DEP-03: Scaling-up a single-node to multi-node etcd cluster deployed by etcd-druid
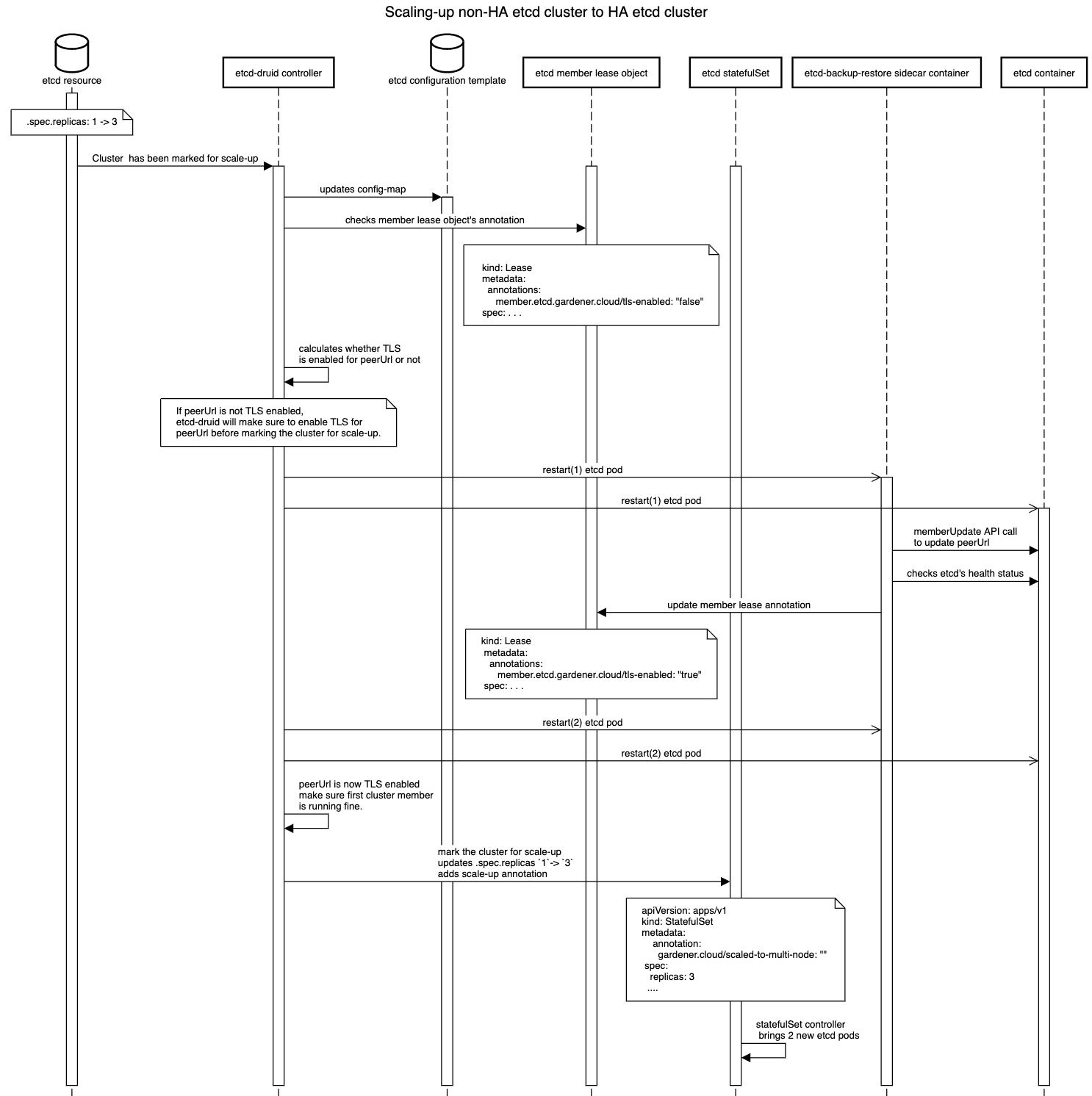
To mark a cluster for scale-up from single node to multi-node etcd, just patch the etcd custom resource's .spec.replicas from 1 to 3 (for example).
Challenges for scale-up
- Etcd cluster with single replica don't have any peers, so no peer communication is required hence peer URL may or may not be TLS enabled. However, while scaling up from single node etcd to multi-node etcd, there will be a requirement to have peer communication between members of the etcd cluster. Peer communication is required for various reasons, for instance for members to sync up cluster state, data, and to perform leader election or any cluster wide operation like removal or addition of a member etc. Hence in a multi-node etcd cluster we need to have TLS enable peer URL for peer communication.
- Providing the correct configuration to start new etcd members as it is different from boostrapping a cluster since these new etcd members will join an existing cluster.
Approach
We first went through the etcd doc of update-advertise-peer-urls to find out information regarding peer URL updation. Interestingly, etcd doc has mentioned the following:
To update the advertise peer URLs of a member, first update it explicitly via member command and then restart the member.But we can't assume peer URL is not TLS enabled for single-node cluster as it depends on end-user. A user may or may not enable the TLS for peer URL for a single node etcd cluster. So, How do we detect whether peer URL was enabled or not when cluster is marked for scale-up?
Detecting if peerURL TLS is enabled or not
For this we use an annotation in member lease object member.etcd.gardener.cloud/tls-enabled set by backup-restore sidecar of etcd. As etcd configuration is provided by backup-restore, so it can find out whether TLS is enabled or not and accordingly set this annotation member.etcd.gardener.cloud/tls-enabled to either true or false in member lease object. And with the help of this annotation and config-map values etcd-druid is able to detect whether there is a change in a peer URL or not.
Etcd-Druid helps in scaling up etcd cluster
Now, it is detected whether peer URL was TLS enabled or not for single node etcd cluster. Etcd-druid can now use this information to take action:
- If peer URL was already TLS enabled then no action is required from etcd-druid side. Etcd-druid can proceed with scaling up the cluster.
- If peer URL was not TLS enabled then etcd-druid has to intervene and make sure peer URL should be TLS enabled first for the single node before marking the cluster for scale-up.
Action taken by etcd-druid to enable the peerURL TLS
- Etcd-druid will update the
{etcd.Name}-configconfig-map with new config like initial-cluster,initial-advertise-peer-urls etc. Backup-restore will detect this change and update the member lease annotation tomember.etcd.gardener.cloud/tls-enabled: "true". - In case the peer URL TLS has been changed to
enabled: Etcd-druid will add tasks to the deployment flow:- Check if peer TLS has been enabled for existing StatefulSet pods, by checking the member leases for the annotation
member.etcd.gardener.cloud/tls-enabled. - If peer TLS enablement is pending for any of the members, then check and patch the StatefulSet with the peer TLS volume mounts, if not already patched. This will cause a rolling update of the existing StatefulSet pods, which allows etcd-backup-restore to update the member peer URL in the etcd cluster.
- Requeue this reconciliation flow until peer TLS has been enabled for all the existing etcd members.
- Check if peer TLS has been enabled for existing StatefulSet pods, by checking the member leases for the annotation
After PeerURL is TLS enabled
After peer URL TLS enablement for single node etcd cluster, now etcd-druid adds a scale-up annotation: gardener.cloud/scaled-to-multi-node to the etcd statefulset and etcd-druid will patch the statefulsets .spec.replicas to 3(for example). The statefulset controller will then bring up new pods(etcd with backup-restore as a sidecar). Now etcd's sidecar i.e backup-restore will check whether this member is already a part of a cluster or not and incase it is unable to check (may be due to some network issues) then backup-restore checks presence of this annotation: gardener.cloud/scaled-to-multi-node in etcd statefulset to detect scale-up. If it finds out it is the scale-up case then backup-restore adds new etcd member as a learner first and then starts the etcd learner by providing the correct configuration. Once learner gets in sync with the etcd cluster leader, it will get promoted to a voting member.
Providing the correct etcd config
As backup-restore detects that it's a scale-up scenario, backup-restore sets initial-cluster-state to existing as this member will join an existing cluster and it calculates the rest of the config from the updated config-map provided by etcd-druid.
Future improvements:
The need of restarting etcd pods twice will change in the future. please refer: https://github.com/gardener/etcd-backup-restore/issues/538