Frequently Asked Questions
The answers in this FAQ apply to the newest (HEAD) version of Machine Controller Manager. If you're using an older version of MCM please refer to corresponding version of this document. Few of the answers assume that the MCM being used is in conjuction with cluster-autoscaler:
Table of Contents:
- Frequently Asked Questions
- Table of Contents:
- Basics
- How to?
- How to install MCM in a Kubernetes cluster?
- How to run MCM in different cluster setups?
- How to better control the rollout process of the worker nodes?
- How to scale down MachineDeployment by selective deletion of machines?
- How to force delete a machine?
- How to pause the ongoing rolling-update of the machinedeployment?
- How to delete machine object immediately if I don't have access to it?
- How to avoid garbage collection of your node?
- How to trigger rolling update of a machinedeployment?
- Internals
- What is the high level design of MCM?
- What are the different configuration options in MCM?
- What are the different timeouts/configurations in a machine's lifecycle?
- How is the drain of a machine implemented?
- How are the stateful applications drained during machine deletion?
- How does
maxEvictRetriesconfiguration work withdrainTimeoutconfiguration? - What are the different phases of a machine?
- What health checks are performed on a machine?
- How does rate limiting replacement of machine work in MCM? How is it related to meltdown protection?
- How MCM responds when scale-out/scale-in is done during rolling update of a machinedeployment?
- How does MCM prioritize the machines for deletion on scale-down of machinedeployment?
- How some unhealthy machines are drained quickly?
- Troubleshooting
- Developer
- In the context of Gardener
Basics
What is Machine Controller Manager?
Machine Controller Manager aka MCM is a bunch of controllers used for the lifecycle management of the worker machines. It reconciles a set of CRDs such as Machine, MachineSet, MachineDeployment which depicts the functionality of Pod, Replicaset, Deployment of the core Kubernetes respectively. Read more about it at README.
- Gardener uses MCM to manage its Kubernetes nodes of the shoot cluster. However, by design, MCM can be used independent of Gardener.
Why is my machine deleted?
A machine is deleted by MCM generally for 2 reasons-
- Machine is unhealthy for at least
MachineHealthTimeoutperiod. The defaultMachineHealthTimeoutis 10 minutes.- By default, a machine is considered unhealthy if any of the following node conditions -
DiskPressure,KernelDeadlock,FileSystem,Readonlyis set totrue, orKubeletReadyis set tofalse. However, this is something that is configurable using the following flag.
- By default, a machine is considered unhealthy if any of the following node conditions -
- Machine is scaled down by the
MachineDeploymentresource.- This is very usual when an external controller cluster-autoscaler (aka CA) is used with MCM. CA deletes the under-utilized machines by scaling down the
MachineDeployment. Read more about cluster-autoscaler's scale down behavior here.
- This is very usual when an external controller cluster-autoscaler (aka CA) is used with MCM. CA deletes the under-utilized machines by scaling down the
What are the different sub-controllers in MCM?
MCM mainly contains the following sub-controllers:
MachineDeployment Controller: Responsible for reconciling theMachineDeploymentobjects. It manages the lifecycle of theMachineSetobjects.MachineSet Controller: Responsible for reconciling theMachineSetobjects. It manages the lifecycle of theMachineobjects.Machine Controller: responsible for reconciling theMachineobjects. It manages the lifecycle of the actual VMs/machines created in cloud/on-prem. This controller has been moved out of tree. Please refer an AWS machine controller for more info - link.- Safety-controller: Responsible for handling the unidentified/unknown behaviors from the cloud providers. Please read more about its functionality below.
What is Safety Controller in MCM?
Safety Controller contains following functions:
- Orphan VM handler:
- It lists all the VMs in the cloud matching the
tagof given cluster name and maps the VMs with themachineobjects using theProviderIDfield. VMs without any backingmachineobjects are logged and deleted after confirmation. - This handler runs every 30 minutes and is configurable via machine-safety-orphan-vms-period flag.
- It lists all the VMs in the cloud matching the
- Freeze mechanism:
Safety Controllerfreezes theMachineDeploymentandMachineSetcontroller if the number ofmachineobjects goes beyond a certain threshold on top ofSpec.Replicas. It can be configured by the flag --safety-up or --safety-down and also machine-safety-overshooting-period.Safety Controllerfreezes the functionality of the MCM if either of thetarget-apiserveror thecontrol-apiserveris not reachable.Safety Controllerunfreezes the MCM automatically once situation is resolved to normal. Afreezelabel is applied onMachineDeployment/MachineSetto enforce the freeze condition.
How to?
How to install MCM in a Kubernetes cluster?
MCM can be installed in a cluster with following steps:
- Apply all the CRDs from here
- Apply all the deployment, role-related objects from here.
- Control cluster is the one where the
machine-*objects are stored. Target cluster is where all the node objects are registered.
- Control cluster is the one where the
How to run MCM in different cluster setups?
In the standard setup, MCM connects to the target cluster, i.e., the cluster that the machines should join. This is configured via the --target-kubeconfig flag. If the flag is omitted or empty, it uses the in-cluster credentials (i.e., the pod's ServiceAccount).
By default, MCM works with the Machine* resources in the target cluster, unless a different "control cluster" is configured via the --control-kubeconfig flag. In standard Gardener Shoot clusters, MCM uses the Seed cluster as the control cluster for managing machines of the Shoot cluster (target cluster).
MCM can also be configured to run without a target cluster by specifying --target-kubeconfig=none. This requires explicitly configuring a control cluster via --control-kubeconfig. In this mode, MCM only provisions/deletes machines on the configured infrastructure without considering the target cluster's Node objects. As a consequence, MCM doesn't create bootstrap tokens, doesn't wait for Nodes to be registered/drained, and does not perform health checks for Machines. Once the machine has been successfully created in the infrastructure, Machine.status.currentStatus.phase transitions to Available as a target state (see this section) – in contrast to the standard Pending and Running phases. Accordingly, the owning MachineSet and MachineDeployment objects will have "available" replicas but no "ready" replicas as indicated in the corresponding status fields. This mode is used for provisioning control plane machines of autonomous shoot clusters (gardenadm bootstrap command, medium-touch scenario).
How to better control the rollout process of the worker nodes?
MCM allows configuring the rollout of the worker machines using maxSurge and maxUnavailable fields. These fields are applicable only during the rollout process and means nothing in general scale up/down scenarios. The overall process is very similar to how the Deployment Controller manages pods during RollingUpdate.
maxSurgerefers to the number of additional machines that can be added on top of theSpec.Replicasof MachineDeployment during rollout process.maxUnavailablerefers to the number of machines that can be deleted fromSpec.Replicasfield of the MachineDeployment during rollout process.
How to scale down MachineDeployment by selective deletion of machines?
During scale down, triggered via MachineDeployment/MachineSet, MCM prefers to delete the machine/s which have the least priority set. Each machine object has an annotation machinepriority.machine.sapcloud.io set to 3 by default. Admin can reduce the priority of the given machines by changing the annotation value to 1. The next scale down by MachineDeployment shall delete the machines with the least priority first.
How to force delete a machine?
A machine can be force deleted by adding the label force-deletion: "True" on the machine object before executing the actual delete command. During force deletion, MCM skips the drain function and simply triggers the deletion of the machine. This label should be used with caution as it can violate the PDBs for pods running on the machine.
How to pause the ongoing rolling-update of the machinedeployment?
An ongoing rolling-update of the machine-deployment can be paused by using spec.paused field. See the example below:
apiVersion: machine.sapcloud.io/v1alpha1
kind: MachineDeployment
metadata:
name: test-machine-deployment
spec:
paused: trueIt can be unpaused again by removing the Paused field from the machine-deployment.
How to delete machine object immediately if I don't have access to it?
If access to the machine object is available, it can be deleted directly. Alternatively, when the machine object is not accessible, the corresponding node object may be deleted directly. This action immediately marks the associated machine object for deletion and triggers the creation of a replacement machine to maintain the desired replica count specified in the machineDeployment or machineSet. This can also be used if the user wants to expedite the replacement of unhealthy nodes
NOTE:
- The
node.machine.sapcloud.io/trigger-deletion-by-mcmannotation is no longer supported on node objects. It is however, still used on the machineDeployment objects (used by the CA-MCM cloud provider integration). - Setting the annotation to
"false"is NOT acted upon by MCM and does not prevent machine replacement. - Deleting a node will trigger machine deletion and replacement. A new machine will be created to maintain the
desired replicasspecified for the machineDeployment/machineSet. Currently if the user doesn't have access to machineDeployment/machineSet then they cannot remove a machine without replacement.
How to avoid garbage collection of your node?
MCM provides an in-built safety mechanism to garbage collect VMs which have no corresponding machine object. This is done to save costs and is one of the key features of MCM. However, sometimes users might like to add nodes directly to the cluster without the help of MCM and would prefer MCM to not garbage collect such VMs. To do so they should remove/not-use tags on their VMs containing the following strings:
kubernetes.io/cluster/kubernetes.io/role/kubernetes-io-cluster-kubernetes-io-role-
How to trigger rolling update of a machinedeployment?
Rolling update can be triggered for a machineDeployment by updating one of the following:
.spec.template.metadata.annotations.spec.template.spec.class.name
Internals
What is the high level design of MCM?
Please refer the following document.
What are the different configuration options in MCM?
MCM allows configuring many knobs to fine-tune its behavior according to the user's need. Please refer to the link to check the exact configuration options.
What are the different timeouts/configurations in a machine's lifecycle?
A machine's lifecycle is governed by mainly following timeouts, which can be configured here.
MachineDrainTimeout: Amount of time after which drain times out and the machine is force deleted. Default ~2 hours.MachineHealthTimeout: Amount of time after which an unhealthy machine is declaredFailedand the machine is replaced byMachineSetcontroller.MachineCreationTimeout: Amount of time after which a machine creation is declaredFailedand the machine is replaced by theMachineSetcontroller.NodeConditions: List of node conditions which if set to true forMachineHealthTimeoutperiod, the machine is declaredFailedand replaced byMachineSetcontroller.MaxEvictRetries: An integer number depicting the number of times a failed eviction should be retried on a pod during drain process. A pod is deleted aftermax-retries.
How is the drain of a machine implemented?
MCM imports the functionality from the upstream Kubernetes-drain library. Although, few parts have been modified to make it work best in the context of MCM. Drain is executed before machine deletion for graceful migration of the applications. Drain internally uses the EvictionAPI to evict the pods and triggers the Deletion of pods after MachineDrainTimeout. Please note:
- Stateless pods are evicted in parallel.
- Stateful applications (with PVCs) are serially evicted. Please find more info in this answer below.
How are the stateful applications drained during machine deletion?
Drain function serially evicts the stateful-pods. It is observed that serial eviction of stateful pods yields better overall availability of pods as the underlying cloud in most cases detaches and reattaches disks serially anyways. It is implemented in the following manner:
- Drain lists all the pods with attached volumes. It evicts very first stateful-pod and waits for its related entry in Node object's
.status.volumesAttachedto be removed by KCM. It does the same for all the stateful-pods. - It waits for
PvDetachTimeout(default 2 minutes) for a given pod's PVC to be removed, else moves forward.
How does maxEvictRetries configuration work with drainTimeout configuration?
It is recommended to only set MachineDrainTimeout. It satisfies the related requirements. MaxEvictRetries is auto-calculated based on MachineDrainTimeout, if maxEvictRetries is not provided. Following will be the overall behavior of both configurations together:
- If
maxEvictRetriesisn't set and onlymaxDrainTimeoutis set:- MCM auto calculates the
maxEvictRetriesbased on thedrainTimeout.
- MCM auto calculates the
- If
drainTimeoutisn't set and onlymaxEvictRetriesis set:- Default
drainTimeoutand user providedmaxEvictRetriesfor each pod is considered.
- Default
- If both
maxEvictRetriesanddrainTimoeutare set:- Then both will be respected.
- If none are set:
- Defaults are respected.
What are the different phases of a machine?
A phase of a machine can be identified with Machine.Status.CurrentStatus.Phase. Following are the possible phases of a machine object:
Pending: Machine creation call has succeeded. MCM is waiting for machine to join the cluster.Available: Machine creation call has succeeded. MCM is running without a target cluster and does not wait for the machine to join the cluster.CrashLoopBackOff: Machine creation call has failed. MCM will retry the operation after a minor delay.Running: Machine creation call has succeeded. Machine has joined the cluster successfully and corresponding node doesn't havenode.gardener.cloud/critical-components-not-readytaint.Unknown: Machine health checks are failing, e.g.,kubelethas stopped posting the status.Failed: Machine health checks have failed for a prolonged time. Hence it is declared failed byMachinecontroller in a rate limited fashion.Failedmachines get replaced immediately.Terminating: Machine is being terminated. Terminating state is set immediately when the deletion is triggered for themachineobject. It also includes time when it's being drained.
NOTE: No phase means the machine is being created on the cloud-provider.
Below is a simple phase transition diagram: 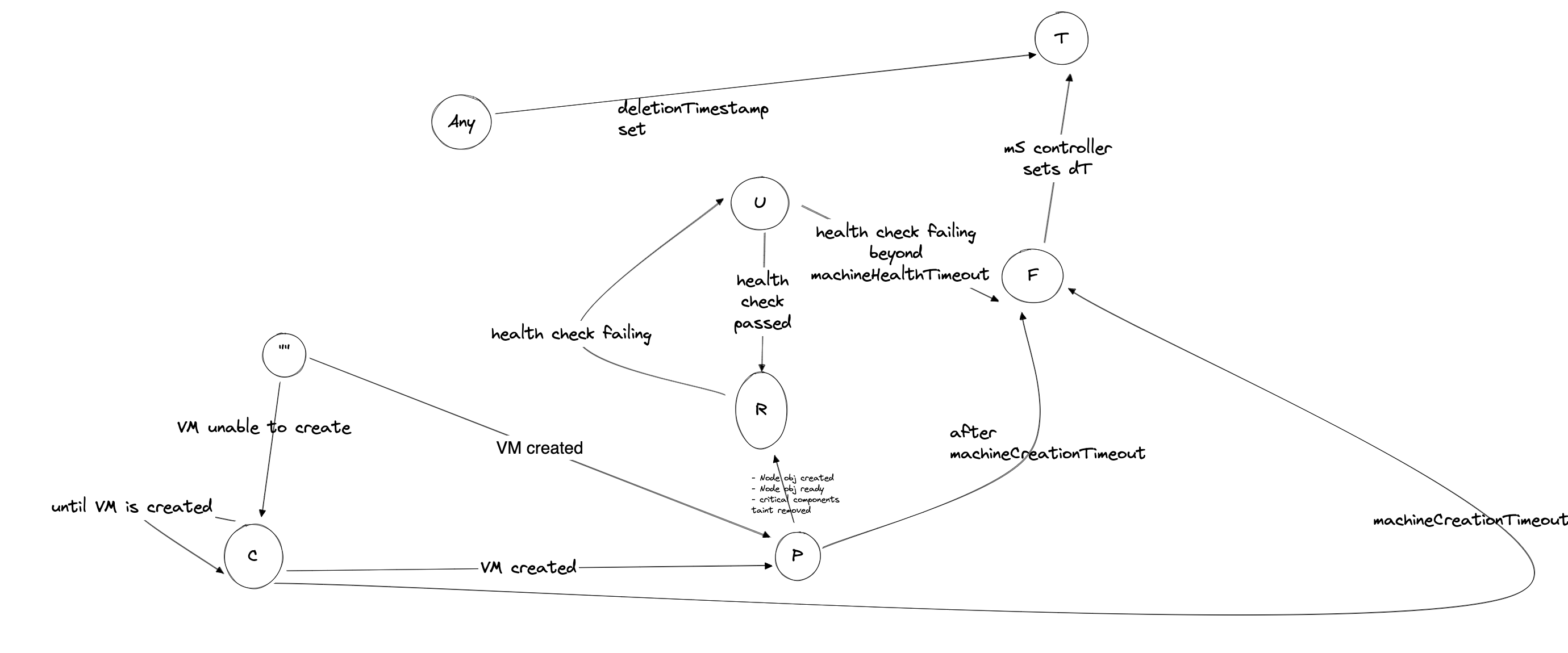
What health checks are performed on a machine?
Health check performed on a machine are:
- Existense of corresponding node obj
- Status of certain user-configurable node conditions.
- These conditions can be specified using the flag
--node-conditionsfor OOT MCM provider or can be specified per machine object. - The default user configurable node conditions can be found here
- These conditions can be specified using the flag
Truestatus ofNodeReadycondition . This condition shows kubelet's status
If any of the above checks fails , the machine turns to Unknown phase.
How does rate limiting replacement of machine work in MCM? How is it related to meltdown protection?
Currently MCM replaces only 1 Unknown machine at a time per machinedeployment. This means until the particular Unknown machine get terminated and its replacement joins, no other Unknown machine would be removed.
The above is achieved by enabling Machine controller to turn machine from Unknown -> Failed only if the above condition is met. MachineSet controller on the other hand marks Failed machine as Terminating immediately.
One reason for this rate limited replacement was to ensure that in case of network failures , where node's kubelet can't reach out to kube-apiserver , all nodes are not removed together i.e. meltdown protection. In gardener context however, DWD is deployed to deal with this scenario, but to stay protected from corner cases, this mechanism has been introduced in MCM.
NOTE: Rate limiting replacement is not yet configurable
How MCM responds when scale-out/scale-in is done during rolling update of a machinedeployment?
Machinedeployment controller executes the logic of scaling BEFORE logic of rollout. It identifies scaling by comparing the deployment.kubernetes.io/desired-replicas of each machineset under the machinedeployment with machinedeployment's .spec.replicas. If the difference is found for any machineSet, a scaling event is detected.
- Case
scale-out-> ONLY New machineSet is scaled out - Case
scale-in-> ALL machineSets(new or old) are scaled in , in proportion to their replica count , any leftover is adjusted in the largest machineSet.
During update for scaling event, a machineSet is updated if any of the below is true for it:
.spec.Replicasneeds updatedeployment.kubernetes.io/desired-replicasneeds update
Once scaling is achieved, rollout continues.
How does MCM prioritize the machines for deletion on scale-down of machinedeployment?
There could be many machines under a machinedeployment with different phases, creationTimestamp. When a scale down is triggered, MCM decides to remove the machine using the following logic:
- Machine with least value of
machinepriority.machine.sapcloud.ioannotation is picked up. - If all machines have equal priorities, then following precedence is followed:
- Terminating > Failed > CrashloopBackoff > Unknown > Pending > Available > Running
- If still there is no match, the machine with oldest creation time (.i.e. creationTimestamp) is picked up.
How some unhealthy machines are drained quickly?
If a node is unhealthy for more than the machine-health-timeout specified for the machine-controller, the controller health-check moves the machine phase to Failed. By default, the machine-health-timeout is 10` minutes.
Failed machines have their deletion timestamp set and the machine then moves to the Terminating phase. The node drain process is initiated. The drain process is invoked either gracefully or forcefully.
The usual drain process is graceful. Pods are evicted from the node and the drain process waits until any existing attached volumes are mounted on new node. However, if the node Ready is False or the ReadonlyFilesystem is True for greater than 5 minutes (non-configurable), then a forceful drain is initiated. In a forceful drain, pods are deleted and VolumeAttachment objects associated with the old node are also marked for deletion. This is followed by the deletion of the cloud provider VM associated with the Machine and then finally ending with the Node object deletion.
During the deletion of the VM we only delete the local data disks and boot disks associated with the VM. The disks associated with persistent volumes are left un-touched as their attach/de-detach, mount/unmount processes are handled by k8s attach-detach controller in conjunction with the CSI driver.
Troubleshooting
My machine is stuck in deletion for 1 hr, why?
In most cases, the Machine.Status.LastOperation provides information around why a machine can't be deleted. Though following could be the reasons but not limited to:
- Pod/s with misconfigured PDBs block the drain operation. PDBs with
maxUnavailableset to 0, doesn't allow the eviction of the pods. Hence, drain/eviction is retried tillMachineDrainTimeout. DefaultMachineDrainTimeoutcould be as large as ~2hours. Hence, blocking the machine deletion.- Short term: User can manually delete the pod in the question, with caution.
- Long term: Please set more appropriate PDBs which allow disruption of at least one pod.
- Expired cloud credentials can block the deletion of the machine from infrastructure.
- Cloud provider can't delete the machine due to internal errors. Such situations are best debugged by using cloud provider specific CLI or cloud console.
My machine is not joining the cluster, why?
In most cases, the Machine.Status.LastOperation provides information around why a machine can't be created. It could possibly be debugged with following steps:
- Firstly make sure all the relevant controllers like
kube-controller-manager,cloud-controller-managerare running. - Verify if the machine is actually created in the cloud. User can use the
Machine.Spec.ProviderIdto query the machine in cloud. - A Kubernetes node is generally bootstrapped with the cloud-config. Please verify, if
MachineDeploymentis pointing the correctMachineClass, andMachineClassis pointing to the correctSecret. The secret object contains the actual cloud-config inbase64format which will be used to boot the machine. - User must also check the logs of the MCM pod to understand any broken logical flow of reconciliation.
My rolling update is stuck, why?
The following can be the reason:
- Insufficient capacity for the new instance type the machineClass mentions.
- Old machines are stuck in deletion
- If you are using Gardener for setting up kubernetes cluster, then machine object won't turn to
Runningstate untilnode-critical-componentsare ready. Refer this for more details.
Developer
How should I test my code before submitting a PR?
Developer can locally setup the MCM using following guide
Developer must also enhance the unit tests related to the incoming changes.
Developer can run the unit test locally by executing:
shmake test-unitDeveloper can locally run integration tests to ensure basic functionality of MCM is not altered.
I need to change the APIs, what are the recommended steps?
Developer should add/update the API fields at both of the following places:
Once API changes are done, auto-generate the code using following command:
make generatePlease ignore the API-violation errors for now.
How can I update the dependencies of MCM?
MCM uses gomod for depedency management. Developer should add/udpate depedency in the go.mod file. Please run following command to automatically tidy the dependencies.
make tidyIn the context of Gardener
How can I configure MCM using Shoot resource?
All of the knobs of MCM can be configured by the workers section of the shoot resource.
- Gardener creates a
MachineDeploymentper zone for each worker-pool underworkerssection. workers.dataVolumesallows to attach multiple disks to a machine during creation. Refer the link.workers.machineControllerManagerallows configuration of multiple knobs of theMachineDeploymentfrom the shoot resource.
How is my worker-pool spread across zones?
Shoot resource allows the worker-pool to spread across multiple zones using the field workers.zones. Refer link.
Gardener creates one
MachineDeploymentper zone. EachMachineDeploymentis initiated with the following replica:yamlMachineDeployment.Spec.Replicas = (Workers.Minimum)/(Number of availability zones)