Settings for Seeds
The Seed resource offers a few settings that are used to control the behaviour of certain Gardener components. This document provides an overview over the available settings:
Dependency Watchdog
Gardenlet can deploy two instances of the dependency-watchdog into the garden namespace of the seed cluster. One instance only activates the weeder while the second instance only activates the prober.
Weeder
The weeder helps to alleviate the delay where control plane components remain unavailable by finding the respective pods in CrashLoopBackoff status and restarting them once their dependents become ready and available again. For example, if etcd goes down then also kube-apiserver goes down (and into a CrashLoopBackoff state). If etcd comes up again then (without the endpoint controller) it might take some time until kube-apiserver gets restarted as well.
⚠️ .spec.settings.dependencyWatchdog.endpoint.enabled is deprecated and will be removed in a future version of Gardener. Use .spec.settings.dependencyWatchdog.weeder.enabled instead.
It can be enabled/disabled via the .spec.settings.dependencyWatchdog.endpoint.enabled field. It defaults to true.
Prober
The probe controller scales down the kube-controller-manager of shoot clusters in case their respective kube-apiserver is not reachable via its external ingress. This is in order to avoid melt-down situations, since the kube-controller-manager uses in-cluster communication when talking to the kube-apiserver, i.e., it wouldn't be affected if the external access to the kube-apiserver is interrupted for whatever reason. The kubelets on the shoot worker nodes, however, would indeed be affected since they typically run in different networks and use the external ingress when talking to the kube-apiserver. Hence, without scaling down kube-controller-manager, the nodes might be marked as NotReady and eventually replaced (since the kubelets cannot report their status anymore). To prevent such unnecessary turbulence, kube-controller-manager is being scaled down until the external ingress becomes available again. In addition, as a precautionary measure, machine-controller-manager is also scaled down, along with cluster-autoscaler which depends on machine-controller-manager.
⚠️ .spec.settings.dependencyWatchdog.probe.enabled is deprecated and will be removed in a future version of Gardener. Use .spec.settings.dependencyWatchdog.prober.enabled instead.
It can be enabled/disabled via the .spec.settings.dependencyWatchdog.probe.enabled field. It defaults to true.
Reserve Excess Capacity
If the excess capacity reservation is enabled, then the gardenlet will deploy a special Deployment into the garden namespace of the seed cluster. This Deployment's pod template has only one container, the pause container, which simply runs in an infinite loop. The priority of the deployment is very low, so any other pod will preempt these pause pods. This is especially useful if new shoot control planes are created in the seed. In case the seed cluster runs at its capacity, then there is no waiting time required during the scale-up. Instead, the low-priority pause pods will be preempted and allow newly created shoot control plane pods to be scheduled fast. In the meantime, the cluster-autoscaler will trigger the scale-up because the preempted pause pods want to run again. However, this delay doesn't affect the important shoot control plane pods, which will improve the user experience.
Use .spec.settings.excessCapacityReservation.configs to create excess capacity reservation deployments which allow to specify custom values for resources, nodeSelector and tolerations. Each config creates a deployment with a minimum number of 2 replicas and a maximum equal to the number of zones configured for this seed. It defaults to a config reserving 2 CPUs and 6Gi of memory for each pod with no nodeSelector and no tolerations.
Excess capacity reservation is enabled when .spec.settings.excessCapacityReservation.enabled is true or not specified while configs are present. It can be disabled by setting the field to false.
Scheduling
By default, the Gardener Scheduler will consider all seed clusters when a new shoot cluster shall be created. However, administrators/operators might want to exclude some of them from being considered by the scheduler. Therefore, seed clusters can be marked as "invisible". In this case, the scheduler simply ignores them as if they wouldn't exist. Shoots can still use the invisible seed but only by explicitly specifying the name in their .spec.seedName field.
Seed clusters can be marked visible/invisible via the .spec.settings.scheduling.visible field. It defaults to true.
ℹ️ In previous Gardener versions (< 1.5) these settings were controlled via taint keys (seed.gardener.cloud/{disable-capacity-reservation,invisible}). The taint keys are no longer supported and removed in version 1.12. The rationale behind it is the implementation of tolerations similar to Kubernetes tolerations. More information about it can be found in #2193.
Load Balancer Services
Gardener creates certain Kubernetes Service objects of type LoadBalancer in the seed cluster. Most prominently, they are used for exposing the shoot control planes, namely the kube-apiserver of the shoot clusters. In most cases, the cloud-controller-manager (responsible for managing these load balancers on the respective underlying infrastructure) supports certain customization and settings via annotations. This document provides a good overview and many examples.
By setting the .spec.settings.loadBalancerServices.annotations field the Gardener administrator can specify a list of annotations, which will be injected into the Services of type LoadBalancer.
Load Balancer Class
By default, Gardener creates Services without the spec.loadBalancerClass field set, meaning that the default load balancer implementation of the underlying cloud infrastructure is used (implemented by the Service controller of cloud-controller-manager). If a non-default load balancer implementation should be used for load balancer services in the seed cluster, the spec.settings.loadBalancerServices.loadBalancerClass field can be configured accordingly to set the spec.loadBalancerClass on the created Service objects. Note that changing the loadBalancerClass of existing load balancer services is denied by Kubernetes, i.e., this setting can only be applied automatically to newly created load balancer services. If an existing load balancer service should use a different load balancer class, the migration needs to be performed manually by the operator.
External Traffic Policy
Setting the external traffic policy to Local can be beneficial as it preserves the source IP address of client requests. In addition to that, it removes one hop in the data path and hence reduces request latency. On some cloud infrastructures, it can furthermore be used in conjunction with Service annotations as described above to prevent cross-zonal traffic from the load balancer to the backend pod.
The default external traffic policy is Cluster, meaning that all traffic from the load balancer will be sent to any cluster node, which then itself will redirect the traffic to the actual receiving pod. This approach adds a node to the data path, may cross the zone boundaries twice, and replaces the source IP with one of the cluster nodes.
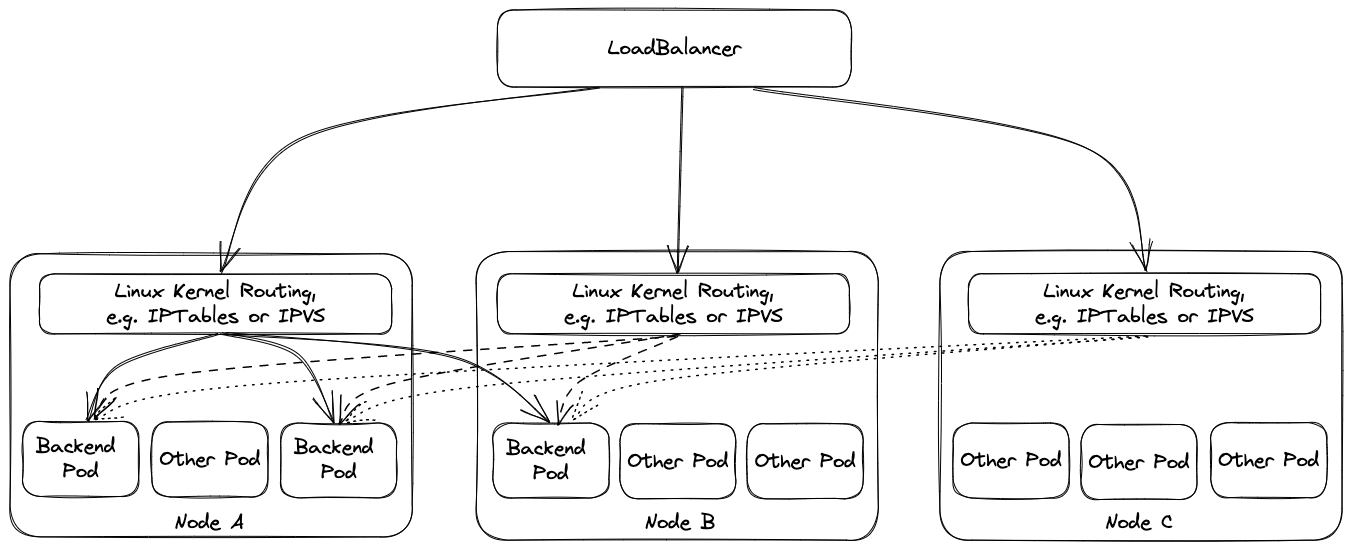
Using external traffic policy Local drops the additional node, i.e., only cluster nodes with corresponding backend pods will be in the list of backends of the load balancer. However, this has multiple implications. The health check port in this scenario is exposed by kube-proxy , i.e., if kube-proxy is not working on a node a corresponding pod on the node will not receive traffic from the load balancer as the load balancer will see a failing health check. (This is quite different from ordinary service routing where kube-proxy is only responsible for setup, but does not need to run for its operation.) Furthermore, load balancing may become imbalanced if multiple pods run on the same node because load balancers will split the load equally among the nodes and not among the pods. This is mitigated by corresponding node anti affinities.
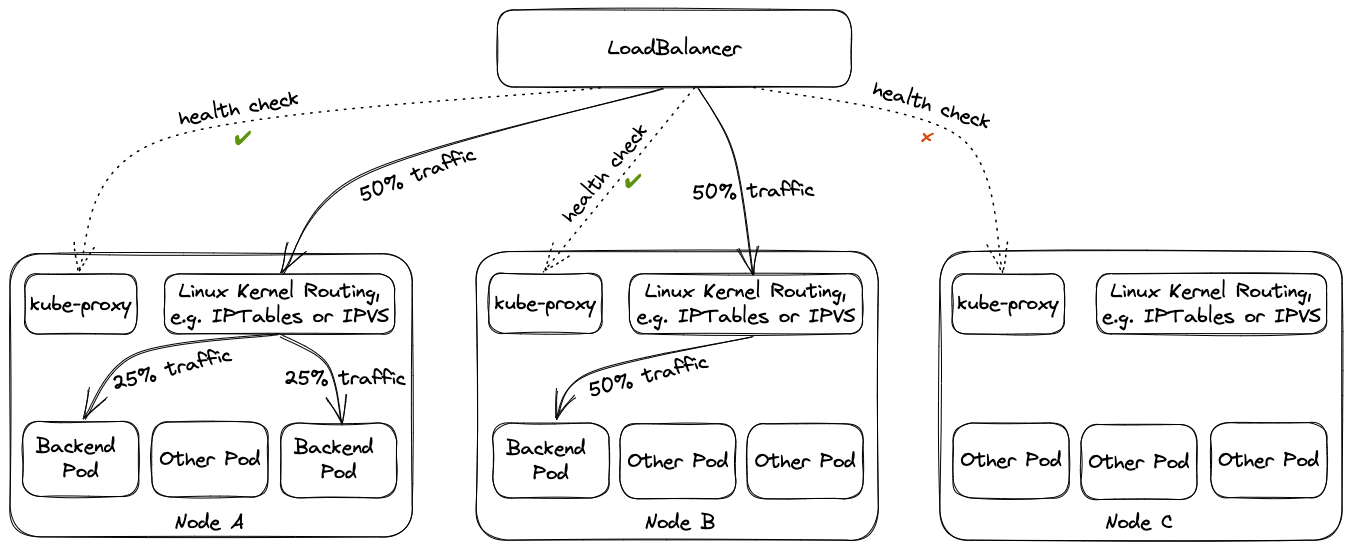
Operators need to take these implications into account when considering switching external traffic policy to Local.
Proxy Protocol
Traditionally, the client IP address can be used for security filtering measures, e.g. IP allow listing. However, for this to have any usefulness, the client IP address needs to be correctly transferred to the filtering entity.
Load balancers can either act transparently and simply pass the client IP on, or they terminate one connection and forward data on a new connection. The latter (intransparant) approach requires a separate way to propagate the client IP address. Common approaches are an HTTP header for TLS terminating load balancers or (HA) proxy protocol.
For level 3 load balancers, (HA) proxy protocol is the default way to preserve client IP addresses. As it prepends a small proxy protocol header before the actual workload data, the receiving server needs to be aware of it and handle it properly. This means that activating proxy protocol needs to happen on both load balancer and receiving server at/around the same time, as otherwise the receiving server will incorrectly interpret data as workload/proxy protocol header.
For disruption-free migration to proxy protocol, set .spec.settings.loadBalancerServices.proxyProtocol.allow to true. The migration path should be to enable the option and shortly thereafter also enable proxy protocol on the load balancer with infrastructure-specific means, e.g. a corresponding load balancer annotation.
When switching back from use of proxy protocol to no use of it, use the inverse order, i.e. disable proxy protocol first on the load balancer before disabling .spec.settings.loadBalancerServices.proxyProtocol.allow.
Zonal Ingress
By default, Gardener deploys Istio ingress gateways in each availability zone of a seed. This reduces cross-zonal traffic for single-zone shoot control planes.
If cross-zonal traffic costs are not a concern and minimizing the number of load balancers is preferred to save resources, zonal Istio ingress gateways can be disabled.
The behavior is controlled by the .spec.settings.loadBalancerServices.zonalIngress.enabled field, which defaults to true.
Impact of Disabling Zonal Ingress
When zonal ingress is disabled:
- A single default Istio ingress gateway is deployed, spanning all availability zones
- All shoot control plane traffic (single-zone and multi-zone) is routed through the default gateway
- Cross-zonal traffic may increase, since single-zone shoots no longer use zonal gateways
- Fewer load balancers are created, potentially reducing infrastructure costs
Migration Guide
To disable zonal ingress gateways, follow these steps:
- Set
.spec.settings.loadBalancerServices.zonalIngress.enabled=falsein theSeedspecification - Wait for all shoots to reconcile (during reconciliation, single-zone shoots will update their
Gatewayresources to use the default gateway) - Once all shoots have reconciled, zonal ingress gateways are automatically cleaned up
During migration, zonal ingress gateways remain deployed as long as any shoot Gateway resource still selects them. This ensures minimal downtime for shoot control planes during the transition.
CAUTION
When disabling zonal ingress gateways, expect temporary unavailability of shoot control planes due to DNS propagation delays. During migration, DNS entries are updated to point to the default gateway, but clients may continue using cached DNS entries pointing to the zonal gateways for up to the configured DNS TTL. Additionally, existing long-running connections will be interrupted when the Gateway resources are updated to no longer use the zonal ingress gateways. This downtime should be scheduled during a maintenance window.
For more about Istio's multi-zone behavior, see the Istio documentation.
Zone-Specific Settings
In case a seed cluster is configured to use multiple zones via .spec.provider.zones, it may be necessary to configure the load balancers in individual zones in different way, e.g., by utilizing different annotations. One reason may be to reduce cross-zonal traffic and have zone-specific load balancers in place. Zone-specific load balancers may then be bound to zone-specific subnets or availability zones in the cloud infrastructure.
Besides the load balancer annotations, it is also possible to set proxy protocol termination and the external traffic policy for each zone-specific load balancer individually.
Vertical Pod Autoscaler
Gardener heavily relies on the Kubernetes vertical-pod-autoscaler component. By default, the seed controller deploys the VPA components into the garden namespace of the respective seed clusters. In case you want to manage the VPA deployment on your own or have a custom one, then you might want to disable the automatic deployment of Gardener. Otherwise, you might end up with two VPAs, which will cause erratic behaviour. By setting the .spec.settings.verticalPodAutoscaler.enabled=false, you can disable the automatic deployment.
⚠️ In any case, there must be a VPA available for your seed cluster. Using a seed without VPA is not supported.
VPA Pitfall: Excessive Resource Requests Making Pod Unschedulable
VPA is unaware of node capacity, and can increase the resource requests of a pod beyond the capacity of any single node. Such pod is likely to become permanently unschedulable. That problem can be partly mitigated by using the VerticalPodAutoscaler.Spec.ResourcePolicy.ContainerPolicies[].MaxAllowed field to constrain pod resource requests to the level of nodes' allocatable resources. The downside is that a pod constrained in such fashion would be using more resources than it has requested, and can starve for resources and/or negatively impact neighbour pods with which it is sharing a node.
As an alternative, in scenarios where MaxAllowed is not set, it is important to maintain a worker pool which can accommodate the highest level of resources that VPA would actually request for the pods it controls.
Finally, the optimal strategy typically is to both ensure large enough worker pools, and, as an insurance, use MaxAllowed aligned with the allocatable resources of the largest worker.
Topology-Aware Traffic Routing
Refer to the Topology-Aware Traffic Routing documentation as this document contains the documentation for the topology-aware routing Seed setting.
Zone Selection
NOTE
Zone selection only has an effect on non-HA shoots and HA shoots with failure tolerance type node. These are the cases where the control plane runs in a single availability zone. HA shoots with failure tolerance type zone spread the control plane across multiple zones by definition, so there is no single zone to pin and zone selection has no effect on them.
By default, Gardener randomly selects an availability zone from .spec.provider.zones[] in the Seed when creating the shoot control plane namespace in the seed cluster. This works well for most use cases, but operators with stretched seeds (multi-AZ) and single-zone shoots may want the control plane pods to run in the same availability zone as the shoot's worker nodes, minimizing cross-zonal traffic and latency.
The .spec.settings.zoneSelection field allows seed operators to configure this behavior. When zone selection is enabled, Gardener can derive the control plane zone from the shoot's worker pool zones instead of selecting randomly.
NOTE
Zone assignment only happens during shoot creation or when the shoot is being restored on a new seed. Adding or changing worker zones retrospectively won't change the zone of the control plane.
Modes
Two modes are supported:
Prefer
Gardener attempts to match the shoot's collected worker zones to the zones available in the seed. If a non-empty intersection is found, those matching zones are used for the control plane namespace. If no intersection exists (e.g., due to a zone name mismatch across providers), Gardener falls back to the default random zone selection. The Gardener Scheduler prefers seeds in Prefer mode whose zones overlap with the shoot's worker zones, but falls back to all candidates if no such seed exists. This mode will never fail scheduling — it is safe to enable broadly.
Single-zone shoot (worker in eu-central-1a, seed has [eu-central-1a, eu-central-1b, eu-central-1c]): → Control plane namespace is pinned to eu-central-1a.
Multi-zone shoot (workers in [eu-central-1a, eu-central-1b], seed has [eu-central-1a, eu-central-1b, eu-central-1c]): → One zone is picked randomly from the intersection (eu-central-1a or eu-central-1b).
No overlap (workers in [us-east-1a], seed has [eu-central-1a, eu-central-1b]): → Falls back to random zone selection; scheduling still succeeds.
Enforce
Gardener requires at least one of the shoot's collected worker zones to be present in the seed's zone list. If the intersection is non-empty, one of the matching zones is used for the control plane namespace. If no intersection exists, the control plane reconciliation fails with an error. Additionally, the Gardener Scheduler filters out seeds in Enforce mode that have no zone overlap with the shoot's worker zones, preventing assignment of incompatible shoots to those seeds.
Single-zone shoot (worker in eu-central-1a, seed has [eu-central-1a, eu-central-1b]): → Control plane namespace is pinned to eu-central-1a.
Multi-zone shoot (workers in [eu-central-1a, eu-central-1b], seed has [eu-central-1a, eu-central-1b, eu-central-1c]): → One zone is picked randomly from the intersection (eu-central-1a or eu-central-1b).
No overlap (workers in [eu-central-1a], seed has [eu-central-1b, eu-central-1c]): → The scheduler excludes this seed; if no compatible seed is found, scheduling fails with an error.
Temporarily Disabling Shoot Reconciliations
There may be emergency situations where you need to temporarily stop the reconciliation of Shoot clusters in a Seed cluster, for example, to prevent faulty updates from propagating further or to avoid gardenlet performing unintended actions.
CAUTION
This mechanism should only be used in exceptional cases and not as part of regular operations, as it can have significant implications for cluster health and update consistency.
To temporarily disable reconciliations, add the annotation shoot.gardener.cloud/emergency-stop-reconciliations=true to the Seed resource.
While this annotation is present:
- The
Shootcontroller will not reconcile anyShootclusters in the affectedSeed. - New
Shootclusters will not be scheduled to thisSeed. - The
Seedwill expose theSeedDisabledShootReconciliationscondition.
NOTE
When you remove this annotation, reconciliation will resume, but Shoot clusters will only be reconciled during their next scheduled reconciliation window. They are not reconciled immediately. This is important if you expect all clusters to be updated right away after re-enabling reconciliations.
To annotate all Seed resources at once, run:
kubectl annotate seed --all shoot.gardener.cloud/emergency-stop-reconciliations=true