknown with reason LeaseExpired and with id populated from spec.holderIdentity of the lease if they are not already updated so.
Mark the n - l members corresponding to the active leases as Ready with reason LeaseSucceeded and with id populated from spec.holderIdentity of the lease if they are not already updated so.
Please refer here for more details.
3. All members are Ready but AllMembersReady condition is stale
Observed state
- Cluster Size
- Desired: N/A
- Current: N/A
StatefulSetreplicas- Desired:
n - Ready: N/A
- Desired:
Etcdstatus- members
- Total:
n - Ready:
n - Members
NotReadyfor long enough to be evicted, i.e.lastTransitionTime > notReadyGracePeriod:0 - Members with readiness status
Unknownlong enough to be consideredNotReady, i.e.lastTransitionTime > unknownGracePeriod:0 - Members with expired
lease:0
- Total:
- conditions:
- Ready: N/A
- AllMembersReady: false
- BackupReady: N/A
- members
Recommended Action
Mark the status condition type AllMembersReady to true.
4. Not all members are Ready but AllMembersReady condition is stale
Observed state
Cluster Size
- Desired: N/A
- Current: N/A
StatefulSetreplicas- Desired:
n - Ready: N/A
- Desired:
Etcdstatus- members
- Total: N/A
- Ready:
rwhere0 <= r < n - Members
NotReadyfor long enough to be evicted, i.e.lastTransitionTime > notReadyGracePeriod:nrwhere0 < nr < n - Members with readiness status
Unknownlong enough to be consideredNotReady, i.e.lastTransitionTime > unknownGracePeriod:uwhere0 < u < n - Members with expired
lease:hwhere0 < h < n
- conditions:
- Ready: N/A
- AllMembersReady: true
- BackupReady: N/A
where
(nr + u + h) > 0orr < n- members
Recommended Action
Mark the status condition type AllMembersReady to false.
5. Majority members are Ready but Ready condition is stale
Observed state
Cluster Size
- Desired: N/A
- Current: N/A
StatefulSetreplicas- Desired:
n - Ready: N/A
- Desired:
Etcdstatus- members
- Total:
n - Ready:
rwherer > n/2 - Members
NotReadyfor long enough to be evicted, i.e.lastTransitionTime > notReadyGracePeriod:nrwhere0 < nr < n/2 - Members with readiness status
Unknownlong enough to be consideredNotReady, i.e.lastTransitionTime > unknownGracePeriod:uwhere0 < u < n/2 - Members with expired
lease: N/A
- Total:
- conditions:
- Ready:
false - AllMembersReady: N/A
- BackupReady: N/A
- Ready:
where
0 < (nr + u + h) < n/2- members
Recommended Action
Mark the status condition type Ready to true.
6. Majority members are NotReady but Ready condition is stale
Observed state
Cluster Size
- Desired: N/A
- Current: N/A
StatefulSetreplicas- Desired:
n - Ready: N/A
- Desired:
Etcdstatus- members
- Total:
n - Ready:
rwhere0 < r < n - Members
NotReadyfor long enough to be evicted, i.e.lastTransitionTime > notReadyGracePeriod:nrwhere0 < nr < n - Members with readiness status
Unknownlong enough to be consideredNotReady, i.e.lastTransitionTime > unknownGracePeriod:uwhere0 < u < n - Members with expired
lease: N/A
- Total:
- conditions:
- Ready:
true - AllMembersReady: N/A
- BackupReady: N/A
- Ready:
where
(nr + u + h) > n/2orr < n/2- members
Recommended Action
Mark the status condition type Ready to false.
7. Some members have been in Unknown status for a while
Observed state
- Cluster Size
- Desired: N/A
- Current:
n
StatefulSetreplicas- Desired: N/A
- Ready: N/A
Etcdstatus- members
- Total: N/A
- Ready: N/A
- Members
NotReadyfor long enough to be evicted, i.e.lastTransitionTime > notReadyGracePeriod: N/A - Members with readiness status
Unknownlong enough to be consideredNotReady, i.e.lastTransitionTime > unknownGracePeriod:uwhereu <= n - Members with expired
lease: N/A
- conditions:
- Ready: N/A
- AllMembersReady: N/A
- BackupReady: N/A
- members
Recommended Action
Mark the u members as NotReady in Etcd status with reason: UnknownGracePeriodExceeded.
8. Some member pods are not Ready but have not had the chance to update their status
Observed state
- Cluster Size
- Desired: N/A
- Current:
n
StatefulSetreplicas- Desired:
n - Ready:
swheres < n
- Desired:
Etcdstatus- members
- Total: N/A
- Ready: N/A
- Members
NotReadyfor long enough to be evicted, i.e.lastTransitionTime > notReadyGracePeriod: N/A - Members with readiness status
Unknownlong enough to be consideredNotReady, i.e.lastTransitionTime > unknownGracePeriod: N/A - Members with expired
lease: N/A
- conditions:
- Ready: N/A
- AllMembersReady: N/A
- BackupReady: N/A
- members
Recommended Action
Mark the n - s members (corresponding to the pods that are not Ready) as NotReady in Etcd status with reason: PodNotReady
9. Quorate cluster with a minority of members NotReady
Observed state
- Cluster Size
- Desired: N/A
- Current:
n
StatefulSetreplicas- Desired: N/A
- Ready: N/A
Etcdstatus- members
- Total:
n - Ready:
n - f - Members
NotReadyfor long enough to be evicted, i.e.lastTransitionTime > notReadyGracePeriod:fwheref < n/2 - Members with readiness status
Unknownlong enough to be consideredNotReady, i.e.lastTransitionTime > unknownGracePeriod:0 - Members with expired
lease: N/A
- Total:
- conditions:
- Ready: true
- AllMembersReady: false
- BackupReady: true
- members
Recommended Action
Delete the f NotReady member pods to force restart of the pods if they do not automatically restart via failed livenessProbe. The expectation is that they will either re-join the cluster as an existing member or remove themselves and join as new members on restart of the container or pod and renew their leases.
10. Quorum lost with a majority of members NotReady
Observed state
- Cluster Size
- Desired: N/A
- Current:
n
StatefulSetreplicas- Desired: N/A
- Ready: N/A
Etcdstatus- members
- Total:
n - Ready:
n - f - Members
NotReadyfor long enough to be evicted, i.e.lastTransitionTime > notReadyGracePeriod:fwheref >= n/2 - Members with readiness status
Unknownlong enough to be consideredNotReady, i.e.lastTransitionTime > unknownGracePeriod: N/A - Members with expired
lease: N/A
- Total:
- conditions:
- Ready: false
- AllMembersReady: false
- BackupReady: true
- members
Recommended Action
Scale down the StatefulSet to replicas: 0. Ensure that all member pods are deleted. Ensure that all the members are removed from Etcd status. Delete and recreate all the member leases. Recover the cluster from loss of quorum as discussed here.
11. Scale up of a healthy cluster
Observed state
- Cluster Size
- Desired:
d - Current:
nwhered > n
- Desired:
StatefulSetreplicas- Desired: N/A
- Ready:
n
Etcdstatus- members
- Total:
n - Ready:
n - Members
NotReadyfor long enough to be evicted, i.e.lastTransitionTime > notReadyGracePeriod: 0 - Members with readiness status
Unknownlong enough to be consideredNotReady, i.e.lastTransitionTime > unknownGracePeriod: 0 - Members with expired
lease: 0
- Total:
- conditions:
- Ready: true
- AllMembersReady: true
- BackupReady: true
- members
Recommended Action
Add d - n new members by scaling the StatefulSet to replicas: d. The rest of the StatefulSet spec need not be updated until the next cluster bootstrapping (alternatively, the rest of the StatefulSet spec can be updated pro-actively once the new members join the cluster. This will trigger a rolling update).
Also, create the additional member leases for the d - n new members.
12. Scale down of a healthy cluster
Observed state
- Cluster Size
- Desired:
d - Current:
nwhered < n
- Desired:
StatefulSetreplicas- Desired:
n - Ready:
n
- Desired:
Etcdstatus- members
- Total:
n - Ready:
n - Members
NotReadyfor long enough to be evicted, i.e.lastTransitionTime > notReadyGracePeriod: 0 - Members with readiness status
Unknownlong enough to be consideredNotReady, i.e.lastTransitionTime > unknownGracePeriod: 0 - Members with expired
lease: 0
- Total:
- conditions:
- Ready: true
- AllMembersReady: true
- BackupReady: true
- members
Recommended Action
Remove d - n existing members (numbered d, d + 1 … n) by scaling the StatefulSet to replicas: d. The StatefulSet spec need not be updated until the next cluster bootstrapping (alternatively, the StatefulSet spec can be updated pro-actively once the superfluous members exit the cluster. This will trigger a rolling update).
Also, delete the member leases for the d - n members being removed.
The superfluous entries in the members array will be cleaned up as explained here.
The superfluous members in the ETCD cluster will be cleaned up by the leading etcd-backup-restore sidecar.
13. Superfluous member entries in Etcd status
Observed state
- Cluster Size
- Desired: N/A
- Current:
n
StatefulSetreplicas- Desired: n
- Ready: n
Etcdstatus- members
- Total:
mwherem > n - Ready: N/A
- Members
NotReadyfor long enough to be evicted, i.e.lastTransitionTime > notReadyGracePeriod: N/A - Members with readiness status
Unknownlong enough to be consideredNotReady, i.e.lastTransitionTime > unknownGracePeriod: N/A - Members with expired
lease: N/A
- Total:
- conditions:
- Ready: N/A
- AllMembersReady: N/A
- BackupReady: N/A
- members
Recommended Action
Remove the superfluous m - n member entries from Etcd status (numbered n, n+1 … m).
Remove the superfluous m - n member leases if they exist.
The superfluous members in the ETCD cluster will be cleaned up by the leading etcd-backup-restore sidecar.
Decision table for etcd-backup-restore during initialization
As discussed above, the initialization sequence of etcd-backup-restore in a member pod needs to generate suitable etcd configuration for its etcd container.
It also might have to handle the etcd database verification and restoration functionality differently in different scenarios.
The initialization sequence itself is proposed to be as follows.
It is an enhancement of the existing initialization sequence.
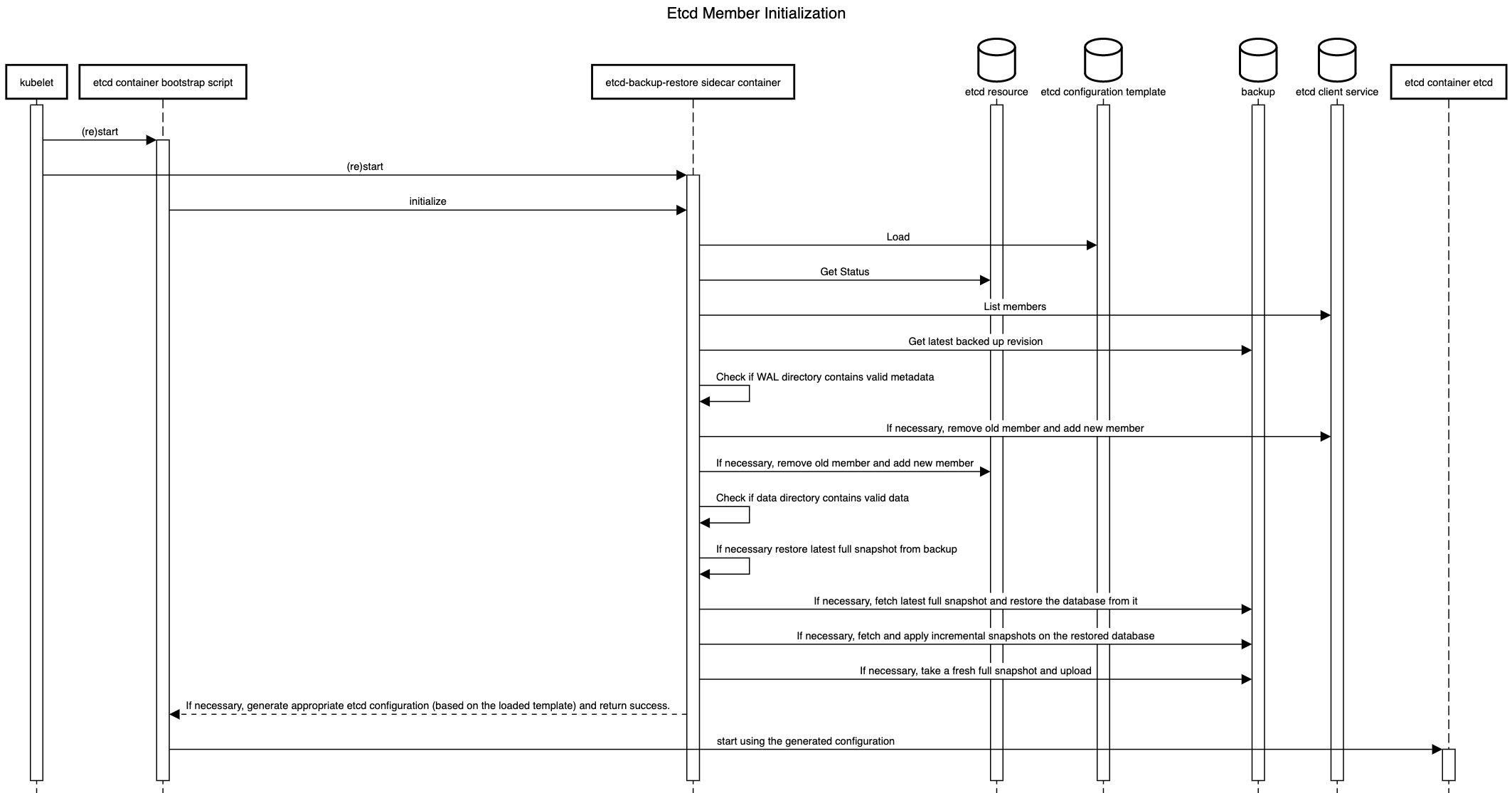
The details of the decisions to be taken during the initialization are given below.
1. First member during bootstrap of a fresh etcd cluster
Observed state
- Cluster Size:
n Etcdstatus members:- Total:
0 - Ready:
0 - Status contains own member:
false
- Total:
- Data persistence
- WAL directory has cluster/ member metadata:
false - Data directory is valid and up-to-date:
false
- WAL directory has cluster/ member metadata:
- Backup
- Backup exists:
false - Backup has incremental snapshots:
false
- Backup exists:
Recommended Action
Generate etcd configuration with n initial cluster peer URLs and initial cluster state new and return success.
2. Addition of a new following member during bootstrap of a fresh etcd cluster
Observed state
- Cluster Size:
n Etcdstatus members:- Total:
mwhere0 < m < n - Ready:
m - Status contains own member:
false
- Total:
- Data persistence
- WAL directory has cluster/ member metadata:
false - Data directory is valid and up-to-date:
false
- WAL directory has cluster/ member metadata:
- Backup
- Backup exists:
false - Backup has incremental snapshots:
false
- Backup exists:
Recommended Action
Generate etcd configuration with n initial cluster peer URLs and initial cluster state new and return success.
3. Restart of an existing member of a quorate cluster with valid metadata and data
Observed state
- Cluster Size:
n Etcdstatus members:- Total:
mwherem > n/2 - Ready:
rwherer > n/2 - Status contains own member:
true
- Total:
- Data persistence
- WAL directory has cluster/ member metadata:
true - Data directory is valid and up-to-date:
true
- WAL directory has cluster/ member metadata:
- Backup
- Backup exists: N/A
- Backup has incremental snapshots: N/A
Recommended Action
Re-use previously generated etcd configuration and return success.
4. Restart of an existing member of a quorate cluster with valid metadata but without valid data
Observed state
- Cluster Size:
n Etcdstatus members:- Total:
mwherem > n/2 - Ready:
rwherer > n/2 - Status contains own member:
true
- Total:
- Data persistence
- WAL directory has cluster/ member metadata:
true - Data directory is valid and up-to-date:
false
- WAL directory has cluster/ member metadata:
- Backup
- Backup exists: N/A
- Backup has incremental snapshots: N/A
Recommended Action
Remove self as a member (old member ID) from the etcd cluster as well as Etcd status. Add self as a new member of the etcd cluster as well as in the Etcd status. If backups do not exist, create an empty data and WAL directory. If backups exist, restore only the latest full snapshot (please see here for the reason for not restoring incremental snapshots). Generate etcd configuration with n initial cluster peer URLs and initial cluster state existing and return success.
5. Restart of an existing member of a quorate cluster without valid metadata
Observed state
- Cluster Size:
n Etcdstatus members:- Total:
mwherem > n/2 - Ready:
rwherer > n/2 - Status contains own member:
true
- Total:
- Data persistence
- WAL directory has cluster/ member metadata:
false - Data directory is valid and up-to-date: N/A
- WAL directory has cluster/ member metadata:
- Backup
- Backup exists: N/A
- Backup has incremental snapshots: N/A
Recommended Action
Remove self as a member (old member ID) from the etcd cluster as well as Etcd status. Add self as a new member of the etcd cluster as well as in the Etcd status. If backups do not exist, create an empty data and WAL directory. If backups exist, restore only the latest full snapshot (please see here for the reason for not restoring incremental snapshots). Generate etcd configuration with n initial cluster peer URLs and initial cluster state existing and return success.
6. Restart of an existing member of a non-quorate cluster with valid metadata and data
Observed state
- Cluster Size:
n Etcdstatus members:- Total:
mwherem < n/2 - Ready:
rwherer < n/2 - Status contains own member:
true
- Total:
- Data persistence
- WAL directory has cluster/ member metadata:
true - Data directory is valid and up-to-date:
true
- WAL directory has cluster/ member metadata:
- Backup
- Backup exists: N/A
- Backup has incremental snapshots: N/A
Recommended Action
Re-use previously generated etcd configuration and return success.
7. Restart of the first member of a non-quorate cluster without valid data
Observed state
- Cluster Size:
n Etcdstatus members:- Total:
0 - Ready:
0 - Status contains own member:
false
- Total:
- Data persistence
- WAL directory has cluster/ member metadata: N/A
- Data directory is valid and up-to-date:
false
- Backup
- Backup exists: N/A
- Backup has incremental snapshots: N/A
Recommended Action
If backups do not exist, create an empty data and WAL directory. If backups exist, restore the latest full snapshot. Start a single-node embedded etcd with initial cluster peer URLs containing only own peer URL and initial cluster state new. If incremental snapshots exist, apply them serially (honouring source transactions). Take and upload a full snapshot after incremental snapshots are applied successfully (please see here for more reasons why). Generate etcd configuration with n initial cluster peer URLs and initial cluster state new and return success.
8. Restart of a following member of a non-quorate cluster without valid data
Observed state
- Cluster Size:
n Etcdstatus members:- Total:
mwhere1 < m < n - Ready:
rwhere1 < r < n - Status contains own member:
false
- Total:
- Data persistence
- WAL directory has cluster/ member metadata: N/A
- Data directory is valid and up-to-date:
false
- Backup
- Backup exists: N/A
- Backup has incremental snapshots: N/A
Recommended Action
If backups do not exist, create an empty data and WAL directory. If backups exist, restore only the latest full snapshot (please see here for the reason for not restoring incremental snapshots). Generate etcd configuration with n initial cluster peer URLs and initial cluster state existing and return success.
Backup
Only one of the etcd-backup-restore sidecars among the members are required to take the backup for a given ETCD cluster. This can be called a backup leader. There are two possibilities to ensure this.
Leading ETCD main container’s sidecar is the backup leader
The backup-restore sidecar could poll the etcd cluster and/or its own etcd main container to see if it is the leading member in the etcd cluster. This information can be used by the backup-restore sidecars to decide that sidecar of the leading etcd main container is the backup leader (i.e. responsible to for taking/uploading backups regularly).
The advantages of this approach are as follows.
- The approach is operationally and conceptually simple. The leading etcd container and backup-restore sidecar are always located in the same pod.
- Network traffic between the backup container and the etcd cluster will always be local.
The disadvantage is that this approach may not age well in the future if we think about moving the backup-restore container as a separate pod rather than a sidecar container.
Independent leader election between backup-restore sidecars
We could use the etcd lease mechanism to perform leader election among the backup-restore sidecars. For example, using something like go.etcd.io/etcd/clientv3/concurrency.
The advantage and disadvantages are pretty much the opposite of the approach above. The advantage being that this approach may age well in the future if we think about moving the backup-restore container as a separate pod rather than a sidecar container.
The disadvantages are as follows.
- The approach is operationally and conceptually a bit complex. The leading etcd container and backup-restore sidecar might potentially belong to different pods.
- Network traffic between the backup container and the etcd cluster might potentially be across nodes.
History Compaction
This proposal recommends to configure automatic history compaction on the individual members.
Defragmentation
Defragmentation is already triggered periodically by etcd-backup-restore.
This proposal recommends to enhance this functionality to be performed only by the leading backup-restore container.
The defragmentation must be performed only when etcd cluster is in full health and must be done in a rolling manner for each members to avoid disruption.
The leading member should be defragmented last after all the rest of the members have been defragmented to minimise potential leadership changes caused by defragmentation.
If the etcd cluster is unhealthy when it is time to trigger scheduled defragmentation, the defragmentation must be postponed until the cluster becomes healthy. This check must be done before triggering defragmentation for each member.
Work-flows in etcd-backup-restore
There are different work-flows in etcd-backup-restore.
Some existing flows like initialization, scheduled backups and defragmentation have been enhanced or modified.
Some new work-flows like status updates have been introduced.
Some of these work-flows are sensitive to which etcd-backup-restore container is leading and some are not.
The life-cycle of these work-flows is shown below.
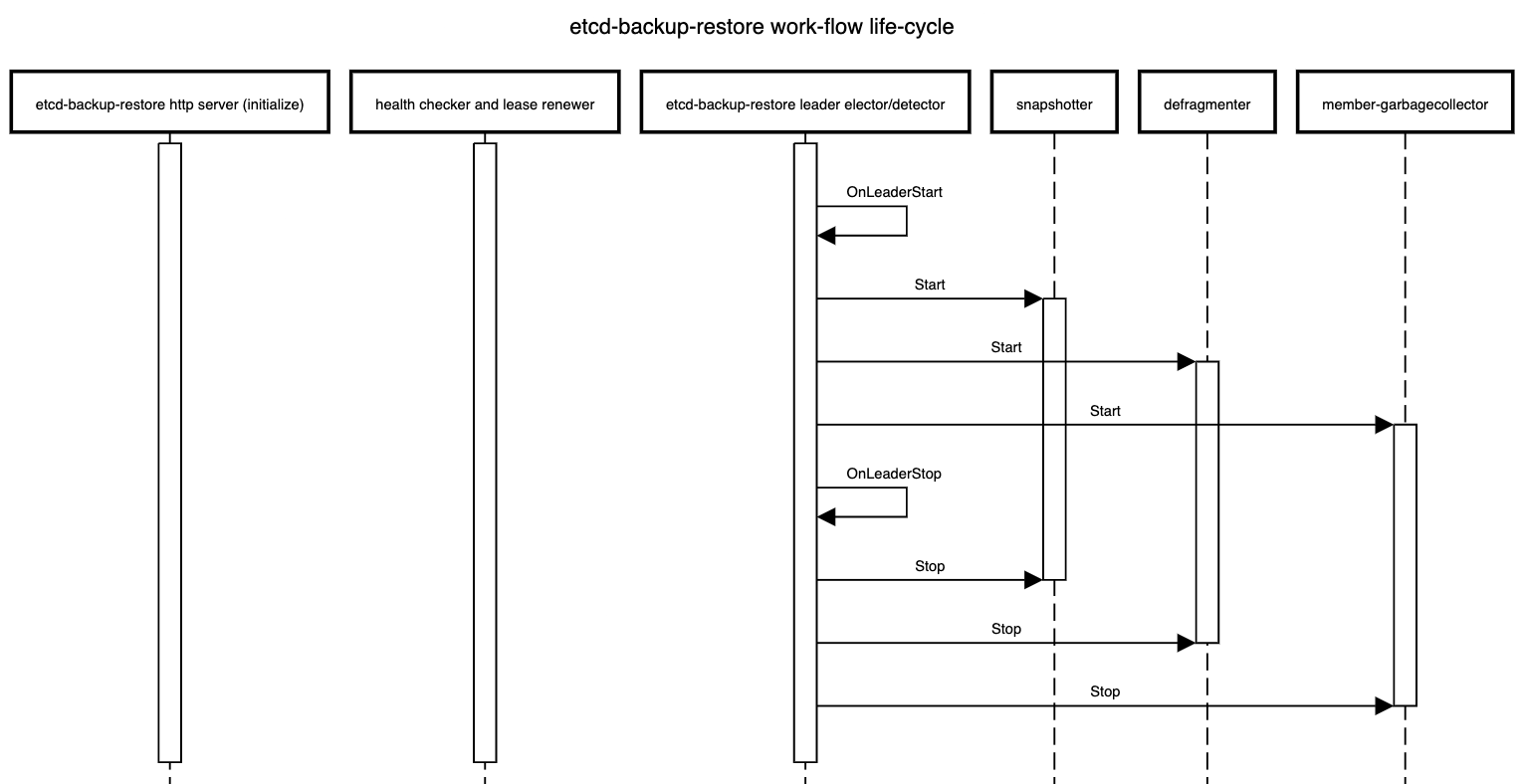
Work-flows independent of leader election in all members
- Serve the HTTP API that all members are expected to support currently but some HTTP API call which are used to take out-of-sync delta or full snapshot should delegate the incoming HTTP requests to the
leading-sidecarand one of the possible approach to achieve this is via an HTTP reverse proxy. - Check the health of the respective etcd member and renew the corresponding member
lease.
Work-flows only on the leading member
- Take backups (full and incremental) at configured regular intervals
- Defragment all the members sequentially at configured regular intervals
- Cleanup superflous members from the ETCD cluster for which there is no corresponding pod (the ordinal in the pod name is greater than the cluster size) at regular intervals (or whenever the
Etcdresource status changes by watching it)- The cleanup of superfluous entries in
status.membersarray is already covered here
- The cleanup of superfluous entries in
High Availability
Considering that high-availability is the primary reason for using a multi-node etcd cluster, it makes sense to distribute the individual member pods of the etcd cluster across different physical nodes. If the underlying Kubernetes cluster has nodes from multiple availability zones, it makes sense to also distribute the member pods across nodes from different availability zones.
One possibility to do this is via SelectorSpreadPriority of kube-scheduler but this is only best-effort and may not always be enforced strictly.
It is better to use pod anti-affinity to enforce such distribution of member pods.
Zonal Cluster - Single Availability Zone
A zonal cluster is configured to consist of nodes belonging to only a single availability zone in a region of the cloud provider. In such a case, we can at best distribute the member pods of a multi-node etcd cluster instance only across different nodes in the configured availability zone.
This can be done by specifying pod anti-affinity in the specification of the member pods using kubernetes.io/hostname as the topology key.
apiVersion: apps/v1
kind: StatefulSet
...
spec:
...
template:
...
spec:
...
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector: {} # podSelector that matches the member pods of the given etcd cluster instance
topologyKey: "kubernetes.io/hostname"
...
...
...
The recommendation is to keep etcd-druid agnostic of such topics related scheduling and cluster-topology and to use kupid to orthogonally inject the desired pod anti-affinity.
Alternative
Another option is to build the functionality into etcd-druid to include the required pod anti-affinity when it provisions the StatefulSet that manages the member pods.
While this has the advantage of avoiding a dependency on an external component like kupid, the disadvantage is that we might need to address development or testing use-cases where it might be desirable to avoid distributing member pods and schedule them on as less number of nodes as possible.
Also, as mentioned below, kupid can be used to distribute member pods of an etcd cluster instance across nodes in a single availability zone as well as across nodes in multiple availability zones with very minor variation.
This keeps the solution uniform regardless of the topology of the underlying Kubernetes cluster.
Regional Cluster - Multiple Availability Zones
A regional cluster is configured to consist of nodes belonging to multiple availability zones (typically, three) in a region of the cloud provider. In such a case, we can distribute the member pods of a multi-node etcd cluster instance across nodes belonging to different availability zones.
This can be done by specifying pod anti-affinity in the specification of the member pods using topology.kubernetes.io/zone as the topology key.
In Kubernetes clusters using Kubernetes release older than 1.17, the older (and now deprecated) failure-domain.beta.kubernetes.io/zone might have to be used as the topology key.
apiVersion: apps/v1
kind: StatefulSet
...
spec:
...
template:
...
spec:
...
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector: {} # podSelector that matches the member pods of the given etcd cluster instance
topologyKey: "topology.kubernetes.io/zone
...
...
...
The recommendation is to keep etcd-druid agnostic of such topics related scheduling and cluster-topology and to use kupid to orthogonally inject the desired pod anti-affinity.
Alternative
Another option is to build the functionality into etcd-druid to include the required pod anti-affinity when it provisions the StatefulSet that manages the member pods.
While this has the advantage of avoiding a dependency on an external component like kupid, the disadvantage is that such built-in support necessarily limits what kind of topologies of the underlying cluster will be supported.
Hence, it is better to keep etcd-druid altogether agnostic of issues related to scheduling and cluster-topology.
PodDisruptionBudget
This proposal recommends that etcd-druid should deploy PodDisruptionBudget (minAvailable set to floor(<cluster size>/2) + 1) for multi-node etcd clusters (if AllMembersReady condition is true) to ensure that any planned disruptive operation can try and honour the disruption budget to ensure high availability of the etcd cluster while making potentially disrupting maintenance operations.
Also, it is recommended to toggle the minAvailable field between floor(<cluster size>/2) and <number of members with status Ready true> whenever the AllMembersReady condition toggles between true and false.
This is to disable eviction of any member pods when not all members are Ready.
In case of a conflict, the recommendation is to use the highest of the applicable values for minAvailable.
Rolling updates to etcd members
Any changes to the Etcd resource spec that might result in a change to StatefulSet spec or otherwise result in a rolling update of member pods should be applied/propagated by etcd-druid only when the etcd cluster is fully healthy to reduce the risk of quorum loss during the updates.
This would include vertical autoscaling changes (via, HVPA).
If the cluster status unhealthy (i.e. if either AllMembersReady or BackupReady conditions are false), etcd-druid must restore it to full health before proceeding with such operations that lead to rolling updates.
This can be further optimized in the future to handle the cases where rolling updates can still be performed on an etcd cluster that is not fully healthy.
Follow Up
Ephemeral Volumes
See section Ephemeral Volumes.
Shoot Control-Plane Migration
This proposal adds support for multi-node etcd clusters but it should not have significant impact on shoot control-plane migration any more than what already present in the single-node etcd cluster scenario. But to be sure, this needs to be discussed further.
Performance impact of multi-node etcd clusters
Multi-node etcd clusters incur a cost on write performance as compared to single-node etcd clusters. This performance impact needs to be measured and documented. Here, we should compare different persistence option for the multi-nodeetcd clusters so that we have all the information necessary to take the decision balancing the high-availability, performance and costs.
Metrics, Dashboards and Alerts
There are already metrics exported by etcd and etcd-backup-restore which are visualized in monitoring dashboards and also used in triggering alerts.
These might have hidden assumptions about single-node etcd clusters.
These might need to be enhanced and potentially new metrics, dashboards and alerts configured to cover the multi-node etcd cluster scenario.
Especially, a high priority alert must be raised if BackupReady condition becomes false.
Costs
Multi-node etcd clusters will clearly involve higher cost (when compared with single-node etcd clusters) just going by the CPU and memory usage for the additional members. Also, the different options for persistence for etcd data for the members will have different cost implications. Such cost impact needs to be assessed and documented to help navigate the trade offs between high availability, performance and costs.
Future Work
Gardener Ring
Gardener Ring, requires provisioning and management of an etcd cluster with the members distributed across more than one Kubernetes cluster. This cannot be achieved by etcd-druid alone which has only the view of a single Kubernetes cluster. An additional component that has the view of all the Kubernetes clusters involved in setting up the gardener ring will be required to achieve this. However, etcd-druid can be used by such a higher-level component/controller (for example, by supplying the initial cluster configuration) such that individual etcd-druid instances in the individual Kubernetes clusters can manage the corresponding etcd cluster members.
Autonomous Shoot Clusters
Autonomous Shoot Clusters also will require a highly availble etcd cluster to back its control-plane and the multi-node support proposed here can be leveraged in that context. However, the current proposal will not meet all the needs of a autonomous shoot cluster. Some additional components will be required that have the overall view of the autonomous shoot cluster and they can use etcd-druid to manage the multi-node etcd cluster. But this scenario may be different from that of Gardener Ring in that the individual etcd members of the cluster may not be hosted on different Kubernetes clusters.
Optimization of recovery from non-quorate cluster with some member containing valid data
It might be possible to optimize the actions during the recovery of a non-quorate cluster where some of the members contain valid data and some other don’t. The optimization involves verifying the data of the valid members to determine the data of which member is the most recent (even considering the latest backup) so that the full snapshot can be taken from it before recovering the etcd cluster. Such an optimization can be attempted in the future.
Optimization of rolling updates to unhealthy etcd clusters
As mentioned above, optimizations to proceed with rolling updates to unhealthy etcd clusters (without first restoring the cluster to full health) can be pursued in future work.
2.2 - 02 Snapshot Compaction
DEP-02: Snapshot Compaction for Etcd
Current Problem
To ensure recoverability of Etcd, backups of the database are taken at regular interval. Backups are of two types: Full Snapshots and Incremental Snapshots.
Full Snapshots
Full snapshot is a snapshot of the complete database at given point in time.The size of the database keeps changing with time and typically the size is relatively large (measured in 100s of megabytes or even in gigabytes. For this reason, full snapshots are taken after some large intervals.
Incremental Snapshots
Incremental Snapshots are collection of events on Etcd database, obtained through running WATCH API Call on Etcd. After some short intervals, all the events that are accumulated through WATCH API Call are saved in a file and named as Incremental Snapshots at relatively short time intervals.
Recovery from the Snapshots
Recovery from Full Snapshots
As the full snapshots are snapshots of the complete database, the whole database can be recovered from a full snapshot in one go. Etcd provides API Call to restore the database from a full snapshot file.
Recovery from Incremental Snapshots
Delta snapshots are collection of retrospective Etcd events. So, to restore from Incremental snapshot file, the events from the file are needed to be applied sequentially on Etcd database through Etcd Put/Delete API calls. As it is heavily dependent on Etcd calls sequentially, restoring from Incremental Snapshot files can take long if there are numerous commands captured in Incremental Snapshot files.
Delta snapshots are applied on top of running Etcd database. So, if there is inconsistency between the state of database at the point of applying and the state of the database when the delta snapshot commands were captured, restoration will fail.
Currently, in Gardener setup, Etcd is restored from the last full snapshot and then the delta snapshots, which were captured after the last full snapshot.
The main problem with this is that the complete restoration time can be unacceptably large if the rate of change coming into the etcd database is quite high because there are large number of events in the delta snapshots to be applied sequentially. A secondary problem is that, though auto-compaction is enabled for etcd, it is not quick enough to compact all the changes from the incremental snapshots being re-applied during the relatively short period of time of restoration (as compared to the actual period of time when the incremental snapshots were accumulated). This may lead to the etcd pod (the backup-restore sidecar container, to be precise) to run out of memory and/or storage space even if it is sufficient for normal operations.
Solution
Compaction command
To help with the problem mentioned earlier, our proposal is to introduce compact subcommand with etcdbrctl. On execution of compact command, A separate embedded Etcd process will be started where the Etcd data will be restored from the snapstore (exactly as in the restoration scenario today). Then the new Etcd database will be compacted and defragmented using Etcd API calls. The compaction will strip off the Etcd database of old revisions as per the Etcd auto-compaction configuration. The defragmentation will free up the unused fragment memory space released after compaction. Then a full snapshot of the compacted database will be saved in snapstore which then can be used as the base snapshot during any subsequent restoration (or backup compaction).
How the solution works
The newly introduced compact command does not disturb the running Etcd while compacting the backup snapshots. The command is designed to run potentially separately (from the main Etcd process/container/pod). Etcd Druid can be configured to run the newly introduced compact command as a separate job (scheduled periodically) based on total number of Etcd events accumulated after the most recent full snapshot.
Etcd-druid flags:
Etcd-druid introduces the following flags to configure the compaction job:
--enable-backup-compaction(defaultfalse): Set this flag totrueto enable the automatic compaction of etcd backups when the threshold value denoted by CLI flag--etcd-events-thresholdis exceeded.--compaction-workers(default3): Number of worker threads of the CompactionJob controller. The controller creates a backup compaction job if a certain etcd event threshold is reached. If compaction is enabled, the value for this flag must be greater than zero.--etcd-events-threshold(default1000000): Total number of etcd events that can be allowed before a backup compaction job is triggered.--active-deadline-duration(default3h): Duration after which a running backup compaction job will be terminated.--metrics-scrape-wait-duration(default0s): Duration to wait for after compaction job is completed, to allow Prometheus metrics to be scraped.
Points to take care while saving the compacted snapshot:
As compacted snapshot and the existing periodic full snapshots are taken by different processes running in different pods but accessing same store to save the snapshots, some problems may arise:
- When uploading the compacted snapshot to the snapstore, there is the problem of how does the restorer know when to start using the newly compacted snapshot. This communication needs to be atomic.
- With a regular schedule for compaction that happens potentially separately from the main etcd pod, is there a need for regular scheduled full snapshots anymore?
- We are planning to introduce new directory structure, under v2 prefix, for saving the snapshots (compacted and full), as mentioned in details below. But for backward compatibility, we also need to consider the older directory, which is currently under v1 prefix, during accessing snapshots.
How to swap full snapshot with compacted snapshot atomically
Currently, full snapshots and the subsequent delta snapshots are grouped under same prefix path in the snapstore. When a full snapshot is created, it is placed under a prefix/directory with the name comprising of timestamp. Then subsequent delta snapshots are also pushed into the same directory. Thus each prefix/directory contains a single full snapshot and the subsequent delta snapshots. So far, it is the job of ETCDBR to start main Etcd process and snapshotter process which takes full snapshot and delta snapshot periodically. But as per our proposal, compaction will be running as parallel process to main Etcd process and snapshotter process. So we can’t reliably co-ordinate between the processes to achieve switching to the compacted snapshot as the base snapshot atomically.
Current Directory Structure
- Backup-192345
- Full-Snapshot-0-1-192345
- Incremental-Snapshot-1-100-192355
- Incremental-Snapshot-100-200-192365
- Incremental-Snapshot-200-300-192375
- Backup-192789
- Full-Snapshot-0-300-192789
- Incremental-Snapshot-300-400-192799
- Incremental-Snapshot-400-500-192809
- Incremental-Snapshot-500-600-192819
To solve the problem, proposal is:
- ETCDBR will take the first full snapshot after it starts main Etcd Process and snapshotter process. After taking the first full snapshot, snapshotter will continue taking full snapshots. On the other hand, ETCDBR compactor command will be run as periodic job in a separate pod and use the existing full or compacted snapshots to produce further compacted snapshots. Full snapshots and compacted snapshots will be named after same fashion. So, there is no need of any mechanism to choose which snapshots(among full and compacted snapshot) to consider as base snapshots.
- Flatten the directory structure of backup folder. Save all the full snapshots, delta snapshots and compacted snapshots under same directory/prefix. Restorer will restore from full/compacted snapshots and delta snapshots sorted based on the revision numbers in name (or timestamp if the revision numbers are equal).
Proposed Directory Structure
Backup :
- Full-Snapshot-0-1-192355 (Taken by snapshotter)
- Incremental-Snapshot-revision-1-100-192365
- Incremental-Snapshot-revision-100-200-192375
- Full-Snapshot-revision-0-200-192379 (Taken by snapshotter)
- Incremental-Snapshot-revision-200-300-192385
- Full-Snapshot-revision-0-300-192386 (Taken by compaction job)
- Incremental-Snapshot-revision-300-400-192396
- Incremental-Snapshot-revision-400-500-192406
- Incremental-Snapshot-revision-500-600-192416
- Full-Snapshot-revision-0-600-192419 (Taken by snapshotter)
- Full-Snapshot-revision-0-600-192420 (Taken by compaction job)
What happens to the delta snapshots that were compacted?
The proposed compaction sub-command in etcdbrctl (and hence, the CronJob provisioned by etcd-druid that will schedule it at a regular interval) would only upload the compacted full snapshot.
It will not delete the snapshots (delta or full snapshots) that were compacted.
These snapshots which were superseded by a freshly uploaded compacted snapshot would follow the same life-cycle as other older snapshots.
I.e. they will be garbage collected according to the configured backup snapshot retention policy.
For example, if an exponential retention policy is configured and if compaction is done every 30m then there might be at most 48 additional (compacted) full snapshots (24h * 2) in the backup for the latest day. As time rolls forward to the next day, these additional compacted snapshots (along with the delta snapshots that were compacted into them) will get garbage collected retaining only one full snapshot for the day before according to the retention policy.
Future work
In the future, we have plan to stop the snapshotter just after taking the first full snapshot. Then, the compaction job will be solely responsible for taking subsequent full snapshots. The directory structure would be looking like following:
Backup :
- Full-Snapshot-0-1-192355 (Taken by snapshotter)
- Incremental-Snapshot-revision-1-100-192365
- Incremental-Snapshot-revision-100-200-192375
- Incremental-Snapshot-revision-200-300-192385
- Full-Snapshot-revision-0-300-192386 (Taken by compaction job)
- Incremental-Snapshot-revision-300-400-192396
- Incremental-Snapshot-revision-400-500-192406
- Incremental-Snapshot-revision-500-600-192416
- Full-Snapshot-revision-0-600-192420 (Taken by compaction job)
Backward Compatibility
- Restoration : The changes to handle the newly proposed backup directory structure must be backward compatible with older structures at least for restoration because we need have to restore from backups in the older structure. This includes the support for restoring from a backup without a metadata file if that is used in the actual implementation.
- Backup : For new snapshots (even on a backup containing the older structure), the new structure may be used. The new structure must be setup automatically including creating the base full snapshot.
- Garbage collection : The existing functionality of garbage collection of snapshots (full and incremental) according to the backup retention policy must be compatible with both old and new backup folder structure. I.e. the snapshots in the older backup structure must be retained in their own structure and the snapshots in the proposed backup structure should be retained in the proposed structure. Once all the snapshots in the older backup structure go out of the retention policy and are garbage collected, we can think of removing the support for older backup folder structure.
Note: Compactor will run parallel to current snapshotter process and work only if there is any full snapshot already present in the store. By current design, a full snapshot will be taken if there is already no full snapshot or the existing full snapshot is older than 24 hours. It is not limitation but a design choice. As per proposed design, the backup storage will contain both periodic full snapshots as well as periodic compacted snapshot. Restorer will pickup the base snapshot whichever is latest one.
2.3 - 03 Scaling Up An Etcd Cluster
DEP-03: Scaling-up a single-node to multi-node etcd cluster deployed by etcd-druid
To mark a cluster for scale-up from single node to multi-node etcd, just patch the etcd custom resource’s .spec.replicas from 1 to 3 (for example).
Challenges for scale-up
- Etcd cluster with single replica don’t have any peers, so no peer communication is required hence peer URL may or may not be TLS enabled. However, while scaling up from single node etcd to multi-node etcd, there will be a requirement to have peer communication between members of the etcd cluster. Peer communication is required for various reasons, for instance for members to sync up cluster state, data, and to perform leader election or any cluster wide operation like removal or addition of a member etc. Hence in a multi-node etcd cluster we need to have TLS enable peer URL for peer communication.
- Providing the correct configuration to start new etcd members as it is different from boostrapping a cluster since these new etcd members will join an existing cluster.
Approach
We first went through the etcd doc of update-advertise-peer-urls to find out information regarding peer URL updation. Interestingly, etcd doc has mentioned the following:
To update the advertise peer URLs of a member, first update it explicitly via member command and then restart the member.
But we can’t assume peer URL is not TLS enabled for single-node cluster as it depends on end-user. A user may or may not enable the TLS for peer URL for a single node etcd cluster. So, How do we detect whether peer URL was enabled or not when cluster is marked for scale-up?
Detecting if peerURL TLS is enabled or not
For this we use an annotation in member lease object member.etcd.gardener.cloud/tls-enabled set by backup-restore sidecar of etcd. As etcd configuration is provided by backup-restore, so it can find out whether TLS is enabled or not and accordingly set this annotation member.etcd.gardener.cloud/tls-enabled to either true or false in member lease object.
And with the help of this annotation and config-map values etcd-druid is able to detect whether there is a change in a peer URL or not.
Etcd-Druid helps in scaling up etcd cluster
Now, it is detected whether peer URL was TLS enabled or not for single node etcd cluster. Etcd-druid can now use this information to take action:
- If peer URL was already TLS enabled then no action is required from etcd-druid side. Etcd-druid can proceed with scaling up the cluster.
- If peer URL was not TLS enabled then etcd-druid has to intervene and make sure peer URL should be TLS enabled first for the single node before marking the cluster for scale-up.
Action taken by etcd-druid to enable the peerURL TLS
- Etcd-druid will update the
{etcd.Name}-configconfig-map with new config like initial-cluster,initial-advertise-peer-urls etc. Backup-restore will detect this change and update the member lease annotation tomember.etcd.gardener.cloud/tls-enabled: "true". - In case the peer URL TLS has been changed to
enabled: Etcd-druid will add tasks to the deployment flow:- Check if peer TLS has been enabled for existing StatefulSet pods, by checking the member leases for the annotation
member.etcd.gardener.cloud/tls-enabled. - If peer TLS enablement is pending for any of the members, then check and patch the StatefulSet with the peer TLS volume mounts, if not already patched. This will cause a rolling update of the existing StatefulSet pods, which allows etcd-backup-restore to update the member peer URL in the etcd cluster.
- Requeue this reconciliation flow until peer TLS has been enabled for all the existing etcd members.
- Check if peer TLS has been enabled for existing StatefulSet pods, by checking the member leases for the annotation
After PeerURL is TLS enabled
After peer URL TLS enablement for single node etcd cluster, now etcd-druid adds a scale-up annotation: gardener.cloud/scaled-to-multi-node to the etcd statefulset and etcd-druid will patch the statefulsets .spec.replicas to 3(for example). The statefulset controller will then bring up new pods(etcd with backup-restore as a sidecar). Now etcd’s sidecar i.e backup-restore will check whether this member is already a part of a cluster or not and incase it is unable to check (may be due to some network issues) then backup-restore checks presence of this annotation: gardener.cloud/scaled-to-multi-node in etcd statefulset to detect scale-up. If it finds out it is the scale-up case then backup-restore adds new etcd member as a learner first and then starts the etcd learner by providing the correct configuration. Once learner gets in sync with the etcd cluster leader, it will get promoted to a voting member.
Providing the correct etcd config
As backup-restore detects that it’s a scale-up scenario, backup-restore sets initial-cluster-state to existing as this member will join an existing cluster and it calculates the rest of the config from the updated config-map provided by etcd-druid.

Future improvements:
The need of restarting etcd pods twice will change in the future. please refer: https://github.com/gardener/etcd-backup-restore/issues/538
2.4 - Add New Etcd Cluster Component
Add A New Etcd Cluster Component
etcd-druid defines an Operator which is responsible for creation, deletion and update of a resource that is created for an Etcd cluster. If you want to introduce a new resource for an Etcd cluster then you must do the following:
Add a dedicated
packagefor the resource under component.Implement
Operatorinterface.Define a new Kind for this resource in the operator Registry.
Every resource a.k.a
Componentneeds to have the following set of default labels:app.kubernetes.io/name- value of this label is the name of this component. Helper functions are defined here to create the name of each component using the parentEtcdresource. Please define a new helper function to generate the name of your resource using the parentEtcdresource.app.kubernetes.io/component- value of this label is the type of the component. All component type label values are defined here where you can add an entry for your component.- In addition to the above component specific labels, each resource/component should have default labels defined on the
Etcdresource. You can use GetDefaultLabels function.
These labels are also part of recommended labels by kubernetes. NOTE: Constants for the label keys are already defined here.
Ensure that there is no
waitintroduced in anyOperatormethod implementation in your component. In case there are multiple steps to be executed in a sequence then re-queue the event with a special error code in case there is an error or if the pre-conditions check to execute the next step are not yet satisfied.All errors should be wrapped with a custom DruidError.
2.5 - API Reference
Packages:
druid.gardener.cloud/v1alpha1
Package v1alpha1 is the v1alpha1 version of the etcd-druid API.
Resource Types:BackupSpec
(Appears on: EtcdSpec)
BackupSpec defines parameters associated with the full and delta snapshots of etcd.
| Field | Description |
|---|---|
portint32 | (Optional) Port define the port on which etcd-backup-restore server will be exposed. |
tlsTLSConfig | (Optional) |
imagestring | (Optional) Image defines the etcd container image and tag |
storeStoreSpec | (Optional) Store defines the specification of object store provider for storing backups. |
resourcesKubernetes core/v1.ResourceRequirements | (Optional) Resources defines compute Resources required by backup-restore container. More info: https://kubernetes.io/docs/concepts/configuration/manage-compute-resources-container/ |
compactionResourcesKubernetes core/v1.ResourceRequirements | (Optional) CompactionResources defines compute Resources required by compaction job. More info: https://kubernetes.io/docs/concepts/configuration/manage-compute-resources-container/ |
fullSnapshotSchedulestring | (Optional) FullSnapshotSchedule defines the cron standard schedule for full snapshots. |
garbageCollectionPolicyGarbageCollectionPolicy | (Optional) GarbageCollectionPolicy defines the policy for garbage collecting old backups |
garbageCollectionPeriodKubernetes meta/v1.Duration | (Optional) GarbageCollectionPeriod defines the period for garbage collecting old backups |
deltaSnapshotPeriodKubernetes meta/v1.Duration | (Optional) DeltaSnapshotPeriod defines the period after which delta snapshots will be taken |
deltaSnapshotMemoryLimitk8s.io/apimachinery/pkg/api/resource.Quantity | (Optional) DeltaSnapshotMemoryLimit defines the memory limit after which delta snapshots will be taken |
compressionCompressionSpec | (Optional) SnapshotCompression defines the specification for compression of Snapshots. |
enableProfilingbool | (Optional) EnableProfiling defines if profiling should be enabled for the etcd-backup-restore-sidecar |
etcdSnapshotTimeoutKubernetes meta/v1.Duration | (Optional) EtcdSnapshotTimeout defines the timeout duration for etcd FullSnapshot operation |
leaderElectionLeaderElectionSpec | (Optional) LeaderElection defines parameters related to the LeaderElection configuration. |
ClientService
(Appears on: EtcdConfig)
ClientService defines the parameters of the client service that a user can specify
| Field | Description |
|---|---|
annotationsmap[string]string | (Optional) Annotations specify the annotations that should be added to the client service |
labelsmap[string]string | (Optional) Labels specify the labels that should be added to the client service |
CompactionMode
(string alias)
(Appears on: SharedConfig)
CompactionMode defines the auto-compaction-mode: ‘periodic’ or ‘revision’. ‘periodic’ for duration based retention and ‘revision’ for revision number based retention.
CompressionPolicy
(string alias)
(Appears on: CompressionSpec)
CompressionPolicy defines the type of policy for compression of snapshots.
CompressionSpec
(Appears on: BackupSpec)
CompressionSpec defines parameters related to compression of Snapshots(full as well as delta).
| Field | Description |
|---|---|
enabledbool | (Optional) |
policyCompressionPolicy | (Optional) |
Condition
(Appears on: EtcdCopyBackupsTaskStatus, EtcdStatus)
Condition holds the information about the state of a resource.
| Field | Description |
|---|---|
typeConditionType | Type of the Etcd condition. |
statusConditionStatus | Status of the condition, one of True, False, Unknown. |
lastTransitionTimeKubernetes meta/v1.Time | Last time the condition transitioned from one status to another. |
lastUpdateTimeKubernetes meta/v1.Time | Last time the condition was updated. |
reasonstring | The reason for the condition’s last transition. |
messagestring | A human-readable message indicating details about the transition. |
ConditionStatus
(string alias)
(Appears on: Condition)
ConditionStatus is the status of a condition.
ConditionType
(string alias)
(Appears on: Condition)
ConditionType is the type of condition.
CrossVersionObjectReference
(Appears on: EtcdStatus)
CrossVersionObjectReference contains enough information to let you identify the referred resource.
| Field | Description |
|---|---|
kindstring | Kind of the referent |
namestring | Name of the referent |
apiVersionstring | (Optional) API version of the referent |
Etcd
Etcd is the Schema for the etcds API
| Field | Description | ||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
metadataKubernetes meta/v1.ObjectMeta | Refer to the Kubernetes API documentation for the fields of the
metadata field. | ||||||||||||||||||||||||
specEtcdSpec |
| ||||||||||||||||||||||||
statusEtcdStatus |
EtcdConfig
(Appears on: EtcdSpec)
EtcdConfig defines parameters associated etcd deployed
| Field | Description |
|---|---|
quotak8s.io/apimachinery/pkg/api/resource.Quantity | (Optional) Quota defines the etcd DB quota. |
defragmentationSchedulestring | (Optional) DefragmentationSchedule defines the cron standard schedule for defragmentation of etcd. |
serverPortint32 | (Optional) |
clientPortint32 | (Optional) |
imagestring | (Optional) Image defines the etcd container image and tag |
authSecretRefKubernetes core/v1.SecretReference | (Optional) |
metricsMetricsLevel | (Optional) Metrics defines the level of detail for exported metrics of etcd, specify ‘extensive’ to include histogram metrics. |
resourcesKubernetes core/v1.ResourceRequirements | (Optional) Resources defines the compute Resources required by etcd container. More info: https://kubernetes.io/docs/concepts/configuration/manage-compute-resources-container/ |
clientUrlTlsTLSConfig | (Optional) ClientUrlTLS contains the ca, server TLS and client TLS secrets for client communication to ETCD cluster |
peerUrlTlsTLSConfig | (Optional) PeerUrlTLS contains the ca and server TLS secrets for peer communication within ETCD cluster Currently, PeerUrlTLS does not require client TLS secrets for gardener implementation of ETCD cluster. |
etcdDefragTimeoutKubernetes meta/v1.Duration | (Optional) EtcdDefragTimeout defines the timeout duration for etcd defrag call |
heartbeatDurationKubernetes meta/v1.Duration | (Optional) HeartbeatDuration defines the duration for members to send heartbeats. The default value is 10s. |
clientServiceClientService | (Optional) ClientService defines the parameters of the client service that a user can specify |
EtcdCopyBackupsTask
EtcdCopyBackupsTask is a task for copying etcd backups from a source to a target store.
| Field | Description | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
metadataKubernetes meta/v1.ObjectMeta | Refer to the Kubernetes API documentation for the fields of the
metadata field. | ||||||||||
specEtcdCopyBackupsTaskSpec |
| ||||||||||
statusEtcdCopyBackupsTaskStatus |
EtcdCopyBackupsTaskSpec
(Appears on: EtcdCopyBackupsTask)
EtcdCopyBackupsTaskSpec defines the parameters for the copy backups task.
| Field | Description |
|---|---|
sourceStoreStoreSpec | SourceStore defines the specification of the source object store provider for storing backups. |
targetStoreStoreSpec | TargetStore defines the specification of the target object store provider for storing backups. |
maxBackupAgeuint32 | (Optional) MaxBackupAge is the maximum age in days that a backup must have in order to be copied. By default all backups will be copied. |
maxBackupsuint32 | (Optional) MaxBackups is the maximum number of backups that will be copied starting with the most recent ones. |
waitForFinalSnapshotWaitForFinalSnapshotSpec | (Optional) WaitForFinalSnapshot defines the parameters for waiting for a final full snapshot before copying backups. |
EtcdCopyBackupsTaskStatus
(Appears on: EtcdCopyBackupsTask)
EtcdCopyBackupsTaskStatus defines the observed state of the copy backups task.
| Field | Description |
|---|---|
conditions[]Condition | (Optional) Conditions represents the latest available observations of an object’s current state. |
observedGenerationint64 | (Optional) ObservedGeneration is the most recent generation observed for this resource. |
lastErrorstring | (Optional) LastError represents the last occurred error. |
EtcdMemberConditionStatus
(string alias)
(Appears on: EtcdMemberStatus)
EtcdMemberConditionStatus is the status of an etcd cluster member.
EtcdMemberStatus
(Appears on: EtcdStatus)
EtcdMemberStatus holds information about a etcd cluster membership.
| Field | Description |
|---|---|
namestring | Name is the name of the etcd member. It is the name of the backing |
idstring | (Optional) ID is the ID of the etcd member. |
roleEtcdRole | (Optional) Role is the role in the etcd cluster, either |
statusEtcdMemberConditionStatus | Status of the condition, one of True, False, Unknown. |
reasonstring | The reason for the condition’s last transition. |
lastTransitionTimeKubernetes meta/v1.Time | LastTransitionTime is the last time the condition’s status changed. |
EtcdRole
(string alias)
(Appears on: EtcdMemberStatus)
EtcdRole is the role of an etcd cluster member.
EtcdSpec
(Appears on: Etcd)
EtcdSpec defines the desired state of Etcd
| Field | Description |
|---|---|
selectorKubernetes meta/v1.LabelSelector | selector is a label query over pods that should match the replica count. It must match the pod template’s labels. More info: https://kubernetes.io/docs/concepts/overview/working-with-objects/labels/#label-selectors |
labelsmap[string]string | |
annotationsmap[string]string | (Optional) |
etcdEtcdConfig | |
backupBackupSpec | |
sharedConfigSharedConfig | (Optional) |
schedulingConstraintsSchedulingConstraints | (Optional) |
replicasint32 | |
priorityClassNamestring | (Optional) PriorityClassName is the name of a priority class that shall be used for the etcd pods. |
storageClassstring | (Optional) StorageClass defines the name of the StorageClass required by the claim. More info: https://kubernetes.io/docs/concepts/storage/persistent-volumes#class-1 |
storageCapacityk8s.io/apimachinery/pkg/api/resource.Quantity | (Optional) StorageCapacity defines the size of persistent volume. |
volumeClaimTemplatestring | (Optional) VolumeClaimTemplate defines the volume claim template to be created |
EtcdStatus
(Appears on: Etcd)
EtcdStatus defines the observed state of Etcd.
| Field | Description |
|---|---|
observedGenerationint64 | (Optional) ObservedGeneration is the most recent generation observed for this resource. |
etcdCrossVersionObjectReference | (Optional) |
conditions[]Condition | (Optional) Conditions represents the latest available observations of an etcd’s current state. |
serviceNamestring | (Optional) ServiceName is the name of the etcd service. |
lastErrorstring | (Optional) LastError represents the last occurred error. |
clusterSizeint32 | (Optional) Cluster size is the size of the etcd cluster. |
currentReplicasint32 | (Optional) CurrentReplicas is the current replica count for the etcd cluster. |
replicasint32 | (Optional) Replicas is the replica count of the etcd resource. |
readyReplicasint32 | (Optional) ReadyReplicas is the count of replicas being ready in the etcd cluster. |
readybool | (Optional) Ready is |
updatedReplicasint32 | (Optional) UpdatedReplicas is the count of updated replicas in the etcd cluster. |
labelSelectorKubernetes meta/v1.LabelSelector | (Optional) LabelSelector is a label query over pods that should match the replica count. It must match the pod template’s labels. |
members[]EtcdMemberStatus | (Optional) Members represents the members of the etcd cluster |
peerUrlTLSEnabledbool | (Optional) PeerUrlTLSEnabled captures the state of peer url TLS being enabled for the etcd member(s) |
GarbageCollectionPolicy
(string alias)
(Appears on: BackupSpec)
GarbageCollectionPolicy defines the type of policy for snapshot garbage collection.
LeaderElectionSpec
(Appears on: BackupSpec)
LeaderElectionSpec defines parameters related to the LeaderElection configuration.
| Field | Description |
|---|---|
reelectionPeriodKubernetes meta/v1.Duration | (Optional) ReelectionPeriod defines the Period after which leadership status of corresponding etcd is checked. |
etcdConnectionTimeoutKubernetes meta/v1.Duration | (Optional) EtcdConnectionTimeout defines the timeout duration for etcd client connection during leader election. |
MetricsLevel
(string alias)
(Appears on: EtcdConfig)
MetricsLevel defines the level ‘basic’ or ‘extensive’.
SchedulingConstraints
(Appears on: EtcdSpec)
SchedulingConstraints defines the different scheduling constraints that must be applied to the pod spec in the etcd statefulset. Currently supported constraints are Affinity and TopologySpreadConstraints.
| Field | Description |
|---|---|
affinityKubernetes core/v1.Affinity | (Optional) Affinity defines the various affinity and anti-affinity rules for a pod that are honoured by the kube-scheduler. |
topologySpreadConstraints[]Kubernetes core/v1.TopologySpreadConstraint | (Optional) TopologySpreadConstraints describes how a group of pods ought to spread across topology domains, that are honoured by the kube-scheduler. |
SecretReference
(Appears on: TLSConfig)
SecretReference defines a reference to a secret.
| Field | Description |
|---|---|
SecretReferenceKubernetes core/v1.SecretReference | (Members of |
dataKeystring | (Optional) DataKey is the name of the key in the data map containing the credentials. |
SharedConfig
(Appears on: EtcdSpec)
SharedConfig defines parameters shared and used by Etcd as well as backup-restore sidecar.
| Field | Description |
|---|---|
autoCompactionModeCompactionMode | (Optional) AutoCompactionMode defines the auto-compaction-mode:‘periodic’ mode or ‘revision’ mode for etcd and embedded-Etcd of backup-restore sidecar. |
autoCompactionRetentionstring | (Optional) AutoCompactionRetention defines the auto-compaction-retention length for etcd as well as for embedded-Etcd of backup-restore sidecar. |
StorageProvider
(string alias)
(Appears on: StoreSpec)
StorageProvider defines the type of object store provider for storing backups.
StoreSpec
(Appears on: BackupSpec, EtcdCopyBackupsTaskSpec)
StoreSpec defines parameters related to ObjectStore persisting backups
| Field | Description |
|---|---|
containerstring | (Optional) Container is the name of the container the backup is stored at. |
prefixstring | Prefix is the prefix used for the store. |
providerStorageProvider | (Optional) Provider is the name of the backup provider. |
secretRefKubernetes core/v1.SecretReference | (Optional) SecretRef is the reference to the secret which used to connect to the backup store. |
TLSConfig
(Appears on: BackupSpec, EtcdConfig)
TLSConfig hold the TLS configuration details.
| Field | Description |
|---|---|
tlsCASecretRefSecretReference | |
serverTLSSecretRefKubernetes core/v1.SecretReference | |
clientTLSSecretRefKubernetes core/v1.SecretReference | (Optional) |
WaitForFinalSnapshotSpec
(Appears on: EtcdCopyBackupsTaskSpec)
WaitForFinalSnapshotSpec defines the parameters for waiting for a final full snapshot before copying backups.
| Field | Description |
|---|---|
enabledbool | Enabled specifies whether to wait for a final full snapshot before copying backups. |
timeoutKubernetes meta/v1.Duration | (Optional) Timeout is the timeout for waiting for a final full snapshot. When this timeout expires, the copying of backups will be performed anyway. No timeout or 0 means wait forever. |
Generated with gen-crd-api-reference-docs
2.6 - Changing Api
Change the API
This guide provides detailed information on what needs to be done when the API needs to be changed.
etcd-druid API follows the same API conventions and guidelines which Kubernetes defines and adopts. The Kubernetes API Conventions as well as Changing the API topics already provide a good overview and general explanation of the basic concepts behind it. We adhere to the principles laid down by Kubernetes.
Etcd Druid API
The etcd-druid API is defined here.
!!! info
The current version of the API is v1alpha1. We are currently working on migration to v1beta1 API.
Changing the API
If there is a need to make changes to the API, then one should do the following:
- If new fields are added then ensure that these are added as
optionalfields. They should have the+optionalcomment and anomitemptyJSON tag should be added against the field. - Ensure that all new fields or changing the existing fields are well documented with doc-strings.
- Care should be taken that incompatible API changes should not be made in the same version of the API. If there is a real necessity to introduce a backward incompatible change then a newer version of the API should be created and an API conversion webhook should be put in place to support more than one version of the API.
- After the changes to the API are finalized, run
make generateto ensure that the changes are also reflected in the CRD. - If necessary, implement or adapt the validation for the API.
- If necessary, adapt the examples YAML manifests.
- When opening a pull-request, always add a release note informing the end-users of the changes that are coming in.
Removing a Field
If field(s) needs to be removed permanently from the API, then one should ensure the following:
- Field should not be directly removed, instead first a deprecation notice should be put which should follow a well-defined deprecation period. Ensure that the release note in the pull-request is properly categorized so that this is easily visible to the end-users and clearly mentiones which field(s) have been deprecated. Clearly suggest a way in which clients need to adapt.
- To allow sufficient time to the end-users to adapt to the API changes, deprecated field(s) should only be removed once the deprecation period is over. It is generally recommended that this be done in 2 stages:
- First stage: Remove the code that refers to the deprecated fields. This ensures that the code no longer has dependency on the deprecated field(s).
- Second Stage: Remove the field from the API.
2.7 - Configure Etcd Druid
etcd-druid CLI Flags
etcd-druid process can be started with the following command line flags.
Command line flags
!!! note “Deprecation Notice”
All existing command line flags have been marked as deprecated. To configure etcd-druid the recommended way is to define a single --config CLI flag which points to a configuration YAML file containing etcd-druid OperatorConfiguration. For backward compatibility both new --config CLI flag and now deprecated existing CLI flags are supported.
Operator Configuration
The recommended way to configure etcd-druid is via OperatorConfiguration.
| Flag | Description | Default |
|---|---|---|
| config | Path to the mounted operator configuration. | NA |
You can see the default values for OperatorConfiguration at api/config/v1alpha1/defaults.go.
!!! note
It is required to define the --config CLI flag and point to the configuration YAML file path.
If you are deploying etcd-druid in a kubernetes cluster, then it is assumed that you have done the following:
- Created a
ConfigMapwhich contains the serialized operator configuration. - Mount the
ConfigMapto etcd-druidDeployment.
Leader election (Deprecated)
If you wish to setup etcd-druid in high-availability mode then leader election needs to be enabled to ensure that at a time only one replica services the incoming events and does the reconciliation.
| Flag | Description | Default |
|---|---|---|
| enable-leader-election | Leader election provides the capability to select one replica as a leader where active reconciliation will happen. The other replicas will keep waiting for leadership change and not do active reconciliations. | false |
| leader-election-id | Name of the k8s lease object that leader election will use for holding the leader lock. By default etcd-druid will use lease resource lock for leader election which is also a natural usecase for leases and is also recommended by k8s. | “druid-leader-election” |
| leader-election-resource-lock | Deprecated: This flag will be removed in later version of druid. By default lease.coordination.k8s.io resources will be used for leader election resource locking for the controller manager. | “leases” |
Metrics (Deprecated)
etcd-druid exposes a /metrics endpoint which can be scrapped by tools like Prometheus. If the default metrics endpoint configuration is not suitable then consumers can change it via the following options.
| Flag | Description | Default |
|---|---|---|
| metrics-bind-address | The IP address that the metrics endpoint binds to | "" |
| metrics-port | The port used for the metrics endpoint | 8080 |
| metrics-addr | Duration to wait for after compaction job is completed, to allow Prometheus metrics to be scraped. Deprecated: Please use --metrics-bind-address and --metrics-port instead | “:8080” |
Metrics bind-address is computed by joining the host and port. By default its value is computed as :8080.
!!! tip
Ensure that the metrics-port is also reflected in the etcd-druid deployment specification.
Webhook Server (Deprecated)
etcd-druid provides the following CLI flags to configure webhook server. These CLI flags are used to construct a new webhook.Server by configuring Options.
| Flag | Description | Default |
|---|---|---|
| webhook-server-bind-address | It is the address that the webhook server will listen on. | "" |
| webhook-server-port | Port is the port number that the webhook server will serve. | 9443 |
| webhook-server-tls-server-cert-dir | The path to a directory containing the server’s TLS certificate and key (the files must be named tls.crt and tls.key respectively). | /etc/webhook-server-tls |
Etcd-Components Webhook (Deprecated)
etcd-druid provisions and manages several Kubernetes resources which we call Etcdcluster components. To ensure that there is no accidental changes done to these managed resources, a webhook is put in place to check manual changes done to any managed etcd-cluster Kubernetes resource. It rejects most of these changes except a few. The details on how to enable the etcd-components webhook, which resources are protected and in which scenarios is the change allowed is documented here.
Following CLI flags are provided to configure the etcd-components webhook:
| Flag | Description | Default |
|---|---|---|
| enable-etcd-components-webhook | Enable EtcdComponents Webhook to prevent unintended changes to resources managed by etcd-druid. | false |
| reconciler-service-account | The fully qualified name of the service account used by etcd-druid for reconciling etcd resources. If unspecified, the default service account mounted for etcd-druid will be used | etcd-druid-service-account |
| etcd-components-exempt-service-accounts | In case there is a need to allow changes to Etcd resources from external controllers like vertical-pod-autoscaler then one must list the ServiceAaccount that is used by each such controller. | "" |
Reconcilers (Deprecated)
Following set of flags configures the reconcilers running within etcd-druid. To know more about different reconcilers read this document.
Etcd Reconciler (Deprecated)
| Flag | Description | Default |
|---|---|---|
| etcd-workers | Number of workers spawned for concurrent reconciles of Etcd resources. | 3 |
| enable-etcd-spec-auto-reconcile | If true then automatically reconciles Etcd Spec. If false, waits for explicit annotation gardener.cloud/operation: reconcile to be placed on the Etcd resource to trigger reconcile. | false |
| disable-etcd-serviceaccount-automount | For each Etcd cluster a ServiceAccount is created which is used by the StatefulSet pods and tied to Role via RoleBinding. If false then pods running as this ServiceAccount will have the API token automatically mounted. You can consider disabling it if you wish to use Projected Volumes allowing one to set an expirationSeconds on the mounted token for better security. To use projected volumes ensure that you have set relevant kube-apiserver flags.Note: With Kubernetes version >=1.24 projected service account token is the default. This means that we no longer need this flag. Issue #872 has been raised to address this. | false |
| etcd-status-sync-period | Etcd.Status is periodically updated. This interval defines the status sync frequency. | 15s |
| etcd-member-notready-threshold | Threshold after which an etcd member is considered not ready if the status was unknown before. This is currently used to update EtcdMemberConditionStatus. | 5m |
| etcd-member-unknown-threshold | Threshold after which an etcd member is considered unknown. This is currently used to update EtcdMemberConditionStatus. | 1m |
Compaction Reconciler (Deprecated)
| Flag | Description | Default |
|---|---|---|
| enable-backup-compaction | Enable automatic compaction of etcd backups | false |
| compaction-workers | Number of workers that can be spawned for concurrent reconciles for compaction Jobs. The controller creates a backup compaction job if a certain etcd event threshold is reached. If compaction is enabled, the value for this flag must be greater than zero. | 3 |
| etcd-events-threshold | Defines the threshold in terms of total number of etcd events before a backup compaction job is triggered. | 1000000 |
| active-deadline-duration | Duration after which a running backup compaction job will be terminated. | 3h |
| metrics-scrape-wait-duration | Duration to wait for after compaction job is completed, to allow Prometheus metrics to be scraped. | 0s |
Etcd Copy-Backup Task & Secret Reconcilers (Deprecated)
| Flag | Description | Default |
|---|---|---|
| etcd-copy-backups-task-workers | Number of workers spawned for concurrent reconciles for EtcdCopyBackupTask resources. | 3 |
| secret-workers | Number of workers spawned for concurrent reconciles for secrets. | 10 |
Miscellaneous (Deprecated)
| Flag | Description | Default |
|---|---|---|
| feature-gates | A set of key=value pairs that describe feature gates for alpha/experimental features. Please check feature-gates for more information. | "" |
| disable-lease-cache | Disable cache for lease.coordination.k8s.io resources. | false |
2.8 - Contribution
Contributors Guide
etcd-druid is an actively maintained project which has organically evolved to be a mature and stable etcd operator. We welcome active participation from the community and to this end this guide serves as a good starting point.
Code of Conduct
All maintainers and contributors must abide by Contributor Covenant. Real progress can only happen in a collaborative environment which fosters mutual respect, openeness and disruptive innovation.
Developer Certificate of Origin
Due to legal reasons, contributors will be asked to accept a Developer Certificate of Origin (DCO) before they submit the first pull request to the IronCore project, this happens in an automated fashion during the submission process. We use the standard DCO text of the Linux Foundation.
License
Your contributions to etcd-druid must be licensed properly:
- Code contributions must be licensed under the Apache 2.0 License.
- Documentation contributions must be licensed under the Creative Commons Attribution 4.0 International License.
Contributing
etcd-druid use Github to manage reviews of pull requests.
- If you are looking to make your first contribution, follow Steps to Contribute.
- If you have a trivial fix or improvement, go ahead and create an issue first followed by a pull request.
- If you plan to do something more involved, first discuss your ideas by creating an issue. This will avoid unnecessary work and surely give you and us a good deal of inspiration.
Steps to Contribute
- If you wish to contribute and have not done that in the past, then first try and filter the list of issues with label
exp/beginner. Once you find the issue that interests you, add a comment stating that you would like to work on it. This is to prevent duplicated efforts from contributors on the same issue. - If you have questions about one of the issues please comment on them and one of the maintainers will clarify it.
We kindly ask you to follow the Pull Request Checklist to ensure reviews can happen accordingly.
Issues and Planning
We use GitHub issues to track bugs and enhancement requests. Please provide as much context as possible when you open an issue. The information you provide must be comprehensive enough to understand, reproduce the behavior and find related reports of that issue for the assignee. Therefore, contributors may use but aren’t restricted to the issue template provided by the etcd-druid maintainers.
2.9 - Controllers
Controllers
etcd-druid is an operator to manage etcd clusters, and follows the Operator pattern for Kubernetes.
It makes use of the Kubebuilder framework which makes it quite easy to define Custom Resources (CRs) such as Etcds and EtcdCopyBackupTasks through Custom Resource Definitions (CRDs), and define controllers for these CRDs.
etcd-druid uses Kubebuilder to define the Etcd CR and its corresponding controllers.
All controllers that are a part of etcd-druid reside in package internal/controller, as sub-packages.
Etcd-druid currently consists of the following controllers, each having its own responsibility:
- etcd : responsible for the reconciliation of the
EtcdCR spec, which allows users to run etcd clusters within the specified Kubernetes cluster, and also responsible for periodically updating theEtcdCR status with the up-to-date state of the managed etcd cluster. - compaction : responsible for snapshot compaction.
- etcdcopybackupstask : responsible for the reconciliation of the
EtcdCopyBackupsTaskCR, which helps perform the job of copying snapshot backups from one object store to another. - secret : responsible in making sure
Secrets being referenced byEtcdresources are not deleted while in use.
Package Structure
The typical package structure for the controllers that are part of etcd-druid is shown with the compaction controller:
internal/controller/compaction
├── config.go
├── reconciler.go
└── register.go
config.go: contains all the logic for the configuration of the controller, including feature gate activations, CLI flag parsing and validations.register.go: contains the logic for registering the controller with the etcd-druid controller manager.reconciler.go: contains the controller reconciliation logic.
Each controller package also contains auxiliary files which are relevant to that specific controller.
Controller Manager
A manager is first created for all controllers that are a part of etcd-druid.
The controller manager is responsible for all the controllers that are associated with CRDs.
Once the manager is Start()ed, all the controllers that are registered with it are started.
Each controller is built using a controller builder, configured with details such as the type of object being reconciled, owned objects whose owner object is reconciled, event filters (predicates), etc. Predicates are filters which allow controllers to filter which type of events the controller should respond to and which ones to ignore.
The logic relevant to the controller manager like the creation of the controller manager and registering each of the controllers with the manager, is contained in internal/manager/manager.go.
Etcd Controller
The etcd controller is responsible for the reconciliation of the Etcd resource spec and status. It handles the provisioning and management of the etcd cluster. Different components that are required for the functioning of the cluster like Leases, ConfigMaps, and the Statefulset for the etcd cluster are all deployed and managed by the etcd controller.
Additionally, etcd controller also periodically updates the Etcd resource status with the latest available information from the etcd cluster, as well as results and errors from the recent-most reconciliation of the Etcd resource spec.
The etcd controller is essential to the functioning of the etcd cluster and etcd-druid, thus the minimum number of worker threads is 1 (default being 3), controlled by the CLI flag --etcd-workers.
Etcd Spec Reconciliation
While building the controller, an event filter is set such that the behavior of the controller, specifically for Etcd update operations, depends on the gardener.cloud/operation: reconcile annotation. This is controlled by the --enable-etcd-spec-auto-reconcile CLI flag, which, if set to false, tells the controller to perform reconciliation only when this annotation is present. If the flag is set to true, the controller will reconcile the etcd cluster anytime the Etcd spec, and thus generation, changes, and the next queued event for it is triggered.
!!! note
Creation and deletion of Etcd resources are not affected by the above flag or annotation.
The reason this filter is present is that any disruption in the Etcd resource due to reconciliation (due to changes in the Etcd spec, for example) while workloads are being run would cause unwanted downtimes to the etcd cluster. Hence, any user who wishes to avoid such disruptions, can choose to set the --enable-etcd-spec-auto-reconcile CLI flag to false. An example of this is Gardener’s gardenlet, which reconciles the Etcd resource only during a shoot cluster’s maintenance window.
The controller adds a finalizer to the Etcd resource in order to ensure that it does not get deleted until all dependent resources managed by etcd-druid, aka managed components, are properly cleaned up. Only the etcd controller can delete a resource once it adds finalizers to it. This ensures that the proper deletion flow steps are followed while deleting the resource. During deletion flow, managed components are deleted in parallel.
Etcd Status Updates
The Etcd resource status is updated periodically by etcd controller, the interval for which is determined by the CLI flag --etcd-status-sync-period.
Status fields of the Etcd resource such as LastOperation, LastErrors and ObservedGeneration, are updated to reflect the result of the recent reconciliation of the Etcd resource spec.
LastOperationholds information about the last operation performed on the etcd cluster, indicated by fieldsType,State,DescriptionandLastUpdateTime. Additionally, a fieldRunIDindicates the unique ID assigned to the specific reconciliation run, to allow for better debugging of issues.LastErrorsis a slice of errors encountered by the last reconciliation run. Each error consists of fieldsCodeto indicate the custom etcd-druid error code for the error, a human-readableDescription, and theObservedAttime when the error was seen.ObservedGenerationindicates the latestgenerationof theEtcdresource that etcd-druid has “observed” and consequently reconciled. It helps identify whether a change in theEtcdresource spec was acted upon by druid or not.
Status fields of the Etcd resource which correspond to the StatefulSet like CurrentReplicas, ReadyReplicas and Replicas are updated to reflect those of the StatefulSet by the controller.
Status fields related to the etcd cluster itself, such as Members, PeerUrlTLSEnabled and Ready are updated as follows:
- Cluster Membership: The controller updates the information about etcd cluster membership like
Role,Status,Reason,LastTransitionTimeand identifying information like theNameandID. For theStatusfield, the member is checked for the Ready condition, where the member can be inReady,NotReadyandUnknownstatuses.
Etcd resource conditions are indicated by status field Conditions. The condition checks that are currently performed are:
AllMembersReady: indicates readiness of all members of the etcd cluster.Ready: indicates overall readiness of the etcd cluster in serving traffic.BackupReady: indicates health of the etcd backups, i.e., whether etcd backups are being taken regularly as per schedule. This condition is applicable only when backups are enabled for the etcd cluster.DataVolumesReady: indicates health of the persistent volumes containing the etcd data.
Compaction Controller
The compaction controller deploys the snapshot compaction job whenever required. To understand the rationale behind this controller, please read snapshot-compaction.md.
The controller watches the number of events accumulated as part of delta snapshots in the etcd cluster’s backups, and triggers a snapshot compaction when the number of delta events crosses the set threshold, which is configurable through the --etcd-events-threshold CLI flag (1M events by default).
The controller watches for changes in snapshot Leases associated with Etcd resources.
It checks the full and delta snapshot Leases and calculates the difference in events between the latest delta snapshot and the previous full snapshot, and initiates the compaction job if the event threshold is crossed.
The number of worker threads for the compaction controller needs to be greater than or equal to 0 (default 3), controlled by the CLI flag --compaction-workers.
This is unlike other controllers which need at least one worker thread for the proper functioning of etcd-druid as snapshot compaction is not a core functionality for the etcd clusters to be deployed.
The compaction controller should be explicitly enabled by the user, through the --enable-backup-compaction CLI flag.
EtcdCopyBackupsTask Controller
The etcdcopybackupstask controller is responsible for deploying the etcdbrctl copy command as a job.
This controller reacts to create/update events arising from EtcdCopyBackupsTask resources, and deploys the EtcdCopyBackupsTask job with source and target backup storage providers as arguments, which are derived from source and target bucket secrets referenced by the EtcdCopyBackupsTask resource.
The number of worker threads for the etcdcopybackupstask controller needs to be greater than or equal to 0 (default being 3), controlled by the CLI flag --etcd-copy-backups-task-workers.
This is unlike other controllers who need at least one worker thread for the proper functioning of etcd-druid as EtcdCopyBackupsTask is not a core functionality for the etcd clusters to be deployed.
Secret Controller
The secret controller’s primary responsibility is to add a finalizer on Secrets referenced by the Etcd resource.
The secret controller is registered for Secrets, and the controller keeps a watch on the Etcd CR.
This finalizer is added to ensure that Secrets which are referenced by the Etcd CR aren’t deleted while still being used by the Etcd resource.
Events arising from the Etcd resource are mapped to a list of Secrets such as backup and TLS secrets that are referenced by the Etcd resource, and are enqueued into the request queue, which the reconciler then acts on.
The number of worker threads for the secret controller must be at least 1 (default being 10) for this core controller, controlled by the CLI flag --secret-workers, since the referenced TLS and infrastructure access secrets are essential to the proper functioning of the etcd cluster.
2.10 - DEP Title
DEP-NN: Your short, descriptive title
Summary
Motivation
Goals
Non-Goals
Proposal
Alternatives
2.11 - Dependency Management
Dependency Management
We use Go Modules for dependency management. In order to add a new package dependency to the project, you can perform go get <package@version> or edit the go.mod file and append the package along with the version you want to use.
Organize Dependencies
Unfortunately go does not differentiate between dev and test dependencies. It becomes cleaner to organize dev and test dependencies in their respective require clause which gives a clear view on existing set of dependencies. The goal is to keep the dependencies to a minimum and only add a dependency when absolutely required.
Updating Dependencies
The Makefile contains a rule called tidy which performs go mod tidy which ensures that the go.mod file matches the source code in the module. It adds any missing module requirements necessary to build the current module’s packages and dependencies, and it removes requirements on modules that don’t provide any relevant packages. It also adds any missing entries to go.sum and removes unnecessary entries.
make tidy
!!! warning Make sure that you test the code after you have updated the dependencies!
2.12 - Etcd Cluster Components
Etcd Cluster Components
For every Etcd cluster that is provisioned by etcd-druid it deploys a set of resources. Following sections provides information and code reference to each such resource.
StatefulSet
StatefulSet is the primary kubernetes resource that gets provisioned for an etcd cluster.
Replicas for the StatefulSet are derived from
Etcd.Spec.Replicasin the custom resource.Each pod comprises two containers:
etcd-wrapper: This is the main container which runs an etcd process.etcd-backup-restore: This is a side-container which does the following:- Orchestrates the initialization of etcd. This includes validation of any existing etcd data directory, restoration in case of corrupt etcd data directory files for a single-member etcd cluster.
- Periodically renews member lease.
- Optionally takes schedule and threshold based delta and full snapshots and pushes them to a configured object store.
- Orchestrates scheduled etcd-db defragmentation.
NOTE: This is not a complete list of functionalities offered out of
etcd-backup-restore.
Code reference: StatefulSet-Component
For detailed information on each container you can visit etcd-wrapper and etcd-backup-restore repositories.
ConfigMap
Every etcd member requires configuration with which it must be started. etcd-druid creates a ConfigMap which gets mounted onto the etcd-backup-restore container. etcd-backup-restore container will modify the etcd configuration and serve it to the etcd-wrapper container upon request.
Code reference: ConfigMap-Component
PodDisruptionBudget
An etcd cluster requires quorum for all write operations. Clients can additionally configure quorum based reads as well to ensure linearizable reads (kube-apiserver’s etcd client is configured for linearizable reads and writes). In a cluster of size 3, only 1 member failure is tolerated. Failure tolerance for an etcd cluster with replicas n is computed as (n-1)/2.
To ensure that etcd pods are not evicted more than its failure tolerance, etcd-druid creates a PodDisruptionBudget.
!!! note
For a single node etcd cluster a PodDisruptionBudget will be created, however pdb.spec.minavailable is set to 0 effectively disabling it.
Code reference: PodDisruptionBudget-Component
ServiceAccount
etcd-backup-restore container running as a side-car in every etcd-member, requires permissions to access resources like Lease, StatefulSet etc. A dedicated ServiceAccount is created per Etcd cluster for this purpose.
Code reference: ServiceAccount-Component
Role & RoleBinding
etcd-backup-restore container running as a side-car in every etcd-member, requires permissions to access resources like Lease, StatefulSet etc. A dedicated Role and RoleBinding is created and linked to the ServiceAccount created per Etcd cluster.
Code reference: Role-Component & RoleBinding-Component
Client & Peer Service
To enable clients to connect to an etcd cluster a ClusterIP Client Service is created. To enable etcd members to talk to each other(for discovery, leader-election, raft consensus etc.) etcd-druid also creates a Headless Service.
Code reference: Client-Service-Component & Peer-Service-Component
Member Lease
Every member in an Etcd cluster has a dedicated Lease that gets created which signifies that the member is alive. It is the responsibility of the etcd-backup-store side-car container to periodically renew the lease.
!!! note
Today the lease object is also used to indicate the member-ID and the role of the member in an etcd cluster. Possible roles are Leader, Member(which denotes that this is a member but not a leader). This will change in the future with EtcdMember resource.
Code reference: Member-Lease-Component
Delta & Full Snapshot Leases
One of the responsibilities of etcd-backup-restore container is to take periodic or threshold based snapshots (delta and full) of the etcd DB. Today etcd-backup-restore communicates the end-revision of the latest full/delta snapshots to etcd-druid operator via leases.
etcd-druid creates two Lease resources one for delta and another for full snapshot. This information is used by the operator to trigger snapshot-compaction jobs. Snapshot leases are also used to derive the health of backups which gets updated in the Status subresource of every Etcd resource.
In future these leases will be replaced by EtcdMember resource.
Code reference: Snapshot-Lease-Component
2.13 - Etcd Cluster Resource Protection
Etcd Cluster Resource Protection
etcd-druid provisions and manages kubernetes resources (a.k.a components) for each Etcd cluster. To ensure that each component’s specification is in line with the configured attributes defined in Etcd custom resource and to protect unintended changes done to any of these managed components a Validating Webhook is employed.
Etcd Components Webhook is the validating webhook which prevents unintended UPDATE and DELETE operations on all managed resources. Following sections describe what is prohibited and in which specific conditions the changes are permitted.
Configure Etcd Components Webhook
Prerequisite to enable the validation webhook is to configure the Webhook Server. Additionally you need to enable the Etcd Components validating webhook and optionally configure other options. You can look at all the options here.
What is allowed?
Modifications to managed resources under the following circumstances will be allowed:
CreateandConnectoperations are allowed and no validation is done.- Changes to a kubernetes resource (e.g. StatefulSet, ConfigMap etc) not managed by etcd-druid are allowed.
- Changes to a resource whose Group-Kind is amongst the resources managed by etcd-druid but does not have a parent
Etcdresource are allowed. - It is possible that an operator wishes to explicitly disable etcd-component protection. This can be done by setting
druid.gardener.cloud/disable-etcd-component-protectionannotation on anEtcdresource. If this annotation is present then changes to managed components will be allowed. - If
Etcdresource has a deletion timestamp set indicating that it is marked for deletion and is awaiting etcd-druid to delete all managed resources then deletion requests for all managed resources for this etcd cluster will be allowed if:- The deletion request has come from a
ServiceAccountassociated to etcd-druid. If not explicitly specified via--reconciler-service-accountthen a default-reconciler-service-account will be assumed. - The deletion request has come from a
ServiceAccountconfigured via--etcd-components-webhook-exempt-service-accounts.
- The deletion request has come from a
Leaseobjects are periodically updated by each etcd member pod. A singleServiceAccountis created for all members.Updateoperation onLeaseobjects from this ServiceAccount is allowed.- If an active reconciliation is in-progress then only allow operations that are initiated by etcd-druid.
- If no active reconciliation is currently in-progress, then allow updates to managed resource from
ServiceAccountsconfigured via--etcd-components-webhook-exempt-service-accounts.
2.14 - Etcd Druid Api
API Reference
Packages
config.druid.gardener.cloud/v1alpha1
ClientConnectionConfiguration
ClientConnectionConfiguration defines the configuration for constructing a client.Client to connect to k8s kube-apiserver.
Appears in:
| Field | Description | Default | Validation |
|---|---|---|---|
qps float | QPS controls the number of queries per second allowed for a connection. Setting this to a negative value will disable client-side rate limiting. | ||
burst integer | Burst allows extra queries to accumulate when a client is exceeding its rate. | ||
contentType string | ContentType is the content type used when sending data to the server from this client. | ||
acceptContentTypes string | AcceptContentTypes defines the Accept header sent by clients when connecting to the server, overriding the default value of ‘application/json’. This field will control all connections to the server used by a particular client. |
CompactionControllerConfiguration
CompactionControllerConfiguration defines the configuration for the compaction controller.
Appears in:
| Field | Description | Default | Validation |
|---|---|---|---|
enabled boolean | Enabled specifies whether backup compaction should be enabled. | ||
concurrentSyncs integer | ConcurrentSyncs is the max number of concurrent workers that can be run, each worker servicing a reconcile request. | ||
eventsThreshold integer | EventsThreshold denotes total number of etcd events to be reached upon which a backup compaction job is triggered. | ||
activeDeadlineDuration Duration | ActiveDeadlineDuration is the duration after which a running compaction job will be killed. | ||
metricsScrapeWaitDuration Duration | MetricsScrapeWaitDuration is the duration to wait for after compaction job is completed, to allow Prometheus metrics to be scraped |
ControllerConfiguration
ControllerConfiguration defines the configuration for the controllers.
Appears in:
| Field | Description | Default | Validation |
|---|---|---|---|
disableLeaseCache boolean | DisableLeaseCache disables the cache for lease.coordination.k8s.io resources. Deprecated: This field will be eventually removed. It is recommended to not use this. It has only been introduced to allow for backward compatibility with the old CLI flags. | ||
etcd EtcdControllerConfiguration | Etcd is the configuration for the Etcd controller. | ||
compaction CompactionControllerConfiguration | Compaction is the configuration for the compaction controller. | ||
etcdCopyBackupsTask EtcdCopyBackupsTaskControllerConfiguration | EtcdCopyBackupsTask is the configuration for the EtcdCopyBackupsTask controller. | ||
secret SecretControllerConfiguration | Secret is the configuration for the Secret controller. |
EtcdComponentProtectionWebhookConfiguration
EtcdComponentProtectionWebhookConfiguration defines the configuration for EtcdComponentProtection webhook. NOTE: At least one of ReconcilerServiceAccountFQDN or ServiceAccountInfo must be set. It is recommended to switch to ServiceAccountInfo.
Appears in:
| Field | Description | Default | Validation |
|---|---|---|---|
enabled boolean | Enabled indicates whether the EtcdComponentProtection webhook is enabled. | ||
reconcilerServiceAccountFQDN string | ReconcilerServiceAccountFQDN is the FQDN of the reconciler service account used by the etcd-druid operator. Deprecated: Please use ServiceAccountInfo instead and ensure that both Name and Namespace are set via projected volumes and downward API in the etcd-druid deployment spec. | ||
serviceAccountInfo ServiceAccountInfo | ServiceAccountInfo contains paths to gather etcd-druid service account information. | ||
exemptServiceAccounts string array | ExemptServiceAccounts is a list of service accounts that are exempt from Etcd Components Webhook checks. |
EtcdControllerConfiguration
EtcdControllerConfiguration defines the configuration for the Etcd controller.
Appears in:
| Field | Description | Default | Validation |
|---|---|---|---|
concurrentSyncs integer | ConcurrentSyncs is the max number of concurrent workers that can be run, each worker servicing a reconcile request. | ||
enableEtcdSpecAutoReconcile boolean | EnableEtcdSpecAutoReconcile controls how the Etcd Spec is reconciled. If set to true, then any change in Etcd spec will automatically trigger a reconciliation of the Etcd resource. If set to false, then an operator needs to explicitly set gardener.cloud/operation=reconcile annotation on the Etcd resource to trigger reconciliation of the Etcd spec. NOTE: Decision to enable it should be carefully taken as spec updates could potentially result in rolling update of the StatefulSet which will cause a minor downtime for a single node etcd cluster and can potentially cause a downtime for a multi-node etcd cluster. | ||
disableEtcdServiceAccountAutomount boolean | DisableEtcdServiceAccountAutomount controls the auto-mounting of service account token for etcd StatefulSets. | ||
etcdStatusSyncPeriod Duration | EtcdStatusSyncPeriod is the duration after which an event will be re-queued ensuring etcd status synchronization. | ||
etcdMember EtcdMemberConfiguration | EtcdMember holds configuration related to etcd members. |
EtcdCopyBackupsTaskControllerConfiguration
EtcdCopyBackupsTaskControllerConfiguration defines the configuration for the EtcdCopyBackupsTask controller.
Appears in:
| Field | Description | Default | Validation |
|---|---|---|---|
enabled boolean | Enabled specifies whether EtcdCopyBackupsTaskController should be enabled. | ||
concurrentSyncs integer | ConcurrentSyncs is the max number of concurrent workers that can be run, each worker servicing a reconcile request. |
EtcdMemberConfiguration
EtcdMemberConfiguration holds configuration related to etcd members.
Appears in:
| Field | Description | Default | Validation |
|---|---|---|---|
notReadyThreshold Duration | NotReadyThreshold is the duration after which an etcd member’s state is considered NotReady. | ||
unknownThreshold Duration | UnknownThreshold is the duration after which an etcd member’s state is considered Unknown. |
LeaderElectionConfiguration
LeaderElectionConfiguration defines the configuration for the leader election. It should be enabled when you deploy etcd-druid in HA mode. For single replica etcd-druid deployments it will not really serve any purpose.
Appears in:
| Field | Description | Default | Validation |
|---|---|---|---|
enabled boolean | Enabled specifies whether leader election is enabled. Set this to true when running replicated instances of the operator for high availability. | ||
leaseDuration Duration | LeaseDuration is the duration that non-leader candidates will wait after observing a leadership renewal until attempting to acquire leadership of the occupied but un-renewed leader slot. This is effectively the maximum duration that a leader can be stopped before it is replaced by another candidate. This is only applicable if leader election is enabled. | ||
renewDeadline Duration | RenewDeadline is the interval between attempts by the acting leader to renew its leadership before it stops leading. This must be less than or equal to the lease duration. This is only applicable if leader election is enabled. | ||
retryPeriod Duration | RetryPeriod is the duration leader elector clients should wait between attempting acquisition and renewal of leadership. This is only applicable if leader election is enabled. | ||
resourceLock string | ResourceLock determines which resource lock to use for leader election. This is only applicable if leader election is enabled. | ||
resourceName string | ResourceName determines the name of the resource that leader election will use for holding the leader lock. This is only applicable if leader election is enabled. |
LogConfiguration
LogConfiguration contains the configuration for logging.
Appears in:
| Field | Description | Default | Validation |
|---|---|---|---|
logLevel LogLevel | LogLevel is the level/severity for the logs. Must be one of [info,debug,error]. | ||
logFormat LogFormat | LogFormat is the output format for the logs. Must be one of [text,json]. |
LogFormat
Underlying type: string
LogFormat is the format of the log.
Appears in:
| Field | Description |
|---|---|
json | LogFormatJSON is the JSON log format. |
text | LogFormatText is the text log format. |
LogLevel
Underlying type: string
LogLevel represents the level for logging.
Appears in:
| Field | Description |
|---|---|
debug | LogLevelDebug is the debug log level, i.e. the most verbose. |
info | LogLevelInfo is the default log level. |
error | LogLevelError is a log level where only errors are logged. |
SecretControllerConfiguration
SecretControllerConfiguration defines the configuration for the Secret controller.
Appears in:
| Field | Description | Default | Validation |
|---|---|---|---|
concurrentSyncs integer | ConcurrentSyncs is the max number of concurrent workers that can be run, each worker servicing a reconcile request. |
Server
Server contains information for HTTP(S) server configuration.
Appears in:
| Field | Description | Default | Validation |
|---|---|---|---|
bindAddress string | BindAddress is the IP address on which to listen for the specified port. | ||
port integer | Port is the port on which to serve unsecured, unauthenticated access. |
ServerConfiguration
ServerConfiguration contains the server configurations.
Appears in:
| Field | Description | Default | Validation |
|---|---|---|---|
webhooks TLSServer | Webhooks is the configuration for the TLS webhook server. | ||
metrics Server | Metrics is the configuration for serving the metrics endpoint. |
ServiceAccountInfo
ServiceAccountInfo contains paths to gather etcd-druid service account information. Usually downward API and projected volumes are used in the deployment specification of etcd-druid to provide this information as mounted volume files.
Appears in:
| Field | Description | Default | Validation |
|---|---|---|---|
name string | Name is the name of the service account associated with etcd-druid deployment. | ||
namespace string | Namespace is the namespace in which the service account has been deployed. Usually this information is usually available at /var/run/secrets/kubernetes.io/serviceaccount/namespace. However, if automountServiceAccountToken is set to false then this file will not be available. |
TLSServer
TLSServer is the configuration for a TLS enabled server.
Appears in:
| Field | Description | Default | Validation |
|---|---|---|---|
bindAddress string | BindAddress is the IP address on which to listen for the specified port. | ||
port integer | Port is the port on which to serve unsecured, unauthenticated access. | ||
serverCertDir string | ServerCertDir is the path to a directory containing the server’s TLS certificate and key (the files must be named tls.crt and tls.key respectively). |
WebhookConfiguration
WebhookConfiguration defines the configuration for admission webhooks.
Appears in:
| Field | Description | Default | Validation |
|---|---|---|---|
etcdComponentProtection EtcdComponentProtectionWebhookConfiguration | EtcdComponentProtection is the configuration for EtcdComponentProtection webhook. |
druid.gardener.cloud/v1alpha1
Package v1alpha1 contains API Schema definitions for the druid v1alpha1 API group
Resource Types
BackupSpec
BackupSpec defines parameters associated with the full and delta snapshots of etcd.
Appears in:
| Field | Description | Default | Validation |
|---|---|---|---|
port integer | Port define the port on which etcd-backup-restore server will be exposed. | ||
tls TLSConfig | |||
image string | Image defines the etcd container image and tag | ||
store StoreSpec | Store defines the specification of object store provider for storing backups. | ||
resources ResourceRequirements | Resources defines compute Resources required by backup-restore container. More info: https://kubernetes.io/docs/concepts/configuration/manage-compute-resources-container/ | ||
compactionResources ResourceRequirements | CompactionResources defines compute Resources required by compaction job. More info: https://kubernetes.io/docs/concepts/configuration/manage-compute-resources-container/ | ||
fullSnapshotSchedule string | FullSnapshotSchedule defines the cron standard schedule for full snapshots. | Pattern: ^(\*|[1-5]?[0-9]|[1-5]?[0-9]-[1-5]?[0-9]|(?:[1-9]|[1-4][0-9]|5[0-9])\/(?:[1-9]|[1-4][0-9]|5[0-9]|60)|\*\/(?:[1-9]|[1-4][0-9]|5[0-9]|60))\s+(\*|[0-9]|1[0-9]|2[0-3]|[0-9]-(?:[0-9]|1[0-9]|2[0-3])|1[0-9]-(?:1[0-9]|2[0-3])|2[0-3]-2[0-3]|(?:[1-9]|1[0-9]|2[0-3])\/(?:[1-9]|1[0-9]|2[0-4])|\*\/(?:[1-9]|1[0-9]|2[0-4]))\s+(\*|[1-9]|[12][0-9]|3[01]|[1-9]-(?:[1-9]|[12][0-9]|3[01])|[12][0-9]-(?:[12][0-9]|3[01])|3[01]-3[01]|(?:[1-9]|[12][0-9]|30)\/(?:[1-9]|[12][0-9]|3[01])|\*\/(?:[1-9]|[12][0-9]|3[01]))\s+(\*|[1-9]|1[0-2]|[1-9]-(?:[1-9]|1[0-2])|1[0-2]-1[0-2]|(?:[1-9]|1[0-2])\/(?:[1-9]|1[0-2])|\*\/(?:[1-9]|1[0-2]))\s+(\*|[1-7]|[1-6]-[1-7]|[1-6]\/[1-7]|\*\/[1-7])$ | |
garbageCollectionPolicy GarbageCollectionPolicy | GarbageCollectionPolicy defines the policy for garbage collecting old backups | Enum: [Exponential LimitBased] | |
maxBackupsLimitBasedGC integer | MaxBackupsLimitBasedGC defines the maximum number of Full snapshots to retain in Limit Based GarbageCollectionPolicy All full snapshots beyond this limit will be garbage collected. | ||
garbageCollectionPeriod Duration | GarbageCollectionPeriod defines the period for garbage collecting old backups | Pattern: ^([0-9]+([.][0-9]+)?h)?([0-9]+([.][0-9]+)?m)?([0-9]+([.][0-9]+)?s)?([0-9]+([.][0-9]+)?d)?$Type: string | |
deltaSnapshotPeriod Duration | DeltaSnapshotPeriod defines the period after which delta snapshots will be taken | Pattern: ^([0-9]+([.][0-9]+)?h)?([0-9]+([.][0-9]+)?m)?([0-9]+([.][0-9]+)?s)?([0-9]+([.][0-9]+)?d)?$Type: string | |
deltaSnapshotMemoryLimit Quantity | DeltaSnapshotMemoryLimit defines the memory limit after which delta snapshots will be taken | ||
deltaSnapshotRetentionPeriod Duration | DeltaSnapshotRetentionPeriod defines the duration for which delta snapshots will be retained, excluding the latest snapshot set. The value should be a string formatted as a duration (e.g., ‘1s’, ‘2m’, ‘3h’, ‘4d’) | Pattern: ^([0-9]+([.][0-9]+)?h)?([0-9]+([.][0-9]+)?m)?([0-9]+([.][0-9]+)?s)?([0-9]+([.][0-9]+)?d)?$Type: string | |
compression CompressionSpec | SnapshotCompression defines the specification for compression of Snapshots. | ||
enableProfiling boolean | EnableProfiling defines if profiling should be enabled for the etcd-backup-restore-sidecar | ||
etcdSnapshotTimeout Duration | EtcdSnapshotTimeout defines the timeout duration for etcd FullSnapshot operation | Pattern: ^([0-9]+([.][0-9]+)?h)?([0-9]+([.][0-9]+)?m)?([0-9]+([.][0-9]+)?s)?([0-9]+([.][0-9]+)?d)?$Type: string | |
leaderElection LeaderElectionSpec | LeaderElection defines parameters related to the LeaderElection configuration. |
ClientService
ClientService defines the parameters of the client service that a user can specify
Appears in:
| Field | Description | Default | Validation |
|---|---|---|---|
annotations object (keys:string, values:string) | Annotations specify the annotations that should be added to the client service | ||
labels object (keys:string, values:string) | Labels specify the labels that should be added to the client service | ||
trafficDistribution string | TrafficDistribution defines the traffic distribution preference that should be added to the client service. More info: https://kubernetes.io/docs/reference/networking/virtual-ips/#traffic-distribution | Enum: [PreferClose] |
CompactionMode
Underlying type: string
CompactionMode defines the auto-compaction-mode: ‘periodic’ or ‘revision’. ‘periodic’ for duration based retention and ‘revision’ for revision number based retention.
Validation:
- Enum: [periodic revision]
Appears in:
| Field | Description |
|---|---|
periodic | Periodic is a constant to set auto-compaction-mode ‘periodic’ for duration based retention. |
revision | Revision is a constant to set auto-compaction-mode ‘revision’ for revision number based retention. |
CompressionPolicy
Underlying type: string
CompressionPolicy defines the type of policy for compression of snapshots.
Validation:
- Enum: [gzip lzw zlib]
Appears in:
| Field | Description |
|---|---|
gzip | GzipCompression is constant for gzip compression policy. |
lzw | LzwCompression is constant for lzw compression policy. |
zlib | ZlibCompression is constant for zlib compression policy. |
CompressionSpec
CompressionSpec defines parameters related to compression of Snapshots(full as well as delta).
Appears in:
| Field | Description | Default | Validation |
|---|---|---|---|
enabled boolean | |||
policy CompressionPolicy | Enum: [gzip lzw zlib] |
Condition
Condition holds the information about the state of a resource.
Appears in:
| Field | Description | Default | Validation |
|---|---|---|---|
type ConditionType | Type of the Etcd condition. | ||
status ConditionStatus | Status of the condition, one of True, False, Unknown. | ||
lastTransitionTime Time | Last time the condition transitioned from one status to another. | ||
lastUpdateTime Time | Last time the condition was updated. | ||
reason string | The reason for the condition’s last transition. | ||
message string | A human-readable message indicating details about the transition. |
ConditionStatus
Underlying type: string
ConditionStatus is the status of a condition.
Appears in:
| Field | Description |
|---|---|
True | ConditionTrue means a resource is in the condition. |
False | ConditionFalse means a resource is not in the condition. |
Unknown | ConditionUnknown means Gardener can’t decide if a resource is in the condition or not. |
Progressing | ConditionProgressing means the condition was seen true, failed but stayed within a predefined failure threshold. In the future, we could add other intermediate conditions, e.g. ConditionDegraded. Deprecated: Will be removed in the future since druid conditions will be replaced by metav1.Condition which has only three status options: True, False, Unknown. |
ConditionCheckError | ConditionCheckError is a constant for a reason in condition. Deprecated: Will be removed in the future since druid conditions will be replaced by metav1.Condition which has only three status options: True, False, Unknown. |
ConditionType
Underlying type: string
ConditionType is the type of condition.
Appears in:
| Field | Description |
|---|---|
Ready | ConditionTypeReady is a constant for a condition type indicating that the etcd cluster is ready. |
AllMembersReady | ConditionTypeAllMembersReady is a constant for a condition type indicating that all members of the etcd cluster are ready. |
AllMembersUpdated | ConditionTypeAllMembersUpdated is a constant for a condition type indicating that all members of the etcd cluster have been updated with the desired spec changes. |
BackupReady | ConditionTypeBackupReady is a constant for a condition type indicating that the etcd backup is ready. |
DataVolumesReady | ConditionTypeDataVolumesReady is a constant for a condition type indicating that the etcd data volumes are ready. |
Succeeded | EtcdCopyBackupsTaskSucceeded is a condition type indicating that a EtcdCopyBackupsTask has succeeded. |
Failed | EtcdCopyBackupsTaskFailed is a condition type indicating that a EtcdCopyBackupsTask has failed. |
CrossVersionObjectReference
CrossVersionObjectReference contains enough information to let you identify the referred resource.
Appears in:
| Field | Description | Default | Validation |
|---|---|---|---|
kind string | Kind of the referent | ||
name string | Name of the referent | ||
apiVersion string | API version of the referent |
ErrorCode
Underlying type: string
ErrorCode is a string alias representing an error code that identifies an error.
Appears in:
Etcd
Etcd is the Schema for the etcds API
| Field | Description | Default | Validation |
|---|---|---|---|
apiVersion string | druid.gardener.cloud/v1alpha1 | ||
kind string | Etcd | ||
metadata ObjectMeta | Refer to Kubernetes API documentation for fields of metadata. | ||
spec EtcdSpec | |||
status EtcdStatus |
EtcdConfig
EtcdConfig defines the configuration for the etcd cluster to be deployed.
Appears in:
| Field | Description | Default | Validation |
|---|---|---|---|
quota Quantity | Quota defines the etcd DB quota. | ||
snapshotCount integer | SnapshotCount defines the number of applied Raft entries to hold in-memory before compaction. More info: https://etcd.io/docs/v3.4/op-guide/maintenance/#raft-log-retention | ||
defragmentationSchedule string | DefragmentationSchedule defines the cron standard schedule for defragmentation of etcd. | Pattern: ^(\*|[1-5]?[0-9]|[1-5]?[0-9]-[1-5]?[0-9]|(?:[1-9]|[1-4][0-9]|5[0-9])\/(?:[1-9]|[1-4][0-9]|5[0-9]|60)|\*\/(?:[1-9]|[1-4][0-9]|5[0-9]|60))\s+(\*|[0-9]|1[0-9]|2[0-3]|[0-9]-(?:[0-9]|1[0-9]|2[0-3])|1[0-9]-(?:1[0-9]|2[0-3])|2[0-3]-2[0-3]|(?:[1-9]|1[0-9]|2[0-3])\/(?:[1-9]|1[0-9]|2[0-4])|\*\/(?:[1-9]|1[0-9]|2[0-4]))\s+(\*|[1-9]|[12][0-9]|3[01]|[1-9]-(?:[1-9]|[12][0-9]|3[01])|[12][0-9]-(?:[12][0-9]|3[01])|3[01]-3[01]|(?:[1-9]|[12][0-9]|30)\/(?:[1-9]|[12][0-9]|3[01])|\*\/(?:[1-9]|[12][0-9]|3[01]))\s+(\*|[1-9]|1[0-2]|[1-9]-(?:[1-9]|1[0-2])|1[0-2]-1[0-2]|(?:[1-9]|1[0-2])\/(?:[1-9]|1[0-2])|\*\/(?:[1-9]|1[0-2]))\s+(\*|[1-7]|[1-6]-[1-7]|[1-6]\/[1-7]|\*\/[1-7])$ | |
serverPort integer | |||
clientPort integer | |||
wrapperPort integer | |||
image string | Image defines the etcd container image and tag | ||
authSecretRef SecretReference | |||
metrics MetricsLevel | Metrics defines the level of detail for exported metrics of etcd, specify ’extensive’ to include histogram metrics. | Enum: [basic extensive] | |
resources ResourceRequirements | Resources defines the compute Resources required by etcd container. More info: https://kubernetes.io/docs/concepts/configuration/manage-compute-resources-container/ | ||
clientUrlTls TLSConfig | ClientUrlTLS contains the ca, server TLS and client TLS secrets for client communication to ETCD cluster | ||
peerUrlTls TLSConfig | PeerUrlTLS contains the ca and server TLS secrets for peer communication within ETCD cluster Currently, PeerUrlTLS does not require client TLS secrets for gardener implementation of ETCD cluster. | ||
etcdDefragTimeout Duration | EtcdDefragTimeout defines the timeout duration for etcd defrag call | Pattern: ^([0-9]+([.][0-9]+)?h)?([0-9]+([.][0-9]+)?m)?([0-9]+([.][0-9]+)?s)?([0-9]+([.][0-9]+)?d)?$Type: string | |
heartbeatDuration Duration | HeartbeatDuration defines the duration for members to send heartbeats. The default value is 10s. | Pattern: ^([0-9]+([.][0-9]+)?h)?([0-9]+([.][0-9]+)?m)?([0-9]+([.][0-9]+)?s)?$Type: string | |
clientService ClientService | ClientService defines the parameters of the client service that a user can specify |
EtcdCopyBackupsTask
EtcdCopyBackupsTask is a task for copying etcd backups from a source to a target store.
| Field | Description | Default | Validation |
|---|---|---|---|
apiVersion string | druid.gardener.cloud/v1alpha1 | ||
kind string | EtcdCopyBackupsTask | ||
metadata ObjectMeta | Refer to Kubernetes API documentation for fields of metadata. | ||
spec EtcdCopyBackupsTaskSpec | |||
status EtcdCopyBackupsTaskStatus |
EtcdCopyBackupsTaskSpec
EtcdCopyBackupsTaskSpec defines the parameters for the copy backups task.
Appears in:
| Field | Description | Default | Validation |
|---|---|---|---|
podLabels object (keys:string, values:string) | PodLabels is a set of labels that will be added to pod(s) created by the copy backups task. | ||
sourceStore StoreSpec | SourceStore defines the specification of the source object store provider for storing backups. | ||
targetStore StoreSpec | TargetStore defines the specification of the target object store provider for storing backups. | ||
maxBackupAge integer | MaxBackupAge is the maximum age in days that a backup must have in order to be copied. By default, all backups will be copied. | ||
maxBackups integer | MaxBackups is the maximum number of backups that will be copied starting with the most recent ones. | ||
waitForFinalSnapshot WaitForFinalSnapshotSpec | WaitForFinalSnapshot defines the parameters for waiting for a final full snapshot before copying backups. |
EtcdCopyBackupsTaskStatus
EtcdCopyBackupsTaskStatus defines the observed state of the copy backups task.
Appears in:
| Field | Description | Default | Validation |
|---|---|---|---|
conditions Condition array | Conditions represents the latest available observations of an object’s current state. | ||
observedGeneration integer | ObservedGeneration is the most recent generation observed for this resource. | ||
lastError string | LastError represents the last occurred error. |
EtcdMemberConditionStatus
Underlying type: string
EtcdMemberConditionStatus is the status of an etcd cluster member.
Appears in:
| Field | Description |
|---|---|
Ready | EtcdMemberStatusReady indicates that the etcd member is ready. |
NotReady | EtcdMemberStatusNotReady indicates that the etcd member is not ready. |
Unknown | EtcdMemberStatusUnknown indicates that the status of the etcd member is unknown. |
EtcdMemberStatus
EtcdMemberStatus holds information about etcd cluster membership.
Appears in:
| Field | Description | Default | Validation |
|---|---|---|---|
name string | Name is the name of the etcd member. It is the name of the backing Pod. | ||
id string | ID is the ID of the etcd member. | ||
role EtcdRole | Role is the role in the etcd cluster, either Leader or Member. | ||
status EtcdMemberConditionStatus | Status of the condition, one of True, False, Unknown. | ||
reason string | The reason for the condition’s last transition. | ||
lastTransitionTime Time | LastTransitionTime is the last time the condition’s status changed. |
EtcdRole
Underlying type: string
EtcdRole is the role of an etcd cluster member.
Appears in:
| Field | Description |
|---|---|
Leader | EtcdRoleLeader describes the etcd role Leader. |
Member | EtcdRoleMember describes the etcd role Member. |
EtcdSpec
EtcdSpec defines the desired state of Etcd
Appears in:
| Field | Description | Default | Validation |
|---|---|---|---|
selector LabelSelector | selector is a label query over pods that should match the replica count. It must match the pod template’s labels. More info: https://kubernetes.io/docs/concepts/overview/working-with-objects/labels/#label-selectors Deprecated: this field will be removed in the future. | ||
labels object (keys:string, values:string) | |||
annotations object (keys:string, values:string) | |||
etcd EtcdConfig | |||
backup BackupSpec | |||
sharedConfig SharedConfig | |||
schedulingConstraints SchedulingConstraints | |||
replicas integer | |||
priorityClassName string | PriorityClassName is the name of a priority class that shall be used for the etcd pods. | ||
storageClass string | StorageClass defines the name of the StorageClass required by the claim. More info: https://kubernetes.io/docs/concepts/storage/persistent-volumes#class-1 | ||
storageCapacity Quantity | StorageCapacity defines the size of persistent volume. | ||
volumeClaimTemplate string | VolumeClaimTemplate defines the volume claim template to be created | ||
runAsRoot boolean | RunAsRoot defines whether the securityContext of the pod specification should indicate that the containers shall run as root. By default, they run as non-root with user ’nobody’. |
EtcdStatus
EtcdStatus defines the observed state of Etcd.
Appears in:
| Field | Description | Default | Validation |
|---|---|---|---|
observedGeneration integer | ObservedGeneration is the most recent generation observed for this resource. | ||
etcd CrossVersionObjectReference | |||
conditions Condition array | Conditions represents the latest available observations of an etcd’s current state. | ||
lastErrors LastError array | LastErrors captures errors that occurred during the last operation. | ||
lastOperation LastOperation | LastOperation indicates the last operation performed on this resource. | ||
currentReplicas integer | CurrentReplicas is the current replica count for the etcd cluster. | ||
replicas integer | Replicas is the replica count of the etcd cluster. | ||
readyReplicas integer | ReadyReplicas is the count of replicas being ready in the etcd cluster. | ||
ready boolean | Ready is true if all etcd replicas are ready. | ||
labelSelector LabelSelector | LabelSelector is a label query over pods that should match the replica count. It must match the pod template’s labels. Deprecated: this field will be removed in the future. | ||
members EtcdMemberStatus array | Members represents the members of the etcd cluster | ||
peerUrlTLSEnabled boolean | PeerUrlTLSEnabled captures the state of peer url TLS being enabled for the etcd member(s) | ||
selector string | Selector is a label query over pods that should match the replica count. It must match the pod template’s labels. |
GarbageCollectionPolicy
Underlying type: string
GarbageCollectionPolicy defines the type of policy for snapshot garbage collection.
Validation:
- Enum: [Exponential LimitBased]
Appears in:
LastError
LastError stores details of the most recent error encountered for a resource.
Appears in:
| Field | Description | Default | Validation |
|---|---|---|---|
code ErrorCode | Code is an error code that uniquely identifies an error. | ||
description string | Description is a human-readable message indicating details of the error. | ||
observedAt Time | ObservedAt is the time the error was observed. |
LastOperation
LastOperation holds the information on the last operation done on the Etcd resource.
Appears in:
| Field | Description | Default | Validation |
|---|---|---|---|
type LastOperationType | Type is the type of last operation. | ||
state LastOperationState | State is the state of the last operation. | ||
description string | Description describes the last operation. | ||
runID string | RunID correlates an operation with a reconciliation run. Every time an Etcd resource is reconciled (barring status reconciliation which is periodic), a unique ID is generated which can be used to correlate all actions done as part of a single reconcile run. Capturing this as part of LastOperation aids in establishing this correlation. This further helps in also easily filtering reconcile logs as all structured logs in a reconciliation run should have the runID referenced. | ||
lastUpdateTime Time | LastUpdateTime is the time at which the operation was last updated. |
LastOperationState
Underlying type: string
LastOperationState is a string alias representing the state of the last operation.
Appears in:
| Field | Description |
|---|---|
Processing | LastOperationStateProcessing indicates that an operation is in progress. |
Succeeded | LastOperationStateSucceeded indicates that an operation has completed successfully. |
Error | LastOperationStateError indicates that an operation is completed with errors and will be retried. |
Requeue | LastOperationStateRequeue indicates that an operation is not completed and either due to an error or unfulfilled conditions will be retried. |
LastOperationType
Underlying type: string
LastOperationType is a string alias representing type of the last operation.
Appears in:
| Field | Description |
|---|---|
Create | LastOperationTypeCreate indicates that the last operation was a creation of a new Etcd resource. |
Reconcile | LastOperationTypeReconcile indicates that the last operation was a reconciliation of the spec of an Etcd resource. |
Delete | LastOperationTypeDelete indicates that the last operation was a deletion of an existing Etcd resource. |
LeaderElectionSpec
LeaderElectionSpec defines parameters related to the LeaderElection configuration.
Appears in:
| Field | Description | Default | Validation |
|---|---|---|---|
reelectionPeriod Duration | ReelectionPeriod defines the Period after which leadership status of corresponding etcd is checked. | Pattern: ^([0-9]+([.][0-9]+)?h)?([0-9]+([.][0-9]+)?m)?([0-9]+([.][0-9]+)?s)?([0-9]+([.][0-9]+)?d)?$Type: string | |
etcdConnectionTimeout Duration | EtcdConnectionTimeout defines the timeout duration for etcd client connection during leader election. | Pattern: ^([0-9]+([.][0-9]+)?h)?([0-9]+([.][0-9]+)?m)?([0-9]+([.][0-9]+)?s)?([0-9]+([.][0-9]+)?d)?$Type: string |
MetricsLevel
Underlying type: string
MetricsLevel defines the level ‘basic’ or ’extensive’.
Validation:
- Enum: [basic extensive]
Appears in:
| Field | Description |
|---|---|
basic | Basic is a constant for metrics level basic. |
extensive | Extensive is a constant for metrics level extensive. |
SchedulingConstraints
SchedulingConstraints defines the different scheduling constraints that must be applied to the pod spec in the etcd statefulset. Currently supported constraints are Affinity and TopologySpreadConstraints.
Appears in:
| Field | Description | Default | Validation |
|---|---|---|---|
affinity Affinity | Affinity defines the various affinity and anti-affinity rules for a pod that are honoured by the kube-scheduler. | ||
topologySpreadConstraints TopologySpreadConstraint array | TopologySpreadConstraints describes how a group of pods ought to spread across topology domains, that are honoured by the kube-scheduler. |
SecretReference
SecretReference defines a reference to a secret.
Appears in:
| Field | Description | Default | Validation |
|---|---|---|---|
dataKey string | DataKey is the name of the key in the data map containing the credentials. |
SharedConfig
SharedConfig defines parameters shared and used by Etcd as well as backup-restore sidecar.
Appears in:
| Field | Description | Default | Validation |
|---|---|---|---|
autoCompactionMode CompactionMode | AutoCompactionMode defines the auto-compaction-mode:‘periodic’ mode or ‘revision’ mode for etcd and embedded-etcd of backup-restore sidecar. | Enum: [periodic revision] | |
autoCompactionRetention string | AutoCompactionRetention defines the auto-compaction-retention length for etcd as well as for embedded-etcd of backup-restore sidecar. |
StorageProvider
Underlying type: string
StorageProvider defines the type of object store provider for storing backups.
Appears in:
StoreSpec
StoreSpec defines parameters related to ObjectStore persisting backups
Appears in:
| Field | Description | Default | Validation |
|---|---|---|---|
container string | Container is the name of the container the backup is stored at. | ||
prefix string | Prefix is the prefix used for the store. | ||
provider StorageProvider | Provider is the name of the backup provider. | ||
secretRef SecretReference | SecretRef is the reference to the secret which used to connect to the backup store. |
TLSConfig
TLSConfig hold the TLS configuration details.
Appears in:
| Field | Description | Default | Validation |
|---|---|---|---|
tlsCASecretRef SecretReference | |||
serverTLSSecretRef SecretReference | |||
clientTLSSecretRef SecretReference |
WaitForFinalSnapshotSpec
WaitForFinalSnapshotSpec defines the parameters for waiting for a final full snapshot before copying backups.
Appears in:
| Field | Description | Default | Validation |
|---|---|---|---|
enabled boolean | Enabled specifies whether to wait for a final full snapshot before copying backups. | ||
timeout Duration | Timeout is the timeout for waiting for a final full snapshot. When this timeout expires, the copying of backups will be performed anyway. No timeout or 0 means wait forever. |
2.15 - etcd Network Latency
Network Latency analysis: sn-etcd-sz vs mn-etcd-sz vs mn-etcd-mz
This page captures the etcd cluster latency analysis for below scenarios using the benchmark tool (build from etcd benchmark tool).
sn-etcd-sz -> single-node etcd single zone (Only single replica of etcd will be running)
mn-etcd-sz -> multi-node etcd single zone (Multiple replicas of etcd pods will be running across nodes in a single zone)
mn-etcd-mz -> multi-node etcd multi zone (Multiple replicas of etcd pods will be running across nodes in multiple zones)
PUT Analysis
Summary
sn-etcd-szlatency is ~20% less thanmn-etcd-szwhen benchmark tool with single client.mn-etcd-szlatency is less thanmn-etcd-mzbut the difference is~+/-5%.- Compared to
mn-etcd-sz,sn-etcd-szlatency is higher and gradually grows with more clients and larger value size. - Compared to
mn-etcd-mz,mn-etcd-szlatency is higher and gradually grows with more clients and larger value size. - Compared to
follower,leaderlatency is less, when benchmark tool with single client for all cases. - Compared to
follower,leaderlatency is high, when benchmark tool with multiple clients for all cases.
Sample commands:
# write to leader
benchmark put --target-leader --conns=1 --clients=1 --precise \
--sequential-keys --key-starts 0 --val-size=256 --total=10000 \
--endpoints=$ETCD_HOST
# write to follower
benchmark put --conns=1 --clients=1 --precise \
--sequential-keys --key-starts 0 --val-size=256 --total=10000 \
--endpoints=$ETCD_FOLLOWER_HOST
Latency analysis during PUT requests to etcd
In this case benchmark tool tries to put key with random 256 bytes value.
Benchmark tool loads key/value to
leaderwith single client .sn-etcd-szlatency (~0.815ms) is ~50% lesser thanmn-etcd-sz(~1.74ms ).mn-etcd-szlatency (~1.74ms ) is slightly lesser thanmn-etcd-mz(~1.8ms) but the difference is negligible (within same ms).
Number of keys Value size Number of connections Number of clients Target etcd server Average write QPS Average latency per request zone server name Test name 10000 256 1 1 leader 1220.0520 0.815ms eu-west-1c etcd-main-0 sn-etcd-sz 10000 256 1 1 leader 586.545 1.74ms eu-west-1a etcd-main-1 mn-etcd-sz 10000 256 1 1 leader 554.0155654442634 1.8ms eu-west-1a etcd-main-1 mn-etcd-mz
Benchmark tool loads key/value to
followerwith single client.mn-etcd-szlatency(~2.2ms) is 20% to 30% lesser thanmn-etcd-mz(~2.7ms).- Compare to
follower,leaderhas lower latency. Number of keys Value size Number of connections Number of clients Target etcd server Average write QPS Average latency per request zone server name Test name 10000 256 1 1 follower-1 445.743 2.23ms eu-west-1a etcd-main-0 mn-etcd-sz 10000 256 1 1 follower-1 378.9366747610789 2.63ms eu-west-1c etcd-main-0 mn-etcd-mz Number of keys Value size Number of connections Number of clients Target etcd server Average write QPS Average latency per request zone server name Test name 10000 256 1 1 follower-2 457.967 2.17ms eu-west-1a etcd-main-2 mn-etcd-sz 10000 256 1 1 follower-2 345.6586129825796 2.89ms eu-west-1b etcd-main-2 mn-etcd-mz
Benchmark tool loads key/value to
leaderwith multiple clients.sn-etcd-szlatency(~78.3ms) is ~10% greater thanmn-etcd-sz(~71.81ms).mn-etcd-szlatency(~71.81ms) is less thanmn-etcd-mz(~72.5ms) but the difference is negligible.Number of keys Value size Number of connections Number of clients Target etcd server Average write QPS Average latency per request zone server name Test name 100000 256 100 1000 leader 12638.905 78.32ms eu-west-1c etcd-main-0 sn-etcd-sz 100000 256 100 1000 leader 13789.248 71.81ms eu-west-1a etcd-main-1 mn-etcd-sz 100000 256 100 1000 leader 13728.446436395223 72.5ms eu-west-1a etcd-main-1 mn-etcd-mz
Benchmark tool loads key/value to
followerwith multiple clients.mn-etcd-szlatency(~69.8ms) is ~5% greater thanmn-etcd-mz(~72.6ms).- Compare to
leader,followerhas lower latency. Number of keys Value size Number of connections Number of clients Target etcd server Average write QPS Average latency per request zone server name Test name 100000 256 100 1000 follower-1 14271.983 69.80ms eu-west-1a etcd-main-0 mn-etcd-sz 100000 256 100 1000 follower-1 13695.98 72.62ms eu-west-1a etcd-main-1 mn-etcd-mz Number of keys Value size Number of connections Number of clients Target etcd server Average write QPS Average latency per request zone server name Test name 100000 256 100 1000 follower-2 14325.436 69.47ms eu-west-1a etcd-main-2 mn-etcd-sz 100000 256 100 1000 follower-2 15750.409490407475 63.3ms eu-west-1b etcd-main-2 mn-etcd-mz
In this case benchmark tool tries to put key with random 1 MB value.
Benchmark tool loads key/value to
leaderwith single client.sn-etcd-szlatency(~16.35ms) is ~20% lesser thanmn-etcd-sz(~20.64ms).mn-etcd-szlatency(~20.64ms) is less thanmn-etcd-mz(~21.08ms) but the difference is negligible..Number of keys Value size Number of connections Number of clients Target etcd server Average write QPS Average latency per request zone server name Test name 1000 1000000 1 1 leader 61.117 16.35ms eu-west-1c etcd-main-0 sn-etcd-sz 1000 1000000 1 1 leader 48.416 20.64ms eu-west-1a etcd-main-1 mn-etcd-sz 1000 1000000 1 1 leader 45.7517341664802 21.08ms eu-west-1a etcd-main-1 mn-etcd-mz
Benchmark tool loads key/value withto
followersingle client.mn-etcd-szlatency(~23.10ms) is ~10% greater thanmn-etcd-mz(~21.8ms).- Compare to
follower,leaderhas lower latency. Number of keys Value size Number of connections Number of clients Target etcd server Average write QPS Average latency per request zone server name Test name 1000 1000000 1 1 follower-1 43.261 23.10ms eu-west-1a etcd-main-0 mn-etcd-sz 1000 1000000 1 1 follower-1 45.7517341664802 21.8ms eu-west-1c etcd-main-0 mn-etcd-mz 1000 1000000 1 1 follower-1 45.33 22.05ms eu-west-1c etcd-main-0 mn-etcd-mz Number of keys Value size Number of connections Number of clients Target etcd server Average write QPS Average latency per request zone server name Test name 1000 1000000 1 1 follower-2 40.0518 24.95ms eu-west-1a etcd-main-2 mn-etcd-sz 1000 1000000 1 1 follower-2 43.28573155709838 23.09ms eu-west-1b etcd-main-2 mn-etcd-mz 1000 1000000 1 1 follower-2 45.92 21.76ms eu-west-1a etcd-main-1 mn-etcd-mz 1000 1000000 1 1 follower-2 35.5705 28.1ms eu-west-1b etcd-main-2 mn-etcd-mz
Benchmark tool loads key/value to
leaderwith multiple clients.sn-etcd-szlatency(~6.0375secs) is ~30% greater thanmn-etcd-sz``~4.000secs).mn-etcd-szlatency(~4.000secs) is less thanmn-etcd-mz(~ 4.09secs) but the difference is negligible.Number of keys Value size Number of connections Number of clients Target etcd server Average write QPS Average latency per request zone server name Test name 1000 1000000 100 300 leader 55.373 6.0375secs eu-west-1c etcd-main-0 sn-etcd-sz 1000 1000000 100 300 leader 67.319 4.000secs eu-west-1a etcd-main-1 mn-etcd-sz 1000 1000000 100 300 leader 65.91914167957594 4.09secs eu-west-1a etcd-main-1 mn-etcd-mz
Benchmark tool loads key/value to
followerwith multiple clients.mn-etcd-szlatency(~4.04secs) is ~5% greater thanmn-etcd-mz(~ 3.90secs).- Compare to
leader,followerhas lower latency. Number of keys Value size Number of connections Number of clients Target etcd server Average write QPS Average latency per request zone server name Test name 1000 1000000 100 300 follower-1 66.528 4.0417secs eu-west-1a etcd-main-0 mn-etcd-sz 1000 1000000 100 300 follower-1 70.6493461856332 3.90secs eu-west-1c etcd-main-0 mn-etcd-mz 1000 1000000 100 300 follower-1 71.95 3.84secs eu-west-1c etcd-main-0 mn-etcd-mz Number of keys Value size Number of connections Number of clients Target etcd server Average write QPS Average latency per request zone server name Test name 1000 1000000 100 300 follower-2 66.447 4.0164secs eu-west-1a etcd-main-2 mn-etcd-sz 1000 1000000 100 300 follower-2 67.53038086369484 3.87secs eu-west-1b etcd-main-2 mn-etcd-mz 1000 1000000 100 300 follower-2 68.46 3.92secs eu-west-1a etcd-main-1 mn-etcd-mz
Range Analysis
Sample commands are:
# Single connection read request with sequential keys
benchmark range 0 --target-leader --conns=1 --clients=1 --precise \
--sequential-keys --key-starts 0 --total=10000 \
--consistency=l \
--endpoints=$ETCD_HOST
# --consistency=s [Serializable]
benchmark range 0 --target-leader --conns=1 --clients=1 --precise \
--sequential-keys --key-starts 0 --total=10000 \
--consistency=s \
--endpoints=$ETCD_HOST
# Each read request with range query matches key 0 9999 and repeats for total number of requests.
benchmark range 0 9999 --target-leader --conns=1 --clients=1 --precise \
--total=10 \
--consistency=s \
--endpoints=https://etcd-main-client:2379
# Read requests with multiple connections
benchmark range 0 --target-leader --conns=100 --clients=1000 --precise \
--sequential-keys --key-starts 0 --total=100000 \
--consistency=l \
--endpoints=$ETCD_HOST
benchmark range 0 --target-leader --conns=100 --clients=1000 --precise \
--sequential-keys --key-starts 0 --total=100000 \
--consistency=s \
--endpoints=$ETCD_HOST
Latency analysis during Range requests to etcd
In this case benchmark tool tries to get specific key with random 256 bytes value.
Benchmark tool range requests to
leaderwith single client.sn-etcd-szlatency(~1.24ms) is ~40% greater thanmn-etcd-sz(~0.67ms).mn-etcd-szlatency(~0.67ms) is ~20% lesser thanmn-etcd-mz(~0.85ms).Number of requests Value size Number of connections Number of clients sequential-keys Consistency Target etcd server Average write QPS Average latency per request zone server name Test name 10000 256 1 1 true l leader 800.272 1.24ms eu-west-1c etcd-main-0 sn-etcd-sz 10000 256 1 1 true l leader 1173.9081 0.67ms eu-west-1a etcd-main-1 mn-etcd-sz 10000 256 1 1 true l leader 999.3020189178693 0.85ms eu-west-1a etcd-main-1 mn-etcd-mz Compare to consistency
Linearizable,Serializableis ~40% less for all casesNumber of requests Value size Number of connections Number of clients sequential-keys Consistency Target etcd server Average write QPS Average latency per request zone server name Test name 10000 256 1 1 true s leader 1411.229 0.70ms eu-west-1c etcd-main-0 sn-etcd-sz 10000 256 1 1 true s leader 2033.131 0.35ms eu-west-1a etcd-main-1 mn-etcd-sz 10000 256 1 1 true s leader 2100.2426362012025 0.47ms eu-west-1a etcd-main-1 mn-etcd-mz
Benchmark tool range requests to
followerwith single client .mn-etcd-szlatency(~1.3ms) is ~20% lesser thanmn-etcd-mz(~1.6ms).- Compare to
follower,leaderread request latency is ~50% less for bothmn-etcd-sz,mn-etcd-mz Number of requests Value size Number of connections Number of clients sequential-keys Consistency Target etcd server Average write QPS Average latency per request zone server name Test name 10000 256 1 1 true l follower-1 765.325 1.3ms eu-west-1a etcd-main-0 mn-etcd-sz 10000 256 1 1 true l follower-1 596.1 1.6ms eu-west-1c etcd-main-0 mn-etcd-mz - Compare to consistency
Linearizable,Serializableis ~50% less for all cases Number of requests Value size Number of connections Number of clients sequential-keys Consistency Target etcd server Average write QPS Average latency per request zone server name Test name 10000 256 1 1 true s follower-1 1823.631 0.54ms eu-west-1a etcd-main-0 mn-etcd-sz 10000 256 1 1 true s follower-1 1442.6 0.69ms eu-west-1c etcd-main-0 mn-etcd-mz 10000 256 1 1 true s follower-1 1416.39 0.70ms eu-west-1c etcd-main-0 mn-etcd-mz 10000 256 1 1 true s follower-1 2077.449 0.47ms eu-west-1a etcd-main-1 mn-etcd-mz
Benchmark tool range requests to
leaderwith multiple client.sn-etcd-szlatency(~84.66ms) is ~20% greater thanmn-etcd-sz(~73.95ms).mn-etcd-szlatency(~73.95ms) is more or less equal tomn-etcd-mz(~ 73.8ms).Number of requests Value size Number of connections Number of clients sequential-keys Consistency Target etcd server Average write QPS Average latency per request zone server name Test name 100000 256 100 1000 true l leader 11775.721 84.66ms eu-west-1c etcd-main-0 sn-etcd-sz 100000 256 100 1000 true l leader 13446.9598 73.95ms eu-west-1a etcd-main-1 mn-etcd-sz 100000 256 100 1000 true l leader 13527.19810605353 73.8ms eu-west-1a etcd-main-1 mn-etcd-mz Compare to consistency
Linearizable,Serializableis ~20% lesser for all casessn-etcd-szlatency(~69.37ms) is more or less equal tomn-etcd-sz(~69.89ms).mn-etcd-szlatency(~69.89ms) is slightly higher thanmn-etcd-mz(~67.63ms).Number of requests Value size Number of connections Number of clients sequential-keys Consistency Target etcd server Average write QPS Average latency per request zone server name Test name 100000 256 100 1000 true s leader 14334.9027 69.37ms eu-west-1c etcd-main-0 sn-etcd-sz 100000 256 100 1000 true s leader 14270.008 69.89ms eu-west-1a etcd-main-1 mn-etcd-sz 100000 256 100 1000 true s leader 14715.287354023869 67.63ms eu-west-1a etcd-main-1 mn-etcd-mz
Benchmark tool range requests to
followerwith multiple client.mn-etcd-szlatency(~60.69ms) is ~20% lesser thanmn-etcd-mz(~70.76ms).Compare to
leader,followerhas lower read request latency.Number of requests Value size Number of connections Number of clients sequential-keys Consistency Target etcd server Average write QPS Average latency per request zone server name Test name 100000 256 100 1000 true l follower-1 11586.032 60.69ms eu-west-1a etcd-main-0 mn-etcd-sz 100000 256 100 1000 true l follower-1 14050.5 70.76ms eu-west-1c etcd-main-0 mn-etcd-mz mn-etcd-szlatency(~86.09ms) is ~20 higher thanmn-etcd-mz(~64.6ms).- Compare to
mn-etcd-szconsistencyLinearizable,Serializableis ~20% higher.*
- Compare to
Compare to
mn-etcd-mzconsistencyLinearizable,Serializableis ~slightly less.Number of requests Value size Number of connections Number of clients sequential-keys Consistency Target etcd server Average write QPS Average latency per request zone server name Test name 100000 256 100 1000 true s follower-1 11582.438 86.09ms eu-west-1a etcd-main-0 mn-etcd-sz 100000 256 100 1000 true s follower-1 15422.2 64.6ms eu-west-1c etcd-main-0 mn-etcd-mz
Benchmark tool range requests to
leaderall keys.sn-etcd-szlatency(~678.77ms) is ~5% slightly lesser thanmn-etcd-sz(~697.29ms).mn-etcd-szlatency(~697.29ms) is less thanmn-etcd-mz(~701ms) but the difference is negligible.Number of requests Value size Number of connections Number of clients sequential-keys Consistency Target etcd server Average write QPS Average latency per request zone server name Test name 20 256 2 5 false l leader 6.8875 678.77ms eu-west-1c etcd-main-0 sn-etcd-sz 20 256 2 5 false l leader 6.720 697.29ms eu-west-1a etcd-main-1 mn-etcd-sz 20 256 2 5 false l leader 6.7 701ms eu-west-1a etcd-main-1 mn-etcd-mz - Compare to consistency
Linearizable,Serializableis ~5% slightly higher for all cases
- Compare to consistency
sn-etcd-szlatency(~687.36ms) is less thanmn-etcd-sz(~692.68ms) but the difference is negligible.mn-etcd-szlatency(~692.68ms) is ~5% slightly lesser thanmn-etcd-mz(~735.7ms).Number of requests Value size Number of connections Number of clients sequential-keys Consistency Target etcd server Average write QPS Average latency per request zone server name Test name 20 256 2 5 false s leader 6.76 687.36ms eu-west-1c etcd-main-0 sn-etcd-sz 20 256 2 5 false s leader 6.635 692.68ms eu-west-1a etcd-main-1 mn-etcd-sz 20 256 2 5 false s leader 6.3 735.7ms eu-west-1a etcd-main-1 mn-etcd-mz
Benchmark tool range requests to
followerall keysmn-etcd-sz(~737.68ms) latency is ~5% slightly higher thanmn-etcd-mz(~713.7ms).Compare to
leaderconsistencyLinearizableread request,followeris ~5% slightly higher.Number of requests Value size Number of connections Number of clients sequential-keys Consistency Target etcd server Average write QPS Average latency per request zone server name Test name 20 256 2 5 false l follower-1 6.163 737.68ms eu-west-1a etcd-main-0 mn-etcd-sz 20 256 2 5 false l follower-1 6.52 713.7ms eu-west-1c etcd-main-0 mn-etcd-mz mn-etcd-szlatency(~757.73ms) is ~10% higher thanmn-etcd-mz(~690.4ms).Compare to
followerconsistencyLinearizableread request,followerconsistencySerializableis ~3% slightly higher formn-etcd-sz.Compare to
followerconsistencyLinearizableread request,followerconsistencySerializableis ~5% less formn-etcd-mz.*Compare to
leaderconsistencySerializableread request,followerconsistencySerializableis ~5% less formn-etcd-mz. *Number of requests Value size Number of connections Number of clients sequential-keys Consistency Target etcd server Average write QPS Average latency per request zone server name Test name 20 256 2 5 false s follower-1 6.0295 757.73ms eu-west-1a etcd-main-0 mn-etcd-sz 20 256 2 5 false s follower-1 6.87 690.4ms eu-west-1c etcd-main-0 mn-etcd-mz
In this case benchmark tool tries to get specific key with random `1MB` value.
Benchmark tool range requests to
leaderwith single client.sn-etcd-szlatency(~5.96ms) is ~5% lesser thanmn-etcd-sz(~6.28ms).mn-etcd-szlatency(~6.28ms) is ~10% higher thanmn-etcd-mz(~5.3ms).Number of requests Value size Number of connections Number of clients sequential-keys Consistency Target etcd server Average write QPS Average latency per request zone server name Test name 1000 1000000 1 1 true l leader 167.381 5.96ms eu-west-1c etcd-main-0 sn-etcd-sz 1000 1000000 1 1 true l leader 158.822 6.28ms eu-west-1a etcd-main-1 mn-etcd-sz 1000 1000000 1 1 true l leader 187.94 5.3ms eu-west-1a etcd-main-1 mn-etcd-mz Compare to consistency
Linearizable,Serializableis ~15% less forsn-etcd-sz,mn-etcd-sz,mn-etcd-mzNumber of requests Value size Number of connections Number of clients sequential-keys Consistency Target etcd server Average write QPS Average latency per request zone server name Test name 1000 1000000 1 1 true s leader 184.95 5.398ms eu-west-1c etcd-main-0 sn-etcd-sz 1000 1000000 1 1 true s leader 176.901 5.64ms eu-west-1a etcd-main-1 mn-etcd-sz 1000 1000000 1 1 true s leader 209.99 4.7ms eu-west-1a etcd-main-1 mn-etcd-mz
Benchmark tool range requests to
followerwith single client.mn-etcd-szlatency(~6.66ms) is ~10% higher thanmn-etcd-mz(~6.16ms).Compare to
leader,followerread request latency is ~10% high formn-etcd-szCompare to
leader,followerread request latency is ~20% high formn-etcd-mzNumber of requests Value size Number of connections Number of clients sequential-keys Consistency Target etcd server Average write QPS Average latency per request zone server name Test name 1000 1000000 1 1 true l follower-1 150.680 6.66ms eu-west-1a etcd-main-0 mn-etcd-sz 1000 1000000 1 1 true l follower-1 162.072 6.16ms eu-west-1c etcd-main-0 mn-etcd-mz Compare to consistency
Linearizable,Serializableis ~15% less formn-etcd-sz(~5.84ms),mn-etcd-mz(~5.01ms).Compare to
leader,followerread request latency is ~5% slightly high formn-etcd-sz,mn-etcd-mzNumber of requests Value size Number of connections Number of clients sequential-keys Consistency Target etcd server Average write QPS Average latency per request zone server name Test name 1000 1000000 1 1 true s follower-1 170.918 5.84ms eu-west-1a etcd-main-0 mn-etcd-sz 1000 1000000 1 1 true s follower-1 199.01 5.01ms eu-west-1c etcd-main-0 mn-etcd-mz
Benchmark tool range requests to
leaderwith multiple clients.sn-etcd-szlatency(~1.593secs) is ~20% lesser thanmn-etcd-sz(~1.974secs).mn-etcd-szlatency(~1.974secs) is ~5% greater thanmn-etcd-mz(~1.81secs).Number of requests Value size Number of connections Number of clients sequential-keys Consistency Target etcd server Average write QPS Average latency per request zone server name Test name 1000 1000000 100 500 true l leader 252.149 1.593secs eu-west-1c etcd-main-0 sn-etcd-sz 1000 1000000 100 500 true l leader 205.589 1.974secs eu-west-1a etcd-main-1 mn-etcd-sz 1000 1000000 100 500 true l leader 230.42 1.81secs eu-west-1a etcd-main-1 mn-etcd-mz Compare to consistency
Linearizable,Serializableis more or less same forsn-etcd-sz(~1.57961secs),mn-etcd-mz(~1.8secs) not a big differenceCompare to consistency
Linearizable,Serializableis ~10% high formn-etcd-sz(~ 2.277secs).Number of requests Value size Number of connections Number of clients sequential-keys Consistency Target etcd server Average write QPS Average latency per request zone server name Test name 1000 1000000 100 500 true s leader 252.406 1.57961secs eu-west-1c etcd-main-0 sn-etcd-sz 1000 1000000 100 500 true s leader 181.905 2.277secs eu-west-1a etcd-main-1 mn-etcd-sz 1000 1000000 100 500 true s leader 227.64 1.8secs eu-west-1a etcd-main-1 mn-etcd-mz
Benchmark tool range requests to
followerwith multiple client.mn-etcd-szlatency is ~20% less thanmn-etcd-mz.Compare to
leaderconsistencyLinearizable,followerread request latency is ~15 less formn-etcd-sz(~1.694secs).Compare to
leaderconsistencyLinearizable,followerread request latency is ~10% higher formn-etcd-sz(~1.977secs).Number of requests Value size Number of connections Number of clients sequential-keys Consistency Target etcd server Average write QPS Average latency per request zone server name Test name 1000 1000000 100 500 true l follower-1 248.489 1.694secs eu-west-1a etcd-main-0 mn-etcd-sz 1000 1000000 100 500 true l follower-1 210.22 1.977secs eu-west-1c etcd-main-0 mn-etcd-mz Number of requests Value size Number of connections Number of clients sequential-keys Consistency Target etcd server Average write QPS Average latency per request zone server name Test name 1000 1000000 100 500 true l follower-2 205.765 1.967secs eu-west-1a etcd-main-2 mn-etcd-sz 1000 1000000 100 500 true l follower-2 195.2 2.159secs eu-west-1b etcd-main-2 mn-etcd-mz Number of requests Value size Number of connections Number of clients sequential-keys Consistency Target etcd server Average write QPS Average latency per request zone server name Test name 1000 1000000 100 500 true s follower-1 231.458 1.7413secs eu-west-1a etcd-main-0 mn-etcd-sz 1000 1000000 100 500 true s follower-1 214.80 1.907secs eu-west-1c etcd-main-0 mn-etcd-mz Number of requests Value size Number of connections Number of clients sequential-keys Consistency Target etcd server Average write QPS Average latency per request zone server name Test name 1000 1000000 100 500 true s follower-2 183.320 2.2810secs eu-west-1a etcd-main-2 mn-etcd-sz 1000 1000000 100 500 true s follower-2 195.40 2.164secs eu-west-1b etcd-main-2 mn-etcd-mz
Benchmark tool range requests to
leaderall keys.sn-etcd-szlatency(~8.993secs) is ~3% slightly lower thanmn-etcd-sz(~9.236secs).mn-etcd-szlatency(~9.236secs) is ~2% slightly lower thanmn-etcd-mz(~9.100secs).Number of requests Value size Number of connections Number of clients sequential-keys Consistency Target etcd server Average write QPS Average latency per request zone server name Test name 20 1000000 2 5 false l leader 0.5139 8.993secs eu-west-1c etcd-main-0 sn-etcd-sz 20 1000000 2 5 false l leader 0.506 9.236secs eu-west-1a etcd-main-1 mn-etcd-sz 20 1000000 2 5 false l leader 0.508 9.100secs eu-west-1a etcd-main-1 mn-etcd-mz Compare to consistency
Linearizableread request,followerforsn-etcd-sz(~9.secs) is a slight difference10ms.Compare to consistency
Linearizableread request,followerformn-etcd-sz(~9.113secs) is ~1% less, not a big difference.Compare to consistency
Linearizableread request,followerformn-etcd-mz(~8.799secs) is ~3% less, not a big difference.sn-etcd-szlatency(~9.secs) is ~1% slightly less thanmn-etcd-sz(~9.113secs).mn-etcd-szlatency(~9.113secs) is ~3% slightly higher thanmn-etcd-mz(~8.799secs).Number of requests Value size Number of connections Number of clients sequential-keys Consistency Target etcd server Average write QPS Average latency per request zone server name Test name 20 1000000 2 5 false s leader 0.51125 9.0003secs eu-west-1c etcd-main-0 sn-etcd-sz 20 1000000 2 5 false s leader 0.4993 9.113secs eu-west-1a etcd-main-1 mn-etcd-sz 20 1000000 2 5 false s leader 0.522 8.799secs eu-west-1a etcd-main-1 mn-etcd-mz
Benchmark tool range requests to
followerall keysmn-etcd-szlatency(~9.065secs) is ~1% slightly higher thanmn-etcd-mz(~9.007secs).Compare to
leaderconsistencyLinearizableread request,followeris ~1% slightly higher for both casesmn-etcd-sz,mn-etcd-mz.Number of requests Value size Number of connections Number of clients sequential-keys Consistency Target etcd server Average write QPS Average latency per request zone server name Test name 20 1000000 2 5 false l follower-1 0.512 9.065secs eu-west-1a etcd-main-0 mn-etcd-sz 20 1000000 2 5 false l follower-1 0.533 9.007secs eu-west-1c etcd-main-0 mn-etcd-mz Compare to consistency
Linearizableread request,followerformn-etcd-sz(~9.553secs) is ~5% high.Compare to consistency
Linearizableread request,followerformn-etcd-mz(~7.7433secs) is ~15% less.mn-etcd-sz(~9.553secs) latency is ~20% higher thanmn-etcd-mz(~7.7433secs).Number of requests Value size Number of connections Number of clients sequential-keys Consistency Target etcd server Average write QPS Average latency per request zone server name Test name 20 1000000 2 5 false s follower-1 0.4743 9.553secs eu-west-1a etcd-main-0 mn-etcd-sz 20 1000000 2 5 false s follower-1 0.5500 7.7433secs eu-west-1c etcd-main-0 mn-etcd-mz
NOTE: This Network latency analysis is inspired by etcd performance.
2.16 - EtcdMember Custom Resource
DEP-04: EtcdMember Custom Resource
Summary
Today, etcd-druid mainly acts as an etcd cluster provisioner, and seldom takes remediatory actions if the etcd cluster goes into an undesired state that needs to be resolved by a human operator. In other words, etcd-druid cannot perform day-2 operations on etcd clusters in its current form, and hence cannot carry out its full set of responsibilities as a true “operator” of etcd clusters. For etcd-druid to be fully capable of its responsibilities, it must know the latest state of the etcd clusters and their individual members at all times.
This proposal aims to bridge that gap by introducing EtcdMember custom resource allowing individual etcd cluster members to publish information/state (previously unknown to etcd-druid). This provides etcd-druid a handle to potentially take cluster-scoped remediatory actions.
Terminology
druid: etcd-druid - an operator for etcd clusters.
etcd-member: A single etcd pod in an etcd cluster that is realised as a StatefulSet.
backup-sidecar: It is the etcd-backup-restore sidecar container in each etcd-member pod.
NOTE: Term sidecar can now be confused with the latest definition in KEP-73. etcd-backup-restore container is currently not set as an
init-containeras proposed in the KEP but as a regular container in a multi-container [Pod](Pods | Kubernetes).leading-backup-sidecar: A backup-sidecar that is associated to an etcd leader.
restoration: It refers to an individual etcd-member restoring etcd data from an existing backup (comprising of full and delta snapshots). The authors have deliberately chosen to distinguish between restoration and learning. Learning refers to a process where a learner “learns” from an etcd-cluster leader.
Motivation
Sharing state of an individual etcd-member with druid is essential for diagnostics, monitoring, cluster-wide-operations and potential remediation. At present, only a subset of etcd-member state is shared with druid using leases. It was always meant as a stopgap arrangement as mentioned in the corresponding issue and is not the best use of leases.
There is a need to have a clear distinction between an etcd-member state and etcd cluster state since most of an etcd cluster state is often derived by looking at individual etcd-member states. In addition, actors which update each of these states should be clearly identified so as to prevent multiple actors updating a single resource holding the state of either an etcd cluster or an etcd-member. As a consequence, etcd-members should not directly update the Etcd resource status and would therefore need a new custom resource allowing each member to publish detailed information about its latest state.
Goals
- Introduce
EtcdMembercustom resource via which each etcd-member can publish information about its state. This enables druid to deterministically orchestrate out-of-turn operations like compaction, defragmentation, volume management etc. - Define and capture states, sub-states and deterministic transitions amongst states of an etcd-member.
- Today leases are misused to share member-specific information with druid. Their usage to share member state [leader, follower, learner], member-id, snapshot revisions etc should be removed.
Non-Goals
- Auto-recovery from quorum loss or cluster-split due to network partitioning.
- Auto-recovery of an etcd-member due to volume mismatch.
- Relooking at segregating responsiblities between
etcdandbackup-sidecarcontainers.
Proposal
This proposal introduces a new custom resource EtcdMember, and in the following sections describes different sets of information that should be captured as part of the new resource.
Etcd Member Metadata
Every etcd-member has a unique memberID and it is part of an etcd cluster which has a unique clusterID. In a well-formed etcd cluster every member must have the same clusterID. Publishing this information to druid helps in identifying issues when one or more etcd-members form their own individual clusters, thus resulting in multiple clusters where only one was expected. Issues Issue#419, Canary#4027, Canary#3973 are some such occurrences.
Today, this information is published by using a member lease. Both these fields are populated in the leases’ Spec.HolderIdentity by the backup-sidecar container.
The authors propose to publish member metadata information in EtcdMember resource.
id: <etcd-member id>
clusterID: <etcd cluster id>
NOTE: Druid would not do any auto-recovery when it finds out that there are more than one clusters being formed. Instead this information today will be used for diagnostic and alerting.
Etcd Member State Transitions
Each etcd-member goes through different States during its lifetime. State is a derived high-level summary of where an etcd-member is in its lifecycle. A SubState gives additional information about the state. This proposal extends the concept of states with the notion of a SubState, since State indicates a top-level state of an EtcdMember resource, which can have one or more SubStates.
While State is sufficient for many human operators, the notion of a SubState provides operators with an insight about the discrete stage of an etcd-member in its lifecycle. For example, consider a top-level State: Starting, which indicates that an etcd-member is starting. Starting is meant to be a transient state for an etcd-member. If an etcd-member remains in this State longer than expected, then an operator would require additional insight, which the authors propose to provide via SubState (in this case, the possible SubStates could be PendingLearner and Learner, which are detailed in the following sections).
At present, these states are not captured and only the final state is known - i.e the etcd-member either fails to come up (all re-attempts to bring up the pod via the StatefulSet controller has exhausted) or it comes up. Getting an insight into all its state transitions would help in diagnostics.
The status of an etcd-member at any given point in time can be best categorized as a combination of a top-level State and a SubState. The authors propose to introduce the following states and sub-states:
States and Sub-States
NOTE: Abbreviations have been used wherever possible, only to represent sub-states. These representations are chosen only for brevity and will have proper longer names.
| States | Sub-States | Description |
|---|---|---|
| New | - | Every newly created etcd-member will start in this state and is termed as the initial state or the start state. |
| Initializing | DBV-S (DBValidationSanity) | This state denotes that backup-restore container in etcd-member pod has started initialization. Sub-State DBV-S which is an abbreviation for DBValidationSanity denotes that currently sanity etcd DB validation is in progress. |
| Initializing | DBV-F (DBValidationFull) | This state denotes that backup-restore container in etcd-member pod has started initialization. Sub-State DBV-F which is an abbreviation for DBValidationFull denotes that currently full etcd DB validation is in progress. |
| Initializing | R (Restoration) | This state denotes that backup-restore container in etcd-member pod has started initialization. Sub-State R which is an abbreviation for Restoration denotes that DB validation failed and now backup-restore has commenced restoration of etcd DB from the backup (comprising of full snapshot and delta-snapshots). An etcd-member will transition to this sub-state only when it is part of a single-node etcd-cluster. |
| Starting (SI) | PL (PendingLearner) | An etcd-member can transition from Initializing state to PendingLearner state. In this state backup-restore container will optionally delete any existing etcd data directory and then attempts to add its peer etcd-member process as a learner. Since there can be only one learner at a time in an etcd cluster, an etcd-member could be in this state for some time till its request to get added as a learner is accepted. |
| Starting (SI) | Learner | When backup-restore is successfully able to add its peer etcd-member process as a Learner. In this state the etcd-member process will start its DB sync from an etcd leader. |
| Started (Sd) | Follower | A follower is a voting raft member. A Learner etcd-member will get promoted to a Follower once its DB is in sync with the leader. It could also become a follower if during a re-election it loses leadership and transitions from being a Leader to Follower. |
| Started (Sd) | Leader | A leader is an etcd-member which will handle all client write requests and linearizable read requests. A member could transition to being a Leader from an existing Follower role due to winning a leader election or for a single node etcd cluster it directly transitions from Initializing state to Leader state as there is no other member. |
In the following sub-sections, the state transitions are categorized into several flows making it easier to grasp the different transitions.
Top Level State Transitions
Following DFA represents top level state transitions (without any representation of sub-states). As described in the table above there are 4 top level states:
New- this is a start state for all newly created etcd-membersInitializing- In this state backup-restore will perform pre-requisite actions before it triggers the start of an etcd process. DB validation and optionally restoration is done in this state. Possible sub-states are:DBValidationSanity,DBValidationFullandRestorationStarting- Once the optional initialization is done backup-restore will trigger the start of an etcd process. It can either directly go toLearnersub-state or wait for getting added as a learner and therefore be inPendingLearnersub-state.Started- In this state the etcd-member is a full voting member. It can either be inLeaderorFollowersub-states.
Starting an Etcd-Member in a Single-Node Etcd Cluster
Following DFA represents the states, sub-states and transitions of a single etcd-member for a cluster that is bootstrapped from cluster size of 0 -> 1.
Addition of a New Etcd-Member in a Multi-Node Etcd Cluster
Following DFA represents the states, sub-states and transitions of an etcd cluster which starts with having a single member (Leader) and then one or more new members are added which represents a scale-up of an etcd cluster from 1 -> n, where n is odd.
Restart of a Voting Etcd-Member in a Multi-Node Etcd Cluster
Following DFA represents the states, sub-states and transitions when a voting etcd-member in a multi-node etcd cluster restarts.
NOTE: If the DB validation fails then data directory of the etcd-member is removed and etcd-member is removed from cluster membership, thus transitioning it to
Newstate. The state transitions fromNewstate are depicted by this section.
Deterministic Etcd Member Creation/Restart During Scale-Up
Bootstrap information:
When an etcd-member starts, then it needs to find out:
If it should join an existing cluster or start a new cluster.
If it should add itself as a
Learneror directly start as a voting member.
Issue with the current approach:
At present, this is facilitated by three things:
During scale-up, druid adds an annotation
gardener.cloud/scaled-to-multi-nodeto theStatefulSet. Each etcd-members looks up this annotation.backup-sidecar attempts to fetch etcd cluster member-list and checks if this etcd-member is already part of the cluster.
Size of the cluster by checking
initial-clusterin the etcd config.
Druid adds an annotation gardener.cloud/scaled-to-multi-node on the StatefulSet which is then shared by all etcd-members irrespective of the starting state of an etcd-member (as Learner or Voting-Member). This especially creates an issue for the current leader (often pod with index 0) during the scale-up of an etcd cluster as described in this issue.
It has been agreed that the current solution to this issue is a quick and dirty fix and needs to be revisited to be uniformly applied to all etcd-members. The authors propose to provide a more deterministic approach to scale-up using the EtcdMember resource.
New approach
Instead of adding an annotation gardener.cloud/scaled-to-multi-node on the StatefulSet, a new annotation druid.gardener.cloud/create-as-learner should be added by druid on an EtcdMember resource. This annotation will only be added to newly created members during scale-up.
Each etcd-member should look at the following to deterministically compute the bootstrap information specified above:
druid.gardener.cloud/create-as-learnerannotation on its respectiveEtcdMemberresource. This new annotation will be honored in the following cases:When an etcd-member is created for the very first time.
An etcd-member is restarted while it is in
Startingstate (PendingLearnerandLearnersub-states).
Etcd-cluster member list. to check if it is already part of the cluster.
Existing etcd data directory and its validity.
NOTE: When the etcd-member gets promoted to a voting-member, then it should remove the annotation on its respective
EtcdMemberresource.
TLS Enablement for Peer Communication
Etcd-members in a cluster use peer URL(s) to communicate amongst each other. If the advertised peer URL(s) for an etcd-member are updated then etcd mandates a restart of the etcd-member.
Druid only supports toggling the transport level security for the advertised peer URL(s). To indicate that the etcd process within the etcd-member has the updated advertised peer URL(s), an annotation member.etcd.gardener.cloud/tls-enabled is added by backup-sidecar container to the member lease object.
During the reconciliation run for an Etcd resource in druid, if reconciler detects a change in advertised peer URL(s) TLS configuration then it will watch for the above mentioned annotation on the member lease. If the annotation has a value of false then it will trigger a restart of the etcd-member pod.
The authors propose to publish member metadata information in EtcdMember resource and not misuse member leases.
peerTLSEnabled: <bool>
Monitoring Backup Health
Backup-sidecar takes delta and full snapshot both periodically and threshold based. These backed-up snapshots are essential for restoration operations for bootstrapping an etcd cluster from 0 -> 1 replicas. It is essential that leading-backup-sidecar container which is responsible for taking delta/full snapshots and uploading these snapshots to the configured backup store, publishes this information for druid to consume.
At present, information about backed-up snapshot (only latest-revision-number) is published by leading-backup-sidecar container by updating Spec.HolderIdentity of the delta-snapshot and full-snapshot leases.
Druid maintains conditions in the Etcd resource status, which include but are not limited to maintaining information on whether backups being taken for an etcd cluster are healthy (up-to-date) or stale (outdated in context to a configured schedule). Druid computes these conditions using information from full/delta snapshot leases.
In order to provide a holistic view of the health of backups to human operators, druid requires additional information about the snapshots that are being backed-up. The authors propose to not misuse leases and instead publish the following snapshot information as part EtcdMember custom resource:
snapshots:
lastFull:
timestamp: <time of full snapshot>
name: <name of the file that is uploaded>
size: <size of the un-compressed snapshot file uploaded>
startRevision: <start revision of etcd db captured in the snapshot>
endRevision: <end revision of etcd db captured in the snapshot>
lastDelta:
timestamp: <time of delta snapshot>
name: <name of the file that is uploaded>
size: <size of the un-compressed snapshot file uploaded>
startRevision: <start revision of etcd db captured in the snapshot>
endRevision: <end revision of etcd db captured in the snapshot>
While this information will primarily help druid compute accurate conditions regarding backup health from snapshot information and publish this to human operators, it could be further utilised by human operators to take remediatory actions (e.g. manually triggering a full or delta snapshot or further restarting the leader if the issue is still not resolved) if backup is unhealthy.
Enhanced Snapshot Compaction
Druid can be configured to perform regular snapshot compactions for etcd clusters, to reduce the total number of delta snapshots to be restored if and when a DB restoration for an etcd cluster is required. Druid triggers a snapshot compaction job when the accumulated etcd events in the latest set of delta snapshots (taken after the last full snapshot) crosses a specified threshold.
As described in Issue#591 scheduling compaction only based on number of accumulated etcd events is not sufficient to ensure a successful compaction. This is specifically targeted for kubernetes clusters where each etcd event is larger in size owing to large spec or status fields or respective resources.
Druid will now need information regarding snapshot sizes, and more importantly the total size of accumulated delta snapshots since the last full snapshot.
The authors propose to enhance the proposed snapshots field described in Use Case #3 with the following additional field:
snapshots:
accumulatedDeltaSize: <total size of delta snapshots since last full snapshot>
Druid can then use this information in addition to the existing revision information to decide to trigger an early snapshot compaction job. This effectively allows druid to be proactive in performing regular compactions for etcds receiving large events, reducing the probability of a failed snapshot compaction or restoration.
Enhanced Defragmentation
Reader is recommended to read Etcd Compaction & Defragmentation in order to understand the following terminology:
dbSize - total storage space used by the etcd database
dbSizeInUse - logical storage space used by the etcd database, not accounting for free pages in the DB due to etcd history compaction
The leading-backup-sidecar performs periodic defragmentations of the DBs of all the etcd-members in the cluster, controlled via a defragmentation cron schedule provided to each backup-sidecar. Defragmentation is a costly maintenance operation and causes a brief downtime to the etcd-member being defragmented, due to which the leading-backup-sidecar defragments each etcd-member sequentially. This ensures that only one etcd-member would be unavailable at any given time, thus avoiding an accidental quorum loss in the etcd cluster.
The authors propose to move the responsibility of orchestrating these individual defragmentations to druid due to the following reasons:
- Since each backup-sidecar only has knowledge of the health of its own etcd, it can only determine whether its own etcd can be defragmented or not, based on etcd-member health. Trying to defragment a different healthy etcd-member while another etcd-member is unhealthy would lead to a transient quorum loss.
- Each backup-sidecar is only a
sidecarto its own etcd-member, and by good design principles, it must not be performing any cluster-wide maintenance operations, and this responsibility should remain with the etcd cluster operator.
Additionally, defragmentation of an etcd DB becomes inevitable if the DB size exceeds the specified DB space quota, since the etcd DB then becomes read-only, ie no write operations on the etcd would be possible unless the etcd DB is defragmented and storage space is freed up. In order to automate this, druid will now need information about the etcd DB size from each member, specifically the leading etcd-member, so that a cluster-wide defragmentation can be triggered if the DB size reaches a certain threshold, as already described by this issue.
The authors propose to enhance each etcd-member to regularly publish information about the dbSize and dbSizeInUse so that druid may trigger defragmentation for the etcd cluster.
dbSize: <db-size> # e.g 6Gi
dbSizeInUse: <db-size-in-use> # e.g 3.5Gi
Difference between dbSize and dbSizeInUse gives a clear indication of how much storage space would be freed up if a defragmentation is performed. If the difference is not significant (based on a configurable threshold provided to druid), then no defragmentation should be performed. This will ensure that druid does not perform frequent defragmentations that do not yield much benefit. Effectively it is to maximise the benefit of defragmentation since this operations involves transient downtime for each etcd-member.
Monitoring Defragmentations
As discussed in the previous section, every etcd-member is defragmented periodically, and can also be defragmented based on the DB size reaching a certain threshold. It is beneficial for druid to have knowledge of this data from each etcd-member for the following reasons:
[Diagnostics] It is expected that
backup-sidecarwill push releveant metrics and configure alerts on these metrics.[Operational] Derive status of defragmentation at etcd cluster level. In case of partial failures for a subset of etcd-members druid can potentially re-trigger defragmentation only for those etcd-members.
The authors propose to capture this information as part of lastDefragmentation section in the EtcdMember resource.
lastDefragmentation:
startTime: <start time of defragmentation>
endTime: <end time of defragmentation>
status: <Succeeded | Failed>
message: <success or failure message>
initialDBSize: <size of etcd DB prior to defragmentation>
finalDBSize: <size of etcd DB post defragmentation>
NOTE: Defragmentation is a cluster-wide operation, and insights derived from aggregating defragmentation data from individual etcd-members would be captured in the
Etcdresource status
Monitoring Restorations
Each etcd-member may perform restoration of data multiple times throughout its lifecycle, possibly owing to data corruptions. It would be useful to capture this information as part of an EtcdMember resource, for the following use cases:
[Diagnostics] It is expected that
backup-sidecarwill push a metric indicating failure to restore.[Operational] Restoration from backup-bucket only happens for a single node etcd cluster. If restoration is failing then druid cannot take any remediatory actions since there is no etcd quorum.
The authors propose to capture this information under lastRestoration section in the EtcdMember resource.
lastRestoration:
status: <Failed | Success | In-Progress>
reason: <reason-code for status>
message: <human readable message for status>
startTime: <start time of restoration>
endTime: <end time of restoration>
Authors have considered the following cases to better understand how errors during restoration will be handled:
Case #1 - Failure to connect to Provider Object Store
At present full and delta snapshots are downloaded during restoration. If there is a failure then initialization status transitions to Failed followed by New which forces etcd-wrapper to trigger the initialization again. This in a way forces a retry and currently there is no limit on the number of attempts.
Authors propose to improve the retry logic but keep the overall behavior of not forcing a container restart the same.
Case #2 - Read-Only Mounted volume
If a mounted volume which is used to create the etcd data directory turns read-only then authors propose to capture this state via EtcdMember.
Authors propose that druid should initiate recovery by deleting the PVC for this etcd-member and letting StatefulSet controller re-create the Pod and the PVC. Removing PVC and deleting the pod is considered safe because:
- Data directory is present and is the DB is corrupt resulting in an un-usasble etcd.
- Data directory is not present but any attempt to create a directory structure fails due to
read-onlyFS.
In both these cases there is no side-effect of deleting the PVC and the Pod.
Case #3 - Revision mismatch
There is currently an issue in backup-sidecar which results in a revision mismatch in the snapshots (full/delta) taken by leading the backup-sidecar container. This results in a restoration failure. One occurance of such issue has been captured in Issue#583. This occurence points to a bug which should be fixed however there is a rare possibility that these snapshots (full/delta) get corrupted. In this rare situation, backup-sidecar should only raise an alert.
Authors propose that druid should not take any remediatory actions as this involves:
- Inspecting snapshots
- If the full snapshot is corrupt then a decision needs to be taken to recover from the last full snapshot as the base snapshot. This can result in data loss and therefore needs manual intervention.
- If a delta snapshot is corrupt, then recovery can be done till the corrupt revision in the delta snapshot. Since this will also result in a loss of data therefore this decision needs to be take by an operator.
Monitoring Volume Mismatches
Each etcd-member checks for possible etcd data volume mismatches, based on which it decides whether to start the etcd process or not, but this information is not captured anywhere today. It would be beneficial to capture this information as part of the EtcdMember resource so that a human operator may check this and manually fix the underlying problem with the wrong volume being attached or mounted to an etcd-member pod.
The authors propose to capture this information under volumeMismatches section in the EtcdMember resource.
volumeMismatches:
- identifiedAt: <time at which wrong volume mount was identified>
fixedAt: <time at which correct volume was mounted>
volumeID: <volume ID of wrong volume that got mounted>
numRestarts: <num of etcd-member restarts that were attempted>
Each entry under volumeMismatches will be for a unique volumeID. If there is a pod restart and it results in yet another unexpected volumeID (different from the already captured volumeIDs) then a new entry will get created. numRestarts denotes the number of restarts seen by the etcd-member for a specific volumeID.
Based on information from the volumeMismatches section, druid may choose to perform rudimentary remediatory actions as simple as restarting the member pod to force a possible rescheduling of the pod to a different node which could potentially force the correct volume to be mounted to the member.
Custom Resource API
Spec vs Status
Information that is captured in the etcd-member custom resource could be represented either as EtcdMember.Status or EtcdMemberState.Spec.
Gardener has a similar need to capture a shoot state and they have taken the decision to represent it via ShootState resource where the state or status of a shoot is captured as part of the Spec field in the ShootState custom resource.
The authors wish to instead align themselves with the K8S API conventions and choose to use EtcdMember custom resource and capture the status of each member in Status field of this resource. This has the following advantages:
Specrepresents a desired state of a resource and what is intended to be captured is theAs-Isstate of a resource whichStatusis meant to capture. Therefore, semantically usingStatusis the correct choice.Not mis-using
Specnow to representAs-Isstate provides us with a choice to extend the custom resource with any future need for aSpeca.k.a desired state.
Representing State Transitions
The authors propose to use a custom representation for states, sub-states and transitions.
Consider the following representation:
transitions:
- state: <name of the state that the etcd-member has transitioned to>
subState: <name of the sub-state if any>
reason: <reason code for the transition>
transitionTime: <time of transition to this state>
message: <detailed message if any>
As an example, consider the following transitions which represent addition of an etcd-member during scale-up of an etcd cluster, followed by a restart of the etcd-member which detects a corrupt DB:
status:
transitions:
- state: New
subState: New
reason: ClusterScaledUp
transitionTime: "2023-07-17T05:00:00Z"
message: "New member added due to etcd cluster scale-up"
- state: Starting
subState: PendingLearner
reason: WaitingToJoinAsLearner
transitionTime: "2023-07-17T05:00:30Z"
message: "Waiting to join the cluster as a learner"
- state: Starting
subState: Learner
reason: JoinedAsLearner
transitionTime: "2023-07-17T05:01:20Z"
message: "Joined the cluster as a learner"
- state: Started
subState: Follower
reason: PromotedAsVotingMember
transitionTime: "2023-07-17T05:02:00Z"
message: "Now in sync with leader, promoted as voting member"
- state: Initializing
subState: DBValidationFull
reason: DetectedPreviousUncleanExit
transitionTime: "2023-07-17T08:00:00Z"
message: "Detected previous unclean exit, requires full DB validation"
- state: New
subState: New
reason: DBCorruptionDetected
transitionTime: "2023-07-17T08:01:30Z"
message: "Detected DB corruption during initialization, removing member from cluster"
- state: Starting
subState: PendingLearner
reason: WaitingToJoinAsLearner
transitionTime: "2023-07-17T08:02:10Z"
message: "Waiting to join the cluster as a learner"
- state: Starting
subState: Learner
reason: JoinedAsLearner
transitionTime: "2023-07-17T08:02:20Z"
message: "Joined the cluster as a learner"
- state: Started
subState: Follower
reason: PromotedAsVotingMember
transitionTime: "2023-07-17T08:04:00Z"
message: "Now in sync with leader, promoted as voting member"
Reason Codes
The authors propose the following list of possible reason codes for transitions. This list is not exhaustive, and can be further enhanced to capture any new transitions in the future.
| Reason | Transition From State (SubState) | Transition To State (SubState) |
|---|---|---|
ClusterScaledUp | NewSingleNodeClusterCreated | nil | New |
DetectedPreviousCleanExit | New | Started (Leader) | Started (Follower) | Initializing (DBValidationSanity) |
DetectedPreviousUncleanExit | New | Started (Leader) | Started (Follower) | Initializing (DBValidationFull) |
DBValidationFailed | Initializing (DBValidationSanity) | Initializing (DBValidationFull) | Initializing (Restoration) | New |
DBValidationSucceeded | Initializing (DBValidationSanity) | Initializing (DBValidationFull) | Started (Leader) | Started (Follower) |
Initializing (Restoration)Succeeded | Initializing (Restoration) | Started (Leader) |
WaitingToJoinAsLearner | New | Starting (PendingLearner) |
JoinedAsLearner | Starting (PendingLearner) | Starting (Learner) |
PromotedAsVotingMember | Starting (Learner) | Started (Follower) |
GainedClusterLeadership | Started (Follower) | Started (Leader) |
LostClusterLeadership | Started (Leader) | Started (Follower) |
API
EtcdMember
The authors propose to add the EtcdMember custom resource API to etcd-druid APIs and initially introduce it with v1alpha1 version.
apiVersion: druid.gardener.cloud/v1alpha1
kind: EtcdMember
metadata:
labels:
gardener.cloud/owned-by: <name of parent Etcd resource>
name: <name of the etcd-member>
namespace: <namespace | will be the same as that of parent Etcd resource>
ownerReferences:
- apiVersion: druid.gardener.cloud/v1alpha1
blockOwnerDeletion: true
controller: true
kind: Etcd
name: <name of the parent Etcd resource>
uid: <UID of the parent Etcd resource>
status:
id: <etcd-member id>
clusterID: <etcd cluster id>
peerTLSEnabled: <bool>
dbSize: <db-size>
dbSizeInUse: <db-size-in-use>
snapshots:
lastFull:
timestamp: <time of full snapshot>
name: <name of the file that is uploaded>
size: <size of the un-compressed snapshot file uploaded>
startRevision: <start revision of etcd db captured in the snapshot>
endRevision: <end revision of etcd db captured in the snapshot>
lastDelta:
timestamp: <time of delta snapshot>
name: <name of the file that is uploaded>
size: <size of the un-compressed snapshot file uploaded>
startRevision: <start revision of etcd db captured in the snapshot>
endRevision: <end revision of etcd db captured in the snapshot>
accumulatedDeltaSize: <total size of delta snapshots since last full snapshot>
lastRestoration:
type: <FromSnapshot | FromLeader>
status: <Failed | Success | In-Progress>
startTime: <start time of restoration>
endTime: <end time of restoration>
lastDefragmentation:
startTime: <start time of defragmentation>
endTime: <end time of defragmentation>
reason:
message:
initialDBSize: <size of etcd DB prior to defragmentation>
finalDBSize: <size of etcd DB post defragmentation>
volumeMismatches:
- identifiedAt: <time at which wrong volume mount was identified>
fixedAt: <time at which correct volume was mounted>
volumeID: <volume ID of wrong volume that got mounted>
numRestarts: <num of pod restarts that were attempted>
transitions:
- state: <name of the state that the etcd-member has transitioned to>
subState: <name of the sub-state if any>
reason: <reason code for the transition>
transitionTime: <time of transition to this state>
message: <detailed message if any>
Etcd
Authors propose the following changes to the Etcd API:
- In the
Etcd.Statusresource API, member status is computed and stored. This field will be marked as deprecated and in a later version of druid it will be removed. In its place, the authors propose to introduce the following:
type EtcdStatus struct {
// MemberRefs contains references to all existing EtcdMember resources
MemberRefs []CrossVersionObjectReference
}
- In
Etcd.Statusresource API, PeerUrlTLSEnabled reflects the status of enabling TLS for peer communication across all etcd-members. Currentlty this field is not been used anywhere. In this proposal, the authors have also proposed that eachEtcdMemberresource should capture the status of TLS enablement of peer URL. The authors propose to relook at the need to have this field underEtcdStatus.
Lifecycle of an EtcdMember
Creation
Druid creates an EtcdMember resource for every replica in etcd.Spec.Replicas during reconciliation of an etcd resource. For a fresh etcd cluster this is done prior to creation of the StatefulSet resource and for an existing cluster which has now been scaled-up, it is done prior to updating the StatefulSet resource.
Updation
All fields in EtcdMember.Status are only updated by the corresponding etcd-member. Druid only consumes the information published via EtcdMember resources.
Deletion
Druid is responsible for deletion of all existing EtcdMember resources for an etcd cluster. There are three scenarios where an EtcdMember resource will be deleted:
Deletion of etcd resource.
Scale down of an etcd cluster to 0 replicas due to hibernation of the k8s control plane.
Transient scale down of an etcd cluster to 0 replicas to recover from a quorum loss.
Authors found no reason to retain EtcdMember resources when the etcd cluster is scale down to 0 replicas since the information contained in each EtcdMember resource would no longer represent the current state of each member and would thus be stale. Any controller in druid which acts upon the EtcdMember.Status could potentially take incorrect actions.
Reconciliation
Authors propose to introduce a new controller (let’s call it etcd-member-controller) which watches for changes to the EtcdMember resource(s). If a reconciliation of an Etcd resource is required as a result of change in EtcdMember status then this controller should enqueue an event and force a reconciliation via existing etcd-controller, thus preserving the single-actor-principal constraint which ensures deterministic changes to etcd cluster resources.
NOTE: Further decisions w.r.t responsibility segregation will be taken during implementation and will not be documented in this proposal.
Stale EtcdMember Status Handling
It is possible that an etcd-member is unable to update its respective EtcdMember resource. Following can be some of the implications which should be kept in mind while reconciling EtcdMember resource in druid:
- Druid sees stale state transitions (this assumes that the backup-sidecar attempts to update the state/sub-state in
etcdMember.status.transitionswith best attempt). There is currently no implication other than an operator seeing a stale state. dbSizeanddbSizeInUsecould not be updated. A consequence could be that druid continues to see high value fordbSize - dbSizeInUsefor a extended amount of time. Druid should ensure that it does not trigger repeated defragmentations.- If
VolumeMismatchesis stale, then druid should no longer attempt to recover by repeatedly restarting the pod. - Failed
restorationwas recorded last and further updates to this array failed. Druid should not repeatedly take full-snapshots. - If
snapshots.accumulatedDeltaSizecould not be updated, then druid should not schedule repeated compaction Jobs.
Reference
2.17 - Feature Gates in Etcd-Druid
Feature Gates in Etcd-Druid
This page contains an overview of the various feature gates an administrator can specify on etcd-druid.
Overview
Feature gates are a set of key=value pairs that describe etcd-druid features. You can turn these features on or off by passing them to the --feature-gates CLI flag in the etcd-druid command.
The following tables are a summary of the feature gates that you can set on etcd-druid.
- The “Since” column contains the etcd-druid release when a feature is introduced or its release stage is changed.
- The “Until” column, if not empty, contains the last etcd-druid release in which you can still use a feature gate.
- If a feature is in the Alpha or Beta state, you can find the feature listed in the Alpha/Beta feature gate table.
- If a feature is stable you can find all stages for that feature listed in the Graduated/Deprecated feature gate table.
- The Graduated/Deprecated feature gate table also lists deprecated and withdrawn features.
Feature Gates for Alpha or Beta Features
| Feature | Default | Stage | Since | Until |
|---|
Feature Gates for Graduated or Deprecated Features
| Feature | Default | Stage | Since | Until |
|---|---|---|---|---|
UseEtcdWrapper | false | Alpha | 0.19 | 0.21 |
UseEtcdWrapper | true | Beta | 0.22 | 0.24 |
UseEtcdWrapper | true | GA | 0.25 | 0.27 |
UseEtcdWrapper | Removed | 0.28 |
Using a Feature
A feature can be in Alpha, Beta or GA stage.
Alpha feature
- Disabled by default.
- Might be buggy. Enabling the feature may expose bugs.
- Support for feature may be dropped at any time without notice.
- The API may change in incompatible ways in a later software release without notice.
- Recommended for use only in short-lived testing clusters, due to increased risk of bugs and lack of long-term support.
Beta feature
- Enabled by default.
- The feature is well tested. Enabling the feature is considered safe.
- Support for the overall feature will not be dropped, though details may change.
- The schema and/or semantics of objects may change in incompatible ways in a subsequent beta or stable release. When this happens, we will provide instructions for migrating to the next version. This may require deleting, editing, and re-creating API objects. The editing process may require some thought. This may require downtime for applications that rely on the feature.
- Recommended for only non-critical uses because of potential for incompatible changes in subsequent releases.
Please do try Beta features and give feedback on them! After they exit beta, it may not be practical for us to make more changes.
General Availability (GA) feature
This is also referred to as a stable feature which should have the following characteristics:
- The feature is always enabled; you cannot disable it.
- The corresponding feature gate is no longer needed.
- Stable versions of features will appear in released software for many subsequent versions.
List of Feature Gates
| Feature | Description |
|---|---|
UseEtcdWrapper | Enables the use of etcd-wrapper image and a compatible version of etcd-backup-restore, along with component-specific configuration changes necessary for the usage of the etcd-wrapper image. |
2.18 - Getting Started Locally
Setup Etcd-Druid Locally
This document will guide you on how to setup etcd-druid on your local machine and how to provision and manage Etcd cluster(s).
00-Prerequisites
Before we can setup etcd-druid and use it to provision Etcd clusters, we need to prepare the development environment. Follow the Prepare Dev Environment Guide for detailed instructions.
01-Setting up KIND cluster
etcd-druid uses kind as it’s local Kubernetes engine. The local setup is configured for kind due to its convenience only. Any other Kubernetes setup would also work.
make kind-up
This command sets up a new Kind cluster and stores the kubeconfig at ./hack/kind/kubeconfig. Additionally, this command also deploys a local container registry as a docker container. This ensures faster image push/pull times. The local registry can be accessed as localhost:5001 for pushing and pulling images.
To target this newly created cluster, set the KUBECONFIG environment variable to the kubeconfig file.
export KUBECONFIG=$PWD/hack/kind/kubeconfig
Note: If you wish to configure kind cluster differently then you can directly invoke the script and check its help to know about all configuration options.
./hack/kind-up.sh -h
usage: kind-up.sh [Options]
Options:
--cluster-name <cluster-name> Name of the kind cluster to create. Default value is 'etcd-druid-e2e'
--skip-registry Skip creating a local docker registry. Default value is false.
--feature-gates <feature-gates> Comma separated list of feature gates to enable on the cluster.
02-Setting up etcd-druid
Configuring etcd-druid
Prior to deploying etcd-druid, it can be configured via CLI-args and environment variables.
- To configure CLI args you can modify
charts/druid/values.yaml. For example, if you wish toauto-reconcileany change done toEtcdCR, then you should setenableEtcdSpecAutoReconcileto true. By default this will be switched off. DRUID_E2E_TEST=true: sets specific configuration for etcd-druid for optimal e2e test runs, like a lower sync period for the etcd controller.
Deploying etcd-druid
Any variant of make deploy-* command uses helm and skaffold to build and deploy etcd-druid to the target Kubernetes cluster. In addition to deploying etcd-druid it will also install the Etcd CRD and EtcdCopyBackupTask CRD.
Regular mode
make deploy
The above command will use skaffold to build and deploy etcd-druid to the k8s kind cluster pointed to by KUBECONFIG environment variable.
Dev mode
make deploy-dev
This is similar to make deploy but additionally starts a skaffold dev loop. After the initial deployment, skaffold starts watching source files. Once it has detected changes, you can press any key to update the etcd-druid deployment.
Debug mode
make deploy-debug
This is similar to make deploy-dev but additionally configures containers in pods for debugging as required for each container’s runtime technology. The associated debugging ports are exposed and labelled so that they can be port-forwarded to the local machine. Skaffold disables automatic image rebuilding and syncing when using the debug mode as compared to dev mode.
Go debugging uses Delve. Please see the skaffold debugging documentation how to setup your IDE accordingly.
!!! note Resuming or stopping only a single goroutine (Go Issue 25578, 31132) is currently not supported, so the action will cause all the goroutines to get activated or paused.
This means that when a goroutine is paused on a breakpoint, then all the other goroutines are also paused. This should be kept in mind when using skaffold debug.
03-Configure Backup [Optional]
Deploying a Local Backup Store Emulator
!!! info This section is Optional and is only meant to describe steps to deploy a local object store which can be used for testing and development. If you either do not wish to enable backups or you wish to use remote (infra-provider-specific) object store then this section can be skipped.
An Etcd cluster provisioned via etcd-druid provides a capability to take regular delta and full snapshots which are stored in an object store. You can enable this functionality by ensuring that you fill in spec.backup.store section of the Etcd CR.
| Backup Store Variant | Setup Guide |
|---|---|
| Azure Object Storage Emulator | Manage Azurite (Steps 00-03) |
| S3 Object Store Emulator | Manage LocalStack (Steps 00-03) |
| GCS Object Store Emulator | Manage GCS Emulator (Steps 00-03) |
Setting up Cloud Provider Object Store Secret
!!! info This section is Optional. If you have disabled backup functionality or if you are using local storage or one of the supported object store emulators then you can skip this section.
A Kubernetes Secret needs to be created for cloud provider Object Store access. You can refer to the Secret YAML templates here. Replace the dummy values with the actual configuration and ensure that you have added the metadata.name and metadata.namespace to the secret.
!!! tip
* Secret should be deployed in the same namespace as the Etcd resource.
* All the values in the data field of the secret YAML should in base64 encoded format.
To apply the secret run:
kubectl apply -f <path/to/secret>
04-Preparing Etcd CR
Choose an appropriate variant of Etcd CR from examples directory.
If you wish to enable functionality to backup delta & full snapshots then uncomment spec.backup.store section.
# Configuration for storage provider
store:
secretRef:
name: etcd-backup-secret-name
container: object-storage-container-name
provider: aws # options: aws,azure,gcp,openstack,alicloud,dell,openshift,local
prefix: etcd-test
Brief explanation of the keys:
secretRef.nameis the name of the secret that was applied as mentioned above.store.containeris the object storage bucket name.store.provideris the bucket provider. Pick from the options mentioned in comment.store.prefixis the folder name that you want to use for your snapshots inside the bucket.
!!! tip For developer convenience we have provided object store emulator specific etcd CR variants which can be used as if as well.
05-Applying Etcd CR
Create the Etcd CR (Custom Resource) by applying the Etcd yaml to the cluster
kubectl apply -f <path-to-etcd-cr-yaml>
06-Verify the Etcd Cluster
To obtain information on the etcd cluster you can invoke the following command:
kubectl get etcd -o=wide
We adhere to a naming convention for all resources that are provisioned for an Etcd cluster. Refer to etcd-cluster-components document to get details of all resources that are provisioned.
Verify Etcd Pods’ Functionality
etcd-wrapper uses a distroless image, which lacks a shell. To interact with etcd, use an Ephemeral container as a debug container. Refer to this documentation for building and using an ephemeral container which gets attached to the etcd-wrapper pod.
# Put a key-value pair into the etcd
etcdctl put <key1> <value1>
# Retrieve all key-value pairs from the etcd db
etcdctl get --prefix ""
For a multi-node etcd cluster, insert the key-value pair using the etcd container of one etcd member and retrieve it from the etcd container of another member to verify consensus among the multiple etcd members.
07-Updating Etcd CR
Etcd CR can be updated with new changes. To ensure that etcd-druid reconciles the changes you can refer to options that etcd-druid provides here.
08-Cleaning up the setup
If you wish to only delete the Etcd cluster then you can use the following command:
kubectl delete etcd <etcd-name>
This will add the deletionTimestamp to the Etcd resource. At the time the creation of the Etcd cluster, etcd-druid will add a finalizer to ensure that it cleans up all Etcd cluster resources before the CR is removed.
finalizers:
- druid.gardener.cloud/etcd-druid
etcd-druid will automatically pick up the deletion event and attempt clean up Etcd cluster resources. It will only remove the finalizer once all resources have been cleaned up.
If you only wish to remove etcd-druid but retain the kind cluster then you can use the following make target:
make undeploy
If you wish to delete the kind cluster then you can use the following make target:
make kind-down
This cleans up the entire setup as the kind cluster gets deleted.
2.19 - Getting Started Locally
Developing etcd-druid locally
You can setup etcd-druid locally by following detailed instructions in this document.
- For best development experience you should use
make deploy-dev- this helps during development where you wish to make changes to the code base and with a key-press allow automatic re-deployment of the application to the target Kubernetes cluster. - In case you wish to start a debugging session then use
make deploy-debug- this will additionally disable leader election and prevent leases to expire and process to stop.
!!! info We leverage skaffold debug and skaffold dev features.
2.20 - Immutable etcd Cluster Backups
DEP-06: Immutable etcd Cluster Backups
Summary
This proposal introduces immutable backups for etcd clusters managed by etcd-druid. By leveraging cloud provider immutability features, backups taken by etcd-backup-restore can neither be modified nor deleted once created for a configurable retention duration (immutability period). This approach strengthens the reliability and fault tolerance of the etcd restoration process.
Terminology
- etcd-druid: An etcd operator that configures, provisions, reconciles, and monitors etcd clusters.
- etcd-backup-restore: A sidecar container that manages backups and restores of etcd cluster state. For more information, see the etcd-backup-restore documentation.
- WORM (Write Once, Read Many): A storage model in which data, once written, cannot be modified or deleted until certain conditions are met.
- Immutability: The property of an object that prevents it from being modified or deleted after creation.
- Immutability Period: The duration for which data must remain immutable before it can be modified or deleted.
- Bucket-Level Immutability: A policy that applies a uniform immutability period to all objects within a bucket.
- Object-Level Immutability: A policy that allows setting immutability periods individually for objects within a bucket, offering more granular control.
- Garbage Collection: The process of deleting old snapshot data that is no longer needed, in order to free up storage space. For more information, see the garbage collection documentation.
- Hibernation: A state in which an etcd cluster is scaled down to zero replicas, effectively pausing its operations. This is typically done to save costs when the cluster is not needed for an extended period. During hibernation, the cluster’s data remains intact, and it can be resumed to its previous state when required.
Motivation
etcd-druid provisions etcd clusters and manages their lifecycle. For every etcd cluster, consumers can enable periodic backups of the cluster state by configuring the spec.backup section in an Etcd custom resource. Periodic backups are taken via the etcd-backup-restore sidecar container that runs in each etcd member pod.
Periodic backups of an etcd cluster state ensure the ability to recover from a data loss or a quorum loss, enhancing reliability and fault tolerance. It is crucial that these backups, which are vital for restoring the etcd cluster, remain protected from any form of tampering, whether intentional or accidental. To safeguard the integrity of these backups, the authors recommend utilizing WORM protection, a feature offered by various cloud providers, to ensure the backups remain immutable and secure.
Goals
- Protect backup data against modifications and deletions post-creation through immutability policies offered by storage providers.
Non-Goals
- Implementing a mechanism to signal hibernation intent for handling snapshot immutability for hibernated etcd clusters, such as adding functionality via
etcd.specor annotations on theEtcdCR, to indicate when an etcd cluster should enter or exit hibernation, as discussed in gardener/etcd-druid#922. - Supporting immutable backups on storage providers that do not offer immutability features (e.g., OpenStack Swift).
Proposal
This proposal aims to improve backup storage integrity and security by using immutability features available on major cloud providers.
Supported Cloud Providers
- Google Cloud Storage (GCS): Bucket Lock
- Amazon S3 (S3): Object Lock
- Azure Blob Storage (ABS): Immutable Blob Storage
Note
Currently, Openstack object storage (swift) doesn’t support immutability for objects: https://blueprints.launchpad.net/swift/+spec/immutability-middleware.
Types of Immutability
- Object-Level Immutability: Allows setting immutability periods independently for each object within a bucket.
- Bucket-Level Immutability: Applies a uniform immutability policy to all objects in a bucket.
Comparison of Bucket-Level and Object-Level Immutability
| Feature | GCS | S3 | ABS |
|---|---|---|---|
| Can bucket-level immutability period be increased? | Yes | Yes* | Yes (only 5 times) |
| Can bucket-level immutability period be decreased? | No | Yes* | No |
| Is bucket-level immutability a prerequisite for object-level immutability? | No | Yes | Yes (for existing buckets) |
| Can object-level immutability period be increased? | Yes | Yes | Yes |
| Can object-level immutability period be decreased? | No | No | No |
| Support for enabling object-level immutability in existing buckets | No | Yes | Yes |
| Support for enabling object-level immutability in new buckets | Yes | Yes | Yes |
| Support for enabling bucket-level immutability in existing buckets | Yes | Yes | Yes |
| Support for enabling bucket-level immutability in new buckets | Yes | Yes | Yes |
| Precedence between bucket-level and object-level immutability periods | Max(bucket, object) | Object-level | Max(bucket, object) |
Note
In AWS S3, it is possible to increase and decrease the bucket-level immutability period; however, this action can be blocked by configuring specific bucket policy settings.
For GCS, object-level immutability is not yet supported for existing buckets; see this issue.
Recommended Approach
At the time of writing this proposal, these are the current limitations seen across providers:
- S3 and ABS: typically require bucket-level immutability as a prerequisite for object-level immutability.
- GCS does not currently support object-level immutability in existing buckets.
- ABS requires a migration process to enable version-level immutability on existing containers.
Consequently, the authors recommend bucket-level immutability. This approach simplifies configuration and ensures a uniform immutability policy for all backups in a bucket across all support providers.
Configuring Immutable Backups
Creating and configuring immutable buckets on providers is not handled by etcd-druid and must be done by the consumers. For a large-scale consumer like Gardener, provider extensions are leveraged to automate both the creation and configuration of buckets. For more details, see BackupBucket and refer to this issue.
Prerequisites
Configure or Update the Immutable Bucket
- Use your cloud provider’s CLI, SDK, or console to create (or update) a bucket/container with a WORM (write-once-read-many) immutability policy.
- Refer to the Configure Bucket-Level Immutability for step-by-step instructions on configuring or updating the immutable bucket across different cloud providers.
Provide Valid Credentials in a Kubernetes Secret
- The
storesection of theEtcdCR must reference aSecretcontaining valid credentials.apiVersion: druid.gardener.cloud/v1alpha1 kind: Etcd metadata: name: example-etcd spec: backup: store: prefix: etcd-backups container: my-immutable-backups # Bucket name provider: aws # Supported: aws, gcp, azure secretRef: name: etcd-backup-credentials # Reference to the Secret immutability: retentionType: bucket # Enables bucket-level immutability - Confirm that this secret has the proper permissions to upload and retrieve snapshots from the immutable bucket.
- See the Getting Started guide for an example.
Note
The
etcd-druiddoes not handle the rotation of cloud provider credentials. Credential rotation must be managed by the operator.
By following these steps, you will have set up an immutable bucket for storing etcd backups, along with the necessary references in your Etcd specification and Kubernetes secret.
Handling of Hibernated Clusters
When an etcd cluster remains hibernated beyond the bucket’s immutability period, backups might become mutable again, depending on the cloud provider (see Comparison of Storage Provider Properties). This could compromise the intended guarantees of immutability, exposing backups to accidental or malicious alterations.
As mentioned in gardener/etcd-druid#922, a clear hibernation signal is needed. Since etcd-druid does not currently support hibernation natively and addressing that is out of scope for this proposal, we focus solely on maintaining immutability.
Proposal
To mitigate the risk of backups becoming mutable during extended hibernation under bucket-level immutability, the authors propose the following approach:
Prerequisite: Cut-off Traffic and Take a Final Full Snapshot Before Hibernation
- Before scaling the etcd cluster down to zero replicas, the etcd controller removes etcd’s client ports (2379/2380) from the etcd Service to block application traffic.
- The etcd controller then triggers an on-demand full snapshot. This ensures that the latest state of the etcd cluster is captured and securely stored before hibernation begins.
Periodically Re-Upload the Snapshot
- Re-uploading the latest full snapshot resets its immutability period in the bucket, ensuring backups remain protected during hibernation.
- By default, the re-upload schedule follows
etcd.spec.backup.fullSnapshotSchedule. Currently, this interval cannot be customized exclusively for re-uploads; future enhancements may introduce a dedicated configuration parameter. - A new operator task type,
ExtendFullSnapshotImmutabilityTask, periodically calls a new CLI command,extend-snapshot-immutability, to re-upload the snapshot and extend its immutability. ExtendFullSnapshotImmutabilityTaskalso manages garbage collection, ensuring that only the latest immutable snapshots are retained while deleting older snapshots created by the task itself.
By capturing a final full snapshot before hibernation, periodically re-uploading it to preserve immutability, and removing stale backups, etcd backups remain safeguarded against accidental or malicious alterations until the cluster is resumed.
Important
Limitation: There is a potential edge case where a snapshot might become corrupted before hibernation or during the re-upload process by
ExtendFullSnapshotImmutabilityTask. If this happens, the process could repeatedly re-upload the same corrupted snapshot, failing to ensure a reliable backup.
An alternative solution could be to trigger the snapshot compaction which runs in separate pod and takes a fresh snapshot of the compacted etcd data and re-uploads it to the object store.
While this approach ensures that only valid snapshots are re-uploaded, it is resource-intensive, requiring an operational etcd instance even in hibernation. Given the high cost in terms of compute and memory, the authors recommend the snapshot re-upload approach as a more practical solution.
Etcd CR API Changes
A new field is introduced in Etcd.spec.backup.store to indicate the immutability strategy:
// StoreSpec defines parameters for storing etcd backups.
type StoreSpec struct {
// ...
// Immutability configuration for the backup store.
Immutability *ImmutabilitySpec `json:"immutability,omitempty"`
}
// ImmutabilitySpec defines immutability settings.
type ImmutabilitySpec struct {
// RetentionType indicates the type of immutability approach. For example, "bucket".
RetentionType string `json:"retentionType,omitempty"`
}
If immutability is not specified, etcd-druid will assume that the bucket is mutable, and no immutability-related logic applies. We have defined a new type to allow us future enhancements to the immutability specification.
etcd-backup-restore Enhancements
The authors propose adding new sub-command to the etcd-backup-restore CLI (etcdbrctl) to maintain immutability during hibernation and to clean up snapshots created by ExtendFullSnapshotImmutabilityTask:
extend-snapshot-immutability- Downloads the latest full snapshot from the object store.
- Renames the snapshot (for instance, updates its Unix timestamp) to avoid overwriting an existing immutable snapshot.
- Uploads the renamed snapshot back to object storage, thereby restarting its immutability timer.
- Introduces the
--gc-from-timestamp=<timestamp>parameter, where<timestamp>is the creation timestamp of the task. This ensures that only snapshots created by the task are subject to garbage collection.
As an alternative to the download/upload approach, the authors document the possibility of using provider APIs to perform a server-side object copy. This method could significantly reduce network costs and latency by directly copying the snapshot within the cloud provider’s infrastructure. While this option is not implemented in the current version, feasibility of server-side copy can be explored in etcd-backup-restore during implementation.
etcd Controller Enhancements
When a hibernation flow is initiated (by external tooling or higher-level operators), the etcd controller can:
- Remove etcd’s client ports (2379/2380) from the etcd Service to block application traffic.
- Trigger an on-demand full snapshot via an
EtcdOperatorTask. - Scale down the
StatefulSetreplicas to zero, provided the previous snapshot step is successful. - Create the
ExtendFullSnapshotImmutabilityTaskifetcd.spec.backup.store.immutability.retentionTypeis"bucket"and based onetcd.spec.backup.fullSnapshotSchedule.
Operator Task Enhancements
The ExtendFullSnapshotImmutabilityTask will create a cron job that:
- Runs
etcdbrctl extend-snapshot-immutability --gc-from-timestamp=<creation timestamp of task>to preserve the immutability period of the most recent snapshot. This command re-uploads the latest snapshot, effectively resetting its immutability period. Additionally, it removes any snapshots that have become mutable after the creation timestamp of the task.
By periodically re-uploading (extending) the latest snapshot during hibernation, the authors ensure that the immutability period is extended, and the backups remain protected throughout the hibernation period.
Lifecycle of ExtendFullSnapshotImmutabilityTask
The ExtendFullSnapshotImmutabilityTask is active during hibernation and is automatically managed by the etcd-controller. Its lifecycle is tied to the cluster’s hibernation state:
Task Creation
- When the etcd cluster enters hibernation (e.g., scaling down to zero replicas), the etcd controller:
- Triggers a final full snapshot.
- Creates the
ExtendFullSnapshotImmutabilityTaskto runextend-snapshot-immutability --gc-from-timestamp=<creation timestamp of this task>
- When the etcd cluster enters hibernation (e.g., scaling down to zero replicas), the etcd controller:
Task Deletion
- When the cluster resumes from hibernation (scales up to non-zero replicas), the controller:
- Deletes the
ExtendFullSnapshotImmutabilityTaskto stop extending snapshots. - Resumes the normal backup schedule defined in
spec.backup.fullSnapshotSchedule.
- Deletes the
- When the immutability configuration is removed from the
etcd.spec.backup.store, the controller:- Deletes the
ExtendFullSnapshotImmutabilityTaskto stop extending snapshots.
- Deletes the
- When the cluster resumes from hibernation (scales up to non-zero replicas), the controller:
Example Task Config
type ExtendFullSnapshotImmutabilityTaskConfig struct {
// Schedule defines a cron schedule (e.g., "0 0 * * *").
Schedule *string `json:"schedule,omitempty"`
}
Sample YAML:
spec:
config:
schedule: "0 0 * * *"
Disabling Immutability
If you remove the immutability configuration from etcd.spec.backup.store, hibernation-based immutability support no longer applies. However, once the bucket itself is locked at the provider level, it cannot be reverted to a mutable state. Any objects uploaded by etcd-backup-restore are still subject to the existing WORM policy.
If you genuinely require a mutable backup again, the recommended approach is:
- Use a new bucket. In your
Etcdcustom resource, reference a different bucket that does not have immutability enabled. - Use
EtcdCopyBackupsTask. If you want to start the cluster with a new bucket but retain old data, use theEtcdCopyBackupsTaskto copy existing backups from the old immutable bucket to the new mutable bucket. - Reconcile the
EtcdCR. After pointingetcd.spec.backup.storeto the new bucket,etcd-druidwill start storing backups there.
Note: Existing snapshots in the old immutable bucket remain locked according to the configured immutability period.
Compatibility
These changes are compatible with existing etcd clusters and current backup processes.
- Backward Compatibility:
- Clusters without immutable buckets continue to function without any changes.
- Forward Compatibility:
- Clusters can opt in to use immutable backups by configuring the bucket accordingly (as described in Configuring Immutable Backups) and setting
etcd.spec.backup.store.immutability.retentionType == "bucket". - The enhanced hibernation logic in the etcd controller is additive, meaning it does not interfere with existing workflows.
- Clusters can opt in to use immutable backups by configuring the bucket accordingly (as described in Configuring Immutable Backups) and setting
Impact for Operators
In scenarios where you want to exclude certain snapshots from an etcd restore, you previously could simply delete them from object storage. However, when bucket-level immutability is enabled, deleting existing immutable snapshots is no longer possible. To address this need, most cloud providers allow adding custom annotations or tags to objects—even immutable ones—so they can be logically excluded without physically removing them.
etcd-backup-restore supports ignoring snapshots based on annotations or tags, rather than deleting them. Operators can add the following key-value pair to any snapshot object to exclude it from future restores:
- Key:
x-etcd-snapshot-exclude - Value:
true
Because these tags or annotations do not modify the underlying snapshot data, they are permissible even for immutable objects. Once these annotations are in place, etcd-backup-restore will detect them and skip the tagged snapshots during restoration, thus preventing unwanted snapshots from being used. For more details, see the Ignoring Snapshots during Restoration.
Note
At the time of writing this proposal, this feature is not supported for AWS S3 buckets.
References
- GCS Bucket Lock
- AWS S3 Object Lock
- Azure Immutable Blob Storage
- etcd-backup-restore Documentation
- Gardener Issue: 10866
2.21 - Local e2e Tests
e2e Test Suite
Developers can run extended e2e tests, in addition to unit tests, for Etcd-Druid in or from their local environments. This is recommended to verify the desired behavior of several features and to avoid regressions in future releases.
The very same tests typically run as part of the component’s release job as well as on demand, e.g., when triggered by Etcd-Druid maintainers for open pull requests.
Testing Etcd-Druid automatically involves a certain test coverage for gardener/etcd-backup-restore
which is deployed as a side-car to the actual etcd container.
Prerequisites
The e2e test lifecycle is managed with the help of skaffold. Every involved step like setup,
deploy, undeploy or cleanup is executed against a Kubernetes cluster which makes it a mandatory prerequisite at the same time.
Only skaffold itself with involved docker, helm and kubectl executions as well as
the e2e-tests are executed locally. Required binaries are automatically downloaded if you use the corresponding make target,
as described in this document.
It’s expected that especially the deploy step is run against a Kubernetes cluster which doesn’t contain an Druid deployment or any left-overs like druid.gardener.cloud CRDs.
The deploy step will likely fail in such scenarios.
Tip: Create a fresh KinD cluster or a similar one with a small footprint before executing the tests.
Providers
The following providers are supported for e2e tests:
- AWS
- Azure
- GCP
- Local
Valid credentials need to be provided when tests are executed with mentioned cloud providers.
Flow
An e2e test execution involves the following steps:
| Step | Description |
|---|---|
setup | Create a storage bucket which is used for etcd backups (only with cloud providers). |
deploy | Build Docker image, upload it to registry (if remote cluster - see Docker build), deploy Helm chart (charts/druid) to Kubernetes cluster. |
test | Execute e2e tests as defined in test/e2e. |
undeploy | Remove the deployed artifacts from Kubernetes cluster. |
cleanup | Delete storage bucket and Druid deployment from test cluster. |
Make target
Executing e2e-tests is as easy as executing the following command with defined Env-Vars as desribed in the following section and as needed for your test scenario.
make test-e2e
Common Env Variables
The following environment variables influence how the flow described above is executed:
PROVIDERS: Providers used for testing (all,aws,azure,gcp,local). Multiple entries must be comma separated.Note: Some tests will use very first entry from env
PROVIDERSfor e2e testing (ex: multi-node tests). So for multi-node tests to use specific provider, specify that provider as first entry in envPROVIDERS.KUBECONFIG: Kubeconfig pointing to cluster where Etcd-Druid will be deployed (preferably KinD).TEST_ID: Some ID which is used to create assets for and during testing.STEPS: Steps executed bymaketarget (setup,deploy,test,undeploy,cleanup- default: all steps).
AWS Env Variables
AWS_ACCESS_KEY_ID: Key ID of the user.AWS_SECRET_ACCESS_KEY: Access key of the user.AWS_REGION: Region in which the test bucket is created.
Example:
make \
AWS_ACCESS_KEY_ID="abc" \
AWS_SECRET_ACCESS_KEY="xyz" \
AWS_REGION="eu-central-1" \
KUBECONFIG="$HOME/.kube/config" \
PROVIDERS="aws" \
TEST_ID="some-test-id" \
STEPS="setup,deploy,test,undeploy,cleanup" \
test-e2e
Azure Env Variables
STORAGE_ACCOUNT: Storage account used for managing the storage container.STORAGE_KEY: Key of storage account.
Example:
make \
STORAGE_ACCOUNT="abc" \
STORAGE_KEY="eHl6Cg==" \
KUBECONFIG="$HOME/.kube/config" \
PROVIDERS="azure" \
TEST_ID="some-test-id" \
STEPS="setup,deploy,test,undeploy,cleanup" \
test-e2e
GCP Env Variables
GCP_SERVICEACCOUNT_JSON_PATH: Path to the service account json file used for this test.GCP_PROJECT_ID: ID of the GCP project.
Example:
make \
GCP_SERVICEACCOUNT_JSON_PATH="/var/lib/secrets/serviceaccount.json" \
GCP_PROJECT_ID="xyz-project" \
KUBECONFIG="$HOME/.kube/config" \
PROVIDERS="gcp" \
TEST_ID="some-test-id" \
STEPS="setup,deploy,test,undeploy,cleanup" \
test-e2e
Local Env Variables
No special environment variables are required for running e2e tests with Local provider.
Example:
make \
KUBECONFIG="$HOME/.kube/config" \
PROVIDERS="local" \
TEST_ID="some-test-id" \
STEPS="setup,deploy,test,undeploy,cleanup" \
test-e2e
e2e test with local storage emulators [AWS, GCP, AZURE]
The above-mentioned e2e tests need storage from real cloud providers to be setup. But there are tools such as localstack, fake-gcs-server and azurite that enable developers to run e2e tests with emulators for AWS S3, Google GCS and Azure ABS respectively. We can provision a KIND cluster for running the e2e tests against. Thus, by using cloud storage emulators alongside the KIND cluster, we eliminate the need for any actual cloud provider infrastructure to be set up for running e2e tests.
How are the KIND cluster and Emulators set up
KIND or Kubernetes-In-Docker is a kubernetes cluster that is set up inside a docker container. This cluster is with limited capability as it does not have much compute power. But this cluster can easily be setup inside a container and can be tear down easily just by removing a container. That’s why KIND cluster is very easy to use for e2e tests. Makefile command helps to spin up a KIND cluster and use the cluster to run e2e tests.
Localstack setup
There is a docker image for localstack. The image is deployed as pod inside the KIND cluster through hack/e2e-test/infrastructure/localstack/localstack.yaml. Makefile takes care of deploying the yaml file in a KIND cluster.
The developer needs to run make ci-e2e-kind command. This command in turn runs hack/ci-e2e-kind.sh which spin up the KIND cluster and deploy localstack in it and then run the e2e tests using localstack as mock AWS storage provider. e2e tests are actually run on host machine but deploy the druid controller inside KIND cluster. Druid controller spawns multinode etcd clusters inside KIND cluster. e2e tests verify whether the druid controller performs its jobs correctly or not. Mock localstack storage is cleaned up after every e2e tests. That’s why the e2e tests need to access the localstack pod running inside KIND cluster. The network traffic between host machine and localstack pod is resolved via mapping localstack pod port to host port while setting up the KIND cluster via hack/e2e-test/infrastructure/kind/cluster.yaml
How to execute e2e tests with localstack and KIND cluster
Run the following make command to spin up a KinD cluster, deploy localstack and run the e2e tests with provider aws:
make ci-e2e-kind
Fake-GCS-Server setup
Fake-gcs-server is run inside a pod using this docker image in a KIND cluster.
The user needs to run make ci-e2e-kind-gcs to start the e2e tests for druid with GCS emulator as the object storage for etcd backups. The above command internally runs the script hack/ci-e2e-kind-gcs.sh which initializes the setup with required steps before going on to create a KIND cluster and deploy fakegcs in it and use that emulator to run e2e tests.
The fake-gcs-server running inside the pod serves HTTP requests at port-8000 and HTTPS requests at port-4443. As the e2e tests runs on the host machine while the emulator runs on KIND, both ports i.e 8000 & 4443 needs to be port-forwarded from the host machine to fake-gcs service running inside the KIND cluster. The port forwardings is defined in the hack/kind-up.sh file which is used to setup the KIND cluster.
How to execute e2e tests with fake-gcs-server and KIND cluster
Run the following make command to spin up a KinD cluster, deploy fakegcs and run the e2e tests with provider gcp:
make ci-e2e-kind-gcs
Azurite setup
Azurite is run inside a pod using this docker image (tag:latest) in a KIND cluster.
The user needs to run make ci-e2e-kind-azure to start the e2e tests for druid with Azurite as the object storage for etcd backups. The above command internally runs the script hack/ci-e2e-kind-azure.sh which initializes the setup with required steps before going on to create a KIND cluster and deploy Azurite in it and use that emulator to run e2e tests.
The azurite running inside the pod serves HTTP requests at port 10000. As the e2e tests runs on the host machine while the emulator runs on KIND cluster, the port 10000 needs to be port-forwarded from the host machine to azurite service running inside the KIND cluster. The port forwardings is defined in the hack/kind-up.sh file which is used to setup the KIND cluster.
How to execute e2e tests with Azurite and KIND cluster
Run the following make command to spin up a KinD cluster, deploy Azurite and run the e2e tests with provider azure:
make ci-e2e-kind-azure
2.22 - Manage Azurite Emulator
Manage Azure Blob Storage Emulator
This document is a step-by-step guide on how to configure, deploy and cleanup Azurite, the Azure Blob Storage emulator, within a kind cluster. This setup is ideal for local development and testing.
00-Prerequisites
Ensure that you have setup the development environment as per the documentation.
Note: It is assumed that you have already created kind cluster and the
KUBECONFIGis pointing to this Kubernetes cluster.
Installing Azure CLI
To interact with Azurite you must also install the Azure CLI (version >=2.55.0)
On macOS run:
brew install azure-cli
For other OS, please check the Azure CLI installation documentation.
01-Deploy Azurite
make deploy-azurite
The above make target will deploy Azure emulator in the target Kubernetes cluster.
02-Setup ABS Container
We will be using the azure-cli to create an ABS container. Export the connection string to enable azure-cli to connect to Azurite emulator.
export AZURE_STORAGE_CONNECTION_STRING="DefaultEndpointsProtocol=http;AccountName=devstoreaccount1;AccountKey=Eby8vdM02xNOcqFlqUwJPLlmEtlCDXJ1OUzFT50uSRZ6IFsuFq2UVErCz4I6tq/K1SZFPTOtr/KBHBeksoGMGw==;BlobEndpoint=http://127.0.0.1:10000/devstoreaccount1;"
To create an Azure Blob Storage Container in Azurite, run the following command:
az storage container create -n <container-name>
03-Configure Secret
Connection details for an Azure Object Store Container are put into a Kubernetes Secret. Apply the Kubernetes Secret manifest through:
kubectl apply -f examples/objstore-emulator/etcd-secret-azurite.yaml
Note: The secret created should be referred to in the
EtcdCR inspec.backup.store.secretRef.
04-Cleanup
To clean the setup, unset the environment variable set in step-03 above and delete the Azurite deployment:
unset AZURE_STORAGE_CONNECTION_STRING
kubectl delete -f ./hack/e2e-test/infrastructure/azurite/azurite.yaml
2.23 - Manage Gcs Emulator
Manage GCS Emulator
This document is a step-by-step guide on how to configure, deploy and cleanup GCS Emulator, within a kind cluster. GCS Emulator emulates Google Cloud Storage locally, which allows the Etcd cluster to interact with GCS. This setup is ideal for local development and testing.
00-Prerequisites
Ensure that you have setup the development environment as per the documentation.
Note: It is assumed that you have already created kind cluster and the
KUBECONFIGis pointing to this Kubernetes cluster.
Installing gsutil
To interact with GCS Emulator you must also install the gsutil utility. Follow the instructions here to install gsutil.
01-Deploy FakeGCS
Deploy FakeGCS onto the Kubernetes cluster using the command below:
make deploy-fakegcs
02-Setup GCS Bucket
To create a GCS bucket for Etcd backup purposes, execute the following command:
gsutil -o "Credentials:gs_json_host=127.0.0.1" -o "Credentials:gs_json_port=4443" -o "Boto:https_validate_certificates=False" mb "gs://etcd-bucket"
03-Configure Secret
Connection details for a GCS Object Store are put into a Kubernetes Secret. Apply the Kubernetes Secret manifest through:
kubectl apply -f examples/objstore-emulator/etcd-secret-fakegcs.yaml
Note: The secret created should be referred to in the
EtcdCR inspec.backup.store.secretRef.
04-Cleanup
To clean the setup, delete the FakeGCS deployment:
kubectl delete -f ./hack/e2e-test/infrastructure/fake-gcs-server/fake-gcs-server.yaml
2.24 - Manage S3 Emulator
Manage S3 Emulator
This document is a step-by-step guide on how to configure, deploy and cleanup LocalStack, within a kind cluster. LocalStack emulates AWS services locally, which allows the Etcd cluster to interact with AWS S3. This setup is ideal for local development and testing.
00-Prerequisites
Ensure that you have setup the development environment as per the documentation.
Note: It is assumed that you have already created kind cluster and the
KUBECONFIGis pointing to this Kubernetes cluster.
Installing AWS CLI
To interact with LocalStack you must also install the AWS CLI (version >=1.29.0 or version >=2.13.0)
On macOS run:
brew install awscli
For other OS, please check the AWS CLI installation documentation.
01-Deploy LocalStack
make deploy-localstack
The above make target will deploy LocalStack in the target Kubernetes cluster.
02-Setup S3 Bucket
Configure AWS CLI to interact with LocalStack by setting the necessary environment variables. This configuration redirects S3 commands to the LocalStack endpoint and provides the required credentials for authentication.
export AWS_ENDPOINT_URL_S3="http://localhost:4566"
export AWS_ACCESS_KEY_ID=ACCESSKEYAWSUSER
export AWS_SECRET_ACCESS_KEY=sEcreTKey
export AWS_DEFAULT_REGION=us-east-2
Create a S3 bucket using the following command:
aws s3api create-bucket --bucket <bucket-name> --region <region> --create-bucket-configuration LocationConstraint=<region> --acl private
To verify if the bucket has been created, you can use the following command:
aws s3api head-bucket --bucket <bucket-name>
03-Configure Secret
Connection details for an Azure S3 Object Store are put into a Kubernetes Secret. Apply the Kubernetes Secret manifest through:
kubectl apply -f examples/objstore-emulator/etcd-secret-localstack.yaml
Note: The secret created should be referred to in the
EtcdCR inspec.backup.store.secretRef.
04-Cleanup
To clean the setup,, unset the environment variable set in step-03 above and delete the LocalStack deployment:
unset AWS_ENDPOINT_URL_S3 AWS_ACCESS_KEY_ID AWS_SECRET_ACCESS_KEY AWS_DEFAULT_REGION
kubectl delete -f ./hack/e2e-test/infrastructure/localstack/localstack.yaml
2.25 - Managing Etcd Clusters
Managing ETCD Clusters
Create an Etcd Cluster
Creating an Etcd cluster can be done either by explicitly creating a manifest file or it can also be done programmatically. You can refer to and/or modify any sample Etcd manifest to create an etcd cluster. In order to programmatically create an Etcd cluster you can refer to the Golang API to create an Etcd custom resource and using a k8s client you can apply an instance of a Etcd custom resource targetting any namespace in a k8s cluster.
Prior to v0.23.0 version of etcd-druid, after creating an Etcd custom resource, you will have to annotate the resource with gardener.cloud/operation=reconcile in order to trigger a reconciliation for the newly created Etcd resource. Post v0.23.0 version of etcd-druid, there is no longer any need to explicitly trigger reconciliations for creating new Etcd clusters.
Track etcd cluster creation
In order to track the progress of creation of etcd cluster resources you can do the following:
status.lastOperationcan be monitored to check the status of reconciliation.Additional printer columns have been defined for
Etcdcustom resource. You can execute the following command to know if anEtcdcluster is ready/quorate.
kubectl get etcd <etcd-name> -n <namespace> -owide
# you will see additional columns which will indicate the state of an etcd cluster
NAME READY QUORATE ALL MEMBERS READY BACKUP READY AGE CLUSTER SIZE CURRENT REPLICAS READY REPLICAS
etcd-main true True True True 235d 3 3 3
You can additional monitor all etcd cluster resources that are created for every etcd cluster.
For etcd-druid version <v0.23.0 use the following command:
kubectl get all,cm,role,rolebinding,lease,sa -n <namespace> --selector=instance=<etcd-name>
For etcd-druid version >=v0.23.0 use the following command:
kubectl get all,cm,role,rolebinding,lease,sa -n <namespace> --selector=app.kubernetes.io/managed-by=etcd-druid,app.kubernetes.io/part-of=<etcd-name>
Update & Reconcile an Etcd Cluster
Edit the Etcd custom resource
To update an etcd cluster, you should usually only be updating the Etcd custom resource representing the etcd cluster.
You can make changes to the existing Etcd resource by invoking the following command:
kubectl edit etcd <etcd-name> -n <namespace>
This will open up the linked editor where you can make the edits.
Scale the Etcd cluster horizontally
To scale an etcd cluster horizontally, you can update the spec.replicas field in the Etcd custom resource. For example, to scale an etcd cluster to 5 replicas, you can run:
kubectl patch etcd <etcd-name> -n <namespace> --type merge -p '{"spec":{"replicas":5}}'
Alternatively, you can use the /scale subresource to scale an etcd cluster horizontally. For example, to scale an etcd cluster to 5 replicas, you can run:
kubectl scale etcd <etcd-name> -n <namespace> --replicas=5
!!! note While an Etcd cluster can be scaled out, it cannot be scaled in, i.e., the replicas cannot be decreased to a non-zero value. An Etcd cluster can still be scaled to 0 replicas, indicating that the cluster is to be “hibernated”. This is beneficial for use-cases where an etcd cluster is not needed for a certain period of time, and the user does not want to pay for the compute resources. A hibernated etcd cluster can be resumed later by scaling it back to a non-zero value. Please note that the data volumes backing an Etcd cluster will be retained during hibernation, and will still be charged for.
Scale the Etcd cluster vertically
To scale an Etcd cluster vertically, you can update the spec.etcd.resources and spec.backup.resources fields in the Etcd custom resource. For example, to scale an Etcd cluster’s etcd container to 2 CPU and 4Gi memory, you can run:
kubectl patch etcd <etcd-name> -n <namespace> --type merge -p '{"spec":{"etcd":{"resources":{"requests":{"cpu":"2","memory":"4Gi"}}}}}'
Additionally, you can use an external pod autoscaler such as vertical pod autoscaler to scale an Etcd cluster vertically. This is made possible by the /scale subresource on the Etcd custom resource.
!!! note Scaling an Etcd cluster vertically can potentially result in downtime, based on its failure tolerance. This is due to the fact that an etcd cluster is actuated by pods, and the pods need to be restarted in order to apply the new resource values. A multi-member etcd cluster can tolerate a failure of one member, but if the number of replicas is set to 1, then the etcd cluster will not be able to tolerate any failures. Therefore, it is recommended to scale a single-member etcd cluster vertically only when it is deemed necessary, and to monitor the cluster closely during the scaling process. A multi-member Etcd cluster can be scaled vertically, one member at a time. A pod disruption budget for this can ensure that the cluster can tolerate a certain number of failures. This pod disruption budget is automatically deployed and managed by etcd-druid for multi-member Etcd clusters, and it is recommended to not modify this PDB manually.
!!! note While the replicas and resources in an Etcd resource spec can be modified, please ensure to read the next section to understand when and how these changes are reconciled by etcd-druid.
Reconcile
There are two ways to control reconciliation of any changes done to Etcd custom resources.
Auto reconciliation
If etcd-druid has been deployed with auto-reconciliation then any change done to an Etcd resource will be automatically reconciled. You use --enable-etcd-spec-auto-reconcile CLI flag to enable auto-reconciliation of the etcd spec.
For a complete list of CLI args you can see this document.
Explicit reconciliation
If --enable-etcd-spec-auto-reconcile is set to false or not set at all, then any change to an Etcd resource will not be automatically reconciled. To trigger a reconcile you must set the following annotation on the Etcd resource:
kubectl annotate etcd <etcd-name> gardener.cloud/operation=reconcile -n <namespace>
This option is sometimes recommeded as you would like avoid auto-reconciliation of accidental changes to Etcd resources outside the maintenance time window, thus preventing a potential transient quorum loss due to misconfiguration, attach-detach issues of persistent volumes etc.
Overwrite Container OCI Images
To find out image versions of etcd-backup-restore and etcd-wrapper used by a specific version of etcd-druid one way is look for the image versions in images.yaml. There are times that you might wish to override these images that come bundled with etcd-druid. There are two ways in which you can do that:
Option #1
We leverage Overwrite ImageVector facility provided by gardener. This capability can be used without bringing in gardener as well. To illustrate this in context of etcd-druid you will create a ConfigMap with the following content:
apiVersion: v1
kind: ConfigMap
metadata:
name: etcd-druid-images-overwrite
namespace: <etcd-druid-namespace>
data:
images_overwrite.yaml: |
images:
- name: etcd-backup-restore
sourceRepository: github.com/gardener/etcd-backup-restore
repository: <your-own-custom-etcd-backup-restore-repo-url>
tag: "v<custom-tag>"
- name: etcd-wrapper
sourceRepository: github.com/gardener/etcd-wrapper
repository: <your-own-custom-etcd-wrapper-repo-url>
tag: "v<custom-tag>"
- name: alpine
repository: <your-own-custom-alpine-repo-url>
tag: "v<custom-tag>"
You can use images.yaml as a reference to create the overwrite images YAML ConfigMap.
Edit the etcd-druid Deployment with:
- Mount the
ConfigMap - Set
IMAGEVECTOR_OVERWRITEenvironment variable whose value must be the path you choose to mount theConfigMap.
To illustrate the changes you can see the following etcd-druid Deployment YAML:
apiVersion: apps/v1
kind: Deployment
metadata:
name: etcd-druid
namespace: <etcd-druid-namespace>
spec:
template:
spec:
containers:
- name: etcd-druid
env:
- name: IMAGEVECTOR_OVERWRITE
value: /imagevector-overwrite/images_overwrite.yaml
volumeMounts:
- name: etcd-druid-images-overwrite
mountPath: /imagevector-overwrite
volumes:
- name: etcd-druid-images-overwrite
configMap:
name: etcd-druid-images-overwrite
!!! info
Image overwrites specified in the mounted ConfigMap will be respected by successive reconciliations for this Etcd custom resource.
Option #2
We provide a generic way to suspend etcd cluster reconciliation via etcd-druid, allowing a human operator to take control. This option should be excercised only in case of troubleshooting or quick fixes which are not possible to do via the reconciliation loop in etcd-druid. However one of the use cases to use this option is to perhaps update the container image to apply a hot patch and speed up recovery of an etcd cluster.
Manually modify individual etcd cluster resources
etcd cluster resources are managed by etcd-druid and since v0.23.0 version of etcd-druid any changes to these managed resources are protected via a validating webhook. You can find more information about this webhook here. To be able to manually modify etcd cluster managed resources two things needs to be done:
- Annotate the target
Etcdresource suspending any reconciliation byetcd-druid. You can do this by invoking the following command:
kubectl annotate etcd <etcd-name> -n <namespace> druid.gardener.cloud/suspend-etcd-spec-reconcile=
- Add another annotation to the target
Etcdresource disabling managed resource protection via the webhook. You can do this by invoking the following command:
kubectl annotate etcd <etcd-name> -n <namespace> druid.gardener.cloud/disable-etcd-component-protection=
Now you are free to make changes to any managed etcd cluster resource.
!!! note
As long as the above two annotations are there, no reconciliation will be done for this etcd cluster by etcd-druid. Therefore it is essential that you remove this annotations eventually.
2.26 - Metrics
Monitoring
etcd-druid uses Prometheus for metrics reporting. The metrics can be used for real-time monitoring and debugging of compaction jobs.
The simplest way to see the available metrics is to cURL the metrics endpoint /metrics. The format is described here.
Follow the Prometheus getting started doc to spin up a Prometheus server to collect etcd metrics.
The naming of metrics follows the suggested Prometheus best practices. All compaction related metrics are put under namespace etcddruid and the respective subsystems.
Snapshot Compaction
These metrics provide information about the compaction jobs that run after some interval in shoot control planes. Studying the metrics, we can deduce how many compaction job ran successfully, how many failed, how many delta events compacted etc.
| Name | Description | Type |
|---|---|---|
| etcddruid_compaction_jobs_total | Total number of compaction jobs initiated by compaction controller. | Counter |
| etcddruid_compaction_jobs_current | Number of currently running compaction job. | Gauge |
| etcddruid_compaction_job_duration_seconds | Total time taken in seconds to finish a running compaction job. | Histogram |
| etcddruid_compaction_num_delta_events | Total number of etcd events to be compacted by a compaction job. | Gauge |
There are two labels for etcddruid_compaction_jobs_total metrics. The label succeeded shows how many of the compaction jobs are succeeded and label failed shows how many of compaction jobs are failed.
There are two labels for etcddruid_compaction_job_duration_seconds metrics. The label succeeded shows how much time taken by a successful job to complete and label failed shows how much time taken by a failed compaction job.
etcddruid_compaction_jobs_current metric comes with label etcd_namespace that indicates the namespace of the Etcd running in the control plane of a shoot cluster..
Etcd
These metrics are exposed by the etcd process that runs in each etcd pod.
The following list metrics is applicable to clustering of a multi-node etcd cluster. The full list of metrics exposed by etcd is available here.
| No. | Metrics Name | Description | Comments |
|---|---|---|---|
| 1 | etcd_disk_wal_fsync_duration_seconds | latency distributions of fsync called by WAL. | High disk operation latencies indicate disk issues. |
| 2 | etcd_disk_backend_commit_duration_seconds | latency distributions of commit called by backend. | High disk operation latencies indicate disk issues. |
| 3 | etcd_server_has_leader | whether or not a leader exists. 1: leader exists, 0: leader not exists. | To capture quorum loss or to check the availability of etcd cluster. |
| 4 | etcd_server_is_leader | whether or not this member is a leader. 1 if it is, 0 otherwise. | |
| 5 | etcd_server_leader_changes_seen_total | number of leader changes seen. | Helpful in fine tuning the zonal cluster like etcd-heartbeat time etc, it can also indicates the etcd load and network issues. |
| 6 | etcd_server_is_learner | whether or not this member is a learner. 1 if it is, 0 otherwise. | |
| 7 | etcd_server_learner_promote_successes | total number of successful learner promotions while this member is leader. | Might be helpful in checking the success of API calls called by backup-restore. |
| 8 | etcd_network_client_grpc_received_bytes_total | total number of bytes received from grpc clients. | Client Traffic In. |
| 9 | etcd_network_client_grpc_sent_bytes_total | total number of bytes sent to grpc clients. | Client Traffic Out. |
| 10 | etcd_network_peer_sent_bytes_total | total number of bytes sent to peers. | Useful for network usage. |
| 11 | etcd_network_peer_received_bytes_total | total number of bytes received from peers. | Useful for network usage. |
| 12 | etcd_network_active_peers | current number of active peer connections. | Might be useful in detecting issues like network partition. |
| 13 | etcd_server_proposals_committed_total | total number of consensus proposals committed. | A consistently large lag between a single member and its leader indicates that member is slow or unhealthy. |
| 14 | etcd_server_proposals_pending | current number of pending proposals to commit. | Pending proposals suggests there is a high client load or the member cannot commit proposals. |
| 15 | etcd_server_proposals_failed_total | total number of failed proposals seen. | Might indicates downtime caused by a loss of quorum. |
| 16 | etcd_server_proposals_applied_total | total number of consensus proposals applied. | Difference between etcd_server_proposals_committed_total and etcd_server_proposals_applied_total should usually be small. |
| 17 | etcd_mvcc_db_total_size_in_bytes | total size of the underlying database physically allocated in bytes. | |
| 18 | etcd_server_heartbeat_send_failures_total | total number of leader heartbeat send failures. | Might be helpful in fine-tuning the cluster or detecting slow disk or any network issues. |
| 19 | etcd_network_peer_round_trip_time_seconds | round-trip-time histogram between peers. | Might be helpful in fine-tuning network usage specially for zonal etcd cluster. |
| 20 | etcd_server_slow_apply_total | total number of slow apply requests. | Might indicate overloaded from slow disk. |
| 21 | etcd_server_slow_read_indexes_total | total number of pending read indexes not in sync with leader’s or timed out read index requests. |
The full list of metrics is available here.
Etcd-Backup-Restore
These metrics are exposed by the etcd-backup-restore container in each etcd pod.
The following list metrics is applicable to clustering of a multi-node etcd cluster. The full list of metrics exposed by etcd-backup-restore is available here.
| No. | Metrics Name | Description |
|---|---|---|
| 1. | etcdbr_cluster_size | to capture the scale-up/scale-down scenarios. |
| 2. | etcdbr_is_learner | whether or not this member is a learner. 1 if it is, 0 otherwise. |
| 3. | etcdbr_is_learner_count_total | total number times member added as the learner. |
| 4. | etcdbr_restoration_duration_seconds | total latency distribution required to restore the etcd member. |
| 5. | etcdbr_add_learner_duration_seconds | total latency distribution of adding the etcd member as a learner to the cluster. |
| 6. | etcdbr_member_remove_duration_seconds | total latency distribution removing the etcd member from the cluster. |
| 7. | etcdbr_member_promote_duration_seconds | total latency distribution of promoting the learner to the voting member. |
| 8. | etcdbr_defragmentation_duration_seconds | total latency distribution of defragmentation of each etcd cluster member. |
Prometheus supplied metrics
The Prometheus client library provides a number of metrics under the go and process namespaces.
2.27 - operator out-of-band tasks
DEP-05: Operator Out-of-band Tasks
Summary
This DEP proposes an enhancement to etcd-druid’s capabilities to handle out-of-band tasks, which are presently performed manually or invoked programmatically via suboptimal APIs. The document proposes the establishment of a unified interface by defining a well-structured API to harmonize the initiation of any out-of-band task, monitor its status, and simplify the process of adding new tasks and managing their lifecycles.
Terminology
etcd-druid: etcd-druid is an operator to manage the etcd clusters.
backup-sidecar: It is the etcd-backup-restore sidecar container running in each etcd-member pod of etcd cluster.
leading-backup-sidecar: A backup-sidecar that is associated to an etcd leader of an etcd cluster.
out-of-band task: Any on-demand tasks/operations that can be executed on an etcd cluster without modifying the Etcd custom resource spec (desired state).
Motivation
Today, etcd-druid mainly acts as an etcd cluster provisioner (creation, maintenance and deletion). In future, capabilities of etcd-druid will be enhanced via etcd-member proposal by providing it access to much more detailed information about each etcd cluster member. While we enhance the reconciliation and monitoring capabilities of etcd-druid, it still lacks the ability to allow users to invoke out-of-band tasks on an existing etcd cluster.
There are new learnings while operating etcd clusters at scale. It has been observed that we regularly need capabilities to trigger out-of-band tasks which are outside of the purview of a regular etcd reconciliation run. Many of these tasks are multi-step processes, and performing them manually is error-prone, even if an operator follows a well-written step-by-step guide. Thus, there is a need to automate these tasks.
Some examples of an on-demand/out-of-band tasks:
- Recover from a permanent quorum loss of etcd cluster.
- Trigger an on-demand full/delta snapshot.
- Trigger an on-demand snapshot compaction.
- Trigger an on-demand maintenance of etcd cluster.
- Copy the backups from one object store to another object store.
Goals
- Establish a unified interface for operator tasks by defining a single dedicated custom resource for
out-of-bandtasks. - Define a contract (in terms of prerequisites) which needs to be adhered to by any task implementation.
- Facilitate the easy addition of new
out-of-bandtask(s) through this custom resource. - Provide CLI capabilities to operators, making it easy to invoke supported
out-of-bandtasks.
Non-Goals
- In the current scope, capability to abort/suspend an
out-of-bandtask is not going to be provided. This could be considered as an enhancement based on pull. - Ordering (by establishing dependency) of
out-of-bandtasks submitted for the same etcd cluster has not been considered in the first increment. In a future version based on how operator tasks are used, we will enhance this proposal and the implementation.
Proposal
Authors propose creation of a new single dedicated custom resource to represent an out-of-band task. Etcd-druid will be enhanced to process the task requests and update its status which can then be tracked/observed.
Custom Resource Golang API
EtcdOperatorTask is the new custom resource that will be introduced. This API will be in v1alpha1 version and will be subject to change. We will be respecting Kubernetes Deprecation Policy.
// EtcdOperatorTask represents an out-of-band operator task resource.
type EtcdOperatorTask struct {
metav1.TypeMeta
metav1.ObjectMeta
// Spec is the specification of the EtcdOperatorTask resource.
Spec EtcdOperatorTaskSpec `json:"spec"`
// Status is most recently observed status of the EtcdOperatorTask resource.
Status EtcdOperatorTaskStatus `json:"status,omitempty"`
}
Spec
The authors propose that the following fields should be specified in the spec (desired state) of the EtcdOperatorTask custom resource.
- To capture the type of
out-of-bandoperator task to be performed,.spec.typefield should be defined. It can have values from all supportedout-of-bandtasks eg. “OnDemandSnaphotTask”, “QuorumLossRecoveryTask” etc. - To capture the configuration specific to each task, a
.spec.configfield should be defined of typestringas each task can have different input configuration.
// EtcdOperatorTaskSpec is the spec for a EtcdOperatorTask resource.
type EtcdOperatorTaskSpec struct {
// Type specifies the type of out-of-band operator task to be performed.
Type string `json:"type"`
// Config is a task specific configuration.
Config string `json:"config,omitempty"`
// TTLSecondsAfterFinished is the time-to-live to garbage collect the
// related resource(s) of task once it has been completed.
// +optional
TTLSecondsAfterFinished *int32 `json:"ttlSecondsAfterFinished,omitempty"`
// OwnerEtcdReference refers to the name and namespace of the corresponding
// Etcd owner for which the task has been invoked.
OwnerEtcdRefrence types.NamespacedName `json:"ownerEtcdRefrence"`
}
Status
The authors propose the following fields for the Status (current state) of the EtcdOperatorTask custom resource to monitor the progress of the task.
// EtcdOperatorTaskStatus is the status for a EtcdOperatorTask resource.
type EtcdOperatorTaskStatus struct {
// ObservedGeneration is the most recent generation observed for the resource.
ObservedGeneration *int64 `json:"observedGeneration,omitempty"`
// State is the last known state of the task.
State TaskState `json:"state"`
// Time at which the task has moved from "pending" state to any other state.
InitiatedAt metav1.Time `json:"initiatedAt"`
// LastError represents the errors when processing the task.
// +optional
LastErrors []LastError `json:"lastErrors,omitempty"`
// Captures the last operation status if task involves many stages.
// +optional
LastOperation *LastOperation `json:"lastOperation,omitempty"`
}
type LastOperation struct {
// Name of the LastOperation.
Name opsName `json:"name"`
// Status of the last operation, one of pending, progress, completed, failed.
State OperationState `json:"state"`
// LastTransitionTime is the time at which the operation state last transitioned from one state to another.
LastTransitionTime metav1.Time `json:"lastTransitionTime"`
// A human readable message indicating details about the last operation.
Reason string `json:"reason"`
}
// LastError stores details of the most recent error encountered for the task.
type LastError struct {
// Code is an error code that uniquely identifies an error.
Code ErrorCode `json:"code"`
// Description is a human-readable message indicating details of the error.
Description string `json:"description"`
// ObservedAt is the time at which the error was observed.
ObservedAt metav1.Time `json:"observedAt"`
}
// TaskState represents the state of the task.
type TaskState string
const (
TaskStateFailed TaskState = "Failed"
TaskStatePending TaskState = "Pending"
TaskStateRejected TaskState = "Rejected"
TaskStateSucceeded TaskState = "Succeeded"
TaskStateInProgress TaskState = "InProgress"
)
// OperationState represents the state of last operation.
type OperationState string
const (
OperationStateFailed OperationState = "Failed"
OperationStatePending OperationState = "Pending"
OperationStateCompleted OperationState = "Completed"
OperationStateInProgress OperationState = "InProgress"
)
Custom Resource YAML API
apiVersion: druid.gardener.cloud/v1alpha1
kind: EtcdOperatorTask
metadata:
name: <name of operator task resource>
namespace: <cluster namespace>
generation: <specific generation of the desired state>
spec:
type: <type/category of supported out-of-band task>
ttlSecondsAfterFinished: <time-to-live to garbage collect the custom resource after it has been completed>
config: <task specific configuration>
ownerEtcdRefrence: <refer to corresponding etcd owner name and namespace for which task has been invoked>
status:
observedGeneration: <specific observedGeneration of the resource>
state: <last known current state of the out-of-band task>
initiatedAt: <time at which task move to any other state from "pending" state>
lastErrors:
- code: <error-code>
description: <description of the error>
observedAt: <time the error was observed>
lastOperation:
name: <operation-name>
state: <task state as seen at the completion of last operation>
lastTransitionTime: <time of transition to this state>
reason: <reason/message if any>
Lifecycle
Creation
Task(s) can be created by creating an instance of the EtcdOperatorTask custom resource specific to a task.
Note: In future, either a
kubectlextension plugin or adruidctltool will be introduced. Dedicated sub-commands will be created for eachout-of-bandtask. This will drastically increase the usability for an operator for performing such tasks, as the CLI extension will automatically create relevant instance(s) ofEtcdOperatorTaskwith the provided configuration.
Execution
- Authors propose to introduce a new controller which watches for
EtcdOperatorTaskcustom resource. - Each
out-of-bandtask may have some task specific configuration defined in .spec.config. - The controller needs to parse this task specific config, which comes as a string, according to the schema defined for each task.
- For every
out-of-bandtask, a set ofpre-conditionscan be defined. These pre-conditions are evaluated against the current state of the target etcd cluster. Based on the evaluation result (boolean), the task is permitted or denied execution. - If multiple tasks are invoked simultaneously or in
pendingstate, then they will be executed in a First-In-First-Out (FIFO) manner.
Note: Dependent ordering among tasks will be addressed later which will enable concurrent execution of tasks when possible.
Deletion
Upon completion of the task, irrespective of its final state, Etcd-druid will ensure the garbage collection of the task custom resource and any other Kubernetes resources created to execute the task. This will be done according to the .spec.ttlSecondsAfterFinished if defined in the spec, or a default expiry time will be assumed.
Use Cases
Recovery from permanent quorum loss
Recovery from permanent quorum loss involves two phases - identification and recovery - both of which are done manually today. This proposal intends to automate the latter. Recovery today is a multi-step process and needs to be performed carefully by a human operator. Automating these steps would be prudent, to make it quicker and error-free. The identification of the permanent quorum loss would remain a manual process, requiring a human operator to investigate and confirm that there is indeed a permanent quorum loss with no possibility of auto-healing.
Task Config
We do not need any config for this task. When creating an instance of EtcdOperatorTask for this scenario, .spec.config will be set to nil (unset).
Pre-Conditions
- There should be a quorum loss in a multi-member etcd cluster. For a single-member etcd cluster, invoking this task is unnecessary as the restoration of the single member is automatically handled by the backup-restore process.
- There should not already be a permanent-quorum-loss-recovery-task running for the same etcd cluster.
Trigger on-demand snapshot compaction
Etcd-druid provides a configurable etcd-events-threshold flag. When this threshold is breached, then a snapshot compaction is triggered for the etcd cluster. However, there are scenarios where an ad-hoc snapshot compaction may be required.
Possible Scenarios
- If an operator anticipates a scenario of permanent quorum loss, they can trigger an
on-demand snapshot compactionto create a compacted full-snapshot. This can potentially reduce the recovery time from a permanent quorum loss. - As an additional benefit, a human operator can leverage the current implementation of snapshot compaction, which internally triggers
restoration. Hence, by initiating anon-demand snapshot compactiontask, the operator can verify the integrity of etcd cluster backups, particularly in cases of potential backup corruption or re-encryption. The success or failure of this snapshot compaction can offer valuable insights into these scenarios.
Task Config
We do not need any config for this task. When creating an instance of EtcdOperatorTask for this scenario, .spec.config will be set to nil (unset).
Pre-Conditions
- There should not be a
on-demand snapshot compactiontask already running for the same etcd cluster.
Note:
on-demand snapshot compactionruns as a separate job in a separate pod, which interacts with the backup bucket and not the etcd cluster itself, hence it doesn’t depend on the health of etcd cluster members.
Trigger on-demand full/delta snapshot
Etcd custom resource provides an ability to set FullSnapshotSchedule which currently defaults to run once in 24 hrs. DeltaSnapshotPeriod is also made configurable which defines the duration after which a delta snapshot will be taken.
If a human operator does not wish to wait for the scheduled full/delta snapshot, they can trigger an on-demand (out-of-schedule) full/delta snapshot on the etcd cluster, which will be taken by the leading-backup-restore.
Possible Scenarios
- An on-demand full snapshot can be triggered if scheduled snapshot fails due to any reason.
- Gardener Shoot Hibernation: Every etcd cluster incurs an inherent cost of preserving the volumes even when a gardener shoot control plane is scaled down, i.e the shoot is in a hibernated state. However, it is possible to save on hyperscaler costs by invoking this task to take a full snapshot before scaling down the etcd cluster, and deleting the etcd data volumes afterwards.
- Gardener Control Plane Migration: In gardener, a cluster control plane can be moved from one seed cluster to another. This process currently requires the etcd data to be replicated on the target cluster, so a full snapshot of the etcd cluster in the source seed before the migration would allow for faster restoration of the etcd cluster in the target seed.
Task Config
// SnapshotType can be full or delta snapshot.
type SnapshotType string
const (
SnapshotTypeFull SnapshotType = "full"
SnapshotTypeDelta SnapshotType = "delta"
)
type OnDemandSnapshotTaskConfig struct {
// Type of on-demand snapshot.
Type SnapshotType `json:"type"`
}
spec:
config: |
type: <type of on-demand snapshot>
Pre-Conditions
- Etcd cluster should have a quorum.
- There should not already be a
on-demand snapshottask running with the sameSnapshotTypefor the same etcd cluster.
Trigger on-demand maintenance of etcd cluster
Operator can trigger on-demand maintenance of etcd cluster which includes operations like etcd compaction, etcd defragmentation etc.
Possible Scenarios
- If an etcd cluster is heavily loaded, which is causing performance degradation of an etcd cluster, and the operator does not want to wait for the scheduled maintenance window then an
on-demand maintenancetask can be triggered which will invoke etcd-compaction, etcd-defragmentation etc. on the target etcd cluster. This will make the etcd cluster lean and clean, thus improving cluster performance.
Task Config
type OnDemandMaintenanceTaskConfig struct {
// MaintenanceType defines the maintenance operations need to be performed on etcd cluster.
MaintenanceType maintenanceOps `json:"maintenanceType`
}
type maintenanceOps struct {
// EtcdCompaction if set to true will trigger an etcd compaction on the target etcd.
// +optional
EtcdCompaction bool `json:"etcdCompaction,omitempty"`
// EtcdDefragmentation if set to true will trigger a etcd defragmentation on the target etcd.
// +optional
EtcdDefragmentation bool `json:"etcdDefragmentation,omitempty"`
}
spec:
config: |
maintenanceType:
etcdCompaction: <true/false>
etcdDefragmentation: <true/false>
Pre-Conditions
- Etcd cluster should have a quorum.
- There should not already be a duplicate task running with same
maintenanceType.
Copy Backups Task
Copy the backups(full and delta snapshots) of etcd cluster from one object store(source) to another object store(target).
Possible Scenarios
- In Gardener, the Control Plane Migration process utilizes the copy-backups task. This task is responsible for copying backups from one object store to another, typically located in different regions.
Task Config
// EtcdCopyBackupsTaskConfig defines the parameters for the copy backups task.
type EtcdCopyBackupsTaskConfig struct {
// SourceStore defines the specification of the source object store provider.
SourceStore StoreSpec `json:"sourceStore"`
// TargetStore defines the specification of the target object store provider for storing backups.
TargetStore StoreSpec `json:"targetStore"`
// MaxBackupAge is the maximum age in days that a backup must have in order to be copied.
// By default all backups will be copied.
// +optional
MaxBackupAge *uint32 `json:"maxBackupAge,omitempty"`
// MaxBackups is the maximum number of backups that will be copied starting with the most recent ones.
// +optional
MaxBackups *uint32 `json:"maxBackups,omitempty"`
}
spec:
config: |
sourceStore: <source object store specification>
targetStore: <target object store specification>
maxBackupAge: <maximum age in days that a backup must have in order to be copied>
maxBackups: <maximum no. of backups that will be copied>
Note: For detailed object store specification please refer here
Pre-Conditions
- There should not already be a
copy-backupstask running.
Note:
copy-backups-taskruns as a separate job, and it operates only on the backup bucket, hence it doesn’t depend on health of etcd cluster members.
Note:
copy-backups-taskhas already been implemented and it’s currently being used in Control Plane Migration butcopy-backups-taskwill be harmonized withEtcdOperatorTaskcustom resource.
Metrics
Authors proposed to introduce the following metrics:
etcddruid_operator_task_duration_seconds: Histogram which captures the runtime for each etcd operator task. Labels:- Key:
type, Value: all supported tasks - Key:
state, Value: One-Of {failed, succeeded, rejected} - Key:
etcd, Value: name of the target etcd resource - Key:
etcd_namespace, Value: namespace of the target etcd resource
- Key:
etcddruid_operator_tasks_total: Counter which counts the number of etcd operator tasks. Labels:- Key:
type, Value: all supported tasks - Key:
state, Value: One-Of {failed, succeeded, rejected} - Key:
etcd, Value: name of the target etcd resource - Key:
etcd_namespace, Value: namespace of the target etcd resource
- Key:
2.28 - Prepare Dev Environment
Prepare Dev Environment
This guide will provide with detailed instructions on installing all dependencies and tools that are required to start developing and testing etcd-druid.
[macOS only] Installing Homebrew
Hombrew is a popular package manager for macOS. You can install it by executing the following command in a terminal:
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
Installing Go
On macOS run:
brew install go
Alternatively you can also follow the Go installation documentation.
Installing Git
We use git as VCS which you need to install.
On macOS run:
brew install git
For other OS, please check the Git installation documentation.
Installing Docker
You need to have docker installed and running. This will allow starting a kind cluster or a minikube cluster for locally deploying etcd-druid.
On macOS run:
brew install docker
Alternatively you can also follow the Docker installation documentation.
Installing Kubectl
To interact with the local Kubernetes cluster you will need kubectl. On macOS run:
brew install kubernetes-cli
For other OS, please check the Kubectl installation documentation.
Other tools that might come in handy
To operate etcd-druid you do not need these tools but they usually come in handy when working with YAML/JSON files.
On macOS run:
# jq (https://jqlang.github.io/jq/) is a lightweight and flexible command-line JSON processor
brew install jq
# yq (https://mikefarah.gitbook.io/yq) is a lightweight and portable command-line YAML processor.
brew install yq
Get the sources
Clone the repository from Github into your $GOPATH.
mkdir -p $(go env GOPATH)/src/github.com/gardener
cd $(go env GOPATH)src/github.com/gardener
git clone https://github.com/gardener/etcd-druid.git
# alternatively you can also use `git clone git@github.com:gardener/etcd-druid.git`
2.29 - Prepare Helm Charts
Prepare etcd-druid Helm charts
etcd-druid operator can be deployed via helm charts. The charts can be found here. All Makefile deploy* targets employ skaffold which internally uses the same helm charts to deploy all resources to setup etcd-druid. In the following sections you will learn on the prerequisites, generated/copied resources and kubernetes resources that are deployed via helm charts to setup etcd-druid.
Prerequisite
Installing Helm
If you wish to directly use helm charts then please ensure that helm is already installed.
On macOS, you can install via brew:
brew install helm
For all other OS please check Helm installation instructions.
Installing OpenSSL
OpenSSL is used to generate PKI resources that are used to configure TLS connectivity with the webhook(s). On macOS, you can install via brew:
brew install openssl
For all other OS please check OpenSSL download instructions.
NOTE: On linux, the library is available via native package managers like
apt,yumetc. On Windows, you can get the installer here.
Generated/Copied resources
To leverage etcd-druid helm charts you need to ensure that the charts contains the required CRD yaml files and PKI resources.
CRDs
Heml-3 provides special status to CRDs. CRD YAML files should be placed in crds/ directory inside of a chart. Helm will attempt to load all the files in this directory. We now generate the CRDs and keep these at etcd-druid/api/core/v1alpha1/crds which serves as a single source of truth for all custom resource specifications under etcd-druid operator. These CRDs needs to be copied to etcd-druid/charts/crds.
PKI resources
Webhooks communicate over TLS with the kube-apiserver. It is therefore essential to generate PKI resources (CA certificate, Server certificate and Server key) to be used to configure Webhook configuration and mount it to the etcd-druid operator Deployment.
Kubernetes Resources
etcd-druid helm charts creates the following kubernetes resources:
| Resource | Description |
|---|---|
| ApiVersion: apps/v1 Kind: Deployment | This is the etcd-druid Deployment which runs etcd-druid operator. All reconcilers run as part of this operator. |
| ApiVersion: rbac.authorization.k8s.io/v1 Kind: ClusterRole | etcd-druid manages Etcd resources deployed across namespaces. A cluster role provides required roles to etcd-druid operator for all the resources that are created for an etcd cluster. |
| ApiVersion: v1 Kind: ServiceAccount | It defines a system user with which etcd-druid operator will function. The service account name will be configured in the Deployment at spec.template.spec.serviceAccountName |
| ApiVersion:rbac.authorization.k8s.io/v1 Kind: ClusterRoleBinding | Binds the cluster roles to the ServiceAccount thus associating all cluster roles to the system user with which etcd-druid operator will be run. |
| ApiVersion: v1 Kind: Service | ClusterIP service which will provide a logical endpoint to reach any etcd-druid pods. |
| ApiVersion: v1 Kind: Secret | A secret containing the webhook server certificate and key will be created and mounted onto the Deployment. |
| ApiVersion: admissionregistration.k8s.io/v1 Kind: ValidatingWebhookConfiguration | It is the validation webhook configuration. Currently there is only one webhook etcdcomponents . For more details see here. |
Chart Values
A values.yaml is defined which contains the default set of values for all configurable properties. You can change the values as per your needs. A few properties of note:
image
Points to the image URL that will be configured in etcd-druid Deployment. If you are building the image on your own and pushing it to the repository of your choice then ensure that you change the value accordingly.
webhookPKI
This YAML map contains paths to required PKI artifacts. If you are generating these on your own then ensure that you provide correct paths to these resources.
etcdComponentProtection
By default, this webhook is enabled. This is a good default for production environments. However, while you are actively developing then you can choose to disable this webhook.
If you have switched to using OperatorConfiguration then you must set enabledOperatorConfig to true (for backward compatibility reasons it is defaulted to false) and then control the enablement of EtcdComponentProctection webhook via operatorConfig.webhooks.etcdComponentProtection.enabled property.
If you have not yet switched to using OperatorConfiguration then you can control the enablement of this webhook via webhooks.etcdComponentProtection.enabled property.
Makefile target
A convenience Makefile target make prepare-helm-charts is provided which leverages OpenSSL to generate the required PKI artifacts.
If you wish to deploy etcd-druid in a specific namespace then prior to running this Makefile target you can run:
export NAMESPACE=<namespace>
!!! info
Specifying a namespace other than default will result in additional SAN being added in the webhook server certificate.
By default, the certificates generated have an expiry of 12h. If you wish to have a different expiry then prior to running this Makefile target you can run:
export CERT_EXPIRY=<duration-of-your-choice>
# example: export CERT_EXPIRY=6h
!!! note
If you are using make deploy* targets directly which leverages skaffold then Makefile target prepare-helm-charts will be invoked automatically.
2.30 - Production Setup Recommendations
Setting up etcd-druid in Production
You can get familiar with etcd-druid and all the resources that it creates by setting up etcd-druid locally by following the detailed guide. This document lists down recommendations for a productive setup of etcd-druid.
Helm Charts
You can use helm charts at this location to deploy druid. Values for charts are present here and can be configured as per your requirement. Following charts are present:
deployment.yaml- defines a kubernetes Deployment for etcd-druid. To configure the CLI flags for druid you can refer to this document which explains these flags in detail.serviceaccount.yaml- defines a kubernetes ServiceAccount which will serve as a technical user to which role/clusterroles can be bound.clusterrole.yaml- etcd-druid can manage multiple etcd clusters. In ahosted control planesetup (e.g. Gardener), one would typically create separate namespace per control-plane. This would require a ClusterRole to be defined which gives etcd-druid permissions to operate across namespaces. Packing control-planes via namespaces provides you better resource utilisation while providing you isolation from the data-plane (where the actual workload is scheduled).rolebinding.yaml- binds the ClusterRole defined indruid-clusterrole.yamlto the ServiceAccount defined inservice-account.yaml.service.yaml- defines aCluster IPService allowing other control-plane components to communicate tohttpendpoints exposed out of etcd-druid (e.g. enables prometheus to scrap metrics, validating webhook to be invoked upon change toEtcdCR etc.)secret-ca-crt.yaml- Contains the base64 encoded CA certificate used for the etcd-druid webhook server.secret-server-tls-crt.yaml- Contains the base64 encoded server certificate used for the etcd-druid webhook server.validating-webhook-config.yaml- Configuration for all webhooks that etcd-druid registers to the webhook server. At the time of writing this document EtcdComponents webhook gets registered.
Etcd cluster size
Recommendation from upstream etcd is to always have an odd number of members in an Etcd cluster.
Mounted Volume
All Etcd cluster member Pods provisioned by etcd-druid mount a Persistent Volume. A mounted persistent storage helps in faster recovery in case of single-member transient failures. etcd is I/O intensive and its performance is heavily dependent on the Storage Class. It is therefore recommended that high performance SSD drives be used.
At the time of writing this document etcd-druid provisions the following volume types:
| Cloud Provider | Type | Size |
|---|---|---|
| AWS | GP3 | 25Gi |
| Azure | Premium SSD | 33Gi |
| GCP | Performance (SSD) Persistent Disks (pd-ssd) | 25Gi |
Also refer: Etcd Disk recommendation.
Additionally, each cloud provider offers redundancy for managed disks. You should choose redundancy as per your availability requirement.
Backup & Restore
A permanent quorum loss or data-volume corruption is a reality in production clusters and one must ensure that data loss is minimized. Etcd clusters provisioned via etcd-druid offer two levels of data-protection
Via etcd-backup-restore all clusters started via etcd-druid get the capability to regularly take delta & full snapshots. These snapshots are stored in an object store. Additionally, a snapshot-compaction job is run to compact and defragment the latest snapshot, thereby reducing the time it takes to restore a cluster in case of a permanent quorum loss. You can read the detailed guide on how to restore from permanent quorum loss.
It is therefore recommended that you configure an Object store in the cloud/infra provider of your choice, enabled backup & restore functionality by filling in store configuration of an Etcd custom CR.
Ransomware protection
Ransomware is a form of malware designed to encrypt files on a device, rendering any files and the systems that rely on them unusable. All cloud providers (aws, gcp, azure) provide a feature of immutability that can be set at the bucket/object level which provides WORM access to objects as long as the bucket/lock retention duration.
All delta & full snapshots that are periodically taken by etcd-backup-restore are stored in Object store provided by a cloud provider. It is recommended that these backups be protected from ransomware protection by turning locking at the bucket/object level.
Security
Use Distroless Container Images
It is generally recommended to use a minimal base image which additionally reduces the attack surface. Google’s Distroless is one way to reduce the attack surface and also minimize the size of the base image. It provides the following benefits:
- Reduces the attack surface
- Minimizes vulnerabilities
- No shell
- Reduced size - only includes what is necessary
For every Etcd cluster provisioned by etcd-druid, distroless images are used as base images.
Enable TLS for Peer and Client communication
Generally you should enable TLS for peer and client communication for an Etcd cluster. To enable TLS CA certificate, server and client certificates needs to be generated.
You can refer to the list of TLS artifacts that are generated for an Etcd cluster provisioned by etcd-druid here.
Enable TLS for Druid Webhooks
If you choose to enable webhooks in etcd-druid then it is necessary to create a separate CA and server certificate to be used by the webhooks.
Rotate TLS artifacts
It is generally recommended to rotate all TLS certificates to reduce the chances of it getting leaked or have expired. Kubernetes does not support revocation of certificates (see issue#18982). One possible way to revoke certificates is to also revoke the entire chain including CA certificates.
Scaling etcd pods
etcd clusters cannot be scaled-out horizontly to meet the increased traffic/storage demand for the following reasons:
- There is a soft limit of 8GB and a hard limit of 10GB for the etcd DB beyond which perfomance and stability of etcd is not guaranteed.
- All members of etcd maintain the entire replica of the entire DB, thus scaling-out will not really help if the storage demand grows.
- Increasing the number of cluster members beyond 5 also increases the cost of consensus amongst now a larger quorum, increases load on the single leader as it needs to also participate in bringing up etcd learner.
Therefore the following is recommended:
- To meet the increased demand, configure a VPA. You have to be careful on selection of
containerPolicies,targetRef. - To meet the increased demand in storage etcd-druid already configures each etcd member to auto-compact and it also configures periodic defragmentation of the etcd DB. The only case this will not help is when you only have unique writes all the time.
!!! note
Care should be taken with usage of VPA. While it helps to vertically scale up etcd-member pods, it also can cause transient quorum loss. This is a direct consequence of the design of VPA - where recommendation is done by Recommender component, Updater evicts the pods that do not have the resources recommended by the Recommender and Admission Controller which updates the resources on the Pods. All these three components act asynchronously and can fail independently, so while VPA respects PDB’s it can easily enter into a state where updater evicts a pod while respecting PDB but the admission controller fails to apply the recommendation. The pod comes with a default resources which still differ from the recommended values, thus causing a repeat eviction. There are other race conditions that can also occur and one needs to be careful of using VPA for quorum based workloads.
High Availability
To ensure that an Etcd cluster is highly available, following is recommended:
Ensure that the Etcd cluster members are spread
Etcd cluster members should always be spread across nodes. This provides you failure tolerance at the node level. For failure tolerance of a zone, it is recommended that you spread the Etcd cluster members across zones.
We recommend that you use a combination of TopologySpreadConstraints and Pod Anti-Affinity. To set the scheduling constraints you can either specify these constraints using SchedulingConstraints in the Etcd custom resource or use a MutatingWebhook to dynamically inject these into pods.
An example of scheduling constraints for a multi-node cluster with zone failure tolerance will be:
topologySpreadConstraints:
- labelSelector:
matchLabels:
app.kubernetes.io/component: etcd-statefulset
app.kubernetes.io/managed-by: etcd-druid
app.kubernetes.io/name: etcd-main
app.kubernetes.io/part-of: etcd-main
maxSkew: 1
minDomains: 3
topologyKey: kubernetes.io/hostname
whenUnsatisfiable: DoNotSchedule
- labelSelector:
matchLabels:
app.kubernetes.io/component: etcd-statefulset
app.kubernetes.io/managed-by: etcd-druid
app.kubernetes.io/name: etcd-main
app.kubernetes.io/part-of: etcd-main
maxSkew: 1
minDomains: 3
topologyKey: topology.kubernetes.io/zone
whenUnsatisfiable: DoNotSchedule
For a 3 member etcd-cluster, the above TopologySpreadConstraints will ensure that the members will be spread across zones (assuming there are 3 zones -> minDomains=3) and no two members will be on the same node.
Optimize Network Cost
In most cloud providers there is no network cost (ingress/egress) for any traffic that is confined within a single zone. For Zonal failure tolerance, it will become imperative to spread the Etcd cluster across zones within a region. Knowing that an Etcd cluster members are quite chatty (leader election, consensus building for writes and linearizable reads etc.), this can add to the network cost.
One could evaluate using TopologyAwareRouting which reduces cross-zonal traffic thus saving costs and latencies.
!!! tip You can read about how it is done in Gardener here.
Metrics & Alerts
Monitoring etcd metrics is essential for fine tuning Etcd clusters. etcd already exports a lot of metrics. You can see the complete list of metrics that are exposed out of an Etcd cluster provisioned by etcd-druid here. It is also recommended that you configure an alert for etcd space quota alarms.
Hibernation
If you have a concept of hibernating kubernetes clusters, then following should be kept in mind:
- Before you bring down the
Etcdcluster, leverage the capability to take afull snapshotwhich captures the state of the etcd DB and stores it in the configured Object store. This ensures that when the cluster is woken up from hibernation it can restore from the last state with no data loss. - To save costs you should consider deleting the PersistentVolumeClaims associated to the StatefulSet pods. However, it must be ensured that you take a full snapshot as highlighted in the previous point.
- When the cluster is woken up from hibernation then you should do the following (assuming prior to hibernation the cluster had a size of 3 members):
- Start the
Etcdcluster with 1 replica. Let it restore from the last full snapshot. - Once the cluster reports that it is ready, only then increase the replicas to its original value (e.g. 3). The other two members will start up each as learners and post learning they will join as voting members (
Followers).
- Start the
Reference
- A nicely written blog post on
High Availability and Zone Outage Tolerationhas a lot of recommendations that one can borrow from.
2.31 - Raising A Pr
Raising a Pull Request
We welcome active contributions from the community. This document details out the things-to-be-done in order for us to consider a PR for review. Contributors should follow the guidelines mentioned in this document to minimize the time it takes to get the PR reviewed.
00-Prerequisites
In order to make code contributions you must setup your development environment. Follow the Prepare Dev Environment Guide for detailed instructions.
01-Raise an Issue
For every pull-request, it is mandatory to raise an Issue which should describe the problem in detail. We have created a few categories, each having its own dedicated template.
03-Prepare Code Changes
It is not recommended to create a branch on the main repository for raising pull-requests. Instead you must fork the
etcd-druidrepository and create a branch in the fork. You can follow the detailed instructions on how to fork a repository and set it up for contributions.Ensure that you follow the coding guidelines while introducing new code.
If you are making changes to the API then please read Changing-API documentation.
If you are introducing new go mod dependencies then please read Dependency Management documentation.
If you are introducing a new
Etcdcluster component then please read Add new Cluster Component documentation.For guidance on testing, follow the detailed instructions here.
Before you submit your PR, please ensure that the following is done:
Run
make checkwhich will do the following:- Runs
make format- this target will ensure a common formatting of the code and ordering of imports across all source files. - Runs
make manifests- this target will re-generate manifests if there are any changes in the API. - Only when the above targets have run without errorrs, then
make checkwill be run linters against the code. The rules for the linter are configured here.
- Runs
Ensure that all the tests pass by running the following
maketargets:make test-unit- this target will run all unit tests.make test-integration- this target will run all integration tests (controller level tests) usingenvtestframework.make ci-e2e-kindor any of its variants - these targets will run etcd-druid e2e tests.
!!! warning Please ensure that after introduction of new code the code coverage does not reduce. An increase in code coverage is always welcome.
If you add new features, make sure that you create relevant documentation under
/docs.
04-Raise a pull request
- Create Work In Progress [WIP] pull requests only if you need a clarification or an explicit review before you can continue your work item.
- Ensure that you have rebased your fork’s development branch with
upstreammain/master branch. - Squash all commits into a minimal number of commits.
- Fill in the PR template with appropriate details and provide the link to the
Issuefor which a PR has been raised. - If your patch is not getting reviewed, or you need a specific person to review it, you can @-reply a reviewer asking for a review in the pull request or a comment.
05-Post review
- If a reviewer requires you to change your commit(s), please test the changes again.
- Amend the affected commit(s) and force push onto your branch.
- Set respective comments in your GitHub review as resolved.
- Create a general PR comment to notify the reviewers that your amendments are ready for another round of review.
06-Merging a pull request
- Merge can only be done if the PR has approvals from atleast 2 reviewers.
- Add an appropriate release note detailing what is introduced as part of this PR.
- Before merging the PR, ensure that you squash and then merge.
2.32 - Recovering Etcd Clusters
Recovery from Quorum Loss
In an Etcd cluster, quorum is a majority of nodes/members that must agree on updates to a cluster state before the cluster can authorise the DB modification. For a cluster with n members, quorum is (n/2)+1. An Etcd cluster is said to have lost quorum when majority of nodes (greater than or equal to (n/2)+1) are unhealthy or down and as a consequence cannot participate in consensus building.
For a multi-node Etcd cluster quorum loss can either be Transient or Permanent.
Transient quorum loss
If quorum is lost through transient network failures (e.g. n/w partitions) or there is a spike in resource usage which results in OOM, etcd automatically and safely resumes (once the network recovers or the resource consumption has come down) and restores quorum. In other cases like transient power loss, etcd persists the Raft log to disk and replays the log to the point of failure and resumes cluster operation.
Permanent quorum loss
In case the quorum is lost due to hardware failures or disk corruption etc, automatic recovery is no longer possible and it is categorized as a permanent quorum loss.
Note: If one has capability to detect
Failednodes and replace them, then eventually new nodes can be launched and etcd cluster can recover automatically. But sometimes this is just not possible.
Recovery
At present, recovery from a permanent quorum loss is achieved by manually executing the steps listed in this section.
Note: In the near future etcd-druid will offer capability to automate the recovery from a permanent quorum loss via Out-Of-Band Operator Tasks. An operator only needs to ascertain that there is a permanent quorum loss and the etcd-cluster is beyond auto-recovery. Once that is established then an operator can invoke a task whose status an operator can check.
!!! warning Please note that manually restoring etcd can result in data loss. This guide is the last resort to bring an Etcd cluster up and running again.
00-Identify the etcd cluster
It is possible to shard the etcd cluster based on resource types using –etcd-servers-overrides CLI flag of kube-apiserver. Any sharding results in more than one etcd-cluster.
!!! info
In gardener, each shoot control plane has two etcd clusters, etcd-events which only stores events and etcd-main - stores everything else except events.
Identify the etcd-cluster which has a permanent quorum loss. Most of the resources of an etcd-cluster can be identified by its name. The resources of interest to recover from permanent quorum loss are: Etcd CR, StatefulSet, ConfigMap and PVC.
To identify the
ConfigMapresource use the following command:
kubectl get sts <sts-name> -o jsonpath='{.spec.template.spec.volumes[?(@.name=="etcd-config-file")].configMap.name}'
01-Prepare Etcd Resource to allow manual updates
To ensure that only one actor (in this case an operator) makes changes to the Etcd resource and also to the Etcd cluster resources, following must be done:
Add the annotation to the Etcd resource:
kubectl annotate etcd <etcd-name> -n <namespace> druid.gardener.cloud/suspend-etcd-spec-reconcile=
The above annotation will prevent any reconciliation by etcd-druid for this Etcd cluster.
Add another annotation to the Etcd resource:
kubectl annotate etcd <etcd-name> -n <namespace> druid.gardener.cloud/disable-etcd-component-protection=
The above annotation will allow manual edits to Etcd cluster resources that are managed by etcd-druid.
02-Scale-down Etcd StatefulSet resource to 0
kubectl scale sts <sts-name> --replicas=0 -n <namespace>
03-Delete all PVCs for the Etcd cluster
kubectl delete pvc -l instance=<sts-name> -n <namespace>
04-Delete All Member Leases
For a n member Etcd cluster there should be n member Lease objects. The lease names should start with the Etcd name.
Example leases for a 3 node Etcd cluster:
NAME HOLDER AGE
<etcd-name>-0 4c37667312a3912b:Member 1m
<etcd-name>-1 75a9b74cfd3077cc:Member 1m
<etcd-name>-2 c62ee6af755e890d:Leader 1m
Delete all the member leases.
kubectl delete lease <space separated lease names>
# Alternatively you can use label selector. From v0.23.0 onwards leases will have common set of labels
kubectl delete lease -l app.kubernetes.io.component=etcd-member-lease, app.kubernetes.io/part-of=<etcd-name> -n <namespace>
05-Modify ConfigMap
Prerequisite to scale up etcd-cluster from 0->1 is to change the fields initial-cluster, initial-advertise-peer-urls, and advertise-client-urls in the ConfigMap.
Assuming that prior to scale-down to 0, there were 3 members:
The initial-cluster field would look like the following (assuming that the name of the etcd resource is etcd-main):
# Initial cluster
initial-cluster: etcd-main-0=https://etcd-main-0.etcd-main-peer.default.svc:2380,etcd-main-1=https://etcd-main-1.etcd-main-peer.default.svc:2380,etcd-main-2=https://etcd-main-2.etcd-main-peer.default.svc:2380
Change the initial-cluster field to have only one member (in this case etcd-main-0). After the change it should look like:
# Initial cluster
initial-cluster: etcd-main-0=https://etcd-main-0.etcd-main-peer.default.svc:2380
The initial-advertise-peer-urls field would look like the following:
# Initial advertise peer urls
initial-advertise-peer-urls:
etcd-main-0:
- http://etcd-main-0.etcd-main-peer.default.svc:2380
etcd-main-1:
- http://etcd-main-1.etcd-main-peer.default.svc:2380
etcd-main-2:
- http://etcd-main-2.etcd-main-peer.default.svc:2380
Change the initial-advertise-peer-urls field to have only one member (in this case etcd-main-0). After the change it should look like:
# Initial advertise peer urls
initial-advertise-peer-urls:
etcd-main-0:
- http://etcd-main-0.etcd-main-peer.default.svc:2380
The advertise-client-urls field would look like the following:
advertise-client-urls:
etcd-main-0:
- http://etcd-main-0.etcd-main-peer.default.svc:2379
etcd-main-1:
- http://etcd-main-1.etcd-main-peer.default.svc:2379
etcd-main-2:
- http://etcd-main-2.etcd-main-peer.default.svc:2379
Change the advertise-client-urls field to have only one member (in this case etcd-main-0). After the change it should look like:
advertise-client-urls:
etcd-main-0:
- http://etcd-main-0.etcd-main-peer.default.svc:2379
06-Scale up Etcd cluster to size 1
kubectl scale sts <sts-name> -n <namespace> --replicas=1
07-Wait for Single-Member etcd cluster to be completely ready
To check if the single-member etcd cluster is ready check the status of the pod.
kubectl get pods <etcd-name-0> -n <namespace>
NAME READY STATUS RESTARTS AGE
<etcd-name>-0 2/2 Running 0 1m
If both containers report readiness (as seen above), then the etcd-cluster is considered ready.
08-Enable Etcd reconciliation and resource protection
All manual changes are now done. We must now re-enable etcd-cluster resource protection and also enable reconciliation by etcd-druid by doing the following:
kubectl annotate etcd <etcd-name> -n <namespace> druid.gardener.cloud/suspend-etcd-spec-reconcile-
kubectl annotate etcd <etcd-name> -n <namespace> druid.gardener.cloud/disable-etcd-component-protection-
09-Scale-up Etcd Cluster to 3 and trigger reconcile
Scale etcd-cluster to its original size (we assumed 3 below).
kubectl scale sts <sts-name> -n namespace --replicas=3
If etcd-druid has been set up with --enable-etcd-spec-auto-reconcile switched-off then to ensure reconciliation one must annotate Etcd resource with the following command:
# Annotate etcd CR to reconcile
kubectl annotate etcd <etcd-name> -n <namespace> gardener.cloud/operation="reconcile"
10-Verify Etcd cluster health
Check if all the member pods have both of their containers in Running state.
kubectl get pods -n <namespace> -l app.kubernetes.io/part-of=<etcd-name>
NAME READY STATUS RESTARTS AGE
<etcd-name>-0 2/2 Running 0 5m
<etcd-name>-1 2/2 Running 0 1m
<etcd-name>-2 2/2 Running 0 1m
Additionally, check if the Etcd CR is ready:
kubectl get etcd <etcd-name> -n <namespace>
NAME READY AGE
<etcd-name> true 13d
Check member leases, whose holderIdentity should reflect the member role. Check if all members are voting members (their role should either be Member or Leader). Monitor the leases for some time and check if the leases are getting updated. You can monitor the AGE field.
NAME HOLDER AGE
<etcd-name>-0 4c37667312a3912b:Member 1m
<etcd-name>-1 75a9b74cfd3077cc:Member 1m
<etcd-name>-2 c62ee6af755e890d:Leader 1m
2.33 - Securing Etcd Clusters
Securing etcd cluster
This document will describe all the TLS artifacts that are typically generated for setting up etcd-druid and etcd clusters in Gardener clusters. You can take inspiration from this and decide which communication lines are essential to be TLS enabled.
Communication lines
In order to undertand all the TLS artifacts that are required to setup etcd-druid and one or more etcd-clusters, one must have a clear view of all the communication channels that needs to be protected via TLS. In the diagram below all communication lines in a typical 3-node etcd cluster along with kube-apiserver and etcd-druid is illustrated.
!!! info For Gardener setup all the communication lines are TLS enabled.
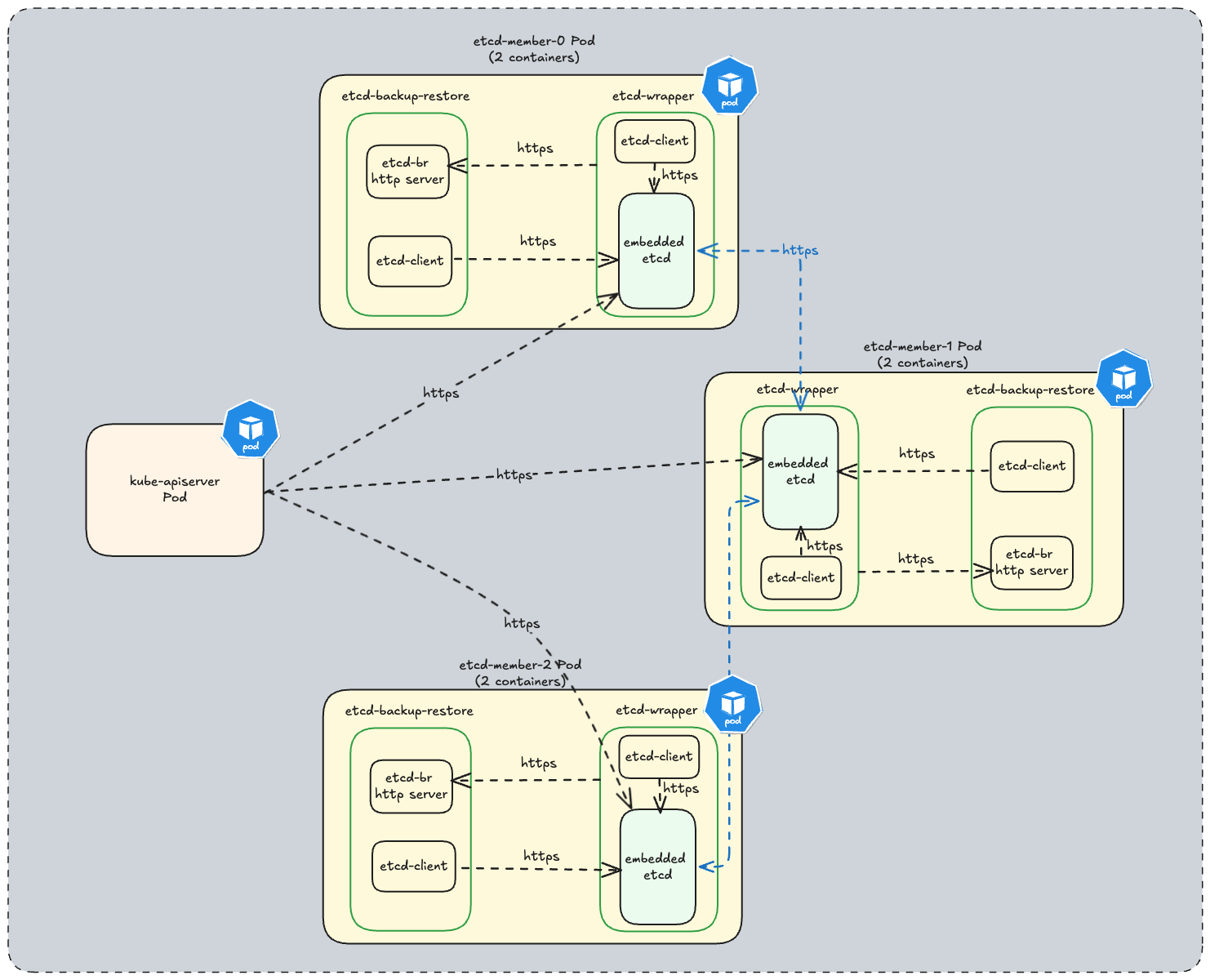
TLS artifacts
An etcd cluster setup by etcd-druid leverages the following TLS artifacts:
Certificate Authority used to sign server and client certificate key-pair for
etcd-backup-restorespecified viaetcd.spec.backup.tls.tlsCASecretRef.Server certificate key-pair specified via
etcd.spec.backup.tls.serverTLSSecretRefused byetcd-backup-restoreHTTPS server.Client certificate key-pair specified via
etcd.spec.backup.tls.clientTLSSecretRefused byetcd-wrapperto securely communicate to theetcd-backup-restoreHTTPS server.Certificate Authority used to sign server and client certificate key-pair for
etcdandetcd-wrapperspecified viaetcd.spec.etcd.clientUrlTls.tlsCASecretReffor etcd client communication.Server certificate key-pair specified via
etcd.spec.etcd.clientUrlTls.serverTLSSecretRefused byetcdandetcd-wrapperHTTPS servers.Client certificate key-pair specified via
etcd.spec.etcd.clientUrlTls.clientTLSSecretRefused by:etcd-wrapperandetcd-backup-restoreto securely communicate to theetcdHTTPS server.etcd-backup-restoreto securely communicate to theetcd-wrapperHTTPS server.
Certificate Authority used to sign server certificate key-pair for
etcdpeer communication specified viaetcd.spec.etcd.peerUrlTls.tlsCASecretRef.Server certificate key-pair specified via
etcd.spec.etcd.peerUrlTls.serverTLSSecretRefused foretcdpeer communication.
!!! note
TLS artifacts should be created prior to creating Etcd clusters. etcd-druid currently does not provide a convenience way to generate these TLS artifacts. etcd recommends to use cfssl to generate certificates. However you can use any other tool as well. We do provide a convenience script for local development here which can be used to generate TLS artifacts. Currently this script is part of etcd-wrapper github repository but we will harmonize these scripts to be used across all github projects under the etcd-druid ecosystem.
2.34 - Testing
Testing Strategy and Developer Guideline
Intent of this document is to introduce you (the developer) to the following:
- Libraries that are used to write tests.
- Best practices to write tests that are correct, stable, fast and maintainable.
- How to run tests.
The guidelines are not meant to be absolute rules. Always apply common sense and adapt the guideline if it doesn’t make much sense for some cases. If in doubt, don’t hesitate to ask questions during a PR review (as an author, but also as a reviewer). Add new learnings as soon as we make them!
For any new contributions tests are a strict requirement. Boy Scouts Rule is followed: If you touch a code for which either no tests exist or coverage is insufficient then it is expected that you will add relevant tests.
Common guidelines for writing tests
We use the
Testingpackage provided by the standard library in golang for writing all our tests. Refer to its official documentation to learn how to write tests usingTestingpackage. You can also refer to this example.We use gomega as our matcher or assertion library. Refer to Gomega’s official documentation for details regarding its installation and application in tests.
For naming the individual test/helper functions, ensure that the name describes what the function tests/helps-with. Naming is important for code readability even when writing tests - example-testcase-naming.
Introduce helper functions for assertions to make test more readable where applicable - example-assertion-function.
Introduce custom matchers to make tests more readable where applicable - example-custom-matcher.
Do not use
time.Sleepand friends as it renders the tests flaky.If a function returns a specific error then ensure that the test correctly asserts the expected error instead of just asserting that an error occurred. To help make this assertion consider using DruidError where possible. example-test-utility & usage.
Creating sample data for tests can be a high effort. Consider writing test utilities to generate sample data instead. example-test-object-builder.
If tests require any arbitrary sample data then ensure that you create a
testdatadirectory within the package and keep the sample data as files in it. From https://pkg.go.dev/cmd/go/internal/testThe go tool will ignore a directory named “testdata”, making it available to hold ancillary data needed by the tests.
Avoid defining shared variable/state across tests. This can lead to race conditions causing non-deterministic state. Additionally it limits the capability to run tests concurrently via
t.Parallel().Do not assume or try and establish an order amongst different tests. This leads to brittle tests as the codebase evolves.
If you need to have logs produced by test runs (especially helpful in failing tests), then consider using t.Log or t.Logf.
Unit Tests
- If you need a kubernetes
client.Client, prefer using fake client instead of mocking the client. You can inject errors when building the client which enables you test error handling code paths.- Mocks decrease maintainability because they expect the tested component to follow a certain way to reach the desired goal (e.g., call specific functions with particular arguments).
- All unit tests should be run quickly. Do not use envtest and do not set up a Kind cluster in unit tests.
- If you have common setup for variations of a function, consider using table-driven tests. See this as an example.
- An individual test should only test one and only one thing. Do not try and test multiple variants in a single test. Either use table-driven tests or write individual tests for each variation.
- If a function/component has multiple steps, its probably better to split/refactor it into multiple functions/components that can be unit tested individually.
- If there are a lot of edge cases, extract dedicated functions that cover them and use unit tests to test them.
Running Unit Tests
!!! info
For unit tests we are currently transitioning away from ginkgo to using golang native tests. The make test-unit target runs both ginkgo and golang native tests. Once the transition is complete this target will be simplified.
Run all unit tests
make test-unit
Run unit tests of specific packages:
# if you have not already installed gotestfmt tool then install it once.
# make test-unit target automatically installs this in ./hack/tools/bin. You can alternatively point the GOBIN to this directory and then directly invoke test-go.sh
> go install github.com/gotesttools/gotestfmt/v2/cmd/gotestfmt@v2.5.0
> ./hack/test-go.sh <package-1> <package-2>
De-flaking Unit Tests
If tests have sporadic failures, then trying running ./hack/stress-test.sh which internally uses stress tool.
# install the stress tool
go install golang.org/x/tools/cmd/stress@latest
# invoke the helper script to execute the stress test
./hack/stress-test.sh test-package=<test-package> test-func=<test-function> tool-params="<tool-params>"
An example invocation:
./hack/stress-test.sh test-package=./internal/utils test-func=TestRunConcurrentlyWithAllSuccessfulTasks tool-params="-p 10"
5s: 877 runs so far, 0 failures
10s: 1906 runs so far, 0 failures
15s: 2885 runs so far, 0 failures
...
stress tool will output a path to a file containing the full failure message when a test run fails.
Integration Tests (envtests)
Integration tests in etcd-druid use envtest. It sets up a minimal temporary control plane (etcd + kube-apiserver) and runs the test against it. Test suites (group of tests) start their individual envtest environment before running the tests for the respective controller/webhook. Before exiting, the temporary test environment is shutdown.
!!! info For integration-tests we are currently transitioning away from ginkgo to using golang native tests. All ginkgo integration tests can be found here and golang native integration tests can be found here.
- Integration tests in etcd-druid only targets a single controller. It is therefore advised that code (other than common utility functions should not be shared between any two controllers).
- If you are sharing a common
envtestenvironment across tests then it is recommended that an individual test is run in a dedicatednamespace. - Since
envtestis used to setup a minimum environment where no controller (e.g. KCM, Scheduler) other thanetcdandkube-apiserverruns, status updates to resources controller/reconciled by not-deployed-controllers will not happen. Tests should refrain from asserting changes to status. In case status needs to be set as part of a test setup then it must be done explicitly. - If you have common setup and teardown, then consider using TestMain -example.
- If you have to wait for resources to be provisioned or reach a specific state, then it is recommended that you create smaller assertion functions and use Gomega’s AsyncAssertion functions - example.
- Beware of the default
Eventually/Consistentlytimeouts / poll intervals: docs. - Don’t forget to call
{Eventually,Consistently}.Should(), otherwise the assertions always silently succeeds without errors: onsi/gomega#561
- Beware of the default
Running Integration Tests
make test-integration
Debugging Integration Tests
There are two ways in which you can debug Integration Tests:
Using IDE
All commonly used IDE’s provide in-built or easy integration with delve debugger. For debugging integration tests the only additional requirement is to set KUBEBUILDER_ASSETS environment variable. You can get the value of this environment variable by executing the following command:
# ENVTEST_K8S_VERSION is the k8s version that you wish to use for testing.
setup-envtest --os $(go env GOOS) --arch $(go env GOARCH) use $ENVTEST_K8S_VERSION -p path
!!! tip All integration tests usually have a timeout. If you wish to debug a failing integration-test then increase the timeouts.
Use standalone envtest
We also provide a capability to setup a stand-alone envtest and leverage the cluster to run individual integration-test. This allows you more control over when this k8s control plane is destroyed and allows you to inspect the resources at the end of the integration-test run using kubectl.
While you can use an existing cluster (e.g.,
kind), some test suites expect that no controllers and no nodes are running in the test environment (as it is the case inenvtesttest environments). Hence, using a full-blown cluster with controllers and nodes might sometimes be impractical, as you would need to stop cluster components for the tests to work.
To setup a standalone envtest and run an integration test against it, do the following:
# In a terminal session use the following make target to setup a standalone envtest
make start-envtest
# As part of output path to kubeconfig will be also be printed on the console.
# In another terminal session setup resource(s) watch:
kubectl get po -A -w # alternatively you can also use `watch -d <command>` utility.
# In another terminal session:
export KUBECONFIG=<envtest-kubeconfig-path>
export USE_EXISTING_K8S_CLUSTER=true
# run the test
go test -run="<regex-for-test>" <package>
# example: go test -run="^TestEtcdDeletion/test deletion of all*" ./test/it/controller/etcd
Once you are done the testing you can press Ctrl+C in the terminal session where you started envtest. This will shutdown the kubernetes control plane.
End-To-End (e2e) Tests
End-To-End tests are run using Kind cluster and Skaffold. These tests provide a high level of confidence that the code runs as expected by users when deployed to production.
Purpose of running these tests is to be able to catch bugs which result from interaction amongst different components within etcd-druid.
In CI pipelines e2e tests are run with S3 compatible LocalStack (in cases where backup functionality has been enabled for an etcd cluster).
In future we will only be using a file-system based local provider to reduce the run times for the e2e tests when run in a CI pipeline.
e2e tests can be triggered either with other cloud provider object-store emulators or they can also be run against actual/remove cloud provider object-store services.
In contrast to integration tests, in e2e tests, it might make sense to specify higher timeouts for Gomega’s AsyncAssertion calls.
Running e2e tests locally
Detailed instructions on how to run e2e tests can be found here.
2.35 - Updating Documentation
Updating Documentation
All documentation for etcd-druid resides in docs directory. If you wish to update the existing documentation or create new documentation files then read on.
Prerequisite: Setup Mkdocs locally
Material for Mkdocs is used to generate GitHub Pages from all the Markdown files present under the docs directory. To locally validate that the documentation renders correctly, it is recommended that you perform the following setup.
- Install python3 if not already installed.
- Setup a virtual environment via
python -m venv venv
- Activate the virtual environment
source venv/bin/activate
- In the virtual environment install the packages.
(venv) > pip install mkdocs-material
(venv) > pip install pymdown-extensions
(venv) > pip install mkdocs-glightbox
(venv) > pip install mkdocs-pymdownx-material-extras
!!! note Complete list of packages installed should be in sync with Github Actions Configuration.
- Serve the documentation
(venv) > mkdocs serve
You can now view the rendered documentation at localhost:8000. Any changes that you make to the docs will get hot-reloaded and you can immediately view the changes.
Updating Documentation
All documentation should be in markdown only. Ensure that you take care of the following:
- The index.md is the home page for the documentation rendered as Github Pages. Please do not remove this file.
- If you are using a new feature (that is not already used) by
Mkdocsthen ensure that it is properly configured in mkdocs.yml. Additionally, if new plugins or Markdown extensions are used, make sure that you update the Github Actions Configuration accordingly. - If new files are being added and you wish to show these files in Github Pages then ensure that you have added them under appropriate sections in the navigation section of
mkdocs.yml. - If you are linking to any file outside the docs directory then relative links will not work on Github Pages. Please get the
httpslink to the file or section of the file that you wish to link.
Raise a Pull Request
Once you have made the documentation changes then follow the guide on how to raise a PR.
!!! info Once the documentation update PR has been merged, you will be able to see the updated documentation here.
2.36 - Using Druid Client
Using Druid Golang Client
Etcd Druid provides a generated typed Golang client which can be used to invoke CRUD operations on Etcd and EtcdCopyBackupsTask custom resources.
A simple example is provided to demonstrate how an Etcd resource can be created using client package.
To run the example ensure that you have the following setup:
Follow the Getting Started Guide to set up a KIND cluster and deploy
etcd-druidoperator.Run the example:
go run examples/client/main.go
You should see the following output:
INFO Successfully created Etcd cluster Etcd=default/etcd-test
You can further list the resources that are created for an Etcd cluster.
See this document for information on all resources created for an Etcd cluster.
2.37 - Validating Etcd Clusters
CRD Validations for etcd
- The validations for the fields within the
etcdresource are done via kubebuilder markers for CRD validation. - The validations for clusters with kubernetes versions
>= 1.29are written using a combination of CEL expressions via thex-validationtag which provides a straightforward syntax to write validation rules for the fields, and pattern matching with the use of thevalidationtag. - The validations for clusters with kubernetes versions
< 1.29will not contain validations viaCELexpressions since this is GA for kubernetes version 1.29 or higher. - Upon any changes to the validation rules to the etcd resource, the
yamlfiles for the same can be generated by running themake generatecommand.
Validation rules:
Type Validation rules:
The validations for fields of types Duration(metav1.Duration) and cron expressions are done via regex matching. These use the validation:Pattern marker.(The checking for the Quantity(resource.Quantity) fields are done by default, hence, no explicit validation is needed for the fields of this type):
Duration fields:
'^([0-9]+([.][0-9]+)?h)?([0-9]+([.][0-9]+)?m)?([0-9]+([.][0-9]+)?s)?([0-9]+([.][0-9]+)?d)?$')Cron expression:
^(\*|[1-5]?[0-9]|[1-5]?[0-9]-[1-5]?[0-9]|(?:[1-9]|[1-4][0-9]|5[0-9])\/(?:[1-9]|[1-4][0-9]|5[0-9]|60)|\*\/(?:[1-9]|[1-4][0-9]|5[0-9]|60))\s+(\*|[0-9]|1[0-9]|2[0-3]|[0-9]-(?:[0-9]|1[0-9]|2[0-3])|1[0-9]-(?:1[0-9]|2[0-3])|2[0-3]-2[0-3]|(?:[1-9]|1[0-9]|2[0-3])\/(?:[1-9]|1[0-9]|2[0-4])|\*\/(?:[1-9]|1[0-9]|2[0-4]))\s+(\*|[1-9]|[12][0-9]|3[01]|[1-9]-(?:[1-9]|[12][0-9]|3[01])|[12][0-9]-(?:[12][0-9]|3[01])|3[01]-3[01]|(?:[1-9]|[12][0-9]|30)\/(?:[1-9]|[12][0-9]|3[01])|\*\/(?:[1-9]|[12][0-9]|3[01]))\s+(\*|[1-9]|1[0-2]|[1-9]-(?:[1-9]|1[0-2])|1[0-2]-1[0-2]|(?:[1-9]|1[0-2])\/(?:[1-9]|1[0-2])|\*\/(?:[1-9]|1[0-2]))\s+(\*|[1-7]|[1-6]-[1-7]|[1-6]\/[1-7]|\*\/[1-7])$- NOTE: The provided regex does not account for
special stringssuch as@yearlyor@monthly. Additionally, it fails to invalidate cases involving thestep operator (x/y)and therange operator (x-y), where the cron expression is considered valid even ifx > y. Please ensure these values are validated before passing the expression.
- NOTE: The provided regex does not account for
Update validations
These validations are triggered when an update operation is done on the etcd resource.
Immutable fields: The fields
etcd.spec.StorageClass,etcd.spec.StorageCapacityandetcd.spec.VolumeClaimTemplateare immutable. The immutability is enforced by the CEL expression :self == oldSelf.The value set for the field
etcd.spec.replicascan either be decreased to0or increased. This is enforced by the CEL expression:self==0 ? true : self < oldSelf ? false : true
Field validations
- The fields which expect only a particular set of values are checked by using the kubebuilder marker:
+kubebuilder:validation:Enum=<value1>;<value2>- The
etcd.spec.etcd.metricscan only be set as eitherbasicorextensive. - The
etcd.spec.backup.garbageCollectionPolicycan only be set asExponentialorLimitBased - The
etcd.spec.backup.compression.policycan only be set as eithergziporlzworzlib. - The
etcd.spec.sharedConfig.autoCompactionModecan only be set as eitherperiodicorrevision.
- The
The value of
etcd.spec.backup.garbageCollectionPeriodmust be greater thanetcd.spec.backup.deltaSnapshotPeriod. This is enforced by the CEL expression!(has(self.deltaSnapshotPeriod) && has(self.garbageCollectionPeriod)) || duration(self.deltaSnapshotPeriod).getSeconds() < duration(self.garbageCollectionPeriod).getSeconds(). The first part of the expression ensures that both the fields are present and then compares the values of the garbageCollectionPeriod and deltaSnapshotPeriod fields, if not, skips the check.The value of
etcd.spec.StorageCapacitymust be more than 3 times that of theetcd.spec.etcd.quotaif backups are enabled. If not, the value must be greater than that of theetcd.spec.etcd.quotafield. This is enforced by using the CEL expression:has(self.storageCapacity) && has(self.etcd.quota) ? (has(self.backup.store) ? quantity(self.storageCapacity).compareTo(quantity(self.etcd.quota).add(quantity(self.etcd.quota)).add(quantity(self.etcd.quota))) > 0 : quantity(self.storageCapacity).compareTo(quantity(self.etcd.quota)) > 0 ): trueThe check for whether backups are enabled or not is done by checking if the fieldetcd.spec.backup.storeexists.
2.38 - Version Compatibility Matrix
Version Compatibility
Kubernetes
We strongly recommend using etcd-druid with the supported kubernetes versions, published in this document.
The following is a list of kubernetes versions supported by the respective etcd-druid versions.
| etcd-druid version | Kubernetes version |
|---|---|
| >=v0.20 | >=v1.21 |
| >=v0.14 && <0.20 | All versions supported |
| <v0.14 | < v1.25 |
etcd-backup-restore & etcd-wrapper
| etcd-druid version | etcd-backup-restore version | etcd-wrapper version |
|---|---|---|
| >=v0.23.1 | >=v0.30.2 | >=v0.2.0 |
3 - Gardener Discovery Server
Gardener Discovery Server
A server capable of serving public metadata about different Gardener resources like shoot OIDC discovery documents and Gardener Workload Identity discovery.
Development
As a prerequisite you need to have a Garden cluster up and running. The easiest way to get started is to follow the Getting Started Locally Guide which explains how to setup Gardener for local development.
Once the Garden cluster is up and running, export the kubeconfig pointing to the cluster as an environment variable.
export KUBECONFIG=/path-to/garden-kubeconfig
You should be able to start the discovery server with the following command.
make start
Alternatively you can deploy the discovery server in the local cluster with the following command.
make server-up
3.1 - Api
Gardener Discovery Server API
The Gardener Discovery Server currently handles the following operations:
Garden Operations
Retrieve the OpenID Configuration of the Workload Identity Issuer of the Garden cluster
Request
GET /garden/workload-identity/issuer/.well-known/openid-configuration
Response
{
"issuer": "https://local.gardener.cloud/garden/workload-identity/issuer",
"jwks_uri": "https://local.gardener.cloud/garden/workload-identity/issuer/jwks",
"response_types_supported": [
"id_token"
],
"subject_types_supported": [
"public"
],
"id_token_signing_alg_values_supported": [
"RS256"
]
}
Retrieve the JWKS of the Workload Identity Issuer of the Garden cluster
Request
GET /garden/workload-identity/issuer/jwks
Response
{
"keys": [
{
"use": "sig",
"kty": "RSA",
"kid": "AvI...vWZ4",
"alg": "RS256",
"n": "1X1fsFJluuanoKq6c_...TUsX5bTv6c_c1xoqayFQc",
"e": "AQAB"
}
]
}
Shoot Operations
Retrieve the OpenID Configuration of a Shoot cluster
Request
GET /projects/{projectName}/shoots/{shootUID}/issuer/.well-known/openid-configuration
Response
{
"issuer": "https://local.gardener.cloud/projects/local/shoots/7b4ed380-2eea-4cf5-87d9-fd220727bb54/issuer",
"jwks_uri": "https://local.gardener.cloud/projects/local/shoots/7b4ed380-2eea-4cf5-87d9-fd220727bb54/issuer/jwks",
"response_types_supported": [
"id_token"
],
"subject_types_supported": [
"public"
],
"id_token_signing_alg_values_supported": [
"RS256"
]
}
Retrieve the JWKS of a Shoot cluster
Request
GET /projects/{projectName}/shoots/{shootUID}/issuer/jwks
Response
{
"keys": [
{
"use": "sig",
"kty": "RSA",
"kid": "AvI...vWZ4",
"alg": "RS256",
"n": "1X1fsFJluuanoKq6c_...TUsX5bTv6c_c1xoqayFQc",
"e": "AQAB"
}
]
}
Retrieve the CA of a Shoot cluster
Request
GET /projects/{projectName}/shoots/{shootUID}/cluster-ca
Response
{
"certs": "-----BEGIN CERTIFICATE-----\n...\n-----END CERTIFICATE-----\n"
}
4 - Machine Controller Manager
machine-controller-manager
Note One can add support for a new cloud provider by following Adding support for new provider.
Overview
Machine Controller Manager aka MCM is a group of cooperative controllers that manage the lifecycle of the worker machines. It is inspired by the design of Kube Controller Manager in which various sub controllers manage their respective Kubernetes Clients. MCM gives you the following benefits:
- seamlessly manage machines/nodes with a declarative API (of course, across different cloud providers)
- integrate generically with the cluster autoscaler
- plugin with tools such as the node-problem-detector
- transport the immutability design principle to machine/nodes
- implement e.g. rolling upgrades of machines/nodes
MCM supports following providers. These provider code is maintained externally (out-of-tree), and the links for the same are linked below:
It can easily be extended to support other cloud providers as well.
Example of managing machine:
kubectl create/get/delete machine vm1
Key terminologies
Nodes/Machines/VMs are different terminologies used to represent similar things. We use these terms in the following way
- VM: A virtual machine running on any cloud provider. It could also refer to a physical machine (PM) in case of a bare metal setup.
- Node: Native kubernetes node objects. The objects you get to see when you do a “kubectl get nodes”. Although nodes can be either physical/virtual machines, for the purposes of our discussions it refers to a VM.
- Machine: A VM that is provisioned/managed by the Machine Controller Manager.
Design of Machine Controller Manager
The design of the Machine Controller Manager is influenced by the Kube Controller Manager, where-in multiple sub-controllers are used to manage the Kubernetes clients.
Design Principles
It’s designed to run in the master plane of a Kubernetes cluster. It follows the best principles and practices of writing controllers, including, but not limited to:
- Reusing code from kube-controller-manager
- leader election to allow HA deployments of the controller
workqueuesand multiple thread-workersSharedInformersthat limit to minimum network calls, de-serialization and provide helpful create/update/delete events for resources- rate-limiting to allow back-off in case of network outages and general instability of other cluster components
- sending events to respected resources for easy debugging and overview
- Prometheus metrics, health and (optional) profiling endpoints
Objects of Machine Controller Manager
Machine Controller Manager reconciles a set of Custom Resources namely MachineDeployment, MachineSet and Machines which are managed & monitored by their controllers MachineDeployment Controller, MachineSet Controller, Machine Controller respectively along with another cooperative controller called the Safety Controller.
Machine Controller Manager makes use of 4 CRD objects and 1 Kubernetes secret object to manage machines. They are as follows:
| Custom ResourceObject | Description |
|---|---|
MachineClass | A MachineClass represents a template that contains cloud provider specific details used to create machines. |
Machine | A Machine represents a VM which is backed by the cloud provider. |
MachineSet | A MachineSet ensures that the specified number of Machine replicas are running at a given point of time. |
MachineDeployment | A MachineDeployment provides a declarative update for MachineSet and Machines. |
Secret | A Secret here is a Kubernetes secret that stores cloudconfig (initialization scripts used to create VMs) and cloud specific credentials. |
See here for CRD API Documentation
Components of Machine Controller Manager
| Controller | Description |
|---|---|
| MachineDeployment controller | Machine Deployment controller reconciles the MachineDeployment objects and manages the lifecycle of MachineSet objects. MachineDeployment consumes provider specific MachineClass in its spec.template.spec which is the template of the VM spec that would be spawned on the cloud by MCM. |
| MachineSet controller | MachineSet controller reconciles the MachineSet objects and manages the lifecycle of Machine objects. |
| Safety controller | There is a Safety Controller responsible for handling the unidentified or unknown behaviours from the cloud providers. Safety Controller:
|
Along with the above Custom Controllers and Resources, MCM requires the MachineClass to use K8s Secret that stores cloudconfig (initialization scripts used to create VMs) and cloud specific credentials. All these controllers work in an co-operative manner. They form a parent-child relationship with MachineDeployment Controller being the grandparent, MachineSet Controller being the parent, and Machine Controller being the child.
Development
To start using or developing the Machine Controller Manager, see the documentation in the /docs repository.
FAQ
An FAQ is available here.
cluster-api Implementation
cluster-apibranch of machine-controller-manager implements the machine-api aspect of the cluster-api project.- Link: https://github.com/gardener/machine-controller-manager/tree/cluster-api
- Once cluster-api project gets stable, we may make
masterbranch of MCM as well cluster-api compliant, with well-defined migration notes.
4.1 - Documents
4.1.1 - Apis
Specification
ProviderSpec Schema
Machine
Machine is the representation of a physical or virtual machine.
| Field | Type | Description | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
apiVersion | string | machine.sapcloud.io/v1alpha1 | ||||||||||||
kind | string | Machine | ||||||||||||
metadata | Kubernetes meta/v1.ObjectMeta | ObjectMeta for machine object Refer to the Kubernetes API documentation for the fields of themetadata field. | ||||||||||||
spec | MachineSpec | Spec contains the specification of the machine
| ||||||||||||
status | MachineStatus | Status contains fields depicting the status |
MachineClass
MachineClass can be used to templatize and re-use provider configuration across multiple Machines / MachineSets / MachineDeployments.
| Field | Type | Description |
|---|---|---|
apiVersion | string | machine.sapcloud.io/v1alpha1 |
kind | string | MachineClass |
metadata | Kubernetes meta/v1.ObjectMeta | (Optional)
Refer to the Kubernetes API documentation for the fields of the
metadata field. |
nodeTemplate | NodeTemplate | (Optional) NodeTemplate contains subfields to track all node resources and other node info required to scale nodegroup from zero |
credentialsSecretRef | Kubernetes core/v1.SecretReference | CredentialsSecretRef can optionally store the credentials (in this case the SecretRef does not need to store them). This might be useful if multiple machine classes with the same credentials but different user-datas are used. |
providerSpec | k8s.io/apimachinery/pkg/runtime.RawExtension | Provider-specific configuration to use during node creation. |
provider | string | Provider is the combination of name and location of cloud-specific drivers. |
secretRef | Kubernetes core/v1.SecretReference | SecretRef stores the necessary secrets such as credentials or userdata. |
MachineDeployment
MachineDeployment enables declarative updates for machines and MachineSets.
| Field | Type | Description | |||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
apiVersion | string | machine.sapcloud.io/v1alpha1 | |||||||||||||||||||||||||||
kind | string | MachineDeployment | |||||||||||||||||||||||||||
metadata | Kubernetes meta/v1.ObjectMeta | (Optional) Standard object metadata. Refer to the Kubernetes API documentation for the fields of themetadata field. | |||||||||||||||||||||||||||
spec | MachineDeploymentSpec | (Optional) Specification of the desired behavior of the MachineDeployment.
| |||||||||||||||||||||||||||
status | MachineDeploymentStatus | (Optional) Most recently observed status of the MachineDeployment. |
MachineSet
MachineSet TODO
| Field | Type | Description | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
apiVersion | string | machine.sapcloud.io/v1alpha1 | |||||||||||||||
kind | string | MachineSet | |||||||||||||||
metadata | Kubernetes meta/v1.ObjectMeta | (Optional)
Refer to the Kubernetes API documentation for the fields of the
metadata field. | |||||||||||||||
spec | MachineSetSpec | (Optional)
| |||||||||||||||
status | MachineSetStatus | (Optional) |
ClassSpec
(Appears on: MachineSetSpec, MachineSpec)
ClassSpec is the class specification of machine
| Field | Type | Description |
|---|---|---|
apiGroup | string | API group to which it belongs |
kind | string | Kind for machine class |
name | string | Name of machine class |
ConditionStatus
(string alias)
(Appears on: MachineDeploymentCondition, MachineSetCondition)
ConditionStatus are valid condition statuses
CurrentStatus
(Appears on: MachineStatus)
CurrentStatus contains information about the current status of Machine.
| Field | Type | Description |
|---|---|---|
phase | MachinePhase | |
timeoutActive | bool | |
lastUpdateTime | Kubernetes meta/v1.Time | Last update time of current status |
InPlaceUpdateMachineDeployment
(Appears on: MachineDeploymentStrategy)
InPlaceUpdateMachineDeployment specifies the spec to control the desired behavior of inplace update.
| Field | Type | Description |
|---|---|---|
UpdateConfiguration | UpdateConfiguration | (Members of |
orchestrationType | OrchestrationType | OrchestrationType specifies the orchestration type for the inplace update. |
LastOperation
(Appears on: MachineSetStatus, MachineStatus, MachineSummary)
LastOperation suggests the last operation performed on the object
| Field | Type | Description |
|---|---|---|
description | string | Description of the current operation |
errorCode | string | (Optional) ErrorCode of the current operation if any |
lastUpdateTime | Kubernetes meta/v1.Time | Last update time of current operation |
state | MachineState | State of operation |
type | MachineOperationType | Type of operation |
MachineConfiguration
(Appears on: MachineSpec)
MachineConfiguration describes the configurations useful for the machine-controller.
| Field | Type | Description |
|---|---|---|
drainTimeout | Kubernetes meta/v1.Duration | (Optional) MachineDraintimeout is the timeout after which machine is forcefully deleted. |
healthTimeout | Kubernetes meta/v1.Duration | (Optional) MachineHealthTimeout is the timeout after which machine is declared unhealhty/failed. |
creationTimeout | Kubernetes meta/v1.Duration | (Optional) MachineCreationTimeout is the timeout after which machinie creation is declared failed. |
inPlaceUpdateTimeout | Kubernetes meta/v1.Duration | (Optional) MachineInPlaceUpdateTimeout is the timeout after which in-place update is declared failed. |
disableHealthTimeout | *bool | (Optional) DisableHealthTimeout if set to true, health timeout will be ignored. Leading to machine never being declared failed. |
maxEvictRetries | *int32 | (Optional) MaxEvictRetries is the number of retries that will be attempted while draining the node. |
nodeConditions | *string | (Optional) NodeConditions are the set of conditions if set to true for MachineHealthTimeOut, machine will be declared failed. |
MachineDeploymentCondition
(Appears on: MachineDeploymentStatus)
MachineDeploymentCondition describes the state of a MachineDeployment at a certain point.
| Field | Type | Description |
|---|---|---|
type | MachineDeploymentConditionType | Type of MachineDeployment condition. |
status | ConditionStatus | Status of the condition, one of True, False, Unknown. |
lastUpdateTime | Kubernetes meta/v1.Time | The last time this condition was updated. |
lastTransitionTime | Kubernetes meta/v1.Time | Last time the condition transitioned from one status to another. |
reason | string | The reason for the condition’s last transition. |
message | string | A human readable message indicating details about the transition. |
MachineDeploymentConditionType
(string alias)
(Appears on: MachineDeploymentCondition)
MachineDeploymentConditionType are valid conditions of MachineDeployments
MachineDeploymentSpec
(Appears on: MachineDeployment)
MachineDeploymentSpec is the specification of the desired behavior of the MachineDeployment.
| Field | Type | Description |
|---|---|---|
replicas | int32 | (Optional) Number of desired machines. This is a pointer to distinguish between explicit zero and not specified. Defaults to 0. |
selector | Kubernetes meta/v1.LabelSelector | (Optional) Label selector for machines. Existing MachineSets whose machines are selected by this will be the ones affected by this MachineDeployment. |
template | MachineTemplateSpec | Template describes the machines that will be created. |
strategy | MachineDeploymentStrategy | (Optional) The MachineDeployment strategy to use to replace existing machines with new ones. |
minReadySeconds | int32 | (Optional) Minimum number of seconds for which a newly created machine should be ready without any of its container crashing, for it to be considered available. Defaults to 0 (machine will be considered available as soon as it is ready) |
revisionHistoryLimit | *int32 | (Optional) The number of old MachineSets to retain to allow rollback. This is a pointer to distinguish between explicit zero and not specified. |
paused | bool | (Optional) Indicates that the MachineDeployment is paused and will not be processed by the MachineDeployment controller. |
rollbackTo | RollbackConfig | (Optional) DEPRECATED. The config this MachineDeployment is rolling back to. Will be cleared after rollback is done. |
progressDeadlineSeconds | *int32 | (Optional) The maximum time in seconds for a MachineDeployment to make progress before it is considered to be failed. The MachineDeployment controller will continue to process failed MachineDeployments and a condition with a ProgressDeadlineExceeded reason will be surfaced in the MachineDeployment status. Note that progress will not be estimated during the time a MachineDeployment is paused. This is not set by default, which is treated as infinite deadline. |
MachineDeploymentStatus
(Appears on: MachineDeployment)
MachineDeploymentStatus is the most recently observed status of the MachineDeployment.
| Field | Type | Description |
|---|---|---|
observedGeneration | int64 | (Optional) The generation observed by the MachineDeployment controller. |
replicas | int32 | (Optional) Total number of non-terminated machines targeted by this MachineDeployment (their labels match the selector). |
updatedReplicas | int32 | (Optional) Total number of non-terminated machines targeted by this MachineDeployment that have the desired template spec. |
readyReplicas | int32 | (Optional) Total number of ready machines targeted by this MachineDeployment. |
availableReplicas | int32 | (Optional) Total number of available machines (ready for at least minReadySeconds) targeted by this MachineDeployment. |
unavailableReplicas | int32 | (Optional) Total number of unavailable machines targeted by this MachineDeployment. This is the total number of machines that are still required for the MachineDeployment to have 100% available capacity. They may either be machines that are running but not yet available or machines that still have not been created. |
conditions | []MachineDeploymentCondition | Represents the latest available observations of a MachineDeployment’s current state. |
collisionCount | *int32 | (Optional) Count of hash collisions for the MachineDeployment. The MachineDeployment controller uses this field as a collision avoidance mechanism when it needs to create the name for the newest MachineSet. |
failedMachines | []*github.com/gardener/machine-controller-manager/pkg/apis/machine/v1alpha1.MachineSummary | (Optional) FailedMachines has summary of machines on which lastOperation Failed |
MachineDeploymentStrategy
(Appears on: MachineDeploymentSpec)
MachineDeploymentStrategy describes how to replace existing machines with new ones.
| Field | Type | Description |
|---|---|---|
type | MachineDeploymentStrategyType | (Optional) Type of MachineDeployment. Can be “Recreate” or “RollingUpdate”. Default is RollingUpdate. |
rollingUpdate | RollingUpdateMachineDeployment | (Optional) Rolling update config params. Present only if MachineDeploymentStrategyType = RollingUpdate.TODO: Update this to follow our convention for oneOf, whatever we decide it to be. |
inPlaceUpdate | InPlaceUpdateMachineDeployment | (Optional) InPlaceUpdate update config params. Present only if MachineDeploymentStrategyType = InPlaceUpdate. |
MachineDeploymentStrategyType
(string alias)
(Appears on: MachineDeploymentStrategy)
MachineDeploymentStrategyType are valid strategy types for rolling MachineDeployments
MachineOperationType
(string alias)
(Appears on: LastOperation)
MachineOperationType is a label for the operation performed on a machine object.
MachinePhase
(string alias)
(Appears on: CurrentStatus)
MachinePhase is a label for the condition of a machine at the current time.
MachineSetCondition
(Appears on: MachineSetStatus)
MachineSetCondition describes the state of a machine set at a certain point.
| Field | Type | Description |
|---|---|---|
type | MachineSetConditionType | Type of machine set condition. |
status | ConditionStatus | Status of the condition, one of True, False, Unknown. |
lastTransitionTime | Kubernetes meta/v1.Time | (Optional) The last time the condition transitioned from one status to another. |
reason | string | (Optional) The reason for the condition’s last transition. |
message | string | (Optional) A human readable message indicating details about the transition. |
MachineSetConditionType
(string alias)
(Appears on: MachineSetCondition)
MachineSetConditionType is the condition on machineset object
MachineSetSpec
(Appears on: MachineSet)
MachineSetSpec is the specification of a MachineSet.
| Field | Type | Description |
|---|---|---|
replicas | int32 | (Optional) |
selector | Kubernetes meta/v1.LabelSelector | (Optional) |
machineClass | ClassSpec | (Optional) |
template | MachineTemplateSpec | (Optional) |
minReadySeconds | int32 | (Optional) |
MachineSetStatus
(Appears on: MachineSet)
MachineSetStatus holds the most recently observed status of MachineSet.
| Field | Type | Description |
|---|---|---|
replicas | int32 | Replicas is the number of actual replicas. |
fullyLabeledReplicas | int32 | (Optional) The number of pods that have labels matching the labels of the pod template of the replicaset. |
readyReplicas | int32 | (Optional) The number of ready replicas for this replica set. |
availableReplicas | int32 | (Optional) The number of available replicas (ready for at least minReadySeconds) for this replica set. |
observedGeneration | int64 | (Optional) ObservedGeneration is the most recent generation observed by the controller. |
machineSetCondition | []MachineSetCondition | (Optional) Represents the latest available observations of a replica set’s current state. |
lastOperation | LastOperation | LastOperation performed |
failedMachines | []github.com/gardener/machine-controller-manager/pkg/apis/machine/v1alpha1.MachineSummary | (Optional) FailedMachines has summary of machines on which lastOperation Failed |
MachineSpec
(Appears on: Machine, MachineTemplateSpec)
MachineSpec is the specification of a Machine.
| Field | Type | Description |
|---|---|---|
class | ClassSpec | (Optional) Class contains the machineclass attributes of a machine |
providerID | string | (Optional) ProviderID represents the provider’s unique ID given to a machine |
nodeTemplate | NodeTemplateSpec | (Optional) NodeTemplateSpec describes the data a node should have when created from a template |
MachineConfiguration | MachineConfiguration | (Members of Configuration for the machine-controller. |
MachineState
(string alias)
(Appears on: LastOperation)
MachineState is a current state of the operation.
MachineStatus
(Appears on: Machine)
MachineStatus holds the most recently observed status of Machine.
| Field | Type | Description |
|---|---|---|
conditions | []Kubernetes core/v1.NodeCondition | Conditions of this machine, same as node |
lastOperation | LastOperation | Last operation refers to the status of the last operation performed |
currentStatus | CurrentStatus | Current status of the machine object |
lastKnownState | string | (Optional) LastKnownState can store details of the last known state of the VM by the plugins. It can be used by future operation calls to determine current infrastucture state |
MachineSummary
MachineSummary store the summary of machine.
| Field | Type | Description |
|---|---|---|
name | string | Name of the machine object |
providerID | string | ProviderID represents the provider’s unique ID given to a machine |
lastOperation | LastOperation | Last operation refers to the status of the last operation performed |
ownerRef | string | OwnerRef |
MachineTemplateSpec
(Appears on: MachineDeploymentSpec, MachineSetSpec)
MachineTemplateSpec describes the data a machine should have when created from a template
| Field | Type | Description | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
metadata | Kubernetes meta/v1.ObjectMeta | (Optional) Standard object’s metadata. More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#metadata Refer to the Kubernetes API documentation for the fields of themetadata field. | ||||||||||||
spec | MachineSpec | (Optional) Specification of the desired behavior of the machine. More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#spec-and-status
|
NodeTemplate
(Appears on: MachineClass)
NodeTemplate contains subfields to track all node resources and other node info required to scale nodegroup from zero
| Field | Type | Description |
|---|---|---|
capacity | Kubernetes core/v1.ResourceList | Capacity contains subfields to track all node resources required to scale nodegroup from zero |
instanceType | string | Instance type of the node belonging to nodeGroup |
region | string | Region of the expected node belonging to nodeGroup |
zone | string | Zone of the expected node belonging to nodeGroup |
architecture | *string | (Optional) CPU Architecture of the node belonging to nodeGroup |
NodeTemplateSpec
(Appears on: MachineSpec)
NodeTemplateSpec describes the data a node should have when created from a template
| Field | Type | Description | |||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
metadata | Kubernetes meta/v1.ObjectMeta | (Optional)
Refer to the Kubernetes API documentation for the fields of the
metadata field. | |||||||||||||||||||||
spec | Kubernetes core/v1.NodeSpec | (Optional) NodeSpec describes the attributes that a node is created with.
|
OrchestrationType
(string alias)
(Appears on: InPlaceUpdateMachineDeployment)
OrchestrationType specifies the orchestration type for the inplace update.
RollbackConfig
(Appears on: MachineDeploymentSpec)
RollbackConfig is the config to rollback a MachineDeployment
| Field | Type | Description |
|---|---|---|
revision | int64 | (Optional) The revision to rollback to. If set to 0, rollback to the last revision. |
RollingUpdateMachineDeployment
(Appears on: MachineDeploymentStrategy)
RollingUpdateMachineDeployment is the spec to control the desired behavior of rolling update.
| Field | Type | Description |
|---|---|---|
UpdateConfiguration | UpdateConfiguration | (Members of |
UpdateConfiguration
(Appears on: InPlaceUpdateMachineDeployment, RollingUpdateMachineDeployment)
UpdateConfiguration specifies the udpate configuration for the deployment strategy.
| Field | Type | Description |
|---|---|---|
maxUnavailable | k8s.io/apimachinery/pkg/util/intstr.IntOrString | (Optional) The maximum number of machines that can be unavailable during the update. Value can be an absolute number (ex: 5) or a percentage of desired machines (ex: 10%). Absolute number is calculated from percentage by rounding down. This can not be 0 if MaxSurge is 0. Example: when this is set to 30%, the old machine set can be scaled down to 70% of desired machines immediately when the update starts. Once new machines are ready, old machine set can be scaled down further, followed by scaling up the new machine set, ensuring that the total number of machines available at all times during the update is at least 70% of desired machines. |
maxSurge | k8s.io/apimachinery/pkg/util/intstr.IntOrString | (Optional) The maximum number of machines that can be scheduled above the desired number of machines. Value can be an absolute number (ex: 5) or a percentage of desired machines (ex: 10%). This can not be 0 if MaxUnavailable is 0. Absolute number is calculated from percentage by rounding up. Example: when this is set to 30%, the new machine set can be scaled up immediately when the update starts, such that the total number of old and new machines does not exceed 130% of desired machines. Once old machines have been killed, new machine set can be scaled up further, ensuring that total number of machines running at any time during the update is utmost 130% of desired machines. |
Generated with gen-crd-api-reference-docs
4.2 - Proposals
4.2.1 - Excess Reserve Capacity
Excess Reserve Capacity
Goal
Currently, autoscaler optimizes the number of machines for a given application-workload. Along with effective resource utilization, this feature brings concern where, many times, when new application instances are created - they don’t find space in existing cluster. This leads the cluster-autoscaler to create new machines via MachineDeployment, which can take from 3-4 minutes to ~10 minutes, for the machine to really come-up and join the cluster. In turn, application-instances have to wait till new machines join the cluster.
One of the promising solutions to this issue is Excess Reserve Capacity. Idea is to keep a certain number of machines or percent of resources[cpu/memory] always available, so that new workload, in general, can be scheduled immediately unless huge spike in the workload. Also, the user should be given enough flexibility to choose how many resources or how many machines should be kept alive and non-utilized as this affects the Cost directly.
Note
- We decided to go with Approach-4 which is based on low priority pods. Please find more details here: https://github.com/gardener/gardener/issues/254
- Approach-3 looks more promising in long term, we may decide to adopt that in future based on developments/contributions in autoscaler-community.
Possible Approaches
Following are the possible approaches, we could think of so far.
Approach 1: Enhance Machine-controller-manager to also entertain the excess machines
Machine-controller-manager currently takes care of the machines in the shoot cluster starting from creation-deletion-health check to efficient rolling-update of the machines. From the architecture point of view, MachineSet makes sure that X number of machines are always running and healthy. MachineDeployment controller smartly uses this facility to perform rolling-updates.
We can expand the scope of MachineDeployment controller to maintain excess number of machines by introducing new parallel independent controller named MachineTaint controller. This will result in MCM to include Machine, MachineSet, MachineDeployment, MachineSafety, MachineTaint controllers. MachineTaint controller does not need to introduce any new CRD - analogy fits where taint-controller also resides into kube-controller-manager.
Only Job of MachineTaint controller will be:
- List all the Machines under each MachineDeployment.
- Maintain taints of noSchedule and noExecute on
Xlatest MachineObjects. - There should be an event-based informer mechanism where MachineTaintController gets to know about any Update/Delete/Create event of MachineObjects - in turn, maintains the noSchedule and noExecute taints on all the latest machines.
- Why latest machines?
- Whenever autoscaler decides to add new machines - essentially ScaleUp event - taints from the older machines are removed and newer machines get the taints. This way X number of Machines immediately becomes free for new pods to be scheduled.
- While ScaleDown event, autoscaler specifically mentions which machines should be deleted, and that should not bring any concerns. Though we will have to put proper label/annotation defined by autoscaler on taintedMachines, so that autoscaler does not consider the taintedMachines for deletion while scale-down.
* Annotation on tainted node:
"cluster-autoscaler.kubernetes.io/scale-down-disabled": "true"
Implementation Details:
- Expect new optional field ExcessReplicas in
MachineDeployment.Spec. MachineDeployment controller now adds bothSpec.ReplicasandSpec.ExcessReplicas[if provided], and considers that as a standard desiredReplicas. - Current working of MCM will not be affected if ExcessReplicas field is kept nil. - MachineController currently reads the NodeObject and sets the MachineConditions in MachineObject. Machine-controller will now also read the taints/labels from the MachineObject - and maintains it on the NodeObject.
- Expect new optional field ExcessReplicas in
We expect cluster-autoscaler to intelligently make use of the provided feature from MCM.
- CA gets the input of min:max:excess from Gardener. CA continues to set the
MachineDeployment.Spec.Replicasas usual based on the application-workload. - In addition, CA also sets the
MachieDeployment.Spec.ExcessReplicas. - Corner-case: * CA should decrement the excessReplicas field accordingly when desiredReplicas+excessReplicas on MachineDeployment goes beyond max.
- CA gets the input of min:max:excess from Gardener. CA continues to set the
Approach 2: Enhance Cluster-autoscaler by simulating fake pods in it
- There was already an attempt by community to support this feature.
- Refer for details to: https://github.com/kubernetes/autoscaler/pull/77/files
Approach 3: Enhance cluster-autoscaler to support pluggable scaling-events
- Forked version of cluster-autoscaler could be improved to plug-in the algorithm for excess-reserve capacity.
- Needs further discussion around upstream support.
- Create golang channel to separate the algorithms to trigger scaling (hard-coded in cluster-autoscaler, currently) from the algorithms about how to to achieve the scaling (already pluggable in cluster-autoscaler). This kind of separation can help us introduce/plug-in new algorithms (such as based node resource utilisation) without affecting existing code-base too much while almost completely re-using the code-base for the actual scaling.
- Also this approach is not specific to our fork of cluster-autoscaler. It can be made upstream eventually as well.
Approach 4: Make intelligent use of Low-priority pods
- Refer to: pod-priority-preemption
- TL; DR:
- High priority pods can preempt the low-priority pods which are already scheduled.
- Pre-create bunch[equivivalent of X shoot-control-planes] of low-priority pods with priority of zero, then start creating the workload pods with better priority which will reschedule the low-priority pods or otherwise keep them in pending state if the limit for max-machines has reached.
- This is still alpha feature.
4.2.2 - GRPC Based Implementation of Cloud Providers
GRPC based implementation of Cloud Providers - WIP
Goal:
Currently the Cloud Providers’ (CP) functionalities ( Create(), Delete(), List() ) are part of the Machine Controller Manager’s (MCM)repository. Because of this, adding support for new CPs into MCM requires merging code into MCM which may not be required for core functionalities of MCM itself. Also, for various reasons it may not be feasible for all CPs to merge their code with MCM which is an Open Source project.
Because of these reasons, it was decided that the CP’s code will be moved out in separate repositories so that they can be maintained separately by the respective teams. Idea is to make MCM act as a GRPC server, and CPs as GRPC clients. The CP can register themselves with the MCM using a GRPC service exposed by the MCM. Details of this approach is discussed below.
How it works:
MCM acts as GRPC server and listens on a pre-defined port 5000. It implements below GRPC services. Details of each of these services are mentioned in next section.
Register()GetMachineClass()GetSecret()
GRPC services exposed by MCM:
Register()
rpc Register(stream DriverSide) returns (stream MCMside) {}
The CP GRPC client calls this service to register itself with the MCM. The CP passes the kind and the APIVersion which it implements, and MCM maintains an internal map for all the registered clients. A GRPC stream is returned in response which is kept open througout the life of both the processes. MCM uses this stream to communicate with the client for machine operations: Create(), Delete() or List().
The CP client is responsible for reading the incoming messages continuously, and based on the operationType parameter embedded in the message, it is supposed to take the required action. This part is already handled in the package grpc/infraclient.
To add a new CP client, import the package, and implement the ExternalDriverProvider interface:
type ExternalDriverProvider interface {
Create(machineclass *MachineClassMeta, credentials, machineID, machineName string) (string, string, error)
Delete(machineclass *MachineClassMeta, credentials, machineID string) error
List(machineclass *MachineClassMeta, credentials, machineID string) (map[string]string, error)
}
GetMachineClass()
rpc GetMachineClass(MachineClassMeta) returns (MachineClass) {}
As part of the message from MCM for various machine operations, the name of the machine class is sent instead of the full machine class spec. The CP client is expected to use this GRPC service to get the full spec of the machine class. This optionally enables the client to cache the machine class spec, and make the call only if the machine calass spec is not already cached.
GetSecret()
rpc GetSecret(SecretMeta) returns (Secret) {}
As part of the message from MCM for various machine operations, the Cloud Config (CC) and CP credentials are not sent. The CP client is expected to use this GRPC service to get the secret which has CC and CP’s credentials from MCM. This enables the client to cache the CC and credentials, and to make the call only if the data is not already cached.
How to add a new Cloud Provider’s support
Import the package grpc/infraclient and grpc/infrapb from MCM (currently in MCM’s “grpc-driver” branch)
- Implement the interface
ExternalDriverProviderCreate(): Creates a new machineDelete(): Deletes a machineList(): Lists machines
- Use the interface
MachineClassDataProviderGetMachineClass(): Makes the call to MCM to get machine class specGetSecret(): Makes the call to MCM to get secret containing Cloud Config and CP’s credentials
Example implementation:
Refer GRPC based implementation for AWS client: https://github.com/ggaurav10/aws-driver-grpc
4.2.3 - Hotupdate Instances
Hot-Update VirtualMachine tags without triggering a rolling-update
- Hot-Update VirtualMachine tags without triggering a rolling-update
Motivation
MCM Issue#750 There is a requirement to provide a way for consumers to add tags which can be hot-updated onto VMs. This requirement can be generalized to also offer a convenient way to specify tags which can be applied to VMs, NICs, Devices etc.
MCM Issue#635 which in turn points to MCM-Provider-AWS Issue#36 - The issue hints at other fields like enable/disable source/destination checks for NAT instances which needs to be hot-updated on network interfaces.
In GCP provider -
instance.ServiceAccountscan be updated without the need to roll-over the instance. See
Boundary Condition
All tags that are added via means other than MachineClass.ProviderSpec should be preserved as-is. Only updates done to tags in MachineClass.ProviderSpec should be applied to the infra resources (VM/NIC/Disk).
What is available today?
WorkerPool configuration inside shootYaml provides a way to set labels. As per the definition these labels will be applied on Node resources. Currently these labels are also passed to the VMs as tags. There is no distinction made between Node labels and VM tags.
MachineClass has a field which holds provider specific configuration and one such configuration is tags. Gardener provider extensions updates the tags in MachineClass.
- AWS provider extension directly passes the labels to the tag section of machineClass.
- Azure provider extension sanitizes the woker pool labels and adds them as tags in MachineClass.
- GCP provider extension sanitizes them, and then sets them as labels in the MachineClass. In GCP tags only have keys and are currently hard coded.
Let us look at an example of MachineClass.ProviderSpec in AWS:
providerSpec:
ami: ami-02fe00c0afb75bbd3
tags:
#[section-1] pool lables added by gardener extension
#########################################################
kubernetes.io/arch: amd64
networking.gardener.cloud/node-local-dns-enabled: "true"
node.kubernetes.io/role: node
worker.garden.sapcloud.io/group: worker-ser234
worker.gardener.cloud/cri-name: containerd
worker.gardener.cloud/pool: worker-ser234
worker.gardener.cloud/system-components: "true"
#[section-2] Tags defined in the gardener-extension-provider-aws
###########################################################
kubernetes.io/cluster/cluster-full-name: "1"
kubernetes.io/role/node: "1"
#[section-3]
###########################################################
user-defined-key1: user-defined-val1
user-defined-key2: user-defined-val2
Refer src for tags defined in
section-1. Refer src for tags defined insection-2. Tags insection-3are defined by the user.
Out of the above three tag categories, MCM depends section-2 tags (mandatory-tags) for its orphan collection and Driver’s DeleteMachineand GetMachineStatus to work.
ProviderSpec.Tags are transported to the provider specific resources as follows:
| Provider | Resources Tags are set on | Code Reference | Comment |
|---|---|---|---|
| AWS | Instance(VM), Volume, Network-Interface | aws-VM-Vol-NIC | No distinction is made between tags set on VM, NIC or Volume |
| Azure | Instance(VM), Network-Interface | azure-VM-parameters & azureNIC-Parameters | |
| GCP | Instance(VM), 1 tag: name (denoting the name of the worker) is added to Disk | gcp-VM & gcp-Disk | In GCP key-value pairs are called labels while network tags have only keys |
| AliCloud | Instance(VM) | aliCloud-VM |
What are the problems with the current approach?
There are a few shortcomings in the way tags/labels are handled:
- Tags can only be set at the time a machine is created.
- There is no distinction made amongst tags/labels that are added to VM’s, disks or network interfaces. As stated above for AWS same set of tags are added to all. There is a limit defined on the number of tags/labels that can be associated to the devices (disks, VMs, NICs etc). Example: In AWS a max of 50 user created tags are allowed. Similar restrictions are applied on different resources across providers. Therefore adding all tags to all devices even if the subset of tags are not meant for that resource exhausts the total allowed tags/labels for that resource.
- The only placeholder in shoot yaml as mentioned above is meant to only hold labels that should be applied on primarily on the Node objects. So while you could use the node labels for extended resources, using it also for tags is not clean.
- There is no provision in the shoot YAML today to add tags only to a subset of resources.
MachineClass Update and its impact
When Worker.ProviderConfig is changed then a worker-hash is computed which includes the raw ProviderConfig. This hash value is then used as a suffix when constructing the name for a MachineClass. See aws-extension-provider as an example. A change in the name of the MachineClass will then in-turn trigger a rolling update of machines. Since tags are provider specific and therefore will be part of ProviderConfig, any update to them will result in a rolling-update of machines.
Proposal
Shoot YAML changes
Provider specific configuration is set via providerConfig section for each worker pool.
Example worker provider config (current):
providerConfig:
apiVersion: aws.provider.extensions.gardener.cloud/v1alpha1
kind: WorkerConfig
volume:
iops: 10000
dataVolumes:
- name: kubelet-dir
snapshotID: snap-13234
iamInstanceProfile: # (specify either ARN or name)
name: my-profile
arn: my-instance-profile-arn
It is proposed that an additional field be added for tags under providerConfig. Proposed changed YAML:
providerConfig:
apiVersion: aws.provider.extensions.gardener.cloud/v1alpha1
kind: WorkerConfig
volume:
iops: 10000
dataVolumes:
- name: kubelet-dir
snapshotID: snap-13234
iamInstanceProfile: # (specify either ARN or name)
name: my-profile
arn: my-instance-profile-arn
tags:
vm:
key1: val1
key2: val2
..
# for GCP network tags are just keys (there is no value associated to them).
# What is shown below will work for AWS provider.
network:
key3: val3
key4: val4
Under tags clear distinction is made between tags for VMs, Disks, network interface etc. Each provider has a different allowed-set of characters that it accepts as key names, has different limits on the tags that can be set on a resource (disk, NIC, VM etc.) and also has a different format (GCP network tags are only keys).
TODO:
Check if worker.labels are getting added as tags on infra resources. We should continue to support it and double check that these should only be added to VMs and not to other resources.
Should we support users adding VM tags as node labels?
Provider specific WorkerConfig API changes
Taking
AWSprovider extension as an example to show the changes.
WorkerConfig will now have the following changes:
- A new field for tags will be introduced.
- Additional metadata for struct fields will now be added via
struct tags.
type WorkerConfig struct {
metav1.TypeMeta
Volume *Volume
// .. all fields are not mentioned here.
// Tags are a collection of tags to be set on provider resources (e.g. VMs, Disks, Network Interfaces etc.)
Tags *Tags `hotupdatable:true`
}
// Tags is a placeholder for all tags that can be set/updated on VMs, Disks and Network Interfaces.
type Tags struct {
// VM tags set on the VM instances.
VM map[string]string
// Network tags set on the network interfaces.
Network map[string]string
// Disk tags set on the volumes/disks.
Disk map[string]string
}
There is a need to distinguish fields within ProviderSpec (which is then mapped to the above WorkerConfig) which can be updated without the need to change the hash suffix for MachineClass and thus trigger a rolling update on machines.
To achieve that we propose to use struct tag hotupdatable whose value indicates if the field can be updated without the need to do a rolling update. To ensure backward compatibility, all fields which do not have this tag or have hotupdatable set to false will be considered as immutable and will require a rolling update to take affect.
Gardener provider extension changes
Taking AWS provider extension as an example. Following changes should be made to all gardener provider extensions
AWS Gardener Extension generates machine config using worker pool configuration. As part of that it also computes the workerPoolHash which is then used to create the name of the MachineClass.
Currently WorkerPoolHash function uses the entire providerConfig to compute the hash. Proposal is to do the following:
- Remove the code from function
WorkerPoolHash. - Add another function to compute hash using all immutable fields in the provider config struct and then pass that to
worker.WorkerPoolHashasadditionalData.
The above will ensure that tags and any other field in WorkerConfig which is marked with updatable:true is not considered for hash computation and will therefore not contribute to changing the name of MachineClass object thus preventing a rolling update.
WorkerConfig and therefore the contained tags will be set as ProviderSpec in MachineClass.
If only fields which have updatable:true are changed then it should result in update/patch of MachineClass and not creation.
Driver interface changes
Driver interface which is a facade to provider specific API implementations will have one additional method.
type Driver interface {
// .. existing methods are not mentioned here for brevity.
UpdateMachine(context.Context, *UpdateMachineRequest) error
}
// UpdateMachineRequest is the request to update machine tags.
type UpdateMachineRequest struct {
ProviderID string
LastAppliedProviderSpec raw.Extension
MachineClass *v1alpha1.MachineClass
Secret *corev1.Secret
}
If any
machine-controller-manager-provider-<providername>has not implementedUpdateMachinethen updates of tags on Instances/NICs/Disks will not be done. An error message will be logged instead.
Machine Class reconciliation
Current MachineClass reconciliation does not reconcile MachineClass resource updates but it only enqueues associated machines. The reason is that it is assumed that anything that is changed in a MachineClass will result in a creation of a new MachineClass with a different name. This will result in a rolling update of all machines using the MachineClass as a template.
However, it is possible that there is data that all machines in a MachineSet share which do not require a rolling update (e.g. tags), therefore there is a need to reconcile the MachineClass as well.
Reconciliation Changes
In order to ensure that machines get updated eventually with changes to the hot-updatable fields defined in the MachineClass.ProviderConfig as raw.Extension.
We should only fix MCM Issue#751 in the MachineClass reconciliation and let it enqueue the machines as it does today. We additionally propose the following two things:
Introduce a new annotation
last-applied-providerspecon every machine resource. This will capture the last successfully appliedMachineClass.ProviderSpecon this instance.Enhance the machine reconciliation to include code to hot-update machine.
In machine-reconciliation there are currently two flows triggerDeletionFlow and triggerCreationFlow. When a machine gets enqueued due to changes in MachineClass then in this method following changes needs to be introduced:
Check if the machine has last-applied-providerspec annotation.
Case 1.1
If the annotation is not present then there can be just 2 possibilities:
It is a fresh/new machine and no backing resources (VM/NIC/Disk) exist yet. The current flow checks if the providerID is empty and
Status.CurrenStatus.Phaseis empty then it enters into thetriggerCreationFlow.It is an existing machine which does not yet have this annotation. In this case call
Driver.UpdateMachine. If the driver returns no error then addlast-applied-providerspecannotation with the value ofMachineClass.ProviderSpecto this machine.
Case 1.2
If the annotation is present then compare the last applied provider-spec with the current provider-spec. If there are changes (check their hash values) then call Driver.UpdateMachine. If the driver returns no error then add last-applied-providerspec annotation with the value of MachineClass.ProviderSpec to this machine.
NOTE: It is assumed that if there are changes to the fields which are not marked as
hotupdatablethen it will result in the change of name for MachineClass resulting in a rolling update of machines. If the name has not changed + machine is enqueued + there is a change in machine-class then it will be change to a hotupdatable fields in the spec.
Trigger update flow can be done after reconcileMachineHealth and syncMachineNodeTemplates in machine-reconciliation.
There are 2 edge cases that needs attention and special handling:
Premise: It is identified that there is an update done to one or more hotupdatable fields in the MachineClass.ProviderSpec.
Edge-Case-1
In the machine reconciliation, an update-machine-flow is triggered which in-turn calls Driver.UpdateMachine. Consider the case where the hot update needs to be done to all VM, NIC and Disk resources. The driver returns an error which indicates a partial-failure. As we have mentioned above only when Driver.UpdateMachine returns no error will last-applied-providerspec be updated. In case of partial failure the annotation will not be updated. This event will be re-queued for a re-attempt. However consider a case where before the item is re-queued, another update is done to MachineClass reverting back the changes to the original spec.
| At T1 | At T2 (T2 > T1) | At T3 (T3> T2) |
|---|---|---|
| last-applied-providerspec=S1 MachineClass.ProviderSpec = S1 | last-applied-providerspec=S1 MachineClass.ProviderSpec = S2 Another update to MachineClass.ProviderConfig = S3 is enqueue (S3 == S1) | last-applied-providerspec=S1 Driver.UpdateMachine for S1-S2 update - returns partial failure Machine-Key is requeued |
At T4 (T4> T3) when a machine is reconciled then it checks that last-applied-providerspec is S1 and current MachineClass.ProviderSpec = S3 and since S3 is same as S1, no update is done. At T2 Driver.UpdateMachine was called to update the machine with S2 but it partially failed. So now you will have resources which are partially updated with S2 and no further updates will be attempted.
Edge-Case-2
The above situation can also happen when Driver.UpdateMachine is in the process of updating resources. It has hot-updated lets say 1 resource. But now MCM crashes. By the time it comes up another update to MachineClass.ProviderSpec is done essentially reverting back the previous change (same case as above). In this case reconciliation loop never got a chance to get any response from the driver.
To handle the above edge cases there are 2 options:
Option #1
Introduce a new annotation inflight-providerspec-hash . The value of this annotation will be the hash value of the MachineClass.ProviderSpec that is in the process of getting applied on this machine. The machine will be updated with this annotation just before calling Driver.UpdateMachine (in the trigger-update-machine-flow). If the driver returns no error then (in a single update):
last-applied-providerspecwill be updatedinflight-providerspec-hashannotation will be removed.
Option #2 - Preferred
Leverage Machine.Status.LastOperation with Type set to MachineOperationUpdate and State set to MachineStateProcessing This status will be updated just before calling Driver.UpdateMachine.
Semantically LastOperation captures the details of the operation post-operation and not pre-operation. So this solution would be a divergence from the norm.
4.2.4 - Initialize Machine
Post-Create Initialization of Machine Instance
Background
Today the driver.Driver facade represents the boundary between the the machine-controller and its various provider specific implementations.
We have abstract operations for creation/deletion and listing of machines (actually compute instances) but we do not correctly handle post-creation initialization logic. Nor do we provide an abstract operation to represent the hot update of an instance after creation.
We have found this to be necessary for several use cases. Today in the MCM AWS Provider, we already misuse driver.GetMachineStatus which is supposed to be a read-only operation obtaining the status of an instance.
Each AWS EC2 instance performs source/destination checks by default. For EC2 NAT instances these should be disabled. This is done by issuing a ModifyInstanceAttribute request with the
SourceDestCheckset tofalse. The MCM AWS Provider, decodes the AWSProviderSpec, readsproviderSpec.SrcAndDstChecksEnabledand correspondingly issues the call to modify the already launched instance. However, this should be done as an action after creating the instance and should not be part of the VM status retrieval.Similarly, there is a pending PR to add the
Ipv6AddessCountandIpv6PrefixCountto enable the assignment of an ipv6 address and an ipv6 prefix to instances. This requires constructing and issuing an AssignIpv6Addresses request after the EC2 instance is available.We have other uses-cases such as MCM Issue#750 where there is a requirement to provide a way for consumers to add tags which can be hot-updated onto instances. This requirement can be generalized to also offer a convenient way to specify tags which can be applied to VMs, NICs, Devices etc.
We have a need for “machine-instance-not-ready” taint as described in MCM#740 which should only get removed once the post creation updates are finished.
Objectives
We will split the fulfilment of this overall need into 2 stages of implementation.
Stage-A: Support post-VM creation initialization logic of the instance suing a proposed
Driver.InitializeMachineby permitting provider implementors to add initialization logic after VM creation, return with special new error codecodes.Initializationfor initialization errors and correspondingly support a new machine operation stageInstanceInitializationwhich will be updated in the machineLastOperation. The triggerCreationFlow - a reconciliation sub-flow of the MCM responsible for orchestrating instance creation and updating machine status will be changed to support this behaviour.Stage-B: Introduction of
Driver.UpdateMachineand enhancing the MCM, MCM providers and gardener extension providers to support hot update of instances throughDriver.UpdateMachine. The MCM triggerUpdationFlow - a reconciliation sub-flow of the MCM which is supposed to be responsible for orchestrating instance update - but currently not used, will be updated to invoke the providerDriver.UpdateMachineon hot-updates to to theMachineobject
Stage-A Proposal
Current MCM triggerCreationFlow
Today, reconcileClusterMachine which is the main routine for the Machine object reconciliation invokes triggerCreationFlow at the end when the machine.Spec.ProviderID is empty or if the machine.Status.CurrentStatus.Phase is empty or in CrashLoopBackOff
%%{ init: {
'themeVariables':
{ 'fontSize': '12px'}
} }%%
flowchart LR
other["..."]
-->chk{"machine ProviderID empty
OR
Phase empty or CrashLoopBackOff ?
"}--yes-->triggerCreationFlow
chk--noo-->LongRetry["return machineutils.LongRetry"]Today, the triggerCreationFlow is illustrated below with some minor details omitted/compressed for brevity
NOTES
- The
lastopbelow is an abbreviation formachine.Status.LastOperation. This, along with the machine phase is generally updated on theMachineobject just before returning from the method. - regarding
phase=CrashLoopBackOff|Failed. the machine phase may either beCrashLoopBackOffor move toFailedif the difference between current time and themachine.CreationTimestamphas exceeded the configuredMachineCreationTimeout.
%%{ init: {
'themeVariables':
{ 'fontSize': '12px'}
} }%%
flowchart TD
end1(("end"))
begin((" "))
medretry["return MediumRetry, err"]
shortretry["return ShortRetry, err"]
medretry-->end1
shortretry-->end1
begin-->AddBootstrapTokenToUserData
-->gms["statusResp,statusErr=driver.GetMachineStatus(...)"]
-->chkstatuserr{"Check statusErr"}
chkstatuserr--notFound-->chknodelbl{"Chk Node Label"}
chkstatuserr--else-->createFailed["lastop.Type=Create,lastop.state=Failed,phase=CrashLoopBackOff|Failed"]-->medretry
chkstatuserr--nil-->initnodename["nodeName = statusResp.NodeName"]-->setnodename
chknodelbl--notset-->createmachine["createResp, createErr=driver.CreateMachine(...)"]-->chkCreateErr{"Check createErr"}
chkCreateErr--notnil-->createFailed
chkCreateErr--nil-->getnodename["nodeName = createResp.NodeName"]
-->chkstalenode{"nodeName != machine.Name\n//chk stale node"}
chkstalenode--false-->setnodename["if unset machine.Labels['node']= nodeName"]
-->machinepending["if empty/crashloopbackoff lastop.type=Create,lastop.State=Processing,phase=Pending"]
-->shortretry
chkstalenode--true-->delmachine["driver.DeleteMachine(...)"]
-->permafail["lastop.type=Create,lastop.state=Failed,Phase=Failed"]
-->shortretry
subgraph noteA [" "]
permafail -.- note1(["VM was referring to stale node obj"])
end
style noteA opacity:0
subgraph noteB [" "]
setnodename-.- note2(["Proposal: Introduce Driver.InitializeMachine after this"])
endEnhancement of MCM triggerCreationFlow
Relevant Observations on Current Flow
- Observe that we always perform a call to
Driver.GetMachineStatusand only then conditionally perform a call toDriver.CreateMachineif there was was no machine found. - Observe that after the call to a successful
Driver.CreateMachine, the machine phase is set toPending, theLastOperation.Typeis currently set toCreateand theLastOperation.Stateset toProcessingbefore returning with aShortRetry. TheLastOperation.Descriptionis (unfortunately) set to the fixed message:Creating machine on cloud provider. - Observe that after an erroneous call to
Driver.CreateMachine, the machine phase is set toCrashLoopBackOfforFailed(in case of creation timeout).
The following changes are proposed with a view towards minimal impact on current code and no introduction of a new Machine Phase.
MCM Changes
- We propose introducing a new machine operation
Driver.InitializeMachinewith the following signaturetype Driver interface { // .. existing methods are omitted for brevity. // InitializeMachine call is responsible for post-create initialization of the provider instance. InitializeMachine(context.Context, *InitializeMachineRequest) error } // InitializeMachineRequest is the initialization request for machine instance initialization type InitializeMachineRequest struct { // Machine object whose VM instance should be initialized Machine *v1alpha1.Machine // MachineClass backing the machine object MachineClass *v1alpha1.MachineClass // Secret backing the machineClass object Secret *corev1.Secret } - We propose introducing a new MC error code
codes.Initializationindicating that the VM Instance was created but there was an error in initialization after VM creation. The implementor ofDriver.InitializeMachinecan return this error code, indicating thatInitializeMachineneeds to be called again. The Machine Controller will change the phase toCrashLoopBackOffas usual when encountering acodes.Initializationerror. - We will introduce a new machine operation stage
InstanceInitialization. In case of ancodes.Initializationerror- the
machine.Status.LastOperation.Descriptionwill be set toInstanceInitialization, machine.Status.LastOperation.ErrorCodewill be set tocodes.Initialization- the
LastOperation.Typewill be set toCreate - the
LastOperation.Stateset toFailedbefore returning with aShortRetry
- the
- The semantics of
Driver.GetMachineStatuswill be changed. If the instance associated with machine exists, but the instance was not initialized as expected, the provider implementations ofGetMachineStatusshould return an error:status.Error(codes.Initialization). - If
Driver.GetMachineStatusreturned an error encapsulatingcodes.InitializationthenDriver.InitializeMachinewill be invoked again in thetriggerCreationFlow. - As according to the usual logic, the main machine controller reconciliation loop will now re-invoke the
triggerCreationFlowagain if the machine phase isCrashLoopBackOff.
Illustration

AWS Provider Changes
Driver.InitializeMachine
The implementation for the AWS Provider will look something like:
- After the VM instance is available, check
providerSpec.SrcAndDstChecksEnabled, constructModifyInstanceAttributeInputand callModifyInstanceAttribute. In case of an error returncodes.Initializationinstead of the currentcodes.Internal - Check
providerSpec.NetworkInterfacesand ifIpv6PrefixCountis notnil, then constructAssignIpv6AddressesInputand callAssignIpv6Addresses. In case of an error returncodes.Initialization. Don’t use the genericcodes.Internal
The existing Ipv6 PR will need modifications.
Driver.GetMachineStatus
- If
providerSpec.SrcAndDstChecksEnabledisfalse, checkec2.Instance.SourceDestCheck. If it does not match then returnstatus.Error(codes.Initialization) - Check
providerSpec.NetworkInterfacesand ifIpv6PrefixCountis notnil, checkec2.Instance.NetworkInterfacesand check ifInstanceNetworkInterface.Ipv6Addresseshas a non-nil slice. If this is not the case then returnstatus.Error(codes.Initialization)
Instance Not Ready Taint
- Due to the fact that creation flow for machines will now be enhanced to correctly support post-creation startup logic, we should not scheduled workload until this startup logic is complete. Even without this feature we have a need for such a taint as described in MCM#740
- We propose a new taint
node.machine.sapcloud.io/instance-not-readywhich will be added as a node startup taint in gardener core KubeletConfiguration.RegisterWithTaints - The will will then removed by MCM in health check reconciliation, once the machine becomes fully ready. (when moving to
Runningphase) - We will add this taint as part of
--ignore-taintin CA - We will introduce a disclaimer / prerequisite in the MCM FAQ, to add this taint as part of kubelet config under
--register-with-taints, otherwise workload could get scheduled , before machine beomesRunning
Stage-B Proposal
Enhancement of Driver Interface for Hot Updation
Kindly refer to the Hot-Update Instances design which provides elaborate detail.
4.3 - To-Do
4.3.1 - Outline
Machine Controller Manager
CORE – ./machine-controller-manager(provider independent) Out of tree : Machine controller (provider specific) MCM is a set controllers:
Machine Deployment Controller
Machine Set Controller
Machine Controller
Machine Safety Controller
Questions and refactoring Suggestions
Refactoring
| Statement | FilePath | Status |
|---|---|---|
| ConcurrentNodeSyncs” bad name - nothing to do with node syncs actually. If its value is ’10’ then it will start 10 goroutines (workers) per resource type (machine, machinist, machinedeployment, provider-specific-class, node - study the different resource types. | cmd/machine-controller-manager/app/options/options.go | pending |
| LeaderElectionConfiguration is very similar to the one present in “client-go/tools/leaderelection/leaderelection.go” - can we simply used the one in client-go instead of defining again? | pkg/options/types.go - MachineControllerManagerConfiguration | pending |
| Have all userAgents as constant. Right now there is just one. | cmd/app/controllermanager.go | pending |
| Shouldn’t run function be defined on MCMServer struct itself? | cmd/app/controllermanager.go | pending |
| clientcmd.BuildConfigFromFlags fallsback to inClusterConfig which will surely not work as that is not the target. Should it not check and exit early? | cmd/app/controllermanager.go - run Function | pending |
A more direct way to create an in cluster config is using k8s.io/client-go/rest -> rest.InClusterConfig instead of using clientcmd.BuildConfigFromFlags passing empty arguments and depending upon the implementation to fallback to creating a inClusterConfig. If they change the implementation that you get affected. | cmd/app/controllermanager.go - run Function | pending |
| Introduce a method on MCMServer which gets a target KubeConfig and controlKubeConfig or alternatively which creates respective clients. | cmd/app/controllermanager.go - run Function | pending |
| Why can’t we use Kubernetes.NewConfigOrDie also for kubeClientControl? | cmd/app/controllermanager.go - run Function | pending |
| I do not see any benefit of client builders actually. All you need to do is pass in a config and then directly use client-go functions to create a client. | cmd/app/controllermanager.go - run Function | pending |
| Function: getAvailableResources - rename this to getApiServerResources | cmd/app/controllermanager.go | pending |
| Move the method which waits for API server to up and ready to a separate method which returns a discoveryClient when the API server is ready. | cmd/app/controllermanager.go - getAvailableResources function | pending |
| Many methods in client-go used are now deprecated. Switch to the ones that are now recommended to be used instead. | cmd/app/controllermanager.go - startControllers | pending |
| This method needs a general overhaul | cmd/app/controllermanager.go - startControllers | pending |
| If the design is influenced/copied from KCM then its very different. There are different controller structs defined for deployment, replicaset etc which makes the code much more clearer. You can see “kubernetes/cmd/kube-controller-manager/apps.go” and then follow the trail from there. - agreed needs to be changed in future (if time permits) | pkg/controller/controller.go | pending |
| I am not sure why “MachineSetControlInterface”, “RevisionControlInterface”, “MachineControlInterface”, “FakeMachineControl” are defined in this file? | pkg/controller/controller_util.go | pending |
IsMachineActive - combine the first 2 conditions into one with OR. | pkg/controller/controller_util.go | pending |
| Minor change - correct the comment, first word should always be the method name. Currently none of the comments have correct names. | pkg/controller/controller_util.go | pending |
| There are too many deep copies made. What is the need to make another deep copy in this method? You are not really changing anything here. | pkg/controller/deployment.go - updateMachineDeploymentFinalizers | pending |
| Why can’t these validations be done as part of a validating webhook? | pkg/controller/machineset.go - reconcileClusterMachineSet | pending |
Small change to the following if condition. else if is not required a simple else is sufficient. Code1 | ||
| pkg/controller/machineset.go - reconcileClusterMachineSet | pending | |
Why call these inactiveMachines, these are live and running and therefore active. | pkg/controller/machineset.go - terminateMachines | pending |
Clarification
| Statement | FilePath | Status |
|---|---|---|
| Why are there 2 versions - internal and external versions? | General | pending |
| Safety controller freezes MCM controllers in the following cases: * Num replicas go beyond a threshold (above the defined replicas) * Target API service is not reachable There seems to be an overlap between DWD and MCM Safety controller. In the meltdown scenario why is MCM being added to DWD, you could have used Safety controller for that. | General | pending |
| All machine resources are v1alpha1 - should we not promote it to beta. V1alpha1 has a different semantic and does not give any confidence to the consumers. | cmd/app/controllermanager.go | pending |
Shouldn’t controller manager use context.Context instead of creating a stop channel? - Check if signals (os.Interrupt and SIGTERM are handled properly. Do not see code where this is handled currently.) | cmd/app/controllermanager.go | pending |
| What is the rationale behind a timeout of 10s? If the API server is not up, should this not just block as it can anyways not do anything. Also, if there is an error returned then you exit the MCM which does not make much sense actually as it will be started again and you will again do the poll for the API server to come back up. Forcing an exit of MCM will not have any impact on the reachability of the API server in anyway so why exit? | cmd/app/controllermanager.go - getAvailableResources | pending |
There is a very weird check - availableResources[machineGVR] || availableResources[machineSetGVR] || availableResources[machineDeploymentGVR]Shouldn’t this be conjunction instead of disjunction? * What happens if you do not find one or all of these resources? Currently an error log is printed and nothing else is done. MCM can be used outside gardener context where consumers can directly create MachineClass and Machine and not create MachineSet / Maching Deployment. There is no distinction made between context (gardener or outside-gardener). | cmd/app/controllermanager.go - StartControllers | pending |
| Instead of having an empty select {} to block forever, isn’t it better to wait on the stop channel? | cmd/app/controllermanager.go - StartControllers | pending |
| Do we need provider specific queues and syncs and listers | pkg/controller/controller.go | pending |
| Why are resource types prefixed with “Cluster”? - not sure , check PR | pkg/controller/controller.go | pending |
| When will forgetAfterSuccess be false and why? - as per the current code this is never the case. - Himanshu will check | cmd/app/controllermanager.go - createWorker | pending |
| What is the use of “ExpectationsInterface” and “UIDTrackingContExpectations”? * All expectations related code should be in its own file “expectations.go” and not in this file. | pkg/controller/controller_util.go | pending |
| Why do we not use lister but directly use the controlMachingClient to get the deployment? Is it because you want to avoid any potential delays caused by update of the local cache held by the informer and accessed by the lister? What is the load on API server due to this? | pkg/controller/deployment.go - reconcileClusterMachineDeployment | pending |
| Why is this conversion needed? code2 | pkg/controller/deployment.go - reconcileClusterMachineDeployment | pending |
A deep copy of machineDeployment is already passed and within the function another deepCopy is made. Any reason for it? | pkg/controller/deployment.go - addMachineDeploymentFinalizers | pending |
What is an Status.ObservedGeneration?*Read more about generations and observedGeneration at: https://github.com/kubernetes/community/blob/master/contributors/devel/sig-architecture/api-conventions.md#metadata https://alenkacz.medium.com/kubernetes-operator-best-practices-implementing-observedgeneration-250728868792 Ideally the update to the ObservedGeneration should only be made after successful reconciliation and not before. I see that this is just copied from deployment_controller.go as is | pkg/controller/deployment.go - reconcileClusterMachineDeployment | pending |
Why and when will a MachineDeployment be marked as frozen and when will it be un-frozen? | pkg/controller/deployment.go - reconcileClusterMachineDeployment | pending |
| Shoudn’t the validation of the machine deployment be done during the creation via a validating webhook instead of allowing it to be stored in etcd and then failing the validation during sync? I saw the checks and these can be done via validation webhook. | pkg/controller/deployment.go - reconcileClusterMachineDeployment | pending |
| RollbackTo has been marked as deprecated. What is the replacement? code3 | pkg/controller/deployment.go - reconcileClusterMachineDeployment | pending |
| What is the max machineSet deletions that you could process in a single run? The reason for asking this question is that for every machineSetDeletion a new goroutine spawned. * Is the Delete call a synchrounous call? Which means it blocks till the machineset deletion is triggered which then also deletes the machines (due to cascade-delete and blockOwnerDeletion= true)? | pkg/controller/deployment.go - terminateMachineSets | pending |
If there are validation errors or error when creating label selector then a nil is returned. In the worker reconcile loop if the return value is nil then it will remove it from the queue (forget + done). What is the way to see any errors? Typically when we describe a resource the errors are displayed. Will these be displayed when we discribe a MachineDeployment? | pkg/controller/deployment.go - reconcileClusterMachineSet | pending |
If an error is returned by updateMachineSetStatus and it is IsNotFound error then returning an error will again queue the MachineSet. Is this desired as IsNotFound indicates the MachineSet has been deleted and is no longer there? | pkg/controller/deployment.go - reconcileClusterMachineSet | pending |
is machineControl.DeleteMachine a synchronous operation which will wait till the machine has been deleted? Also where is the DeletionTimestamp set on the Machine? Will it be automatically done by the API server? | pkg/controller/deployment.go - prepareMachineForDeletion | pending |
Bugs/Enhancements
| Statement + TODO | FilePath | Status |
|---|---|---|
| This defines QPS and Burst for its requests to the KAPI. Check if it would make sense to explicitly define a FlowSchema and PriorityLevelConfiguration to ensure that the requests from this controller are given a well-defined preference. What is the rational behind deciding these values? | pkg/options/types.go - MachineControllerManagerConfiguration | pending |
| In function “validateMachineSpec” fldPath func parameter is never used. | pkg/apis/machine/validation/machine.go | pending |
| If there is an update failure then this method recursively calls itself without any sort of delays which could lead to a LOT of load on the API server. (opened: https://github.com/gardener/machine-controller-manager/issues/686) | pkg/controller/deployment.go - updateMachineDeploymentFinalizers | pending |
We are updating filteredMachines by invoking syncMachinesNodeTemplates, syncMachinesConfig and syncMachinesClassKind but we do not create any deepCopy here. Everywhere else the general principle is when you mutate always make a deepCopy and then mutate the copy instead of the original as a lister is used and that changes the cached copy.Fix: SatisfiedExpectations check has been commented and there is a TODO there to fix it. Is there a PR for this? | pkg/controller/machineset.go - reconcileClusterMachineSet | pending |
Code references
1.1 code1
if machineSet.DeletionTimestamp == nil {
// manageReplicas is the core machineSet method where scale up/down occurs
// It is not called when deletion timestamp is set
manageReplicasErr = c.manageReplicas(ctx, filteredMachines, machineSet)
} else if machineSet.DeletionTimestamp != nil {
//FIX: change this to simple else without the if
1.2 code2
defer dc.enqueueMachineDeploymentAfter(deployment, 10*time.Minute)
* `Clarification`: Why is this conversion needed?
err = v1alpha1.Convert_v1alpha1_MachineDeployment_To_machine_MachineDeployment(deployment, internalMachineDeployment, nil)
1.3 code3
// rollback is not re-entrant in case the underlying machine sets are updated with a new
// revision so we should ensure that we won't proceed to update machine sets until we
// make sure that the deployment has cleaned up its rollback spec in subsequent enqueues.
if d.Spec.RollbackTo != nil {
return dc.rollback(ctx, d, machineSets, machineMap)
}
4.4 - FAQ
Frequently Asked Questions
The answers in this FAQ apply to the newest (HEAD) version of Machine Controller Manager. If you’re using an older version of MCM please refer to corresponding version of this document. Few of the answers assume that the MCM being used is in conjuction with cluster-autoscaler:
Table of Contents:
- Frequently Asked Questions
- Table of Contents:
- Basics
- How to?
- How to install MCM in a Kubernetes cluster?
- How to run MCM in different cluster setups?
- How to better control the rollout process of the worker nodes?
- How to scale down MachineDeployment by selective deletion of machines?
- How to force delete a machine?
- How to pause the ongoing rolling-update of the machinedeployment?
- How to delete machine object immedietly if I don’t have access to it?
- How to avoid garbage collection of your node?
- How to trigger rolling update of a machinedeployment?
- Internals
- What is the high level design of MCM?
- What are the different configuration options in MCM?
- What are the different timeouts/configurations in a machine’s lifecycle?
- How is the drain of a machine implemented?
- How are the stateful applications drained during machine deletion?
- How does
maxEvictRetriesconfiguration work withdrainTimeoutconfiguration? - What are the different phases of a machine?
- What health checks are performed on a machine?
- How does rate limiting replacement of machine work in MCM? How is it related to meltdown protection?
- How MCM responds when scale-out/scale-in is done during rolling update of a machinedeployment?
- How does MCM prioritize the machines for deletion on scale-down of machinedeployment?
- How some unhealthy machines are drained quickly?
- Troubleshooting
- Developer
- In the context of Gardener
Basics
What is Machine Controller Manager?
Machine Controller Manager aka MCM is a bunch of controllers used for the lifecycle management of the worker machines. It reconciles a set of CRDs such as Machine, MachineSet, MachineDeployment which depicts the functionality of Pod, Replicaset, Deployment of the core Kubernetes respectively. Read more about it at README.
- Gardener uses MCM to manage its Kubernetes nodes of the shoot cluster. However, by design, MCM can be used independent of Gardener.
Why is my machine deleted?
A machine is deleted by MCM generally for 2 reasons-
- Machine is unhealthy for at least
MachineHealthTimeoutperiod. The defaultMachineHealthTimeoutis 10 minutes.- By default, a machine is considered unhealthy if any of the following node conditions -
DiskPressure,KernelDeadlock,FileSystem,Readonlyis set totrue, orKubeletReadyis set tofalse. However, this is something that is configurable using the following flag.
- By default, a machine is considered unhealthy if any of the following node conditions -
- Machine is scaled down by the
MachineDeploymentresource.- This is very usual when an external controller cluster-autoscaler (aka CA) is used with MCM. CA deletes the under-utilized machines by scaling down the
MachineDeployment. Read more about cluster-autoscaler’s scale down behavior here.
- This is very usual when an external controller cluster-autoscaler (aka CA) is used with MCM. CA deletes the under-utilized machines by scaling down the
What are the different sub-controllers in MCM?
MCM mainly contains the following sub-controllers:
MachineDeployment Controller: Responsible for reconciling theMachineDeploymentobjects. It manages the lifecycle of theMachineSetobjects.MachineSet Controller: Responsible for reconciling theMachineSetobjects. It manages the lifecycle of theMachineobjects.Machine Controller: responsible for reconciling theMachineobjects. It manages the lifecycle of the actual VMs/machines created in cloud/on-prem. This controller has been moved out of tree. Please refer an AWS machine controller for more info - link.- Safety-controller: Responsible for handling the unidentified/unknown behaviors from the cloud providers. Please read more about its functionality below.
What is Safety Controller in MCM?
Safety Controller contains following functions:
- Orphan VM handler:
- It lists all the VMs in the cloud matching the
tagof given cluster name and maps the VMs with themachineobjects using theProviderIDfield. VMs without any backingmachineobjects are logged and deleted after confirmation. - This handler runs every 30 minutes and is configurable via machine-safety-orphan-vms-period flag.
- It lists all the VMs in the cloud matching the
- Freeze mechanism:
Safety Controllerfreezes theMachineDeploymentandMachineSetcontroller if the number ofmachineobjects goes beyond a certain threshold on top ofSpec.Replicas. It can be configured by the flag –safety-up or –safety-down and also machine-safety-overshooting-period.Safety Controllerfreezes the functionality of the MCM if either of thetarget-apiserveror thecontrol-apiserveris not reachable.Safety Controllerunfreezes the MCM automatically once situation is resolved to normal. Afreezelabel is applied onMachineDeployment/MachineSetto enforce the freeze condition.
How to?
How to install MCM in a Kubernetes cluster?
MCM can be installed in a cluster with following steps:
- Apply all the CRDs from here
- Apply all the deployment, role-related objects from here.
- Control cluster is the one where the
machine-*objects are stored. Target cluster is where all the node objects are registered.
- Control cluster is the one where the
How to run MCM in different cluster setups?
In the standard setup, MCM connects to the target cluster, i.e., the cluster that the machines should join. This is configured via the --target-kubeconfig flag.
If the flag is omitted or empty, it uses the in-cluster credentials (i.e., the pod’s ServiceAccount).
By default, MCM works with the Machine* resources in the target cluster, unless a different “control cluster” is configured via the --control-kubeconfig flag.
In standard Gardener Shoot clusters, MCM uses the Seed cluster as the control cluster for managing machines of the Shoot cluster (target cluster).
MCM can also be configured to run without a target cluster by specifying --target-kubeconfig=none.
This requires explicitly configuring a control cluster via --control-kubeconfig.
In this mode, MCM only provisions/deletes machines on the configured infrastructure without considering the target cluster’s Node objects.
As a consequence, MCM doesn’t create bootstrap tokens, doesn’t wait for Nodes to be registered/drained, and does not perform health checks for Machines.
Once the machine has been successfully created in the infrastructure, Machine.status.currentStatus.phase transitions to Available as a target state (see this section) – in contrast to the standard Pending and Running phases.
Accordingly, the owning MachineSet and MachineDeployment objects will have “available” replicas but no “ready” replicas as indicated in the corresponding status fields.
This mode is used for provisioning control plane machines of autonomous shoot clusters (gardenadm bootstrap command, medium-touch scenario).
How to better control the rollout process of the worker nodes?
MCM allows configuring the rollout of the worker machines using maxSurge and maxUnavailable fields. These fields are applicable only during the rollout process and means nothing in general scale up/down scenarios.
The overall process is very similar to how the Deployment Controller manages pods during RollingUpdate.
maxSurgerefers to the number of additional machines that can be added on top of theSpec.Replicasof MachineDeployment during rollout process.maxUnavailablerefers to the number of machines that can be deleted fromSpec.Replicasfield of the MachineDeployment during rollout process.
How to scale down MachineDeployment by selective deletion of machines?
During scale down, triggered via MachineDeployment/MachineSet, MCM prefers to delete the machine/s which have the least priority set.
Each machine object has an annotation machinepriority.machine.sapcloud.io set to 3 by default. Admin can reduce the priority of the given machines by changing the annotation value to 1. The next scale down by MachineDeployment shall delete the machines with the least priority first.
How to force delete a machine?
A machine can be force deleted by adding the label force-deletion: "True" on the machine object before executing the actual delete command. During force deletion, MCM skips the drain function and simply triggers the deletion of the machine. This label should be used with caution as it can violate the PDBs for pods running on the machine.
How to pause the ongoing rolling-update of the machinedeployment?
An ongoing rolling-update of the machine-deployment can be paused by using spec.paused field. See the example below:
apiVersion: machine.sapcloud.io/v1alpha1
kind: MachineDeployment
metadata:
name: test-machine-deployment
spec:
paused: true
It can be unpaused again by removing the Paused field from the machine-deployment.
How to delete machine object immedietly if I don’t have access to it?
If the user doesn’t have access to the machine objects (like in case of Gardener clusters) and they would like to replace a node immedietly then they can place the annotation node.machine.sapcloud.io/trigger-deletion-by-mcm: "true" on their node. This will start the replacement of the machine with a new node.
On the other hand if the user deletes the node object immedietly then replacement will start only after MachineHealthTimeout.
This annotation can also be used if the user wants to expedite the replacement of unhealthy nodes
NOTE:
node.machine.sapcloud.io/trigger-deletion-by-mcm: "false"annotation is NOT acted upon by MCM , neither does it mean that MCM will not replace this machine.- this annotation would delete the desired machine but another machine would be created to maintain
desired replicasspecified for the machineDeployment/machineSet. Currently if the user doesn’t have access to machineDeployment/machineSet then they cannot remove a machine without replacement.
How to avoid garbage collection of your node?
MCM provides an in-built safety mechanism to garbage collect VMs which have no corresponding machine object. This is done to save costs and is one of the key features of MCM. However, sometimes users might like to add nodes directly to the cluster without the help of MCM and would prefer MCM to not garbage collect such VMs. To do so they should remove/not-use tags on their VMs containing the following strings:
kubernetes.io/cluster/kubernetes.io/role/kubernetes-io-cluster-kubernetes-io-role-
How to trigger rolling update of a machinedeployment?
Rolling update can be triggered for a machineDeployment by updating one of the following:
.spec.template.annotations.spec.template.spec.class.name
Internals
What is the high level design of MCM?
Please refer the following document.
What are the different configuration options in MCM?
MCM allows configuring many knobs to fine-tune its behavior according to the user’s need. Please refer to the link to check the exact configuration options.
What are the different timeouts/configurations in a machine’s lifecycle?
A machine’s lifecycle is governed by mainly following timeouts, which can be configured here.
MachineDrainTimeout: Amount of time after which drain times out and the machine is force deleted. Default ~2 hours.MachineHealthTimeout: Amount of time after which an unhealthy machine is declaredFailedand the machine is replaced byMachineSetcontroller.MachineCreationTimeout: Amount of time after which a machine creation is declaredFailedand the machine is replaced by theMachineSetcontroller.NodeConditions: List of node conditions which if set to true forMachineHealthTimeoutperiod, the machine is declaredFailedand replaced byMachineSetcontroller.MaxEvictRetries: An integer number depicting the number of times a failed eviction should be retried on a pod during drain process. A pod is deleted aftermax-retries.
How is the drain of a machine implemented?
MCM imports the functionality from the upstream Kubernetes-drain library. Although, few parts have been modified to make it work best in the context of MCM. Drain is executed before machine deletion for graceful migration of the applications.
Drain internally uses the EvictionAPI to evict the pods and triggers the Deletion of pods after MachineDrainTimeout. Please note:
- Stateless pods are evicted in parallel.
- Stateful applications (with PVCs) are serially evicted. Please find more info in this answer below.
How are the stateful applications drained during machine deletion?
Drain function serially evicts the stateful-pods. It is observed that serial eviction of stateful pods yields better overall availability of pods as the underlying cloud in most cases detaches and reattaches disks serially anyways. It is implemented in the following manner:
- Drain lists all the pods with attached volumes. It evicts very first stateful-pod and waits for its related entry in Node object’s
.status.volumesAttachedto be removed by KCM. It does the same for all the stateful-pods. - It waits for
PvDetachTimeout(default 2 minutes) for a given pod’s PVC to be removed, else moves forward.
How does maxEvictRetries configuration work with drainTimeout configuration?
It is recommended to only set MachineDrainTimeout. It satisfies the related requirements. MaxEvictRetries is auto-calculated based on MachineDrainTimeout, if maxEvictRetries is not provided. Following will be the overall behavior of both configurations together:
- If
maxEvictRetriesisn’t set and onlymaxDrainTimeoutis set:- MCM auto calculates the
maxEvictRetriesbased on thedrainTimeout.
- MCM auto calculates the
- If
drainTimeoutisn’t set and onlymaxEvictRetriesis set:- Default
drainTimeoutand user providedmaxEvictRetriesfor each pod is considered.
- Default
- If both
maxEvictRetriesanddrainTimoeutare set:- Then both will be respected.
- If none are set:
- Defaults are respected.
What are the different phases of a machine?
A phase of a machine can be identified with Machine.Status.CurrentStatus.Phase. Following are the possible phases of a machine object:
Pending: Machine creation call has succeeded. MCM is waiting for machine to join the cluster.Available: Machine creation call has succeeded. MCM is running without a target cluster and does not wait for the machine to join the cluster.CrashLoopBackOff: Machine creation call has failed. MCM will retry the operation after a minor delay.Running: Machine creation call has succeeded. Machine has joined the cluster successfully and corresponding node doesn’t havenode.gardener.cloud/critical-components-not-readytaint.Unknown: Machine health checks are failing, e.g.,kubelethas stopped posting the status.Failed: Machine health checks have failed for a prolonged time. Hence it is declared failed byMachinecontroller in a rate limited fashion.Failedmachines get replaced immediately.Terminating: Machine is being terminated. Terminating state is set immediately when the deletion is triggered for themachineobject. It also includes time when it’s being drained.
NOTE: No phase means the machine is being created on the cloud-provider.
Below is a simple phase transition diagram:
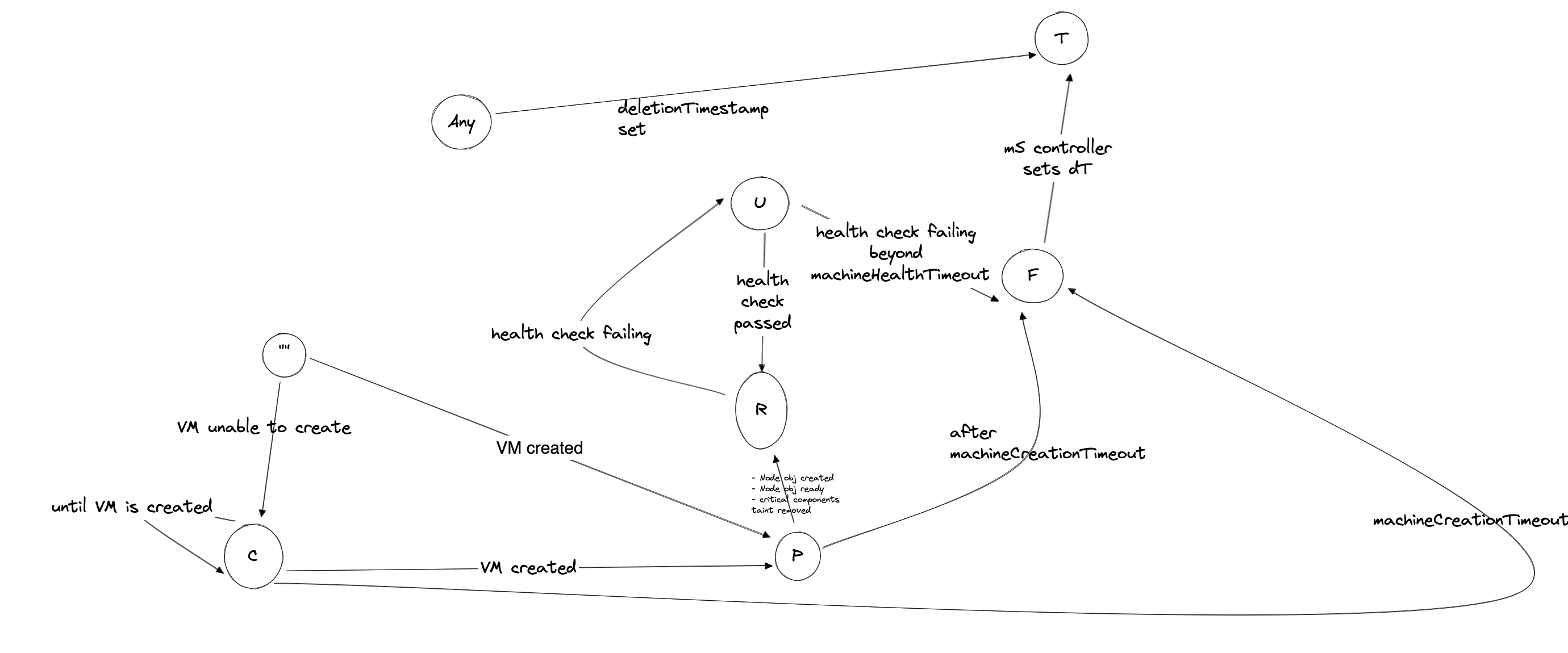
What health checks are performed on a machine?
Health check performed on a machine are:
- Existense of corresponding node obj
- Status of certain user-configurable node conditions.
- These conditions can be specified using the flag
--node-conditionsfor OOT MCM provider or can be specified per machine object. - The default user configurable node conditions can be found here
- These conditions can be specified using the flag
Truestatus ofNodeReadycondition . This condition shows kubelet’s status
If any of the above checks fails , the machine turns to Unknown phase.
How does rate limiting replacement of machine work in MCM? How is it related to meltdown protection?
Currently MCM replaces only 1 Unknown machine at a time per machinedeployment. This means until the particular Unknown machine get terminated and its replacement joins, no other Unknown machine would be removed.
The above is achieved by enabling Machine controller to turn machine from Unknown -> Failed only if the above condition is met. MachineSet controller on the other hand marks Failed machine as Terminating immediately.
One reason for this rate limited replacement was to ensure that in case of network failures , where node’s kubelet can’t reach out to kube-apiserver , all nodes are not removed together i.e. meltdown protection.
In gardener context however, DWD is deployed to deal with this scenario, but to stay protected from corner cases, this mechanism has been introduced in MCM.
NOTE: Rate limiting replacement is not yet configurable
How MCM responds when scale-out/scale-in is done during rolling update of a machinedeployment?
Machinedeployment controller executes the logic of scaling BEFORE logic of rollout. It identifies scaling by comparing the deployment.kubernetes.io/desired-replicas of each machineset under the machinedeployment with machinedeployment’s .spec.replicas. If the difference is found for any machineSet, a scaling event is detected.
- Case
scale-out-> ONLY New machineSet is scaled out - Case
scale-in-> ALL machineSets(new or old) are scaled in , in proportion to their replica count , any leftover is adjusted in the largest machineSet.
During update for scaling event, a machineSet is updated if any of the below is true for it:
.spec.Replicasneeds updatedeployment.kubernetes.io/desired-replicasneeds update
Once scaling is achieved, rollout continues.
How does MCM prioritize the machines for deletion on scale-down of machinedeployment?
There could be many machines under a machinedeployment with different phases, creationTimestamp. When a scale down is triggered, MCM decides to remove the machine using the following logic:
- Machine with least value of
machinepriority.machine.sapcloud.ioannotation is picked up. - If all machines have equal priorities, then following precedence is followed:
- Terminating > Failed > CrashloopBackoff > Unknown > Pending > Available > Running
- If still there is no match, the machine with oldest creation time (.i.e. creationTimestamp) is picked up.
How some unhealthy machines are drained quickly?
If a node is unhealthy for more than the machine-health-timeout specified for the machine-controller, the controller
health-check moves the machine phase to Failed. By default, the machine-health-timeout is 10` minutes.
Failed machines have their deletion timestamp set and the machine then moves to the Terminating phase. The node
drain process is initiated. The drain process is invoked either gracefully or forcefully.
The usual drain process is graceful. Pods are evicted from the node and the drain process waits until any existing
attached volumes are mounted on new node. However, if the node Ready is False or the ReadonlyFilesystem is True
for greater than 5 minutes (non-configurable), then a forceful drain is initiated. In a forceful drain, pods are deleted
and VolumeAttachment objects associated with the old node are also marked for deletion. This is followed by the deletion of the
cloud provider VM associated with the Machine and then finally ending with the Node object deletion.
During the deletion of the VM we only delete the local data disks and boot disks associated with the VM. The disks associated with persistent volumes are left un-touched as their attach/de-detach, mount/unmount processes are handled by k8s attach-detach controller in conjunction with the CSI driver.
Troubleshooting
My machine is stuck in deletion for 1 hr, why?
In most cases, the Machine.Status.LastOperation provides information around why a machine can’t be deleted.
Though following could be the reasons but not limited to:
- Pod/s with misconfigured PDBs block the drain operation. PDBs with
maxUnavailableset to 0, doesn’t allow the eviction of the pods. Hence, drain/eviction is retried tillMachineDrainTimeout. DefaultMachineDrainTimeoutcould be as large as ~2hours. Hence, blocking the machine deletion.- Short term: User can manually delete the pod in the question, with caution.
- Long term: Please set more appropriate PDBs which allow disruption of at least one pod.
- Expired cloud credentials can block the deletion of the machine from infrastructure.
- Cloud provider can’t delete the machine due to internal errors. Such situations are best debugged by using cloud provider specific CLI or cloud console.
My machine is not joining the cluster, why?
In most cases, the Machine.Status.LastOperation provides information around why a machine can’t be created.
It could possibly be debugged with following steps:
- Firstly make sure all the relevant controllers like
kube-controller-manager,cloud-controller-managerare running. - Verify if the machine is actually created in the cloud. User can use the
Machine.Spec.ProviderIdto query the machine in cloud. - A Kubernetes node is generally bootstrapped with the cloud-config. Please verify, if
MachineDeploymentis pointing the correctMachineClass, andMachineClassis pointing to the correctSecret. The secret object contains the actual cloud-config inbase64format which will be used to boot the machine. - User must also check the logs of the MCM pod to understand any broken logical flow of reconciliation.
My rolling update is stuck, why?
The following can be the reason:
- Insufficient capacity for the new instance type the machineClass mentions.
- Old machines are stuck in deletion
- If you are using Gardener for setting up kubernetes cluster, then machine object won’t turn to
Runningstate untilnode-critical-componentsare ready. Refer this for more details.
Developer
How should I test my code before submitting a PR?
Developer can locally setup the MCM using following guide
Developer must also enhance the unit tests related to the incoming changes.
Developer can run the unit test locally by executing:
make test-unitDeveloper can locally run integration tests to ensure basic functionality of MCM is not altered.
I need to change the APIs, what are the recommended steps?
Developer should add/update the API fields at both of the following places:
Once API changes are done, auto-generate the code using following command:
make generate
Please ignore the API-violation errors for now.
How can I update the dependencies of MCM?
MCM uses gomod for depedency management.
Developer should add/udpate depedency in the go.mod file. Please run following command to automatically tidy the dependencies.
make tidy
In the context of Gardener
How can I configure MCM using Shoot resource?
All of the knobs of MCM can be configured by the workers section of the shoot resource.
- Gardener creates a
MachineDeploymentper zone for each worker-pool underworkerssection. workers.dataVolumesallows to attach multiple disks to a machine during creation. Refer the link.workers.machineControllerManagerallows configuration of multiple knobs of theMachineDeploymentfrom the shoot resource.
How is my worker-pool spread across zones?
Shoot resource allows the worker-pool to spread across multiple zones using the field workers.zones. Refer link.
Gardener creates one
MachineDeploymentper zone. EachMachineDeploymentis initiated with the following replica:MachineDeployment.Spec.Replicas = (Workers.Minimum)/(Number of availability zones)
4.5 - Adding Support for a Cloud Provider
Adding support for a new provider
Steps to be followed while implementing a new (hyperscale) provider are mentioned below. This is the easiest way to add new provider support using a blueprint code.
However, you may also develop your machine controller from scratch, which would provide you with more flexibility. First, however, make sure that your custom machine controller adheres to the Machine.Status struct defined in the MachineAPIs. This will make sure the MCM can act with higher-level controllers like MachineSet and MachineDeployment controller. The key is the Machine.Status.CurrentStatus.Phase key that indicates the status of the machine object.
Our strong recommendation would be to follow the steps below. This provides the most flexibility required to support machine management for adding new providers. And if you feel to extend the functionality, feel free to update our machine controller libraries.
Setting up your repository
- Create a new empty repository named
machine-controller-manager-provider-{provider-name}on GitHub username/project. Do not initialize this repository with a README. - Copy the remote repository
URL(HTTPS/SSH) to this repository displayed once you create this repository. - Now, on your local system, create directories as required. {your-github-username} given below could also be {github-project} depending on where you have created the new repository.
mkdir -p $GOPATH/src/github.com/{your-github-username} - Navigate to this created directory.
cd $GOPATH/src/github.com/{your-github-username} - Clone this repository on your local machine.
git clone git@github.com:gardener/machine-controller-manager-provider-sampleprovider.git - Rename the directory from
machine-controller-manager-provider-sampleprovidertomachine-controller-manager-provider-{provider-name}.mv machine-controller-manager-provider-sampleprovider machine-controller-manager-provider-{provider-name} - Navigate into the newly-created directory.
cd machine-controller-manager-provider-{provider-name} - Update the remote
originURL to the newly created repository’s URL you had copied above.git remote set-url origin git@github.com:{your-github-username}/machine-controller-manager-provider-{provider-name}.git - Rename GitHub project from
gardenerto{github-org/your-github-username}wherever you have cloned the repository above. Also, edit all occurrences of the wordsampleproviderto{provider-name}in the code. Then, use the hack script given below to do the same.make rename-project PROJECT_NAME={github-org/your-github-username} PROVIDER_NAME={provider-name} eg: make rename-project PROJECT_NAME=gardener PROVIDER_NAME=AmazonWebServices (or) make rename-project PROJECT_NAME=githubusername PROVIDER_NAME=AWS - Now, commit your changes and push them upstream.
git add -A git commit -m "Renamed SampleProvide to {provider-name}" git push origin master
Code changes required
The contract between the Machine Controller Manager (MCM) and the Machine Controller (MC) AKA driver has been documented here and the machine error codes can be found here. You may refer to them for any queries.
⚠️
- Keep in mind that there should be a unique way to map between machine objects and VMs. This can be done by mapping machine object names with VM-Name/ tags/ other metadata.
- Optionally, there should also be a unique way to map a VM to its machine class object. This can be done by tagging VM objects with tags/resource groups associated with the machine class.
Steps to integrate
- Update the
pkg/provider/apis/provider_spec.gospecification file to reflect the structure of theProviderSpecblob. It typically contains the machine template details in theMachineClassobject. Follow the sample spec provided already in the file. A sample provider specification can be found here. - Fill in the methods described at
pkg/provider/core.goto manage VMs on your cloud provider. Comments are provided above each method to help you fill them up with desiredREQUESTandRESPONSEparameters.- A sample provider implementation for these methods can be found here.
- Fill in the required methods
CreateMachine(), andDeleteMachine()methods. - Optionally fill in methods like
GetMachineStatus(),InitializeMachine,ListMachines(), andGetVolumeIDs(). You may choose to fill these once the working of the required methods seems to be working. GetVolumeIDs()expects VolumeIDs to be decoded from the volumeSpec based on the cloud provider.- There is also an OPTIONAL method
GenerateMachineClassForMigration()that helps in migration of{ProviderSpecific}MachineClasstoMachineClassCR (custom resource). This only makes sense if you have an existing implementation (in-tree) acting on different CRD types. You would like to migrate this. If not, you MUST return an error (machine error UNIMPLEMENTED) to avoid processing this step.
- Perform validation of APIs that you have described and make it a part of your methods as required at each request.
- Write unit tests to make it work with your implementation by running
make test.make test - Tidy the go dependencies.
make tidy - Update the sample YAML files on the
kubernetes/directory to provide sample files through which the working of the machine controller can be tested. - Update
README.mdto reflect any additional changes
Testing your code changes
Make sure $TARGET_KUBECONFIG points to the cluster where you wish to manage machines. Likewise, $CONTROL_NAMESPACE represents the namespaces where MCM is looking for machine CR objects, and $CONTROL_KUBECONFIG points to the cluster that holds these machine CRs.
- On the first terminal running at
$GOPATH/src/github.com/{github-org/your-github-username}/machine-controller-manager-provider-{provider-name},- Run the machine controller (driver) using the command below.
make start
- Run the machine controller (driver) using the command below.
- On the second terminal pointing to
$GOPATH/src/github.com/gardener,- Clone the latest MCM code
git clone git@github.com:gardener/machine-controller-manager.git - Navigate to the newly-created directory.
cd machine-controller-manager - Deploy the required CRDs from the machine-controller-manager repo,
kubectl apply -f kubernetes/crds - Run the machine-controller-manager in the
masterbranchmake start
- Clone the latest MCM code
- On the third terminal pointing to
$GOPATH/src/github.com/{github-org/your-github-username}/machine-controller-manager-provider-{provider-name}- Fill in the object files given below and deploy them as described below.
- Deploy the
machine-classkubectl apply -f kubernetes/machine-class.yaml - Deploy the
kubernetes secretif required.kubectl apply -f kubernetes/secret.yaml - Deploy the
machineobject and make sure it joins the cluster successfully.kubectl apply -f kubernetes/machine.yaml - Once the machine joins, you can test by deploying a machine-deployment.
- Deploy the
machine-deploymentobject and make sure it joins the cluster successfully.kubectl apply -f kubernetes/machine-deployment.yaml - Make sure to delete both the
machineandmachine-deploymentobjects after use.kubectl delete -f kubernetes/machine.yaml kubectl delete -f kubernetes/machine-deployment.yaml
Releasing your docker image
- Make sure you have logged into gcloud/docker using the CLI.
- To release your docker image, run the following.
make release IMAGE_REPOSITORY=<link-to-image-repo>
- A sample kubernetes deploy file can be found at
kubernetes/deployment.yaml. Update the same (with your desired MCM and MC images) to deploy your MCM pod.
4.6 - Deployment
Deploying the Machine Controller Manager into a Kubernetes cluster
As already mentioned, the Machine Controller Manager is designed to run as controller in a Kubernetes cluster. The existing source code can be compiled and tested on a local machine as described in Setting up a local development environment. You can deploy the Machine Controller Manager using the steps described below.
Prepare the cluster
- Connect to the remote kubernetes cluster where you plan to deploy the Machine Controller Manager using the kubectl. Set the environment variable KUBECONFIG to the path of the yaml file containing the cluster info.
- Now, create the required CRDs on the remote cluster using the following command,
$ kubectl apply -f kubernetes/crds
Build the Docker image
⚠️ Modify the
Makefileto refer to your own registry.
- Run the build which generates the binary to
bin/machine-controller-manager
$ make build
- Build docker image from latest compiled binary
$ make docker-image
- Push the last created docker image onto the online docker registry.
$ make push
- Now you can deploy this docker image to your cluster. A sample development file is provided. By default, the deployment manages the cluster it is running in. Optionally, the kubeconfig could also be passed as a flag as described in
/kubernetes/deployment/out-of-tree/deployment.yaml. This is done when you want your controller running outside the cluster to be managed from.
$ kubectl apply -f kubernetes/deployment/out-of-tree/deployment.yaml
- Also deploy the required clusterRole and clusterRoleBindings
$ kubectl apply -f kubernetes/deployment/out-of-tree/clusterrole.yaml
$ kubectl apply -f kubernetes/deployment/out-of-tree/clusterrolebinding.yaml
Configuring optional parameters while deploying
Machine-controller-manager supports several configurable parameters while deploying. Refer to the following lines, to know how each parameter can be configured, and what it’s purpose is for.
Usage
To start using Machine Controller Manager, follow the links given at usage here.
4.7 - Integration Tests
Integration tests
Usage
General setup & configurations
Integration tests for machine-controller-manager-provider-{provider-name} can be executed manually by following below steps.
- Clone the repository
machine-controller-manager-provider-{provider-name}on the local system. - Navigate to
machine-controller-manager-provider-{provider-name}directory and create adevsub-directory in it. - If the tags on instances & associated resources on the provider are of
Stringtype (for example, GCP tags on its instances are of typeStringand not key-value pair) then addTAGS_ARE_STRINGS := truein theMakefileand export it. For GCP this has already been hard coded in theMakefile.
Running the tests
- There is a rule
test-integrationin theMakefileof the provider repository, which can be used to start the integration test:$ make test-integration - This will ask for additional inputs. Most of them are self explanatory except:
- The script assumes that both the control and target clusters are already being created.
- In case of non-gardener setup (control cluster is not a gardener seed), the name of the machineclass must be
test-mc-v1and the value ofproviderSpec.secretRef.nameshould betest-mc-secret. - In case of azure,
TARGET_CLUSTER_NAMEmust be same as the name of the Azure ResourceGroup for the cluster. - If you are deploying the secret manually, a
Secretnamedtest-mc-secret(that contains the provider secret and cloud-config) in thedefaultnamespace of the Control Cluster should be created.
- The controllers log files (
mcm_process.logandmc_process.log) are stored in.ci/controllers-test/logsrepo and can be used later.
Adding Integration Tests for new providers
For a new provider, Running Integration tests works with no changes. But for the orphan resource test cases to work correctly, the provider-specific API calls and the Resource Tracker Interface (RTI) should be implemented. Please check machine-controller-manager-provider-aws for reference.
Extending integration tests
- Update ControllerTests to be extend the testcases for all providers. Common testcases for machine|machineDeployment creation|deletion|scaling are packaged into ControllerTests.
- To extend the provider specfic test cases, the changes should be done in the
machine-controller-manager-provider-{provider-name}repository. For example, to extended the testcases formachine-controller-manager-provider-aws, make changes totest/integration/controller/controller_test.goinside themachine-controller-manager-provider-awsrepository.commonscontains theClusterandClientsetobjects that makes it easy to extend the tests.
4.8 - Local Setup
Preparing the Local Development Setup (Mac OS X)
Conceptionally, the Machine Controller Manager is designed to run in a container within a Pod inside a Kubernetes cluster. For development purposes, you can run the Machine Controller Manager as a Go process on your local machine. This process connects to your remote cluster to manage VMs for that cluster. That means that the Machine Controller Manager runs outside a Kubernetes cluster which requires providing a Kubeconfig in your local filesystem and point the Machine Controller Manager to it when running it (see below).
Although the following installation instructions are for Mac OS X, similar alternate commands could be found for any Linux distribution.
Installing Golang environment
Install the latest version of Golang (at least v1.8.3 is required) by using Homebrew:
$ brew install golang
In order to perform linting on the Go source code, install Golint:
$ go get -u golang.org/x/lint/golint
Installing Docker (Optional)
In case you want to build Docker images for the Machine Controller Manager you have to install Docker itself. We recommend using Docker for Mac OS X which can be downloaded from here.
Setup Docker Hub account (Optional)
Create a Docker hub account at Docker Hub if you don’t already have one.
Local development
⚠️ Before you start developing, please ensure to comply with the following requirements:
- You have understood the principles of Kubernetes, and its components, what their purpose is and how they interact with each other.
- You have understood the architecture of the Machine Controller Manager
The development of the Machine Controller Manager could happen by targeting any cluster. You basically need a Kubernetes cluster running on a set of machines. You just need the Kubeconfig file with the required access permissions attached to it.
Installing the Machine Controller Manager locally
Clone the repository from GitHub.
$ git clone git@github.com:gardener/machine-controller-manager.git
$ cd machine-controller-manager
Prepare the cluster
- Connect to the remote kubernetes cluster where you plan to deploy the Machine Controller Manager using kubectl. Set the environment variable KUBECONFIG to the path of the yaml file containing your cluster info
- Now, create the required CRDs on the remote cluster using the following command,
$ kubectl apply -f kubernetes/crds.yaml
Getting started
Setup and Restore with Gardener
Setup
In gardener access to static kubeconfig files is no longer supported due to security reasons. One needs to generate short-lived (max TTL = 1 day) admin kube configs for target and control clusters. A convenience script/Makefile target has been provided to do the required initial setup which includes:
- Creating a temporary directory where target and control kubeconfigs will be stored.
- Create a request to generate the short lived admin kubeconfigs. These are downloaded and stored in the temporary folder created above.
- In gardener clusters
DWD (Dependency Watchdog)runs as an additional component which can interfere when MCM/CA is scaled down. To prevent that an annotationdependency-watchdog.gardener.cloud/ignore-scalingis added tomachine-controller-managerdeployment which preventsDWDfrom scaling up the deployment replicas. - Scales down
machine-controller-managerdeployment in the control cluster to 0 replica. - Creates the required
.envfile and populates required environment variables which are then used by theMakefilein bothmachine-controller-managerand inmachine-controller-manager-provider-<provider-name>projects. - Copies the generated and downloaded kubeconfig files for the target and control clusters to
machine-controller-manager-provider-<provider-name>project as well.
To do the above you can either invoke make gardener-setup or you can directly invoke the script ./hack/gardener_local_setup.sh. If you invoke the script with -h or --help option then it will give you all CLI options that one can pass.
Restore
Once the testing is over you can invoke a convenience script/Makefile target which does the following:
- Removes all generated admin kubeconfig files from both
machine-controller-managerand inmachine-controller-manager-provider-<provider-name>projects. - Removes the
.envfile that was generated as part of the setup from bothmachine-controller-managerand inmachine-controller-manager-provider-<provider-name>projects. - Scales up
machine-controller-managerdeployment in the control cluster back to 1 replica. - Removes the annotation
dependency-watchdog.gardener.cloud/ignore-scalingthat was added to preventDWDto scale up MCM.
To do the above you can either invoke make gardener-restore or you can directly invoke the script ./hack/gardener_local_restore.sh. If you invoke the script with -h or --help option then it will give you all CLI options that one can pass.
Setup and Restore without Gardener
Setup
If you are not running MCM components in a gardener cluster, then it is assumed that there is not going to be any DWD (Dependency Watchdog) component.
A convenience script/Makefile target has been provided to the required initial setup which includes:
- Copies the provided control and target kubeconfig files to
machine-controller-manager-provider-<provider-name>project. - Scales down
machine-controller-managerdeployment in the control cluster to 0 replica. - Creates the required
.envfile and populates required environment variables which are then used by theMakefilein bothmachine-controller-managerand inmachine-controller-manager-provider-<provider-name>projects.
To do the above you can either invoke make non-gardener-setup or you can directly invoke the script ./hack/non_gardener_local_setup.sh. If you invoke the script with -h or --help option then it will give you all CLI options that one can pass.
Restore
Once the testing is over you can invoke a convenience script/Makefile target which does the following:
- Removes all provided kubeconfig files from both
machine-controller-managerand inmachine-controller-manager-provider-<provider-name>projects. - Removes the
.envfile that was generated as part of the setup from bothmachine-controller-managerand inmachine-controller-manager-provider-<provider-name>projects. - Scales up
machine-controller-managerdeployment in the control cluster back to 1 replica.
To do the above you can either invoke make non-gardener-restore or you can directly invoke the script ./hack/non_gardener_local_restore.sh. If you invoke the script with -h or --help option then it will give you all CLI options that one can pass.
Once the setup is done then you can start the machine-controller-manager as a local process using the following Makefile target:
$ make start
I1227 11:08:19.963638 55523 controllermanager.go:204] Starting shared informers
I1227 11:08:20.766085 55523 controller.go:247] Starting machine-controller-manager
⚠️ The file dev/target-kubeconfig.yaml points to the cluster whose nodes you want to manage. dev/control-kubeconfig.yaml points to the cluster from where you want to manage the nodes from. However, dev/control-kubeconfig.yaml is optional.
The Machine Controller Manager should now be ready to manage the VMs in your kubernetes cluster.
⚠️ This is assuming that your MCM is built to manage machines for any in-tree supported providers. There is a new way to deploy and manage out of tree (external) support for providers whose development can be found here
Testing Machine Classes
To test the creation/deletion of a single instance for one particular machine class you can use the managevm cli. The corresponding INFRASTRUCTURE-machine-class.yaml and the INFRASTRUCTURE-secret.yaml need to be defined upfront. To build and run it
GO111MODULE=on go build -o managevm cmd/machine-controller-manager-cli/main.go
# create machine
./managevm --secret PATH_TO/INFRASTRUCTURE-secret.yaml --machineclass PATH_TO/INFRASTRUCTURE-machine-class.yaml --classkind INFRASTRUCTURE --machinename test
# delete machine
./managevm --secret PATH_TO/INFRASTRUCTURE-secret.yaml --machineclass PATH_TO/INFRASTRUCTURE-machine-class.yaml --classkind INFRASTRUCTURE --machinename test --machineid INFRASTRUCTURE:///REGION/INSTANCE_ID
Usage
To start using Machine Controller Manager, follow the links given at usage here.
4.9 - Machine
Creating/Deleting machines (VM)
Setting up your usage environment
- Follow the steps described here
Important :
Make sure that the
kubernetes/machine_objects/machine.yamlpoints to the same class name as thekubernetes/machine_classes/aws-machine-class.yaml.
Similarly
kubernetes/machine_objects/aws-machine-class.yamlsecret name and namespace should be same as that mentioned inkubernetes/secrets/aws-secret.yaml
Creating machine
- Modify
kubernetes/machine_objects/machine.yamlas per your requirement and create the VM as shown below:
$ kubectl apply -f kubernetes/machine_objects/machine.yaml
You should notice that the Machine Controller Manager has immediately picked up your manifest and started to create a new machine by talking to the cloud provider.
- Check Machine Controller Manager machines in the cluster
$ kubectl get machine
NAME STATUS AGE
test-machine Running 5m
A new machine is created with the name provided in the kubernetes/machine_objects/machine.yaml file.
- After a few minutes (~3 minutes for AWS), you should notice a new node joining the cluster. You can verify this by running:
$ kubectl get nodes
NAME STATUS AGE VERSION
ip-10-250-14-52.eu-east-1.compute.internal. Ready 1m v1.8.0
This shows that a new node has successfully joined the cluster.
Inspect status of machine
To inspect the status of any created machine, run the command given below.
$ kubectl get machine test-machine -o yaml
apiVersion: machine.sapcloud.io/v1alpha1
kind: Machine
metadata:
annotations:
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"machine.sapcloud.io/v1alpha1","kind":"Machine","metadata":{"annotations":{},"labels":{"test-label":"test-label"},"name":"test-machine","namespace":""},"spec":{"class":{"kind":"AWSMachineClass","name":"test-aws"}}}
clusterName: ""
creationTimestamp: 2017-12-27T06:58:21Z
finalizers:
- machine.sapcloud.io/operator
generation: 0
initializers: null
labels:
node: ip-10-250-14-52.eu-east-1.compute.internal
test-label: test-label
name: test-machine
namespace: ""
resourceVersion: "12616948"
selfLink: /apis/machine.sapcloud.io/v1alpha1/test-machine
uid: 535e596c-ead3-11e7-a6c0-828f843e4186
spec:
class:
kind: AWSMachineClass
name: test-aws
providerID: aws:///eu-east-1/i-00bef3f2618ffef23
status:
conditions:
- lastHeartbeatTime: 2017-12-27T07:00:46Z
lastTransitionTime: 2017-12-27T06:59:16Z
message: kubelet has sufficient disk space available
reason: KubeletHasSufficientDisk
status: "False"
type: OutOfDisk
- lastHeartbeatTime: 2017-12-27T07:00:46Z
lastTransitionTime: 2017-12-27T06:59:16Z
message: kubelet has sufficient memory available
reason: KubeletHasSufficientMemory
status: "False"
type: MemoryPressure
- lastHeartbeatTime: 2017-12-27T07:00:46Z
lastTransitionTime: 2017-12-27T06:59:16Z
message: kubelet has no disk pressure
reason: KubeletHasNoDiskPressure
status: "False"
type: DiskPressure
- lastHeartbeatTime: 2017-12-27T07:00:46Z
lastTransitionTime: 2017-12-27T07:00:06Z
message: kubelet is posting ready status
reason: KubeletReady
status: "True"
type: Ready
currentStatus:
lastUpdateTime: 2017-12-27T07:00:06Z
phase: Running
lastOperation:
description: Machine is now ready
lastUpdateTime: 2017-12-27T07:00:06Z
state: Successful
type: Create
node: ip-10-250-14-52.eu-west-1.compute.internal
Delete machine
To delete the VM using the kubernetes/machine_objects/machine.yaml as shown below
$ kubectl delete -f kubernetes/machine_objects/machine.yaml
Now the Machine Controller Manager picks up the manifest immediately and starts to delete the existing VM by talking to the cloud provider. The node should be detached from the cluster in a few minutes (~1min for AWS).
4.10 - Machine Deployment
Maintaining machine replicas using machines-deployments
- Maintaining machine replicas using machines-deployments
Setting up your usage environment
Follow the steps described here
Important ⚠️
Make sure that the
kubernetes/machine_objects/machine-deployment.yamlpoints to the same class name as thekubernetes/machine_classes/aws-machine-class.yaml.
Similarly
kubernetes/machine_classes/aws-machine-class.yamlsecret name and namespace should be same as that mentioned inkubernetes/secrets/aws-secret.yaml
Creating machine-deployment
- Modify
kubernetes/machine_objects/machine-deployment.yamlas per your requirement. Modify the number of replicas to the desired number of machines. Then, create an machine-deployment.
$ kubectl apply -f kubernetes/machine_objects/machine-deployment.yaml
Now the Machine Controller Manager picks up the manifest immediately and starts to create a new machines based on the number of replicas you have provided in the manifest.
- Check Machine Controller Manager machine-deployments in the cluster
$ kubectl get machinedeployment
NAME READY DESIRED UP-TO-DATE AVAILABLE AGE
test-machine-deployment 3 3 3 0 10m
You will notice a new machine-deployment with your given name
- Check Machine Controller Manager machine-sets in the cluster
$ kubectl get machineset
NAME DESIRED CURRENT READY AGE
test-machine-deployment-5bc6dd7c8f 3 3 0 10m
You will notice a new machine-set backing your machine-deployment
- Check Machine Controller Manager machines in the cluster
$ kubectl get machine
NAME STATUS AGE
test-machine-deployment-5bc6dd7c8f-5d24b Pending 5m
test-machine-deployment-5bc6dd7c8f-6mpn4 Pending 5m
test-machine-deployment-5bc6dd7c8f-dpt2q Pending 5m
Now you will notice N (number of replicas specified in the manifest) new machines whose name are prefixed with the machine-deployment object name that you created.
- After a few minutes (~3 minutes for AWS), you would see that new nodes have joined the cluster. You can see this using
$ kubectl get nodes
NAME STATUS AGE VERSION
ip-10-250-20-19.eu-west-1.compute.internal Ready 1m v1.8.0
ip-10-250-27-123.eu-west-1.compute.internal Ready 1m v1.8.0
ip-10-250-31-80.eu-west-1.compute.internal Ready 1m v1.8.0
This shows how new nodes have joined your cluster
Inspect status of machine-deployment
To inspect the status of any created machine-deployment run the command below,
$ kubectl get machinedeployment test-machine-deployment -o yaml
You should get the following output.
apiVersion: machine.sapcloud.io/v1alpha1
kind: MachineDeployment
metadata:
annotations:
deployment.kubernetes.io/revision: "1"
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"machine.sapcloud.io/v1alpha1","kind":"MachineDeployment","metadata":{"annotations":{},"name":"test-machine-deployment","namespace":""},"spec":{"minReadySeconds":200,"replicas":3,"selector":{"matchLabels":{"test-label":"test-label"}},"strategy":{"rollingUpdate":{"maxSurge":1,"maxUnavailable":1},"type":"RollingUpdate"},"template":{"metadata":{"labels":{"test-label":"test-label"}},"spec":{"class":{"kind":"AWSMachineClass","name":"test-aws"}}}}}
clusterName: ""
creationTimestamp: 2017-12-27T08:55:56Z
generation: 0
initializers: null
name: test-machine-deployment
namespace: ""
resourceVersion: "12634168"
selfLink: /apis/machine.sapcloud.io/v1alpha1/test-machine-deployment
uid: c0b488f7-eae3-11e7-a6c0-828f843e4186
spec:
minReadySeconds: 200
replicas: 3
selector:
matchLabels:
test-label: test-label
strategy:
rollingUpdate:
maxSurge: 1
maxUnavailable: 1
type: RollingUpdate
template:
metadata:
creationTimestamp: null
labels:
test-label: test-label
spec:
class:
kind: AWSMachineClass
name: test-aws
status:
availableReplicas: 3
conditions:
- lastTransitionTime: 2017-12-27T08:57:22Z
lastUpdateTime: 2017-12-27T08:57:22Z
message: Deployment has minimum availability.
reason: MinimumReplicasAvailable
status: "True"
type: Available
readyReplicas: 3
replicas: 3
updatedReplicas: 3
Health monitoring
Health monitor is also applied similar to how it’s described for machine-sets
Update your machines
Let us consider the scenario where you wish to update all nodes of your cluster from t2.xlarge machines to m5.xlarge machines. Assume that your current test-aws has its spec.machineType: t2.xlarge and your deployment test-machine-deployment points to this AWSMachineClass.
Inspect existing cluster configuration
- Check Nodes present in the cluster
$ kubectl get nodes
NAME STATUS AGE VERSION
ip-10-250-20-19.eu-west-1.compute.internal Ready 1m v1.8.0
ip-10-250-27-123.eu-west-1.compute.internal Ready 1m v1.8.0
ip-10-250-31-80.eu-west-1.compute.internal Ready 1m v1.8.0
- Check Machine Controller Manager machine-sets in the cluster. You will notice one machine-set backing your machine-deployment
$ kubectl get machineset
NAME DESIRED CURRENT READY AGE
test-machine-deployment-5bc6dd7c8f 3 3 3 10m
- Login to your cloud provider (AWS). In the VM management console, you will find N VMs created of type t2.xlarge.
Perform a rolling update
To update this machine-deployment VMs to m5.xlarge, we would do the following:
- Copy your existing aws-machine-class.yaml
cp kubernetes/machine_classes/aws-machine-class.yaml kubernetes/machine_classes/aws-machine-class-new.yaml
- Modify aws-machine-class-new.yaml, and update its metadata.name: test-aws2 and spec.machineType: m5.xlarge
- Now create this modified MachineClass
kubectl apply -f kubernetes/machine_classes/aws-machine-class-new.yaml
- Edit your existing machine-deployment
kubectl edit machinedeployment test-machine-deployment
- Update from spec.template.spec.class.name: test-aws to spec.template.spec.class.name: test-aws2
Re-check cluster configuration
After a few minutes (~3mins)
- Check nodes present in cluster now. They are different nodes.
$ kubectl get nodes
NAME STATUS AGE VERSION
ip-10-250-11-171.eu-west-1.compute.internal Ready 4m v1.8.0
ip-10-250-17-213.eu-west-1.compute.internal Ready 5m v1.8.0
ip-10-250-31-81.eu-west-1.compute.internal Ready 5m v1.8.0
- Check Machine Controller Manager machine-sets in the cluster. You will notice two machine-sets backing your machine-deployment
$ kubectl get machineset
NAME DESIRED CURRENT READY AGE
test-machine-deployment-5bc6dd7c8f 0 0 0 1h
test-machine-deployment-86ff45cc5 3 3 3 20m
- Login to your cloud provider (AWS). In the VM management console, you will find N VMs created of type t2.xlarge in terminated state, and N new VMs of type m5.xlarge in running state.
This shows how a rolling update of a cluster from nodes with t2.xlarge to m5.xlarge went through.
More variants of updates
- The above demonstration was a simple use case. This could be more complex like - updating the system disk image versions/ kubelet versions/ security patches etc.
- You can also play around with the maxSurge and maxUnavailable fields in machine-deployment.yaml
- You can also change the update strategy from rollingupdate to recreate
Undo an update
- Edit the existing machine-deployment
$ kubectl edit machinedeployment test-machine-deployment
- Edit the deployment to have this new field of spec.rollbackTo.revision: 0 as shown as comments in
kubernetes/machine_objects/machine-deployment.yaml - This will undo your update to the previous version.
Pause an update
- You can also pause the update while update is going on by editing the existing machine-deployment
$ kubectl edit machinedeployment test-machine-deployment
Edit the deployment to have this new field of spec.paused: true as shown as comments in
kubernetes/machine_objects/machine-deployment.yamlThis will pause the rollingUpdate if it’s in process
To resume the update, edit the deployment as mentioned above and remove the field spec.paused: true updated earlier
Delete machine-deployment
- To delete the VM using the
kubernetes/machine_objects/machine-deployment.yaml
$ kubectl delete -f kubernetes/machine_objects/machine-deployment.yaml
The Machine Controller Manager picks up the manifest and starts to delete the existing VMs by talking to the cloud provider. The nodes should be detached from the cluster in a few minutes (~1min for AWS).
4.11 - Machine Error Codes
Machine Error code handling
Notational Conventions
The keywords “MUST”, “MUST NOT”, “REQUIRED”, “SHALL”, “SHALL NOT”, “SHOULD”, “SHOULD NOT”, “RECOMMENDED”, “NOT RECOMMENDED”, “MAY”, and “OPTIONAL” are to be interpreted as described in RFC 2119 (Bradner, S., “Key words for use in RFCs to Indicate Requirement Levels”, BCP 14, RFC 2119, March 1997).
The key words “unspecified”, “undefined”, and “implementation-defined” are to be interpreted as described in the rationale for the C99 standard.
An implementation is not compliant if it fails to satisfy one or more of the MUST, REQUIRED, or SHALL requirements for the protocols it implements. An implementation is compliant if it satisfies all the MUST, REQUIRED, and SHALL requirements for the protocols it implements.
Terminology
| Term | Definition |
|---|---|
| CR | Custom Resource (CR) is defined by a cluster admin using the Kubernetes Custom Resource Definition primitive. |
| VM | A Virtual Machine (VM) provisioned and managed by a provider. It could also refer to a physical machine in case of a bare metal provider. |
| Machine | Machine refers to a VM that is provisioned/managed by MCM. It typically describes the metadata used to store/represent a Virtual Machine |
| Node | Native kubernetes Node object. The objects you get to see when you do a “kubectl get nodes”. Although nodes can be either physical/virtual machines, for the purposes of our discussions it refers to a VM. |
| MCM | Machine Controller Manager (MCM) is the controller used to manage higher level Machine Custom Resource (CR) such as machine-set and machine-deployment CRs. |
| Provider/Driver/MC | Provider (or) Driver (or) Machine Controller (MC) is the driver responsible for managing machine objects present in the cluster from whom it manages these machines. A simple example could be creation/deletion of VM on the provider. |
Pre-requisite
MachineClass Resources
MCM introduces the CRD MachineClass. This is a blueprint for creating machines that join a certain cluster as nodes in a certain role. The provider only works with MachineClass resources that have the structure described here.
ProviderSpec
The MachineClass resource contains a providerSpec field that is passed in the ProviderSpec request field to CMI methods such as CreateMachine. The ProviderSpec can be thought of as a machine template from which the VM specification must be adopted. It can contain key-value pairs of these specs. An example for these key-value pairs are given below.
| Parameter | Mandatory | Type | Description |
|---|---|---|---|
vmPool | Yes | string | VM pool name, e.g. TEST-WOKER-POOL |
size | Yes | string | VM size, e.g. xsmall, small, etc. Each size maps to a number of CPUs and memory size. |
rootFsSize | No | int | Root (/) filesystem size in GB |
tags | Yes | map | Tags to be put on the created VM |
Most of the ProviderSpec fields are not mandatory. If not specified, the provider passes an empty value in the respective Create VM parameter.
The tags can be used to map a VM to its corresponding machine object’s Name
The ProviderSpec is validated by methods that receive it as a request field for presence of all mandatory parameters and tags, and for validity of all parameters.
Secrets
The MachineClass resource also contains a secretRef field that contains a reference to a secret. The keys of this secret are passed in the Secrets request field to CMI methods.
The secret can contain sensitive data such as
cloud-credentialssecret data used to authenticate at the providercloud-initscripts used to initialize a new VM. The cloud-init script is expected to contain scripts to initialize the Kubelet and make it join the cluster.
Identifying Cluster Machines
To implement certain methods, the provider should be able to identify all machines associated with a particular Kubernetes cluster. This can be achieved using one/more of the below mentioned ways:
- Names of VMs created by the provider are prefixed by the cluster ID specified in the ProviderSpec.
- VMs created by the provider are tagged with the special tags like
kubernetes.io/cluster(for the cluster ID) andkubernetes.io/role(for the role), specified in the ProviderSpec. - Mapping
Resource Groupsto individual cluster.
Error Scheme
All provider API calls defined in this spec MUST return a machine error status, which is very similar to standard machine status.
Machine Provider Interface
- The provider MUST have a unique way to map a
machine objectto aVMwhich triggers the deletion for the corresponding VM backing the machine object. - The provider SHOULD have a unique way to map the
ProviderSpecof a machine-class to a uniqueCluster. This avoids deletion of other machines, not backed by the MCM.
CreateMachine
A Provider is REQUIRED to implement this interface method. This interface method will be called by the MCM to provision a new VM on behalf of the requesting machine object.
This call requests the provider to create a VM backing the machine-object.
If VM backing the
Machine.Namealready exists, and is compatible with the specifiedMachineobject in theCreateMachineRequest, the Provider MUST reply0 OKwith the correspondingCreateMachineResponse.The provider can OPTIONALLY make use of the MachineClass supplied in the
MachineClassin theCreateMachineRequestto communicate with the provider.The provider can OPTIONALLY make use of the secrets supplied in the
Secretin theCreateMachineRequestto communicate with the provider.The provider can OPTIONALLY make use of the
Status.LastKnownStatein theMachineobject to decode the state of the VM operation based on the last known state of the VM. This can be useful to restart/continue an operations which are mean’t to be atomic.The provider MUST have a unique way to map a
machine objectto aVM. This could be implicitly provided by the provider by letting you set VM-names (or) could be explicitly specified by the provider using appropriate tags to map the same.This operation SHOULD be idempotent.
The
CreateMachineResponsereturned by this method is expected to returnProviderIDthat uniquely identifys the VM at the provider. This is expected to match with the node.Spec.ProviderID on the node object.NodeNamethat is the expected name of the machine when it joins the cluster. It must match with the node name.LastKnownStateis an OPTIONAL field that can store details of the last known state of the VM. It can be used by future operation calls to determine current infrastucture state. This state is saved on the machine object.
// CreateMachine call is responsible for VM creation on the provider
CreateMachine(context.Context, *CreateMachineRequest) (*CreateMachineResponse, error)
// CreateMachineRequest is the create request for VM creation
type CreateMachineRequest struct {
// Machine object from whom VM is to be created
Machine *v1alpha1.Machine
// MachineClass backing the machine object
MachineClass *v1alpha1.MachineClass
// Secret backing the machineClass object
Secret *corev1.Secret
}
// CreateMachineResponse is the create response for VM creation
type CreateMachineResponse struct {
// ProviderID is the unique identification of the VM at the cloud provider.
// ProviderID typically matches with the node.Spec.ProviderID on the node object.
// Eg: gce://project-name/region/vm-ID
ProviderID string
// NodeName is the name of the node-object registered to kubernetes.
NodeName string
// LastKnownState represents the last state of the VM during an creation/deletion error
LastKnownState string
}
CreateMachine Errors
If the provider is unable to complete the CreateMachine call successfully, it MUST return a non-ok ginterface method code in the machine status. If the conditions defined below are encountered, the provider MUST return the specified machine error code. The MCM MUST implement the specified error recovery behavior when it encounters the machine error code.
| machine Code | Condition | Description | Recovery Behavior | Auto Retry Required |
|---|---|---|---|---|
| 0 OK | Successful | The call was successful in creating/adopting a VM that matches supplied creation request. The CreateMachineResponse is returned with desired values | N | |
| 1 CANCELED | Cancelled | Call was cancelled. Perform any pending clean-up tasks and return the call | N | |
| 2 UNKNOWN | Something went wrong | Not enough information on what went wrong | Retry operation after sometime | Y |
| 3 INVALID_ARGUMENT | Re-check supplied parameters | Re-check the supplied Machine.Name and ProviderSpec. Make sure all parameters are in permitted range of values. Exact issue to be given in .message | Update providerSpec to fix issues. | N |
| 4 DEADLINE_EXCEEDED | Timeout | The call processing exceeded supplied deadline | Retry operation after sometime | Y |
| 6 ALREADY_EXISTS | Already exists but desired parameters doesn’t match | Parameters of the existing VM don’t match the ProviderSpec | Create machine with a different name | N |
| 7 PERMISSION_DENIED | Insufficent permissions | The requestor doesn’t have enough permissions to create an VM and it’s required dependencies | Update requestor permissions to grant the same | N |
| 8 RESOURCE_EXHAUSTED | Resource limits have been reached | The requestor doesn’t have enough resource limits to process this creation request | Enhance resource limits associated with the user/account to process this | N |
| 9 PRECONDITION_FAILED | VM is in inconsistent state | The VM is in a state that is invalid for this operation | Manual intervention might be needed to fix the state of the VM | N |
| 10 ABORTED | Operation is pending | Indicates that there is already an operation pending for the specified machine | Wait until previous pending operation is processed | Y |
| 11 OUT_OF_RANGE | Resources were out of range | The requested number of CPUs, memory size, of FS size in ProviderSpec falls outside of the corresponding valid range | Update request paramaters to request valid resource requests | N |
| 12 UNIMPLEMENTED | Not implemented | Unimplemented indicates operation is not implemented or not supported/enabled in this service. | Retry with an alternate logic or implement this method at the provider. Most methods by default are in this state | N |
| 13 INTERNAL | Major error | Means some invariants expected by underlying system has been broken. If you see one of these errors, something is very broken. | Needs manual intervension to fix this | N |
| 14 UNAVAILABLE | Not Available | Unavailable indicates the service is currently unavailable. | Retry operation after sometime | Y |
| 16 UNAUTHENTICATED | Missing provider credentials | Request does not have valid authentication credentials for the operation | Fix the provider credentials | N |
The status message MUST contain a human readable description of error, if the status code is not OK.
This string MAY be surfaced by MCM to end users.
InitializeMachine
Provider can OPTIONALLY implement this driver call. Else should return a UNIMPLEMENTED status in error.
This interface method will be called by the MCM to initialize a new VM just after creation. This can be used to configure network configuration etc.
- This call requests the provider to initialize a newly created VM backing the machine-object.
- The
InitializeMachineResponsereturned by this method is expected to returnProviderIDthat uniquely identifys the VM at the provider. This is expected to match with thenode.Spec.ProviderIDon the node object.NodeNamethat is the expected name of the machine when it joins the cluster. It must match with the node name.
// InitializeMachine call is responsible for VM initialization on the provider.
InitializeMachine(context.Context, *InitializeMachineRequest) (*InitializeMachineResponse, error)
// InitializeMachineRequest encapsulates params for the VM Initialization operation (Driver.InitializeMachine).
type InitializeMachineRequest struct {
// Machine object representing VM that must be initialized
Machine *v1alpha1.Machine
// MachineClass backing the machine object
MachineClass *v1alpha1.MachineClass
// Secret backing the machineClass object
Secret *corev1.Secret
}
// InitializeMachineResponse is the response for VM instance initialization (Driver.InitializeMachine).
type InitializeMachineResponse struct {
// ProviderID is the unique identification of the VM at the cloud provider.
// ProviderID typically matches with the node.Spec.ProviderID on the node object.
// Eg: gce://project-name/region/vm-ID
ProviderID string
// NodeName is the name of the node-object registered to kubernetes.
NodeName string
}
InitializeMachine Errors
If the provider is unable to complete the InitializeMachine call successfully, it MUST return a non-ok machine code in the machine status.
If the conditions defined below are encountered, the provider MUST return the specified machine error code. The MCM MUST implement the specified error recovery behavior when it encounters the machine error code.
| machine Code | Condition | Description | Recovery Behavior | Auto Retry Required |
|---|---|---|---|---|
| 0 OK | Successful | The call was successful in initializing a VM that matches supplied initialization request. The InitializeMachineResponse is returned with desired values | N | |
| 5 NOT_FOUND | Timeout | VM Instance for Machine isn’t found at provider | Skip Initialization and Continue | N |
| 12 UNIMPLEMENTED | Not implemented | Unimplemented indicates operation is not implemented or not supported/enabled in this service. | Skip Initialization and continue | N |
| 13 INTERNAL | Major error | Means some invariants expected by underlying system has been broken. | Needs investigation and possible intervention to fix this | Y |
| 17 UNINITIALIZED | Failed Initialization | VM Instance could not be initializaed | Initialization is reattempted in next reconcile cycle | Y |
The status message MUST contain a human readable description of error, if the status code is not OK.
This string MAY be surfaced by MCM to end users.
DeleteMachine
A Provider is REQUIRED to implement this driver call. This driver call will be called by the MCM to deprovision/delete/terminate a VM backed by the requesting machine object.
If a VM corresponding to the specified machine-object’s name does not exist or the artifacts associated with the VM do not exist anymore (after deletion), the Provider MUST reply
0 OK.The provider SHALL only act on machines belonging to the cluster-id/cluster-name obtained from the
ProviderSpec.The provider can OPTIONALY make use of the secrets supplied in the
Secretsmap in theDeleteMachineRequestto communicate with the provider.The provider can OPTIONALY make use of the
Spec.ProviderIDmap in theMachineobject.The provider can OPTIONALLY make use of the
Status.LastKnownStatein theMachineobject to decode the state of the VM operation based on the last known state of the VM. This can be useful to restart/continue an operations which are mean’t to be atomic.This operation SHOULD be idempotent.
The provider must have a unique way to map a
machine objectto aVMwhich triggers the deletion for the corresponding VM backing the machine object.The
DeleteMachineResponsereturned by this method is expected to returnLastKnownStateis an OPTIONAL field that can store details of the last known state of the VM. It can be used by future operation calls to determine current infrastucture state. This state is saved on the machine object.
// DeleteMachine call is responsible for VM deletion/termination on the provider
DeleteMachine(context.Context, *DeleteMachineRequest) (*DeleteMachineResponse, error)
// DeleteMachineRequest is the delete request for VM deletion
type DeleteMachineRequest struct {
// Machine object from whom VM is to be deleted
Machine *v1alpha1.Machine
// MachineClass backing the machine object
MachineClass *v1alpha1.MachineClass
// Secret backing the machineClass object
Secret *corev1.Secret
}
// DeleteMachineResponse is the delete response for VM deletion
type DeleteMachineResponse struct {
// LastKnownState represents the last state of the VM during an creation/deletion error
LastKnownState string
}
DeleteMachine Errors
If the provider is unable to complete the DeleteMachine call successfully, it MUST return a non-ok machine code in the machine status. If the conditions defined below are encountered, the provider MUST return the specified machine error code.
| machine Code | Condition | Description | Recovery Behavior | Auto Retry Required |
|---|---|---|---|---|
| 0 OK | Successful | The call was successful in deleting a VM that matches supplied deletion request. | N | |
| 1 CANCELED | Cancelled | Call was cancelled. Perform any pending clean-up tasks and return the call | N | |
| 2 UNKNOWN | Something went wrong | Not enough information on what went wrong | Retry operation after sometime | Y |
| 3 INVALID_ARGUMENT | Re-check supplied parameters | Re-check the supplied Machine.Name and make sure that it is in the desired format and not a blank value. Exact issue to be given in .message | Update Machine.Name to fix issues. | N |
| 4 DEADLINE_EXCEEDED | Timeout | The call processing exceeded supplied deadline | Retry operation after sometime | Y |
| 7 PERMISSION_DENIED | Insufficent permissions | The requestor doesn’t have enough permissions to delete an VM and it’s required dependencies | Update requestor permissions to grant the same | N |
| 9 PRECONDITION_FAILED | VM is in inconsistent state | The VM is in a state that is invalid for this operation | Manual intervention might be needed to fix the state of the VM | N |
| 10 ABORTED | Operation is pending | Indicates that there is already an operation pending for the specified machine | Wait until previous pending operation is processed | Y |
| 12 UNIMPLEMENTED | Not implemented | Unimplemented indicates operation is not implemented or not supported/enabled in this service. | Retry with an alternate logic or implement this method at the provider. Most methods by default are in this state | N |
| 13 INTERNAL | Major error | Means some invariants expected by underlying system has been broken. If you see one of these errors, something is very broken. | Needs manual intervension to fix this | N |
| 14 UNAVAILABLE | Not Available | Unavailable indicates the service is currently unavailable. | Retry operation after sometime | Y |
| 16 UNAUTHENTICATED | Missing provider credentials | Request does not have valid authentication credentials for the operation | Fix the provider credentials | N |
The status message MUST contain a human readable description of error, if the status code is not OK.
This string MAY be surfaced by MCM to end users.
GetMachineStatus
A Provider can OPTIONALLY implement this driver call. Else should return a UNIMPLEMENTED status in error.
This call will be invoked by the MC to get the status of a machine.
This optional driver call helps in optimizing the working of the provider by avoiding unwanted calls to CreateMachine() and DeleteMachine().
- If a VM corresponding to the specified machine object’s
Machine.Nameexists on provider theGetMachineStatusResponsefields are to be filled similar to theCreateMachineResponse. - The provider SHALL only act on machines belonging to the cluster-id/cluster-name obtained from the
ProviderSpec. - The provider can OPTIONALY make use of the secrets supplied in the
Secretsmap in theGetMachineStatusRequestto communicate with the provider. - The provider can OPTIONALY make use of the VM unique ID (returned by the provider on machine creation) passed in the
ProviderIDmap in theGetMachineStatusRequest. - This operation MUST be idempotent.
// GetMachineStatus call get's the status of the VM backing the machine object on the provider
GetMachineStatus(context.Context, *GetMachineStatusRequest) (*GetMachineStatusResponse, error)
// GetMachineStatusRequest is the get request for VM info
type GetMachineStatusRequest struct {
// Machine object from whom VM status is to be fetched
Machine *v1alpha1.Machine
// MachineClass backing the machine object
MachineClass *v1alpha1.MachineClass
// Secret backing the machineClass object
Secret *corev1.Secret
}
// GetMachineStatusResponse is the get response for VM info
type GetMachineStatusResponse struct {
// ProviderID is the unique identification of the VM at the cloud provider.
// ProviderID typically matches with the node.Spec.ProviderID on the node object.
// Eg: gce://project-name/region/vm-ID
ProviderID string
// NodeName is the name of the node-object registered to kubernetes.
NodeName string
}
GetMachineStatus Errors
If the provider is unable to complete the GetMachineStatus call successfully, it MUST return a non-ok machine code in the machine status. If the conditions defined below are encountered, the provider MUST return the specified machine error code.
| machine Code | Condition | Description | Recovery Behavior | Auto Retry Required |
|---|---|---|---|---|
| 0 OK | Successful | The call was successful in getting machine details for given machine Machine.Name | N | |
| 1 CANCELED | Cancelled | Call was cancelled. Perform any pending clean-up tasks and return the call | N | |
| 2 UNKNOWN | Something went wrong | Not enough information on what went wrong | Retry operation after sometime | Y |
| 3 INVALID_ARGUMENT | Re-check supplied parameters | Re-check the supplied Machine.Name and make sure that it is in the desired format and not a blank value. Exact issue to be given in .message | Update Machine.Name to fix issues. | N |
| 4 DEADLINE_EXCEEDED | Timeout | The call processing exceeded supplied deadline | Retry operation after sometime | Y |
| 5 NOT_FOUND | Machine isn’t found at provider | The machine could not be found at provider | Not required | N |
| 7 PERMISSION_DENIED | Insufficent permissions | The requestor doesn’t have enough permissions to get details for the VM and it’s required dependencies | Update requestor permissions to grant the same | N |
| 9 PRECONDITION_FAILED | VM is in inconsistent state | The VM is in a state that is invalid for this operation | Manual intervention might be needed to fix the state of the VM | N |
| 11 OUT_OF_RANGE | Multiple VMs found | Multiple VMs found with matching machine object names | Orphan VM handler to cleanup orphan VMs / Manual intervention maybe required if orphan VM handler isn’t enabled. | Y |
| 12 UNIMPLEMENTED | Not implemented | Unimplemented indicates operation is not implemented or not supported/enabled in this service. | Retry with an alternate logic or implement this method at the provider. Most methods by default are in this state | N |
| 13 INTERNAL | Major error | Means some invariants expected by underlying system has been broken. If you see one of these errors, something is very broken. | Needs manual intervension to fix this | N |
| 14 UNAVAILABLE | Not Available | Unavailable indicates the service is currently unavailable. | Retry operation after sometime | Y |
| 16 UNAUTHENTICATED | Missing provider credentials | Request does not have valid authentication credentials for the operation | Fix the provider credentials | N |
| 17 UNINITIALIZED | Failed Initialization | VM Instance could not be initializaed | Initialization is reattempted in next reconcile cycle | N |
The status message MUST contain a human readable description of error, if the status code is not OK.
This string MAY be surfaced by MCM to end users.
ListMachines
A Provider can OPTIONALLY implement this driver call. Else should return a UNIMPLEMENTED status in error.
The Provider SHALL return the information about all the machines associated with the MachineClass.
Make sure to use appropriate filters to achieve the same to avoid data transfer overheads.
This optional driver call helps in cleaning up orphan VMs present in the cluster. If not implemented, any orphan VM that might have been created incorrectly by the MCM/Provider (due to bugs in code/infra) might require manual clean up.
- If the Provider succeeded in returning a list of
Machine.Namewith their correspondingProviderID, then return0 OK. - The
ListMachineResponsecontains a map ofMachineListwhose- Key is expected to contain the
ProviderID& - Value is expected to contain the
Machine.Namecorresponding to it’s kubernetes machine CR object
- Key is expected to contain the
- The provider can OPTIONALY make use of the secrets supplied in the
Secretsmap in theListMachinesRequestto communicate with the provider.
// ListMachines lists all the machines that might have been created by the supplied machineClass
ListMachines(context.Context, *ListMachinesRequest) (*ListMachinesResponse, error)
// ListMachinesRequest is the request object to get a list of VMs belonging to a machineClass
type ListMachinesRequest struct {
// MachineClass object
MachineClass *v1alpha1.MachineClass
// Secret backing the machineClass object
Secret *corev1.Secret
}
// ListMachinesResponse is the response object of the list of VMs belonging to a machineClass
type ListMachinesResponse struct {
// MachineList is the map of list of machines. Format for the map should be <ProviderID, MachineName>.
MachineList map[string]string
}
ListMachines Errors
If the provider is unable to complete the ListMachines call successfully, it MUST return a non-ok machine code in the machine status. If the conditions defined below are encountered, the provider MUST return the specified machine error code. The MCM MUST implement the specified error recovery behavior when it encounters the machine error code.
| machine Code | Condition | Description | Recovery Behavior | Auto Retry Required |
|---|---|---|---|---|
| 0 OK | Successful | The call for listing all VMs associated with ProviderSpec was successful. | N | |
| 1 CANCELED | Cancelled | Call was cancelled. Perform any pending clean-up tasks and return the call | N | |
| 2 UNKNOWN | Something went wrong | Not enough information on what went wrong | Retry operation after sometime | Y |
| 3 INVALID_ARGUMENT | Re-check supplied parameters | Re-check the supplied ProviderSpec and make sure that all required fields are present in their desired value format. Exact issue to be given in .message | Update ProviderSpec to fix issues. | N |
| 4 DEADLINE_EXCEEDED | Timeout | The call processing exceeded supplied deadline | Retry operation after sometime | Y |
| 7 PERMISSION_DENIED | Insufficent permissions | The requestor doesn’t have enough permissions to list VMs and it’s required dependencies | Update requestor permissions to grant the same | N |
| 12 UNIMPLEMENTED | Not implemented | Unimplemented indicates operation is not implemented or not supported/enabled in this service. | Retry with an alternate logic or implement this method at the provider. Most methods by default are in this state | N |
| 13 INTERNAL | Major error | Means some invariants expected by underlying system has been broken. If you see one of these errors, something is very broken. | Needs manual intervension to fix this | N |
| 14 UNAVAILABLE | Not Available | Unavailable indicates the service is currently unavailable. | Retry operation after sometime | Y |
| 16 UNAUTHENTICATED | Missing provider credentials | Request does not have valid authentication credentials for the operation | Fix the provider credentials | N |
The status message MUST contain a human readable description of error, if the status code is not OK.
This string MAY be surfaced by MCM to end users.
GetVolumeIDs
A Provider can OPTIONALLY implement this driver call. Else should return a UNIMPLEMENTED status in error.
This driver call will be called by the MCM to get the VolumeIDs for the list of PersistentVolumes (PVs) supplied.
This OPTIONAL (but recommended) driver call helps in serailzied eviction of pods with PVs while draining of machines. This implies applications backed by PVs would be evicted one by one, leading to shorter application downtimes.
- On succesful returnal of a list of
Volume-IDsfor all suppliedPVSpecs, the Provider MUST reply0 OK. - The
GetVolumeIDsResponseis expected to return a repeated list ofstringsconsisting of theVolumeIDsforPVSpecthat could be extracted. - If for any
PVthe Provider wasn’t able to identify theVolume-ID, the provider MAY chose to ignore it and return theVolume-IDsfor the rest of thePVsfor whom theVolume-IDwas found. - Getting the
VolumeIDfrom thePVSpecdepends on the Cloud-provider. You can extract this information by parsing thePVSpecbased on theProviderType - This operation MUST be idempotent.
// GetVolumeIDsRequest is the request object to get a list of VolumeIDs for a PVSpec
type GetVolumeIDsRequest struct {
// PVSpecsList is a list of PV specs for whom volume-IDs are required
// Plugin should parse this raw data into pre-defined list of PVSpecs
PVSpecs []*corev1.PersistentVolumeSpec
}
// GetVolumeIDsResponse is the response object of the list of VolumeIDs for a PVSpec
type GetVolumeIDsResponse struct {
// VolumeIDs is a list of VolumeIDs.
VolumeIDs []string
}
GetVolumeIDs Errors
| machine Code | Condition | Description | Recovery Behavior | Auto Retry Required |
|---|---|---|---|---|
| 0 OK | Successful | The call getting list of VolumeIDs for the list of PersistentVolumes was successful. | N | |
| 1 CANCELED | Cancelled | Call was cancelled. Perform any pending clean-up tasks and return the call | N | |
| 2 UNKNOWN | Something went wrong | Not enough information on what went wrong | Retry operation after sometime | Y |
| 3 INVALID_ARGUMENT | Re-check supplied parameters | Re-check the supplied PVSpecList and make sure that it is in the desired format. Exact issue to be given in .message | Update PVSpecList to fix issues. | N |
| 4 DEADLINE_EXCEEDED | Timeout | The call processing exceeded supplied deadline | Retry operation after sometime | Y |
| 12 UNIMPLEMENTED | Not implemented | Unimplemented indicates operation is not implemented or not supported/enabled in this service. | Retry with an alternate logic or implement this method at the provider. Most methods by default are in this state | N |
| 13 INTERNAL | Major error | Means some invariants expected by underlying system has been broken. If you see one of these errors, something is very broken. | Needs manual intervension to fix this | N |
| 14 UNAVAILABLE | Not Available | Unavailable indicates the service is currently unavailable. | Retry operation after sometime | Y |
The status message MUST contain a human readable description of error, if the status code is not OK.
This string MAY be surfaced by MCM to end users.
GenerateMachineClassForMigration
A Provider SHOULD implement this driver call, else it MUST return a UNIMPLEMENTED status in error.
This driver call will be called by the Machine Controller to try to perform a machineClass migration for an unknown machineClass Kind. This helps in migration of one kind of machineClass to another kind. For instance an machineClass custom resource of AWSMachineClass to MachineClass.
- On successful generation of machine class the Provider MUST reply
0 OK(or)nilerror. GenerateMachineClassForMigrationRequestexpects the provider-specific machine class (eg. AWSMachineClass) to be supplied as theProviderSpecificMachineClass. The provider is responsible for unmarshalling the golang struct. It also passes a reference to an existingMachineClassobject.- The provider is expected to fill in this
MachineClassobject based on the conversions. - An optional
ClassSpeccontaining thetype ClassSpec structis also provided to decode the provider info. GenerateMachineClassForMigrationis only responsible for filling up the passedMachineClassobject.- The task of creating the new
CRof the new kind (MachineClass) with the same name as the previous one and also annotating the old machineClass CR with a migrated annotation and migrating existing references is done by the calling library implicitly. - This operation MUST be idempotent.
// GenerateMachineClassForMigrationRequest is the request for generating the generic machineClass
// for the provider specific machine class
type GenerateMachineClassForMigrationRequest struct {
// ProviderSpecificMachineClass is provider specfic machine class object.
// E.g. AWSMachineClass
ProviderSpecificMachineClass interface{}
// MachineClass is the machine class object generated that is to be filled up
MachineClass *v1alpha1.MachineClass
// ClassSpec contains the class spec object to determine the machineClass kind
ClassSpec *v1alpha1.ClassSpec
}
// GenerateMachineClassForMigrationResponse is the response for generating the generic machineClass
// for the provider specific machine class
type GenerateMachineClassForMigrationResponse struct{}
MigrateMachineClass Errors
| machine Code | Condition | Description | Recovery Behavior | Auto Retry Required |
|---|---|---|---|---|
| 0 OK | Successful | Migration of provider specific machine class was successful | Machine reconcilation is retried once the new class has been created | Y |
| 12 UNIMPLEMENTED | Not implemented | Unimplemented indicates operation is not implemented or not supported/enabled in this provider. | None | N |
| 13 INTERNAL | Major error | Means some invariants expected by underlying system has been broken. If you see one of these errors, something is very broken. | Might need manual intervension to fix this | Y |
The status message MUST contain a human readable description of error, if the status code is not OK.
This string MAY be surfaced by MCM to end users.
Configuration and Operation
Supervised Lifecycle Management
- For Providers packaged in software form:
- Provider Packages SHOULD use a well-documented container image format (e.g., Docker, OCI).
- The chosen package image format MAY expose configurable Provider properties as environment variables, unless otherwise indicated in the section below. Variables so exposed SHOULD be assigned default values in the image manifest.
- A Provider Supervisor MAY programmatically evaluate or otherwise scan a Provider Package’s image manifest in order to discover configurable environment variables.
- A Provider SHALL NOT assume that an operator or Provider Supervisor will scan an image manifest for environment variables.
Environment Variables
- Variables defined by this specification SHALL be identifiable by their
MC_name prefix. - Configuration properties not defined by the MC specification SHALL NOT use the same
MC_name prefix; this prefix is reserved for common configuration properties defined by the MC specification. - The Provider Supervisor SHOULD supply all RECOMMENDED MC environment variables to a Provider.
- The Provider Supervisor SHALL supply all REQUIRED MC environment variables to a Provider.
Logging
- Providers SHOULD generate log messages to ONLY standard output and/or standard error.
- In this case the Provider Supervisor SHALL assume responsibility for all log lifecycle management.
- Provider implementations that deviate from the above recommendation SHALL clearly and unambiguously document the following:
- Logging configuration flags and/or variables, including working sample configurations.
- Default log destination(s) (where do the logs go if no configuration is specified?)
- Log lifecycle management ownership and related guidance (size limits, rate limits, rolling, archiving, expunging, etc.) applicable to the logging mechanism embedded within the Provider.
- Providers SHOULD NOT write potentially sensitive data to logs (e.g. secrets).
Available Services
- Provider Packages MAY support all or a subset of CMI services; service combinations MAY be configurable at runtime by the Provider Supervisor.
- This specification does not dictate the mechanism by which mode of operation MUST be discovered, and instead places that burden upon the VM Provider.
- Misconfigured provider software SHOULD fail-fast with an OS-appropriate error code.
Linux Capabilities
- Providers SHOULD clearly document any additionally required capabilities and/or security context.
Cgroup Isolation
- A Provider MAY be constrained by cgroups.
Resource Requirements
- VM Providers SHOULD unambiguously document all of a Provider’s resource requirements.
Deploying
- Recommended: The MCM and Provider are typically expected to run as two containers inside a common
Pod. - However, for the security reasons they could execute on seperate Pods provided they have a secure way to exchange data between them.
4.12 - Machine Set
Maintaining machine replicas using machines-sets
Setting up your usage environment
- Follow the steps described here
Important ⚠️
Make sure that the
kubernetes/machines_objects/machine-set.yamlpoints to the same class name as thekubernetes/machine_classes/aws-machine-class.yaml.
Similarly
kubernetes/machine_classes/aws-machine-class.yamlsecret name and namespace should be same as that mentioned inkubernetes/secrets/aws-secret.yaml
Creating machine-set
- Modify
kubernetes/machine_objects/machine-set.yamlas per your requirement. You can modify the number of replicas to the desired number of machines. Then, create an machine-set:
$ kubectl apply -f kubernetes/machine_objects/machine-set.yaml
You should notice that the Machine Controller Manager has immediately picked up your manifest and started to create a new machines based on the number of replicas you have provided in the manifest.
- Check Machine Controller Manager machine-sets in the cluster
$ kubectl get machineset
NAME DESIRED CURRENT READY AGE
test-machine-set 3 3 0 1m
You will see a new machine-set with your given name
- Check Machine Controller Manager machines in the cluster:
$ kubectl get machine
NAME STATUS AGE
test-machine-set-b57zs Pending 5m
test-machine-set-c4bg8 Pending 5m
test-machine-set-kvskg Pending 5m
Now you will see N (number of replicas specified in the manifest) new machines whose names are prefixed with the machine-set object name that you created.
- After a few minutes (~3 minutes for AWS), you should notice new nodes joining the cluster. You can verify this by running:
$ kubectl get nodes
NAME STATUS AGE VERSION
ip-10-250-0-234.eu-west-1.compute.internal Ready 3m v1.8.0
ip-10-250-15-98.eu-west-1.compute.internal Ready 3m v1.8.0
ip-10-250-6-21.eu-west-1.compute.internal Ready 2m v1.8.0
This shows how new nodes have joined your cluster
Inspect status of machine-set
- To inspect the status of any created machine-set run the following command:
$ kubectl get machineset test-machine-set -o yaml
apiVersion: machine.sapcloud.io/v1alpha1
kind: MachineSet
metadata:
annotations:
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"machine.sapcloud.io/v1alpha1","kind":"MachineSet","metadata":{"annotations":{},"name":"test-machine-set","namespace":"","test-label":"test-label"},"spec":{"minReadySeconds":200,"replicas":3,"selector":{"matchLabels":{"test-label":"test-label"}},"template":{"metadata":{"labels":{"test-label":"test-label"}},"spec":{"class":{"kind":"AWSMachineClass","name":"test-aws"}}}}}
clusterName: ""
creationTimestamp: 2017-12-27T08:37:42Z
finalizers:
- machine.sapcloud.io/operator
generation: 0
initializers: null
name: test-machine-set
namespace: ""
resourceVersion: "12630893"
selfLink: /apis/machine.sapcloud.io/v1alpha1/test-machine-set
uid: 3469faaa-eae1-11e7-a6c0-828f843e4186
spec:
machineClass: {}
minReadySeconds: 200
replicas: 3
selector:
matchLabels:
test-label: test-label
template:
metadata:
creationTimestamp: null
labels:
test-label: test-label
spec:
class:
kind: AWSMachineClass
name: test-aws
status:
availableReplicas: 3
fullyLabeledReplicas: 3
machineSetCondition: null
lastOperation:
lastUpdateTime: null
observedGeneration: 0
readyReplicas: 3
replicas: 3
Health monitoring
- If you try to delete/terminate any of the machines backing the machine-set by either talking to the Machine Controller Manager or from the cloud provider, the Machine Controller Manager recreates a matching healthy machine to replace the deleted machine.
- Similarly, if any of your machines are unreachable or in an unhealthy state (kubelet not ready / disk pressure) for longer than the configured timeout (~ 5mins), the Machine Controller Manager recreates the nodes to replace the unhealthy nodes.
Delete machine-set
- To delete the VM using the
kubernetes/machine_objects/machine-set.yaml:
$ kubectl delete -f kubernetes/machine-set.yaml
Now the Machine Controller Manager has immediately picked up your manifest and started to delete the existing VMs by talking to the cloud provider. Your nodes should be detached from the cluster in a few minutes (~1min for AWS).
4.13 - Prerequisite
Setting up the usage environment
Important ⚠️
All paths are relative to the root location of this project repository.
Run the Machine Controller Manager either as described in Setting up a local development environment or Deploying the Machine Controller Manager into a Kubernetes cluster.
Make sure that the following steps are run before managing machines/ machine-sets/ machine-deploys.
Set KUBECONFIG
Using the existing Kubeconfig, open another Terminal panel/window with the KUBECONFIG environment variable pointing to this Kubeconfig file as shown below,
$ export KUBECONFIG=<PATH_TO_REPO>/dev/kubeconfig.yaml
Replace provider credentials and desired VM configurations
Open kubernetes/machine_classes/aws-machine-class.yaml and replace required values there with the desired VM configurations.
Similarily open kubernetes/secrets/aws-secret.yaml and replace - userData, providerAccessKeyId, providerSecretAccessKey with base64 encoded values of cloudconfig file, AWS access key id, and AWS secret access key respectively. Use the following command to get the base64 encoded value of your details
$ echo "sample-cloud-config" | base64
base64-encoded-cloud-config
Do the same for your access key id and secret access key.
Deploy required CRDs and Objects
Create all the required CRDs in the cluster using kubernetes/crds.yaml
$ kubectl apply -f kubernetes/crds.yaml
Create the class template that will be used as an machine template to create VMs using kubernetes/machine_classes/aws-machine-class.yaml
$ kubectl apply -f kubernetes/machine_classes/aws-machine-class.yaml
Create the secret used for the cloud credentials and cloudconfig using kubernetes/secrets/aws-secret.yaml
$ kubectl apply -f kubernetes/secrets/aws-secret.yaml
Check current cluster state
Get to know the current cluster state using the following commands,
- Checking aws-machine-class in the cluster
$ kubectl get awsmachineclass
NAME MACHINE TYPE AMI AGE
test-aws t2.large ami-123456 5m
- Checking kubernetes secrets in the cluster
$ kubectl get secret
NAME TYPE DATA AGE
test-secret Opaque 3 21h
- Checking kubernetes nodes in the cluster
$ kubectl get nodes
Lists the default set of nodes attached to your cluster
- Checking Machine Controller Manager machines in the cluster
$ kubectl get machine
No resources found.
- Checking Machine Controller Manager machine-sets in the cluster
$ kubectl get machineset
No resources found.
- Checking Machine Controller Manager machine-deploys in the cluster
$ kubectl get machinedeployment
No resources found.
4.14 - Testing And Dependencies
Dependency management
We use golang modules to manage golang dependencies. In order to add a new package dependency to the project, you can perform go get <PACKAGE>@<VERSION> or edit the go.mod file and append the package along with the version you want to use.
Updating dependencies
The Makefile contains a rule called tidy which performs go mod tidy.
go mod tidy makes sure go.mod matches the source code in the module. It adds any missing modules necessary to build the current module’s packages and dependencies, and it removes unused modules that don’t provide any relevant packages.
$ make tidy
The dependencies are installed into the go mod cache folder.
⚠️ Make sure you test the code after you have updated the dependencies!
5 - Network Problem Detector
Network Problem Detector
The Network Problem Detector performs network-related periodic checks between all nodes of a Kubernetes cluster, to its Kube API server and/or external endpoints. Checks are performed using TCP connections, HTTPS GET requests, DNS lookups (UDP), or Ping (ICMP).
Architecture
The Network Problem Detector (NWPD) consists of two daemon sets and a separate controller.
- one daemon set on the cluster network running a first set of agents on all worker nodes
- another daemon set on the host network running a second set of agents on all worker node
- the controller watches for changes on nodes and agent pods and updates the cluster config consumed by the agents.
A agent pod performs checks periodically as defined by the configuration in agent config ConfigMap.
The agents need to know about all nodes and agent pods on the cluster network for checking node-to-node communication.
But they don’t communicate with the kube apiserver to watch for resources.
Instead they rely on the information provided by the cluster config ConfigMap
which is mounted as a volume in the pod. This ConfigMap is updated by the NWPD controller, which watches for changes on
nodes and pods in the kube-system namespace. As soon as a kubelet discovers these changes, the agents see them as a file change.
The results of the checks are stored locally on the node filesystem for later inspection with the nwpdcli command line tool.
Additionally they are also exposed as metrics for scrapping by Prometheus.
By enabling the K8s exporter, the agents periodically patch the node conditions ClusterNetworkProblem and HostNetworkProblem in
the status of the node resources. If checks are failing, a summarising event is created too.
The K8s exporter is the only part of the agent which talks to the kube-apiserver.

Note: When the NWPD is deployed by the gardener-extension-shoot-networking-problemdetector, the NWPD controller is deployed in the shoot control plane.
Deployment
Get Started: Adhoc stand-alone deployment
To get started, the Network Problem Detector is deployed without integration with other tools.
Side remark:
This is the fatest way to get started with NWPD. In a productive environment, you may prefer to scrap the check results using Prometheus from metrics HTTP endpoints exposed by the agent pods. You may still follow this stand-alone installation, but you will need additional configuration on the Prometheus side which is not covered here. For more details see Access check results by Prometheus metrics below.
Here we rely on the local collection created by each agent on the node file system. This collection keeps the check results for the last several hours before they are garbage collected.
Follow these steps to deploy NWPD to a Kubernetes cluster:
Checkout the latest release and build the
nwpdcliwithmake build-localSet the
KUBECONFIGenvironment variable to the kubeconfig of the clusterApply the two daemon sets (one for the host network, one for the pod network) with
./nwpdcli deploy agentThis step will also provide a default configuration with jobs for the daemon sets on node and pod networks. See below for more details.
Note: Run
./nwpdcli deploy agent --helpto see more options.To enable automatic update of the configuration on changes of nodes and pod endpoints of the pod network daemon set, run the controller in a second shell with
./nwpdcli run-controllerAlternatively, install the agent controller with
./nwpdcli deploy controllerCollect the observations from all nodes with
./nwpdcli collectAggregate the observations in text or SVG form
./nwpdcli aggr --minutes 10 --svg-output aggr.html open aggr.html # to open the html on Mac OSYour may apply filters on time window, source, destination or job ID to restrict the aggregation. See
./nwpdcli aggr --helpfor more details.Optional: Repeat steps 5. and 6. anytime
Drill down with query for specific observations
If you need to drill down to specific observations, you may use
./nwpdcli query --helpRemove daemon sets with
./nwpdcli deploy agent --deleteOptional: Remove controller deployment with
./nwpdcli deploy controller --delete
Deployment in a Gardener landscape
The Network Problem Detector can be deployed automatically in a Gardener landscape. Please see project gardener-extension-shoot-networking-problemdetector for more details.
In this case, the check results are available as Prometheus metrics and can be accessed by a predefined Grafana dashboard.
Access check results by Prometheus metrics
Two metrics are exposed.
nwpd_aggregated_observationsThis is a counter vector with the total count of an observation (result of a check) and has these labels:src: name of node the checking agent is runningdest: name of the destination node or endpointjobid: job id of the job definitionstatus: result of the check, eitherokorfailed
nwpd_aggregated_observations_latency_secsThis is a gauge vector with the duration of the last successful observation in seconds and has these labels:src: name of node the checking agent is runningdest: name of the destination node or endpointjobid: job id of the job definition
Default Configuration of Check Jobs
Checks are defined as jobs using virtual command lines. These command lines are just Go routines executed periodically from the agent running in the pods of the two daemon sets. There are two daemon sets. One running in the host network (i.e. using the host network in the pod), the other one running in the cluster (=pod) network.
Default configuration
To examine the current default configuration, run the command
./nwpdcli deploy print-default-config
Job types
checkTCPPort [--period <duration>] [--scale-period] [--endpoints <host1:ip1:port1>,<host2:ip2:port2>,...] [--endpoints-of-pod-ds] [--node-port <port>] [--endpoint-internal-kube-apiserver] [--endpoint-external-kube-apiserver]Tries to open a connection to the given
IP:port. There are multipe variants:- using an explicit list of endpoints with
--endpoints - using the known pod endpoints of the pod network daemon set
- using a node port on all known nodes
- the cluster internal address of the kube-apiserver (IP address of
kubernetes.default.svc.cluster.local) - the external address of the kube-apiserver
The checks run in a robin round fashion after an initial random shuffle. The global default period between two checks can overwritten with the
--periodoption. With--scale-periodthe period length is increased by a factorsqrt(<number-of-nodes>)to reduce the number of checks per node.Note that known nodes and pod endpoints are only updated by the controller. Changes are applied as soon as the changed config maps are discovered by the kubelets. This typically happens within a minute.
- using an explicit list of endpoints with
checkHTTPSGet [--period <duration>] [--scale-period] [--endpoints <host1[:port1]>,<host2[:port2]>,...] [--endpoint-internal-kube-apiserver] [--endpoint-external-kube-apiserver]Tries to open a connection to the given
IP:port. There are multipe variants:- using an explicit list of endpoints with
--endpoints - the cluster internal address of the kube-apiserver
- the external address of the kube-apiserver
The checks run in a robin round fashion after an inital random shuffle. The global default period between two checks can overwritten with the
--periodoption. With--scale-periodthe period length is increased by a factorsqrt(<number-of-nodes>)to reduce the number of checks per node.- using an explicit list of endpoints with
nslookup [--period <duration>] [--scale-period] [--names host1,host2,...] [--name-internal-kube-apiserver"] [--name-external-kube-apiserver]Looks up hosts using the local resolver of the pod or the node (for agents running in the host network).
pingHost [--period <duration>] [--scale-period] [--hosts <host1:ip1>,<host2:ip2>,...]Robin round ping to all nodes or the provided host list. The node or host list is shuffled randomly on start. The global default period between two pings can overwritten with the
--periodoption.The pod needs
NET_ADMINcapabilities to be allowed to perform pings.
Default jobs for the daemon set on the host network
| Job ID | Job Type | Description |
|---|---|---|
https-n2api-ext | checkHTTPSGet | HTTPS Get check from all pods of the daemon set of the host network to the external address of the Kube API server. |
nslookup-n | nslookup | DNS Lookup of IP addresses for the domain name europe-docker.pkg.dev, and external name of Kube API server. |
tcp-n2api-ext | checkTCPPort | TCP connection check from all pods of the daemon set of the host network to the external address of the Kube API server. |
tcp-n2api-int | checkTCPPort | TCP connection check from all pods of the daemon set of the host network to the internal address of the Kube API server. |
tcp-n2n | checkTCPPort | TCP connection check from all pods of the daemon set of the host network to the node port used by the NWPD agent on the host network. |
tcp-n2p | checkTCPPort | TCP connection check from all pods of the daemon set of the host network to pod endpoints (pod IP, port of GRPC server) of the daemon set running in the pod network. |
tcp-n2n-ipv6 | checkTCPPort | TCP connection check from all pods of the daemon set of the host network to the node port used by the NWPD agent on the host network using the IPv6 address of the node. |
tcp-n2p-ipv6 | checkTCPPort | TCP connection check from all pods of the daemon set of the host network to pod IPv6 endpoints (IPv6 address of the pod, port of GRPC server) of the daemon set running in the pod network. |
| The job IDs of the default configuration on the host (=node) network are using the naming convention ` | ext | ipv6)]`. |
Default jobs for the daemon set on the cluster network
| Job ID | Job Type | Description |
|---|---|---|
https-p2api-ext | checkHTTPSGet | HTTPS Get check from all pods of the daemon set on the cluster network to the external address of the Kube API server. |
https-p2api-int | checkHTTPSGet | HTTPS Get check from all pods of the daemon set on the cluster network to the internal address of the Kube API server (kubernetes.default.svc.cluster.local.:443). |
nslookup-p | nslookup | Lookup of IP addresses for external DNS name europe-docker.pkg.dev, and internal and external names of Kube API server. |
tcp-p2api-ext | checkTCPPort | TCP connection check from all pods of the daemon set on the cluster network to the external address of the Kube API server. |
tcp-p2api-int | checkTCPPort | TCP connection check from all pods of the daemon set of the cluster network to the internal address of the Kube API server. |
tcp-p2n | checkTCPPort | TCP connection check from all pods of the daemon set of the cluster network to the node port used by the NWPD agent on the host network. |
tcp-p2p | checkTCPPort | TCP connection check from all pods of the daemon set of the cluster network to pod endpoints (pod IP, port of GRPC server) of the daemon set running in the pod network. |
tcp-p2n-ipv6 | checkTCPPort | TCP connection check from all pods of the daemon set of the cluster network to the node port used by the NWPD agent on the host network using the IPv6 address of the node. |
tcp-p2p-ipv6 | checkTCPPort | TCP connection check from all pods of the daemon set of the cluster network to pod IPv6 endpoints (IPv6 address of the pod, port of GRPC server) of the daemon set running in the pod network. |
The job IDs of the default configuration on the cluster (=pod) network are using the naming convention <jobtype-shortcut>-p[2<destination>][-(int|ext|ipv6)].