Machine Controller Manager
Declarative way of managing machines for Kubernetes cluster
machine-controller-manager



Note
One can add support for a new cloud provider by following Adding support for new provider.
Overview
Machine Controller Manager aka MCM is a group of cooperative controllers that manage the lifecycle of the worker machines. It is inspired by the design of Kube Controller Manager in which various sub controllers manage their respective Kubernetes Clients. MCM gives you the following benefits:
- seamlessly manage machines/nodes with a declarative API (of course, across different cloud providers)
- integrate generically with the cluster autoscaler
- plugin with tools such as the node-problem-detector
- transport the immutability design principle to machine/nodes
- implement e.g. rolling upgrades of machines/nodes
MCM supports following providers. These provider code is maintained externally (out-of-tree), and the links for the same are linked below:
It can easily be extended to support other cloud providers as well.
Example of managing machine:
kubectl create/get/delete machine vm1
Key terminologies
Nodes/Machines/VMs are different terminologies used to represent similar things. We use these terms in the following way
- VM: A virtual machine running on any cloud provider. It could also refer to a physical machine (PM) in case of a bare metal setup.
- Node: Native kubernetes node objects. The objects you get to see when you do a “kubectl get nodes”. Although nodes can be either physical/virtual machines, for the purposes of our discussions it refers to a VM.
- Machine: A VM that is provisioned/managed by the Machine Controller Manager.
Design of Machine Controller Manager
The design of the Machine Controller Manager is influenced by the Kube Controller Manager, where-in multiple sub-controllers are used to manage the Kubernetes clients.
Design Principles
It’s designed to run in the master plane of a Kubernetes cluster. It follows the best principles and practices of writing controllers, including, but not limited to:
- Reusing code from kube-controller-manager
- leader election to allow HA deployments of the controller
workqueues and multiple thread-workersSharedInformers that limit to minimum network calls, de-serialization and provide helpful create/update/delete events for resources- rate-limiting to allow back-off in case of network outages and general instability of other cluster components
- sending events to respected resources for easy debugging and overview
- Prometheus metrics, health and (optional) profiling endpoints
Objects of Machine Controller Manager
Machine Controller Manager reconciles a set of Custom Resources namely MachineDeployment, MachineSet and Machines which are managed & monitored by their controllers MachineDeployment Controller, MachineSet Controller, Machine Controller respectively along with another cooperative controller called the Safety Controller.
Machine Controller Manager makes use of 4 CRD objects and 1 Kubernetes secret object to manage machines. They are as follows:
| Custom ResourceObject | Description |
|---|
MachineClass | A MachineClass represents a template that contains cloud provider specific details used to create machines. |
Machine | A Machine represents a VM which is backed by the cloud provider. |
MachineSet | A MachineSet ensures that the specified number of Machine replicas are running at a given point of time. |
MachineDeployment | A MachineDeployment provides a declarative update for MachineSet and Machines. |
Secret | A Secret here is a Kubernetes secret that stores cloudconfig (initialization scripts used to create VMs) and cloud specific credentials. |
See here for CRD API Documentation
Components of Machine Controller Manager
| Controller | Description |
|---|
| MachineDeployment controller | Machine Deployment controller reconciles the MachineDeployment objects and manages the lifecycle of MachineSet objects. MachineDeployment consumes provider specific MachineClass in its spec.template.spec which is the template of the VM spec that would be spawned on the cloud by MCM. |
| MachineSet controller | MachineSet controller reconciles the MachineSet objects and manages the lifecycle of Machine objects. |
| Safety controller | There is a Safety Controller responsible for handling the unidentified or unknown behaviours from the cloud providers. Safety Controller:- freezes the MachineDeployment controller and MachineSet controller if the number of
Machine objects goes beyond a certain threshold on top of Spec.replicas. It can be configured by the flag --safety-up or --safety-down and also --machine-safety-overshooting-period. - freezes the functionality of the MCM if either of the
target-apiserver or the control-apiserver is not reachable. - unfreezes the MCM automatically once situation is resolved to normal. A
freeze label is applied on MachineDeployment/MachineSet to enforce the freeze condition.
|
Along with the above Custom Controllers and Resources, MCM requires the MachineClass to use K8s Secret that stores cloudconfig (initialization scripts used to create VMs) and cloud specific credentials. All these controllers work in an co-operative manner. They form a parent-child relationship with MachineDeployment Controller being the grandparent, MachineSet Controller being the parent, and Machine Controller being the child.
Development
To start using or developing the Machine Controller Manager, see the documentation in the /docs repository.
FAQ
An FAQ is available here.
cluster-api Implementation
1 - Documents
1.1 - Apis
Specification
ProviderSpec Schema
Machine
Machine is the representation of a physical or virtual machine.
| Field | Type | Description |
|---|
apiVersion | string | machine.sapcloud.io/v1alpha1 |
kind | string | Machine |
metadata | Kubernetes meta/v1.ObjectMeta | ObjectMeta for machine object Refer to the Kubernetes API documentation for the fields of the
metadata field. |
spec | MachineSpec | Spec contains the specification of the machine
class | ClassSpec | (Optional) Class contains the machineclass attributes of a machine | providerID | string | (Optional) ProviderID represents the provider’s unique ID given to a machine | nodeTemplate | NodeTemplateSpec | (Optional) NodeTemplateSpec describes the data a node should have when created from a template | MachineConfiguration | MachineConfiguration | (Members of MachineConfiguration are embedded into this type.) (Optional)Configuration for the machine-controller. |
|
status | MachineStatus | Status contains fields depicting the status |
MachineClass
MachineClass can be used to templatize and re-use provider configuration
across multiple Machines / MachineSets / MachineDeployments.
| Field | Type | Description |
|---|
apiVersion | string | machine.sapcloud.io/v1alpha1 |
kind | string | MachineClass |
metadata | Kubernetes meta/v1.ObjectMeta | (Optional)
Refer to the Kubernetes API documentation for the fields of the
metadata field. |
nodeTemplate | NodeTemplate | (Optional) NodeTemplate contains subfields to track all node resources and other node info required to scale nodegroup from zero |
credentialsSecretRef | Kubernetes core/v1.SecretReference | CredentialsSecretRef can optionally store the credentials (in this case the SecretRef does not need to store them).
This might be useful if multiple machine classes with the same credentials but different user-datas are used. |
providerSpec | k8s.io/apimachinery/pkg/runtime.RawExtension | Provider-specific configuration to use during node creation. |
provider | string | Provider is the combination of name and location of cloud-specific drivers. |
secretRef | Kubernetes core/v1.SecretReference | SecretRef stores the necessary secrets such as credentials or userdata. |
MachineDeployment
MachineDeployment enables declarative updates for machines and MachineSets.
| Field | Type | Description |
|---|
apiVersion | string | machine.sapcloud.io/v1alpha1 |
kind | string | MachineDeployment |
metadata | Kubernetes meta/v1.ObjectMeta | (Optional) Standard object metadata. Refer to the Kubernetes API documentation for the fields of the
metadata field. |
spec | MachineDeploymentSpec | (Optional) Specification of the desired behavior of the MachineDeployment.
replicas | int32 | (Optional) Number of desired machines. This is a pointer to distinguish between explicit
zero and not specified. Defaults to 0. | selector | Kubernetes meta/v1.LabelSelector | (Optional) Label selector for machines. Existing MachineSets whose machines are
selected by this will be the ones affected by this MachineDeployment. | template | MachineTemplateSpec | Template describes the machines that will be created. | strategy | MachineDeploymentStrategy | (Optional) The MachineDeployment strategy to use to replace existing machines with new ones. | minReadySeconds | int32 | (Optional) Minimum number of seconds for which a newly created machine should be ready
without any of its container crashing, for it to be considered available.
Defaults to 0 (machine will be considered available as soon as it is ready) | revisionHistoryLimit | *int32 | (Optional) The number of old MachineSets to retain to allow rollback.
This is a pointer to distinguish between explicit zero and not specified. | paused | bool | (Optional) Indicates that the MachineDeployment is paused and will not be processed by the
MachineDeployment controller. | rollbackTo | RollbackConfig | (Optional) DEPRECATED.
The config this MachineDeployment is rolling back to. Will be cleared after rollback is done. | progressDeadlineSeconds | *int32 | (Optional) The maximum time in seconds for a MachineDeployment to make progress before it
is considered to be failed. The MachineDeployment controller will continue to
process failed MachineDeployments and a condition with a ProgressDeadlineExceeded
reason will be surfaced in the MachineDeployment status. Note that progress will
not be estimated during the time a MachineDeployment is paused. This is not set
by default, which is treated as infinite deadline. |
|
status | MachineDeploymentStatus | (Optional) Most recently observed status of the MachineDeployment. |
MachineSet
MachineSet TODO
ClassSpec
(Appears on:
MachineSetSpec,
MachineSpec)
ClassSpec is the class specification of machine
| Field | Type | Description |
|---|
apiGroup | string | API group to which it belongs |
kind | string | Kind for machine class |
name | string | Name of machine class |
ConditionStatus
(string alias)
(Appears on:
MachineDeploymentCondition,
MachineSetCondition)
ConditionStatus are valid condition statuses
CurrentStatus
(Appears on:
MachineStatus)
CurrentStatus contains information about the current status of Machine.
InPlaceUpdateMachineDeployment
(Appears on:
MachineDeploymentStrategy)
InPlaceUpdateMachineDeployment specifies the spec to control the desired behavior of inplace update.
| Field | Type | Description |
|---|
UpdateConfiguration | UpdateConfiguration | (Members of UpdateConfiguration are embedded into this type.) |
orchestrationType | OrchestrationType | OrchestrationType specifies the orchestration type for the inplace update. |
LastOperation
(Appears on:
MachineSetStatus,
MachineStatus,
MachineSummary)
LastOperation suggests the last operation performed on the object
| Field | Type | Description |
|---|
description | string | Description of the current operation |
errorCode | string | (Optional) ErrorCode of the current operation if any |
lastUpdateTime | Kubernetes meta/v1.Time | Last update time of current operation |
state | MachineState | State of operation |
type | MachineOperationType | Type of operation |
MachineConfiguration
(Appears on:
MachineSpec)
MachineConfiguration describes the configurations useful for the machine-controller.
| Field | Type | Description |
|---|
drainTimeout | Kubernetes meta/v1.Duration | (Optional) MachineDraintimeout is the timeout after which machine is forcefully deleted. |
healthTimeout | Kubernetes meta/v1.Duration | (Optional) MachineHealthTimeout is the timeout after which machine is declared unhealhty/failed. |
creationTimeout | Kubernetes meta/v1.Duration | (Optional) MachineCreationTimeout is the timeout after which machinie creation is declared failed. |
inPlaceUpdateTimeout | Kubernetes meta/v1.Duration | (Optional) MachineInPlaceUpdateTimeout is the timeout after which in-place update is declared failed. |
disableHealthTimeout | *bool | (Optional) DisableHealthTimeout if set to true, health timeout will be ignored. Leading to machine never being declared failed. |
maxEvictRetries | *int32 | (Optional) MaxEvictRetries is the number of retries that will be attempted while draining the node. |
nodeConditions | *string | (Optional) NodeConditions are the set of conditions if set to true for MachineHealthTimeOut, machine will be declared failed. |
MachineDeploymentCondition
(Appears on:
MachineDeploymentStatus)
MachineDeploymentCondition describes the state of a MachineDeployment at a certain point.
| Field | Type | Description |
|---|
type | MachineDeploymentConditionType | Type of MachineDeployment condition. |
status | ConditionStatus | Status of the condition, one of True, False, Unknown. |
lastUpdateTime | Kubernetes meta/v1.Time | The last time this condition was updated. |
lastTransitionTime | Kubernetes meta/v1.Time | Last time the condition transitioned from one status to another. |
reason | string | The reason for the condition’s last transition. |
message | string | A human readable message indicating details about the transition. |
MachineDeploymentConditionType
(string alias)
(Appears on:
MachineDeploymentCondition)
MachineDeploymentConditionType are valid conditions of MachineDeployments
MachineDeploymentSpec
(Appears on:
MachineDeployment)
MachineDeploymentSpec is the specification of the desired behavior of the MachineDeployment.
| Field | Type | Description |
|---|
replicas | int32 | (Optional) Number of desired machines. This is a pointer to distinguish between explicit
zero and not specified. Defaults to 0. |
selector | Kubernetes meta/v1.LabelSelector | (Optional) Label selector for machines. Existing MachineSets whose machines are
selected by this will be the ones affected by this MachineDeployment. |
template | MachineTemplateSpec | Template describes the machines that will be created. |
strategy | MachineDeploymentStrategy | (Optional) The MachineDeployment strategy to use to replace existing machines with new ones. |
minReadySeconds | int32 | (Optional) Minimum number of seconds for which a newly created machine should be ready
without any of its container crashing, for it to be considered available.
Defaults to 0 (machine will be considered available as soon as it is ready) |
revisionHistoryLimit | *int32 | (Optional) The number of old MachineSets to retain to allow rollback.
This is a pointer to distinguish between explicit zero and not specified. |
paused | bool | (Optional) Indicates that the MachineDeployment is paused and will not be processed by the
MachineDeployment controller. |
rollbackTo | RollbackConfig | (Optional) DEPRECATED.
The config this MachineDeployment is rolling back to. Will be cleared after rollback is done. |
progressDeadlineSeconds | *int32 | (Optional) The maximum time in seconds for a MachineDeployment to make progress before it
is considered to be failed. The MachineDeployment controller will continue to
process failed MachineDeployments and a condition with a ProgressDeadlineExceeded
reason will be surfaced in the MachineDeployment status. Note that progress will
not be estimated during the time a MachineDeployment is paused. This is not set
by default, which is treated as infinite deadline. |
MachineDeploymentStatus
(Appears on:
MachineDeployment)
MachineDeploymentStatus is the most recently observed status of the MachineDeployment.
| Field | Type | Description |
|---|
observedGeneration | int64 | (Optional) The generation observed by the MachineDeployment controller. |
replicas | int32 | (Optional) Total number of non-terminated machines targeted by this MachineDeployment (their labels match the selector). |
updatedReplicas | int32 | (Optional) Total number of non-terminated machines targeted by this MachineDeployment that have the desired template spec. |
readyReplicas | int32 | (Optional) Total number of ready machines targeted by this MachineDeployment. |
availableReplicas | int32 | (Optional) Total number of available machines (ready for at least minReadySeconds) targeted by this MachineDeployment. |
unavailableReplicas | int32 | (Optional) Total number of unavailable machines targeted by this MachineDeployment. This is the total number of
machines that are still required for the MachineDeployment to have 100% available capacity. They may
either be machines that are running but not yet available or machines that still have not been created. |
conditions | []MachineDeploymentCondition | Represents the latest available observations of a MachineDeployment’s current state. |
collisionCount | *int32 | (Optional) Count of hash collisions for the MachineDeployment. The MachineDeployment controller uses this
field as a collision avoidance mechanism when it needs to create the name for the
newest MachineSet. |
failedMachines | []*github.com/gardener/machine-controller-manager/pkg/apis/machine/v1alpha1.MachineSummary | (Optional) FailedMachines has summary of machines on which lastOperation Failed |
MachineDeploymentStrategy
(Appears on:
MachineDeploymentSpec)
MachineDeploymentStrategy describes how to replace existing machines with new ones.
| Field | Type | Description |
|---|
type | MachineDeploymentStrategyType | (Optional) Type of MachineDeployment. Can be “Recreate” or “RollingUpdate”. Default is RollingUpdate. |
rollingUpdate | RollingUpdateMachineDeployment | (Optional) Rolling update config params. Present only if MachineDeploymentStrategyType = RollingUpdate.TODO: Update this to follow our convention for oneOf, whatever we decide it
to be. |
inPlaceUpdate | InPlaceUpdateMachineDeployment | (Optional) InPlaceUpdate update config params. Present only if MachineDeploymentStrategyType =
InPlaceUpdate. |
MachineDeploymentStrategyType
(string alias)
(Appears on:
MachineDeploymentStrategy)
MachineDeploymentStrategyType are valid strategy types for rolling MachineDeployments
MachineOperationType
(string alias)
(Appears on:
LastOperation)
MachineOperationType is a label for the operation performed on a machine object.
MachinePhase
(string alias)
(Appears on:
CurrentStatus)
MachinePhase is a label for the condition of a machine at the current time.
MachineSetCondition
(Appears on:
MachineSetStatus)
MachineSetCondition describes the state of a machine set at a certain point.
| Field | Type | Description |
|---|
type | MachineSetConditionType | Type of machine set condition. |
status | ConditionStatus | Status of the condition, one of True, False, Unknown. |
lastTransitionTime | Kubernetes meta/v1.Time | (Optional) The last time the condition transitioned from one status to another. |
reason | string | (Optional) The reason for the condition’s last transition. |
message | string | (Optional) A human readable message indicating details about the transition. |
MachineSetConditionType
(string alias)
(Appears on:
MachineSetCondition)
MachineSetConditionType is the condition on machineset object
MachineSetSpec
(Appears on:
MachineSet)
MachineSetSpec is the specification of a MachineSet.
MachineSetStatus
(Appears on:
MachineSet)
MachineSetStatus holds the most recently observed status of MachineSet.
| Field | Type | Description |
|---|
replicas | int32 | Replicas is the number of actual replicas. |
fullyLabeledReplicas | int32 | (Optional) The number of pods that have labels matching the labels of the pod template of the replicaset. |
readyReplicas | int32 | (Optional) The number of ready replicas for this replica set. |
availableReplicas | int32 | (Optional) The number of available replicas (ready for at least minReadySeconds) for this replica set. |
observedGeneration | int64 | (Optional) ObservedGeneration is the most recent generation observed by the controller. |
machineSetCondition | []MachineSetCondition | (Optional) Represents the latest available observations of a replica set’s current state. |
lastOperation | LastOperation | LastOperation performed |
failedMachines | []github.com/gardener/machine-controller-manager/pkg/apis/machine/v1alpha1.MachineSummary | (Optional) FailedMachines has summary of machines on which lastOperation Failed |
MachineSpec
(Appears on:
Machine,
MachineTemplateSpec)
MachineSpec is the specification of a Machine.
| Field | Type | Description |
|---|
class | ClassSpec | (Optional) Class contains the machineclass attributes of a machine |
providerID | string | (Optional) ProviderID represents the provider’s unique ID given to a machine |
nodeTemplate | NodeTemplateSpec | (Optional) NodeTemplateSpec describes the data a node should have when created from a template |
MachineConfiguration | MachineConfiguration | (Members of MachineConfiguration are embedded into this type.) (Optional)Configuration for the machine-controller. |
MachineState
(string alias)
(Appears on:
LastOperation)
MachineState is a current state of the operation.
MachineStatus
(Appears on:
Machine)
MachineStatus holds the most recently observed status of Machine.
| Field | Type | Description |
|---|
conditions | []Kubernetes core/v1.NodeCondition | Conditions of this machine, same as node |
lastOperation | LastOperation | Last operation refers to the status of the last operation performed |
currentStatus | CurrentStatus | Current status of the machine object |
lastKnownState | string | (Optional) LastKnownState can store details of the last known state of the VM by the plugins.
It can be used by future operation calls to determine current infrastucture state |
MachineSummary
MachineSummary store the summary of machine.
| Field | Type | Description |
|---|
name | string | Name of the machine object |
providerID | string | ProviderID represents the provider’s unique ID given to a machine |
lastOperation | LastOperation | Last operation refers to the status of the last operation performed |
ownerRef | string | OwnerRef |
MachineTemplateSpec
(Appears on:
MachineDeploymentSpec,
MachineSetSpec)
MachineTemplateSpec describes the data a machine should have when created from a template
NodeTemplate
(Appears on:
MachineClass)
NodeTemplate contains subfields to track all node resources and other node info required to scale nodegroup from zero
| Field | Type | Description |
|---|
capacity | Kubernetes core/v1.ResourceList | Capacity contains subfields to track all node resources required to scale nodegroup from zero |
instanceType | string | Instance type of the node belonging to nodeGroup |
region | string | Region of the expected node belonging to nodeGroup |
zone | string | Zone of the expected node belonging to nodeGroup |
architecture | *string | (Optional) CPU Architecture of the node belonging to nodeGroup |
NodeTemplateSpec
(Appears on:
MachineSpec)
NodeTemplateSpec describes the data a node should have when created from a template
| Field | Type | Description |
|---|
metadata | Kubernetes meta/v1.ObjectMeta | (Optional)
Refer to the Kubernetes API documentation for the fields of the
metadata field. |
spec | Kubernetes core/v1.NodeSpec | (Optional) NodeSpec describes the attributes that a node is created with.
podCIDR | string | (Optional) PodCIDR represents the pod IP range assigned to the node. | podCIDRs | []string | (Optional) podCIDRs represents the IP ranges assigned to the node for usage by Pods on that node. If this
field is specified, the 0th entry must match the podCIDR field. It may contain at most 1 value for
each of IPv4 and IPv6. | providerID | string | (Optional) ID of the node assigned by the cloud provider in the format: :// | unschedulable | bool | (Optional) Unschedulable controls node schedulability of new pods. By default, node is schedulable.
More info: https://kubernetes.io/docs/concepts/nodes/node/#manual-node-administration | taints | []Kubernetes core/v1.Taint | (Optional) If specified, the node’s taints. | configSource | Kubernetes core/v1.NodeConfigSource | (Optional) Deprecated: Previously used to specify the source of the node’s configuration for the DynamicKubeletConfig feature. This feature is removed. | externalID | string | (Optional) Deprecated. Not all kubelets will set this field. Remove field after 1.13.
see: https://issues.k8s.io/61966 |
|
OrchestrationType
(string alias)
(Appears on:
InPlaceUpdateMachineDeployment)
OrchestrationType specifies the orchestration type for the inplace update.
RollbackConfig
(Appears on:
MachineDeploymentSpec)
RollbackConfig is the config to rollback a MachineDeployment
| Field | Type | Description |
|---|
revision | int64 | (Optional) The revision to rollback to. If set to 0, rollback to the last revision. |
RollingUpdateMachineDeployment
(Appears on:
MachineDeploymentStrategy)
RollingUpdateMachineDeployment is the spec to control the desired behavior of rolling update.
| Field | Type | Description |
|---|
UpdateConfiguration | UpdateConfiguration | (Members of UpdateConfiguration are embedded into this type.) |
UpdateConfiguration
(Appears on:
InPlaceUpdateMachineDeployment,
RollingUpdateMachineDeployment)
UpdateConfiguration specifies the udpate configuration for the deployment strategy.
| Field | Type | Description |
|---|
maxUnavailable | k8s.io/apimachinery/pkg/util/intstr.IntOrString | (Optional) The maximum number of machines that can be unavailable during the update.
Value can be an absolute number (ex: 5) or a percentage of desired machines (ex: 10%).
Absolute number is calculated from percentage by rounding down.
This can not be 0 if MaxSurge is 0.
Example: when this is set to 30%, the old machine set can be scaled down to 70% of desired machines
immediately when the update starts. Once new machines are ready, old machine set
can be scaled down further, followed by scaling up the new machine set, ensuring
that the total number of machines available at all times during the update is at
least 70% of desired machines. |
maxSurge | k8s.io/apimachinery/pkg/util/intstr.IntOrString | (Optional) The maximum number of machines that can be scheduled above the desired number of
machines.
Value can be an absolute number (ex: 5) or a percentage of desired machines (ex: 10%).
This can not be 0 if MaxUnavailable is 0.
Absolute number is calculated from percentage by rounding up.
Example: when this is set to 30%, the new machine set can be scaled up immediately when
the update starts, such that the total number of old and new machines does not exceed
130% of desired machines. Once old machines have been killed,
new machine set can be scaled up further, ensuring that total number of machines running
at any time during the update is utmost 130% of desired machines. |
Generated with gen-crd-api-reference-docs
2 - Proposals
2.1 - Excess Reserve Capacity
Excess Reserve Capacity
Goal
Currently, autoscaler optimizes the number of machines for a given application-workload. Along with effective resource utilization, this feature brings concern where, many times, when new application instances are created - they don’t find space in existing cluster. This leads the cluster-autoscaler to create new machines via MachineDeployment, which can take from 3-4 minutes to ~10 minutes, for the machine to really come-up and join the cluster. In turn, application-instances have to wait till new machines join the cluster.
One of the promising solutions to this issue is Excess Reserve Capacity. Idea is to keep a certain number of machines or percent of resources[cpu/memory] always available, so that new workload, in general, can be scheduled immediately unless huge spike in the workload. Also, the user should be given enough flexibility to choose how many resources or how many machines should be kept alive and non-utilized as this affects the Cost directly.
Note
- We decided to go with Approach-4 which is based on low priority pods. Please find more details here: https://github.com/gardener/gardener/issues/254
- Approach-3 looks more promising in long term, we may decide to adopt that in future based on developments/contributions in autoscaler-community.
Possible Approaches
Following are the possible approaches, we could think of so far.
Approach 1: Enhance Machine-controller-manager to also entertain the excess machines
Machine-controller-manager currently takes care of the machines in the shoot cluster starting from creation-deletion-health check to efficient rolling-update of the machines. From the architecture point of view, MachineSet makes sure that X number of machines are always running and healthy. MachineDeployment controller smartly uses this facility to perform rolling-updates.
We can expand the scope of MachineDeployment controller to maintain excess number of machines by introducing new parallel independent controller named MachineTaint controller. This will result in MCM to include Machine, MachineSet, MachineDeployment, MachineSafety, MachineTaint controllers. MachineTaint controller does not need to introduce any new CRD - analogy fits where taint-controller also resides into kube-controller-manager.
Only Job of MachineTaint controller will be:
- List all the Machines under each MachineDeployment.
- Maintain taints of noSchedule and noExecute on
X latest MachineObjects. - There should be an event-based informer mechanism where MachineTaintController gets to know about any Update/Delete/Create event of MachineObjects - in turn, maintains the noSchedule and noExecute taints on all the latest machines.
- Why latest machines?
- Whenever autoscaler decides to add new machines - essentially ScaleUp event - taints from the older machines are removed and newer machines get the taints. This way X number of Machines immediately becomes free for new pods to be scheduled.
- While ScaleDown event, autoscaler specifically mentions which machines should be deleted, and that should not bring any concerns. Though we will have to put proper label/annotation defined by autoscaler on taintedMachines, so that autoscaler does not consider the taintedMachines for deletion while scale-down.
* Annotation on tainted node:
"cluster-autoscaler.kubernetes.io/scale-down-disabled": "true"
Implementation Details:
- Expect new optional field ExcessReplicas in
MachineDeployment.Spec. MachineDeployment controller now adds both Spec.Replicas and Spec.ExcessReplicas[if provided], and considers that as a standard desiredReplicas.
- Current working of MCM will not be affected if ExcessReplicas field is kept nil. - MachineController currently reads the NodeObject and sets the MachineConditions in MachineObject. Machine-controller will now also read the taints/labels from the MachineObject - and maintains it on the NodeObject.
We expect cluster-autoscaler to intelligently make use of the provided feature from MCM.
- CA gets the input of min:max:excess from Gardener. CA continues to set the
MachineDeployment.Spec.Replicas as usual based on the application-workload. - In addition, CA also sets the
MachieDeployment.Spec.ExcessReplicas . - Corner-case:
* CA should decrement the excessReplicas field accordingly when desiredReplicas+excessReplicas on MachineDeployment goes beyond max.
Approach 2: Enhance Cluster-autoscaler by simulating fake pods in it
- There was already an attempt by community to support this feature.
Approach 3: Enhance cluster-autoscaler to support pluggable scaling-events
- Forked version of cluster-autoscaler could be improved to plug-in the algorithm for excess-reserve capacity.
- Needs further discussion around upstream support.
- Create golang channel to separate the algorithms to trigger scaling (hard-coded in cluster-autoscaler, currently) from the algorithms about how to to achieve the scaling (already pluggable in cluster-autoscaler). This kind of separation can help us introduce/plug-in new algorithms (such as based node resource utilisation) without affecting existing code-base too much while almost completely re-using the code-base for the actual scaling.
- Also this approach is not specific to our fork of cluster-autoscaler. It can be made upstream eventually as well.
Approach 4: Make intelligent use of Low-priority pods
- Refer to: pod-priority-preemption
- TL; DR:
- High priority pods can preempt the low-priority pods which are already scheduled.
- Pre-create bunch[equivivalent of X shoot-control-planes] of low-priority pods with priority of zero, then start creating the workload pods with better priority which will reschedule the low-priority pods or otherwise keep them in pending state if the limit for max-machines has reached.
- This is still alpha feature.
2.2 - GRPC Based Implementation of Cloud Providers
GRPC based implementation of Cloud Providers - WIP
Goal:
Currently the Cloud Providers’ (CP) functionalities ( Create(), Delete(), List() ) are part of the Machine Controller Manager’s (MCM)repository. Because of this, adding support for new CPs into MCM requires merging code into MCM which may not be required for core functionalities of MCM itself. Also, for various reasons it may not be feasible for all CPs to merge their code with MCM which is an Open Source project.
Because of these reasons, it was decided that the CP’s code will be moved out in separate repositories so that they can be maintained separately by the respective teams. Idea is to make MCM act as a GRPC server, and CPs as GRPC clients. The CP can register themselves with the MCM using a GRPC service exposed by the MCM. Details of this approach is discussed below.
How it works:
MCM acts as GRPC server and listens on a pre-defined port 5000. It implements below GRPC services. Details of each of these services are mentioned in next section.
Register()GetMachineClass()GetSecret()
GRPC services exposed by MCM:
Register()
rpc Register(stream DriverSide) returns (stream MCMside) {}
The CP GRPC client calls this service to register itself with the MCM. The CP passes the kind and the APIVersion which it implements, and MCM maintains an internal map for all the registered clients. A GRPC stream is returned in response which is kept open througout the life of both the processes. MCM uses this stream to communicate with the client for machine operations: Create(), Delete() or List().
The CP client is responsible for reading the incoming messages continuously, and based on the operationType parameter embedded in the message, it is supposed to take the required action. This part is already handled in the package grpc/infraclient.
To add a new CP client, import the package, and implement the ExternalDriverProvider interface:
type ExternalDriverProvider interface {
Create(machineclass *MachineClassMeta, credentials, machineID, machineName string) (string, string, error)
Delete(machineclass *MachineClassMeta, credentials, machineID string) error
List(machineclass *MachineClassMeta, credentials, machineID string) (map[string]string, error)
}
GetMachineClass()
rpc GetMachineClass(MachineClassMeta) returns (MachineClass) {}
As part of the message from MCM for various machine operations, the name of the machine class is sent instead of the full machine class spec. The CP client is expected to use this GRPC service to get the full spec of the machine class. This optionally enables the client to cache the machine class spec, and make the call only if the machine calass spec is not already cached.
GetSecret()
rpc GetSecret(SecretMeta) returns (Secret) {}
As part of the message from MCM for various machine operations, the Cloud Config (CC) and CP credentials are not sent. The CP client is expected to use this GRPC service to get the secret which has CC and CP’s credentials from MCM. This enables the client to cache the CC and credentials, and to make the call only if the data is not already cached.
How to add a new Cloud Provider’s support
Import the package grpc/infraclient and grpc/infrapb from MCM (currently in MCM’s “grpc-driver” branch)
- Implement the interface
ExternalDriverProviderCreate(): Creates a new machineDelete(): Deletes a machineList(): Lists machines
- Use the interface
MachineClassDataProviderGetMachineClass(): Makes the call to MCM to get machine class specGetSecret(): Makes the call to MCM to get secret containing Cloud Config and CP’s credentials
Example implementation:
Refer GRPC based implementation for AWS client:
https://github.com/ggaurav10/aws-driver-grpc
2.3 - Hotupdate Instances
Motivation
MCM Issue#750 There is a requirement to provide a way for consumers to add tags which can be hot-updated onto VMs. This requirement can be generalized to also offer a convenient way to specify tags which can be applied to VMs, NICs, Devices etc.
MCM Issue#635 which in turn points to MCM-Provider-AWS Issue#36 - The issue hints at other fields like enable/disable source/destination checks for NAT instances which needs to be hot-updated on network interfaces.
In GCP provider - instance.ServiceAccounts can be updated without the need to roll-over the instance. See
Boundary Condition
All tags that are added via means other than MachineClass.ProviderSpec should be preserved as-is. Only updates done to tags in MachineClass.ProviderSpec should be applied to the infra resources (VM/NIC/Disk).
What is available today?
WorkerPool configuration inside shootYaml provides a way to set labels. As per the definition these labels will be applied on Node resources. Currently these labels are also passed to the VMs as tags. There is no distinction made between Node labels and VM tags.
MachineClass has a field which holds provider specific configuration and one such configuration is tags. Gardener provider extensions updates the tags in MachineClass.
Let us look at an example of MachineClass.ProviderSpec in AWS:
providerSpec:
ami: ami-02fe00c0afb75bbd3
tags:
#[section-1] pool lables added by gardener extension
#########################################################
kubernetes.io/arch: amd64
networking.gardener.cloud/node-local-dns-enabled: "true"
node.kubernetes.io/role: node
worker.garden.sapcloud.io/group: worker-ser234
worker.gardener.cloud/cri-name: containerd
worker.gardener.cloud/pool: worker-ser234
worker.gardener.cloud/system-components: "true"
#[section-2] Tags defined in the gardener-extension-provider-aws
###########################################################
kubernetes.io/cluster/cluster-full-name: "1"
kubernetes.io/role/node: "1"
#[section-3]
###########################################################
user-defined-key1: user-defined-val1
user-defined-key2: user-defined-val2
Refer src for tags defined in section-1.
Refer src for tags defined in section-2.
Tags in section-3 are defined by the user.
Out of the above three tag categories, MCM depends section-2 tags (mandatory-tags) for its orphan collection and Driver’s DeleteMachineand GetMachineStatus to work.
ProviderSpec.Tags are transported to the provider specific resources as follows:
| Provider | Resources Tags are set on | Code Reference | Comment |
|---|
| AWS | Instance(VM), Volume, Network-Interface | aws-VM-Vol-NIC | No distinction is made between tags set on VM, NIC or Volume |
| Azure | Instance(VM), Network-Interface | azure-VM-parameters & azureNIC-Parameters | |
| GCP | Instance(VM), 1 tag: name (denoting the name of the worker) is added to Disk | gcp-VM & gcp-Disk | In GCP key-value pairs are called labels while network tags have only keys |
| AliCloud | Instance(VM) | aliCloud-VM | |
What are the problems with the current approach?
There are a few shortcomings in the way tags/labels are handled:
- Tags can only be set at the time a machine is created.
- There is no distinction made amongst tags/labels that are added to VM’s, disks or network interfaces. As stated above for AWS same set of tags are added to all. There is a limit defined on the number of tags/labels that can be associated to the devices (disks, VMs, NICs etc). Example: In AWS a max of 50 user created tags are allowed. Similar restrictions are applied on different resources across providers. Therefore adding all tags to all devices even if the subset of tags are not meant for that resource exhausts the total allowed tags/labels for that resource.
- The only placeholder in shoot yaml as mentioned above is meant to only hold labels that should be applied on primarily on the Node objects. So while you could use the node labels for extended resources, using it also for tags is not clean.
- There is no provision in the shoot YAML today to add tags only to a subset of resources.
MachineClass Update and its impact
When Worker.ProviderConfig is changed then a worker-hash is computed which includes the raw ProviderConfig. This hash value is then used as a suffix when constructing the name for a MachineClass. See aws-extension-provider as an example. A change in the name of the MachineClass will then in-turn trigger a rolling update of machines. Since tags are provider specific and therefore will be part of ProviderConfig, any update to them will result in a rolling-update of machines.
Proposal
Shoot YAML changes
Provider specific configuration is set via providerConfig section for each worker pool.
Example worker provider config (current):
providerConfig:
apiVersion: aws.provider.extensions.gardener.cloud/v1alpha1
kind: WorkerConfig
volume:
iops: 10000
dataVolumes:
- name: kubelet-dir
snapshotID: snap-13234
iamInstanceProfile: # (specify either ARN or name)
name: my-profile
arn: my-instance-profile-arn
It is proposed that an additional field be added for tags under providerConfig. Proposed changed YAML:
providerConfig:
apiVersion: aws.provider.extensions.gardener.cloud/v1alpha1
kind: WorkerConfig
volume:
iops: 10000
dataVolumes:
- name: kubelet-dir
snapshotID: snap-13234
iamInstanceProfile: # (specify either ARN or name)
name: my-profile
arn: my-instance-profile-arn
tags:
vm:
key1: val1
key2: val2
..
# for GCP network tags are just keys (there is no value associated to them).
# What is shown below will work for AWS provider.
network:
key3: val3
key4: val4
Under tags clear distinction is made between tags for VMs, Disks, network interface etc. Each provider has a different allowed-set of characters that it accepts as key names, has different limits on the tags that can be set on a resource (disk, NIC, VM etc.) and also has a different format (GCP network tags are only keys).
TODO:
Check if worker.labels are getting added as tags on infra resources. We should continue to support it and double check that these should only be added to VMs and not to other resources.
Should we support users adding VM tags as node labels?
Provider specific WorkerConfig API changes
Taking AWS provider extension as an example to show the changes.
WorkerConfig will now have the following changes:
- A new field for tags will be introduced.
- Additional metadata for struct fields will now be added via
struct tags.
type WorkerConfig struct {
metav1.TypeMeta
Volume *Volume
// .. all fields are not mentioned here.
// Tags are a collection of tags to be set on provider resources (e.g. VMs, Disks, Network Interfaces etc.)
Tags *Tags `hotupdatable:true`
}
// Tags is a placeholder for all tags that can be set/updated on VMs, Disks and Network Interfaces.
type Tags struct {
// VM tags set on the VM instances.
VM map[string]string
// Network tags set on the network interfaces.
Network map[string]string
// Disk tags set on the volumes/disks.
Disk map[string]string
}
There is a need to distinguish fields within ProviderSpec (which is then mapped to the above WorkerConfig) which can be updated without the need to change the hash suffix for MachineClass and thus trigger a rolling update on machines.
To achieve that we propose to use struct tag hotupdatable whose value indicates if the field can be updated without the need to do a rolling update. To ensure backward compatibility, all fields which do not have this tag or have hotupdatable set to false will be considered as immutable and will require a rolling update to take affect.
Gardener provider extension changes
Taking AWS provider extension as an example. Following changes should be made to all gardener provider extensions
AWS Gardener Extension generates machine config using worker pool configuration. As part of that it also computes the workerPoolHash which is then used to create the name of the MachineClass.
Currently WorkerPoolHash function uses the entire providerConfig to compute the hash. Proposal is to do the following:
- Remove the code from function
WorkerPoolHash. - Add another function to compute hash using all immutable fields in the provider config struct and then pass that to
worker.WorkerPoolHash as additionalData.
The above will ensure that tags and any other field in WorkerConfig which is marked with updatable:true is not considered for hash computation and will therefore not contribute to changing the name of MachineClass object thus preventing a rolling update.
WorkerConfig and therefore the contained tags will be set as ProviderSpec in MachineClass.
If only fields which have updatable:true are changed then it should result in update/patch of MachineClass and not creation.
Driver interface changes
Driver interface which is a facade to provider specific API implementations will have one additional method.
type Driver interface {
// .. existing methods are not mentioned here for brevity.
UpdateMachine(context.Context, *UpdateMachineRequest) error
}
// UpdateMachineRequest is the request to update machine tags.
type UpdateMachineRequest struct {
ProviderID string
LastAppliedProviderSpec raw.Extension
MachineClass *v1alpha1.MachineClass
Secret *corev1.Secret
}
If any machine-controller-manager-provider-<providername> has not implemented UpdateMachine then updates of tags on Instances/NICs/Disks will not be done. An error message will be logged instead.
Machine Class reconciliation
Current MachineClass reconciliation does not reconcile MachineClass resource updates but it only enqueues associated machines. The reason is that it is assumed that anything that is changed in a MachineClass will result in a creation of a new MachineClass with a different name. This will result in a rolling update of all machines using the MachineClass as a template.
However, it is possible that there is data that all machines in a MachineSet share which do not require a rolling update (e.g. tags), therefore there is a need to reconcile the MachineClass as well.
Reconciliation Changes
In order to ensure that machines get updated eventually with changes to the hot-updatable fields defined in the MachineClass.ProviderConfig as raw.Extension.
We should only fix MCM Issue#751 in the MachineClass reconciliation and let it enqueue the machines as it does today. We additionally propose the following two things:
Introduce a new annotation last-applied-providerspec on every machine resource. This will capture the last successfully applied MachineClass.ProviderSpec on this instance.
Enhance the machine reconciliation to include code to hot-update machine.
In machine-reconciliation there are currently two flows triggerDeletionFlow and triggerCreationFlow. When a machine gets enqueued due to changes in MachineClass then in this method following changes needs to be introduced:
Check if the machine has last-applied-providerspec annotation.
Case 1.1
If the annotation is not present then there can be just 2 possibilities:
It is a fresh/new machine and no backing resources (VM/NIC/Disk) exist yet. The current flow checks if the providerID is empty and Status.CurrenStatus.Phase is empty then it enters into the triggerCreationFlow.
It is an existing machine which does not yet have this annotation. In this case call Driver.UpdateMachine. If the driver returns no error then add last-applied-providerspec annotation with the value of MachineClass.ProviderSpec to this machine.
Case 1.2
If the annotation is present then compare the last applied provider-spec with the current provider-spec. If there are changes (check their hash values) then call Driver.UpdateMachine. If the driver returns no error then add last-applied-providerspec annotation with the value of MachineClass.ProviderSpec to this machine.
NOTE: It is assumed that if there are changes to the fields which are not marked as hotupdatable then it will result in the change of name for MachineClass resulting in a rolling update of machines. If the name has not changed + machine is enqueued + there is a change in machine-class then it will be change to a hotupdatable fields in the spec.
Trigger update flow can be done after reconcileMachineHealth and syncMachineNodeTemplates in machine-reconciliation.
There are 2 edge cases that needs attention and special handling:
Premise: It is identified that there is an update done to one or more hotupdatable fields in the MachineClass.ProviderSpec.
Edge-Case-1
In the machine reconciliation, an update-machine-flow is triggered which in-turn calls Driver.UpdateMachine. Consider the case where the hot update needs to be done to all VM, NIC and Disk resources. The driver returns an error which indicates a partial-failure. As we have mentioned above only when Driver.UpdateMachine returns no error will last-applied-providerspec be updated. In case of partial failure the annotation will not be updated. This event will be re-queued for a re-attempt. However consider a case where before the item is re-queued, another update is done to MachineClass reverting back the changes to the original spec.
| At T1 | At T2 (T2 > T1) | At T3 (T3> T2) |
|---|
last-applied-providerspec=S1
MachineClass.ProviderSpec = S1 | last-applied-providerspec=S1
MachineClass.ProviderSpec = S2
Another update to MachineClass.ProviderConfig = S3 is enqueue (S3 == S1) | last-applied-providerspec=S1
Driver.UpdateMachine for S1-S2 update - returns partial failure
Machine-Key is requeued |
At T4 (T4> T3) when a machine is reconciled then it checks that last-applied-providerspec is S1 and current MachineClass.ProviderSpec = S3 and since S3 is same as S1, no update is done. At T2 Driver.UpdateMachine was called to update the machine with S2 but it partially failed. So now you will have resources which are partially updated with S2 and no further updates will be attempted.
Edge-Case-2
The above situation can also happen when Driver.UpdateMachine is in the process of updating resources. It has hot-updated lets say 1 resource. But now MCM crashes. By the time it comes up another update to MachineClass.ProviderSpec is done essentially reverting back the previous change (same case as above). In this case reconciliation loop never got a chance to get any response from the driver.
To handle the above edge cases there are 2 options:
Option #1
Introduce a new annotation inflight-providerspec-hash . The value of this annotation will be the hash value of the MachineClass.ProviderSpec that is in the process of getting applied on this machine. The machine will be updated with this annotation just before calling Driver.UpdateMachine (in the trigger-update-machine-flow). If the driver returns no error then (in a single update):
last-applied-providerspec will be updated
inflight-providerspec-hash annotation will be removed.
Option #2 - Preferred
Leverage Machine.Status.LastOperation with Type set to MachineOperationUpdate and State set to MachineStateProcessing This status will be updated just before calling Driver.UpdateMachine.
Semantically LastOperation captures the details of the operation post-operation and not pre-operation. So this solution would be a divergence from the norm.
2.4 - Initialize Machine
Post-Create Initialization of Machine Instance
Background
Today the driver.Driver facade represents the boundary between the the machine-controller and its various provider specific implementations.
We have abstract operations for creation/deletion and listing of machines (actually compute instances) but we do not correctly handle post-creation initialization logic. Nor do we provide an abstract operation to represent the hot update of an instance after creation.
We have found this to be necessary for several use cases. Today in the MCM AWS Provider, we already misuse driver.GetMachineStatus which is supposed to be a read-only operation obtaining the status of an instance.
Each AWS EC2 instance performs source/destination checks by default.
For EC2 NAT instances
these should be disabled. This is done by issuing
a ModifyInstanceAttribute request with the SourceDestCheck set to false. The MCM AWS Provider, decodes the AWSProviderSpec, reads providerSpec.SrcAndDstChecksEnabled and correspondingly issues the call to modify the already launched instance. However, this should be done as an action after creating the instance and should not be part of the VM status retrieval.
Similarly, there is a pending PR to add the Ipv6AddessCount and Ipv6PrefixCount to enable the assignment of an ipv6 address and an ipv6 prefix to instances. This requires constructing and issuing an AssignIpv6Addresses request after the EC2 instance is available.
We have other uses-cases such as MCM Issue#750 where there is a requirement to provide a way for consumers to add tags which can be hot-updated onto instances. This requirement can be generalized to also offer a convenient way to specify tags which can be applied to VMs, NICs, Devices etc.
We have a need for “machine-instance-not-ready” taint as described in MCM#740 which should only get removed once the post creation updates are finished.
Objectives
We will split the fulfilment of this overall need into 2 stages of implementation.
Stage-A: Support post-VM creation initialization logic of the instance suing a proposed Driver.InitializeMachine by permitting provider implementors to add initialization logic after VM creation, return with special new error code codes.Initialization for initialization errors and correspondingly support a new machine operation stage InstanceInitialization which will be updated in the machine LastOperation. The triggerCreationFlow - a reconciliation sub-flow of the MCM responsible for orchestrating instance creation and updating machine status will be changed to support this behaviour.
Stage-B: Introduction of Driver.UpdateMachine and enhancing the MCM, MCM providers and gardener extension providers to support hot update of instances through Driver.UpdateMachine. The MCM triggerUpdationFlow - a reconciliation sub-flow of the MCM which is supposed to be responsible for orchestrating instance update - but currently not used, will be updated to invoke the provider Driver.UpdateMachine on hot-updates to to the Machine object
Stage-A Proposal
Current MCM triggerCreationFlow
Today, reconcileClusterMachine which is the main routine for the Machine object reconciliation invokes triggerCreationFlow at the end when the machine.Spec.ProviderID is empty or if the machine.Status.CurrentStatus.Phase is empty or in CrashLoopBackOff
%%{ init: {
'themeVariables':
{ 'fontSize': '12px'}
} }%%
flowchart LR
other["..."]
-->chk{"machine ProviderID empty
OR
Phase empty or CrashLoopBackOff ?
"}--yes-->triggerCreationFlow
chk--noo-->LongRetry["return machineutils.LongRetry"]Today, the triggerCreationFlow is illustrated below with some minor details omitted/compressed for brevity
NOTES
- The
lastop below is an abbreviation for machine.Status.LastOperation. This, along with the machine phase is generally updated on the Machine object just before returning from the method. - regarding
phase=CrashLoopBackOff|Failed. the machine phase may either be CrashLoopBackOff or move to Failed if the difference between current time and the machine.CreationTimestamp has exceeded the configured MachineCreationTimeout.
%%{ init: {
'themeVariables':
{ 'fontSize': '12px'}
} }%%
flowchart TD
end1(("end"))
begin((" "))
medretry["return MediumRetry, err"]
shortretry["return ShortRetry, err"]
medretry-->end1
shortretry-->end1
begin-->AddBootstrapTokenToUserData
-->gms["statusResp,statusErr=driver.GetMachineStatus(...)"]
-->chkstatuserr{"Check statusErr"}
chkstatuserr--notFound-->chknodelbl{"Chk Node Label"}
chkstatuserr--else-->createFailed["lastop.Type=Create,lastop.state=Failed,phase=CrashLoopBackOff|Failed"]-->medretry
chkstatuserr--nil-->initnodename["nodeName = statusResp.NodeName"]-->setnodename
chknodelbl--notset-->createmachine["createResp, createErr=driver.CreateMachine(...)"]-->chkCreateErr{"Check createErr"}
chkCreateErr--notnil-->createFailed
chkCreateErr--nil-->getnodename["nodeName = createResp.NodeName"]
-->chkstalenode{"nodeName != machine.Name\n//chk stale node"}
chkstalenode--false-->setnodename["if unset machine.Labels['node']= nodeName"]
-->machinepending["if empty/crashloopbackoff lastop.type=Create,lastop.State=Processing,phase=Pending"]
-->shortretry
chkstalenode--true-->delmachine["driver.DeleteMachine(...)"]
-->permafail["lastop.type=Create,lastop.state=Failed,Phase=Failed"]
-->shortretry
subgraph noteA [" "]
permafail -.- note1(["VM was referring to stale node obj"])
end
style noteA opacity:0
subgraph noteB [" "]
setnodename-.- note2(["Proposal: Introduce Driver.InitializeMachine after this"])
endEnhancement of MCM triggerCreationFlow
Relevant Observations on Current Flow
- Observe that we always perform a call to
Driver.GetMachineStatus and only then conditionally perform a call to Driver.CreateMachine if there was was no machine found. - Observe that after the call to a successful
Driver.CreateMachine, the machine phase is set to Pending, the LastOperation.Type is currently set to Create and the LastOperation.State set to Processing before returning with a ShortRetry. The LastOperation.Description is (unfortunately) set to the fixed message: Creating machine on cloud provider. - Observe that after an erroneous call to
Driver.CreateMachine, the machine phase is set to CrashLoopBackOff or Failed (in case of creation timeout).
The following changes are proposed with a view towards minimal impact on current code and no introduction of a new Machine Phase.
MCM Changes
- We propose introducing a new machine operation
Driver.InitializeMachine with the following signaturetype Driver interface {
// .. existing methods are omitted for brevity.
// InitializeMachine call is responsible for post-create initialization of the provider instance.
InitializeMachine(context.Context, *InitializeMachineRequest) error
}
// InitializeMachineRequest is the initialization request for machine instance initialization
type InitializeMachineRequest struct {
// Machine object whose VM instance should be initialized
Machine *v1alpha1.Machine
// MachineClass backing the machine object
MachineClass *v1alpha1.MachineClass
// Secret backing the machineClass object
Secret *corev1.Secret
}
- We propose introducing a new MC error code
codes.Initialization indicating that the VM Instance was created but there was an error in initialization after VM creation. The implementor of Driver.InitializeMachine can return this error code, indicating that InitializeMachine needs to be called again. The Machine Controller will change the phase to CrashLoopBackOff as usual when encountering a codes.Initialization error. - We will introduce a new machine operation stage
InstanceInitialization. In case of an codes.Initialization error- the
machine.Status.LastOperation.Description will be set to InstanceInitialization, machine.Status.LastOperation.ErrorCode will be set to codes.Initialization- the
LastOperation.Type will be set to Create - the
LastOperation.State set to Failed before returning with a ShortRetry
- The semantics of
Driver.GetMachineStatus will be changed. If the instance associated with machine exists, but the instance was not initialized as expected, the provider implementations of GetMachineStatus should return an error: status.Error(codes.Initialization). - If
Driver.GetMachineStatus returned an error encapsulating codes.Initialization then Driver.InitializeMachine will be invoked again in the triggerCreationFlow. - As according to the usual logic, the main machine controller reconciliation loop will now re-invoke the
triggerCreationFlow again if the machine phase is CrashLoopBackOff.
Illustration

AWS Provider Changes
Driver.InitializeMachine
The implementation for the AWS Provider will look something like:
- After the VM instance is available, check
providerSpec.SrcAndDstChecksEnabled, construct ModifyInstanceAttributeInput and call ModifyInstanceAttribute. In case of an error return codes.Initialization instead of the current codes.Internal - Check
providerSpec.NetworkInterfaces and if Ipv6PrefixCount is not nil, then construct AssignIpv6AddressesInput and call AssignIpv6Addresses. In case of an error return codes.Initialization. Don’t use the generic codes.Internal
The existing Ipv6 PR will need modifications.
Driver.GetMachineStatus
- If
providerSpec.SrcAndDstChecksEnabled is false, check ec2.Instance.SourceDestCheck. If it does not match then return status.Error(codes.Initialization) - Check
providerSpec.NetworkInterfaces and if Ipv6PrefixCount is not nil, check ec2.Instance.NetworkInterfaces and check if InstanceNetworkInterface.Ipv6Addresses has a non-nil slice. If this is not the case then return status.Error(codes.Initialization)
Instance Not Ready Taint
- Due to the fact that creation flow for machines will now be enhanced to correctly support post-creation startup logic, we should not scheduled workload until this startup logic is complete. Even without this feature we have a need for such a taint as described in MCM#740
- We propose a new taint
node.machine.sapcloud.io/instance-not-ready which will be added as a node startup taint in gardener core KubeletConfiguration.RegisterWithTaints - The will will then removed by MCM in health check reconciliation, once the machine becomes fully ready. (when moving to
Running phase) - We will add this taint as part of
--ignore-taint in CA - We will introduce a disclaimer / prerequisite in the MCM FAQ, to add this taint as part of kubelet config under
--register-with-taints, otherwise workload could get scheduled , before machine beomes Running
Stage-B Proposal
Enhancement of Driver Interface for Hot Updation
Kindly refer to the Hot-Update Instances design which provides elaborate detail.
3 - To-Do
3.1 - Outline
Machine Controller Manager
CORE – ./machine-controller-manager(provider independent)
Out of tree : Machine controller (provider specific)
MCM is a set controllers:
Questions and refactoring Suggestions
Refactoring
| Statement | FilePath | Status |
|---|
ConcurrentNodeSyncs” bad name - nothing to do with node syncs actually.
If its value is ’10’ then it will start 10 goroutines (workers) per resource type (machine, machinist, machinedeployment, provider-specific-class, node - study the different resource types. | cmd/machine-controller-manager/app/options/options.go | pending |
| LeaderElectionConfiguration is very similar to the one present in “client-go/tools/leaderelection/leaderelection.go” - can we simply used the one in client-go instead of defining again? | pkg/options/types.go - MachineControllerManagerConfiguration | pending |
| Have all userAgents as constant. Right now there is just one. | cmd/app/controllermanager.go | pending |
| Shouldn’t run function be defined on MCMServer struct itself? | cmd/app/controllermanager.go | pending |
| clientcmd.BuildConfigFromFlags fallsback to inClusterConfig which will surely not work as that is not the target. Should it not check and exit early? | cmd/app/controllermanager.go - run Function | pending |
A more direct way to create an in cluster config is using k8s.io/client-go/rest -> rest.InClusterConfig instead of using clientcmd.BuildConfigFromFlags passing empty arguments and depending upon the implementation to fallback to creating a inClusterConfig. If they change the implementation that you get affected. | cmd/app/controllermanager.go - run Function | pending |
| Introduce a method on MCMServer which gets a target KubeConfig and controlKubeConfig or alternatively which creates respective clients. | cmd/app/controllermanager.go - run Function | pending |
| Why can’t we use Kubernetes.NewConfigOrDie also for kubeClientControl? | cmd/app/controllermanager.go - run Function | pending |
| I do not see any benefit of client builders actually. All you need to do is pass in a config and then directly use client-go functions to create a client. | cmd/app/controllermanager.go - run Function | pending |
| Function: getAvailableResources - rename this to getApiServerResources | cmd/app/controllermanager.go | pending |
| Move the method which waits for API server to up and ready to a separate method which returns a discoveryClient when the API server is ready. | cmd/app/controllermanager.go - getAvailableResources function | pending |
| Many methods in client-go used are now deprecated. Switch to the ones that are now recommended to be used instead. | cmd/app/controllermanager.go - startControllers | pending |
| This method needs a general overhaul | cmd/app/controllermanager.go - startControllers | pending |
| If the design is influenced/copied from KCM then its very different. There are different controller structs defined for deployment, replicaset etc which makes the code much more clearer. You can see “kubernetes/cmd/kube-controller-manager/apps.go” and then follow the trail from there. - agreed needs to be changed in future (if time permits) | pkg/controller/controller.go | pending |
| I am not sure why “MachineSetControlInterface”, “RevisionControlInterface”, “MachineControlInterface”, “FakeMachineControl” are defined in this file? | pkg/controller/controller_util.go | pending |
IsMachineActive - combine the first 2 conditions into one with OR. | pkg/controller/controller_util.go | pending |
| Minor change - correct the comment, first word should always be the method name. Currently none of the comments have correct names. | pkg/controller/controller_util.go | pending |
| There are too many deep copies made. What is the need to make another deep copy in this method? You are not really changing anything here. | pkg/controller/deployment.go - updateMachineDeploymentFinalizers | pending |
| Why can’t these validations be done as part of a validating webhook? | pkg/controller/machineset.go - reconcileClusterMachineSet | pending |
Small change to the following if condition. else if is not required a simple else is sufficient. Code1 | | |
| pkg/controller/machineset.go - reconcileClusterMachineSet | pending | |
Why call these inactiveMachines, these are live and running and therefore active. | pkg/controller/machineset.go - terminateMachines | pending |
Clarification
| Statement | FilePath | Status |
|---|
| Why are there 2 versions - internal and external versions? | General | pending |
Safety controller freezes MCM controllers in the following cases:
* Num replicas go beyond a threshold (above the defined replicas)
* Target API service is not reachable
There seems to be an overlap between DWD and MCM Safety controller. In the meltdown scenario why is MCM being added to DWD, you could have used Safety controller for that. | General | pending |
| All machine resources are v1alpha1 - should we not promote it to beta. V1alpha1 has a different semantic and does not give any confidence to the consumers. | cmd/app/controllermanager.go | pending |
Shouldn’t controller manager use context.Context instead of creating a stop channel? - Check if signals (os.Interrupt and SIGTERM are handled properly. Do not see code where this is handled currently.) | cmd/app/controllermanager.go | pending |
| What is the rationale behind a timeout of 10s? If the API server is not up, should this not just block as it can anyways not do anything. Also, if there is an error returned then you exit the MCM which does not make much sense actually as it will be started again and you will again do the poll for the API server to come back up. Forcing an exit of MCM will not have any impact on the reachability of the API server in anyway so why exit? | cmd/app/controllermanager.go - getAvailableResources | pending |
There is a very weird check - availableResources[machineGVR] || availableResources[machineSetGVR] || availableResources[machineDeploymentGVR]
Shouldn’t this be conjunction instead of disjunction?
* What happens if you do not find one or all of these resources?
Currently an error log is printed and nothing else is done. MCM can be used outside gardener context where consumers can directly create MachineClass and Machine and not create MachineSet / Maching Deployment. There is no distinction made between context (gardener or outside-gardener).
| cmd/app/controllermanager.go - StartControllers | pending |
| Instead of having an empty select {} to block forever, isn’t it better to wait on the stop channel? | cmd/app/controllermanager.go - StartControllers | pending |
| Do we need provider specific queues and syncs and listers | pkg/controller/controller.go | pending |
| Why are resource types prefixed with “Cluster”? - not sure , check PR | pkg/controller/controller.go | pending |
| When will forgetAfterSuccess be false and why? - as per the current code this is never the case. - Himanshu will check | cmd/app/controllermanager.go - createWorker | pending |
What is the use of “ExpectationsInterface” and “UIDTrackingContExpectations”?
* All expectations related code should be in its own file “expectations.go” and not in this file. | pkg/controller/controller_util.go | pending |
| Why do we not use lister but directly use the controlMachingClient to get the deployment? Is it because you want to avoid any potential delays caused by update of the local cache held by the informer and accessed by the lister? What is the load on API server due to this? | pkg/controller/deployment.go - reconcileClusterMachineDeployment | pending |
| Why is this conversion needed? code2 | pkg/controller/deployment.go - reconcileClusterMachineDeployment | pending |
A deep copy of machineDeployment is already passed and within the function another deepCopy is made. Any reason for it? | pkg/controller/deployment.go - addMachineDeploymentFinalizers | pending |
What is an Status.ObservedGeneration?
*Read more about generations and observedGeneration at:
https://github.com/kubernetes/community/blob/master/contributors/devel/sig-architecture/api-conventions.md#metadata
https://alenkacz.medium.com/kubernetes-operator-best-practices-implementing-observedgeneration-250728868792
Ideally the update to the ObservedGeneration should only be made after successful reconciliation and not before. I see that this is just copied from deployment_controller.go as is | pkg/controller/deployment.go - reconcileClusterMachineDeployment | pending |
Why and when will a MachineDeployment be marked as frozen and when will it be un-frozen? | pkg/controller/deployment.go - reconcileClusterMachineDeployment | pending |
| Shoudn’t the validation of the machine deployment be done during the creation via a validating webhook instead of allowing it to be stored in etcd and then failing the validation during sync? I saw the checks and these can be done via validation webhook. | pkg/controller/deployment.go - reconcileClusterMachineDeployment | pending |
| RollbackTo has been marked as deprecated. What is the replacement? code3 | pkg/controller/deployment.go - reconcileClusterMachineDeployment | pending |
What is the max machineSet deletions that you could process in a single run? The reason for asking this question is that for every machineSetDeletion a new goroutine spawned.
* Is the Delete call a synchrounous call? Which means it blocks till the machineset deletion is triggered which then also deletes the machines (due to cascade-delete and blockOwnerDeletion= true)? | pkg/controller/deployment.go - terminateMachineSets | pending |
If there are validation errors or error when creating label selector then a nil is returned. In the worker reconcile loop if the return value is nil then it will remove it from the queue (forget + done). What is the way to see any errors? Typically when we describe a resource the errors are displayed. Will these be displayed when we discribe a MachineDeployment? | pkg/controller/deployment.go - reconcileClusterMachineSet | pending |
If an error is returned by updateMachineSetStatus and it is IsNotFound error then returning an error will again queue the MachineSet. Is this desired as IsNotFound indicates the MachineSet has been deleted and is no longer there? | pkg/controller/deployment.go - reconcileClusterMachineSet | pending |
is machineControl.DeleteMachine a synchronous operation which will wait till the machine has been deleted? Also where is the DeletionTimestamp set on the Machine? Will it be automatically done by the API server? | pkg/controller/deployment.go - prepareMachineForDeletion | pending |
Bugs/Enhancements
| Statement + TODO | FilePath | Status |
|---|
| This defines QPS and Burst for its requests to the KAPI. Check if it would make sense to explicitly define a FlowSchema and PriorityLevelConfiguration to ensure that the requests from this controller are given a well-defined preference. What is the rational behind deciding these values? | pkg/options/types.go - MachineControllerManagerConfiguration | pending |
| In function “validateMachineSpec” fldPath func parameter is never used. | pkg/apis/machine/validation/machine.go | pending |
| If there is an update failure then this method recursively calls itself without any sort of delays which could lead to a LOT of load on the API server. (opened: https://github.com/gardener/machine-controller-manager/issues/686) | pkg/controller/deployment.go - updateMachineDeploymentFinalizers | pending |
We are updating filteredMachines by invoking syncMachinesNodeTemplates, syncMachinesConfig and syncMachinesClassKind but we do not create any deepCopy here. Everywhere else the general principle is when you mutate always make a deepCopy and then mutate the copy instead of the original as a lister is used and that changes the cached copy.
Fix: SatisfiedExpectations check has been commented and there is a TODO there to fix it. Is there a PR for this? | pkg/controller/machineset.go - reconcileClusterMachineSet | pending |
Code references
1.1 code1
if machineSet.DeletionTimestamp == nil {
// manageReplicas is the core machineSet method where scale up/down occurs
// It is not called when deletion timestamp is set
manageReplicasErr = c.manageReplicas(ctx, filteredMachines, machineSet)
} else if machineSet.DeletionTimestamp != nil {
//FIX: change this to simple else without the if
1.2 code2
defer dc.enqueueMachineDeploymentAfter(deployment, 10*time.Minute)
* `Clarification`: Why is this conversion needed?
err = v1alpha1.Convert_v1alpha1_MachineDeployment_To_machine_MachineDeployment(deployment, internalMachineDeployment, nil)
1.3 code3
// rollback is not re-entrant in case the underlying machine sets are updated with a new
// revision so we should ensure that we won't proceed to update machine sets until we
// make sure that the deployment has cleaned up its rollback spec in subsequent enqueues.
if d.Spec.RollbackTo != nil {
return dc.rollback(ctx, d, machineSets, machineMap)
}
4 - FAQ
Commonly asked questions about MCM
Frequently Asked Questions
The answers in this FAQ apply to the newest (HEAD) version of Machine Controller Manager. If
you’re using an older version of MCM please refer to corresponding version of
this document. Few of the answers assume that the MCM being used is in conjuction with cluster-autoscaler:
Table of Contents:
Basics
What is Machine Controller Manager?
Machine Controller Manager aka MCM is a bunch of controllers used for the lifecycle management of the worker machines. It reconciles a set of CRDs such as Machine, MachineSet, MachineDeployment which depicts the functionality of Pod, Replicaset, Deployment of the core Kubernetes respectively. Read more about it at README.
- Gardener uses MCM to manage its Kubernetes nodes of the shoot cluster. However, by design, MCM can be used independent of Gardener.
Why is my machine deleted?
A machine is deleted by MCM generally for 2 reasons-
- Machine is unhealthy for at least
MachineHealthTimeout period. The default MachineHealthTimeout is 10 minutes.- By default, a machine is considered unhealthy if any of the following node conditions -
DiskPressure, KernelDeadlock, FileSystem, Readonly is set to true, or KubeletReady is set to false. However, this is something that is configurable using the following flag.
- Machine is scaled down by the
MachineDeployment resource.- This is very usual when an external controller cluster-autoscaler (aka CA) is used with MCM. CA deletes the under-utilized machines by scaling down the
MachineDeployment. Read more about cluster-autoscaler’s scale down behavior here.
What are the different sub-controllers in MCM?
MCM mainly contains the following sub-controllers:
MachineDeployment Controller: Responsible for reconciling the MachineDeployment objects. It manages the lifecycle of the MachineSet objects.MachineSet Controller: Responsible for reconciling the MachineSet objects. It manages the lifecycle of the Machine objects.Machine Controller: responsible for reconciling the Machine objects. It manages the lifecycle of the actual VMs/machines created in cloud/on-prem. This controller has been moved out of tree. Please refer an AWS machine controller for more info - link.- Safety-controller: Responsible for handling the unidentified/unknown behaviors from the cloud providers. Please read more about its functionality below.
What is Safety Controller in MCM?
Safety Controller contains following functions:
- Orphan VM handler:
- It lists all the VMs in the cloud matching the
tag of given cluster name and maps the VMs with the machine objects using the ProviderID field. VMs without any backing machine objects are logged and deleted after confirmation. - This handler runs every 30 minutes and is configurable via machine-safety-orphan-vms-period flag.
- Freeze mechanism:
Safety Controller freezes the MachineDeployment and MachineSet controller if the number of machine objects goes beyond a certain threshold on top of Spec.Replicas. It can be configured by the flag –safety-up or –safety-down and also machine-safety-overshooting-period.Safety Controller freezes the functionality of the MCM if either of the target-apiserver or the control-apiserver is not reachable.Safety Controller unfreezes the MCM automatically once situation is resolved to normal. A freeze label is applied on MachineDeployment/MachineSet to enforce the freeze condition.
How to?
How to install MCM in a Kubernetes cluster?
MCM can be installed in a cluster with following steps:
- Apply all the CRDs from here
- Apply all the deployment, role-related objects from here.
- Control cluster is the one where the
machine-* objects are stored. Target cluster is where all the node objects are registered.
How to better control the rollout process of the worker nodes?
MCM allows configuring the rollout of the worker machines using maxSurge and maxUnavailable fields. These fields are applicable only during the rollout process and means nothing in general scale up/down scenarios.
The overall process is very similar to how the Deployment Controller manages pods during RollingUpdate.
maxSurge refers to the number of additional machines that can be added on top of the Spec.Replicas of MachineDeployment during rollout process.maxUnavailable refers to the number of machines that can be deleted from Spec.Replicas field of the MachineDeployment during rollout process.
How to scale down MachineDeployment by selective deletion of machines?
During scale down, triggered via MachineDeployment/MachineSet, MCM prefers to delete the machine/s which have the least priority set.
Each machine object has an annotation machinepriority.machine.sapcloud.io set to 3 by default. Admin can reduce the priority of the given machines by changing the annotation value to 1. The next scale down by MachineDeployment shall delete the machines with the least priority first.
How to force delete a machine?
A machine can be force deleted by adding the label force-deletion: "True" on the machine object before executing the actual delete command. During force deletion, MCM skips the drain function and simply triggers the deletion of the machine. This label should be used with caution as it can violate the PDBs for pods running on the machine.
How to pause the ongoing rolling-update of the machinedeployment?
An ongoing rolling-update of the machine-deployment can be paused by using spec.paused field. See the example below:
apiVersion: machine.sapcloud.io/v1alpha1
kind: MachineDeployment
metadata:
name: test-machine-deployment
spec:
paused: true
It can be unpaused again by removing the Paused field from the machine-deployment.
How to delete machine object immedietly if I don’t have access to it?
If the user doesn’t have access to the machine objects (like in case of Gardener clusters) and they would like to replace a node immedietly then they can place the annotation node.machine.sapcloud.io/trigger-deletion-by-mcm: "true" on their node. This will start the replacement of the machine with a new node.
On the other hand if the user deletes the node object immedietly then replacement will start only after MachineHealthTimeout.
This annotation can also be used if the user wants to expedite the replacement of unhealthy nodes
NOTE:
node.machine.sapcloud.io/trigger-deletion-by-mcm: "false" annotation is NOT acted upon by MCM , neither does it mean that MCM will not replace this machine.- this annotation would delete the desired machine but another machine would be created to maintain
desired replicas specified for the machineDeployment/machineSet. Currently if the user doesn’t have access to machineDeployment/machineSet then they cannot remove a machine without replacement.
How to avoid garbage collection of your node?
MCM provides an in-built safety mechanism to garbage collect VMs which have no corresponding machine object. This is done to save costs and is one of the key features of MCM.
However, sometimes users might like to add nodes directly to the cluster without the help of MCM and would prefer MCM to not garbage collect such VMs.
To do so they should remove/not-use tags on their VMs containing the following strings:
kubernetes.io/cluster/kubernetes.io/role/kubernetes-io-cluster-kubernetes-io-role-
How to trigger rolling update of a machinedeployment?
Rolling update can be triggered for a machineDeployment by updating one of the following:
.spec.template.annotations.spec.template.spec.class.name
Internals
What is the high level design of MCM?
Please refer the following document.
What are the different configuration options in MCM?
MCM allows configuring many knobs to fine-tune its behavior according to the user’s need.
Please refer to the link to check the exact configuration options.
What are the different timeouts/configurations in a machine’s lifecycle?
A machine’s lifecycle is governed by mainly following timeouts, which can be configured here.
MachineDrainTimeout: Amount of time after which drain times out and the machine is force deleted. Default ~2 hours.MachineHealthTimeout: Amount of time after which an unhealthy machine is declared Failed and the machine is replaced by MachineSet controller.MachineCreationTimeout: Amount of time after which a machine creation is declared Failed and the machine is replaced by the MachineSet controller.NodeConditions: List of node conditions which if set to true for MachineHealthTimeout period, the machine is declared Failed and replaced by MachineSet controller.MaxEvictRetries: An integer number depicting the number of times a failed eviction should be retried on a pod during drain process. A pod is deleted after max-retries.
How is the drain of a machine implemented?
MCM imports the functionality from the upstream Kubernetes-drain library. Although, few parts have been modified to make it work best in the context of MCM. Drain is executed before machine deletion for graceful migration of the applications.
Drain internally uses the EvictionAPI to evict the pods and triggers the Deletion of pods after MachineDrainTimeout. Please note:
- Stateless pods are evicted in parallel.
- Stateful applications (with PVCs) are serially evicted. Please find more info in this answer below.
How are the stateful applications drained during machine deletion?
Drain function serially evicts the stateful-pods. It is observed that serial eviction of stateful pods yields better overall availability of pods as the underlying cloud in most cases detaches and reattaches disks serially anyways.
It is implemented in the following manner:
- Drain lists all the pods with attached volumes. It evicts very first stateful-pod and waits for its related entry in Node object’s
.status.volumesAttached to be removed by KCM. It does the same for all the stateful-pods. - It waits for
PvDetachTimeout (default 2 minutes) for a given pod’s PVC to be removed, else moves forward.
How does maxEvictRetries configuration work with drainTimeout configuration?
It is recommended to only set MachineDrainTimeout. It satisfies the related requirements. MaxEvictRetries is auto-calculated based on MachineDrainTimeout, if maxEvictRetries is not provided. Following will be the overall behavior of both configurations together:
- If
maxEvictRetries isn’t set and only maxDrainTimeout is set:- MCM auto calculates the
maxEvictRetries based on the drainTimeout.
- If
drainTimeout isn’t set and only maxEvictRetries is set:- Default
drainTimeout and user provided maxEvictRetries for each pod is considered.
- If both
maxEvictRetries and drainTimoeut are set:- Then both will be respected.
- If none are set:
What are the different phases of a machine?
A phase of a machine can be identified with Machine.Status.CurrentStatus.Phase. Following are the possible phases of a machine object:
Pending: Machine creation call has succeeded. MCM is waiting for machine to join the cluster.
CrashLoopBackOff: Machine creation call has failed. MCM will retry the operation after a minor delay.
Running: Machine creation call has succeeded. Machine has joined the cluster successfully and corresponding node doesn’t have node.gardener.cloud/critical-components-not-ready taint.
Unknown: Machine health checks are failing, e.g., kubelet has stopped posting the status.
Failed: Machine health checks have failed for a prolonged time. Hence it is declared failed by Machine controller in a rate limited fashion. Failed machines get replaced immediately.
Terminating: Machine is being terminated. Terminating state is set immediately when the deletion is triggered for the machine object. It also includes time when it’s being drained.
NOTE: No phase means the machine is being created on the cloud-provider.
Below is a simple phase transition diagram:
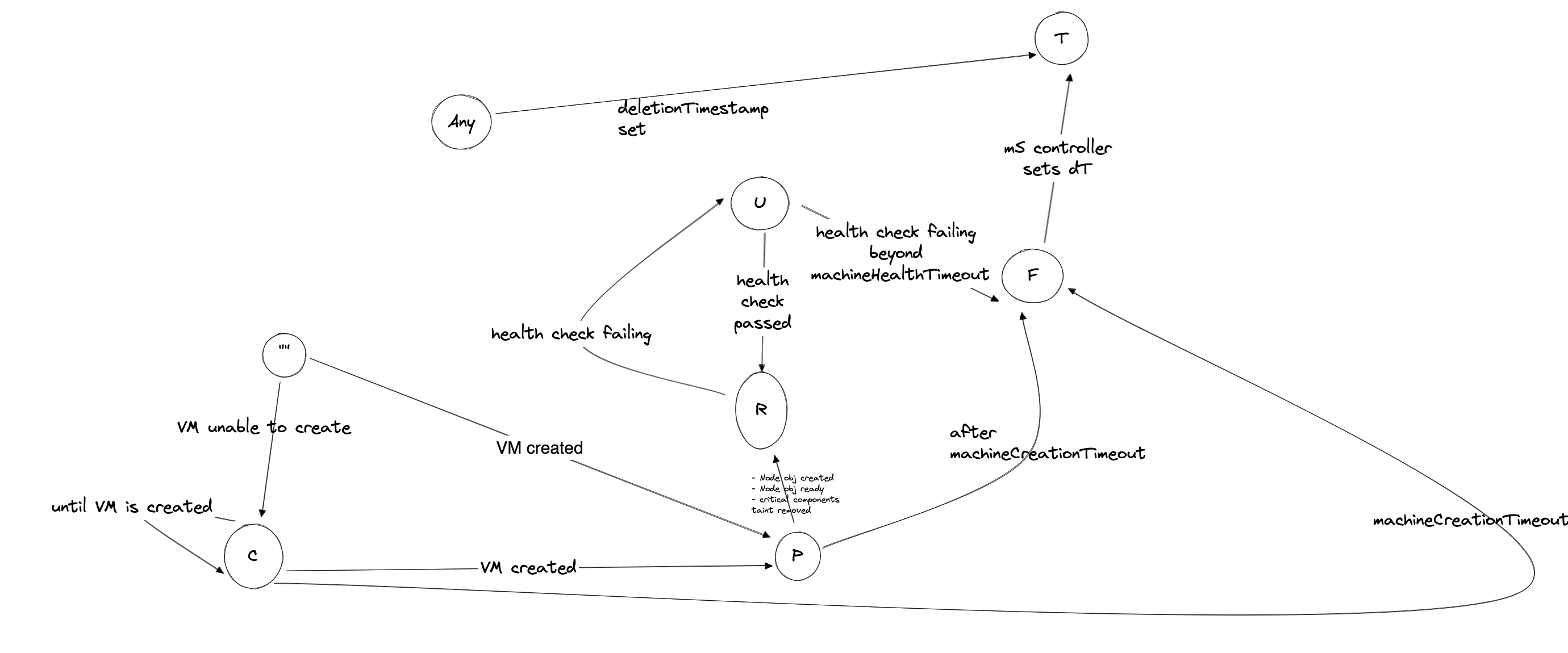
Health check performed on a machine are:
- Existense of corresponding node obj
- Status of certain user-configurable node conditions.
- These conditions can be specified using the flag
--node-conditions for OOT MCM provider or can be specified per machine object. - The default user configurable node conditions can be found here
True status of NodeReady condition . This condition shows kubelet’s status
If any of the above checks fails , the machine turns to Unknown phase.
Currently MCM replaces only 1 Unknown machine at a time per machinedeployment. This means until the particular Unknown machine get terminated and its replacement joins, no other Unknown machine would be removed.
The above is achieved by enabling Machine controller to turn machine from Unknown -> Failed only if the above condition is met. MachineSet controller on the other hand marks Failed machine as Terminating immediately.
One reason for this rate limited replacement was to ensure that in case of network failures , where node’s kubelet can’t reach out to kube-apiserver , all nodes are not removed together i.e. meltdown protection.
In gardener context however, DWD is deployed to deal with this scenario, but to stay protected from corner cases, this mechanism has been introduced in MCM.
NOTE: Rate limiting replacement is not yet configurable
How MCM responds when scale-out/scale-in is done during rolling update of a machinedeployment?
Machinedeployment controller executes the logic of scaling BEFORE logic of rollout. It identifies scaling by comparing the deployment.kubernetes.io/desired-replicas of each machineset under the machinedeployment with machinedeployment’s .spec.replicas. If the difference is found for any machineSet, a scaling event is detected.
- Case
scale-out -> ONLY New machineSet is scaled out - Case
scale-in -> ALL machineSets(new or old) are scaled in , in proportion to their replica count , any leftover is adjusted in the largest machineSet.
During update for scaling event, a machineSet is updated if any of the below is true for it:
.spec.Replicas needs updatedeployment.kubernetes.io/desired-replicas needs update
Once scaling is achieved, rollout continues.
How does MCM prioritize the machines for deletion on scale-down of machinedeployment?
There could be many machines under a machinedeployment with different phases, creationTimestamp. When a scale down is triggered, MCM decides to remove the machine using the following logic:
- Machine with least value of
machinepriority.machine.sapcloud.io annotation is picked up. - If all machines have equal priorities, then following precedence is followed:
- Terminating > Failed > CrashloopBackoff > Unknown > Pending > Available > Running
- If still there is no match, the machine with oldest creation time (.i.e. creationTimestamp) is picked up.
How some unhealthy machines are drained quickly?
If a node is unhealthy for more than the machine-health-timeout specified for the machine-controller, the controller
health-check moves the machine phase to Failed. By default, the machine-health-timeout is 10` minutes.
Failed machines have their deletion timestamp set and the machine then moves to the Terminating phase. The node
drain process is initiated. The drain process is invoked either gracefully or forcefully.
The usual drain process is graceful. Pods are evicted from the node and the drain process waits until any existing
attached volumes are mounted on new node. However, if the node Ready is False or the ReadonlyFilesystem is True
for greater than 5 minutes (non-configurable), then a forceful drain is initiated. In a forceful drain, pods are deleted
and VolumeAttachment objects associated with the old node are also marked for deletion. This is followed by the deletion of the
cloud provider VM associated with the Machine and then finally ending with the Node object deletion.
During the deletion of the VM we only delete the local data disks and boot disks associated with the VM. The disks associated
with persistent volumes are left un-touched as their attach/de-detach, mount/unmount processes are handled by k8s
attach-detach controller in conjunction with the CSI driver.
Troubleshooting
My machine is stuck in deletion for 1 hr, why?
In most cases, the Machine.Status.LastOperation provides information around why a machine can’t be deleted.
Though following could be the reasons but not limited to:
- Pod/s with misconfigured PDBs block the drain operation. PDBs with
maxUnavailable set to 0, doesn’t allow the eviction of the pods. Hence, drain/eviction is retried till MachineDrainTimeout. Default MachineDrainTimeout could be as large as ~2hours. Hence, blocking the machine deletion.- Short term: User can manually delete the pod in the question, with caution.
- Long term: Please set more appropriate PDBs which allow disruption of at least one pod.
- Expired cloud credentials can block the deletion of the machine from infrastructure.
- Cloud provider can’t delete the machine due to internal errors. Such situations are best debugged by using cloud provider specific CLI or cloud console.
My machine is not joining the cluster, why?
In most cases, the Machine.Status.LastOperation provides information around why a machine can’t be created.
It could possibly be debugged with following steps:
- Firstly make sure all the relevant controllers like
kube-controller-manager , cloud-controller-manager are running. - Verify if the machine is actually created in the cloud. User can use the
Machine.Spec.ProviderId to query the machine in cloud. - A Kubernetes node is generally bootstrapped with the cloud-config. Please verify, if
MachineDeployment is pointing the correct MachineClass, and MachineClass is pointing to the correct Secret. The secret object contains the actual cloud-config in base64 format which will be used to boot the machine. - User must also check the logs of the MCM pod to understand any broken logical flow of reconciliation.
My rolling update is stuck, why?
The following can be the reason:
- Insufficient capacity for the new instance type the machineClass mentions.
- Old machines are stuck in deletion
- If you are using Gardener for setting up kubernetes cluster, then machine object won’t turn to
Running state until node-critical-components are ready. Refer this for more details.
Developer
How should I test my code before submitting a PR?
Developer can locally setup the MCM using following guide
Developer must also enhance the unit tests related to the incoming changes.
Developer can run the unit test locally by executing:
Developer can locally run integration tests to ensure basic functionality of MCM is not altered.
I need to change the APIs, what are the recommended steps?
Developer should add/update the API fields at both of the following places:
Once API changes are done, auto-generate the code using following command:
Please ignore the API-violation errors for now.
How can I update the dependencies of MCM?
MCM uses gomod for depedency management.
Developer should add/udpate depedency in the go.mod file. Please run following command to automatically tidy the dependencies.
In the context of Gardener
All of the knobs of MCM can be configured by the workers section of the shoot resource.
- Gardener creates a
MachineDeployment per zone for each worker-pool under workers section. workers.dataVolumes allows to attach multiple disks to a machine during creation. Refer the link.workers.machineControllerManager allows configuration of multiple knobs of the MachineDeployment from the shoot resource.
How is my worker-pool spread across zones?
Shoot resource allows the worker-pool to spread across multiple zones using the field workers.zones. Refer link.
5 - Adding Support for a Cloud Provider
Adding support for a new provider
Steps to be followed while implementing a new (hyperscale) provider are mentioned below. This is the easiest way to add new provider support using a blueprint code.
However, you may also develop your machine controller from scratch, which would provide you with more flexibility. First, however, make sure that your custom machine controller adheres to the Machine.Status struct defined in the MachineAPIs. This will make sure the MCM can act with higher-level controllers like MachineSet and MachineDeployment controller. The key is the Machine.Status.CurrentStatus.Phase key that indicates the status of the machine object.
Our strong recommendation would be to follow the steps below. This provides the most flexibility required to support machine management for adding new providers. And if you feel to extend the functionality, feel free to update our machine controller libraries.
Setting up your repository
- Create a new empty repository named
machine-controller-manager-provider-{provider-name} on GitHub username/project. Do not initialize this repository with a README. - Copy the remote repository
URL (HTTPS/SSH) to this repository displayed once you create this repository. - Now, on your local system, create directories as required. {your-github-username} given below could also be {github-project} depending on where you have created the new repository.
mkdir -p $GOPATH/src/github.com/{your-github-username}
- Navigate to this created directory.
cd $GOPATH/src/github.com/{your-github-username}
- Clone this repository on your local machine.
git clone git@github.com:gardener/machine-controller-manager-provider-sampleprovider.git
- Rename the directory from
machine-controller-manager-provider-sampleprovider to machine-controller-manager-provider-{provider-name}.mv machine-controller-manager-provider-sampleprovider machine-controller-manager-provider-{provider-name}
- Navigate into the newly-created directory.
cd machine-controller-manager-provider-{provider-name}
- Update the remote
origin URL to the newly created repository’s URL you had copied above.git remote set-url origin git@github.com:{your-github-username}/machine-controller-manager-provider-{provider-name}.git
- Rename GitHub project from
gardener to {github-org/your-github-username} wherever you have cloned the repository above. Also, edit all occurrences of the word sampleprovider to {provider-name} in the code. Then, use the hack script given below to do the same.make rename-project PROJECT_NAME={github-org/your-github-username} PROVIDER_NAME={provider-name}
eg:
make rename-project PROJECT_NAME=gardener PROVIDER_NAME=AmazonWebServices (or)
make rename-project PROJECT_NAME=githubusername PROVIDER_NAME=AWS
- Now, commit your changes and push them upstream.
git add -A
git commit -m "Renamed SampleProvide to {provider-name}"
git push origin master
Code changes required
The contract between the Machine Controller Manager (MCM) and the Machine Controller (MC) AKA driver has been documented here and the machine error codes can be found here. You may refer to them for any queries.
⚠️
- Keep in mind that there should be a unique way to map between machine objects and VMs. This can be done by mapping machine object names with VM-Name/ tags/ other metadata.
- Optionally, there should also be a unique way to map a VM to its machine class object. This can be done by tagging VM objects with tags/resource groups associated with the machine class.
Steps to integrate
- Update the
pkg/provider/apis/provider_spec.go specification file to reflect the structure of the ProviderSpec blob. It typically contains the machine template details in the MachineClass object. Follow the sample spec provided already in the file. A sample provider specification can be found here. - Fill in the methods described at
pkg/provider/core.go to manage VMs on your cloud provider. Comments are provided above each method to help you fill them up with desired REQUEST and RESPONSE parameters.- A sample provider implementation for these methods can be found here.
- Fill in the required methods
CreateMachine(), and DeleteMachine() methods. - Optionally fill in methods like
GetMachineStatus(), InitializeMachine, ListMachines(), and GetVolumeIDs(). You may choose to fill these once the working of the required methods seems to be working. GetVolumeIDs() expects VolumeIDs to be decoded from the volumeSpec based on the cloud provider.- There is also an OPTIONAL method
GenerateMachineClassForMigration() that helps in migration of {ProviderSpecific}MachineClass to MachineClass CR (custom resource). This only makes sense if you have an existing implementation (in-tree) acting on different CRD types. You would like to migrate this. If not, you MUST return an error (machine error UNIMPLEMENTED) to avoid processing this step.
- Perform validation of APIs that you have described and make it a part of your methods as required at each request.
- Write unit tests to make it work with your implementation by running
make test. - Tidy the go dependencies.
- Update the sample YAML files on the
kubernetes/ directory to provide sample files through which the working of the machine controller can be tested. - Update
README.md to reflect any additional changes
Testing your code changes
Make sure $TARGET_KUBECONFIG points to the cluster where you wish to manage machines. Likewise, $CONTROL_NAMESPACE represents the namespaces where MCM is looking for machine CR objects, and $CONTROL_KUBECONFIG points to the cluster that holds these machine CRs.
- On the first terminal running at
$GOPATH/src/github.com/{github-org/your-github-username}/machine-controller-manager-provider-{provider-name},- Run the machine controller (driver) using the command below.
- On the second terminal pointing to
$GOPATH/src/github.com/gardener,- Clone the latest MCM code
git clone git@github.com:gardener/machine-controller-manager.git
- Navigate to the newly-created directory.
cd machine-controller-manager
- Deploy the required CRDs from the machine-controller-manager repo,
kubectl apply -f kubernetes/crds
- Run the machine-controller-manager in the
master branch
- On the third terminal pointing to
$GOPATH/src/github.com/{github-org/your-github-username}/machine-controller-manager-provider-{provider-name}- Fill in the object files given below and deploy them as described below.
- Deploy the
machine-classkubectl apply -f kubernetes/machine-class.yaml
- Deploy the
kubernetes secret if required.kubectl apply -f kubernetes/secret.yaml
- Deploy the
machine object and make sure it joins the cluster successfully.kubectl apply -f kubernetes/machine.yaml
- Once the machine joins, you can test by deploying a machine-deployment.
- Deploy the
machine-deployment object and make sure it joins the cluster successfully.kubectl apply -f kubernetes/machine-deployment.yaml
- Make sure to delete both the
machine and machine-deployment objects after use.kubectl delete -f kubernetes/machine.yaml
kubectl delete -f kubernetes/machine-deployment.yaml
Releasing your docker image
- Make sure you have logged into gcloud/docker using the CLI.
- To release your docker image, run the following.
make release IMAGE_REPOSITORY=<link-to-image-repo>
- A sample kubernetes deploy file can be found at
kubernetes/deployment.yaml. Update the same (with your desired MCM and MC images) to deploy your MCM pod.
6 - Deployment
Deploying the Machine Controller Manager into a Kubernetes cluster
As already mentioned, the Machine Controller Manager is designed to run as controller in a Kubernetes cluster. The existing source code can be compiled and tested on a local machine as described in Setting up a local development environment. You can deploy the Machine Controller Manager using the steps described below.
Prepare the cluster
- Connect to the remote kubernetes cluster where you plan to deploy the Machine Controller Manager using the kubectl. Set the environment variable KUBECONFIG to the path of the yaml file containing the cluster info.
- Now, create the required CRDs on the remote cluster using the following command,
$ kubectl apply -f kubernetes/crds
Build the Docker image
⚠️ Modify the Makefile to refer to your own registry.
- Run the build which generates the binary to
bin/machine-controller-manager
- Build docker image from latest compiled binary
- Push the last created docker image onto the online docker registry.
- Now you can deploy this docker image to your cluster. A sample development file is provided. By default, the deployment manages the cluster it is running in. Optionally, the kubeconfig could also be passed as a flag as described in
/kubernetes/deployment/out-of-tree/deployment.yaml. This is done when you want your controller running outside the cluster to be managed from.
$ kubectl apply -f kubernetes/deployment/out-of-tree/deployment.yaml
- Also deploy the required clusterRole and clusterRoleBindings
$ kubectl apply -f kubernetes/deployment/out-of-tree/clusterrole.yaml
$ kubectl apply -f kubernetes/deployment/out-of-tree/clusterrolebinding.yaml
Configuring optional parameters while deploying
Machine-controller-manager supports several configurable parameters while deploying. Refer to the following lines, to know how each parameter can be configured, and what it’s purpose is for.
Usage
To start using Machine Controller Manager, follow the links given at usage here.
7 - Integration Tests
Integration tests
Usage
General setup & configurations
Integration tests for machine-controller-manager-provider-{provider-name} can be executed manually by following below steps.
- Clone the repository
machine-controller-manager-provider-{provider-name} on the local system. - Navigate to
machine-controller-manager-provider-{provider-name} directory and create a dev sub-directory in it. - If the tags on instances & associated resources on the provider are of
String type (for example, GCP tags on its instances are of type String and not key-value pair) then add TAGS_ARE_STRINGS := true in the Makefile and export it. For GCP this has already been hard coded in the Makefile.
Running the tests
- There is a rule
test-integration in the Makefile of the provider repository, which can be used to start the integration test: - This will ask for additional inputs. Most of them are self explanatory except:
- The script assumes that both the control and target clusters are already being created.
- In case of non-gardener setup (control cluster is not a gardener seed), the name of the machineclass must be
test-mc-v1 and the value of providerSpec.secretRef.name should be test-mc-secret. - In case of azure,
TARGET_CLUSTER_NAME must be same as the name of the Azure ResourceGroup for the cluster. - If you are deploying the secret manually, a
Secret named test-mc-secret (that contains the provider secret and cloud-config) in the default namespace of the Control Cluster should be created.
- The controllers log files (
mcm_process.log and mc_process.log) are stored in .ci/controllers-test/logs repo and can be used later.
Adding Integration Tests for new providers
For a new provider, Running Integration tests works with no changes. But for the orphan resource test cases to work correctly, the provider-specific API calls and the Resource Tracker Interface (RTI) should be implemented. Please check machine-controller-manager-provider-aws for reference.
Extending integration tests
- Update ControllerTests to be extend the testcases for all providers. Common testcases for machine|machineDeployment creation|deletion|scaling are packaged into ControllerTests.
- To extend the provider specfic test cases, the changes should be done in the
machine-controller-manager-provider-{provider-name} repository. For example, to extended the testcases for machine-controller-manager-provider-aws, make changes to test/integration/controller/controller_test.go inside the machine-controller-manager-provider-aws repository. commons contains the Cluster and Clientset objects that makes it easy to extend the tests.
8 - Local Setup
Preparing the Local Development Setup (Mac OS X)
Conceptionally, the Machine Controller Manager is designed to run in a container within a Pod inside a Kubernetes cluster. For development purposes, you can run the Machine Controller Manager as a Go process on your local machine. This process connects to your remote cluster to manage VMs for that cluster. That means that the Machine Controller Manager runs outside a Kubernetes cluster which requires providing a Kubeconfig in your local filesystem and point the Machine Controller Manager to it when running it (see below).
Although the following installation instructions are for Mac OS X, similar alternate commands could be found for any Linux distribution.
Installing Golang environment
Install the latest version of Golang (at least v1.8.3 is required) by using Homebrew:
In order to perform linting on the Go source code, install Golint:
$ go get -u golang.org/x/lint/golint
Installing Docker (Optional)
In case you want to build Docker images for the Machine Controller Manager you have to install Docker itself. We recommend using Docker for Mac OS X which can be downloaded from here.
Setup Docker Hub account (Optional)
Create a Docker hub account at Docker Hub if you don’t already have one.
Local development
⚠️ Before you start developing, please ensure to comply with the following requirements:
- You have understood the principles of Kubernetes, and its components, what their purpose is and how they interact with each other.
- You have understood the architecture of the Machine Controller Manager
The development of the Machine Controller Manager could happen by targeting any cluster. You basically need a Kubernetes cluster running on a set of machines. You just need the Kubeconfig file with the required access permissions attached to it.
Installing the Machine Controller Manager locally
Clone the repository from GitHub.
$ git clone git@github.com:gardener/machine-controller-manager.git
$ cd machine-controller-manager
Prepare the cluster
- Connect to the remote kubernetes cluster where you plan to deploy the Machine Controller Manager using kubectl. Set the environment variable KUBECONFIG to the path of the yaml file containing your cluster info
- Now, create the required CRDs on the remote cluster using the following command,
$ kubectl apply -f kubernetes/crds.yaml
Getting started
Setup and Restore with Gardener
Setup
In gardener access to static kubeconfig files is no longer supported due to security reasons. One needs to generate short-lived (max TTL = 1 day) admin kube configs for target and control clusters.
A convenience script/Makefile target has been provided to do the required initial setup which includes:
- Creating a temporary directory where target and control kubeconfigs will be stored.
- Create a request to generate the short lived admin kubeconfigs. These are downloaded and stored in the temporary folder created above.
- In gardener clusters
DWD (Dependency Watchdog) runs as an additional component which can interfere when MCM/CA is scaled down. To prevent that an annotation dependency-watchdog.gardener.cloud/ignore-scaling is added to machine-controller-manager deployment which prevents DWD from scaling up the deployment replicas. - Scales down
machine-controller-manager deployment in the control cluster to 0 replica. - Creates the required
.env file and populates required environment variables which are then used by the Makefile in both machine-controller-manager and in machine-controller-manager-provider-<provider-name> projects. - Copies the generated and downloaded kubeconfig files for the target and control clusters to
machine-controller-manager-provider-<provider-name> project as well.
To do the above you can either invoke make gardener-setup or you can directly invoke the script ./hack/gardener_local_setup.sh. If you invoke the script with -h or --help option then it will give you all CLI options that one can pass.
Restore
Once the testing is over you can invoke a convenience script/Makefile target which does the following:
- Removes all generated admin kubeconfig files from both
machine-controller-manager and in machine-controller-manager-provider-<provider-name> projects. - Removes the
.env file that was generated as part of the setup from both machine-controller-manager and in machine-controller-manager-provider-<provider-name> projects. - Scales up
machine-controller-manager deployment in the control cluster back to 1 replica. - Removes the annotation
dependency-watchdog.gardener.cloud/ignore-scaling that was added to prevent DWD to scale up MCM.
To do the above you can either invoke make gardener-restore or you can directly invoke the script ./hack/gardener_local_restore.sh. If you invoke the script with -h or --help option then it will give you all CLI options that one can pass.
Setup and Restore without Gardener
Setup
If you are not running MCM components in a gardener cluster, then it is assumed that there is not going to be any DWD (Dependency Watchdog) component.
A convenience script/Makefile target has been provided to the required initial setup which includes:
- Copies the provided control and target kubeconfig files to
machine-controller-manager-provider-<provider-name> project. - Scales down
machine-controller-manager deployment in the control cluster to 0 replica. - Creates the required
.env file and populates required environment variables which are then used by the Makefile in both machine-controller-manager and in machine-controller-manager-provider-<provider-name> projects.
To do the above you can either invoke make non-gardener-setup or you can directly invoke the script ./hack/non_gardener_local_setup.sh. If you invoke the script with -h or --help option then it will give you all CLI options that one can pass.
Restore
Once the testing is over you can invoke a convenience script/Makefile target which does the following:
- Removes all provided kubeconfig files from both
machine-controller-manager and in machine-controller-manager-provider-<provider-name> projects. - Removes the
.env file that was generated as part of the setup from both machine-controller-manager and in machine-controller-manager-provider-<provider-name> projects. - Scales up
machine-controller-manager deployment in the control cluster back to 1 replica.
To do the above you can either invoke make non-gardener-restore or you can directly invoke the script ./hack/non_gardener_local_restore.sh. If you invoke the script with -h or --help option then it will give you all CLI options that one can pass.
Once the setup is done then you can start the machine-controller-manager as a local process using the following Makefile target:
$ make start
I1227 11:08:19.963638 55523 controllermanager.go:204] Starting shared informers
I1227 11:08:20.766085 55523 controller.go:247] Starting machine-controller-manager
⚠️ The file dev/target-kubeconfig.yaml points to the cluster whose nodes you want to manage. dev/control-kubeconfig.yaml points to the cluster from where you want to manage the nodes from. However, dev/control-kubeconfig.yaml is optional.
The Machine Controller Manager should now be ready to manage the VMs in your kubernetes cluster.
⚠️ This is assuming that your MCM is built to manage machines for any in-tree supported providers. There is a new way to deploy and manage out of tree (external) support for providers whose development can be found here
Testing Machine Classes
To test the creation/deletion of a single instance for one particular machine class you can use the managevm cli. The corresponding INFRASTRUCTURE-machine-class.yaml and the INFRASTRUCTURE-secret.yaml need to be defined upfront. To build and run it
GO111MODULE=on go build -o managevm cmd/machine-controller-manager-cli/main.go
# create machine
./managevm --secret PATH_TO/INFRASTRUCTURE-secret.yaml --machineclass PATH_TO/INFRASTRUCTURE-machine-class.yaml --classkind INFRASTRUCTURE --machinename test
# delete machine
./managevm --secret PATH_TO/INFRASTRUCTURE-secret.yaml --machineclass PATH_TO/INFRASTRUCTURE-machine-class.yaml --classkind INFRASTRUCTURE --machinename test --machineid INFRASTRUCTURE:///REGION/INSTANCE_ID
Usage
To start using Machine Controller Manager, follow the links given at usage here.
9 - Machine
Creating/Deleting machines (VM)
Setting up your usage environment
Important :
Make sure that the kubernetes/machine_objects/machine.yaml points to the same class name as the kubernetes/machine_classes/aws-machine-class.yaml.
Similarly kubernetes/machine_objects/aws-machine-class.yaml secret name and namespace should be same as that mentioned in kubernetes/secrets/aws-secret.yaml
Creating machine
- Modify
kubernetes/machine_objects/machine.yaml as per your requirement and create the VM as shown below:
$ kubectl apply -f kubernetes/machine_objects/machine.yaml
You should notice that the Machine Controller Manager has immediately picked up your manifest and started to create a new machine by talking to the cloud provider.
- Check Machine Controller Manager machines in the cluster
$ kubectl get machine
NAME STATUS AGE
test-machine Running 5m
A new machine is created with the name provided in the kubernetes/machine_objects/machine.yaml file.
- After a few minutes (~3 minutes for AWS), you should notice a new node joining the cluster. You can verify this by running:
$ kubectl get nodes
NAME STATUS AGE VERSION
ip-10-250-14-52.eu-east-1.compute.internal. Ready 1m v1.8.0
This shows that a new node has successfully joined the cluster.
Inspect status of machine
To inspect the status of any created machine, run the command given below.
$ kubectl get machine test-machine -o yaml
apiVersion: machine.sapcloud.io/v1alpha1
kind: Machine
metadata:
annotations:
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"machine.sapcloud.io/v1alpha1","kind":"Machine","metadata":{"annotations":{},"labels":{"test-label":"test-label"},"name":"test-machine","namespace":""},"spec":{"class":{"kind":"AWSMachineClass","name":"test-aws"}}}
clusterName: ""
creationTimestamp: 2017-12-27T06:58:21Z
finalizers:
- machine.sapcloud.io/operator
generation: 0
initializers: null
labels:
node: ip-10-250-14-52.eu-east-1.compute.internal
test-label: test-label
name: test-machine
namespace: ""
resourceVersion: "12616948"
selfLink: /apis/machine.sapcloud.io/v1alpha1/test-machine
uid: 535e596c-ead3-11e7-a6c0-828f843e4186
spec:
class:
kind: AWSMachineClass
name: test-aws
providerID: aws:///eu-east-1/i-00bef3f2618ffef23
status:
conditions:
- lastHeartbeatTime: 2017-12-27T07:00:46Z
lastTransitionTime: 2017-12-27T06:59:16Z
message: kubelet has sufficient disk space available
reason: KubeletHasSufficientDisk
status: "False"
type: OutOfDisk
- lastHeartbeatTime: 2017-12-27T07:00:46Z
lastTransitionTime: 2017-12-27T06:59:16Z
message: kubelet has sufficient memory available
reason: KubeletHasSufficientMemory
status: "False"
type: MemoryPressure
- lastHeartbeatTime: 2017-12-27T07:00:46Z
lastTransitionTime: 2017-12-27T06:59:16Z
message: kubelet has no disk pressure
reason: KubeletHasNoDiskPressure
status: "False"
type: DiskPressure
- lastHeartbeatTime: 2017-12-27T07:00:46Z
lastTransitionTime: 2017-12-27T07:00:06Z
message: kubelet is posting ready status
reason: KubeletReady
status: "True"
type: Ready
currentStatus:
lastUpdateTime: 2017-12-27T07:00:06Z
phase: Running
lastOperation:
description: Machine is now ready
lastUpdateTime: 2017-12-27T07:00:06Z
state: Successful
type: Create
node: ip-10-250-14-52.eu-west-1.compute.internal
Delete machine
To delete the VM using the kubernetes/machine_objects/machine.yaml as shown below
$ kubectl delete -f kubernetes/machine_objects/machine.yaml
Now the Machine Controller Manager picks up the manifest immediately and starts to delete the existing VM by talking to the cloud provider. The node should be detached from the cluster in a few minutes (~1min for AWS).
10 - Machine Deployment
Maintaining machine replicas using machines-deployments
Setting up your usage environment
Follow the steps described here
Important ⚠️
Make sure that the kubernetes/machine_objects/machine-deployment.yaml points to the same class name as the kubernetes/machine_classes/aws-machine-class.yaml.
Similarly kubernetes/machine_classes/aws-machine-class.yaml secret name and namespace should be same as that mentioned in kubernetes/secrets/aws-secret.yaml
Creating machine-deployment
- Modify
kubernetes/machine_objects/machine-deployment.yaml as per your requirement. Modify the number of replicas to the desired number of machines. Then, create an machine-deployment.
$ kubectl apply -f kubernetes/machine_objects/machine-deployment.yaml
Now the Machine Controller Manager picks up the manifest immediately and starts to create a new machines based on the number of replicas you have provided in the manifest.
- Check Machine Controller Manager machine-deployments in the cluster
$ kubectl get machinedeployment
NAME READY DESIRED UP-TO-DATE AVAILABLE AGE
test-machine-deployment 3 3 3 0 10m
You will notice a new machine-deployment with your given name
- Check Machine Controller Manager machine-sets in the cluster
$ kubectl get machineset
NAME DESIRED CURRENT READY AGE
test-machine-deployment-5bc6dd7c8f 3 3 0 10m
You will notice a new machine-set backing your machine-deployment
- Check Machine Controller Manager machines in the cluster
$ kubectl get machine
NAME STATUS AGE
test-machine-deployment-5bc6dd7c8f-5d24b Pending 5m
test-machine-deployment-5bc6dd7c8f-6mpn4 Pending 5m
test-machine-deployment-5bc6dd7c8f-dpt2q Pending 5m
Now you will notice N (number of replicas specified in the manifest) new machines whose name are prefixed with the machine-deployment object name that you created.
- After a few minutes (~3 minutes for AWS), you would see that new nodes have joined the cluster. You can see this using
$ kubectl get nodes
NAME STATUS AGE VERSION
ip-10-250-20-19.eu-west-1.compute.internal Ready 1m v1.8.0
ip-10-250-27-123.eu-west-1.compute.internal Ready 1m v1.8.0
ip-10-250-31-80.eu-west-1.compute.internal Ready 1m v1.8.0
This shows how new nodes have joined your cluster
Inspect status of machine-deployment
To inspect the status of any created machine-deployment run the command below,
$ kubectl get machinedeployment test-machine-deployment -o yaml
You should get the following output.
apiVersion: machine.sapcloud.io/v1alpha1
kind: MachineDeployment
metadata:
annotations:
deployment.kubernetes.io/revision: "1"
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"machine.sapcloud.io/v1alpha1","kind":"MachineDeployment","metadata":{"annotations":{},"name":"test-machine-deployment","namespace":""},"spec":{"minReadySeconds":200,"replicas":3,"selector":{"matchLabels":{"test-label":"test-label"}},"strategy":{"rollingUpdate":{"maxSurge":1,"maxUnavailable":1},"type":"RollingUpdate"},"template":{"metadata":{"labels":{"test-label":"test-label"}},"spec":{"class":{"kind":"AWSMachineClass","name":"test-aws"}}}}}
clusterName: ""
creationTimestamp: 2017-12-27T08:55:56Z
generation: 0
initializers: null
name: test-machine-deployment
namespace: ""
resourceVersion: "12634168"
selfLink: /apis/machine.sapcloud.io/v1alpha1/test-machine-deployment
uid: c0b488f7-eae3-11e7-a6c0-828f843e4186
spec:
minReadySeconds: 200
replicas: 3
selector:
matchLabels:
test-label: test-label
strategy:
rollingUpdate:
maxSurge: 1
maxUnavailable: 1
type: RollingUpdate
template:
metadata:
creationTimestamp: null
labels:
test-label: test-label
spec:
class:
kind: AWSMachineClass
name: test-aws
status:
availableReplicas: 3
conditions:
- lastTransitionTime: 2017-12-27T08:57:22Z
lastUpdateTime: 2017-12-27T08:57:22Z
message: Deployment has minimum availability.
reason: MinimumReplicasAvailable
status: "True"
type: Available
readyReplicas: 3
replicas: 3
updatedReplicas: 3
Health monitoring
Health monitor is also applied similar to how it’s described for machine-sets
Update your machines
Let us consider the scenario where you wish to update all nodes of your cluster from t2.xlarge machines to m5.xlarge machines. Assume that your current test-aws has its spec.machineType: t2.xlarge and your deployment test-machine-deployment points to this AWSMachineClass.
Inspect existing cluster configuration
- Check Nodes present in the cluster
$ kubectl get nodes
NAME STATUS AGE VERSION
ip-10-250-20-19.eu-west-1.compute.internal Ready 1m v1.8.0
ip-10-250-27-123.eu-west-1.compute.internal Ready 1m v1.8.0
ip-10-250-31-80.eu-west-1.compute.internal Ready 1m v1.8.0
- Check Machine Controller Manager machine-sets in the cluster. You will notice one machine-set backing your machine-deployment
$ kubectl get machineset
NAME DESIRED CURRENT READY AGE
test-machine-deployment-5bc6dd7c8f 3 3 3 10m
- Login to your cloud provider (AWS). In the VM management console, you will find N VMs created of type t2.xlarge.
To update this machine-deployment VMs to m5.xlarge, we would do the following:
- Copy your existing aws-machine-class.yaml
cp kubernetes/machine_classes/aws-machine-class.yaml kubernetes/machine_classes/aws-machine-class-new.yaml
- Modify aws-machine-class-new.yaml, and update its metadata.name: test-aws2 and spec.machineType: m5.xlarge
- Now create this modified MachineClass
kubectl apply -f kubernetes/machine_classes/aws-machine-class-new.yaml
- Edit your existing machine-deployment
kubectl edit machinedeployment test-machine-deployment
- Update from spec.template.spec.class.name: test-aws to spec.template.spec.class.name: test-aws2
Re-check cluster configuration
After a few minutes (~3mins)
- Check nodes present in cluster now. They are different nodes.
$ kubectl get nodes
NAME STATUS AGE VERSION
ip-10-250-11-171.eu-west-1.compute.internal Ready 4m v1.8.0
ip-10-250-17-213.eu-west-1.compute.internal Ready 5m v1.8.0
ip-10-250-31-81.eu-west-1.compute.internal Ready 5m v1.8.0
- Check Machine Controller Manager machine-sets in the cluster. You will notice two machine-sets backing your machine-deployment
$ kubectl get machineset
NAME DESIRED CURRENT READY AGE
test-machine-deployment-5bc6dd7c8f 0 0 0 1h
test-machine-deployment-86ff45cc5 3 3 3 20m
- Login to your cloud provider (AWS). In the VM management console, you will find N VMs created of type t2.xlarge in terminated state, and N new VMs of type m5.xlarge in running state.
This shows how a rolling update of a cluster from nodes with t2.xlarge to m5.xlarge went through.
More variants of updates
- The above demonstration was a simple use case. This could be more complex like - updating the system disk image versions/ kubelet versions/ security patches etc.
- You can also play around with the maxSurge and maxUnavailable fields in machine-deployment.yaml
- You can also change the update strategy from rollingupdate to recreate
Undo an update
- Edit the existing machine-deployment
$ kubectl edit machinedeployment test-machine-deployment
- Edit the deployment to have this new field of spec.rollbackTo.revision: 0 as shown as comments in
kubernetes/machine_objects/machine-deployment.yaml - This will undo your update to the previous version.
Pause an update
- You can also pause the update while update is going on by editing the existing machine-deployment
$ kubectl edit machinedeployment test-machine-deployment
Edit the deployment to have this new field of spec.paused: true as shown as comments in kubernetes/machine_objects/machine-deployment.yaml
This will pause the rollingUpdate if it’s in process
To resume the update, edit the deployment as mentioned above and remove the field spec.paused: true updated earlier
Delete machine-deployment
- To delete the VM using the
kubernetes/machine_objects/machine-deployment.yaml
$ kubectl delete -f kubernetes/machine_objects/machine-deployment.yaml
The Machine Controller Manager picks up the manifest and starts to delete the existing VMs by talking to the cloud provider. The nodes should be detached from the cluster in a few minutes (~1min for AWS).
11 - Machine Error Codes
Machine Error code handling
Notational Conventions
The keywords “MUST”, “MUST NOT”, “REQUIRED”, “SHALL”, “SHALL NOT”, “SHOULD”, “SHOULD NOT”, “RECOMMENDED”, “NOT RECOMMENDED”, “MAY”, and “OPTIONAL” are to be interpreted as described in RFC 2119 (Bradner, S., “Key words for use in RFCs to Indicate Requirement Levels”, BCP 14, RFC 2119, March 1997).
The key words “unspecified”, “undefined”, and “implementation-defined” are to be interpreted as described in the rationale for the C99 standard.
An implementation is not compliant if it fails to satisfy one or more of the MUST, REQUIRED, or SHALL requirements for the protocols it implements.
An implementation is compliant if it satisfies all the MUST, REQUIRED, and SHALL requirements for the protocols it implements.
Terminology
| Term | Definition |
|---|
| CR | Custom Resource (CR) is defined by a cluster admin using the Kubernetes Custom Resource Definition primitive. |
| VM | A Virtual Machine (VM) provisioned and managed by a provider. It could also refer to a physical machine in case of a bare metal provider. |
| Machine | Machine refers to a VM that is provisioned/managed by MCM. It typically describes the metadata used to store/represent a Virtual Machine |
| Node | Native kubernetes Node object. The objects you get to see when you do a “kubectl get nodes”. Although nodes can be either physical/virtual machines, for the purposes of our discussions it refers to a VM. |
| MCM | Machine Controller Manager (MCM) is the controller used to manage higher level Machine Custom Resource (CR) such as machine-set and machine-deployment CRs. |
| Provider/Driver/MC | Provider (or) Driver (or) Machine Controller (MC) is the driver responsible for managing machine objects present in the cluster from whom it manages these machines. A simple example could be creation/deletion of VM on the provider. |
Pre-requisite
MachineClass Resources
MCM introduces the CRD MachineClass. This is a blueprint for creating machines that join a certain cluster as nodes in a certain role. The provider only works with MachineClass resources that have the structure described here.
ProviderSpec
The MachineClass resource contains a providerSpec field that is passed in the ProviderSpec request field to CMI methods such as CreateMachine. The ProviderSpec can be thought of as a machine template from which the VM specification must be adopted. It can contain key-value pairs of these specs. An example for these key-value pairs are given below.
| Parameter | Mandatory | Type | Description |
|---|
vmPool | Yes | string | VM pool name, e.g. TEST-WOKER-POOL |
size | Yes | string | VM size, e.g. xsmall, small, etc. Each size maps to a number of CPUs and memory size. |
rootFsSize | No | int | Root (/) filesystem size in GB |
tags | Yes | map | Tags to be put on the created VM |
Most of the ProviderSpec fields are not mandatory. If not specified, the provider passes an empty value in the respective Create VM parameter.
The tags can be used to map a VM to its corresponding machine object’s Name
The ProviderSpec is validated by methods that receive it as a request field for presence of all mandatory parameters and tags, and for validity of all parameters.
Secrets
The MachineClass resource also contains a secretRef field that contains a reference to a secret. The keys of this secret are passed in the Secrets request field to CMI methods.
The secret can contain sensitive data such as
cloud-credentials secret data used to authenticate at the providercloud-init scripts used to initialize a new VM. The cloud-init script is expected to contain scripts to initialize the Kubelet and make it join the cluster.
Identifying Cluster Machines
To implement certain methods, the provider should be able to identify all machines associated with a particular Kubernetes cluster. This can be achieved using one/more of the below mentioned ways:
- Names of VMs created by the provider are prefixed by the cluster ID specified in the ProviderSpec.
- VMs created by the provider are tagged with the special tags like
kubernetes.io/cluster (for the cluster ID) and kubernetes.io/role (for the role), specified in the ProviderSpec. - Mapping
Resource Groups to individual cluster.
Error Scheme
All provider API calls defined in this spec MUST return a machine error status, which is very similar to standard machine status.
Machine Provider Interface
- The provider MUST have a unique way to map a
machine object to a VM which triggers the deletion for the corresponding VM backing the machine object. - The provider SHOULD have a unique way to map the
ProviderSpec of a machine-class to a unique Cluster. This avoids deletion of other machines, not backed by the MCM.
CreateMachine
A Provider is REQUIRED to implement this interface method.
This interface method will be called by the MCM to provision a new VM on behalf of the requesting machine object.
This call requests the provider to create a VM backing the machine-object.
If VM backing the Machine.Name already exists, and is compatible with the specified Machine object in the CreateMachineRequest, the Provider MUST reply 0 OK with the corresponding CreateMachineResponse.
The provider can OPTIONALLY make use of the MachineClass supplied in the MachineClass in the CreateMachineRequest to communicate with the provider.
The provider can OPTIONALLY make use of the secrets supplied in the Secret in the CreateMachineRequest to communicate with the provider.
The provider can OPTIONALLY make use of the Status.LastKnownState in the Machine object to decode the state of the VM operation based on the last known state of the VM. This can be useful to restart/continue an operations which are mean’t to be atomic.
The provider MUST have a unique way to map a machine object to a VM. This could be implicitly provided by the provider by letting you set VM-names (or) could be explicitly specified by the provider using appropriate tags to map the same.
This operation SHOULD be idempotent.
The CreateMachineResponse returned by this method is expected to return
ProviderID that uniquely identifys the VM at the provider. This is expected to match with the node.Spec.ProviderID on the node object.NodeName that is the expected name of the machine when it joins the cluster. It must match with the node name.LastKnownState is an OPTIONAL field that can store details of the last known state of the VM. It can be used by future operation calls to determine current infrastucture state. This state is saved on the machine object.
// CreateMachine call is responsible for VM creation on the provider
CreateMachine(context.Context, *CreateMachineRequest) (*CreateMachineResponse, error)
// CreateMachineRequest is the create request for VM creation
type CreateMachineRequest struct {
// Machine object from whom VM is to be created
Machine *v1alpha1.Machine
// MachineClass backing the machine object
MachineClass *v1alpha1.MachineClass
// Secret backing the machineClass object
Secret *corev1.Secret
}
// CreateMachineResponse is the create response for VM creation
type CreateMachineResponse struct {
// ProviderID is the unique identification of the VM at the cloud provider.
// ProviderID typically matches with the node.Spec.ProviderID on the node object.
// Eg: gce://project-name/region/vm-ID
ProviderID string
// NodeName is the name of the node-object registered to kubernetes.
NodeName string
// LastKnownState represents the last state of the VM during an creation/deletion error
LastKnownState string
}
CreateMachine Errors
If the provider is unable to complete the CreateMachine call successfully, it MUST return a non-ok ginterface method code in the machine status.
If the conditions defined below are encountered, the provider MUST return the specified machine error code.
The MCM MUST implement the specified error recovery behavior when it encounters the machine error code.
| machine Code | Condition | Description | Recovery Behavior | Auto Retry Required |
|---|
| 0 OK | Successful | The call was successful in creating/adopting a VM that matches supplied creation request. The CreateMachineResponse is returned with desired values | | N |
| 1 CANCELED | Cancelled | Call was cancelled. Perform any pending clean-up tasks and return the call | | N |
| 2 UNKNOWN | Something went wrong | Not enough information on what went wrong | Retry operation after sometime | Y |
| 3 INVALID_ARGUMENT | Re-check supplied parameters | Re-check the supplied Machine.Name and ProviderSpec. Make sure all parameters are in permitted range of values. Exact issue to be given in .message | Update providerSpec to fix issues. | N |
| 4 DEADLINE_EXCEEDED | Timeout | The call processing exceeded supplied deadline | Retry operation after sometime | Y |
| 6 ALREADY_EXISTS | Already exists but desired parameters doesn’t match | Parameters of the existing VM don’t match the ProviderSpec | Create machine with a different name | N |
| 7 PERMISSION_DENIED | Insufficent permissions | The requestor doesn’t have enough permissions to create an VM and it’s required dependencies | Update requestor permissions to grant the same | N |
| 8 RESOURCE_EXHAUSTED | Resource limits have been reached | The requestor doesn’t have enough resource limits to process this creation request | Enhance resource limits associated with the user/account to process this | N |
| 9 PRECONDITION_FAILED | VM is in inconsistent state | The VM is in a state that is invalid for this operation | Manual intervention might be needed to fix the state of the VM | N |
| 10 ABORTED | Operation is pending | Indicates that there is already an operation pending for the specified machine | Wait until previous pending operation is processed | Y |
| 11 OUT_OF_RANGE | Resources were out of range | The requested number of CPUs, memory size, of FS size in ProviderSpec falls outside of the corresponding valid range | Update request paramaters to request valid resource requests | N |
| 12 UNIMPLEMENTED | Not implemented | Unimplemented indicates operation is not implemented or not supported/enabled in this service. | Retry with an alternate logic or implement this method at the provider. Most methods by default are in this state | N |
| 13 INTERNAL | Major error | Means some invariants expected by underlying system has been broken. If you see one of these errors, something is very broken. | Needs manual intervension to fix this | N |
| 14 UNAVAILABLE | Not Available | Unavailable indicates the service is currently unavailable. | Retry operation after sometime | Y |
| 16 UNAUTHENTICATED | Missing provider credentials | Request does not have valid authentication credentials for the operation | Fix the provider credentials | N |
The status message MUST contain a human readable description of error, if the status code is not OK.
This string MAY be surfaced by MCM to end users.
InitializeMachine
Provider can OPTIONALLY implement this driver call. Else should return a UNIMPLEMENTED status in error.
This interface method will be called by the MCM to initialize a new VM just after creation. This can be used to configure network configuration etc.
- This call requests the provider to initialize a newly created VM backing the machine-object.
- The
InitializeMachineResponse returned by this method is expected to returnProviderID that uniquely identifys the VM at the provider. This is expected to match with the node.Spec.ProviderID on the node object.NodeName that is the expected name of the machine when it joins the cluster. It must match with the node name.
// InitializeMachine call is responsible for VM initialization on the provider.
InitializeMachine(context.Context, *InitializeMachineRequest) (*InitializeMachineResponse, error)
// InitializeMachineRequest encapsulates params for the VM Initialization operation (Driver.InitializeMachine).
type InitializeMachineRequest struct {
// Machine object representing VM that must be initialized
Machine *v1alpha1.Machine
// MachineClass backing the machine object
MachineClass *v1alpha1.MachineClass
// Secret backing the machineClass object
Secret *corev1.Secret
}
// InitializeMachineResponse is the response for VM instance initialization (Driver.InitializeMachine).
type InitializeMachineResponse struct {
// ProviderID is the unique identification of the VM at the cloud provider.
// ProviderID typically matches with the node.Spec.ProviderID on the node object.
// Eg: gce://project-name/region/vm-ID
ProviderID string
// NodeName is the name of the node-object registered to kubernetes.
NodeName string
}
InitializeMachine Errors
If the provider is unable to complete the InitializeMachine call successfully, it MUST return a non-ok machine code in the machine status.
If the conditions defined below are encountered, the provider MUST return the specified machine error code.
The MCM MUST implement the specified error recovery behavior when it encounters the machine error code.
| machine Code | Condition | Description | Recovery Behavior | Auto Retry Required |
|---|
| 0 OK | Successful | The call was successful in initializing a VM that matches supplied initialization request. The InitializeMachineResponse is returned with desired values | | N |
| 5 NOT_FOUND | Timeout | VM Instance for Machine isn’t found at provider | Skip Initialization and Continue | N |
| 12 UNIMPLEMENTED | Not implemented | Unimplemented indicates operation is not implemented or not supported/enabled in this service. | Skip Initialization and continue | N |
| 13 INTERNAL | Major error | Means some invariants expected by underlying system has been broken. | Needs investigation and possible intervention to fix this | Y |
| 17 UNINITIALIZED | Failed Initialization | VM Instance could not be initializaed | Initialization is reattempted in next reconcile cycle | Y |
The status message MUST contain a human readable description of error, if the status code is not OK.
This string MAY be surfaced by MCM to end users.
DeleteMachine
A Provider is REQUIRED to implement this driver call.
This driver call will be called by the MCM to deprovision/delete/terminate a VM backed by the requesting machine object.
If a VM corresponding to the specified machine-object’s name does not exist or the artifacts associated with the VM do not exist anymore (after deletion), the Provider MUST reply 0 OK.
The provider SHALL only act on machines belonging to the cluster-id/cluster-name obtained from the ProviderSpec.
The provider can OPTIONALY make use of the secrets supplied in the Secrets map in the DeleteMachineRequest to communicate with the provider.
The provider can OPTIONALY make use of the Spec.ProviderID map in the Machine object.
The provider can OPTIONALLY make use of the Status.LastKnownState in the Machine object to decode the state of the VM operation based on the last known state of the VM. This can be useful to restart/continue an operations which are mean’t to be atomic.
This operation SHOULD be idempotent.
The provider must have a unique way to map a machine object to a VM which triggers the deletion for the corresponding VM backing the machine object.
The DeleteMachineResponse returned by this method is expected to return
LastKnownState is an OPTIONAL field that can store details of the last known state of the VM. It can be used by future operation calls to determine current infrastucture state. This state is saved on the machine object.
// DeleteMachine call is responsible for VM deletion/termination on the provider
DeleteMachine(context.Context, *DeleteMachineRequest) (*DeleteMachineResponse, error)
// DeleteMachineRequest is the delete request for VM deletion
type DeleteMachineRequest struct {
// Machine object from whom VM is to be deleted
Machine *v1alpha1.Machine
// MachineClass backing the machine object
MachineClass *v1alpha1.MachineClass
// Secret backing the machineClass object
Secret *corev1.Secret
}
// DeleteMachineResponse is the delete response for VM deletion
type DeleteMachineResponse struct {
// LastKnownState represents the last state of the VM during an creation/deletion error
LastKnownState string
}
DeleteMachine Errors
If the provider is unable to complete the DeleteMachine call successfully, it MUST return a non-ok machine code in the machine status.
If the conditions defined below are encountered, the provider MUST return the specified machine error code.
| machine Code | Condition | Description | Recovery Behavior | Auto Retry Required |
|---|
| 0 OK | Successful | The call was successful in deleting a VM that matches supplied deletion request. | | N |
| 1 CANCELED | Cancelled | Call was cancelled. Perform any pending clean-up tasks and return the call | | N |
| 2 UNKNOWN | Something went wrong | Not enough information on what went wrong | Retry operation after sometime | Y |
| 3 INVALID_ARGUMENT | Re-check supplied parameters | Re-check the supplied Machine.Name and make sure that it is in the desired format and not a blank value. Exact issue to be given in .message | Update Machine.Name to fix issues. | N |
| 4 DEADLINE_EXCEEDED | Timeout | The call processing exceeded supplied deadline | Retry operation after sometime | Y |
| 7 PERMISSION_DENIED | Insufficent permissions | The requestor doesn’t have enough permissions to delete an VM and it’s required dependencies | Update requestor permissions to grant the same | N |
| 9 PRECONDITION_FAILED | VM is in inconsistent state | The VM is in a state that is invalid for this operation | Manual intervention might be needed to fix the state of the VM | N |
| 10 ABORTED | Operation is pending | Indicates that there is already an operation pending for the specified machine | Wait until previous pending operation is processed | Y |
| 12 UNIMPLEMENTED | Not implemented | Unimplemented indicates operation is not implemented or not supported/enabled in this service. | Retry with an alternate logic or implement this method at the provider. Most methods by default are in this state | N |
| 13 INTERNAL | Major error | Means some invariants expected by underlying system has been broken. If you see one of these errors, something is very broken. | Needs manual intervension to fix this | N |
| 14 UNAVAILABLE | Not Available | Unavailable indicates the service is currently unavailable. | Retry operation after sometime | Y |
| 16 UNAUTHENTICATED | Missing provider credentials | Request does not have valid authentication credentials for the operation | Fix the provider credentials | N |
The status message MUST contain a human readable description of error, if the status code is not OK.
This string MAY be surfaced by MCM to end users.
GetMachineStatus
A Provider can OPTIONALLY implement this driver call. Else should return a UNIMPLEMENTED status in error.
This call will be invoked by the MC to get the status of a machine.
This optional driver call helps in optimizing the working of the provider by avoiding unwanted calls to CreateMachine() and DeleteMachine().
- If a VM corresponding to the specified machine object’s
Machine.Name exists on provider the GetMachineStatusResponse fields are to be filled similar to the CreateMachineResponse. - The provider SHALL only act on machines belonging to the cluster-id/cluster-name obtained from the
ProviderSpec. - The provider can OPTIONALY make use of the secrets supplied in the
Secrets map in the GetMachineStatusRequest to communicate with the provider. - The provider can OPTIONALY make use of the VM unique ID (returned by the provider on machine creation) passed in the
ProviderID map in the GetMachineStatusRequest. - This operation MUST be idempotent.
// GetMachineStatus call get's the status of the VM backing the machine object on the provider
GetMachineStatus(context.Context, *GetMachineStatusRequest) (*GetMachineStatusResponse, error)
// GetMachineStatusRequest is the get request for VM info
type GetMachineStatusRequest struct {
// Machine object from whom VM status is to be fetched
Machine *v1alpha1.Machine
// MachineClass backing the machine object
MachineClass *v1alpha1.MachineClass
// Secret backing the machineClass object
Secret *corev1.Secret
}
// GetMachineStatusResponse is the get response for VM info
type GetMachineStatusResponse struct {
// ProviderID is the unique identification of the VM at the cloud provider.
// ProviderID typically matches with the node.Spec.ProviderID on the node object.
// Eg: gce://project-name/region/vm-ID
ProviderID string
// NodeName is the name of the node-object registered to kubernetes.
NodeName string
}
GetMachineStatus Errors
If the provider is unable to complete the GetMachineStatus call successfully, it MUST return a non-ok machine code in the machine status.
If the conditions defined below are encountered, the provider MUST return the specified machine error code.
| machine Code | Condition | Description | Recovery Behavior | Auto Retry Required |
|---|
| 0 OK | Successful | The call was successful in getting machine details for given machine Machine.Name | | N |
| 1 CANCELED | Cancelled | Call was cancelled. Perform any pending clean-up tasks and return the call | | N |
| 2 UNKNOWN | Something went wrong | Not enough information on what went wrong | Retry operation after sometime | Y |
| 3 INVALID_ARGUMENT | Re-check supplied parameters | Re-check the supplied Machine.Name and make sure that it is in the desired format and not a blank value. Exact issue to be given in .message | Update Machine.Name to fix issues. | N |
| 4 DEADLINE_EXCEEDED | Timeout | The call processing exceeded supplied deadline | Retry operation after sometime | Y |
| 5 NOT_FOUND | Machine isn’t found at provider | The machine could not be found at provider | Not required | N |
| 7 PERMISSION_DENIED | Insufficent permissions | The requestor doesn’t have enough permissions to get details for the VM and it’s required dependencies | Update requestor permissions to grant the same | N |
| 9 PRECONDITION_FAILED | VM is in inconsistent state | The VM is in a state that is invalid for this operation | Manual intervention might be needed to fix the state of the VM | N |
| 11 OUT_OF_RANGE | Multiple VMs found | Multiple VMs found with matching machine object names | Orphan VM handler to cleanup orphan VMs / Manual intervention maybe required if orphan VM handler isn’t enabled. | Y |
| 12 UNIMPLEMENTED | Not implemented | Unimplemented indicates operation is not implemented or not supported/enabled in this service. | Retry with an alternate logic or implement this method at the provider. Most methods by default are in this state | N |
| 13 INTERNAL | Major error | Means some invariants expected by underlying system has been broken. If you see one of these errors, something is very broken. | Needs manual intervension to fix this | N |
| 14 UNAVAILABLE | Not Available | Unavailable indicates the service is currently unavailable. | Retry operation after sometime | Y |
| 16 UNAUTHENTICATED | Missing provider credentials | Request does not have valid authentication credentials for the operation | Fix the provider credentials | N |
| 17 UNINITIALIZED | Failed Initialization | VM Instance could not be initializaed | Initialization is reattempted in next reconcile cycle | N |
The status message MUST contain a human readable description of error, if the status code is not OK.
This string MAY be surfaced by MCM to end users.
ListMachines
A Provider can OPTIONALLY implement this driver call. Else should return a UNIMPLEMENTED status in error.
The Provider SHALL return the information about all the machines associated with the MachineClass.
Make sure to use appropriate filters to achieve the same to avoid data transfer overheads.
This optional driver call helps in cleaning up orphan VMs present in the cluster. If not implemented, any orphan VM that might have been created incorrectly by the MCM/Provider (due to bugs in code/infra) might require manual clean up.
- If the Provider succeeded in returning a list of
Machine.Name with their corresponding ProviderID, then return 0 OK. - The
ListMachineResponse contains a map of MachineList whose- Key is expected to contain the
ProviderID & - Value is expected to contain the
Machine.Name corresponding to it’s kubernetes machine CR object
- The provider can OPTIONALY make use of the secrets supplied in the
Secrets map in the ListMachinesRequest to communicate with the provider.
// ListMachines lists all the machines that might have been created by the supplied machineClass
ListMachines(context.Context, *ListMachinesRequest) (*ListMachinesResponse, error)
// ListMachinesRequest is the request object to get a list of VMs belonging to a machineClass
type ListMachinesRequest struct {
// MachineClass object
MachineClass *v1alpha1.MachineClass
// Secret backing the machineClass object
Secret *corev1.Secret
}
// ListMachinesResponse is the response object of the list of VMs belonging to a machineClass
type ListMachinesResponse struct {
// MachineList is the map of list of machines. Format for the map should be <ProviderID, MachineName>.
MachineList map[string]string
}
ListMachines Errors
If the provider is unable to complete the ListMachines call successfully, it MUST return a non-ok machine code in the machine status.
If the conditions defined below are encountered, the provider MUST return the specified machine error code.
The MCM MUST implement the specified error recovery behavior when it encounters the machine error code.
| machine Code | Condition | Description | Recovery Behavior | Auto Retry Required |
|---|
| 0 OK | Successful | The call for listing all VMs associated with ProviderSpec was successful. | | N |
| 1 CANCELED | Cancelled | Call was cancelled. Perform any pending clean-up tasks and return the call | | N |
| 2 UNKNOWN | Something went wrong | Not enough information on what went wrong | Retry operation after sometime | Y |
| 3 INVALID_ARGUMENT | Re-check supplied parameters | Re-check the supplied ProviderSpec and make sure that all required fields are present in their desired value format. Exact issue to be given in .message | Update ProviderSpec to fix issues. | N |
| 4 DEADLINE_EXCEEDED | Timeout | The call processing exceeded supplied deadline | Retry operation after sometime | Y |
| 7 PERMISSION_DENIED | Insufficent permissions | The requestor doesn’t have enough permissions to list VMs and it’s required dependencies | Update requestor permissions to grant the same | N |
| 12 UNIMPLEMENTED | Not implemented | Unimplemented indicates operation is not implemented or not supported/enabled in this service. | Retry with an alternate logic or implement this method at the provider. Most methods by default are in this state | N |
| 13 INTERNAL | Major error | Means some invariants expected by underlying system has been broken. If you see one of these errors, something is very broken. | Needs manual intervension to fix this | N |
| 14 UNAVAILABLE | Not Available | Unavailable indicates the service is currently unavailable. | Retry operation after sometime | Y |
| 16 UNAUTHENTICATED | Missing provider credentials | Request does not have valid authentication credentials for the operation | Fix the provider credentials | N |
The status message MUST contain a human readable description of error, if the status code is not OK.
This string MAY be surfaced by MCM to end users.
GetVolumeIDs
A Provider can OPTIONALLY implement this driver call. Else should return a UNIMPLEMENTED status in error.
This driver call will be called by the MCM to get the VolumeIDs for the list of PersistentVolumes (PVs) supplied.
This OPTIONAL (but recommended) driver call helps in serailzied eviction of pods with PVs while draining of machines. This implies applications backed by PVs would be evicted one by one, leading to shorter application downtimes.
- On succesful returnal of a list of
Volume-IDs for all supplied PVSpecs, the Provider MUST reply 0 OK. - The
GetVolumeIDsResponse is expected to return a repeated list of strings consisting of the VolumeIDs for PVSpec that could be extracted. - If for any
PV the Provider wasn’t able to identify the Volume-ID, the provider MAY chose to ignore it and return the Volume-IDs for the rest of the PVs for whom the Volume-ID was found. - Getting the
VolumeID from the PVSpec depends on the Cloud-provider. You can extract this information by parsing the PVSpec based on the ProviderType - This operation MUST be idempotent.
// GetVolumeIDsRequest is the request object to get a list of VolumeIDs for a PVSpec
type GetVolumeIDsRequest struct {
// PVSpecsList is a list of PV specs for whom volume-IDs are required
// Plugin should parse this raw data into pre-defined list of PVSpecs
PVSpecs []*corev1.PersistentVolumeSpec
}
// GetVolumeIDsResponse is the response object of the list of VolumeIDs for a PVSpec
type GetVolumeIDsResponse struct {
// VolumeIDs is a list of VolumeIDs.
VolumeIDs []string
}
GetVolumeIDs Errors
| machine Code | Condition | Description | Recovery Behavior | Auto Retry Required |
|---|
| 0 OK | Successful | The call getting list of VolumeIDs for the list of PersistentVolumes was successful. | | N |
| 1 CANCELED | Cancelled | Call was cancelled. Perform any pending clean-up tasks and return the call | | N |
| 2 UNKNOWN | Something went wrong | Not enough information on what went wrong | Retry operation after sometime | Y |
| 3 INVALID_ARGUMENT | Re-check supplied parameters | Re-check the supplied PVSpecList and make sure that it is in the desired format. Exact issue to be given in .message | Update PVSpecList to fix issues. | N |
| 4 DEADLINE_EXCEEDED | Timeout | The call processing exceeded supplied deadline | Retry operation after sometime | Y |
| 12 UNIMPLEMENTED | Not implemented | Unimplemented indicates operation is not implemented or not supported/enabled in this service. | Retry with an alternate logic or implement this method at the provider. Most methods by default are in this state | N |
| 13 INTERNAL | Major error | Means some invariants expected by underlying system has been broken. If you see one of these errors, something is very broken. | Needs manual intervension to fix this | N |
| 14 UNAVAILABLE | Not Available | Unavailable indicates the service is currently unavailable. | Retry operation after sometime | Y |
The status message MUST contain a human readable description of error, if the status code is not OK.
This string MAY be surfaced by MCM to end users.
A Provider SHOULD implement this driver call, else it MUST return a UNIMPLEMENTED status in error.
This driver call will be called by the Machine Controller to try to perform a machineClass migration for an unknown machineClass Kind. This helps in migration of one kind of machineClass to another kind. For instance an machineClass custom resource of AWSMachineClass to MachineClass.
- On successful generation of machine class the Provider MUST reply
0 OK (or) nil error. GenerateMachineClassForMigrationRequest expects the provider-specific machine class (eg. AWSMachineClass)
to be supplied as the ProviderSpecificMachineClass. The provider is responsible for unmarshalling the golang struct. It also passes a reference to an existing MachineClass object.- The provider is expected to fill in this
MachineClass object based on the conversions. - An optional
ClassSpec containing the type ClassSpec struct is also provided to decode the provider info. GenerateMachineClassForMigration is only responsible for filling up the passed MachineClass object.- The task of creating the new
CR of the new kind (MachineClass) with the same name as the previous one and also annotating the old machineClass CR with a migrated annotation and migrating existing references is done by the calling library implicitly. - This operation MUST be idempotent.
// GenerateMachineClassForMigrationRequest is the request for generating the generic machineClass
// for the provider specific machine class
type GenerateMachineClassForMigrationRequest struct {
// ProviderSpecificMachineClass is provider specfic machine class object.
// E.g. AWSMachineClass
ProviderSpecificMachineClass interface{}
// MachineClass is the machine class object generated that is to be filled up
MachineClass *v1alpha1.MachineClass
// ClassSpec contains the class spec object to determine the machineClass kind
ClassSpec *v1alpha1.ClassSpec
}
// GenerateMachineClassForMigrationResponse is the response for generating the generic machineClass
// for the provider specific machine class
type GenerateMachineClassForMigrationResponse struct{}
MigrateMachineClass Errors
| machine Code | Condition | Description | Recovery Behavior | Auto Retry Required |
|---|
| 0 OK | Successful | Migration of provider specific machine class was successful | Machine reconcilation is retried once the new class has been created | Y |
| 12 UNIMPLEMENTED | Not implemented | Unimplemented indicates operation is not implemented or not supported/enabled in this provider. | None | N |
| 13 INTERNAL | Major error | Means some invariants expected by underlying system has been broken. If you see one of these errors, something is very broken. | Might need manual intervension to fix this | Y |
The status message MUST contain a human readable description of error, if the status code is not OK.
This string MAY be surfaced by MCM to end users.
Configuration and Operation
Supervised Lifecycle Management
- For Providers packaged in software form:
- Provider Packages SHOULD use a well-documented container image format (e.g., Docker, OCI).
- The chosen package image format MAY expose configurable Provider properties as environment variables, unless otherwise indicated in the section below.
Variables so exposed SHOULD be assigned default values in the image manifest.
- A Provider Supervisor MAY programmatically evaluate or otherwise scan a Provider Package’s image manifest in order to discover configurable environment variables.
- A Provider SHALL NOT assume that an operator or Provider Supervisor will scan an image manifest for environment variables.
Environment Variables
- Variables defined by this specification SHALL be identifiable by their
MC_ name prefix. - Configuration properties not defined by the MC specification SHALL NOT use the same
MC_ name prefix; this prefix is reserved for common configuration properties defined by the MC specification. - The Provider Supervisor SHOULD supply all RECOMMENDED MC environment variables to a Provider.
- The Provider Supervisor SHALL supply all REQUIRED MC environment variables to a Provider.
Logging
- Providers SHOULD generate log messages to ONLY standard output and/or standard error.
- In this case the Provider Supervisor SHALL assume responsibility for all log lifecycle management.
- Provider implementations that deviate from the above recommendation SHALL clearly and unambiguously document the following:
- Logging configuration flags and/or variables, including working sample configurations.
- Default log destination(s) (where do the logs go if no configuration is specified?)
- Log lifecycle management ownership and related guidance (size limits, rate limits, rolling, archiving, expunging, etc.) applicable to the logging mechanism embedded within the Provider.
- Providers SHOULD NOT write potentially sensitive data to logs (e.g. secrets).
Available Services
- Provider Packages MAY support all or a subset of CMI services; service combinations MAY be configurable at runtime by the Provider Supervisor.
- This specification does not dictate the mechanism by which mode of operation MUST be discovered, and instead places that burden upon the VM Provider.
- Misconfigured provider software SHOULD fail-fast with an OS-appropriate error code.
Linux Capabilities
- Providers SHOULD clearly document any additionally required capabilities and/or security context.
Cgroup Isolation
- A Provider MAY be constrained by cgroups.
Resource Requirements
- VM Providers SHOULD unambiguously document all of a Provider’s resource requirements.
Deploying
- Recommended: The MCM and Provider are typically expected to run as two containers inside a common
Pod. - However, for the security reasons they could execute on seperate Pods provided they have a secure way to exchange data between them.
12 - Machine Set
Maintaining machine replicas using machines-sets
Setting up your usage environment
Important ⚠️
Make sure that the kubernetes/machines_objects/machine-set.yaml points to the same class name as the kubernetes/machine_classes/aws-machine-class.yaml.
Similarly kubernetes/machine_classes/aws-machine-class.yaml secret name and namespace should be same as that mentioned in kubernetes/secrets/aws-secret.yaml
Creating machine-set
- Modify
kubernetes/machine_objects/machine-set.yaml as per your requirement. You can modify the number of replicas to the desired number of machines. Then, create an machine-set:
$ kubectl apply -f kubernetes/machine_objects/machine-set.yaml
You should notice that the Machine Controller Manager has immediately picked up your manifest and started to create a new machines based on the number of replicas you have provided in the manifest.
- Check Machine Controller Manager machine-sets in the cluster
$ kubectl get machineset
NAME DESIRED CURRENT READY AGE
test-machine-set 3 3 0 1m
You will see a new machine-set with your given name
- Check Machine Controller Manager machines in the cluster:
$ kubectl get machine
NAME STATUS AGE
test-machine-set-b57zs Pending 5m
test-machine-set-c4bg8 Pending 5m
test-machine-set-kvskg Pending 5m
Now you will see N (number of replicas specified in the manifest) new machines whose names are prefixed with the machine-set object name that you created.
- After a few minutes (~3 minutes for AWS), you should notice new nodes joining the cluster. You can verify this by running:
$ kubectl get nodes
NAME STATUS AGE VERSION
ip-10-250-0-234.eu-west-1.compute.internal Ready 3m v1.8.0
ip-10-250-15-98.eu-west-1.compute.internal Ready 3m v1.8.0
ip-10-250-6-21.eu-west-1.compute.internal Ready 2m v1.8.0
This shows how new nodes have joined your cluster
Inspect status of machine-set
- To inspect the status of any created machine-set run the following command:
$ kubectl get machineset test-machine-set -o yaml
apiVersion: machine.sapcloud.io/v1alpha1
kind: MachineSet
metadata:
annotations:
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"machine.sapcloud.io/v1alpha1","kind":"MachineSet","metadata":{"annotations":{},"name":"test-machine-set","namespace":"","test-label":"test-label"},"spec":{"minReadySeconds":200,"replicas":3,"selector":{"matchLabels":{"test-label":"test-label"}},"template":{"metadata":{"labels":{"test-label":"test-label"}},"spec":{"class":{"kind":"AWSMachineClass","name":"test-aws"}}}}}
clusterName: ""
creationTimestamp: 2017-12-27T08:37:42Z
finalizers:
- machine.sapcloud.io/operator
generation: 0
initializers: null
name: test-machine-set
namespace: ""
resourceVersion: "12630893"
selfLink: /apis/machine.sapcloud.io/v1alpha1/test-machine-set
uid: 3469faaa-eae1-11e7-a6c0-828f843e4186
spec:
machineClass: {}
minReadySeconds: 200
replicas: 3
selector:
matchLabels:
test-label: test-label
template:
metadata:
creationTimestamp: null
labels:
test-label: test-label
spec:
class:
kind: AWSMachineClass
name: test-aws
status:
availableReplicas: 3
fullyLabeledReplicas: 3
machineSetCondition: null
lastOperation:
lastUpdateTime: null
observedGeneration: 0
readyReplicas: 3
replicas: 3
Health monitoring
- If you try to delete/terminate any of the machines backing the machine-set by either talking to the Machine Controller Manager or from the cloud provider, the Machine Controller Manager recreates a matching healthy machine to replace the deleted machine.
- Similarly, if any of your machines are unreachable or in an unhealthy state (kubelet not ready / disk pressure) for longer than the configured timeout (~ 5mins), the Machine Controller Manager recreates the nodes to replace the unhealthy nodes.
Delete machine-set
- To delete the VM using the
kubernetes/machine_objects/machine-set.yaml:
$ kubectl delete -f kubernetes/machine-set.yaml
Now the Machine Controller Manager has immediately picked up your manifest and started to delete the existing VMs by talking to the cloud provider. Your nodes should be detached from the cluster in a few minutes (~1min for AWS).
13 - Prerequisite
Setting up the usage environment
Important ⚠️
All paths are relative to the root location of this project repository.
Run the Machine Controller Manager either as described in Setting up a local development environment or Deploying the Machine Controller Manager into a Kubernetes cluster.
Make sure that the following steps are run before managing machines/ machine-sets/ machine-deploys.
Set KUBECONFIG
Using the existing Kubeconfig, open another Terminal panel/window with the KUBECONFIG environment variable pointing to this Kubeconfig file as shown below,
$ export KUBECONFIG=<PATH_TO_REPO>/dev/kubeconfig.yaml
Replace provider credentials and desired VM configurations
Open kubernetes/machine_classes/aws-machine-class.yaml and replace required values there with the desired VM configurations.
Similarily open kubernetes/secrets/aws-secret.yaml and replace - userData, providerAccessKeyId, providerSecretAccessKey with base64 encoded values of cloudconfig file, AWS access key id, and AWS secret access key respectively. Use the following command to get the base64 encoded value of your details
$ echo "sample-cloud-config" | base64
base64-encoded-cloud-config
Do the same for your access key id and secret access key.
Deploy required CRDs and Objects
Create all the required CRDs in the cluster using kubernetes/crds.yaml
$ kubectl apply -f kubernetes/crds.yaml
Create the class template that will be used as an machine template to create VMs using kubernetes/machine_classes/aws-machine-class.yaml
$ kubectl apply -f kubernetes/machine_classes/aws-machine-class.yaml
Create the secret used for the cloud credentials and cloudconfig using kubernetes/secrets/aws-secret.yaml
$ kubectl apply -f kubernetes/secrets/aws-secret.yaml
Check current cluster state
Get to know the current cluster state using the following commands,
- Checking aws-machine-class in the cluster
$ kubectl get awsmachineclass
NAME MACHINE TYPE AMI AGE
test-aws t2.large ami-123456 5m
- Checking kubernetes secrets in the cluster
$ kubectl get secret
NAME TYPE DATA AGE
test-secret Opaque 3 21h
- Checking kubernetes nodes in the cluster
Lists the default set of nodes attached to your cluster
- Checking Machine Controller Manager machines in the cluster
$ kubectl get machine
No resources found.
- Checking Machine Controller Manager machine-sets in the cluster
$ kubectl get machineset
No resources found.
- Checking Machine Controller Manager machine-deploys in the cluster
$ kubectl get machinedeployment
No resources found.
14 - Testing And Dependencies
Dependency management
We use golang modules to manage golang dependencies. In order to add a new package dependency to the project, you can perform go get <PACKAGE>@<VERSION> or edit the go.mod file and append the package along with the version you want to use.
Updating dependencies
The Makefile contains a rule called tidy which performs go mod tidy.
go mod tidy makes sure go.mod matches the source code in the module. It adds any missing modules necessary to build the current module’s packages and dependencies, and it removes unused modules that don’t provide any relevant packages.
The dependencies are installed into the go mod cache folder.
⚠️ Make sure you test the code after you have updated the dependencies!