Weeder
Overview
Weeder watches for an update to service endpoints and on receiving such an event it will create a time-bound watch for all configured dependent pods that need to be actively recovered in case they have not yet recovered from CrashLoopBackoff state. In a nutshell it accelerates recovery of pods when an upstream service recovers.
An interference in automatic recovery for dependent pods is required because kubernetes pod restarts a container with an exponential backoff when the pod is in CrashLoopBackOff state. This backoff could become quite large if the service stays down for long. Presence of weeder would not let that happen as it'll restart the pod.
Prerequisites
Before we understand how Weeder works, we need to be familiar with kubernetes services & endpoints.
NOTE: If a kubernetes service is created with selectors then kubernetes will create corresponding endpoint resource which will have the same name as that of the service. In weeder implementation service and endpoint name is used interchangeably.
Config
Weeder can be configured via command line arguments and a weeder configuration. See configure weeder.
Internals
Weeder keeps a watch on the events for the specified endpoints in the config. For every endpoints a list of podSelectors can be specified. It cretes a weeder object per endpoints resource when it receives a satisfactory Create or Update event. Then for every podSelector it creates a goroutine. This goroutine keeps a watch on the pods with labels as per the podSelector and kills any pod which turn into CrashLoopBackOff. Each weeder lives for watchDuration interval which has a default value of 5 mins if not explicitly set.
To understand the actions taken by the weeder lets use the following diagram as a reference. 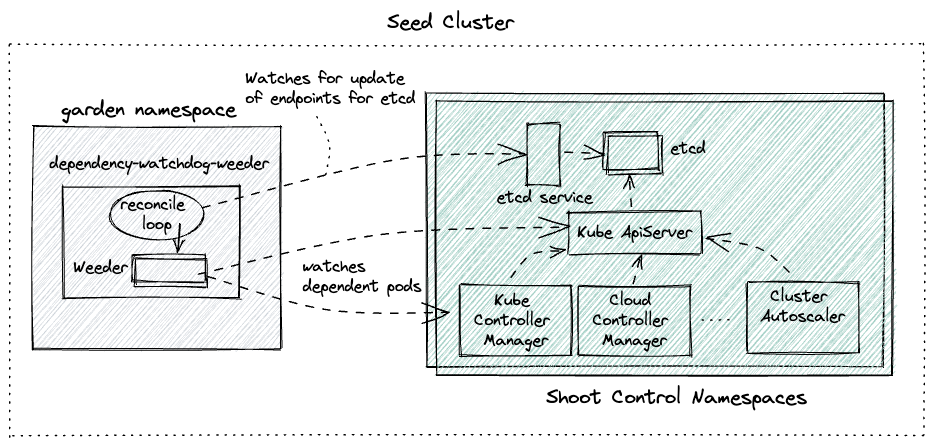 Let us also assume the following configuration for the weeder:
Let us also assume the following configuration for the weeder:
watchDuration: 2m0s
servicesAndDependantSelectors:
etcd-main-client: # name of the service/endpoint for etcd statefulset that weeder will receive events for.
podSelectors: # all pods matching the label selector are direct dependencies for etcd service
- matchExpressions:
- key: gardener.cloud/role
operator: In
values:
- controlplane
- key: role
operator: In
values:
- apiserver
kube-apiserver: # name of the service/endpoint for kube-api-server pods that weeder will receive events for.
podSelectors: # all pods matching the label selector are direct dependencies for kube-api-server service
- matchExpressions:
- key: gardener.cloud/role
operator: In
values:
- controlplane
- key: role
operator: NotIn
values:
- main
- apiserverOnly for the sake of demonstration lets pick the first service -> dependent pods tuple (etcd-main-client as the service endpoint).
- Assume that there are 3 replicas for etcd statefulset.
- Time here is just for showing the series of events
t=0-> all etcd pods go downt=10-> kube-api-server pods transition to CrashLoopBackOfft=100-> all etcd pods recover togethert=101-> Weeder seesUpdateevent foretcd-main-clientendpoints resourcet=102-> go routine created to keep watch on kube-api-server podst=103-> Since kube-api-server pods are still in CrashLoopBackOff, weeder deletes the pods to accelerate the recovery.t=104-> new kube-api-server pod created by replica-set controller in kube-controller-manager
Points to Note
- Weeder only respond on
Updateevents where anotReadyendpoints resource turn toReady. Thats why there was no weeder action at timet=10in the example above.notReady-> no backing pod is ReadyReady-> atleast one backing pod is Ready
- Weeder doesn't respond on
Deleteevents - Weeder will always wait for the entire
watchDuration. If the dependent pods transition to CrashLoopBackOff after the watch duration or even after repeated deletion of these pods they do not recover then weeder will exit. Quality of service offered via a weeder is only Best-Effort.